Python打卡训练营day40——2025.05.30
知识点回顾:
彩色和灰度图片测试和训练的规范写法:封装在函数中
展平操作:除第一个维度batchsize外全部展平
dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。这个模型结构是一个简单的全连接神经网络,用于处理输入大小为 28×28(即 784 个特征)的数据,通常用于 MNIST 手写数字识别任务
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform)# 3. 创建数据加载器batch_size = 64 # 每批处理64个样本train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 检查GPU是否可用device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型model = MLP()model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失(原逻辑保留,用于 epoch 级统计)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 原 epoch 级逻辑(测试、打印 epoch 结果)不变epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率# 6. 测试模型def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率# 7.绘制每个 iteration 的损失曲线def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)epochs = 2 print("开始训练模型...")final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")@浙大疏锦行
相关文章:

Python打卡训练营day40——2025.05.30
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中 展平操作:除第一个维度batchsize外全部展平 dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练…...

Java八股-数据类型转换有哪些?类型互转会有什么问题?为什么用bigDecimal 不用double ?自动装箱和拆箱?包装类?
Java中有哪些数据类型转换? 显示类型转换:在前面一个括号,里面写上要转换的类型 隐式类型转换:小范围的数据类型转大范围的,int到long,float到double 字符串转整形或浮点:整形:In…...

redis未授权(CVE-2022-0543)
概述 Redis 默认绑定在 0.0.0.0:6379,在未配置防火墙或访问控制的情况下会将服务暴露在公网上。若未设置访问密码(默认通常为空),攻击者可直接未授权访问 Redis。利用 Redis 提供的 CONFIG 命令,攻击者可修改配置并将…...

【运维实战】Linux 中su和sudo之间的区别以及如何配置sudo!
Linux 系统相比其他操作系统具有更高的安全性,其安全机制的核心之一在于用户管理策略和权限控制--普通用户默认无权执行任何系统级操作。 若普通用户需要进行系统级变更,必须通过su或sudo命令提权。 1.su与sudo的本质区别 su 要求直接共享 root 密码&…...

LevelDB、BoltDB 和 RocksDB区块链应用比较
LevelDB、BoltDB 和 RocksDB 是三种常用的键值存储数据库,它们在区块链领域(如以太坊、比特币等)或其他高性能应用中有广泛应用。虽然它们都是嵌入式键值存储,但设计目标、性能特性、功能支持和适用场景有显著差异。以下是它们的详…...

c/c++的opencv图像金字塔缩放
图像金字塔缩放:OpenCV C/C 实践 📐 图像金字塔是计算机视觉中一种重要且基础的多尺度表示方法。它通过对原始图像进行连续的下采样(缩小)或上采样(放大)操作,生成一系列不同分辨率的图像。这些…...

PDF文件转换之输出指定页到新的 PDF 文件
背景 一份 PDF 学习资料需要打印其中某几页,文件有几百兆,看到 WPS 有PDF拆分功能,但是需要会员,开了一个月会员后完成了转换。突然想到,会员到期后如果还要拆解的话,怎么办呢?PDF 文件拆解功能…...

浏览器之禁止打开控制台【F12】
前言 在有时我们的日常开发工作中,有些项目要求我们增加禁用控制台的要求,这种虽然很鸡肋,但是它确实存在,并且会让哈哈心里觉得很有成就感。 所以今天他来了。 文章目录 前言无限debugger实现思路:效果如下࿱…...
(帮你生成 模块划分+页面+表设计、状态机、工作流、ER模型))
进阶智能体实战九、图文需求分析助手(ChatGpt多模态版)(帮你生成 模块划分+页面+表设计、状态机、工作流、ER模型)
🧠 基于 ChatGPT 多模态大模型的需求文档分析助手 本文将介绍如何利用 OpenAI 的 GPT-4o 多模态能力,构建一个智能的需求文档分析助手,自动提取功能模块、菜单设计、字段设计、状态机、流程图和 ER 模型等关键内容。 一、🔧 环境准备 在开始之前,请确保您已经完成了基础…...

GEARS以及与基础模型结合
理解基因扰动的反应是众多生物医学应用的核心。然而,可能的多基因扰动组合数量呈指数级增长,严重限制了实验探究的范围。在此,图增强基因激活与抑制模拟器(GEARS),将深度学习与基因-基因关系知识图谱相结合…...
机制详解详解)
SFINAE(替换并不是错误)机制详解详解
C—SFINAE机制详解 1. 核心概念 SFINAE(替换失败并非错误)是C模板元编程的核心机制,它规定了: 在模板参数推导/替换过程中如果某个替换导致无效代码不会引发编译错误而是从候选函数集中静默移除该模板特化 关键特性 template …...

怎么用外网打开内网的网址?如在异地在家连接访问公司局域网办公网站
什么是内网:即本地网络,私有网,内网IP,如学校局域网,家庭内网,公司内部网络等。可以简单理解为同一个路由下的几个电脑网络。 外网概念:即公网,互联网,是相对于内网而言…...
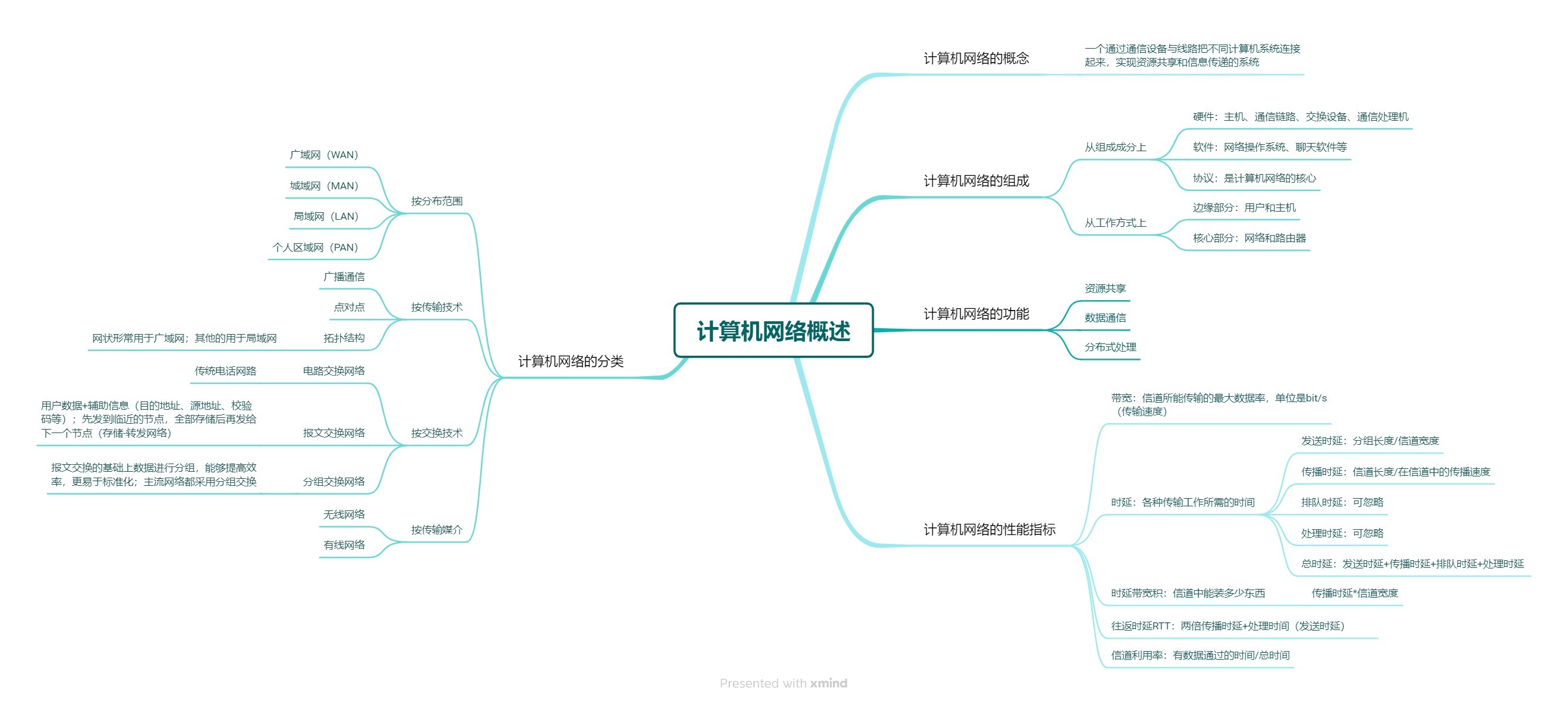
计算机网络 | 1.1 计算机网络概述思维导图
附大纲: 计算机网络的概念 一个通过通信设备与线路把不同计算机系统连接起来,实现资源共享和信息传递的系统 计算机网络的组成 从组成成分上 硬件:主机、通信链路、交换设备、通信处理机软件:网络操作系统、聊天软件等协议&…...

AI对软件工程的影响及未来发展路径分析报告
目录 第一部分:引言 研究背景与意义 报告框架与方法论 第二部分:AI对不同行业软件工程的影响分析 数字化行业 制造业 零售业 工业领域 第三部分:大厂AI软件工程实践案例分析 微软 谷歌 阿里巴巴 华为 第四部分:未来…...

redis缓存与数据库协调读写机制设计
1.读机制: 读机制没有太大的争议点,因为缓存机制的设计,就是为了更快的命中目标数据,所以读机制先天固定好了:先去读取缓存,缓存未命中再去读取数据库。 2.写机制: 写机制其实也没什么争议点…...

最悉心的指导教程——阿里云创建ECS实例教程+Vue+Django前后端的服务器部署(通过宝塔面板)
各位看官老爷们,点击关注不迷路哟。你的点赞、收藏,一键三连,是我持续更新的动力哟!!! 阿里云创建ECS实例教程 注意: 阿里云有300元额度的免费适用期哟 白嫖~~~~ 注册了阿里云账户后&#x…...

【Python】os模块
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明 🧠 一、技术原理剖析📊 核心架构图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选…...

Syslog 全面介绍及在 C 语言中的应用
Syslog 概述 Syslog 是一种工业标准的日志记录协议,用于在网络设备之间传递日志消息。它最早由 Eric Allman 在 1980 年代为 BSD Unix 开发,现在已成为系统和网络管理的重要组成部分。Syslog 协议允许设备将事件消息发送到中央服务器(称为 sy…...
windows中Redis、MySQL 和 Elasticsearch启动并正确监听指定端口
Redis:在 localhost 上启动,并监听端口 6379 MySQL:在 localhost 上启动,并监听端口 3306 Elasticsearch:在 127.0.0.1 上启动,并监听端口 9300 1. Redis 确保 Redis 在 localhost 上启动并监听端口 6379…...

Paimon远程文件系统连接机制解析
Paimon 在处理与远程文件系统的连接和使用方面,设计了一套灵活的抽象机制。下面将结合源代码分析 Paimon 是如何实现这一点的。 核心思想是定义一个通用的 FileIO 接口,然后为不同的文件系统提供具体的实现。对于常见的 HDFS、S3、OSS 等,Pa…...

学者观察 | Web3.0的技术革新与挑战——北京理工大学教授沈蒙
导语 沈蒙老师认为Web3.0正推动形成新型数据基础设施架构和数据要素流通机制,有望在数字经济时代发挥重要作用,对我国经济发展和社会进步将产生深远影响。AI在推动Web3.0发展方面具有巨大的潜力,但在隐私保护、公平性与安全性等方面也存在“…...
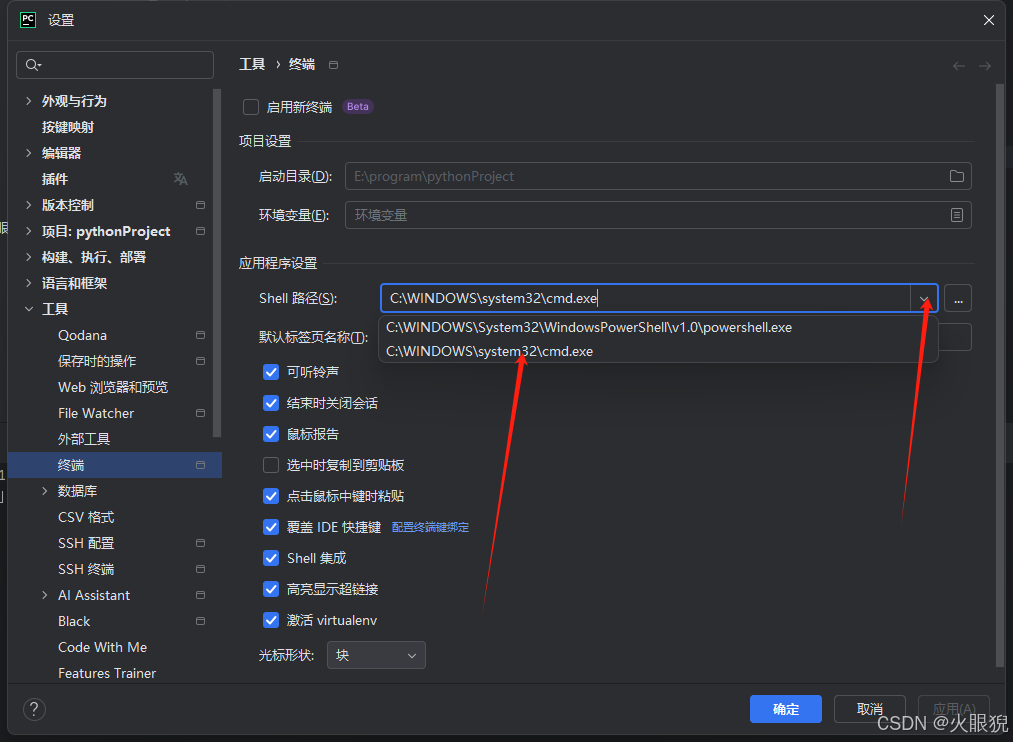
pycharm终端遇不显示虚拟环境的问题
大部分我们用pycharm会配合我们的anaconda来使用,但是配置好后,可能会出现pycharm终端不显示虚拟环境的问题。 首先是确定不显示环境,下图中如果没有这个方框,就是不显示虚拟环境。此时用pip或者conda的命令是会提示不是 “不是内…...

聊聊网络变压器的浪涌等级标准是怎样划分的呢?
Hqst盈盛(华强盛)电子导读:聊聊网络变压器的浪涌等级标准是怎样划分的呢? 在和做防雷产品的客户的深度沟通网络变压器产品选型中发现:客户对网络变压器的浪涌等级划分也很希望有更深的了解,今天就这个问题和…...

2025年Google I/O大会上,谷歌展示了一系列旨在提升开发效率与Web体验的全新功能
每周跟踪AI热点新闻动向和震撼发展 想要探索生成式人工智能的前沿进展吗?订阅我们的简报,深入解析最新的技术突破、实际应用案例和未来的趋势。与全球数同行一同,从行业内部的深度分析和实用指南中受益。不要错过这个机会,成为AI领…...
ONLYOFFICE文档API:编辑器的品牌定制化
在当今数字化办公时代,文档编辑器已成为各类企业、组织和开发者不可或缺的工具之一。ONLYOFFICE 文档提供的功能丰富且强大的文档编辑 API,让开发者能够根据自己的产品需求和品牌特点,定制编辑器界面,实现品牌化展示,为…...
HTTP/HTTPS与SOCKS5三大代理IP协议,如何选择最佳协议?
在复杂多变的网络环境中,代理协议的选择直接影响数据安全、访问效率和业务稳定性。HTTP、HTTPS和SOCKS5作为三大主流代理协议,各自针对不同场景提供独特的解决方案。本文将从协议特性、性能对比到选型策略,为您揭示如何根据业务需求精准匹配最…...

远程调用 | OpenFeign+LoadBalanced的使用
目录 RestTemplate 注入 OpenFeign 服务 LoadBalanced 服务 LoadBalanced 注解 RestTemplate 注入 创建 配置类,这里配置后 就不用再重新new一个了,而是直接调用即可 import org.springframework.cloud.client.loadbalancer.LoadBalanced; import …...
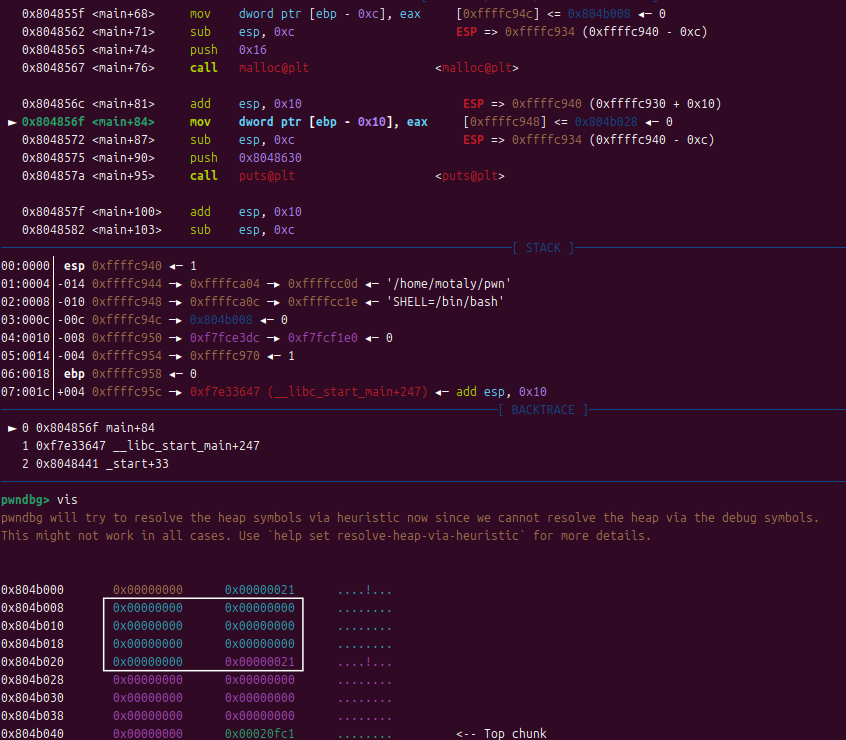
NSSCTF [NISACTF 2022]ezheap
2058.[NISACTF 2022]ezheap(堆溢出) [NISACTF 2022]ezheap 1.准备 2.ida分析 main函数 int __cdecl main(int argc, const char **argv, const char **envp) {char *command; // [esp8h] [ebp-10h]char *s; // [espCh] [ebp-Ch]setbuf(stdin, 0);setbuf(stdout, 0);s (cha…...

ADB推送文件到指定路径解析
您执行的命令 adb push ota.zip /sdcard/Download 中,目标路径 /sdcard/Download 是您显式指定的,因此 ADB 会直接将文件推送到此位置。具体过程如下: 1. 命令结构解析 adb push:ADB 的推送指令。ota.zip:本地计算机上…...
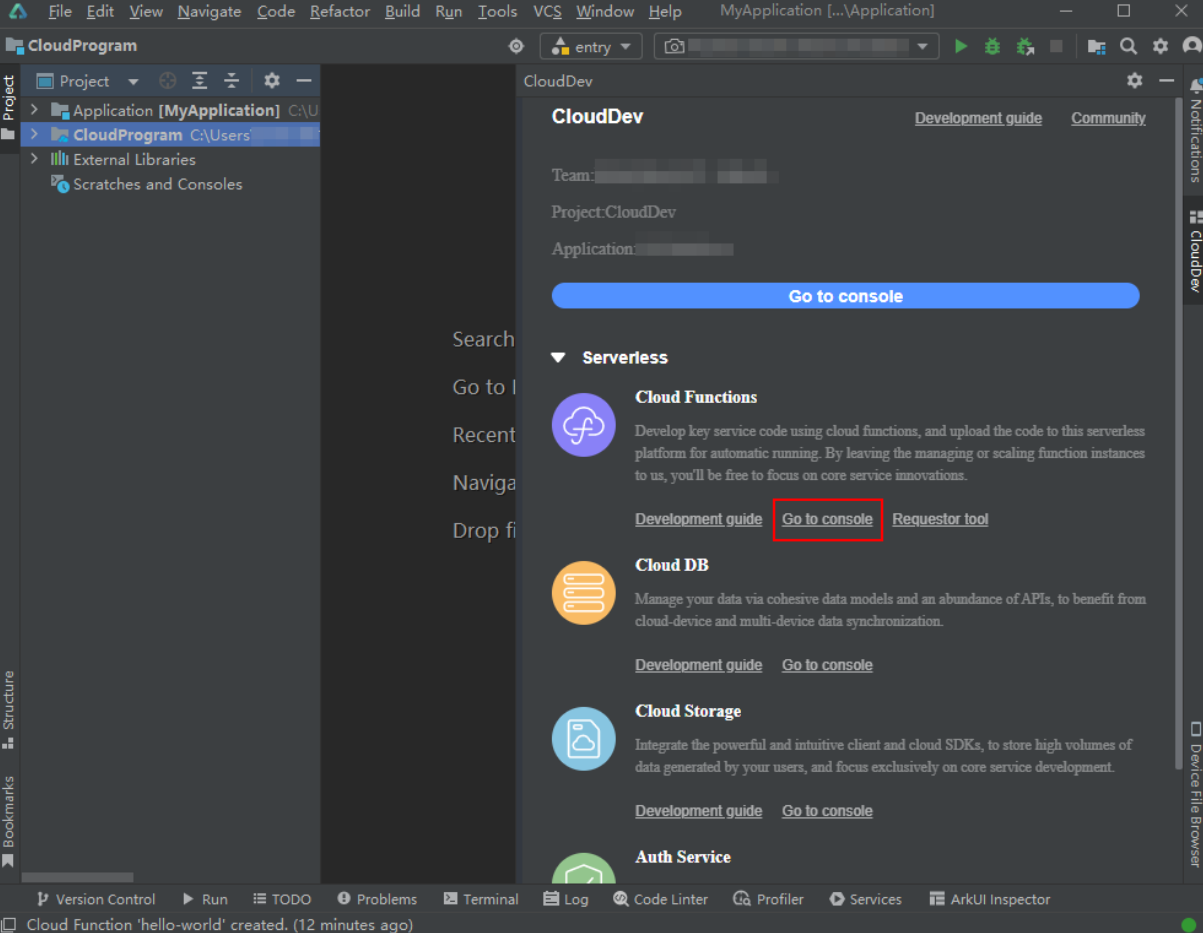
【HarmonyOS Next之旅】DevEco Studio使用指南(二十七) -> 开发云函数
目录 1 -> 开发流程 2 -> 创建并配置函数 2.1 -> 创建函数 2.2 -> 配置函数 3 -> 开发函数 4 -> 调试函数 4.1 -> 前提条件 4.2 -> 通过本地调用方式调试函数 4.3 -> 通过远程调用方式调试函数 5 -> 部署函数 1 -> 开发流程 云函数…...