机器学习Day5-模型诊断
实现机器学习算法的技巧。当我们训练模型或使用模型时,发现预测误差很
大,可以考虑进行以下优化:
(1)获取更多的训练样本
(2)使用更少的特征
(3)获取其他特征
(4)添加多项式特征
(5)减小正则化参数
(6)增大正则化参数
如果对以上方法一一尝试或在错误的方向上进行调整会浪费大量的时间,下面介绍一些模型诊断方法来判断哪些因素对模型性能产生了影响,并确定优化方向。下面将介绍如何评估模型性能并做出正确的选择。
5.1 模型选择
对于一个任务,如何确定选择什么样的模型?例如,在线性回归问题中,想要构建一个多项式回归模型,如何确定多项式的阶数;在分类问题中使用神经网络,如何确定神经网络的层数和神经元个数。
为了确定一个模型是否合适,需要对模型进行评估。首先将数据集划分成训练集和测试集,划分比例通常为 7 : 3 或 8 : 2。当训练一个模型时,首先定义代价函数,代价函数可能包含正则化项,然后通过最小化训练集的代价来拟合参数。接下来在测试集上使用训练好的模型计算测试集的代价,这里要注意在测试集上计算代价时不包括正则化项,这一指标叫做测试误差。另一个衡量模型性能的指标是训练误差,它衡量算法在训练集上的指标,训练误差计算训练集的代价,同
样不包括正则化项。
在模型选择过程中,首先定义好一些大概可行的模型,然后进行训练,在数据集上计算已经训练好的模型的误差,选择误差最小的模型作为最终模型。通常训练误差无法很好地衡量算法在新样本上的表现,而为了公平地评估模型性能,测试集要保留到最后用于模型的性能评估。因此,可以将数据集划分为训练集、交叉验证集(也称验证集)和测试集三部分,划分比例通常为 6 : 2 : 2。在交叉验证集上计算模型误差,并选择交叉验证误差最小的模型。以上就是模型选择的
过程。
在参加比赛或者科研过程中通常需要对比不同模型的性能,使用交叉验证集进行模型选择,然后使用测试集进行评估,保证了评估结果的公平性,因为测试集中的数据是所有模型都没有见过的。
5.2 偏差(Bias)与方差(Variance)
当训练好的模型没有达到期望的效果时,接下来的关键在于决定下一步该做什么以提高模型性能。偏差与方差可以指导我们下一步应该尝试做什么。
前面在讲过拟合和欠拟合时,因为只有一个或两个特征,所以能够从图像上看出是否发生过拟合或欠拟合。然而,在实际问题中,通常有很多特征,无法绘制图像进行观察。因此,需要一个更系统的方式进行诊断,这里可以使用偏差与方差来诊断是否发生了过拟合或欠拟合。
偏差是指模型的预测值与真实值之间的差异,偏差越大,说明模型对数据的拟合能力较差,偏差越小,说明模型对数据的拟合能力较好。机器学习中偏差的计算方法如下:
Bais = 预测值的平均值 - 真实值的平均值
方差是指模型在不同数据集上的预测结果的波动程度,反映了模型对数据变化的敏感度。方差衡量的是模型预测的稳定性,如果模型在不同数据集上预测偏差的差异很大,方差就大,反之,方差就小。方差的计算方法如下:
![]()
其中 是模型在不同数据集上的预测值。当发生欠拟合时,模型在训练集和验证集上的表现都很差。此时训练偏差和验证偏差都比较高,方差低,模型过于简单,无法捕捉数据的复杂关系。当发生过拟合时,模型在训练集上的表现很好,但在验证集上的表现很差。此时训练偏差低验证偏差高,方差高,模型过于复杂,对训练数据的细节和噪声过于敏感。
在机器学习中,理想的情况是找到一个模型,其偏差和方差都较低,从而实现良好的泛化性能。然而,实际上,降低偏差往往会增加方差,反之亦然。这是因为增加模型的复杂性可以降低偏差,但同时也可能使模型对训练数据更加敏感,从而使方差增大。
Part5-1 动手练
绘制不同复杂度模型的偏差与方差
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split # 加载数据
data = pd.read_csv('ex2data2.txt',names=['x1','x2',
'accepted'])# 生成多项式特征
def map_feature(x1, x2, degree=5):out = np.ones((x1.shape[0], 1)) # 添加偏置项 for i in range(1, degree+1):for j in range(0, i + 1):new_feature = (x1 ** (i - j)) * (x2 ** j)out = np.hstack((out, new_feature.reshape(-1, 1))) return out
# sigmoid 函数
def sigmoid(z):return 1 / (1 + np.exp(-z))
# 正则化代价函数
def cost_reg(X, y, theta, lamda): m = len(y)epsilon = 1e-15 # 防止 log(0)y_pred = sigmoid(np.dot(X, theta))y_pred = np.clip(y_pred, epsilon, 1 - epsilon)cost = -1 / m * (np.dot(y, np.log(y_pred)) + np.dot((1 - y),
np.log(1 - y_pred)))reg = (lamda / (2 * m) * np.sum(np.power(theta[1:], 2))) cost_reg = cost + regreturn cost_reg
# 定义正则化梯度下降法
def gradientDescent(X, y, theta, learning_rate=0.01,
epochs=1000, lamda=1):m, n = X.shapecost = np.zeros(epochs) # 初始化代价函数值为 0 数组,元素个数为
迭代次数for i in range(epochs):y_pred = sigmoid(np.dot(X, theta))dw = (1 / m) * np.dot(X.T, (y_pred - y)) reg = (lamda / m) * thetareg[0] = 0 # 不对偏置项进行正则化 dw = dw + regtheta = theta - learning_rate * dwcost[i] = cost_reg(X, y, theta, lamda) # 计算每一次的代
价函数return theta, cost
# 使用训练好的模型进行预测
def predict_probabilities(theta, X): return sigmoid(np.dot(X, theta))
# 初始化参数
alpha = 0.1
lamda = 0
epochs = 3000
bias = []
variance = []
error = []
x1 = data['x1'].values
x2 = data['x2'].values
y = data['accepted'].values
for degree in range(1, 20):X = map_feature(x1, x2, degree) theta = np.zeros(X.shape[1]) # 划分数据集为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=42, stratify=y)
# 执行梯度下降函数theta, cost = gradientDescent(X_train, y_train, theta,
alpha, epochs, lamda)# 计算训练偏差(基于训练集)train_probs = predict_probabilities(theta, X_train) train_bias = np.mean((train_probs - y_train) ** 2) # 使用
均方误差作为偏差的简化计算# 计算测试方差(基于测试集)test_probs = predict_probabilities(theta, X) test_variance = np.var(test_probs)# 计算测试错误率test_pred_y = [1 if x >= 0.5 else 0 for x in test_probs] test_error = np.mean(test_pred_y != y)bias.append(train_bias) variance.append(test_variance) error.append(test_error)
plt.plot(range(1, 20), bias, 'r', label='bias')
plt.plot(range(1, 20), variance, 'g', label='variance')
plt.plot(range(1, 20), error, 'b', label='error')
plt.xlabel('degree')
plt.ylabel('Error')
plt.legend()
plt.show()5.3 正则化与偏差方差
当代价函数引入正则化项时,正则化参数 的选择会影响偏差和方差的大小,通过调整参数 ,观察偏差和方差的变化,从而选择更好的 。在选择参数时,设置不同的值并进行训练,再用训练好的模型在验证集上进行验证。
Part5-2 动手练
绘制并观察不同正则化参数的偏差与方差,模型定义、代价函数、梯度下降法等定义都与 Part5-1 相同,下面代码直接设置不同的正则化参数并进行训练。
# 初始化参数
alpha = 0.1
epochs = 3000
degree = 5
x1 = data['x1'].values
x2 = data['x2'].values
y = data['accepted'].values
X = map_feature(x1, x2, degree)
theta = np.zeros(X.shape[1])
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=42, stratify=y)
bias = []
variance = []
error = []
for lamda in np.arange(0, 0.5, 0.01): # 执行梯度下降函数theta, cost = gradientDescent(X_train, y_train, theta,
alpha, epochs, lamda)# 计算训练偏差(基于训练集)train_probs = predict_probabilities(theta, X_train) train_bias = np.mean((train_probs - y_train) ** 2) # 使用
均方误差作为偏差的简化计算# 计算测试方差(基于测试集)test_probs = predict_probabilities(theta, X) test_variance = np.var(test_probs)# 计算测试错误率test_pred_y = [1 if x >= 0.5 else 0 for x in test_probs] test_error = np.mean(test_pred_y != y)bias.append(train_bias) variance.append(test_variance) error.append(test_error)
plt.plot(np.arange(0, 0.5, 0.01), bias, 'r', label='bias')
plt.plot(np.arange(0, 0.5, 0.01), variance, 'g',
label='variance')
plt.plot(np.arange(0, 0.5, 0.01), error, 'b', label='error')
plt.xlabel('lambda')
plt.ylabel('Error')
plt.legend()
plt.show()5.4 基准性能水平
在判断一个模型是高偏差还是高方差时,可以设置一个基准性能水平(baseline level of performance)。例如,在语音识别的例子中,任务的目标是将一段语音转成文字,通常一些语音中包含噪音,导致人类也无法准确识别语音中的文字,因此,可以将人类识别语音的误差设置为模型的基准性能水平,而不是要求模型的误差为 0。假设人类识别语音的误差为 5%,则设置 5%为基准性能水平 , 当 模 型 在 训 练 集 上 的 误 差 为 10% 时 , 则 该 模 型 在 训 练 集 上 的 偏 差 为10%-5%=5%。当然也可以将基准性能水平设置为 0,此时认为人类有能力做到100%的准确率。
5.5 学习曲线(Learning Curve)
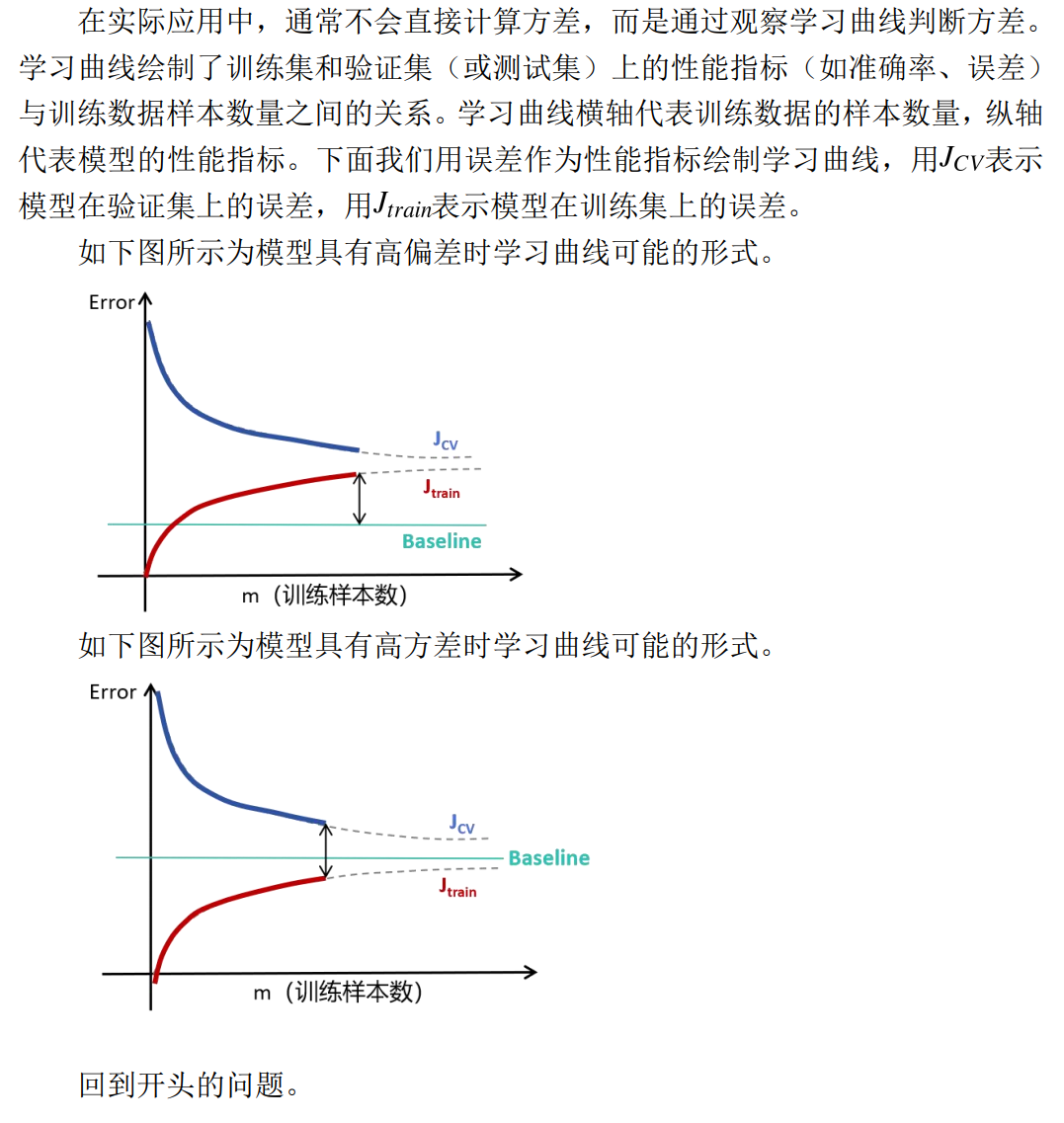
Part5-3 动手练
绘制并观察学习曲线,模型定义、代价函数、梯度下降法等定义都与 Part5-1相同,下面代码直接按不同比例划分训练集与测试集并进行训练。
# 初始化参数
alpha = 0.1
epochs = 3000
lamda = 0
degree = 5
x1 = data['x1'].values
x2 = data['x2'].values
y = data['accepted'].values
X = map_feature(x1, x2, degree)
theta = np.zeros(X.shape[1])
bias_train = []
bias_test = []
for train_size in np.arange(0.1, 0.8, 0.1): # 划分数据集为训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y,
train_size=train_size, random_state=42, stratify=y)# 执行梯度下降函数theta, cost = gradientDescent(X_train, y_train, theta,
alpha, epochs, lamda)# 计算训练偏差(基于训练集)train_probs = predict_probabilities(theta, X_train) train_bias = np.mean((train_probs - y_train) ** 2) # 使用
均方误差作为偏差的简化计算# 计算测试偏差(基于测试集)test_probs = predict_probabilities(theta, X) test_bias = np.mean((test_probs - y) ** 2) bias_train.append(train_bias)bias_test.append(test_bias)
plt.plot(np.arange(0.1, 0.8, 0.1), bias_train, 'r',
label='train_bias')
plt.plot(np.arange(0.1, 0.8, 0.1), bias_test, 'g',
label='test_bias')
plt.xlabel('m')
plt.ylabel('Error')
plt.legend()
plt.show()5.6 神经网络中的偏差与方差
在前面的介绍过程中,评估模型时需要在偏差与方差之间进行权衡。而在神经网络中,有一种可以无需权衡偏差与方差的方法。事实证明,大型神经网络在小型或中等规模的数据集上训练时,总是具有低偏差。也就是说,当神经网络规模足够大时,几乎总是能很好地拟合数据。因此无需在偏差和方差之间进行权衡,而是根据需要去降低偏差和方差。
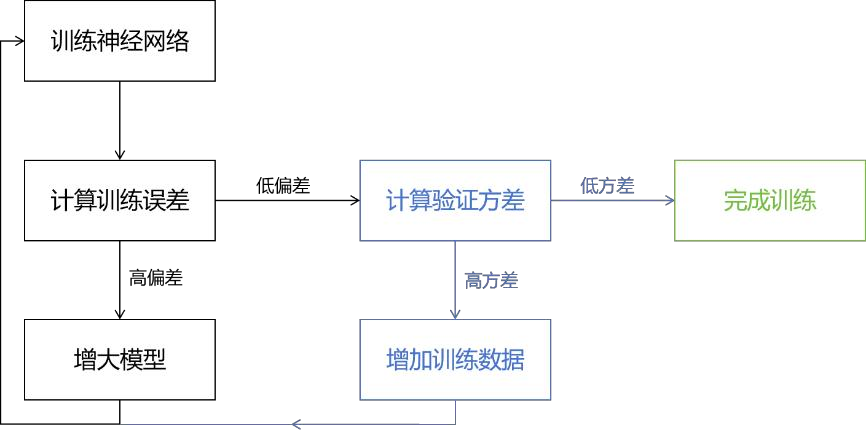
这种方法也存在局限性,因为训练更大的神经网络需要更多的计算资源,当神经网络大过一定程度时,模型过于庞大,训练时间过长,这种方法变得不可行。另一个限制是数据方面的,当训练数据集大到一定程度时,就无法再获取更多的数据。但该方法依然是一种在训练神经网络过程中指导我们选择下一步操作的有效方法。
Part5-4 动手练
计算训练集和测试集误差,模型、训练过程定义与 Part4-4 中使用 PyTorch 的代码相同,下面只给出代码的不同部分。调整隐藏层或者神经元的数量观察模型在训练集的误差,如果误差太大无法接受,可以增加训练轮次,增加层数或神经元数量,如果误差可以接受,则观察模型在训练集的误差和模型在测试集的误差之间的差距(即方差),如果差距太大则增加训练数据继续训练,直至达到比较好的性能。
# 测试模型
def predict(model, test_loader): model.eval() # 设置为评估模式 correct = 0total = 0with torch.no_grad():for images, labels in test_loader: images, labels = images.to(device),
labels.to(device) # 将数据移动到 GPUoutputs = model.forward(images.reshape(-1, 28 * 28))probabilities =
torch.nn.functional.softmax(outputs, dim=1)_, predicted = torch.max(probabilities, dim=1) total += labels.size(0)correct += (predicted == labels).sum().item() accuracy = 100 * correct / totalreturn accuracy
# 加载和预处理数据
train_dataset = datasets.MNIST(root='./', train=True,
transform=transforms.ToTensor(), download=False)
test_dataset = datasets.MNIST(root='./', train=False,
transform=transforms.ToTensor(), download=False)
train_loader =
torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader =
torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=False)
model = NeuralNet(input_size, hidden_size, num_classes)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练并测试模型
train(model, train_loader, optimizer, criterion, num_epochs=1)
test_accuracy = predict(model, test_loader)
train_accuracy = predict(model, train_loader)
print(f'Validation Error (1 - Accuracy): {100 -
test_accuracy:.2f}%')
print(f'Training Error (1 - Accuracy): {100 -
train_accuracy:.2f}%')5.7 构建机器学习系统的流程
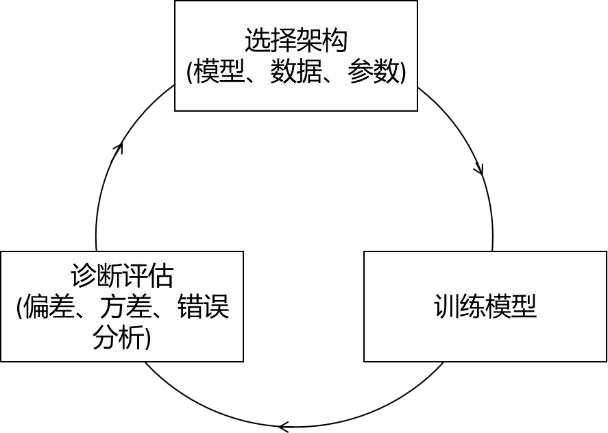
下图为构建一个机器学习系统的总体流程,首先根据任务需求选择模型的类型、训练数据、设置参数,然后对模型进行训练,接下来对训练好的模型进行诊断,评估偏差、方差以及进行错误分析,根据评估和分析结果调整模型、数据和参数再接着训练。在实际应用中,通常需要多次重复此过程直到模型达到理想性能。
5.8 错误分析
偏差和方差是评估模型性能的两个最重要的指标,错误分析是另外一个决定下一步该怎么做的重要方法。例如,在垃圾邮件分类任务中,我们发现训练好的模型方差高,下一步可以增加训练数据来降低方差,然而在此之前我们可以通过错误分析来确定增加什么样的数据对提升模型性能最有效。下面举例说明错误分析的过程,首先取出 100 个被错误分类的数据,即这 100 条数据的正确标签是垃圾邮件,但模型却没有将它们识别出来,认为它们是正常邮件。人工对这 100条数据进行查看,发现有 31 条数据是关于股票的,有 3 条是故意拼写错误的,有 7 条是非正常的发件地址,有 8 条是关于钓鱼网站的,有 5 条是将垃圾信息嵌入在图片里的,等等。此时在增加训练数据时,可以有针对性地增加内容中包含股票的数据,而不是没有目的地增加数据。这种方法的目的是把时间放在更重要的事情上,快速提高模型性能。
在机器学习训练过程中,更多的数据总是好的,但获取所有类型的数据可能代价昂贵而且浪费时间,因此可以通过错误分析添加对模型性能影响更大的数据。
5.9 增加训练数据
增加数据除了获取全新的样本之外,还有其他的方法。一种称为数据增强(Data Augmentation)的方法广泛用于图像和音频数据中,数据增强利用现有数据去构建新数据。
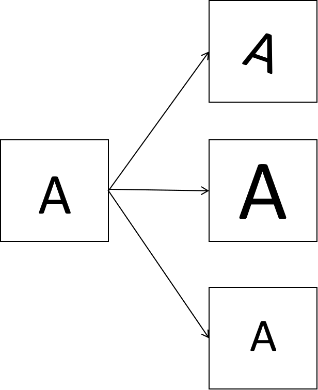
在光学字符识别问题中,识别的不仅是数字还包括字母。如下图所示可以对一张图片进行旋转、放大、缩小等处理来获取更多的图片。这些操作不会改变图片的本质,标签不变。
对于语音数据,可以向音频中加入一些人群、汽车等噪声。数据增强是一种通过变换和处理现有数据来生成新的训练样本的技术。其核心目的是增加数据的多样性和数量,从而提高模型的泛化能力和鲁棒性。与数据增强不同的另外一种增加数据的方法称为数据合成(Data Synthesis)。数据合成是从头开始创建全新的数据,而不是对现有数据进行修改。在光学字符识别问题中,可以用文本编辑器编辑不同字体、大小的字符,然后通过截图获取数据。当然也可以编写代码进行数据合成,这种方式虽然比较耗时,但有时可以极大提升模型性能,因此也是值得的。数据合成通常用于计算机视觉任务,较少用于其他任务。
5.10 迁移学习(Transfer Learning)


为什么迁移学习有效?为什么通过识别一些动物图片学习到的参数能用于识别手写数字这样不同的任务?因为在图像识别问题中,神经网络的第一层可能识别图像的边缘,下一层可能识别简单的角点形状,再下一层可能识别曲线之类的形状。所以神经网络在图像检测问题中,每一层学习的是识别边缘、角点等基本形状,这些在同类型的任务中也是有用的。因此,迁移学习在同类型的任务中有效,但无法应用到不同类型的任务中。
5.11 精确率与召回率
当处理数据集中类别比例不均衡的问题时,偏差和方差通常不再适用。假设任务的目标是根据患者信息预测他患有糖尿病还是一种罕见病,这种罕见病非常少见,在数据集中可能只有 1%的样本标记为这种罕见病。在这种情况下,即使模型完全没有预测出这种罕见病,误差也只有 1%,偏差和方差都很低,但这个模型效果其实是不好的,因为模型无法预测出罕见病。因此需要其他的评估指标来评估模型性能,下面介绍精确率(Precision)和召回率 (Recall)。
在二分类问题中,测试样本中正样本被判定为正样本的数量记为 TP(True Positive),正样本被判定为负样本的数量记为 FN(False Negative);负样本被分类器判定为负样本的数量记为 TN(True Negative),负样本被判定为正样本的数量记为 FP(False Positive)。
精确率也称为精度,是指被模型判定为正样本的样本中真正的正样本所占的比例,公式为:
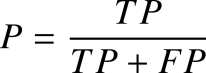
召回率是指所有正样本中被分类器判定为正样本的比例,公式为:
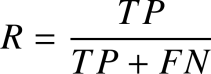
精确率 P 和召回率 R 是一对相互矛盾的量,当 P 高时,R 往往相对较低,当 R 高时, P 往往相对较低,因此很难在二者之间进行权衡。为了更好的评价模型的性能,一般使用 F1-Score 作为评价标准来衡量分类器的综合性能。
F1-Score:精确率与召回率的调和平均,F1-Score 更关注的是精确率与召回率较低的那个值。 即:
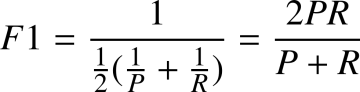
Part5-5 动手练
计算精确率、召回率、F1-Score。模型、训练过程定义与 Part4-4 中的代码相同,下面只给出代码的不同部分。
from sklearn.metrics import precision_score, recall_score,
f1_score
import numpy as np
# 测试模型
def predict(model, test_loader): model.eval() # 设置为评估模式 all_labels = []all_predictions = [] with torch.no_grad():for images, labels in test_loader: images, labels = images.to(device),
labels.to(device) # 将数据移动到 GPUoutputs = model.forward(images.reshape(-1, 28 * 28)) probabilities =
torch.nn.functional.softmax(outputs, dim=1)_, predicted = torch.max(probabilities, dim=1) all_labels.extend(labels.cpu().numpy())all_predictions.extend(predicted.cpu().numpy())# 计算准确率accuracy = 100 * np.mean(np.array(all_predictions) ==
np.array(all_labels))# 计算精确率和召回率precision = precision_score(all_labels, all_predictions,
average='macro')recall = recall_score(all_labels, all_predictions,
average='macro')f1 = f1_score(all_labels, all_predictions, average='macro') return accuracy, precision, recall, f1
# 加载和预处理数据
train_dataset = datasets.MNIST(root='./', train=True,
transform=transforms.ToTensor(), download=False)
test_dataset = datasets.MNIST(root='./', train=False,transform=transforms.ToTensor(), download=False)
train_loader =
torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size, shuffle=True)
test_loader =
torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size, shuffle=False)
model = NeuralNet(input_size, hidden_size, num_classes)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
# 训练并测试模型
train(model, train_loader, optimizer, criterion, num_epochs=1)
accuracy, precision, recall, f1 = predict(model, test_loader)
print(f'Validation Accuracy: {accuracy:.2f}%')
print(f'Precision: {precision:.4f}%')
print(f'Recall: {recall:.4f}%')
print(f'F1-Score: {f1:.4f}%')相关文章:
机器学习Day5-模型诊断
实现机器学习算法的技巧。当我们训练模型或使用模型时,发现预测误差很 大,可以考虑进行以下优化: (1)获取更多的训练样本 (2)使用更少的特征 (3)获取其他特征 ÿ…...

如何将 WSL 的 Ubuntu-24.04 迁移到其他电脑
在使用 Windows Subsystem for Linux (WSL) 时,我们可能会遇到需要将现有的 WSL 环境迁移到其他电脑的情况。无论是为了备份、更换设备,还是在不同电脑之间共享开发环境,掌握迁移 WSL 子系统的方法都是非常有用的。本文将以 Ubuntu-24.04 为例…...

金融欺诈有哪些检测手段
金融欺诈检测是一个多层次的动态防御过程,需要结合技术手段、数据分析、人工智能和人工审核。以下是当前主流的检测手段和技术分类。 ### **一、核心技术手段** 1. **规则引擎(Rule-Based Systems)** - **原理**:预设基于历史…...

HTML5 全面知识点总结
一、HTML 基础概念 HTML:超文本标记语言,用于创建网页和 Web 应用的结构。 超文本:可以包含文字、图片、音频、视频、链接等多种媒体。 标记语言:通过标签标记网页的各个部分。 二、HTML5 的新特性(区别于 HTML4&am…...
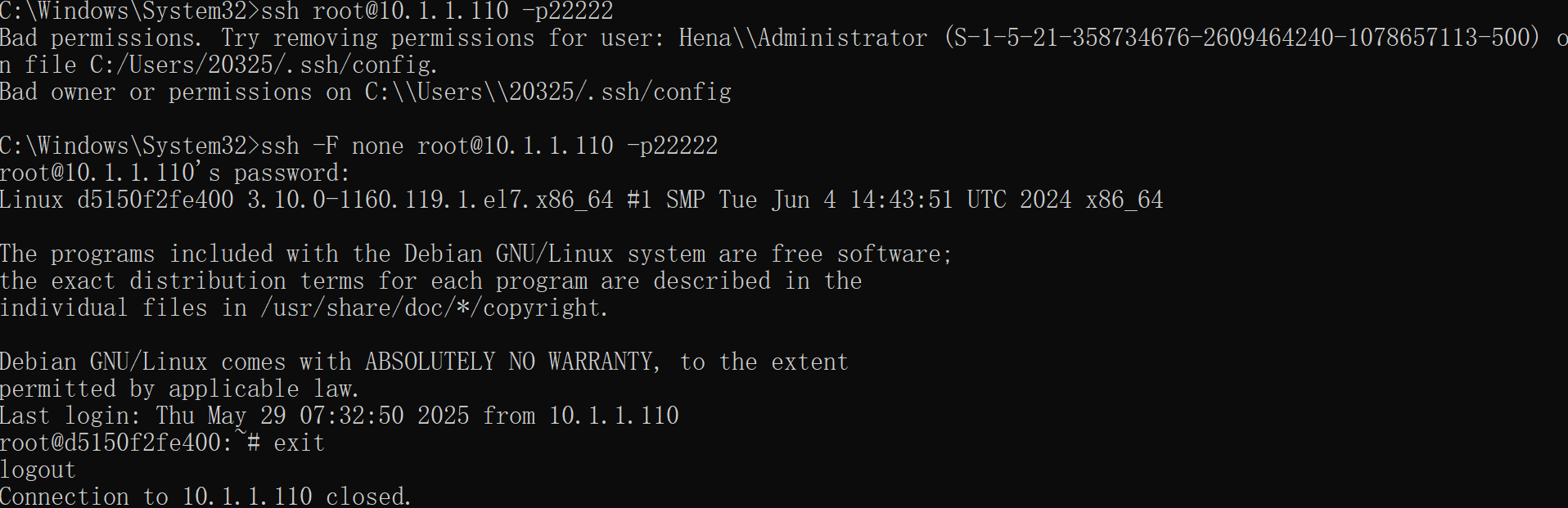
vscode一直连接不上虚拟机或者虚拟机容器怎么办?
1. 检查并修复文件权限 右键点击 C:\Users\20325\.ssh\config 文件,选择 属性 → 安全 选项卡。 确保只有你的用户账户有完全控制权限,移除其他用户(如 Hena\Administrator)的权限。 如果 .ssh 文件夹权限也有问题,同…...

初学c语言21(文件操作)
一.为什么使用文件 之前我们写的程序的数据都是存储到内存里面的,当程序结束时,内存回收,数据丢失, 再次运行程序时,就看不到上次程序的数据,如果要程序的数据一直保存得使用文件 二.文件 文件一般可以…...

数学复习笔记 21
4.15 稍微有点难啊。克拉默法则忘掉了,然后第二类数学归纳法是第一次见。行列式和矩阵,向量和方程组。这是前面四章。现在考研只剩下一个大题。所以就是考最后两章,特征值和二次型。感觉看网课的作用就是辅助理解,自己看书的话&am…...

华为OD机试真题——数据分类(2025B卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 B卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 本文收录于专栏:《2025华为OD真题目录+全流程解析/备考攻略/经验分享》 华为OD机试真题《数据…...
JavaWeb开发基础Servlet生命周期与工作原理
Servlet生命周期 Servlet的生命周期由Servlet容器(如Tomcat、Jetty等)管理,主要包括以下5个阶段: 加载Servlet类 创建Servlet实例 调用init方法 调用service方法 调用destroy方法 加载(Loading): 当Servlet容器启动或第一次接收到对某个…...

三防平板科普:有什么特殊功能?应用在什么场景?
在数字化浪潮席卷全球的今天,智能设备已成为现代工业、应急救援、户外作业等领域的核心工具。然而,常规平板电脑在极端环境下的脆弱性,如高温、粉尘、水浸或撞击,往往成为制约效率与安全的短板。三防平板(防水、防尘、…...

百度外链生态的优劣解构与优化策略深度研究
本文基于搜索引擎算法演进与外链建设实践,系统剖析百度外链的作用机制与价值模型。通过数据统计、案例分析及算法逆向工程,揭示不同类型外链在权重传递、流量获取、信任背书等维度的差异化表现,提出符合搜索引擎规则的外链建设技术方案&#…...

笔记: 在WPF中ContentElement 和 UIElement 的主要区别
一、目的:简要姐扫在WPF中ContentElement 和 UIElement 的主要区别 ContentElement 和 UIElement 是 WPF 中的两个基类,它们在功能和用途上有显著的区别。 二、主要区别 ContentElement 主要特点: • 没有视觉表示: ContentElement 本身不直接渲染任…...

项目中使用到了多个UI组件库,也使用了Tailwindcss,如何确保新开发的组件样式隔离?
在项目中使用多个组件库,同时使用 TailwindCSS,确保新开发的组件样式隔离是非常重要的。样式隔离可以避免样式冲突、全局污染以及意外的样式覆盖问题。以下是一些常见的策略和最佳实践: 1. 使用 TailwindCSS 的 layer 机制 TailwindCSS 提供…...
高级技巧详解)
AI提示工程(Prompt Engineering)高级技巧详解
AI提示工程(Prompt Engineering)高级技巧详解 文章目录 一、基础设计原则二、高级提示策略三、输出控制技术四、工程化实践五、专业框架应用提示工程是与大型语言模型(LLM)高效交互的关键技术,精心设计的提示可以显著提升模型输出的质量和相关性。以下是经过验证的详细提示工…...
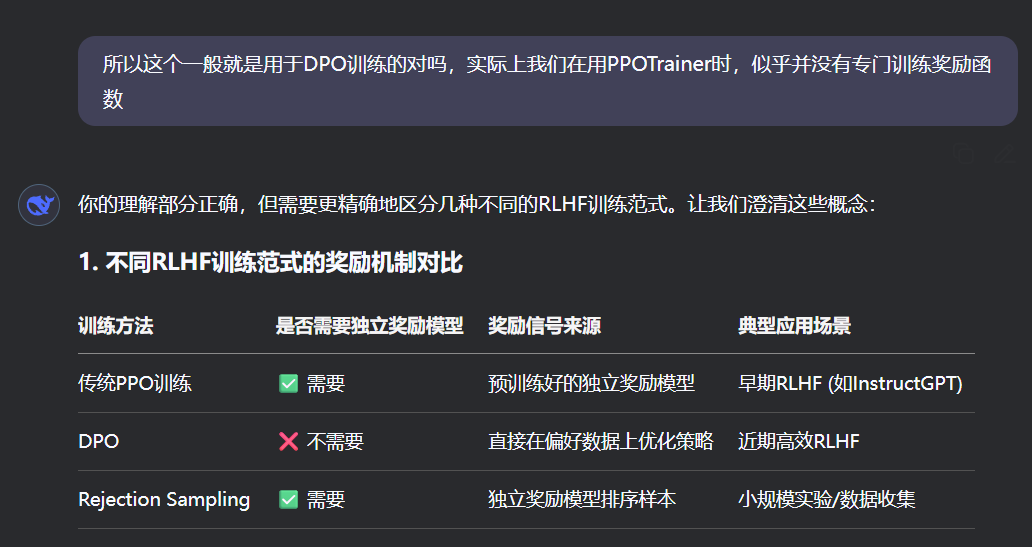
【速写】PPOTrainer样例与错误思考(少量DAPO)
文章目录 序言1 TRL的PPO官方样例分析2 确实可行的PPOTrainer版本3 附录:DeepSeek关于PPOTrainer示例代码的对话记录Round 1(给定模型数据集,让它开始写PPO示例)Round 2 (指出PPOTrainer的参数问题)关键问题…...
5.26 面经整理 360共有云 golang
select … for update 参考:https://www.cnblogs.com/goloving/p/13590955.html select for update是一种常用的加锁机制,它可以在查询数据的同时对所选的数据行进行锁定,避免其他事务对这些数据行进行修改。 比如涉及到金钱、库存等。一般这…...

中国移动咪咕助力第五届全国人工智能大赛“AI+数智创新”专项赛道开展
第五届全国人工智能大赛由鹏城实验室主办,新一代人工智能产业技术创新战略联盟承办,华为、中国移动、鹏城实验室科教基金会等单位协办,广东省人工智能与机器人学会支持。 大赛发布“AI图像编码”、“AI增强视频质量评价”、“AI数智创新”三大…...

模具制造业数字化转型:精密模塑,以数字之力铸就制造基石
模具被誉为 “工业之母”,是制造业的重要基石,其精度直接决定了工业产品的质量与性能。在工业制造向高精度、智能化发展的当下,《模具制造业数字化转型:精密模塑,以数字之力铸就制造基石》这一主题,精准点明…...

PECVD 生成 SiO₂ 的反应方程式
在PECVD工艺中,沉积氧化硅薄膜以SiH₄基与TEOS基两种工艺路线为主。 IMD Oxide(USG) 这部分主要沉积未掺杂的SiO₂,也叫USG(Undoped Silicate Glass),常用于IMD(Inter-Metal Diele…...

React与Vue核心区别对比
React 和 Vue 都是当今最流行、功能强大的前端 JavaScript 框架,用于构建用户界面。它们有很多相似之处(比如组件化、虚拟 DOM、响应式数据绑定),但也存在一些核心差异。以下是它们的主要区别: 1. 核心设计与哲学 Rea…...
2024 CKA模拟系统制作 | Step-By-Step | 17、题目搭建-排查故障节点
目录 免费获取题库配套 CKA_v1.31_模拟系统 一、题目 二、考点分析 1. Kubernetes 节点状态诊断 2. 节点故障修复技能 3. 持久化修复方案 4. SSH 特权操作 三、考点详细讲解 1. 节点状态机制详解 2. 常见故障原因深度分析 3. 永久修复技术方案 四、实验环境搭建步骤…...

如何将图像插入 PDF:最佳工具比较
无论您是编辑营销材料、写报告还是改写原来的PDF文件,将图像插入 PDF 都至关重要。幸运的是,有多种在线和离线工具可以简化此任务。在本文中,我们将比较一些常用的 PDF 添加图像工具,并根据您的使用场景推荐最佳解决方案ÿ…...

Linux 文件 IO 性能监控与分析指南
Linux 文件 I/O 性能监控与分析指南 继 CPU 和网络之后,文件系统 I/O 是影响系统性能的第三大关键领域。无论是数据库响应缓慢、应用加载时间过长,还是日志写入延迟,其根源都可能指向磁盘 I/O 瓶颈。本章将深入探讨文件 I/O 的核心概念、监控…...

ABP VNext + Apache Flink 实时流计算:打造高可用“交易风控”系统
ABP VNext Apache Flink 实时流计算:打造高可用“交易风控”系统 🌐 📚 目录 ABP VNext Apache Flink 实时流计算:打造高可用“交易风控”系统 🌐一、背景🚀二、系统整体架构 🏗️三、实战展示…...

前端面试题-HTML篇
1. 请谈谈你对 Web 标准以及 W3C 的理解和认识。 我对 Web 标准 的理解是,它就像是互联网世界的“交通规则”,由 W3C(World Wide Web Consortium,万维网联盟) 这样一个国际性组织制定。这些规则规范了我们在编写 HTML…...
 与扩展运算符的深度解析与最佳实践)
JS数组 concat() 与扩展运算符的深度解析与最佳实践
文章目录 前言一、语法对比1. Array.prototype.concat()2. 扩展运算符(解构赋值) 二、性能差异(大规模数组)关键差异原因 三、适用场景建议总结 前言 最近工作中遇到了一个大规模数组合并相关的问题,在数据合并时有些…...
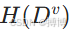
人工智能与机器学习从理论、技术与实践的多维对比
人工智能(Artificial Intelligence, AI)提出“让机器像人类一样思考”的目标,其核心理论围绕符号系统假设展开——认为智能行为可通过逻辑符号系统(如谓词逻辑、产生式规则)建模。 机器学习(Machine Learning, ML)是人工智能的子集,聚焦于通过数据自动改进算法性能的理…...

Netty 实战篇:手写一个轻量级 RPC 框架原型
本文将基于前文实现的编解码与心跳机制,构建一个简单的 RPC 框架,包括请求封装、响应解析、动态代理调用。为打造微服务通信基础打下基础。 一、什么是 RPC? RPC(Remote Procedure Call,远程过程调用)允许…...

什么是 WPF 技术?什么是 WPF 样式?下载、安装、配置、基本语法简介教程
什么是 WPF 技术?什么是 WPF 样式?下载、安装、配置、基本语法简介教程 摘要 WPF教程、WPF开发、.NET 8 WPF、Visual Studio 2022 WPF、WPF下载、WPF安装、WPF配置、WPF样式、WPF样式详解、XAML语法、XAML基础、MVVM架构、数据绑定、依赖属性、资源字典…...

亚远景-ISO 21434标准:汽车网络安全实践的落地指南
一、ISO 21434标准概述 ISO 21434是针对道路车辆网络安全的国际标准,旨在确保汽车组织在车辆的整个生命周期内采用结构化方法进行网络安全风险管理。 该标准适用于参与车辆开发的所有利益相关者,包括OEM、一级和二级供应商、汽车软件供应商以及网络安全…...