python打卡训练营打卡记录day40
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
昨天我们介绍了图像数据的格式以及模型定义的过程,发现和之前结构化数据的略有不同,主要差异体现在2处:
1. 模型定义的时候需要展平图像
2. 由于数据过大,需要将数据集进行分批次处理,这往往涉及到了dataset和dataloader来规范代码的组织
现在我们把注意力放在训练和测试代码的规范写法上。
单通道图片的规范写法
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失(原逻辑保留,用于 epoch 级统计)running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 原 epoch 级逻辑(测试、打印 epoch 结果)不变epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)# plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率# 6. 测试模型
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率# 7.绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")开始训练模型...
Epoch: 1/2 | Batch: 100/938 | 单Batch损失: 0.3583 | 累计平均损失: 0.6321
Epoch: 1/2 | Batch: 200/938 | 单Batch损失: 0.2035 | 累计平均损失: 0.4776
Epoch: 1/2 | Batch: 300/938 | 单Batch损失: 0.3044 | 累计平均损失: 0.4053
Epoch: 1/2 | Batch: 400/938 | 单Batch损失: 0.1427 | 累计平均损失: 0.3669
Epoch: 1/2 | Batch: 500/938 | 单Batch损失: 0.1742 | 累计平均损失: 0.3321
Epoch: 1/2 | Batch: 600/938 | 单Batch损失: 0.3089 | 累计平均损失: 0.3104
Epoch: 1/2 | Batch: 700/938 | 单Batch损失: 0.0455 | 累计平均损失: 0.2921
Epoch: 1/2 | Batch: 800/938 | 单Batch损失: 0.1018 | 累计平均损失: 0.2762
Epoch: 1/2 | Batch: 900/938 | 单Batch损失: 0.2935 | 累计平均损失: 0.2628
Epoch 1/2 完成 | 训练准确率: 92.42% | 测试准确率: 95.84%
Epoch: 2/2 | Batch: 100/938 | 单Batch损失: 0.1767 | 累计平均损失: 0.1356
Epoch: 2/2 | Batch: 200/938 | 单Batch损失: 0.1742 | 累计平均损失: 0.1289
Epoch: 2/2 | Batch: 300/938 | 单Batch损失: 0.1273 | 累计平均损失: 0.1282
Epoch: 2/2 | Batch: 400/938 | 单Batch损失: 0.2078 | 累计平均损失: 0.1234
Epoch: 2/2 | Batch: 500/938 | 单Batch损失: 0.0236 | 累计平均损失: 0.1209
Epoch: 2/2 | Batch: 600/938 | 单Batch损失: 0.0573 | 累计平均损失: 0.1193
Epoch: 2/2 | Batch: 700/938 | 单Batch损失: 0.0990 | 累计平均损失: 0.1170
Epoch: 2/2 | Batch: 800/938 | 单Batch损失: 0.1580 | 累计平均损失: 0.1152
Epoch: 2/2 | Batch: 900/938 | 单Batch损失: 0.0749 | 累计平均损失: 0.1139
Epoch 2/2 完成 | 训练准确率: 96.63% | 测试准确率: 96.93%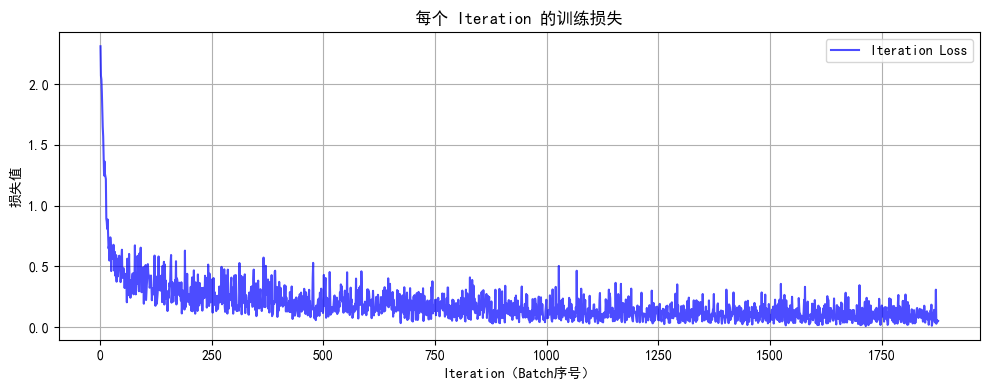
训练完成!最终测试准确率: 96.93%
彩色图片的规范写法
彩色的通道也是在第一步被直接展平,其他代码一致
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")开始训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.9130 | 累计平均损失: 1.9142
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 1.7181 | 累计平均损失: 1.8331
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.6971 | 累计平均损失: 1.7934
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.4990 | 累计平均损失: 1.7678
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.6183 | 累计平均损失: 1.7442
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5543 | 累计平均损失: 1.7267
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 1.7159 | 累计平均损失: 1.7129
Epoch 1/20 完成 | 训练准确率: 39.84% | 测试准确率: 45.88%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 1.4124 | 累计平均损失: 1.4658
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 1.6699 | 累计平均损失: 1.4697
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 1.7102 | 累计平均损失: 1.4671
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 1.4926 | 累计平均损失: 1.4676
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 1.3666 | 累计平均损失: 1.4650
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 1.3310 | 累计平均损失: 1.4607
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 1.4583 | 累计平均损失: 1.4586
Epoch 2/20 完成 | 训练准确率: 48.62% | 测试准确率: 49.68%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 1.1293 | 累计平均损失: 1.3566
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 1.4640 | 累计平均损失: 1.3403
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 1.2351 | 累计平均损失: 1.3399
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 1.3131 | 累计平均损失: 1.3401
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 1.2970 | 累计平均损失: 1.3390
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 1.3351 | 累计平均损失: 1.3405
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 1.5919 | 累计平均损失: 1.3426
...
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.3302 | 累计平均损失: 0.3606
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.3446 | 累计平均损失: 0.3678
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.5340 | 累计平均损失: 0.3799
Epoch 20/20 完成 | 训练准确率: 86.23% | 测试准确率: 52.44%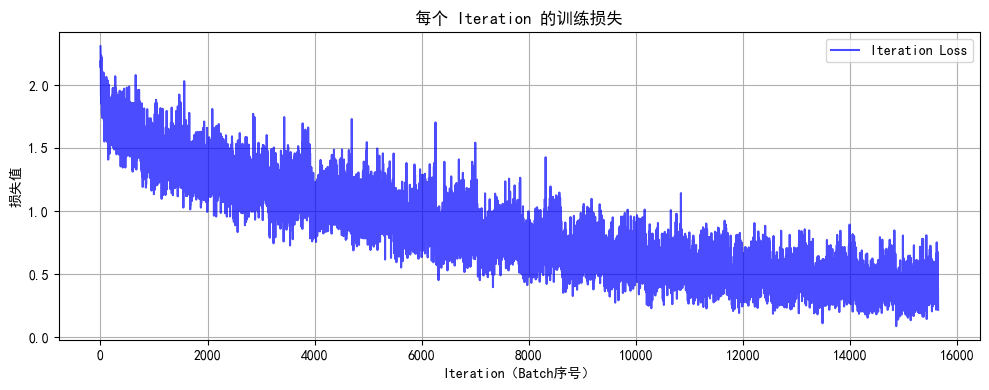
训练完成!最终测试准确率: 52.44%
由于深度mlp的参数过多,为了避免过拟合在这里引入了dropout这个操作,他可以在训练阶段随机丢弃一些神经元,避免过拟合情况。dropout的取值也是超参数。
在测试阶段,由于开启了eval模式,会自动关闭dropout。
可以继续调用这个函数来复用。
# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")开始训练模型...
Epoch: 1/20 | Batch: 100/782 | 单Batch损失: 1.1690 | 累计平均损失: 1.3007
Epoch: 1/20 | Batch: 200/782 | 单Batch损失: 0.9294 | 累计平均损失: 1.2487
Epoch: 1/20 | Batch: 300/782 | 单Batch损失: 1.2073 | 累计平均损失: 1.2097
Epoch: 1/20 | Batch: 400/782 | 单Batch损失: 1.0061 | 累计平均损失: 1.1792
Epoch: 1/20 | Batch: 500/782 | 单Batch损失: 1.0305 | 累计平均损失: 1.1537
Epoch: 1/20 | Batch: 600/782 | 单Batch损失: 1.5181 | 累计平均损失: 1.1305
Epoch: 1/20 | Batch: 700/782 | 单Batch损失: 0.9825 | 累计平均损失: 1.1136
Epoch 1/20 完成 | 训练准确率: 63.69% | 测试准确率: 52.15%
Epoch: 2/20 | Batch: 100/782 | 单Batch损失: 0.3530 | 累计平均损失: 0.4892
Epoch: 2/20 | Batch: 200/782 | 单Batch损失: 0.3962 | 累计平均损失: 0.4302
Epoch: 2/20 | Batch: 300/782 | 单Batch损失: 0.3235 | 累计平均损失: 0.4046
Epoch: 2/20 | Batch: 400/782 | 单Batch损失: 0.3666 | 累计平均损失: 0.3863
Epoch: 2/20 | Batch: 500/782 | 单Batch损失: 0.2378 | 累计平均损失: 0.3766
Epoch: 2/20 | Batch: 600/782 | 单Batch损失: 0.4059 | 累计平均损失: 0.3716
Epoch: 2/20 | Batch: 700/782 | 单Batch损失: 0.2039 | 累计平均损失: 0.3690
Epoch 2/20 完成 | 训练准确率: 87.11% | 测试准确率: 52.81%
Epoch: 3/20 | Batch: 100/782 | 单Batch损失: 0.1667 | 累计平均损失: 0.2780
Epoch: 3/20 | Batch: 200/782 | 单Batch损失: 0.1784 | 累计平均损失: 0.2727
Epoch: 3/20 | Batch: 300/782 | 单Batch损失: 0.1975 | 累计平均损失: 0.2778
Epoch: 3/20 | Batch: 400/782 | 单Batch损失: 0.2125 | 累计平均损失: 0.2834
Epoch: 3/20 | Batch: 500/782 | 单Batch损失: 0.1700 | 累计平均损失: 0.2937
Epoch: 3/20 | Batch: 600/782 | 单Batch损失: 0.4179 | 累计平均损失: 0.3023
Epoch: 3/20 | Batch: 700/782 | 单Batch损失: 0.3614 | 累计平均损失: 0.3117
Epoch 3/20 完成 | 训练准确率: 88.84% | 测试准确率: 51.97%
Epoch: 4/20 | Batch: 100/782 | 单Batch损失: 0.3458 | 累计平均损失: 0.3014
Epoch: 4/20 | Batch: 200/782 | 单Batch损失: 0.3180 | 累计平均损失: 0.2991
Epoch: 4/20 | Batch: 300/782 | 单Batch损失: 0.2757 | 累计平均损失: 0.3060
Epoch: 4/20 | Batch: 400/782 | 单Batch损失: 0.2953 | 累计平均损失: 0.3019
Epoch: 4/20 | Batch: 500/782 | 单Batch损失: 0.4005 | 累计平均损失: 0.3065
Epoch: 4/20 | Batch: 600/782 | 单Batch损失: 0.2583 | 累计平均损失: 0.3105
Epoch: 4/20 | Batch: 700/782 | 单Batch损失: 0.3109 | 累计平均损失: 0.3162
Epoch 4/20 完成 | 训练准确率: 88.52% | 测试准确率: 51.82%
Epoch: 5/20 | Batch: 100/782 | 单Batch损失: 0.3924 | 累计平均损失: 0.2956
Epoch: 5/20 | Batch: 200/782 | 单Batch损失: 0.3494 | 累计平均损失: 0.2924
Epoch: 5/20 | Batch: 300/782 | 单Batch损失: 0.2822 | 累计平均损失: 0.3106
Epoch: 5/20 | Batch: 400/782 | 单Batch损失: 0.1936 | 累计平均损失: 0.3136
Epoch: 5/20 | Batch: 500/782 | 单Batch损失: 0.5070 | 累计平均损失: 0.3189
Epoch: 5/20 | Batch: 600/782 | 单Batch损失: 0.2527 | 累计平均损失: 0.3242
Epoch: 5/20 | Batch: 700/782 | 单Batch损失: 0.3267 | 累计平均损失: 0.3261
Epoch 5/20 完成 | 训练准确率: 88.36% | 测试准确率: 52.00%
Epoch: 6/20 | Batch: 100/782 | 单Batch损失: 0.1880 | 累计平均损失: 0.3100
Epoch: 6/20 | Batch: 200/782 | 单Batch损失: 0.2353 | 累计平均损失: 0.2915
Epoch: 6/20 | Batch: 300/782 | 单Batch损失: 0.2529 | 累计平均损失: 0.2942
Epoch: 6/20 | Batch: 400/782 | 单Batch损失: 0.4678 | 累计平均损失: 0.2997
Epoch: 6/20 | Batch: 500/782 | 单Batch损失: 0.3993 | 累计平均损失: 0.3007
Epoch: 6/20 | Batch: 600/782 | 单Batch损失: 0.4105 | 累计平均损失: 0.3078
Epoch: 6/20 | Batch: 700/782 | 单Batch损失: 0.2575 | 累计平均损失: 0.3126
Epoch 6/20 完成 | 训练准确率: 88.84% | 测试准确率: 52.95%
Epoch: 7/20 | Batch: 100/782 | 单Batch损失: 0.2817 | 累计平均损失: 0.2499
Epoch: 7/20 | Batch: 200/782 | 单Batch损失: 0.1256 | 累计平均损失: 0.2508
Epoch: 7/20 | Batch: 300/782 | 单Batch损失: 0.4671 | 累计平均损失: 0.2559
Epoch: 7/20 | Batch: 400/782 | 单Batch损失: 0.1727 | 累计平均损失: 0.2640
Epoch: 7/20 | Batch: 500/782 | 单Batch损失: 0.2598 | 累计平均损失: 0.2703
Epoch: 7/20 | Batch: 600/782 | 单Batch损失: 0.3861 | 累计平均损失: 0.2827
Epoch: 7/20 | Batch: 700/782 | 单Batch损失: 0.3786 | 累计平均损失: 0.2914
Epoch 7/20 完成 | 训练准确率: 89.71% | 测试准确率: 52.77%
Epoch: 8/20 | Batch: 100/782 | 单Batch损失: 0.3253 | 累计平均损失: 0.2668
Epoch: 8/20 | Batch: 200/782 | 单Batch损失: 0.2284 | 累计平均损失: 0.2659
Epoch: 8/20 | Batch: 300/782 | 单Batch损失: 0.1499 | 累计平均损失: 0.2636
Epoch: 8/20 | Batch: 400/782 | 单Batch损失: 0.2084 | 累计平均损失: 0.2650
Epoch: 8/20 | Batch: 500/782 | 单Batch损失: 0.2098 | 累计平均损失: 0.2700
Epoch: 8/20 | Batch: 600/782 | 单Batch损失: 0.2286 | 累计平均损失: 0.2801
Epoch: 8/20 | Batch: 700/782 | 单Batch损失: 0.4029 | 累计平均损失: 0.2830
Epoch 8/20 完成 | 训练准确率: 89.82% | 测试准确率: 52.35%
Epoch: 9/20 | Batch: 100/782 | 单Batch损失: 0.0950 | 累计平均损失: 0.2447
Epoch: 9/20 | Batch: 200/782 | 单Batch损失: 0.1702 | 累计平均损失: 0.2450
Epoch: 9/20 | Batch: 300/782 | 单Batch损失: 0.1907 | 累计平均损失: 0.2457
Epoch: 9/20 | Batch: 400/782 | 单Batch损失: 0.1766 | 累计平均损失: 0.2520
Epoch: 9/20 | Batch: 500/782 | 单Batch损失: 0.3625 | 累计平均损失: 0.2576
Epoch: 9/20 | Batch: 600/782 | 单Batch损失: 0.2169 | 累计平均损失: 0.2570
Epoch: 9/20 | Batch: 700/782 | 单Batch损失: 0.1956 | 累计平均损失: 0.2635
Epoch 9/20 完成 | 训练准确率: 90.41% | 测试准确率: 51.64%
Epoch: 10/20 | Batch: 100/782 | 单Batch损失: 0.2936 | 累计平均损失: 0.2489
Epoch: 10/20 | Batch: 200/782 | 单Batch损失: 0.2909 | 累计平均损失: 0.2324
Epoch: 10/20 | Batch: 300/782 | 单Batch损失: 0.1375 | 累计平均损失: 0.2305
Epoch: 10/20 | Batch: 400/782 | 单Batch损失: 0.0812 | 累计平均损失: 0.2352
Epoch: 10/20 | Batch: 500/782 | 单Batch损失: 0.3469 | 累计平均损失: 0.2392
Epoch: 10/20 | Batch: 600/782 | 单Batch损失: 0.1433 | 累计平均损失: 0.2467
Epoch: 10/20 | Batch: 700/782 | 单Batch损失: 0.4560 | 累计平均损失: 0.2535
Epoch 10/20 完成 | 训练准确率: 90.85% | 测试准确率: 51.52%
Epoch: 11/20 | Batch: 100/782 | 单Batch损失: 0.1649 | 累计平均损失: 0.2532
Epoch: 11/20 | Batch: 200/782 | 单Batch损失: 0.2458 | 累计平均损失: 0.2379
Epoch: 11/20 | Batch: 300/782 | 单Batch损失: 0.1691 | 累计平均损失: 0.2427
Epoch: 11/20 | Batch: 400/782 | 单Batch损失: 0.1717 | 累计平均损失: 0.2456
Epoch: 11/20 | Batch: 500/782 | 单Batch损失: 0.3952 | 累计平均损失: 0.2559
Epoch: 11/20 | Batch: 600/782 | 单Batch损失: 0.3514 | 累计平均损失: 0.2661
Epoch: 11/20 | Batch: 700/782 | 单Batch损失: 0.3663 | 累计平均损失: 0.2691
Epoch 11/20 完成 | 训练准确率: 90.59% | 测试准确率: 52.22%
Epoch: 12/20 | Batch: 100/782 | 单Batch损失: 0.1177 | 累计平均损失: 0.2207
Epoch: 12/20 | Batch: 200/782 | 单Batch损失: 0.1346 | 累计平均损失: 0.2176
Epoch: 12/20 | Batch: 300/782 | 单Batch损失: 0.2742 | 累计平均损失: 0.2289
Epoch: 12/20 | Batch: 400/782 | 单Batch损失: 0.2813 | 累计平均损失: 0.2345
Epoch: 12/20 | Batch: 500/782 | 单Batch损失: 0.2469 | 累计平均损失: 0.2344
Epoch: 12/20 | Batch: 600/782 | 单Batch损失: 0.2058 | 累计平均损失: 0.2381
Epoch: 12/20 | Batch: 700/782 | 单Batch损失: 0.5586 | 累计平均损失: 0.2473
Epoch 12/20 完成 | 训练准确率: 91.18% | 测试准确率: 52.62%
Epoch: 13/20 | Batch: 100/782 | 单Batch损失: 0.1948 | 累计平均损失: 0.2062
Epoch: 13/20 | Batch: 200/782 | 单Batch损失: 0.1775 | 累计平均损失: 0.2080
Epoch: 13/20 | Batch: 300/782 | 单Batch损失: 0.0834 | 累计平均损失: 0.2194
Epoch: 13/20 | Batch: 400/782 | 单Batch损失: 0.1640 | 累计平均损失: 0.2163
Epoch: 13/20 | Batch: 500/782 | 单Batch损失: 0.2912 | 累计平均损失: 0.2265
Epoch: 13/20 | Batch: 600/782 | 单Batch损失: 0.4307 | 累计平均损失: 0.2348
Epoch: 13/20 | Batch: 700/782 | 单Batch损失: 0.5615 | 累计平均损失: 0.2456
Epoch 13/20 完成 | 训练准确率: 91.39% | 测试准确率: 52.30%
Epoch: 14/20 | Batch: 100/782 | 单Batch损失: 0.1902 | 累计平均损失: 0.2704
Epoch: 14/20 | Batch: 200/782 | 单Batch损失: 0.1832 | 累计平均损失: 0.2474
Epoch: 14/20 | Batch: 300/782 | 单Batch损失: 0.1021 | 累计平均损失: 0.2310
Epoch: 14/20 | Batch: 400/782 | 单Batch损失: 0.3127 | 累计平均损失: 0.2318
Epoch: 14/20 | Batch: 500/782 | 单Batch损失: 0.1489 | 累计平均损失: 0.2332
Epoch: 14/20 | Batch: 600/782 | 单Batch损失: 0.2432 | 累计平均损失: 0.2343
Epoch: 14/20 | Batch: 700/782 | 单Batch损失: 0.2338 | 累计平均损失: 0.2398
Epoch 14/20 完成 | 训练准确率: 91.78% | 测试准确率: 51.89%
Epoch: 15/20 | Batch: 100/782 | 单Batch损失: 0.1551 | 累计平均损失: 0.1924
Epoch: 15/20 | Batch: 200/782 | 单Batch损失: 0.0794 | 累计平均损失: 0.2037
Epoch: 15/20 | Batch: 300/782 | 单Batch损失: 0.1742 | 累计平均损失: 0.2068
Epoch: 15/20 | Batch: 400/782 | 单Batch损失: 0.2041 | 累计平均损失: 0.2106
Epoch: 15/20 | Batch: 500/782 | 单Batch损失: 0.2483 | 累计平均损失: 0.2176
Epoch: 15/20 | Batch: 600/782 | 单Batch损失: 0.3731 | 累计平均损失: 0.2215
Epoch: 15/20 | Batch: 700/782 | 单Batch损失: 0.1749 | 累计平均损失: 0.2280
Epoch 15/20 完成 | 训练准确率: 92.07% | 测试准确率: 51.83%
Epoch: 16/20 | Batch: 100/782 | 单Batch损失: 0.2730 | 累计平均损失: 0.1971
Epoch: 16/20 | Batch: 200/782 | 单Batch损失: 0.0863 | 累计平均损失: 0.1945
Epoch: 16/20 | Batch: 300/782 | 单Batch损失: 0.1693 | 累计平均损失: 0.2008
Epoch: 16/20 | Batch: 400/782 | 单Batch损失: 0.2598 | 累计平均损失: 0.2119
Epoch: 16/20 | Batch: 500/782 | 单Batch损失: 0.3095 | 累计平均损失: 0.2262
Epoch: 16/20 | Batch: 600/782 | 单Batch损失: 0.1129 | 累计平均损失: 0.2349
Epoch: 16/20 | Batch: 700/782 | 单Batch损失: 0.2049 | 累计平均损失: 0.2365
Epoch 16/20 完成 | 训练准确率: 91.83% | 测试准确率: 52.04%
Epoch: 17/20 | Batch: 100/782 | 单Batch损失: 0.1754 | 累计平均损失: 0.1977
Epoch: 17/20 | Batch: 200/782 | 单Batch损失: 0.1466 | 累计平均损失: 0.1984
Epoch: 17/20 | Batch: 300/782 | 单Batch损失: 0.0957 | 累计平均损失: 0.1946
Epoch: 17/20 | Batch: 400/782 | 单Batch损失: 0.0544 | 累计平均损失: 0.1984
Epoch: 17/20 | Batch: 500/782 | 单Batch损失: 0.2236 | 累计平均损失: 0.2093
Epoch: 17/20 | Batch: 600/782 | 单Batch损失: 0.2258 | 累计平均损失: 0.2079
Epoch: 17/20 | Batch: 700/782 | 单Batch损失: 0.3008 | 累计平均损失: 0.2127
Epoch 17/20 完成 | 训练准确率: 92.65% | 测试准确率: 52.30%
Epoch: 18/20 | Batch: 100/782 | 单Batch损失: 0.1159 | 累计平均损失: 0.2092
Epoch: 18/20 | Batch: 200/782 | 单Batch损失: 0.2773 | 累计平均损失: 0.2215
Epoch: 18/20 | Batch: 300/782 | 单Batch损失: 0.2862 | 累计平均损失: 0.2173
Epoch: 18/20 | Batch: 400/782 | 单Batch损失: 0.1915 | 累计平均损失: 0.2194
Epoch: 18/20 | Batch: 500/782 | 单Batch损失: 0.4617 | 累计平均损失: 0.2189
Epoch: 18/20 | Batch: 600/782 | 单Batch损失: 0.4545 | 累计平均损失: 0.2212
Epoch: 18/20 | Batch: 700/782 | 单Batch损失: 0.2722 | 累计平均损失: 0.2231
Epoch 18/20 完成 | 训练准确率: 92.38% | 测试准确率: 52.37%
Epoch: 19/20 | Batch: 100/782 | 单Batch损失: 0.0859 | 累计平均损失: 0.1813
Epoch: 19/20 | Batch: 200/782 | 单Batch损失: 0.3460 | 累计平均损失: 0.1917
Epoch: 19/20 | Batch: 300/782 | 单Batch损失: 0.1972 | 累计平均损失: 0.1989
Epoch: 19/20 | Batch: 400/782 | 单Batch损失: 0.4092 | 累计平均损失: 0.1989
Epoch: 19/20 | Batch: 500/782 | 单Batch损失: 0.2398 | 累计平均损失: 0.2045
Epoch: 19/20 | Batch: 600/782 | 单Batch损失: 0.3333 | 累计平均损失: 0.2080
Epoch: 19/20 | Batch: 700/782 | 单Batch损失: 0.0849 | 累计平均损失: 0.2097
Epoch 19/20 完成 | 训练准确率: 92.86% | 测试准确率: 52.97%
Epoch: 20/20 | Batch: 100/782 | 单Batch损失: 0.0850 | 累计平均损失: 0.1737
Epoch: 20/20 | Batch: 200/782 | 单Batch损失: 0.2993 | 累计平均损失: 0.1756
Epoch: 20/20 | Batch: 300/782 | 单Batch损失: 0.2127 | 累计平均损失: 0.1772
Epoch: 20/20 | Batch: 400/782 | 单Batch损失: 0.0924 | 累计平均损失: 0.1753
Epoch: 20/20 | Batch: 500/782 | 单Batch损失: 0.1720 | 累计平均损失: 0.1829
Epoch: 20/20 | Batch: 600/782 | 单Batch损失: 0.1470 | 累计平均损失: 0.1943
Epoch: 20/20 | Batch: 700/782 | 单Batch损失: 0.3909 | 累计平均损失: 0.2011
Epoch 20/20 完成 | 训练准确率: 93.22% | 测试准确率: 52.42%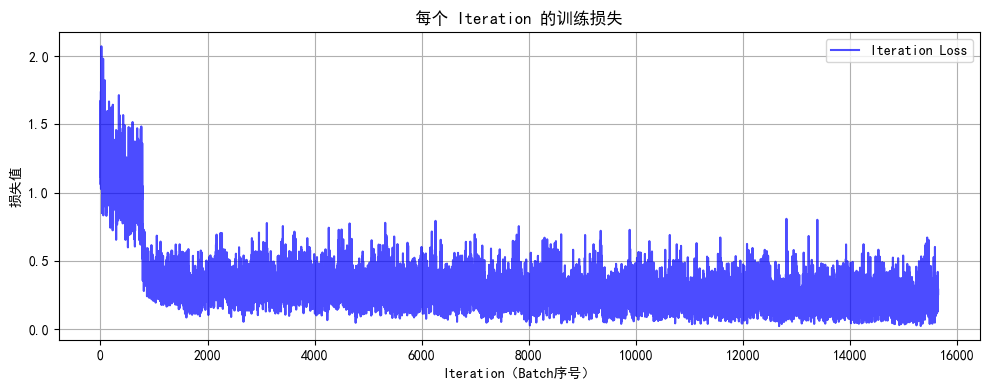
训练完成!最终测试准确率: 52.42%
此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
1. MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 “汽车轮胎” 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
2. 深层 MLP 的参数规模呈指数级增长,容易过拟合。
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。
@浙大疏锦行
相关文章:
python打卡训练营打卡记录day40
知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业:仔细学习下测试和训练代码…...

互联网大厂Java求职面试:Spring Boot 3.2+自动配置原理、AOT编译及原生镜像
标题:互联网大厂Java求职面试:Spring Boot 3.2自动配置原理、AOT编译及原生镜像 简述 本文详细探讨了在互联网大厂Java求职面试中,技术总监级别面试官与求职者郑薪苦之间的精彩对话,主题聚焦于Spring Boot 3.2自动配置原理、AOT…...
)
小型图书管理系统案例(用于spring mvc 实践)
小型图书管理系统案例 (Spring MVC Spring Data JPA Thymeleaf) 本项目案例旨在基于先前模块学习的 Spring MVC 知识,构建一个贴近企业实际的简单 Web 应用:小型图书管理系统。通过实现图书的 CRUD 操作、列表展示(含分页概念)…...
【清晰教程】利用Git工具将本地项目push上传至GitHub仓库中
Git 是一个分布式版本控制系统,由 Linus Torvalds 创建,用于有效、高速地处理从小到大的项目版本管理。GitHub 是一个基于 Git 的代码托管平台,提供了额外的协作和社交功能,使项目管理更加高效。它们为项目代码管理、团队协作和持…...

20250529-C#知识:静态类、静态构造函数和拓展方法
C#知识:静态类、静态构造函数和拓展方法 静态类一般用来编写工具类 1、静态类 用static关键字修饰的类一般充当工具类只能包含静态成员,不能包含静态索引器不能被实例化静态方法只能使用静态成员非静态方法既可以使用非静态成员,也可以使用静态成员 sta…...

实验设计与分析(第6版,Montgomery)第4章随机化区组,拉丁方, 及有关设计4.5节思考题4.18~4.19 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第章随机化区组,拉丁方, 及有关设计4.5节思考题4.18~4.19 R语言解题。主要涉及方差分析,拉丁方。 batch <- c(rep("batch1",5), rep(&quo…...

第十篇:MySQL 实战:数据迁移、分库分表与分区技术指南
随着系统数据量与访问压力的增长,MySQL 单实例常面临性能瓶颈。本篇系统讲解如何进行 数据迁移、分库分表 与 分区表设计,并结合实践案例提供完整的优化思路。 一、MySQL 数据迁移方式 1. 场景分类 场景推荐工具同版本、本地迁移mysqldump、cpibdata跨…...
【吾爱】逆向实战crackme160学习记录(一)
前言 最近想拿吾爱上的crackme程序练练手,发现论坛上已经有pk8900总结好的160个crackme,非常方便,而且有很多厉害的前辈已经写好经验贴和方法了,我这里只是做一下自己练习的记录,欢迎讨论学习,感谢吾爱论坛…...
vue2 + webpack 老项目升级 node v22 + vite + vue2 实战全记录
前言 随着这些年前端技术的飞速发展,几年前的一些老项目在最新的环境下很可能会出现烂掉的情况。如果项目不需要升级,只需要把编译后的文件放在那里跑而不用管的话还好。但是,某一天产品跑过来给你讲要升级某一个功能,你不得不去…...

opengauss 数据库安装主备 非om方式
一. 准备两台服务器 192.168.141.130 --主 192.168.141.131 --备 1.关闭防火墙 systemctl stop firewalld systemctl disable firewalld 2.关闭 selinux 服务 setenforce 0 vim /etc/selinux/config #设置 SELINUXdisabled 3.关闭透明大页 echo never > /sys/kern…...
STM32的HAL编码流程总结(上部)
目录 一、GPIO二、中断系统三、USART串口通信四、I2C通信五、定时器 一、GPIO 1.选择调试类型 在SYS中Debug选择Serial Wire模式 2.选择时钟源 在RCC中将HSE和LSH都选择为内部晶振 3.时钟树配置 4.GPIO配置 在芯片图上选择开启的引脚和其功能 配置引脚的各自属性 5.工…...

深度学习|pytorch基本运算
【1】引言 pytorch是深度学习常用的包,顾名思义,就是python适用的torch包,在python里面使用时直接import torch就可以调用。 需要注意的是,pytorch包与电脑配置、python版本有很大关系,一定要仔细阅读安装要求、找到…...
Java学习-5.15(模糊搜索,收藏,购物车))
(自用)Java学习-5.15(模糊搜索,收藏,购物车)
1. 模糊搜索商品功能 前端实现: 通过解析URL参数(如search联想)获取搜索关键字,发送AJAX GET请求到后端接口/product/searchGoodsMessage。 动态渲染搜索结果:若结果非空,循环遍历返回的商品数据ÿ…...
替代 WPS 的新思路?快速将 Word 转为图片 PDF
在这个数字化办公日益普及的时代,越来越多的人开始关注文档处理工具的功能与体验。当我们习惯了某些便捷操作时,却发现一些常用功能正逐渐变为付费项目——比如 WPS 中的一项实用功能也开始收费了。 这款工具最特别的地方在于,可以直接把 W…...
【K8S】K8S基础概念
一、 K8S组件 1.1 控制平面组件 kube-apiserver:公开 Kubernetes HTTP API 的核心组件服务器。 etcd:具备一致性和高可用性的键值存储,用于所有 API 服务器的数据存储。 kube-scheduler:查找尚未绑定到节点的 Pod,并将…...

FEMFAT许可分析的数据可视化方法
随着企业对FEMFAT软件使用的增加,如何有效地管理和分析许可数据成为了关键。数据可视化作为一种强大的工具,能够帮助企业直观地理解FEMFAT许可的使用情况,从而做出更明智的决策。本文将介绍FEMFAT许可分析的数据可视化方法,并探讨…...

打印机无法远程打印?可以本地打印,本地网络打印机设置给异地使用
很多小伙伴常有打印、远程打印的需求,特别是对于电商人、跨境电商、教师、产品经理、实验人员等群体来说掌握这项技能可谓是能够在很多场景下带来便捷,大幅提升做事效率!打印机是家庭和企业经常用到的设备,很多情况下会遇到本地可…...
包含Javascript的HTML静态页面调取本机摄像头
在实际业务开发中,需要在带有摄像头的工作机上拍摄施工现场工作过程的图片,然后上传到服务器备存。 这便需要编写可以运行在浏览器上的代码,并在代码中实现Javascript调取摄像头、截取帧保存为图片的功能。 为了使用户更快掌握JS调取摄像头…...

PCB设计实践(三十一)PCB设计中机械孔的合理设计与应用指南
一、机械孔的基本概念与分类 机械孔是PCB设计中用于实现机械固定、结构支撑、散热及电气连接的关键结构元件,其分类基于功能特性、制造工艺和应用场景的差异,主要分为以下几类: 1. 金属化机械孔 通过电镀工艺在孔内壁形成导电层,…...
)
deepseek问答记录:请讲解一下torch.full_like()
torch.full_like() 是 PyTorch 中的一个张量创建函数,用于创建一个与输入张量形状相同但所有元素值都填充为指定标量值的新张量。下面详细讲解其用法和特性: 1. 函数签名 torch.full_like(input, fill_value, *, dtypeNone, layoutNone, deviceNone, r…...
【Linux篇章】Linux 进程信号2:解锁系统高效运作的 “隐藏指令”,开启性能飞跃新征程(精讲捕捉信号及OS运行机制)
本篇文章将以一个小白视角,通俗易懂带你了解信号在产生,保存之后如何进行捕捉;以及在信号这个话题中;OS扮演的角色及背后是如何进行操作的;如何理解用户态内核态;还有一些可以引出的其他知识点;…...
多功能秒达开源工具箱源码|完全开源的中文工具箱
源码介绍 完全开源的中文工具箱永远的自由软件轻量级运行全平台支持(包括ARMv8)类似GPT的智能支持高效UI高度集成提供Docker映像和便携式版本支持桌面版开源插件库 下载地址 百度网盘下载 提取码:p9ck ▌本文由 6v6-博客网 整理分享 ▶ 更多…...

如何在腾讯云 OpenCloudOS 上安装 Docker 和 Docker Compose
从你提供的 /etc/os-release 文件内容来看,你的服务器运行的是 OpenCloudOS 9.2。这是一个基于 CentOS 和 RHEL 的开源操作系统,因此它属于 CentOS/RHEL 系列。 关键信息总结 操作系统名称:OpenCloudOS版本:9.2ID:op…...

清理skywalking历史索引
import requests from datetime import datetime, timedelta import os import re# 配置参数 ES_HOST os.getenv("ES_HOST", "http://192.168.0.250:9200") # ES地址 ES_USER os.getenv("ES_USER", "") # 用户…...
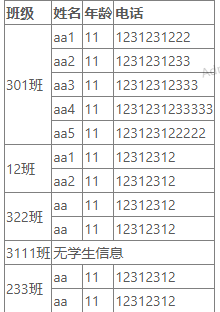
用nz-tabel写一个合并表格
用nz-tabel写一个合并表格 <nz-table #basicTable [nzData]"tableSearchStatus.dataList" nzBordered><thead><tr><th>班级</th><th>姓名</th><th>年龄</th><th>电话</th></tr></thead&…...

matlab计算转子系统的固有频率、振型、不平衡响应
可以计算转子系统的固有频率、振型、不平衡响应 MatrixRiccati/code/Dichotomy_1 (2).m , 2210 MatrixRiccati/code/Dichotomy_1.m , 2210 MatrixRiccati/code/RiccatiSY_1.m , 2756 MatrixRiccati/code/Trans1x (2).m , 451 MatrixRiccati/code/Trans1x.m , 451 MatrixRiccat…...
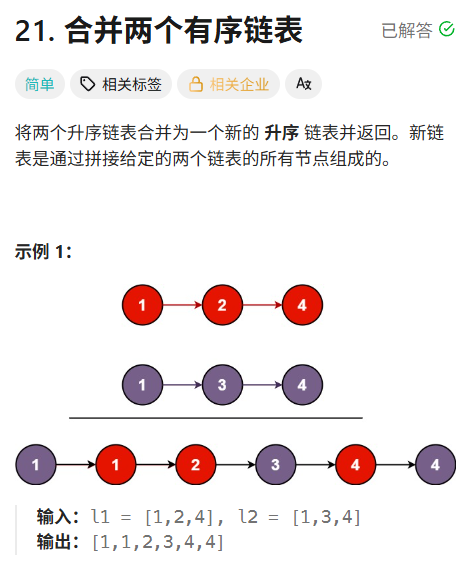
leetcode hot100刷题日记——29.合并两个有序链表
解答: 方法一:递归 递归的边界条件是啥呢? 递归别想那么多具体步骤,考虑大步骤,小的递归自己会去做的 class Solution { public:ListNode* mergeTwoLists(ListNode* list1, ListNode* list2) {//递归比较大小//先考虑…...

【机器人】具身导航 VLN 最新论文汇总 | Vision-and-Language Navigation
本文汇总了具身导航的论文,供大家参考学习,涵盖2025、2024、2023等 覆盖的会议和期刊:CVPR、IROS、ICRA、RSS、arXiv等等 论文和方法会持续更新的~ 一、🏠 中文标题版 2025 😆 [2025] WMNav:…...

Windows 安装 WSL2 并运行 Ubuntu 22.04 指南
Windows 安装 WSL2 并运行 Ubuntu 22.04 指南 本文为 Windows 10 和 Windows 11 用户提供从零开始搭建 WSL2 环境的详细指南,涵盖安装 Ubuntu 22.04、自定义存储位置、性能优化以及常见问题排查。无论你是开发者、运维工程师还是 Linux 爱好者,本文将助你…...

AI情感陪伴在医疗领域的核心应用潜力
一、精准情绪监测与干预 多模态情感识别系统 通过整合语音语调分析(降调与语速异常检测抑郁倾向)、微表情捕捉(面部肌肉运动追踪焦虑状态)、生理指标监测(心率变异幅度反映应激水平)等技术,构建…...