Python打卡训练营Day41
DAY 41 简单CNN
知识回顾
- 数据增强
- 卷积神经网络定义的写法
- batch归一化:调整一个批次的分布,常用与图像数据
- 特征图:只有卷积操作输出的才叫特征图
- 调度器:直接修改基础学习率
卷积操作常见流程如下:
1. 输入 → 卷积层 → Batch归一化层(可选) → 池化层 → 激活函数 → 下一层
- Flatten -> Dense (with Dropout,可选) -> Dense (Output)
这里相关的概念比较多,如果之前没有学习过计算机视觉部分,请自行上网检索视频了解下基础概念,也可以对照讲义学习下。
计算机视觉入门
作业:尝试手动修改下不同的调度器和CNN的结构,观察训练的差异。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
# 训练集:使用多种数据增强方法提高模型泛化能力
train_transform = transforms.Compose([# 随机裁剪图像,从原图中随机截取32x32大小的区域transforms.RandomCrop(32, padding=4),# 随机水平翻转图像(概率0.5)transforms.RandomHorizontalFlip(),# 随机颜色抖动:亮度、对比度、饱和度和色调随机变化transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),# 随机旋转图像(最大角度15度)transforms.RandomRotation(15),# 将PIL图像或numpy数组转换为张量transforms.ToTensor(),# 标准化处理:每个通道的均值和标准差,使数据分布更合理transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 测试集:仅进行必要的标准化,保持数据原始特性,标准化不损失数据信息,可还原
test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=train_transform # 使用增强后的预处理
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=test_transform # 测试集不使用增强
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 4. 定义CNN模型的定义(替代原MLP)
class CNN(nn.Module):def __init__(self):super(CNN, self).__init__() # 继承父类初始化# ---------------------- 第一个卷积块 ----------------------# 卷积层1:输入3通道(RGB),输出32个特征图,卷积核3x3,边缘填充1像素self.conv1 = nn.Conv2d(in_channels=3, # 输入通道数(图像的RGB通道)out_channels=32, # 输出通道数(生成32个新特征图)kernel_size=3, # 卷积核尺寸(3x3像素)padding=1 # 边缘填充1像素,保持输出尺寸与输入相同)# 批量归一化层:对32个输出通道进行归一化,加速训练self.bn1 = nn.BatchNorm2d(num_features=32)# ReLU激活函数:引入非线性,公式:max(0, x)self.relu1 = nn.ReLU()# 最大池化层:窗口2x2,步长2,特征图尺寸减半(32x32→16x16)self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2) # stride默认等于kernel_size# ---------------------- 第二个卷积块 ----------------------# 卷积层2:输入32通道(来自conv1的输出),输出64通道self.conv2 = nn.Conv2d(in_channels=32, # 输入通道数(前一层的输出通道数)out_channels=64, # 输出通道数(特征图数量翻倍)kernel_size=3, # 卷积核尺寸不变padding=1 # 保持尺寸:16x16→16x16(卷积后)→8x8(池化后))self.bn2 = nn.BatchNorm2d(num_features=64)self.relu2 = nn.ReLU()self.pool2 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:16x16→8x8# ---------------------- 第三个卷积块 ----------------------# 卷积层3:输入64通道,输出128通道self.conv3 = nn.Conv2d(in_channels=64, # 输入通道数(前一层的输出通道数)out_channels=128, # 输出通道数(特征图数量再次翻倍)kernel_size=3,padding=1 # 保持尺寸:8x8→8x8(卷积后)→4x4(池化后))self.bn3 = nn.BatchNorm2d(num_features=128)self.relu3 = nn.ReLU() # 复用激活函数对象(节省内存)self.pool3 = nn.MaxPool2d(kernel_size=2) # 尺寸减半:8x8→4x4# ---------------------- 全连接层(分类器) ----------------------# 计算展平后的特征维度:128通道 × 4x4尺寸 = 128×16=2048维self.fc1 = nn.Linear(in_features=128 * 4 * 4, # 输入维度(卷积层输出的特征数)out_features=512 # 输出维度(隐藏层神经元数))# Dropout层:训练时随机丢弃50%神经元,防止过拟合self.dropout = nn.Dropout(p=0.5)# 输出层:将512维特征映射到10个类别(CIFAR-10的类别数)self.fc2 = nn.Linear(in_features=512, out_features=10)def forward(self, x):# 输入尺寸:[batch_size, 3, 32, 32](batch_size=批量大小,3=通道数,32x32=图像尺寸)# ---------- 卷积块1处理 ----------x = self.conv1(x) # 卷积后尺寸:[batch_size, 32, 32, 32](padding=1保持尺寸)x = self.bn1(x) # 批量归一化,不改变尺寸x = self.relu1(x) # 激活函数,不改变尺寸x = self.pool1(x) # 池化后尺寸:[batch_size, 32, 16, 16](32→16是因为池化窗口2x2)# ---------- 卷积块2处理 ----------x = self.conv2(x) # 卷积后尺寸:[batch_size, 64, 16, 16](padding=1保持尺寸)x = self.bn2(x)x = self.relu2(x)x = self.pool2(x) # 池化后尺寸:[batch_size, 64, 8, 8]# ---------- 卷积块3处理 ----------x = self.conv3(x) # 卷积后尺寸:[batch_size, 128, 8, 8](padding=1保持尺寸)x = self.bn3(x)x = self.relu3(x)x = self.pool3(x) # 池化后尺寸:[batch_size, 128, 4, 4]# ---------- 展平与全连接层 ----------# 将多维特征图展平为一维向量:[batch_size, 128*4*4] = [batch_size, 2048]x = x.view(-1, 128 * 4 * 4) # -1自动计算批量维度,保持批量大小不变x = self.fc1(x) # 全连接层:2048→512,尺寸变为[batch_size, 512]x = self.relu3(x) # 激活函数(复用relu3,与卷积块3共用)x = self.dropout(x) # Dropout随机丢弃神经元,不改变尺寸x = self.fc2(x) # 全连接层:512→10,尺寸变为[batch_size, 10](未激活,直接输出logits)return x # 输出未经过Softmax的logits,适用于交叉熵损失函数# 初始化模型
model = CNN()
#model = model.to(device) # 将模型移至GPU(如果可用)
# 5. 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类任务
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器,学习率0.001
# 引入学习率调度器,在训练过程中动态调整学习率--训练初期使用较大的 LR 快速降低损失,训练后期使用较小的 LR 更精细地逼近全局最优解。
# 在每个 epoch 结束后,需要手动调用调度器来更新学习率,可以在训练过程中调用 scheduler.step()
scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, # 指定要控制的优化器(这里是Adam)mode='min', # 监测的指标是"最小化"(如损失函数)patience=3, # 如果连续3个epoch指标没有改善,才降低LRfactor=0.5 # 降低LR的比例(新LR = 旧LR × 0.5)
)
# scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.1)
# # 每5个epoch,LR = LR × 0.1 # scheduler = optim.lr_scheduler.MultiStepLR(optimizer, milestones=[10, 20, 30], gamma=0.5)
# # 当epoch=10、20、30时,LR = LR × 0.5 # scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=0.0001)
# # LR在[0.0001, LR_initial]之间按余弦曲线变化,周期为2×T_max
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号# 记录每个 epoch 的准确率和损失train_acc_history = []test_acc_history = []train_loss_history = []test_loss_history = []for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totaltrain_acc_history.append(epoch_train_acc)train_loss_history.append(epoch_train_loss)# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testtest_acc_history.append(epoch_test_acc)test_loss_history.append(epoch_test_loss)# 更新学习率调度器scheduler.step(epoch_test_loss)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 绘制每个 epoch 的准确率和损失曲线plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
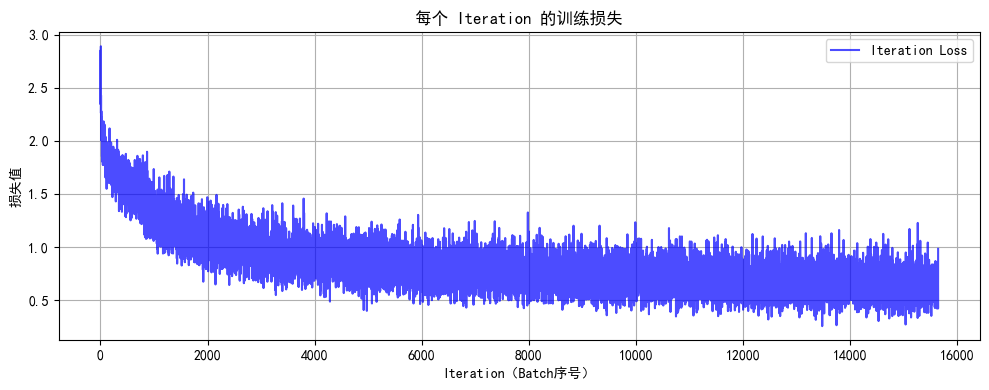
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 4))# 绘制准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('训练和测试准确率')plt.legend()plt.grid(True)# 绘制损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('训练和测试损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 8. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始使用CNN训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_cnn_model.pth')
# print("模型已保存为: cifar10_cnn_model.pth")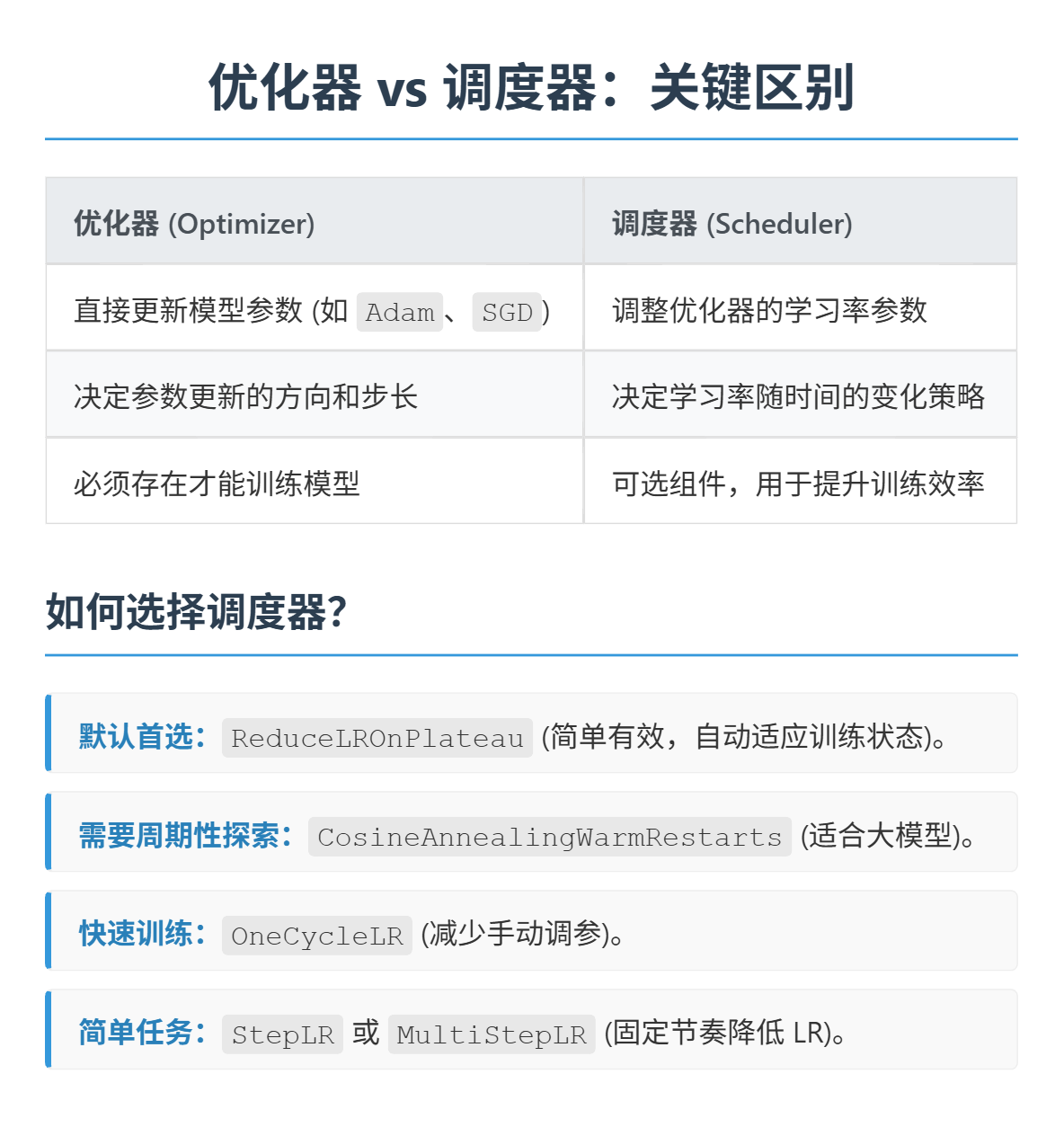
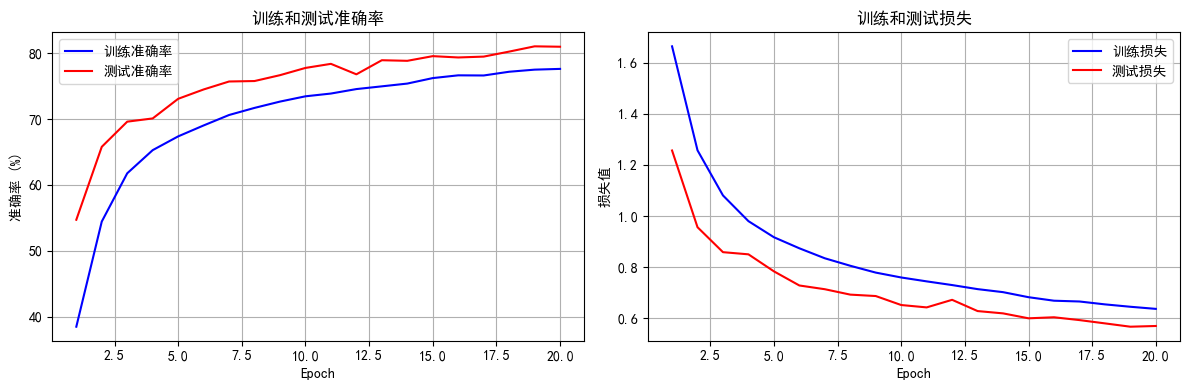 一般来说,在一个训练良好的深度学习模型中,训练集上的准确率应该等于或略高于测试集上的准确率。如果测试集上的准确率显著优于训练集,这通常是一个异常情况,可能暗示着以下几种潜在的问题或特殊情况:
一般来说,在一个训练良好的深度学习模型中,训练集上的准确率应该等于或略高于测试集上的准确率。如果测试集上的准确率显著优于训练集,这通常是一个异常情况,可能暗示着以下几种潜在的问题或特殊情况:
正则化层(最常见原因):
许多深度学习模型包含在训练和测试阶段表现不同的层,最典型的就是:
- Dropout 层: 在训练阶段,Dropout 层会随机关闭一部分神经元,引入噪声,降低模型在训练集上的表现(因为它每次都在一个“残缺”的网络上学习)。但在测试阶段,Dropout 层是关闭的,所有神经元都参与计算,模型使用其全部学习到的能力进行预测。因此,测试时 Dropout 的关闭可能会导致模型在测试集上表现略好于训练集。
- Batch Normalization(批归一化)层: 在训练阶段,Batch Normalization 使用当前批次数据的均值和方差进行归一化。但在测试阶段,它使用在训练过程中累积的全局均值和方差(移动平均)。这种行为上的差异也可能导致在某些情况下测试集准确率略高于训练集。
- 解决方法: 在评估模型性能时,确保正确切换模型的模式。例如,在 PyTorch 中使用
model.eval()模式进行评估,而在 TensorFlow/Keras 中,确保在评估函数中设置training=False。在评估训练集准确率时,也应切换到eval()模式,以进行公平比较。如果这是原因,切换模式后,训练集准确率通常会提高,并接近或略高于测试集准确率。 -
数据泄露(Data Leakage):
-
这是机器学习中最严重的问题之一。如果测试集中的信息在无意中“泄露”到了训练过程中,模型就会在测试集上表现得异常好,因为它已经“见过”这部分数据了。常见的数据泄露形式包括:
-
特征工程在划分数据集之前完成: 例如,计算了整个数据集的均值、标准差来标准化数据,然后再进行训练/测试集划分。这样测试集的信息就通过这些统计量进入了训练集。
- 不小心将测试数据混入训练数据: 复制粘贴错误,或者数据集划分逻辑有误。
- 使用“未来”信息进行预测: 在时间序列数据中,如果使用了未来的数据来训练模型,然后在测试集上预测,也会出现数据泄露。
- 解决方法: 严格遵循数据处理的最佳实践,即先将数据集划分为训练集、验证集和测试集,然后只在训练集上进行特征工程和数据预处理,并将这些处理规则应用到验证集和测试集。
浙大疏锦行-CSDN博客
相关文章:
Python打卡训练营Day41
DAY 41 简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 →…...

【Java进阶】图像处理:从基础概念掌握实际操作
一、核心概念:BufferedImage - 图像的画布与数据载体 在Java图像处理的世界里,BufferedImage是当之无愧的核心。你可以将它想象成一块内存中的画布,所有的像素数据、颜色模型以及图像的宽度、高度等信息都存储在其中。 BufferedImage继承自…...

JAVA网络编程——socket套接字的介绍下(详细)
目录 前言 1.TCP 套接字编程 与 UDP 数据报套接字的区别 2.TCP流套接字编程 API 介绍 TCP回显式服务器 Scanner 的多种使用方式 PrintWriter 的多种使用方式 TCP客户端 3. TCP 服务器中引入多线程 结尾 前言 各位读者大家好,今天笔者继续更新socket套接字的下半部分…...

Apache SeaTunnel 引擎深度解析:原理、技术与高效实践
Apache SeaTunnel 作为新一代高性能分布式数据集成平台,其核心引擎设计融合了现代大数据处理架构的精髓。 Apache SeaTunnel引擎通过分布式架构革新、精细化资源控制及企业级可靠性设计,显著提升了数据集成管道的执行效率与运维体验。其模块化设计允许用…...

深入理解 Maven 循环依赖问题及其解决方案
在 Java 开发领域,Maven 作为主流构建工具极大简化了依赖管理和项目构建。然而**循环依赖(circular dependency)**问题仍是常见挑战,轻则导致构建失败,重则引发类加载异常和系统架构混乱。 本文将从根源分析循环依赖的…...

pytest中的元类思想与实战应用
在Python编程世界里,元类是一种强大而高级的特性,它能在类定义阶段深度定制类的创建与行为。而pytest作为热门的测试框架,虽然没有直接使用元类,但在设计机制上,却暗含了许多与元类思想相通的地方。接下来,…...

前端生成UUID
UUID(Universally Unique Identifier)是一种在分布式系统中广泛使用的标识符,具有全球唯一性。在前端开发中,生成可靠的UUID对于数据追踪、会话管理、缓存键生成等场景至关重要。接下来将深入探讨UUID的实现原理、前端生成方案及最佳实践。 一、UUID标准与版本 1. UUID结构…...

玩客云WS1608控制LED灯的颜色
玩客云WS1608控制LED灯的颜色 玩客云设备有个红、绿、蓝三色led灯,在刷入armbian系统以后,这个灯的颜色就会显示异常,往往是一直显示红色。 如果要自动动手调整led灯的颜色,控制命令如下(需要root用户执行࿰…...
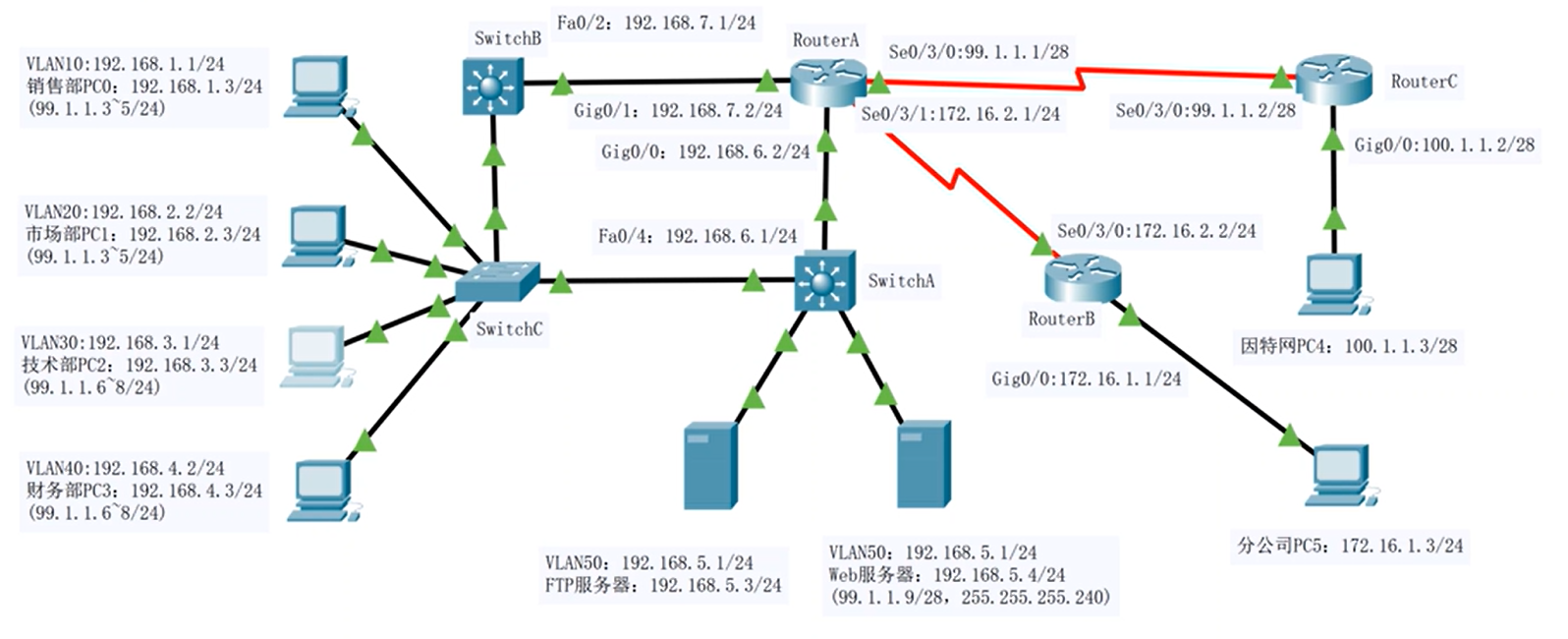
实验三 企业网络搭建及应用
实验三 企业网络搭建及应用 一、实验目的 1.掌握企业网络组建方法。 2.掌握企业网中常用网络技术配置方法。 二、实验描述 某企业设有销售部、市场部、技术部和财务部四个部门。公司内部网络使用二层交换机作为用户的接入设备。为了使网络更加稳定可靠,公司决定…...
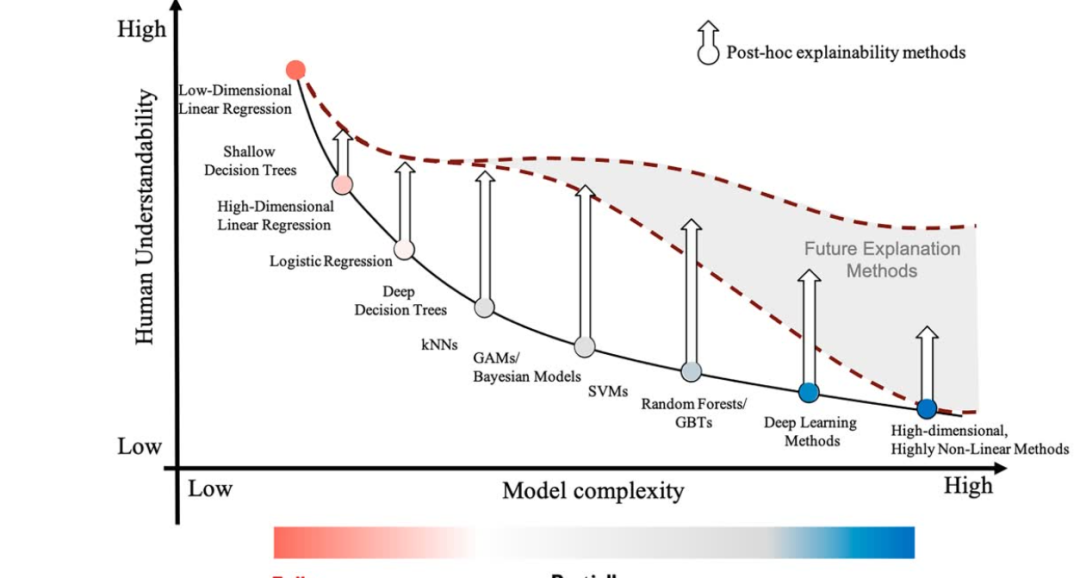
顶会新热门:机器学习可解释性
🧀机器学习模型的可解释性一直是研究的热点和挑战之一,同样也是近两年各大顶会的投稿热门。 🧀这是因为模型的决策过程不仅需要高准确性,还需要能被我们理解,不然我们很难将它迁移到其它的问题中,也很难进…...

ReactJS 中的 JSX工作原理
文章目录 前言✅ 1. JSX 是什么?🔧 2. 编译后的样子(核心机制)🧱 3. React.createElement 做了什么?🧠 4. JSX 与组件的关系🔄 5. JSX 到真实 DOM 的过程📘 6. JSX 与 Fr…...
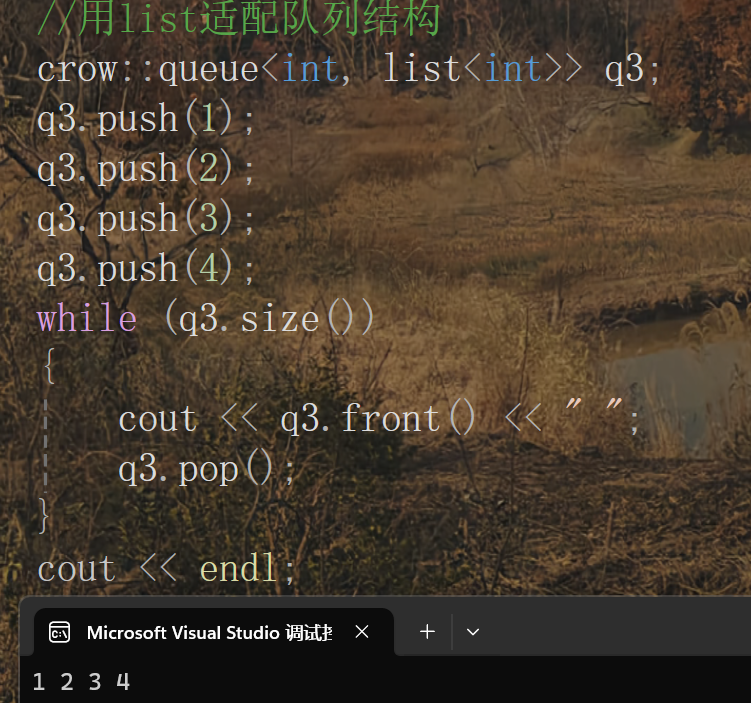
《STL--stack 和 queue 的使用及其底层实现》
引言: 上次我们学习了容器list的使用及其底层实现,相对来说是比较复杂的,今天我们要学习的适配器stack和queue与list相比就简单很多了,下面我们就开始今天的学习: 一:stack(后进先出ÿ…...

ArcGIS Pro 3.4 二次开发 - 地理处理
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 地理处理1 通用1.1 如何执行模型工具1.2 设置地理处理范围环境1.3 在 Geoprocessing 窗格中打开脚本工具对话框1.4 打开特定工具的地理处理工具窗格1.5 获取地理处理项目项1.6 阻止通过GP创建的特征类自动添加到地图中1.7 GPExecut…...

基于springboot的医护人员排班系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...

Asp.Net Core FluentValidation校验框架
文章目录 前言一、使用步骤1.安装 NuGet 包2.创建模型3.创建验证器4.配置 Program.cs5.创建控制器6.测试结果 二、常见问题及注意事项三、性能优化建议总结 前言 FluentValidation 是一个流行的 .NET 库,用于构建强类型的验证规则。它通常用于验证领域模型、DTO等对…...
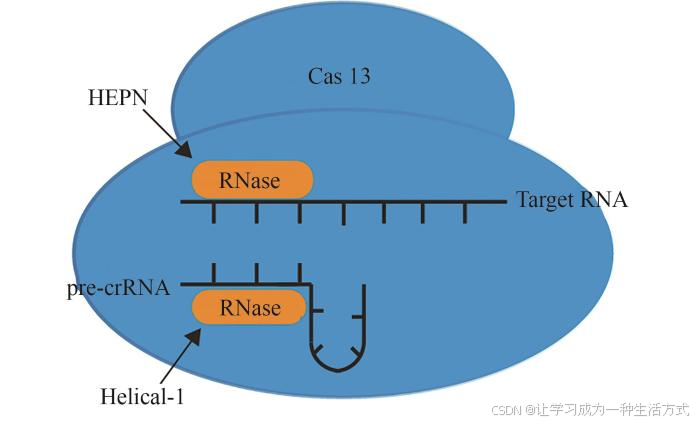
CRISPR-Cas系统的小型化研究进展-文献精读137
Progress in the miniaturization of CRISPR-Cas systems CRISPR-Cas系统的小型化研究进展 摘要 CRISPR-Cas基因编辑技术由于其简便性和高效性,已被广泛应用于生物学、医学、农学等领域的基础与应用研究。目前广泛使用的Cas核酸酶均具有较大的分子量(通…...
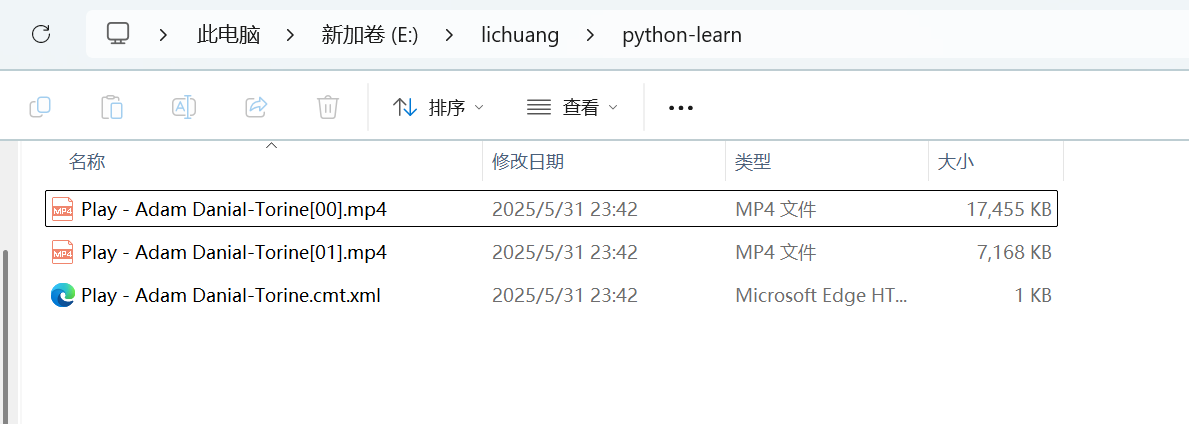
利用python工具you-get下载网页的视频文件
有时候我们可能在一个网站看到一个视频(比如B站),想下载,但是页面没有下载视频的按钮。这时候,我们可以借助python工具you-get来实现下载功能。下面简要说下步骤 (一)因为使用的是python工具&a…...

Wi-Fi 切换 5G 的时机
每天都希望 Wi-Fi 在我离开信号覆盖范围时能尽快切到 5G,但每次它都能坚挺到最后半格信号,我却连看个天气预报都看不了…我不得不手工关闭 Wi-Fi,然后等走远了之后再打开,如此反复,不厌其烦。 早上出门上班,…...

【请关注】各类数据库优化,抓大重点整改,快速优化空间mysql,Oracle,Neo4j等
各类数据库优化,抓大重点整改,快速优化,首先分析各数据库查询全部表的空间大小及记录条数的语句: MySQL -- 查看所有表的空间大小 SELECT TABLE_SCHEMA AS 数据库名, TABLE_NAME AS 表名, ENGINE AS 存储引擎, CONCAT(ROUND(DAT…...

Mybatis Plus JSqlParser解析sql语句及JSqlParser安装步骤
MyBatis Plus 整合 JSqlParser 进行 SQL 解析的实现方案,主要包括环境配置和具体应用。通过 Maven 添加mybatis-plus-core 和 jsqlparser 依赖后,可用 CCJSqlParserUtil 解析 SQL 语句,支持对 SELECT、UPDATE 等语句的语法树分析和重构。技术…...

React从基础入门到高级实战:React 高级主题 - 性能优化:深入探索与实践指南
React 性能优化:深入探索与实践指南 引言 在现代Web开发中,尤其是2025年的技术环境下,React应用的性能优化已成为开发者不可忽视的核心课题。随着用户对应用速度和体验的要求日益提高,React应用的规模和复杂性不断增加ÿ…...

负载均衡群集---Haproxy
目录 一、HAproxy 一、概念 二、核心作用 三、主要功能特性 四、应用场景 五、优势与特点 二、 案例分析 1. 案例概述 2. 案例前置知识点 (1)HTTP 请求 (2)负载均衡常用调度算法 (3)常见的 web …...

2025年5月个人工作生活总结
本文为 2025年5月工作生活总结。 研发编码 一个项目的临时记录 月初和另一项目同事向业主汇报方案,两个项目都不满意,后来领导做了调整,将项目合并,拆分了好几大块。原来我做的一些工作,如数据库、中间件等ÿ…...
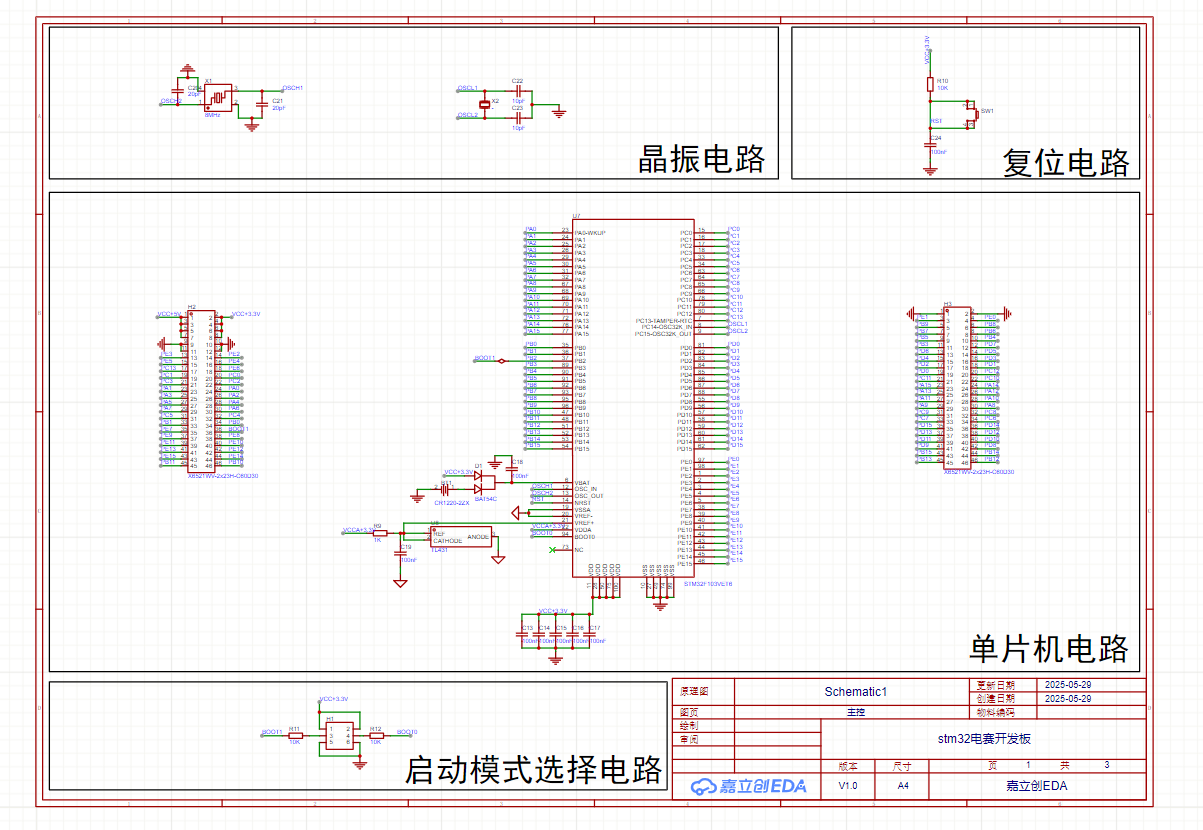
【stm32开发板】单片机最小系统原理图设计
一、批量添加网络标签 可以选择浮动工具中的N,单独为引脚添加网络标签。 当芯片引脚非常多的时候,选中芯片,右键选择扇出网络标签/非连接标识 按住ctrl键即可选中多个引脚 点击将引脚名称填入网络名 就完成了引脚标签的批量添加 二、电源引…...
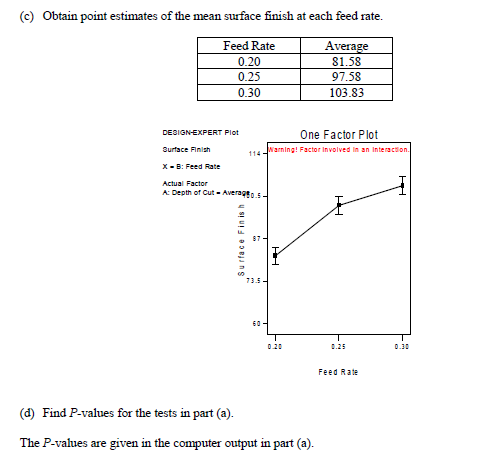
实验设计与分析(第6版,Montgomery)第5章析因设计引导5.7节思考题5.2 R语言解题
本文是实验设计与分析(第6版,Montgomery著,傅珏生译) 第5章析因设计引导5.7节思考题5.2 R语言解题。主要涉及方差分析,正态假设检验,残差分析,交互作用。 dataframe<-data.frame( Surfacec(74,64,60,92…...
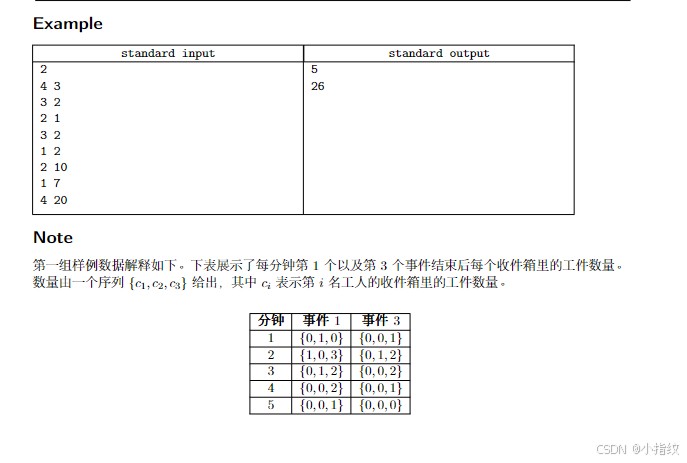
2025山东CCPC题解
文章目录 L - StellaD - Distributed SystemI - Square PuzzleE - Greatest Common DivisorG - Assembly Line L - Stella 题目来源:L - Stella 解题思路 签到题,因为给出的字母不是按顺序,可以存起来赋其值,然后在比较。 代码…...

【解决办法】ubuntu重启不起来,输入用户名和密码进不去,又重新返回登录页。
项目场景: ubuntu重启不起来,输入用户名和密码进不去,又重新返回登录页。 问题描述 在华硕天选一代笔记本上面安装了ubuntu22.04.5桌面版,但是重启以后出现,输入了用户名和密码,等待一会还让输入用户名和…...

CentOS Stream 9 中部署 MySQL 8.0 MGR(MySQL Group Replication)一主两从高可用集群
🐇明明跟你说过:个人主页 🏅个人专栏:《MySQL技术精粹》🏅 🔖行路有良友,便是天堂🔖 目录 一、前言 1、MySQL 8.0 中的高可用方案 2、适用场景 二、环境准备 1、系统环境说明…...
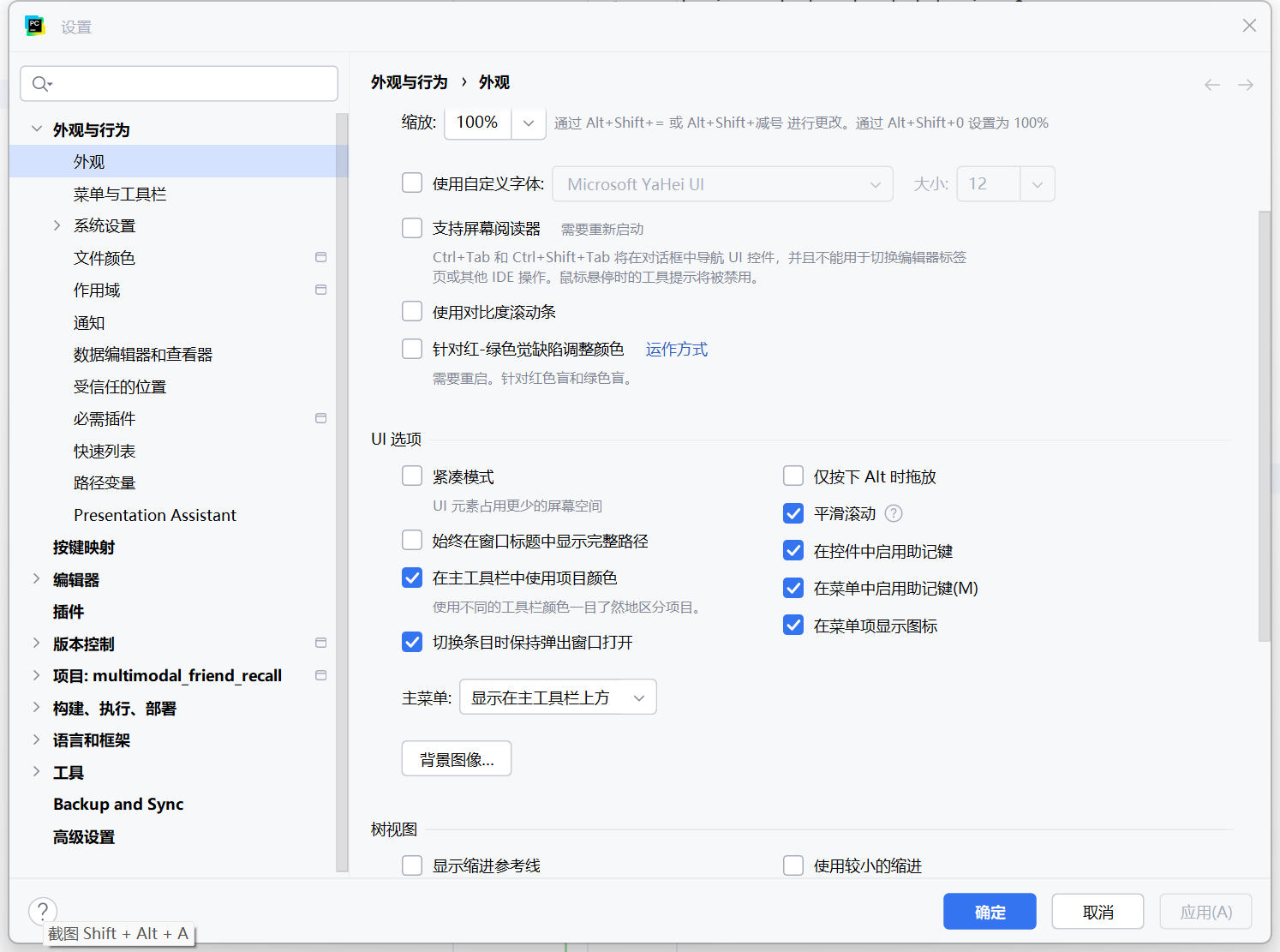
pycharm 新UI 固定菜单栏 pycharm2025 中文版
pycharm 新UI 文件 -> 设置 -> 外观与行为 -> 外观 -> UI选项 -> 主菜单:显示在主工具栏上方. 即可固定...

跟单业务和量化交易业务所涉及到的设计模式
🔁 跟单业务中常用的设计模式: 1. 观察者模式(Observer) 场景:一个大V下单,系统需要自动通知所有跟随者进行同步下单。好处:解耦下单者与跟随者,支持灵活扩展、异步通知。面试亮点…...