数据分析案例-基于红米和华为手机的用户评论分析

🤵♂️ 个人主页:@艾派森的个人主页
✍🏻作者简介:Python学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
1.项目背景
2.数据集介绍
3.技术工具
4.实验过程
4.1导入数据
4.2数据预处理
4.3数据可视化
4.4snowmlp情感分析
源代码
1.项目背景
在智能手机市场日益繁荣的今天,红米与华为手机作为国产手机品牌的佼佼者,凭借其各自独特的品牌魅力和技术实力,赢得了广泛的用户群体和高度关注。随着技术的不断进步和消费者需求的日益多样化,用户对手机的期望已不仅限于基本的通讯功能,更涵盖了性能、拍照、续航、用户体验等多个方面。因此,深入探究红米与华为手机在用户长期使用过程中的实际表现,尤其是用户评论中所反映出的真实反馈,对于理解市场需求、优化产品设计及提升用户体验具有重要意义。
本实验的背景正是基于这样的市场环境和技术发展趋势。我们旨在通过收集并分析红米与华为手机的用户评论,全面、客观地揭示两款手机在性能、拍照、续航、用户体验等多个维度的真实表现。这些用户评论来自不同渠道,包括官方网站、社交媒体、电商平台等,涵盖了广泛的用户群体和多样化的使用场景,为实验提供了丰富而真实的数据基础。
通过本次实验,我们期望能够解答以下问题:在长期使用过程中,红米与华为手机在哪些方面表现出色?哪些方面仍有改进空间?用户对于两款手机的整体满意度如何?以及用户评论中反映出的共同需求和痛点是什么?基于以上背景,本实验将采用文本挖掘、情感分析等方法,对用户评论进行深入挖掘和分析,以揭示出隐藏在海量数据背后的有价值信息。通过对比红米与华为手机的用户评论,我们可以更加清晰地看到两款手机在市场上的竞争态势和用户需求的差异,为手机厂商提供有益的参考和启示。同时,本次实验也将为消费者在选择手机时提供更加全面、客观的参考依据,帮助他们根据自己的实际需求和预算做出更加明智的决策。
2.数据集介绍
本次实验数据集来源于京东网,采用Python爬虫获取了红米和华为手机的用户评论,共计1570条数据,10个变量,变量含义分别为用户ID、用户昵称、IP属地、评论时间、产品颜色、产品大小、评分、评论点赞量、评论回复量和评论内容。

3.技术工具
Python版本:3.9
代码编辑器:jupyter notebook
4.实验过程
4.1导入数据


查看数据大小

查看数据基本信息
查看数值型变量的描述性统计
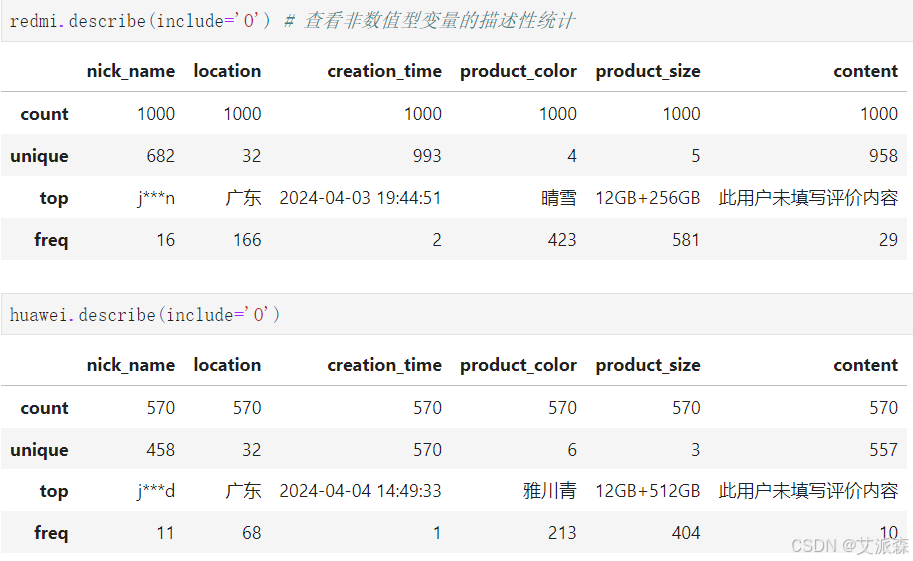
查看非数值型变量的描述性统计
4.2数据预处理
统计缺失值情况
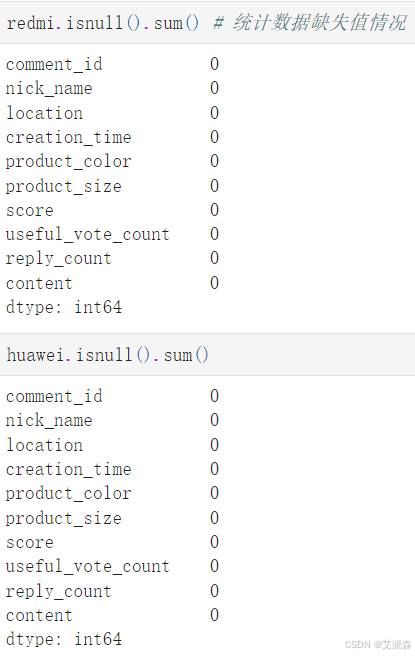
发现没有缺失值
统计重复值情况

发现红米数据集中存在7个重复值,删除即可


4.3数据可视化










因与地图相关的图片会被和谐,所有这里自行运行即可!
因与地图相关的图片会被和谐,所有这里自行运行即可!
import collections
import stylecloud
import re
import jieba
from PIL import Imagedef draw_WorldCloud(df,pic_name,color='white'):data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])# 文本预处理 :去除一些无用的字符只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data)result_list = []with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉读取每一行数据的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word)word_counts = collections.Counter(result_list)# 词频统计:获取前100最高频的词word_counts_top = word_counts.most_common(100)with open(f'{pic_name}词频统计.txt','w',encoding='utf-8')as f:for i in word_counts_top:f.write(str(i[0]))f.write('\t')f.write(str(i[1]))f.write('\n')print(word_counts_top)# 绘制词云图stylecloud.gen_stylecloud(text=' '.join(result_list), collocations=False, # 是否包括两个单词的搭配(二字组)font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为 size=800, # stylecloud 的大小palette='cartocolors.qualitative.Bold_7', # 调色板background_color=color, # 背景颜色icon_name='fas fa-cloud', # 形状的图标名称 gradient='horizontal', # 梯度方向max_words=2000, # stylecloud 可包含的最大单词数max_font_size=150, # stylecloud 中的最大字号stopwords=True, # 布尔值,用于筛除常见禁用词output_name=f'{pic_name}.png') # 输出图片# 打开图片展示img=Image.open(f'{pic_name}.png')img.show()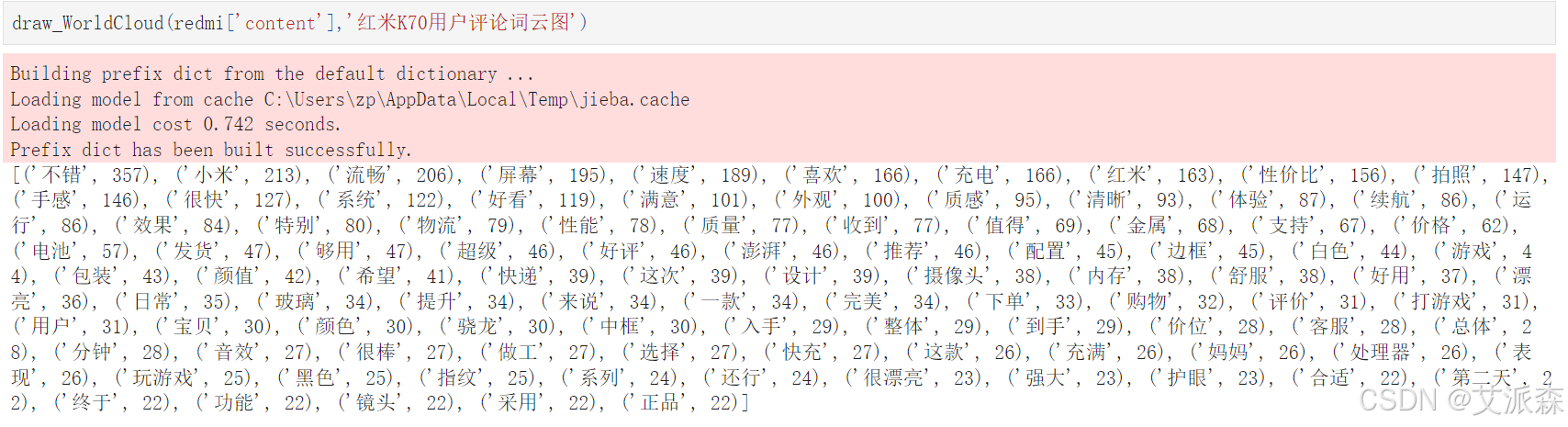



4.4snowmlp情感分析












源代码
import pandas as pd
import matplotlib.pylab as plt
import numpy as np
import seaborn as sns
sns.set(font='SimHei')
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
import warnings
warnings.filterwarnings('ignore')redmi = pd.read_csv('JD_comment_100075799823--0-时间排序.csv')
huawei = pd.read_csv('JD_comment_100064695864--0-时间排序.csv')
redmi.head(5)
huawei.head()
redmi.shape # 查看数据大小
huawei.shape
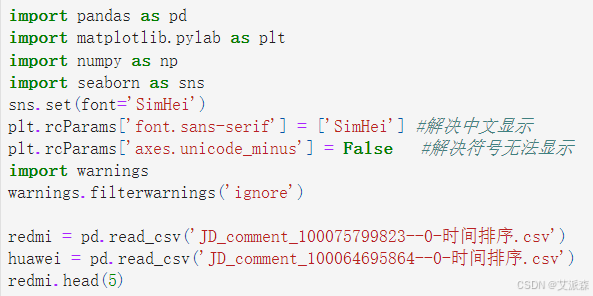
redmi.info() # 查看数据基本信息
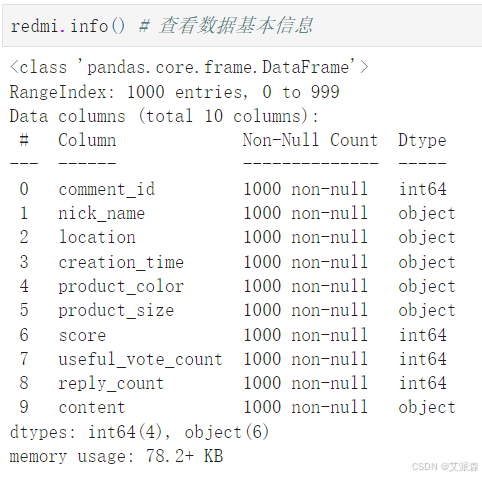
huawei.info()
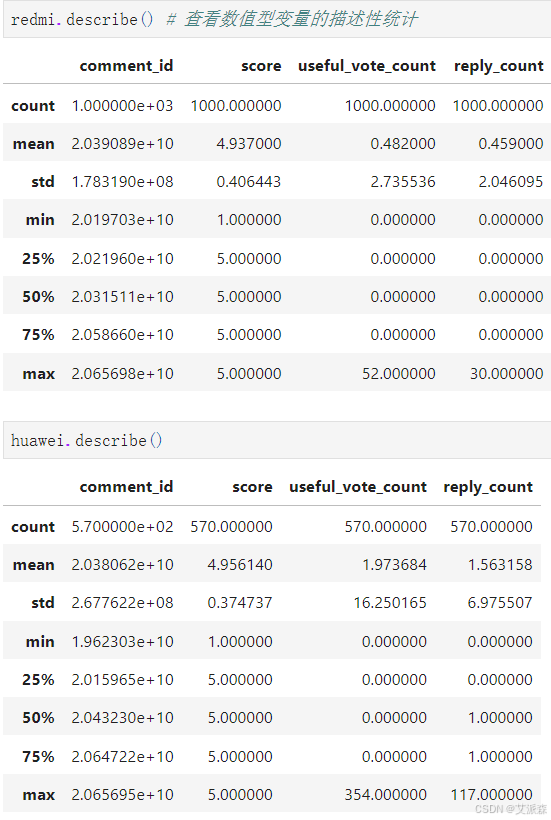
redmi.describe() # 查看数值型变量的描述性统计
huawei.describe()
redmi.describe(include='O') # 查看非数值型变量的描述性统计
huawei.describe(include='O')
redmi.isnull().sum() # 统计数据缺失值情况
huawei.isnull().sum()
redmi.duplicated().sum() # 统计数据重复值情况
huawei.duplicated().sum()
redmi.drop_duplicates(inplace=True) # 删除重复值
# 去除评论为“此用户未及时填写评价内容”的数据
redmi = redmi[redmi['content']!='此用户未填写评价内容']
huawei = huawei[huawei['content']!='此用户未填写评价内容']
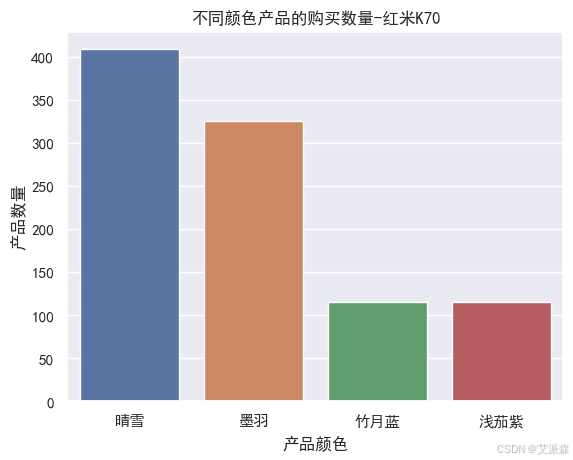
# 不同颜色产品的购买数量
sns.countplot(redmi['product_color'])
plt.xticks()
plt.xlabel('产品颜色')
plt.ylabel('产品数量')
plt.title('不同颜色产品的购买数量-红米K70')
plt.show()
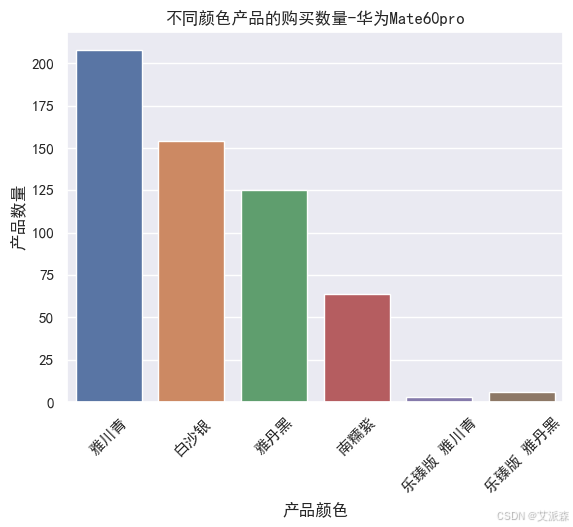
# 不同颜色产品的购买数量
sns.countplot(huawei['product_color'])
plt.xticks(rotation=45)
plt.xlabel('产品颜色')
plt.ylabel('产品数量')
plt.title('不同颜色产品的购买数量-华为Mate60pro')
plt.show()
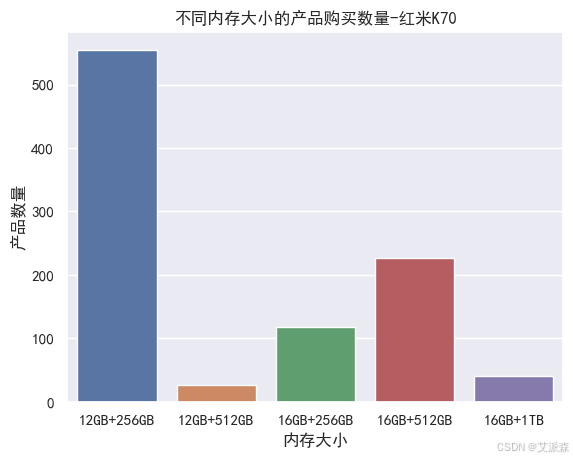
# 不同内存大小的产品购买数量
sns.countplot(redmi['product_size'])
plt.xlabel('内存大小')
plt.ylabel('产品数量')
plt.title('不同内存大小的产品购买数量-红米K70')
plt.show()
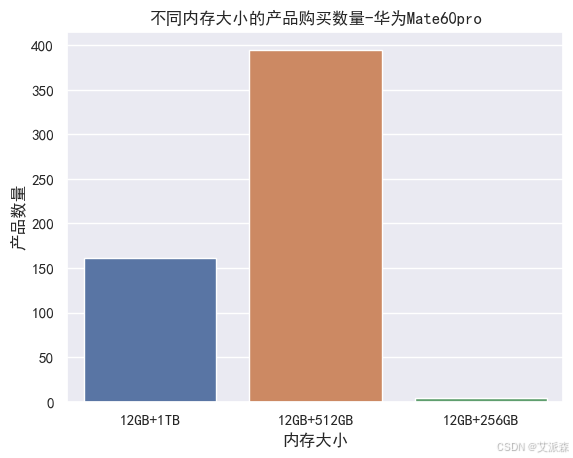
# 不同内存大小的产品购买数量
sns.countplot(huawei['product_size'])
plt.xlabel('内存大小')
plt.ylabel('产品数量')
plt.title('不同内存大小的产品购买数量-华为Mate60pro')
plt.show()
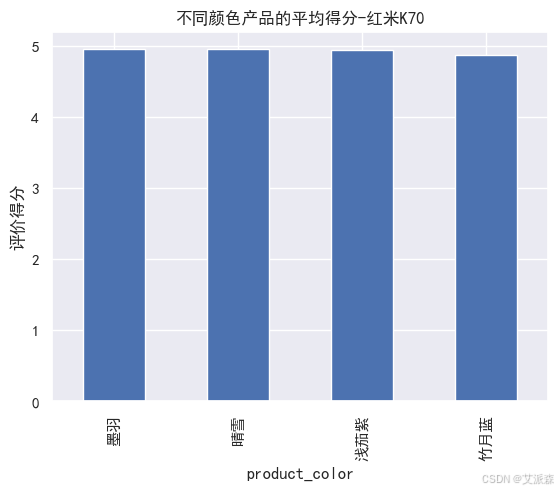
# 不同颜色产品的平均得分-红米K70
redmi.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks()
plt.ylabel('评价得分')
plt.title('不同颜色产品的平均得分-红米K70')
plt.show()
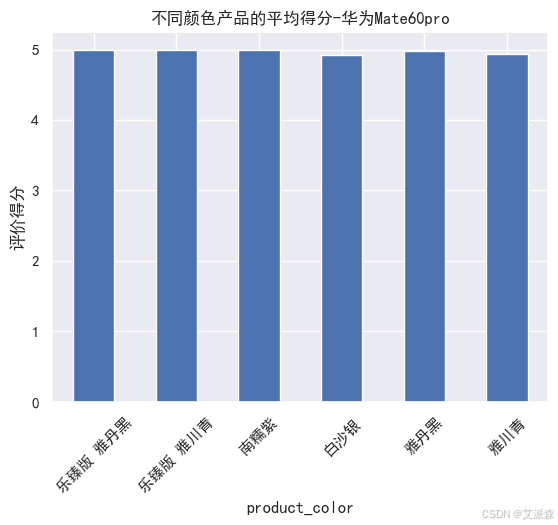
# 不同颜色产品的平均得分-华为Mate60pro
huawei.groupby('product_color').mean()['score'].plot(kind='bar')
plt.xticks(rotation=45)
plt.ylabel('评价得分')
plt.title('不同颜色产品的平均得分-华为Mate60pro')
plt.show()
# 不同型号产品的平均得分-红米K70
redmi.groupby('product_size').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('评价得分')
plt.title('不同型号产品的平均得分-红米K70')
plt.show()
# 不同型号产品的平均得分-华为Mate60pro
huawei.groupby('product_size').mean()['score'].plot(kind='bar')
plt.xticks(rotation=0)
plt.ylabel('评价得分')
plt.title('不同型号产品的平均得分-华为Mate60pro')
plt.show()
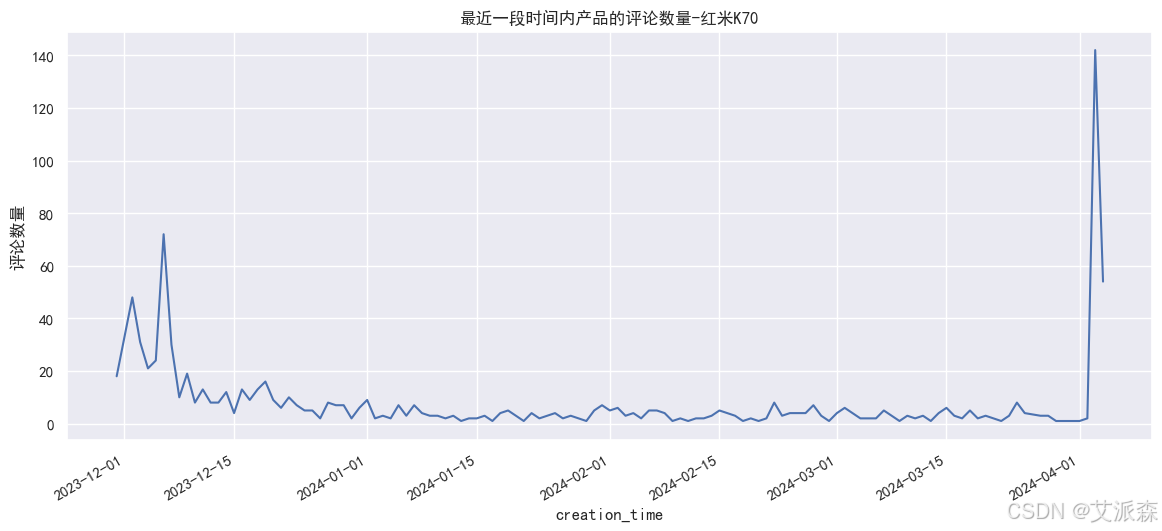
# 最近一段时间内产品的评论数量
redmi['creation_time'] = redmi['creation_time'].astype('datetime64[D]')
plt.figure(figsize=(14,6))
redmi.groupby(redmi['creation_time']).count()['content'].plot()
plt.ylabel('评论数量')
plt.title('最近一段时间内产品的评论数量-红米K70')
plt.show()
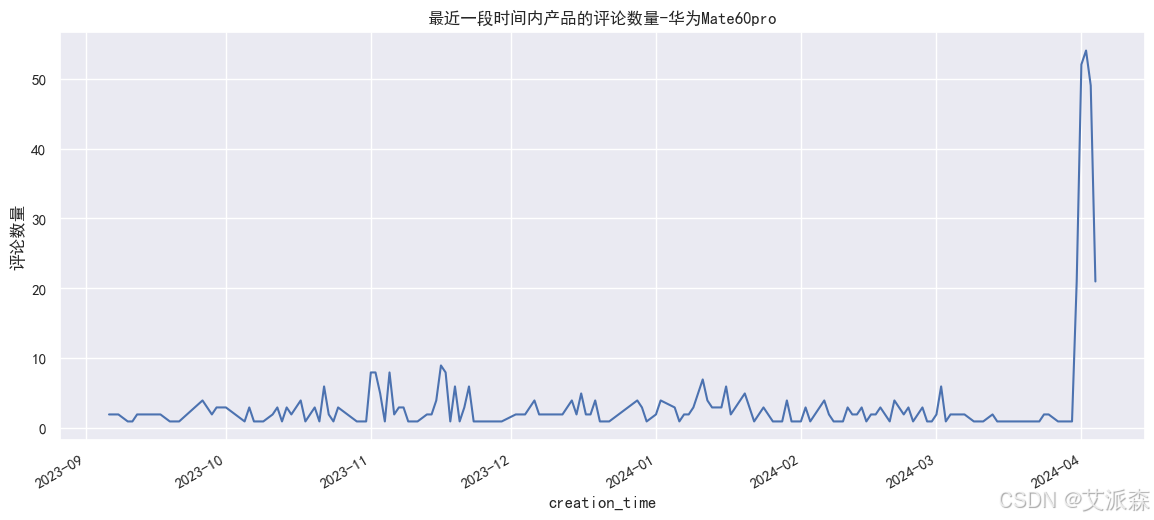
# 最近一段时间内产品的评论数量
huawei['creation_time'] = huawei['creation_time'].astype('datetime64[D]')
plt.figure(figsize=(14,6))
huawei.groupby(huawei['creation_time']).count()['content'].plot()
plt.ylabel('评论数量')
plt.title('最近一段时间内产品的评论数量-华为Mate60pro')
plt.show()
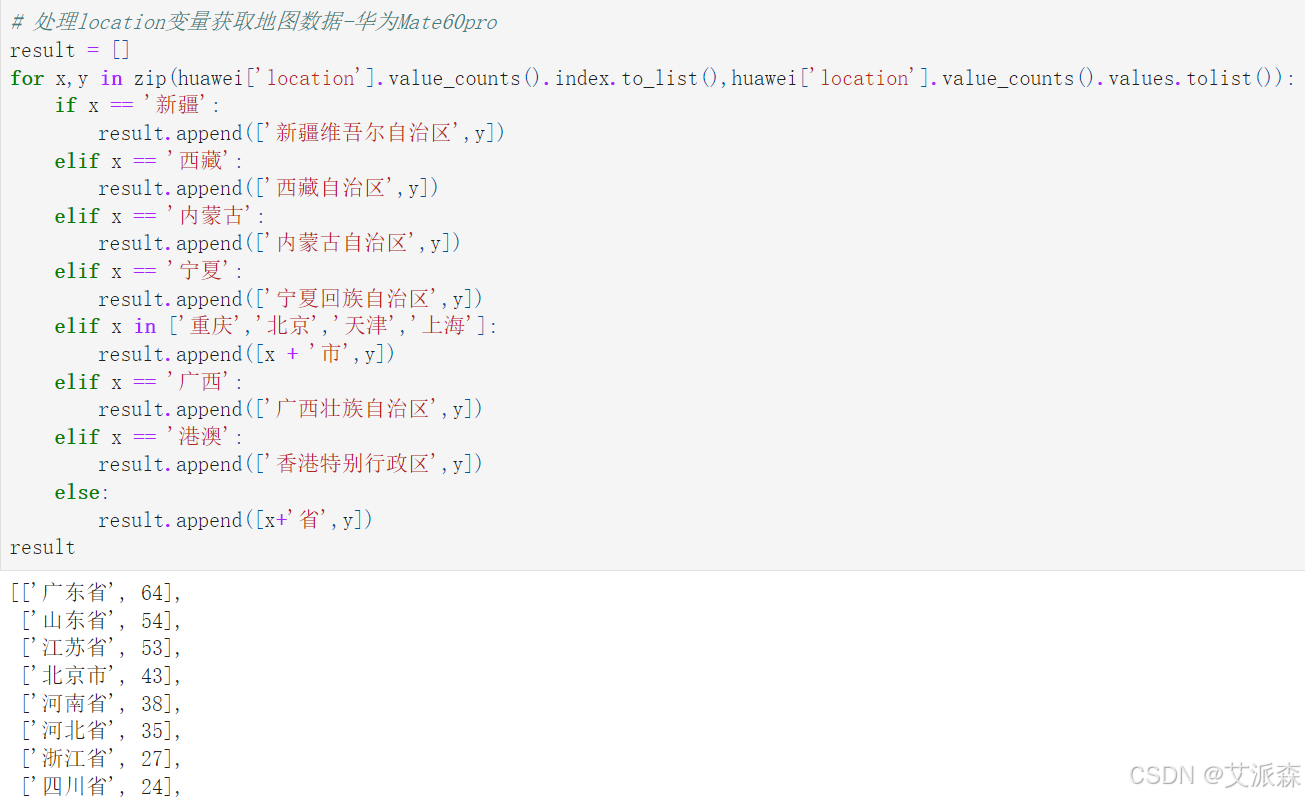
# 处理location变量获取地图数据-红米K70
result = []
for x,y in zip(redmi['location'].value_counts().index.to_list(),redmi['location'].value_counts().values.tolist()):if x == '新疆':result.append(['新疆维吾尔自治区',y])elif x == '西藏':result.append(['西藏自治区',y])elif x == '内蒙古':result.append(['内蒙古自治区',y])elif x == '宁夏':result.append(['宁夏回族自治区',y])elif x in ['重庆','北京','天津','上海']:result.append([x + '市',y])elif x == '广西':result.append(['广西壮族自治区',y])elif x == '港澳':result.append(['香港特别行政区',y])else:result.append([x+'省',y])
result
from pyecharts.charts import *
from pyecharts import options as opts
map = Map()
map.add('各省份购买数量-红米K70',result,maptype='china',is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=100,min_=1)
)
map.render(path='各城市岗位数量分布-红米K70.html')
map.render_notebook()
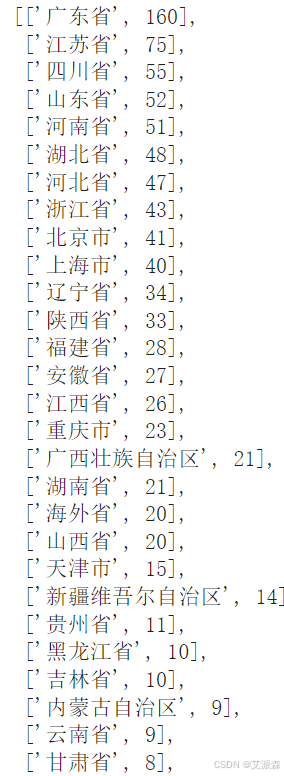
# 处理location变量获取地图数据-华为Mate60pro
result = []
for x,y in zip(huawei['location'].value_counts().index.to_list(),huawei['location'].value_counts().values.tolist()):if x == '新疆':result.append(['新疆维吾尔自治区',y])elif x == '西藏':result.append(['西藏自治区',y])elif x == '内蒙古':result.append(['内蒙古自治区',y])elif x == '宁夏':result.append(['宁夏回族自治区',y])elif x in ['重庆','北京','天津','上海']:result.append([x + '市',y])elif x == '广西':result.append(['广西壮族自治区',y])elif x == '港澳':result.append(['香港特别行政区',y])else:result.append([x+'省',y])
result
from pyecharts.charts import *
from pyecharts import options as opts
map = Map()
map.add('各省份购买数量-华为Mate60pro',result,maptype='china',is_map_symbol_show=False,label_opts=opts.LabelOpts(is_show=False))
map.set_global_opts(visualmap_opts=opts.VisualMapOpts(max_=50,min_=1)
)
map.render(path='各城市岗位数量分布-华为Mate60pro.html')
map.render_notebook()
import collections
import stylecloud
import re
import jieba
from PIL import Imagedef draw_WorldCloud(df,pic_name,color='white'):data = ''.join([re.sub(r'[^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z][^0-9A-Za-z]:','',item) for item in df])# 文本预处理 :去除一些无用的字符只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', data, re.S)new_data = "".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data)result_list = []with open('停用词库.txt', encoding='utf-8') as f: #可根据需要打开停用词库,然后加上不想显示的词语con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉读取每一行数据的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word)word_counts = collections.Counter(result_list)# 词频统计:获取前100最高频的词word_counts_top = word_counts.most_common(100)with open(f'{pic_name}词频统计.txt','w',encoding='utf-8')as f:for i in word_counts_top:f.write(str(i[0]))f.write('\t')f.write(str(i[1]))f.write('\n')print(word_counts_top)# 绘制词云图stylecloud.gen_stylecloud(text=' '.join(result_list), collocations=False, # 是否包括两个单词的搭配(二字组)font_path=r'C:\Windows\Fonts\msyh.ttc', #设置字体,参考位置为 size=800, # stylecloud 的大小palette='cartocolors.qualitative.Bold_7', # 调色板background_color=color, # 背景颜色icon_name='fas fa-cloud', # 形状的图标名称 gradient='horizontal', # 梯度方向max_words=2000, # stylecloud 可包含的最大单词数max_font_size=150, # stylecloud 中的最大字号stopwords=True, # 布尔值,用于筛除常见禁用词output_name=f'{pic_name}.png') # 输出图片# 打开图片展示img=Image.open(f'{pic_name}.png')img.show()
draw_WorldCloud(redmi['content'],'红米K70用户评论词云图')
draw_WorldCloud(huawei['content'],'华为Mate60pro用户评论词云图')
snowmlp情感分析
#加载情感分析模块
from snownlp import SnowNLP
# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in redmi['content']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:if (i>=0.7):myval.append("积极")good=good+1elif 0.2<i<0.7:myval.append("中性")mid+=1else:myval.append("消极")bad=bad+1
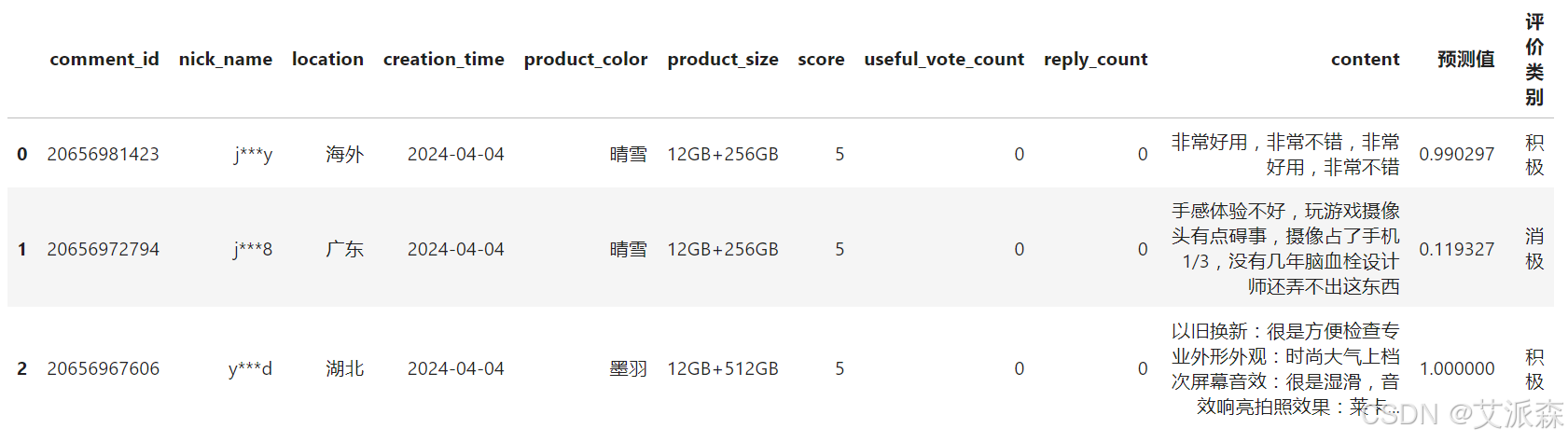
redmi['预测值']=values
redmi['评价类别']=myval
redmi.head(3)
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
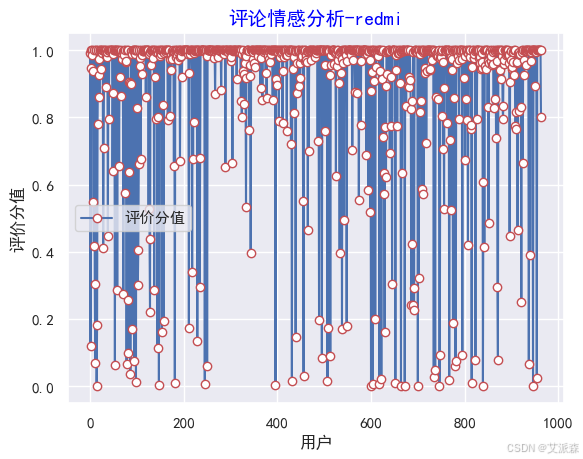
#作图
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析-redmi',family='SimHei',size=14,color='blue')
plt.show()
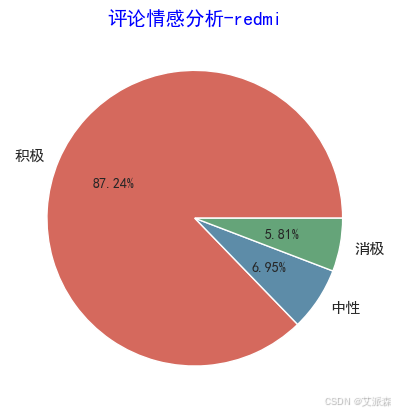
y = redmi['评价类别'].value_counts().values.tolist()
plt.pie(y,labels=['积极','中性','消极'], # 设置饼图标签colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色autopct='%.2f%%', # 格式化输出百分比)
plt.title('评论情感分析-redmi',family='SimHei',size=14,color='blue')
plt.show()
draw_WorldCloud(redmi[redmi['评价类别']=='积极']['content'],'红米K70用户评论词云图-好评')
draw_WorldCloud(redmi[redmi['评价类别']=='消极']['content'],'红米K70用户评论词云图-差评')
#加载情感分析模块
from snownlp import SnowNLP
# 遍历每条评论进行预测
values=[SnowNLP(i).sentiments for i in huawei['content']]
#输出积极的概率,大于0.5积极的,小于0.5消极的
#myval保存预测值
myval=[]
good=0
mid=0
bad=0
for i in values:if (i>=0.7):myval.append("积极")good=good+1elif 0.2<i<0.7:myval.append("中性")mid+=1else:myval.append("消极")bad=bad+1
huawei['预测值']=values
huawei['评价类别']=myval
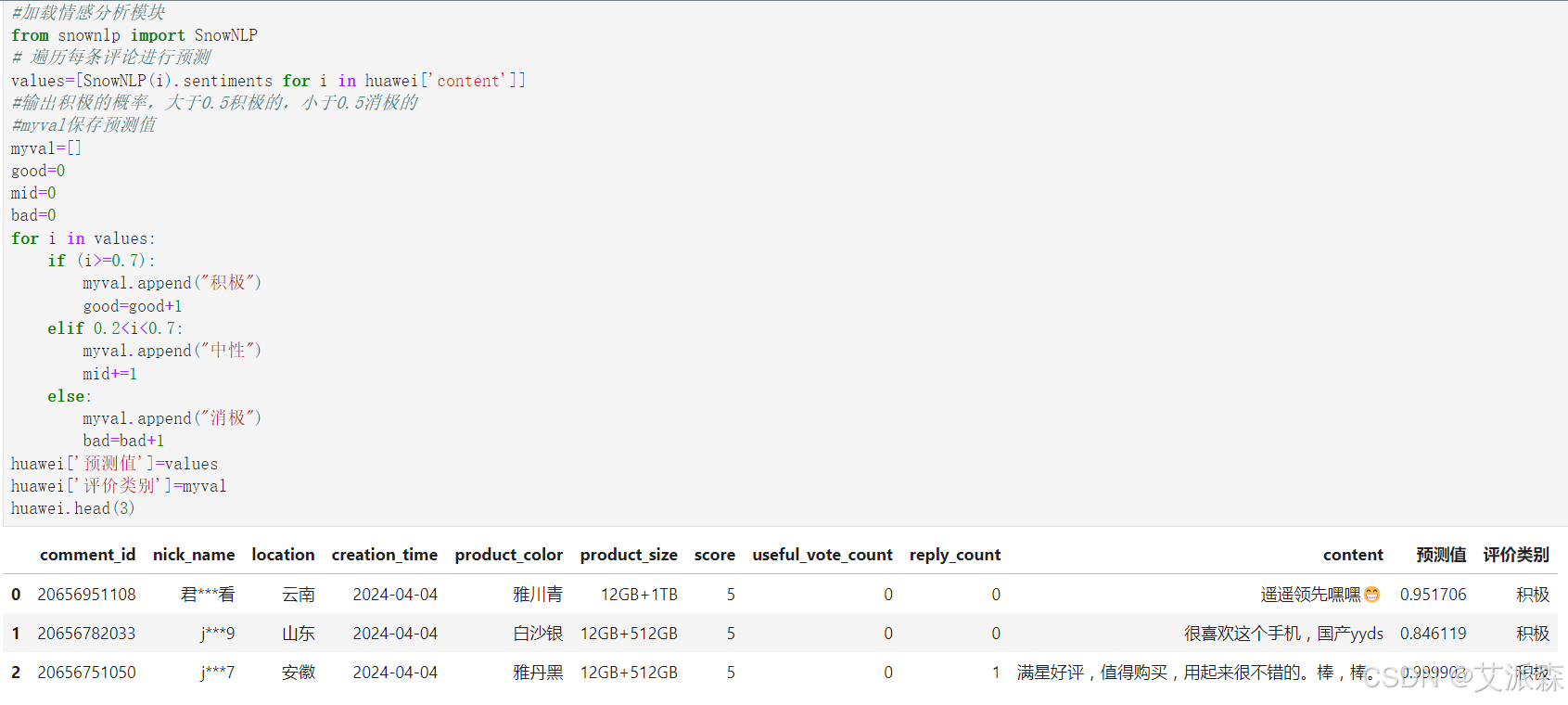
huawei.head(3)
rate=good/(good+bad+mid)
print('好评率','%.f%%' % (rate * 100)) #格式化为百分比
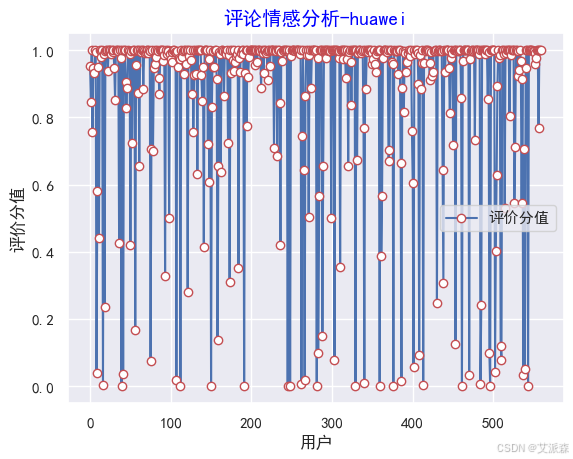
#作图
y=values
plt.rc('font', family='SimHei', size=10)
plt.plot(y, marker='o', mec='r', mfc='w',label=u'评价分值')
plt.xlabel('用户')
plt.ylabel('评价分值')
# 让图例生效
plt.legend()
#添加标题
plt.title('评论情感分析-huawei',family='SimHei',size=14,color='blue')
plt.show()
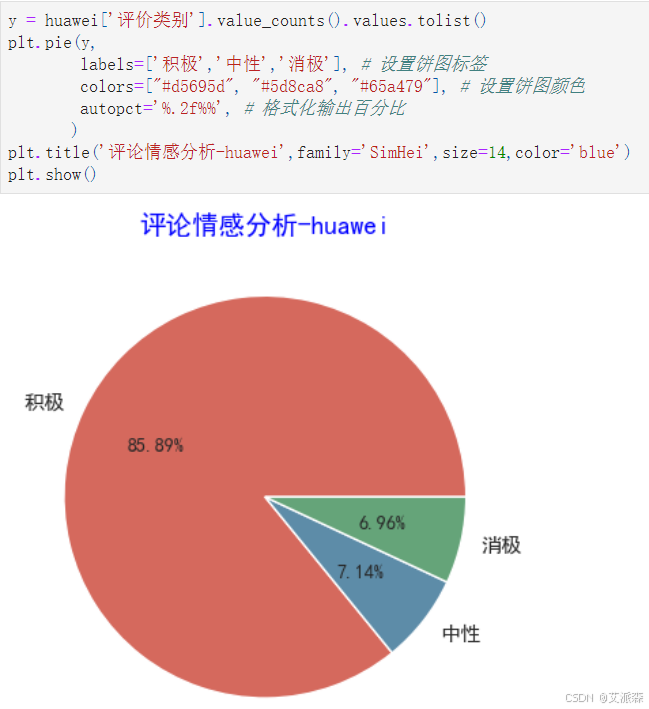
y = huawei['评价类别'].value_counts().values.tolist()
plt.pie(y,labels=['积极','中性','消极'], # 设置饼图标签colors=["#d5695d", "#5d8ca8", "#65a479"], # 设置饼图颜色autopct='%.2f%%', # 格式化输出百分比)
plt.title('评论情感分析-huawei',family='SimHei',size=14,color='blue')
plt.show()
draw_WorldCloud(huawei[huawei['评价类别']=='积极']['content'],'华为Mate60pro用户评论词云图-好评')
draw_WorldCloud(huawei[huawei['评价类别']=='消极']['content'],'华为Mate60pro用户评论词云图-差评')
LDA主题分析
import re
import jiebadef chinese_word_cut(mytext):# 文本预处理 :去除一些无用的字符只提取出中文出来new_data = re.findall('[\u4e00-\u9fa5]+', mytext, re.S)new_data = " ".join(new_data)# 文本分词seg_list_exact = jieba.cut(new_data)result_list = []with open('停用词库.txt', encoding='utf-8') as f: # 可根据需要打开停用词库,然后加上不想显示的词语con = f.readlines()stop_words = set()for i in con:i = i.replace("\n", "") # 去掉读取每一行数据的\nstop_words.add(i)for word in seg_list_exact:if word not in stop_words and len(word) > 1:result_list.append(word) return " ".join(result_list)test = '在这里选购安全方便快捷💜,快递小哥态度非常好,这个价格非常给力💪,十分推荐,会继续回购😃大品牌!值得信赖!效果超级好!贵有贵的道理!很棒的商品!'
chinese_word_cut(test)
# 中文分词
redmi["content_cutted"] = redmi.content.apply(chinese_word_cut)
redmi.head()
# 中文分词
huawei["content_cutted"] = huawei.content.apply(chinese_word_cut)
huawei.head()
import tomotopy as tpdef find_k(docs, min_k=1, max_k=20, min_df=2):# min_df 词语最少出现在2个文档中scores = []for k in range(min_k, max_k):mdl = tp.LDAModel(min_df=min_df, k=k, seed=555)for words in docs:if words:mdl.add_doc(words)mdl.train(20)coh = tp.coherence.Coherence(mdl)scores.append(coh.get_score())plt.plot(range(min_k, max_k), scores)plt.xlabel("number of topics")plt.ylabel("coherence")plt.show()
find_k(docs=redmi['content_cutted'], min_k=1, max_k=10, min_df=2)
find_k(docs=huawei['content_cutted'], min_k=1, max_k=10, min_df=2)
# 初始化LDA
mdl = tp.LDAModel(k=2, min_df=2, seed=555)
for words in redmi['content_cutted']:#确认words 是 非空词语列表if words:mdl.add_doc(words=words.split())#训 练
mdl.train()
# 查看每个topic feature words
for k in range(mdl.k):print('Top 20 words of topic #{}'.format(k))print(mdl.get_topic_words(k, top_n=20))print('\n')
# 查看话题模型信息
mdl.summary()
import pyLDAvis
import numpy as np# 在notebook显示
pyLDAvis.enable_notebook()# 获取pyldavis需要的参数
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freqprepared_data = pyLDAvis.prepare(topic_term_dists, doc_topic_dists, doc_lengths, vocab, term_frequency,start_index=0, # tomotopy话题id从0开始,pyLDAvis话题id从1开始sort_topics=False # 注意:否则pyLDAvis与tomotopy内的话题无法一一对应。
)# 可视化结果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis-redmi.html')# notebook中显示
pyLDAvis.display(prepared_data)
# 初始化LDA
mdl = tp.LDAModel(k=5, min_df=2, seed=555)
for words in huawei['content_cutted']:#确认words 是 非空词语列表if words:mdl.add_doc(words=words.split())#训 练
mdl.train()
# 查看每个topic feature words
for k in range(mdl.k):print('Top 20 words of topic #{}'.format(k))print(mdl.get_topic_words(k, top_n=20))print('\n')
# 查看话题模型信息
mdl.summary()
import pyLDAvis
import numpy as np# 在notebook显示
pyLDAvis.enable_notebook()# 获取pyldavis需要的参数
topic_term_dists = np.stack([mdl.get_topic_word_dist(k) for k in range(mdl.k)])
doc_topic_dists = np.stack([doc.get_topic_dist() for doc in mdl.docs])
doc_topic_dists /= doc_topic_dists.sum(axis=1, keepdims=True)
doc_lengths = np.array([len(doc.words) for doc in mdl.docs])
vocab = list(mdl.used_vocabs)
term_frequency = mdl.used_vocab_freqprepared_data = pyLDAvis.prepare(topic_term_dists, doc_topic_dists, doc_lengths, vocab, term_frequency,start_index=0, # tomotopy话题id从0开始,pyLDAvis话题id从1开始sort_topics=False # 注意:否则pyLDAvis与tomotopy内的话题无法一一对应。
)# 可视化结果存到html文件中
pyLDAvis.save_html(prepared_data, 'ldavis-huawei.html')# notebook中显示
pyLDAvis.display(prepared_data)
资料获取,更多粉丝福利,关注下方公众号获取

相关文章:
数据分析案例-基于红米和华为手机的用户评论分析
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

leetcode617.合并二叉树:递归思想下的树结构融合艺术
一、题目深度解析与核心规则 题目描述 合并两棵二叉树是一个经典的树结构操作问题,题目要求我们将两棵二叉树合并成一棵新二叉树。合并规则如下: 若两棵树的对应节点都存在,则将两个节点的值相加作为新节点的值若其中一棵树的节点存在&…...
深度学习入门:从零搭建你的第一个神经网络
深度学习入门:从零搭建你的第一个神经网络 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 深度学习入门:从零搭建你的第一个神经网络摘要引言第一章:神经网络基础原理1.1 神经元…...

【HTML-13】HTML表格合并技术详解:打造专业数据展示
表格是HTML中展示结构化数据的重要元素,而表格合并则是提升表格表现力的关键技术。本文将全面介绍HTML中的表格合并方法,帮助您创建更专业、更灵活的数据展示界面。 1. 表格合并基础概念 在HTML中,表格合并主要通过两个属性实现:…...

鸿蒙OSUniApp 制作自定义的进度条组件#三方框架 #Uniapp
使用 UniApp 制作自定义的进度条组件 在移动应用开发中,进度条是非常常见的 UI 组件,无论是文件上传、下载、任务进度还是表单填写反馈,进度条都能为用户提供直观的进度提示。虽然 UniApp 提供了一些基础的进度条能力,但在实际项…...
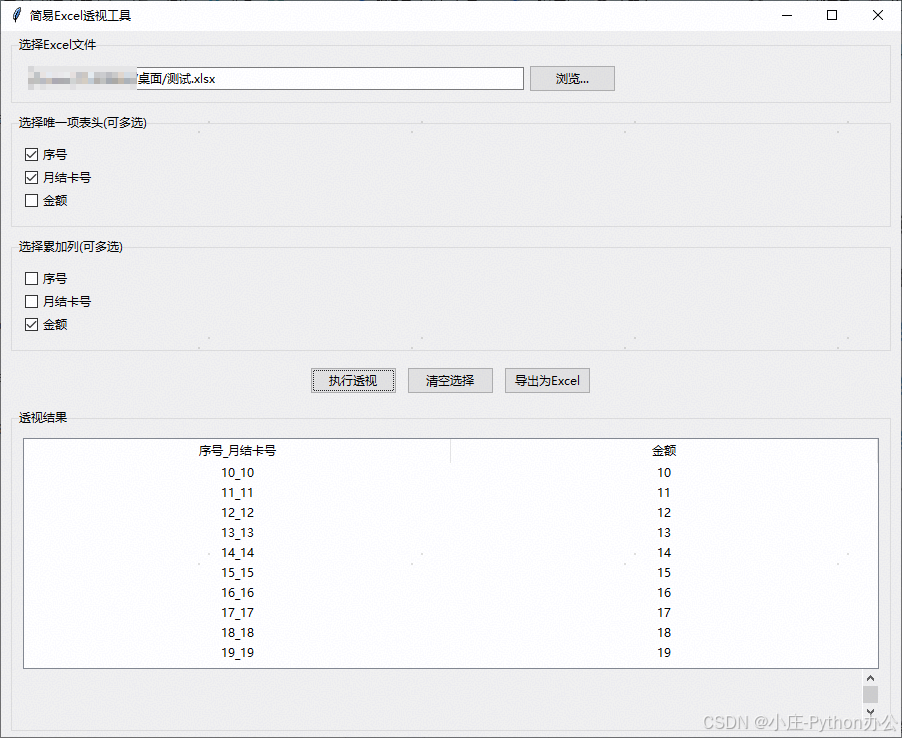
【Python办公】Excel简易透视办公小工具
目录 专栏导读1. 背景介绍2. 功能介绍3. 库的安装4. 界面展示5. 使用方法6. 实际应用场景7. 优化方向完整代码总结专栏导读 🌸 欢迎来到Python办公自动化专栏—Python处理办公问题,解放您的双手 🏳️🌈 博客主页:请点击——> 一晌小贪欢的博客主页求关注 👍 该系…...

m1 运行renrenfastvue出现的问题和解决方案
1. chromedriver 报错解决:执行 npm install --ignore-scripts。 2. node-sass 报错 "Node Sass does not yet support your current environment: OS X Unsupported ...": - 降低 Node 版本至 14。 - 安装版本控制工具:sudo npm insta…...
)
开源模型应用落地-qwen模型小试-Qwen3-8B-推理加速-vLLM-Docker(二)
一、前言 在AI模型部署效率竞争日益激烈的当下,如何将前沿大模型与高效推理框架结合,成为开发者关注的焦点。Qwen3-8B作为阿里云推出的混合推理模型,凭借80亿参数规模与128K超长上下文支持,展现了“快思考”与“慢思考”的协同能力,而vLLM框架则通过优化内存管理与并行计算…...

【C/C++】记录一次麻烦的Kafka+Json体验
文章目录 麻烦的KafkaJson体验1 目标2 工程搭建2.1 docker配置2.2 代码2.3 工程压缩包 3 执行结果 麻烦的KafkaJson体验 1 目标 初心:结合kafka json docker,验证基本的数据生产/消费。 Kafka 配合 JSON 工具,主要是为了数据的序列化和反…...
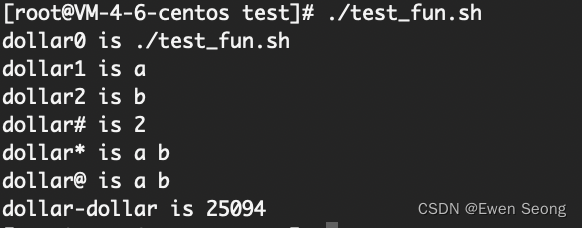
Linux系列-2 Shell常用命令收集
背景 本文用于收集Linux常用命令(基于Centos7),是一个持续更新的博客,建议收藏,编写shell时遇到问题可以随时查阅。 1.Shell类型 shell是用C语言编写的程序,作为命令解释器连接着用户和操作系统内核。常见的shell有sh(Bourne She…...

MATLAB使用多个扇形颜色变化表示空间一个点的多种数值
MATLAB使用多个扇形颜色变化表示空间一个点的多种数值 excel中表格中数据格式,多行 lonlatdata1data2data3117380.11100 clear;close all; figure(Position,[100 100 800 800]);num_points 14; [num,txt,raw] xlsread(test.xlsx); x num(:,1); y num(:,2);d…...

mysql:MVCC机制
MVCC机制 MVCC机制主要是mysql的多版本并发控制的一个机制,它主要是允许mysql去保存同一时间对同一份数据的不同历史版本的,从而避免读写之间的锁竞争,从而去提高并发的性能。 像传统的锁机制(读写互斥锁(Read-Write …...

Vue3 + Element Plus 实现树形结构的“单选 + 只选叶子节点 + 默认选中第一个子节点”
在 Vue 项目中,我们常使用树形结构组件来展示层级数据。本文将介绍如何使用 Element Plus 的 <el-tree> 组件,在 Vue3 中实现以下需求: ✅ 只能勾选叶子节点 ✅ 每次只能选中一个节点(单选) ✅ 页面加载时默认…...
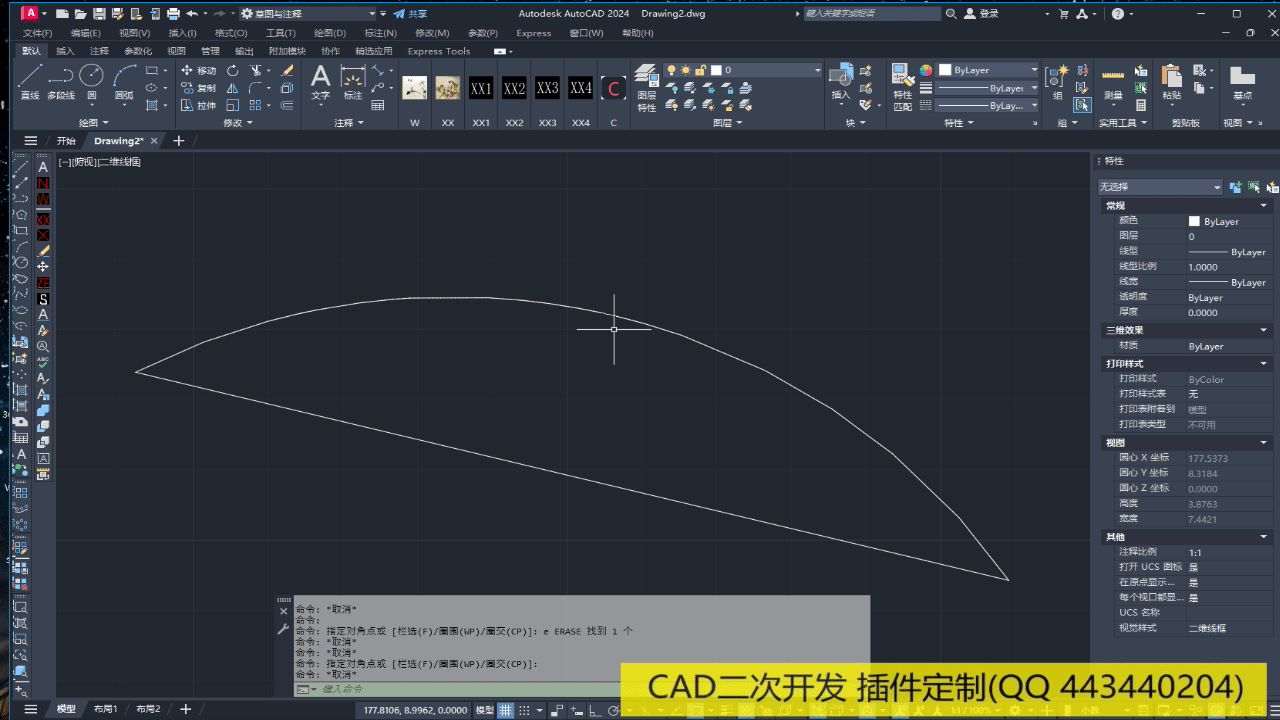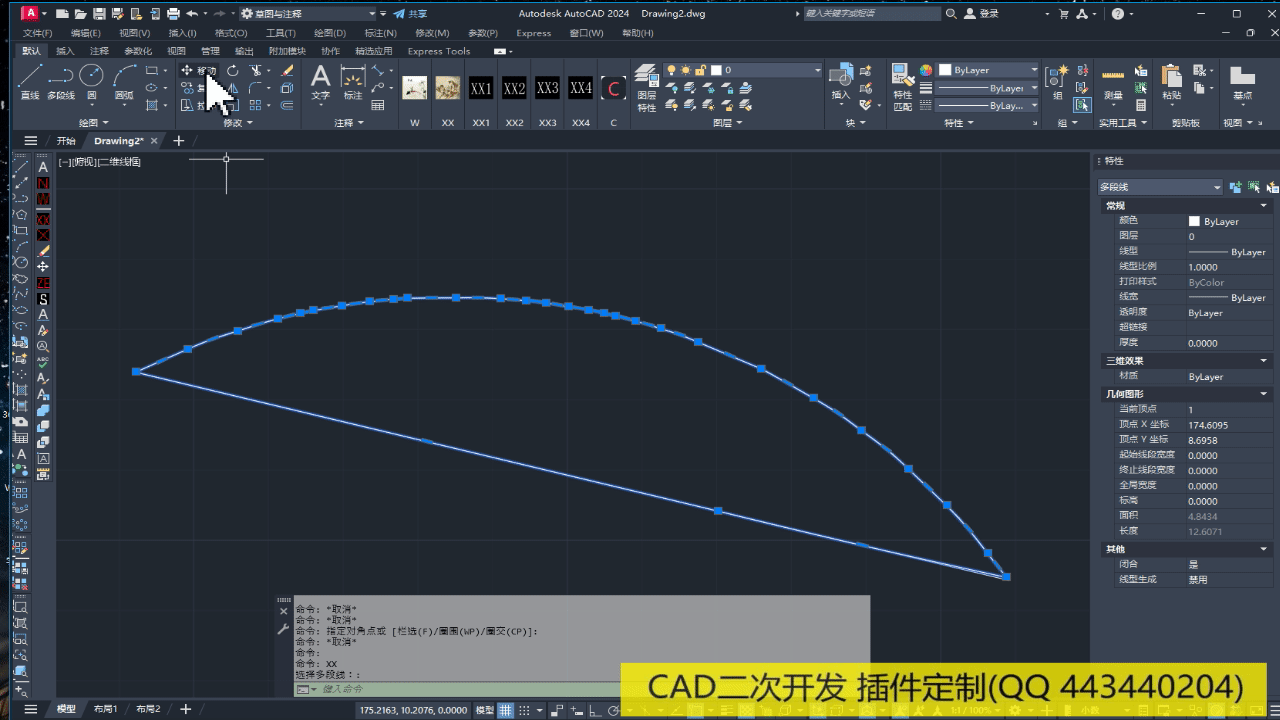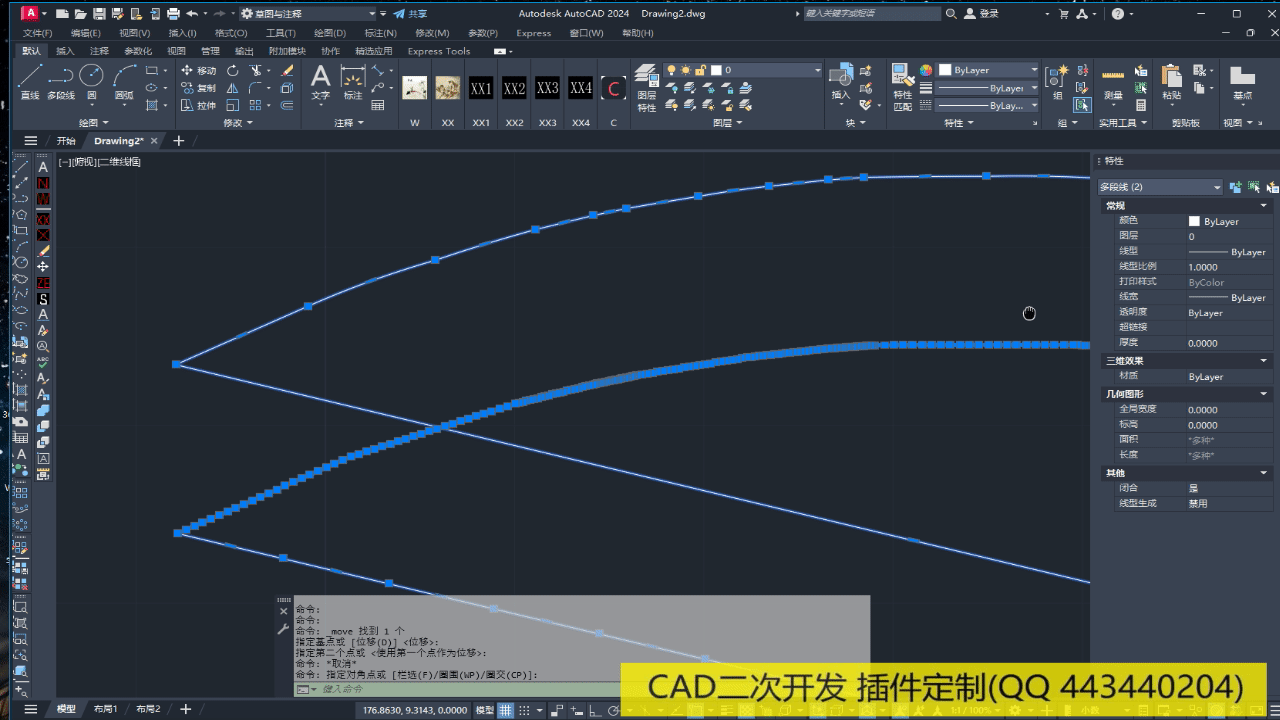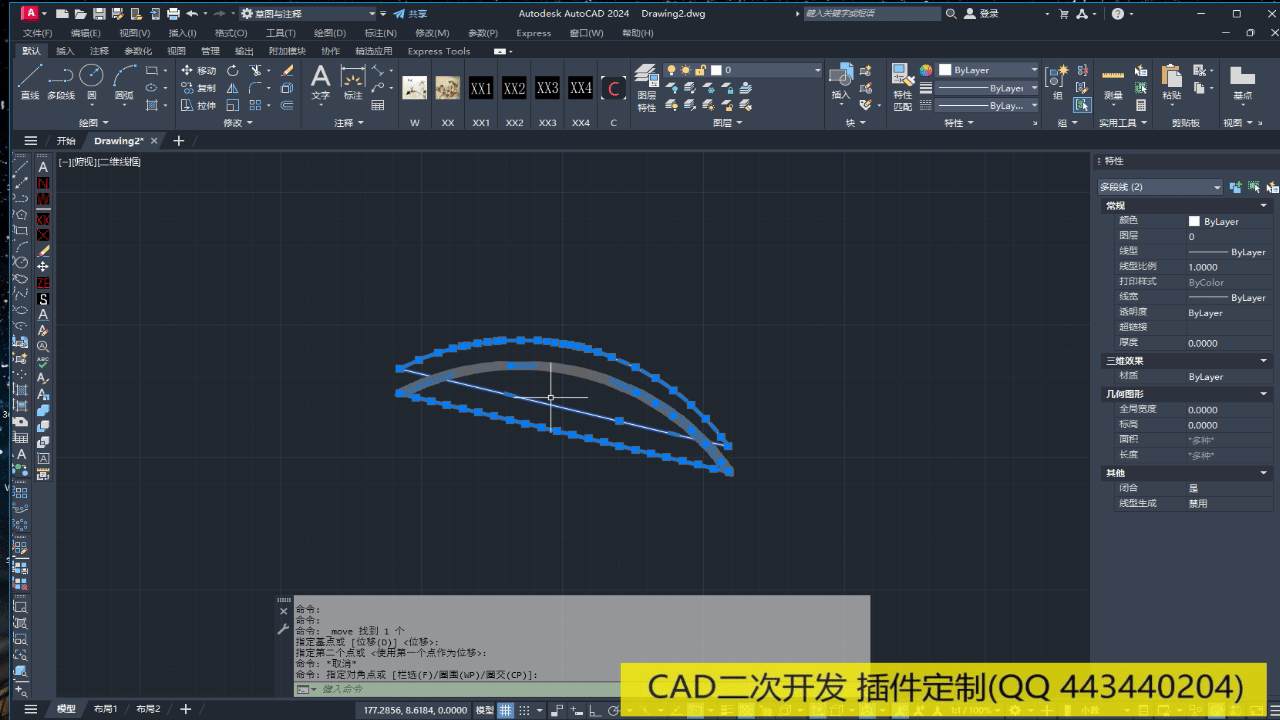
CAD精简多段线顶点、优化、删除多余、重复顶点——CAD c#二次开发
附部分代码如下: public static void Pl精简(){Document doc Autodesk.AutoCAD.ApplicationServices.Application.DocumentManager.MdiActiveDocument;Database db doc.Database;Editor ed doc.Editor;var plOrigon db.SelectCurve("\n选择多段线:");…...

输电线路的“智慧之眼”:全天候可视化监测如何赋能电网安全运维
在电力需求持续攀升、电网规模日益庞大的今天,输电线路的安全稳定运行面临着前所未有的挑战。线路跨越地形复杂多变,尤其是在偏远山区、铁路沿线及恶劣天气条件下,传统的人工巡检方式显得力不从心——效率低、风险高、覆盖有限。如何实现更智…...

Spring 核心知识点补充
Spring 核心知识点补充 1. IoC(控制反转) 核心思想:将对象的创建和依赖管理交给容器,而非在代码中直接控制实现方式: XML 配置:<bean> 标签定义对象注解:Component, Service, Repositor…...
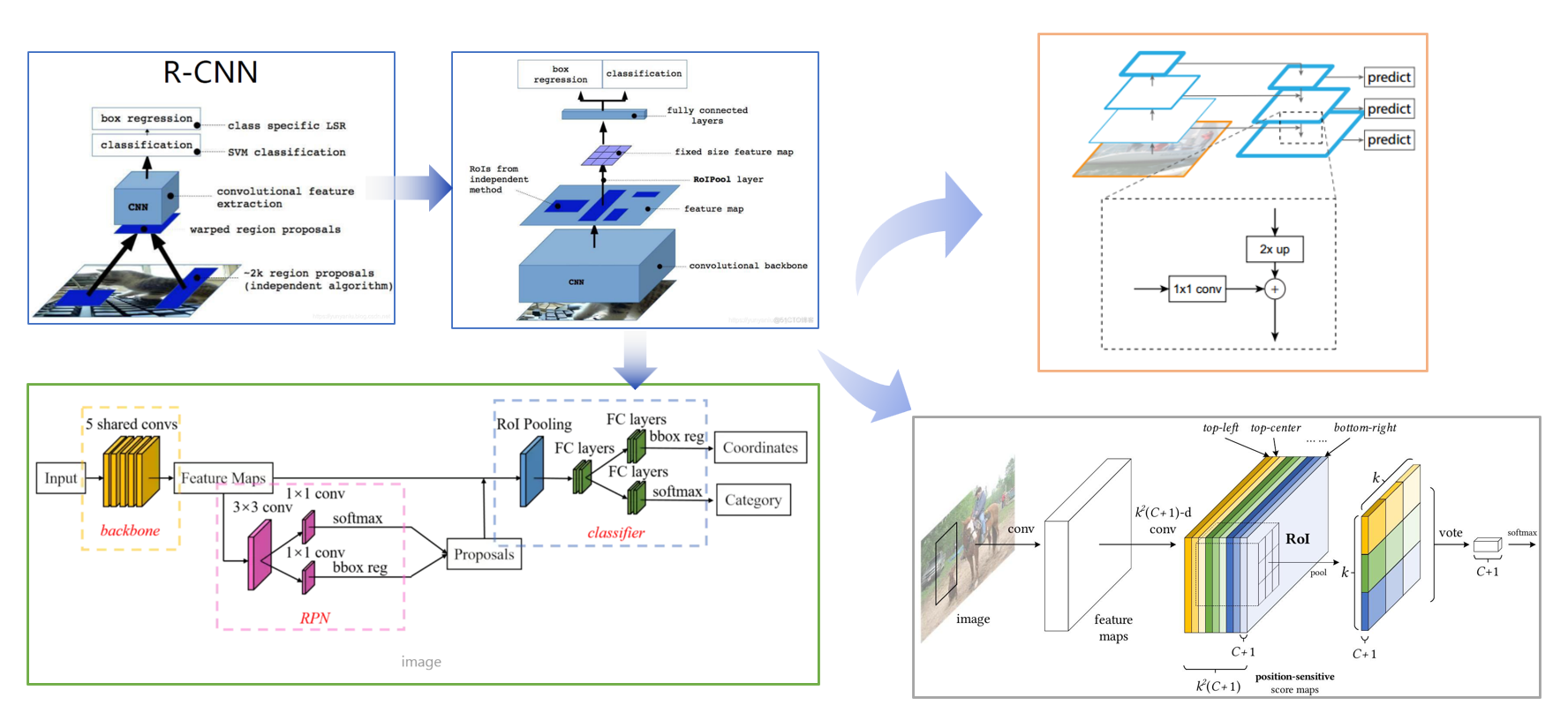
两阶段法目标检测发展脉络
模式识别期末展示大作业,做个记录,希望大家喜欢。 R-CNN Fast R-CNN R-FCN 整个过程可以分解为以下几个步骤: 输入图像 (image) 和初步特征提取 (conv, feature maps): 首先,输入一张原始图像,经过一系列…...

Flannel 支持的后端
Flannel 是一个为 Kubernetes 设计的容器网络解决方案,支持多种后端(backend)来处理节点间的数据包转发。根据官方文档和其他可靠来源,以下是 Flannel 支持的后端类型及其说明: VXLAN(推荐) 描述…...

小白的进阶之路系列之六----人工智能从初步到精通pytorch数据集与数据加载器
本文将介绍以下内容: 数据集与数据加载器 数据迁移 如何建立神经网络 数据集与数据加载器 处理数据样本的代码可能会变得混乱且难以维护;理想情况下,我们希望我们的数据集代码与模型训练代码解耦,以获得更好的可读性和模块化。PyTorch提供了两个数据原语:torch.utils…...

SQL进阶之旅 Day 5: 常用函数与表达式
【SQL进阶之旅 Day 5】常用函数与表达式 在SQL的进阶学习中,掌握常用函数和表达式是提升查询效率、解决复杂业务问题的关键。本篇文章将深入探讨聚合函数、日期函数、条件表达式等核心内容,并结合实际案例分析其应用价值。通过理论讲解、代码示例和性能…...

NestJS——重构日志、数据库、配置
个人简介 👀个人主页: 前端杂货铺 🙋♂️学习方向: 主攻前端方向,正逐渐往全干发展 📃个人状态: 研发工程师,现效力于中国工业软件事业 🚀人生格言: 积跬步…...
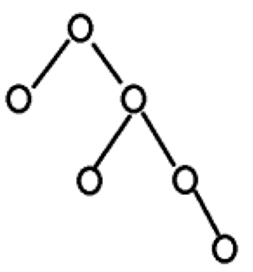
c++数据结构8——二叉树的性质
一、二叉树的基本性质 示图1: 性质1:层节点数上限 在一棵二叉树中,第i层至多有2^{i-1}个节点(首层是第1层) 这个性质可以通过数学归纳法证明: 第1层:2^{1-1}2^01个节点(根节点&am…...

Window Server 2019--08 网络负载均衡与Web Farm
本章要点 1、了解网络负载均衡技术 2、掌握Web Farm核心原理 3、掌握如何使用Windows NLB搭建Web Farm环境 网络负载均衡技术将外部计算机发送的连接请求均匀的分配到服务器集群中的每台服务器上,接受到请求的服务器独立地响应客户的请求。 网络负载均衡技术还…...

arcgis字段计算器中计算矢量面的每个点坐标
python脚本 函数 def ExportCoordinates(feat):coors = []partnum = 0partcount = feat.partCountwhile partnum < partcount:part = feat.getPart(partnum)pnt = part.next()while pnt:coors.append("({}, {})".format(pnt.X,pnt.Y))pnt = part.next()if not p…...
SpringBoot:统一功能处理、拦截器、适配器模式
文章目录 拦截器什么是拦截器?为什么要使用拦截器?拦截器的使用拦截路径执行流程典型应用场景DispatcherServlet源码分析 适配器模式适配器模式定义适配器模式角色适配器模式的实现适配器模式应用场景 统⼀数据返回格式优点 统一处理异常总结 拦截器 什…...

AI Agent工具全景解析:从Coze到RAGflow,探索智能体自动化未来!
在人工智能技术持续深入行业应用的背景下,越来越多的企业和个人寻求通过自动化技术来提高效率和减少重复性劳动,AI Agent的崛起已经成为了不可忽视的趋势。AI Agent,即人工智能代理,是一种基于先进的人工智能技术,特别…...

GitLab CI流水线权限隔离
方案概述 本方案实现在GitLab CI/CD中根据不同人员的权限级别执行不同的流水线步骤,主要基于GitLab的以下特性: rules 条件判断variables 变量传递only/except 条件限制用户权限API查询 基础权限模型设计 1. 用户角色定义 角色描述对应GitLab权限De…...

xcode卡死问题,无论打开什么程序xcode总是在转菊花,重启电脑,卸载重装都不行
很可能是因为我们上次没有正常关闭Xcode,而Xcode保留了上次错误的一些记录,而这次打开Xcode依然去加载错误的记录,所以必须完全删除这些记录Xcode才能加载正常的项目。 那么也就是说,我们是不是只需要删除这部分错误记录文件就可以…...

Onvif协议:IPC客户端开发-IPC相机控制(c语言版)
前言: 本博文主要是借鉴OceanStar大神的博文,在他的博文的基础之上做了一部分修改与简化。 博文链接: Onvif协议:IPC客户端开发之鉴权_onvif鉴权方式-CSDN博客 Onvif协议:IPC客户端开发之PTZ控制_onvif ptz-CSDN博客…...

如何最简单、通俗地理解Pytorch?神经网络中的“梯度”是怎么自动求出来的?PyTorch的动态计算图是如何实现即时执行的?
PyTorch是一门科学——现代深度学习工程中的一把锋利利器。它的简洁、优雅、强大,正在让越来越多的AI研究者、开发者深度应用。 1. PyTorch到底是什么?为什么它重要? PyTorch是一个开源的深度学习框架,由Facebook AI Research(FAIR)于2016年发布,它的名字由两个部分组成…...