基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
在企业数字化转型进程中,非结构化文本数据的处理与分析已成为核心技术挑战。传统自然语言处理方法在处理客户反馈、社交媒体内容和内部文档等复杂数据集时,往往难以有效捕获文本间的深层语义关联和结构化关系。大型概念模型(Large Concept Models, LCMs)与图神经网络的融合为这一挑战提供了创新解决方案,通过构建基于LangGraph的混合符号-语义处理管道,实现了更精准的情感分析、实体识别和主题建模能力。
大型概念模型的技术原理与架构
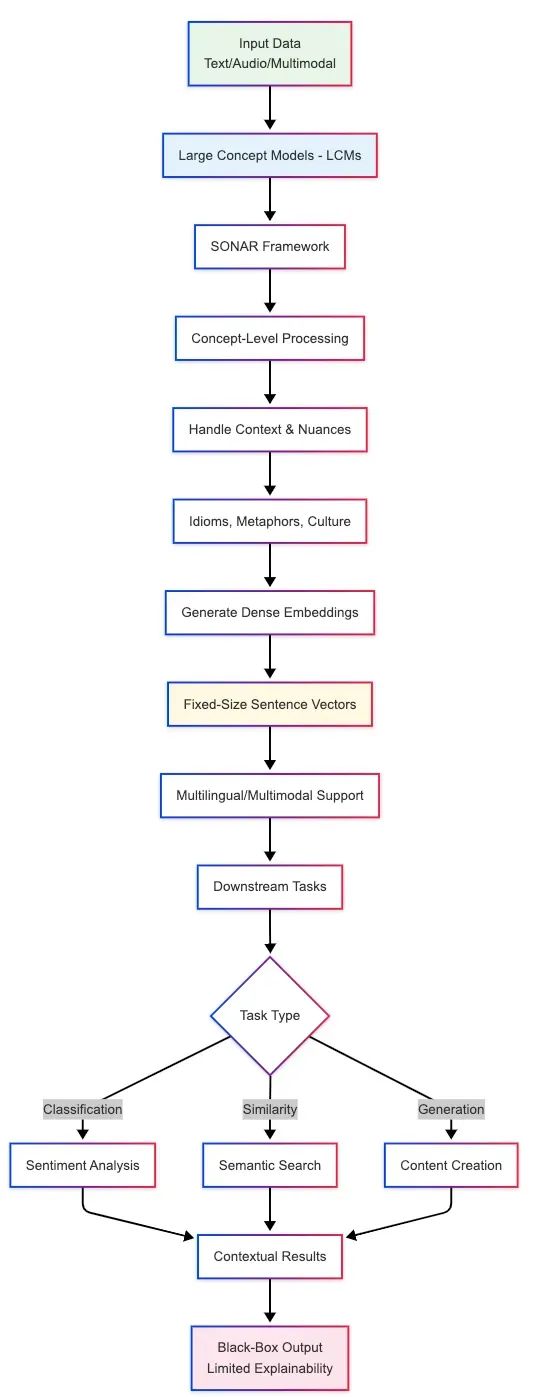
大型概念模型(Large Concept Models)代表了自然语言处理领域的重要技术进展,其核心创新在于将处理粒度从传统的词元级别提升到概念级别。与基于词汇分割的大型语言模型不同,LCMs在语言无关和模态无关的抽象表示空间中运行,能够直接处理完整的句子或语音话语单元。这种架构设计使得模型能够在更高层次上理解和生成语言内容,类似于先构建叙事框架再填充具体细节的创作过程。
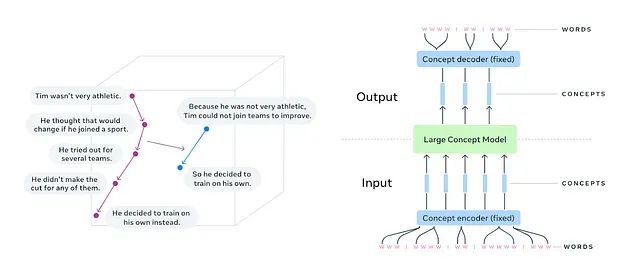
大型概念模型通过支持长序列上下文理解和语义连贯性维护,正在重新定义自然语言处理的技术边界。其在企业应用中的核心功能体现在多个维度上。
在语义理解方面,LCMs能够将整个句子或思想单元作为统一的语义概念进行处理,这种能力在情感分析任务中表现尤为突出。例如,在处理"这款手机改变了游戏规则!"这类表达时,模型能够将其正面情感倾向识别为单一概念,而非基于词汇序列的累积判断。此外,LCMs在处理习语、隐喻和文化特定表达时具有显著优势,能够通过语义意图分析实现跨语言的准确理解,如将"It’s raining cats and dogs"准确解释为强降雨的语义概念。
在上下文推理能力方面,LCMs通过概念级别的语义分析实现精确的词义消歧和实体识别。在处理"I deposited money in the bank"这样的句子时,模型能够通过句子概念分析准确判断"bank"指代金融机构而非河岸。这种以句子为中心的处理机制在长文本推理任务中表现出色,能够在多段落文档中维持语义连贯性和逻辑一致性。
LCMs在嵌入表示生成方面采用固定维度向量来编码完整句子的语义信息,为文本分类、聚类分析和语义相似度计算提供了高质量的特征表示。这些嵌入具有语言和模态无关特性,支持文本、语音乃至图像等多模态输入的统一处理。
在文本生成和摘要任务中,LCMs能够产生语义连贯的句子级输出,在抽象摘要和故事生成等任务中展现出优异性能。与传统的逐词生成机制相比,LCMs通过概念级别的规划机制显著降低了内容重复率并提升了上下文相关性,这一优势在Meta公司基于CNN/Daily Mail数据集的实验中得到了验证。
图神经网络增强的概念模型架构
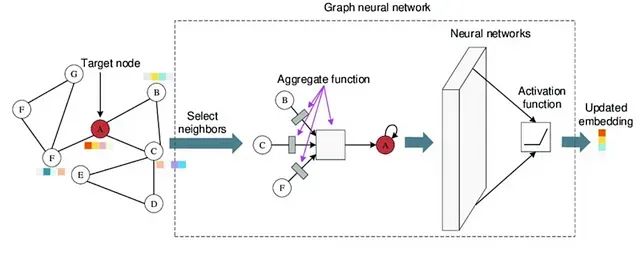
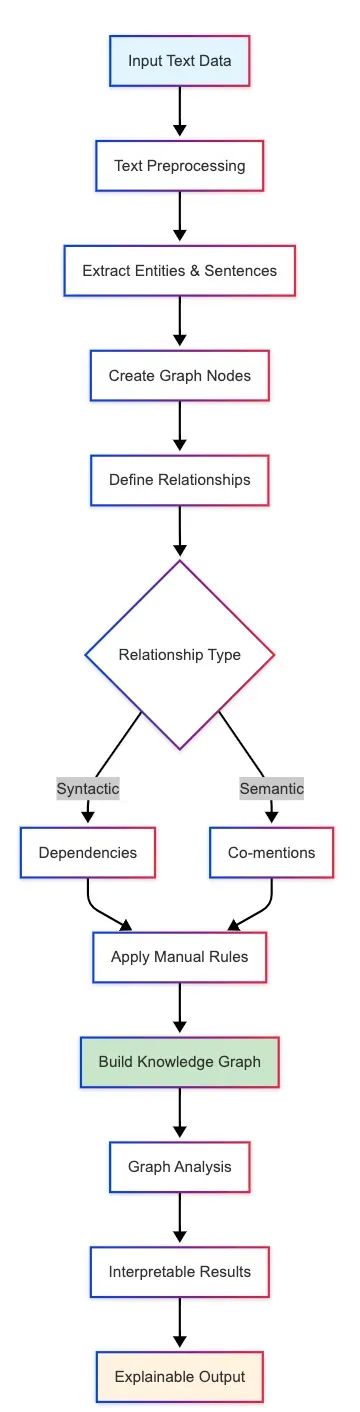
为了解决LCMs在建模文本间关系方面的局限性,基于图神经网络的增强方法将文本数据组织为具有明确拓扑结构的图形表示。在这种架构中,图节点可以表示句子、实体或文档等不同粒度的语言单元,而边则编码语法依赖、共现关系或语义关联等多种类型的结构信息。这种方法充分发挥了图结构在建模复杂关系方面的优势,为LCMs的语义理解能力提供了重要的结构化补充。
以智能手机用户评论分析为例,可以构建以评论为节点、以产品特征提及为边的图结构。LCMs负责生成每个评论的概念级嵌入表示,而图神经网络则通过边的信息传播机制发现跨评论的情感趋势和产品特征关联。例如,当多个评论都提及"相机"功能时,GNN能够聚合这些分散的评价信息,识别出用户对相机性能的整体满意度趋势,这种关联分析是单独使用LCMs难以实现的。
图结构的构建可以通过NetworkX等专业工具实现,支持基于文本分析技术的自动化节点和边定义,包括共现检测、句法解析等多种方法。LangGraph在整个系统中承担着工作流编排的重要角色,协调实体提取(基于LCMs)与关系识别(基于图分析)等多个处理环节,确保系统在企业级应用中的可扩展性和处理效率。
混合符号-语义处理架构的设计与实现
在处理复杂的企业文本分析任务时,单一的处理范式往往难以兼顾语义理解的深度和关系建模的精度。混合架构通过整合符号方法的结构化表示能力与语义方法的上下文理解能力,为复杂的自然语言处理任务提供了更全面的解决方案。这种架构特别适合处理需要同时考虑文本内在语义和文本间关联的应用场景,如多源客户反馈的综合分析。
符号化图表示方法
符号化方法采用图论的数学框架来建模文本数据的结构化信息。该方法将文本表示为由节点和边构成的图结构,其中节点可以是实体、句子或文档等语言单元,边则表示句法依赖、共现关系或语义关联等结构化关系。这种显式的关系建模是符号方法的核心优势,能够为文本分析提供清晰的解释性框架。
在客户反馈分析的实际应用中,符号化图可以将讨论相同产品的评论通过边连接,并使用边属性标记共同提及的主题,如"相机质量"或"电池续航"。这种明确的关系表示使得分析结果具有高度的可解释性,分析人员能够追溯推理路径和决策依据,这在金融、医疗等监管严格的行业中具有重要价值。
然而,符号方法的局限性在于其对预定义规则和本体的依赖性。基于规则的系统在处理自然语言的复杂性和歧义性时可能表现不足,特别是在理解讽刺、隐喻等需要深层语义推理的表达时。例如,对于"干得好,我的手机一小时就没电了!"这样包含讽刺意味的评论,纯粹的符号方法可能难以准确识别其负面情感倾向。
语义嵌入表示方法
语义方法的核心在于通过密集向量表示来捕获自然语言的深层语义信息。大型概念模型在这一范式中发挥着核心作用,通过SONAR等多语言多模态框架为完整的句子或概念单元生成统一的向量表示。与传统的词汇级嵌入不同,LCMs生成的概念级嵌入能够封装句子的完整语义信息,无论其表达语言或模态形式如何。
语义方法的主要优势在于其对语言复杂性和上下文依赖的适应能力。LCMs能够有效处理习语、隐喻、文化特定表达等复杂语言现象,通过深层语义理解实现准确的意图识别。然而,纯语义方法在建模文本间关系时存在局限性,难以明确表示不同文本片段之间的结构化关联,同时其黑盒特性也限制了结果的可解释性。
混合模型的系统架构
混合模型通过系统性整合符号方法的结构化优势和语义方法的理解深度,构建了一个多层次的文本处理架构。该架构的实现过程包含几个关键阶段。
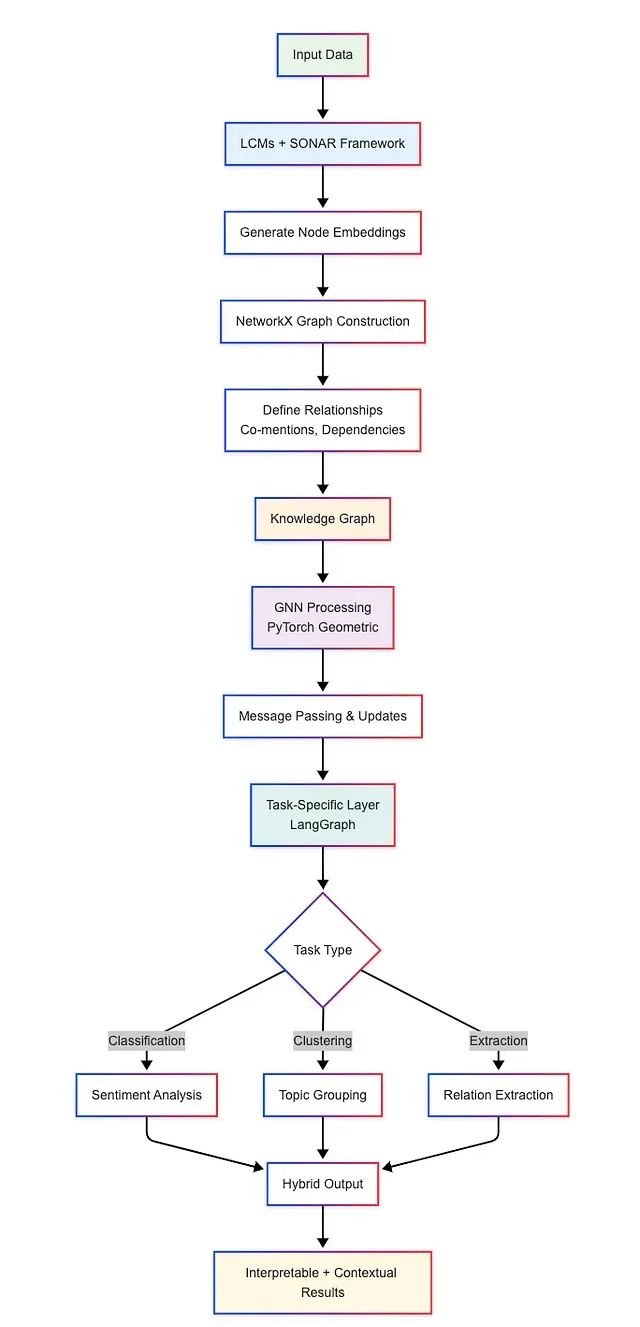
首先在嵌入生成阶段,LCMs为图中的各类节点生成SONAR嵌入表示。这些节点可以表示不同粒度的语言单元,从单个句子到实体提及,再到完整文档。与传统LLMs的词汇级处理不同,LCMs生成的固定维度向量能够完整保持句子级语义信息,为后续的图分析提供高质量的节点特征。
在图构建阶段,系统使用NetworkX等图处理工具构建包含LCM嵌入的图结构。节点被赋予相应的嵌入向量,而边的定义基于多种关系类型,包括实体共现、句法依赖和语义相似性等。这种图结构作为语义信息的组织框架,将分散的概念信息整合为结构化的知识表示。
图神经网络处理阶段是混合架构的核心环节。通过PyTorch Geometric等专业框架实现的GNNs在图的边上传播LCM生成的嵌入信息,通过邻居节点的信息聚合来更新每个节点的表示。这种机制使得图中的语义信息能够通过结构关系进行传播和融合,从而发现单个节点分析难以识别的全局模式和趋势。
最后,系统通过添加任务特定的输出层来适应不同的应用需求。这些输出层可以实现分类、聚类、关系抽取等多种功能,如情感极性分类、主题聚类分析或产品特征识别等。LangGraph框架在整个处理流程中负责任务协调和资源管理,确保从实体识别到关系分析的各个环节能够高效协作,满足企业级应用的性能和可扩展性要求。
情感分析的LangGraph实现方案
基于前述理论框架,我们将构建一个完整的LangGraph处理管道,该系统集成了大型概念模型、图神经网络和混合符号-语义方法,专门针对多渠道客户反馈的情感分析应用场景进行优化。该实现方案采用LCMs的概念级处理能力替代传统的BERT等词汇级模型,并充分体现了混合架构在企业应用中的技术优势。
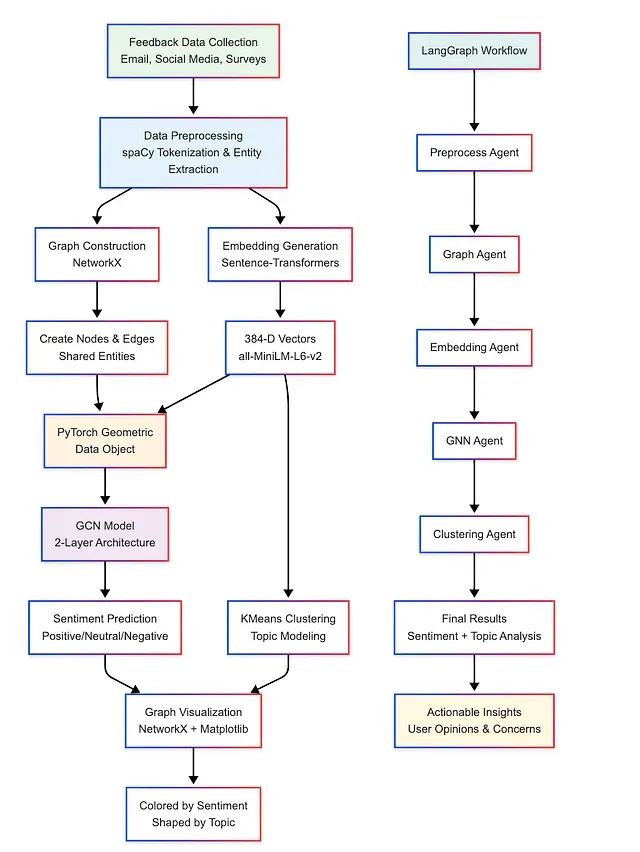
由于LCMs目前尚未作为开源预训练模型发布,本实现采用多语言句子编码器(sentence-transformers)作为SONAR嵌入的技术代理,并提供完整的可执行和可解释的处理管道。
环境配置与依赖安装
在开始实现之前,需要安装必要的Python库并配置GPU环境以优化处理性能:
pip install torch torch-geometric sentence-transformers networkx matplotlib spacy langgraph python -m spacy download en_core_web_sm
数据获取与预处理模块
该模块负责处理来自不同渠道的客户反馈数据,通过标准化的预处理流程为后续分析做准备。
#
importtorch
importnumpyasnp
fromsentence_transformersimportSentenceTransformer
importnetworkxasnx
importmatplotlib.pyplotasplt
importspacy
fromtorch_geometric.dataimportData
fromtorch_geometric.nnimportGCNConv
fromlanggraph.graphimportStateGraph
fromsklearn.clusterimportKMeans
fromtypingimportDict, List, Any # 数据获取与预处理模块
# 多渠道客户反馈数据示例,模拟企业实际应用场景
feedback_data= [ {"source": "email", "text": "The camera on this phone is amazing, but the battery life is poor."}, {"source": "social_media", "text": "Love the phone's camera quality! Price is a bit high."}, {"source": "survey", "text": "Battery drains too fast. Otherwise, great device."}, {"source": "email", "text": "Camera is top-notch, but customer service was unhelpful."}
] # 初始化spaCy模型用于语言学预处理
nlp=spacy.load("en_core_web_sm") defpreprocess_text(data: List[Dict[str, str]]) ->List[Dict[str, Any]]: """执行文本预处理操作,包括分词、词形还原和命名实体识别该函数为后续的图构建和语义分析提供结构化的输入数据"""processed_data= [] foritemindata: doc=nlp(item["text"]) # 执行词形还原并过滤停用词和非字母字符tokens= [token.lemma_fortokenindocifnottoken.is_stopandtoken.is_alpha] # 提取产品相关实体和特征术语entities= [(ent.text, ent.label_) forentindoc.ents] processed_data.append({ "source": item["source"], "text": item["text"], "tokens": tokens, "entities": entities }) returnprocessed_data # 执行预处理操作
processed_feedback=preprocess_text(feedback_data) print("预处理结果:", processed_feedback)
该模块通过spaCy自然语言处理库对多渠道反馈数据进行标准化处理。处理流程包括词汇标准化、实体识别和语义单元提取,为构建语义图和概念分析提供结构化的输入数据。
图结构构建模块
该模块基于预处理结果构建表示反馈间关系的图结构,为后续的图神经网络分析提供拓扑基础。
# 图结构构建模块
defbuild_feedback_graph(processed_data: List[Dict[str, Any]]) ->nx.Graph: """构建反馈关系图,节点表示反馈项,边表示基于实体共现的语义关联该图结构为GNN分析提供了明确的关系拓扑"""G=nx.Graph() # 为每个反馈项创建图节点fori, iteminenumerate(processed_data): G.add_node(i, text=item["text"], entities=[e[0] foreinitem["entities"]]) # 基于实体共现建立节点间的边连接fori, item_iinenumerate(processed_data): forj, item_jinenumerate(processed_data[i+1:], start=i+1): common_entities=set([e[0] foreinitem_i["entities"]]) &set([e[0] foreinitem_j["entities"]]) ifcommon_entities: G.add_edge(i, j, common_entities=common_entities) returnG # 构建反馈关系图
feedback_graph=build_feedback_graph(processed_feedback)
print("图节点信息:", feedback_graph.nodes(data=True)) print("图边信息:", feedback_graph.edges(data=True))
通过NetworkX构建的图结构将反馈数据的关系信息显式建模。每个反馈作为图节点,而共享相同实体提及的反馈通过边连接,形成了反映主题关联的网络拓扑结构。
概念嵌入生成模块
该模块负责生成高质量的语义嵌入表示,为图神经网络提供节点特征。
# 概念嵌入生成模块 (采用sentence-transformers模拟LCM能力)
# 使用多语言句子编码器作为SONAR嵌入的技术代理
sentence_model=SentenceTransformer('all-MiniLM-L6-v2') defgenerate_concept_embeddings(processed_data: List[Dict[str, Any]]) ->torch.Tensor: """生成句子级概念嵌入,模拟LCM的语义表示能力返回的嵌入矩阵将作为图神经网络的节点特征输入"""sentences= [item["text"] foriteminprocessed_data] embeddings=sentence_model.encode(sentences, convert_to_tensor=True) returnembeddings # 生成概念嵌入矩阵
embeddings=generate_concept_embeddings(processed_feedback) print("嵌入矩阵维度:", embeddings.shape) # 输出: [样本数量, 嵌入维度]
该模块使用sentence-transformers库生成384维的句子级嵌入向量,每个向量封装了对应反馈的完整语义信息。这些嵌入将作为图神经网络的节点特征,支持后续的关系推理和情感传播分析。
PyTorch Geometric数据适配模块
该模块将NetworkX图结构和嵌入数据转换为PyTorch Geometric兼容的格式。
# PyTorch Geometric数据适配模块
defcreate_graph_data(embeddings: torch.Tensor, graph: nx.Graph) ->Data: """将NetworkX图和嵌入矩阵转换为PyTorch Geometric数据对象该转换为GNN模型提供了标准化的输入接口"""# 将图的边列表转换为edge_index张量格式edge_index=torch.tensor(list(graph.edges), dtype=torch.long).t().contiguous() # 节点特征矩阵由概念嵌入构成x=embeddings returnData(x=x, edge_index=edge_index) # 创建GNN输入数据对象graph_data=create_graph_data(embeddings, feedback_graph)
该模块完成了从通用图表示到深度学习框架专用格式的转换,确保后续的GNN模型能够正确处理图结构数据和节点特征。
图卷积神经网络模型
该模块定义了用于情感分析的图卷积网络架构。
# 图卷积神经网络模型定义
classGCN(torch.nn.Module): def__init__(self, in_channels: int, hidden_channels: int, out_channels: int): super(GCN, self).__init__() self.conv1=GCNConv(in_channels, hidden_channels) self.conv2=GCNConv(hidden_channels, out_channels) # 支持三分类:正面、中性、负面defforward(self, data: Data) ->torch.Tensor: x, edge_index=data.x, data.edge_index # 第一层图卷积后应用ReLU激活x=self.conv1(x, edge_index) x=torch.relu(x) # 第二层图卷积生成最终分类logitsx=self.conv2(x, edge_index) returnx # 初始化GCN模型 (MiniLM嵌入维度为384)gcn_model=GCN(in_channels=384, hidden_channels=16, out_channels=3)
该GCN模型采用两层图卷积结构,能够通过图的边关系传播节点信息,实现基于结构信息的情感分类预测。
情感预测执行模块
该模块执行基于GCN的情感分类推理。
# 情感预测执行模块
# 注意:此处使用随机初始化权重进行演示,实际应用需要基于标注数据训练模型
withtorch.no_grad(): sentiment_logits=gcn_model(graph_data) sentiment_preds=sentiment_logits.argmax(dim=1) sentiment_labels= {0: "Positive", 1: "Neutral", 2: "Negative"} sentiment_results= [sentiment_labels[p.item()] forpinsentiment_preds]
该模块展示了GNN模型在图数据上的推理过程,通过softmax层输出每个反馈节点的情感分类结果。在生产环境中,模型需要基于标注数据进行充分训练。
主题聚类分析模块
该模块通过聚类算法识别反馈数据中的主题结构。
# 主题聚类分析模块
defcluster_graph_nodes(embeddings: torch.Tensor, num_clusters: int=2) ->List[int]: """基于概念嵌入执行主题聚类分析该方法能够识别反馈数据中的潜在主题结构"""kmeans=KMeans(n_clusters=num_clusters, random_state=42) cluster_labels=kmeans.fit_predict(embeddings.cpu().numpy()) returncluster_labels # 执行主题聚类
cluster_labels=cluster_graph_nodes(embeddings, num_clusters=2) print("聚类结果:", cluster_labels)
该模块通过K-means算法对概念嵌入进行聚类,能够发现反馈数据中的主题模式,为企业提供客户关注点的结构化洞察。
结果可视化模块
该模块提供图结构和分析结果的可视化展示。
# 结果可视化模块
def visualize_graph(graph: nx.Graph, sentiment_preds: List[str], cluster_labels: List[int]): """可视化图结构及分析结果节点颜色表示情感倾向,节点形状表示主题聚类"""plt.figure(figsize=(10, 8)) pos = nx.spring_layout(graph) # 定义情感颜色映射color_map = {"Positive": "green", "Neutral": "gray", "Negative": "red"} node_colors = [color_map[pred] for pred in sentiment_preds] # 定义聚类形状映射node_shapes = ['o' if label == 0 else 's' for label in cluster_labels] # 按形状分组绘制节点for shape in set(node_shapes): nodes = [i for i, s in enumerate(node_shapes) if s == shape] nx.draw_networkx_nodes( graph, pos, nodelist=nodes, node_color=[node_colors[i] for i in nodes], node_shape=shape, node_size=500, label=f"主题聚类 {node_shapes[nodes[0]] == 'o' and 0 or 1}" ) # 绘制边和标签nx.draw_networkx_edges(graph, pos) nx.draw_networkx_labels(graph, pos, labels={i: f"R{i}" for i in graph.nodes}) plt.title("客户反馈关系图:情感分析(颜色)与主题聚类(形状)") plt.legend() plt.show() # 执行可视化
visualize_graph(feedback_graph, sentiment_results, cluster_labels)
该可视化模块通过颜色编码情感倾向、形状编码主题聚类,提供了分析结果的直观展示,帮助业务人员理解客户反馈的整体模式。
LangGraph工作流编排
该模块使用LangGraph框架实现完整的处理管道编排。
# LangGraph工作流编排模块
# 定义状态类用于管理处理流程中的数据流
class FeedbackState(Dict[str, Any]): feedback: List[Dict[str, Any]] processed_data: List[Dict[str, Any]] graph: nx.Graph embeddings: torch.Tensor graph_data: Data sentiment_preds: List[str] cluster_labels: List[int] # 定义处理代理函数
def preprocess_agent(state: FeedbackState) -> FeedbackState: """文本预处理代理"""state["processed_data"] = preprocess_text(state["feedback"]) return state def graph_agent(state: FeedbackState) -> FeedbackState: """图构建代理"""state["graph"] = build_feedback_graph(state["processed_data"]) return state def embedding_agent(state: FeedbackState) -> FeedbackState: """嵌入生成代理"""state["embeddings"] = generate_concept_embeddings(state["processed_data"]) return state def gnn_agent(state: FeedbackState) -> FeedbackState: """图神经网络推理代理"""state["graph_data"] = create_graph_data(state["embeddings"], state["graph"]) with torch.no_grad(): logits = gcn_model(state["graph_data"]) preds = logits.argmax(dim=1) state["sentiment_preds"] = [sentiment_labels[p.item()] for p in preds] return state def clustering_agent(state: FeedbackState) -> FeedbackState: """聚类分析代理"""state["cluster_labels"] = cluster_graph_nodes(state["embeddings"]) return state # 构建LangGraph工作流
workflow = StateGraph(FeedbackState)
workflow.add_node("preprocess", preprocess_agent)
workflow.add_node("graph", graph_agent)
workflow.add_node("embedding", embedding_agent)
workflow.add_node("gnn", gnn_agent)
workflow.add_node("clustering", clustering_agent) # 定义处理流程的执行顺序
workflow.add_edge("preprocess", "graph")
workflow.add_edge("graph", "embedding")
workflow.add_edge("embedding", "gnn")
workflow.add_edge("gnn", "clustering")
workflow.set_entry_point("preprocess") # 编译并执行工作流
graph = workflow.compile()
initial_state = FeedbackState(feedback=feedback_data)
final_state = graph.invoke(initial_state)
LangGraph工作流编排确保了各个处理模块的有序执行和状态管理,通过代理模式实现了松耦合的模块化设计,便于系统的维护和扩展。
结果输出与报告生成
该模块负责格式化输出分析结果并生成业务报告。
# 结果输出与报告生成模块
print("\n=== 情感分析结果 ===")
for i, (item, pred) in enumerate(zip(feedback_data, final_state["sentiment_preds"])): print(f"反馈 {i}: {item['text']} -> 情感倾向: {pred}") print("\n=== 主题聚类分析 ===")
for cluster_id in set(final_state["cluster_labels"]): cluster_reviews = [ item["text"] for i, item in enumerate(feedback_data) if final_state["cluster_labels"][i] == cluster_id ] print(f"主题聚类 {cluster_id}: {cluster_reviews}")
该输出模块提供了结构化的分析结果展示,包括每个反馈项的情感分类和基于主题的聚类结果,为企业决策提供了清晰的数据支撑。
通过LangGraph驱动的处理管道成功实现了符号推理与语义理解的有机融合,通过模拟大型概念模型的句子级处理能力和图神经网络的关系建模能力,为多渠道客户反馈提供了综合的情感分析和主题发现解决方案。
需要注意的是,当前实现中的GCN模型采用随机初始化权重用于演示目的。在实际生产环境中,需要基于标注的情感数据和适当的损失函数(如交叉熵)进行模型训练。此外,由于LCMs尚未公开发布,本实现采用sentence-transformers作为SONAR嵌入的近似替代。在真实的LCM部署环境中,应当使用Meta公司的SONAR编码器来获得真正的多语言多模态嵌入能力。
总结
基于图神经网络的自然语言处理技术,特别是与大型概念模型和LangGraph框架的结合,为企业级文本分析提供了革命性的解决方案。LCMs通过概念级的语义理解超越了传统的词汇级处理局限,而图结构建模则有效捕获了文本间的复杂关系。混合符号-语义架构不仅提高了分析精度,还增强了结果的可解释性和业务价值。这种技术融合使企业能够更深入地挖掘非结构化数据的价值,为数据驱动的商业决策提供了强有力的技术支撑。
https://avoid.overfit.cn/post/868acec8585a49e48d02be45e3f7109a
作者:Samvardhan Singh
相关文章:
基于图神经网络的自然语言处理:融合LangGraph与大型概念模型的情感分析实践
在企业数字化转型进程中,非结构化文本数据的处理与分析已成为核心技术挑战。传统自然语言处理方法在处理客户反馈、社交媒体内容和内部文档等复杂数据集时,往往难以有效捕获文本间的深层语义关联和结构化关系。大型概念模型(Large Concept Mo…...
R 语言科研绘图 --- 热力图-汇总
在发表科研论文的过程中,科研绘图是必不可少的,一张好看的图形会是文章很大的加分项。 为了便于使用,本系列文章介绍的所有绘图都已收录到了 sciRplot 项目中,获取方式: R 语言科研绘图模板 --- sciRplothttps://mp.…...

基于DFT码本的波束方向图生成MATLAB实现
基于DFT码本的波束方向图生成MATLAB实现,包含参数配置、方向图生成和可视化模块: %% 基于DFT码本的波束方向图生成 clc; clear; close all;%% 参数配置 params struct(...N, 8, % 阵元数d, 0.5, % 阵元间距(λ/2)theta_sc…...
)
vBulletin未认证API方法调用漏洞(CVE-2025-48827)
免责声明 本文档所述漏洞详情及复现方法仅限用于合法授权的安全研究和学术教育用途。任何个人或组织不得利用本文内容从事未经许可的渗透测试、网络攻击或其他违法行为。使用者应确保其行为符合相关法律法规,并取得目标系统的明确授权。 对于因不当使用本文信息而造成的任何直…...
解决访问网站提示“405 很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被阻断”问题
一、问题描述 本来前几天都可以正常访问的网站,但是今天当我们访问网站的时候会显示“405 很抱歉,由于您访问的URL有可能对网站造成安全威胁,您的访问被阻断。您的请求ID是:XXXX”,而不能正常的访问网站,如…...

FeignClient发送https请求时的证书验证原理分析
背景 微服务之间存在调用关系,且部署为 SSL 协议时,Feignt 请求报异常: Caused by: javax.net.ssl.SSLHandshakeException: PKIX path building failed: sun.security.provider.certpath.SunCertPathBuilderException: unable to find vali…...

UDP组播套接字与URI/URL/URN技术详解
UDP组播套接字基础 Java通过MulticastSocket类提供对UDP组播通信的支持,该机制允许单个数据报同时发送给多个接收者。组播套接字的工作机制与标准DatagramSocket类似,但核心区别在于其基于组播组成员关系的通信模型。 组播组成员管理 创建并绑定组播套接字后,必须调用joi…...
机器学习中的关键术语及其含义
神经元及神经网络 机器学习中的神经网络是一种模仿生物神经网络的结构和功能的数学模型或计算模型。它是指按照一定的规则将多个神经元连接起来的网络。 神经网络是一种运算模型,由大量的节点(或称神经元)之间相互联接构成。每个节点代表一…...

点云识别模型汇总整理
点云识别模型主要分类: 目前主流的点云识别模型主要分为 基于点直接处理的方法:PointNet、PointNet 、DGCNN、 PointCNN、 Point Transformer、 RandLA-Net、 PointMLP、 PointNeXt ;基于体素化的方法:VoxelNet、SECOND、PV-RCN…...

项目更改权限后都被git标记为改变,怎么去除
❗问题描述: 当你修改了项目中的文件权限(如使用 chmod 改了可执行权限),Git 会把这些文件标记为“已更改”,即使内容并没有发生任何改变。 ✅ 解决方法: ✅ 方法一:告诉 Git 忽略权限变化&am…...
网络编程1_网络编程引入
为什么需要网络编程? 用户再在浏览器中,打开在线视频资源等等,实质上说通过网络,获取到从网络上传输过来的一个资源。 与打开本地的文件类似,只是这个文件的来源是网络。相比本地资源来说,网络提供了更为…...

【Day38】
DAY 38 Dataset和Dataloader类 对应5. 27作业 知识点回顾: Dataset类的__getitem__和__len__方法(本质是python的特殊方法)Dataloader类minist手写数据集的了解 作业:了解下cifar数据集,尝试获取其中一张图片 import …...

HTML Day04
Day04 0.引言1. HTML字符实体2. HTML表单2.1 表单标签2.2 表单示例 3. HTML框架4. HTML颜色4.1 16进制表示法4.2 rgba表示法4.3 名称表达法 5. HTML脚本 0.引言 刚刚回顾了前面几篇博客,感觉写的内容倒是很详细,每个知识点都做了说明。但是感觉在知识组织…...

佳能 Canon G3030 Series 打印机信息
基本参数 连接方式:Hi-Speed USB 接口,支持 IEEE802.11n/802.11g/802.11b/802.11a/802.11ac 无线连接,可同时使用 USB 和网络连接。尺寸重量:外观尺寸约为 416337177mm,重量约为 6.0kg。电源规格:AC 100-2…...
云原生安全基石:Kubernetes 核心概念与安全实践指南
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. Kubernetes 架构全景 Kubernetes(简称 K8s)采用主从架构,由控制平面(Control Plane&…...

图像修复的可视化demo代码
做项目的时候需要用到一个windows窗口可视化来展示我们的工作,我们的工作是一个文本指导的人脸图像修复,所以窗口需要包括输入图像,文本指导输入和修复结果,并且提供在输入图像上画mask的功能,使用tkinter来实现&#…...

autodl 安装了多个conda虚拟环境 选择合适虚拟环境的语句
1.conda env list 列出所有虚拟环境 可以看到,我有两个虚拟环境,一个是joygen,一个是base conda activate base 或者 conda activate joygen 激活对应的环境。我选择激活 joygen 环境 然后就可以在joygen环境下进行操作了 base环境也是同理…...

【AI工具应用】使用 trae 实现 word 转成 html
假如我们要实现某个网站的《隐私协议》等静态页面,产品给了一个 word 文档,以前我都是手动从 word 文档复制一行的文字,然后粘贴到一个html文件中,还得自己加各种标签,很麻烦。 我们可以使用 trae 等 ai 工具实现 wor…...
ansible-playbook 进阶 接上一章内容
1.异常中断 做法1:强制正常 编写 nginx 的 playbook 文件 01-zuofa .yml - hosts : web remote_user : root tasks : - name : create new user user : name nginx-test system yes uid 82 shell / sbin / nologin - name : test new user shell : gete…...
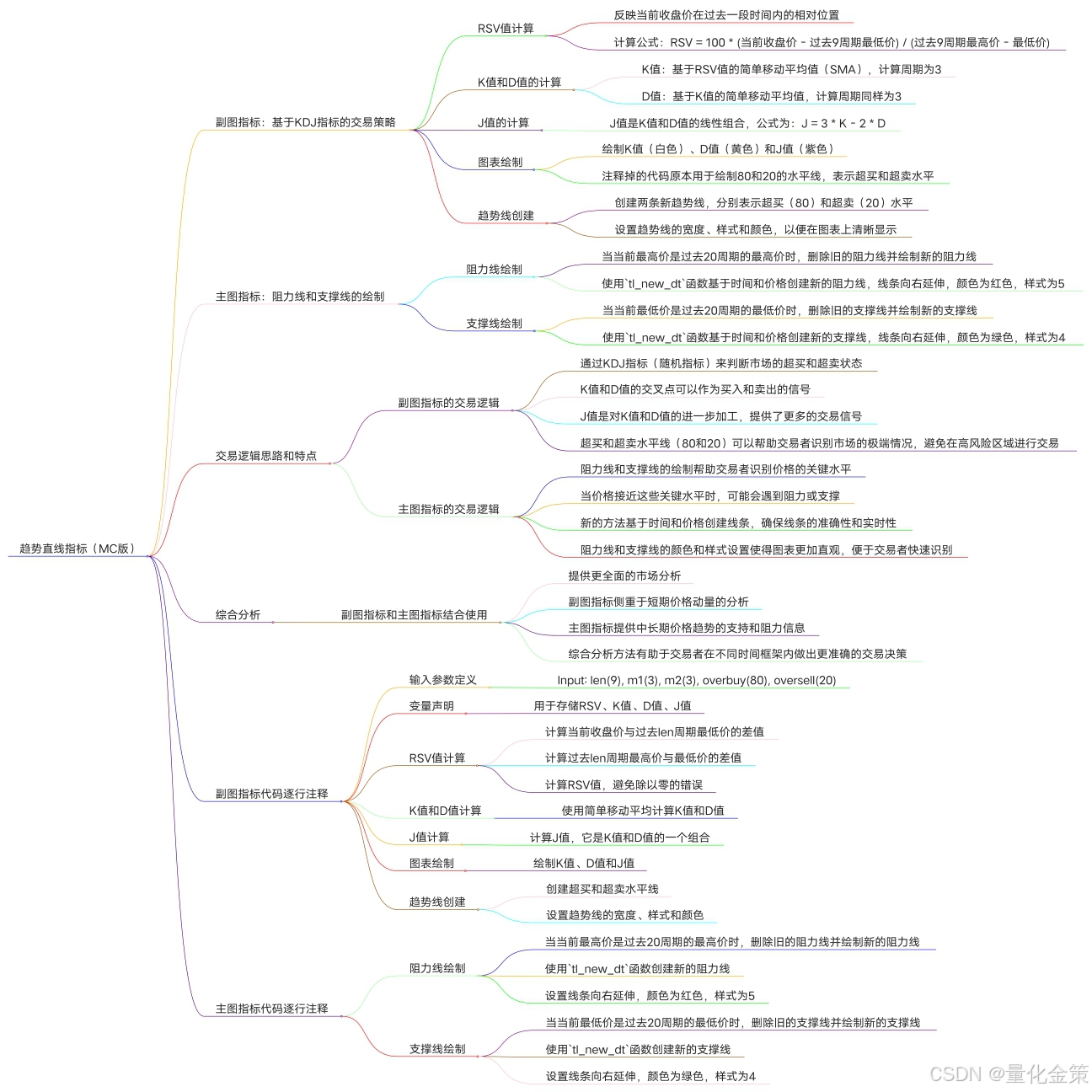
趋势直线指标
趋势直线副图和主图指标,旨在通过技术分析工具帮助交易者识别市场趋势和潜在的买卖点。 副图指标:基于KDJ指标的交易策略 1. RSV值计算: - RSV(未成熟随机值)反映了当前收盘价在过去一段时间内的相对位置。通过计算当前…...

基线配置管理:为什么它对网络稳定性至关重要
什么是基线配置(Baseline Configuration) 基线配置(Baseline Configuration)是经过批准的标准化主设置,代表所有设备应遵循的安全、合规且运行稳定的配置基准,可作为评估变更、偏差或未授权修改的参考基准…...
)
AWS WebRTC:获取ICE服务地址(part 1)
建立WebRTC连接的第二步是获取ICE服务地址。 ICE全称:Interactive Connectivity Establishment,建立互动连接。 ICE 服务地址,主要是 TURN 和 STUN 服务器的地址,用于 WebRTC 在 NAT 网络环境中协商建立连接。 上代码ÿ…...
Nest全栈到失业(一):Nest基础知识扫盲
Nest 是什么? 问你一个问题,node是不是把js拉出来浏览器环境运行了?当然,他使用了v8引擎加上自己的底层模块从而实现了,在外部编辑处理文件等;然后它使用很多方式来发送请求是吧,你知道的什么http.request 或 https.request; 我们浏览器中,使用AJAX以及封装AJAX和http的Axios…...
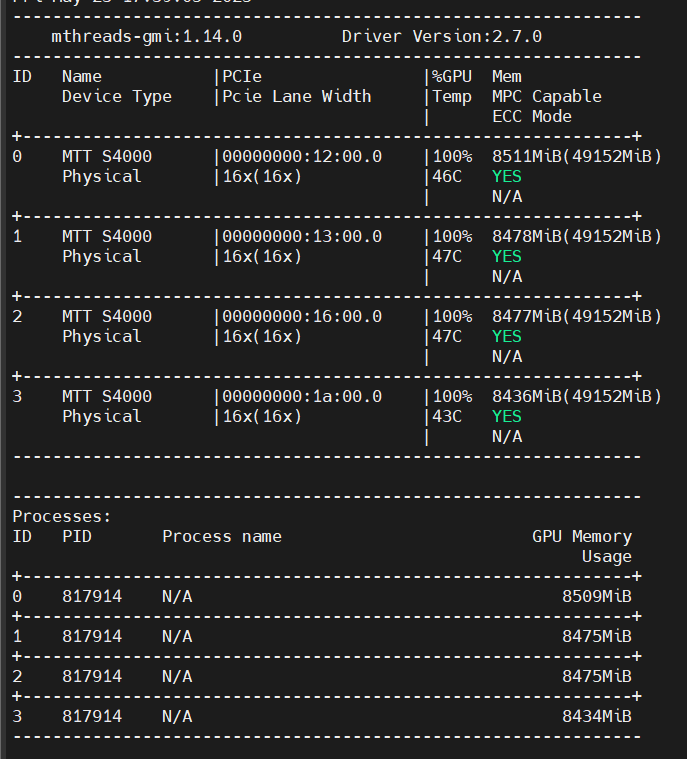
摩尔线程S4000国产信创计算卡性能实战——Pytorch转译,多卡P2P通信与MUSA编程
简介 MTT S4000 是基于摩尔线程曲院 GPU 架构打造的全功能元计算卡,为千亿规模大语言模型的训练、微调和推理进行了定制优化,结合先进的图形渲染能力、视频编解码能力和超高清 8K HDR 显示能力,助力人工智能、图形渲染、多媒体、科学计算与物…...
Tesseract OCR 安装与中文+英文识别实现
一、下载 https://digi.bib.uni-mannheim.de/tesseract/ 下载,尽量选择时间靠前的(识别更好些)。符合你的运行机(我的是windows64) 持续点击下一步安装,安装你认可的路径即可,没必要配置环境变…...

Cypress + React + TypeScript
🧪 Cypress + React + TypeScript 组件测试全流程实战:从入门到自动化集成 在现代前端开发中,组件测试 是保障 UI 行为可靠性的重要手段。本文将通过一个 React 项目示例,实战演示如何结合 Cypress + React + TypeScript 实现从零配置到自动化集成的完整测试链路。 一、项…...

每个路由器接口,都必须分配所属网络内的 IP 地址,用于转发数据包
在IP网络中,主机(Host)和路由器接口(Router Interface)都需要分配网络地址(IP地址)。 1. 主机(Host)的IP地址分配 (1) 作用 主机的IP地址用于唯一标识该设备࿰…...
——布尔变量)
c++第四课(基础c)——布尔变量
1.前言 好,今天我们来学布尔变量(bool),开搞! 2.正文 2.1布尔数据的定义值 布尔数据的定义值,是只有真和假 顺便提一句0是假,非0的数字都是真 不过为了简便 我们一般都用0和1 2.2布尔数…...
第2期:APM32微控制器键盘PCB设计实战教程
第2期:APM32微控制器键盘PCB设计实战教程 一、APM32小系统介绍 使用apm32键盘小系统开源工程操作 APM32是一款与STM32兼容的微控制器,可以直接替代STM32进行使用。本教程基于之前开源的APM32小系统,链接将放在录播评论区中供大家参考。 1…...
Docker-搭建MySQL主从复制与双主双从
Docker -- 搭建MySQL主从复制与双主双从 一、MySQL主从复制1.1 准备工作从 Harbor 私有仓库拉取镜像直接拉取镜像运行容器 1.2 配置主、从服务器1.3 创建主、从服务器1.4 启动主库,创建同步用户1.5 配置启动从库1.6 主从复制测试 二、MySQL双主双从2.1 创建网络2.2 …...