PaddleNLP 的文本分类项目
以下是一个基于 PaddleNLP 的文本分类项目,按照标准工程结构组织,并包含测试数据集和完整流程。这个示例使用ERNIE模型处理IMDB电影评论情感分析任务。
项目工程结构
ernie_sentiment_analysis/
├── data/ # 数据集目录
│ ├── train.csv # 训练数据
│ ├── dev.csv # 验证数据
│ └── test.csv # 测试数据
├── configs/ # 配置文件
│ └── train_config.json # 训练参数配置
├── src/ # 源代码
│ ├── data_loader.py # 数据加载与处理
│ ├── model.py # 模型定义
│ ├── train.py # 训练脚本
│ ├── evaluate.py # 评估脚本
│ └── predict.py # 预测脚本
├── utils/ # 工具函数
│ ├── logger.py # 日志工具
│ └── metrics.py # 评估指标
├── output/ # 模型输出目录
│ └── ernie_model/ # 保存的模型文件
├── inference/ # 推理模型
│ └── model/ # 导出的推理模型
├── requirements.txt # 依赖包
└── README.md # 项目说明
测试数据集示例
data/test.csv(电影评论情感分析):
text,label
This movie is really amazing! I love it.,1
The plot is so boring and the acting is terrible.,0
Best film I've seen this year. Highly recommended.,1
Waste of time and money. Avoid this film.,0
核心代码实现
1. 数据加载与处理 (src/data_loader.py)
import pandas as pd
import paddle
from paddlenlp.datasets import load_dataset
from paddlenlp.transformers import ErnieTokenizer
from paddlenlp.data import Stack, Tuple, Paddef read_csv(data_path):df = pd.read_csv(data_path)for _, row in df.iterrows():yield {'text': row['text'], 'label': row['label']}def get_dataloader(data_path, tokenizer, batch_size=32, max_seq_len=128, shuffle=False):# 加载数据集dataset = load_dataset(read_csv, data_path=data_path, lazy=False)# 数据处理函数def convert_example(example):encoded_inputs = tokenizer(text=example['text'],max_seq_len=max_seq_len,pad_to_max_seq_len=True)return {'input_ids': encoded_inputs['input_ids'],'token_type_ids': encoded_inputs['token_type_ids'],'labels': example['label']}# 转换数据集dataset = dataset.map(convert_example)# 批量处理batchify_fn = lambda samples, fn=Tuple(Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_idsPad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_idsStack(dtype="int64") # labels): fn(samples)# 创建数据加载器dataloader = paddle.io.DataLoader(dataset=dataset,batch_size=batch_size,shuffle=shuffle,collate_fn=batchify_fn)return dataloader
2. 模型定义 (src/model.py)
from paddlenlp.transformers import ErnieForSequenceClassificationdef create_model(num_classes, pretrained_model="ernie-1.0"):model = ErnieForSequenceClassification.from_pretrained(pretrained_model,num_classes=num_classes)return model
3. 训练脚本 (src/train.py)
import os
import json
import paddle
from paddlenlp.transformers import ErnieTokenizer
from data_loader import get_dataloader
from model import create_model
from utils.logger import setup_logger
from utils.metrics import compute_metrics# 加载配置
with open('../configs/train_config.json', 'r') as f:config = json.load(f)# 设置日志
logger = setup_logger('train')# 初始化设备
device = paddle.set_device('gpu' if paddle.is_available() else 'cpu')# 加载分词器和模型
tokenizer = ErnieTokenizer.from_pretrained(config['pretrained_model'])
model = create_model(num_classes=2, pretrained_model=config['pretrained_model'])
model.to(device)# 数据加载
train_dataloader = get_dataloader(data_path='../data/train.csv',tokenizer=tokenizer,batch_size=config['batch_size'],max_seq_len=config['max_seq_len'],shuffle=True
)dev_dataloader = get_dataloader(data_path='../data/dev.csv',tokenizer=tokenizer,batch_size=config['batch_size'],max_seq_len=config['max_seq_len']
)# 优化器和损失函数
optimizer = paddle.optimizer.AdamW(learning_rate=config['learning_rate'],parameters=model.parameters()
)
criterion = paddle.nn.CrossEntropyLoss()# 训练循环
for epoch in range(config['epochs']):model.train()total_loss = 0for batch in train_dataloader:input_ids, token_type_ids, labels = batchinput_ids = input_ids.to(device)token_type_ids = token_type_ids.to(device)labels = labels.to(device)logits = model(input_ids, token_type_ids)loss = criterion(logits, labels)loss.backward()optimizer.step()optimizer.clear_grad()total_loss += loss.item()# 验证model.eval()predictions, labels = [], []with paddle.no_grad():for batch in dev_dataloader:input_ids, token_type_ids, label = batchinput_ids = input_ids.to(device)token_type_ids = token_type_ids.to(device)logits = model(input_ids, token_type_ids)pred = paddle.argmax(logits, axis=1)predictions.extend(pred.cpu().numpy())labels.extend(label.cpu().numpy())metrics = compute_metrics(predictions, labels)logger.info(f'Epoch [{epoch+1}/{config["epochs"]}]')logger.info(f'Train Loss: {total_loss/len(train_dataloader):.4f}')logger.info(f'Dev Metrics: {metrics}')# 保存模型model.save_pretrained(os.path.join('../output/ernie_model', f'epoch_{epoch+1}'))tokenizer.save_pretrained(os.path.join('../output/ernie_model', f'epoch_{epoch+1}'))
4. 评估脚本 (src/evaluate.py)
import paddle
from paddlenlp.transformers import ErnieTokenizer
from data_loader import get_dataloader
from model import create_model
from utils.metrics import compute_metrics# 加载模型和分词器
model = create_model(num_classes=2)
model.set_state_dict(paddle.load('../output/ernie_model/best_model/model_state.pdparams'))
tokenizer = ErnieTokenizer.from_pretrained('../output/ernie_model/best_model')# 加载测试数据
test_dataloader = get_dataloader(data_path='../data/test.csv',tokenizer=tokenizer,batch_size=32
)# 评估
model.eval()
predictions, labels = [], []
with paddle.no_grad():for batch in test_dataloader:input_ids, token_type_ids, label = batchlogits = model(input_ids, token_type_ids)pred = paddle.argmax(logits, axis=1)predictions.extend(pred.numpy())labels.extend(label.numpy())# 计算指标
metrics = compute_metrics(predictions, labels)
print(f'Test Metrics: {metrics}')
5. 预测脚本 (src/predict.py)
import paddle
from paddlenlp.transformers import ErnieTokenizer
from model import create_modeldef predict(text, model, tokenizer, max_seq_len=128):model.eval()encoded_inputs = tokenizer(text=text,max_seq_len=max_seq_len,pad_to_max_seq_len=True,return_tensors='pd')with paddle.no_grad():logits = model(encoded_inputs['input_ids'], encoded_inputs['token_type_ids'])probs = paddle.nn.functional.softmax(logits, axis=1)pred = paddle.argmax(probs, axis=1).item()confidence = probs[0][pred].item()sentiment = 'Positive' if pred == 1 else 'Negative'return {'text': text,'sentiment': sentiment,'confidence': confidence}# 加载模型和分词器
model = create_model(num_classes=2)
model.set_state_dict(paddle.load('../output/ernie_model/best_model/model_state.pdparams'))
tokenizer = ErnieTokenizer.from_pretrained('../output/ernie_model/best_model')# 示例预测
text = "This movie is absolutely fantastic! I can't wait to watch it again."
result = predict(text, model, tokenizer)
print(f"预测结果: {result}")
配置文件示例 (configs/train_config.json)
{"pretrained_model": "ernie-1.0","batch_size": 32,"max_seq_len": 128,"learning_rate": 2e-5,"epochs": 3,"save_dir": "../output/ernie_model"
}
测试数据集生成脚本
import pandas as pd# 示例数据
data = {'text': ["This movie is really amazing! I love it.","The plot is so boring and the acting is terrible.","Best film I've seen this year. Highly recommended.","Waste of time and money. Avoid this film.","The special effects are incredible, but the story is weak.","I couldn't stop laughing. Great comedy!","Terrible. Don't waste your time.","A masterpiece. Definitely worth watching."],'label': [1, 0, 1, 0, 0, 1, 0, 1]
}# 创建DataFrame
df = pd.DataFrame(data)# 划分训练集、验证集和测试集
train_df = df.iloc[:5]
dev_df = df.iloc[5:7]
test_df = df.iloc[7:]# 保存到CSV
train_df.to_csv('data/train.csv', index=False)
dev_df.to_csv('data/dev.csv', index=False)
test_df.to_csv('data/test.csv', index=False)print("数据集生成完成!")
使用说明
-
安装依赖:
pip install -r requirements.txt -
训练模型:
python src/train.py -
评估模型:
python src/evaluate.py -
预测新文本:
python src/predict.py
扩展建议
- 添加更多任务:如命名实体识别、文本生成等。
- 增加模型选择:支持BERT、RoBERTa等不同预训练模型。
- 添加早停和模型选择:根据验证集性能自动选择最佳模型。
- 添加超参数调优:集成optuna等工具进行超参数搜索。
这个项目结构清晰,模块化程度高,便于扩展和维护,可以作为NLP项目的基础框架。
相关文章:

PaddleNLP 的文本分类项目
以下是一个基于 PaddleNLP 的文本分类项目,按照标准工程结构组织,并包含测试数据集和完整流程。这个示例使用ERNIE模型处理IMDB电影评论情感分析任务。 项目工程结构 ernie_sentiment_analysis/ ├── data/ # 数据集目录 │ ├─…...

git 一台电脑一个git账户,对应多个仓库ssh
生成ssh # 为账户A生成SSH密钥 ssh-keygen -t rsa -b 4096 -C "your_email_for_account_Aexample.com" -f ~/.ssh/id_ed25519 # 为账户B生成SSH密钥 ssh-keygen -t rsa -b 4096 -C "your_email_for_account_Bexample.com" -f ~/.ssh/id_rsa_yswq进入文件…...
node-DeepResearch开源ai程序用于深入调查查询,继续搜索、阅读网页、推理,直到找到答案
一、软件介绍 文末提供程序和源码下载 node-DeepResearch开源ai程序用于深入调查查询,继续搜索、阅读网页、推理,直到找到答案。 重要提示 与 OpenAI/Gemini/Perfasciity 的“深度研究”不同,我们只专注于通过迭代过程找到正确的答案 。我…...

Asp.Net Core 托管服务
文章目录 前言一、说明二、使用步骤1.创建托管服务方式一:继承 BackgroundService方式二:直接实现 IHostedService 2.注册托管服务3.处理作用域服务4.使用定时器(System.Threading.Timer)5.结合 Quartz.NET 实现复杂调度 三、. 注…...

Dockerfile 编写经验:优化大小与效率
文章目录 Dockerfile 通用的技巧总结1. 使用多阶段构建2. 最小化层数3. 彻底清理4. 选择合适的基镜像5. 仅安装必要的依赖6. 利用构建缓存 常见陷阱总结 Dockerfile 通用的技巧总结 1. 使用多阶段构建 利用多阶段构建分离构建和运行时环境,仅将必要的产物ÿ…...

JMeter 是什么
JMeter 是一款由 Apache 基金会开发的 开源性能测试工具,主要用于对 Web 应用、API、数据库、消息队列等系统进行 压力测试、负载测试和功能测试。它通过模拟大量用户并发操作,帮助开发者评估系统的性能、稳定性和扩展能力。以下是其核心特性和使用详解&…...

压测服务器和线上环境的区别
在进行服务器压测时,测试环境与线上环境的差异会直接影响测试结果的可靠性。以下是两者的关键区别及注意事项: 1. 压测服务器的常见类型 本地开发机:低配虚拟机(如4核8GB),仅用于功能验证…...

C#、C++、Java、Python 选择哪个好
选择哪种语言取决于具体需求:若关注性能和底层控制选C、若开发企业级应用选Java、若偏好快速开发和丰富生态选Python、若构建Windows生态应用选C#。 以Python为例,它因语法简洁、开发效率高、应用广泛而在AI、数据分析、Web开发等领域大放异彩。根据TIOB…...
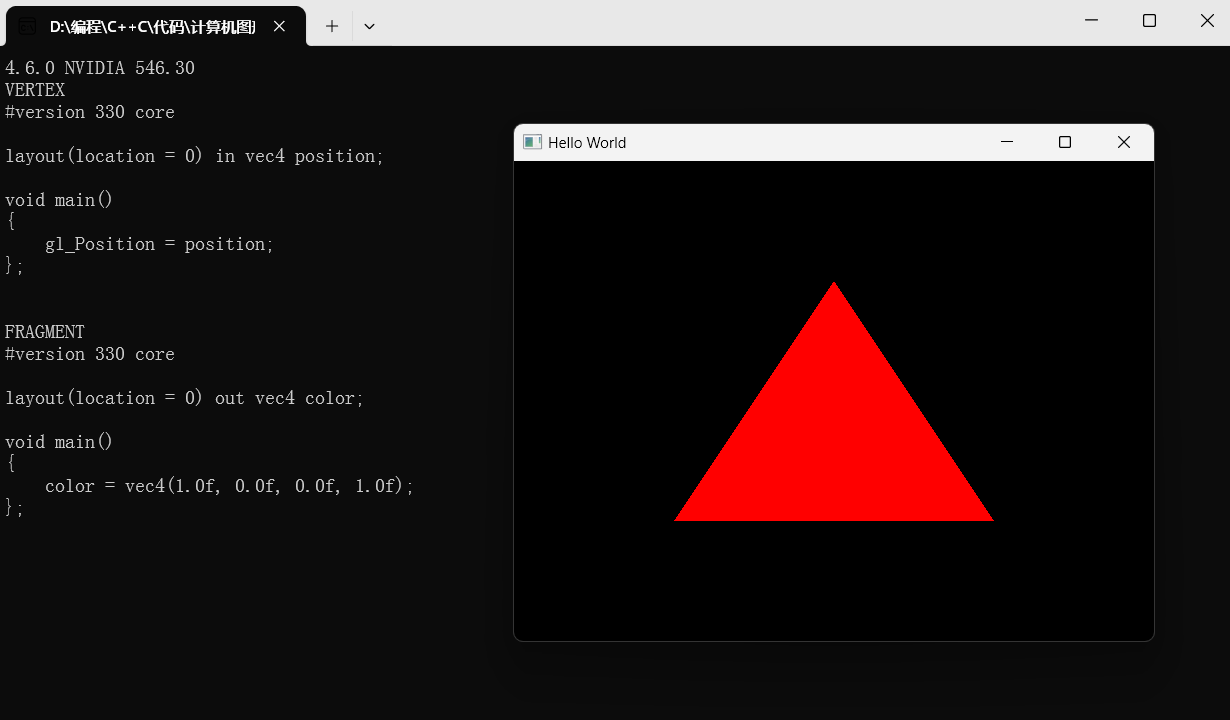
OpenGL Chan视频学习-8 How I Deal with Shaders in OpenGL
bilibili视频链接: 【最好的OpenGL教程之一】https://www.bilibili.com/video/BV1MJ411u7Bc?p5&vd_source44b77bde056381262ee55e448b9b1973 函数网站: docs.gl 说明: 1.之后就不再整理具体函数了,网站直接翻译会更直观也…...
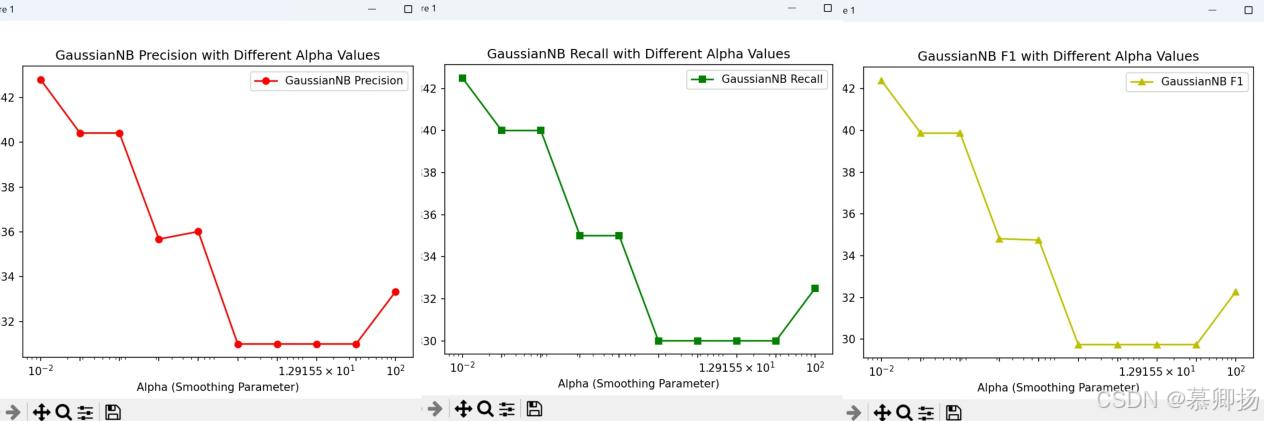
机器学习课程设计报告 —— 基于口红数据集的情感分析
目录 一、课程设计目的 二、数据预处理及分析 2.1 数据预处理 2.2 数据分析 三、特征选择 3.1 特征选择的重要性 3.2 如何进行特征选择 3.3 特征选择的依据 3.4 数据集的划分 四、模型训练与模型评估 4.1 所有算法模型不调参 4.2 K-近邻分类模型 4.3 GaussianNB模…...

Windows安装Docker部署dify,接入阿里云api-key进行rag测试
一、安装docker 1.1 傻瓜式安装docker Get Docker | Docker Docs Docker原理(图解秒懂史上最全)-CSDN博客 官网选择好windows的安装包下载,傻瓜式安装。如果出现下面的报错,说明主机没有安装WSL 1.2 解决办法 安装 WSL | Mic…...
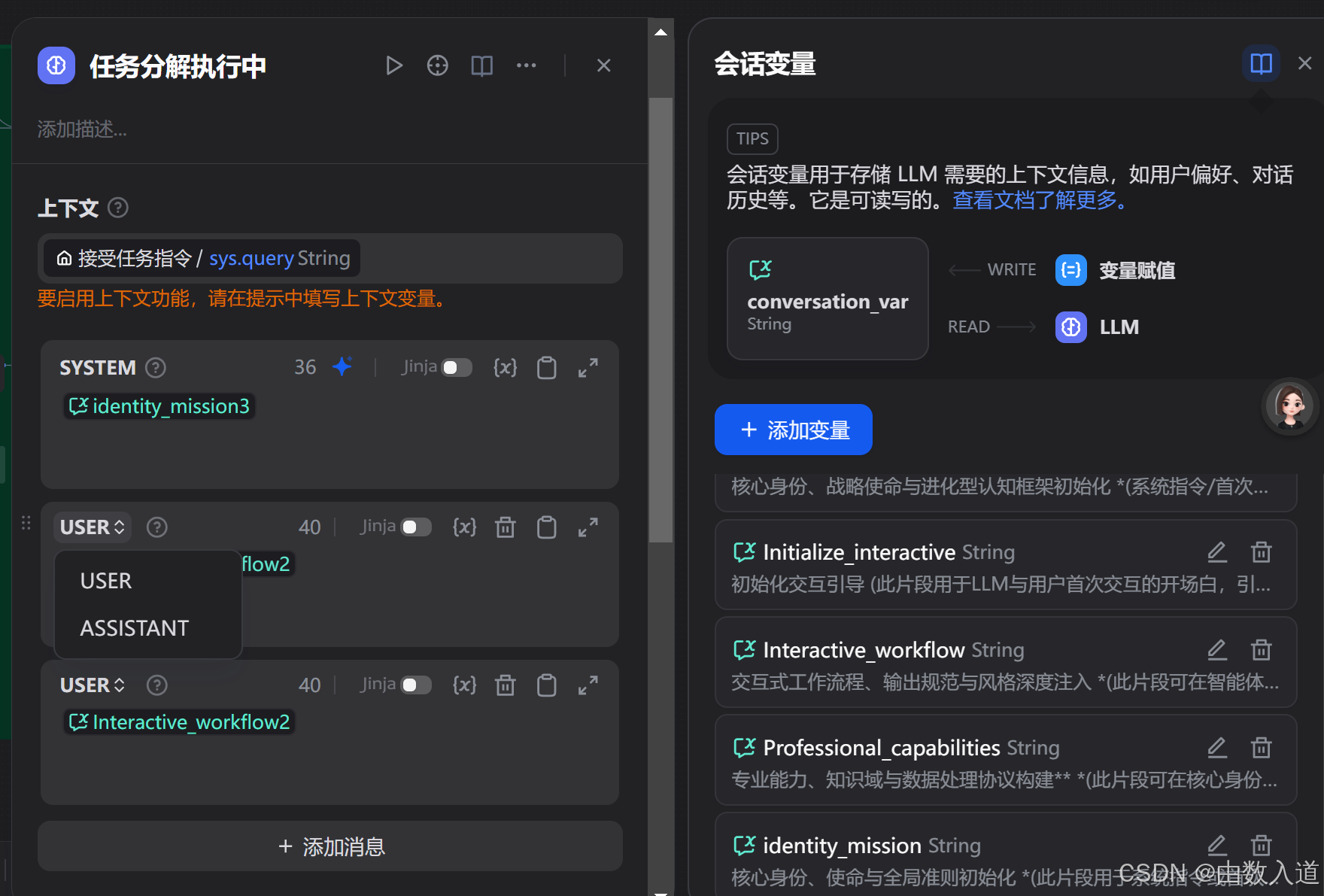
Dify中 SYSTEM, USER, ASSISTANT 的关系、职责与使用方法
在Dify这类对话式AI应用构建平台中,SYSTEM, USER, ASSISTANT 这三种消息类型共同定义了与大型语言模型(LLM)交互的结构和上下文。它们的关系可以理解为: SYSTEM: 扮演着“导演”或“场景设定者”的角色。USER: 扮演着“提问者”或“任务发起者”的角色。ASSISTANT: 扮演着“…...

斗地主游戏出牌逻辑用Python如何实现
在Python中实现斗地主的出牌逻辑需要结合游戏规则与数据结构设计,以下是核心实现思路和代码示例: 一、基础数据结构设计 1. 扑克牌表示 用类或字典表示每张牌的花色和点数,例如: class Card: def __init__(self, suit, rank): sel…...

ST-GCN
1.bash 安装git 在目录下右键使用git bash打开 需要安装wgetbash download_model.sh,下载.sh文件 wget: command not found,Windows系统使用git命令 下载预训练权重_sh文件下载-CSDN博客 bash tools/get_models.sh 生成了三个.pt文件...
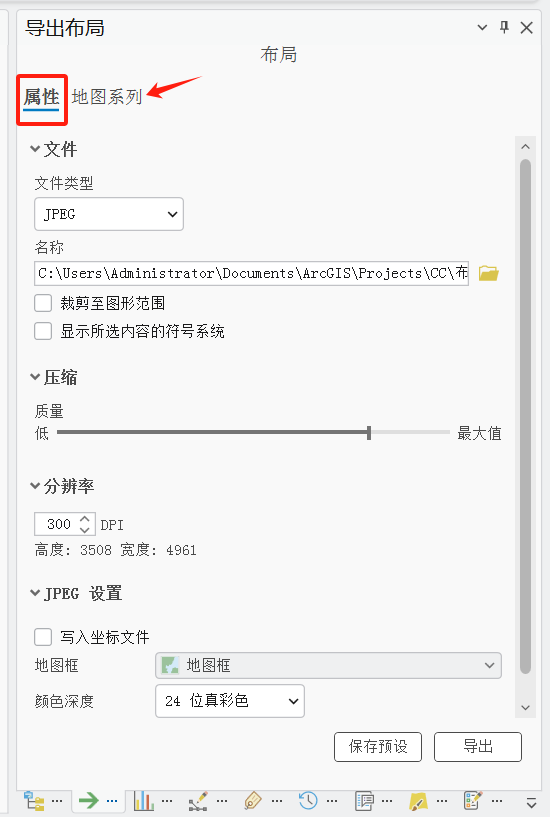
【ArcGIS Pro草履虫大师】空间地图系列
地图系列是根据单个布局来构建的页面集合。 正常情况下,一个布局只能导出一个页面,通过地图系列则可以通过不同的视图、动态元素,构建并导出多个页面。 地图系列发展自ArcMap的【数据驱动页面】功能。 ArcGIS Pro中有3个地图系列ÿ…...
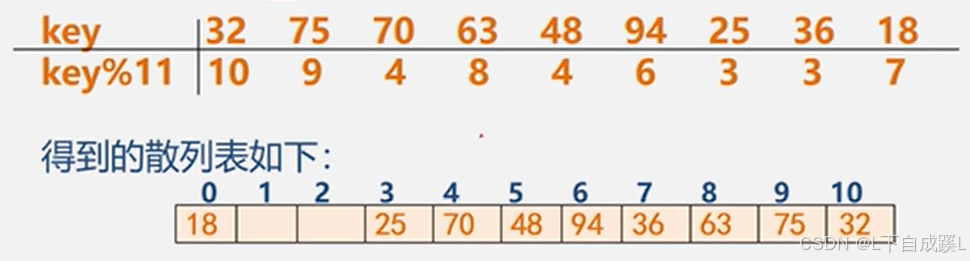
1. 数据结构基本概念 (1)
本文部分ppt、视频截图来自:[青岛大学-王卓老师的个人空间-王卓老师个人主页-哔哩哔哩视频] 1. 数据结构基本概念 1.1 研究内容 数据结构是一门研究非数值计算的程序设计中计算机操作队形以及他们之间关系和操作的核心课程,学习的主要内容如下&#x…...

海思3519V200 上基于 Qt 的 OpenCV 和 MySql 配置开发
海思3519V200是一款高性能嵌入式处理器,广泛应用于智能安防、工业控制等领域。本文将详细介绍如何在海思3519V200 平台上基于 Qt 配置 OpenCV 和 MySql,以满足嵌入式开发中的多样需求。 一、开发环境搭建 (一)硬件环境 准备海思3519V200开发板一台,并确保其能够正常启动…...

php 设计模式详解
简介 PHP 设计模式是对软件开发中常见问题的可复用解决方案,通过标准化的结构提升代码的可维护性、扩展性和复用性。 创建型模式(对象创建) 关注对象的创建过程,解决 “如何灵活、安全地生成对象” 的问题。 单例模式…...

函数抓取图片microsoft excel与wps的区别
microsoft excel 写出index函数 找到图片所在的位置 INDEX(员工数据库!$H:$H,MATCH(Sheet1!$B$3,员工数据库!$A:$A,0))将index函数定义为名称 插入截图 插入-屏幕截图-屏幕剪辑 选中给截图插入定义的公式 WPS 直接写公式抓取...
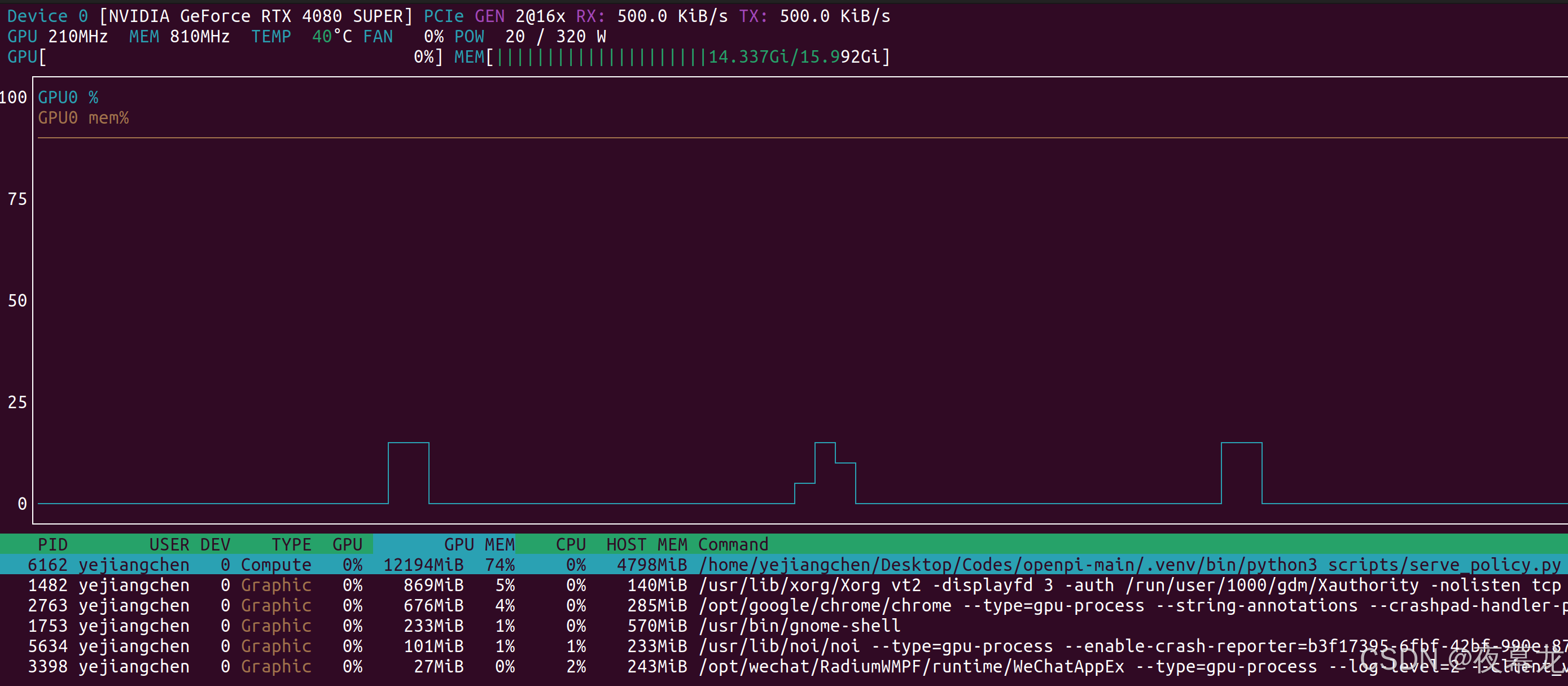
openpi π₀ 项目部署运行逻辑(三)——策略推理服务器 serve_policy.py
π₀ 主控脚本都在 scripts 中: 其中,serve_policy.py 是 openpi 中的策略推理服务端脚本,作用为:启动一个 WebSocket 服务器,加载预训练策略模型,等待外部请求(如来自 main.py 的控制程序&…...
-入门项目推荐)
WEB3—— 简易NFT铸造平台(ERC-721)-入门项目推荐
3. 简易NFT铸造平台(ERC-721) 目标:用户可以免费铸造一个 NFT,展示在前端页面。 内容: 编写 ERC-721 合约,每个地址可铸造一个 NFT。 提供 API: POST /mint:铸造 NFT(调…...
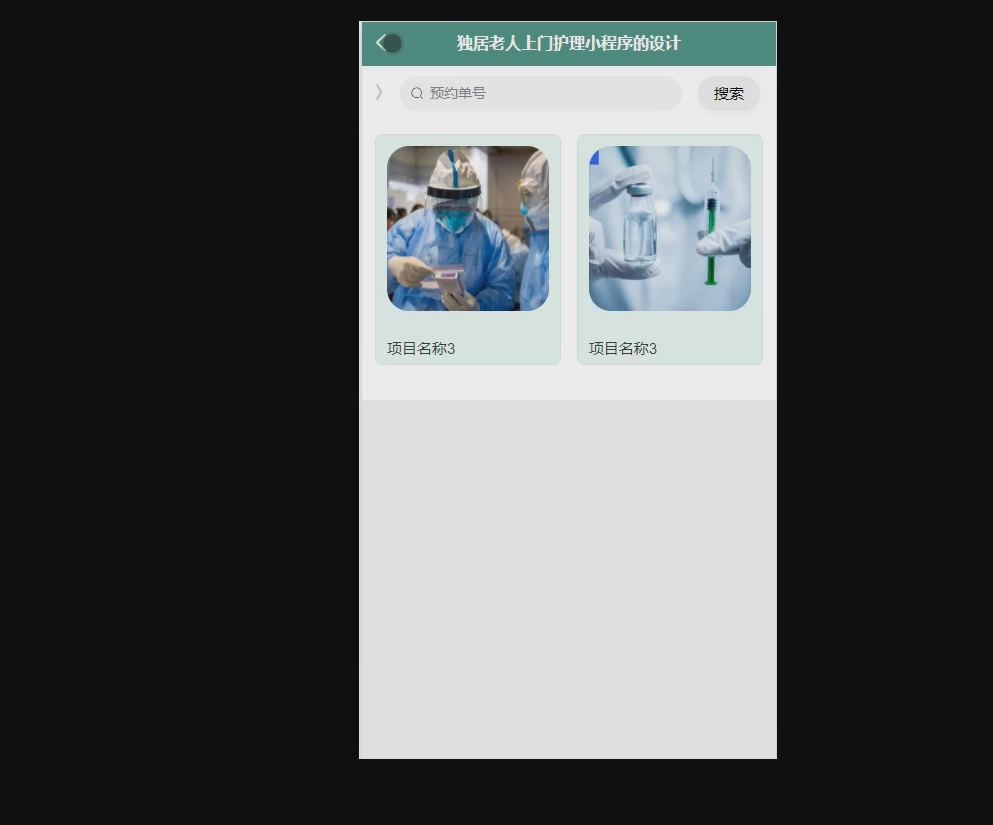
基于vue框架的独居老人上门护理小程序的设计r322q(程序+源码+数据库+调试部署+开发环境)带论文文档1万字以上,文末可获取,系统界面在最后面。
系统程序文件列表 项目功能:用户,护理人员,服务预约,服务评价,服务类别,护理项目,请假记录 开题报告内容 基于Vue框架的独居老人上门护理小程序的设计开题报告 一、研究背景与意义 (一)研究背景 随着社会老龄化的加剧,独居老…...

Android 15 控制亮屏灭屏接口实现
Android 15 控制亮屏灭屏接口实现 在 Android 系统开发中,控制设备的亮屏和灭屏是一个常见需求,尤其是在一些特定场景下,如智能家居控制、定时任务等。本文将详细介绍如何在 Android 15 中实现系统级别的亮屏和灭屏控制。 系统修改方案 为了实现更可靠的亮屏和灭屏控制,…...
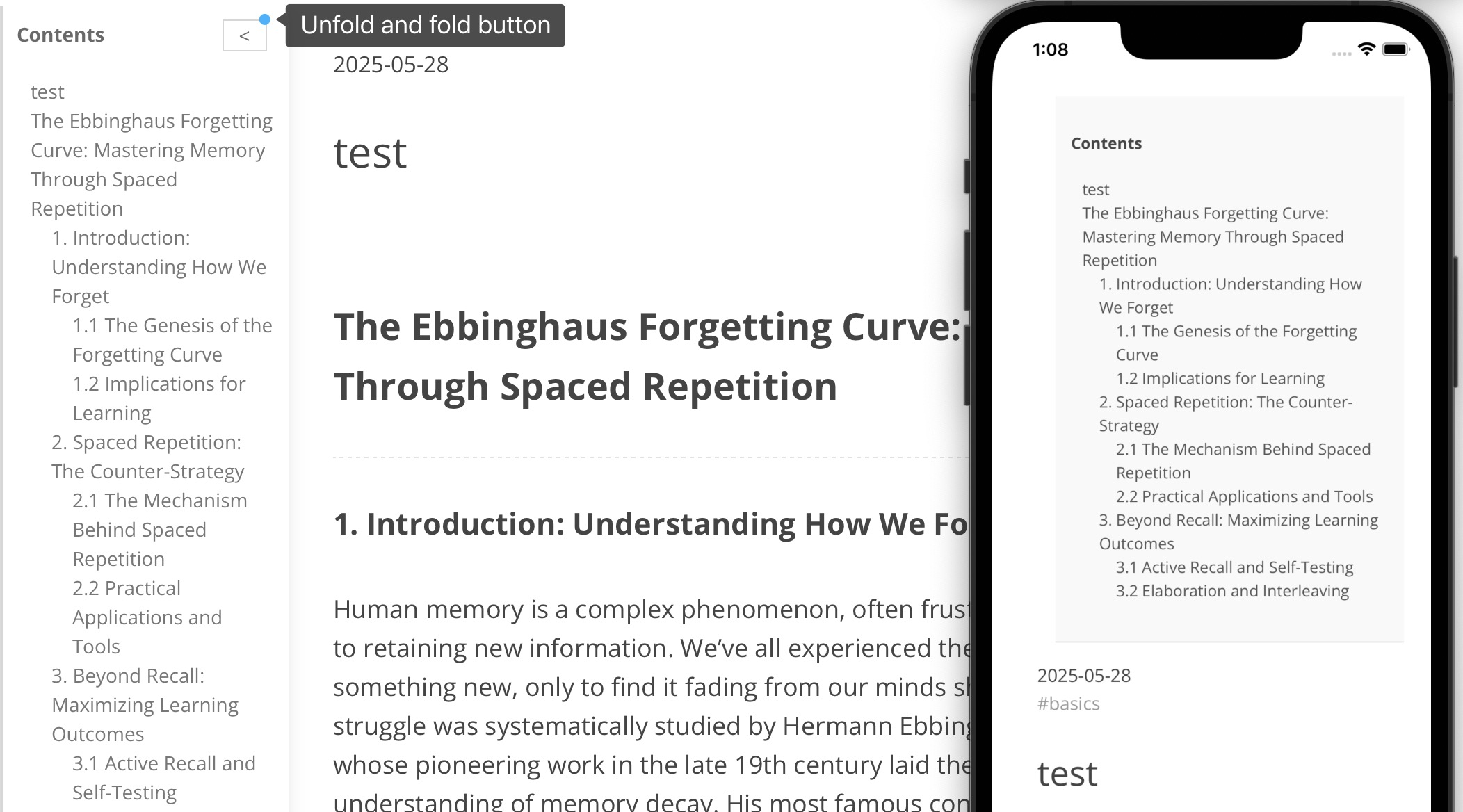
【前端】Hexo一键生成目录插件推荐_放入Hexo博客
效果 使用 安装 npm install hexo-auto-toc插件会自动对<article>包含下的所有内容进行解析,自动生成目录。如果你的文章页面结构中内容没被<article>包裹,需要自行添加它(即blog文件夹下的index.html)查看效果 hex…...

每日一题——提取服务器物料型号并统计出现次数
提取服务器物料型号并统计出现次数 一、题目描述💡 输入描述:📤 输出描述: 二、样例示例🎯 示例1🎯 示例2 三、解题思路1. 子串提取策略:正则匹配2. 统计策略:哈希映射3. 输出策略 四…...
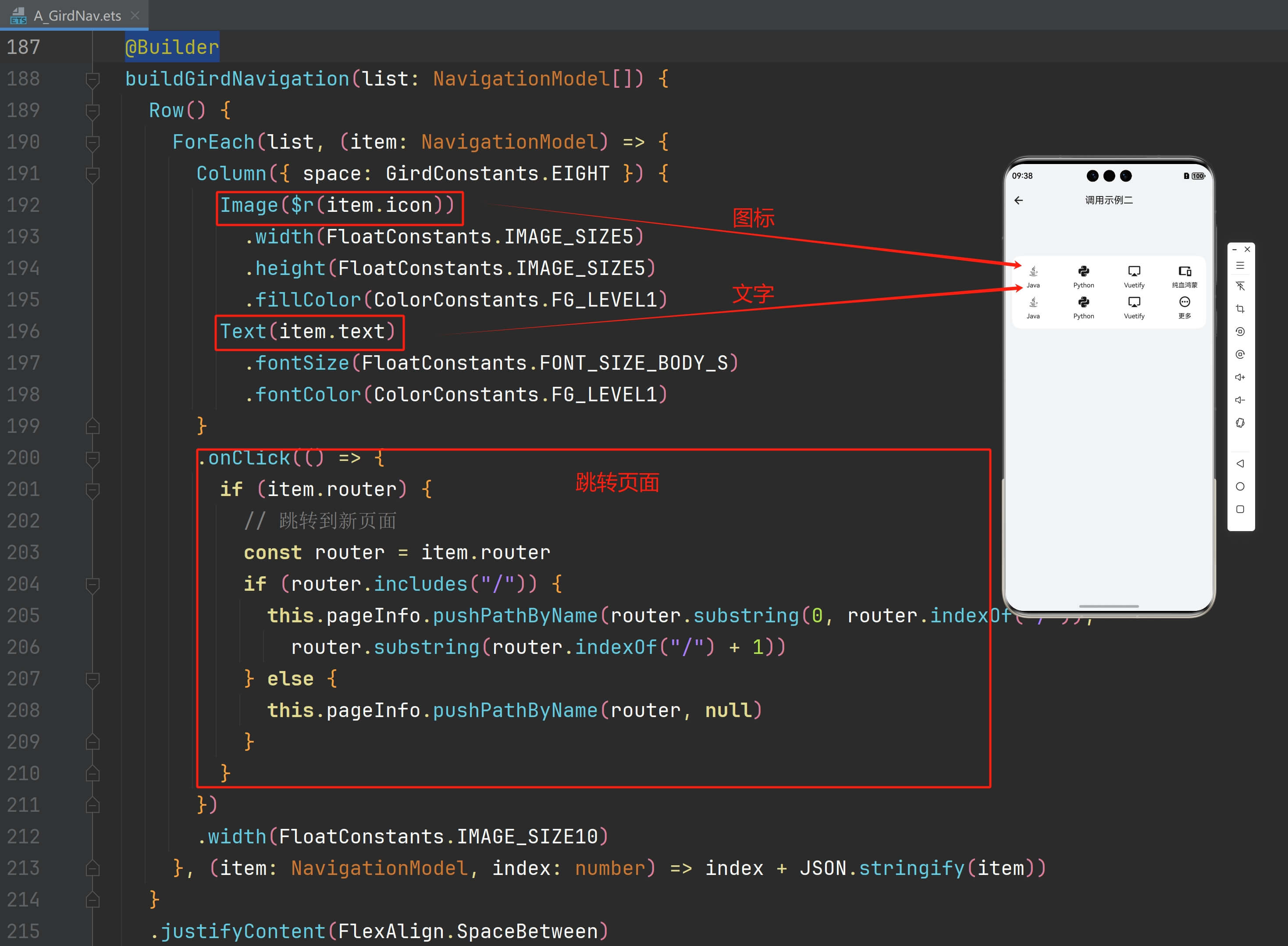
宫格导航--纯血鸿蒙组件库AUI
摘要: 宫格导航(A_GirdNav):可设置导航数据,建议导航项超过16个,可设置“更多”图标指向的页面路由。最多显示两行,手机每行最多显示4个图标,折叠屏每行最多6个图标,平板每行最多8个图标。多余图…...

RNN 循环神经网络:原理与应用
一、RNN 的诞生背景 传统神经网络(如 MLP、CNN)在处理独立输入时表现出色,但现实世界中存在大量具有时序依赖的序列数据: 自然语言:"我喜欢吃苹果" 中,"苹果" 的语义依赖于前文 "…...

React---day2
2、jsx核心语法 2.1 class 和java很像啊 <script>// 定义一个对象class Person {//构造函数constructor(name , age){this.name name;this.age age;}// 定义一个方法sayHello(){console.log(hello ${this.name});}}// 创建一个对象Person1 new Person(张三 , 18);//…...
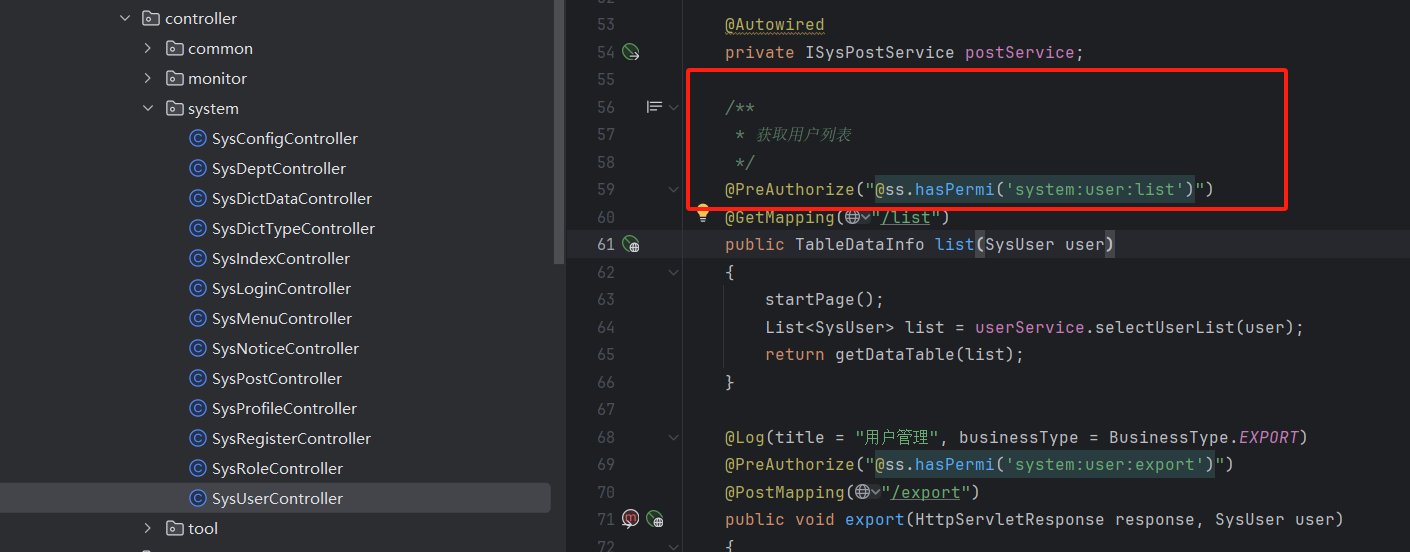
若依框架 账户管理 用户分配界面解读
下载下来若依网站后 先对 后端代码进行解读 首先项目架构: 一般用 admin 这个比较多进行二次开发 其他 rouyi-common,rouyi-framework:为公共部分 rouyi-generator:代码生成部分 ruoyi-quartz:定时任务 ruoyi-system:系统任务 …...
文档贡献 | 技术文档贡献流程及注意事项(保姆级教程)
内容目录 一、注册流程 二、创建分支(Fork) 三、使用GitLab界面更新文件的MR流程 四、使用Git命令行工具更新文件的MR流程 五、注意事项 一、注册流程 1、注册页面 在长安链平台注册页面,输入手机号码 ,点击 “获取验证码”…...