【目标检测】【ICCV 2021】条件式DETR实现快速训练收敛
Conditional DETR for Fast Training Convergence
条件式DETR实现快速训练收敛

代码链接
论文链接
摘要
最近提出的DETR方法将Transformer编码器-解码器架构应用于目标检测领域,并取得了显著性能。本文针对其训练收敛速度慢这一关键问题,提出了一种条件化交叉注意力机制以实现快速训练。我们的方法基于以下发现:DETR中的交叉注意力机制高度依赖内容嵌入来定位物体四极坐标并预测边界框,这加大了对高质量内容嵌入的需求,从而增加了训练难度。
我们提出的方法名为条件式DETR,该方法从解码器嵌入中学习条件空间查询以进行解码器多头交叉注意力。其优势在于通过条件空间查询,每个交叉注意力头能够专注于包含特定区域的波段,例如物体端点或物体框内部区域。这缩小了定位分类区域和边界框回归的空间范围,从而降低了对内容嵌入的依赖并简化了训练过程。实验结果表明,条件式DETR在R50和R101骨干网络上收敛速度加快6.7倍,在更强骨干网络DC5-R50和DC5-R101上收敛速度提升10倍。
1.引言
DETR(DEtection TRansformer)方法[3]将Transformer编码器-解码器架构应用于目标检测任务并取得了优异性能。该方法有效消除了对非极大值抑制、锚框生成等人工设计组件的依赖。
DETR方法存在训练收敛速度慢的问题,需要500个训练周期才能获得良好性能。最新提出的可变形DETR[53]通过采用可变形注意力机制替换全局密集注意力机制(自注意力与交叉注意力),仅关注少量关键采样点,并利用高分辨率多尺度编码器。相反,我们仍采用全局密集注意力,并提出一种改进的解码器交叉注意力机制以加速训练过程。解决了这一问题。
我们的方法源于对内容嵌入的高度依赖以及空间嵌入在交叉注意力中的次要贡献。DETR[3]的实验结果表明,若从第二解码器层开始移除键中的位置嵌入和对象查询,仅保留键与查询中的内容嵌入,检测AP值仅会出现轻微下降。
[3]中表3报告了R50模型在300个训练周期下AP值下降1.4个点的情况。我们通过实验得到了相同趋势的观测结果:当训练周期为50时,AP值从34.9降至34.0。
图1(第二行)展示了经过50个训练周期后DETR模型中交叉注意力生成的空间注意力权重图。可见四幅图中两幅未能正确突出对应肢体的条带区域,因此在缩小空间范围方面表现较弱。内容查询难以精确定位末端部位的原因在于:(i) 空间查询(即object queries)仅提供通用的注意力权重图,未能利用特定图像信息;(ii) 由于训练时长不足,内容查询在匹配空间键时表现欠佳,因其同时需匹配内容键。这增强了对高质量内容嵌入的依赖性,从而增加了训练难度。

图1. 我们提出的条件式DETR-R50模型(50训练周期,第一行)、原始DETR-R50模型(50训练周期,第二行)与原始DETR-R50模型(500训练周期,第三行)的空间注意力权重图对比。我们的条件式DETR与500周期训练的DETR生成的权重图能较好地突出四肢区域,而50周期训练的DETR生成的空间注意力权重图(第二行第三、四幅图像)在左右边缘区域未能有效突出肢体末端。绿色框为真实标注框。
我们提出了一种条件式DETR方法,该方法从解码器前一层的输出嵌入中为每个查询学习条件性空间嵌入,从而形成所谓的条件空间查询用于解码器多头交叉注意力。该条件空间查询通过将回归目标框的信息映射到嵌入空间来预测,该空间与键的二维坐标所映射的空间相同。
我们通过实验观察到,使用空间查询和键时,每个交叉注意力头会在空间上关注包含物体 extremities或物体框内部区域的带状范围(图1第一行)。这缩小了内容查询的空间范围,使其能更精准地定位用于类别和边界框预测的有效区域。因此,模型对内容嵌入的依赖得以减轻,训练过程更加容易。实验表明,条件式DETR在骨干网络R50和R101上的收敛速度提升了6.7倍,在更强骨干网络DC5-R50和DC5-R101上则达到10倍加速。图2展示了条件式DETR与原始DETR[3]的收敛曲线对比。
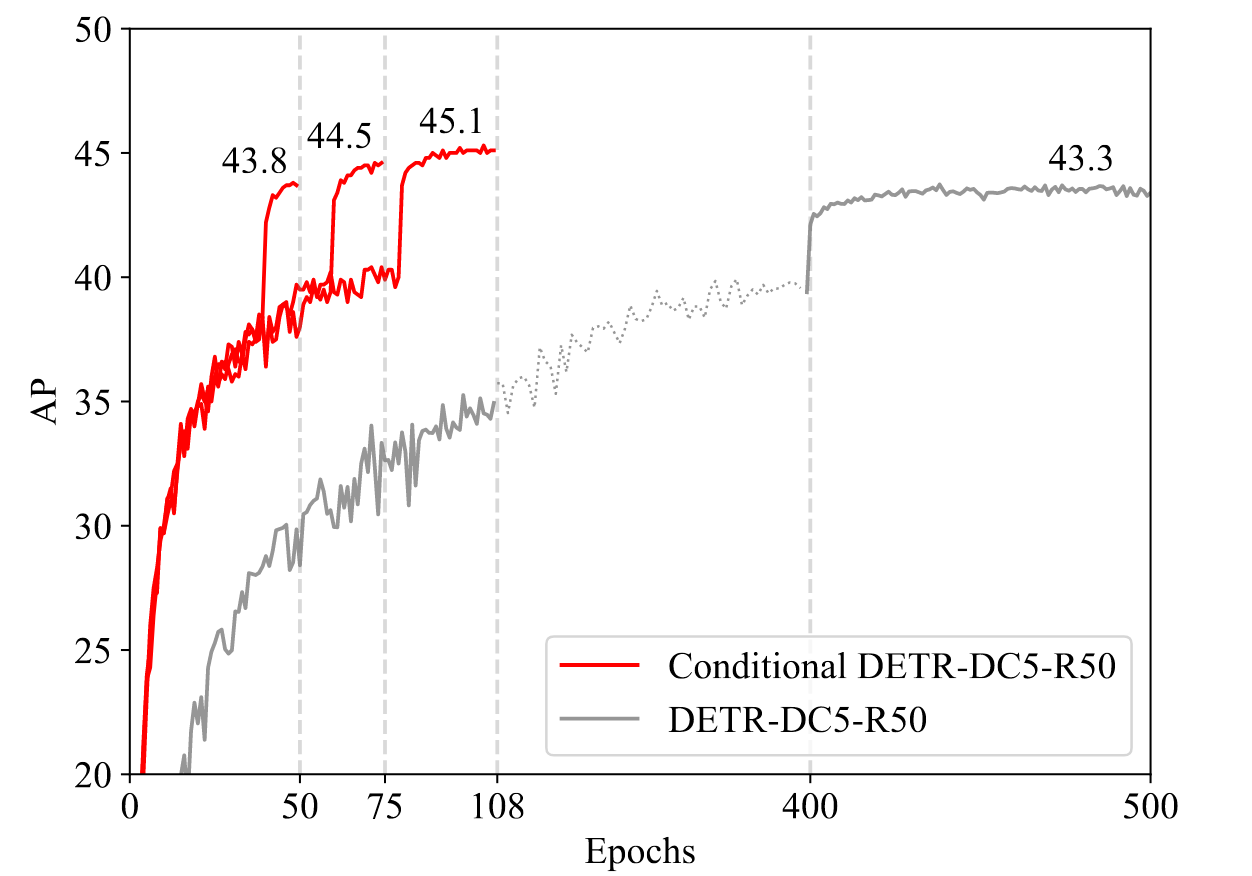
图2. 条件式DETR-DC5-R50与DETR-DC5-R50在COCO 2017验证集上的收敛曲线。条件式DETR分别训练50、75、108个周期。条件式DETR的训练收敛速度显著快于DETR。
2.相关工作
基于锚点与无锚点检测
现有大多数目标检测方法均基于精心设计的初始猜测进行预测。主要存在两种初始猜测:锚框(anchor boxes)或目标中心点。基于锚框的方法继承了Fast R-CNN这类基于候选框方法的思路,典型算法包括Faster R-CNN[9]、SSD[26]、YOLOv2[31]、YOLOv3[32]、YOLOv4[1]、RetinaNet[24]、Cascade R-CNN[2]、Libra R-CNN[29]、TSD[35]等。
无锚框检测器通过在物体中心附近的关键点预测边界框。典型方法包括YOLOv1 [30]、CornerNet [21]、ExtremeNet [50]、CenterNet [49, 6]、FCOS [39]及其他[23, 28, 52, 19, 51, 22, 15, 46, 47]。
DETR及其变体
DETR成功将Transformer架构应用于目标检测任务,有效消除了对非极大值抑制、初始候选框生成等人工设计组件的依赖。针对全局编码器自注意力机制导致的高计算复杂度问题,自适应聚类Transformer[48]和可变形DETR[53]分别通过自适应聚类策略和稀疏注意力机制予以解决。
另一个关键问题——训练收敛速度缓慢,近期已引起大量研究关注。基于Transformer的集合预测方法(TSP)[37]通过移除交叉注意力模块,将FCOS与类R-CNN检测头相结合。可变形DETR[53]则采用可变形注意力机制替代解码器交叉注意力,该机制通过学习内容嵌入生成的稀疏位置进行注意力计算。
与本研究同期提出的空间调制协同注意力方法(SMCA)[7]与本方法高度相似。该方法通过从解码器嵌入中学习到的若干(偏移)中心点周围的高斯映射,对DETR的多头全局交叉注意力进行调制,使模型更聚焦于预测框内的特定区域。而本文提出的条件式DETR方法则从解码器内容嵌入中学习条件式空间查询,无需人工设计注意力衰减机制即可预测空间注意力权重图——该图在边界框回归时强化四个极值点特征,在目标分类时突出物体内部差异化区域特征。
条件动态卷积
所提出的条件空间查询方案与条件卷积核生成相关。动态滤波器网络[16]从输入中学习卷积核,该技术被应用于CondInst[38]和SOLOv2[42]中以学习实例相关的卷积核。CondConv[44]和动态卷积[4]通过混合从输入中学习到的权重与卷积核来实现。SENet[14]、GENet[13]及Lite-HRNet[45]则从输入中学习通道级权重。
这些方法从输入中学习卷积核权重,随后对输入施加卷积运算。相比之下,我们方法中的线性投影是通过解码器嵌入学习而来,用于表征位移与缩放信息。
Transformers
Transformer模型[40]依托注意力机制(自注意力与交叉注意力)建立输入与输出间的全局依赖关系。现有若干研究与本方法密切相关:高斯Transformer[11]和T-GSA(采用高斯加权自注意力的Transformer)[18]以及后续的SMCA[7],均通过学习或人工设定的高斯方差,根据目标符号与上下文符号的距离衰减注意力权重。与本研究类似,TUPE[17]同样通过空间注意力权重与内容注意力权重计算注意力权重。而本方法的核心创新在于采用可学习形式的注意力衰减机制(而非高斯函数),该机制有望在语音增强[18]和自然语言推理[11]任务中产生效益。
3.Conditional DETR
3.1. 概述
Pipeline
所提出的方法遵循端到端目标检测器DETR(检测transformer),无需非极大值抑制(NMS)或锚框生成即可一次性预测所有目标。该架构由CNN主干网络、transformer编码器、transformer解码器以及目标类别与边界框位置预测器组成。transformer编码器旨在优化CNN主干网络输出的内容嵌入表示,其由多个编码层堆叠而成,每层主要包含自注意力机制层和前馈神经网络层。
Transformer解码器由若干解码层堆叠而成。如图3所示,每个解码层包含三个主要组成部分:(1) 用于消除重复预测的自注意力层,该层对前一层解码器输出的嵌入向量进行交互处理,这些向量将用于类别和边界框预测;(2) 交叉注意力层,通过聚合编码器输出的嵌入向量来优化解码器嵌入表示,从而提升类别和边界框预测精度;(3) 前馈神经网络层。
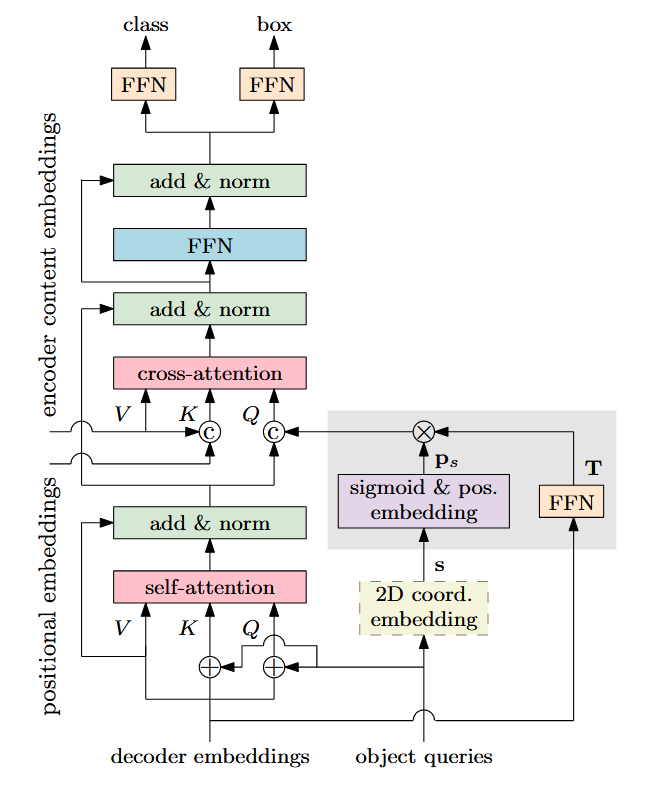
图3. 展示Conditional DETR中的单个解码器层。其与原始DETR[3]的主要区别在于输入查询项及交叉注意力机制的输入键。条件式空间查询通过灰色阴影框所示操作,从可学习的二维坐标s及前一解码器层输出的嵌入向量中预测得出。二维坐标s可从对象查询项(虚线框)预测获得,或直接作为模型参数学习。空间查询(键)与内容查询(键)拼接后形成最终查询(键),由此产生的交叉注意力称为条件式交叉注意力。与DETR[3]相同,该解码器层会重复6次。
框回归
每个解码器嵌入都会按如下方式预测一个候选框,
b = s i g m o i d ( F F N ( f ) + [ s ⊤ 00 ] ⊤ ) . \mathbf{b}=\mathrm{sigmoid}(\mathrm{FFN}(\mathbf{f})+[\mathbf{s}^\top00]^\top). b=sigmoid(FFN(f)+[s⊤00]⊤).
此处,f为解码器嵌入向量。b是一个四维向量 [ b c x b c y b w b h ] ⊤ [b_{cx}\quad b_{cy} \quad b_w \quad b_h]^⊤ [bcxbcybwbh]⊤,包含框体中心坐标、宽度及高度。sigmoid()函数用于将预测值b归一化至[0, 1]范围。FFN()用于预测未归一化的框体。s是参考点的未归一化二维坐标,在原版DETR中默认为(0, 0)。本方法提出两种方案:将参考点s作为每个候选框预测的可学习参数,或由其对应的对象查询生成该坐标。
类别预测
每个候选框的分类分数同样通过解码器嵌入经前馈神经网络预测得出,e = FFN(f)。
主要工作
交叉注意力机制旨在定位不同区域(四肢用于框检测,框内区域用于目标分类),并聚合相应嵌入特征。我们提出一种条件式交叉注意力机制,通过引入条件空间查询来提升定位能力并加速训练过程。
3.2. DETR解码器交叉注意力
DETR解码器的交叉注意力机制接收三个输入:查询项、键项和值项。每个键项由内容键 c k c_k ck(编码器输出的内容嵌入)与空间键 p k p_k pk(对应归一化二维坐标的位置嵌入)相加构成。值项则源自编码器输出的内容嵌入,与内容键的来源相同。
在原始DETR方法中,每个查询由内容查询 c q c_q cq(解码器自注意力输出的嵌入向量)和空间查询 p q p_q pq(即对象查询 o q o_q oq)相加构成。我们的实现中设置了N=300个对象查询,相应地会产生N个查询,每个查询在单个解码器层输出一个候选检测结果。
为简化描述并保持清晰性,我们省略查询、键与值的索引。
注意力权重基于查询与键的点积,用于注意力权重计算。
( c q + p q ) ⊤ ( c k + p k ) = c q ⊤ c k + c q ⊤ p k + p q ⊤ c k + p q ⊤ p k = c q ⊤ c k + c q ⊤ p k + o q ⊤ c k + o q ⊤ p k . ( 2 ) \begin{aligned}&(\mathbf{c}_q+\mathbf{p}_q)^\top(\mathbf{c}_k+\mathbf{p}_k)\\&=\mathbf{c}_q^\top\mathbf{c}_k+\mathbf{c}_q^\top\mathbf{p}_k+\mathbf{p}_q^\top\mathbf{c}_k+\mathbf{p}_q^\top\mathbf{p}_k\\&=\mathbf{c}_q^\top\mathbf{c}_k+\mathbf{c}_q^\top\mathbf{p}_k+\mathbf{o}_q^\top\mathbf{c}_k+\mathbf{o}_q^\top\mathbf{p}_k.&\mathrm{(2)}\end{aligned} (cq+pq)⊤(ck+pk)=cq⊤ck+cq⊤pk+pq⊤ck+pq⊤pk=cq⊤ck+cq⊤pk+oq⊤ck+oq⊤pk.(2)
3.3. 条件交叉注意力
所提出的条件性交叉注意力机制通过将解码器自注意力输出的内容查询 c q c_q cq与空间查询 p q p_q pq进行拼接以形成查询向量。相应地,键向量则由内容键 c k c_k ck与空间键 p k p_k pk的拼接构成。
交叉注意力权重由两个部分组成:内容注意力权重和空间注意力权重。这两个权重分别源自两个点积运算——内容点积与空间点积。
c q ⊤ c k + p q ⊤ p k . \mathbf{c}_q^\top\mathbf{c}_k+\mathbf{p}_q^\top\mathbf{p}_k. cq⊤ck+pq⊤pk.
另一项重要任务是从上一解码器层的嵌入f中计算出空间查询 p q p_q pq。我们首先明确不同区域的空间信息由解码器嵌入和参考点这两个因素共同决定,随后演示如何将它们映射到嵌入空间以形成查询 p q p_q pq,从而使空间查询与键的二维坐标所映射至的空间保持一致。
解码器嵌入层包含各离散区域相对于参考点的位移量。公式1中的边界框预测过程分为两步:(1) 在非归一化空间中预测相对于参考点的边界框;(2) 将预测框归一化至[0,1]范围内。
原始DETR方法中未归一化空间的原点(0, 0)通过sigmoid函数映射到归一化空间中的(0.5, 0.5)(即图像空间中心位置)。
步骤(1)意味着解码器嵌入f包含未归一化空间中四个边界点(构成检测框)相对于参考点s的位移。这表明,要确定各独立区域(四个边界点及分类得分预测区域)的空间信息,必须同时使用嵌入f和参考点s。
条件空间查询预测
我们根据嵌入f和参考点s预测条件空间查询。
( s , f ) → p q , (\mathbf{s},\mathbf{f})\to\mathbf{p}_{q}, (s,f)→pq,
使其与归一化后的二维关键点坐标所映射到的位置空间对齐。该过程如图3中灰色阴影框区域所示。
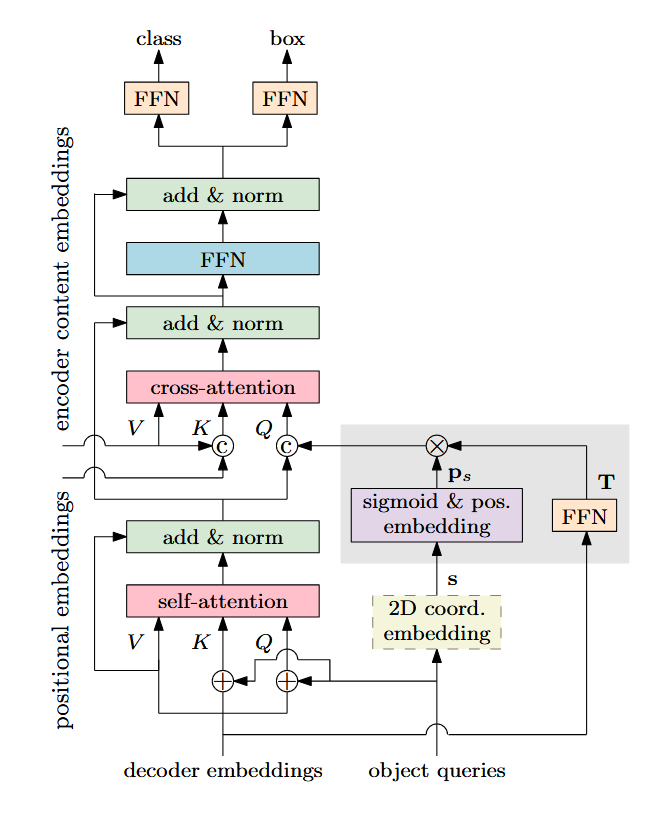
图3. 展示Conditional DETR中的单个解码器层。其与原始DETR[3]的主要区别在于输入查询项及交叉注意力机制的输入键。条件式空间查询通过灰色阴影框所示操作,从可学习的二维坐标s及前一解码器层输出的嵌入向量中预测得出。二维坐标s可从对象查询项(虚线框)预测获得,或直接作为模型参数学习。空间查询(键)与内容查询(键)拼接后形成最终查询(键),由此产生的交叉注意力称为条件式交叉注意力。与DETR[3]相同,该解码器层会重复6次。
我们将参考点s归一化后,采用与键的位置嵌入相同的方式,将其映射为一个256维的正弦位置嵌入:
p s = sinusoidal ( s i g m o i d ( s ) ) . \mathbf{p}_{s}=\text{sinusoidal}(\mathrm{sigmoid}(\mathbf{s})). ps=sinusoidal(sigmoid(s)).
随后,我们将解码器嵌入特征f中包含的位移信息,通过一个由可学习线性投影+ReLU+可学习线性投影构成的前馈神经网络(FFN)映射至同一空间中的线性投影:T = FFN(f)。
条件空间查询通过嵌入空间中的参考点变换计算得到: p q = T p s p_q = Tp_s pq=Tps。我们选择简单且计算高效的投影矩阵——对角矩阵,其256个对角元素记作向量 λ q λ_q λq。条件空间查询通过逐元素乘法计算:
p q = T p s = λ q ⊙ p s . \mathbf{p}_{q}=\mathbf{T}\mathbf{p}_{s}=\mathbf{\lambda}_{q}\odot\mathbf{p}_{s}. pq=Tps=λq⊙ps.
多头交叉注意力
继DETR[3]之后,我们采用标准的多头交叉注意力机制。目标检测通常需要隐式或显式地定位物体的四个边界以实现精准的边界框回归,并定位物体区域以实现准确的目标分类。多头机制有助于解耦这些定位任务。
我们通过可学习的线性投影将查询、键和值分别进行M=8次低维投影,实现多头并行注意力计算。空间查询(键)与内容查询(键)通过不同的线性投影独立映射至每个注意力头。值的投影方式与原始DETR保持一致,且仅针对内容部分进行投影。
3.4. 可视化与分析
可视化
图4展示了每个注意力头的权重分布图:空间注意力权重图、内容注意力权重图以及组合注意力权重图。这些权重图分别基于空间点积 p q ⊤ p k p_q^⊤p_k pq⊤pk、内容点积 c q ⊤ c k c_q^⊤c_k cq⊤ck以及组合点积 c q ⊤ c k + p q ⊤ p k c_q^⊤c_k + p_q^⊤p_k cq⊤ck+pq⊤pk进行softmax归一化处理。图中展示了8个权重图中的5个,其余三个为重复项,分别对应目标框底部与顶部边缘区域以及框内小范围区域。多次训练的模型可能产生不同的重复项,但检测性能几乎相同。

图4展示了由我们的条件式DETR计算得到的空间注意力权重图(第一行)、内容注意力权重图(第二行)及融合注意力权重图(第三行)。这些注意力权重图选自8个头中的5个头,分别负责物体框的四个边缘区域及一个内部区域。针对四个边缘区域的内容注意力权重图会突出框内离散区域(自行车)或两个物体实例中的相似区域(奶牛),而相应的融合注意力权重图在空间注意力权重图辅助下强化了边缘区域特征。物体框内部区域的融合注意力权重图主要依赖于空间注意力权重图,这表明物体内部区域的表征可能已编码足够的类别信息。本图取自训练50个周期的条件式DETR-R50模型。
我们可以观察到,每个注意力头生成的空间注意力权重图都能定位到一个独特区域——要么是包含某处肢体的区域,要么是物体框内部的区域。有趣的是,与肢体对应的空间注意力权重图会突出显示与物体框相应边缘重叠的空间带状区域,而针对物体框内部区域的另一张空间注意力图仅会突出一个小范围区域,该区域的表征可能已编码足够信息用于物体分类。
与四肢相对应的四个注意力头的内容权重映射,除四肢区域外还凸显了分散区域。通过结合空间映射与内容映射,可过滤其他高亮部分并保留肢体高亮特征,从而实现精准的边界框回归。
与DETR的对比
图1展示了我们提出的条件DETR(第一行)与训练50个周期的原始DETR(第二行)的空间注意力权重图。本方法生成的权重图通过对空间键与查询的点积 p q ⊤ p k p_q^\top p_k pq⊤pk进行softmax归一化计算获得,而DETR的权重图则通过对空间键的点积 ( o q + c q ) ⊤ p k (o_q + c_q)^\top p_k (oq+cq)⊤pk进行softmax归一化计算得到。
可以看出,我们的空间注意力权重图能精确定位四肢等不同区域。相比之下,原始DETR模型经过50轮训练生成的定位图无法准确标定两处肢体末端,而500轮训练(第三行)则能增强内容查询能力,从而实现精确定位。这表明要让内容查询 c q c_q cq同时承担匹配内容键与空间键的双重角色极为困难,因此需要更多训练轮次。
严格来说,经过更多训练轮次后解码器自注意力机制生成的嵌入输出同时包含空间与内容信息。为便于讨论,我们仍将其称为内容查询。
分析
图4所示的空间注意力权重图表明,用于构建空间查询的条件性空间查询至少产生两种效应:(i) 将高亮位置转换至物体框的四个边缘及内部区域:值得注意的是,高亮位置在物体框内的空间分布呈现相似性;(ii) 对边缘高亮区域的空间扩散进行尺度调整:大物体对应大范围扩散,小物体对应小范围扩散。
两种效应通过在空间嵌入空间中对 p s p_s ps施加变换 T T T(进一步通过交叉注意力中包含的图像无关线性投影解耦并分配到每个头)得以实现。这表明变换T不仅包含先前讨论的位移,还包含物体尺度。
3.5. 实现细节
架构
我们的架构与DETR架构[3]几乎相同,包含CNN主干网络、Transformer编码器、Transformer解码器,以及每个解码层(最后一层和内部5个解码层)后接的预测前馈网络(FFNs),这6个预测FFNs共享参数。超参数设置与DETR保持一致。
主要架构差异在于:我们引入条件空间嵌入作为条件多头交叉注意力的空间查询,且空间查询(键)与内容查询(键)通过拼接而非相加方式结合。在首层交叉注意力中不含解码器内容嵌入,基于DETR实现[3]进行简单修改:将对象查询预测的位置嵌入(即位置编码)拼接到原始查询(键)中。
参考点
在原始DETR方法中, s = [ 00 ] ⊤ s = [0 0]^⊤ s=[00]⊤对所有解码器嵌入均相同。我们研究了两种生成参考点的方式:将未归一化的2D坐标视为可学习参数,以及通过物体查询 o q o_q oq预测未归一化的2D坐标。后一种方式与可变形DETR[53]类似,其预测单元为一个FFN(前馈网络),由可学习线性投影+ReLU+可学习线性投影构成: s = F F N ( o q ) s = FFN(o_q) s=FFN(oq)。当用于构建条件空间查询时,2D坐标通过sigmoid函数进行归一化处理。
损失函数
我们遵循DETR[3]的方法,采用匈牙利算法在预测目标与真实目标之间建立最优二分匹配[20],进而构建损失函数以计算梯度并反向传播。我们与可变形DETR[53]采用相同的损失函数构建方式:使用相同的匹配代价函数、包含300个目标查询的相同损失函数以及相同的权衡参数;分类损失函数采用焦点损失[24],边界框回归损失(包含L1损失和GIoU[34]损失)与DETR[3]保持一致。
4.实验
4.1 实验设置
数据集
我们在COCO 2017[25]检测数据集上进行了实验。该数据集包含约11.8万张训练图像和5000张验证(val)图像。
训练
我们遵循DETR训练方案[3]。主干网络采用TORCHVISION提供的ImageNet预训练模型并固定其批归一化层,transformer参数采用Xavier初始化方案[10]。权重衰减设置为10−4,优化器选用AdamW[27]。主干网络与transformer的初始学习率分别设为10−5和10−4。transformer中dropout率为0.1。学习率在40个训练周期后降低10倍(总周期50次)、60个周期后降低10倍(总周期75次)、80个周期后降低10倍(总周期108次)时进行衰减。
我们采用与DETR[3]相同的增强方案:将输入图像调整为短边至少480像素且不超过800像素,长边不超过1333像素;以0.5的概率对训练图像进行随机矩形裁剪。
评估
我们采用标准COCO评估方法,报告平均精度(AP)以及阈值为0.50、0.75时的AP分数,同时针对小、中、大目标物体分别给出AP评分。
4.2 结论
与DETR的对比
我们将提出的条件式DETR与原始DETR[3]进行对比。遵循[3]的方法,我们在四种骨干网络上报告结果:ResNet-50[12]、ResNet-101及其16倍分辨率扩展版本DC5-ResNet-50和DC5-ResNet-101。
对应的DETR模型分别命名为DETR-R50、DETR-R101、DETR-DC5-R50和DETR-DC5-R101。我们的模型分别命名为conditional DETR-R50、conditional DETR-R101、conditional DETR-DC5-R50和conditional DETR-DC5-R101。
表1展示了DETR与条件式DETR的实验结果。采用50训练周期的DETR模型表现显著逊于500训练周期版本。以R50和R101为骨干网络的条件式DETR在50训练周期下表现略优于500训练周期的DETR;而采用DC5-R50和DC5-R101骨干网络时,50训练周期的条件式DETR即可达到与500训练周期DETR相当的效果。当训练周期提升至75/108时,四种骨干网络的条件式DETR均超越500训练周期的DETR。总体而言,针对高分辨率骨干网络DC5-R50和DC5-R101,条件式DETR的训练速度可达原始DETR的10倍;对于低分辨率骨干网络R50和R101则达到6.67倍加速。这表明条件式DETR在性能更强的骨干网络上能实现更优表现。
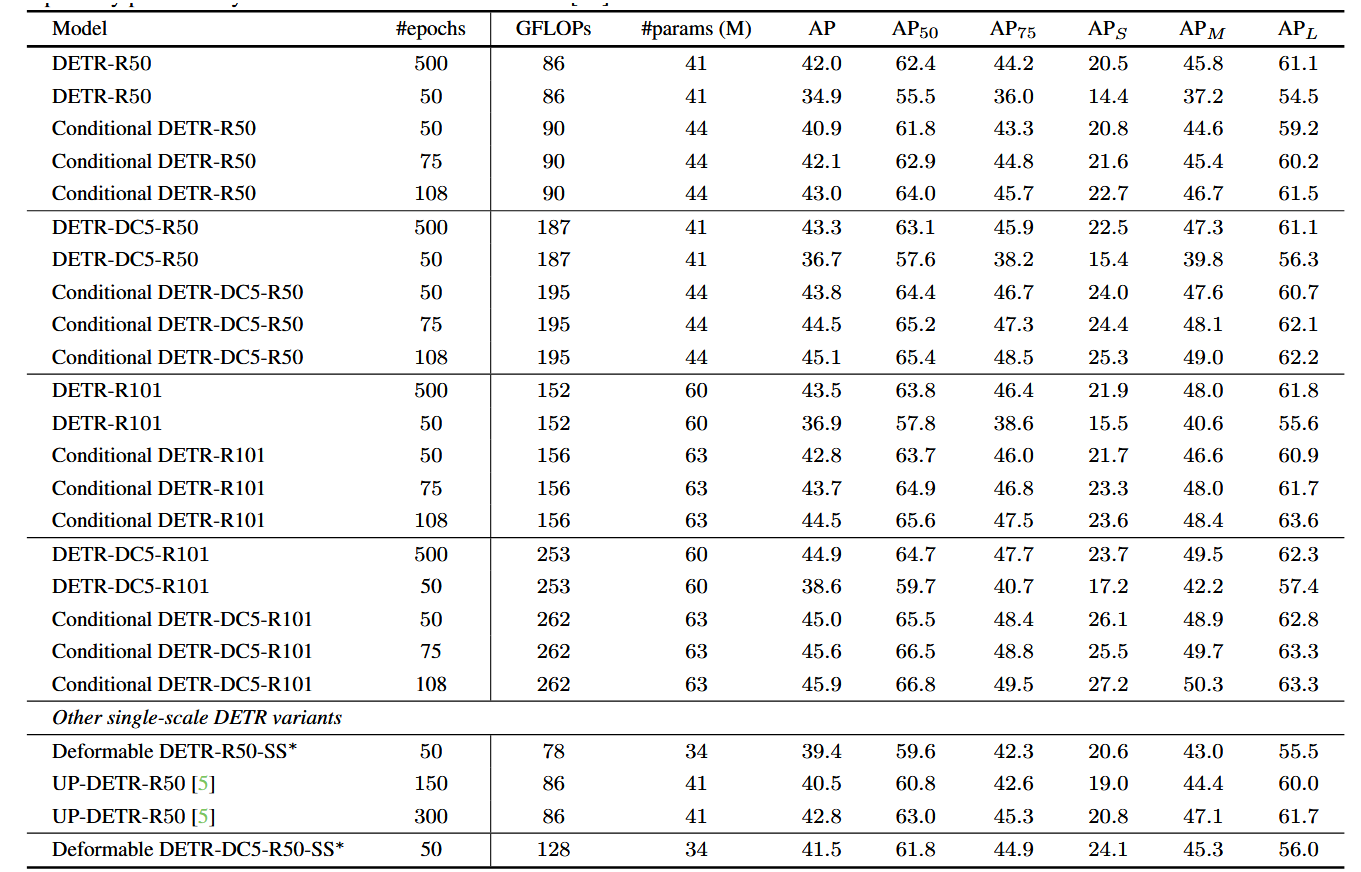
表1. Conditional DETR与DETR在COCO 2017验证集上的对比。我们的conditional DETR方法在高分辨率骨干网络DC5-R50和DC5-R101上比原始DETR快10倍,在低分辨率骨干网络R50和R101上快6.67倍。实验表明conditional DETR优于另外两种单尺度DETR变体。∗可变形DETR的结果来自其作者在GitHub仓库提供的数据[53]。
此外,我们在表1中汇报了单尺度DETR扩展模型的实验结果:可变形DETR-SS[53]和UP-DETR[5]。基于R50和DC5-R50架构,我们的结果优于可变形DETR-SS(40.9对39.4;43.8对41.5)。尽管该对比可能不完全公平——例如参数规模与计算复杂度存在差异,但表明条件化交叉注意力机制具有优势。与UP-DETR-R50相比,我们在更少训练周期下取得的结果明显更优。
与多尺度及高分辨率DETR变体的比较
我们专注于加速DETR的训练过程,但并未解决编码器中计算复杂度高的问题。我们不期望所提出的方法能达到采用多尺度注意力机制与8倍分辨率编码器的DETR变体(例如TSP-FCOS、TSPRCNN[37]及可变形DETR[53])的性能水平——这些方法通过多尺度与更高分辨率机制既降低了编码器计算复杂度,又提升了模型性能。
表2中的对比结果出人意料地显示,我们提出的DC5-R50(16×)方法与可变形DETR-R50(多尺度,8×)表现相当。考虑到单尺度可变形DETR-DC5-R50-SS的AP值为41.5(低于我们的43.8)(表1),可以看出可变形DETR从多尺度和更高分辨率的编码器中获益良多——这种设计同样可能使我们的方法受益,但目前并非我们研究的重点,将作为未来工作展开。
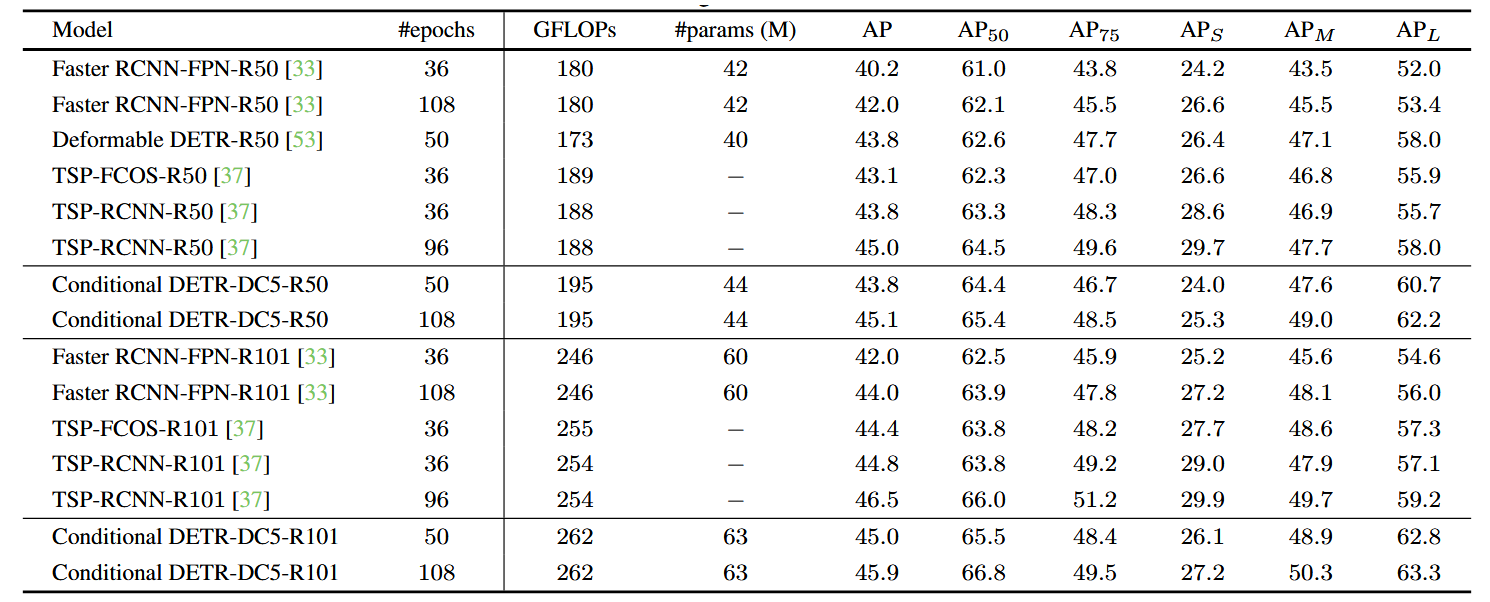
表2. 多尺度与高分辨率DETR变体的实验结果。由于我们的方法(单尺度,16×分辨率)未采用强多尺度或8×分辨率编码器,其性能本不应与这些变体相当。但出乎意料的是,采用DC5-R50和DC5-R101的模型在AP指标上接近两种多尺度高分辨率变体。
我们方法的性能也与TSP-FCOS和TSP-RCNN相当。这两种方法在少量选定位置/区域(TSP-FCOS中的兴趣特征和TSP-RCNN中的区域提议)上使用transformer编码器而未采用transformer解码器,是FCOS[39]与Faster RCNN[33]的扩展方案。需注意的是,位置/区域选择机制消除了自注意力中的冗余计算,显著降低了计算复杂度。
4.3 消融实验
参考点
我们比较了三种参考点s的生成方式:(i) s = (0, 0),与原版DETR相同;(ii) 将s作为模型参数学习,每个预测对应不同的参考点;(iii) 根据各对象查询预测对应的参考点s。实验采用ResNet-50作为主干网络,AP得分分别为36.8、40.7和40.9,表明方法(ii)与(iii)性能相当且优于方法(i)。
形成条件空间查询方式的影响
我们通过实证研究用于构建条件空间查询 p q = λ q ⊙ p s p_q = λ_q ⊙ p_s pq=λq⊙ps的变换 λ q λ_q λq和参考点位置嵌入 p s p_s ps如何影响检测性能。
我们报告了条件DETR的实验结果,以及以下四种构建空间查询的方式:(i) CSQ-P - 仅使用位置嵌入ps;(ii) CSQ-T - 仅使用变换λq;(iii) CSQ-C - 使用解码器内容嵌入f;(iv) CSQ-I - 对解码器自注意力输出cq预测的变换与参考点位置嵌入ps进行逐元素乘积。表3研究表明,我们提出的CSQ方法整体性能最优,这验证了第3.3节关于解码器嵌入预测变换与参考点位置嵌入的分析。

表3. 条件空间查询生成方式的消融研究。CSQ=我们提出的条件空间查询方案,各变体含义详见5.3节前两段。我们提出的CSQ方式表现更优。主干网络采用ResNet-50。
关于学习参考点的焦点损失与偏移回归
我们的方法遵循可变形DETR[53]:采用焦点损失函数配合300个目标查询构建分类损失,并通过相对于参考点的偏移量回归预测框体中心。表4展示了两种方案对DETR性能的影响。可见单独使用焦点损失或中心偏移回归而不学习参考点时AP值略有提升,二者结合则带来更大AP增益。本方法在焦点损失与偏移回归基础上构建的条件交叉注意力机制实现了4.0的显著性能提升。
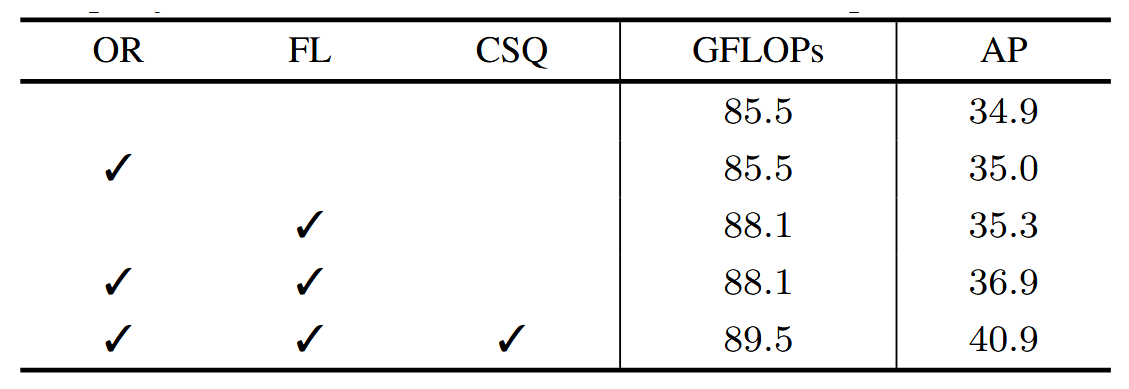
表4. 关于焦点损失(FL)、框中心预测的偏移回归(OR)及我们提出的条件空间查询(CSQ)的实证结果,采用ResNet-50作为主干网络。
线性变换T的投影效应构成该转换
预测条件空间查询需要学习从解码器嵌入到线性投影T的映射(参见公式6)。我们通过实验研究线性投影形式如何影响性能。线性投影形式包括:单位矩阵(表示不学习线性投影)、单一标量、块对角矩阵。意味着每个头都有一个学习到的32×32线性投影矩阵,这是一个无约束的完整矩阵,外加一个对角矩阵。图5展示了结果。有趣的是,单一标量有助于提升性能,这可能是由于将空间范围缩小至目标区域所致。其余三种形式——块对角、完整矩阵和对角矩阵(本方案)——表现相当。"
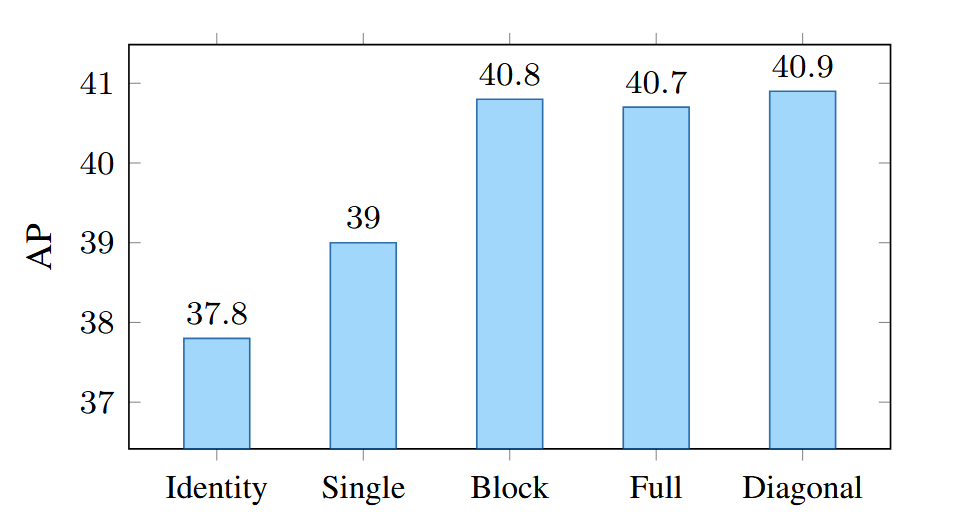
图5. 用于计算条件多头交叉注意力空间查询的不同线性投影形式的实证结果:对角(本方法)、全矩阵及分块矩阵表现相当。实验采用ResNet-50作为主干网络。
5.结论
我们提出了一种简单的条件交叉注意力机制。其核心在于从对应的参考点和解码器嵌入中学习空间查询,该空间查询包含前一层解码器挖掘的用于类别与边界框预测的空间信息,并生成突出显示物体框内肢体部位和小区域的空间注意力权重图。这一机制缩小了内容查询的定位范围以聚焦于显著区域,从而降低对内容查询的依赖并减轻训练难度。未来我们将研究该条件交叉注意力机制在人体姿态估计[8,41,36]和线段检测[43]中的应用。
6.引用文献
- [1] Alexey Bochkovskiy, Chien-Yao Wang, and HongYuan Mark Liao. Yolov4: Optimal speed and accuracy of object detection. CoRR, abs/2004.10934, 2020. 2
- [2] Zhaowei Cai and Nuno Vasconcelos. Cascade R-CNN: delving into high quality object detection. In CVPR, 2018. 2
- [3] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-toend object detection with transformers. In ECCV, 2020. 1, 2, 3, 4, 5, 6, 7
- [4] Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic convolution: Attention over convolution kernels. In CVPR, 2020. 2
- [5] Zhigang Dai, Bolun Cai, Yugeng Lin, and Junying Chen. UP-DETR: unsupervised pre-training for object detection with transformers. CoRR, abs/2011.09094, 2020. 6, 7
- [6] Kaiwen Duan, Song Bai, Lingxi Xie, Honggang Qi, Qingming Huang, and Qi Tian. Centernet: Keypoint triplets for object detection. In ICCV, 2019. 2
- [7] Peng Gao, Minghang Zheng, Xiaogang Wang, Jifeng Dai, and Hongsheng Li. Fast convergence of DETR with spatially modulated co-attention. CoRR, abs/2101.07448, 2021. 2, 3
- [8] Zigang Geng, Ke Sun, Bin Xiao, Zhaoxiang Zhang, and Jingdong Wang. Bottom-up human pose estimation via disentangled keypoint regression. In CVPR, pages 14676–14686, June 2021. 8
- [9] Ross B. Girshick. Fast R-CNN. In ICCV, 2015. 2
- [10] Xavier Glorot and Yoshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In AISTATS, 2010. 6
- [11] Maosheng Guo, Yu Zhang, and Ting Liu. Gaussian transformer: A lightweight approach for natural language inference. In AAAI, 2019. 3
- [12] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016. 7
- [13] Jie Hu, Li Shen, Samuel Albanie, Gang Sun, and Andrea Vedaldi. Gather-excite: Exploiting feature context in convolutional neural networks. In NeurIPS, 2018. 2
- [14] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. In CVPR, 2018. 2
- [15] Lichao Huang, Yi Yang, Yafeng Deng, and Yinan Yu. Densebox: Unifying landmark localization with end to end object detection. CoRR, abs/1509.04874, 2015. 2
- [16] Xu Jia, Bert De Brabandere, Tinne Tuytelaars, and Luc Van Gool. Dynamic filter networks. In NeurIPS, 2016. 2
- [17] Guolin Ke, Di He, and Tie-Yan Liu. Rethinking positional encoding in language pre-training. CoRR, abs/2006.15595, 2020. 3
- [18] Jaeyoung Kim, Mostafa El-Khamy, and Jungwon Lee. TGSA: transformer with gaussian-weighted self-attention for speech enhancement. In ICASSP, 2020. 3
- [19] Tao Kong, Fuchun Sun, Huaping Liu, Yuning Jiang, and Jianbo Shi. Foveabox: Beyond anchor-based object detector. CoRR, abs/1904.03797, 2019. 2
- [20] Harold W. Kuhn. The hungarian method for the assignment problem. Naval Research Logistics Quarterly, 1995. 6
- [21] Hei Law and Jia Deng. Cornernet: Detecting objects as paired keypoints. In ECCV, 2018. 2
- [22] Hei Law, Yun Teng, Olga Russakovsky, and Jia Deng. Cornernet-lite: Efficient keypoint based object detection. In BMVC. BMVA Press, 2020. 2
- [23] Yanghao Li, Yuntao Chen, Naiyan Wang, and Zhaoxiang Zhang. Scale-aware trident networks for object detection. In ICCV, pages 6054–6063, 2019. 2
- [24] Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dolla ́r. Focal loss for dense object detection. TPAMI, 2020. 2, 6
- [25] Tsung-Yi Lin, Michael Maire, Serge J. Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll ́ar, and C. Lawrence Zitnick. Microsoft COCO: common objects in context. In ECCV, 2014. 6
- [26] Wei Liu, Dragomir Anguelov, Dumitru Erhan, Christian Szegedy, Scott E. Reed, Cheng-Yang Fu, and Alexander C. Berg. SSD: single shot multibox detector. In ECCV, 2016. 2
- [27] Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam. In ICLR, 2017. 6
- [28] Xin Lu, Buyu Li, Yuxin Yue, Quanquan Li, and Junjie Yan. Grid R-CNN. In CVPR, 2019. 2
- [29] Jiangmiao Pang, Kai Chen, Jianping Shi, Huajun Feng, Wanli Ouyang, and Dahua Lin. Libra R-CNN: towards balanced learning for object detection. In CVPR, 2019. 2
- [30] Joseph Redmon, Santosh Kumar Divvala, Ross B. Girshick, and Ali Farhadi. You only look once: Unified, real-time object detection. In CVPR, 2016. 2
- [31] Joseph Redmon and Ali Farhadi. YOLO9000: better, faster, stronger. In CVPR, 2017. 2
- [32] Joseph Redmon and Ali Farhadi. Yolov3: An incremental improvement. CoRR, abs/1804.02767, 2018. 2
- [33] Shaoqing Ren, Kaiming He, Ross B. Girshick, and Jian Sun. Faster R-CNN: towards real-time object detection with region proposal networks. TPAMI, 2017. 7
- [34] Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian D. Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. In CVPR, 2019. 6
- [35] Guanglu Song, Yu Liu, and Xiaogang Wang. Revisiting the sibling head in object detector. In CVPR, 2020. 2
- [36] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In CVPR, pages 5693–5703, 2019. 8
- [37] Zhiqing Sun, Shengcao Cao, Yiming Yang, and Kris Kitani. Rethinking transformer-based set prediction for object detection. CoRR, abs/2011.10881, 2020. 2, 7
- [38] Zhi Tian, Chunhua Shen, and Hao Chen. Conditional convolutions for instance segmentation. In ECCV, 2020. 2
- [39] Zhi Tian, Chunhua Shen, Hao Chen, and Tong He. FCOS: fully convolutional one-stage object detection. In ICCV, 2019. 2, 7
- [40] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017. 2
- [41] Jingdong Wang, Ke Sun, Tianheng Cheng, Borui Jiang, Chaorui Deng, Yang Zhao, Dong Liu, Yadong Mu, Mingkui Tan, Xinggang Wang, Wenyu Liu, and Bin Xiao. Deep high-resolution representation learning for visual recognition. TPAMI, 2019. 8
- [42] Xinlong Wang, Rufeng Zhang, Tao Kong, Lei Li, and Chunhua Shen. Solov2: Dynamic and fast instance segmentation. In NeurIPS, 2020. 2
- [43] Yifan Xu, Weijian Xu, David Cheung, and Zhuowen Tu. Line segment detection using transformers without edges. In CVPR, pages 4257–4266, June 2021. 8
- [44] Brandon Yang, Gabriel Bender, Quoc V. Le, and Jiquan Ngiam. Condconv: Conditionally parameterized convolutions for efficient inference. In NeurIPS, 2019. 2
- [45] Changqian Yu, Bin Xiao, Changxin Gao, Lu Yuan, Lei Zhang, Nong Sang, and Jingdong Wang. Lite-hrnet: A lightweight high-resolution network. In CVPR, pages 10440–10450, June 2021. 2
- [46] Jiahui Yu, Yuning Jiang, Zhangyang Wang, Zhimin Cao, and Thomas S. Huang. Unitbox: An advanced object detection network. In MM, 2016. 2
- [47] Shifeng Zhang, Cheng Chi, Yongqiang Yao, Zhen Lei, and Stan Z. Li. Bridging the gap between anchor-based and anchor-free detection via adaptive training sample selection. In CVPR, 2020. 2
- [48] Minghang Zheng, Peng Gao, Xiaogang Wang, Hongsheng Li, and Hao Dong. End-to-end object detection with adaptive clustering transformer. CoRR, abs/2011.09315, 2020. 2
- [49] Xingyi Zhou, Dequan Wang, and Philipp Kra ̈henbu ̈hl. Objects as points. CoRR, abs/1904.07850, 2019. 2
- [50] Xingyi Zhou, Jiacheng Zhuo, and Philipp Kr ̈ahenbu ̈hl. Bottom-up object detection by grouping extreme and center points. In CVPR, 2019. 2
- [51] Chenchen Zhu, Fangyi Chen, Zhiqiang Shen, and Marios Savvides. Soft anchor-point object detection. In ECCV, 2020. 2
- [52] Chenchen Zhu, Yihui He, and Marios Savvides. Feature selective anchor-free module for single-shot object detection. In CVPR, 2019. 2
- [53] Xizhou Zhu, Weijie Su, Lewei Lu, Bin Li, Xiaogang Wang, and Jifeng Dai. Deformable DETR: deformable transformers for end-to-end object detection. CoRR, abs/2010.04159, 2020. 1, 2, 6, 7, 8
相关文章:
【目标检测】【ICCV 2021】条件式DETR实现快速训练收敛
Conditional DETR for Fast Training Convergence 条件式DETR实现快速训练收敛 代码链接 论文链接 摘要 最近提出的DETR方法将Transformer编码器-解码器架构应用于目标检测领域,并取得了显著性能。本文针对其训练收敛速度慢这一关键问题,提出了一种条…...
【工作笔记】 WSL开启报错
【工作笔记】 WSL开启报错 时间:2025年5月30日16:50:42 1.现象 Installing, this may take a few minutes... WslRegisterDistribution failed with error: 0x80370114 Error: 0x80370114 ??????????????????Press any key to continue......
VMware使用时出现的问题,此文章会不断更新分享使用过程中会出现的问题
VMware使用时出现的问题,此文章会不断更新分享使用过程中会出现的问题 一、VMware安装后没有虚拟网卡,VMnet1,VMnet8显示黄色三角警告 此文章会不断更新,分享VMware使用过程中出现的问题 如果没找到你的问题可以私信我 一、VMware…...

UniApp微信小程序自定义导航栏实现
UniApp微信小程序自定义导航栏 在UniApp开发微信小程序时,页面左上角默认有一个返回按钮(在导航栏左侧),但有时我们需要自定义这个按钮的样式和功能,同时保持与导航栏中间的标题和右侧胶囊按钮(药丸屏&…...

【Ubuntu】Ubuntu网络管理
Ubuntu 网络管理 ubuntu/debian 中的网络管理 NetworkManager,使用nmcli查询与操作网络配置 /run/NetworkManager/no-stub-resolv.conf 对应命令行例子: nmcli device showsystemd-networkd,使用netplan的yaml文件来配置网络 /usr/lib/systemd/systemd-networkdsystemd-resol…...
)
GitHub 趋势日报 (2025年05月27日)
本日报由 TrendForge 系统生成 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日整体趋势 Top 10 排名项目名称项目描述今日获星总星数语言1Fosowl/agenticSeek完全本地的马努斯AI。没有API,没有200美元的每…...

VR视角下,浙西南革命的热血重生
VR 浙西南革命项目依托先进的 VR 技术,为浙西南革命历史的展示开辟了一条全新的道路 ,打破了时间与空间的限制,使革命历史变得触手可及。 (一)沉浸式体验革命场景 借助 VR 技术,在 VR 浙西南革命的展示…...

深入解析Kafka JVM堆内存:优化策略与监控实践
💝💝💝欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:「storms…...
【高级终端Termux】在安卓手机/平板上使用Termux 搭建 Debian 环境并运行 PC 级 Linux 应用教程(含安装WPS,VS Code)
Termux 搭建 Debian 环境并运行 PC 级 Linux 应用教程 一、前言 1. 背景 众所周知,最新搭载澎湃OS和鸿蒙OS的平板都内置了PC级WPS,办公效率直接拉满(板子终于从“泡面盖”升级为“生产力”了)。但问题来了:如果不是这…...

基于BERT-Prompt的领域句子向量训练方法
基于BERT-Prompt的领域句子向量训练方法 一、核心原理:基于BERT-Prompt的领域句子向量训练方法 论文提出一种结合提示学习(Prompt Learning)和BERT的领域句子向量训练方法,旨在解决装备保障领域文本的语义表示问题。核心原理如下: 以下通过具体例子解释传统词向量方法和…...

高频面试--redis
Reids 1. 常见的数据结构(string, list, hash, set, zset) 答法模板: Redis 提供五种核心数据结构: String:最基本的类型,支持整数、自增、自减、位操作。 List:双端链表,支持消息…...
CRMEB 单商户Java版 v2.3公测版发布,欢迎体验!
当商城管理后台一成不变时,你是否也有过换换风格的想法? 当商城流量激增时,你是否也希望随时观察服务器负载状况,确保系统稳定运行? CRMEB单商户Java版v2.3公测版发布,更新200管理后台页面、弹窗…...
 本地YARN集群的部署)
(四) 本地YARN集群的部署
一、部署说明 Hadoop YARN分布式资源调度,会启动: ResourceManager进程作为管理节点NodeManager进程作为工作节点ProxyServer、JobHistoryServer这两个辅助节点 二、配置文件 在 $HADOOP_HOME/etc/hadoop 文件夹内,修改: 1.m…...

华为OD机试真题——求最多可以派出多少支队伍(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
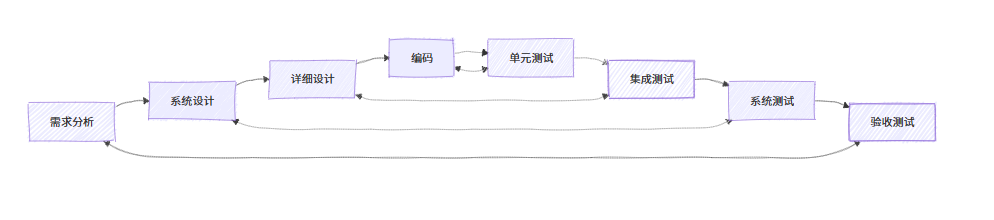
《软件工程》第 12 章 - 软件测试
软件测试是确保软件质量的关键环节,它通过执行程序来发现错误,验证软件是否满足需求。本章将依据目录,结合 Java 代码示例、可视化图表,深入讲解软件测试的概念、过程、方法及实践。 12.1 软件测试的概念 12.1.1 软件测试的任务 …...
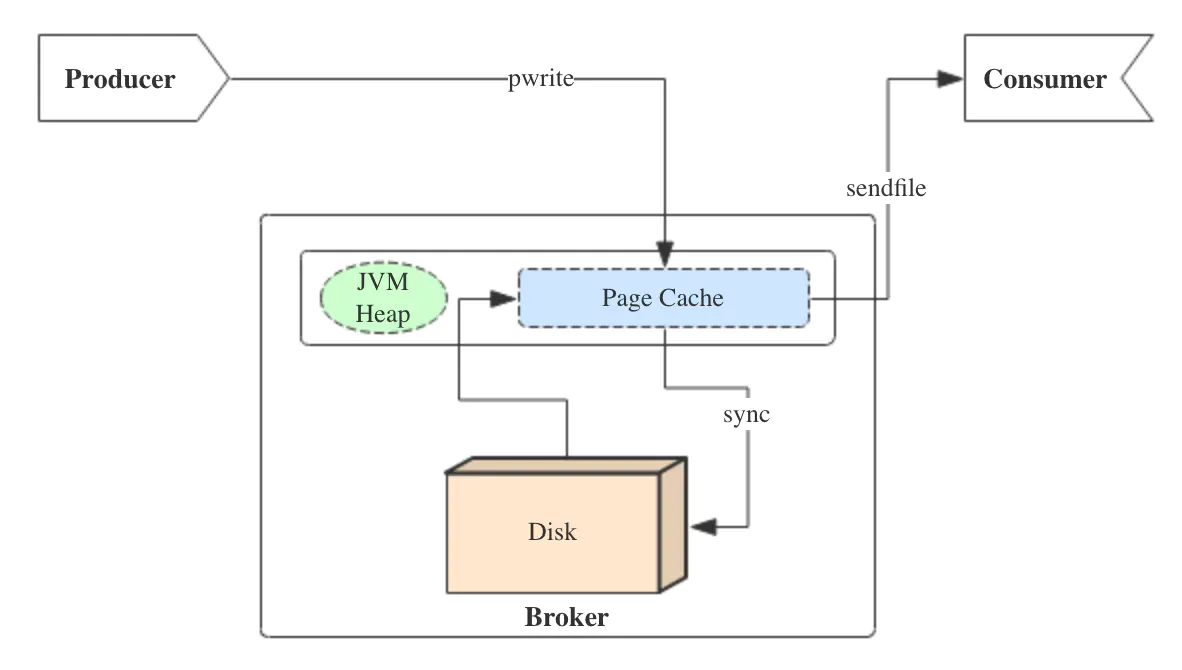
消息队列-kafka为例
目录 消息队列应用场景和基础知识MQ常见的应用场景MQ消息队列的两种消息模式如何保证消息队列的高可用?如何保证消息不丢失?如何保证消息不被重复消费?如何保证消息消费的幂等性?重复消费的原因解决方案 如何保证消息被消费的顺序…...

学习STC51单片机20(芯片为STC89C52RCRC)
每日一言 生活不会一帆风顺,但你的勇敢能让风浪变成风景。 串口助手的界面就等于是pc端的页面设置的是pc端的波特率等等参数 程序里面的是单片机的波特率等等参数 串口助手是 PC 端软件 串口助手(如 STC-ISP)是运行在 PC 上的工具&#x…...
链路追踪神器zipkin安装详细教程教程
今天分享下zipkin的详细安装教程,具体代码demo可以参考我上篇文章:Spring Cloud Sleuth与Zipkin深度整合指南:微服务链路追踪实战-CSDN博客 一、Zipkin是什么? Zipkin是由Twitter开源的一款分布式追踪系统(现由OpenZ…...

RabbitMQ备份与恢复技术详解:策略、工具与最佳实践
RabbitMQ作为广泛使用的消息中间件,其高可用性和数据持久化能力使其成为分布式系统的核心组件。然而,硬件故障、人为误操作或灾难性事件仍可能导致数据丢失或服务中断。因此,建立可靠的备份与恢复机制是运维工作的关键环节。本文基于RabbitMQ…...
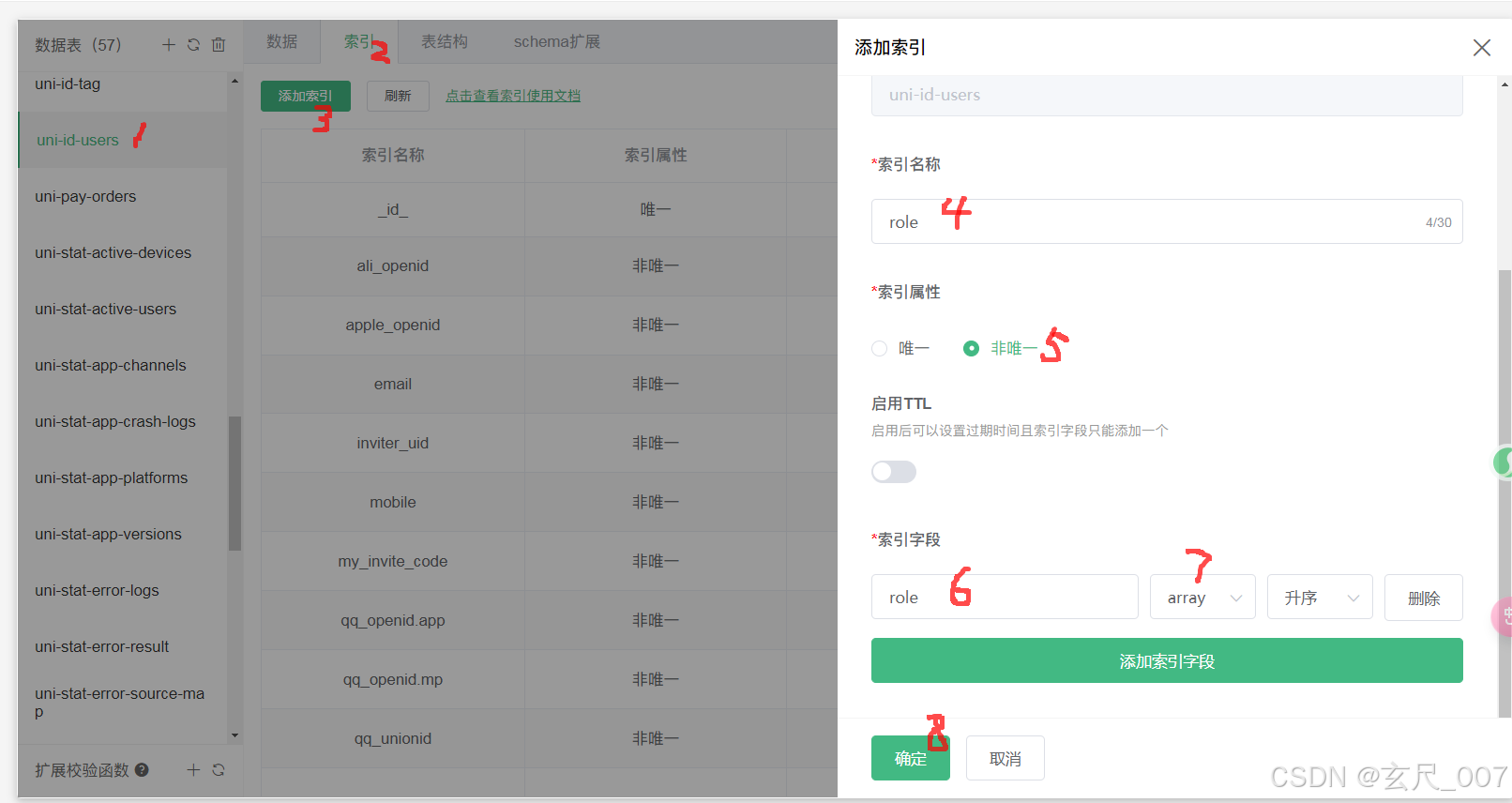
bug: uniCloud 查询数组字段失败
问题根源:使用了支付宝云 官方说:2024年11月之后创建的新的支付宝云空间,数组字段查询强制必须设置 array 类型的索引 布尔类型的查询,强制必须设置 bool 类型的索引。 方案一:找到云服务空间-》云数据库-》对应的表-…...

Php JIT 使用详解
简介 PHP 8 引入的 JIT(Just-In-Time 编译器) 是该版本的一个重要性能特性,首次让 PHP 有了运行时即时编译的能力,从解释型语言迈向了“编译执行”的方向。 什么是 JIT? JIT 是 即时编译(Just-In-Time c…...

视觉分析开发范例:Puppeteer截图+计算机视觉动态定位
一、选型背景:传统爬虫已无力应对的视觉挑战 在现代互联网环境中,尤其是小红书、抖音、B站等视觉驱动型平台,传统基于 HTML 的爬虫已经难以满足精准数据采集需求: 内容加载由 JS 动态触发,难以直接解析 HTML…...

Linux 基础开发工具的使用
目录 前言 一:下载工具yum 二:文本编辑器vim 1. 命令模式 2. 插入模式 3. 底行模式 三:gcc和g 基本使用格式 常用选项及作用 编译过程示例 四、Linux 项目自动化构建工具 ——make/Makefile 1. make 与 Makefile 的关系 2. Make…...

ElasticSearch查询指定时间内出现的次数/2秒内出现的次数
查询指定时间内出现的次数 POST process-log/_search {"size": 0,"query": {"bool": {"filter": [{"range": {"requestTime": {"from": 1722470400000,"to": 1722556800000}}}]}},"agg…...
华为云Flexus+DeepSeek征文 | Dify-LLM平台一键部署教程及问题解决指南
作者简介 我是摘星,一名专注于云计算和AI技术的开发者。本次通过华为云MaaS平台体验DeepSeek系列模型,将实际使用经验分享给大家,希望能帮助开发者快速掌握华为云AI服务的核心能力。 目录 1. 前言 2. 准备工作 2.1 注册华为云账号 2.2 确…...

STP协议:如何消除网络环路风暴
生成树协议(STP,Spanning Tree Protocol)的主要功能: 消除网络环路导致的广播风暴问题(环路会引发MAC地址表不稳定)防止网络中的主机接收重复数据帧 STP工作原理: 选举根桥(Root …...
哈工大计算机系统2025大作业——Hello的程序人生
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 计算学部 学 号 2023113072 班 级 23L0513 学 生 董国帅 指 导 教 师 史先俊 计算机科学与…...

物联网常用协议Modbus、CAN、BACnet介绍
一、Modbus Modbus 作为工业通信领域的基石,是一款被广泛应用的工业通信协议,主要用于实现可编程逻辑控制器(PLC)等工业电子设备之间的连接。1979 年,Modicon 公司(现施耐德电气的一部分)开发了这一协议,旨在简化工厂内设备间的通信流程。经过多年发展,Modbus 衍生出…...

Vue中van-stepper与input值不同步问题及解决方案
一、问题描述 在使用Vant UI的van-stepper步进器组件与原生input输入框绑定同一响应式数据时,出现以下现象: 通过步进器修改值后,页面直接输出{{ count }}和watch监听器均能获取最新值但input输入框显示的数值未同步更新,仍为旧…...

react基础技术栈
react基础技术栈 react项目构建react的事件绑定React组件的响应式数据条件渲染和列表循环表单绑定 Props和组件间传值,插槽react中的样式操作 生命周期ref 和 context函数组件和hook高阶组件React性能问题React-route的三个版本react-router使用步骤react-router提供…...