机器学习多分类逻辑回归和二分类神经网络实践
1、2-17 实现多分类逻辑回归
代码
# 2-17 实现多分类逻辑回归
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt# 参数设置
iterations = 5400 # 迭代次数
learning_rate = 0.1 # 学习率
m_train = 200 # 训练样本数量# 整数索引值转one-hot向量
def index2onehot(index, classes):onehot = np.zeros((classes, index.size))onehot[index.astype(int), np.arange(index.size)] = 1return onehot# 读入轮椅数据
df = pd.read_csv('wheelchair_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0] # 样本数量
d = np.shape(data)[1] - 1 # 输入特征维数
classes = np.amax(data[:, d])
m_test = m_all - m_train # 测试样本的数量
# 构造随机种子为指定值的随机数生成器,并对数据集中样本随机排序
rng = np.random.default_rng(1)
rng.shuffle(data)
# 特征缩放(标准化)
data = data.astype(float)
mean = np.mean(data[0:m_train, 0:d], axis=0)
std = np.std(data[0:m_train, 0:d], axis=0, ddof=1)
data[:, 0:d] = (data[:, 0:d] - mean) / std
# 划分数据集
X_train = data[0:m_train, 0:d].T
Y_train = data[0:m_train, d].reshape((1, -1))
Y_train_onehot = index2onehot(Y_train.astype(int)-1, classes) # 将类别标注值转为one-hot向量
X_test = data[m_train:, 0:d].T
Y_test = data[m_train, d].reshape((1, -1))
# 初始化
W = np.zeros((d, classes))
b = np.zeros((classes, 1))
v = np.ones((1, m_train)) # 1向量
U = np.ones((classes, classes)) # 1矩阵
costs_saved = []
# 迭代循环
for i in range(iterations):# 预测z = np.dot(W.T, X_train) + np.dot(b, v)exp_Z = np.exp(z)Y_hat = exp_Z / (np.dot(U, exp_Z))# 误差E = Y_hat - Y_train_onehot# 更新权重与偏差W = W - learning_rate * np.dot(X_train, E.T) / m_train # 更新权重b = b - learning_rate * np.dot(E, v.T) / m_train # 更新偏差# 保存代价函数的值costs = -np.trace(np.dot(Y_train_onehot.T, np.log(Y_hat))) / m_traincosts_saved.append(costs.item(0))
# 打印最新权重与偏差
print('Weights=\n', np.array2string(W, precision=3))
print('Bias=', np.array2string(np.squeeze(b, axis=1), precision=3))
# 画代价函数值
plt.plot(range(1, np.size(costs_saved) + 1), costs_saved, 'r-o', linewidth=2, markersize=5)
plt.ylabel('costs')
plt.xlabel('iterations')
plt.title('learning rate=' + str(learning_rate))
plt.show()
# 训练数据集上的预测
z = np.dot(W.T, X_train) + b # 广播操作
Y_train_hat = np.argmax(z, axis=0) + 1
# 测试数据集上的预测
z_test = np.dot(W.T, X_test) + b # 广播操作
Y_test_hat = np.argmax(z_test, axis=0) + 1
# 分类错误数量
print('Trainset prediction errors=', np.sum(Y_train != Y_train_hat))
print('Testset prediction errors=', np.sum(Y_test != Y_test_hat))结果图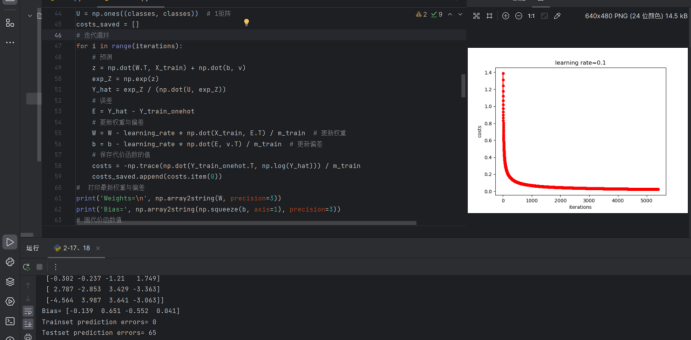
2、2-18实现二分类神经网络
代码
# 2-18 实现二分类神经网络
import pandas
import numpy as np
import matplotlib.pyplot as plt# 参数设置
iterations = 1000 # 迭代次数
learning_rate = 0.1 # 学习率
m_train = 250 # 训练样本的数量
n = 2 # 隐含层节点的数量
# 读入酒驾检测数据集
df = pandas.read_csv('alcohol_dataset.csv')
data = np.array(df)
m_all = np.shape(data)[0]
d = np.shape(data)[1] - 1
m_test = m_all - m_train
# 构造随机种子为指定值的随机数生成器,并对数据集中的样本随机排序
rng = np.random.default_rng(1)
rng.shuffle(data)
# 标准化输入特征
mean = np.mean(data[0:m_train, 0:d], axis=0)
std = np.std(data[0:m_train, 0:d], axis=0, ddof=1)
data[:, 0:d] = (data[:, 0:d] - mean) / std
# 划分数据集
X_train = data[0:m_train, 0:d].T
X_test = data[m_train:, 0:d].T
y_train = data[0:m_train, d].reshape((1, -1))
y_test = data[m_train:, d].reshape((1, -1))
# 初始化
W_1 = rng.random((d, n)) # W[1]
b_1 = rng.random((n, 1)) # b[1]
w_2 = rng.random((n, 1)) # w[2]
b_2 = rng.random() # b[2]
v = np.ones((1, m_train)).reshape((1, -1)) # v
costs_saved = []
for i in range(iterations):# 正向传播Z_1 = np.dot(W_1.T, X_train) + np.dot(b_1, v)A_1 = Z_1 * (Z_1 > 0)z_2 = np.dot(w_2.T, A_1) + b_2 * vy_hat = 1. / (1. + np.exp(-z_2))# 反向传播e = y_hat - y_traindb_2 = np.dot(v, e.T) / m_traindw_2 = np.dot(A_1, e.T) / m_traindb_1 = np.dot(w_2 * (Z_1 > 0), e.T) / m_traindW_1_dot = np.dot(w_2, e) * (Z_1 > 0)dW_1 = np.dot(X_train, dW_1_dot.T) / m_train# 更新权重与偏差参数b_1 = b_1 - learning_rate * db_1W_1 = W_1 - learning_rate * dW_1b_2 = b_2 - learning_rate * db_2w_2 = w_2 - learning_rate * dw_2# 保存代价函数的值costs = - (np.dot(np.log(y_hat), y_train.T) + np.dot(np.log(1 - y_hat), (1 - y_train).T)) / m_traincosts_saved.append(costs.item(0))
# 打印最新权重与偏差
print('W_[1] =\n', np.array2string(W_1, precision=3))
print('b_[1] =', np.array2string(np.squeeze(b_1, axis=1), precision=3))
print('w_[2] =', np.array2string(np.squeeze(w_2, axis=1), precision=3))
print(f'b_[2] = {b_2.item(0):.3f}')
# 画出代价函数的值
plt.plot(range(1, np.size(costs_saved) + 1), costs_saved, 'r-o', linewidth=2, markersize=5)
plt.ylabel('Costs')
plt.xlabel('Iterations')
plt.title('Learning rate = ' + str(learning_rate))
plt.show()
# 训练数据集上的预测
Z_1 = np.dot(W_1.T, X_train) + np.dot(b_1, v)
A_1 = Z_1 * (Z_1 > 0)
z_2 = np.dot(w_2.T, A_1) + b_2 * v
y_hat = 1. / (1. + np.exp(-z_2))
y_train_hat = y_hat >= 0.5
# 测试数据集上的预测
Z_1_test = np.dot(W_1.T, X_test) + b_1 # 广播操作
A_1_test = Z_1_test * (Z_1_test > 0)
z_2_test = np.dot(w_2.T, A_1_test) + b_2 # 广播操作
y_hat_test = 1. / (1. + np.exp(-z_2_test))
y_test_hat = y_hat_test >= 0.5
# 打印预测错误数量
print('Trainset prediction errors =', np.sum(y_train != y_train_hat))
print('Testset prediction errors =', np.sum(y_test != y_test_hat))
结果图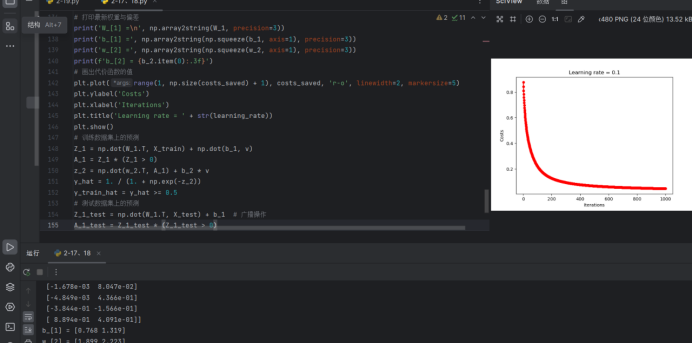
相关文章:
机器学习多分类逻辑回归和二分类神经网络实践
1、2-17 实现多分类逻辑回归 代码 # 2-17 实现多分类逻辑回归 import pandas as pd import numpy as np import matplotlib.pyplot as plt# 参数设置 iterations 5400 # 迭代次数 learning_rate 0.1 # 学习率 m_train 200 # 训练样本数量# 整数索引值转one-hot向量 def…...
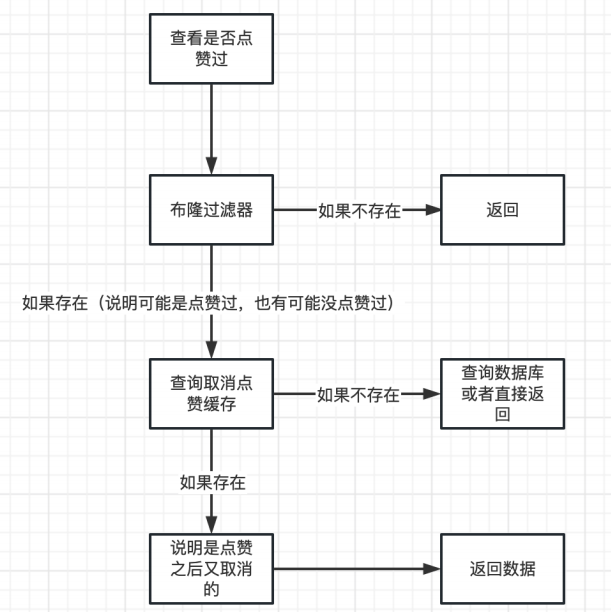
社交类网站设计:经典feed流系统架构详细设计(小红书微博等)
文章目录 一、关注服务1、粉丝、关注数架构设计(1)数据库实现方案1(2)数据库实现方案2(3)基于redis缓存优化(4)使用专用计数服务(5)近似计数(牺牲…...

K6 是什么
K6 是一款现代化的 开源性能测试工具,专注于开发者和 DevOps 团队的易用性,用于对 Web 应用、API 和微服务 进行高性能的负载测试。它采用 JavaScript 脚本编写测试用例,结合命令行工具和云原生设计,特别适合 CI/CD 集成 和 自动化…...

RISC-V PMA、PMP机制深入分析
1 PMA PMA(Physical Memory Attributes),物理内存属性,顾名思义就是用来设置物理内存属性的,但这里说“设置”,并不合理,因为一般情况下各存储的属性,在芯片设计时就固定了…...

git常见命令说明
git branch -avv -a 显示 所有分支-vv (--verbose 的缩写) 额外显示本地分支跟踪的远程分支(如 [origin/main])及其状态对比。 # git branch -v * main abc1234 修复登录bugdev def5678 更新文档# git branch -vv * main abc1234 …...

深入解析 Tomcat 线程管理机制:从设计思想到性能调优
一、Tomcat 线程模型的核心架构 Tomcat 的线程管理机制是其高性能的核心支撑,其设计围绕 Connector(连接器) 和 Executor(执行器) 两大组件展开。以下为架构分层解析: 1. Connector 的线程模型 Tomcat 的…...
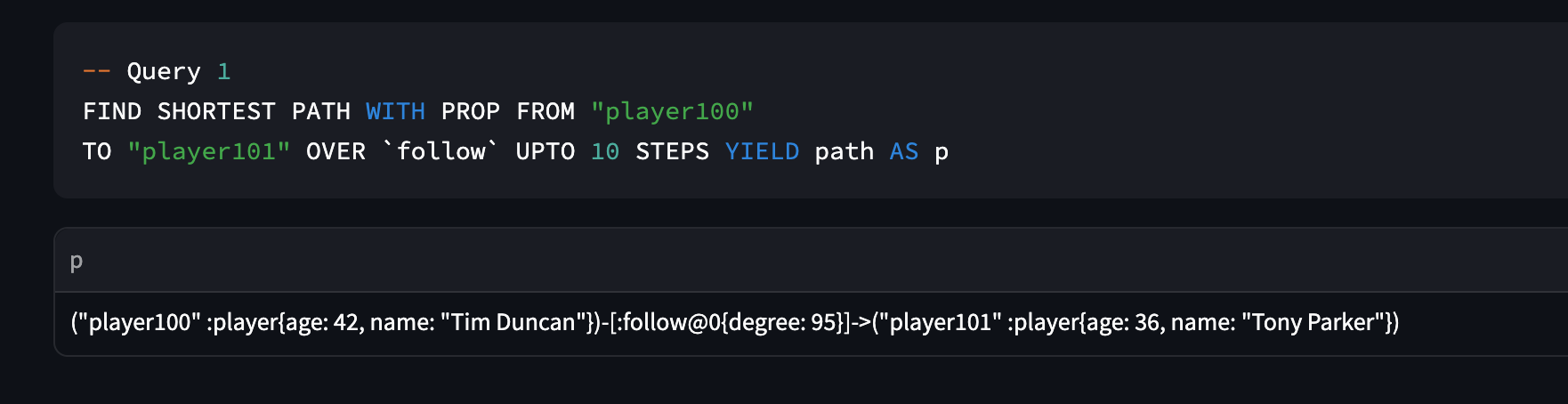
【NebulaGraph】查询案例(七)
【NebulaGraph】查询案例 七 1. 查询语句12. 查询语句23. 查询语句34. 查询语句4 1. 查询语句1 GO FROM "player100" OVER * YIELD type(edge) AS link, properties($$) AS properties,tostring(src(edge)) AS src,tostring(dst(edge)) AS dst, tags($$) AS tagLi…...
从“刚性扩容”到“弹性供给”:移动充电服务重构配电网边际成本
随着新能源技术的快速发展,电动汽车的普及对传统配电网提出了新的挑战。传统的“刚性扩容”模式依赖基础设施的物理扩建,不仅投资成本高,且难以应对动态变化的电力需求。在此背景下,“弹性供给”理念逐渐兴起,特别是移…...

Java与Docker容器化优化:从核心技术到生产实践
在2025年的云原生与微服务时代,容器化技术已成为企业级应用部署的标准,Docker作为主流容器平台,显著提升了应用的 portability、可扩展性和部署效率。根据CNCF 2024年报告,95%的企业在其生产环境中使用Docker,特别是金…...

QT单例模式简单讲解与实现
单例模式是一种创建型设计模式,确保一个类只有一个实例,并提供一个全局访问点。在QT开发中,单例模式常用于管理全局资源,如配置管理、日志系统等。 最简单的QT单例实现 方法一:静态局部变量实现(C11及以上…...

Vite Vue3 配置 Composition API 自动导入与项目插件拆分
为了提升开发效率,减少重复引入 ref、reactive、computed 等 Composition API 的繁琐操作,通过 unplugin-auto-import 插件实现自动导入。 1、配置自动导入 1.1 安装插件 npm install -D unplugin-auto-import1.2 配置 vite.config.js import { def…...

React从基础入门到高级实战:React 生态与工具 - React Query:异步状态管理
React Query:异步状态管理 引言 在现代Web开发中,异步数据管理是React应用开发中的核心挑战之一。无论是从远程API获取数据、处理用户交互,还是同步服务器状态,开发者都需要一种高效、可靠的方式来应对这些复杂场景。传统的状态…...
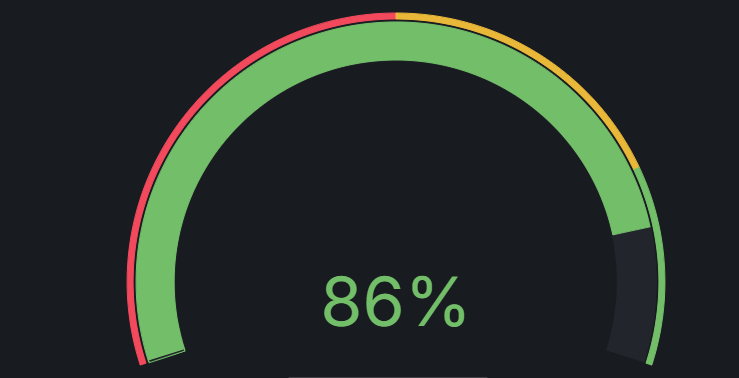
Grafana-Gauge仪表盘
仪表盘是一种单值可视化。 可让您快速直观地查看某个值落在定义的或计算出的最小和最大范围内的位置。 通过重复选项,您可以显示多个仪表盘,每个对应不同的序列、列或行。 支持的数据格式 单值 数据集中只有一个值,会生成一个显示数值的…...

按照状态实现自定义排序的方法
方法一:使用 MyBatis-Plus 的 QueryWrapper 自定义排序 在查询时动态构建排序规则,通过 CASE WHEN 语句实现优先级排序: import com.baomidou.mybatisplus.core.conditions.query.QueryWrapper; import org.springframework.stereotype.Ser…...

游戏引擎学习第313天:回到 Z 层级的工作
回顾并为今天的内容定下基调 昨天我们新增了每个元素级别的排序功能,并且采用了一种我们认为挺有意思的方法。原本计划采用一个更复杂的实现方式,但在中途实现的过程中,突然意识到其实有个更简单的做法,于是我们就改用了这个简单…...

论文阅读:arxiv 2024 SmoothLLM: Defending LLMs Against Jailbreaking Attacks
SmoothLLM: Defending LLMs Against Jailbreaking Attacks 总目录 大模型安全相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328 https://www.doubao.com/chat/6961264964140546 https://github.com/arobey1/smooth-llm https://arxiv.org/pd…...
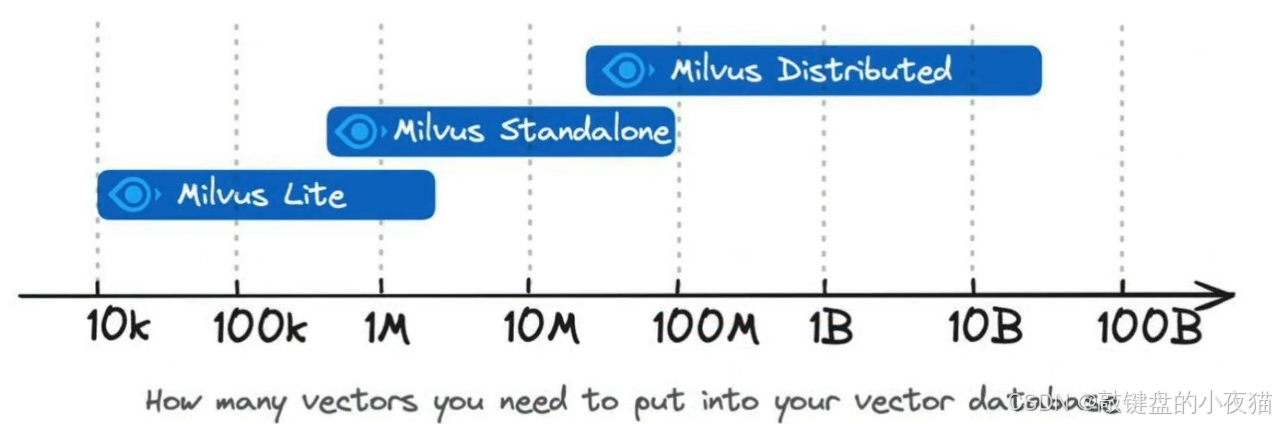
Milvus部署架构选择和Docker部署实战指南
导读:向量数据库作为AI时代的核心基础设施,Milvus凭借其强大的性能和灵活的架构设计在市场中占据重要地位。然而,许多开发者在部署Milvus时面临架构选择困惑和配置复杂性挑战,导致项目进展受阻。 本文将为您提供一套完整的Milvus部…...
高效合并 Excel 表格实用工具
软件介绍 这里介绍一款用于 Excel 合并的软件。 使用反馈与工具引入 之前推荐过 Excel 合并工具,但有小伙伴反馈这些工具对于需要合并单元格的 Excel 文件不太适用,而且无法合并表头。鉴于这些问题,找到了今天要介绍的这款 Excel 合并工具…...

【前端】Vue3 中实现两个组件的动态切换保活
在 Vue3 中实现两个组件的动态切换保活,核心是通过 <component> 动态组件与 <KeepAlive> 缓存组件的组合使用。以下是具体实现方案和进阶技巧: 一、基础实现方案 1. 动态组件 KeepAlive 保活 使用 <component :is> 实现动态切换&am…...
拉取gitlab项目
一、下载nvm管理node 先下载配置好nvm,再用nvm下载node 下载链接:开始 下载nvm - nvm中文官网 情况:npm i 下载依赖缓慢,可能是node版本不对,可能node版本太高 可能得问题:使用nvm 下载低版本的node时,…...

树莓派(Raspberry Pi)安装Docker教程
本章教程,主要介绍如何在树莓派上安装Docker。 一、安装步骤 # 卸载旧版本(如果有): for pkg in docker.io docker-doc docker-compose podman-docker containerd runc; do sudo apt-get remove $pkg;...

计算机视觉---YOLOv4
YOLOv4(You Only Look Once v4)于2020年由Alexey Bochkovskiy等人提出,是YOLO系列的重要里程碑。它在YOLOv3的基础上整合了当时最先进的计算机视觉技术,实现了检测速度与精度的显著提升。以下从主干网络、颈部网络、头部检测、训练…...

在雄性小鼠自发脑网络中定位记忆巩固的因果中枢
目录 简要总结 摘要 1 引言 2 方法 3 结果 简要总结 这篇文章主要研究了雄性小鼠在自发脑网络中记忆巩固的因果中枢定位。记忆巩固涉及学习后休息和睡眠期间全脑网络的自发重组,但具体机制尚不清楚。目前理论认为海马体在这一过程中至关重要,但其他…...

刷机维修进阶教程-----没有开启usb调试 如何在锁定机型的拨号界面特殊手段来开启ADB
有时候我们会遇到一些机型被屏幕锁 账号锁等锁定。无法进入系统界面。也没有开启usb调试的情况下如何通过一些操作来开启adb调试。然后通过adb指令来禁用对应的app顺利进入系统。以此来操作保数据等操作. 通过博文了解💝💝💝 1💝💝💝----了解一些品牌机型锁定状态…...

Selenium 测试框架 - Kotlin
🚀Selenium Kotlin 实践指南:以百度搜索为例的完整测试示例 随着测试自动化的普及,Selenium 已成为 Web 自动化测试的事实标准,而 Kotlin 凭借其简洁语法和高安全性,越来越受到开发者欢迎。本指南将通过一个完整的实战案例——在百度中执行搜索操作,来展示如何使用 Sele…...

docker运行centos提示Operation not permitted
在使用Docker运行CentOS容器时,遇到"Operation not permitted"错误,通常是由于权限问题或容器安全策略引起的。以下是详细的排查和解决步骤: 步骤一:检查Docker版本和系统更新 首先,确保你的Docker和系统软…...

010501上传下载_反弹shell-渗透命令-基础入门-网络安全
文章目录 1 上传下载2 反弹shell命令1. 正向连接(Forward Connection)正向连接示例(nc) 2. 反向连接(Reverse Connection)反向连接示例(反弹 Shell) 对比表格实际应用中的选择防御建…...
Flask集成Selenium实现网页截图
先看效果 程序实现的功能为:截取目标网址对应的页面,并将截取后的页面图片返回到用户端,用户可自由保存该截图。 支持的url参数如下: url:目标网址(必填项),字符串类型,…...

机顶盒CM311-5s纯手机免拆刷机,全网通,当贝桌面
需要用到的工具 安卓手机一台 甲壳虫adb助手(安卓app) OTG转换线一个(或者用usb,typec双头的U盘一个,未测试) 8g U盘一个 用到的刷机文件 1.放入手机中的文件 misc recovery 2. 放入U盘根目录 upda…...

知识图谱:AI时代语义认知的底层重构逻辑
在生成式人工智能(GEO)的技术架构中,知识图谱已从辅助性工具演变为驱动机器认知的核心神经中枢。它通过结构化语义网络的重构,正在突破传统数据处理的线性逻辑,建立机器对复杂业务场景的深度理解能力。 一、语义解构&a…...