60天python训练计划----day40
DAY 40 训练和测试的规范写法
知识点回顾:
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
一.单通道图片的规范写法
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
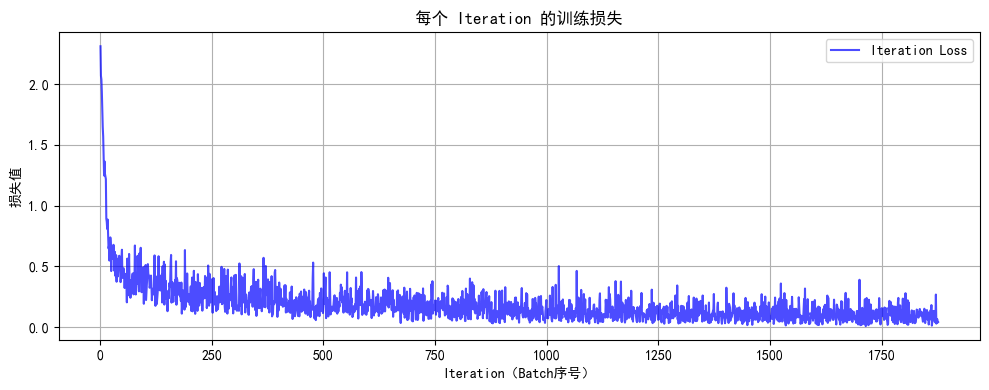
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率之前我们用mlp训练鸢尾花数据集的时候并没有用函数的形式来封装训练和测试过程,这样写会让代码更加具有逻辑-----隔离参数和内容。
1. 后续直接修改参数就行,不需要去找到对应操作的代码
2. 方便复用,未来有多模型对比时,就可以复用这个函数
这里我们先不写早停策略,因为规范的早停策略需要用到验证集,一般还需要划分测试集
1. 划分数据集:训练集(用于训练)、验证集(用于早停和调参)、测试集(用于最终报告性能)。
2. 在训练过程中,使用验证集触发早停。
3. 训练结束后,仅用测试集运行一次测试函数,得到最终准确率。
测试函数和绘图函数均被封装在了train函数中,但是test和绘图函数在定义train函数之后,这是因为在 Python 中,函数定义的顺序不影响调用,只要在调用前已经完成定义即可。
# 6. 测试模型(不变)
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率# 7. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")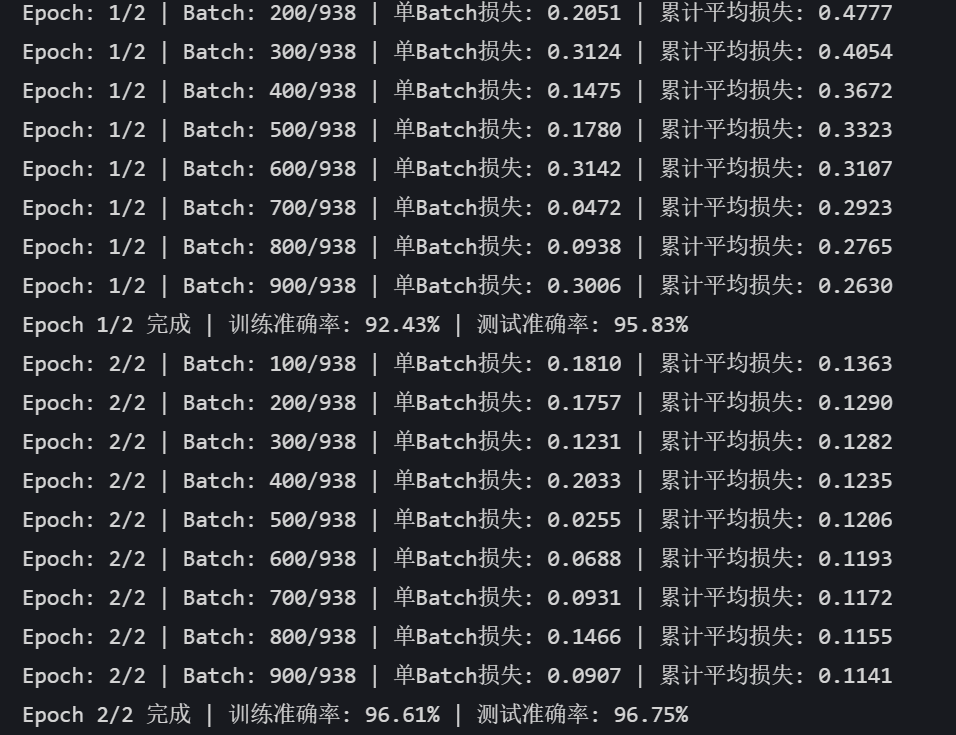



二.彩色图片的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
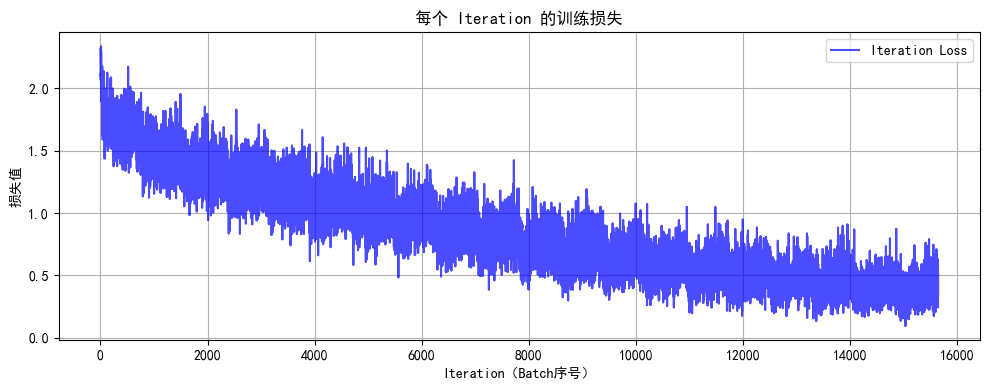
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")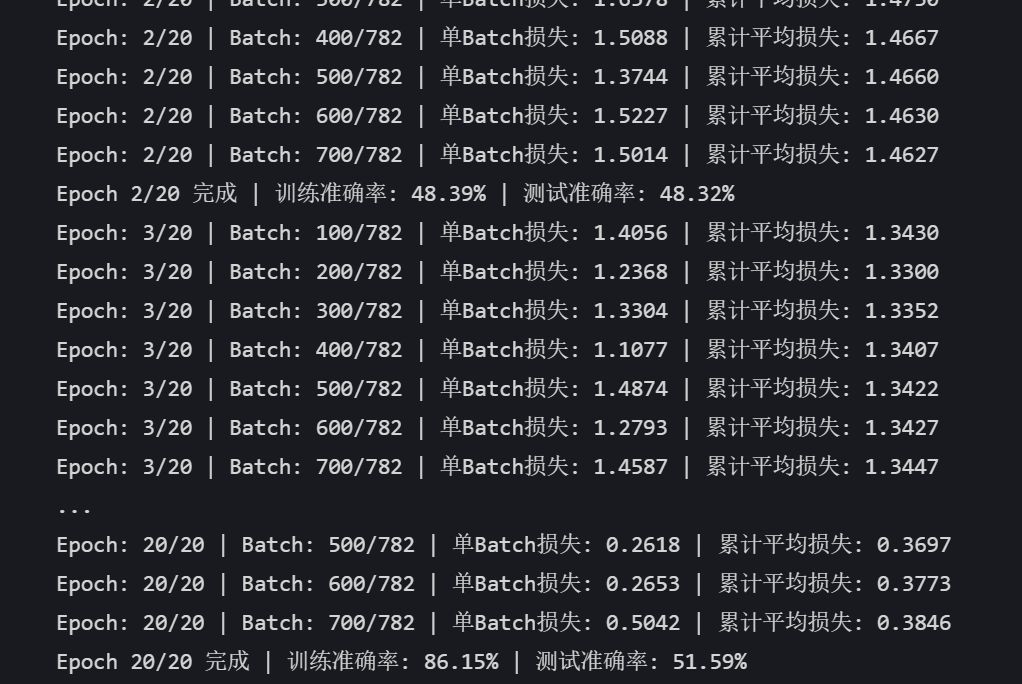
@浙大疏锦行
相关文章:
60天python训练计划----day40
DAY 40 训练和测试的规范写法 知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 一.单通道图…...

干泵,干式螺杆真空泵
干式真空泵: 无油干式机械真空泵(又简称干式机械泵)是指泵能从大气压力下开始抽气,又能将被抽气体直接排到大气中去,泵腔内无油或其他工作介质,而且泵的极限压力与油封式真空泵同等量级或者接近的机械真空泵…...
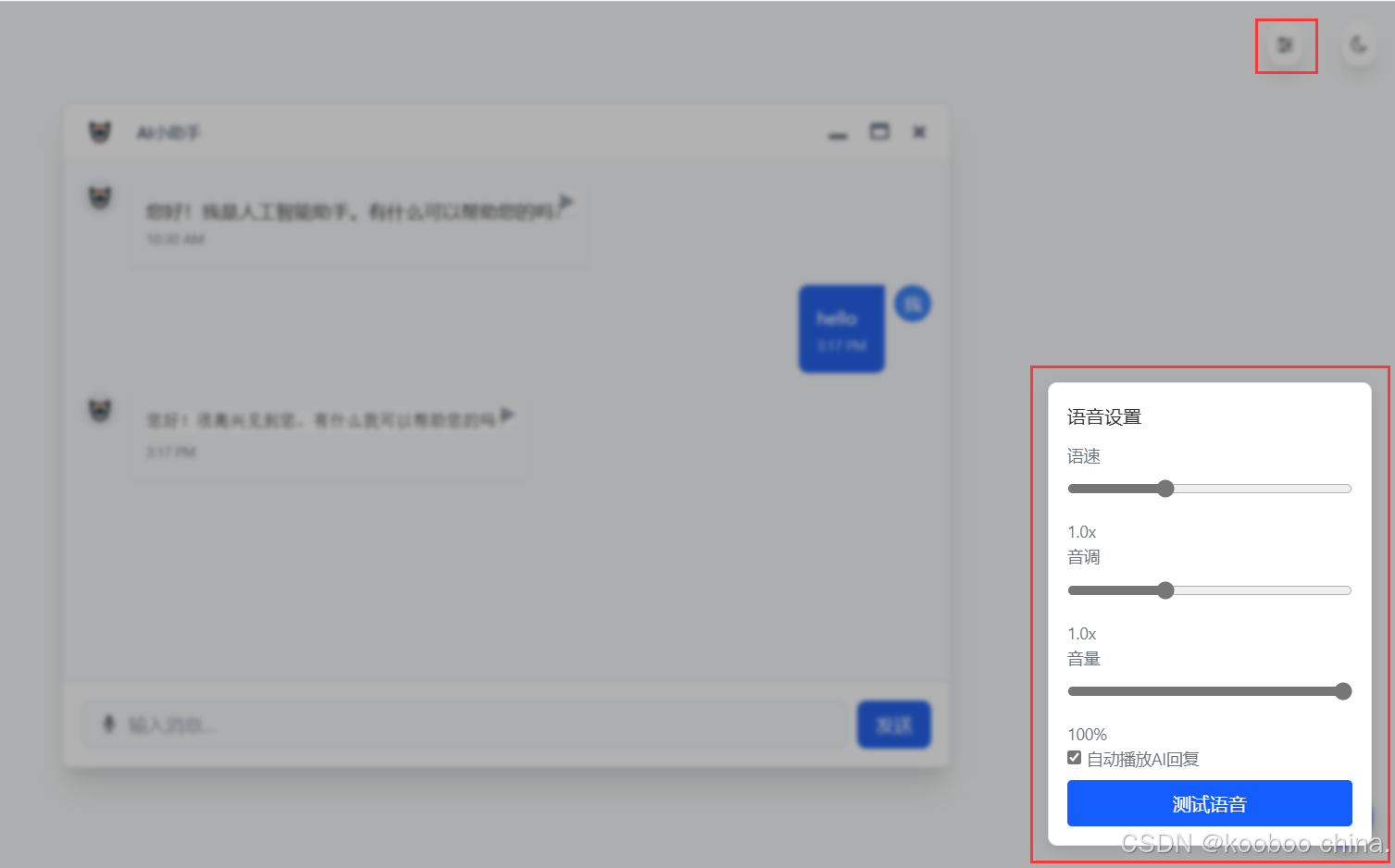
Tailwind CSS 实战:基于 Kooboo 构建 AI 对话框页面(五):语音合成输出与交互增强
Tailwind CSS 实战,基于Kooboo构建AI对话框页面(一) Tailwind CSS 实战,基于Kooboo构建AI对话框页面(二):实现交互功能 Tailwind CSS 实战,基于 Kooboo 构建 AI 对话框页面&#x…...
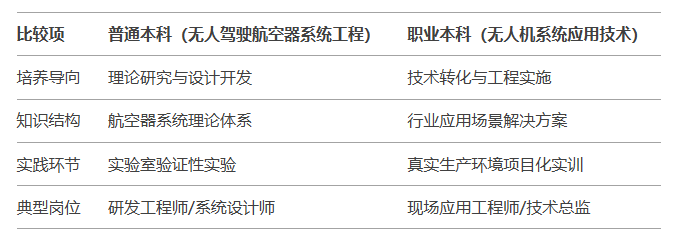
职业本科院校无人机专业人才培养解决方案
2023年的中央经济工作会议强调了以科技创新推动现代化产业体系构建的重要性,并提出发展生物制造、商业航天、低空经济等战略性新兴产业。低空经济,依托民用无人机等低空飞行器,在多场景低空飞行活动的牵引下,正逐步形成一个辐射广…...

利用机器学习优化数据中心能效
数据中心作为现代社会的数字基础设施,支撑着云计算、大数据分析、人工智能等关键技术的发展。然而,随着数据中心规模的不断扩大,其能源消耗问题也日益凸显。如何提高数据中心的能源效率,降低运营成本,同时减少环境影响…...

软件评测机构如何保障质量?检测资质、技术实力缺一不可
软件评测机构在保障软件质量上起着关键作用,对软件行业的健康发展极为关键。它们采用专业的技术手段和严格的评估流程,对软件的运行效果、功能等多方面进行细致的审查,为开发者和使用者提供了客观、公正的参考依据。 检测资质正规软件评测机…...
)
微软开源bitnet b1.58大模型,应用效果测评(问答、知识、数学、逻辑、分析)
微软开源bitnet b1.58大模型,应用效果测评(问答、知识、数学、逻辑、分析) 目 录 1. 前言... 2 2. 应用部署... 2 3. 应用效果... 3 1.1 问答方面... 3 1.2 知识方面... 4 1.3 数字运算... 6 1.4 逻辑方面... …...

ubuntu 安装上传的 ffmpeg_7.1.1.orig.tar.xz并使用
在 Ubuntu 系统上离线安装 make 需要提前准备好所有依赖包。以下是详细的操作步骤: 准备工作:在有网络的机器上下载所需软件包 查找依赖关系 在有网络的 Ubuntu 机器上(需与目标机器相同版本)执行: # 获取 make 及其依…...

Web3怎么开发类似MetaMask的钱包
开发一个类似MetaMask的钱包,关键就是要利用以太坊提供的官方接口和标准,主要涉及以下几点: 1. 你要用到的以太坊官方接口和规范 JSON-RPC API 以太坊节点(如Geth、OpenEthereum等)通过JSON-RPC接口暴露各种功能&…...
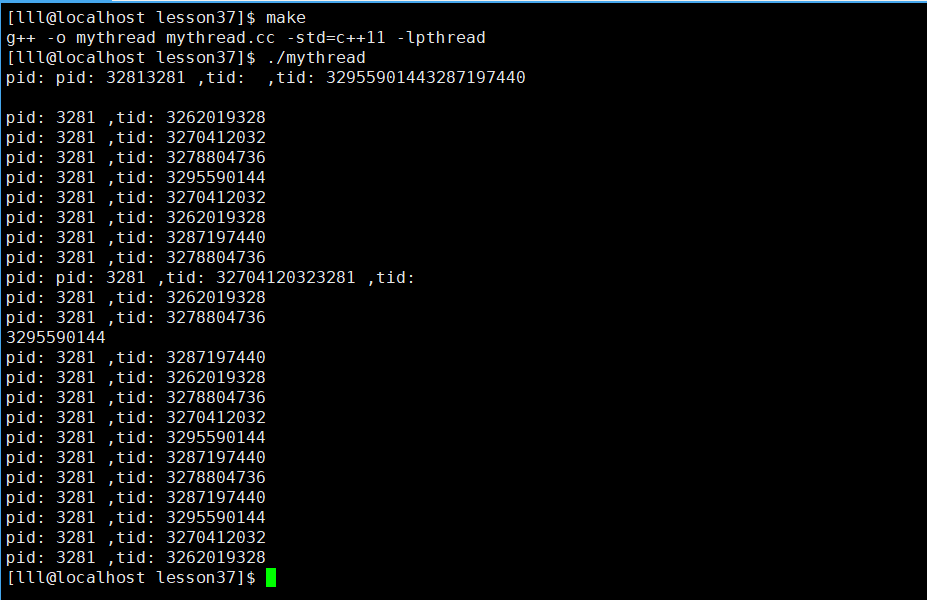
Linux多线程(六)之线程控制4【线程ID及进程地址空间布局】
文章目录 线程ID及进程地址空间布局线程局部存储 线程ID及进程地址空间布局 pthread_ create函数会产生一个线程ID,存放在第一个参数指向的地址中。 该线程ID和前面说的线程ID不是一回事。 前面讲的线程ID属于进程调度的范畴。 因为线程是轻量级进程ÿ…...

1.什么是node.js、npm、vue
一、Node.js 是什么? 😺 定义: Node.js 是一个基于 Chrome V8 引擎的 JavaScript 运行时环境,让你可以在浏览器之外运行 JavaScript 代码,主要用于服务端开发。 😺从计算机底层说:什么是“运…...
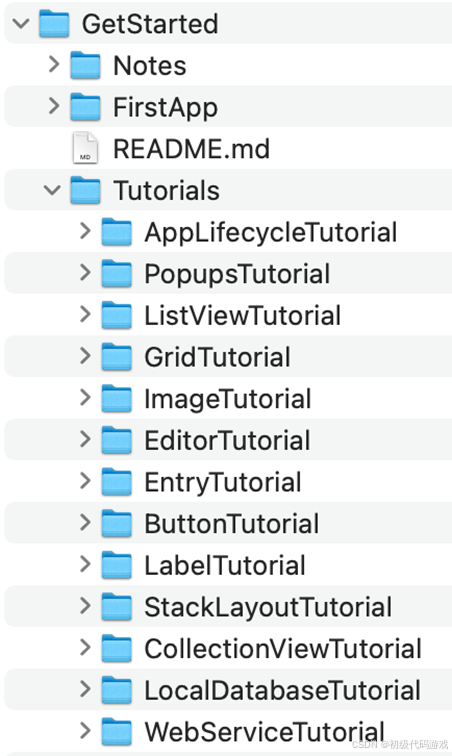
Xamarin入门笔记(Xamarin已经被MAUI取代)
初级代码游戏的专栏介绍与文章目录-CSDN博客 Xamarin入门 概述 环境 Android开发环境比较简单,自带模拟器,实体机打开开发者模式即可。 iOS开发环境比较复杂,必须搭配Mac电脑,Windows连接Mac开发可能有问题(比如发…...
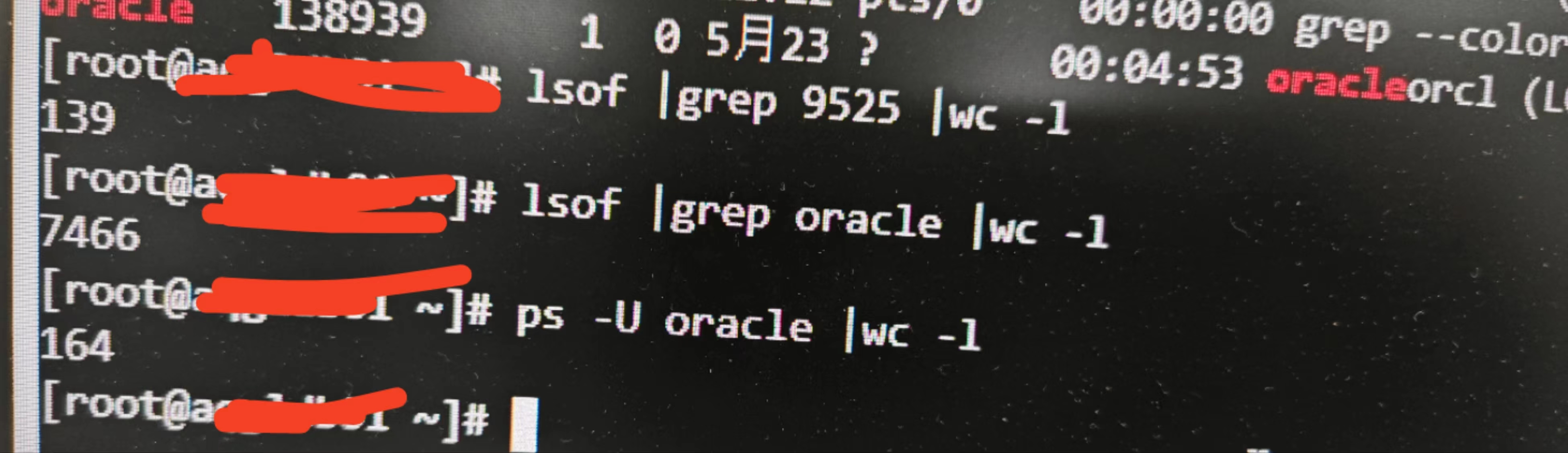
排查Oracle文件打开数过多
Oracle数据库在运行过程中,会打开大量的文件以执行其操作,包括数据文件、控制文件、日志文件等。如果Oracle用户打开的文件数过多,可能会引起系统性能下降。下面将深入分析Oracle用户文件打开数的优化策略,以帮助数据库管理员&…...

应用层协议http(无代码版)
目录 认识URL urlencode 和 urldecode HTTP 协议请求与响应格式 HTTP 的请求方法 GET 方法 POST 方法 HTTP 的状态码 HTTP 常见 Header Location 关于 connection 报头 HTTP版本 远程连接服务器工具 setsockopt 我们来学习应用层协议http。 虽然我们说, 应用层协…...
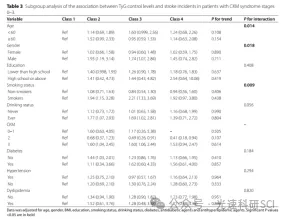
8.5 Q1|广州医科大学CHARLS发文 甘油三酯葡萄糖指数累积变化与 0-3期心血管-肾脏-代谢综合征人群中风发生率的相关性
1.第一段-文章基本信息 文章题目:Association between cumulative changes of the triglyceride glucose index and incidence of stroke in a population with cardiovascular-kidney-metabolic syndrome stage 0-3: a nationwide prospective cohort study 中文标…...

交叉编译tcpdump工具
1.导出交叉编译工具链 export PATH$PATH:/opt/rockchip/gcc-linaro-6.3.1-2017.05-x86_64_arm-linux-gnueabihf/bin 下载源码包libpcap-1.10.5,配置、并编译安装。 github仓库地址 ./configure --hostarm-linux CCarm-linux-gnueabihf-gcc --prefix$PWD/install …...

【Python-Day 20】揭秘Python变量作用域:LEGB规则与global/nonlocal关键字详解
Langchain系列文章目录 01-玩转LangChain:从模型调用到Prompt模板与输出解析的完整指南 02-玩转 LangChain Memory 模块:四种记忆类型详解及应用场景全覆盖 03-全面掌握 LangChain:从核心链条构建到动态任务分配的实战指南 04-玩转 LangChai…...
)
golang 柯里化(Currying)
使用场景:参数在语义上属于不同组,Go 语法无法在单次调用中声明多组可变参数,通过柯里化可以实现分步接收参数。 有的参数是在不同时间段产生,使用Currying可以让函数记住(缓存)参数,避免应用代…...

无人机停机坪运行技术分析!
一、运行方式 1. 自动折叠与展开 部分停机坪采用二次折叠设计,通过传动组件实现自动折叠,缩小体积便于运输;展开后最大化停机面积,适应不同任务需求。例如,珠海双捷科技的专利通过两次折叠使停机坪体积最小化&#x…...

comfyui 工作流中 视频长度和哪些参数有关? 生成15秒的视频,再加上RTX4060 8G显卡,尝试一下
想再消费级显卡上生成15秒长视频,还是比较慢的,不过动漫的画质要求比较低 在ComfyUI中生成15秒视频需综合考虑视频参数配置、模型选择和硬件优化,尤其针对RTX 4060 8G显存的限制。 ⏱️ 一、影响视频长度的核心参数 总帧数(video_…...
【Java Web】速通HTML
参考笔记: JavaWeb 速通HTML_java html页面-CSDN博客 目录 一、前言 1.网页组成 1 结构 2 表现 3 行为 2.HTML入门 1 基本介绍 2 基本结构 3. HTML标签 1 基本说明 2 注意事项 4. HTML概念名词解释 二、HTML常用标签汇总 + 案例演示 1. 字体标签 font (1)定义 (2)案例 2…...
在线制作幼教早教行业自适应网站教程
你想知道怎么做自适应网站吗?今天就来教你在线用模板做个幼教早教行业的网站哦。 首先得了解啥是自适应网站。简单说呢,自适应网站就是能自动匹配不同终端设备的网站,像手机、平板、电脑等。那如何做幼早教自适应网站呢? 在乔拓云…...

WSL 开发环境搭建指南:Java 11 + 中间件全家桶安装实战
在WSL(Windows Subsystem for Linux)环境下一站式安装开发常用工具,能极大提升工作效率。接下来我将分步为你介绍如何在WSL中安装Java 11、Maven、Redis、MySQL、Nacos、RabbitMQ、RocketMQ、Elasticsearch(ES)和Node.…...

matlab天线阵列及GUI框架,可用于相控阵,圆形阵,矩形阵
构建天线阵列及GUI框架,可用于相控阵,圆形阵,矩形阵等 array/array.fig , 35384 array/array.m , 15582 array/circ_array.m , 5959 array/circular_array.m , 4238 array/fig8_5.m , 851 array/fig8_53.m , 441 array/fig8_7.m , 847 array/initialize…...

在 Ubuntu 终端中配置网络代理:优化 npm、apt等的下载速度
文章目录 背景步骤 1:测试网络连通性步骤 2:设置终端代理步骤 3:为 npm 配置代理步骤 4:为 apt 配置代理步骤 5:持久化代理设置注意事项总结 在开发中,网络环境有时会影响工具的下载速度,例如 …...
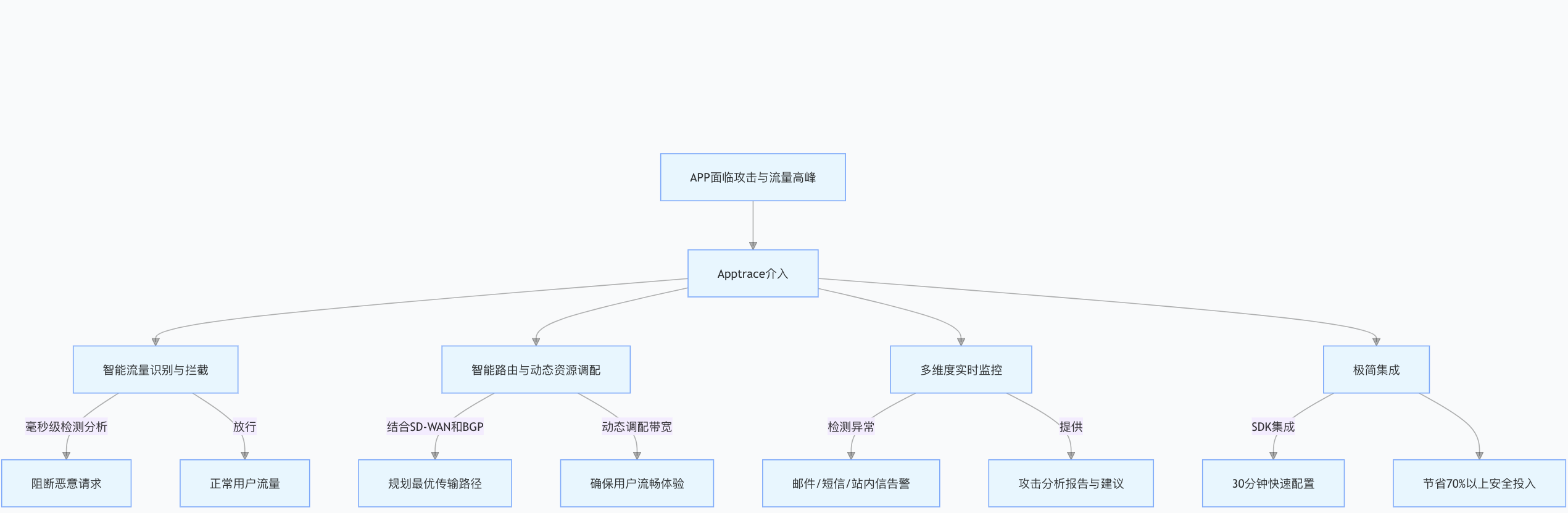
Apptrace:APP安全加速解决方案
2021 年,某知名电商平台在 “618” 大促期间遭遇 DDoS 攻击,支付系统瘫痪近 2 小时;2022 年,一款热门手游在新版本上线时因 CC 攻击导致服务器崩溃。观察发现,电商大促、暑期流量高峰和年末结算期等关键商业周期&#…...

Dockerfile 构建优化的方法
1.选择合适的 Base Image 使用轻量级基础镜像:尽量选择体积较小的基础镜像,例如 alpine 或 distroless。例如: FROM python:3.9-slim FROM alpine:3.14避免使用大型基础镜像:大型镜像会增加构建时间和镜像体积。 2. 减少镜像层数…...
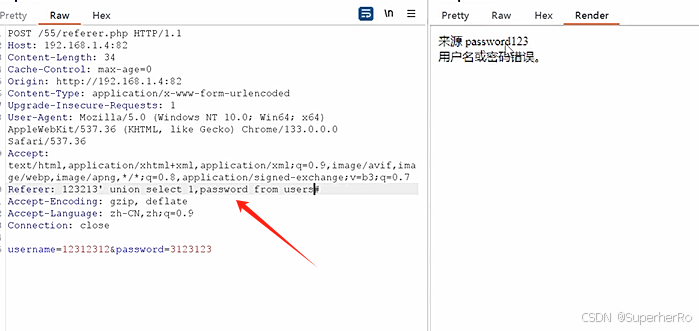
Web攻防-SQL注入增删改查HTTP头UAXFFRefererCookie无回显报错
知识点: 1、Web攻防-SQL注入-操作方法&增删改查 2、Web攻防-SQL注入-HTTP头&UA&Cookie 3、Web攻防-SQL注入-HTTP头&XFF&Referer 案例说明: 在应用中,存在增删改查数据的操作,其中SQL语句结构不一导致注入语句…...

Python中openpyxl库的基础解析与代码实例
目录 1. 前言 2. 安装openpyxl 3. 创建一个新的工作簿 4. 打开一个已有的工作簿 5. 读取和写入单元格 6. 操作工作表 7. 样式设置 8. 插入图像 9. 插入图表 10. 数据验证 11. 条件格式 12. 工作簿保护 13. 保存和关闭工作簿 14. 总结 1. 前言 在数据分析和处理的…...
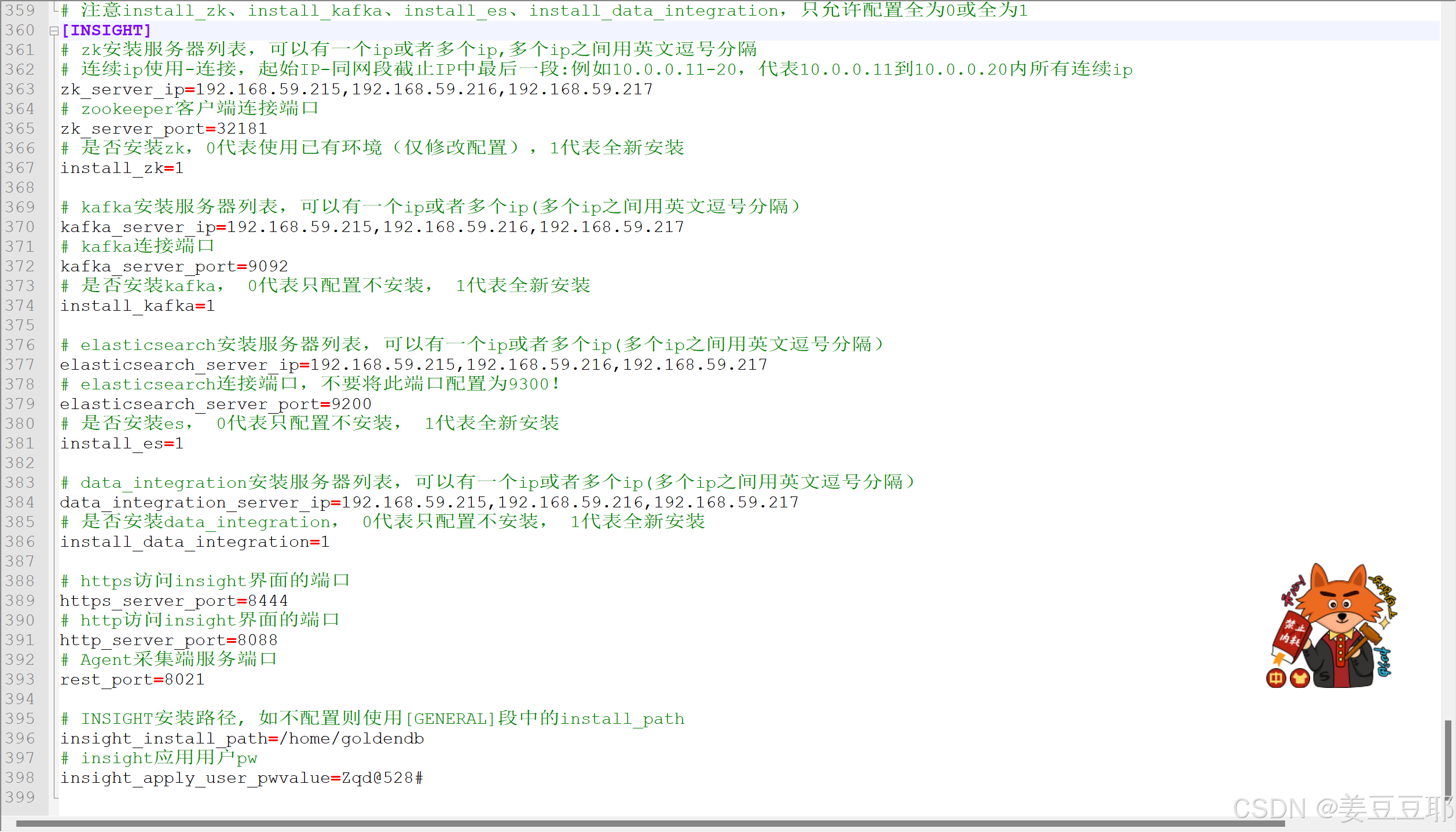
GoldenDB管理节点zk部署
目录 1、准备阶段 1.1、部署规划 1.2、硬件准备 1.3、软件准备 1.4、网络端口开通 1.5、环境清理 2、实施阶段 2.1、操作系统配置 2.1.1、主机名修改 2.1.2、修改hosts文件 2.1.3、禁用防火墙 2.1.4、禁用selinux 2.1.5、禁用透明大页 2.1.6、资源限制调整 2.1.…...