【深度学习】16. Deep Generative Models:生成对抗网络(GAN)
Deep Generative Models:生成对抗网络(GAN)
什么是生成建模(Generative Modeling)
生成模型的主要目标是从数据中学习其分布,从而具备“生成”数据的能力。两个关键任务:
- 密度估计(Density Estimation):学习真实数据的概率分布 p ( x ) p(x) p(x)。
- 样本生成(Sample Generation):从模型学习的分布中采样,生成新样本。
换句话说,生成建模不是仅预测标签,而是要建模整个数据的生成过程,使模型能“想象”并产生新的样本。
图示说明了输入图像 x x x 是由真实分布 p ( x ) p(x) p(x) 生成的。我们希望构建一个模型,也能从噪声或潜变量中生成具有相同分布的新样本。
为什么研究生成建模?
逼真的生成任务
模拟可能的未来规划(如股票市场)
训练生成模型还可以对潜在表征进行推理,这些潜在表征可以作为通用特征
从多个角度说明生成模型的重要性:
- 潜变量结构学习:生成模型能够发现数据中的隐藏因素,如风格、姿态、语义等。
- 半监督学习能力强:即使标签很少,也可以利用未标注数据学到有意义的表示。
- 数据建模能力强:可用于数据修复、风格迁移、图像翻译、图像上色等任务。
- 表示学习(Representation Learning):通过对输入数据建模,生成模型学到的特征常常可迁移用于其他任务。
- 未来模拟与预测:如视频预测、图像到视频生成等。
什么是生成对抗网络(GAN)
生成对抗网络是一种重要的深度生成模型,由两个神经网络组成:
- 生成器 G G G:从随机变量(noise) z ∼ p ( z ) z \sim p(z) z∼p(z) 生成图像 G ( z ) G(z) G(z)。
- 判别器 D D D:判断图像 x x x 是否来自真实数据分布 p d a t a ( x ) p_{data}(x) pdata(x)。
二者的训练过程是一个博弈(对抗)过程。
GAN 的目标函数
GAN 的优化目标是一个极小极大问题:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p(z)}[\log(1 - D(G(z)))] minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼p(z)[log(1−D(G(z)))]
含义如下:
- 第一项鼓励判别器 D D D 对真实图像 x x x 输出概率越接近 1 1 1 越好;
- 第二项鼓励判别器对生成图像 G ( z ) G(z) G(z) 输出概率越接近 0 0 0 越好;
- D的目标:最大化目标,使D(x)接近于1(真实),D(G(z))接近于0(假)
- G的目标:最小化目标,使D(G(z))接近于1(鉴别器被骗以为生成的G(z)是真实的)
因此,判别器和生成器是两个对手:
- 判别器 D D D 试图区分真假;
- 生成器 G G G 则试图以假乱真。
当博弈达到平衡时,判别器无法分辨真假图像,即 D ( G ( z ) ) = 0.5 D(G(z)) = 0.5 D(G(z))=0.5。
GAN 的训练直观理解
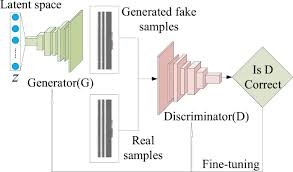
输入是noise,给到G,generated image + real image data as input,两个输入。D用来做binary classification.
可以将 GAN 的训练比喻为“造假者 vs 警察”的博弈:
- 初始时,生成器 G G G 生成的图像非常粗糙,容易被判别器 D D D 识别;
- 随着训练进行, G G G 不断改进生成策略, D D D 也在不断提升识别能力;
- 最终双方达到均衡, G G G 的输出与真实数据无法区分, D D D 的输出变成 0.5 0.5 0.5。
GAN 的总目标函数
生成器和判别器之间的博弈关系形式化为一个极小极大的对抗优化问题:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ log D ( x ) ] + E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{data}(x)}[\log D(x)] + \mathbb{E}_{z \sim p(z)}[\log(1 - D(G(z)))] minGmaxDV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼p(z)[log(1−D(G(z)))]
这个公式表示:
- 判别器试图最大化该表达式,正确区分真实图像和伪造图像;
- 生成器试图最小化该表达式,让伪造图像也被判断为真实;
- 最终博弈平衡点是 p g ( x ) = p d a t a ( x ) p_g(x) = p_{data}(x) pg(x)=pdata(x) 且 D ( x ) = 0.5 D(x) = 0.5 D(x)=0.5。
交替训练策略(Alternate Optimization)
为了求解上述极小极大问题,采用以下 交替更新策略:
1. Gradient Ascent on D
固定生成器参数 θ g \theta_g θg,更新判别器参数 θ d \theta_d θd,最大化以下目标:
max θ d [ E x ∼ p d a t a log D θ d ( x ) + E z ∼ p ( z ) log ( 1 − D θ d ( G θ g ( z ) ) ) ] \max_{\theta_d} \left[ \mathbb{E}_{x \sim p_{data}} \log D_{\theta_d}(x) + \mathbb{E}_{z \sim p(z)} \log(1 - D_{\theta_d}(G_{\theta_g}(z))) \right] maxθd[Ex∼pdatalogDθd(x)+Ez∼p(z)log(1−Dθd(Gθg(z)))]
也就是说:
- 判别器希望对真实样本 x x x 输出接近 1 1 1;
- 对伪造样本 G ( z ) G(z) G(z) 输出接近 0 0 0;
- 因为目标是最大化,所以需要对判别器使用 梯度上升。
2. Gradient Descent on G
固定判别器参数 θ d \theta_d θd,优化生成器参数 θ g \theta_g θg,最小化如下损失函数:
$ \min_{\theta_g} \mathbb{E}{z \sim p(z)} \log(1 - D{\theta_d}(G_{\theta_g}(z))) $
这个目标使得生成器试图提升 D ( G ( z ) ) D(G(z)) D(G(z)),让判别器认为伪造图像也是真实的,即:
- 尽可能让 D ( G ( z ) ) → 1 D(G(z)) \rightarrow 1 D(G(z))→1;
- 所以生成器使用 梯度下降 来最小化该损失。
但注意,这一损失可能在训练初期导致梯度消失,因此实际训练中常采用非饱和形式(non-saturating loss):
min θ g − E z ∼ p ( z ) log D θ d ( G θ g ( z ) ) \min_{\theta_g} - \mathbb{E}_{z \sim p(z)} \log D_{\theta_d}(G_{\theta_g}(z)) minθg−Ez∼p(z)logDθd(Gθg(z))
算法流程
外层:训练轮数
for number of training iterations do
对所有训练轮数重复执行以下步骤(每轮包括 k k k 次判别器更新 + 1 次生成器更新)。
内层:判别器更新(k 次)
for k steps do
每轮训练中先更新 k k k 次判别器, k k k 是一个超参数(原论文中使用 k = 1 k = 1 k=1,以节省计算资源)。
每次判别器更新包含以下步骤:
-
采样 m m m 个噪声样本:
$ {z^{(1)}, \dots, z^{(m)}} \sim p_g(z) $ -
采样 m m m 个真实样本:
$ {x^{(1)}, \dots, x^{(m)}} \sim p_{data}(x) $ -
更新判别器参数(梯度上升):
∇ θ d 1 m ∑ i = 1 m [ log D ( x ( i ) ) + log ( 1 − D ( G ( z ( i ) ) ) ) ] \nabla_{\theta_d} \frac{1}{m} \sum_{i=1}^{m} \left[ \log D(x^{(i)}) + \log(1 - D(G(z^{(i)}))) \right] ∇θdm1i=1∑m[logD(x(i))+log(1−D(G(z(i))))]
此步骤最大化判别器输出正确分类的概率:真实图像输出高,伪造图像输出低。
end for
生成器更新(1 次)
-
采样 m m m 个噪声样本:
$ {z^{(1)}, \dots, z^{(m)}} \sim p_g(z) $ -
更新生成器参数(梯度下降):
∇ θ g 1 m ∑ i = 1 m log ( 1 − D ( G ( z ( i ) ) ) ) \nabla_{\theta_g} \frac{1}{m} \sum_{i=1}^{m} \log \left(1 - D(G(z^{(i)})) \right) ∇θgm1i=1∑mlog(1−D(G(z(i))))
GAN 的训练过程可视化示例:A Simple Example
简单而直观的 1 维高斯分布示例,帮助我们理解 GAN 的对抗训练过程是如何逐步推进的。
图中包括四个子图(a)到(d),展示了生成分布 p g p_g pg 如何逐步接近真实分布 p d a t a p_{data} pdata,以及判别器 D ( x ) D(x) D(x) 的输出如何随着训练而变化。
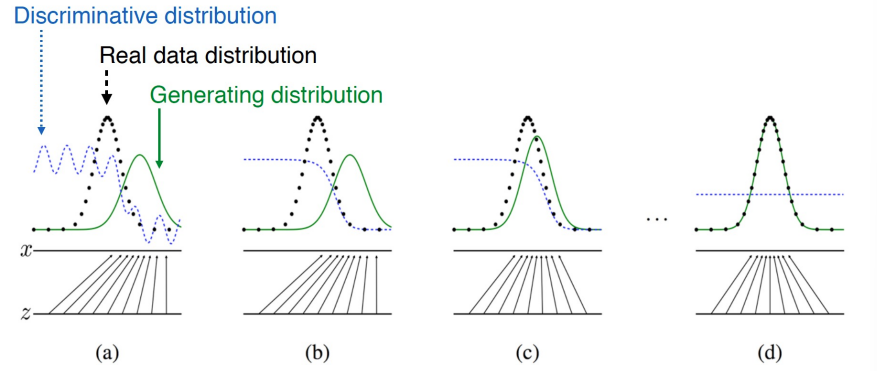
图中元素说明
- 黑色虚线:真实数据分布 p d a t a ( x ) p_{data}(x) pdata(x);
- 绿色曲线:生成器生成的分布 p g ( x ) p_g(x) pg(x);
- 蓝色曲线:判别器的输出 D ( x ) D(x) D(x),即当前判别器认为输入来自真实数据的概率;
- 横轴:样本空间 x x x;
- 下方横线:表示潜变量 z z z 的均匀分布域;
- 向上箭头:生成器 G ( z ) G(z) G(z) 将均匀分布映射到数据空间。
(a) 初始状态
- 真实数据分布 p d a t a ( x ) p_{data}(x) pdata(x) 和生成分布 p g ( x ) p_g(x) pg(x) 相差很远;
- 判别器 D ( x ) D(x) D(x) 在真实样本处输出接近 1,在伪造样本处输出接近 0;
- 说明判别器能很好地区分真假样本。
(b) 中间阶段
- 生成器开始学习, p g ( x ) p_g(x) pg(x) 向 p d a t a ( x ) p_{data}(x) pdata(x) 靠近;
- 判别器 D ( x ) D(x) D(x) 的输出逐渐平滑,对部分区域开始感到“困惑”;
- 说明生成器在某些区域已能成功欺骗判别器。
© 接近收敛
- 生成分布 p g ( x ) p_g(x) pg(x) 与真实分布 p d a t a ( x ) p_{data}(x) pdata(x) 几乎重合;
- 判别器输出趋近于 0.5 0.5 0.5,无法有效判断真假;
- 判别器的能力已接近上限。
(d) 理想收敛状态
- p g ( x ) = p d a t a ( x ) p_g(x) = p_{data}(x) pg(x)=pdata(x);
- 判别器对所有 x x x 的输出都为 D ( x ) = 0.5 D(x) = 0.5 D(x)=0.5;
- 说明两分布完全一致,GAN 达到理论最优状态。
下方生成机制解释
- 均匀采样 z z z:例如在 [ − 1 , 1 ] [-1, 1] [−1,1] 区间;
- 生成器 G G G 将 z z z 映射为 x = G ( z ) x = G(z) x=G(z);
- 当 G ( z ) G(z) G(z) 映射集中于高密度区域时,对应图中箭头密集;
- 当 G G G 映射至低密度区域,箭头稀疏。
文本解析与结论
文中说明如下关键结论:
- 判别器 D D D 学习输出概率来识别样本真假;
- 生成器 G G G 调整生成分布,使其逐步逼近真实分布;
- 当 p g = p d a t a p_g = p_{data} pg=pdata 时,GAN 达到 Nash 均衡;
- 判别器无法区分两者,输出恒为 D ( x ) = 0.5 D(x) = 0.5 D(x)=0.5;
- 此时训练达成目标,GAN 成功生成真实感极强的样本。
核心公式
生成器定义为一个可微分函数:
x = G ( z ; θ ( G ) ) x = G(z; \theta^{(G)}) x=G(z;θ(G))
其中:
- z z z 是从先验分布 p ( z ) p(z) p(z)(通常为均匀分布或高斯分布)中采样的随机变量;
- θ ( G ) \theta^{(G)} θ(G) 是生成器的参数;
- x x x 是生成样本,输出空间与真实数据空间相同;
- G G G 是一个可微的神经网络,用于将潜变量 z z z 映射为样本 x x x。
关键属性
- 无需显式写出 p g ( x ) p_g(x) pg(x) 的公式;
- 只需构建一个能够从 p g p_g pg 分布中采样的生成器 G G G;
- 只要 G G G 可微,就可以使用梯度优化进行训练;
- 这种方式称为隐式建模,相比显式建模(如 VAE)不要求明确分布函数。
GAN 的目标
我们有来自真实分布 p r p_r pr 的训练数据,目标是训练一个生成模型,使得其输出服从 p g p_g pg,并且有:
p g ≈ p r p_g \approx p_r pg≈pr
也就是说,我们不关心生成器输出的分布公式长什么样,只需要它能“以假乱真”。
相关文章:
【深度学习】16. Deep Generative Models:生成对抗网络(GAN)
Deep Generative Models:生成对抗网络(GAN) 什么是生成建模(Generative Modeling) 生成模型的主要目标是从数据中学习其分布,从而具备“生成”数据的能力。两个关键任务: 密度估计࿰…...
)
java操作服务器文件(把解析过的文件迁移到历史文件夹地下)
第一步导出依赖 <dependency><groupId>org.apache.sshd</groupId><artifactId>sshd-core</artifactId><version>2.13.0</version></dependency> 第二步写代码 public void moveFile( List<HmAnalysisFiles> hmAnalys…...

特伦斯 S75 电钢琴:重构演奏美学的极致表达
在数字音乐时代,电钢琴正从功能性乐器升级为融合艺术、科技与生活的美学载体。特伦斯 S75 电钢琴以极简主义哲学重构产品设计,将专业级演奏体验与现代家居美学深度融合,为音乐爱好者打造跨越技术边界的沉浸式艺术空间。 一、极简主义的视觉叙…...

STM32-标准库-GPIO-API函数
1.void GPIO_DeInit(GPIO_TypeDef* GPIOx); 简明 清除GPIOx的外围寄存器下所有引脚的配置, 恢复到默认配置状态(即上电初始值) 参数 GPIOx:其中x可以是(A..G)来选择GPIO外设。 返回值 None void GPIO_DeInit(GPI…...
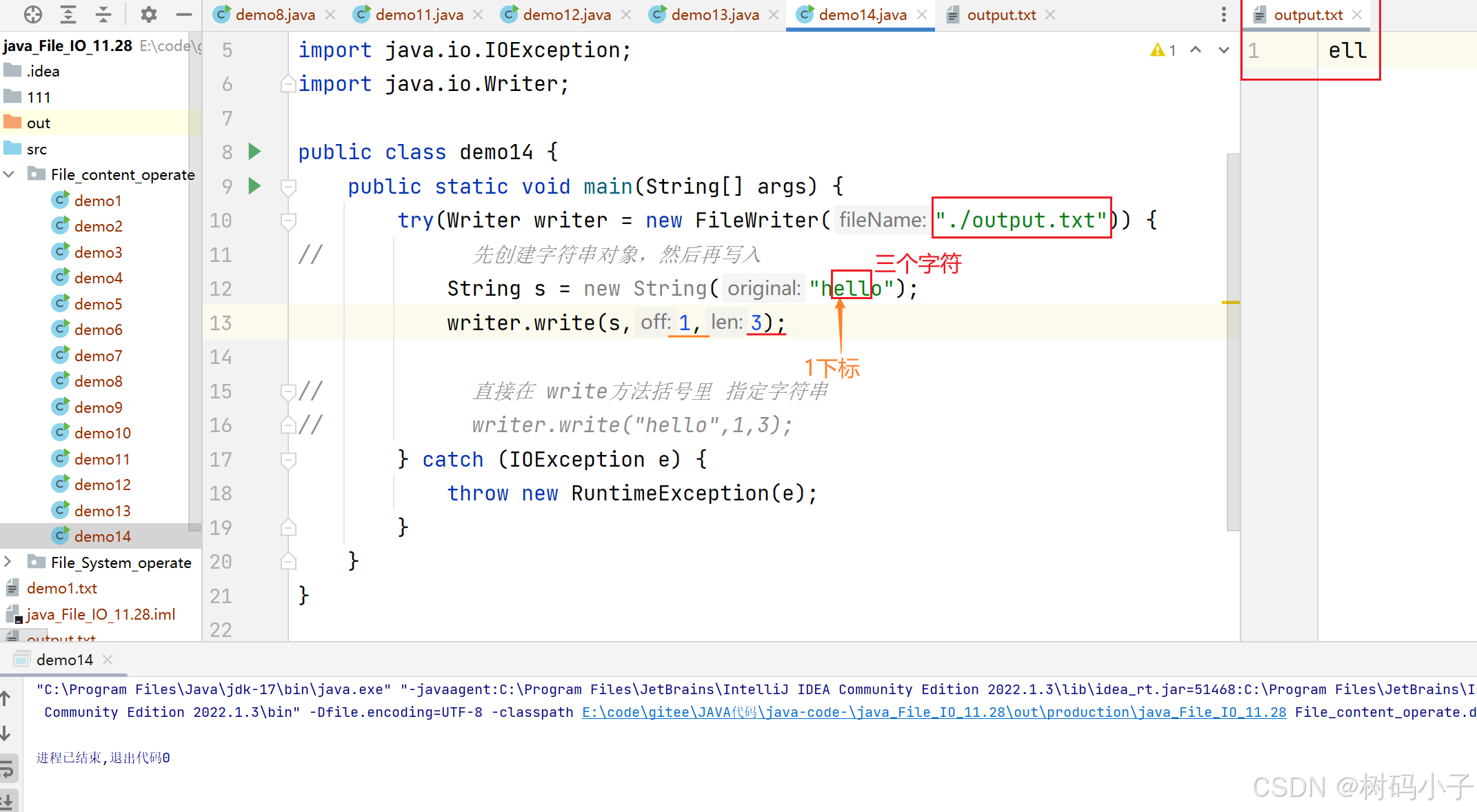
Java 文件操作 和 IO(4)-- Java文件内容操作(2)-- 字符流操作
Java 文件操作 和 IO(4)-- Java文件内容操作(2)-- 字符流操作 文章目录 Java 文件操作 和 IO(4)-- Java文件内容操作(2)-- 字符流操作观前提醒:1. Java中操作文件的简单介…...

机器学习与深度学习06-决策树02
目录 前文回顾5.决策树中的熵和信息增益6.什么是基尼不纯度7.决策树与回归问题8.随机森林是什么 前文回顾 上一篇文章地址:链接 5.决策树中的熵和信息增益 熵和信息增益是在决策树中用于特征选择的重要概念,它们帮助选择最佳特征进行划分。 熵&#…...

Netty 实战篇:构建简易注册中心,实现服务发现与调用路由
本文将为前面构建的轻量级 RPC 框架添加“服务注册与发现”功能,支持多服务节点动态上线、自动感知与调用路由,为构建真正可扩展的分布式系统打好基础。 一、背景:为什么需要注册中心? 如果每个客户端都硬编码连接某个 IP/端口的…...
对接腾讯云IM)
微信小程序(uniapp)对接腾讯云IM
UniApp 对接腾讯云 IM(即时通讯)完整指南 一、项目背景与需求分析 随着社交场景的普及,即时通讯功能已成为移动应用的标配。腾讯云 IM(Tencent IM,即 TIM)提供稳定可靠的即时通讯服务,支持单聊…...
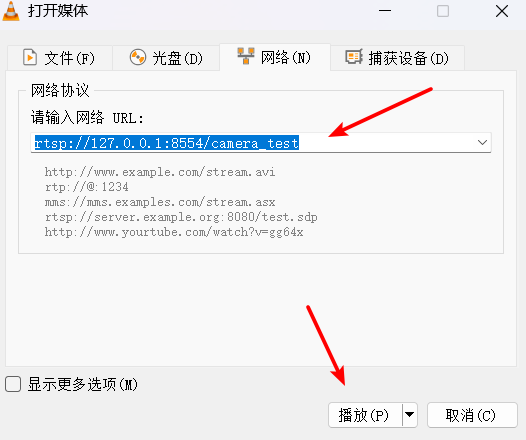
使用摄像头推流+VLC软件拉流
一、作用 使用摄像头创建rtsp链接,并使用VLC软件拉流显示。 二、步骤 1、安装FFmpeg库 下载地址:https://ffmpeg.org/download.htmlFFmpeg库的下载参考之前的博客,下载Win64版本即可:https://blog.csdn.net/beijixingcd/artic…...

python魔法函数
Python 中的魔法方法(Magic Methods),也称为特殊方法(Special Methods)或双下方法(Dunder Methods),是以双下划线 __ 开头和结尾的方法。它们用于定义类的行为,例如运算符…...

XCUITest 是什么
XCUITest(全称 Xcode UI Test)是苹果官方提供的 iOS/macOS UI 自动化测试框架,集成在 Xcode 开发工具中,专门用于测试 Swift/Objective-C 开发的应用程序。 1. XCUITest 的核心特点 ✅ 官方支持:苹果原生框架…...

使用k8s服务进行端口代理
创建registry-service.yaml 使用无Selector的Service Endpoints模式 vi registry-service.yaml编辑以下内容 apiVersion: v1 kind: Service metadata:name: registry-service spec:type: NodePortports:- name: httpprotocol: TCPport: 81 # Service内部端口targ…...
灌水论坛系统总体设计文档
一、实验题目 灌水论坛系统 二、实验目的 旨在通过一个相对完整且功能丰富的Web应用实例,全面地实践和巩固Web开发所需的各项核心技术和工程方法,从而提升其综合应用能力和解决实际开发问题的能力。它不仅仅是完成一个软件,更是一个学习、…...

Mac M1编译OpenCV获取libopencv_java490.dylib文件
Window OpenCV下载地址 https://opencv.org/releases/OpenCV源码下载 https://github.com/opencv/opencv/tree/4.9.0 https://github.com/opencv/opencv_contrib/tree/4.9.0OpenCV依赖 brew install libjpeg libpng libtiff cmake3 ant freetype构建open CV cmake -G Ninja…...

使用 Let‘s Encrypt 和 Certbot 为 Cloudflare 托管的域名申请 SSL 证书
一、准备工作 1. 确保域名解析在 Cloudflare 确保你的域名 jessi53.com 和 www.jessi53.com 的 DNS 记录已经正确配置在 Cloudflare 中,并且状态为 Active。 2. 安装 Certbot 在你的服务器上安装 Certbot 和 Cloudflare 插件。以下是基于 Debian/Ubuntu 和 Cent…...

【Python进阶】元编程、并发
目录 🌟 前言🏗️ 技术背景与价值🩹 当前技术痛点🛠️ 解决方案概述👥 目标读者说明🧠 一、技术原理剖析📊 核心架构图解💡 核心作用讲解🔧 关键技术模块说明⚖️ 技术选型对比🛠️ 二、实战演示⚙️ 环境配置要求💻 核心代码实现案例1:元类实现ORM框架…...

网络协议:[0-RTT 认证 ]
1. 为什么要 0-RTT 认证 降低延迟:SOCKS5 在无认证时需要 2 RTT(握手+请求),若加用户名/密码又要 3 RTT;0-RTT 通过合并步骤,目标是把握手+认证+请求都压缩到 1 RTT。 IE…...

单例模式的类和静态方法的类的区别和使用场景
单例模式的类和使用静态方法的类在功能上都能提供全局访问的能力,但它们在实现方式、特性和使用场景上存在差异,下面从多个方面进行比较: 1. 实现方式 单例模式的类 单例模式确保一个类只有一个实例,并提供一个全局访问点。通常…...
)
flowable中流程变量的概念(作用域)
核心概念:流程变量(Process Variables) 流程变量是 Flowable 工作流引擎中用于存储、传递和共享与业务流程相关的数据的机制。你可以将它们理解为附着在流程实例(或执行流、任务)上的键值对(Key-Value&…...

【基础算法】模拟算法
文章目录 算法简介1. 多项式输出解题思路代码实现 2. 蛇形方阵解题思路代码实现 3. 字符串的展开解题思路代码实现 算法简介 模拟,顾名思义,就是题目让你做什么你就做什么,考察的是将思路转化成代码的代码能力。 这类题一般较为简单…...

项目 react+taro 编写的微信 小程序,什么命令,可以减少console的显示
在 Taro 项目中,为了减少 console 的显示(例如 console.log、console.info 等),可以通过配置 terser-webpack-plugin 来移除生产环境中的 console 调用。 配置步骤: 修改 index.js 文件 在 mini.webpackChain 中添加 …...

Android 开发 Kotlin 全局大喇叭与广播机制
在 Android 开发中,广播机制就像一个神通广大的 “消息快递员”,承担着在不同组件间传递信息的重任。Kotlin 语言的简洁优雅更使其在广播机制的应用中大放异彩。今天,就让我们一同深入探索 Android 开发中 Kotlin 全局大喇叭与广播机制的奥秘…...
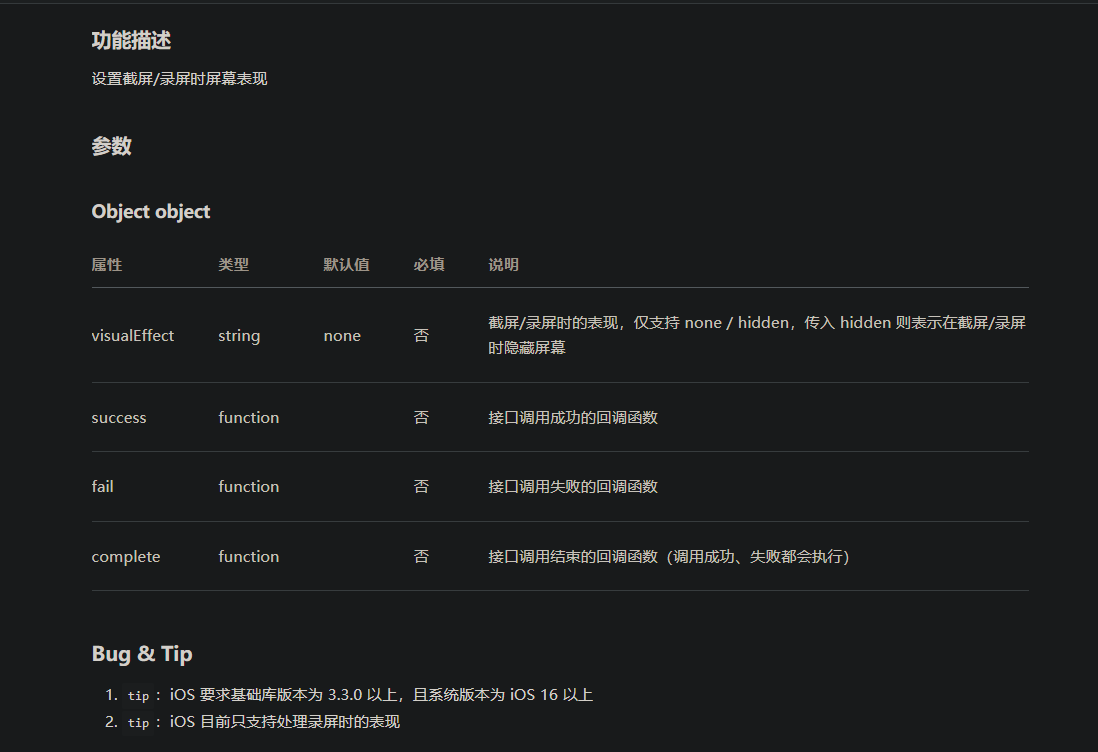
微信小程序关于截图、录屏拦截
1.安卓 安卓: 在需要禁止的页面添加 onShow() {if (wx.setVisualEffectOnCapture) {wx.setVisualEffectOnCapture({visualEffect: hidden,complete: function(res) {}})}},// 页面隐藏和销毁时需要释放防截屏录屏设置onHide() {if (wx.setVisualEffectOnCapture) {w…...
基于51单片机的音乐盒键盘演奏proteus仿真
地址: https://pan.baidu.com/s/1tZCAxQQ7cvyzBfztQpk0UA 提取码:1234 仿真图: 芯片/模块的特点: AT89C52/AT89C51简介: AT89C51 是一款常用的 8 位单片机,由 Atmel 公司(现已被 Microchip 收…...

【unity游戏开发——编辑器扩展】EditorUtility编辑器工具类实现如文件操作、进度条、弹窗等操作
注意:考虑到编辑器扩展的内容比较多,我将编辑器扩展的内容分开,并全部整合放在【unity游戏开发——编辑器扩展】专栏里,感兴趣的小伙伴可以前往逐一查看学习。 文章目录 前言一、确认弹窗1、确认弹窗1.1 主要API1.2 示例 2、三按钮…...

WPF中自定义消息弹窗
WPF 自定义消息弹窗开发笔记 一、XAML 布局设计 文件:MessageInfo.xaml <Window x:Class"AutoFeed.UserControls.MessageInfo"xmlns"http://schemas.microsoft.com/winfx/2006/xaml/presentation"xmlns:x"http://schemas.microsoft.…...
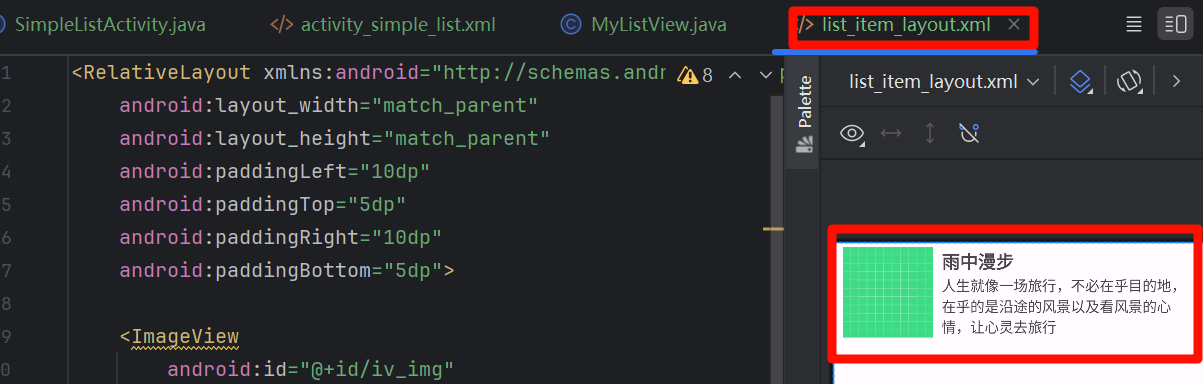
Android之ListView
1:简单列表(ArrayAdapter) 1:运行的结果: 2:首先在MyListView里面创建一个按钮,点击的时候进行跳转。 这里让我吃惊的是,Button里面可以直接设置onClick .java里面的方法。 也即是点击这个按钮之后就会去…...

查服务器信息 常用的一些命令 =^^ =
本文主要记录Linux系统的各项指令工具 目录 一、系统基础信息 1. 操作系统与内核信息 2. 主机名与 IP 二、CPU 和内存使用 1. CPU 与内存占用情况(动态监控) 2. 只看 CPU 与内存用量 三、磁盘与文件系统 1. 磁盘空间使用情况 2. 磁盘 inode 使用…...

PS裁剪后像素未删除?5步解决“删除裁剪像素”失效问题
在Photoshop中遇到“删除裁剪的像素”功能失效的问题时,可能涉及软件设置、版本兼容性或操作流程错误。以下是具体原因和解决方案: 一、常见原因分析 未正确勾选“删除裁剪的像素”选项 在裁剪工具属性栏中,需手动勾选该选项才能永久删除裁剪…...
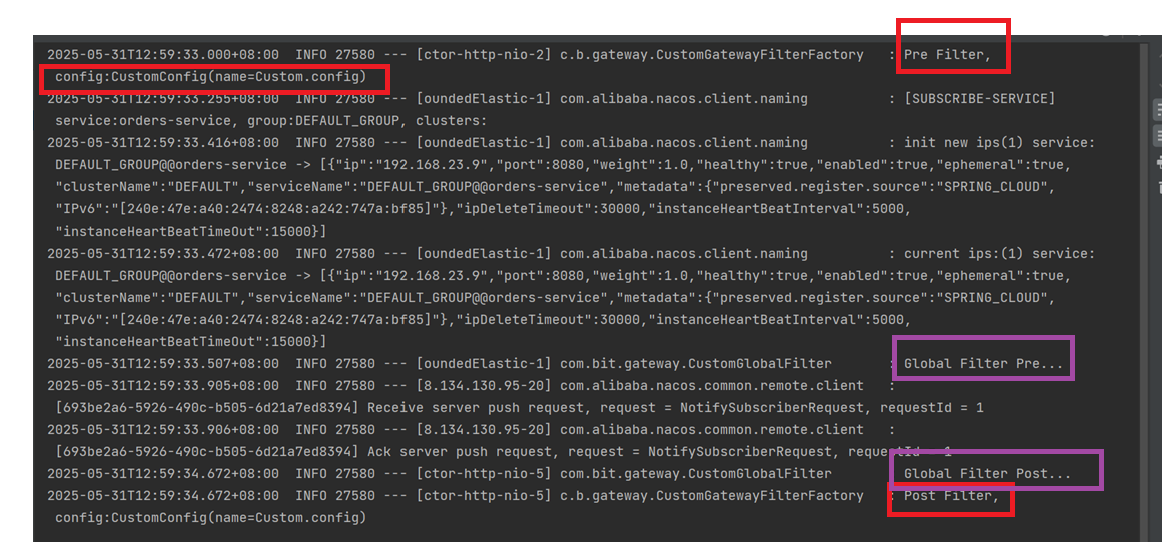
《Spring Cloud Gateway 快速入门:从路由到自定义 Filter 的完整教程》
1.网关介绍 在前面的学习中,我们通过Eureka和Nacos解决了辅助注册,使用Spring Cloud LoadBalance解决了负载均衡的问题,使用OpenFeign解决了远程调用的问题。 但是当前的所有微服务的接口都是直接对外暴露的,外部是可以直接访问…...