day40 python图像数据与显存
目录
一、图像数据的处理与预处理
(一)图像数据的特点
(二)数据预处理
二、神经网络模型的定义
(一)黑白图像模型的定义
(二)彩色图像模型的定义
(三)模型定义与batch size的关系
三、显存占用的主要组成部分
(一)模型参数与梯度
(二)优化器状态
(三)数据批量(batch size)的显存占用
(四)前向/反向传播中间变量
四、batch size的选择与训练影响
一、图像数据的处理与预处理
(一)图像数据的特点
在深度学习中,图像数据与结构化数据(如表格数据)有着显著的区别。结构化数据的形状通常是(样本数,特征数),例如一个形状为(1000, 5)的表格数据表示有1000个样本,每个样本有5个特征。而图像数据需要保留空间信息(高度、宽度、通道数),因此不能直接用一维向量表示。例如,MNIST数据集是手写数字的灰度图像,其图像尺寸统一为28×28像素,通道数为1;而CIFAR-10数据集是彩色图像,图像尺寸为32×32像素,通道数为3。这种复杂性使得图像数据的处理需要特别的方法。
(二)数据预处理
数据预处理是深度学习中非常重要的一环。在处理图像数据时,通常会进行归一化和标准化操作。以MNIST数据集为例,使用transforms.ToTensor()可以将图像转换为张量并归一化到[0,1],然后通过transforms.Normalize((0.1307,), (0.3081,))进行标准化,其中(0.1307,)是均值,(0.3081,)是标准差。这些操作有助于提高模型的训练效果。
以下是完整的代码示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision import datasets, transforms
import matplotlib.pyplot as plt# 设置随机种子,确保结果可复现
torch.manual_seed(42)# 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 随机选择一张图片
sample_idx = torch.randint(0, len(train_dataset), size=(1,)).item()
image, label = train_dataset[sample_idx]# 可视化原始图像(需要反归一化)
def imshow(img):img = img * 0.3081 + 0.1307 # 反标准化npimg = img.numpy()plt.imshow(npimg[0], cmap='gray') # 显示灰度图像plt.show()print(f"Label: {label}")
imshow(image)二、神经网络模型的定义
(一)黑白图像模型的定义
以MNIST数据集为例,定义了一个两层的MLP(多层感知机)神经网络。模型中使用了nn.Flatten()将28×28的图像展平为784维向量,以符合全连接层的输入格式。第一层全连接层有784个输入和128个神经元,第二层全连接层有128个输入和10个输出(对应10个数字类别)。通过torchsummary.summary()可以查看模型的结构信息,包括各层的输出形状和参数数量。
以下是模型定义的代码:
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸(二)彩色图像模型的定义
对于CIFAR-10数据集,定义了一个适用于彩色图像的MLP模型。输入尺寸为3×32×32,展平后为3072维向量。模型结构与黑白图像模型类似,但输入尺寸和参数数量有所不同。通过这种方式,可以处理彩色图像数据。
以下是彩色图像模型的代码:
class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size=128, num_classes=10):super(MLP, self).__init__()# 展平层:将3×32×32的彩色图像转为一维向量# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072self.flatten = nn.Flatten()# 全连接层self.fc1 = nn.Linear(input_size, hidden_size) # 第一层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]x = self.relu(x) # 激活函数x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]return x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32)(三)模型定义与batch size的关系
在PyTorch中,模型定义和输入尺寸的指定不依赖于batch size。无论设置多大的batch size,模型结构和输入尺寸的写法都是不变的。torchsummary.summary()只需要指定样本的形状(通道×高×宽),而无需提及batch size。batch size是在数据加载阶段定义的,与模型结构无关。
以下是数据加载器的代码:
from torch.utils.data import DataLoader# 定义训练集的数据加载器,并指定batch_size
train_loader = DataLoader(dataset=train_dataset, # 加载的数据集batch_size=64, # 每次加载64张图像shuffle=True # 训练时打乱数据顺序
)# 定义测试集的数据加载器(通常batch_size更大,减少测试时间)
test_loader = DataLoader(dataset=test_dataset,batch_size=1000,shuffle=False
)三、显存占用的主要组成部分
在深度学习中,显存的合理使用至关重要。显存一般被以下内容占用:
(一)模型参数与梯度
模型的权重和对应的梯度会占用显存。以MNIST数据集和MLP模型为例,参数总量为101,770个。单精度(float32)参数占用约403 KB,梯度占用与参数相同,合计约806 KB。部分优化器(如Adam)会为每个参数存储动量和平方梯度,进一步增加显存占用。
(二)优化器状态
SGD优化器不存储额外动量,因此无额外显存占用。而Adam优化器会为每个参数存储动量和平方梯度,占用约806 KB。
(三)数据批量(batch size)的显存占用
单张图像的显存占用取决于其尺寸和数据类型。以MNIST数据集为例,单张图像显存占用约为3 KB。批量数据占用为batch size乘以单张图像占用。例如,batch size为64时,数据占用约为192 KB。
(四)前向/反向传播中间变量
对于两层MLP,中间变量(如layer1的输出)占用较小。以batch size为1024为例,中间变量占用约为512 KB。
以下是显存占用的计算代码示例:
# 显存占用计算示例
# 单精度(float32)参数占用
num_params = 101770
param_size = num_params * 4 # 每个参数占用4字节
print(f"模型参数占用显存:{param_size / 1024 / 1024:.2f} MB")# 梯度占用(反向传播时)
gradient_size = param_size
print(f"梯度占用显存:{gradient_size / 1024 / 1024:.2f} MB")# Adam优化器的额外占用
adam_extra_size = param_size * 2 # 动量和平方梯度
print(f"Adam优化器额外占用显存:{adam_extra_size / 1024 / 1024:.2f} MB")# 数据批量(batch size)的显存占用
batch_size = 64
image_size = 28 * 28 * 1 * 4 # 单张图像占用(通道×高×宽×字节数)
data_size = batch_size * image_size
print(f"批量数据占用显存:{data_size / 1024 / 1024:.2f} MB")四、batch size的选择与训练影响
在训练过程中,选择合适的batch size非常重要。如果batch size设置得太大,可能会导致显存不足(OOM);如果设置得过小,则无法充分利用显卡的计算能力。通常从较小的batch size(如16)开始测试,然后逐渐增加,直到出现OOM报错或训练效果下降。合适的batch size可以通过训练效果验证并结合显存占用情况进行调整。使用较大的batch size相比单样本训练有以下优势:并行计算能力最大化,减小训练时间;梯度方向更准确,训练过程更稳定。但需要注意的是,过大的batch size可能会导致训练效果下降,因此需要根据实际情况进行权衡。
以下是训练循环的代码示例:
# 训练循环示例
for epoch in range(num_epochs):for data, target in train_loader:data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()@浙大疏锦行
相关文章:

day40 python图像数据与显存
目录 一、图像数据的处理与预处理 (一)图像数据的特点 (二)数据预处理 二、神经网络模型的定义 (一)黑白图像模型的定义 (二)彩色图像模型的定义 (三)…...

Python+VR:如何让虚拟世界更懂你?——用户行为分析的实践
友友们好! 我是Echo_Wish,我的的新专栏《Python进阶》以及《Python!实战!》正式启动啦!这是专为那些渴望提升Python技能的朋友们量身打造的专栏,无论你是已经有一定基础的开发者,还是希望深入挖掘Python潜力的爱好者,这里都将是你不可错过的宝藏。 在这个专栏中,你将会…...

【华为鸿蒙电脑】首款鸿蒙电脑发布:MateBook Fold 非凡大师 MateBook Pro,擎云星河计划启动
文章目录 前言一、HUAWEI MateBook Fold 非凡大师(一)非凡设计(二)非凡显示(三)非凡科技(四)非凡系统(五)非凡体验 二、HUAWEI MateBook Pro三、预热…...

性能优化深度实践:突破vue应用性能
一、性能优化深度实践:突破 Vue 应用性能边界 1. 虚拟 DOM 性能边界分析 核心原理: 虚拟 DOM 是 Vue 的核心优化策略,通过 JS 对象描述真实 DOM 结构。当状态变化时: 生成新虚拟 DOM 树Diff 算法对比新旧树差异仅更新变化的真实…...

服务器定时任务查看和编辑
在 Ubuntu 系统中,查看当前系统中已开启的定时任务主要有以下几种方式,分别针对不同类型的定时任务管理方式(如 crontab、systemd timer 等): 查看服务器定时任务 一、查看用户级别的 Crontab 任务 每个用户都可以配…...
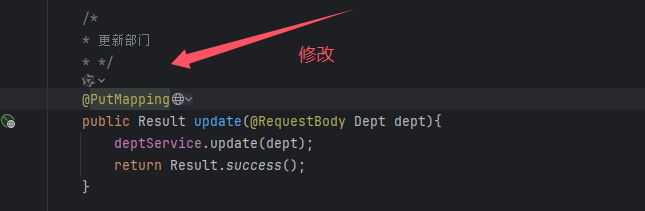
SpringBoot Controller接收参数方式, @RequestMapping
一. 通过原始的HttpServletRequest对象获取请求参数 二. 通过Spring提供的RequestParam注解,将请求参数绑定给方法参数 三. 如果请求参数名与形参变量名相同,直接定义方法形参即可接收。(省略RequestParam) 四. JSON格式的请求参数(POST、PUT) 主要在PO…...

double怎么在c/c++中输出保留输出最小精度为一位
在C中,使用std::cout输出double类型时,可以通过<iomanip>头文件中的std::fixed和std::setprecision来控制小数位数的输出。以下是几种常见场景的解决方案: 1. 输出至少1位小数(不足补零) #include <…...

端午节互动网站
端午节互动网站 项目介绍 这是一个基于 Vue 3 Vite 开发的端午节主题互动网站,旨在通过有趣的交互方式展示中国传统端午节文化。网站包含三个主要功能模块:端午节介绍、互动包粽子游戏和龙舟竞赛游戏。 预览网站:https://duanwujiekuaile…...

[特殊字符] NAT映射类型详解:从基础原理到应用场景全解析
网络地址转换(NAT)是解决IPv4地址短缺的核心技术,通过IP地址映射实现内网与公网的通信。本文将系统梳理NAT映射的三大类型及其子类,助你全面掌握其工作机制与应用场景。 目录 🔧 一、基础NAT映射类型:按转…...
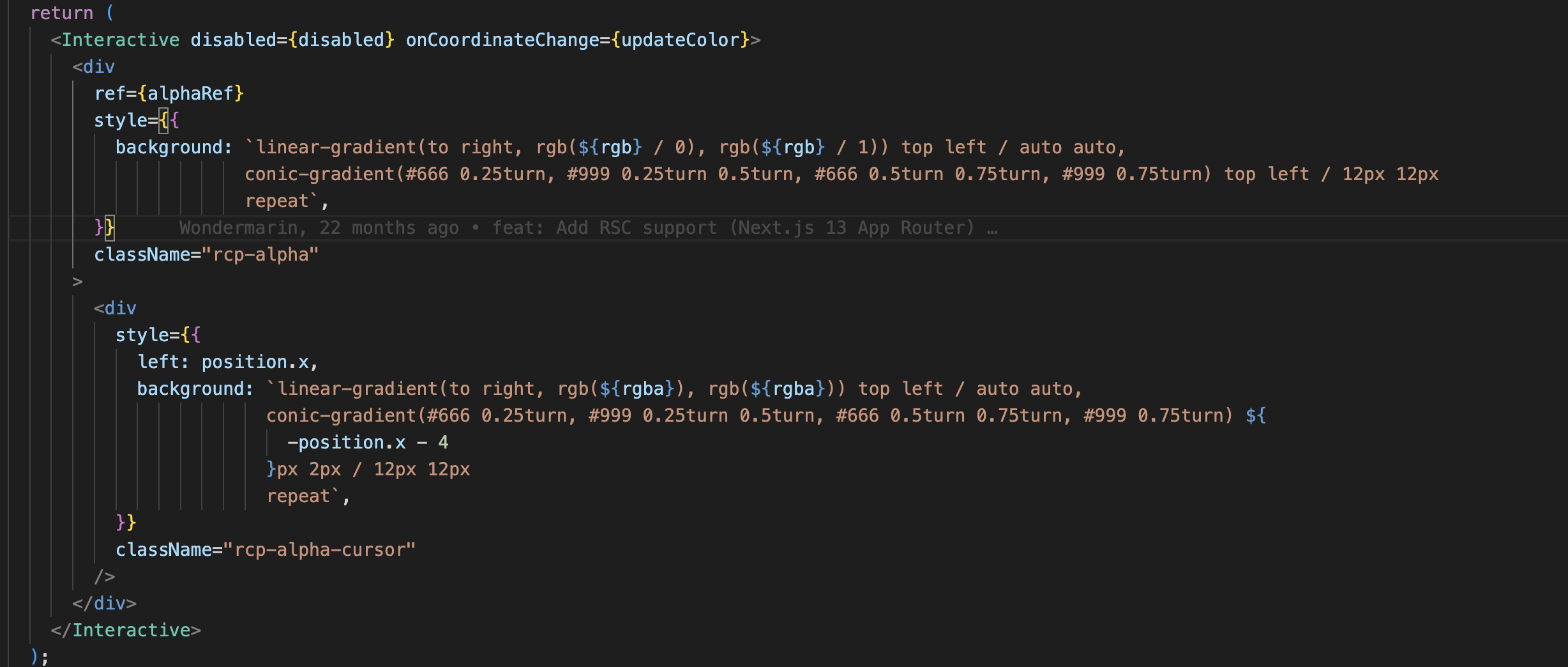
react-color-palette源码解析
项目中用到了react-color-palette组件,以前对第三方组件都是不求甚解,这次想了解一下其实现细节。 简介 react-color-palette 是一个用于创建颜色调色板的 React 组件。它提供了一个简单易用的接口,让开发者可以轻松地创建和管理颜色调色板。…...
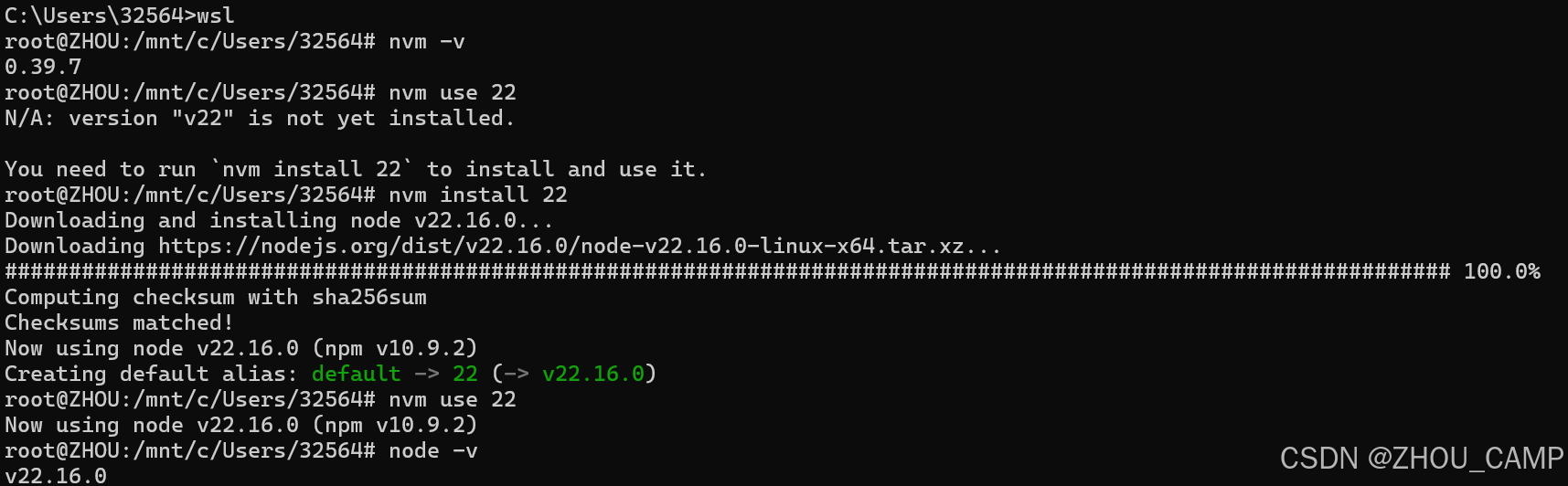
在 Ubuntu 上安装 NVM (Node Version Manager) 的步骤
NVM (Node Version Manager) 是一个用于管理多个 Node.js 版本的工具,它允许您在同一台设备上安装、切换和管理不同版本的 Node.js。以下是在 Ubuntu 上安装 NVM 的详细步骤: 安装前准备 可先在windows上安装ubuntu 参考链接:https://blog.…...

重温经典算法——插入排序
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 基本原理 插入排序是一种基于元素逐步插入的简单排序算法,其核心思想是将待排序序列分为已排序和未排序两部分,每次从未排序部分取出第一个元素&…...

在VirtualBox中打造高效开发环境:CentOS虚拟机安装与优化指南
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、为何选择VirtualBox CentOS组合? 对于程序员而言,构建隔离的开发测试环境是刚需。VirtualBox凭借其跨平台支持(W…...

塔能科技:为多行业工厂量身定制精准节能方案
在当今追求可持续发展的时代,工厂能耗精准节能成为众多企业关注的焦点。塔能科技凭借先进的技术和丰富的经验,服务于广泛的行业客户,其中55.5%来自世界500强和上市公司。针对不同行业工厂的特点和需求,塔能提供了一系列行之有效的…...
【实证分析】上市公司全要素生产率+5种测算方式(1999-2024年)
上市公司的全要素生产率(TFP)衡量企业在资本、劳动及中间投入之外,通过技术进步、管理效率和规模效应等因素提升产出的能力。与单纯的劳动生产率或资本生产率不同,TFP综合反映了企业创新能力、资源配置效率和组织优化水平…...

弥散制氧机工作机制:高原低氧环境的氧浓度重构技术
弥散制氧机通过空气分离与智能扩散技术,将氧气均匀分布于封闭或半封闭空间,实现环境氧浓度的主动调控。其核心在于 “分子筛吸附动态均布智能反馈” 的协同作用机制,为高原、矿井、医疗等场景提供系统性氧环境解决方案。 一、空气分离&#x…...

[Python] 避免 PyPDF2 写入 PDF 出现黑框问题:基于语言自动匹配系统字体的解决方案
在使用 Python 操作 PDF 文件时,尤其是在处理中文、日语等非拉丁字符语言时,常常会遇到一个令人头疼的问题——文字变成“黑框”或“方块”,这通常是由于缺少合适的字体支持所致。本文将介绍一种自动选择系统字体的方式,结合 PyPDF2 模块解决此类问题。 一、问题背景:黑框…...
《基于Keepalived+LVS+Web+NFS的高可用集群搭建》
目 录 1 项目概述 1.1 项目背景 1.2 项目功能 2 项目的部署 2.1 部署环境介绍 2.2 项目的拓扑结构 2.3 项目环境调试 2.4 项目的部署 2.5 项目功能的验证 2.6 项目对应服务使用的日志 3 项目的注意事项 3.1 常见问题与解决方案 3.2 项目适用背…...

RabbitMQ搭建集群
要在 Windows 或 Linux(CentOS 7.9) 上搭建 RabbitMQ 集群,基本思路是: 🗂️ 架构说明 主机角色IP节点名称A主节点10.152.132.1rabbitnode1B备节点10.152.132.2rabbitnode2 集群目标:两台 RabbitMQ 节点加…...
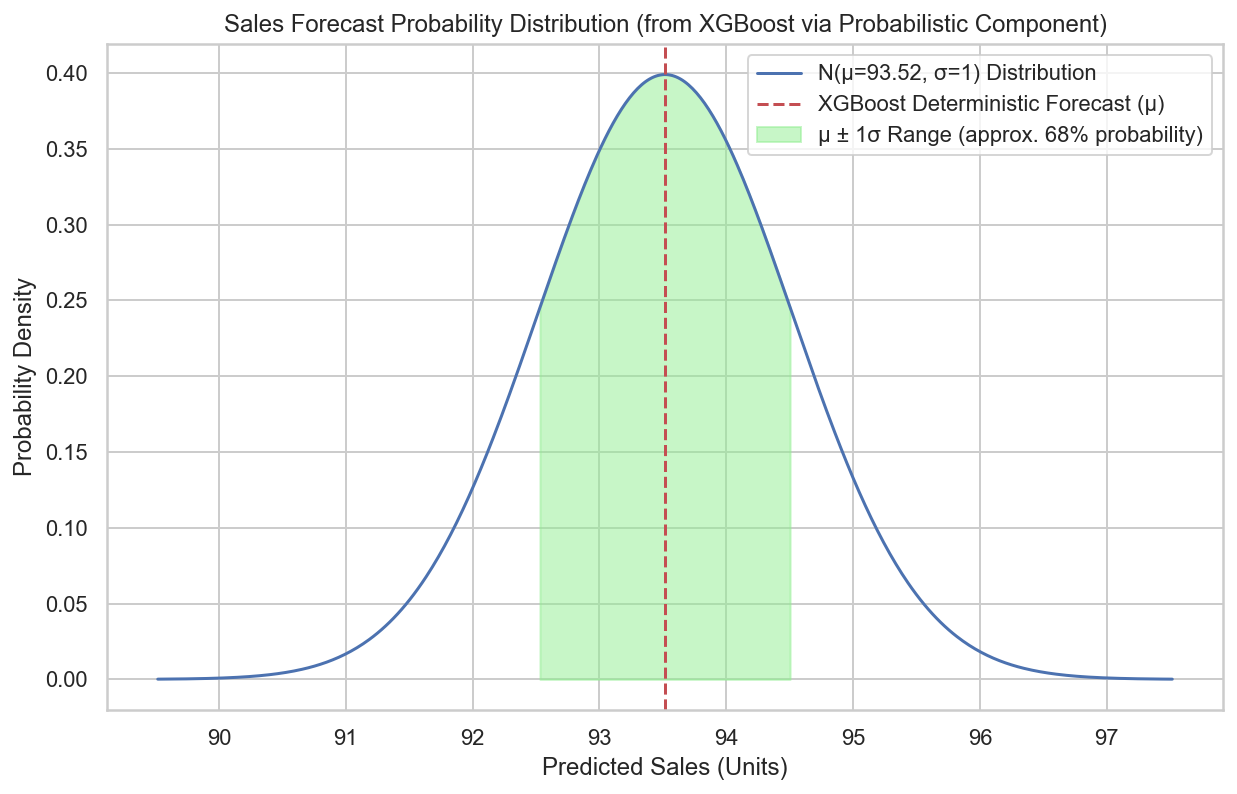
时间序列预测算法中的预测概率化笔记
文章目录 1 预测概率化的前情提要2 预测概率化的代码示例3 预测概率化在实际商业应用场景探索3.1 智能库存与供应链优化 1 预测概率化的前情提要 笔者看到【行业SOTA,京东首个自研十亿级时序大模型揭秘】提到: 预测概率化组件:由于大部分纯时…...

2025-05-28 Python深度学习8——优化器
文章目录 1 工作原理2 常见优化器2.1 SGD2.2 Adam 3 优化器参数4 学习率5 使用最佳实践 本文环境: Pycharm 2025.1Python 3.12.9Pytorch 2.6.0cu124 优化器 (Optimizer) 是深度学习中的核心组件,负责根据损失函数的梯度来更新模型的参数,使…...

篇章二 数据结构——前置知识(二)
目录 1. 包装类 1.1 包装类的概念 1.2 基本数据类型和对应的包装类 1.3 装箱和拆箱 1.4 自动装箱和自动拆箱 1.5 练习 —— 面试题 2. 泛型 2.1 如果没有泛型——会出现什么情况? 2.2 语法 2.3 裸类型 1.没有写<> 但是没有报错为什么? …...

如果是在服务器的tty2终端怎么查看登陆服务器的IP呢
1. 如果是在服务器的tty2终端怎么查看登陆服务器的IP呢 在服务器的 tty2 或其他终端会话中,要查看与该服务器的连接相关的 IP 地址,可以使用几种命令来获取这些信息: 1.1 使用 who 命令: who 命令可以显示当前登录到服务器上的…...

Java求职面试:从核心技术到AI与大数据的全面考核
Java求职面试:从核心技术到AI与大数据的全面考核 第一轮:基础框架与核心技术 面试官:谢飞机,咱们先从简单的开始。请你说说Spring Boot的启动过程。 谢飞机:嗯,Spring Boot启动的时候会自动扫描组件&…...

ubuntu24.04与ubuntu22.04比,有什么新特性?
Ubuntu 24.04 LTS (Noble Numbat) 相较于 Ubuntu 22.04 LTS (Jammy Jellyfish) 带来了许多重要的新特性和改进。以下是一些关键的亮点: Linux Kernel: Ubuntu 24.04 LTS: 搭载了更新的 Linux Kernel 6.8(发布时)。 Ubuntu 22.04 LTS: 发布时…...

Flutter Container组件、Text组件详解
目录 1. Container容器组件 1.1 Container使用 1.2 Container alignment使用 1.3 Container border边框使用 1.4 Container borderRadius圆角的使用 1.5 Container boxShadow阴影的使用 1.6 Container gradient背景颜色渐变 1.7 Container gradient RadialGradient 背景颜色渐…...

Telegram平台分发其聊天机器人Grok
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
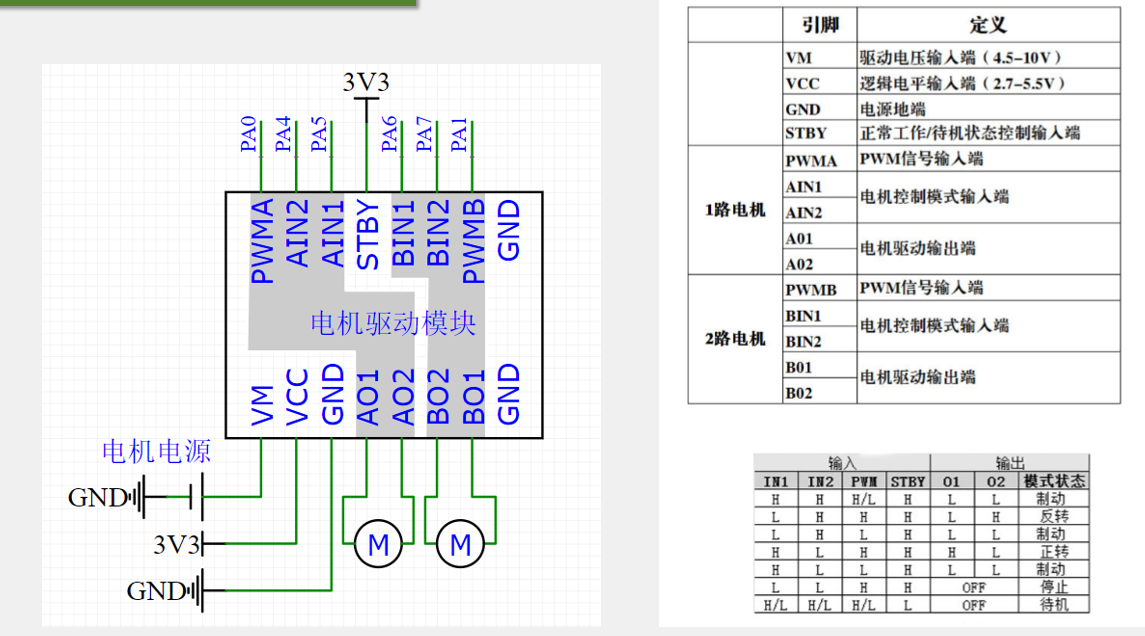
STM32 定时器输出比较深度解析:从原理到电机控制应用 (详解)
文章目录 定时器输出比较定时器通道结构输出比较通道(高级) PWM 信号原理输出比较 8 种工作模式互补输出概念极性选择内容 PWM硬件部分舵机直流电机及驱动简介 定时器输出比较 定时器通道结构 通道组成:定时器有四个通道,以通道一为例,中间是…...

用 NGINX 还原真实客户端 IP ngx_mail_realip_module
一、模块作用与使用前提 作用:解析 TCP 会话第一行的 PROXY 协议头,将客户端 IP/端口写回 NGINX 的内部变量,使后续 ngx_mail_proxy_module、认证模块、日志模块都能获取真实来源。 前提:监听指令中必须启用 proxy_protocol&…...

Mysql中索引B+树、最左前缀匹配
这里需要对索引的相关结构有一个基础的认识,比如线性索引,树形索引(二叉树,平衡二叉树,红黑树等),这个up主我觉得讲的还是比较清楚的,可以看下。 终于把B树搞明白了(一)_B树的引入…...