使用LSTM进行时间序列分析
LSTM(长短期记忆网络,Long Short-Term Memory)是一种特殊的循环神经网络(RNN),专门用于处理时间序列数据。由于其独特的结构设计,LSTM能够有效地捕捉时间序列中的长期依赖关系,这使得它在时间序列分析中表现出色。以下是LSTM如何进行时间序列分析的详细步骤和原理:
1. 时间序列问题的特点
时间序列数据是指按照时间顺序排列的数据点,例如股票价格、天气记录、传感器数据等。这类数据通常具有以下特点:
- 时间依赖性:当前时刻的数据可能与过去多个时刻的数据相关。
- 长期依赖性:某些模式可能跨越较长时间间隔。
- 噪声和非线性:时间序列数据可能包含噪声,并且变化规律可能是非线性的。
传统的统计方法(如ARIMA)难以处理复杂的非线性和长期依赖关系,而LSTM通过其门控机制能够很好地解决这些问题。
2. LSTM的核心结构
LSTM通过引入三个门控单元(输入门、遗忘门、输出门)以及一个细胞状态(cell state)来控制信息的流动。这些组件帮助LSTM在时间序列中保留长期依赖信息并过滤无关信息。
主要组成部分:
- 细胞状态(Cell State):贯穿整个时间序列,负责存储长期信息。
- 遗忘门(Forget Gate):决定哪些信息从细胞状态中丢弃。
- 输入门(Input Gate):决定哪些新信息需要被写入细胞状态。
- 输出门(Output Gate):决定细胞状态的哪部分将作为当前时刻的输出。
数学公式:
假设当前时刻为 t t t,输入为 x t x_t xt,隐藏状态为 h t h_t ht,细胞状态为 C t C_t Ct:
-
遗忘门:
f t = σ ( W f ⋅ [ h t − 1 , x t ] + b f ) f_t = \sigma(W_f \cdot [h_{t-1}, x_t] + b_f) ft=σ(Wf⋅[ht−1,xt]+bf)
决定哪些信息从细胞状态中遗忘。 -
输入门:
i t = σ ( W i ⋅ [ h t − 1 , x t ] + b i ) i_t = \sigma(W_i \cdot [h_{t-1}, x_t] + b_i) it=σ(Wi⋅[ht−1,xt]+bi)
C ~ t = tanh ( W C ⋅ [ h t − 1 , x t ] + b C ) \tilde{C}_t = \tanh(W_C \cdot [h_{t-1}, x_t] + b_C) C~t=tanh(WC⋅[ht−1,xt]+bC)
决定哪些新信息需要被添加到细胞状态中。 -
更新细胞状态:
C t = f t ⋅ C t − 1 + i t ⋅ C ~ t C_t = f_t \cdot C_{t-1} + i_t \cdot \tilde{C}_t Ct=ft⋅Ct−1+it⋅C~t -
输出门:
o t = σ ( W o ⋅ [ h t − 1 , x t ] + b o ) o_t = \sigma(W_o \cdot [h_{t-1}, x_t] + b_o) ot=σ(Wo⋅[ht−1,xt]+bo)
h t = o t ⋅ tanh ( C t ) h_t = o_t \cdot \tanh(C_t) ht=ot⋅tanh(Ct)
决定当前时刻的输出。
3. LSTM在时间序列分析中的应用流程
以下是一个完整的基于 PyTorch 的 LSTM 时间序列分析案例。我们将使用一个简单的正弦波数据集,展示如何用 LSTM 模型进行时间序列预测。具体步骤如下:
- 生成时间序列数据:构造一个正弦波并添加噪声。
- 数据预处理:将时间序列转换为监督学习格式(输入为过去的若干时间步,输出为下一个时间步)。
- 构建 LSTM 模型:定义一个简单的 LSTM 网络。
- 训练模型:使用训练数据拟合模型。
- 预测与可视化:使用训练好的模型进行预测,并绘制结果。
以下是完整的 PyTorch 实现代码:
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt# (1) 数据准备
# 生成正弦波数据并添加噪声
np.random.seed(42)
time_steps = 1000
original_sequence = np.sin(np.linspace(0, 100, time_steps)) + np.random.normal(0, 0.1, time_steps)# 构造滑动窗口数据集
def create_dataset(sequence, look_back=1):X, y = [], []for i in range(len(sequence) - look_back):X.append(sequence[i:i+look_back])y.append(sequence[i+look_back])return np.array(X), np.array(y)look_back = 10 # 使用过去10个时间步预测下一个时间步
X, y = create_dataset(original_sequence, look_back)
X = torch.tensor(X, dtype=torch.float32).unsqueeze(-1) # 调整为LSTM输入格式 [样本数, 时间步, 特征数]
y = torch.tensor(y, dtype=torch.float32).unsqueeze(-1)# 划分训练集和测试集
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]# (2) 模型设计
class LSTMModel(nn.Module):def __init__(self, input_size=1, hidden_size=50, output_size=1, num_layers=1):super(LSTMModel, self).__init__()self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)self.fc = nn.Linear(hidden_size, output_size)def forward(self, x):lstm_out, _ = self.lstm(x) # lstm_out: [batch_size, seq_len, hidden_size]out = self.fc(lstm_out[:, -1, :]) # 取最后一个时间步的输出return outmodel = LSTMModel(input_size=1, hidden_size=50, output_size=1, num_layers=1)
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# (3) 训练模型
epochs = 200
for epoch in range(epochs):model.train()optimizer.zero_grad()outputs = model(X_train)loss = criterion(outputs, y_train)loss.backward()optimizer.step()if (epoch + 1) % 50 == 0:print(f"Epoch [{epoch+1}/{epochs}], Loss: {loss.item():.4f}")# (4) 预测
model.eval()
predicted_sequence = []
current_input = X[0].unsqueeze(0) # 初始化输入
with torch.no_grad():for i in range(len(X)):next_value = model(current_input)[0] # 预测下一个值predicted_sequence.append(next_value.item())# 更新输入序列current_input = torch.cat((current_input[:, 1:, :], next_value.unsqueeze(0).unsqueeze(0)), dim=1)# (5) 可视化
plt.figure(figsize=(12, 6))# 原始序列
plt.plot(original_sequence, label="Original Sequence", color="blue")# LSTM生成的序列
plt.plot(np.arange(look_back, len(original_sequence)), predicted_sequence, label="LSTM Predicted Sequence", color="r")plt.title("LSTM Time Series Prediction")
plt.xlabel("Time Step")
plt.ylabel("Value")
plt.legend()# plt.show()
plt.savefig(f'pmi/images/LSTM_result.png')
代码解析
(1)数据准备
- 我们生成了一个正弦波,并向其添加了随机噪声。
- 使用
create_dataset函数将时间序列转换为监督学习格式。每个输入样本包含过去look_back个时间步的数据,目标值为下一个时间步的值。
(2)LSTM 模型
- 定义了一个简单的 LSTM 模型,包含以下组件:
- LSTM 层:用于捕捉时间序列中的依赖关系。
- 全连接层:将 LSTM 的输出映射到目标值。
(3)训练模型
- 使用均方误差(MSE)作为损失函数,Adam 作为优化器。
- 在每个 epoch 中,计算预测值与真实值之间的损失,并通过反向传播更新模型参数。
(4)预测
- 使用训练好的模型逐点生成预测序列。
- 每次预测后,将预测值加入输入序列,以便生成下一个时间步的预测。
(5)可视化
- 使用 Matplotlib 绘制原始序列和 LSTM 模型生成的预测序列,方便对比。
运行结果

4. LSTM在时间序列分析中的优势
- 长期依赖性:LSTM通过细胞状态和门控机制,能够捕捉时间序列中的长期依赖关系。
- 鲁棒性:对噪声和非线性模式具有较好的适应性。
- 灵活性:可以处理单变量或多变量时间序列数据。
5. 常见变体与改进
在实际应用中,LSTM可能会结合其他技术以提升性能:
- 双向LSTM(BiLSTM):同时考虑时间序列的前向和后向信息。
- 堆叠LSTM(Stacked LSTM):通过多层LSTM提取更深层次的特征。
- 注意力机制(Attention Mechanism):增强模型对重要时间步的关注。
总结
LSTM是时间序列分析的强大工具,其核心在于通过门控机制有效捕捉长期依赖关系。通过合理的数据预处理、模型设计和训练策略,LSTM可以广泛应用于股票预测、天气预报、设备故障检测等领域。如果您有具体的时间序列分析任务或数据,欢迎提供更多信息,我可以进一步为您设计解决方案!
相关文章:
使用LSTM进行时间序列分析
LSTM(长短期记忆网络,Long Short-Term Memory)是一种特殊的循环神经网络(RNN),专门用于处理时间序列数据。由于其独特的结构设计,LSTM能够有效地捕捉时间序列中的长期依赖关系,这使得…...

【密码学——基础理论与应用】李子臣编著 第十三章 数字签名 课后习题
题目 逐题解析 13.1 知道p83,q41,h2,g4,x57,y77。 我看到答案,“消息M56”的意思居然是杂凑值,也就是传统公式的H(M)。 选择k23,那么r(g^k mod p) mod q 51 mod 4110,sk(H(M)xr) mod q29 ws mod q17,u1(mw) mod q9,u2(rw) m…...
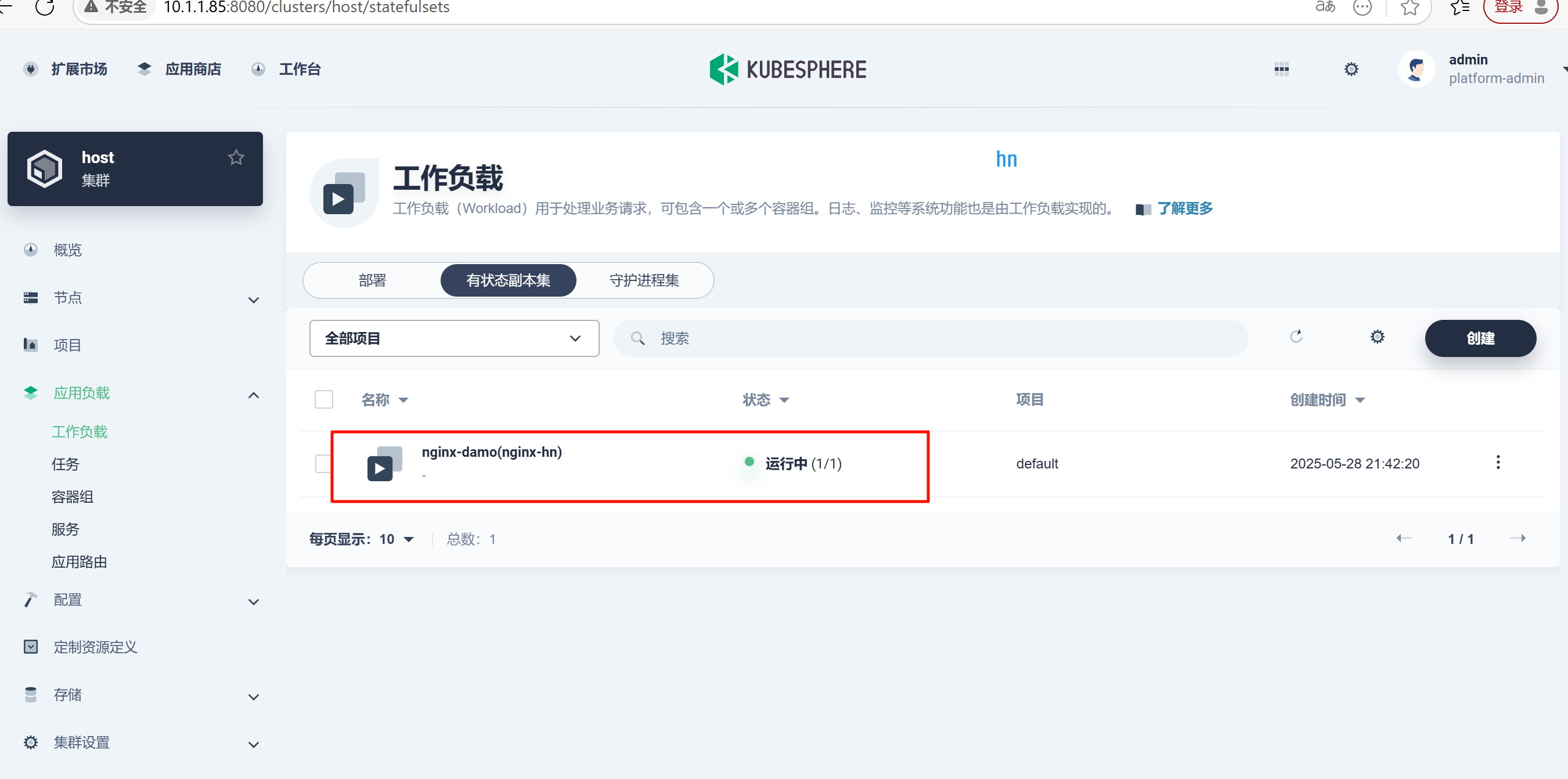
k8s中kubeSphere的安装使用+阿里云私有镜像仓库配置完整步骤
一、实验目的 1、掌握kubeSphere 的安装部署 2、掌握kubesphere 使用外部镜像仓库; 2、熟悉图像化部署任务:产生pod---定义服务--验证访问 本次实验旨在通过 KubeSphere 平台部署基于自定义镜像(nginx:1.26.0 )的有状态副本集…...

Agilent安捷伦Cary3500 UV vis光谱仪Cary60分光光度计Cary1003004000500060007000 UV visible
Agilent安捷伦Cary3500 UV vis光谱仪Cary60分光光度计Cary1003004000500060007000 UV visible...

JSON解析性能优化全攻略:协程调度器选择与线程池饥饿解决方案
简介 JSON解析是现代应用开发中的基础操作,但在使用协程处理时,若调度器选择不当,会导致性能严重下降。特别是当使用Dispatchers.IO处理JSON解析时,可能触发线程池饥饿,进而引发ANR或系统卡顿。本文将深入剖析这一问题的技术原理,提供全面的性能检测方法,并给出多种优化…...
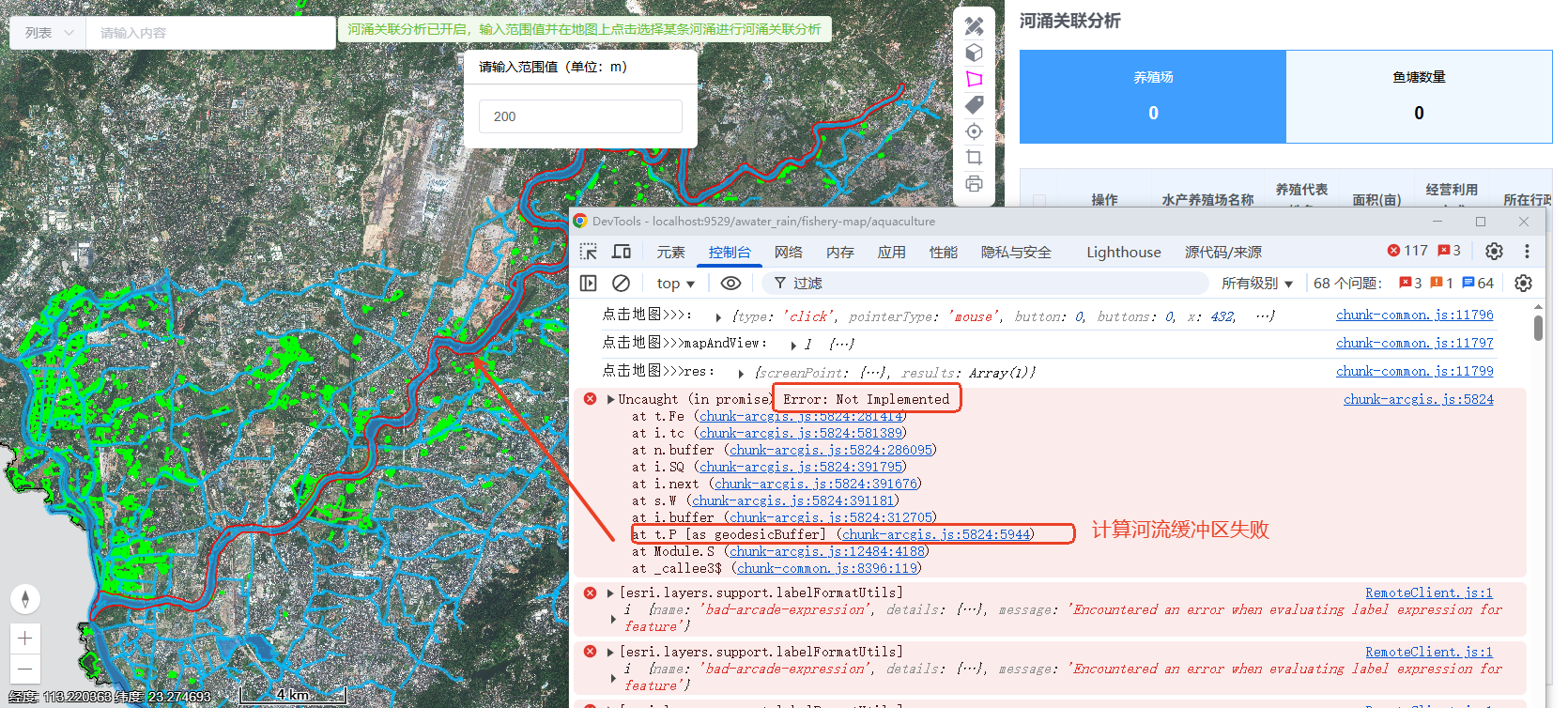
arcgis js 4.x 的geometryEngine计算距离、面积、缓冲区等报错、失败
在arcgis js 4.x版本中geometryEngine.geodesicArea计算面积时,有时会失败,失败的主要原因是,当前底图的坐标系不是WGS84大地坐标系(代号4326)或者web墨卡托投影(代号102113, 102100, 3857这三种之一&#…...

vSphere 7.0 client 提示HTTP状态 500- 内部服务器错误
1 .检查服务状态 通过5480端口登录vCenter管理界面(https://<vCenter_IP>:5480),查看自动启动的服务是否正常运行,尝试手动重启异常服务14若管理界面无法访问,通过SSH连接后执行命令:service-control --start --all 2. …...

用 Python 打造你的专属虚拟试衣间!——AI+AR 如何改变时尚体验
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

Java与Flutter集成开发跨平台应用:从核心概念到生产实践
在2025年的移动开发领域,跨平台技术已成为主流,Flutter凭借其高性能、统一的UI和跨平台能力,成为开发iOS、Android、Web和桌面应用的首选框架。根据2024年Stack Overflow开发者调查,Flutter的使用率增长了35%,特别是在…...
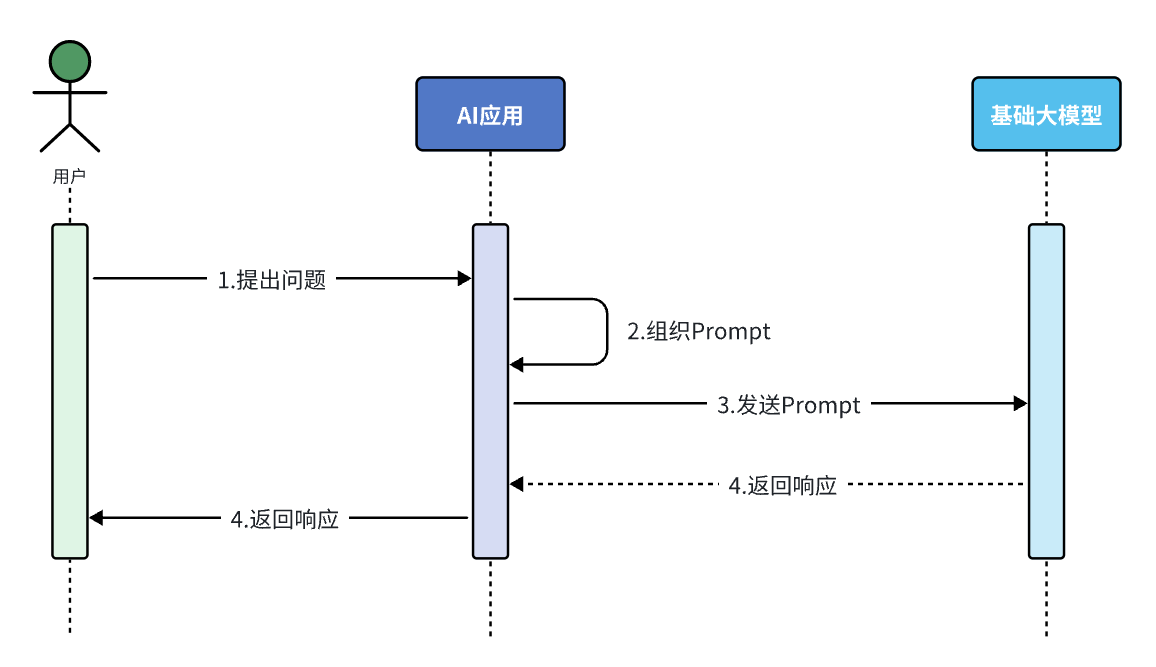
SpringAI 大模型应用开发篇-纯 Prompt 开发(舔狗模拟器)、Function Calling(智能客服)、RAG (知识库 ChatPDF)
🔥博客主页: 【小扳_-CSDN博客】 ❤感谢大家点赞👍收藏⭐评论✍ 文章目录 1.0 大模型应用开发技术框架 2.0 纯 Prompt 模式 2.1 核心策略 2.2 减少模型"幻觉"的技巧 2.3 提示词攻击防范 2.4 纯 Prompt 大模型开发(舔狗模拟器) 3.0 Function Calling 模式 3.1 …...

微信小程序的软件测试用例编写指南及示例--性能测试用例
以下是针对微信小程序的性能测试用例补充,结合代码逻辑和实际使用场景,从加载性能、渲染性能、资源占用、交互流畅度等维度设计测试点,并标注对应的优化方向: 一、加载性能测试用例 测试项测试工具/方法测试步骤预期结果优化方向冷启动加载耗时微信开发者工具「性能」面板…...

Unsupervised Learning-Word Embedding
传统的1 of N 的encoding无法让意义相近的词汇产生联系,word class可以将相近的词汇放到一起 但是word class不能表示class间的关系,所以引入了word embedding(词嵌入) 我们生成词向量是一种无监督的过程(没有label 自编码器是一种人工神经网络,主要用于无监督学习…...

远控安全进阶之战:TeamViewer/ToDesk/向日葵设备安全策略对比
【作者主页】Francek Chen 【文章摘要】在数字化时代,卓越的远程控制软件需兼顾功能与体验,包括流畅连接、高清画质、低门槛UI设计、毫秒级延迟及多功能性,同时要有独树一帜的远控安全技术,通过前瞻性安全策略阻挡网络风险&#x…...

变量的计算
不同类型变量之间的计算 数字型变量可以直接计算 在python中,数字型变量可以直接通过算术运算符计算bool型变量:True 对应数字1 ;False 对应数字0、 字符串变量 使用 拼接字符串 使用 * 拼接指定倍数的相同字符串 变量的输入:&…...

深入了解linux系统—— 库的制作和使用
什么是库? 库,简单来说就是现有的,成熟的代码; 就比如我们使用的C语言标准库,我们经常使用输入scanf和输出printf,都是库里面给我们实现好的,我们可以直接进行服用。 库呢又分为静态库和动态…...

Java中的设计模式:单例模式的深入探讨
单例模式的原理 单例模式的核心在于控制实例的数量。在Java中,类的实例化通常是由new关键字完成的。然而,单例模式通过将构造器私有化(private),阻止了外部通过new关键字直接创建类的实例。取而代之的是,单…...

View的工作流程——measure
1.DecorView被加载到Window当中 调用Activity的startActivity方法的时候,最终调用的是ActivityThread的handleLaunchActivity方法来创建Activity。 onResume方法也是在ActivityThread中的handleResumeActivity方法中被调用的,我们之前提到的DecorView就…...
)
【系统架构设计师】2025年上半年真题论文回忆版: 论软件测试方法及应用(包括解题思路和参考素材)
更多内容请见: 备考系统架构设计师-专栏介绍和目录 文章目录 真题题目(2025年上半年 试题4)解题思路1. 核心问题2. 论文目标3. 突出系统架构与 AI 的协同价值论文素材参考1、AI工具在生成测试用例过程中的具体应用2、AI测试用例生成的基本处理流程真题题目(2025年上半年 试…...
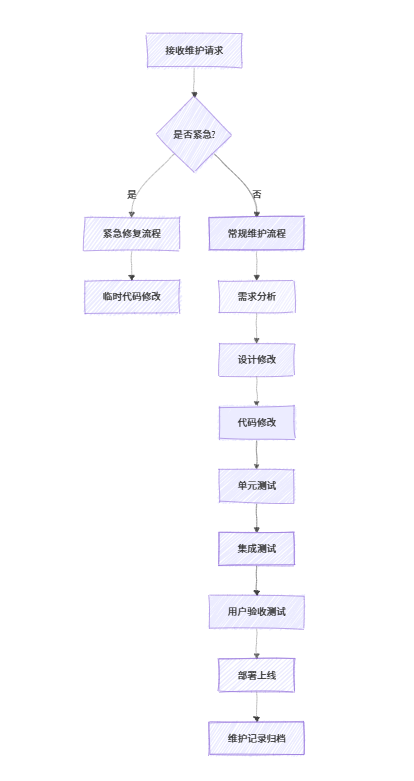
《软件工程》第 13 章 - 软件维护
知识思维导图 13.1 软件维护与进化的概念 1. 核心概念 软件维护:软件交付使用后,为纠正错误、改善性能或其他属性而进行的修改过程软件进化:随着时间推移,软件系统为适应环境变化和用户需求而不断演变的过程 2. 维护类型&#…...
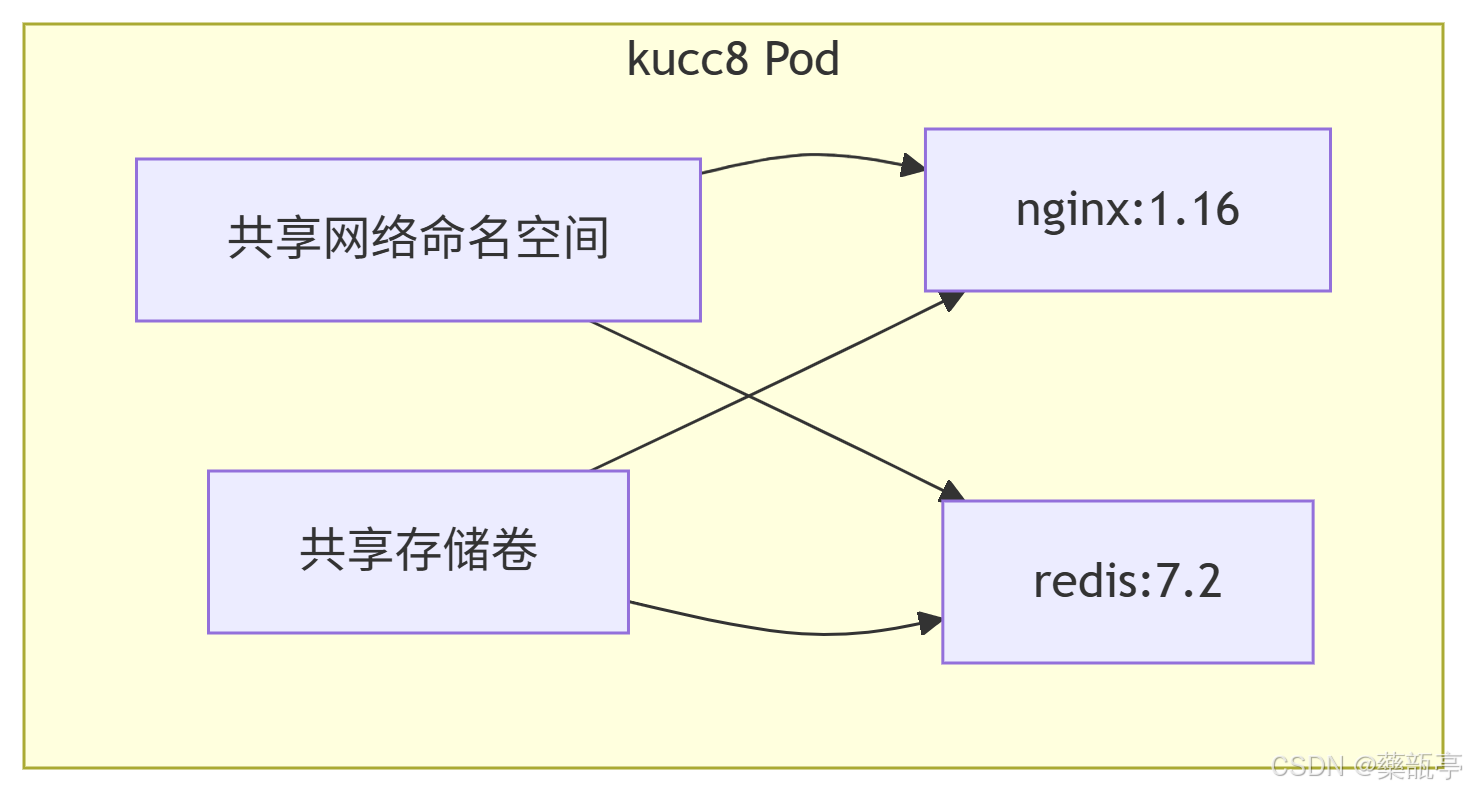
2024 CKA模拟系统制作 | Step-By-Step | 12、创建多容器Pod
目录 免费获取题库配套 CKA_v1.31_模拟系统 一、题目 二、考点分析 1. 多容器 Pod 的理解 2. YAML 配置规范 3. 镜像版本控制 三、考点详细讲解 1. 多容器 Pod 的工作原理 2. 容器端口冲突处理 3. 资源隔离机制 四、实验环境搭建步骤 总结 免费获取题库配套 CKA_v…...
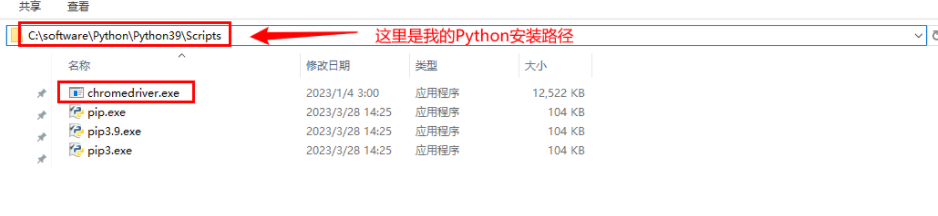
python:selenium爬取网站信息
关注我,精彩不错过! 前言 使用python的requests模块还是存在很大的局限性,例如:只发一次请求;针对ajax动态加载的网页则无法获取数据等等问题。特此,本章节将通过selenium模拟浏览器来完成更高级的爬虫抓…...

Nginx版本平滑迁移方案
Nginx版本平滑迁移方案 最可靠方案:make install后,先-s stop再重启,100%确保版本切换特殊情况:当发现nginx.pid.oldbin文件时,才考虑使用USR2信号无损升级避坑重点:make install只是替换文件,…...

WPF 按钮悬停动画效果实现
WPF 按钮悬停动画效果实现 下面我将实现一个专业的按钮悬停动画效果:当鼠标悬停在按钮上时,按钮上的文字由黑色变为白色,同时加粗并变大。 完整实现方案 MainWindow.xaml <Window x:Class"ButtonHoverEffect.MainWindow"xml…...

满天星之canvas实现【canvas】
展示 文章目录 展示Canvas 介绍【基础】简介兼容性关键特性注意事项应用场景:基本示例 满天星代码实现【重点】代码解释 全量代码【来吧,尽情复制吧少年】html引入JS代码 参考资源 Canvas 介绍【基础】 简介 Canvas是一个基于HTML5的绘图技术࿰…...

我在架构师面前谈 Spring Inner Beans,他直接点头说:这人有料!
“你听说了吗?阿里、字节最近的Java面试题又加难了!” “嗯?咋了?” “Spring又被拿出来问了,这次居然问到了Inner Beans!” “这不是冷门题吗?” “是啊,我一开始还真没答上来……” 是的!今天要跟大家唠嗑的,就是这个在面试中悄悄冒头,但平时开发中却经常被我们忽…...

Java无序数组 vs 有序数组:性能对比与选型指南
在Java中选择使用无序数组还是有序数组,需根据具体的应用需求和操作特性进行权衡。以下是从不同维度分析的详细对比及建议: 一、核心操作的性能对比 操作无序数组有序数组插入/追加O(1)(直接尾部插入)O(n)(需移动元素…...

【Linux 基础知识系列】第二篇-Linux 发行版概述
一、什么是 Linux 发行版? Linux 发行版是指将 Linux 内核和应用程序、工具、库等有机组合在一起,形成一个完整的操作系统。由于 Linux 的开源特性,任何人都可以在 Linux 内核的基础上进行修改和定制,因此产生了许多不同的发行版…...
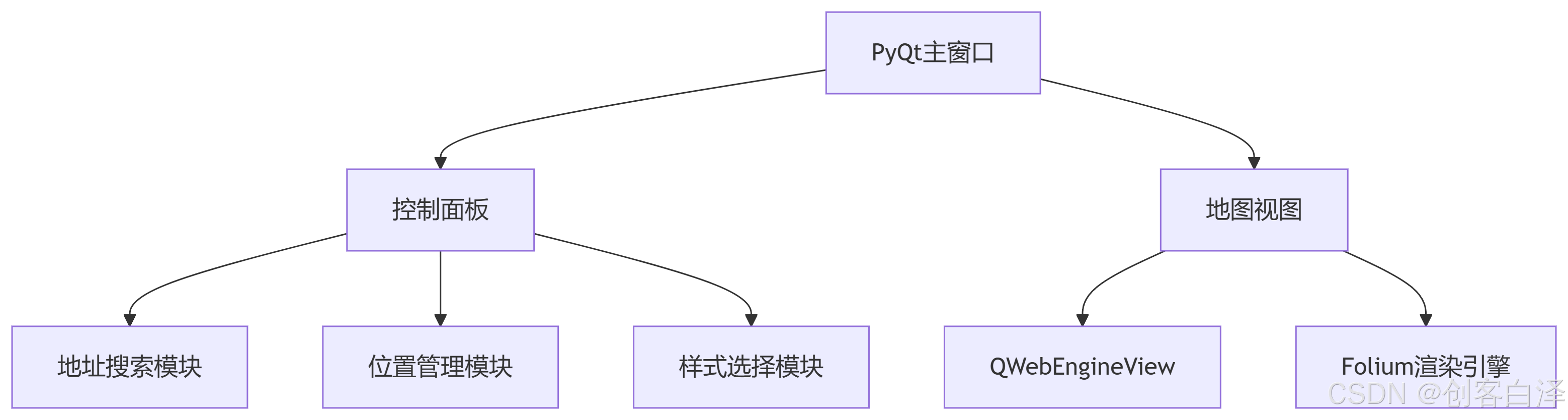
【开源解析】基于PyQt5+Folium的谷歌地图应用开发:从入门到实战
🌐【开源解析】基于PyQt5Folium的谷歌地图应用开发:从入门到实战 🌈 个人主页:创客白泽 - CSDN博客 🔥 系列专栏:🐍《Python开源项目实战》 💡 热爱不止于代码,热情源自每…...
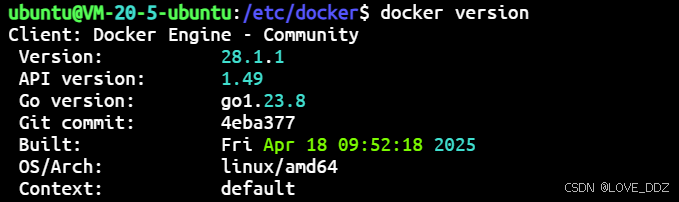
在 Ubuntu 22.04 LTS 上离线安装 Docker
在 Ubuntu 22.04 LTS 上离线安装 Docker 一、准备工作 1.1 获取目标系统信息 在目标 Ubuntu 22.04 LTS 系统上,先执行以下命令确认架构信息: uname -m lsb_release -a一般返回如下信息: 1.2 需要一台可联网的机器 准备一台可以连接互联网…...
python调用langchain实现RAG
一、安装langchain 安装依赖 python -m venv env.\env\Scripts\activatepip3 install langchainpip3 install langchain-corepip3 install langchain-openaipip3 install langchain-communitypip3 install dashscopepip3 install langchain_postgrespip3 install "psyc…...