[预训练]Encoder-only架构的预训练任务核心机制

| 原创文章 | |
| 1 | FFN前馈网络与激活函数技术解析:Transformer模型中的关键模块 |
| 2 | Transformer掩码技术全解析:分类、原理与应用场景 |
| 3 | 【大模型技术】Attention注意力机制详解一 |
| 4 | Transformer核心技术解析LCPO方法:精准控制推理长度的新突破 |
| 5 | Transformer模型中位置编码(Positional Embedding)技术全解析(二) |
| 6 | Transformer模型中位置编码(Positional Embedding)技术全解析(一) |
| 7 | 自然语言处理核心技术词嵌入(Word Embedding),从基础原理到大模型应用 |
| 8 | DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 |
| 9 | 【Tokenization第二章】分词算法深度解析:BPE、WordPiece与Unigram的原理、实现与优化 |
| 10 | Tokenization自然语言处理中分词技术:从传统规则到现代子词粒度方法 |
Encoder-only 预训练任务
BERT引入了深度双向注意力机制和Masking思想,我们主要围绕BERT两大核心训练任务:
Masked Language Modeling(MLM)与Next Sentence Prediction(NSP)
BERT预训练
传统的语言模型中,网络只能从左到右或从右到左进行单向建模,导致无法充分利用上下文信息。BERT 提出了一种 “遮蔽(Masking)” 的策略,通过将部分词隐藏,让模型在训练时同时关注被遮住单词左右两侧的上下文,从而获得真双向的上下文表示。此外,BERT 还引入了句子级别的 NSP 任务,使模型在理解单句语义的同时也能学习到句子之间的衔接与语义关系。
BERT的两个主要预训练任务:
-
MLM:通过遮蔽部分Token,打上[MASK],让模型必须根据上下文推理出被遮蔽的token.
-
NSP:随机抽取句子对,判断第二句是否是第一句的后续(从同一文档中顺序提取),提升句子层次的理解能力
传统的语言模型中,网络只能从左到右或从右到左进行单向建模,导致无法充分利用上下文信息。BERT 提出了一种 “遮蔽(Masking)” 的策略,通过将部分词隐藏,让模型在训练时同时关注被遮住单词左右两侧的上下文,从而获得真双向的上下文表示。此外,BERT 还引入了句子级别的 NSP 任务,使模型在理解单句语义的同时也能学习到句子之间的衔接与语义关系。
BERT进行下游任务(如文本分类、问答等)时,只需在base模型上加一个或少量额外层的微调
传统BERT预训练任务
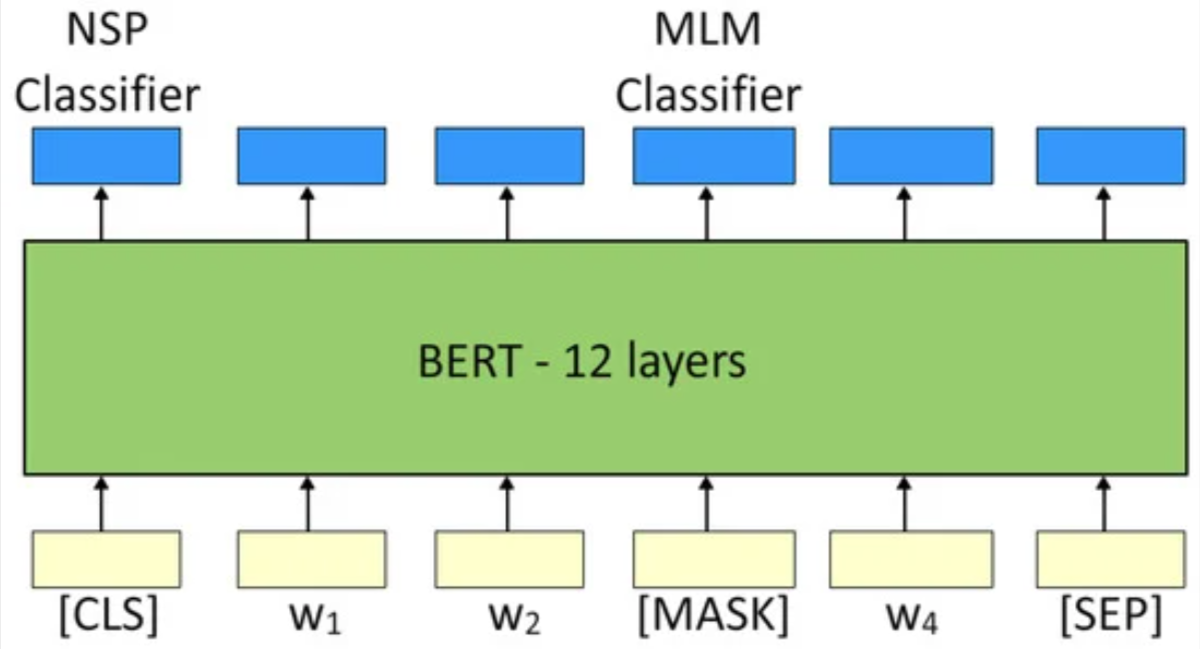
MLM
BERT 会随机选择句子中 15% 的单词进行处理,其中
-
80%概率tokens会被替换为[MASK]
-
10%概率,tokens会称替换为随机的token,这正是解决一词多义的最重要特性
-
10%概率,tokens会保持不变但需要被预测
模型如何 “忽略原词”,仅通过上下文预测?1. 输入层:隐藏原词的真实身份
虽然原词未被替换为[MASK]或随机词,但在模型的输入表示中,它与其他词一样被编码为词向量、位置向量和段向量的叠加。
关键:模型在输入阶段无法 “知道” 哪个词是 “被强制预测的原词”,只能通过后续的编码层从上下文中提取信息。
2. 编码层:通过自注意力机制剥离原词依赖
Transformer 编码器的自注意力机制会让每个词的表示融合整个句子的上下文信息。
即使某个位置是原词,其最终的上下文表示(即编码器输出)也会被周围词的语义 “稀释”,不再单纯依赖自身的原始词义。
例如:句子 “苹果 [原词] 是红色的” 中,“苹果” 未被 mask,但模型需要通过 “是红色的” 来预测 “苹果”,而不是直接利用 “苹果” 本身的词义。
此时,模型的任务等价于:“根据‘[X] 是红色的’,预测 [X] 是什么?”,其中 [X] 的输入是 “苹果” 的词向量,但模型必须忽略这一信息,仅通过 “是红色的” 推断。
3. 预测层:强制基于上下文生成概率分布
编码器输出的向量会输入到一个全连接层(分类器),该层通过与词表的嵌入矩阵相乘,生成每个词的预测概率(不依赖输入词本身)。
即使输入的是原词,模型也会计算 “在上下文中,该位置最可能的词是什么”,而不是直接返回原词。
例如:输入 “苹果” 未被 mask,但模型需要根据 “是红色的” 预测该位置为 “苹果” 的概率,这要求模型必须证明 “苹果” 是上下文中最合理的词,而非直接记忆。MLM训练目标
- 给定sequence
, 令
表示经过Mask后的序列。网络经过输出词向量
并经过全连接层+softmax,预测每个被Mask位置所对应的真实词
- 损失函数:
其中,“Maskset”表示被遮蔽的token索引集合
NSP
让模型在看到“句子对(A,B)”时,判断“B是否真的是A的后续句子”。这样可以帮助模型学习到跨句子的衔接关系
-
从训练语料,随机抽取成对的句子(A,B)
- 50% 的情况,B 是 A 在文档中的下一个句子
- 50% 的情况,B 来自语料库中随机的其他文档或不相关位置
-
模型输入:
- 拼接[CLS]+A+[SEP]+B+[SEP],中间用[SEP]分割句子
- [CLS]放在开头,起到分类标志的作用,其对应的向量
会用于NSP的二分类
-
模型通过自注意力机制后,在[CLS]位置上输出一个向量,通过全连接+softmax,预测是否为后续句子
NSP训练目标
- 二分类NSP任务中,用交叉熵损失表示为:
其中,表示B是A的后续,否则为0
Sentence-Bert的额外训练任务
怎么提取sentence-level的特征用于下游任务,一种直观的想法是使用bert提取句子级别的embedding,那么我们有几种选择:
- CLS Token embedding
Sentence-BERT 说CLS不好,CLS 更关注 句子间的逻辑关系,而非单句的语义表征,原因就是bert原生的CLS是用于NSP分类任务的,对句子表征效果不好
- Pooling Context embedding(平均池化+归一化)
Sentence-BERT 认为这个特征比CLS好,并且在此基础上可以做fine-tune达到更好的表征效果
但是存在各向异性(Anisotropic)的问题,导致词余弦相似与pretrain词频相关
在 BERT 的原生向量空间中,高频词(如 “的”“是”“在”)的向量范数通常较小,分布在空间中心附近;
低频词(如专业术语、罕见词)的向量范数较大,分布在空间边缘。
因此,两个高频词的向量可能因靠近中心而 “虚假相似”,而低频词可能因范数差异大而 “虚假不相似”,与实际语义无关。
如何缓解各向异性:
向量归一化:对池化后的句向量进行 L2 归一化,强制向量范数为 1,消除范数差异对余弦相似度的影响。公式:,此时余弦相似度仅取决于向量方向,与范数无关。层归一化(Layer Normalization):在预训练或微调阶段对 Transformer 层的输出进行归一化,稳定向量分布。
- EOS Token embedding
这是CLIP方法中文本编码器的特征提取方式,其实类似于Pooling Context Embedding,但是注意clip的文本编码器是从随机初始化开始训练的
MLM+NSP模型变体
下表简要列出各个变体与 BERT 的主要特征对比,按提出时间顺序排列。
| 模型 | 时间 | 主要改进点 | 是否保留NSP | Mask策略 | 结构 | 典型应用 |
|---|---|---|---|---|---|---|
| BERT | 2018 | MLM (15%) + NSP 双向Transformer Encoder | Yes | 静态Mask,15% 单词被随机选中 | Encoder-only (12/24层) | 各类NLP理解任务 |
| RoBERTa | 2019 | 1)更大数据/更长训练 2)移除NSP 3)动态Mask 4)GPT-2 BPE | No | 动态Mask (同MLM) | Encoder-only | 同BERT,效果更佳 |
| ALBERT | 2019 | 1)Embedding因式分解 2)跨层权重共享 3)NSP → SOP | SOP | 同MLM (静态Mask) | Encoder-only | 减少参数,大模型部署 |
| SpanBERT | 2019 | 1)Span-level Masking 2)SBO目标 3)移除NSP | No | Span Mask (块状) | Encoder-only (改进BERT实现) | 核心指代、抽取式QA等 |
| XLNet | 2019 | 1)Permutation LM融合AR/AE 2)Two-stream Attention 3)融合Transformer-XL长依赖 | - | 无[Mask]标记,用Permutation+AttentionMask来双向建模 | 类Transformer Encoder | 问答、语言建模,多项SOTA |
| DeBERTa | 2020 | 1)Disentangled Attention (内容/位置分离) 2)Enhanced Mask Decoder 3)更优性能 | - | 同MLM (类似RoBERTa) | Encoder-only | GLUE/SQuAD SOTA,微软大规模应用 |
如果您认为博文还不错,请帮忙点赞、收藏、关注。您的反馈是我的原动力
| 原创文章 | |
| 1 | FFN前馈网络与激活函数技术解析:Transformer模型中的关键模块 |
| 2 | Transformer掩码技术全解析:分类、原理与应用场景 |
| 3 | 【大模型技术】Attention注意力机制详解一 |
| 4 | Transformer核心技术解析LCPO方法:精准控制推理长度的新突破 |
| 5 | Transformer模型中位置编码(Positional Embedding)技术全解析(二) |
| 6 | Transformer模型中位置编码(Positional Embedding)技术全解析(一) |
| 7 | 自然语言处理核心技术词嵌入(Word Embedding),从基础原理到大模型应用 |
| 8 | DeepSeek-v3:基于MLA的高效kv缓存压缩与位置编码优化技术 |
| 9 | 【Tokenization第二章】分词算法深度解析:BPE、WordPiece与Unigram的原理、实现与优化 |
| 10 | Tokenization自然语言处理中分词技术:从传统规则到现代子词粒度方法 |
相关文章:
[预训练]Encoder-only架构的预训练任务核心机制
原创文章1FFN前馈网络与激活函数技术解析:Transformer模型中的关键模块2Transformer掩码技术全解析:分类、原理与应用场景3【大模型技术】Attention注意力机制详解一4Transformer核心技术解析LCPO方法:精准控制推理长度的新突破5Transformer模…...

07-后端Web实战(部门管理)
5. 修改部门 对于任何业务的修改功能来说,一般都会分为两步进行:查询回显、修改数据。 5.1 查询回显 5.1.1 需求 当我们点击 "编辑" 的时候,需要根据ID查询部门数据,然后用于页面回显展示。 5.1.2 接口描述 参照参照…...
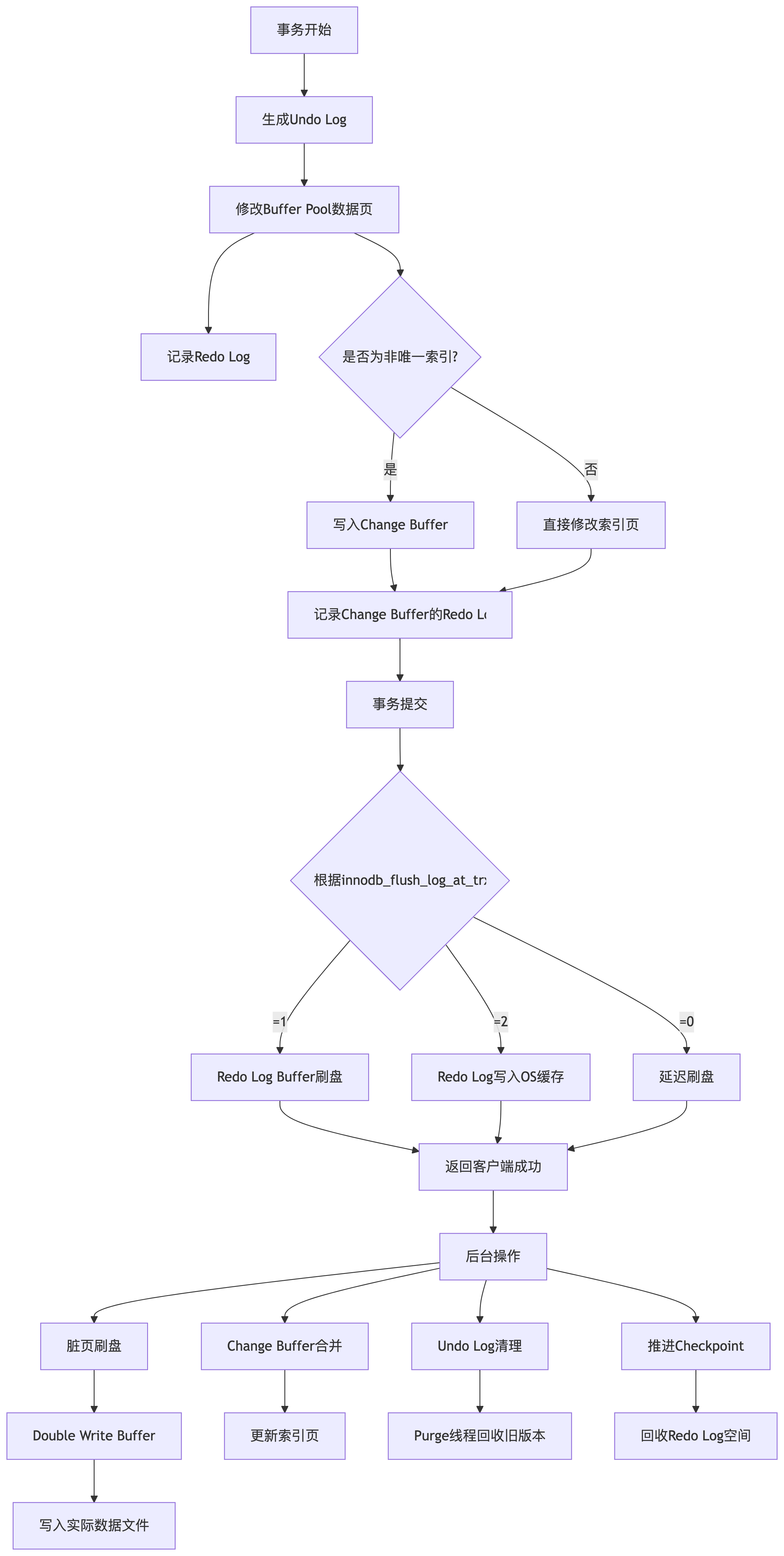
mysql ACID 原理
序言:ACID 是一组数据库设计原则,他是业务数据和关键业务程序的可靠性保障。 1、atomicity(原子性) 依赖如下能力 autocommit commit rollback2、一致性 2.1 double write buffer 1、定义:double write buffer 是…...
[Rust_1] 环境配置 | vs golang | 程序运行 | 包管理
目录 Rust 环境安装 GoLang和Rust 关于Go 关于Rust Rust vs. Go,优缺点 GoLang的优点 GoLang的缺点 Rust的优点 Rust的缺点 数据告诉我们什么? Rust和Go的主要区别 (1) 性能 (2) 并发性 (3) 内存安全性 (4) 开发速度 (5) 开发者体验 Ru…...
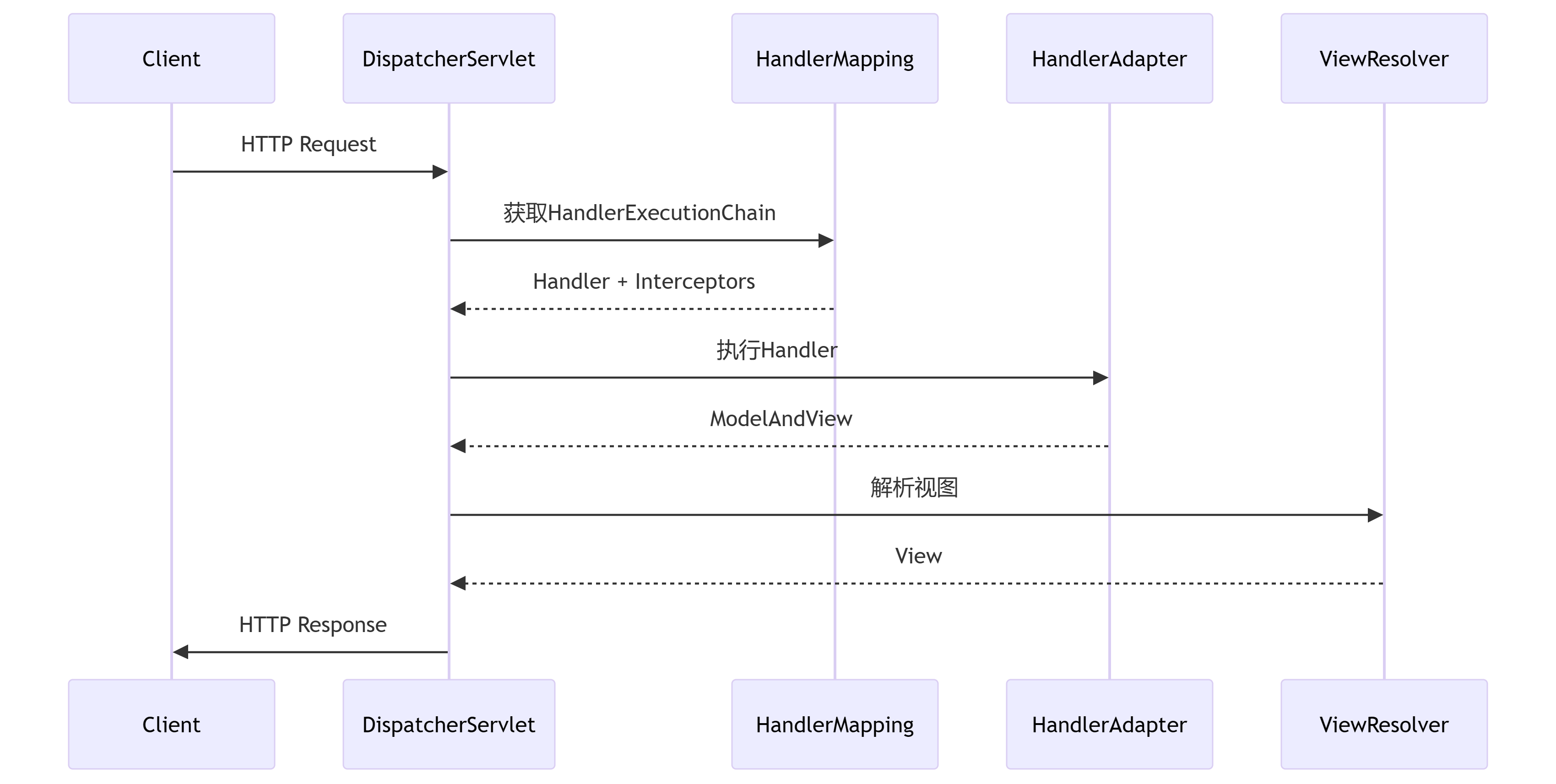
二十五、面向对象底层逻辑-SpringMVC九大组件之HandlerMapping接口设计
一、引言:MVC架构的交通枢纽 在Spring MVC框架中,HandlerMapping接口扮演着"请求导航仪"的关键角色,它决定了HTTP请求如何被路由到对应的Controller处理器。作为MVC模式的核心组件之一,HandlerMapping在请求处理的生命…...

构建安全高效的邮件网关ngx_mail_ssl_module
一、快速上手:最小配置示例 worker_processes auto;mail {server {# 监听 IMAP over TLSlisten 993 ssl;protocol imap;# TLS 协议与密码套件ssl_protocols TLSv1.2 TLSv1.3;ssl_ciphers HIGH:!aNULL:!MD5;# 证书与私钥ssl_…...
HUAWEI交换机配置镜像口验证(eNSP)
技术术语: 流量观察口:就是我们常说的镜像口,被观察的流量的引流目的端口 流量源端口:企业生产端口,作为观察口观察对象。 命令介绍: [核心交换机]observe-port [观察端口ID或编号(数字&am…...

前端vue3实现图片懒加载
场景和指令用法 场景:电商网站的首页通常会很长,用户不一定能访问到页面靠下面的图片,这类图片通过懒加载优化手段可以做到只有进入视口区域才发送图片请求 核心原理:图片进入视口才发送资源请求 首先:我们需要定义一个全局的指令&#x…...

网站每天几点更新,更新频率是否影响网站收录
1. 每天几点更新网站最合适?总怕时间选错影响收录? 刚开始搞网站的时候,是不是老纠结啥时候更新合适?早上刚上班?半夜没人的时候?选不对时间,总担心搜索引擎爬虫来了没抓到新内容,影…...

主流Markdown编辑器的综合评测与推荐
根据2025年最新资料,结合功能特性、用户体验和技术适配性,以下是对主流Markdown编辑器的综合评测与推荐: 一、核心对比维度与评估方法 功能完整性:支持数学公式、流程图、代码高亮等复杂格式。跨平台兼容性:Windows/m…...
计算机网络-MPLS VPN应用场景与组网
上一篇文章我们通过一个基础实验实现了企业分支间的MPLS VPN互联,如果还不理解的可以多看几遍前面的文章或者多敲下实验。今天来学习几种常见的MPLS VPN应用场景与这些场景下MPLS VPN的部署方法。 一、MPLS VPN典型应用 目前,MPLS VPN的主要应用包括企…...

AugmentFree:解除 AugmentCode 限制的终极方案 如何快速清理vscode和AugmentCode缓存—windows端
AugmentFree1.0工具包:解除 AugmentCode 免费试用限制的终极方案 Augment VIP 是一个专为 VS Code 用户设计的实用工具包,旨在帮助用户管理和清理 VS Code 数据库,解除 AugmentCode 免费试用账户的限制。 augment从根源上解决免费额度限制问…...
)
WPF【11_7】WPF实战-重构与美化(ViewModel的嵌套与分解、海量数据不要Join)
11-12 【重构】ViewModel的嵌套与分解 目前我们的代码中有一个不易发现的致命问题,如果工作中这样写代码大概率会被打回去重做。那么这个问题是什么呢? --\ViewModels\MainViewModel.cs 视图模型中的 LoadCustomers() 方法,考虑一下在这里我…...
Linux 的编辑器--vim
1.Linux编辑器-vim使⽤ vi/vim的区别简单点来说,它们都是多模式编辑器,不同的是vim是vi的升级版本,它不仅兼容vi的所有指令,⽽且还有⼀些新的特性在⾥⾯。例如语法加亮,可视化操作不仅可以在终端运⾏,也可以…...

Oracle 慢sql排查
Oracle慢sql排查步骤 1.1. 前言 Oracle 慢查询的排查方向包括以下几个方向 : 基准测试 (吞吐量): 包括 Oracle 本身吞吐量和磁盘 I/O 吞吐量硬件分析 (资源情况): 包括查看服务器 CPU , 硬盘的使用情况SQL分析:分析 SQL 中是否存在慢查询 , 是否命中索引配置优化…...

[Protobuf] 快速上手:安全高效的序列化指南
标题:[Protobuf] (1)快速上手 水墨不写bug 文章目录 一、什么是protobuf?二、protobuf的特点三、使用protobuf的过程?1、定义消息格式(.proto文件)(1)指定语法版本(2)package 声明符 2、使用protoc编译器生成代码&…...

uniapp开发企业微信小程序时 wx.qy.login 在uniapp中使用的时候,需要导包吗?
在 UniApp 中使用 “wx.qy.login” 不需要手动导包,但需要满足以下条件: 一、环境要求与配置 1� 企业微信环境判断 必须确保当前运行环境是企业微信客户端,通过 “uni.getSystemInfoSync().environment” 判断是否为 “wxwork”…...

如何将通话记录从Android传输到Android
“如何将通话记录从 Android 转移到 Android?我换了一部新的 Android 手机,想要将通话记录复制到其中。”您需要将通话记录从 Android 传输到 Android 是一种常见的情况,因为通话记录是手机上最重要的数据之一。幸运的是,如果您从…...

Word 目录自动换行后错位与页码对齐问题解决教程
📘 Word 目录自动换行错位与页码对齐问题解决教程 🎯 目标效果 目录条目过长自动换行后,第二行左对齐整齐;页码始终靠右对齐,前方带有“……”引导符;解决页码错位、制表符消失或格式混乱问题。 …...
数据结构第4章 栈、队列和数组 (竟成)
目录 第 4 章 栈、队列和数组 4.1 栈 4.1.1 栈的基本概念 4.1.2 栈的基本操作 4.1.3 栈的实现 1.顺序栈 2.链式栈 3.共享栈 4.1.4 顺序栈的基本操作实现 1.初始化栈 2.判空 3.判满 4.元素进栈 5.元素出栈 6.获取栈顶元素 4.1.5 链栈的基本操作实现 1.元素进栈 2.元素出栈 4.1.6…...
 方法,结合 Lambda 表达式)
removeIf() 方法,结合 Lambda 表达式
在 Java 8 中,removeIf() 方法是 Collection 接口新增的一个默认方法,用于根据条件批量删除集合中的元素。结合 Lambda 表达式,可以以极简的语法实现复杂的过滤逻辑。以下是详细说明: 1. 方法定义与语法 // java.util.Collection 接口中的定义 default boolean removeIf(P…...

汽车售后诊断数据流详细分析
一、引言 随着汽车电子化程度的不断提升,电控系统已成为车辆运行的核心支撑。据罗兰贝格 2025 年智能汽车白皮书数据显示,中央计算 区域控制架构(Zonal EEA)的普及率已突破 58%,推动整车线束成本下降 41%12。与此同时…...

2025年渗透测试面试题总结-匿名[校招]安全研究员(SAST方向)(题目+回答)
安全领域各种资源,学习文档,以及工具分享、前沿信息分享、POC、EXP分享。不定期分享各种好玩的项目及好用的工具,欢迎关注。 目录 匿名[校招]安全研究员(SAST方向) 一面问题回答框架 1. 自我介绍 2. 简历深挖(漏洞挖掘&#x…...
Unity 游戏优化(持续更新中...)
垃圾回收 是什么? 垃圾回收(Garbage Collection)GC 工作机制 1、Unity 为用户生成的代码和脚本采用了自动内存管理。 2、小块数据(如值类型的局部变量)分配在栈上。大块数据和长期存储分配在托管堆上。 3、垃圾收集…...

LlamaFactory——如何使用魔改后的模型
需求来源:有时我们可能想在llamafactory框架支持的模型上进行一些改动,例如修改forward()方法等,修改方法我们可以通过继承Transformers库中相应的class并重写相应的方法即可,那我们如何使用自己的模型呢? 首先&#…...

【前端】【css预处理器】Sass与Less全面对比与构建对应知识体系
第一章 概述 1.1 Sass和Less简介 1.1.1 Sass简介 Sass(Syntactically Awesome Stylesheets)是一种 CSS 预处理器,它为 CSS 赋予了更多强大的功能和更灵活的语法结构😎。 语法特点:Sass 有两种语法格式。一种是 .sa…...

【请关注】关于VC++实现使用Redis不同方法,有效达到 Redis 性能优化、防击穿
麻烦先关注方便了解最新分享。 关于VC实现使用Redis不同方法,有效达到 Redis 性能优化、防击穿。 一、性能优化核心方法 1. 使用连接池复用连接 // 连接池结构体 struct RedisPool { hiredisContext** connections; int size; sem_t sem; // 信号量控制并发 }; //…...

【加密算法】
计算机网络加密算法详解 在计算机网络中,加密算法是保障数据安全的核心技术,用于防止数据在传输过程中被窃听、篡改或伪造。本文将详细介绍常见的加密算法分类、工作原理及其在网络中的应用。 1. 加密算法分类 加密算法主要分为以下三类: 类型特点典型算法对称加密加密和解…...

20250529-C#知识:索引器
C#知识:索引器 索引器给对象添加了索引访问的功能,实际访问的是对象的成员,感觉不太常用。 1、主要内容及代码示例 索引器中类似属性,也包含get和set方法索引器能够使像访问数组一样访问对象一般当类中有数组类型的成员变量时&am…...
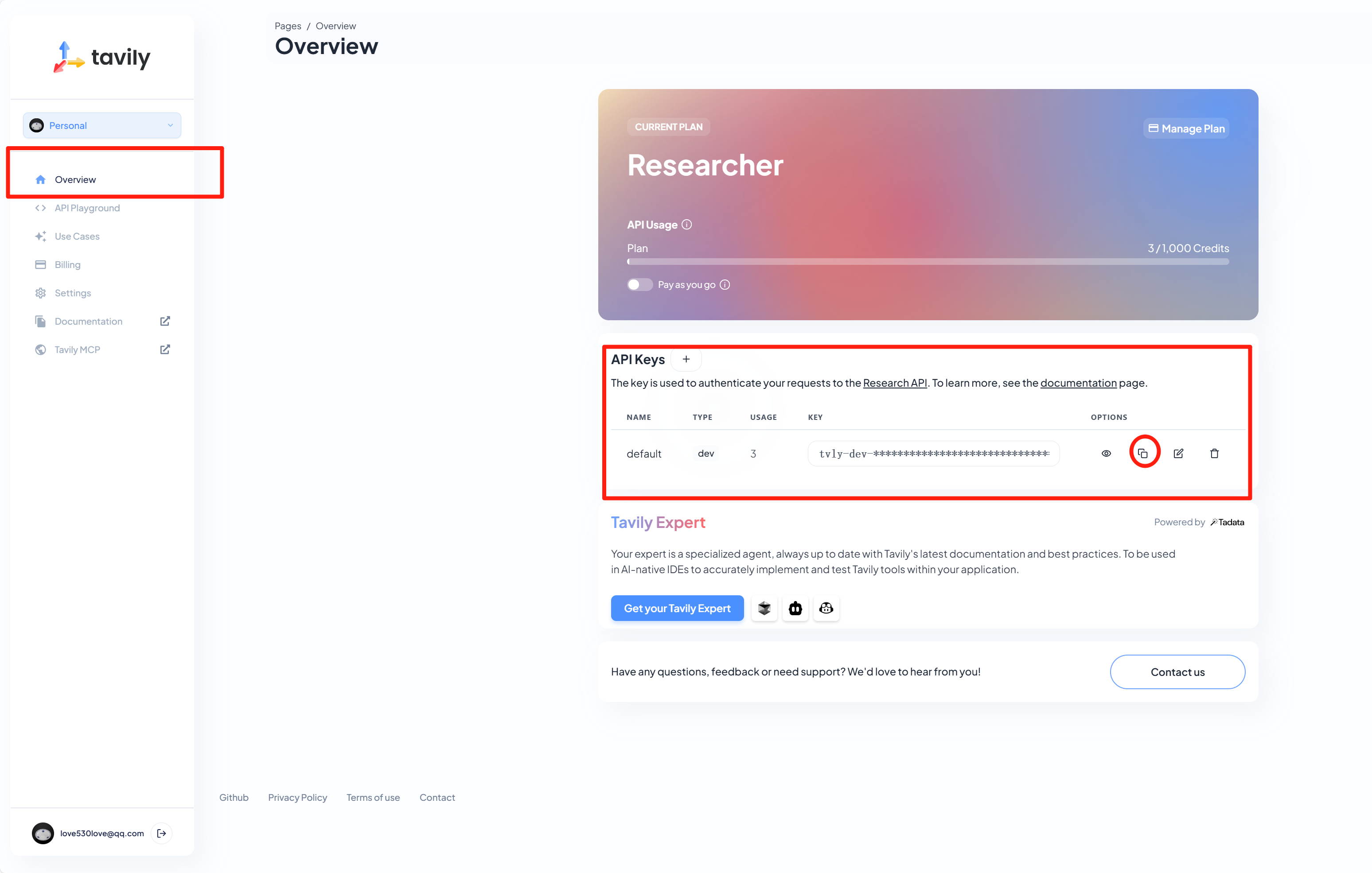
【笔记】suna部署之获取 Tavily API key
#工作记录 Tavily 注册 Tavily 账号5: 打开浏览器,访问 Tavily 官网Tavily AI。点击页面上的 “注册” 按钮,按照提示填写注册信息,如邮箱地址、设置密码等,完成注册流程。也可以选择使用 Google 或 GitHub 账号授权登…...