Python打卡训练营Day40
DAY 40 训练和测试的规范写法
知识点回顾:
- 彩色和灰度图片测试和训练的规范写法:封装在函数中
- 展平操作:除第一个维度batchsize外全部展平
- dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout
作业:仔细学习下测试和训练代码的逻辑,这是基础,这个代码框架后续会一直沿用,后续的重点慢慢就是转向模型定义阶段了。
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader , Dataset # DataLoader 是 PyTorch 中用于加载数据的工具
from torchvision import datasets, transforms # torchvision 是一个用于计算机视觉的库,datasets 和 transforms 是其中的模块
import matplotlib.pyplot as plt
import warnings
# 忽略警告信息
warnings.filterwarnings("ignore")
# 设置随机种子,确保结果可复现
torch.manual_seed(42)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量并归一化到[0,1]transforms.Normalize((0.1307,), (0.3081,)) # MNIST数据集的均值和标准差
])# 2. 加载MNIST数据集
train_dataset = datasets.MNIST(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.MNIST(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64 # 每批处理64个样本
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义模型、损失函数和优化器
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将28x28的图像展平为784维向量self.layer1 = nn.Linear(784, 128) # 第一层:784个输入,128个神经元self.relu = nn.ReLU() # 激活函数self.layer2 = nn.Linear(128, 10) # 第二层:128个输入,10个输出(对应10个数字类别)def forward(self, x):x = self.flatten(x) # 展平图像x = self.layer1(x) # 第一层线性变换x = self.relu(x) # 应用ReLU激活函数x = self.layer2(x) # 第二层线性变换,输出logitsreturn x# 初始化模型
model = MLP()
model = model.to(device) # 将模型移至GPU(如果可用)# from torchsummary import summary # 导入torchsummary库
# print("\n模型结构信息:")
# summary(model, input_size=(1, 28, 28)) # 输入尺寸为MNIST图像尺寸criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,适用于多分类问题
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 新增:记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号(从1开始)for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):# enumerate() 是 Python 内置函数,用于遍历可迭代对象(如列表、元组)并同时获取索引和值。# batch_idx:当前批次的索引(从 0 开始)# (data, target):当前批次的样本数据和对应的标签,是一个元组,这是因为dataloader内置的getitem方法返回的是一个元组,包含数据和标签。# 只需要记住这种固定写法即可#data, target = data.to(device), target.to(device) # 移至GPU(如果可用)optimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失(注意:这里直接使用单 batch 损失,而非累加平均)iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1) # iteration 序号从1开始# 统计准确率和损失running_loss += loss.item() #将loss转化为标量值并且累加到running_loss中,计算总损失_, predicted = output.max(1) # output:是模型的输出(logits),形状为 [batch_size, 10](MNIST 有 10 个类别)# 获取预测结果,max(1) 返回每行(即每个样本)的最大值和对应的索引,这里我们只需要索引total += target.size(0) # target.size(0) 返回当前批次的样本数量,即 batch_size,累加所有批次的样本数,最终等于训练集的总样本数correct += predicted.eq(target).sum().item() # 返回一个布尔张量,表示预测是否正确,sum() 计算正确预测的数量,item() 将结果转换为 Python 数字# 每100个批次打印一次训练信息(可选:同时打印单 batch 损失)if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 测试、打印 epoch 结果epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / totalepoch_test_loss, epoch_test_acc = test(model, test_loader, criterion, device)print(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)# 保留原 epoch 级曲线(可选)plot_metrics(train_losses, test_losses, train_accuracies, test_accuracies, epochs)return epoch_test_acc # 返回最终测试准确率
# 6. 测试模型(不变)
def test(model, test_loader, criterion, device):model.eval() # 设置为评估模式test_loss = 0correct = 0total = 0with torch.no_grad(): # 不计算梯度,节省内存和计算资源for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()avg_loss = test_loss / len(test_loader)accuracy = 100. * correct / totalreturn avg_loss, accuracy # 返回损失和准确率
# 7. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()
# 8. 执行训练和测试(设置 epochs=2 验证效果)
epochs = 2
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")#color
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 1. 数据预处理
transform = transforms.Compose([transforms.ToTensor(), # 转换为张量transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化处理
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./data',train=True,download=True,transform=transform
)test_dataset = datasets.CIFAR10(root='./data',train=False,transform=transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义MLP模型(适应CIFAR-10的输入尺寸)
class MLP(nn.Module):def __init__(self):super(MLP, self).__init__()self.flatten = nn.Flatten() # 将3x32x32的图像展平为3072维向量self.layer1 = nn.Linear(3072, 512) # 第一层:3072个输入,512个神经元self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(0.2) # 添加Dropout防止过拟合self.layer2 = nn.Linear(512, 256) # 第二层:512个输入,256个神经元self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(0.2)self.layer3 = nn.Linear(256, 10) # 输出层:10个类别def forward(self, x):# 第一步:将输入图像展平为一维向量x = self.flatten(x) # 输入尺寸: [batch_size, 3, 32, 32] → [batch_size, 3072]# 第一层全连接 + 激活 + Dropoutx = self.layer1(x) # 线性变换: [batch_size, 3072] → [batch_size, 512]x = self.relu1(x) # 应用ReLU激活函数x = self.dropout1(x) # 训练时随机丢弃部分神经元输出# 第二层全连接 + 激活 + Dropoutx = self.layer2(x) # 线性变换: [batch_size, 512] → [batch_size, 256]x = self.relu2(x) # 应用ReLU激活函数x = self.dropout2(x) # 训练时随机丢弃部分神经元输出# 第三层(输出层)全连接x = self.layer3(x) # 线性变换: [batch_size, 256] → [batch_size, 10]return x # 返回未经过Softmax的logits# 检查GPU是否可用
#device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 初始化模型
model = MLP()
#model = model.to(device) # 将模型移至GPU(如果可用)criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器# 5. 训练模型(记录每个 iteration 的损失)
def train(model, train_loader, test_loader, criterion, optimizer, device, epochs):model.train() # 设置为训练模式# 记录每个 iteration 的损失all_iter_losses = [] # 存储所有 batch 的损失iter_indices = [] # 存储 iteration 序号for epoch in range(epochs):running_loss = 0.0correct = 0total = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device) # 移至GPUoptimizer.zero_grad() # 梯度清零output = model(data) # 前向传播loss = criterion(output, target) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 记录当前 iteration 的损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计准确率和损失running_loss += iter_loss_, predicted = output.max(1)total += target.size(0)correct += predicted.eq(target).sum().item()# 每100个批次打印一次训练信息if (batch_idx + 1) % 100 == 0:print(f'Epoch: {epoch+1}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} 'f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')# 计算当前epoch的平均训练损失和准确率epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct / total# 测试阶段model.eval() # 设置为评估模式test_loss = 0correct_test = 0total_test = 0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_testprint(f'Epoch {epoch+1}/{epochs} 完成 | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')# 绘制所有 iteration 的损失曲线plot_iter_losses(all_iter_losses, iter_indices)return epoch_test_acc # 返回最终测试准确率# 6. 绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('每个 Iteration 的训练损失')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型
# torch.save(model.state_dict(), 'cifar10_mlp_model.pth')
# # print("模型已保存为: cifar10_mlp_model.pth")# 7. 执行训练和测试
epochs = 20 # 增加训练轮次以获得更好效果
print("开始训练模型...")
final_accuracy = train(model, train_loader, test_loader, criterion, optimizer, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")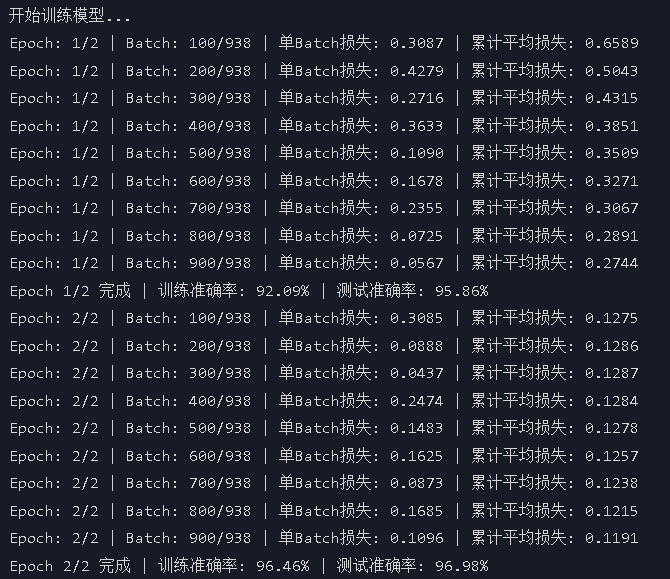

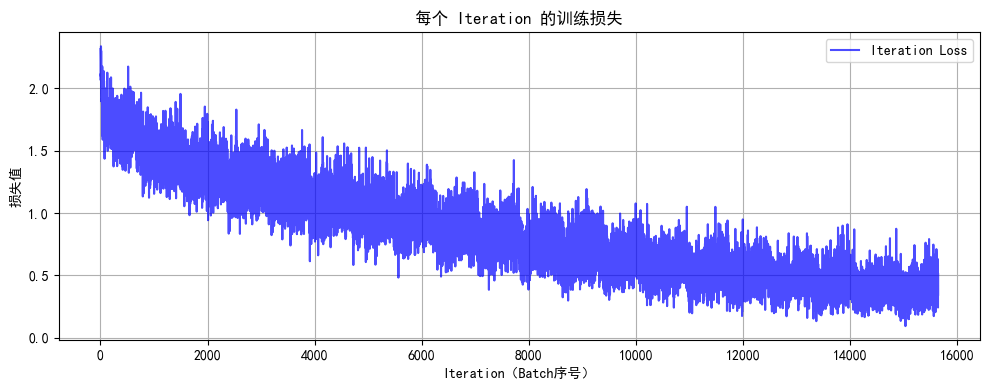
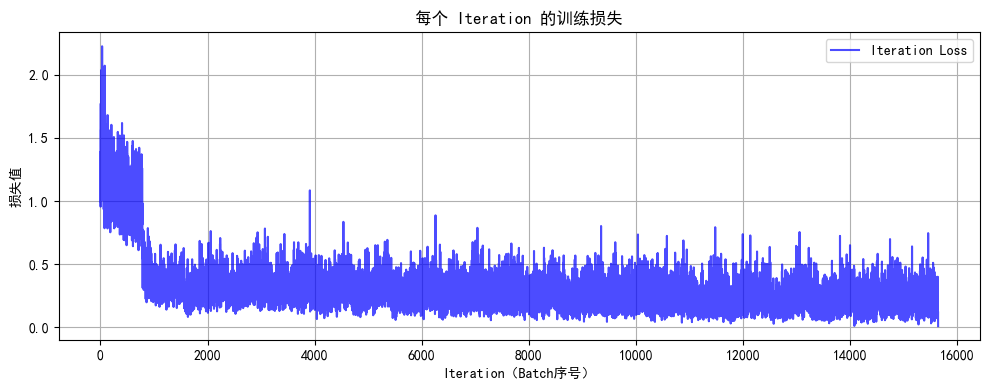
此时你会发现MLP(多层感知机)在图像任务上表现较差(即使增加深度和轮次也只能达到 50-55% 准确率),主要原因与图像数据的空间特性和MLP 的结构缺陷密切相关。
1. MLP 的每一层都是全连接层,输入图像会被展平为一维向量(如 CIFAR-10 的 32x32x3 图像展平为 3072 维向量)。图像中相邻像素通常具有强相关性(如边缘、纹理),但 MLP 将所有像素视为独立特征,无法利用局部空间结构。例如,识别 “汽车轮胎” 需要邻近像素的组合信息,而 MLP 需通过大量参数单独学习每个像素的关联,效率极低。
2. 深层 MLP 的参数规模呈指数级增长,容易过拟合。
所以我们接下来将会学习CNN架构,CNN架构的参数规模相对较小,且训练速度更快,而且CNN架构可以解决图像识别问题,而MLP不能。
@浙大疏锦行-CSDN博客
相关文章:
Python打卡训练营Day40
DAY 40 训练和测试的规范写法 知识点回顾: 彩色和灰度图片测试和训练的规范写法:封装在函数中展平操作:除第一个维度batchsize外全部展平dropout操作:训练阶段随机丢弃神经元,测试阶段eval模式关闭dropout 作业&#x…...
)
【仿生系统】爱丽丝机器人的设想(可行性优先级较高)
非程序化、能够根据环境和交互动态产生情感和思想,并以微妙、高级的方式表达出来的能力 我们不想要一个“假”的智能,一个仅仅通过if-else逻辑或者简单prompt来模拟情感的机器人。您追求的是一种更深层次的、能够学习、成长,并形成独特“个性…...

JS逆向案例—喜马拉雅xm-sign详情页爬取
JS逆向案例——喜马拉雅xm-sign详情页爬取 声明网站流程分析总结 声明 本文章中所有内容仅供学习交流,抓包内容、敏感网址、数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权&am…...
)
钩子函数的作用(register_hook)
钩子函数仅在backward()时才会触发。其中,钩子函数接受梯度作为输入,返回操作后的梯度,操作后的梯度必须要输入的梯度同类型、同形状,否则报错。 主要功能包括: 监控当前的梯度(不返回值)&…...

电子电路:深入了解CMOS技术构造和工作原理
一、CMOS的基本结构与工作原理 1. 核心结构:互补MOSFET CMOS(互补金属氧化物半导体)的核心是成对的NMOS(N沟道MOSFET)和PMOS(P沟道MOSFET)晶体管,两者共享同一硅衬底但通过阱(Well) 隔离: NMOS:构建在P型衬底上,源/漏极为N⁺掺杂区。当栅极电压(V_GS)高于阈值…...
STM32CubeMX定时器配置
STM32CubeMX定时器配置 一,Mode界面1,Slave Mode (从模式)2,Trigger Source (触发源) 三,Channelx(通道模式)1,Input Capture2,Output Compare3,PWM Generation4…...
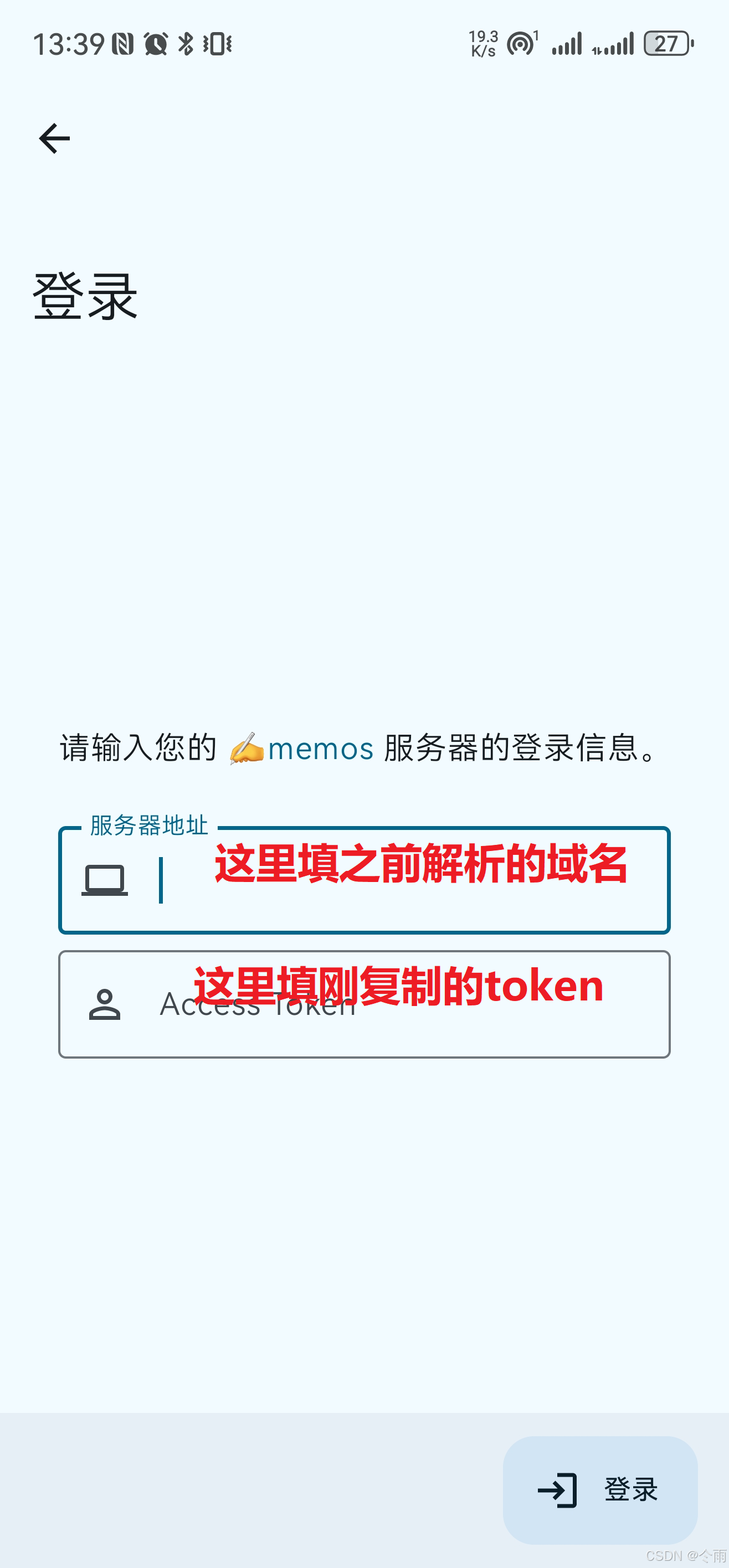
QNAP MEMOS 域名访问 SSL(Lucky)
注意:下述是通过ssh、docker-compose方式安装docker的,不是直接在container station中安装的哈!!! 一、编辑docker-compose.yml文件 用“#”号标识的,在保存文件的时候建议去掉,不然有时候会出…...

跟单业务并发量分析
虚拟货币交易所中的跟单交易(copy trading)业务在高峰期的确可能产生较高的并发量,但具体并发量取决于多个因素,包括交易所的规模、用户数量、热门交易员的活跃度、行情波动频率等。 📌 1. 跟单交易的并发特点 触发集…...

如何将多张图组合到一张图里同时保留高的分辨率(用PPT+AdobeAcrobat)
文章目录 一、用PPT排版得到一页排布了很多图片的PPT二、用AdobeAcrobat打开pdf文件三、最后得到的图片 一、用PPT排版得到一页排布了很多图片的PPT 步骤如下 ①将幻灯片大小的长设置为17.2,宽根据图像多少进行调整,我这里是10 幻灯片大小的长设置步骤&…...
pycharm找不到高版本conda问题
pycharm找不到高版本conda问题 高版本的condaPycharm不能自动识别,需要手动添加。 首先打开你要添加的conda环境win的话在conda终端输入 where conda查找conda的可执行文件位置 进入Pycharm设置,点击添加解释器,点击加载环境,…...

支持selenium的chrome driver更新到137.0.7151.55
最近chrome释放新版本:137.0.7151.55 如果运行selenium自动化测试出现以下问题,是需要升级chromedriver才可以解决的。 selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only su…...

2025年上半年软考系统架构设计师--案例分析试题与答案
必选题一:大模型训练系统 某公司开发一个在线大模型训练平台,支持 Python 代码编写、模型训练和部署,用户通过 python 编写模型代码,将代码交给系统进行模型代码的解析,最终由系统匹配相应的计算机资源进行输出,用户不需要关心底层硬件平台。 a.系统发生…...
Eclipse 插件开发 5.2 编辑器 获取当前编辑器
Eclipse 插件开发 5.2 编辑器 获取当前编辑器 1 获取活跃编辑器2 获取全部编辑器 Manifest-Version: 1.0 Bundle-ManifestVersion: 2 Bundle-Name: Click1 Bundle-SymbolicName: com.xu.click1;singleton:true Bundle-Version: 1.0.0 Bundle-Activator: com.xu.click1.Activato…...

讲述我的plc自学之路 第十二章
“老k,你没想过自己以后怎么过吗?”lora听我夸他漂亮,开始鼓起勇气追问我的过往。 “我还能怎样呢,说实话,家里介绍过几次相亲了,上来就问车问房的,大多数不了了之。”我解释道。 “老k这你就…...
Visual Studio 的下载安装
下载 官网:https://visualstudio.microsoft.com/zh-hans/ 点击免费 Visual Studio。 点击 Visual Studio Community 下的免费下载。 保留并下载。 安装 双击下载的 exe 安装文件,点击继续。 等他下载安装完。 选择你要下载的组件(我只勾了一个 .NET 桌…...

C# 如何获取当前成员函数的函数名
C# 如何获取当前成员函数的函数名 在 C# 中获取当前成员函数的名称,有以下几种常用方法: 1. 使用 MethodBase.GetCurrentMethod()(反射) using System.Reflection;public void MyMethod() {string methodName MethodBase.GetCu…...
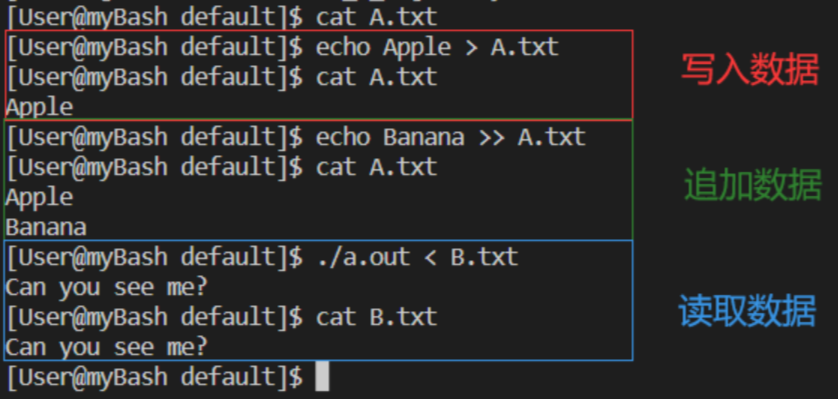
苍茫命令行:linux模拟实现,书写微型bash
文章目录 🌇前言2、需求分析3、基本框架4、核心内容4.2、指令分割4.3、程序替换 5、特殊情况处理5.2、内建命令5.3、cd5.4、export5.5、echo5.6、重定向 6、源码 🌇前言 Linux 系统主要分为内核(kernel)和 外壳(shell),普通用户是无法接触到…...

虚拟DOM和DOM是什么?有什么区别?虚拟DOM的优点是什么?
虚拟DOM与真实DOM的概念 虚拟DOM(Virtual DOM)是一种对真实DOM的抽象表示,其结构通常为一个JavaScript对象,保存了DOM节点的标签、属性、子节点等信息。真实DOM则是浏览器中的实际文档对象模型,由HTML代码解析生成&am…...

累加法求数列通项公式
文章目录 前言如何判断注意事项适用类型方法介绍典例剖析对应练习 前言 累加法,顾名思义,就是多次相加的意思。求通项公式题型中,如果给定条件最终可以转化为 a n 1 − a n f ( n ) a_{n1}-a_nf(n) an1−anf(n)的形式,或者…...

鸿蒙NEXT应用加固工具哪家更好?国内主流的6款对比
随着鸿蒙NEXT系统的推进,越来越多企业将目光投向鸿蒙生态下的应用部署与数据安全。尤其是在核心业务App逐步上架鸿蒙原生平台的当下,如何实现高效、可靠的鸿蒙NEXT应用安全加固,已成为企业技术选型的关键环节。本文将对市面上6款主流的鸿蒙NE…...

高效多线程图像处理实战
引言 在现代计算机视觉和图像处理应用中,处理大量图像数据是常见需求。传统的单线程处理方式在面对成千上万的图像时,往往显得力不从心,导致处理时间过长。本文将介绍如何将一个典型的单线程图像处理任务转换为高效的多线程实现,并讨论其中的关键技术点、线程安全考量以及…...
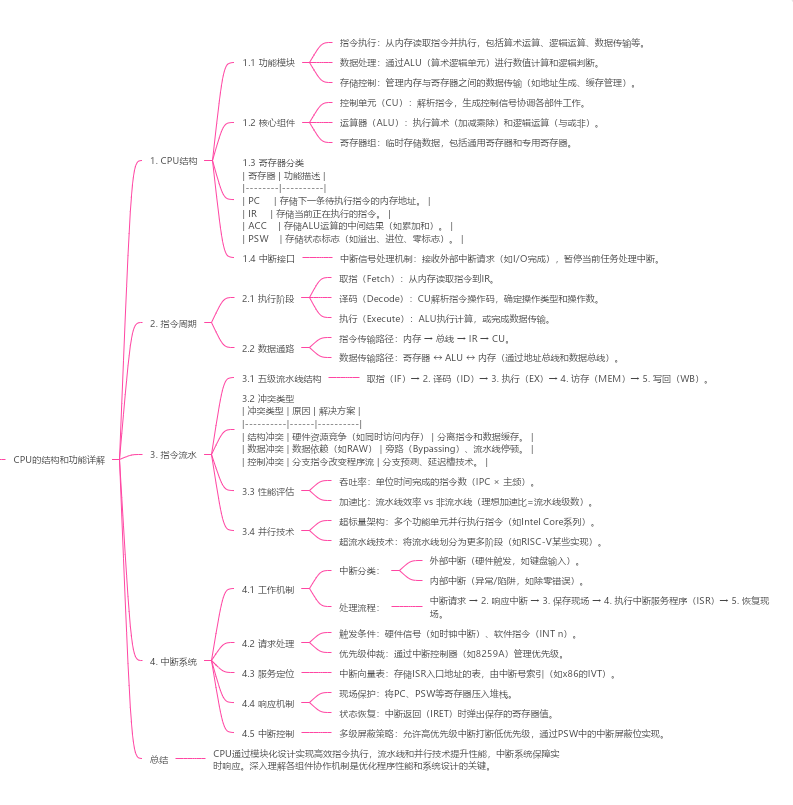
[特殊字符]《计算机组成原理》第 8 章 - CPU 的结构和功能
🔵8.1 CPU 的结构 🔵8.1.1 CPU 的功能 CPU(中央处理器)是计算机的核心部件,主要负责以下任务: 指令执行:解析并执行指令集架构(ISA)定义的指令数据处理:完…...

第八篇:MySQL 备份恢复与数据安全管理实战
在企业数据库运维中,数据安全是第一要务。系统崩溃、误删数据、磁盘损坏等场景都可能造成数据丢失,因此建立可靠的备份与恢复机制是保障业务连续性的关键。 一、为什么需要备份? 防止数据丢失:误操作、故障、黑客攻击等ÿ…...

系统是win11+两个ubuntu,ubuntu20.04和ubuntu22.04,想删除ubuntu20.04且不用保留数据
在 Ubuntu 22.04 的终端里运行这些命令: 重启电脑,选择启动 Ubuntu 22.04;打开终端;从 lsblk 开始操作。 如果你不确定当前启动的是哪个系统,可以在终端输入: lsb_release -a它会输出: Distributor ID: …...
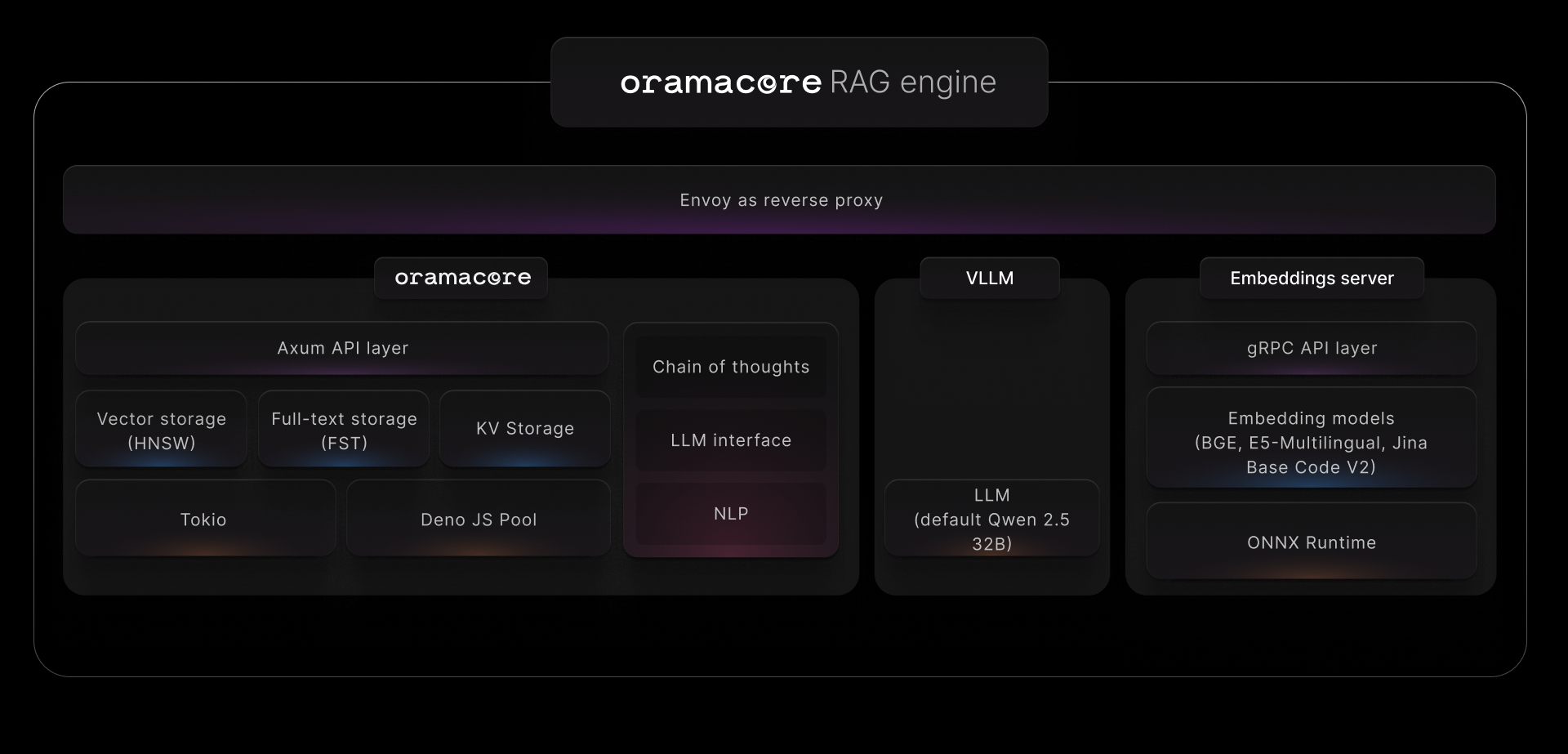
OramaCore 是您 AI 项目、答案引擎、副驾驶和搜索所需的 AI 运行时。它包括一个成熟的全文搜索引擎、矢量数据库、LLM界面和更多实用程序
一、软件介绍 文末提供程序和源码下载 OramaCore 是您的项目、答案引擎、副驾驶和搜索所需的 AI 运行时。 它包括一个成熟的全文搜索引擎、矢量数据库、LLM具有行动计划和推理功能的接口、用于根据数据编写和运行您自己的自定义代理的 JavaScript 运行时,以及更多…...
)
GitHub 趋势日报 (2025年05月28日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 2379 agenticSeek 1521 computer-science 841 n8n 577 langflow 351 qlib 282 skt…...

OpenCV CUDA模块图像处理------颜色空间处理之GPU 上交换图像的通道顺序函数swapChannels()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于在 GPU 上交换图像的通道顺序(例如将 BGR 图像转为 RGB)。 它适用于多通道图像(如 3 通道或 4 通道…...

回归任务损失函数对比曲线
回归任务损失函数曲线可视化对比 本节将可视化对比均方误差(MSE)、平均绝对误差(MAE)、Huber损失函数三种常见回归任务损失函数的曲线,帮助理解它们在不同误差区间的表现差异。 1. 导入所需库 我们需要用到 numpy 进…...

Magentic-UI:人机协作的网页自动化革命
Magentic-UI是微软开源的一款创新浏览器自动化工具,基于多智能体系统和AutoGen框架设计,强调人机协作、透明性和安全控制,通过协作规划、实时执行和计划学习机制,高效处理复杂网页任务如数据抓取和表单填写,显著提升任…...

计算机专业大学生常用的刷题,资源网站(持续更新)
一、刷题网站 1.牛客网 牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网 (nowcoder.com)https://www.nowcoder.com/ 牛客网(Nowcoder)是中国一个主要面向编程和技术学习者的在线教育和职业发展平台。它提供了…...