python 生成复杂表格,自动分页等功能
python 生成复杂表格,自动分页等功能
解决将Python中的树形目录数据转换为Word表格,并生成带有合并单元格的检测报告的问题。首先,要解决“tree目录数据”和“Word表格互换”,指将树形结构的数据转换成Word表格,并在转换过程中合并相应的单元格以反映层次结构。此外,还有自动分页和固定表头的问题,现在可能希望生成的报告能够自动处理这些格式问题。
首先,我需要明确树形目录数据的结构。通常,树形结构有父子节点关系,比如文件夹结构,每个节点可能有名称、类型、大小、修改日期等属性。希望将这些层次结构在Word表格中展示,通过合并单元格来表示父子关系,例如,一个父节点占据一行,其子节点在下方缩进显示,可能需要合并某些列来体现层级。
在Python中,处理树形结构通常使用递归。对于每个节点,可能需要确定其在表格中的行位置,并根据层级决定合并哪些单元格。例如,根节点可能需要合并所有列的一行,子节点可能只在第一列显示名称,后面的列合并或留空,或者根据具体需求调整。
生成Word文档需要使用python-docx库。该库允许创建表格、设置样式、合并单元格等操作。关键点是如何遍历树形数据并动态生成表格行,同时处理合并单元格的逻辑。可能需要为每个节点计算其在表格中的行数和列数,特别是当子节点存在时,父节点可能需要跨多行合并。
以下是试验代码
from docx import Document
from docx.shared import Pt, Cm
from docx.enum.table import WD_TABLE_ALIGNMENT
from docx.oxml.shared import OxmlElement, qn
import randomclass TreeNode:def __init__(self, name, depth=0, is_file=False, size=0, parent=None):self.name = nameself.depth = depthself.is_file = is_fileself.size = f"{size} KB" if is_file else ""self.parent = parentself.children = []self.start_row = 0self.end_row = 0self.col_span = 1 # 新增横向合并跨度class EnhancedDirectoryReport:def __init__(self, filename):self.doc = Document()self.filename = filenameself._setup_document()self.table = Noneself.current_row = 0self.column_map = ['一级目录', '二级目录', '三级目录', '文件名', '路径', '大小']self.current_table = Noneself.current_page_rows = 0self.max_page_rows = 35 # 根据实际内容调整每页行数self.active_directory = {} # 记录当前活跃的目录层级def _setup_document(self):section = self.doc.sections[0]margins = {'left': 2, 'right': 2, 'top': 2.5, 'bottom': 2.5}for attr, cm_val in margins.items():setattr(section, f"{attr}_margin", Cm(cm_val))style = self.doc.styles['Normal']style.font.name = '微软雅黑'style.font.size = Pt(10)def _create_new_page(self):"""创建新页面并初始化表格"""if self.current_table is not None:self.doc.add_page_break()self.current_table = self.doc.add_table(rows=0, cols=6)self.current_table.style = 'Table Grid'widths = [Cm(3.5), Cm(3.5), Cm(3.5), Cm(4), Cm(6), Cm(2.5)]for idx, w in enumerate(widths):self.current_table.columns[idx].width = wself._create_table_header()print('建表头后',self.current_row,self.current_page_rows)self.current_page_rows = 1 # 表头占1行# 重新应用活跃目录self._reapply_active_directory()def _reapply_active_directory(self):"""在新页重新应用当前活跃目录"""for depth in [1, 2, 3]:if depth in self.active_directory:node = self.active_directory[depth]self._add_directory_row(node, depth)def _add_directory_row(self, node, depth):"""添加目录行并更新活跃状态"""row = self.current_table.add_row()cells = row.cells# 填充目录信息cells[depth - 1].text = node.namecells[depth - 1].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.LEFT# 设置跨列合并if depth == 1:cells[0].merge(cells[5])elif depth == 2:cells[1].merge(cells[5])elif depth == 3:cells[2].merge(cells[5])# 更新活跃目录self.active_directory[depth] = nodeself.current_page_rows += 1def _check_page_break(self):"""检查是否需要分页"""if self.current_page_rows >= self.max_page_rows:self._create_new_page()print('分页')def _add_file_row(self, node):"""添加文件行"""self._check_page_break()row = self.current_table.add_row()cells = row.cells# 填充文件信息cells[3].text = node.namecells[4].text = self._get_full_path(node)cells[5].text = node.size# 继承活跃目录for depth in [1, 2, 3]:if depth in self.active_directory:cells[depth - 1].text = self.active_directory[depth].namecells[depth - 1].paragraphs[0].alignment = WD_TABLE_ALIGNMENT.CENTERself.current_page_rows += 1def _get_full_path(self, node):path = []current = node.parentwhile current and current.depth > 0:path.insert(0, current.name)current = current.parentreturn '/' + '/'.join(path)def process_structure(self, root):"""处理目录结构"""self._create_new_page()stack = [(root, False)] # (node, visited)while stack:node, visited = stack.pop()if visited:# 后序遍历处理合并if not node.is_file:self._update_active_directory(node)continueif node.is_file:self._add_file_row(node)else:# 前序遍历添加目录self._check_page_break()self._add_directory_row(node, node.depth)stack.append((node, True))# 逆向添加子节点以保持顺序for child in reversed(node.children):stack.append((child, False))self.doc.save(self.filename)def _update_active_directory(self, node):"""更新活跃目录状态"""# 清除子目录状态for depth in list(self.active_directory.keys()):if depth > node.depth:del self.active_directory[depth]def _create_table_header(self):header = self.table.add_row()for idx, text in enumerate(self.column_map):cell = header.cells[idx]cell.text = textcell.paragraphs[0].runs[0].font.bold = Truecell.paragraphs[0].alignment = WD_TABLE_ALIGNMENT.CENTERself._set_cell_color(cell, 'A3D3D3')tr = header._trtrPr = tr.get_or_add_trPr()tblHeader = OxmlElement('w:tblHeader')tblHeader.set(qn('w:val'), "true")trPr.append(tblHeader)print(self.current_row)self.current_row += 1def _set_cell_color(self, cell, hex_color):shading = OxmlElement('w:shd')shading.set(qn('w:fill'), hex_color)cell._tc.get_or_add_tcPr().append(shading)def _smart_merge(self, node):"""智能合并策略核心方法"""# 垂直合并处理if node.depth <= 3 and not node.is_file:self._vertical_merge(node)# 横向合并处理if node.depth == 1 and not any(not c.is_file for c in node.children):self._horizontal_merge(node, 1, 3) # 一级目录合并到文件名列if node.depth == 2 and not any(not c.is_file for c in node.children):self._horizontal_merge(node, 2, 3) # 二级目录合并到文件名列def _horizontal_merge(self, node, start_col, end_col):"""安全横向合并方法"""for row_idx in range(node.start_row, node.end_row):# 获取需要合并的单元格print('nc ', row_idx, start_col, end_col)start_cell = self.table.cell(row_idx, start_col)end_cell = self.table.cell(row_idx, end_col)print(row_idx, start_col, end_col)print('开结',start_cell, end_cell)# 检查是否已经被合并if start_cell._element is end_cell._element:print('已合并过')continueelse:start_cell.merge(end_cell)def _vertical_merge(self, node):"""垂直方向合并"""if node.start_row >= node.end_row:returndepth_col_map = {1: 0, 2: 1, 3: 2}col_idx = depth_col_map.get(node.depth)if col_idx is not None:try:start_cell = self.table.cell(node.start_row, col_idx)end_cell = self.table.cell(node.end_row - 1, col_idx)start_cell.merge(end_cell)start_cell.text = node.nameexcept IndexError as e:print(f"垂直合并失败:{node.name}")raise edef _fill_row_data(self, node):"""填充数据并设置合并策略"""row = self.table.add_row()cells = row.cells# 文件信息if node.is_file:cells[3].text = node.namecells[4].text = self._get_full_path(node)cells[5].text = node.size# else:# # 设置目录层级# for d in range(1, 4):# print(d, cells[d])# print(node.name, node.depth)# if node.depth == d:# cells[d - 1].text = node.name# # if d < 3:# # cells[d].merge(cells[d])# 设置样式for cell in cells:cell.vertical_alignment = WD_TABLE_ALIGNMENT.CENTERself.current_row += 1return row# def _get_full_path(self, node):# path = []# current = node.parent# while current and current.depth > 0:# path.insert(0, current.name)# current = current.parent# return '/' + '/'.join(path) + ('' if node.is_file else f'/{node.name}')def _process_node(self, node):node.start_row = self.current_row#增限制,如为净空不加行if node.depth > 1 and node.is_file:self._fill_row_data(node)for child in node.children:self._process_node(child)node.end_row = self.current_rowself._smart_merge(node)def generate_report(self, root):self.table = self.doc.add_table(rows=0, cols=6)self.table.style = 'Table Grid'widths = [Cm(3.5), Cm(3.5), Cm(3.5), Cm(4), Cm(6), Cm(2.5)]for idx, w in enumerate(widths):self.table.columns[idx].width = w# self._create_table_header()self._create_new_page()self._process_node(root)print(self.doc.tables)self.doc.save(self.filename)# 测试数据生成器
class TestDataGenerator:@staticmethoddef create_large_structure():root = TreeNode("ROOT", depth=0)# 一级目录(10个)for i in range(1, 11):dir1 = TreeNode(f"一级目录_{i}", depth=1, parent=root)root.children.append(dir1)# 30%概率没有子目录if random.random() < 0.3:# 直接添加文件for j in range(random.randint(2, 5)):file = TreeNode(f"文件_{i}-{j}.docx", depth=4,is_file=True,size=random.randint(100, 5000),parent=dir1)dir1.children.append(file)continue# 二级目录(每个一级目录3-5个)for j in range(random.randint(3, 5)):dir2 = TreeNode(f"二级目录_{i}-{j}", depth=2, parent=dir1)dir1.children.append(dir2)# 50%概率没有三级目录if random.random() < 0.5:# 直接添加文件for k in range(random.randint(3, 6)):file = TreeNode(f"文件_{i}-{j}-{k}.xlsx", depth=4,is_file=True,size=random.randint(100, 5000),parent=dir2)dir2.children.append(file)continue# 三级目录(每个二级目录2-4个)for k in range(random.randint(2, 4)):dir3 = TreeNode(f"三级目录_{i}-{j}-{k}", depth=3, parent=dir2)dir2.children.append(dir3)# 添加文件for m in range(random.randint(3, 8)):file = TreeNode(f"文件_{i}-{j}-{k}-{m}.pptx", depth=4,is_file=True,size=random.randint(100, 5000),parent=dir3)dir3.children.append(file)return rootif __name__ == '__main__':# 生成测试数据data_generator = TestDataGenerator()root_node = data_generator.create_large_structure()# 生成报告report = EnhancedDirectoryReport("上下左右目录2.docx")report.generate_report(root_node)效果如图所示:
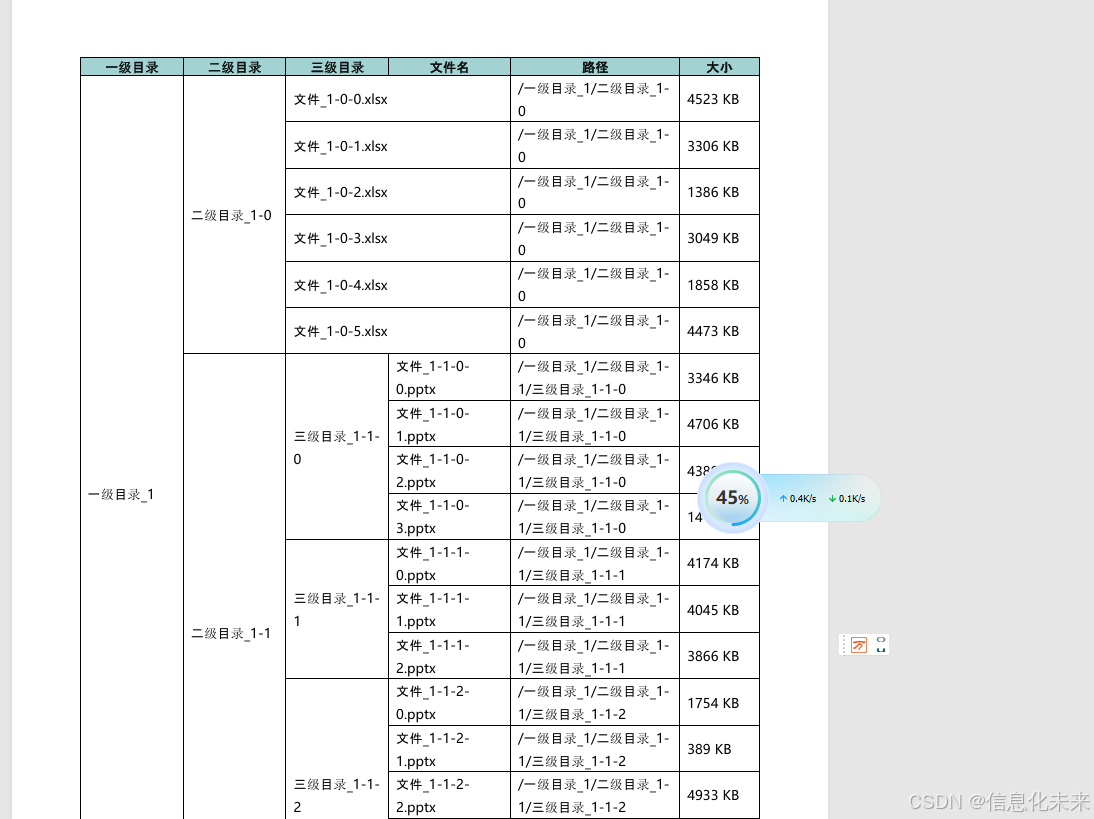
相关文章:
python 生成复杂表格,自动分页等功能
python 生成复杂表格,自动分页等功能 解决将Python中的树形目录数据转换为Word表格,并生成带有合并单元格的检测报告的问题。首先,要解决“tree目录数据”和“Word表格互换”,指将树…...

2025年高防IP与游戏盾深度对比:如何选择最佳防护方案?
2025年,随着DDoS攻击规模的指数级增长和混合攻击的常态化,高防IP与游戏盾成为企业网络安全的核心选择。然而,两者在功能定位、技术实现及适用场景上存在显著差异。本文结合最新行业实践与技术趋势,全面解析两者的优劣,…...

在 Vue + Vite 项目中,直接使用相对路径或绝对路径引用本地图片资源时,图片无法正确显示。
Vue 项目中静态资源引用问题 1.问题描述 在 Vue Vite 项目中,直接使用相对路径或绝对路径引用本地图片资源时,图片无法正确显示。 错误示例 javascript // 错误方式1:使用相对路径 const products [ { name: iPhone 14 Pro, image: .…...
)
判断手机屏幕上的横向滑动(左滑和右滑)
在JavaScript中,你可以通过监听触摸事件(touch events)来判断用户在手机屏幕上的横向滑动方向。以下是实现方法: 基本实现方案 let touchStartX 0; let touchEndX 0;function handleTouchStart(event) {touchStartX event.ch…...

用户有一个Django模型没有设置主键,现在需要设置主键。
用户有一个Django模型没有设置主键,现在需要设置主键。 from django.db import modelsclass CategoryAssistentModel(models.Model):second_level_category models.CharField(max_length100, nullTrue, blankTrue)third_level_category models.CharField(max_len…...
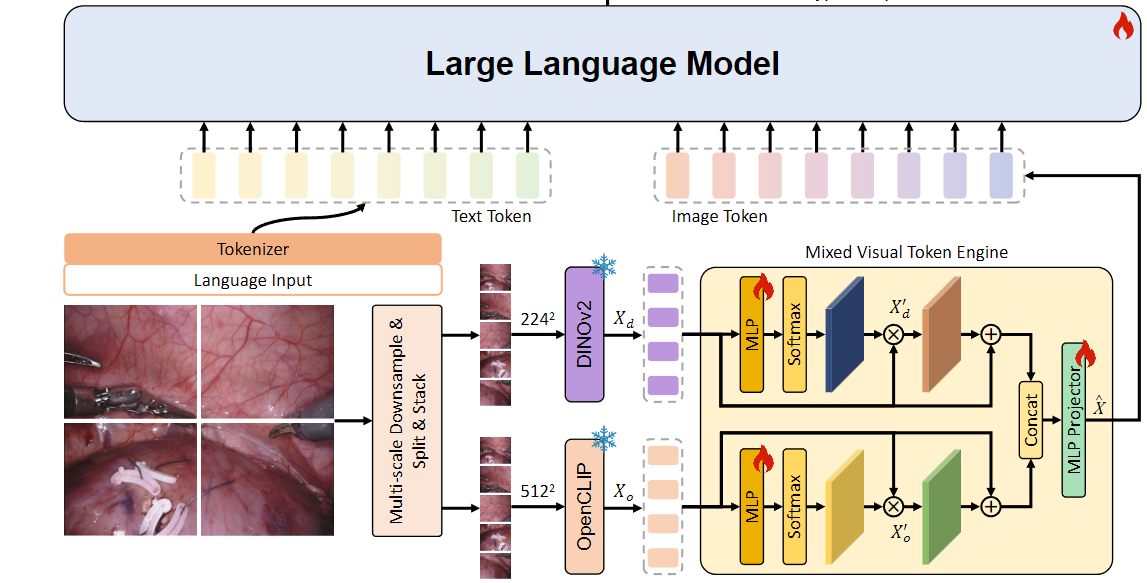
【文献阅读】EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery
[2501.11347] EndoChat: Grounded Multimodal Large Language Model for Endoscopic Surgery 2025年1月 数据可用性 Surg-396K 数据集可在 GitHub - gkw0010/EndoChat 公开获取。 代码可用性 EndoChat 的代码可在 GitHub - gkw0010/EndoChat 下载。 摘要 近年来ÿ…...
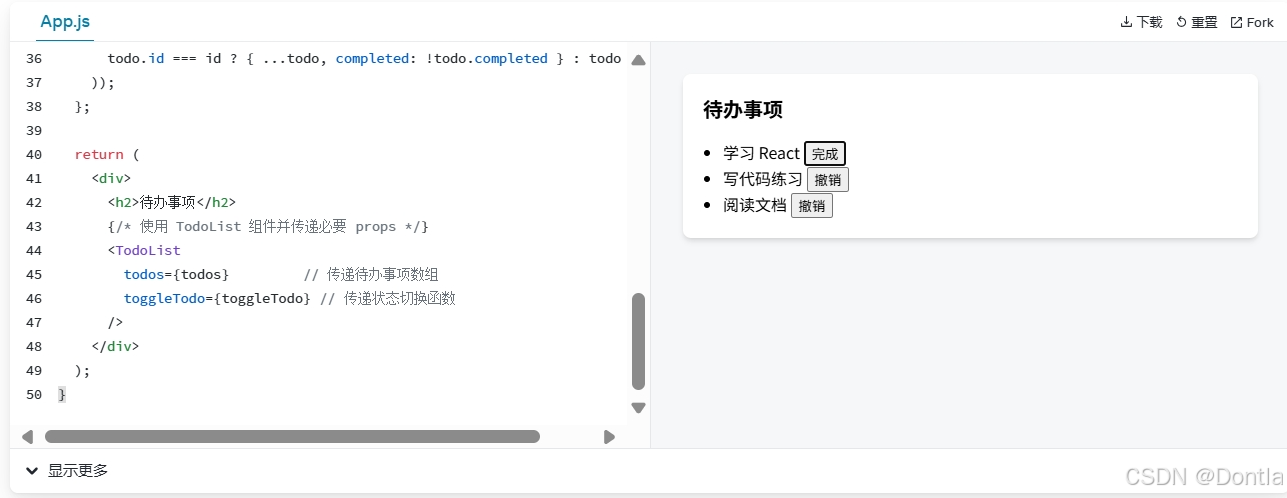
React JSX语法介绍(JS XML)(一种JS语法扩展,允许在JS代码中编写类似HTML的标记语言)Babel编译
在线调试网站:https://zh-hans.react.dev/learn 文章目录 JSX:现代前端开发的声明式语法概述JSX的本质与工作原理什么是JSXJSX转换流程 JSX语法特性表达式嵌入(JSX允许在大括号内嵌入任何有效的JavaScript表达式)属性传递…...

【R语言编程绘图-箱线图】
基本箱线图绘制 使用ggplot2绘制箱线图的核心函数是geom_boxplot()。以下是一个基础示例,展示如何用iris数据集绘制不同物种(Species)的萼片长度(Sepal.Length)分布: library(ggplot2) ggplot(iris, aes(…...

【elasticsearch 7 或8 的安装及配置SSL 操作指引】
1.标题获取安装文件 cd /opt/tools wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-8.11.4-linux-x86_64.tar.gz tar -zxvf elasticsearch-8.11.4-linux-x86_64.tar.gz mv /opt/tools/elasticsearch-8.11.4 /opt/elasticsearch #配置vm.max_map_co…...
)
GitHub 趋势日报 (2025年05月23日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1All-Hands-AI/OpenHands🙌开放式:少代码,做…...

MongoDB索引:原理、实践与优化指南
为什么索引对数据库如此重要? 在现代应用开发中,数据库性能往往是决定用户体验的关键因素。想象一下,当你在电商平台搜索商品时,如果每次搜索都需要等待5-10秒才能看到结果,这种体验是多么令人沮丧。MongoDB作为最流行…...

SQL实战之索引优化(单表、双表、三表、索引失效)
文章目录 单表优化双表优化三表优化结论索引失效 单表优化 总体原则:建立索引并合理使用,避免索引失效 案例说明:查询category_ id 为1且comments大于1的情况下,views最多的article_ id: 传统方案: explain select id, author_ id…...
[7-1] ADC模数转换器 江协科技学习笔记(14个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 DMA(Direct Memory Access,直接内存访问)是一种硬件特性,它允许某些硬件子系统直接访问系统的内存,而无需CPU的介入。这样,CPU就可以处理其他任务,从而提高系…...

SSM整合:Spring+SpringMVC+MyBatis完美融合实战指南
前言 在Java企业级开发领域,SSM(SpringSpringMVCMyBatis)框架组合一直占据着重要地位。这三个轻量级框架各司其职又相互配合,为开发者提供了高效、灵活的开发体验。本文将深入探讨SSM框架的整合过程,揭示整合背后的原…...

Spring Boot分页查询进阶:整合Spring Data REST实现高效数据导航
目录: 引言分页查询基础回顾 2.1 Spring Data JPA分页接口 2.2 Pageable与Page的使用 2.3 常见分页参数设计Spring Data REST简介 3.1 HATEOAS与超媒体驱动API 3.2 Spring Data REST核心功能 3.3 自动暴露Repository接口整合Spring Boot与Spring Data REST 4.1 项目…...
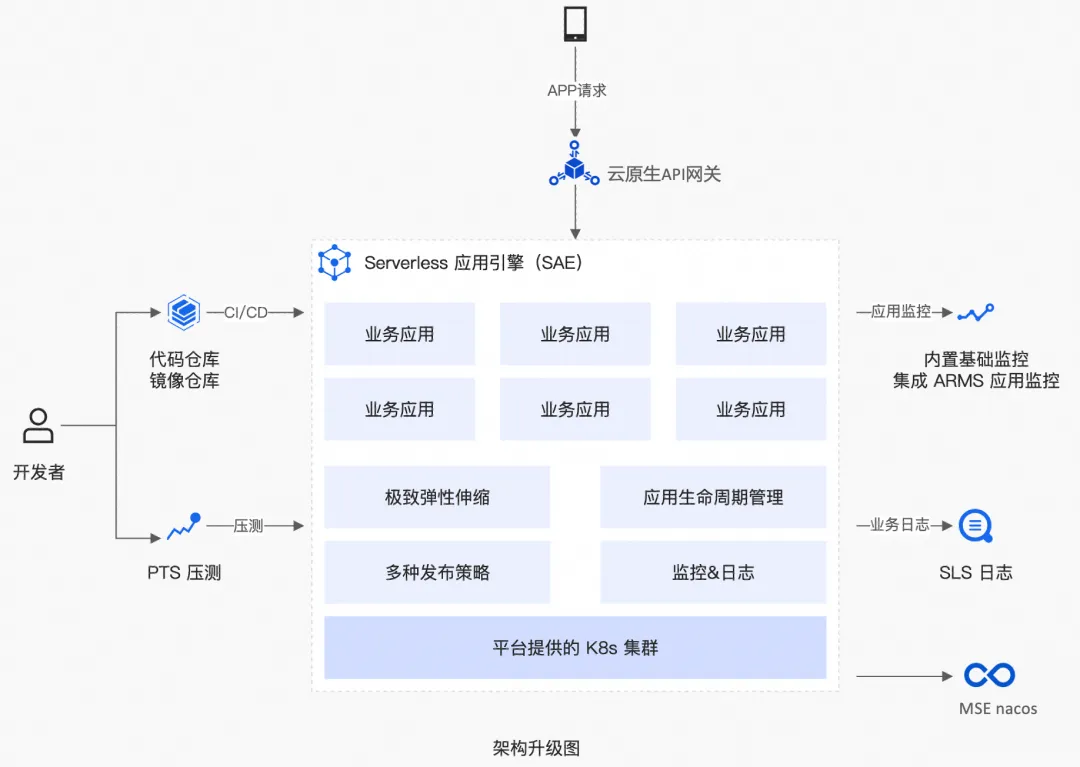
阿里云 Serverless 助力海牙湾构建弹性、高效、智能的 AI 数字化平台
作者:赵世振、十眠、修省 “通过阿里云 Serverless 架构,我们成功解决了弹性能力不足、资源浪费与运维低效的痛点。SAE 的全托管特性大幅降低技术复杂度。未来,我们将进一步探索 Serverless 与 AI 的结合,为客户提供更智能的数字…...

升级node@22后运行npm install报错 distutils not found
从node20升级到node22后,在运行 npm install 的时候报了很多 gyp 错误,其中包括 npm error npm error ModuleNotFoundError: No module named distutils。 问题原因是我在使用 brew install node22 的过程中自动把 python 升级到了 3.13。而 distutils …...

一个开源的多播放源自动采集在线影视网站
这里写自定义目录标题 欢迎使用Markdown编辑器GoFilm简介项目部署1、前置环境准备1.2 redis 配置 film-api 后端服务配置将 GoFilm 项目根目录下的 film 文件夹上传到 linux 服务器的 /opt 目录下 2. 构建运行1. docker 部署1.1 安装 docker , docker compose 环境 注意事项: 2…...
)
【PhysUnits】10 减一操作(sub1.rs)
一、源码 代码实现了一个类型级别的减一操作(Sub1 trait),通过Rust的类型系统在编译期完成数值减一的计算。 //! 减一操作特质实现 / Decrement operation trait implementation //! //! 提供类型级别的减一计算 / Provides type-level decrement operationuse su…...
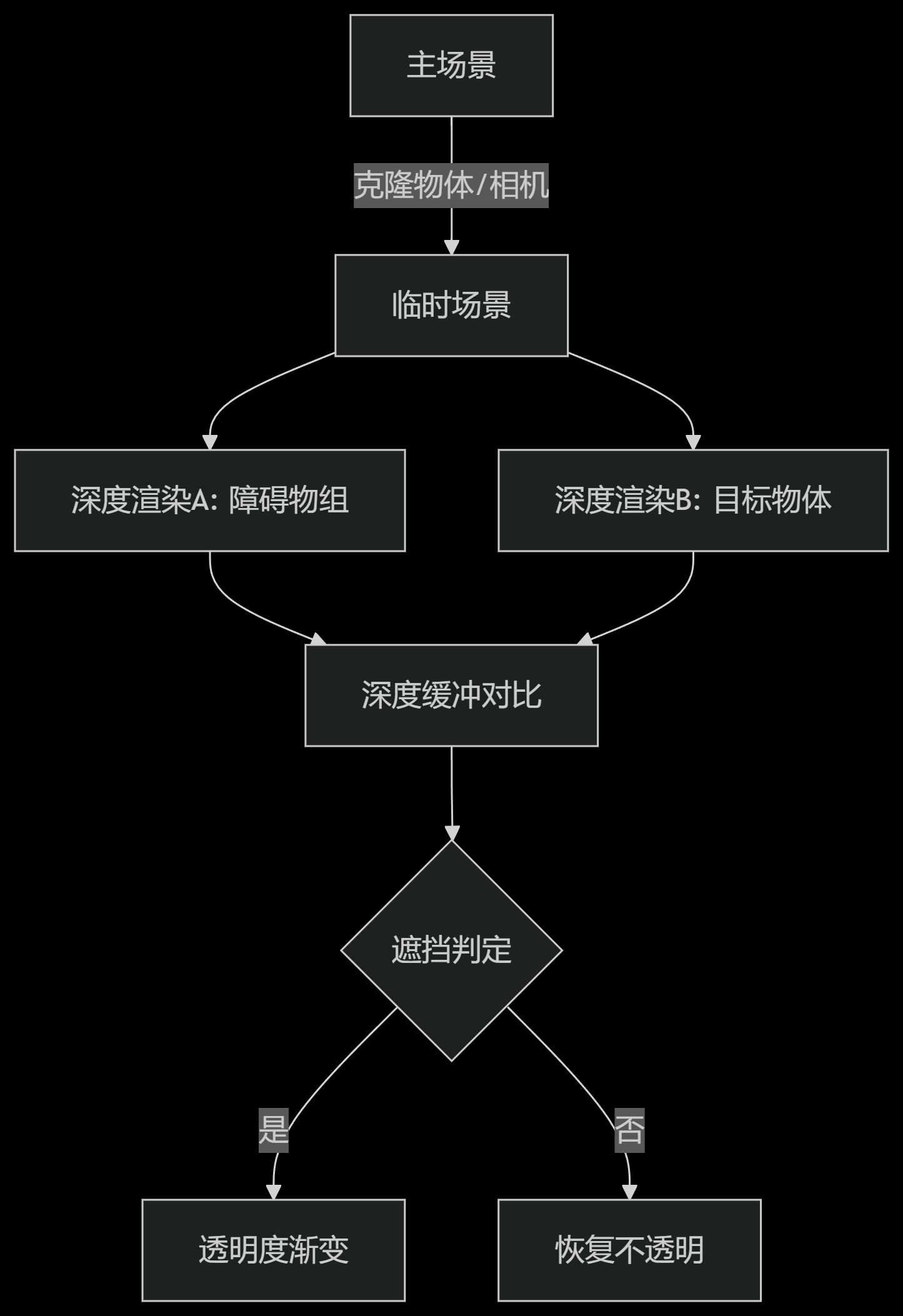
深度检测与动态透明度控制 - 基于Babylon.js的遮挡检测实现解析
首先贴出实现代码: OcclusionFader.ts import { AbstractEngine, Material, type Behavior, type Mesh, type PBRMetallicRoughnessMaterial, type Scene } from "babylonjs/core"; import { OcclusionTester } from "../../OcclusionTester"…...

Linux下使用socat将TCP服务转为虚拟串口设备
Linux下使用socat将TCP服务转为虚拟串口设备 socat是一个强大的网络工具,可以将TCP连接转换为虚拟串口设备,这在嵌入式开发、工业控制等领域非常有用。下面详细介绍如何实现这一功能。 基本原理 socat可以通过创建伪终端(PTY)来模拟串口设备ÿ…...
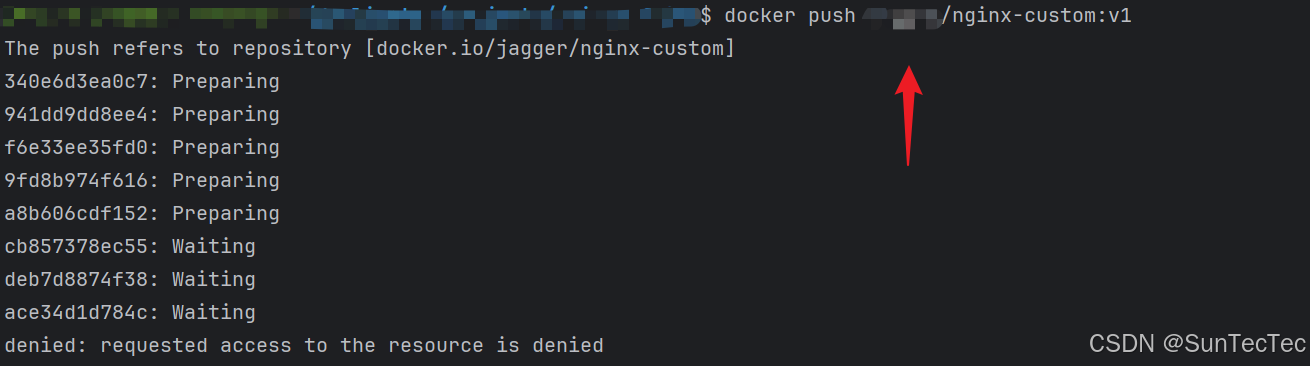
docker push 报错 denied: requested access to the resource is denied
问题:当 docker logout -> docker login 用户登录,但仍然无法 docker push $ docker push <username>/nginx-custom:v1 The push refers to repository [docker.io/jagger/nginx-custom] 340e6d3ea0c7: Preparing 941dd9dd8ee4: Preparing f6…...

epub→pdf | which 在线转换??好用!!
1、PDF派(free&quick) pdf转word_pdf转换成excel_pdf转换成ppt _纬来PDF转换器 评价:目前使用免费,转化的时候有进度条提示,总的来说比较快,50mb的文件在40秒内可以转换完成,推荐 2、pdfconvert(free…...

PBX、IP PBX、FXO 、FXS 、VOIP、SIP 的概念解析以及关系
PBX(Private Branch Exchange) 概念 :PBX 是专用交换机,是一种在企业或组织内部使用的电话交换系统。它允许内部用户之间以及内部用户与外部公共电话网络(PSTN)之间进行通信。例如,在一个大型企…...
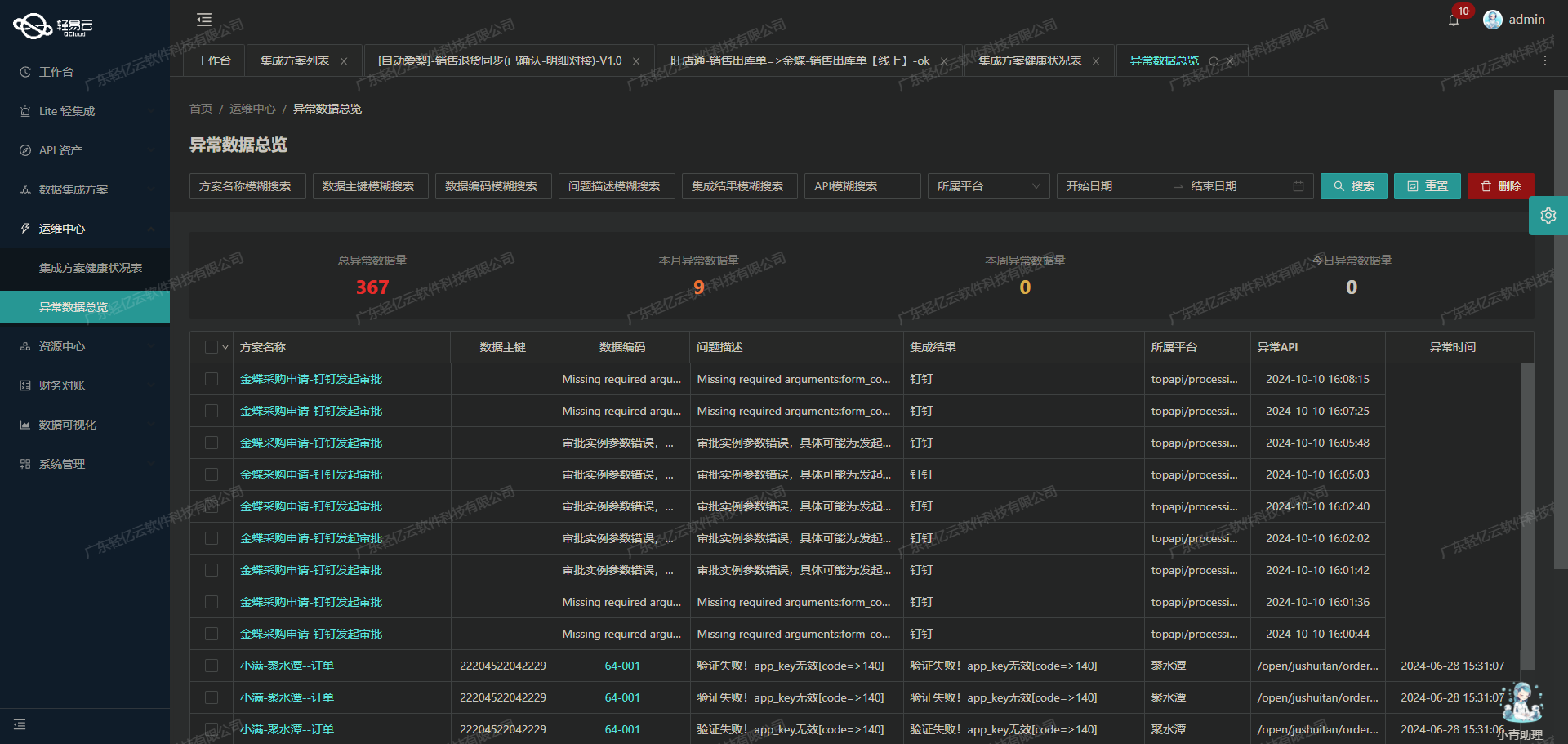
MySQL数据高效集成到金蝶云星空的技术分享
MySQL数据集成到金蝶云星空的技术案例分享:SR新建调拨单内部供应商-深圳天一 在企业信息化系统中,数据的高效流动和准确对接是实现业务流程自动化的关键。本文将聚焦于一个具体的系统对接集成案例——将MySQL中的数据集成到金蝶云星空,以支持…...

git 命令之-git cherry-pick
今天得到一个通知,这个业务版本里面部分已经开发但还没测试的内容要新开一个分支提交,但是我已经有几个提交上去了,难道只能一个一个文件复制到新的分支吗?我不,我找到了这个git命令,可以解决我的困惑&…...

如何在STM32CubeMX下为STM32工程配置调试打印功能
为STM32工程配置调试打印功能 一、配置调试用的打印串口 #include <stdio.h> //标准输入输出库//1.在STM32CubeMX中打开并配置好某串口设备; //2.在main.c文件中添加如下代码行对输入输出重定向; //3.在文件开头包含stdio.h头文件。 #pragma im…...

Linux系统 - 基本概念
介绍一些Linux系统的基本概念 1 操作系统的核心—内核 “操作系统”通常包含两种不同含义。 1.指完整的软件包,这包括用来管理计算机资源的核心层软件,以及附带的所有标准软件工具,诸如命令行解释器、图形用户界面、文件操作工具…...

kerberos在无痕浏览器 获取用户信息失败 如何判断是否无痕浏览器
kerberos在无痕浏览器 获取用户信息失败 如何判断是否无痕浏览器 js 代码 其他地方用直接导入js getCurrentUserId 这是自己后端获取 域账号地址 我是成功返回200 //true普通浏览器 fasle 无痕浏览器 export const checkBrowserMode async () > {try {const response a…...
 recorder-core)
在h5端实现录音发送功能(兼容内嵌微信小程序) recorder-core
本文将通过一个实际的 Vue3 组件示例,带你一步步实现“按住录音,松开发送,上滑取消”的语音录制功能。 我们将使用强大且小巧的开源库 recorder-core,支持 MP3、WAV、AAC 等编码格式,兼容性较好。 🔧 项目…...