python:机器学习(KNN算法)
本文目录:
- 一、K-近邻算法思想
- 二、KNN的应用方式
- ( 一)分类流程
- (二)回归流程
- 三、API介绍
- (一)分类预测操作
- (二)回归预测操作
- 四、距离度量方法
- (一)曼哈顿距离
- (二)切比雪夫距离
- (三)闵式距离
- 五、特征预处理:归一化与标准化
- 六、鸢尾花实例
一、K-近邻算法思想
K-近邻算法(K Nearest Neighbor,简称KNN)。如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别 。就好像根据你的邻居来推断你的类别。
样本相似性:样本都是属于一个任务数据集的,样本距离越近则越相似。
K值的选择:

欧式距离:

二、KNN的应用方式
( 一)分类流程

1.计算未知样本到每一个训练样本的距离(欧式距离);
2.将训练样本根据距离大小升序排列;
3.取出距离最近的 K 个训练样本;
4.进行多数表决,统计 K 个样本中哪个类别的样本个数最多;
5.将未知的样本归属到出现次数最多的类别。
(二)回归流程

1.计算未知样本到每一个训练样本的距离;
2.将训练样本根据距离大小升序排列;
3.取出距离最近的 K 个训练样本;
4.把这 K 个样本的目标值计算其平均值;
5.作为未知的样本预测的值。
三、API介绍
(一)分类预测操作
例:
#分类预测操作
#导包
from sklearn.neighbors import KNeighborsClassifier
# #准备数据集
x_train=[[1,1],[1,2],[2,1],[2,2]]
y_train=[0,0,0,1]
# 创建模型
knn=KNeighborsClassifier(n_neighbors=3)#k默认为5
# 训练模型
knn.fit(x_train,y_train)
# 预测
print(knn.predict([[1.1,1.1]]))
(二)回归预测操作
例:
#回归预测操作
#1.导包
from sklearn.neighbors import KNeighborsRegressor
#2、创建模型算法对象 (回归的)
es = KNeighborsRegressor(n_neighbors=2)
#
#3、准备训练集 x和y
x_train=[[0,0,1],[1,1,0],[3,10,10],[4,11,12]]
y_train=[0.1,0.2,0.3,0.4]
#4、准备测试集
x_test=[[3,10,11]]
#5、模型训练
es.fit(x_train,y_train)
#6、模型预测(并打印结果)
y_test = es.predict(x_test)
print(f"预测结果为{y_test}")
四、距离度量方法
(一)曼哈顿距离
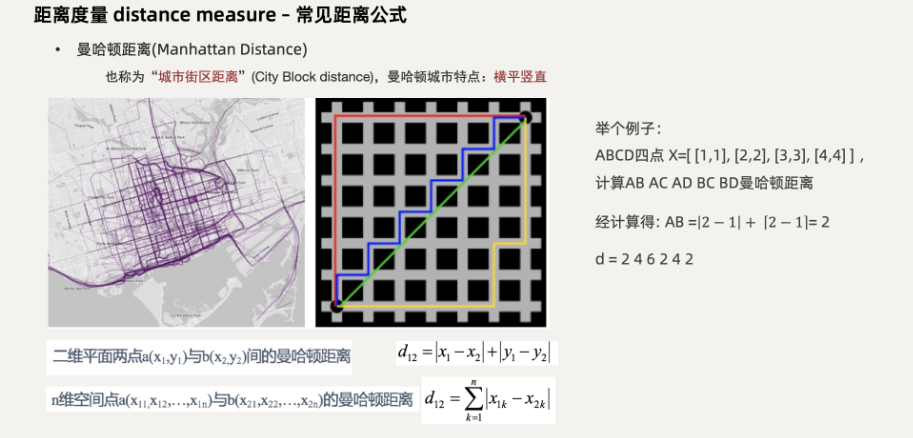
(二)切比雪夫距离
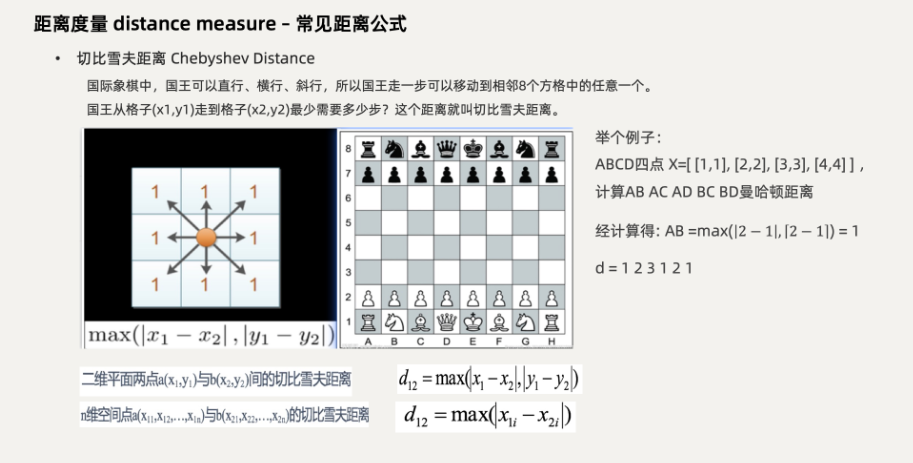
(三)闵式距离

五、特征预处理:归一化与标准化
例:**(一)归一化操作流程**#归一化操作,主要针对数据量较少场景
#1.导包
from sklearn.preprocessing import MinMaxScaler
#2.加载数据
X_TRAIN=[[1,2,3,4,5,6,7,8,9,10],[11,12,13,14,15,16,17,18,19,20],
]
X_TEST=[[21,22,23,24,25,26,27,28,29,30]
]
#3.归一化
scaler = MinMaxScaler(feature_range=(0,1))
#4.特征数据训练集转换
X_TRAIN = scaler.fit_transform(X_TRAIN)
#5.特征数据测试集转换
X_TEST = scaler.transform(X_TEST)
#6.打印
print(X_TRAIN)
print(X_TEST)
**(二)标准化操作流程**#标准化操作,主要针对大数据场景
#1.导包
from sklearn.preprocessing import StandardScaler
#2.建立标准化对象
scaler = StandardScaler()
#3.特征数据训练集转换
scaler.fit(X_TRAIN)
#4.特征数据测试集转换
X_TRAIN = scaler.fit_transform(X_TRAIN)
#5.特征数据测试集转换
X_TEST = scaler.transform(X_TEST)
#6.打印
print(X_TRAIN)
print(X_TEST)
六、鸢尾花实例
例:# 导入工具包
from sklearn.datasets import load_iris # 加载鸢尾花测试集的.
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 分割训练集和测试集的
from sklearn.preprocessing import StandardScaler # 数据标准化的
from sklearn.neighbors import KNeighborsClassifier # KNN算法 分类对象
from sklearn.metrics import accuracy_score # 模型评估的, 计算模型预测的准确率# 1. 定义函数 dm01_loadiris(), 加载数据集.
def dm01_loadiris():# 1. 加载数据集, 查看数据iris_data = load_iris()print(iris_data) # 字典形式, 键: 属性名, 值: 数据.print(iris_data.keys())# 1.1 查看数据集print(iris_data.data[:5])# 1.2 查看目标值.print(iris_data.target)# 1.3 查看目标值名字.print(iris_data.target_names)# 1.4 查看特征名.print(iris_data.feature_names)# 1.5 查看数据集的描述信息.print(iris_data.DESCR)# 1.6 查看数据文件路径print(iris_data.filename)# 2. 定义函数 dm02_showiris(), 显示鸢尾花数据.
def dm02_showiris():# 1. 加载数据集, 查看数据iris_data = load_iris()# 2. 数据展示# 读取数据, 并设置 特征名为列名.iris_df = pd.DataFrame(iris_data.data, columns=iris_data.feature_names)# print(iris_df.head(5))iris_df['label'] = iris_data.target# 可视化, x=花瓣长度, y=花瓣宽度, data=iris的df对象, hue=颜色区分, fit_reg=False 不绘制拟合回归线.sns.lmplot(x='petal length (cm)', y='petal width (cm)', data=iris_df, hue='label', fit_reg=False)plt.title('iris data')plt.show()# 3. 定义函数 dm03_train_test_split(), 实现: 数据集划分
def dm03_train_test_split():# 1. 加载数据集, 查看数据iris_data = load_iris()# 2. 划分数据集, 即: 特征工程(预处理-标准化)x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2,random_state=22)print(f'数据总数量: {len(iris_data.data)}')print(f'训练集中的x-特征值: {len(x_train)}')print(f'训练集中的y-目标值: {len(y_train)}')print(f'测试集中的x-特征值: {len(x_test)}')# 4. 定义函数 dm04_模型训练和预测(), 实现: 模型训练和预测
def dm04_model_train_and_predict():# 1. 加载数据集, 查看数据iris_data = load_iris()# 2. 划分数据集, 即: 数据基本处理x_train, x_test, y_train, y_test = train_test_split(iris_data.data, iris_data.target, test_size=0.2, random_state=22)# 3. 数据集预处理-数据标准化(即: 标准的正态分布的数据集)transfer = StandardScaler()# fit_transform(): 适用于首次对数据进行标准化处理的情况,通常用于训练集, 能同时完成 fit() 和 transform()。x_train = transfer.fit_transform(x_train)# transform(): 适用于对测试集进行标准化处理的情况,通常用于测试集或新的数据. 不需要重新计算统计量。x_test = transfer.transform(x_test)# 4. 机器学习(模型训练)estimator = KNeighborsClassifier(n_neighbors=5)estimator.fit(x_train, y_train)# 5. 模型评估.# 场景1: 对抽取出的测试集做预测.# 5.1 模型评估, 对抽取出的测试集做预测.y_predict = estimator.predict(x_test)print(f'预测结果为: {y_predict}')# 场景2: 对新的数据进行预测.# 5.2 模型预测, 对测试集进行预测.# 5.2.1 定义测试数据集.my_data = [[5.1, 3.5, 1.4, 0.2]]# 5.2.2 对测试数据进行-数据标准化.my_data = transfer.transform(my_data)# 5.2.3 模型预测.my_predict = estimator.predict(my_data)print(f'预测结果为: {my_predict}')# 5.2.4 模型预测概率, 返回每个类别的预测概率my_predict_proba = estimator.predict_proba(my_data)print(f'预测概率为: {my_predict_proba}')# 6. 模型预估, 有两种方式, 均可.# 6.1 模型预估, 方式1: 直接计算准确率, 100个样本中模型预测正确的个数.my_score = estimator.score(x_test, y_test)print(my_score) # 0.9666666666666667# 6.2 模型预估, 方式2: 采用预测值和真实值进行对比, 得到准确率.print(accuracy_score(y_test, y_predict))# 在main方法中测试.
if __name__ == '__main__':# 1. 调用函数 dm01_loadiris(), 加载数据集.# dm01_loadiris()# 2. 调用函数 dm02_showiris(), 显示鸢尾花数据.# dm02_showiris()# 3. 调用函数 dm03_train_test_split(), 查看: 数据集划分# dm03_train_test_split()# 4. 调用函数 dm04_模型训练和预测(), 实现: 模型训练和预测dm04_model_train_and_predict()**【附赠】网格搜索和交叉验证在鸢尾花实例上的应用:**
# 4. 模型训练.
# 4.1 创建估计器对象.
estimator = KNeighborsClassifier()
# 4.2 使用校验验证网格搜索. 指定参数范围.
param_grid = {"n_neighbors": range(1, 10)}
# 4.3 具体的 网格搜索过程 + 交叉验证.
# 参1: 估计器对象, 参2: 参数范围, 参3: 交叉验证的折数.
estimator = GridSearchCV(estimator=estimator, param_grid=param_grid, cv=5)
# 具体的模型训练过程.
estimator.fit(x_train, y_train)# 4.4 交叉验证, 网格搜索结果查看.
print(estimator.best_score_) # 模型在交叉验证中, 所有参数组合中的最高平均测试得分
print(estimator.best_estimator_) # 最优的估计器对象.
print(estimator.cv_results_) # 模型在交叉验证中的结果.
print(estimator.best_params_) # 模型在交叉验证中的结果.# 5. 得到最优模型后, 对模型重新预测.
estimator = KNeighborsClassifier(n_neighbors=6)
estimator.fit(x_train, y_train)
print(f'模型评估: {estimator.score(x_test, y_test)}') # 因为数据量和特征的问题, 该值可能小于上述的平均测试得分.备注:如果存在中文乱码问题,可如下设置:
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
即 通过设置全局变量(默认字体设为‘SimHei’【支持中文】和将unicode里的负号禁止不用【默认的负号无法被识别,禁用后将不再影响】)来处理乱码。
以上代码的简洁版:
#导包
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import GridSearchCV,train_test_split
from sklearn.datasets import load_iris
import seaborn as sns
#解决中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False#加载数据集
def iris_data():data=load_iris()# print(data)iris=pd.DataFrame(data.data,columns=data.feature_names)iris['类别']=data.targetiris.columns=['花萼长度','花萼宽度','花瓣长度','花瓣宽度','类别']print(iris.head())return irisif __name__=='__main__':iris=iris_data()# 绘制回归图,fit_reg=Ture:展示回归线sns.lmplot(data=iris,x='花萼长度',y='花萼宽度',hue='类别',fit_reg=True)#一种绘图方式# iris.plot(kind='scatter',x='花萼长度',y='花萼宽度') #另一种绘图方式,但没有sns精致plt.show()#切割数据x_train,x_test,y_train,y_test=train_test_split(iris[['花萼长度','花萼宽度','花瓣长度','花瓣宽度']],iris['类别'],test_size=0.3,random_state=88)# 数据标准化knn=StandardScaler()new_x_train=knn.fit_transform(x_train)new_x_test=knn.transform(x_test)# 训练模型aa=KNeighborsClassifier()aa=GridSearchCV(aa,param_grid={'n_neighbors':[i for i in range(1,11)]},cv=4)aa.fit(new_x_train,y_train)#打印最佳参数,最佳得分,整体参数print(aa.best_score_,aa.best_params_,aa.cv_results_['params'])#预测并打印准确率print(accuracy_score(aa.predict(new_x_test),y_test))print(aa.score(new_x_test,y_test))
相关文章:
python:机器学习(KNN算法)
本文目录: 一、K-近邻算法思想二、KNN的应用方式( 一)分类流程(二)回归流程 三、API介绍(一)分类预测操作(二)回归预测操作 四、距离度量方法(一)…...
【笔记】2025 年 Windows 系统下 abu 量化交易库部署与适配指南
#工作记录 前言 在量化交易的学习探索中,偶然接触到 2017 年开源的 abu 量化交易库,其代码结构和思路对新手理解量化回测、指标分析等基础逻辑有一定参考价值。然而,当尝试在 2025 年的开发环境中部署这个久未更新的项目时,遇到…...

小程序 - 视图与逻辑
个人简介 👨💻个人主页: 魔术师 📖学习方向: 主攻前端方向,正逐渐往全栈发展 🚴个人状态: 研发工程师,现效力于政务服务网事业 🇨🇳人生格言: “心有多大,舞台就有多大。” 📚推荐学习: 🍉Vue2 🍋Vue3 🍓Vue2/3项目实战 🥝Node.js实战 🍒T…...
ChatGPT Plus/Pro 订阅教程(支持支付宝)
订阅 ChatGPT Plus GPT-4 最简单,成功率最高的方案 1. 登录 chat.openai.com 依次点击 Login ,输入邮箱和密码 2. 点击升级 Upgrade 登录自己的 OpenAI 帐户后,点击左下角的 Upgrade to Plus,在弹窗中选择 Upgrade plan。 如果…...

[蓝帽杯 2022 初赛]网站取证_2
一、找到与数据库有关系的PHP文件 打开内容如下,发现数据库密码是函数my_encrypt()返回的结果。 二、在文件夹encrypt中找到encrypt.php,内容如下,其中mcrypt已不再使用,所以使用php>7版本可能没有执行结果,需要换成较低版本…...

vue3+Pinia+element-plus 后台管理系统项目实战记录
vue3Piniaelement-plus 后台管理系统项目实战记录 参考项目:https://www.bilibili.com/video/BV1L24y1n7tB 全局api provide、inject vue2 import api from/api vue.propotype.$api apithis.$api.xxxvue3 import api from/api app.provide($api, api)import {…...
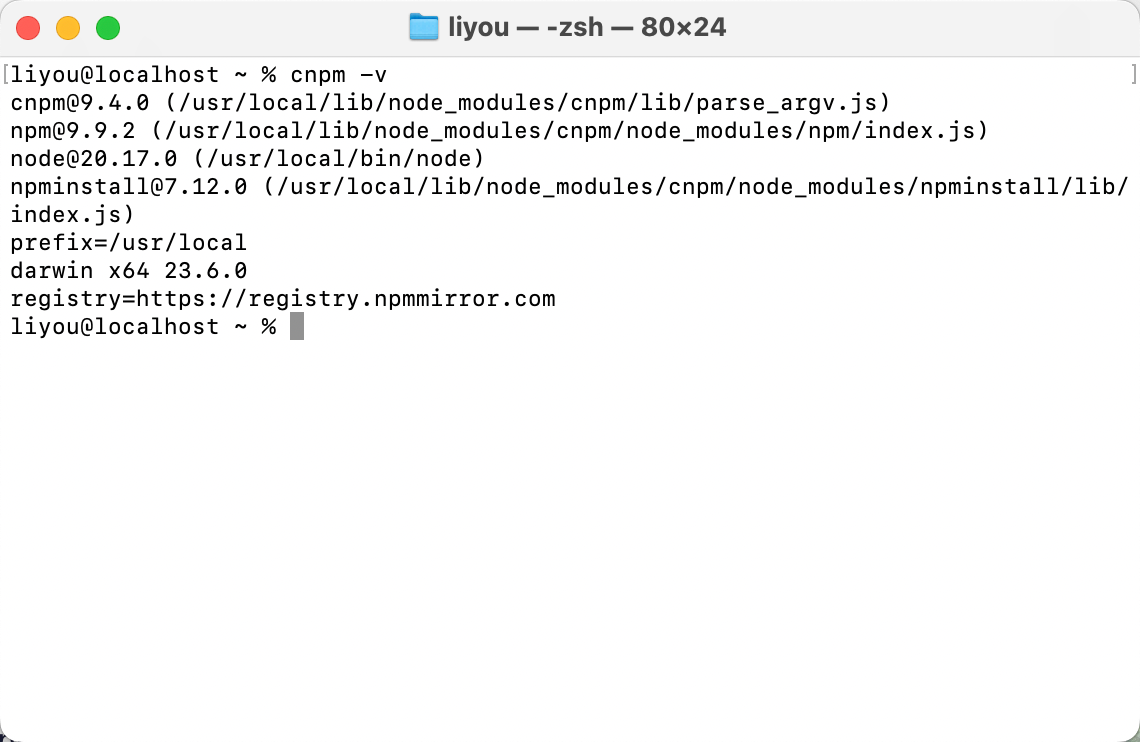
安装 Node.js 和配置 cnpm 镜像源
一、安装 Node.js 方式一:官网下载(适合所有系统) 访问 Node.js 官网 推荐选择 LTS(长期支持)版本,点击下载安装包。 根据系统提示一步步完成安装。 方式二:通过包管理器安装(建…...

MacOS内存管理-删除冗余系统数据System Data
文章目录 一、问题复现二、解决思路三、解决流程四、附录 一、问题复现 以题主的的 Mac 为例,我们可以看到System Data所占数据高达77.08GB,远远超出系统所占内存 二、解决思路 占据大量空间的是分散在系统中各个位置Cache数据; 其中容量最…...

电脑开机后长时间黑屏,桌面图标和任务栏很久才会出现,但是可通过任务管理器打开应用程序,如何解决
目录 一、造成这种情况的主要原因(详细分析): (1)启动项过多,导致系统资源占用过高(最常见) 检测方法: (2)系统服务启动异常(常见&a…...
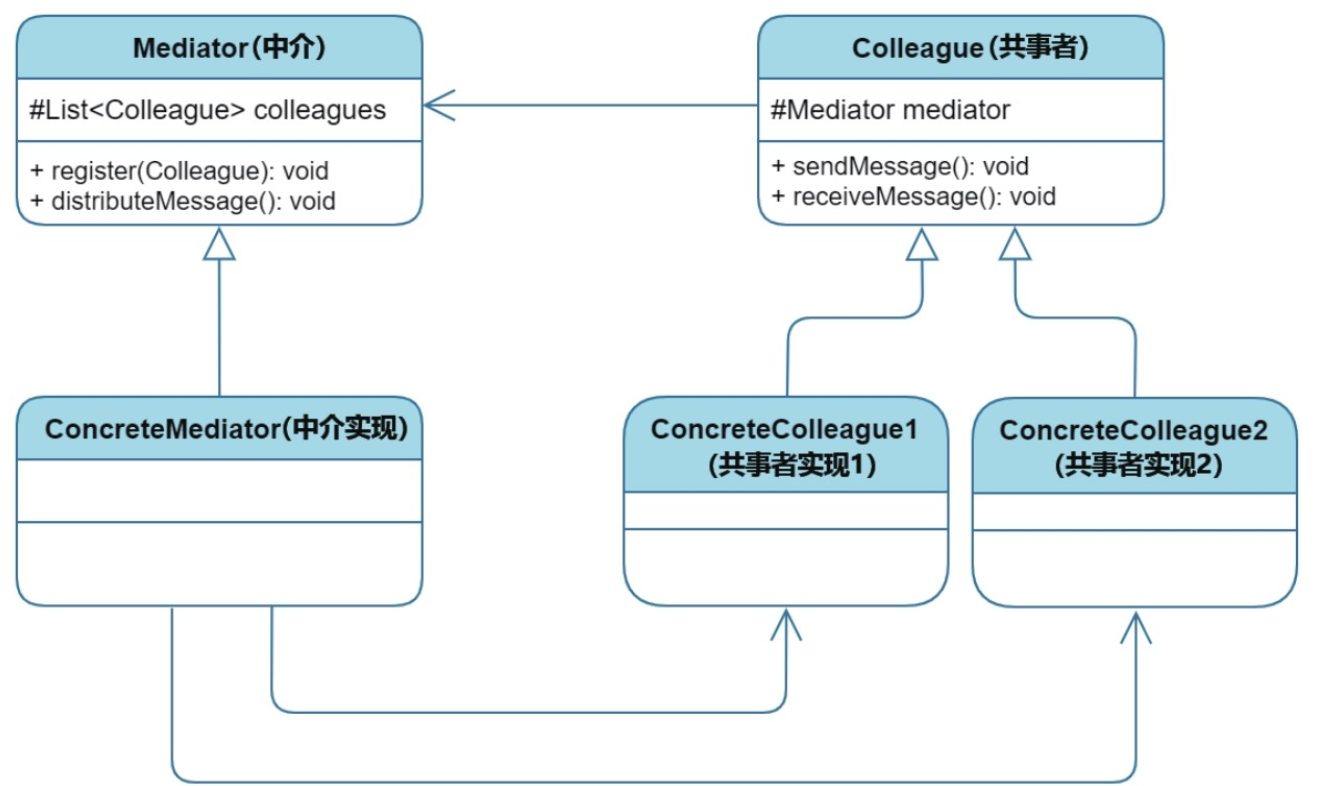
行为型:中介者模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 5、注意事项 1、核心思想 目的:通过引入一个中介对象来封装一组对象之间的交互,解决对象间过度耦合、频繁交互的问题。不管是对象引用维护还是消息的转发&am…...

光谱相机在生态修复监测中的应用
光谱相机通过多维光谱数据采集与智能分析技术,在生态修复监测中构建起“感知-评估-验证”的全周期管理体系,其核心应用方向如下: 一、土壤修复效能量化评估 重金属污染动态监测 通过短波红外(1000-2500nm)波…...
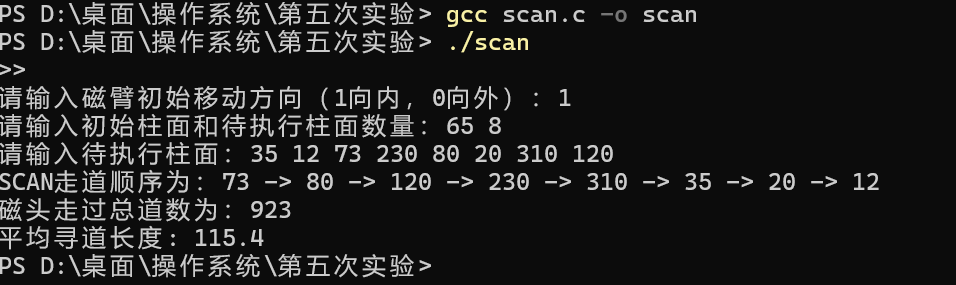
吉林大学操作系统上机实验五(磁盘引臂调度算法(scan算法)实现)
本次实验无参考,从头开始实现。 一.实验内容 模拟实现任意一个磁盘引臂调度算法,对磁盘进行移臂操作列出基于该种算法的磁道访问序列,计算平均寻道长度。 二.实验设计 假设磁盘只有一个盘面,并且磁盘是可移动头磁盘。磁盘是可…...
)
【深度学习-pytorch篇】4. 正则化方法(Regularization Techniques)
正则化方法(Regularization Techniques) 1. 目标 理解什么是过拟合及其影响掌握常见正则化技术:L2 正则化、Dropout、Batch Normalization、Early Stopping能够使用 PyTorch 编程实现这些正则化方法并进行比较分析 2. 数据构造与任务设定 …...
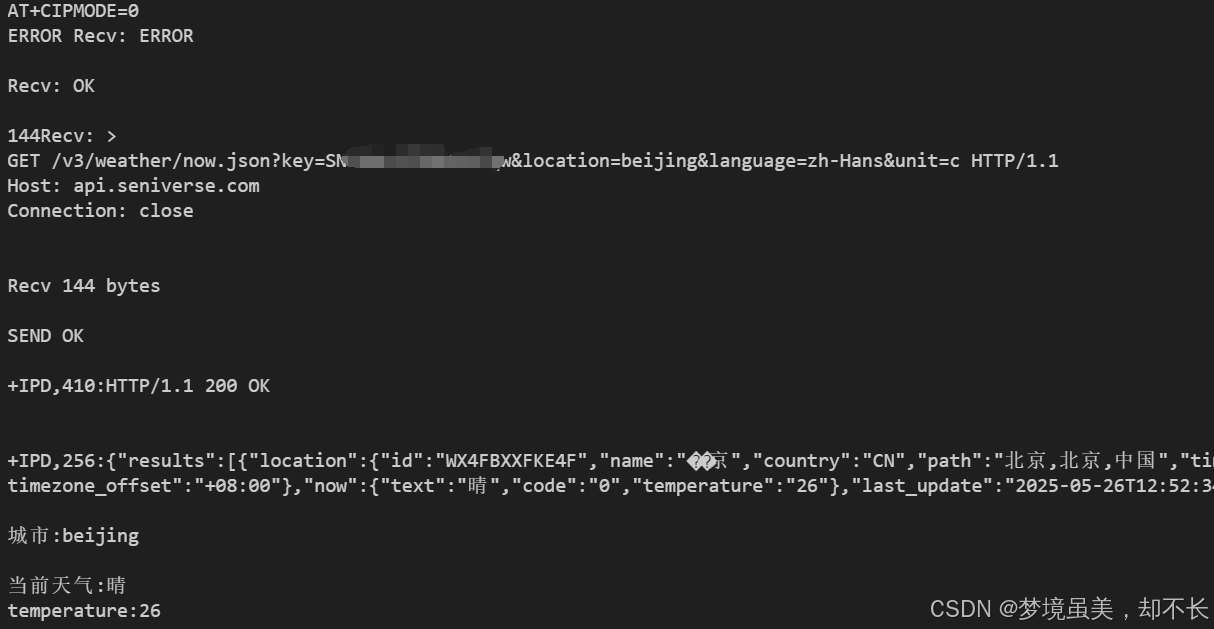
ESP8266+STM32 AT驱动程序,心知天气API 记录时间: 2025年5月26日13:24:11
接线为 串口2 接入ESP8266 esp8266.c #include "stm32f10x.h"//8266预处理文件 #include "esp8266.h"//硬件驱动 #include "delay.h" #include "usart.h"//用得到的库 #include <string.h> #include <stdio.h> #include …...
)
WPF【11_5】WPF实战-重构与美化(MVVM 实战)
11-10 【重构】创建视图模型,显示客户列表 正式进入 MVVM 架构的代码实战。在之前的课程中, Model 和 View 这部分的代码重构实际上已经完成了。 Model 就是在 Models 文件夹中看到的两个文件, Customer 和 Appointment。 而 View 则是所有与…...

⭐️⭐️⭐️ 模拟题及答案 ⭐️⭐️⭐️ 大模型Clouder认证:RAG应用构建及优化
考试注意事项: 一、单选题(21题) 检索增强生成(RAG)的核心技术结合了什么? A. 图像识别与自然语言处理 B. 信息检索与文本生成 C. 语音识别与知识图谱 D. 数据挖掘与机器学习 RAG技术中,“建立索引”步骤不包括以下哪项操作? A. 将文档解析为纯文本 B. 文本片段分割(…...
kali系统的安装及配置
1 kali下载 Kali 下载地址:Get Kali | Kali Linux (https://www.kali.org/get-kali) 下载 kali-linux-2024.4-installer-amd64.iso (http://cdimage.kali.org/kali-2024.4/) 2. 具体安装步骤: 2.1 进入官方地址,点击…...

CSS--background-repeat详解
属性介绍 background-repeat 属性在CSS中用于控制背景图像是否以及如何重复。当背景图像的尺寸小于其容器的尺寸时,该属性决定了图像如何填充额外的空间。默认情况下,背景图像会在横向和纵向上重复,直到覆盖整个元素。 常见取值 repeat …...

Redis的大Key问题如何解决?
大家好,我是锋哥。今天分享关于【Redis的大Key问题如何解决?】面试题。希望对大家有帮助; Redis的大Key问题如何解决? 1000道 互联网大厂Java工程师 精选面试题-Java资源分享网 Redis中的“大Key”问题是指某个键的值占用了过多…...

影楼精修-AI追色算法解析
注意:本文样例图片为了避免侵权,均使用AIGC生成; AI追色是像素蛋糕软件中比较受欢迎的一个功能点,本文将针对AI追色来解析一下大概的技术原理。 功能分析 AI追色实际上可以理解为颜色迁移的一种变体或者叫做升级版,…...
node入门:安装和npm使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、安装npm命令nvm 前言 因为学习vue接触的,一直以为node是和vue绑定的,还以为vue跑起来必须要node,后续发现并不是。 看…...

‘js@https://registry.npmmirror.com/JS/-/JS-0.1.0.tgz‘ is not in this registry
解决方法: 1. npm cache clean --force 2.临时切换到官方源 npm config set registry https://registry.npmjs.org/ npm install js0.1.0 npm config set registry https://registry.npmmirror.com/ # 切换回镜像源...

el-table-column如何获取行数据的值
在Element UI的el-table组件中,你可以通过el-table-column的slot-scope属性(在Vue 2.x中)或者#default插槽的scope属性(在Vue 3.x中)来获取当前行的数据。以下是如何实现这一功能的详细步骤: 在el-table-…...

leetcode450.删除二叉搜索树中的节点:迭代法巧用中间节点应对多场景删除
一、题目深度解析与BST特性剖析 在二叉搜索树(BST)中删除节点,需确保删除操作后树依然保持BST特性。题目要求我们根据给定的节点值key,在BST中删除对应节点。BST的核心特性是左子树所有节点值小于根节点值,右子树所有…...

java虚拟机2
一、垃圾回收机制(GC) 1. 回收区域:GC主要回收堆内存区域。堆用于存放new出来的对象 。程序计数器、元数据区和栈一般不是GC回收的重点区域。 2. 回收单位:GC以对象为单位回收内存,而非字节。按对象维度回收更简便&am…...

自监督软提示调优:跨域NLP新突破
自监督的软提示调优方法(SPSS) 这篇论文提出了一种基于自监督的软提示调优方法(SPSS),用于无监督领域自适应。其核心目标是通过挖掘源域和目标域的内部知识,解决传统提示调优在跨域场景中依赖通用知识、模板生成低效的问题。 一、核心实现原理 1. 自监督分层聚类优化(…...
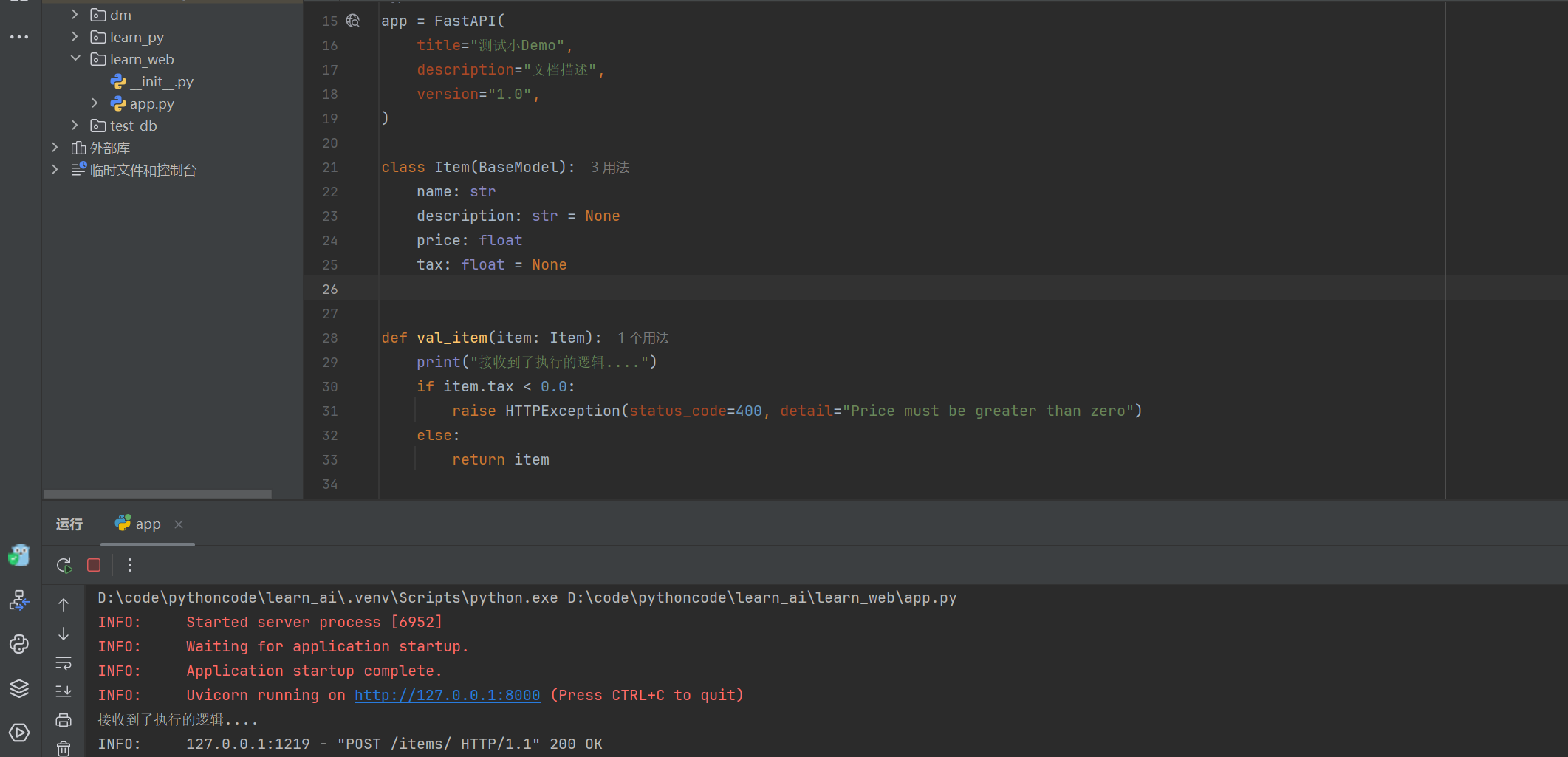
Pydantic 学习与使用
Pydantic 学习与使用 在 Fastapi 的 Web 开发中的数据验证通常都是在使用 Pydantic 来进行数据的校验,本文将对 Pydantic 的使用方法做记录与学习。 **简介:**Pydantic 是一个在 Python 中用于数据验证和解析的第三方库,它现在是 Python 使…...
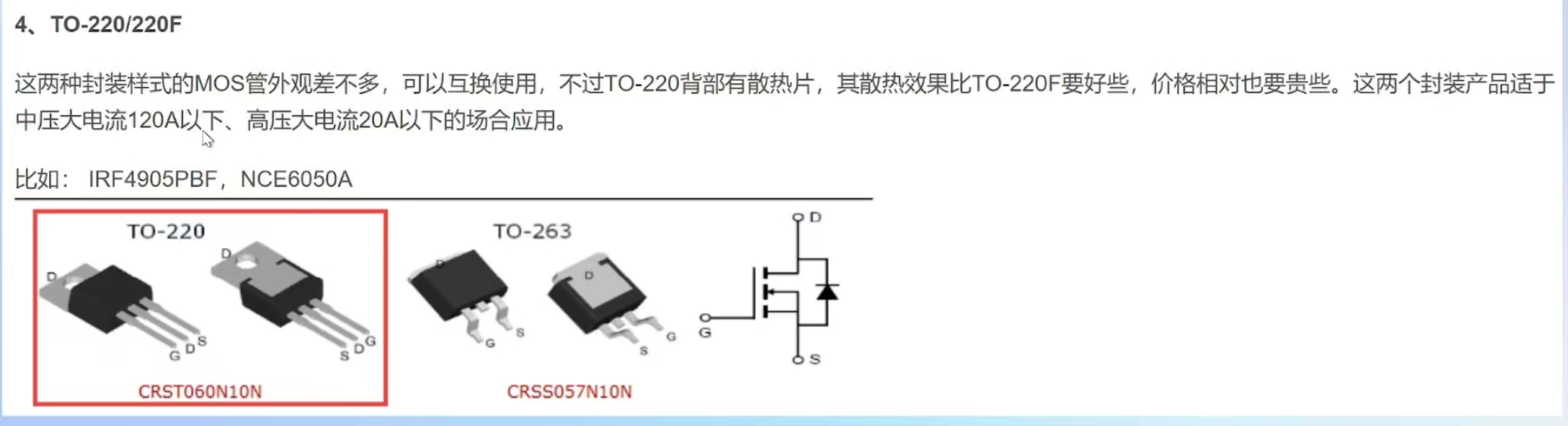
PCB设计教程【入门篇】——电路分析基础-基本元件(二极管三极管场效应管)
前言 本教程基于B站Expert电子实验室的PCB设计教学的整理,为个人学习记录,旨在帮助PCB设计新手入门。所有内容仅作学习交流使用,无任何商业目的。若涉及侵权,请随时联系,将会立即处理、 目录 前言 1.二极管 1.发光…...
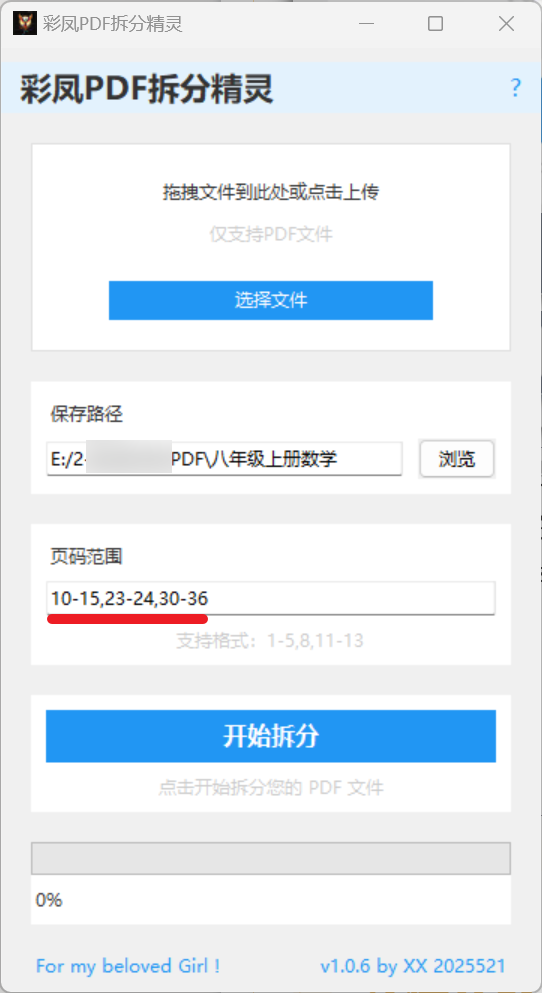
能按需拆分 PDF 为多个文档的工具
软件介绍 彩凤 PDF 拆分精灵是一款具备 PDF 拆分功能的软件。 功能特点 PDF 拆分功能较为常见,很多 PDF 软件都具备,例如 DC 软件提取 PDF 较为方便,但它不能从一个 PDF 里提取出多个 PDF。据印象,其他 PDF 软件也似乎没有能从…...
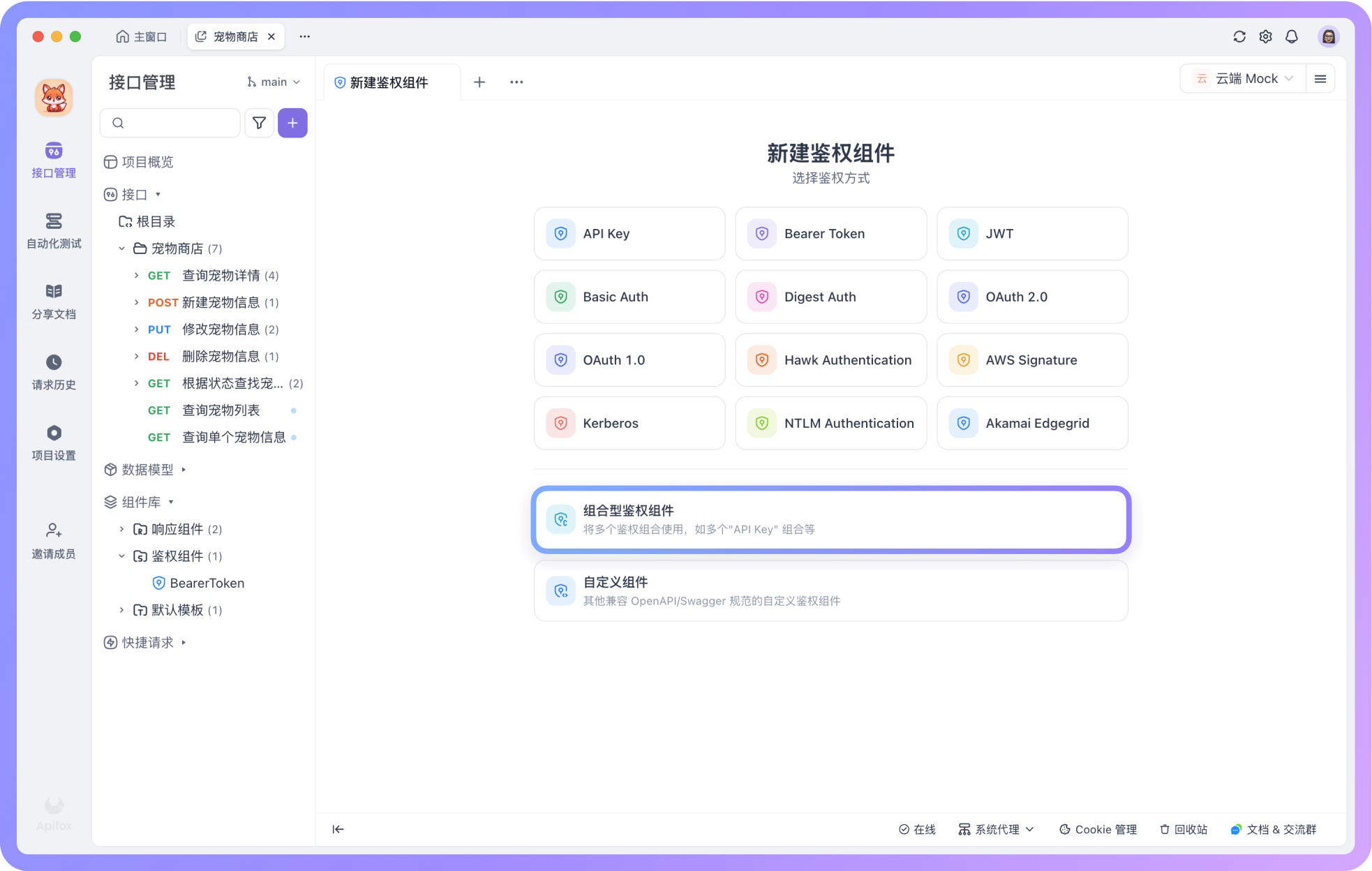
Apifox 5 月产品更新|数据模型支持查看「引用资源」、调试 AI 接口可实时预览 Markdown、性能优化
Apifox 新版本上线啦! 看看本次版本更新主要涵盖的重点内容,有没有你所关注的功能特性: 自动解析 JSON 参数名和参数值调试 AI 接口时,可预览 Markdown 格式的内容性能优化:新增「实验性功能」选项 使用独立进程执行…...