中山大学无人机具身导航新突破!FlightGPT:迈向通用性和可解释性的无人机视觉语言导航

- 作者:Hengxing Cai 1 , 2 ^{1,2} 1,2, Jinhan Dong 2 , 3 ^{2,3} 2,3, Jingjun Tan 1 ^{1} 1, Jingcheng Deng 4 ^{4} 4, Sihang Li 2 ^{2} 2, Zhifeng Gao 2 ^{2} 2, Haidong Wang 1 ^{1} 1, Zicheng Su 5 ^{5} 5, Agachai Sumalee 6 ^{6} 6, Renxin Zhong 1 ^{1} 1
- 单位: 1 ^{1} 1中山大学智能工程学院, 2 ^{2} 2DP Technology, 3 ^{3} 3北京邮电大学, 4 ^{4} 4中国科学院计算技术研究所, 5 ^{5} 5同济大学, 6 ^{6} 6朱拉隆功大学集成创新学院
- 论文标题:FlightGPT: Towards Generalizable and Interpretable UAV Vision-and-Language Navigation with Vision-Language Models
- 论文链接:https://arxiv.org/pdf/2505.12835
- 代码链接:https://github.com/Pendulumclock/FlightGPT
主要贡献
- 提出了一种基于视觉-语言模型(VLMs)的无人机视觉-语言导航(VLN)框架FlightGPT,通过强大的多模态感知能力,有效解决了现有方法在多模态融合、泛化能力和可解释性方面的不足。
- 设计了两阶段训练流程:第一阶段是利用高质量演示数据进行监督式微调(SFT),提升模型初始化和结构化推理能力;第二阶段是采用基于复合奖励的组相对策略优化(GRPO)算法进行强化学习,增强模型的泛化性和适应性。
- 引入了基于思维链的推理机制,通过显式的<think> <answer>标签引导模型进行结构化推理,使模型在决策前能够“先思考再行动”,从而提高推理质量,使推理过程更加完整、连贯和流畅。
- 在大规模城市级数据集CityNav上进行了广泛实验,FlightGPT在所有场景中均实现了最先进的性能,其在未见环境中的成功率比最强基线模型高出9.22%。
研究背景
- 随着无人机(UAV)技术的快速发展,视觉-语言导航(VLN)在灾难响应、物流配送和城市检查等应用中变得至关重要。然而,现有方法在多模态信息融合、泛化能力和动态适应性以及导航决策的可解释性方面存在不足。
- 例如,现有方法在融合图像和文本输入时,往往采用简单的拼接或浅层融合方式,缺乏对深层语义理解和视觉感知的有效整合,导致导航策略容易误解复杂指令和感知错误。
- 此外,现有模型通常严重依赖训练环境,在未见环境(Out-of-Distribution,OOD)中泛化能力不足,遇到不熟悉的环境或动态障碍时,导航性能会显著下降。
- 同时,大多数当前方法直接输出导航决策,没有提供清晰的中间推理步骤,决策逻辑对用户不透明,难以诊断错误或优化导航策略,限制了系统的可靠性和可维护性。
相关工作与动机
UAV视觉-语言导航的发展历程
- 早期方法:
- 早期的UAV VLN方法主要采用序列到序列(Seq2Seq)模型,将语言指令编码为固定表示以生成动作序列。
- 这些方法虽然能够初步实现基于语言指令的导航,但在处理复杂环境时存在不足。
- 注意力机制的引入:
- 随后,交叉模态注意力(Cross-Modal Attention, CMA)机制被提出,用于增强导航指令与视觉观察之间的对齐效果。
- 此外,自监督模型通过引入辅助进度估计来支持导航过程中的自我纠正,进一步提升了导航性能。
- Transformer架构的兴起:
- 随着Transformer架构的出现,预训练模型如VLN-BERT被引入,采用多模态BERT结构整合语言和视觉轨迹,显著提升了多模态融合的效果。
- 数据集的发展:
- 与方法的发展同步,UAV VLN的基准数据集也在不断进化。
- 例如,AerialVLN引入了高保真3D仿真环境用于语言引导的飞行任务,而CityNav则提供了包含GPS、图像和自然语言的城市级数据集,增加了任务的多样性和评估的复杂性。
视觉-语言模型在导航中的多模态感知
- 视觉-语言模型(VLMs):
- VLMs通过在大规模图像-文本数据上进行预训练,展示了在统一视觉和语言模态方面的强大能力。
- 早期模型如UNITER通过在联合嵌入空间中对齐图像和文本特征,而CLIP则通过对比学习实现了开放词汇视觉识别,显著提升了多模态表示的泛化能力。
- 最新进展:
- 近期的VLMs如GPT-4V、Gemini 1.5和Qwen2-VL进一步扩展了这一能力,能够直接处理多模态输入以生成导航轨迹或结构化子任务。
- 这些模型为将视觉感知与语言理解相结合提供了有力支持,是实现导航任务中高级任务解释与低级动作控制之间桥梁的有前途的基础。
强化学习在导航中的泛化能力提升
- 强化学习的作用:
- 强化学习(RL)被证明是增强大型语言模型(LLMs)和具身智能体推理能力和泛化性能的有效机制。
- 例如,DeepSeekR1通过大规模RL优化语言模型中的链式推理,展示了在复杂任务(如数学问题求解和代码生成)中的强大性能。
- 动态环境适应性:
- 除了静态推理,RL还被用于提升模型在交互式环境中的适应性。例如,GROOT通过端到端RL训练通用智能体在3D环境中执行任务,展示了通过对象中心表示在多样化操作任务中实现泛化的能力。
- 这些研究表明,RL不仅能够增强LLMs中的结构化推理,还能提升其在动态和多任务环境中的鲁棒性和迁移能力,这对于UAV VLN任务尤为重要,因为无人机需要在复杂且不断变化的视觉环境中解释多样化的语言输入。
现有工作的局限性与FlightGPT的动机
- 现有局限性:
- 尽管VLMs在多模态感知方面取得了进展,RL在提升策略泛化方面也显示出潜力,但它们在UAV VLN中的应用仍面临挑战,特别是在动作可靠性和训练稳定性方面。
- FlightGPT的动机:
- 为了解决这些局限性,本文提出了FlightGPT框架,将VLMs的感知能力和RL的自适应学习优势相结合,旨在为UAV VLN提供一个更具泛化能力和有效性的解决方案。
- FlightGPT通过结合强大的多模态理解、两阶段训练流程(SFT+RL)以及基于“思维链”(CoT)的推理机制,旨在提升无人机在复杂环境中的导航性能、跨环境泛化能力和决策的可解释性。
方法
问题定义
论文聚焦于无人机视觉-语言导航(UAV VLN)任务,该任务要求无人机在三维环境中根据自然语言描述和视觉感知到达指定目标。具体来说,每个任务可以形式化为一个三元组 ( I , D , E ) (I, D, E) (I,D,E),其中:
-
I I I 表示无人机的初始状态,包括其位置和航向角;
-
D D D 表示目标的自然语言描述,通常包括目标及其周围地标的详细信息;
-
E E E 表示一个具有真实空间布局和丰富地理语义的三维环境,无人机可以从中获取各种感知输入,例如关键地标、RGB/深度图等。
-
无人机通过执行一系列离散动作(如前进、左转、右转、上升、下降、停止)来完成导航任务。
-
当无人机认为自己已到达目标附近时,可以选择“停止”动作。
-
如果无人机的最终位置与目标位置的距离在预定义的阈值(例如20米)以内,则认为导航成功。
FlightGPT框架
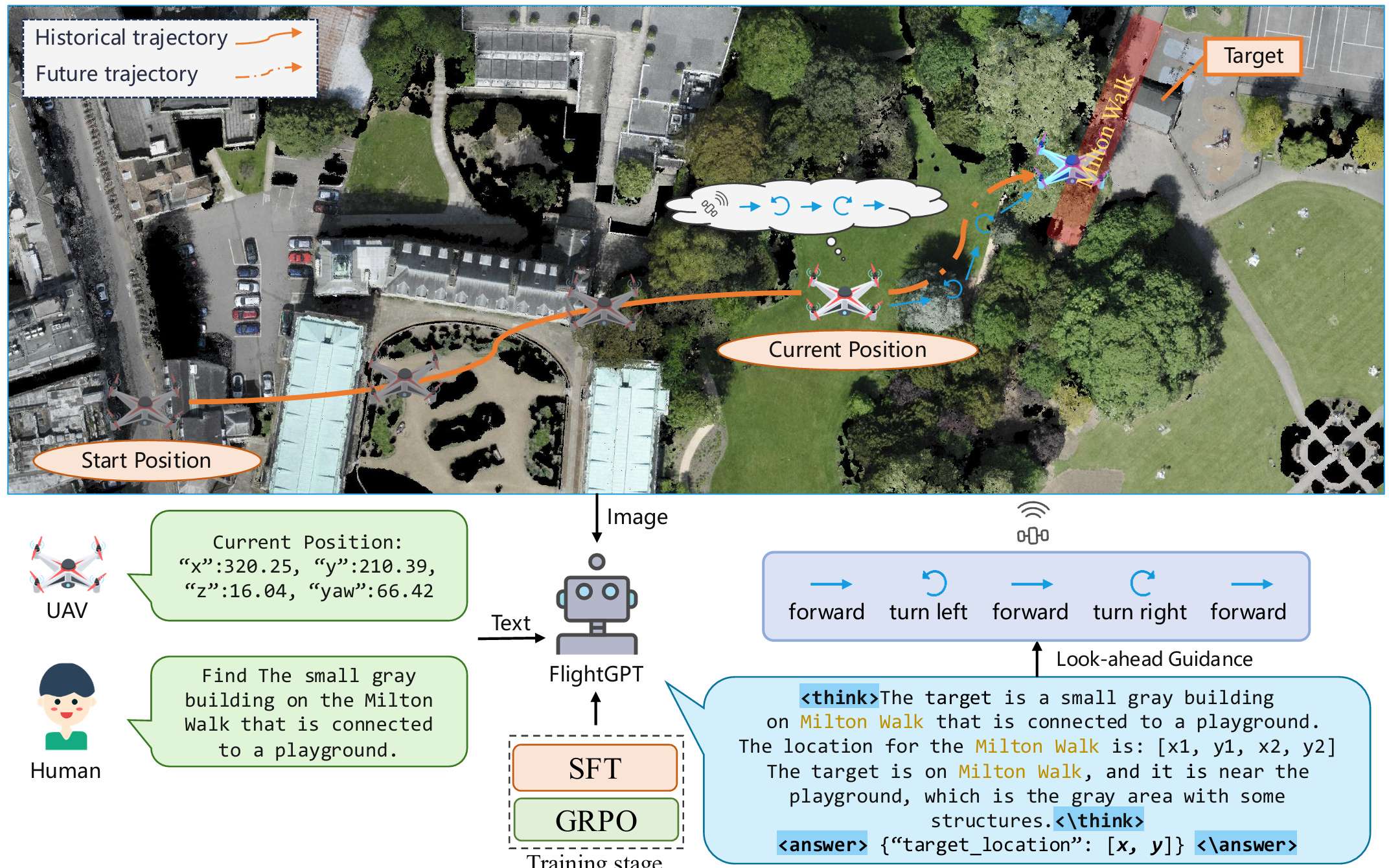
系统概述
FlightGPT的推理过程包括以下步骤:
- 输入获取:系统从环境中收集输入,包括语义地图(标注了无人机当前位置、航向角、第一人称视野区域和已知地标位置)和文本描述(包含无人机当前位置和目标的自然语言描述)。
- 推理与目标预测:FlightGPT生成结构化的推理过程,并输出目标位置的预测。
- 动作规划:系统采用前瞻机制,模拟未来轨迹以生成可执行动作。
- 环境交互:无人机在环境中执行计划的动作并更新状态,直到执行停止动作或达到预定义的最大迭代次数。
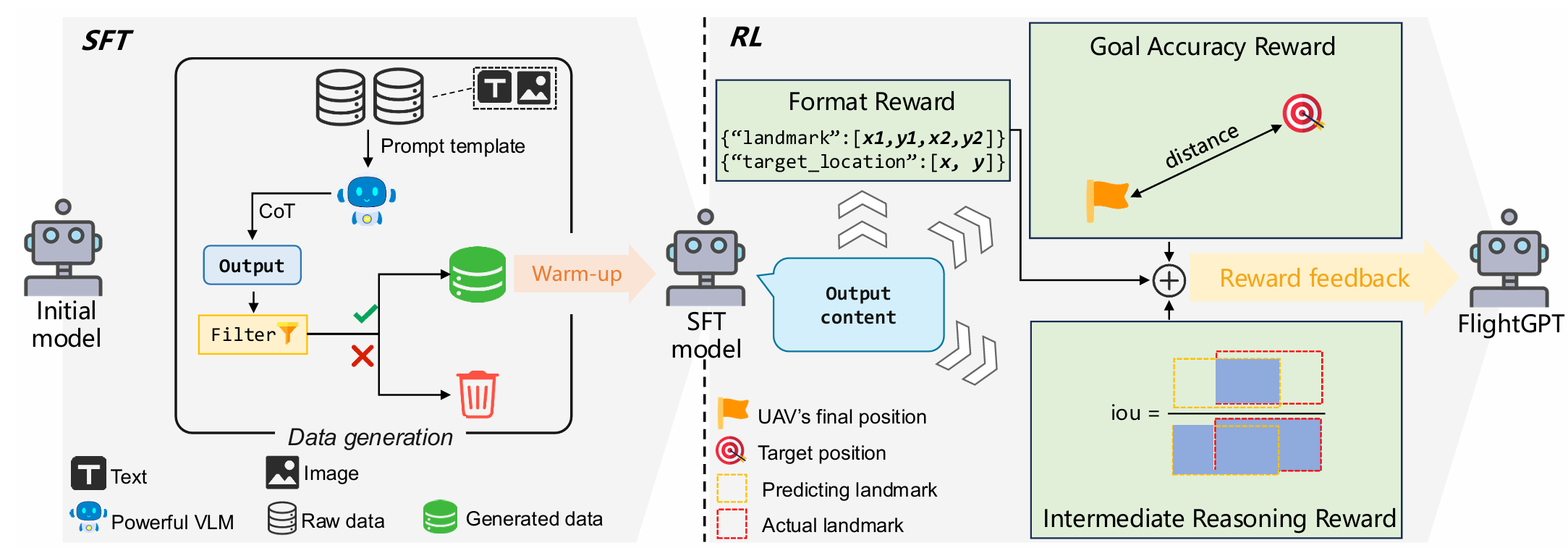
监督式微调(SFT)阶段
为了提升模型在复杂环境中的感知和决策能力,同时解决强化学习从头开始训练时收敛不稳定的问题,论文引入了监督式微调(SFT)阶段,使用高质量演示数据对模型进行预训练,为后续的强化学习优化提供良好的初始化。
-
输入、提示和输出设计:
- 输入:包括语义地图和文本信息。语义地图标注了无人机当前位置、航向角、第一人称视野区域和已知地标位置;文本信息描述了无人机当前状态和目标的自然语言描述。
- 提示:设计了一个详细的提示模板,引导模型进行结构化的“思维链”(CoT)推理过程。提示包括系统消息、目标描述、环境感知信息和操作指导,引导模型在<think>标签内进行逐步推理,并在<answer>标签内输出最终目标位置预测。
- 输出:模型的输出包括两部分:(1) <think>…</think>:模型的中间推理过程,可能包括对目标的理解、地标的识别和空间关系的推理。(2) <answer>…</answer>:最终预测的目标位置,用于生成后续的可执行动作。
-
数据生成:由于缺乏针对UAV VLN任务的推理数据集,论文采用Qwen2.5-VL-32B模型自动生成SFT阶段所需的训练数据。通过比较多个开源和闭源的VLMs,Qwen2.5-VL-32B在相同设置下表现最佳,因此被选为数据生成器。生成数据后,通过以下机制过滤和增强数据质量:
- 丢弃输出格式异常的样本;
- 丢弃预测位置与真实位置距离超过20米的样本;
- 对保留的样本,将Qwen2.5-VL-32B预测的目标位置替换为真实位置。
-
训练策略:SFT阶段的目标是基于给定输入和之前生成的上下文预测下一个标记,逐标记生成完整的输出序列。
强化学习(RL)阶段
尽管模型通过SFT阶段获得了初步的视觉-语言理解和推理能力,但在复杂动态环境中仍缺乏适应性,尤其是在泛化到未见场景方面。为了增强模型的泛化能力和适应性,论文采用组相对策略优化(GRPO)算法进行策略优化,并设计了复合奖励系统,包括以下三个部分:
-
目标准确性奖励(Goal Accuracy Reward):预测目标位置的准确性是系统有效性的关键指标。设无人机预测位置为 p ^ = ( x ^ , y ^ ) \hat{p} = (\hat{x}, \hat{y}) p^=(x^,y^),真实位置为 p ∗ = ( x ∗ , y ∗ ) p^* = (x^*, y^*) p∗=(x∗,y∗),则奖励函数定义为:
R goal = { 1 , if d ( p ^ , p ∗ ) ≤ d success exp ( − d ( p ^ , p ∗ ) − d success τ ) , if d success < d ( p ^ , p ∗ ) ≤ d cutoff 0 , otherwise R_{\text{goal}} = \begin{cases} 1, & \text{if } d(\hat{p}, p^*) \leq d_{\text{success}} \\ \exp\left(-\frac{d(\hat{p}, p^*) - d_{\text{success}}}{\tau}\right), & \text{if } d_{\text{success}} < d(\hat{p}, p^*) \leq d_{\text{cutoff}} \\ 0, & \text{otherwise} \end{cases} Rgoal=⎩ ⎨ ⎧1,exp(−τd(p^,p∗)−dsuccess),0,if d(p^,p∗)≤dsuccessif dsuccess<d(p^,p∗)≤dcutoffotherwise
其中:- 欧几里得距离 d ( p ^ , p ∗ ) = ( x ^ − x ∗ ) 2 + ( y ^ − y ∗ ) 2 d(\hat{p}, p^*) = \sqrt{(\hat{x} - x^*)^2 + (\hat{y} - y^*)^2} d(p^,p∗)=(x^−x∗)2+(y^−y∗)2;
- d success = 20 d_{\text{success}} = 20 dsuccess=20 米:任务成功的阈值;
- d cutoff = 80 d_{\text{cutoff}} = 80 dcutoff=80 米:超过此距离不给予奖励的上限;
- τ = 100 \tau = 100 τ=100:控制指数衰减速度的衰减温度。
-
中间推理奖励(Intermediate Reasoning Reward):为了引导模型在推理过程中关注关键地标,论文引入了基于预测地标边界框与真实边界框的交并比(IoU)的奖励。设预测地标边界框为 B ^ \hat{B} B^,真实边界框为 B B B,则奖励定义为:
R IoU = Area ( B ∩ B ^ ) Area ( B ∪ B ^ ) R_{\text{IoU}} = \frac{\text{Area}(B \cap \hat{B})}{\text{Area}(B \cup \hat{B})} RIoU=Area(B∪B^)Area(B∩B^)
如果模型未能输出有效的边界框,则 R IoU = 0 R_{\text{IoU}} = 0 RIoU=0。 -
格式奖励(Format Reward):为了确保模型生成结构化的输出,论文引入了格式合规性奖励。如果输出包含和标签,并且推理和答案部分清晰呈现且包含所需信息,则给予奖励:
- 如果输出包含和标签,奖励为+0.5;
- 如果在标签内成功提取到格式为 [ x 1 , y 1 , x 2 , y 2 ] [x1, y1, x2, y2] [x1,y1,x2,y2]的“landmark_bbox”字段,额外奖励+0.25;
- 如果在标签内成功提取到格式为 [ x , y ] [x, y] [x,y]的“target_location”字段,再奖励+0.25。
-
总奖励:用于策略优化的总奖励是上述三个奖励的总和:
R total = R goal + R IoU + R format R_{\text{total}} = R_{\text{goal}} + R_{\text{IoU}} + R_{\text{format}} Rtotal=Rgoal+RIoU+Rformat
实验
实验设置
数据集
- 数据集选择:实验使用了CityNav数据集,这是一个专门为城市级UAV VLN任务设计的高质量基准数据集。
- 数据集特点:
- 包含32,637个人类演示轨迹,覆盖5,850个目标对象。
- 基于SensatUrban数据集的3D城市扫描构建,涵盖伯明翰和剑桥两个真实城市,总面积约为4.65平方公里。
- 提供丰富的地理语义信息和多样化的导航场景。
评估指标
- 导航误差(NE):无人机最终位置与目标位置之间的欧几里得距离。值越低表示定位精度越高。
- 成功率(SR):无人机在停止时距离目标位置在20米以内的比例。
- Oracle成功率(OSR):无人机在导航过程中任何时候距离目标位置在20米以内的比例,无论是否停止。
- 按路径长度加权的成功率(SPL):调整SR指标,惩罚不必要的长路径,鼓励高效导航。
这些指标共同反映了代理的目标到达精度、路径效率和整体导航鲁棒性。
基线模型
- Random:简单的随机动作策略,作为性能下限参考。
- Seq2Seq:经典的端到端模型,将指令和视觉输入编码为潜在表示以直接生成动作序列。
- CMA:通过交叉注意力机制整合视觉和语言输入以选择动作的模型。
- MGP:基于语义地图的方法,根据语义地图和自然语言指令预测目标位置。
- GPT-4o:由OpenAI开发的强大的多模态模型,能够处理文本和视觉输入并进行推理。
- Qwen2.5-VL(7B/32B):开源的视觉-语言模型家族,用于评估模型规模对性能的影响。
- LLaMA-3.2-11B-Vision:Meta AI的最新开源多模态模型,支持视觉和语言感知。
模型和训练配置
- 基础模型:采用Qwen2.5-VL-7B作为基础模型,并通过两阶段训练流程进行优化。
- SFT阶段:从Qwen2.5-VL-32B输出中收集并筛选了1,872个样本用于训练。
- RL阶段:从训练集中选择了4,758个样本,涵盖不同的城市、街道场景和目标类型。
- 训练工具:SFT阶段使用LLaMAFactory实现,RL阶段基于VLM-R1框架构建。
- 超参数:
- SFT阶段:批量大小16,学习率2e-5,训练2个epoch。
- RL阶段:批量大小1,学习率1e-5,训练1个epoch。
实验结果
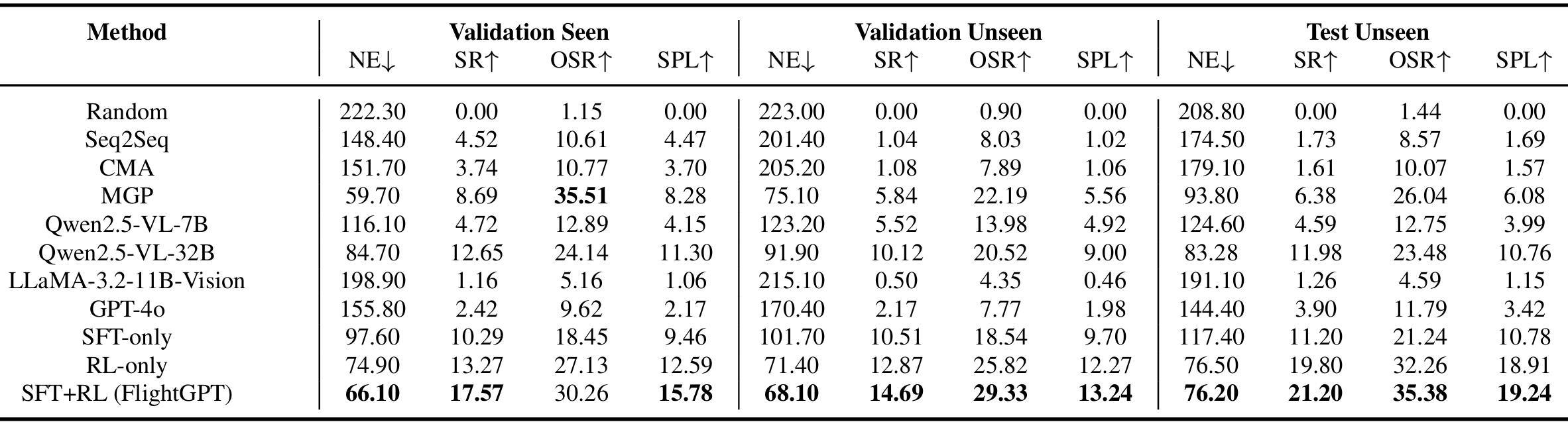
模型性能和泛化分析
- 性能对比:
- Qwen2.5-VL-7B在UAV VLN任务中表现合理,而其更大版本Qwen2.5-VL-32B在多个指标上超越了最强的传统基线MGP。
- FlightGPT在所有评估场景中均优于所有基线模型,在val-seen环境中成功率达到17.57%,导航误差为66.1,SPL为15.78;在更具挑战性的test-unseen环境中,成功率提高了9.22%,SPL几乎翻倍。
- FlightGPT基于相对较轻量级的Qwen2.5-VL-7B模型,通过两阶段训练流程(SFT+RL),性能超过了更大规模的Qwen2.5-VL-32B,这表明适当的建模方法和高效的训练策略比单纯扩大模型规模更重要。
消融研究
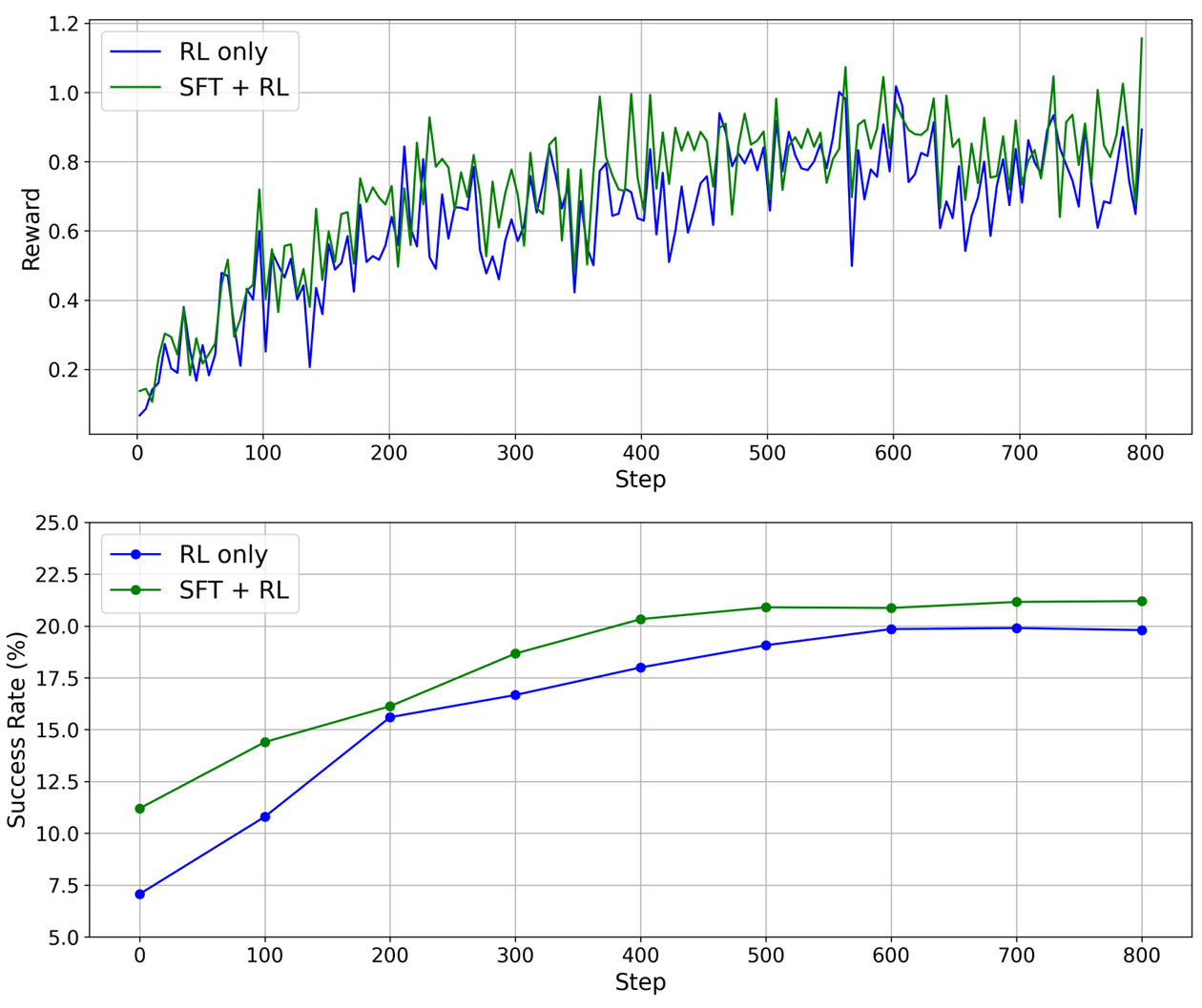
- 消融实验配置:
- SFT-only:仅使用监督式微调进行训练,不使用强化学习。
- RL-only:直接使用强化学习进行训练,不使用SFT初始化。
- SFT+RL:先进行SFT初始化,再通过RL优化。
- 结果分析:
- SFT-only:在val-seen环境中表现不错,但缺乏RL的策略优化和探索能力,导致其在OOD环境中的泛化能力有限。
- RL-only:虽然最终能够达到不错的性能,但训练初期成功率低,收敛速度慢,且最终性能略低于SFT+RL。
- SFT+RL:SFT阶段提供了强大的策略初始化,使得训练过程更加稳定和快速收敛;RL阶段进一步提升了模型在OOD环境中的泛化能力和适应性。该配置在所有评估指标上均优于SFT-only和RL-only基线,并且训练过程更加稳定高效,证明了两阶段训练流程的协同优势。
推理质量分析
-
定性分析:
- 通过随机选择数据集中的几个案例,对比RL-only和SFT+RL配置生成的推理过程。结果表明,SFT+RL生成的推理过程更加连贯、结构化,涵盖了地标识别、空间关系推理和目标位置预测的完整链条;而RL-only模型生成的推理过程较为混乱,缺乏清晰的逻辑结构。
-
定量分析:
- 设计了三个推理质量指标:完整性(Completeness)、连贯性(Coherence)和流畅性(Fluency)。
- 使用GPT-4o自动对5,000个随机样本进行评分,每个样本评分3次,取平均值作为最终结果。
- 评估结果显示,SFT+RL在所有三个推理质量指标上均优于RL-only模型。
-
结论:
- SFT阶段在提升推理质量方面发挥了关键作用,特别是在推理的完整性方面,SFT+RL配置实现了0.44的提升,表明结构化推理训练能够有效引导模型生成更全面、系统的推理过程。
- 此外,连贯性和流畅性也分别提升了0.26和0.08,进一步增强了推理输出的清晰度和可读性。
结论与未来工作
- 结论:
- FlightGPT通过结合VLMs的多模态理解能力和两阶段训练流程(SFT+RL),在城市级无人机VLN任务中实现了显著的性能提升,特别是在泛化能力和决策可解释性方面表现出色。
- 在CityNav数据集上的实验结果表明,FlightGPT在分布内环境和更具挑战性的OOD场景中均优于现有基线模型。
- 未来工作:
- 缩小仿真与现实之间的差距:目前研究主要依赖于高保真仿真平台进行训练和评估,但在现实世界中,无人机操作会受到GPS漂移、天气干扰、动态障碍和意外事件等因素的影响。未来需要进行更多的实地测试和验证,以提高系统在真实环境中的性能、稳定性和鲁棒性。
- 提升与人类导航能力的差距:尽管FlightGPT在CityNav数据集上表现出色,但其导航智能仍落后于人类操作员,尤其是在处理涉及模糊表达、隐式目标或多轮指令的复杂场景时,缺乏常识推理和战略灵活性。未来需要进一步提升模型在多模态语义整合、空间推理和决策一致性方面的能力,以更好地应对动态和高复杂度的导航任务。
- 系统性评估部署可行性:当前研究主要关注性能,而对实际部署的系统要求关注不足。例如,推理延迟、内存使用和计算资源需求等关键因素直接影响系统在资源受限的边缘设备上实时运行的能力,但这些指标尚未得到系统性量化。此外,通信可靠性以及故障恢复机制等工程级实施的关键问题也尚未充分探索,限制了FlightGPT从研究原型向可部署解决方案的转变。

相关文章:
中山大学无人机具身导航新突破!FlightGPT:迈向通用性和可解释性的无人机视觉语言导航
作者:Hengxing Cai 1 , 2 ^{1,2} 1,2, Jinhan Dong 2 , 3 ^{2,3} 2,3, Jingjun Tan 1 ^{1} 1, Jingcheng Deng 4 ^{4} 4, Sihang Li 2 ^{2} 2, Zhifeng Gao 2 ^{2} 2, Haidong Wang 1 ^{1} 1, Zicheng Su 5 ^{5} 5, Agachai Sumalee 6 ^{6} 6, Renxin Zhong 1 ^{1} …...
WIN11+CUDA11.8+VS2019配置BundleFusion
参考: BundleFusion:VS2019 2017 ,CUDA11.5,win11,Realsense D435i离线数据包跑通,环境搭建 - 知乎 Win10VS2017CUDA10.1环境下配置BundleFusion - 知乎 BundleFusionWIN11VS2019 CUDA11.7环境配置-CSDN博客 我的环境:Win 11…...
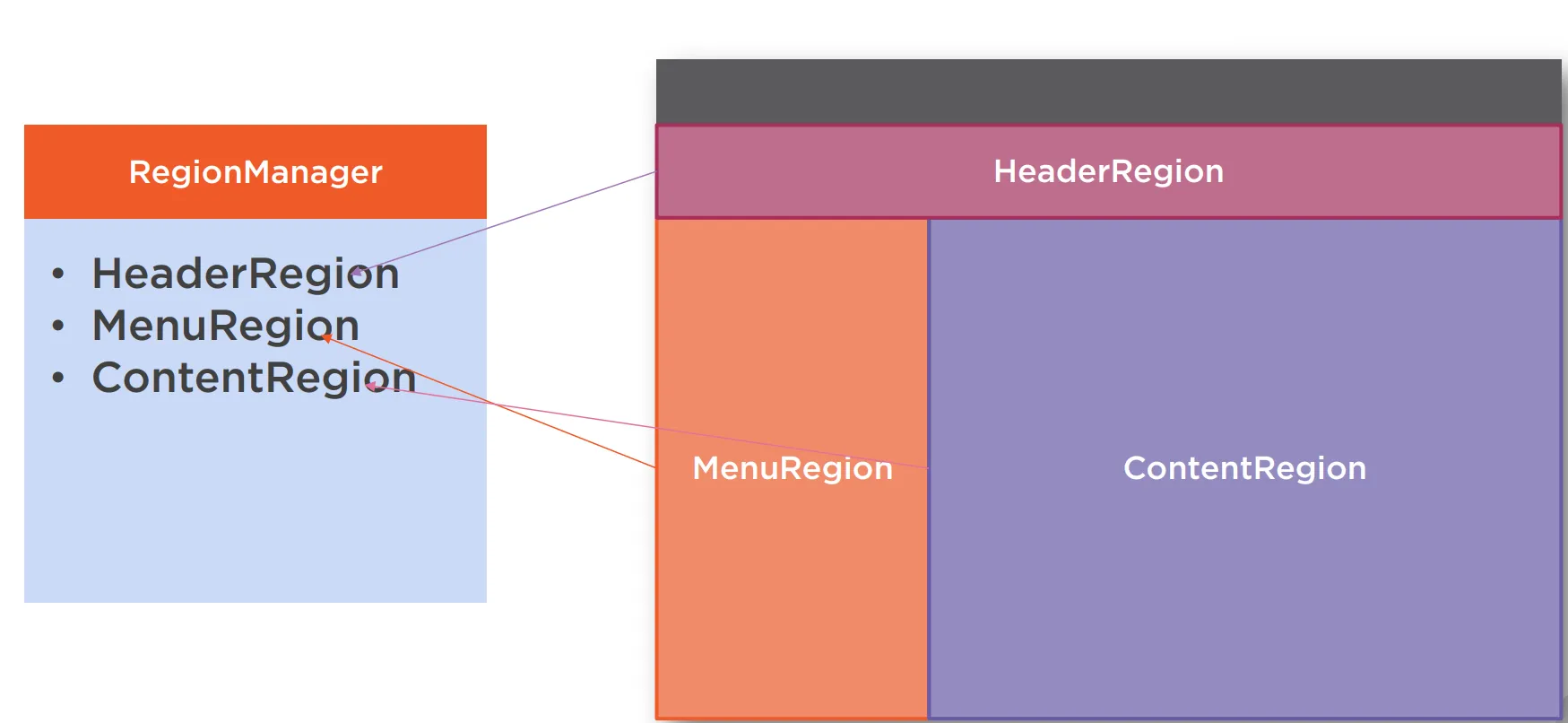
WPF prism
Prism Prism.Dryloc 包 安装 Nuget 包 - Prism.DryIoc 1. 修改 App.xaml 修改 App.xaml 文件,添加 prism 命名空间, 继承由 Application → PrismApplication,删除默认启动 url, StartupUri“MainWindow.xaml” <dryioc:PrismApplicationx:Class…...

实时同步缓存,与阶段性同步缓存——补充理解《补充》
根据 Redis 缓存的数据与 DBMS 中数据的同步性划分,缓存一般可划分为两类:实时同步缓存,与阶段性同步缓存。 实时同步缓存是指,DBMS 中数据更新后,Redis 缓存中的存放的相关数据会被立即清 除,以促使再有对…...

[Redis] Redis:高性能内存数据库与分布式架构设计
标题:[Redis] 浅谈分布式系统 水墨不写bug 文章目录 一、什么是Redis?一、核心定位二、核心优势三、典型应用场景四、Redis vs 传统数据库 二、架构选择与设计1、单机架构(应用程序 数据库服务器)2、应用程序和数据库服务器分离3…...

Mobaxterm解锁Docker
Mobaxterm是一款功能强大的终端模拟器和SSH客户端,它支持Windows、Linux和Mac操作系统,对于使用Docker的开发者和运维人员来说,Mobaxterm是一个非常有用的工具。本文将深入解析Mobaxterm,并分享一些使用Docker时的高效技巧。 Mob…...
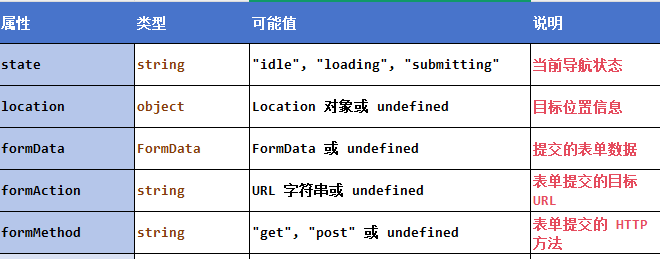
React 第四十九节 Router中useNavigation的具体使用详解及注意事项
前言 useNavigation 是 React Router 中一个强大的钩子,用于获取当前页面导航的状态信息。 它可以帮助开发者根据导航状态优化用户体验,如显示加载指示器、防止重复提交等。 一、useNavigation核心用途 检测导航状态:判断当前是否正在进行…...
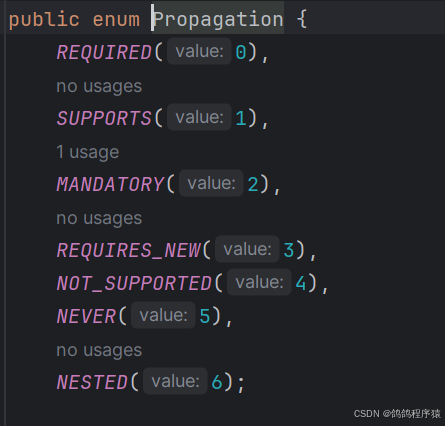
【JavaEE】Spring事务
目录 一、事务简介二、Spring事务的实现2.1 事务的操作2.2 分类2.2.1 Spring编程式事务2.2.2 Spring 声明式事务 Transactional2.2.2.1 Transactional 详解2.2.2.1.1 rollbackFor2.2.2.1.2 Isolation2.2.2.1.3 propagation 一、事务简介 事务:事务是⼀组操作的集合…...

Flink 状态管理深度解析:类型与后端的全面探索
在流处理场景中,数据往往是连续且无界的,为了准确处理这些数据并维持计算的连续性,Flink 引入了状态管理机制。Flink 的状态管理包含状态类型和状态后端两大部分,它们相辅相成,共同为作业的可靠性、容错性和性能提供保障。接下来,我们将深入探究 Flink 状态管理中状态类型…...
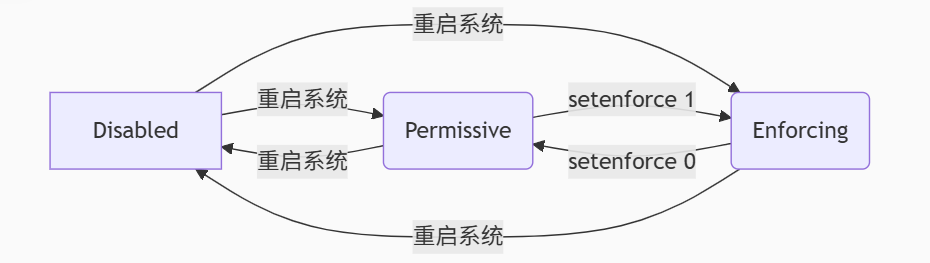
Android15 userdebug版本不能remount
背景描述: 最近调试Android Vendor Hal的时候发现一个奇怪的现象: android userdebug版本刷到设备中,执行adb root没提示错误,但是没有获取到root权限。 Android设备运行的系统版本有三种情况:user版本、userdebug版本和eng版本…...
R包安装报错解决案例系列|R包使用及ARM架构解决data.table安装错误问题
有不少同学是Mac系统的,分析过程中会发现部分R包总是安装不成功,这是因为部分R包基于windowsx86架构编译的,最常见的就是含 C/C/Fortran 的包,对于初学者都是建议linux和win去做,Windows 通常直接安装预编译好的二进制…...

k8s Headless Service
Kubernetes 无头服务(Headless Service)配置与使用场景 1.无头服务概述 无头服务(Headless Service)是 Kubernetes 中的一种特殊服务类型,它**不分配集群 IP(ClusterIP),而是直接暴露…...
Linux上安装MongoDB
目录 一、在Linux系统安装MongoDB服务器 1、下载MongoDB 2、上传MongoDB并解压 3、创建必要目录 4、配置环境变量 5、创建配置文件 6、启动命令 7、验证安装 二、在Linux系统安装MongoDB客户端Shell 1、下载MongoDB Shell 2、上传MongoDB Shell并解压 3、配置环境变…...

Redis最佳实践——安全与稳定性保障之访问控制详解
Redis 在电商应用的安全与稳定性保障之访问控制全面详解 一、安全访问控制体系架构 1. 多层级防护体系 #mermaid-svg-jpkDj2nKxCq9AXIW {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-jpkDj2nKxCq9AXIW .error-ico…...
【华为开发者空间 x DeepSeek】服务器运行Ollama并在本地调用
文章概述 本文介绍了如何在 华为开发者空间 中快速部署并使用 Ollama 模型运行框架,并结合 deepseek-r1 模型进行本地或远程交互推理。内容涵盖环境准备、模型配置、网卡绑定、内网穿透、API调用等多个环节,适合希望在华为云上快速搭建本地类大模型推理…...

Halcon
regiongrowing — Segment an image using regiongrowing. get_obj_class:获取图像的类别名 get_region_points:获取区域的像素 get_contour_xld:获取xld像素点坐标 get_polygon_xld:获取多边形的数据 get_region_polygon:计算一个区域的…...

STM32之IIC(重点)和OLED屏
内部集成电路概述 基本概念 内部集成电路(Inter Integrated Circuit)的简称叫做IIC或者I2C,是一种简单的、半双工同步通信的串行通信接口,IIC总线是上世纪80年代(1982年)由飞利浦公司设计出来,…...
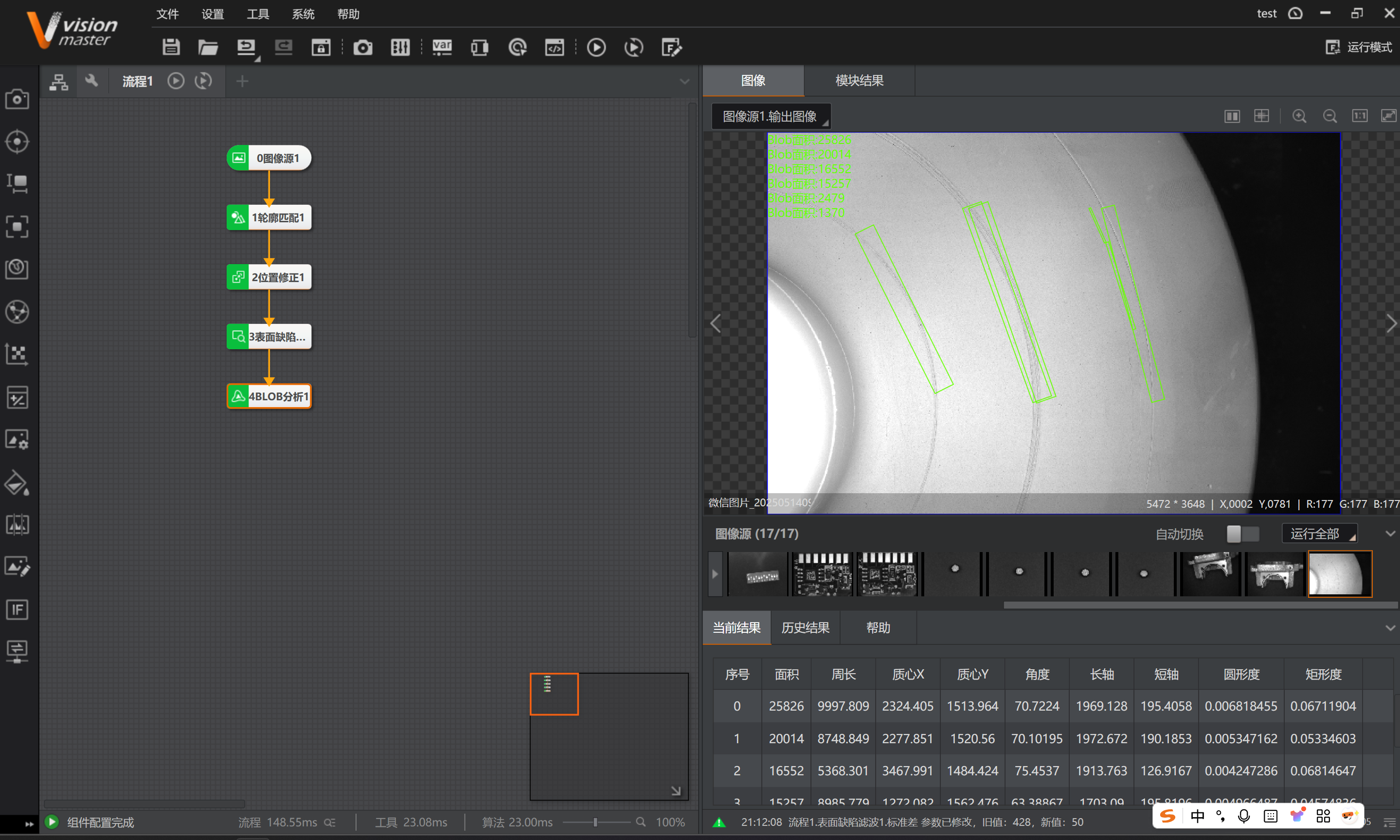
学习海康VisionMaster之表面缺陷滤波
一:进一步学习了 今天学习下VisionMaster中的表面缺陷滤波:简单、无纹理背景的表面缺陷检测,可以检测表面的异物,缺陷,划伤等 二:开始学习 1:什么表面缺陷滤波? 表面缺陷滤波的核心…...

游戏引擎学习第314天:将精灵拆分成多个层
回顾并为今天的工作做准备 我们今天继续昨天开始的工作,现在我们要回到渲染中处理 Z 值的最终环节。我们目前已经有一个我们认为还算合理的排序方式,虽然可能还需要在接下来的过程中进行一些调整,但总体上已经有了一个明确的方向。 我们已经…...

【学习笔记】深度学习-梯度概念
一、定义 梯度向量不仅表示函数变化的速度,还表示函数增长最快的方向 二、【问】为什么说它表示方向? 三、【问】那在深度学习梯度下降的时候,还要判断梯度是正是负来更新参数吗? 假设某个参数是 w,损失函数对它的…...
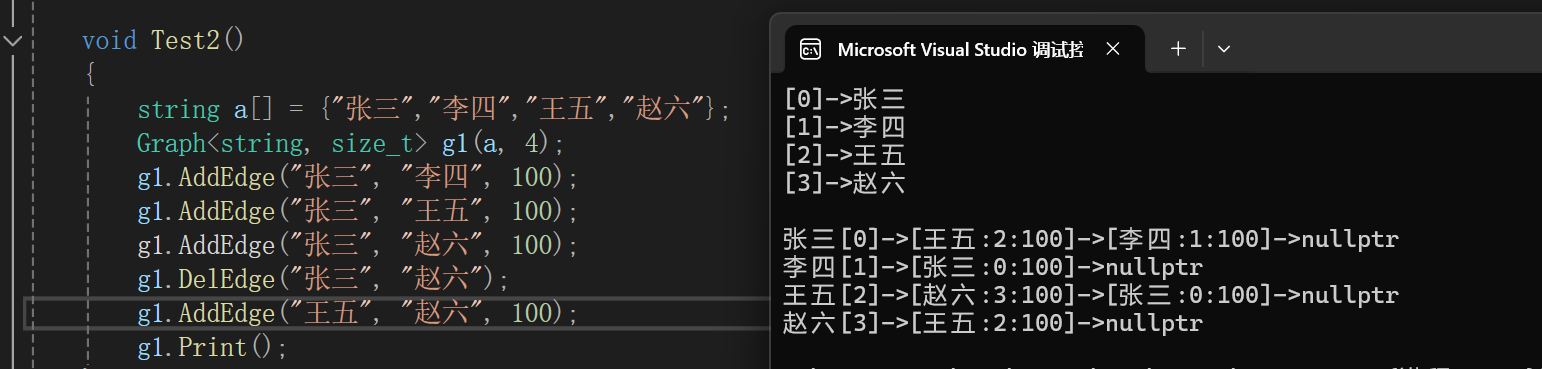
【数据结构】图的存储(邻接矩阵与邻接表)
图的存储结构 因为图中既有节点,又有边(节点与节点之间的关系),因此,在图的存储中,只需要保存:节点和边关系即可。 节点保存比较简单,只需要一段连续空间即可,那边关系该怎么保存呢࿱…...
tomcat yum安装
使用yum安装 yum install -y java-1.7.0-openjdk* tomcat* --disablerepoepel## java-1.7.0-openjdk* 注意:最终安装的是java-1.8.0版本## --disablerepoepel 禁用:EPEL源,防止版本冲突 java -version (2) 启停:Tomcat 7 s…...

【Elasticsearch】suggest_mode
suggest_mode 是 Elasticsearch 中 term suggester 和 phrase suggester 的一个参数,用于控制建议的生成方式。它有以下三种模式: 1. missing:默认值。仅对索引中不存在的词项提供建议。如果输入的词已经在索引中存在,则不会生成建…...
-golang SQLx 实现代码(动态组织 SQL))
数据库只更新特定字段的两种方式(先读后写 vs. 动态组织 SQL)-golang SQLx 实现代码(动态组织 SQL)
文章目录 数据库只更新特定字段的两种方式(先读后写 vs. 动态组织 SQL)go语言例子使用GORM的示例(最常用的Go ORM库)使用SQLx的两种更新方式实现golang SQLx 实现代码(动态组织 SQL) 数据库只更新特定字段的…...
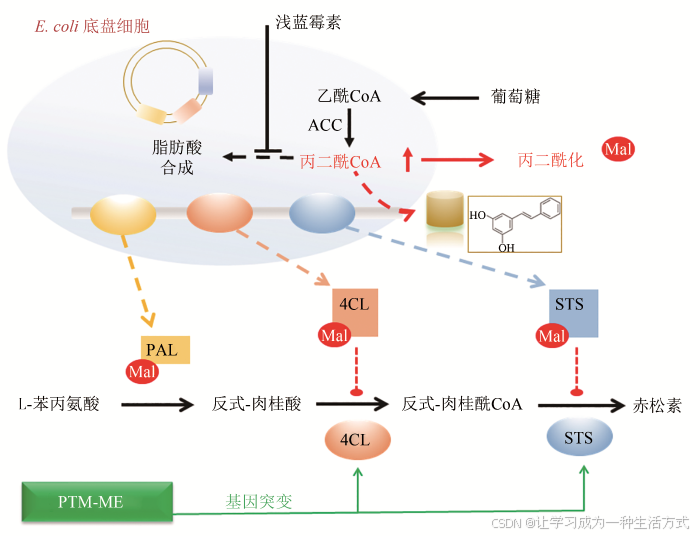
从翻译后修饰角度解析人工合成途径与底盘细胞的适配性-文献精读136
Compatibility between synthetic pathway and chassis cells from the viewpoint of post-translational modifications 从翻译后修饰角度解析人工合成途径与底盘细胞的适配性 摘要 揭示工程化设计的人工合成途径与底盘细胞整体代谢网络的交互作用及适配性机制是合成生物学研…...
Cesium快速入门到精通系列教程一
一、打造第一个Cesium应用 1、官方渠道下载Cesium(可选择历史版本) GitHub Releases页面 访问 Cesium GitHub Releases,此处列出了所有正式发布的版本。 通过标签(如 v1.95.0)选择目标版本,下载…...
[Windows] 剪映 视频编辑处理
附链接:夸克网盘分享(点击蓝色字体自行保存下载)...

决策树 GBDT XGBoost LightGBM
一、决策树 1. 决策树有一个很强的假设: 信息是可分的,否则无法进行特征分支 2. 决策树的种类: 2. ID3决策树: ID3决策树的数划分标准是信息增益: 信息增益衡量的是通过某个特征进行数据划分前后熵的变化量。但是&…...
stm32 / arduino TPL0401A使用教程
这是在给英国的一个学生讲课时用到的一个芯片,做一个dcdc的反馈电路,刚开始用的不是这个,后来发现国内这个芯片用的挺成熟,就选择了这个。 芯片说明 首先我买的是TPL0401A,我发现淘宝上卖的都是A,其实想用C࿰…...
数据结构与算法之单链表面试题(新浪、百度、腾讯)
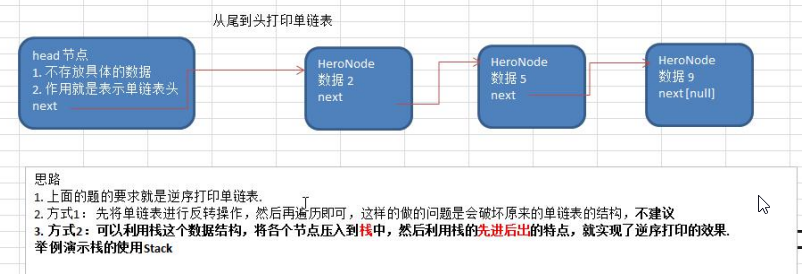
单链表面试题(新浪、百度、腾讯) 求单链表中的有效节点的个数 public int getCount(HeroNode head) {Hero1 cur head.getNext();int count 0;while(cur ! null) {count;cur cur.getNext();}return count;}查找单链表中的倒数第k个结点【新浪面试题】…...