python打卡day39
知识点回顾
- 图像数据的格式:灰度和彩色数据
- 模型的定义
- 显存占用的4种地方
- 模型参数+梯度参数
- 优化器参数
- 数据批量所占显存
- 神经元输出中间状态
- batchisize和训练的关系
课程代码:
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
# 设置随机种子,确保结果可复现
torch.manual_seed(42)# 1. 数据预处理,该写法非常类似于管道pipeline
# transforms 模块提供了一系列常用的图像预处理操作# 先归一化,再标准化
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差,这个值很出名,所以直接使用
])
import matplotlib.pyplot as plt# 2. 加载MNIST数据集,如果没有会自动下载
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 随机选择一张图片,可以重复运行,每次都会随机选择
sample_idx = torch.randint(0, len(train_dataset), size=(1,)).item() # 随机选择一张图片的索引
# len(train_dataset) 表示训练集的图片数量;size=(1,)表示返回一个索引;torch.randint() 函数用于生成一个指定范围内的随机数,item() 方法将张量转换为 Python 数字
image, label = train_dataset[sample_idx] # 获取图片和标签
# 可视化原始图像(需要反归一化)
def imshow(img):img = img * 0.3081 + 0.1307 # 反标准化npimg = img.numpy()plt.imshow(npimg[0], cmap='gray') # 显示灰度图像plt.show()print(f"Label: {label}")
imshow(image)Label: 7
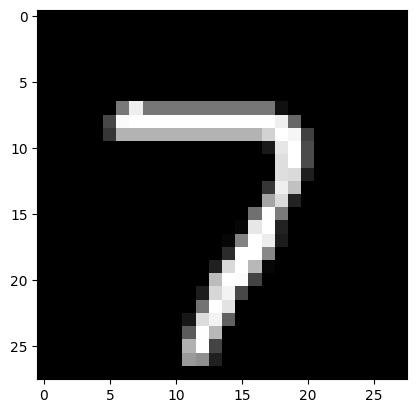
# 打印下图片的形状
image.shapetorch.Size([1, 28, 28])
# 打印一张彩色图像,用cifar-10数据集
import torch
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np# 设置随机种子确保结果可复现
torch.manual_seed(42)
# 定义数据预处理步骤
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 加载CIFAR-10训练集
trainset = torchvision.datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)# 创建数据加载器
trainloader = torch.utils.data.DataLoader(trainset,batch_size=4,shuffle=True
)# CIFAR-10的10个类别
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')# 随机选择一张图片
sample_idx = torch.randint(0, len(trainset), size=(1,)).item()
image, label = trainset[sample_idx]# 打印图片形状
print(f"图像形状: {image.shape}") # 输出: torch.Size([3, 32, 32])
print(f"图像类别: {classes[label]}")# 定义图像显示函数(适用于CIFAR-10彩色图像)
def imshow(img):img = img / 2 + 0.5 # 反标准化处理,将图像范围从[-1,1]转回[0,1]npimg = img.numpy()plt.imshow(np.transpose(npimg, (1, 2, 0))) # 调整维度顺序:(通道,高,宽) → (高,宽,通道)plt.axis('off') # 关闭坐标轴显示plt.show()# 显示图像
imshow(image)图像形状: torch.Size([3, 32, 32])
图像类别: frog

# 先归一化,再标准化
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差,这个值很出名,所以直接使用
])
import matplotlib.pyplot as plt# 2. 加载MNIST数据集,如果没有会自动下载
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)
# 定义两层MLP神经网络
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸模型结构信息:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Flatten-1 [-1, 784] 0
Linear-2 [-1, 128] 100,480
ReLU-3 [-1, 128] 0
Linear-4 [-1, 10] 1,290
================================================================
Total params: 101,770
Trainable params: 101,770
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.00
Forward/backward pass size (MB): 0.01
Params size (MB): 0.39
Estimated Total Size (MB): 0.40
----------------------------------------------------------------
class MLP(nn.Module):def __init__(self, input_size=3072, hidden_size=128, num_classes=10):super(MLP, self).__init__()# 展平层:将3×32×32的彩色图像转为一维向量# 输入尺寸计算:3通道 × 32高 × 32宽 = 3072self.flatten = nn.Flatten()# 全连接层self.fc1 = nn.Linear(input_size, hidden_size) # 第一层self.relu = nn.ReLU()self.fc2 = nn.Linear(hidden_size, num_classes) # 输出层def forward(self, x):x = self.flatten(x) # 展平:[batch, 3, 32, 32] → [batch, 3072]x = self.fc1(x) # 线性变换:[batch, 3072] → [batch, 128]x = self.relu(x) # 激活函数x = self.fc2(x) # 输出层:[batch, 128] → [batch, 10]return x# 初始化模型
model = MLP()device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 将模型移至GPU(如果可用)from torchsummary import summary # 导入torchsummary库
print("\n模型结构信息:")
summary(model, input_size=(3, 32, 32)) # CIFAR-10 彩色图像(3×32×32) 模型结构信息:
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Flatten-1 [-1, 3072] 0
Linear-2 [-1, 128] 393,344
ReLU-3 [-1, 128] 0
Linear-4 [-1, 10] 1,290
================================================================
Total params: 394,634
Trainable params: 394,634
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.01
Forward/backward pass size (MB): 0.03
Params size (MB): 1.51
Estimated Total Size (MB): 1.54
----------------------------------------------------------------
class MLP(nn.Module):def __init__(self):super().__init__()self.flatten = nn.Flatten() # nn.Flatten()会将每个样本的图像展平为 784 维向量,但保留 batch 维度。self.layer1 = nn.Linear(784, 128)self.relu = nn.ReLU()self.layer2 = nn.Linear(128, 10)def forward(self, x):x = self.flatten(x) # 输入:[batch_size, 1, 28, 28] → [batch_size, 784]x = self.layer1(x) # [batch_size, 784] → [batch_size, 128]x = self.relu(x)x = self.layer2(x) # [batch_size, 128] → [batch_size, 10]return xfrom torch.utils.data import DataLoader# 定义训练集的数据加载器,并指定batch_size
train_loader = DataLoader(dataset=train_dataset, # 加载的数据集batch_size=64, # 每次加载64张图像shuffle=True # 训练时打乱数据顺序
)# 定义测试集的数据加载器(通常batch_size更大,减少测试时间)
test_loader = DataLoader(dataset=test_dataset,batch_size=1000,shuffle=False
)@浙大疏锦行
相关文章:
python打卡day39
知识点回顾 图像数据的格式:灰度和彩色数据模型的定义显存占用的4种地方 模型参数梯度参数优化器参数数据批量所占显存神经元输出中间状态 batchisize和训练的关系 课程代码: # 先继续之前的代码 import torch import torch.nn as nn import torch.opti…...

3.8.5 利用RDD统计网站每月访问量
本项目旨在利用Spark RDD统计网站每月访问量。首先,创建名为“SparkRDDWebsiteTraffic”的Maven项目,并添加Spark和Scala的依赖。接着,编写Scala代码,通过SparkContext读取存储在HDFS上的原始数据文件,使用map和reduce…...
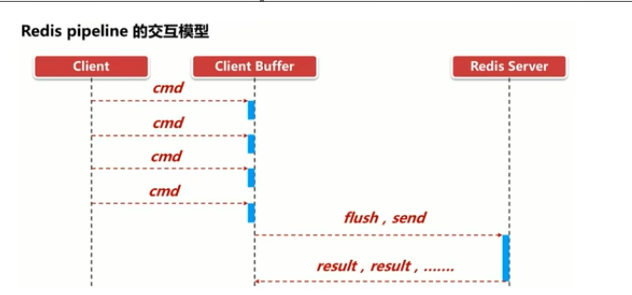
尚硅谷redis7 49-51 redis管道之理论简介
前提redis事务和redis管道有点像,但本质上截然不同 49 redis管道之理论简介 面试题 如何优化频繁命令往返造成的性能瓶颈? redis每秒可以承受8万的写操作和接近10万次以上的读操作。每条命令都发送、处理、返回,能不能批处理一次性搞定呢…...

Spring Boot + MyBatis-Plus实现操作日志记录
创建数据库表 CREATE TABLE sys_operation_log (log_id bigint NOT NULL AUTO_INCREMENT COMMENT 日志ID,operation_type varchar(20) NOT NULL COMMENT 操作类型,operation_module varchar(50) NOT NULL COMMENT 操作模块,operation_desc varchar(200) DEFAULT NULL COMMENT …...

JavaScript入门基础篇-day03
一、为什么需要数组? 在我们正式学习数组之前,先思考一个场景:假设我们要记录一个班级50位同学的期末成绩。如果不用数组,代码会是这样的: let score1 85; let score2 92; let score3 78; // ... 要写50个变量&am…...

Leetcode-5 好数对的数目
Leetcode-5 好数对的数目(简单) 题目描述思路分析通过代码(python) 题目描述 给你一个整数数组 nums 。 如果一组数字 (i,j) 满足 nums[i] nums[j] 且 i < j ,就可以认为这是一组 好数对 。 返回好数对的数目。 示…...
openEuler安装MySql8(tar包模式)
操作系统版本: openEuler release 22.03 (LTS-SP4) MySql版本: 下载地址: https://dev.mysql.com/downloads/mysql/ 准备安装: 关闭防火墙: 停止防火墙 #systemctl stop firewalld.service 关闭防火墙 #systemc…...

Opencv实用操作6 开运算 闭运算 梯度运算 礼帽 黑帽
1.相关函数 开运算 img_open cv2.morphologyEx(img,cv2.MORPH_OPEN,kernel)#(图片,算法,核) 闭运算 img_close cv2.morphologyEx(img,cv2.MORPH_CLOSE,kernel)#(图片,算法,核) 梯度…...
基于python,html,flask,echart,ids/ips,VMware,mysql,在线sdn防御ddos系统
详细视频:【基于python,html,flask,echart,ids/ips,VMware,mysql,在线sdn防御ddos系统-哔哩哔哩】 https://b23.tv/azUqQXe...

Git:现代软件开发的基石——原理、实践与行业智慧·优雅草卓伊凡
Git:现代软件开发的基石——原理、实践与行业智慧优雅草卓伊凡 一、Git的本质与核心原理 1. 技术定义 Git是一个分布式版本控制系统(DVCS),由Linus Torvalds在2005年为管理Linux内核开发而创建。其核心是通过快照(Sna…...
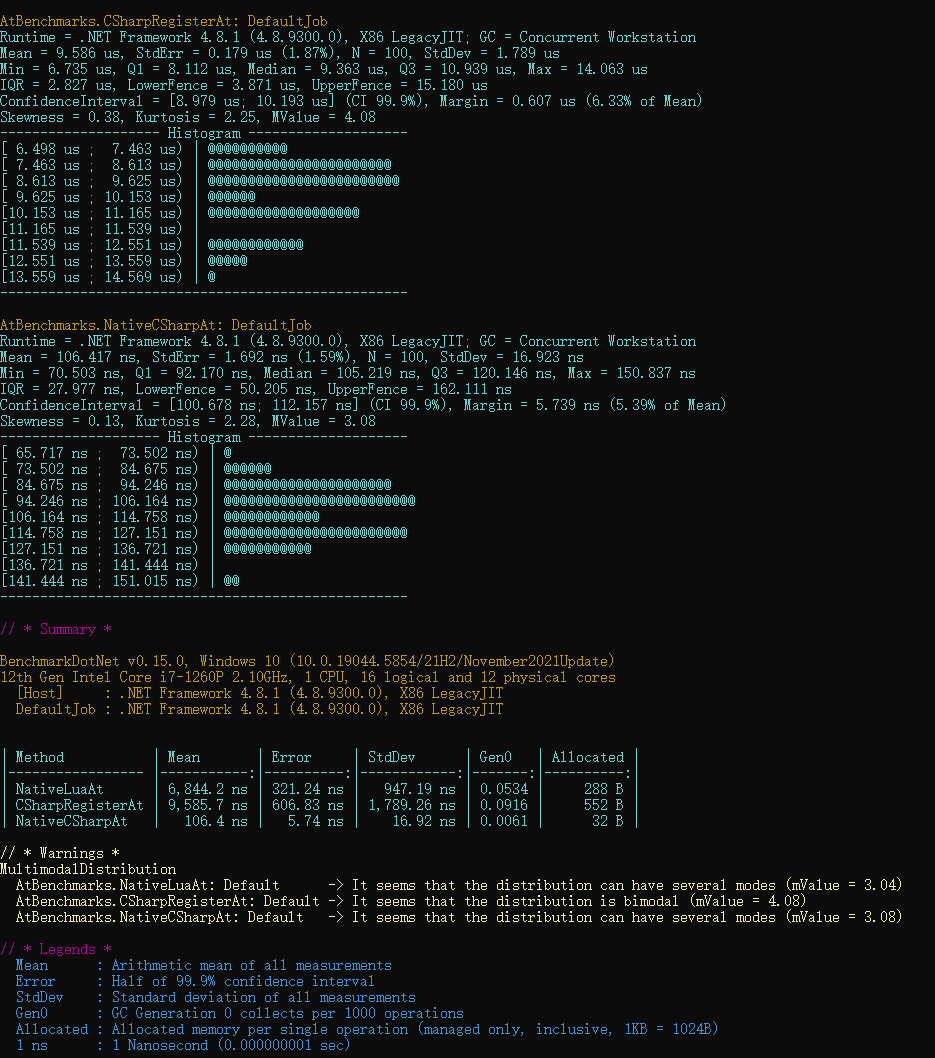
NLua性能对比:C#注册函数 vs 纯Lua实现
引言 在NLua开发中,我们常面临一个重要选择:将C#函数注册到Lua环境调用,还是直接在Lua中实现逻辑? 直觉告诉我们,C#作为编译型语言性能更高,但跨语言调用的开销是否会影响整体性能?本文通过基准…...

【计算机网络】第2章:应用层—Web and HTTP
目录 一、Web 与 HTTP 二、总结 (一)Web 的定义与功能 (二)HTTP 协议的定义与功能 (三)HTTP 协议的核心机制 1. HTTP 请求与响应流程 2. HTTP 的连接类型 3. HTTP 的状态码 (四…...

HarmonyOS 5 应用开发导读:从入门到实践
一、HarmonyOS 5 概述 HarmonyOS 5 是华为推出的新一代分布式操作系统,其核心设计理念是"一次开发,多端部署"。与传统的移动操作系统不同,HarmonyOS 5 提供了更强大的跨设备协同能力,支持手机、平板、智能穿戴、智慧屏…...

大数据治理:分析中的数据安全
引言 随着大数据技术在各行业的深度应用,海量数据蕴含的价值被不断挖掘。然而,数据规模的爆发式增长与分析场景的复杂化,使数据安全问题日益凸显。从数据泄露、隐私侵犯到非法访问,每一个安全漏洞都可能带来难以估量的损失。本文将…...

数字孪生技术赋能西门子安贝格工厂:全球智能制造标杆的数字化重构实践
在工业4.0浪潮席卷全球制造业的当下,西门子安贝格电子制造工厂(Electronic Works Amberg, EWA)凭借数字孪生技术的深度应用,构建起全球制造业数字化转型的典范。这座位于德国巴伐利亚州的“未来工厂”,通过虚实融合的数…...

国内高频混压PCB厂家有哪些?
一、技术领先型厂商(聚焦材料与工艺突破) 猎板PCB 技术亮点:真空层压工艺实现FR-4与罗杰斯高频材料(RO4350B/RO3003)混压,阻抗公差3%,支持64单元/板的5G天线模块,插损降低15%。 应用…...

【图像处理基石】立体匹配的经典算法有哪些?
1. 立体匹配的经典算法有哪些? 立体匹配是计算机视觉中从双目图像中获取深度信息的关键技术,其经典算法按技术路线可分为以下几类,每类包含若干代表性方法: 1.1 基于区域的匹配算法(Local Methods) 通过…...

day12 leetcode-hot100-19(矩阵2)
54. 螺旋矩阵 - 力扣(LeetCode) 1.模拟路径 思路:模拟旋转的路径 (1)设计上下左右方向控制器以及边界。比如zy1向右,zy-1向左;sx1向上,sx-1向下。上边界0,下边界hang-1&a…...

将Java应用集成到CI/CD管道:从理论到生产实践
在2025年的软件开发领域,持续集成与持续部署(CI/CD)已成为敏捷开发和DevOps的核心实践。根据2024年DevOps报告,85%的企业通过CI/CD管道实现了交付周期缩短50%以上,特别是在金融、电商和SaaS行业。Java,作为…...

密钥管理系统在存储加密场景中的深度实践:以TDE透明加密守护文件服务器安全
引言:数据泄露阴影下的存储加密革命 在数字化转型的深水区,企业数据资产正面临前所未有的安全挑战。据IBM《2025年数据泄露成本报告》显示,全球单次数据泄露事件平均成本已达465万美元,其中存储介质丢失或被盗导致的损失占比高达…...
webpack打包基本配置
需要的文件 具体代码 webpack.config.js const path require(path);const HTMLWebpackPlugin require(html-webpack-plugin);const {CleanWebpackPlugin} require(clean-webpack-plugin); module.exports {mode: production,entry: "./src/index.ts",output: {…...

酷派Cool20/20S/30/40手机安装Play商店-谷歌三件套-GMS方法
酷派Cool系列主打低端市场,系统无任何GMS程序,也不支持直接开启或者安装谷歌服务等功能,对于国内部分经常使用谷歌服务商店的小伙伴非常不友好。涉及机型有酷派Cool20/Cool20S /30/40/50/60等旗下多个设备。好在这些机型运行的系统都是安卓11…...
LabVIEW旋转机械智能监测诊断系统
采用 LabVIEW 开发旋转机械智能监测与故障诊断系统,通过集品牌硬件与先进信号处理技术,实现旋转机械振动信号的实时采集、分析及故障预警。系统突破传统监测手段的局限性,解决了复杂工业环境下信号干扰强、故障特征提取难等问题,为…...

数据结构 -- 判断正误
1、栈只能顺序存储。 答案: 错误 原因 栈是一种 逻辑结构,表示“后进先出”(LIFO)的操作规则。栈的实现方式不限于顺序存储,还可以使用链式存储。 顺序存储:使用数组实现栈,称为顺序栈。链式…...

vue3前端实现一键复制,wangeditor富文本复制
首先需要拿到要复制的内容,然后调用https的navigator.clipboard方法进行复制,但是这个因为浏览器策略只能在本地localhost和https环境下才能生效,http环境访问不到这个方法,在http环境在可以使用传统方式创建 textarea 进行复制 …...

小白畅通Linux之旅-----Linux进程管理
目录 一、进程查看命令 1、pstree 2、ps 3、pgrep 4、top、htop 二、进程管理命令 1、kill 2、pkill 和 killall 三、进程类型 1、前台进程 2、后台进程 一、进程查看命令 1、pstree 用于查看进程树之间的关系,谁是父进程,谁是子进程&#…...

【芯片设计中的跨时钟域信号处理:攻克亚稳态的终极指南】
在当今芯片设计中,多时钟域已成为常态。从手机SoC到航天级FPGA,不同功能模块运行在各自的时钟频率下,时钟域间的信号交互如同“语言不通”的对话,稍有不慎就会引发亚稳态、数据丢失等问题。这些隐患轻则导致功能异常,重…...
接地气的方式认识JVM(一)
最近在学jvm,浮于表面的学了之后,发现jvm并没有我想象中的那么神秘,这篇文章将会用接地气的方式来说一说这些jvm的相关概念以及名词解释。 带着下面两个问题来阅读 认识了解JVM大致有什么在代码运行时的都在背后做了什么 JVM是个啥…...

教师申报书课题——项目名称: 基于DeepSeek-R1与飞书妙记的课堂话语智能分析实践计划
明白了!针对教师个人能力范围(无需编程、无需服务器、零预算),我设计一个纯手工+免费工具组合的极简技术方案,用飞书基础功能和DeepSeek网页版就能实现核心分析。申报书重点突出 “轻量、易用、快速启动”。 项目申报书(极简个人实践版) 项目名称: 基于DeepSeek-R1与飞…...

JAVA:Kafka 消息可靠性详解与实践样例
🧱 1、简述 Apache Kafka 是高吞吐、可扩展的流处理平台,在分布式架构中广泛应用于日志采集、事件驱动和微服务解耦场景。但在使用过程中,消息是否会丢?何时丢?如何防止丢? 是很多开发者关心的问题。 Kafka 提供了一套完整的机制来保障消息从生产者 ➜ Broker ➜ 消费…...