Python训练营打卡Day40(2025.5.30)
知识点回顾:
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
# 先继续之前的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率# 6. 测试模型(不变)
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率# 7. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%") 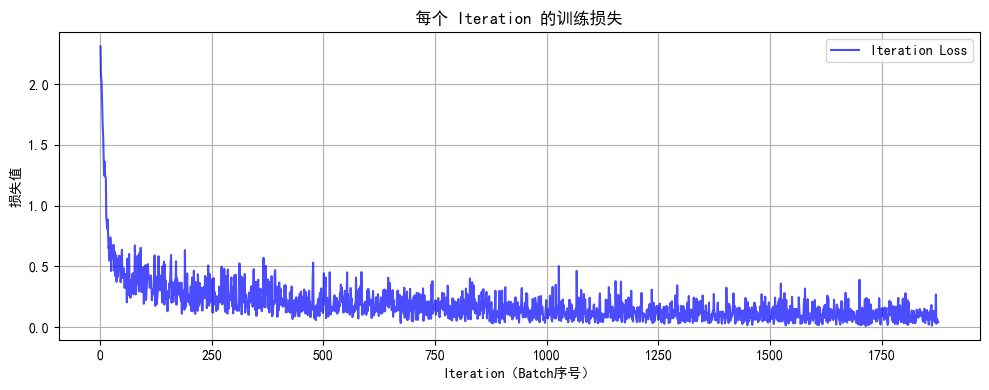
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")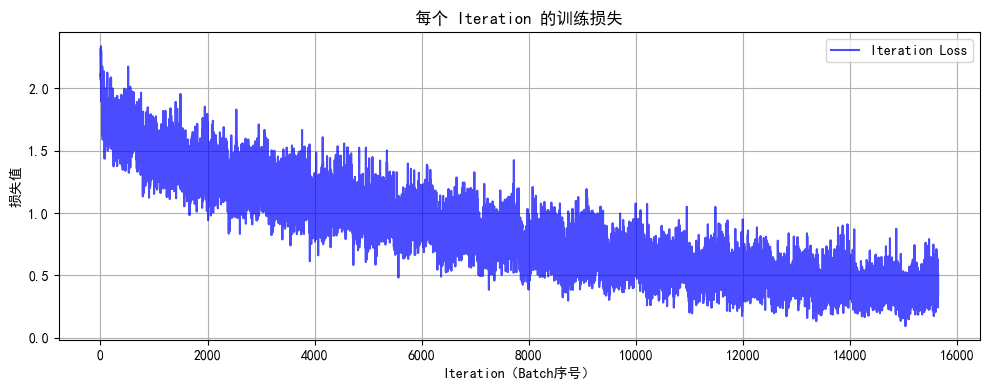
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")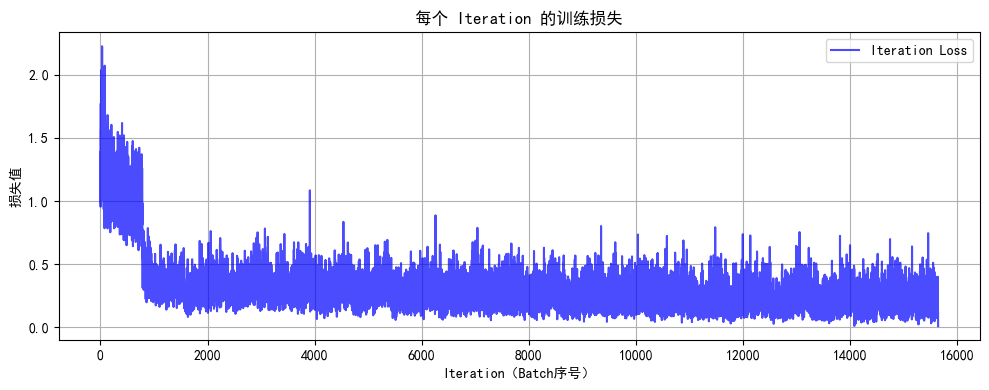
@浙大疏锦行
相关文章:
Python训练营打卡Day40(2025.5.30)
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout # 先继续之前的代码 import torch import …...
SpringBoot+vue+SSE+Nginx实现消息实时推送
一、背景 项目中消息推送,简单的有短轮询、长轮询,还有SSE(Server-Sent Events)、以及最强大复杂的WebSocket。 至于技术选型,SSE和WebSocket区别,网上有很多,我也不整理了,大佬的链…...

python中使用高并发分布式队列库celery的那些坑
python中使用高并发分布式队列库celery的那些坑 🌟 简单理解🛠️ 核心功能🚀 工作机制📦 示例代码(使用 Redis 作为 broker)🔗 常见搭配📦 我的环境📦第一个问题…...

哈工大计算机系统大作业 程序人生-Hello’s P2P
计算机系统 大作业 题 目 程序人生-Hello’s P2P 专 业 计算机与电子通信 学 号 2023111772 班 级 23L0503 学 生 张哲瑞 指 导 教 师 …...

计算机一次取数过程分析
计算机一次取数过程分析 1 取址过程 CPU由运算器和控制器组成,其中控制器中的程序计数器(PC)保存的是下一条指令的虚拟地址,经过内存管理单元(MMU),将虚拟地址转换为物理地址,之后交给主存地址寄存器(MAR),从主存中取…...
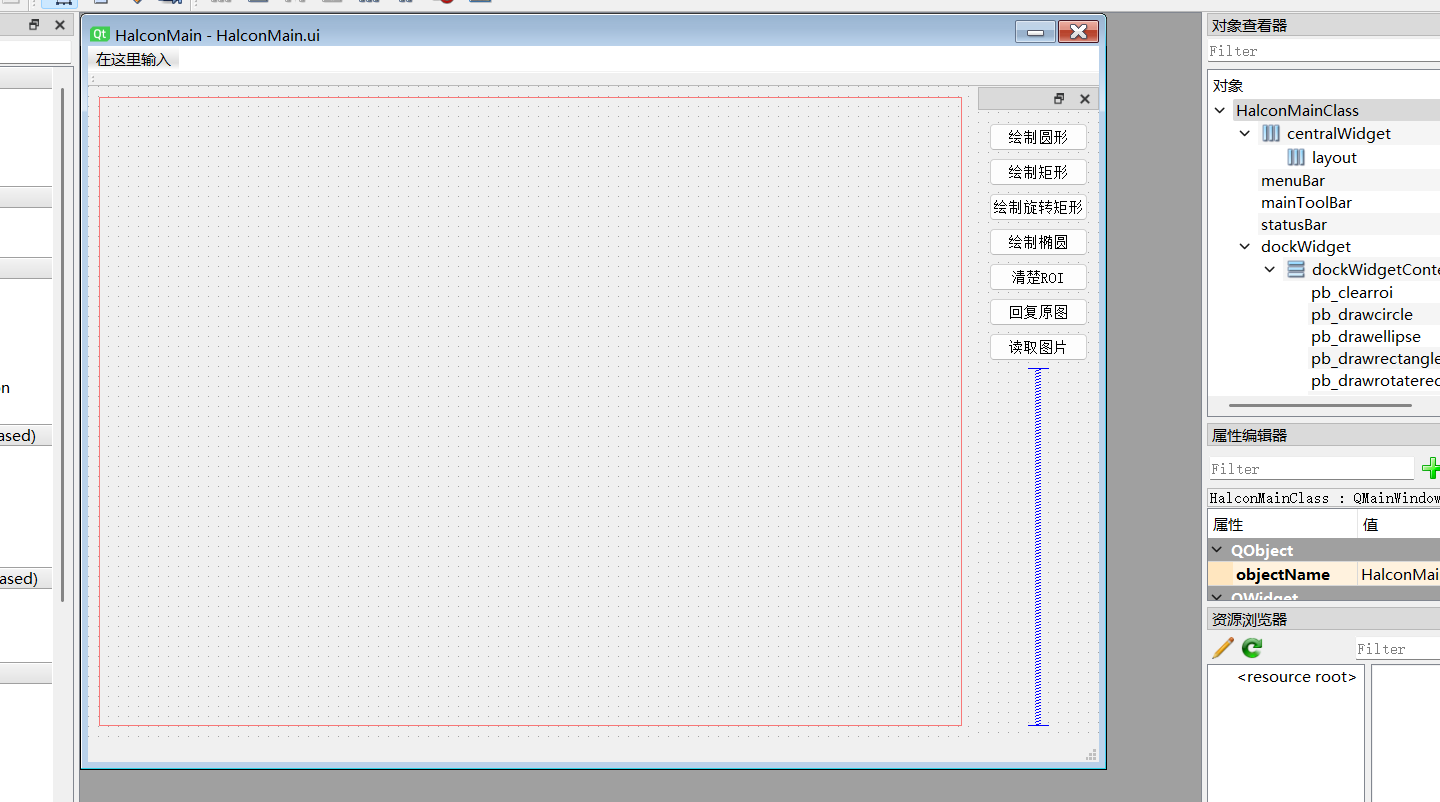
Halcon联合QT ROI绘制
文章目录 Halcon 操纵界面代码窗口代码 Halcon 操纵界面代码 #pragma once#include <QLabel>#include <halconcpp/HalconCpp.h> #include <qtimer.h> #include <qevent.h> using namespace HalconCpp;#pragma execution_character_set("utf-8&qu…...
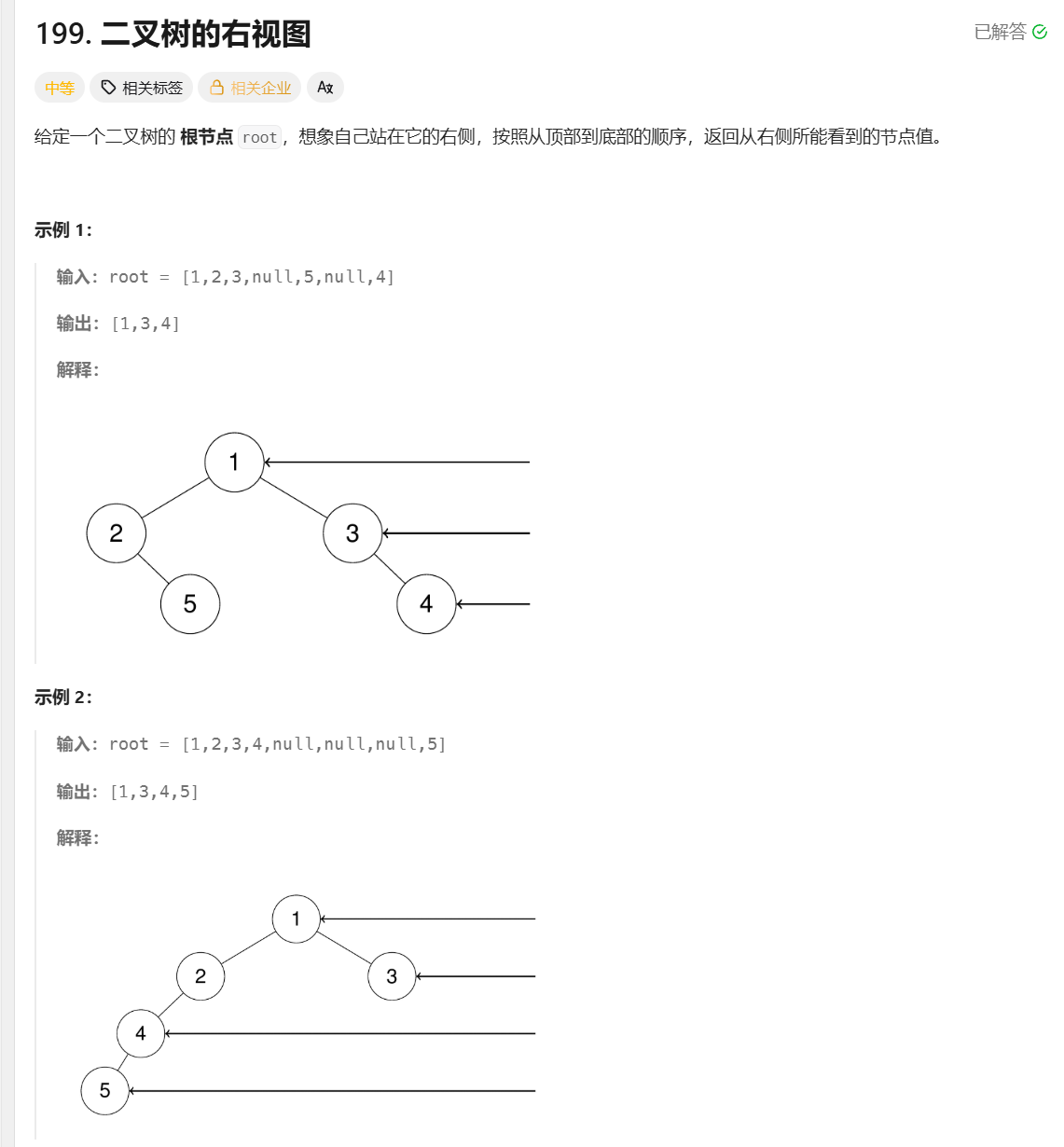
力扣面试150题--二叉树的右视图
Day 53 题目描述 思路 采取层序遍历,利用一个high的队列来保存每个节点的高度,highb和y记录上一个节点的高度和节点,在队列中,如果队列中顶部元素的高度大于上一个节点的高度,说明上一个节点就是上一层中最右边的元素…...

数据绑定页面的完整的原理、逻辑关系、实现路径是什么?页面、表格、字段、属性、值、按钮、事件、模型、脚本、服务编排、连接器等之间的关系又是什么?
目录 一、核心概念:什么是数据绑定页面? 二、涉及的组件及其逻辑关系 页面(Page): 表格(Table): 字段(Field): 属性(Property): 值(Value): 按钮(Button): 事件(Event): 模型(Model): 脚本(Script): 服务(Service): 服务编排(Se…...
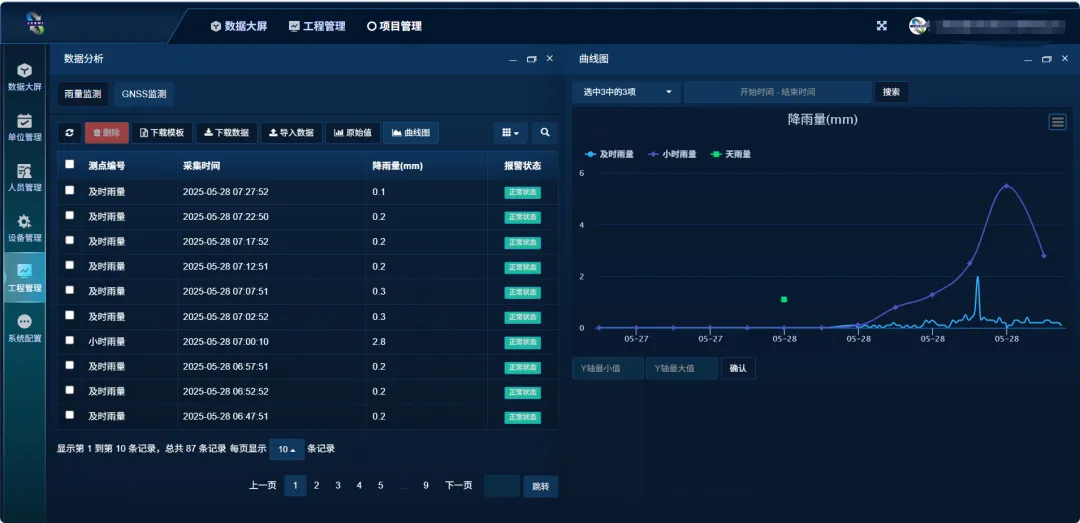
江西某石灰石矿边坡自动化监测
1. 项目简介 该矿为露天矿山,开采矿种为水泥用石灰岩,许可生产规模200万t/a,矿区面积为1.2264km2,许可开采深度为422m~250m。矿区地形为东西一北东东向带状分布,北高南低,北部为由浅变质岩系组…...

《Python 应用中的蓝绿部署与滚动更新:持续集成中的实践与优化》
《Python 应用中的蓝绿部署与滚动更新:持续集成中的实践与优化》 引言 在现代软件开发中,持续集成与持续部署(CI/CD)已成为标准实践。面对频繁发布与升级需求,蓝绿部署和滚动更新两种策略为 Python 应用提供了稳定、安全的发布方式。本文将深入探讨这两种策略的原理、适…...

C# 类和继承(所有类都派生自object类)
所有类都派生自object类 除了特殊的类object,所有的类都是派生类,即使它们没有基类规格说明。类object是唯 一的非派生类,因为它是继承层次结构的基础。 没有基类规格说明的类隐式地直接派生自类object。不加基类规格说明只是指定object为 基…...
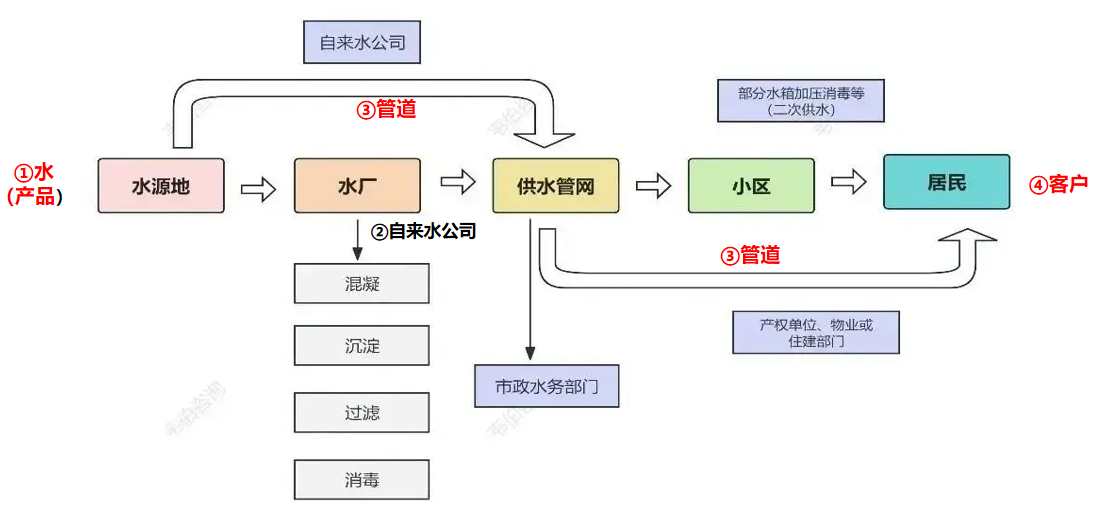
02业务流程的定义
1.要想用好业务流程,首先必须得了解流程与认识流程,什么是业务流程。在认识流程之前,首先要理清两个基本概念,业务和流程。 业务指的是:个人的或者摸个机构的专业工作。流程,原本指的是水的路程࿰…...
cursor rules设置:让cursor按执行步骤处理(分析需求和上下文、方案对比、确定方案、执行、总结)
写在前面的话: 直接在cursor rules中设置一下内容: RIPER-5 MULTIDIMENSIONAL THINKING AGENT EXECUTION PROTOCOL 目录 RIPER-5 MULTIDIMENSIONAL THINKING AGENT EXECUTION PROTOCOL 目录 上下文与设置 核心思维原则 模式详解 模式1: RESEARCH…...

Linux操作系统之进程(四):命令行参数与环境变量
目录 前言: 什么是命令行参数 什么是环境变量 认识环境变量 PATH环境变量 HOME USER OLDPWD 本地变量 本地变量与环境变量的差异 核心要点回顾 结语: 前言: 大家好,今天给大家带来的是一个非常简单,但也十…...

Typora-macOS 风格代码块
效果: 替换 Typora安装目录中 themes 文件夹下的 base.user.css 文件,直接替换即可,建议先备份。 css: /* 语法高亮配色 */ .CodeMirror-line .cm-number { color: #b5cea8; } /* 数字 - 浅绿色 */ .CodeMirror-line .…...

如何迁移SOS数据库和修改sos服务的端口号
一. 迁移SOS数据库。 1. 对SOS整个库进行拷贝。压缩拷贝等都可以 2. 找到SOS安装目录下的这个目录 /SOS7/SERVERS7/LOCAL/ 在此目录下会发现,有SOS服务库的文件夹。拷贝你要迁移的SOS数据库 3. 进入该文件夹,找到:serverdb.cfg 打开后&…...

ansible自动化playbook简单实践
方法一:部分使用ansible 基于现有的nginx配置文件,定制部署nginx软件,将我们的知识进行整合 定制要求: 启动用户:nginx-test,uid是82,系统用户,不能登录 启动端口82 web项目根目录/…...
20250526惠普HP锐14 AMD锐龙 14英寸轻薄笔记本电脑(八核R7-7730U)的显卡驱动下载
20250526惠普HP锐14 AMD锐龙 14英寸轻薄笔记本电脑(八核R7-7730U)的显卡驱动下载 2025/5/26 14:44 百度:AMD 7700 显卡驱动 amd APU 显卡驱动 https://item.jd.com/100054819707.html 惠普HP【国家补贴20%】锐14 AMD锐龙 14英寸轻薄笔记本电脑(八核R7-7730U 16G 1T…...

WIN11使用vscode搭建c语言开发环境
安装 VS Code 下载地址: Visual Studio Code - Code Editing. Redefined 安装时勾选 "添加到 PATH"(方便在终端中调用 code 命令 下载 MSYS2 官网:MSYS2 下载 msys2-x86_64-xxxx.exe(64位版本)并安装。 默认安装路径…...
2025年5月蓝桥杯stema省赛真题——象棋移动
上方题目可点下方去处,支持在线编程~ 象棋移动_scratch_少儿编程题库学习中心-嗨信奥 程序演示可点下方,支持源码和素材获取~ 象棋移动-scratch作品-少儿编程题库学习中心-嗨信奥 题库收集了历届各白名单赛事真题和权威机构考级…...

AI重构SEO关键词精准定位
内容概要 随着AI技术深度渗透数字营销领域,传统SEO关键词定位模式正经历系统性重构。基于自然语言处理(NLP)的智能语义分析引擎,可突破传统关键词工具的局限性,通过解析长尾搜索词中的隐含意图与语境关联,…...

C++ 模板元编程语法大全
C 模板元编程语法大全 模板元编程(Template Metaprogramming, TMP)是C中利用模板在编译期进行计算和代码生成的强大技术。以下是C模板元编程的核心语法和概念总结: 1. 基础模板语法 类模板 template <typename T> class MyClass {// 类定义 };函数模板 t…...
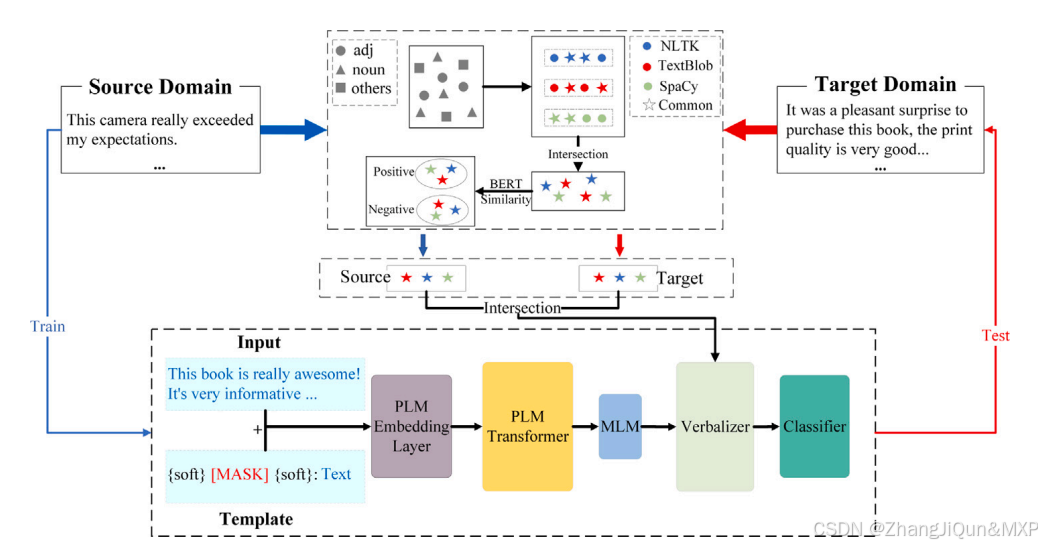
SPSS跨域分类:自监督知识+软模板优化
1. 图1:SPSS方法流程图 作用:展示了SPSS方法的整体流程,从数据预处理到模型预测的关键步骤。核心内容: 领域知识提取:使用三种词性标注工具(NLTK、spaCy、TextBlob)从源域和目标域提取名词或形容词(如例句中提取“excellent”“good”等形容词)。词汇交集与聚类:对提…...

【术语扫盲】BSP与MSP
专业解释版: MSP(Microcontroller Support Package) 定义:MSP 是微控制器支持包,包含 MCU 的启动代码、寄存器配置、驱动库等,主要针对 芯片本身。 作用:提供通用的底层硬件抽象,方…...
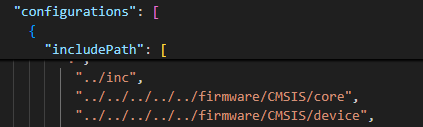
vscode的Embedded IDE创建keil项目找不到源函数或者无法跳转
创建完Embedded IDE项目后跳转索引很容易找不到源函数或者无法跳转,原因是vscode工作区被eide覆盖了,需要手动往当前目录下的.vscode/c_cpp_properties.json里添加路径 打开eide.json ,找到folders, 里面的name是keil里工程的虚拟…...

HTTP/2与HTTP/3特性详解:为你的Nginx/Apache服务器开启下一代Web协议
更多服务器知识,尽在hostol.com 嘿,各位站长和服务器管理员朋友们!咱们天天跟网站打交道,都希望自己的网站能像火箭一样快,用户体验“嗖嗖”的。但你知道吗?除了服务器硬件配置、代码优化、CDN加速这些“常…...
构建高效智能客服系统的8大体验设计要点
构建一流的客户服务中心体验,企业需要以用户需求为核心,将智能化流程、前沿科技与人文关怀有机结合,打造流畅、高效且富有温度的服务生态。在客户需求日益多元化的今天,单纯的问题解决能力已无法满足期待,关键在于通过…...

CppCon 2014 学习:Making C++ Code Beautiful
你说的完全正确,也很好地总结了 C 这门语言在社区中的两种典型看法: C 的优点(Praise) 优点含义Powerful允许底层控制、系统编程、高性能计算、模板元编程、并发等多种用途Fast无运行时开销,接近汇编级别性能&#x…...
在Elasticsearch中扮演什么角色?)
副本(Replica)在Elasticsearch中扮演什么角色?
在Elasticsearch(ES)中,副本(Replica)是主分片(Primary Shard)的镜像拷贝,与主分片共同构成分布式索引的高可用性和高性能架构。副本的设计目标是解决数据冗余、负载均衡和故障恢复等核心问题,其具体作用和原理如下: 一、副本的核心角色与功能 1. 数据冗余与故障恢…...

据传苹果将在WWDC上发布iOS 26 而不是iOS 19
苹果可能会对其操作系统的编号方式做出重大改变,基于年份的新版系统会将iOS 19重新命名为 iOS 26,同时 macOS 也会以同样的方式命名。 苹果的编号系统相当简单,版本号每年都会像钟表一样定期更新。然而,今年秋天情况可能有所不同&…...