使用Yolov8 训练交通标志数据集:TT100K数据集划分
使用Yolov8 训练交通标志数据集:TT100K数据集划分(一)
- 一、数据集下载
- 二、划分数据集
- 三、目录放置
一、数据集下载
-
官方网址:TT100K

-
数据集对比

源码如下:def classes(filedir):with open(filedir) as f:classes = json.load(f)classes_list = classes['types']return len(classes_list)c_2016 = classes("./annotations.json") c_2021 = classes("./annotations_all.json") print(f'TT100K-2016 交通标志的类别:{c_2016}') print(f'TT100K-2021 交通标志的类别:{c_2021}') print(f'差值:{c_2021-c_2016}') -
查看类别数目
# 读TT100K原始数据集标注文件 with open(annotations) as p:# 读取 json 文件file = json.load(p)# 获取图字典img_dict = file['imgs']types = file['types']classes_list = dict()for i in types:# i 为所有的类别: 如:‘pl80’, 'w9', 'p6'# 将每一个类别作为字典中的键,值为: 空列表 []classes_list[i] = 0for img_id in img_dict:img = images_dict[img_id]obj_list = img['objects']# 统计实际有多少种类别for obj in obj_list:classes_list[obj['category']] += 1# 大于0的有201个d = []for keym, val in classes_list.items():if val > 0:d.append(val)print(len(d))
二、划分数据集
数据集划分有四个步骤,依次按照一下步骤执行即可:
-
获取每个类别有多少图片的 classes_statistics.json 文件。此过程会产生一个 json 文件,保存了分类类别,每个类别的详细信息,以及所有图片信息。
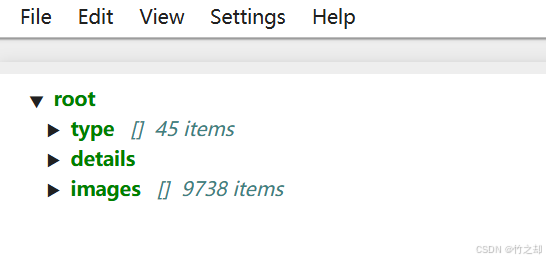

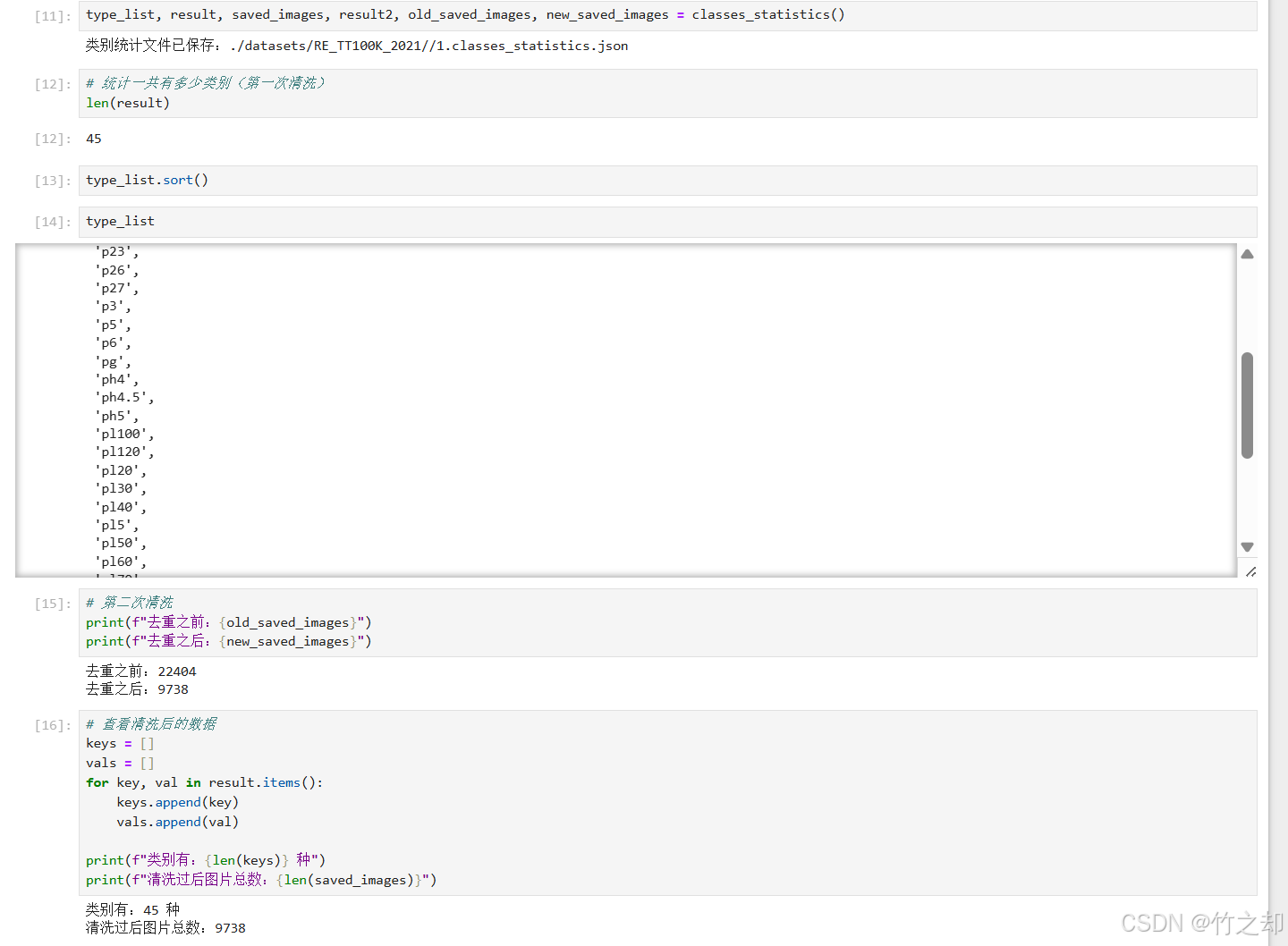
源码如下:def classes_statistics():"""类别统计函数,统计每一个类别下有多少张图片保存在 classes_statistics.json 文件中:return:"""# 读TT100K原始数据集标注文件with open(annotations) as origin_json:# 读取 json 文件origin_dict = json.load(origin_json)# 获取类别列表classes_list = origin_dict['types']# 获取图字典images_dict = origin_dict['imgs']# 建立统计每个类别包含的图片的字典sta = dict()for i in classes_list:# i 为所有的类别: 如:‘pl80’, 'w9', 'p6'# 将每一个类别作为字典中的键,值为: 空列表 []sta[i] = []# 遍历TT100K的imgsfor image_id in images_dict:image_element = images_dict[image_id]image_path = image_element['path']# 添加图像的信息到dataset中image_path = image_path.split('/')[-1] # 如:‘62627.jpg’obj_list = image_element['objects']# 遍历每张图片的标注信息,将每张图片的路径添加到对应类别的字典中去for anno_dic in obj_list:label_key = anno_dic['category']# 防止一个图片多次加入一个标签类别if image_path not in sta[label_key]:sta[label_key].append(image_path)# 数据清洗--只保留包含图片数超过100的类别# 清洗之后还剩下:45种类别result = {k: v for k, v in sta.items() if len(v) > 100}# 将所有标注写入文件 此时写入超过100张图片的with open('./all_classes.json', 'w', encoding="utf-8") as f:json.dump(result, f, ensure_ascii=False, indent=2)# 记录所有保留的图片saved_images = []for i in result:saved_images.extend(result[i])# 第二次数据清洗。同一张图片有多个类别标注,所以要去重old_saved_images = len(saved_images)saved_images = list(set(saved_images))new_saved_images = len(saved_images)# print(f"total types is: {len(result)}")type_list = list(result.keys())# 字典,三个键:类型(列表),详细信息(字典),所有类型的图片数据(列表)result2 = {"type": type_list, "details": result, "images": saved_images}# 保存结果json_name = classes_statistics_namewith open(json_name, 'w', encoding="utf-8") as f:json.dump(result2, f, ensure_ascii=False, indent=2)print(f"类别统计文件已保存:{json_name}")return type_list, result, saved_images, result2, old_saved_images, new_saved_images结果如下:
-
将 TT100K 原始数据集转换为 COCO 数据集格式,并根据图片中各类别的数量比例将数据划分为训练集、验证集和测试集,以便后续的模型训练和评估。此步骤生成,train.json, test.json, val.json 文件,划分比例为7:2:1。
源码如下:def original_datasets2object_datasets_re():'''重新划分数据集将 TT100K 原始数据集转换为 COCO 数据集格式,并根据图片中各类别的数量比例将数据划分为训练集、验证集和测试集,以便后续的模型训练和评估。:return:'''# 读TT100K原始数据集标注文件with open(annotations) as origin_json:origin_dict = json.load(origin_json)with open(classes_statistics_name) as select_json:select_dict = json.load(select_json)classes = select_dict['type']train_dataset = {'info': {}, 'licenses': [], 'categories': [], 'images': [], 'annotations': []}val_dataset = {'info': {}, 'licenses': [], 'categories': [], 'images': [], 'annotations': []}test_dataset = {'info': {}, 'licenses': [], 'categories': [], 'images': [], 'annotations': []}label = {} # 记录每个标志类别的idcount = {} # 记录每个类别的图片数owntype_sum = {}info = {"year": 2021, # 年份"version": '1.0', # 版本"description": "TT100k_to_coco", # 数据集描述"contributor": "Tecent&Tsinghua", # 提供者"url": 'https://cg.cs.tsinghua.edu.cn/traffic-sign/', # 下载地址"date_created": 2021 - 1 - 15}licenses = {"id": 1,"name": "null","url": "null",}train_dataset['info'] = infoval_dataset['info'] = infotest_dataset['info'] = infotrain_dataset['licenses'] = licensesval_dataset['licenses'] = licensestest_dataset['licenses'] = licenses# 建立类别和id的关系for i, cls in enumerate(classes):train_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'traffic_sign'})val_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'traffic_sign'})test_dataset['categories'].append({'id': i, 'name': cls, 'supercategory': 'traffic_sign'})label[cls] = icount[cls] = 0owntype_sum[cls] = 0images_dic = origin_dict['imgs']obj_id = 1# 计算出每个类别共‘包含’的图片数for image_id in images_dic:image_element = images_dic[image_id]image_path = image_element['path']image_name = image_path.split('/')[-1]# 在所选的类别图片中if image_name not in select_dict['images']:continue# 处理TT100K中的标注信息obj_list = image_element['objects']# 记录图片中包含最多的实例所属的typeincludes_type = {}for anno_dic in obj_list:if anno_dic["category"] not in select_dict["type"]:continue# print(anno_dic["category"])if anno_dic["category"] in includes_type:includes_type[anno_dic["category"]] += 1else:includes_type[anno_dic["category"]] = 1# print(includes_type)own_type = max(includes_type, key=includes_type.get)owntype_sum[own_type] += 1# TT100K的annotation_all转换成coco的格式for image_id in images_dic:image_element = images_dic[image_id]image_path = image_element['path']image_name = image_path.split('/')[-1]# 在所选的类别图片中if image_name not in select_dict['images']:continueprint(f"dealing with {image_path} ")# 处理TT100K中的标注信息obj_list = image_element['objects']# 记录图片中包含最多的实例所属的typeincludes_type = {}for anno_dic in obj_list:if anno_dic["category"] not in select_dict["type"]:continue# print(anno_dic["category"])if anno_dic["category"] in includes_type:includes_type[anno_dic["category"]] += 1else:includes_type[anno_dic["category"]] = 1# print(includes_type)own_type = max(includes_type, key=includes_type.get)count[own_type] += 1num_rate = count[own_type] / owntype_sum[own_type]# 划分数据集 7:2:1,train_set,val_set,test_set。if num_rate < 0.7:dataset = train_datasetelif num_rate < 0.9:dataset = val_datasetelse:print("dataset=test_dataset")dataset = test_datasetfor anno_dic in obj_list:if anno_dic["category"] not in select_dict["type"]:continuex = anno_dic['bbox']['xmin']y = anno_dic['bbox']['ymin']width = anno_dic['bbox']['xmax'] - anno_dic['bbox']['xmin']height = anno_dic['bbox']['ymax'] - anno_dic['bbox']['ymin']label_key = anno_dic['category']dataset['annotations'].append({'area': width * height,'bbox': [x, y, width, height],'category_id': label[label_key],'id': obj_id,'image_id': image_id,'iscrowd': 0,'segmentation': [[x, y, x + width, y, x + width, y + height, x, y + height]]})# 每个标注的对象id唯一obj_id += 1im = cv2.imread(os.path.join(datasets_dir, image_path))H, W, _ = im.shape# 添加图像的信息到dataset中dataset['images'].append({'file_name': image_name,'id': image_id,'width': W,'height': H})# 保存结果for phase in ['train', 'val', 'test']:# 创建保存位置的文件夹os.makedirs(RETT100K_dir+'/labels', exist_ok=True)json_name = RETT100K_dir+f'/labels/{phase}.json'with open(json_name, 'w', encoding="utf-8") as f:if phase == 'train':json.dump(train_dataset, f, ensure_ascii=False, indent=2)if phase == 'val':json.dump(val_dataset, f, ensure_ascii=False, indent=2)if phase == 'test':json.dump(test_dataset, f, ensure_ascii=False, indent=2)执行结果:

-
写入归一化的标注文件, 生成 yolo 格式的标注信息。获取标注信息,并划分 yolo 格式的标注信息 *.txt 文件夹
源码如下:def coco_json2yolo_txt(class_json):# 将标注位置坐标做归一化处理def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = box[0] + box[2] / 2.0y = box[1] + box[3] / 2.0w = box[2]h = box[3]x = round(x * dw, 6)w = round(w * dw, 6)y = round(y * dh, 6)h = round(h * dh, 6)return (x, y, w, h)json_file = os.path.join(RETT100K_dir+f'/labels/{class_json}.json')ana_txt_save_path = os.path.join(RETT100K_dir+'labels', class_json) # 保存的路径data = json.load(open(json_file, 'r'))if not os.path.exists(ana_txt_save_path):os.makedirs(ana_txt_save_path)id_map = {} # coco数据集的id不连续!重新映射一下再输出!with open(os.path.join(ana_txt_save_path, 'classes.txt'), 'w') as f:# 写入classes.txtfor i, category in enumerate(data['categories']):f.write(f"{category['name']}\n")id_map[category['id']] = i# 写入图像相对路径的文件位置list_file = open(os.path.join(ana_txt_save_path, '%s.txt' % class_json.format()), 'w')for img in tqdm(data['images']):filename = img["file_name"]img_width = img["width"]img_height = img["height"]img_id = img["id"]head, tail = os.path.splitext(filename)ana_txt_name = head + ".txt" # 对应的txt名字,与jpg一致f_txt = open(os.path.join(ana_txt_save_path, ana_txt_name), 'w')for ann in data['annotations']:if ann['image_id'] == img_id:box = convert((img_width, img_height), ann["bbox"])f_txt.write("%s %s %s %s %s\n" % (id_map[ann["category_id"]], box[0], box[1], box[2], box[3]))f_txt.close()# 将图片的相对路径写入文件list_file.write('/%s/%s.jpg\n' % (class_json.format(), head))list_file.close()# 3. 写入归一化的标注文件, 生成 yolo 格式的标注信息 phase=['train', 'val', 'test'] for phase in phase:coco_json2yolo_txt(phase)执行结果:

-
拷贝图片,数据集划分完成。
源码如下:def divide_TrainValTest(source, target, pre_datasets):'''创建文件路径并复制数据集:param source: 源文件位置:param target: 目标文件位置:param pre_datasets: 预处理数据集路径'''# 创建输出目录for i in ['train', 'val', 'test']:os.makedirs(f"{target}/{i}", exist_ok=True)# 获取当前处理的数据集类型dataset_type = Noneif 'train' in source:dataset_type = 'train'elif 'val' in source:dataset_type = 'val'elif 'test' in source:dataset_type = 'test'# 收集所有需要处理的文件file_list = []for root, dirs, files in os.walk(source):for file in files:file_name = os.path.splitext(file)[0]# 排除无关项if file_name in ['classes', 'test', 'train', 'val', '10106-checkpoint']:continuefile_list.append(file_name)for file_name in tqdm(file_list, desc=f"处理{dataset_type}数据集", unit="文件"):image_path = f"{file_name}.jpg"source_path = os.path.join(pre_datasets, image_path)target_path = os.path.join(target, dataset_type, image_path)# 复制文件并处理异常try:shutil.copyfile(source_path, target_path)except Exception as e:print(f"警告: 无法复制文件 {image_path}: {e}")print(f"{dataset_type}数据集处理完成!")执行结果:

三、目录放置
-
原数据集的目录结构:保持下载时目录不变即可。
E:\机器学习\TT00K\tt100k_2021>tree E:. ├─train ├─test └─other -
处理后的数据集目录结:
E:\机器学习\TT00K\RETT100K_2021>tree E:. ├─images │ ├─test │ ├─train │ └─val └─labels├─test├─train└─val -
处理完之后就可以使用 yolo v8/v11 训练了。
data.yaml 文件如下:path: ../datasets/RE_TT100K_2021/ train: images/train val: images/val test: images/test# 分类总数 nc: 45 # 分类类别 names: ['pl80', 'p6', 'p5', 'pm55', 'pl60', 'ip', 'p11', 'i2r', 'p23', 'pg', 'il80', 'ph4', 'i4', 'pl70', 'pne', 'ph4.5', 'p12', 'p3', 'pl5', 'w13', 'i4l', 'pl30', 'p10', 'pn', 'w55', 'p26', 'p13', 'pr40', 'pl20', 'pm30', 'pl40', 'i2', 'pl120', 'w32', 'ph5', 'il60', 'w57', 'pl100', 'w59', 'il100', 'p19', 'pm20', 'i5', 'p27', 'pl50']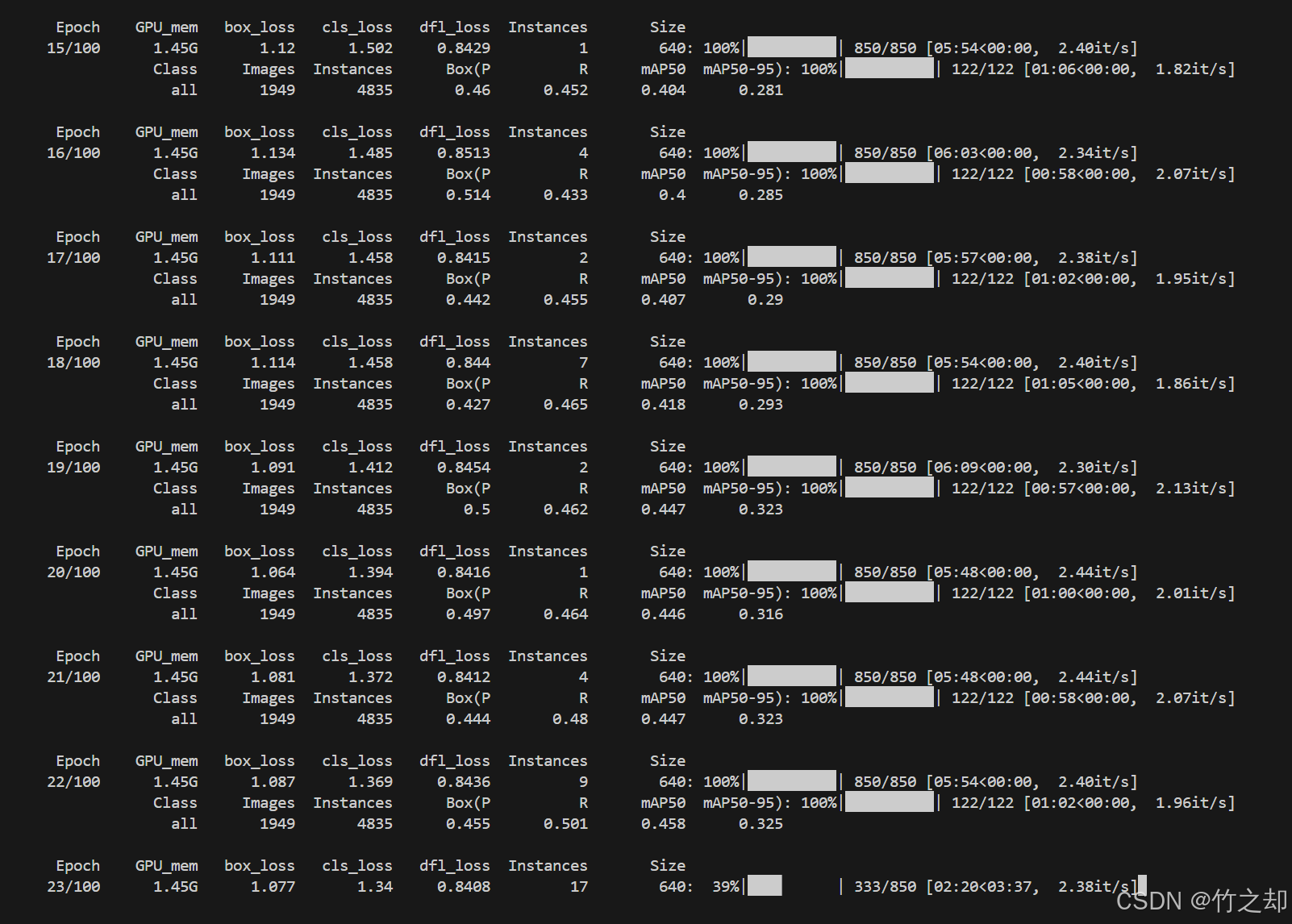
END
相关文章:
使用Yolov8 训练交通标志数据集:TT100K数据集划分
使用Yolov8 训练交通标志数据集:TT100K数据集划分(一) 一、数据集下载二、划分数据集三、目录放置 一、数据集下载 官方网址:TT100K 数据集对比 源码如下: def classes(filedir):with open(filedir) as f:classes …...

NLP学习路线图(十三):正则表达式
在自然语言处理(NLP)的浩瀚宇宙中,原始文本数据如同未经雕琢的璞玉。而文本预处理,尤其是其中至关重要的正则表达式技术,正是将这块璞玉转化为精美玉器的核心工具集。本文将深入探讨正则表达式在NLP文本预处理中的原理…...

[VMM]现代 CPU 中用于加速多级页表查找的Page‐Table Entry原理
现代 CPU 中用于加速多级页表查找的Page‐Table Entry原理 摘要:以下从背景、结构、查找流程、一致性与性能影响等方面,详细介绍现代 CPU 中用于加速多级页表查找的 Page-Walk Cache(也称 Walker Cache 或 Page‐Table Entry Cache࿰…...
javaweb-maven以及http协议
1.maven坐标: 坐标是资源的唯一标识,通过该坐标可以唯一定位资源位置; 2.坐标的组成: groupId:定义当前项目隶书的组织名称; artifactId:定义当前maven项目名称 version:定义项目版本 3.依…...

华为OD机试真题—— 最少数量线段覆盖/多线段数据压缩(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录+全流程解析/备考攻略/经验分享 华为OD机试真题《最少数量线段覆盖/多线段数…...

C语言创意编程:用趣味实例玩转基础语法(2)
文章目录 0. 前言1. 📊 动态条形图1.1 程序效果展示1.2 完整代码解析1.3 关键技术详解1.3.1 Unicode字符应用1.3.2 函数封装思想1.3.3 输入处理1.3.4 跨平台考虑 2. 🔤 字母金字塔2.1 程序效果展示2.2 完整代码解析2.3 关键技术详解2.3.1 嵌套循环结构2.…...

关于近期中国移动民用家庭网络,新增的UDP网络限制。
在近期中国移动在全国一定范围普及新的打击 “PCDN、P2P、HY/HY2” 等流氓网络应用的技术方案,并接入在 “省/州” 的边界网关路由上。 根据遥测数据的具体研究分析,且本人曾非常生气的详细质询过,移动城域网管理人员,可以确认该技…...

OpenCV CUDA模块图像处理------颜色空间处理之GPU 上对两张带有 Alpha 通道的图像进行合成操作函数alphaComp()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 该函数用于在 GPU 上对两张带有 Alpha 通道的图像进行合成操作。支持多种常见的 Alpha 合成模式(Porter-Duff 合成规则)&…...
OpenWebUI(1)源码学习构建
1. 前言 通过docker镜像拉取安装就不介绍了,官方的命令很多。本节主要撸一撸源码,所以,本地构建 2. 技术框架和启动环境 后端python,前端svelte 环境要求:python > 3.11 ,Node.js > 20.10 3. 源…...
npm error Cannot find module ‘negotiator‘ 的处理
本想运行npm create vuelatest,但提示: npm error code MODULE_NOT_FOUND npm error Cannot find module negotiator npm error Require stack: npm error - C:\Users\Administrator\AppData\Roaming\nvm\v18.16.1\node_modules\npm\node_modules\tuf-j…...
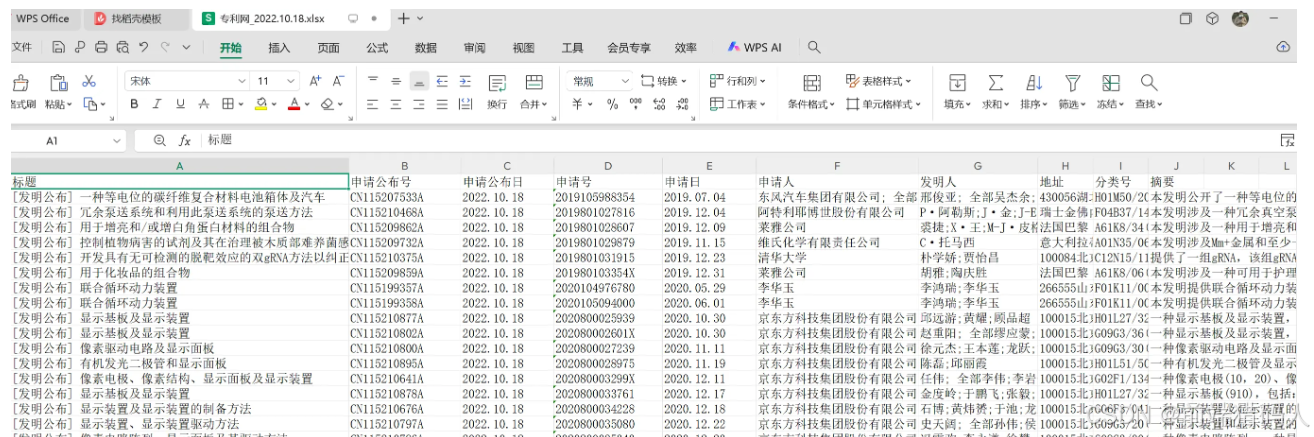
爬虫入门指南-某专利网站的专利数据查询并存储
免责声明 本教程仅用于教育目的,演示如何合法获取公开专利数据。在实际操作前,请务必: 1. 仔细阅读目标网站的robots.txt文件和服务条款 2. 控制请求频率,避免对服务器造成负担 3. 仅获取和使用公开数据 4. 不用于商业用途或…...

SQL(Database Modifications)
目录 Insertion Specifying Attributes in INSERT Adding Default Values(缺省值) Inserting Many Tuples Creating a Table Using the SELECT INTO Statement Deletion Example: Deletion Semantics of Deletion Updates Example: Update Sev…...
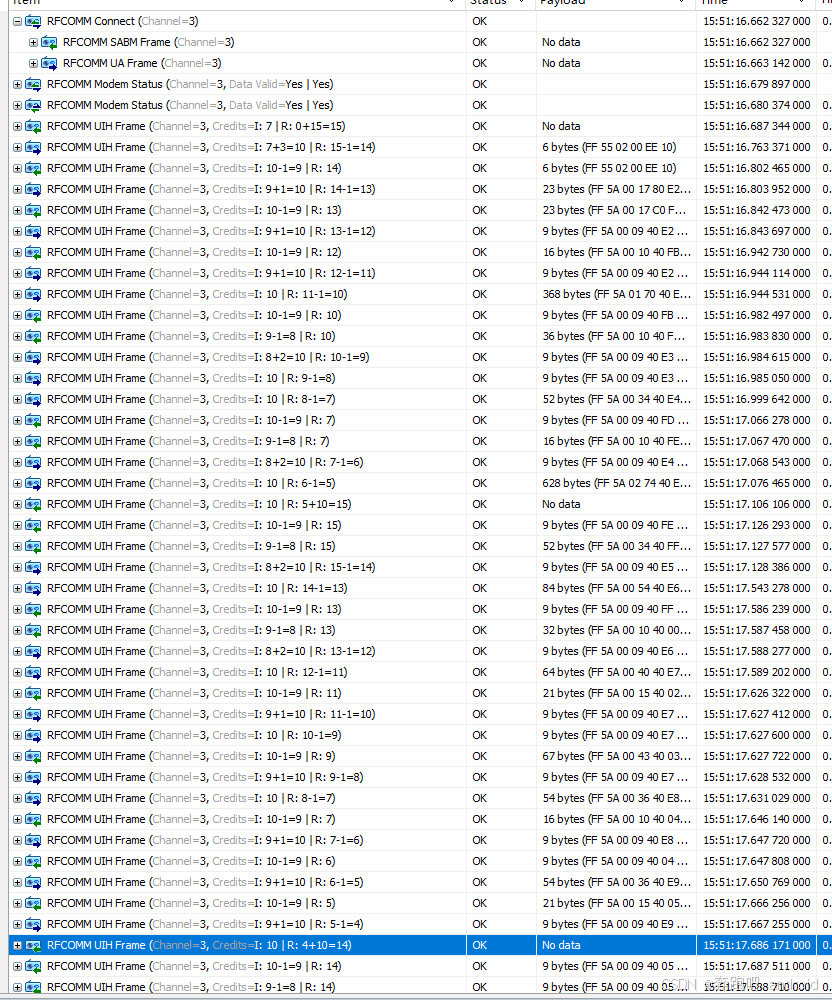
【android bluetooth 案例分析 04】【Carplay 详解 2】【Carplay 连接之手机主动连车机】
1. 背景 在【android bluetooth 案例分析 04】【Carplay 详解 1】【CarPlay 在车机侧的蓝牙通信原理与角色划分详解】中我们从整理上介绍了车机中 carplay 相关基础概念。 本节 将详细分析 iphone手机主动 连接 车机carplay 这一过程。 先回顾一下 上一节, carpla…...

maven离线将jar包导入到本地仓库中
想将本地的 jnetpcap.jar 包安装到 Maven 的本地仓库中,以便在项目中通过如下依赖方式引用。 <dependency><groupId>org.jnetpcap</groupId><artifactId>jnetpcap...
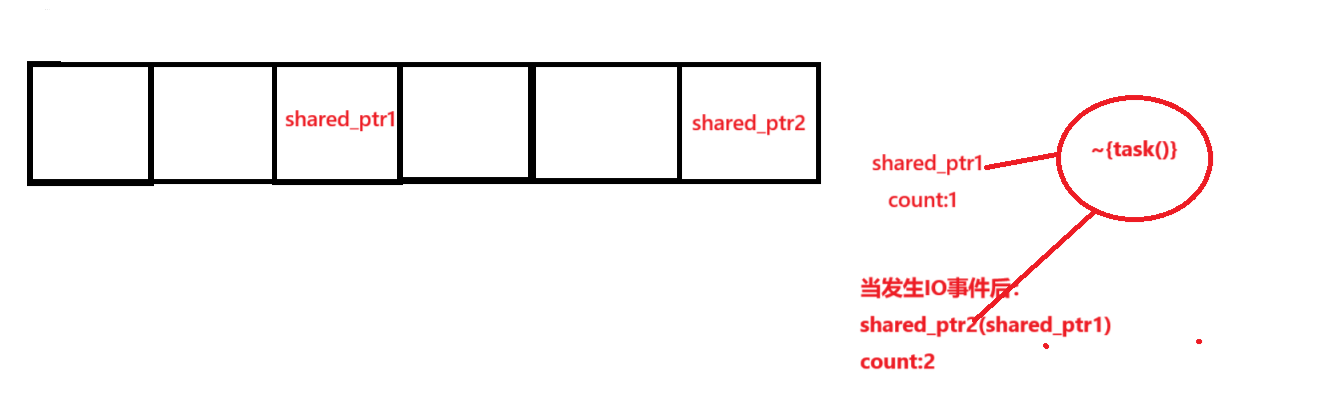
【仿muduo库实现并发服务器】实现时间轮定时器
实现时间轮定时器 1.时间轮定时器原理2.项目中实现目的3.实现功能3.1构造定时任务类3.2构造时间轮定时器每秒钟往后移动添加定时任务刷新定时任务取消定时任务 4.完整代码 1.时间轮定时器原理 时间轮定时器的原理类似于时钟,比如现在12点,定一个3点的闹…...

Conda更换镜像源教程:加速Python包下载
Conda更换镜像源教程:加速Python包下载 为什么要更换conda镜像源? Conda作为Python的包管理和环境管理工具,默认使用的是国外镜像源,在国内下载速度往往较慢。通过更换为国内镜像源,可以显著提高包下载速度ÿ…...

蓝桥杯 盗墓分赃2
原题目链接 问题描述 在一个探险者的团队中,小明和小红是合作的盗墓贼。 他们成功盗取了一座古墓中的宝藏,包括 n 件不同重量的珍贵文物和黄金,第 i 件宝藏的重量为 ai。 现在,他们希望公平地分配这些宝藏,使得小明…...

深度解读 Qwen3 大语言模型的关键技术
一、模型架构设计 Qwen3 延续了当前主流大型语言模型的 Transformer 架构,并在此基础上进行了多项增强设计,包含特殊的 Transformer 变体、位置编码机制改进、混合专家 (MoE) 技术引入,以及支持多模态和双重思考模式的新特性。 1. Transformer 基础架构与增强 基础架构:…...

使用 mysqldump 获取 MySQL 表的完整创建 DDL
要获取 MySQL 中某个表的完整创建 DDL(仅结构,不含数据),可以使用 mysqldump 工具的以下命令: 基本命令格式 bash mysqldump -h [主机名] -u [用户名] -p --no-data --single-transaction --routines --triggers --…...
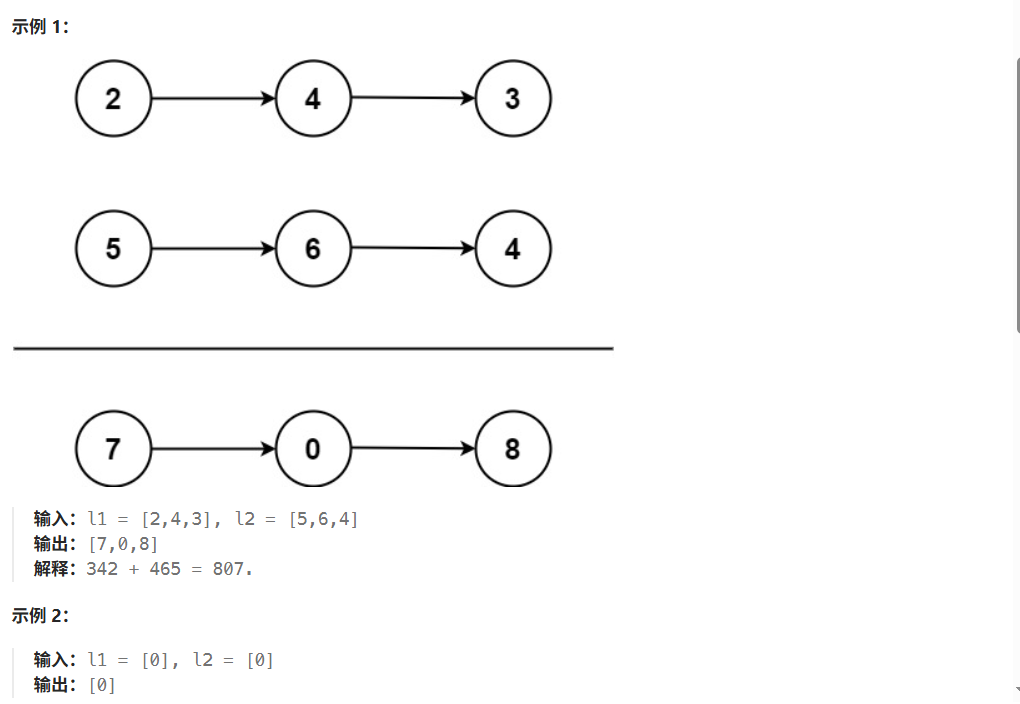
day15 leetcode-hot100-28(链表7)
2. 两数相加 - 力扣(LeetCode) 1.模拟 思路 最核心的一点就是将两个链表模拟为等长,不足的假设为0; (1)设置一个新链表newl来代表相加结果。 (2)链表1与链表2相加,具…...

阿里云云效对接SDK获取流水线制品
参考文档: API旧版 企业令牌 https://help.aliyun.com/zh/yunxiao/developer-reference/api-reference API新版 个人令牌 https://help.aliyun.com/zh/yunxiao/developer-reference/api-reference-standard-proprietary API 个人令牌 https://www.alibabacloud.com…...

Qt 相关 编译流程及交叉编译 部署所遇到的问题总结-持续更新
准备环境和工具 1、主机环境 ubuntu20 2、交叉编译器 gcc-linaro-6.3.1…arm-linux-gnuebihf 3、QT5源码包qt-5.11.3_sources 下载qt-5.11.3的包,自己想办法下载 网盘啥的 都ok,再访问下载目录就可以显示了。 Index of /archive/qt 4、依赖库安装 sudo …...

前端面经 DNSxieyi1
域名解析协议 域名转为目标IP地址 两种方式 1 递归查询 A请求B B一定会告诉IP 2迭代查询 A请求B 如果B无能 ,B会告诉A如何获得改内容,但是B自己不会发出请求1 步骤 1.检查浏览器DNS 2.没有命中继续查询操作系统的DNS缓存 3.查询本地域名服务器&…...

如何通过ES实现SQL风格的查询?
一、Spring项目集成方案 添加依赖(pom.xml): <dependency><groupId>co.elastic.clients</groupId><artifactId>elasticsearch-java</artifactId><version>8.12.0</version> </dependency> <dependency><…...
知识图谱:重构认知的智能革命
在数字经济的浪潮中,知识图谱正悄然掀起一场认知革命。它不仅是技术的迭代,更是人类从“数据依赖”迈向“知识驱动”的里程碑。当谷歌用知识图谱优化搜索引擎、银行用它穿透复杂的金融欺诈网络、医院用它辅助癌症诊疗时,这项技术已悄然渗透到…...
【计算机网络】4网络层①
这篇笔记讲IPv4和IPv6。 为了解决“IP地址耗尽”问题,有三种措施: ①CIDR(延长IPv4使用寿命) ②NAT(延长IPv4使用寿命) ③IPv6(从根本上解决IP地址耗尽问题) IPv6 在考研中考查频率较低,但需掌握基础概念以防冷门考点,重点结合数据报格式和与 IPv4 的对比记忆。…...
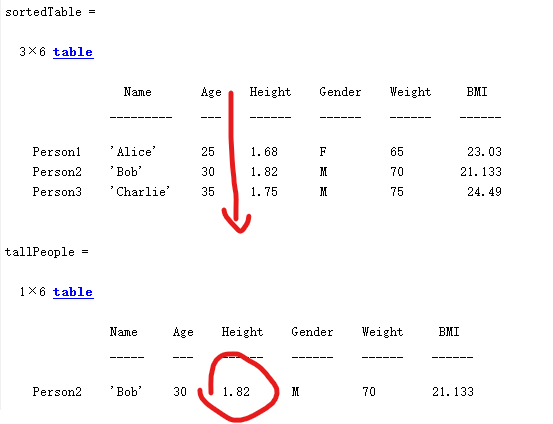
MATLAB中的table数据类型:高效数据管理的利器
MATLAB中的table数据类型:高效数据管理的利器 什么是table数据类型? MATLAB中的table是一种用于存储列向数据的数据类型,它将不同类型的数据组织在一个表格结构中,类似于电子表格或数据库表。自R2013b版本引入以来,t…...
Dropout 在大语言模型中的应用:以 GPT 和 BERT 为例
引言 大型语言模型(LLMs)如 GPT(生成式预训练 Transformer)和 BERT(双向编码器表示 Transformer)通过其强大的语言理解和生成能力,彻底改变了自然语言处理(NLP)领域。然…...

CentOS 7 如何安装libsndfile?
CentOS 7 如何安装libsndfile? # 配置编译环境 yum install -y gcc gcc-c make# 下载libsndfile压缩软件包 wget http://www.mega-nerd.com/libsndfile/files/libsndfile-1.0.25.tar.gztar -xf libsndfile-1.0.25.tar.gz cd libsndfile-1.0.25./configure --prefix/home/libs…...

基于深度学习的语音识别系统设计与实现
以下是为您准备的《基于深度学习的语音识别系统》技术文档,内容包含完整实现方案和详细代码解析: 基于深度学习的语音识别系统设计与实现 目录 语音识别技术概述系统架构设计语音信号预处理深度神经网络模型构建端到端语音识别实现模型训练与优化策略部署与性能优化完整代码…...