知识隔离的视觉-语言-动作模型:训练更快、运行更快、泛化更好
25年5月来自PI的论文“Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better”。
视觉-语言-动作 (VLA) 模型通过将端到端学习与来自网络规模视觉-语言模型 (VLM) 训练的语义知识迁移相结合,为机器人等物理系统训练控制策略提供了一种强大的方法。然而,实时控制的约束通常与 VLM 的设计相冲突:最强大的 VLM 拥有数百亿甚至数千亿个参数,这给实时推理带来障碍,并且 VLM 操作的是离散tokens,而不是控制机器人所需的连续值输出。为了应对这一挑战,近期的 VLA 模型使用了专门的模块来实现高效的连续控制,例如动作专家或连续输出头,这通常需要在预训练的 VLM 主干模型中添加新的未训练参数。虽然这些模块提升了实时性和控制能力,但它们是否会保留或降低预训练 VLM 中包含的语义知识,以及它们对 VLA 训练动态的影响,仍然是一个悬而未决的问题。本文在包含连续扩散或流匹配动作专家的 VLA 环境中研究了这个问题,结果表明,单纯地引入此类专家会严重损害训练速度和知识迁移。为此,本文对各种设计方案及其对性能和知识迁移的影响进行了广泛的分析,并提出一种在 VLA 训练期间隔离 VLM 主干网的技术,以缓解此问题。
大语言模型 (LLM) 的成功可以归因于大规模数据集的可用性,以及强大的模型架构,例如以预测下一个token为目标,在数万亿个tokens上进行训练的 Transformer。LLM 可以用于解决各种任务,从创作诗歌和代码到解决竞赛级数学问题,甚至可以进一步应用于解决视觉推理问题,并通过多模态编码器进行扩展,从而生成视觉语言模型 (VLM)。将 LLM 的强大功能引入物理世界的下一步自然是进一步扩展其以执行物理动作,从而生成视觉语言动作 (VLA) 模型,该模型可以控制机器人执行语言命令,将端到端机器人学习的强大功能与从网络规模的视觉语言预训练中提炼出的语义知识相结合 [59, 24, 7]。然而,将 LLM 和 VLM 应用于现实世界的控制需要应对许多新的挑战。大多数物理系统(例如机器人)需要连续且精确的指令,例如关节角度或目标姿态,这些指令必须以高频实时生成。离散tokens的自回归解码不太适合这种高频连续控制,这既因为离散化动作的分辨率有限,也因为大模型的自回归解码计算成本高昂,而模型规模越大,这一挑战就越严峻。
此外,物理系统通常会产生比训练 VLM 更复杂的观测数据,例如多视角图像和本体感受状态。这些差异使得需要修改原始 VLM 架构以适应机器人控制。
因此,机器人界已经开发出特别适合实时连续控制需求的架构 [54, 11, 45, 55, 7, 32, 6, 8, 25, 22]。虽然许多不同的设计都取得了成功,但一个共同的主题是,用于有效灵巧控制的模型通常会在Transformer或VLM主干上添加某种用于连续输入和输出的适配器,后者最常使用例如扩散或流匹配与动作块(未来动作的短序列)[54]。这使得模型能够表示复杂的连续动作分布,选择非常精确的动作,并捕捉灵巧的高频技能。然而,当将这些附加模块添加到预训练的VLM以创建VLA时,通常需要从头开始初始化它们,并且VLA训练过程必须将它们“嫁接”到VLM主干上。这就引出了一个重要的问题:添加了这些连续状态和动作适配器的VLA实际上在多大程度上继承并受益于网络规模的预训练?
π0 和 π0.5 模型。以 π0 [7] 和 π0-FAST [37] VLA 为基础。π0 引入连续动作专家,它可以捕捉动作块的复杂连续分布,实现高效推理,并支持对灵巧任务(例如叠衣服)的连续控制。然而,正如在实验中所展示的,π0 本身会导致语言跟随和训练速度的下降,因为来自动作专家的梯度会降低预训练的 VLM 主干模型性能。π0-FAST 通过使用token化动作解决了这个问题,它使用基于 DCT 的token化器,可以高效地离散化复杂的动作块,但代价是需要昂贵的自回归推理,并且会降低执行精细动态任务的能力,在实验中也证明了这一点。π0.5 [22] 首先仅使用 FAST token 化动作进行训练,然后在训练后添加一个随机初始化的动作专家,以便通过联合训练对移动操作数据进行微调。
先前用于微调具有连续输出的 VLM 的方法,由于依赖于来自连续适配器(例如扩散头)的梯度作为训练信号,可能会导致训练动态显著下降。这会降低 VLM 解释语言命令的能力,并降低最终 VLA 策略的整体性能。为了应对这一挑战,本文提出一种解决这些问题的训练方案,称之为知识隔离。知识隔离背后的关键思想,是使用离散化动作微调 VLM 主干网络,同时使动作专家适应生成连续动作(例如,通过流匹配或扩散),而不将其梯度传播回 VLM 主干网络,如图所示。实际上,离散动作tokens提供了一种替代学习信号,该信号不受动作专家未初始化权重的影响,因此 VLM 仍然可以学习适合机器人控制的表示,但不会受到动作专家梯度带来的干扰。
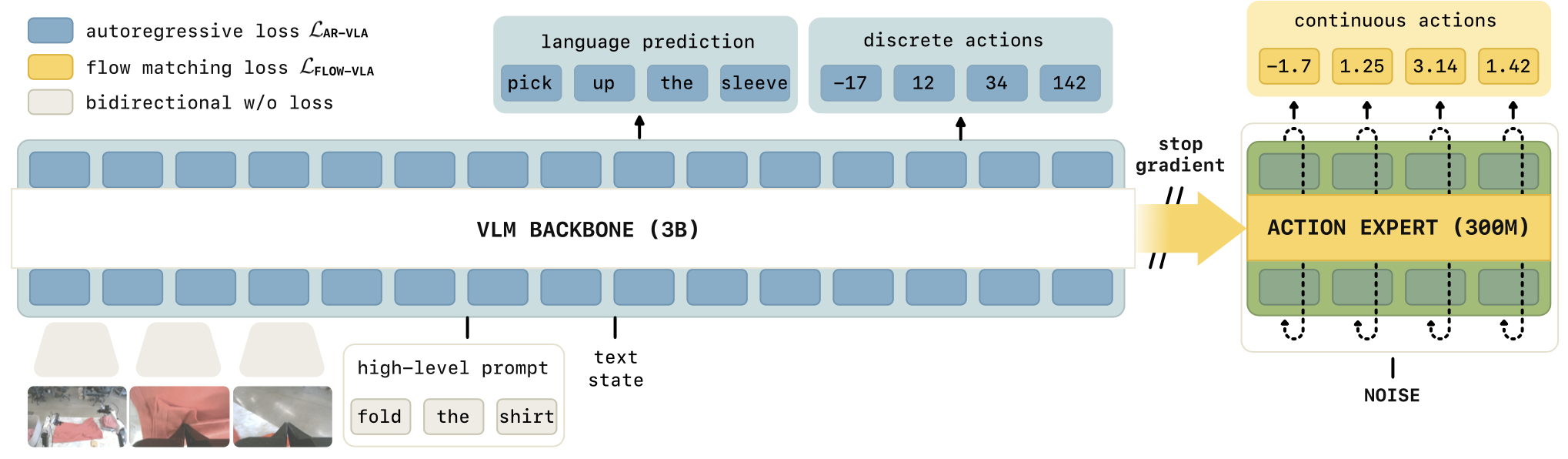
构建和训练视觉-语言-动作模型 (VLA) 的标准方法如下。训练 VLA π 的思路是调整视觉-语言模型 (VLM),使其输出机器人动作 a,该动作以图像观测 I_1:V、机器人本体感受状态 q 和自然语言指令 l 为输入,即 a ∼ π(·|_I1:V , q, l)。VLA 的优势在于,在根据机器人动作进行微调时,能够继承底层已在互联网规模数据上预训练的 VLM 的知识。
动作表示。在大多数情况下,机器人动作 a 是实值向量,通常表示机器人关节角度或末端执行器坐标。一种常见的策略是采用所谓的动作分块 [54],即预测机器人动作 a_1:H 相对于当前机器人状态的轨迹。为了使 VLM 适应 VLA,有多种选择来表示这些动作块。
简单离散化。在最简单的情况下,将块中每个动作的每个维度离散化,然后将每个离散化块与一个特殊的文本token 关联 [59]。这样,块 a_1:H 被映射到 H · d 个tokens。然后,机器人动作预测被构建为下一个token 预测问题,并且该模型可以像一个非机器人特定的、带有 交叉熵损失的可变长度语言模型 (VLM) 一样进行训练。
时间动作抽象。简单离散化的缺点在于,对于高频和高维系统,表示动作的tokens数量会快速增长,这大大增加了计算成本并导致训练收敛速度缓慢。近期的研究,例如 PRISE [57] 和 FAST [37],通过应用一种在时间上压缩信息的变换来缓解这种影响。用 FAST 对动作进行编码,该方法对动作块中的每个维度应用离散余弦变换,然后进行量化和字节对编码 [18] 以生成动作tokens。
扩散和流匹配。许多近期提出的 VLA 模型使用扩散或流匹配 [29, 35] 来生成连续动作,本文实验遵循 π0 的设计,使用流匹配“动作专家” [7],如上图所示。对于流匹配时间索引 τ ∈ [0, 1],模型的输入是动作块 a^1:H_τ,ω = τa_1:H+(1−τ)ω, ω∼N(0,I) 的噪声化版本,并且训练模型预测的投影将连续状态直接映射到主干网络(“连续状态”)。
VLA 架构、训练和专家混合。大多数 VLA 是由多模态Transformer构建的,通常使用预训练的 VLM 权重进行初始化。本文描述一种基于Transformer VLA 架构的通用形式。该模型将 n 个多模态输入tokens x_i 的序列映射到 n 个多模态输出 tokens y 序列上的概率。对于 VLA,通常 y = ya 对应于动作目标。之前的研究考虑联合训练一个模型用于动作预测和 VLM 任务(其中 y = yl 是 token 化的文本输出)[14, 59]。如其模态类型 ρ : i → {图像, 单词, 动作, 状态, . . . . . } 所示,每个 token 可以是文本 tokens (xl_i)、图像块 (xI_i) 或连续输入 (xi),例如机器人状态或动作。token 嵌入不同的编码器 φ_j : T_j → Rd_e,其中 T_j 是所有类型 j 的多模态 token 空间,d_e 是模型的嵌入维度。图像块使用视觉Transformer (Vision-Transformer) 进行编码,文本 token 带有嵌入矩阵,并通过仿射投影进行连续输入。注意掩码 A (ρ(i)) ∈ {−∞, 0} 指示哪些 tokens 可以相互关注。Transformer [47] 是一个函数 f,它将 n 个输入嵌入映射到 n 个输出嵌入。它通过堆叠多个块构建而成,这些块本身由注意层、前馈层和规范化层组成。令 X = x_1:n。标准Transformer中的注意层计算为 attn(X) = E(X)W_V ,其中 E(X) = P(X)V(X),P(X) = softmax(Q(X)K(X)^T),Q(·)、K(·)、V(·) 是所谓的 Q、K 和 V 投影,例如 Q(X) = XQ_m,d_q 是投影的维度。与标准 Transformer 相比,该模型使用不同的权重处理不同的 token,正如 [28] 中提出的。作为 π0 [7],从 PaliGemma [4] 中初始化 VLM,并对动作 token 使用较小的权重集,这显著减少生成动作时的推理时间。主干和动作 token 拥有各自的Q、K和V投影,但这些投影的维度 d_q、d_k、d_v 相同,以便专家之间可以相互交互。
大多数 VLA 都是在大型机器人行为克隆数据集上进行训练的。对于自回归架构,标准的训练程序是最小化目标 token 的负对数似然 LAR-VLA(θ)。在使用流匹配进行动作预测的情况下,损失会被修改 LFLOW-VLA(θ)。
如图将当前 VLA 训练方案中的问题可视化。 自回归 VLA 速度较慢。自回归 VLA 将预测实值动作的问题转化为离散的下一个token预测问题,这既限制了模型能够表示的值分辨率,也导致了缓慢的顺序推理。π0-FAST 在 RTX4090 GPU [37] 上预测 1 秒动作块的推理时间约为 750 毫秒,正如在实验中所展示的,这可能导致动态不匹配和整体轨迹缓慢。 机器人专用架构和模态适配器无法从 VLM 预训练中获益太多。像 π0 [7] 或 GROOT [6] 这样的架构包含机器人专用模块,可以实现更快的推理。例如,π0 架构中的动作专家比 VLM 主干网络的参数更少,因此 π0 可以实现 10 Hz 的控制频率,这比自回归 VLA(1.3 Hz)快得多。
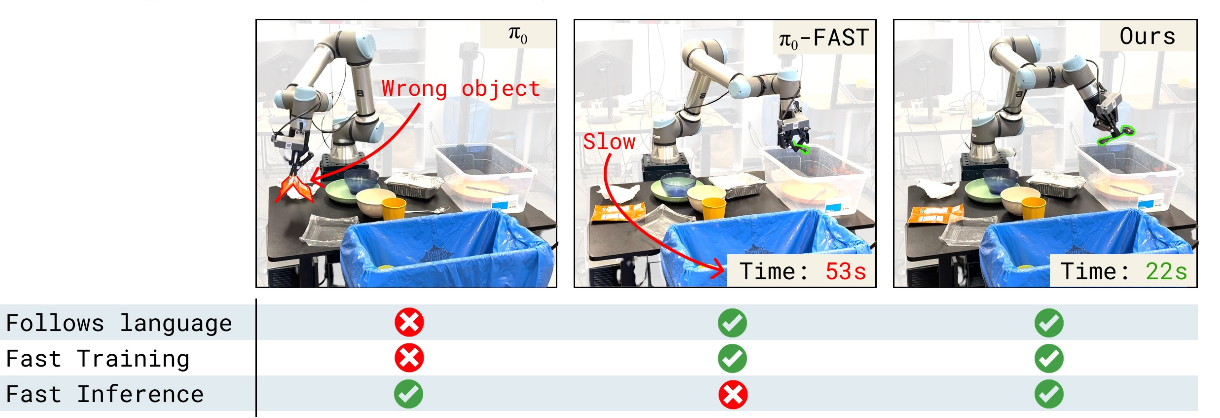
虽然这些模型的部分内容是从预训练的 VLM(例如视觉编码器或语言模型主干网络)初始化的,但机器人专用模块是从头初始化的。使用这种随机初始化的动作专家进行简单的训练会损害模型执行语言命令的能力(可能是由于梯度干扰)。 VLM 预训练没有足够的机器人表征——冻结不起作用。直观地说,维护 VLM 预训练知识并从而避免上述问题的最简单方法是冻结预训练的权重,仅训练新添加的、机器人专用的权重。然而,当前的 VLM 并未使用机器人数据进行预训练。因此,当它们的表征被冻结时,它们不足以训练出高性能的策略。
考虑了一系列措施来克服第四节中概述的先前 VLA 方法的局限性。具体而言,其提出:
- 同时联合训练自回归和流匹配动作预测模型(联合训练)。该模型使用(较小的)动作专家生成连续动作,以便在测试时进行快速推理。自回归目标仅在训练时用作表征学习目标,这使得模型的训练速度更快。
- 在非动作数据集(例如通用视觉-语言数据和机器人规划数据)上联合训练模型(VLM 数据联合训练)。在这些数据源上进行训练可确保模型在适应 VLA 时丢失更少的知识。
- 停止动作专家和主干网络权重之间的梯度流。这样,当将预训练的 VLM 适配到 VLA 时,动作专家新初始化的权重不会干扰预训练的权重。
联合训练和表征学习,结合离散/连续动作预测
为了实现与 VLM 数据的有效协同训练,增强从语言到策略的知识迁移,并实现快速训练,考虑将自回归语言和离散动作预测以及连续动作的流匹配建模结合到一个模型中。具体而言,学习一个模型,从中可以同时采样实值动作块 a_1:H 和文本 lˆ,即模型的输出空间为 y = (a_1:H , yl,a),其中 a_1:H 表示连续动作,yl,a 表示语言 token 和离散动作 token。用 FAST [37] token 化器将连续动作转换为离散 tokens。然后,可以从模型中联合采样动作和文本,(a, lˆ) ∼ π(·, ·|I_1:V , q, l),并使用 token 预测(参见 (L_AR-VLA)和流匹配损失(L_FLOW-VLA)的组合来训练模型,即 L_CO-VLA(θ)。
这种损失函数的构造,能够灵活地混合搭配不同模态的数据进行协同训练。具体而言,将 VLM 数据(仅包含图像和文本标注)与纯动作数据(任务是基于图像和文本的动作预测)以及语言和动作预测任务(其中采用纯动作数据,并额外使用语言描述对其进行标注,以说明机器人下一步应该做什么)相结合 [53]。以这种方式混合不同模态的数据可以增强生成的 VLA 中的知识迁移。lˆ 包含文本(语言)token 和 FAST token 化的动作 token。至关重要的是,设置注意掩码 A,使得任何离散的 FAST 动作 token 都无法关注连续的动作 token,反之亦然。在实验中,这种联合训练目标能够兼顾两者的优势:在训练过程中通过使用 FAST 动作 token 学习良好的表示获得了快速收敛,同时仍然可以通过几个流-集成步骤,获得连续动作的快速推理。
知识隔离与梯度流
使用流匹配训练的动作专家的梯度可能会对图像编码器和语言模型主干网络的训练动态产生不利影响;尤其是在将新的、随机初始化的动作专家添加到预训练的主干网络时。因此,停止从动作专家到模型中预训练权重的梯度流。当且仅当主干网络经过额外训练,能够将动作预测作为其语言输出的一部分时,这种限制才是合理的。
由于对离散动作进行联合训练,因此可以确保 Transformer 层的组合激活包含足够的信息来推断动作。预训练的模型主干网络和动作专家仅通过注意层进行交互。为了阻止从动作专家到主干网络的梯度流,需要按如下方式修改注意层。对于单头注意的情况,可以编写注意操作。结果是针对 token 特征的注意概率,这些概率分解为:来自 VLM 主干网络的特征关注主干网络特征 P_bb 的概率、动作专家特征关注主干网络特征 P_ab 的概率,以及动作专家特征关注其他动作专家特征 P_aa 的概率。鉴于此,可以通过相应地修改 softmax 计算的实现来根据需要限制信息流。
此设计的另一个优点是,可以简单地在 L_CO-VLA(θ) 中设置 α = 1,因为现在扩散损失项适用于一组独立的权重。
在现实世界中针对涵盖多种不同机器人实施例的灵巧、长视野操作任务评估方法(如图所示)。这些任务包括清洁桌子(“桌子清洁”);用双手静态机器人折叠衬衫(“衬衫折叠”);用单个静态机械臂将家居用品放入抽屉(“抽屉中物品”);以及涉及双手移动机械手的多个任务。对于后两者,仅在模型未见过任何数据的留空场景中评估模型进一步展示了在 LIBERO 模拟基准 [30] 和现实世界中的 DROID [23] 上的结果。既在单个机器人实施例上训练模型,也训练通用模型,后者使用来自许多不同机器人的大量混合数据进行训练,这些任务包括非动作预测任务,如图像字幕、边框预测和机器人规划。

通才模型基于一个包含 12 种机器人形态配置的大型数据集进行训练,其中包括单臂静态机械手(ARX、UR5、Franka)、双手静态机械手(ARX、AgileX、Trossen、UR5)和双手移动机械手(Trossen mobile、ARX slate、Galaxea G1、Hexmove H1、Fibocom)。这些机器人数据涵盖了各种各样的任务,远远超出了本文所考虑的评估任务(例如,在各种环境(包括办公室环境和真实家庭环境)下研磨咖啡豆或将毛巾挂在烤箱手柄上)。还纳入了开源 OXE 数据集 [36]。
使用各种通用 VLM 任务来训练通用模型。数据涵盖图像字幕制作(CapsFusion [52]、COCO [10])、视觉问答(Cambrian-7M [46]、PixMo [13]、VQAv2 [19])以及目标定位。对于目标定位,进一步扩展标准数据集,添加了带有边框标注的室内场景和家居物品网络数据。
使用 PaliGemma VLM [4] 架构作为 VLM 的主干,并使用其预训练权重对其进行初始化。动作专家是一个较小的 Transformer,它接收一系列带噪声的动作 aτ,ω_1:H,动作范围为 50,即 H = 50。首先使用单个线性层将带噪声的动作块投影到 Transformer 的嵌入维度。用 MLP 来投影 τ,然后应用自适应 RMSNorm 将时间步长信息注入动作专家的每一层。MLP 的形式为 swish(W2 · swish(W1 · φ(τ ))),其中 φ 是一个正弦位置编码函数 [47]。动作专家输出动作 token y^a_1:H,然后使用最终的线性投影将其解码为目标向量场。
VLM 主干网络和动作专家的维度如下:2B 语言模型主干网络的维度为 { width = 2048, depth = 18, mlp_dim = 16,384, num_heads = 18, num_kv_heads = 1, head_dim = 256 };动作专家的维度除 { width = 1024, mlp_dim = 4096} 外其他维度均相同,因此共有 3 亿个参数。
VLM 和动作专家的嵌入仅通过自注意力机制进行交互。图像、语言标记和文本状态使用完整前缀掩码;FAST 动作标记会关注此前缀,并自回归地关注先前的动作标记。动作专家的嵌入会关注前缀和彼此,但不关注 FAST 动作标记,以避免两种动作表示之间的信息泄漏。实际上,信息从 VLM 单向流向动作专家;没有任何 VLM 嵌入会关注动作专家。我们遵循π0对流匹配时间步长τ进行采样。总而言之,我们偏离了标准的均匀采样τ∼U(0,1)[29, 33]或强调中段时间步长的方法[16],而是使用强调低段时间步长的时间步长采样分布[7],该分布由p(τ) = Beta(s−τ/s; α=1.5, β=1), s=0.999 给出。
考虑机器人本体感受状态 q 的三种不同表示形式:
• 文本状态。此表示形式将状态离散化为 n_b 个容器,然后将这些容器转换为从 1 到 n_b 的数字。这些数字随后作为普通文本输入模型。这是以往 VLA 的标准方法。对于像 Gemma [44] 中的 token化器来说,这意味着最多需要⌊log10(nb) + 2)⌋ · s 个 tokens 来将状态表示为文本。
• 特殊标记状态。与“文本状态”类似,此表示形式直接使用离散化的容器,将每个容器与 VLM token化器中的一个特殊token关联起来。这需要 s 个tokens。
• 连续状态。此表示形式通过将实值向量 q 使用学习的仿射投影投影到 de 维嵌入空间,将其直接输入模型。
文本状态方法的优势在于,它最接近主干网络在预训练期间可能看到的内容,因为它只是自然文本中的数字序列,但它需要最多的 tokens。特殊 token 状态和连续状态都是模型的全新输入,并带有随机初始化的投影/嵌入。
相关文章:
知识隔离的视觉-语言-动作模型:训练更快、运行更快、泛化更好
25年5月来自PI的论文“Knowledge Insulating Vision-Language-Action Models: Train Fast, Run Fast, Generalize Better”。 视觉-语言-动作 (VLA) 模型通过将端到端学习与来自网络规模视觉-语言模型 (VLM) 训练的语义知识迁移相结合,为机器人等物理系统训练控制策…...
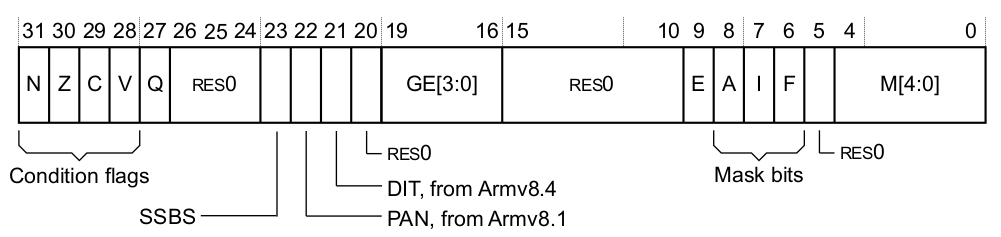
[ARM][架构] 02.AArch32 程序状态
目录 参考资料 1.程序状态 - PSTATE 2.用户模式的 PSTATE 信息 2.1.状态标志 2.2.溢出/饱和标志 2.3.大于等于标志 2.4.指令集状态 2.5.IT 块状态 2.6.端序控制 2.7.指令执行时间控制 3.用户模式访问 PSTATE - APSR 寄存器 4.系统模式的 PSTATE 信息 4.1.状态标志…...

Dockerfile正确写法之现代容器化构建的最佳实践
前言 在容器化的世界里,Dockerfile是构建镜像的核心,但你真的确定自己写的Dockerfile是最佳实践吗?根据我多年的容器化经验,大多数开发者编写的Dockerfile存在效率低下、安全隐患和维护困难等问题。本文将分享现代容器化环境中Dockerfile的正确编写方式,帮助你构建更高效…...

React---day4
3、React脚手架 生成的脚手架的目录结构 什么是PWA PWA全称Progressive Web App,即渐进式WEB应用;一个 PWA 应用首先是一个网页, 可以通过 Web 技术编写出一个网页应用;随后添加上 App Manifest 和 Service Worker 来实现 PWA 的安装和离线…...

ArkUI(方舟UI框架)介绍
ArkUI(方舟UI框架)介绍 构建快速入门 使用ArkWeb构建页面...

【Bug】定时任务中 Jpa Save 方法失效
【Bug】定时任务中 Jpa Save 方法失效 首先说一下问题,在定时任务中调用 jpa 的 save 方法没有效果,但是通过外界调用,比如 controller 中注入 service 来调用是可以的,真是巨巨巨离谱,我被折磨了好几天。 我这个问题…...

英语科研词汇现象及语言演变探讨
一、词汇形态学的进化困境 希腊-拉丁语系遗存 "Pneumoconiosis"(πνεύμωνκονίαωσις)和"electroencephalogram"(ηλεκτρονεγκέφαλοςγράμμα)的构词方式反映了欧洲学者对古…...

C# 打印PDF的常用方法
这里先提供一个helper类的模板 1.使用默认程序打印 using System; using System.Collections.Generic; using System.Diagnostics; using System.Drawing.Printing; using System.IO; using System.Runtime.InteropServices;namespace PDF {public static class PrintHelper{#…...
若依微服务的定制化服务
复制依赖 复制依赖 复制system服务的bootstrap.yml文件,修改port和name 在nacos复制一个新的nacos配置,修改对应的nacos的配置 ,可能不需要修改,看情况。 网关修改 注意curd的事项,模块名称的修改...

Axios 如何通过配置实现通过接口请求下载文件
前言 今天,我写了 《Nodejs 实现 Mysql 数据库的全量备份的代码演示》 和 《NodeJS 基于 Koa, 开发一个读取文件,并返回给客户端文件下载》 两篇文章。在这两篇文章中,我实现了数据库的备份,和提供数据库下载等接口。 但是&…...

小表驱动大表更快吗,不是
背景 head头表(5000),line行表(15万),导出数据包含头和行,一对多。 以行表为维度导出15万数据。 sql 如下两个sql查询,有如下差异 驱动方式:第一个大表驱动小表&…...

20250529-C#知识:运算符重载
C#知识:运算符重载 运算符重载能够让我们像值类型数据那样使用运算符对类或结构体进行运算,并且能够自定义运算逻辑。 1、运算符重载及完整代码示例 作用是让自定义的类或者结构体能够使用运算符运算符重载一定是public static的可以把运算符看成一个函…...

【HW系列】—目录扫描、口令爆破、远程RCE流量特征
本文仅用于技术研究,禁止用于非法用途。 文章目录 目录扫描漏洞的流量特征及检测方法一、基础流量特征二、工具特征差异三、绕过行为特征四、关联行为特征五、检测与防御建议 口令爆破漏洞的流量特征及检测方法一、基础流量特征二、工具标识特征三、绕过行为特征四…...
如何在WordPress网站中添加相册/画廊
在 WordPress 网站上添加相册可以让您展示许多照片。无论您是在寻找标准的网格相册画廊还是独特的瀑布流相册画廊体验,学习如何在 WordPress 网站上添加相册总是一个好主意。在本教程中,我们将介绍两种为 WordPress 网站添加相册的方法:使用区…...

【NLP基础知识系列课程-Tokenizer的前世今生第一课】Tokenizer 是什么?为什么重要?
语言的“颗粒度”:我们到底在切什么? 我们都知道模型要处理文本,第一步是把一段段字符变成“token”。但这些 token 究竟应该是句子、单词,还是更小的片段,比如“un break able”? 这背后涉及的是一个非…...

Codeforces Round 1025 (Div. 2)
Problem - A - Codeforces 查有没有人说谎,有一个必错的情况: 两个人都说输了,必有人撒谎,还有就是所有人都赢了,也是撒谎 来看代码: #include <iostream> #include <vector> using namespa…...
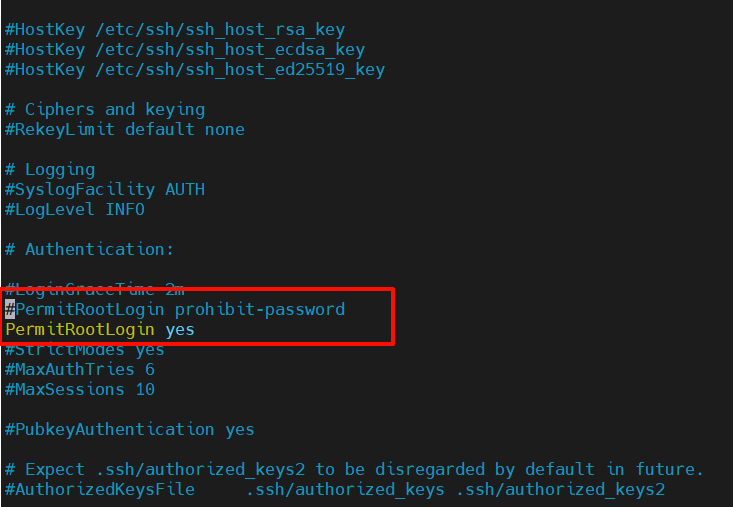
Ubuntu20.04操作系统ssh开启oot账户登录
文章目录 1 前提2 设置root密码3 允许ssh登录root账户3.1 编辑配置文件3.2 重启ssh服务 4 安全注意事项 1 前提 ssh可以使用普通用户正常登录。 2 设置root密码 打开终端,设置密码 sudo passwd root # 设置root密码3 允许ssh登录root账户 3.1 编辑配置文件 su…...

类欧几里得算法(floor_sum)
文章目录 普通floor_sum洛谷P5170 【模板】类欧几里得算法 万能欧几里得算法求 ∑ i 1 n A i B ⌊ a i b c ⌋ \sum_{i1}^{n}A^iB^{\lfloor \frac{aib}{c} \rfloor} ∑i1nAiB⌊caib⌋求 ∑ i 0 n ⌊ a i b c ⌋ \sum_{i0}^n \lfloor\frac{aib}{c}\rfloor ∑i0n⌊caib…...

每日Prompt:卵石拼画
提示词 世界卵石拼画大师杰作,极简风格,贾斯汀.贝特曼的风格,彩色的鹅卵石,斑马头像,鹅卵石拼画,马卡龙浅紫色背景,自然与艺术的结合,新兴的艺术创作形式,石头拼贴画&am…...

湖北理元理律师事务所观察:债务优化如何成为民生安全网
据央行2023年报告,中国家庭债务收入比达137.8%。面对债务高压,湖北理元理律师事务所的实践揭示:专业债务规划的价值不仅是减负数字,更是构建社会稳定的微观防线。 一、从“催收恐惧”到“主动管理”的转变 该所服务数据显示&…...
)
AI时代新词-机器学习即服务(MLaaS)
一、什么是机器学习即服务(MLaaS)? 机器学习即服务(Machine Learning as a Service,简称MLaaS)是一种云计算服务模式,它将机器学习工具和平台作为服务提供给用户。用户可以通过云平台访问机器学…...
规格模式)
设计模式简述(二十)规格模式
规格模式 描述组件 使用 描述 规格模式并不在传统的23设计模式中,属于后面扩展的设计模式。 简单描述就是对一批数据进行多条件(包括逻辑组合、有点装饰器的感觉,可以不断套娃)匹配。 组件 实体 package dp.spec;/*** TODO** …...
)
符合Python风格的对象(覆盖类属性)
覆盖类属性 Python 有个很独特的特性:类属性可用于为实例属性提供默认 值。Vector2d 中有个 typecode 类属性,bytes 方法两次用到了 它,而且都故意使用 self.typecode 读取它的值。因为 Vector2d 实 例本身没有 typecode 属性,所…...

题目 3314: 蓝桥杯2025年第十六届省赛真题-魔法科考试
题目 3314: 蓝桥杯2025年第十六届省赛真题-魔法科考试 时间限制: 3s 内存限制: 512MB 提交: 245 解决: 49 题目描述 小明正在参加魔法科的期末考试,考生需要根据给定的口诀组合出有效的 魔法。其中,老师给定了 n 个上半部分口诀 a1, a2, . . . , an 和 m…...

Java八股-Java优缺点,跨平台,jdk、jre、jvm关系,解释和编译
java优势劣势? 优势:面向对象,平台无关,垃圾回收,强大的生态系统 劣势:运行速度慢(相比于c和rust这样的原生编译语言会比较慢),语法繁琐(相比于python&…...

linux 内核态和用户态定时器函数使用总结
1,场景总结 定时器类型精度范围适用场景注意事项用户态信号定时器秒级简单任务调度、心跳检测信号处理函数中不可调用非异步安全函数timerfdepoll纳秒级高精度事件循环、多媒体处理需要配合IO多路复用机制使用内核timer_list毫秒级设备驱动、硬件交互基于jiffies时…...

支持selenium的chrome driver更新到136.0.7103.113
最近chrome释放新版本:136.0.7103.113 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only s…...

硬件服务器基础
1、硬件服务器基础 2、服务器后面板 3、组件 3.1 CPU 3.2 内存 3.3 硬盘 3.4 风扇 4、服务器品牌 4.1 配置 4.2 CPU 架构 4.2.1 CPU 命名规则 4.2.2 服务器 CPU 和家用 CPU 的区别 4.2.3 CPU 在主板的位置 4.2.4 常见 CPU 安装方式 4.3 内存中组件 4.3.1 内存的分类 4.3.1.1 …...

LVS的DR模式部署
目录 一、引言:高并发场景下的流量调度方案 二、LVS-DR 集群核心原理与架构设计 (一)工作原理与数据流向 数据包流向步骤3: (二)模式特性与53网络要求 三、实战配置:从9环境搭建到参数调整…...

TRS收益互换平台开发实践:从需求分析到系统实现
一、TRS业务概述 TRS(Total Return Swap)收益互换是一种金融衍生工具,允许投资者通过支付固定或浮动利息,换取标的资产(如股票、指数)的收益权。典型应用场景包括: 跨境投资ÿ…...