基于Docker和YARN的大数据环境部署实践最新版
基于Docker和YARN的大数据环境部署实践
目的
本操作手册旨在指导用户通过Docker容器技术,快速搭建一个完整的大数据环境。该环境包含以下核心组件:
- Hadoop HDFS/YARN(分布式存储与资源调度)
- Spark on YARN(分布式计算)
- Kafka(消息队列)
- Hive(数据仓库)
- JupyterLab(交互式开发环境)
通过清晰的步骤说明和验证方法,读者将掌握:
- 容器网络的搭建(Weave)
- Docker Compose编排文件编写技巧
- 多组件协同工作的配置要点
- 集群扩展与验证方法
整体架构
组件功能表
| 组件名称 | 功能描述 | 依赖服务 | 端口配置 | 数据存储 |
|---|---|---|---|---|
| Hadoop NameNode | HDFS元数据管理 | 无 | 9870 (Web UI), 8020 | Docker卷: hadoop_namenode |
| Hadoop DataNode | HDFS数据存储节点 | NameNode | 9864 (数据传输) | 本地卷或Docker卷 |
| YARN ResourceManager | 资源调度与管理 | NameNode | 8088 (Web UI), 8032 | 无 |
| YARN NodeManager | 单个节点资源管理 | ResourceManager | 8042 (Web UI) | 无 |
| Spark (YARN模式) | 分布式计算框架 | YARN ResourceManager | 无 | 集成在YARN中 |
| JupyterLab | 交互式开发环境 | Spark, YARN | 8888 (Web UI) | 本地目录挂载 |
| Kafka | 分布式消息队列 | ZooKeeper | 9092 (Broker) | Docker卷:kafka_data、kafka_logs |
| Hive | 数据仓库服务 | HDFS, MySQL | 10000 (HiveServer2) | MySQL存储元数据 |
| MySQL | 存储Hive元数据 | 无 | 3306 | Docker卷: mysql_data |
| ZooKeeper | 分布式协调服务(Kafka依赖) | 无 | 2181 | Docker卷:zookeeper_data |
关键交互流程
-
数据存储:
- HDFS通过NameNode管理元数据,DataNode存储实际数据。
- JupyterLab通过挂载本地目录访问数据,同时可读写HDFS。
-
资源调度:
- Spark作业通过YARN ResourceManager申请资源,由NodeManager执行任务。
-
数据处理:
- Kafka接收实时数据流,Spark消费后进行实时计算。
- Hive通过HDFS存储表数据,元数据存储在MySQL。
环境搭建步骤
1. 容器网络准备(Weave)
# 安装Weave网络插件
sudo curl -L git.io/weave -o /usr/local/bin/weave
sudo chmod +x /usr/local/bin/weave
# 启动Weave网络
weave launch
# 验证网络状态
weave status
#在其他节点上运行
weave launch 主节点IP
2. Docker Compose编排文件
创建 docker-compose.yml,核心配置如下:
version: "3.8"services:# ZooKeeperzookeeper-1:image: bitnami/zookeeper:3.8.0privileged: true #使用二进制文件安装的docker需要开启特权模式,每个容器都需要开启该模式container_name: zookeeper-1hostname: zookeeper-1ports:- "2181:2181"environment:- ALLOW_ANONYMOUS_LOGIN=yes- TZ=Asia/Shanghaivolumes:- zookeeper_data:/bitnami/zookeepernetworks:- bigdata-netdns:- 172.17.0.1restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"# Kafkakafka-1:image: bitnami/kafka:3.3.1container_name: kafka-1hostname: kafka-1environment:- KAFKA_BROKER_ID=1- KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper-1:2181- ALLOW_PLAINTEXT_LISTENER=yes- TZ=Asia/Shanghaiports:- "9092:9092"volumes:- kafka_data:/bitnami/kafka # Kafka数据持久化- kafka_logs:/kafka-logs # 独立日志目录depends_on:- zookeeper-1networks:- bigdata-netdns:- 172.17.0.1restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"# Hadoop HDFShadoop-namenode:image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8container_name: hadoop-namenodehostname: hadoop-namenodeenvironment:- CLUSTER_NAME=bigdata- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020- HDFS_CONF_dfs_replication=2- TZ=Asia/Shanghaiports:- "9870:9870"- "8020:8020"networks:- bigdata-netdns:- 172.17.0.1volumes:- hadoop_namenode:/hadoop/dfs/namerestart: alwayshadoop-datanode:image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8container_name: hadoop-datanodehostname: hadoop-datanodeenvironment:- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020- HDFS_CONF_dfs_replication=2- TZ=Asia/Shanghaidepends_on:- hadoop-namenodenetworks:- bigdata-netdns:- 172.17.0.1restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"# YARNhadoop-resourcemanager:image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8container_name: hadoop-resourcemanagerhostname: hadoop-resourcemanagerports:- "8088:8088" # YARN Web UIenvironment:- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020- YARN_CONF_yarn_resourcemanager_hostname=hadoop-resourcemanager- TZ=Asia/Shanghaidepends_on:- hadoop-namenodenetworks:- bigdata-netdns:- 172.17.0.1restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"hadoop-nodemanager:image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8container_name: hadoop-nodemanagerhostname: hadoop-nodemanagerenvironment:- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020- YARN_CONF_yarn_resourcemanager_hostname=hadoop-resourcemanager- TZ=Asia/Shanghaidepends_on:- hadoop-resourcemanagernetworks:- bigdata-netdns:- 172.17.0.1volumes:- ./hadoop-conf/yarn-site.xml:/etc/hadoop/yarn-site.xml # 挂载主节点的Hadoop配置文件,用于上报内存与cpu核心数restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"# Hivehive:image: bde2020/hive:2.3.2container_name: hivehostname: hiveenvironment:- HIVE_METASTORE_URI=thrift://hive:9083- SERVICE_PRECONDITION=hadoop-namenode:8020,mysql:3306- TZ=Asia/Shanghaiports:- "10000:10000"- "9083:9083"depends_on:- hadoop-namenode- mysqlnetworks:- bigdata-netdns:- 172.17.0.1restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"# MySQLmysql:image: mysql:8.0container_name: mysqlenvironment:- MYSQL_ROOT_PASSWORD=root- MYSQL_DATABASE=metastore- TZ=Asia/Shanghaiports:- "3306:3306"networks:- bigdata-netdns:- 172.17.0.1volumes:- mysql_data:/var/lib/mysqlrestart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"# JupyterLab(集成Spark on YARN)jupyter:image: jupyter/all-spark-notebook:latestcontainer_name: jupyter-labenvironment:- JUPYTER_ENABLE_LAB=yes- TZ=Asia/Shanghai- SPARK_OPTS="--master yarn --deploy-mode client" # 默认使用YARN模式- HADOOP_CONF_DIR=/etc/hadoop/conf # 必须定义- YARN_CONF_DIR=/etc/hadoop/conf # 必须定义ports:- "8888:8888"volumes:- ./notebooks:/home/jovyan/work- /path/to/local/data:/data- ./hadoop-conf:/etc/hadoop/conf # 挂载Hadoop配置文件,./hadoop-conf代表在docker-compose.yml同目录下的hadoop-confnetworks:- bigdata-netdns:- 172.17.0.1depends_on:- hadoop-resourcemanager- hadoop-namenoderestart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "7"volumes:hadoop_namenode:mysql_data:zookeeper_data:kafka_data:kafka_logs:hadoop-nodemanager:networks:bigdata-net:external: truename: weave
Hadoop配置文件
yarn-site.xml:
<configuration><property><name>yarn.resourcemanager.hostname</name><value>hadoop-resourcemanager</value></property><property><name>yarn.resourcemanager.address</name><value>hadoop-resourcemanager:8032</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property>
</configuration>
core-site.xml:
<configuration><property><name>fs.defaultFS</name><value>hdfs://hadoop-namenode:8020</value></property>
</configuration>
将这两个文件放置到hadoop-conf目录下。
3. 启动服务
# 启动容器
docker-compose up -d# 查看容器状态
docker-compose ps
4. 验证服务是否可用
验证HDFS
(1) 访问HDFS Web UI
-
操作:浏览器打开
http://localhost:9870。 -
预期结果:
Overview 页面显示HDFS总容量。
Datanodes 显示至少1个活跃节点(对应
hadoop-datanode容器)。
(2) 命令行操作HDFS
docker exec -it hadoop-namenode bash
# 创建测试目录
hdfs dfs -mkdir /test
# 上传本地文件
echo "hello hdfs" > test.txt
hdfs dfs -put test.txt /test/
# 查看文件
hdfs dfs -ls /test
#解除安全模式
hdfs dfsadmin -safemode leave
- 预期结果:成功创建目录、上传文件并列出文件。
如图所示:

** 验证YARN**
(1) 访问YARN ResourceManager Web UI
- 操作:浏览器打开
http://localhost:8088。 - 预期结果:
- Cluster Metrics 显示总资源(如内存、CPU)。
- Nodes 显示至少1个NodeManager(对应
hadoop-nodemanager容器)。
(2) 提交测试作业到YARN
# 进入Jupyter容器提交Spark作业
docker exec -it jupyter-lab bash
# 提交Spark Pi示例作业
spark-submit --master yarn --deploy-mode client --class org.apache.spark.examples.SparkPi /usr/local/spark/examples/jars/spark-examples_*.jar 10
- 预期结果:
- 作业输出中包含
Pi is roughly 3.14。 - 在YARN Web UI (
http://localhost:8088) 中看到作业状态为 SUCCEEDED。
- 作业输出中包含
如图所示:
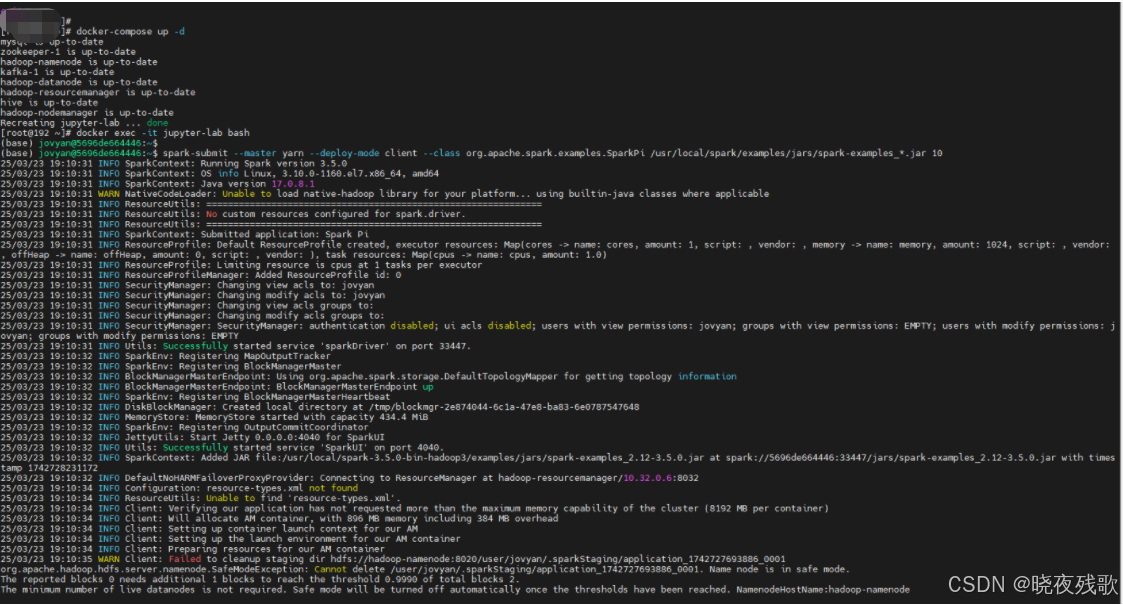
若是出现报错:Permission denied: user=jovyan, access=WRITE, inode=“/user”:root:supergroup:drwxr-xr-x
报错原因:
当前运行 Spark 的用户是:jovyan(Jupyter 默认用户);
Spark 提交任务后,会自动尝试在 HDFS 上创建目录 /user/jovyan;
但是:这个目录不存在,或者 /user 目录不允许 jovyan 写入;
所以 HDFS 拒绝创建临时目录,导致整个作业提交失败;
解决方法
创建目录并赋权
进入NameNode 容器:
docker exec -it hadoop-namenode bash
然后执行 HDFS 命令:
hdfs dfs -mkdir -p /user/jovyan
hdfs dfs -chown jovyan:supergroup /user/jovyan
这一步允许 jovyan 用户有权写入自己的临时目录。
提示:可以先执行
hdfs dfs -ls /user看是否有jovyan子目录。
最后:再次执行 spark-submit 后,可以看到
-
控制台打印:
Submitting application application_xxx to ResourceManager -
YARN 8088 页面:
- 出现作业记录;
- 状态为
RUNNING或FINISHED
验证Spark on YARN(通过JupyterLab)
(1) 访问JupyterLab
- 操作:浏览器打开
http://localhost:8888,使用Token登录(通过docker logs jupyter-lab获取Token)。 - 预期结果:成功进入JupyterLab界面。
(2) 运行PySpark代码
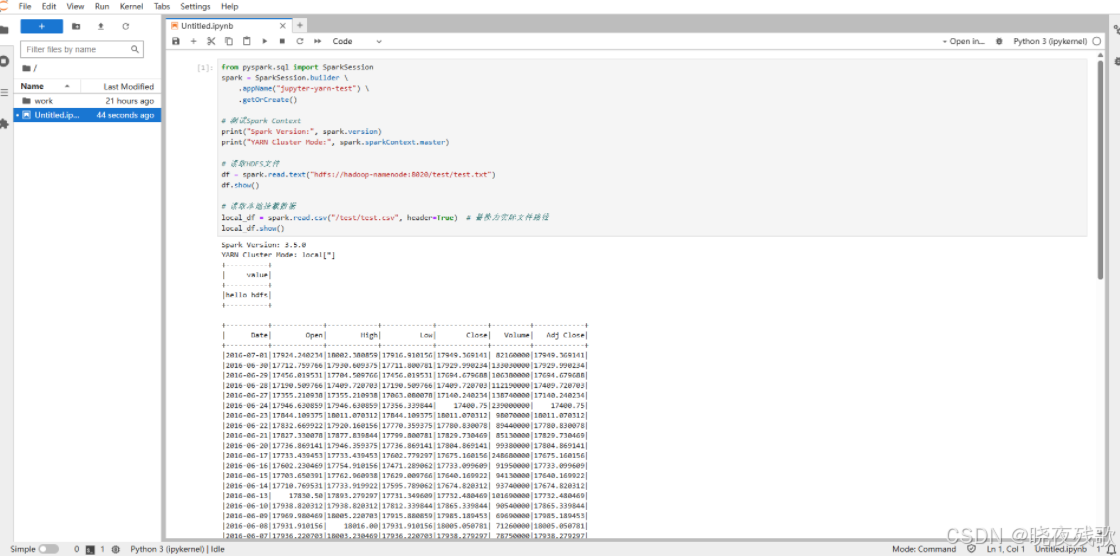
在Jupyter中新建Notebook,执行以下代码:
from pyspark.sql import SparkSession
spark = SparkSession.builder \.appName("jupyter-yarn-test") \.getOrCreate()# 测试Spark Context
print("Spark Version:", spark.version)
print("YARN Cluster Mode:", spark.sparkContext.master)# 读取HDFS文件
df = spark.read.text("hdfs://hadoop-namenode:8020/test/test.txt")
df.show()# 读取数据
local_df = spark.read.csv("/data/example.csv", header=True) # 替换为实际文件路径
local_df.show()
- 预期结果:
- 输出Spark版本和YARN模式(如
yarn)。 - 成功读取HDFS文件并显示内容
hello hdfs。 - 成功读取CSV文件(需提前放置测试文件)。
- 输出Spark版本和YARN模式(如
如图所示:
验证Hive
(1) 创建Hive表并查询
#使用docker cp命令将jdbc驱动放入容器内部,示例:
docker cp mysql-connector-java-8.0.12.jar 容器ID或容器名称:/opt/hive/lib
docker exec -it hive bash
#重新初始化 Hive Metastore
schematool -dbType mysql -initSchema --verbose
#查询MetaStore运行状态
ps -ef | grep MetaStore
# 启动Hive Beeline客户端
beeline -u jdbc:hive2://localhost:10000 -n root
//驱动下载链接:https://downloads.mysql.com/archives/c-j/
若是执行上述命令报错,可以按照以下步骤来进行更改
1、配置hive-site.xml文件:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!--Licensed to the Apache Software Foundation (ASF) under one or morecontributor license agreements. See the NOTICE file distributed withthis work for additional information regarding copyright ownership.The ASF licenses this file to You under the Apache License, Version 2.0(the "License"); you may not use this file except in compliance withthe License. You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License.
--><configuration>
<property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://192.168.0.78:3306/metastore_db?createDatabaseIfNotExist=true</value><description>JDBC connect string for a JDBC metastore</description></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property> <property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>root</value></property><!-- Metastor-->rash<property> <name>hive.metastore.uris</name><value>thrift://localhost:9083</value></property><property><name>hive.metastore.warehouse.dir</name><value>/user/hive/warehouse</value></property><property><name>hive.server2.thrift.bind.host</name><value>0.0.0.0</value></property><property><name>hive.server2.thrift.port</name><value>10000</value></property></configuration>//将此配置使用docker cp命令拷贝至hive容器内的/opt/hive/conf目录下。
2、配置core-site.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!--Licensed under the Apache License, Version 2.0 (the "License");you may not use this file except in compliance with the License.You may obtain a copy of the License athttp://www.apache.org/licenses/LICENSE-2.0Unless required by applicable law or agreed to in writing, softwaredistributed under the License is distributed on an "AS IS" BASIS,WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.See the License for the specific language governing permissions andlimitations under the License. See accompanying LICENSE file.
--><!-- Put site-specific property overrides in this file. --><configuration>
<property><name>fs.defaultFS</name><value>hdfs://hadoop-namenode:8020</value></property>
</configuration>
//hadoop-namenode容器IP可以在宿主机执行weave ps 命令获取,配置文件修改完毕后通过docker cp命令将文件拷贝至hive容器内的/opt/hadoop-2.7.4/etc/hadoop目录与/opt/hive/conf目录。
启动metastore
#在hive容器内部执行
hive --service metastore &
启动hiveserver2
#在hive容器内部执行(执行此命令需要先关闭hadoo-namenode的安全模式)
hive --service hiveserver2 --hiveconf hive.root.logger=DEBUG,console
执行HQL:
CREATE TABLE test_hive (id INT, name STRING);
INSERT INTO test_hive VALUES (1, 'hive-test');
SELECT * FROM test_hive;
- 预期结果:输出
1, hive-test。
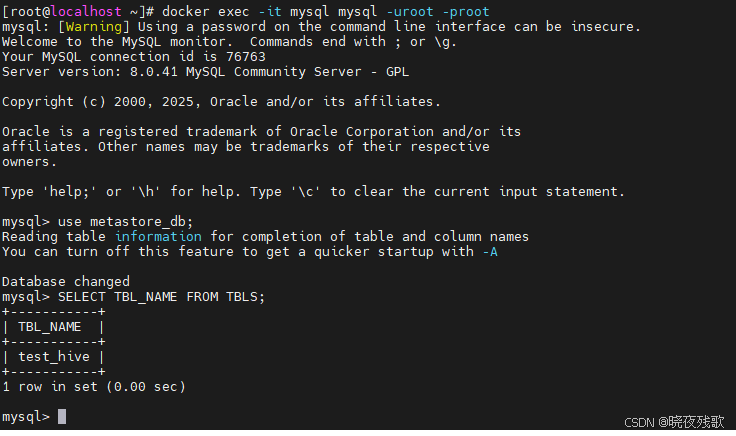
(2) 验证MySQL元数据
docker exec -it mysql mysql -uroot -proot
use metastore_db;
SELECT TBL_NAME FROM TBLS;
- 预期结果:显示
test_hive表名。
如图所示:
验证Kafka
(1) 生产与消费消息
docker exec -it kafka-1 bash
# 创建主题
kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092
# 生产消息
echo "hello kafka" | kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092
# 消费消息(需另开终端)
kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost:9092
- 预期结果:消费者终端输出
hello kafka。
如图所示:

** 验证本地数据挂载**
在JupyterLab中:
- 左侧文件浏览器中检查
/home/jovyan/work(对应本地./notebooks目录)。 - 检查
/data目录是否包含本地挂载的文件(例如/path/to/local/data中的内容)。
子节点设置
version: "3.8"services:# HDFS DataNode 服务hadoop-datanode:image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8privileged: true #使用二进制文件安装的docker需要开启特权模式,每个容器都需要开启该模式container_name: hadoop-datanode-2 # 子节点容器名称唯一(例如按编号命名)hostname: hadoop-datanode-2environment:- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020 # 指向主节点NameNode- HDFS_CONF_dfs_replication=2- TZ=Asia/Shanghainetworks:- bigdata-netdns:- 172.17.0.1volumes:- ./hadoop-conf:/etc/hadoop/conf # 挂载主节点的Hadoop配置文件restart: always
# extra_hosts:
# - "hadoop-namenode:10.32.0.32"logging:driver: "json-file"options:max-size: "100m"max-file: "5"# YARN NodeManager 服务hadoop-nodemanager:image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8privileged: true #使用二进制文件安装的docker需要开启特权模式,每个容器都需要开启该模式container_name: hadoop-nodemanager-2 # 子节点容器名称唯一hostname: hadoop-nodemanager-2environment:- YARN_CONF_yarn_resourcemanager_hostname=hadoop-resourcemanager # 指向主节点ResourceManager- CORE_CONF_fs_defaultFS=hdfs://hadoop-namenode:8020- TZ=Asia/Shanghainetworks:- bigdata-netdns:- 172.17.0.1volumes:- ./hadoop-conf/yarn-site.xml:/etc/hadoop/yarn-site.xml # 挂载主节点的Hadoop配置文件,用于上报内存与cpu核心数depends_on:- hadoop-datanode # 确保DataNode先启动(可选)restart: alwayslogging:driver: "json-file"options:max-size: "100m"max-file: "5"# 共享网络配置(必须与主节点一致)
networks:bigdata-net:external: truename: weave # 使用主节点创建的Weave网络
yarn配置文件
<configuration><property><name>yarn.resourcemanager.hostname</name><value>hadoop-resourcemanager</value></property><property><name>yarn.resourcemanager.address</name><value>hadoop-resourcemanager:8032</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.resource.memory-mb</name><value>4096</value></property><property><name>yarn.nodemanager.resource.cpu-vcores</name><value>8</value></property>
</configuration>
Ps:内存大小和cpu核心数需要按照实际情况填写。
#######################################################################################
今日推荐
小说:《异种的营养是牛肉的六倍?》
简介:【异种天灾】+【美食】+【日常】 变异生物的蛋白质是牛肉的几倍? 刚刚来到这个世界,刘笔就被自己的想法震惊到了。 在被孢子污染后的土地上觉醒了神厨系统,是不是搞错了什么?各种变异生物都能做成美食吗? 那就快端上来罢! 安全区边缘的特色美食饭店,有点非常规的温馨美食日常。

相关文章:
基于Docker和YARN的大数据环境部署实践最新版
基于Docker和YARN的大数据环境部署实践 目的 本操作手册旨在指导用户通过Docker容器技术,快速搭建一个完整的大数据环境。该环境包含以下核心组件: Hadoop HDFS/YARN(分布式存储与资源调度)Spark on YARN(分布式计算…...

【大模型】Bert
一、背景与起源 上下文建模的局限:在 BERT 之前,诸如 Word2Vec、GloVe 等词向量方法只能给出静态的词表示;而基于单向或浅层双向 LSTM/Transformer 的语言模型(如 OpenAI GPT)只能捕捉文本从左到右(或右到…...

《Go小技巧易错点100例》第三十四篇
本期分享: 1.sync.Mutex锁复制导致的异常 2.Go堆栈机制下容易导致的并发问题 sync.Mutex锁复制导致的异常 以下代码片段存在一个隐蔽的并发安全问题: type Counter struct {sync.MutexCount int }func foo(c Counter) {c.Lock()defer c.Unlock()…...

vue3+element-plus el-date-picker日期、年份筛选设置本周、本月、近3年等快捷筛选
一、页面代码: <template> <!-- 日期范围筛选框 --> <el-date-picker v-model"dateRange" value-format"YYYY-MM-DD" type"daterange" range-separator"至" start-placeholder"开始日期" end-…...

Vue 技术文档
一、引言 Vue 是一款用于构建用户界面的渐进式 JavaScript 框架,具有易上手、高性能、灵活等特点,能够帮助开发者快速开发出响应式的单页面应用。本技术文档旨在全面介绍 Vue 的相关技术知识,为开发人员提供参考和指导。 二、环境搭建 2.1…...
3 分钟学会使用 Puppeteer 将 HTML 转 PDF
需求背景 1、网页存档与文档管理 需要将网页内容长期保存或归档为PDF,确保内容不被篡改或丢失,适用于法律文档、合同、技术文档等场景。PDF格式便于存储和检索。 2、电子报告生成 动态生成的HTML内容(如数据分析报告、仪表盘)需导出为PDF供下载或打印。PDF保留排版和样…...

速通《Sklearn 与 TensorFlow 机器学习实用指南》
1.机器学习概览 1.1 什么是机器学习 机器学习是通过编程让计算机从数据中进行学习的科学。 1.2 为什么使用机器学习? 使用机器学习,是为了让计算机通过数据自动学习规律并进行预测或决策,无需显式编程规则。 1.3 机器学习系统的类型 1.…...
Ubuntu 下搭建ESP32 ESP-IDF开发环境,并在windows下用VSCode通过SSH登录Ubuntu开发ESP32应用
Ubuntu 下搭建ESP32 ESP-IDF开发环境,网上操作指南很多,本来一直也没有想过要写这么一篇文章。因为我其实不太习惯在linux下开发应用,平时更习惯windows的软件操作,只是因为windows下开发ESP32的应用编译时太慢,让人受…...

[FreeRTOS- 野火] - - - 临界段
一、介绍 临界段最常出现在对一些全局变量进行操作的场景。 1.1 临界段的定义 临界段是指在多任务系统中,一段需要独占访问共享资源的代码。在这段代码执行期间,必须确保没有任何其他任务或中断可以访问或修改相同的共享资源。 临界段的主要目的是防…...

【洛谷P9303题解】AC代码- [CCC 2023 J5] CCC Word Hunt
在CCC单词搜索游戏中,单词可以隐藏在字母网格中,以直线或直角的方式排列。以下是对代码的详细注释和解题思路的总结: 传送门: https://www.luogu.com.cn/problem/P9303 代码注释 #include <iostream> #include <vecto…...
NodeMediaEdge接入NodeMediaServer
如何使用NME接入NMS 简介 NodeMediaEdge是一款部署在监控摄像机网络前端中,拉取Onvif或者rtsp/rtmp/http视频流并使用rtmp/kmp推送到公网流媒体服务器的工具。 通过云平台协议注册到NodeMediaServer后,可以同NodeMediaServer结合使用。使用图形化的管理…...

【Java基础-环境搭建-创建项目】IntelliJ IDEA创建Java项目的详细步骤
在Java开发的世界里,选择一个强大的集成开发环境(IDE)是迈向高效编程的第一步。而IntelliJ IDEA无疑是Java开发者中最受欢迎的选择之一。它以其强大的功能、智能的代码辅助和简洁的用户界面,帮助无数开发者快速构建和部署Java项目…...

WebSocket指数避让与重连机制
1. 引言 在现代Web应用中,WebSocket技术已成为实现实时通信的重要手段。与传统的HTTP请求-响应模式不同,WebSocket建立持久连接,使服务器能够主动向客户端推送数据,极大地提升了Web应用的实时性和交互体验。然而,在实…...

DrissionPage WebPage模式:动态交互与高效爬取的完美平衡术
在Python自动化领域,开发者常面临两难选择:Selenium虽能处理动态页面但效率低下,Requests库轻量高效却难以应对JavaScript渲染。DrissionPage的WebPage模式创新性地将浏览器控制与数据包收发融为一体,为复杂网页采集场景提供了全新…...

adb查看、设置cpu相关信息
查内存 adb shell dumpsys meminfo查CPU top -m 10打开 system_monitor adb shell am start -n eu.chainfire.perfmon/.LaunchActivity设置CPU的核心数 在/sys/devices/system/cpu目录下可以看到你的CPU有几个核心,如果是双核,就是cpu0和cpu1,…...
PHP7+MySQL5.6 查立得源码授权系统DNS验证版
# PHP7MySQL5.6 查立得源码授权系统DNS验证版 ## 一、系统概述 本系统是一个基于PHP7和MySQL5.6的源码授权系统,使用DNS TXT记录验证域名所有权,实现对软件源码的授权保护。 系统支持多版本管理,可以灵活配置不同版本的价格和下载路径&#…...

68元开发板,开启智能硬件新篇章——明远智睿SSD2351深度解析
在智能硬件开发领域,开发板的选择至关重要。它不仅关系到项目的开发效率,还直接影响到最终产品的性能与稳定性。而今天,我要为大家介绍的这款明远智睿SSD2351开发板,仅需68元,却拥有远超同价位产品的性能与功能&#x…...

【QQ音乐】sign签名| data参数加密 | AES-GCM加密 | webpack (下)
1.目标 网址:https://y.qq.com/n/ryqq/toplist/26 我们知道了 sign P(n.data),其中n.data是明文的请求参数 2.webpack生成data加密参数 那么 L(n.data)就是密文的请求参数。返回一个Promise {<pending>},所以L(n.data) 是一个异步函数…...

基于netmiko模块实现支持SSH or Telnet的多线程多厂商网络设备自动化巡检脚本
自动化巡检的需求 巡检工作通常包含大量的重复性操作,而这些重复性特征意味着其背后存在明确的规则和逻辑。这种规律性为实现自动化提供了理想的前提条件。 自动化工具 我们这里采用python作为自动化的执行工具。 过程 安装 netmiko pip install netmiko 模块的使…...
)
不用 apt 的解决方案(从源码手动安装 PortAudio)
第一步:下载并编译 PortAudio 源码 cd /tmp wget http://www.portaudio.com/archives/pa_stable_v190600_20161030.tgz tar -xvzf pa_stable_v190600_20161030.tgz cd portaudio# 使用 cmake 构建(推荐): mkdir build &&…...

【前端】JS引擎 v.s. 正则表达式引擎
JS引擎 v.s. 正则表达式引擎 它们的转义符都是\ 经过JS引擎会进行一次转义 经过正则表达式会进行一次转义在一次转义中\\\\\的转义过程: 第一个 \ (转义符) 会“吃掉”第二个 \,结果是得到一个字面量的 \。 第三个 \ (转义符) 会“吃掉”第四个 \&#x…...

开发体育平台,怎么接入最合适的数据接口
一、核心需求匹配:明确平台功能定位 1.实时数据驱动型平台 需重点关注毫秒级延迟与多端同步能力。选择支持 WebSocket 协议的接口,可实现比分推送延迟 < 0.5秒。例如某电竞直播平台通过接入支持边缘计算的接口,将团战数据同步速度提升至…...

3D虚拟工厂
1、在线体验 3D虚拟工厂在线体验 vue3three.jsblender 2、功能介绍 1. 全屏显示功能2. 镜头重置功能3. 企业概况信息模块4. 标签隐藏/显示功能5. 模型自动旋转功能6. 办公楼分层分解展示7. 白天/夜晚 切换8. 场景资源预加载功能9. 晴天/雨天/雾天10. 无人机视角模式11. 行人…...

http传输协议的加密
创建目录存放签证 [rootserver100 ~]# mkdir /etc/nginx/certs [rootserver100 ~]# openssl req -newkey rsa:2048 -nodes -sha256 -keyout /etc/nginx/certs/timinglee.org.key -x509 -days 365 -out /etc/nginx/certs/timinglee.org.crt ..................................…...

半导体晶圆制造洁净厂房的微振控制方案-江苏泊苏系统集成有限公司
半导体晶圆制造洁净厂房的微振控制方案-江苏泊苏系统集成有限公司 微振控制在现行国家标准《电子工业洁净厂房设计规范》GB50472中有关微振控制的规定主要有:洁净厂房的微振控制设施的设计分阶段进行,应包括设计、施工和投产等各阶段的微振测试、厂房建…...
:STM32 GPIO与AFIO深度解析:从原理到高阶应用实战)
嵌入式(1):STM32 GPIO与AFIO深度解析:从原理到高阶应用实战
写在前面:本文基于STM32官方参考手册与实际项目经验,系统总结GPIO与AFIO的核心技术要点。每行代码都经过实际验证,可直接用于项目开发。 一、GPIO:芯片与世界的桥梁 1.1 GPIO的8种工作模式详解 工作模式等效电路典型应用场景配置…...

Netty 实战篇:Netty RPC 框架整合 Spring Boot,迈向工程化
本文将基于前面构建的 RPC 能力,尝试将其与 Spring Boot 整合,借助注解、自动扫描、依赖注入等机制,打造“开箱即用”的 Netty RPC 框架,提升开发效率与工程规范。 一、为什么要整合 Spring Boot? 手动 new 实例、写注…...

QML视图组件ListView、TableView、GridView介绍
1 MVD模型 Model:模型,包含数据及其结构。View:视图,用于显示数据。Delegate:代理,规定数据在视图中的显示方式。2 ListView 以列表形式展示数据。2.1 属性 model:设置或获取列表视图的数据模型delegate:定义了列表中每一项的外观和行为currentIndex:获取或设置当前选…...
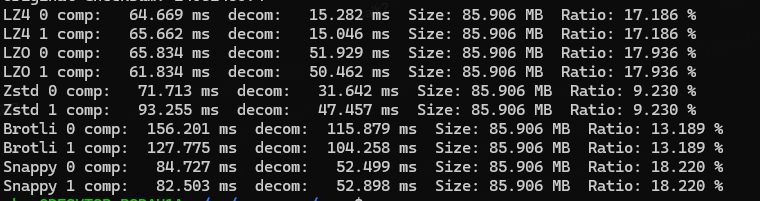
常见压缩算法性能和压缩率对比 LZ4 LZO ZSTD SNAPPY
网传压缩算法对比表 算法压缩率压缩速度解压速度支持流式压缩适用场景LZ4低极快极快是实时数据压缩、日志压缩、内存缓存等Zstandard高快快是文件压缩、网络传输、数据库备份等Brotli很高中等快是静态资源压缩(HTML、CSS、JS)等LZO低极快快是嵌入式系统…...

Spring Boot 应用中实现配置文件敏感信息加密解密方案
Spring Boot 应用中实现配置文件敏感信息加密解密方案 背景与挑战 🚩一、设计目标 🎯二、整体启动流程 🔄三、方案实现详解 ⚙️3.1 配置解密入口:EnvironmentPostProcessor3.2 通用解密工具类:EncryptionTool 四、快速…...