代码随想录算法训练营 Day61 图论ⅩⅠ Floyd A※ 最短路径算法
图论
题目
97. 小明逛公园
本题是经典的多源最短路问题。
在这之前我们讲解过,dijkstra朴素版、dijkstra堆优化、Bellman算法、Bellman队列优化(SPFA) 都是单源最短路,即只能有一个起点。
而本题是多源最短路,即求多个起点到多个终点的多条最短路径。
Floyd 算法对边的权值正负没有要求,都可以处理。
Floyd算法核心思想是动态规划。
例如我们再求节点1 到节点9 的最短距离,用二维数组来表示即:grid[1][9],如果最短距离是10 ,那就是 grid[1][9] = 10。
那节点1 到节点9 的最短距离是不是可以由节点1 到节点5的最短距离 + 节点5到节点9的最短距离组成呢?即 grid[1][9] = grid[1][5] + grid[5][9]
节点1 到节点5的最短距离是不是可以有节点1 到节点3的最短距离 + 节点3 到节点5 的最短距离组成呢? 即 grid[1][5] = grid[1][3] + grid[3][5]
以此类推,节点1 到节点3的最短距离可以由更小的区间组成。
那么这样我们是不是就找到了,子问题推导求出整体最优方案的递归关系呢。
是不是 要选一个最小的,毕竟是求最短路。此时我们已经接近明确递归公式了。之前在讲解动态规划的时候,给出过动规五部曲:
- 确定dp数组(dp table)以及下标的含义
- 确定递推公式
- dp数组如何初始化
- 确定遍历顺序
- 举例推导dp数组
具体讲解
1. Dp 数组表示当前节点 i 到节点 j 以 [1,...,k] 集合节点为中间节点的最短距离grid[i][j][k] = m
节点i 到 节点j 的最短距离为m,这句话可以理解,但 以[1...k]集合为中间节点就理解不了。
节点i 到节点j 的最短路径中一定是经过很多节点,那么这个集合用[1...k] 来表示。
你可以反过来想,节点i 到节点j 中间一定经过很多节点,那么你能用什么方式来表述中间这么多节点呢?所以这里的k不能单独指某个节点,k 一定要表示一个集合,即 [1...k] ,表示节点1 到节点k 一共k个节点的集合。
2. 确定递推公式,我们分两种情况:
1. 节点i 到节点j 的最短路径经过节点k
2. 节点i 到节点j 的最短路径不经过节点k
对于第一种情况,grid[i][j][k] = grid[i][k][k - 1] + grid[k][j][k - 1]
节点i 到节点k 的最短距离是不经过节点k,中间节点集合 [1...k-1],表示为 grid[i][k][k - 1]
节点k 到 节点j 的最短距离也是不经过节点k,中间节点集合[1...k-1],表示为 grid[k][j][k - 1]
第二种情况,grid[i][j][k] = grid[i][j][k - 1]
如果节点i 到 节点j的最短距离 不经过节点k,中间节点集合[1...k-1],表示为 grid[i][j][k - 1]
因为我们是求最短路,对于这两种情况自然是取最小值。
即: grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])
3. Dp 数组初始化
grid[i][j][k] = m,表示 节点i 到 节点j 以[1...k] 集合为中间节点的最短距离为m。
刚开始初始化k 是不确定的。例如题目中只是输入边(节点2 -> 节点6,权值为3),那么grid[2][6][k] = 3,k需要填什么呢?把k 填成1,那如何上来就知道 节点2 经过节点1 到达节点6的最短距离是多少 呢。所以 只能 把k 赋值为 0,本题 节点0 是无意义的,节点是从1 到 n。
这样我们在下一轮计算的时候,就可以根据 grid[i][j][0] 来计算 grid[i][j][1],此时的 grid[i][j][1] 就是节点i 经过节点1 到达节点j 的最小距离了。
grid数组是一个三维数组,那么我们初始化的数据在 i 与 j 构成的平层,如图: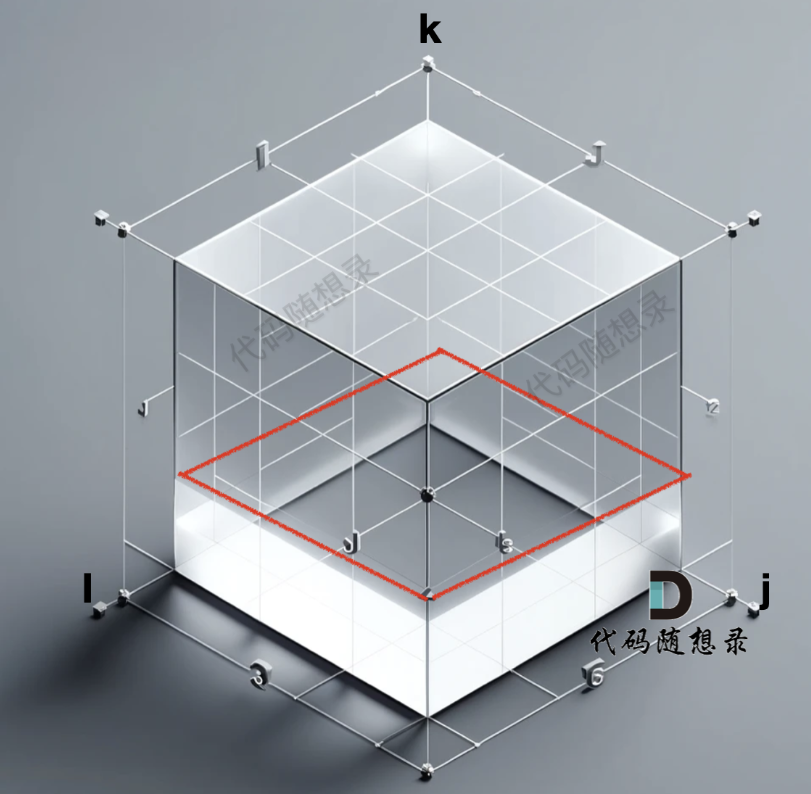
有初始化代码
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005))); // C++定义了一个三位数组,10005是因为边的最大距离是10^4for(int i = 0; i < m; i++){cin >> p1 >> p2 >> val;grid[p1][p2][0] = val;grid[p2][p1][0] = val; // 注意这里是双向图
}
grid数组中其他元素数值应该初始化多少呢?
本题求的是最小值,所以输入数据没有涉及到的节点的情况都应该初始为一个最大数。
这样才不会影响,每次计算去最小值的时候 初始值对计算结果的影响。
所以grid数组的定义可以是:
// C++写法,定义了一个三位数组,10005是因为边的最大距离是10^4
vector<vector<vector<int>>> grid(n + 1, vector<vector<int>>(n + 1, vector<int>(n + 1, 10005)));
- 遍历顺序
从递推公式:grid[i][j][k] = min(grid[i][k][k - 1] + grid[k][j][k - 1], grid[i][j][k - 1])可以看出,我们需要三个for循环,分别遍历i,j 和k
而 k 依赖于 k - 1, i 和j 的到 并不依赖与 i - 1 或者 j - 1 等等。
那么这三个for的嵌套顺序应该是什么样的呢?我们来看初始化,我们是把 k =0 的 i 和j 对应的数值都初始化了,这样才能去计算 k = 1 的时候 i 和 j 对应的数值。这就好比是一个三维坐标,i 和j 是平层,而k 是垂直向上的。遍历的顺序是从底向上一层一层去遍历。所以遍历k 的for循环一定是在最外面,这样才能一层一层去遍历。如图: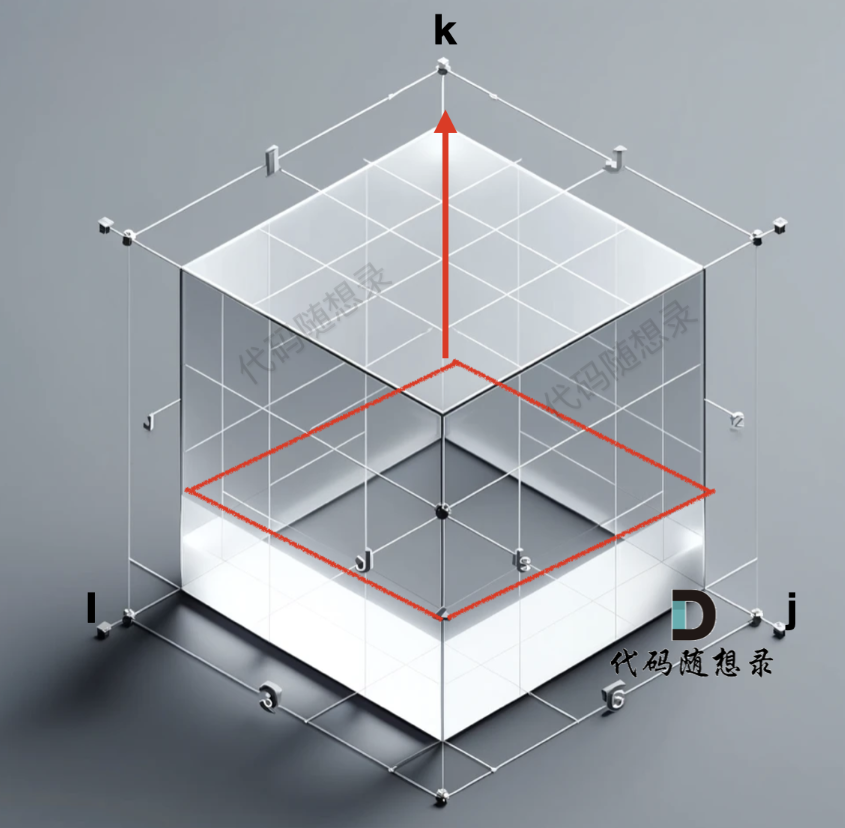
其他情况:[代码随想录](https://www.programmercarl.com/ka其他情况:
5. 打印 dp 数组
#include <iostream>
#include <vector>
#include <list>using namespace std;int main() {int n, m, x, y, val;cin >> n >> m;// 构建dp数组 最大边距离为nvector<vector<vector<int>>> grid(n+1, vector<vector<int>>(n+1, vector<int>(n+1, 10001)));// 初始化dp数组for (int i = 0; i < m; ++i) {cin >> x >> y >> val;grid[x][y][0] = val;grid[y][x][0] = val;}// foryd开始for (int k = 1; k <= n; ++k) {for (int i = 1; i <= n; ++i) {for (int j = 1; j <= n; j++) {// 递推公式grid[i][j][k] = min(grid[i][j][k-1], grid[i][k][k-1] + grid[k][j][k-1]);}}}// 输出结果int q, start, end;cin >> q;while (q--) {cin >> start >> end;if (grid[start][end][n] == 10001) cout << -1 << endl;else cout << grid[start][end][n] << endl;}
}// 空间优化版本
#include <iostream>
#include <vector>using namespace std;int main() {int n, m, x, y, val;cin >> n >> m;// 使用二维数组更新 dp数组定义表明x到y直接距离最近的路径点vector<vector<int>> grid(n+1, vector<int>(n+1, 10001));// 初始化dp数组for (int i = 0; i < m; ++i) {cin >> x >> y >> val;grid[x][y] = val;grid[y][x] = val;}// forydfor (int k = 1; k <= n; ++k) {for (int i = 1; i <= n; ++i) {for (int j = 1; j<= n; ++j) {// 递推公式grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);}}}int q, start, end;cin >> q;while (q--) {cin >> start >> end;if (grid[start][end] == 10001) cout << -1 << endl;else cout << grid[start][end] << endl;}
}#include <iostream>
#include <vector>using namespace std;int main() {int n, m, x, y, val;cin >> n >> m;// 使用二维数组更新 dp数组定义表明x到y直接距离最近的路径点vector<vector<int>> grid(n+1, vector<int>(n+1, 10001));// 初始化dp数组for (int i = 0; i < m; ++i) {cin >> x >> y >> val;grid[x][y] = val;grid[y][x] = val;}// forydfor (int k = 1; k <= n; ++k) {for (int i = 1; i <= n; ++i) {for (int j = 1; j<= n; ++j) {// 递推公式grid[i][j] = min(grid[i][j], grid[i][k] + grid[k][j]);}}}int q, start, end;cin >> q;while (q--) {cin >> start >> end;if (grid[start][end] == 10001) cout << -1 << endl;else cout << grid[start][end] << endl;}
}
感悟
将每个点作为中间点去更新
127. 骑士的攻击
本题可以使用广度优先搜索,每次有 8 种行动路径,带入广度优先搜索,但是广搜会超时
Astar 是一种 广搜的改良版。 有的是 Astar是 dijkstra 的改良版。
其实只是场景不同而已 我们在搜索最短路的时候, 如果是无权图(边的权值都是1) 那就用广搜,代码简洁,时间效率和 dijkstra 差不多 (具体要取决于图的稠密)
如果是有权图(边有不同的权值),优先考虑 dijkstra。
而 Astar 关键在于启发式函数,也就是影响广搜或者 dijkstra 从容器(队列)里取元素的优先顺序。
以下,我用BFS版本的A * 来进行讲解。
BFS中,我们想搜索,从起点到终点的最短路径,要一层一层去遍历 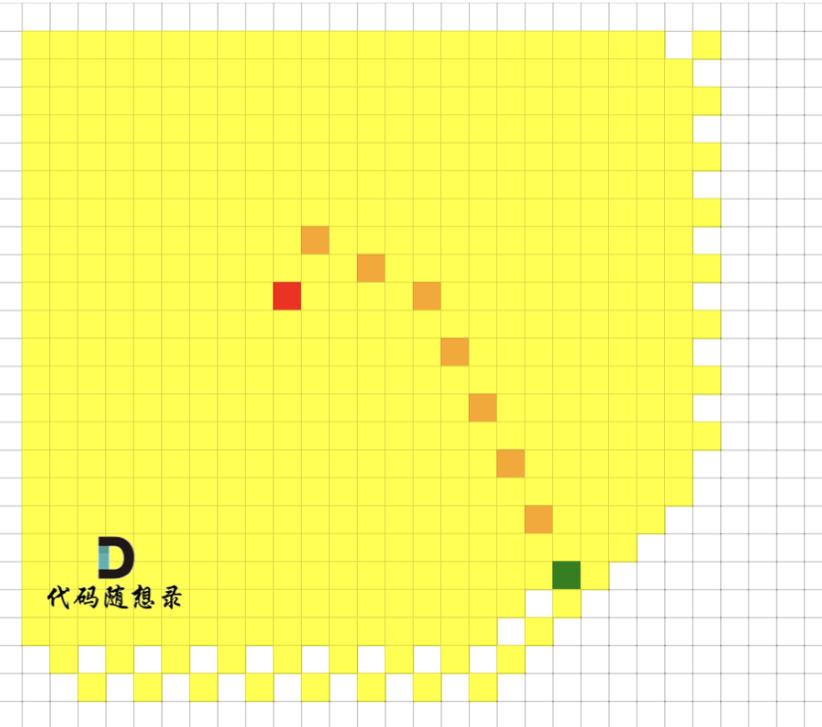
而使用 Astar 算法其搜索过程是这样的,如图,图中着色的都是我们要遍历的点
大家可以发现 **BFS 是没有目的性的 一圈一圈去搜索, 而 A * 是有方向性的去搜索**。
看出 A * 可以节省很多没有必要的遍历步骤。 那么 A * 为什么可以有方向性的去搜索,它的如何知道方向呢?**其关键在于 启发式函数**。
那么启发式函数落实到代码处,如果指引搜索的方向?
int m=q.front();q.pop();
int n=q.front();q.pop();
从队列里取出什么元素,接下来就是从哪里开始搜索。所以 启发式函数 要影响的就是队列里元素的排序!
如何影响元素的选择?
对队列里节点进行排序,就需要给每一个节点权值,如何计算权值呢?
每个节点的权值为F,给出公式为:F = G + H
G:起点达到目前遍历节点的距离
H:目前遍历的节点到达终点的距离
起点达到目前遍历节点的距离 + 目前遍历的节点到达终点的距离 = 起点到达终点的距离。
本题的图是无权网格状,在计算两点距离通常有如下三种计算方式:
1. 曼哈顿距离,计算方式:d = abs(x1-x2)+abs(y1-y2)
2. 欧氏距离(欧拉距离) ,计算方式:d = sqrt( (x1-x2)^2 + (y1-y2)^2 )
3. 切比雪夫距离,计算方式:d = max(abs(x1 - x2), abs(y1 - y2))
x1, x2 为起点坐标,y1, y2 为终点坐标,abs 为求绝对值,sqrt 为求开根号,
选择哪一种距离计算方式也会导致 A * 算法的结果不同。
可以使用 优先级队列 帮我们排好序,每次出队列,就是F最小的节点。
实现代码如下:(启发式函数采用欧拉距离计算方式)
#include <iostream>
#include <vector>
#include <queue>
#include <cstring>using namespace std;// 棋盘网格大小
int moves[1001][1001];
// 可以走的方向
int dir[8][2] = {-1,2,-2,1,-2,-1,-1,-2,1,-2,2,-1,2,1,1,2};
int b1, b2;// F = G + H
// G = 从起点到该节点路径消耗
// H = 该节点到终点的预估消耗struct Knight {int x,y;int g,h,f;bool operator< (const Knight& k) const {return k.f < f;}
};priority_queue<Knight> que;// 欧拉距离公式
int Eular(const Knight& k) {return (k.x - b1) * (k.x - b1) + (k.y - b2) * (k.y - b2);
}void Astar(const Knight& k) {Knight cur, next;que.push(k);while (!que.empty()) {cur = que.top();que.pop();if (cur.x == b1 && cur.y == b2) break;for (int i = 0; i < 8; ++i) {next.x = cur.x + dir[i][0];next.y = cur.y + dir[i][1];if (next.x < 1 || next.x > 1000 || next.y < 1 || next.y > 1000) continue;if (!moves[next.x][next.y]) {moves[next.x][next.y] = moves[cur.x][cur.y] + 1;// 计算F next.g = cur.g + 5; // 5 走日 1*1 + 2*2next.h = Eular(next);next.f = next.g + next.h;que.push(next);}}}
}int main() {int n, a1, a2;cin >> n;while (n--) {cin >> a1 >> a2 >> b1 >> b2;memset(moves, 0, sizeof(moves));Knight start;start.x = a1;start.y = a2;start.g = 0;start.h = Eular(start);start.f = start.g + start.h;Astar(start);while (!que.empty()) que.pop();cout << moves[b1][b2] << endl;}return 0;
}
Astar 缺点
大家看上述 A * 代码的时候,可以看到我们想队列里添加了很多节点,但真正从队列里取出来的仅仅是靠启发式函数判断距离终点最近的节点。
相对了普通BFS,A * 算法只从队列里取出距离终点最近的节点。那么问题来了,A * 在一次路径搜索中,大量不需要访问的节点都在队列里,会造成空间的过度消耗。
IDA * 算法对这一空间增长问题进行了优化,关于 IDA * 算法,本篇不再做讲解,感兴趣的录友可以自行找资料学习。
另外还有一种场景是 A * 解决不了的。
如果题目中,给出多个可能的目标,然后在这多个目标中选择最近的目标,这种 A * 就不擅长了, A * 只擅长给出明确的目标然后找到最短路径。
如果是多个目标找最近目标(特别是潜在目标数量很多的时候),可以考虑 Dijkstra ,BFS 或者 Floyd。
图论总结
深度优先搜索广度优先搜索
在二叉树章节中,其实我们讲过了 深搜和广搜在二叉树上的搜索过程。
在图论章节中,深搜与广搜就是在图这个数据结构上的搜索过程。
深搜与广搜是图论里基本的搜索方法,大家需要掌握三点:
- 搜索方式:深搜是可一个方向搜,不到黄河不回头。 广搜是围绕这起点一圈一圈的去搜。
- 代码模板:需要熟练掌握深搜和广搜的基本写法。
- 应用场景:图论题目基本上可以即用深搜也可用广搜,无疑是用哪个方便而已
并查集
并查集相对来说是比较复杂的数据结构,其实他的代码不长,但想彻底学透并查集,需要从多个维度入手,我在理论基础篇的时候 讲解如下重点:
- 为什么要用并查集,怎么不用个二维数据,或者set、map之类的。
- 并查集能解决那些问题,哪些场景会用到并查集
- 并查集原理以及代码实现
- 并查集写法的常见误区
- 带大家去模拟一遍并查集的过程
- 路径压缩的过程
- 时间复杂度分析
上面这几个维度 大家都去思考了,并查集基本就学明白了。
其实理论基础篇就算是给大家出了一道裸的并查集题目了,所以在后面的题目安排中,会稍稍的拔高一些,重点在于并查集的应用上。
例如 并查集可以判断这个图是否是树,因为树的话,只有一个根,符合并查集判断集合的逻辑,题目:0108.冗余连接。
在 0109.冗余连接II 中对有向树的判断难度更大一些,需要考虑的情况比较多。
最小生成树
最小生成树是所有节点的最小连通子图, 即:以最小的成本(边的权值)将图中所有节点链接到一起。
最小生成树算法,有prim 和 kruskal。
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
在 稀疏图中,用Kruskal更优。 在稠密图中,用prim算法更优。
边数量较少为稀疏图,接近或等于完全图(所有节点皆相连)为稠密图
Prim 算法 时间复杂度为 O(n^2),其中 n 为节点数量,它的运行效率和图中边树无关,适用稠密图。
Kruskal算法 时间复杂度 为 O(nlogn),其中n 为边的数量,适用稀疏图。
关于 prim算法,我自创了三部曲,来帮助大家理解
- 第一步,选距离生成树最近节点
- 第二步,最近节点加入生成树
- 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
大家只要理解这三部曲, prim算法 至少是可以写出一个框架出来,然后在慢慢补充细节,这样不至于 自己在写prim的时候 两眼一抹黑 完全凭感觉去写。
minDist数组 是prim算法的灵魂,它帮助 prim算法完成最重要的一步,就是如何找到 距离最小生成树最近的点。
kruscal的主要思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
而判断节点是否在一个集合 以及将两个节点放入同一个集合,正是并查集的擅长所在。
所以 Kruskal 是需要用到并查集的。
拓扑排序
拓扑排序 是在图上的一种排序。
概括来说,给出一个 有向图,把这个有向图转成线性的排序 就叫拓扑排序。
同样,拓扑排序也可以检测这个有向图 是否有环,即存在循环依赖的情况。
拓扑排序的一些应用场景,例如:大学排课,文件下载依赖 等等。
只要记住如下两步拓扑排序的过程,代码就容易写了:
- 找到入度为0 的节点,加入结果集
- 将该节点从图中移除
最短路径总结
至此已经讲解了四大最短路算法,分别是 Dijkstra、Bellman_ford、SPFA 和 Floyd。
针对这四大最短路算法,我用了七篇长文才彻底讲清楚,分别是:
- Dijkstra 朴素版
- Dijkstra 堆优化版
- Bellman_ford
- Bellman_ford 队列优化算法(又名 SPFA)
- Bellman_ford 算法判断负权回路
- Bellman_ford 之单源有限最短路
- Floyd 算法精讲
- 启发式搜索:A * 算法
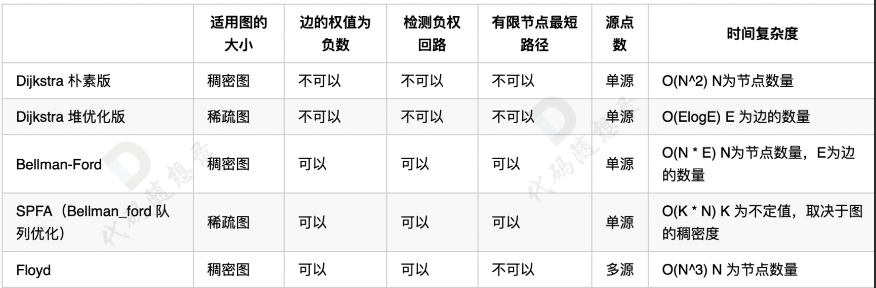
这里我给大家一个大体使用场景的分析:
如果遇到单源且边为正数,直接 Dijkstra。
至于 使用朴素版还是堆优化版还是取决于图的稠密度,多少节点多少边算是稠密图,多少算是稀疏图,这个没有量化,如果想量化只能写出两个版本然后做实验去测试,不同的判题机得出的结果还不太一样。
一般情况下,可以直接用堆优化版本。
如果遇到单源边可为负数,直接 Bellman-Ford,同样 SPFA 还是 Bellman-Ford 取决于图的稠密度。
一般情况下,直接用 SPFA。
如果有负权回路,优先 Bellman-Ford,如果是有限节点最短路也优先 Bellman-Ford,理由是写代码比较方便。如果是遇到多源点求最短路,直接 Floyd。
除非源点特别少,且边都是正数,那可以多次 Dijkstra 求出最短路径,但这种情况很少,一般出现多个源点了,就是想让你用 Floyd 了。
对于 A * ,由于其高效性,所以在实际工程应用中使用最为广泛,由于其结果的不唯一性,也就是可能是次短路的特性,一般不适合作为算法题。
游戏开发、地图导航、数据包路由等都广泛使用 A * 算法。
相关文章:
代码随想录算法训练营 Day61 图论ⅩⅠ Floyd A※ 最短路径算法
图论 题目 97. 小明逛公园 本题是经典的多源最短路问题。 在这之前我们讲解过,dijkstra朴素版、dijkstra堆优化、Bellman算法、Bellman队列优化(SPFA) 都是单源最短路,即只能有一个起点。 而本题是多源最短路,即求多…...

【Python】yield from 功能解析
yield from 功能解析 1.基本功能1.1 传统写法(手动迭代)1.2 使用 yield from 2.与普通 yield 的区别3.yield from 的底层行为4.关键应用场景场景 1:拼接多个生成器(如 gen_concatenate)场景 2:捕获子生成器…...
)
私有云大数据部署:从开发到生产(Docker、K8s、HDFS/Flink on K8s)
✅ 背景 在数据工程进入深水区后,很多企业选择将大数据平台迁移到私有云或混合云部署:一方面降低成本,另一方面增强数据安全掌控。本文将详细介绍如何在私有云中部署高可用的大数据平台,涵盖: 大数据组件的容器化 Flink on Kubernetes 部署方案 HDFS 本地/远程存储支持 运…...
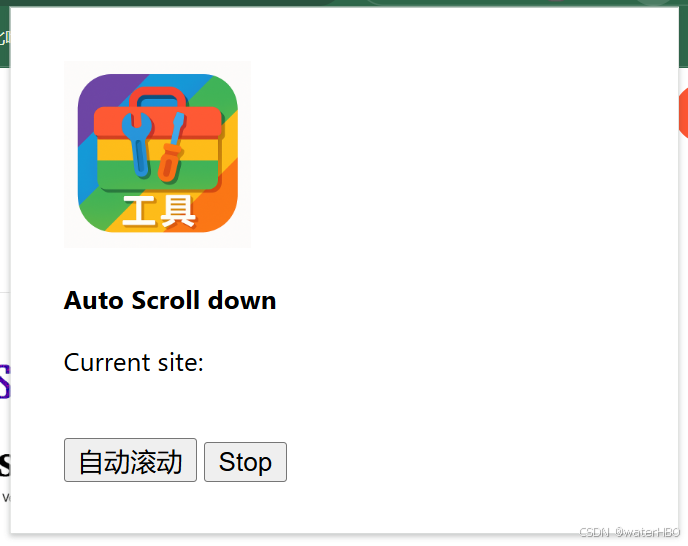
改写自己的浏览器插件工具 myChromeTools
1. 起因, 目的: 前面我写过, 自己的一个浏览器插件小工具 最近又增加一个小功能,可以自动滚动页面,尤其是对于那些瀑布流加载的网页。最新的代码都在这里 2. 先看效果 3. 过程: 代码 1, 模拟鼠标自然滚动 // 处理滚动控制逻辑…...
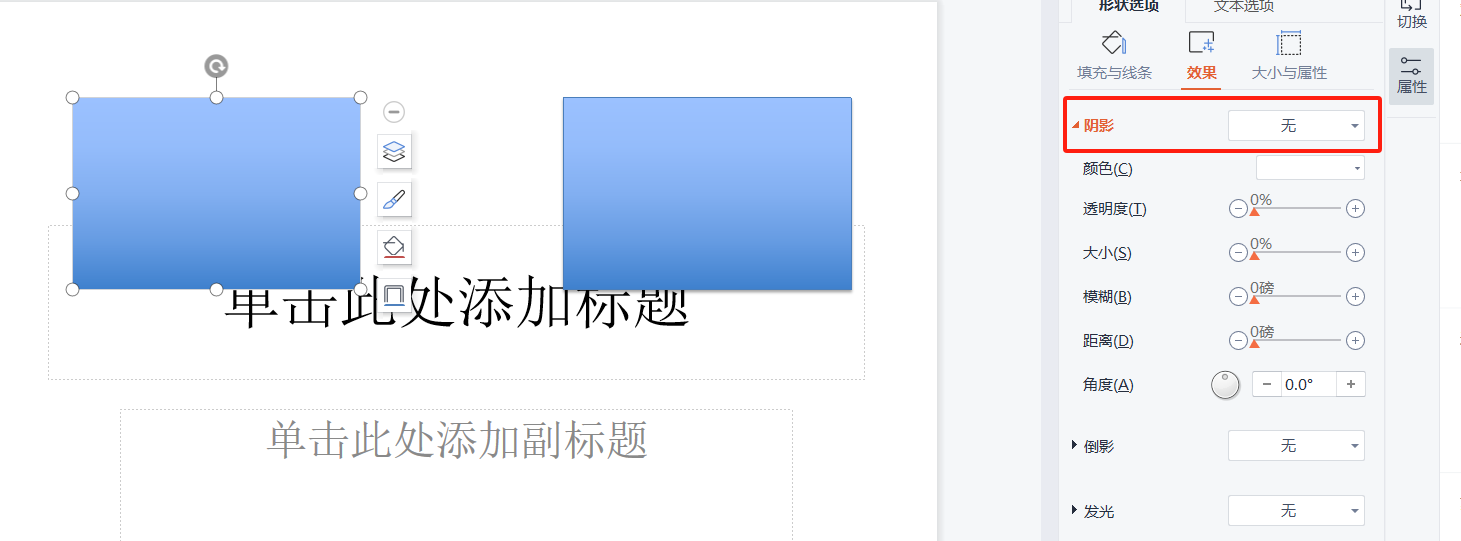
python-pptx去除形状默认的阴影
文章目录 效果原理1. 阴影继承机制解析2. XML层操作细节3. 注意事项 扩展应用1. 批量去除阴影2. 复合效果控制 效果 右边这个是直接添加一个形状。可以看到它会默认被赋予一个阴影。 然而,这个东西在特定的场合,其实是我们所不需要的。 那怎么把这个阴…...

kuboard自带ETCD存储满了处理方案
一、前言 当运行 ETCD 日志报 Erro: mvcc database space exceeded 时,说明 ETCD 存储不足了(默认 ETCD 存储是 2G),配额会触发告警,然后 Etcd 系统将进入操作受限的维护模式。 通过下面命令可以查看 ETCD 存储使用情…...

SpringBoot+tabula+pdfbox解析pdf中的段落和表格数据
一、前言 在日常业务需求中,往往会遇到解析pdf文件中的段落或者表格数据的需求。 常见的做法是使用 pdfbox 来做,但是它只能提取文本数据,没有我们在文件页面上面的那种结构化组织,文本通常是散乱的包含各种换行回车空格等格式&a…...

外包项目交付后还能怎么加固?我用 Ipa Guard 给 iOS IPA 增加了一层保障
在我们技术团队的日常工作中,接手外包开发者提交的 iOS 项目是一件常见的事。但你有没有遇到过这种情况:只交付了 IPA 文件,没有源码,也不方便追溯开发过程,但客户要求“上线前必须加一层安全防护”。 这是我们最近真…...
GitHub push失败解决办法-fatal: unable to access ‘https://github.com/xxx
问题描述: 问题解决: 1、首先查找自己电脑的代理地址和端口 windows教程如下: 1、搜索控制面板-打开Internet选项 2、点击局域网设置: 3、如图为地址和端口号 即可获得本机地址和端口号 2、根据上一步获得的本机地址和端口号为…...

USB MSC SCCI
🔍 数据包完整内容 0000 1b 00 10 09 22 8b 8b 9b ff ff 00 00 00 00 09 00 0010 00 02 00 02 00 02 03 1f 00 00 00 55 53 42 43 10 0020 09 22 8b 00 02 00 00 80 00 0a 28 00 00 00 00 00 0030 00 00 01 00 00 00 00 00 00 00 ⚙️ 一、…...

解决Acrobat印前检查功能提示无法为用户配置文件问题
转载:https://zhuanlan.zhihu.com/p/18845570057 Acrobat整理页面时往往需要用到印前检查功能中的将页面缩放为A4,可以一键统一PDF文件所有页面大小,十分快捷。 不过,最新版本的Acrobat在安装时尽管勾选了可选功能-印前检查往往…...
)
华为OD最新机试真题-反转每对括号间的子串-OD统一考试(B卷)
题目描述: 给出一个字符串s(仅含有小写英文字母和括号)。 请你按照从括号内到外的顺序,逐层反转每对匹配括号中的字符串,并返回最终的结果。注意,您的结果中不应包含任何括号。 示例1: 输入: s = “(abcd)” 输出: “dcba” 示例2:...
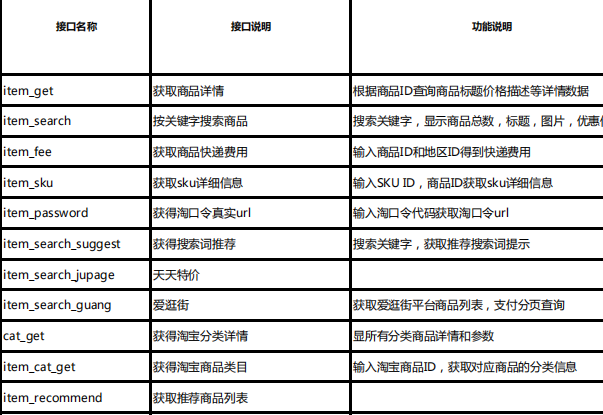
电商平台 API、数据抓取与爬虫技术的区别及优势分析
一、技术定义与核心原理 电商平台 API(应用程序编程接口) 作为平台官方提供的标准化数据交互通道,API 通过 HTTP 协议实现不同系统间的结构化数据传输。开发者需申请授权(如 API 密钥),按照文档规范调用接口…...
)
领域驱动设计 (Domain-Driven Design, DDD)
文章目录 1. 引言1.1 什么是领域驱动设计1.2 为什么需要DDD1.3 DDD适用场景 2. DDD基础概念2.1 领域(Domain)2.2 模型(Model)与领域模型(Domain Model)2.3 通用语言(Ubiquitous Language) 3. 战略设计3.1 限界上下文(Bounded Context)3.2 上下文映射(Context Mapping)3.3 大型核…...
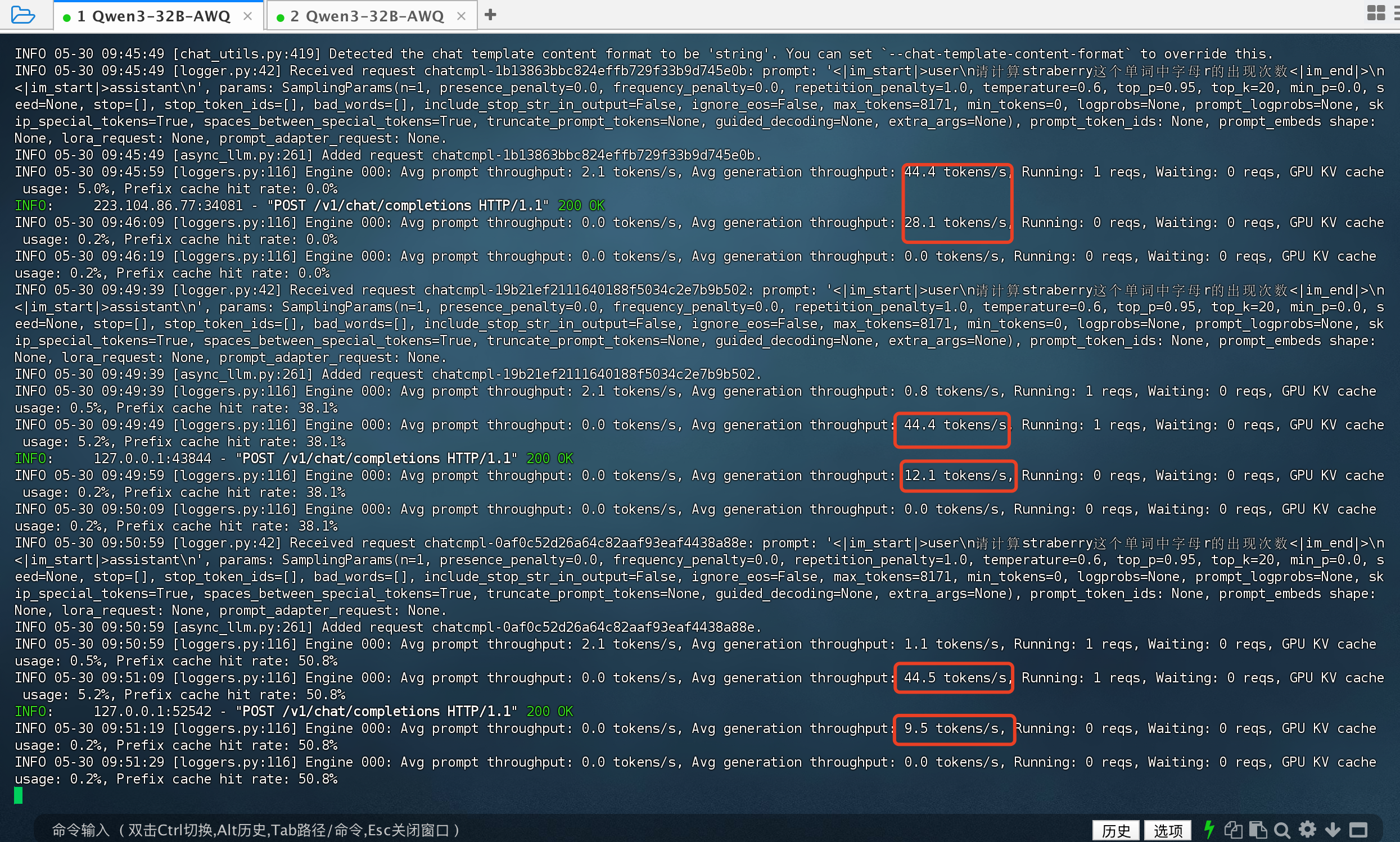
单卡4090部署Qwen3-32B-AWQ(4bit量化)-vllm
单卡4090部署Qwen3-32B-AWQ(4bit量化) 模型:Qwen3-32B-AWQ(4bit量化) 显卡:4090 1 张 python版本 python 3.12 推理框架“vllm 重要包的版本 vllm0.9.0创建GPU云主机 这里我使用的是优云智算平台的GPU,使用链接可以看下面的 https://blog.…...

漫画Android:Handler机制是怎么实现的?
线程之间通信会用到Handler,比如,在子线程中进行耗时的网络请求任务,子线程在获取到数据后,更新界面的时候就需要用到Handler; 子线程在获取到数据后,不直接去更新 界面,而是把数据通过一个消息…...
多部手机连接同一wifi的ip一样吗?如何更改ip
通常情况下,多部手机连接同一个WiFi时,它们的IP地址是各不相同的(在局域网内)。但是,从互联网(外网)的角度看,它们共享同一个公网IP地址。让我详细解释一下,并说明如何更…...

飞牛fnNAS的Docker应用之迅雷篇
目录 一、“迅雷”应用安装 二、启动迅雷 三、迅雷账号登录 四、修改“迅雷”下载保存路径 1、下载路径准备 2、停止“迅雷”Docker容器 3、修改存储位置 4、重新启动Docker容器 5、再次“启用”迅雷 五、测试 1、在PC上添加下载任务 2、手机上管理 3、手机添加下…...

C++中指针与引用的区别详解:从原理到实战
C中指针与引用的区别详解:从原理到实战 1. 引言:指针与引用的重要性 在C编程中,指针和引用是两个极其重要的概念,也是许多初学者容易混淆的地方。作为C的核心特性,它们直接操作内存地址,提供了对内存的直…...

SQLMesh 用户定义变量详解:从全局到局部的全方位配置指南
SQLMesh 提供了灵活的多层级变量系统,支持从全局配置到模型局部作用域的变量定义。本文将详细介绍 SQLMesh 的四类用户定义变量(global、gateway、blueprint 和 local)以及宏函数的使用方法。 一、变量类型概述 SQLMesh 支持四种用户定义变量…...
inviteflood:基于 UDP 的 SIP/SDP 洪水攻击工具!全参数详细教程!Kali Linux教程!
简介 一种通过 UDP/IP 执行 SIP/SDP INVITE 消息泛洪的工具。该工具已在 Linux Red Hat Fedora Core 4 平台(奔腾 IV,2.5 GHz)上测试,但预计该工具可在各种 Linux 发行版上成功构建和执行。 inviteflood 是一款专注于 SIP 协议攻…...

软件工程:关于招标合同履行阶段变更的法律分析
关于招标合同履行阶段建设内容变更的法律分析 一、基本原则 合同严守原则 根据《民法典》第465条,依法成立的合同受法律保护,原则上双方应严格按照约定履行。招标合同作为特殊类型的民事合同,其履行过程应当遵循更为严格的变更规则。 禁止…...

mysql一主多从 k8s部署实际案例
一、Kubernetes配置(MySQL主从集群) 主库StatefulSet配置(master-mysql.yaml): apiVersion: apps/v1 kind: StatefulSet metadata:name: mysql-master spec:serviceName: "mysql-master"replicas: 1select…...
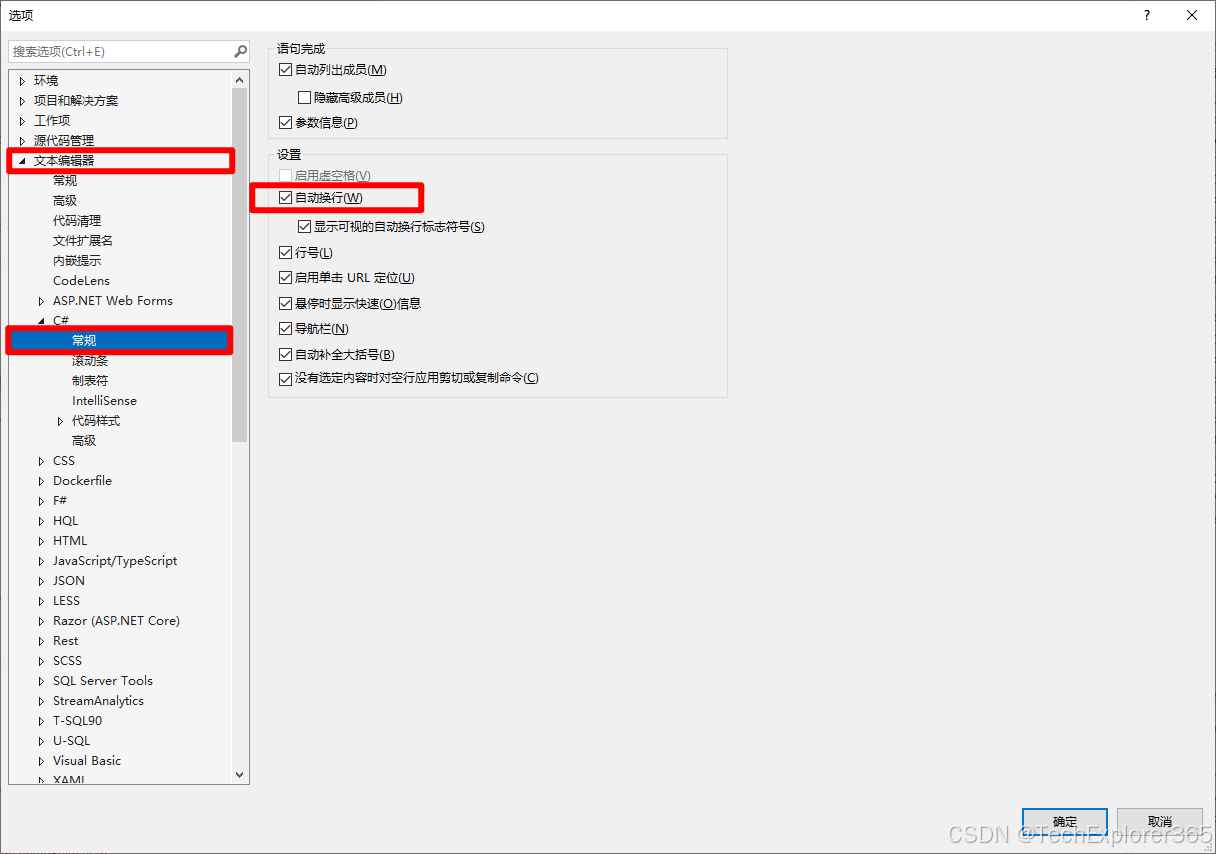
Visual Studio 2022 设置自动换行
Visual Studio 2022 设置自动换行 一、在 Visual Studio 菜单栏上,选择 工具>选项二、选择“文本编辑器”>“所有语言”>“常规” 全局设置此选项。 一、在 Visual Studio 菜单栏上,选择 工具>选项 二、选择“文本编辑器”>“所有语言”&…...

沉浸式 “飞进” 鸟巢:虚拟旅游新体验
(一)全方位视角探秘 开启鸟巢虚拟旅游,借助 VR 技术,能从任意角度欣赏其外观。高空俯瞰,独特的钢结构如精美编织画卷,钢梁交织,阳光下闪耀银光,与绿树、蓝天相衬。拉近镜头&#x…...

Ubuntu 下同名文件替换后编译链接到旧内容的现象分析
Ubuntu 下同名文件替换后编译链接到旧内容的现象分析 在使用 Ubuntu 操作系统编译程序时,常常会遇到一个问题:当我们替换同名文件内容后,若不改变当前命令行目录,再次编译时,系统实际编译的仍是被覆盖前的旧文件内容。…...

【Linux网络篇】:简单的TCP网络程序编写以及相关内容的扩展
✨感谢您阅读本篇文章,文章内容是个人学习笔记的整理,如果哪里有误的话还请您指正噢✨ ✨ 个人主页:余辉zmh–CSDN博客 ✨ 文章所属专栏:Linux篇–CSDN博客 文章目录 一.简单的TCP网络程序相关接口代码实现服务器单进程版服务器多…...

22.代理模式:思考与解读
原文地址:代理模式:思考与解读 更多内容请关注:深入思考与解读设计模式 引言 在软件开发中,尤其是当对象的访问需要控制时,你是否遇到过这样的问题:某些操作或对象可能需要进行额外的检查、优化或延迟加载ÿ…...
Scratch节日 | 粽子收集
端午节怎么过?当然是收粽子啦!这款 粽子收集 小游戏,让你一秒沉浸节日氛围,轻松收集粽子,收获满满快乐! 🎮 玩法介绍f 开始游戏:点击开始按钮,游戏正式开始!…...
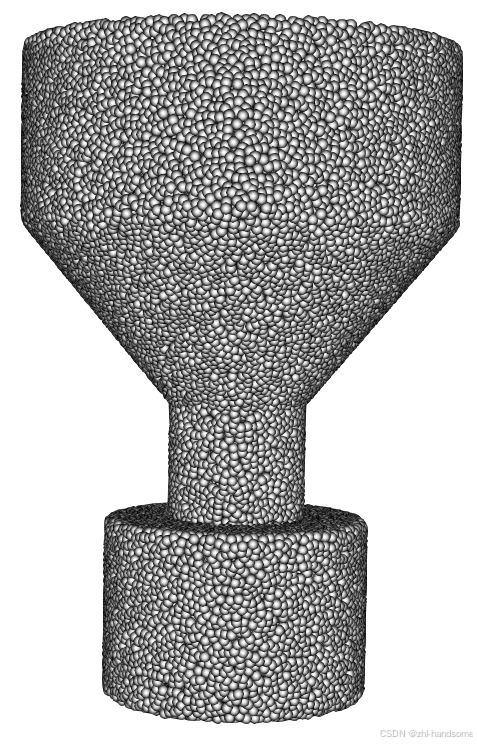
stl三角面元文件转颗粒VTK文件
效果展示: import os import sys import json import argparse import numpy as np import pandas as pd import open3d as o3d from glob import globPARTICLE_RADIUS 0.025def stl_to_particles(objpath, radiusNone):if radius is None:radius PARTICLE_RADIU…...