NLP学习路线图(十五):TF-IDF(词频-逆文档频率)
在自然语言处理(NLP)的浩瀚宇宙中,TF-IDF(词频-逆文档频率) 犹如一颗恒星,虽古老却依然璀璨。当ChatGPT、BERT等大模型光芒四射时,TF-IDF作为传统方法的代表,其简洁性、高效性与可解释性仍在诸多场景中焕发着不可替代的生命力。本文将深入解析TF-IDF的原理、实现、应用及其在现代NLP中的独特价值。
一、 权重之殇:为何需要TF-IDF?
1.1 词频(TF)的局限:常见词的“暴政”
设想你搜索“苹果手机评测”。仅依赖词频(TF)的搜索引擎会陷入困境:
-
“手机”、“评测”等常见词充斥各文档,掩盖了真正重要的“苹果”。
-
大量包含“手机评测”却无关苹果的文档被误判为高相关度。
-
核心问题:常见词携带的区分信息量低,却因高频获得不当权重。
1.2 文档频率(DF)的启示:稀有即珍贵
-
若“苹果”在少数文档出现(低DF),其出现往往标志着文档与查询高度相关。
-
若“的”、“是”几乎在所有文档出现(高DF),其存在对区分文档贡献甚微。
-
核心思想:赋予在少数文档中出现(低DF)的词更高权重。
TF-IDF应运而生:将TF的局部重要性与IDF的全局区分力完美融合。

二、 解构TF-IDF:数学之美与工程实践
2.1 核心公式:简洁的力量
TF-IDF(t, d, D) = TF(t, d) * IDF(t, D)
-
t: 目标词项(Term) -
d: 当前文档(Document) -
D: 文档集合(Corpus) -
TF(t, d): 词t在文档d中的词频 -
IDF(t, D): 词t在语料库D中的逆文档频率
2.2 TF (Term Frequency) 变体:平滑的艺术
-
原始计数:
TF_raw(t, d) = count(t in d)
问题:偏向长文档(词出现机会多)。 -
标准化词频(常用):
TF(t, d) = count(t in d) / len(d)
优势:消除文档长度影响。 -
对数缩放:
TF_log(t, d) = log(1 + count(t in d))
优势:抑制高频词的绝对优势,更关注存在性。 -
增强标准化:
TF_aug(t, d) = 0.5 + 0.5 * (count(t in d) / max_count_in_d)
优势:避免完全忽略低频词,平衡权重分布。
2.3 IDF (Inverse Document Frequency) 演进:对抗零值与平滑
-
基础定义:
IDF(t, D) = log(N / (1 + DF(t)))-
N:语料库中文档总数 -
DF(t):包含词t的文档数(Document Frequency)
-
-
+1平滑(拉普拉斯平滑):
防止DF(t) = 0导致除零错误:IDF(t, D) = log(N / (1 + DF(t))) + 1(或等价变形) -
+1在分子?Sklearn 的独特实现:
IDF(t, D) = log((1 + N) / (1 + DF(t))) + 1
目的:确保即使DF(t) = N(词出现在所有文档),IDF 也不为零(>0),避免完全忽略该词。 -
对数底数选择:自然对数(
ln)或log10常见。数值比例关系不变,不影响排序。
2.4 TF-IDF 计算示例
| 文档 (d) | 内容 | 词 (t) | TF (标准化) | DF (t) | N | IDF (log(N/(DF+1))) | TF-IDF |
|---|---|---|---|---|---|---|---|
| d1 | “苹果是一种水果。” | 苹果 | 1/4 = 0.25 | 2 | 4 | log(4/(2+1)) ≈ 0.29 | 0.25 * 0.29 ≈ 0.07 |
| 水果 | 1/4 = 0.25 | 3 | 4 | log(4/(3+1)) = 0 | 0.25 * 0 = 0 | ||
| d2 | “苹果公司发布新手机。” | 苹果 | 1/5 = 0.2 | 2 | 4 | log(4/(2+1)) ≈ 0.29 | 0.2 * 0.29 ≈ 0.06 |
| 手机 | 1/5 = 0.2 | 1 | 4 | log(4/(1+1)) ≈ 0.69 | 0.2 * 0.69 ≈ 0.14 | ||
| d3 | “我喜欢吃水果沙拉。” | 水果 | 1/4 = 0.25 | 3 | 4 | log(4/(3+1)) = 0 | 0.25 * 0 = 0 |
| d4 | “手机市场竞争激烈。” | 手机 | 1/4 = 0.25 | 1 | 4 | log(4/(1+1)) ≈ 0.69 | 0.25 * 0.69 ≈ 0.17 |
结果解读:
-
“水果” (DF=3) 的 IDF=0,权重为0,无法区分文档。
-
“苹果” (DF=2) 在 d1 和 d2 中有显著权重 (0.07, 0.06)。
-
“手机” (DF=1) 在 d2 和 d4 中获得最高权重 (0.14, 0.17),是强区分词。
2.5 向量化与归一化:从词到文档表示
-
词袋模型(Bag-of-Words, BoW)基础:每个文档表示为一个
|V|维向量(V是词汇表大小),每个维度对应一个词的 TF-IDF 值。 -
稀疏性:向量极度稀疏(大多数词未出现,值为0),高效存储(如 CSR 格式)。
-
归一化(常用 L2):
v_d = [TFIDF(t1,d), ..., TFIDF(tk,d)] / ||v_d||_2
目的:消除不同文档向量长度差异,使相似度计算(如余弦相似度)仅取决于方向而非模长。
三、 实战:TF-IDF的工程实现与应用
3.1 Python (Scikit-learn) 实现示例
from sklearn.feature_extraction.text import TfidfVectorizer# 语料库示例
corpus = ['苹果是一种水果。','苹果公司发布新手机。','我喜欢吃水果沙拉。','手机市场竞争激烈。'
]# 创建 TF-IDF 向量化器 (关键参数解析)
vectorizer = TfidfVectorizer(norm='l2', # 默认 L2 归一化,确保余弦相似度有效use_idf=True, # 启用 IDF 计算 (默认 True)smooth_idf=True, # 应用 IDF 平滑 (默认 True, 即前述 +1 平滑)sublinear_tf=False, # 是否使用 log(1+TF) 替代 TF (默认 False)min_df=1, # 忽略 DF < min_df 的词 (控制特征维度)max_df=1.0, # 忽略 DF > max_df 的词 (e.g., 0.85 忽略出现在 85% 文档以上的词)stop_words=None, # 可指定停用词列表 ('english' 或自定义列表)token_pattern=r'(?u)\b\w\w+\b', # 默认匹配至少2字母的词analyzer='word' # 按词切分 (可改为 'char' 或 'char_wb' 用于n-gram)
)# 拟合语料库并转换文档为 TF-IDF 矩阵
tfidf_matrix = vectorizer.fit_transform(corpus)# 查看词汇表 (特征索引)
print("词汇表 (特征名):", vectorizer.get_feature_names_out())
# 输出: ['一种' '公司' '发布' '喜欢' '市场' '手机' '新手机' '沙拉' '水果' '激烈' '竞争' '苹果' '是一种']# 查看 d2 ('苹果公司发布新手机。') 的 TF-IDF 向量 (稀疏表示)
print("\n文档 d2 的 TF-IDF 向量 (稀疏格式):")
print(tfidf_matrix[1])
# 输出: (0, 11) 0.44 (苹果) | (0, 1) 0.44 (公司) | (0, 2) 0.44 (发布) | (0, 5) 0.32 (手机) | (0, 6) 0.44 (新手机)# 计算文档间余弦相似度矩阵 (基于归一化后的 TF-IDF 向量)
from sklearn.metrics.pairwise import cosine_similarity
cos_sim = cosine_similarity(tfidf_matrix, tfidf_matrix)
print("\n文档间余弦相似度矩阵:")
print(cos_sim)
# 结果: d1 和 d2 因共享 "苹果" 有弱相似 (~0.2),d2 和 d4 因共享 "手机" 有弱相似 (~0.2),d1 和 d3 因共享 "水果" 但 IDF=0 故相似度=0。3.2 关键应用场景
-
信息检索(IR):
-
搜索引擎核心排序因子:查询
q表示为查询词 TF-IDF 向量(常忽略 IDF 或特殊处理),计算q与文档d的余弦相似度作为相关度得分。 -
Lucene/Solr/Elasticsearch 基石:TF-IDF (及 BM25 变种) 是其默认评分算法核心。
-
-
文档分类与聚类:
-
文本分类特征:TF-IDF 向量作为 SVM、朴素贝叶斯、逻辑回归等分类器的输入特征。
-
聚类相似度度量:K-Means、层次聚类等使用余弦相似度(基于 TF-IDF 向量)衡量文档距离。案例:新闻自动归类、用户评论主题划分。
-
-
关键词提取:
-
简单有效的方法:计算文档中各词的 TF-IDF 值,取 Top-N 作为关键词候选。改进:结合词性过滤(名词为主)、位置信息(标题、首段加权)。
-
-
推荐系统:
-
基于内容的推荐:将物品(文章、商品描述)表示为 TF-IDF 向量,为用户画像(历史交互物品向量平均)计算余弦相似度推荐相似物品。
-
-
搜索引擎优化(SEO):
-
内容优化参考:分析目标关键词在竞争页面中的 TF-IDF 分布,指导内容创作中关键词的合理密度与分布。
-
四、 TF-IDF的挑战、局限与改进
4.1 固有局限性
-
语义鸿沟:
-
无法捕捉词义(“苹果”水果 vs 公司)、同义词(“手机” vs “电话”)、多义词。
-
“词袋”假设:完全忽略词序、句法结构和上下文信息。“狗咬人” vs “人咬狗” 向量相同。
-
-
词汇表爆炸与稀疏性:
-
高维稀疏向量对内存和计算有要求(尤其大数据集),虽然稀疏存储可缓解。
-
未登录词(OOV)问题:新词或罕见词在训练词汇表中不存在,直接忽略。
-
-
长文档偏好?:虽然标准化 TF 缓解了绝对长度问题,但长文档有更多机会包含查询词的不同组合,可能获得更高相似度(BM25 针对性改进)。
-
IDF 的全局性假设:IDF 基于整个语料库计算。若语料库主题分布不均或与目标领域不符,IDF 权重可能不最优。
4.2 经典改进方案
-
BM25 (Okapi Best Matching):
-
信息检索的黄金标准:超越 TF-IDF 的事实标准排序函数。
-
核心改进:
-
TF 饱和控制:引入参数
k1,防止单个词频无限增长影响:TF_bm25 = (tf * (k1 + 1)) / (tf + k1) -
文档长度归一化:引入参数
b和平均文档长度avgdl:B = (1 - b) + b * (len(d) / avgdl),惩罚过长文档。 -
IDF 变体:
IDF_bm25 = log((N - DF + 0.5) / (DF + 0.5))
-
-
公式:
Score(q, d) = Σ [IDF_bm25(t) * TF_bm25(t, d) / B](对查询q中每个词t求和)。
-
-
TF-ICF (Inverse Category Frequency):
-
适用于分类场景:用类别频率
CF(t)(包含词t的类别数) 替代文档频率DF(t)计算 IDF。 -
ICF(t) = log(N_categories / CF(t)) -
目的:提升类别区分词的权重,抑制类别通用词。
-
-
n-gram 特征:
-
将连续的词序列(如 bigram “新手机”, trigram “发布新手机”)也作为词项。
-
优势:部分捕捉词序和短语信息(如区分“新手机”和“手机新”)。
-
代价:特征维度急剧膨胀,需更强特征选择。
-
-
特征选择与降维:
-
DF 阈值 (
min_df,max_df):过滤极罕见或极常见词。 -
卡方检验 (Chi-square):选择与类别最相关的词。
-
主成分分析 (PCA) / 潜在语义分析 (LSA):在 TF-IDF 矩阵上降维,捕捉潜在主题,缓解稀疏性和噪声。
-
五、 现代NLP中的TF-IDF:老兵不死,只是逐渐演变
在 Transformer 和预训练语言模型主导的今天,TF-IDF 并未消亡,而是找到了新的定位:
-
轻量级任务的王者:
-
资源受限环境:移动端、嵌入式设备、实时性要求极高的系统(如高频搜索),TF-IDF 的计算效率和低内存占用是巨大优势。
-
小样本/冷启动:当标注数据极少时,TF-IDF 作为强基线或特征工程的一部分,往往比复杂模型更稳定可靠。案例:初创公司快速构建最小可行产品(MVP)的搜索或分类功能。
-
-
深度学习模型的助推器:
-
特征融合:TF-IDF 向量可与词嵌入(Word2Vec, GloVe)、甚至 BERT 的句向量拼接或加权融合,提供互补的统计信息。研究表明,这种融合有时能提升下游任务性能。
-
注意力机制的初始化或补充:TF-IDF 权重可视为一种“硬”注意力,为神经网络提供先验知识。研究:将 TF-IDF 融入图神经网络(GNN)进行文本分类。
-
-
可解释性的灯塔:
-
模型调试与理解:当深度模型做出错误预测时,检查 TF-IDF 高的词是理解输入重要特征的快捷方式。
-
业务沟通的桥梁:向非技术人员解释“为什么这篇文档被分类为科技类?因为‘算法’、‘人工智能’、‘大数据’这些词的 TF-IDF 很高”比解释神经网络注意力权重直观得多。
-
-
特定任务中的持续有效性:
-
短文本匹配/去重:计算微博、商品标题等短文本的 TF-IDF 余弦相似度,仍是快速去重或找相似的有效方法。
-
法律/专利检索:这些领域术语精准、词义相对固定,TF-IDF(或 BM25)结合严格的查询语法,效果依然出色。
-
TF-IDF vs. 词嵌入 vs. 上下文嵌入:
| 特性 | TF-IDF | Word2Vec/GloVe | BERT/Transformer | ||
|---|---|---|---|---|---|
| 语义表示 | 统计权重 (无语义) | 静态词义 (一词一义) | 动态上下文 (一词多义) | ||
| 词序/结构 | 完全忽略 (BoW) | 部分忽略 (CBOW/Skip) | 完全建模 (Self-Att) | ||
| 特征维度 | 高维稀疏 ( | V | ) | 低维稠密 (e.g., 300d) | 高维稠密 (e.g., 768d) |
| 训练需求 | 无监督 (语料统计) | 无监督 (大规模语料) | 大规模有监督预训练 | ||
| 计算开销 | 极低 | 低 (推理) / 中 (训练) | 极高 (训练/推理) | ||
| 可解释性 | 高 (权重直接对应词) | 中 (词相似度) | 低 (黑盒) | ||
| OOV 处理 | 差 (完全忽略) | 差 (固定词表) | 较好 (Subword Token) | ||
| 典型优势场景 | 检索/分类 (轻量/可解释) | 词相似/类比任务 | 复杂理解/生成任务 |
六、 结语:传统智慧与现代创新的交响
TF-IDF 作为 NLP 发展史上的里程碑,其核心思想——通过统计手段量化词在文档中的局部重要性和在整个语料库中的全局区分能力——至今仍闪耀着智慧的光芒。尽管它无法理解语言的深层语义和复杂结构,但在效率、可解释性、作为强基线以及与现代模型协同等方面,展现出持久的价值。
相关文章:
NLP学习路线图(十五):TF-IDF(词频-逆文档频率)
在自然语言处理(NLP)的浩瀚宇宙中,TF-IDF(词频-逆文档频率) 犹如一颗恒星,虽古老却依然璀璨。当ChatGPT、BERT等大模型光芒四射时,TF-IDF作为传统方法的代表,其简洁性、高效性与可解…...

[Redis] Redis命令在Pycharm中的使用
初次学习,如有错误还请指正 目录 String命令 Hash命令 List命令 set命令 SortedSet命令 连接pycharm的过程见:[Redis] 在Linux中安装Redis并连接桌面客户端或Pycharm-CSDN博客 redis命令的使用见:[Redis] Redis命令(1…...

openpnp - 给M4x0.7mm的直油嘴加油的工具选择
文章目录 openpnp - 给M4x0.7mm的直油嘴加油的工具选择概述如果换上带卡口的M4x0.7直油嘴END openpnp - 给M4x0.7mm的直油嘴加油的工具选择 概述 X导轨用了一个HG15的滑块 滑块上的注油口的黄油嘴是M4x0.7mm的直油嘴。 外表面是6边形的柱子,没有可以卡住加油嘴工…...

Azure Devops 系列之三- vscode部署function app
Azure Function App 是 Microsoft Azure 提供的一项无服务器计算服务,它允许您运行事件驱动的应用程序,而无需管理底层基础架构。它使您能够执行代码来响应各种事件,例如 HTTP 请求、队列消息、计时器以及许多其他类型的触发器。 Azure Function App 的主要功能: 无服务器…...
EasyExcel复杂Excel导出
效果图展示 1、引入依赖 <!-- easyExcel --> <dependency><groupId>com.alibaba</groupId><artifactId>easyexcel</artifactId><version>4.0.2</version> </dependency>2、实体类 import com.alibaba.excel.annotatio…...
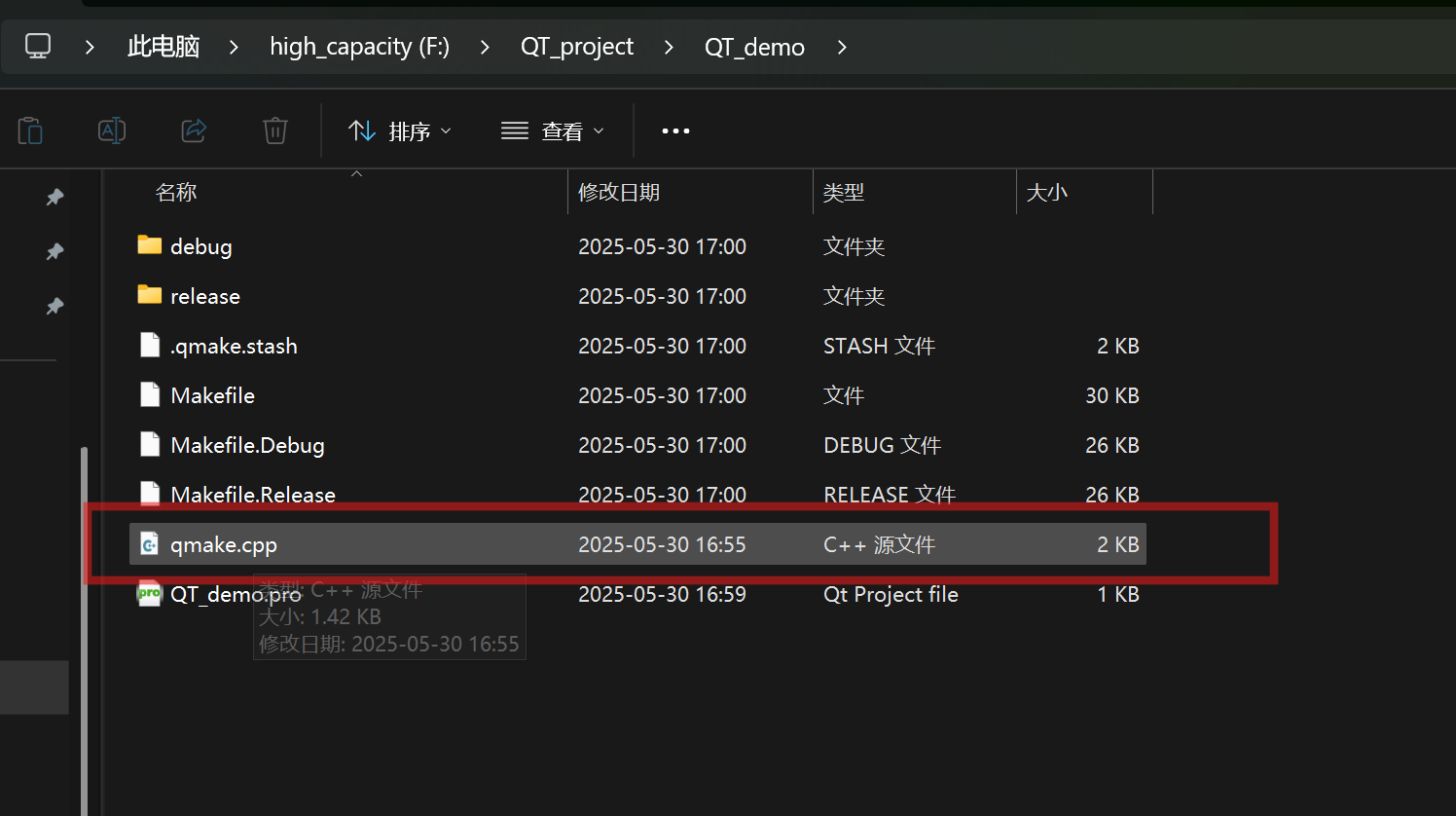
1,QT的编译教程
目录 整体流程: 1,新建project文件 2,编写源代码 3,打开QT的命令行窗口 4,生成工程文件(QT_demo.pro) 5,生成Make file 6,编译工程 7,运行编译好的可执行文件 整体流程: 1,新建project文件 新建文本文件,后缀改为.cpp 2,编写源代码...
)
C++基础算法————深度优先搜索(DFS)
一、DFS算法原理 (一)基本思想 深度优先搜索(Depth-First Search,DFS)是一种用于遍历或搜索树或图的算法。它从一个起始节点开始,沿着一个方向尽可能深入地探索,直到无法继续为止,然后回溯到上一个节点,继续探索其他方向。这一过程可以用递归或栈结构来实现。 (二…...

React 第五十节 Router 中useNavigationType的使用详细介绍
前言 useNavigationType 是 React Router v6 提供的一个钩子,用于确定用户如何导航到当前页面。 它提供了关于导航类型的洞察,有助于优化用户体验和实现特定导航行为。 一、useNavigationType 核心用途 1.1、检测导航方式: 判断用户是通过…...
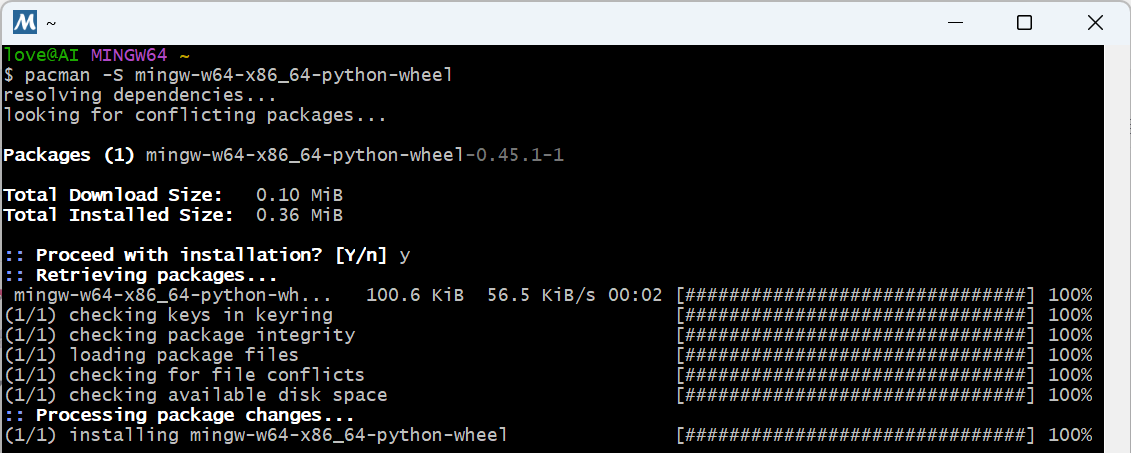
【笔记】在 MSYS2(MINGW64)中安装 Python 工具链的记录
#工作记录 📌 安装背景 操作系统:MSYS2 MINGW64当前时间:2025年6月1日Python 版本:3.12(默认通过 pacman 安装)目标工具链: pipxnumpypipsetuptoolswheel 🛠️ 安装过程与结果记录…...

npm install命令都做了哪些事情
npm install(或其简写 npm i)是 Node.js 项目中最重要的命令之一,它负责安装项目所需的所有依赖项。下面我将详细解释这个命令的完整执行过程和底层机制,让你彻底理解它背后的工作原理。 一、npm install 的完整工作流程 1. 依赖…...
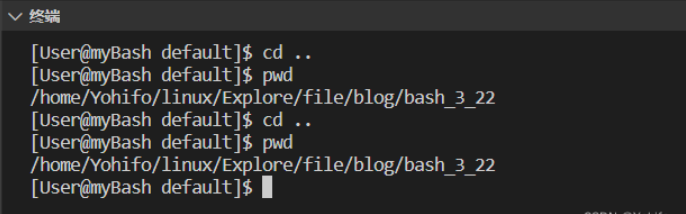
Linux 学习-模拟实现【简易版bash】
1、bash本质 在模拟实现前,先得了解 bash 的本质 bash 也是一个进程,并且是不断运行中的进程 证明:常显示的命令输入提示符就是 bash 不断打印输出的结果 输入指令后,bash 会创建子进程,并进行程序替换 证明&#x…...

【中国・珠海】2025 物联网与边缘计算国际研讨会(IoTEC2025)盛大来袭!
2025 物联网与边缘计算国际研讨会(IoTEC2025)盛大来袭! 科技浪潮奔涌向前,物联网与边缘计算已成为驱动各行业变革的核心力量。在此背景下,2025 物联网与边缘计算国际研讨会(IoTEC2025)即将震撼…...
)
企业级安全实践:SSL/TLS 加密与权限管理(二)
案例分析:成功与失败的经验教训 成功案例分析 以一家知名电商企业 ABC 为例,该企业每天处理数百万笔订单,涉及大量用户的个人信息、支付信息和商品数据。在网络安全建设方面,ABC 电商高度重视 SSL/TLS 加密与权限管理。 在 SSL…...

Java面试:从Spring Boot到分布式系统的技术探讨
场景一:电商平台的订单处理 面试官: “谢先生,假设我们在一个电商平台工作,你将如何使用Spring Boot构建一个订单处理服务?” 谢飞机: “这个简单,我会使用Spring Boot快速启动项目࿰…...

NodeJS全栈开发面试题讲解——P7 DevOps 与部署和跨域等
✅ 7.1 如何部署 Node.js 项目到生产环境?用过哪些工具? 面试官您好,我部署 Node.js 项目通常分为 构建 → 上传 → 启动服务 三步,常用工具包括 PM2、Nginx、Docker、Git Hooks、CI/CD 工具。 🛠️ 主要部署步骤&…...
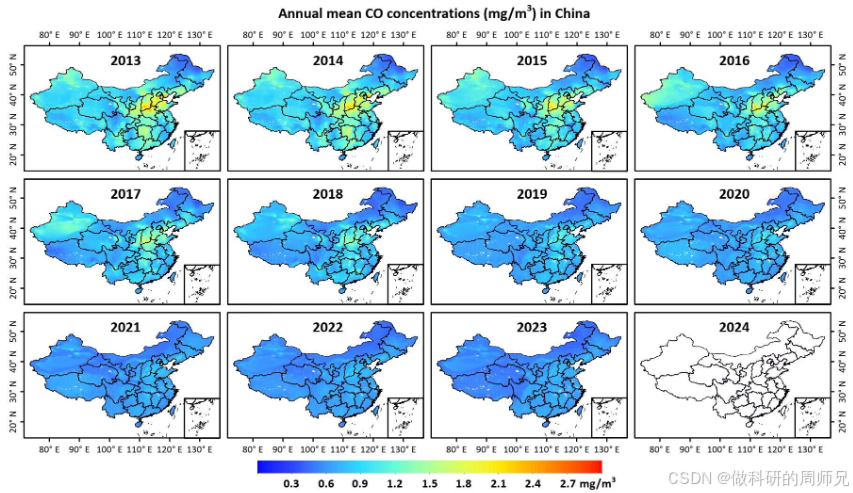
中国高分辨率高质量地面CO数据集(2013-2023)
时间分辨率:日空间分辨率:1km - 10km共享方式:开放获取数据大小:9.83 GB数据时间范围:2013-01-01 — 2023-12-31元数据更新时间:2024-08-19 数据集摘要 ChinaHighCO数据集是中国高分辨率高质量近地表空气污…...
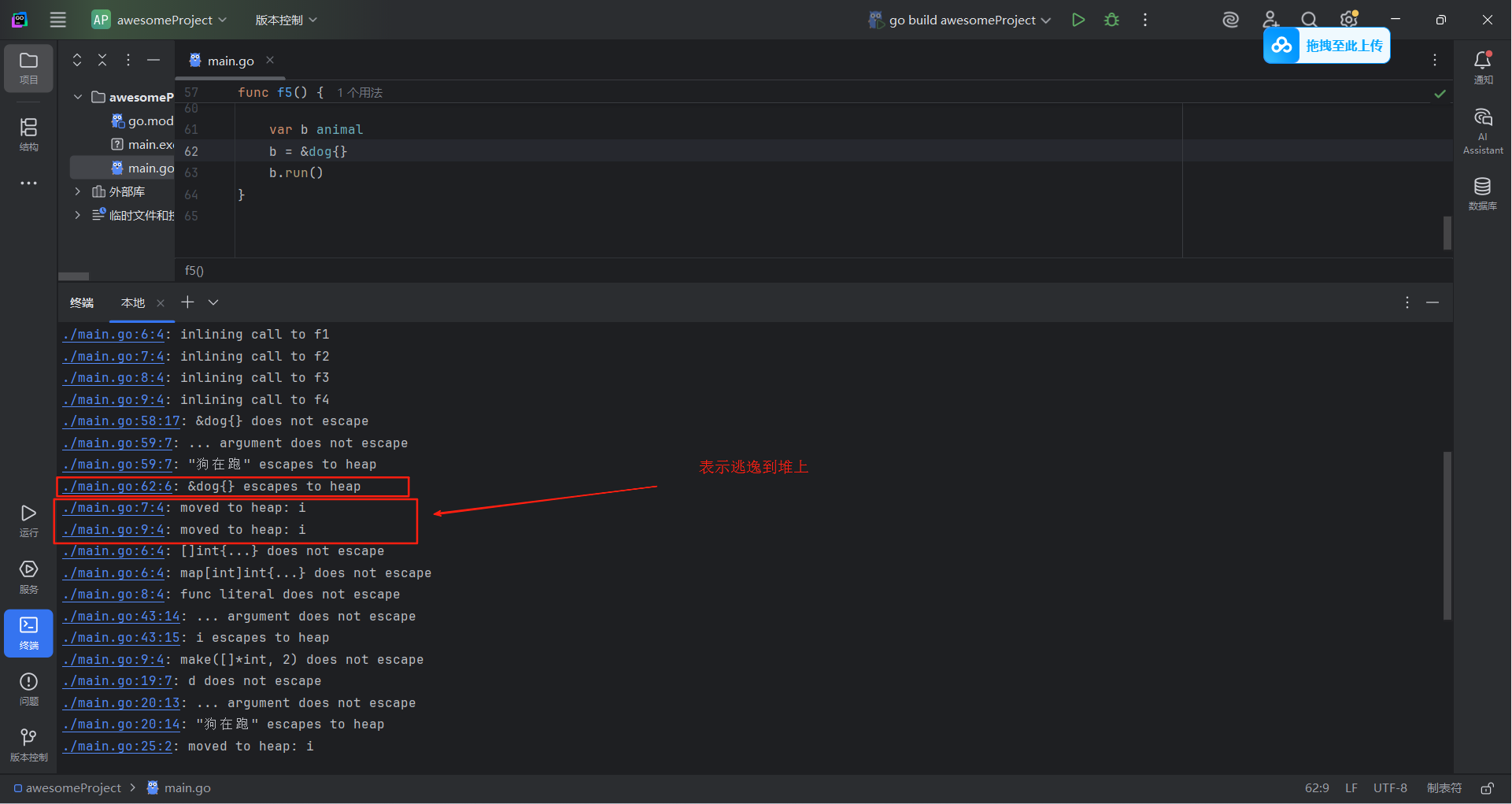
GO——内存逃逸分析
一、可能导致逃逸的5中情况 package mainimport "fmt"func main() {f1()f2()f3()f4()f5() }type animal interface {run() }type dog struct{}func (d *dog) run() {fmt.Println("狗在跑") }// 指针、map、切片为返回值的会发生内存逃逸 func f1() (*int,…...

MinVerse 3D触觉鼠标的技术原理与创新解析
MinVerse3D触觉鼠标通过三维交互和触觉反馈技术,彻底颠覆了传统二维鼠标的操作方式。用户在操作虚拟物体时,可以真实感知表面质感、重量和阻力。这种技术不仅为数字环境注入了深度与临场感,还在3D设计、游戏开发和工程仿真等领域展现了广泛潜…...

Spring Boot整活指南:从Helo World到“真香”定律
📌 一、Spring Boot的"真香"本质(不是996的福报) 你以为Spring Boot只是个简化配置的工具?Too young!它其实是程序员的摸鱼加速器。 经典场景还原: 产品经理:“这个…...

Python-Selenium报错截图
报错截图设计方案: 功能:截图层主要用来存放selenium运行时的报错截图信息 1. 截图路径管理 分层存储:在项目根目录下创建 screenshots 文件夹,并按日期进一步分类(如 20250601)。命名规范࿱…...

数论——质数和合数及求质数
质数和合数及求质数 一个大于 1 的自然数,除了 1 和它自身外,不能被其他自然数整除的数叫做质数;否则称为合数。其中,质数又称素数。有的资料用的词不同,但质数和素数其实是一回事。 规定 1 既不是质数也不是合数。 …...

nc 命令示例
nc -zv 实用示例 示例 1:测试单个 TCP 端口(最常见) 目标: 检查主机 webserver.example.com 上的 80 端口 (HTTP) 是否开放。 nc -zv webserver.example.com 80成功输出: Connection to webserver.example.com (19…...

乾元通渠道商中标青海省自然灾害应急能力提升工程基层防灾项目
近日,乾元通渠道商中标青海省自然灾害应急能力提升工程基层防灾项目,乾元通作为设备厂家,为项目提供通信指挥类装备(多链路聚合设备)QYT-X1。 青岛乾元通数码科技有限公司作为国家应急产业企业,深耕于数据调…...

Ubuntu取消开机用户自动登录
注:配置前请先设置登录密码,不同显示管理器配置方法不同,可用命令查看:cat /etc/X11/default-display-manager 一、LightDM 显示管理器,关闭 Ubuntu 系统用户自动登录 查找自动登录配置文件,可以看到类似 a…...

用 Spring Boot 静态资源映射 vs 用 Nginx 提供静态文件服务总结
【1】Spring Boot 静态资源映射 vs 用 Nginx 提供静态文件服务 ✅ 简短回答: 在性能、并发能力、缓存控制、安全性等方面,Nginx 完胜。 所以:如果你只是提供静态文件下载(如图片、PDF、Excel 等),强烈推荐…...
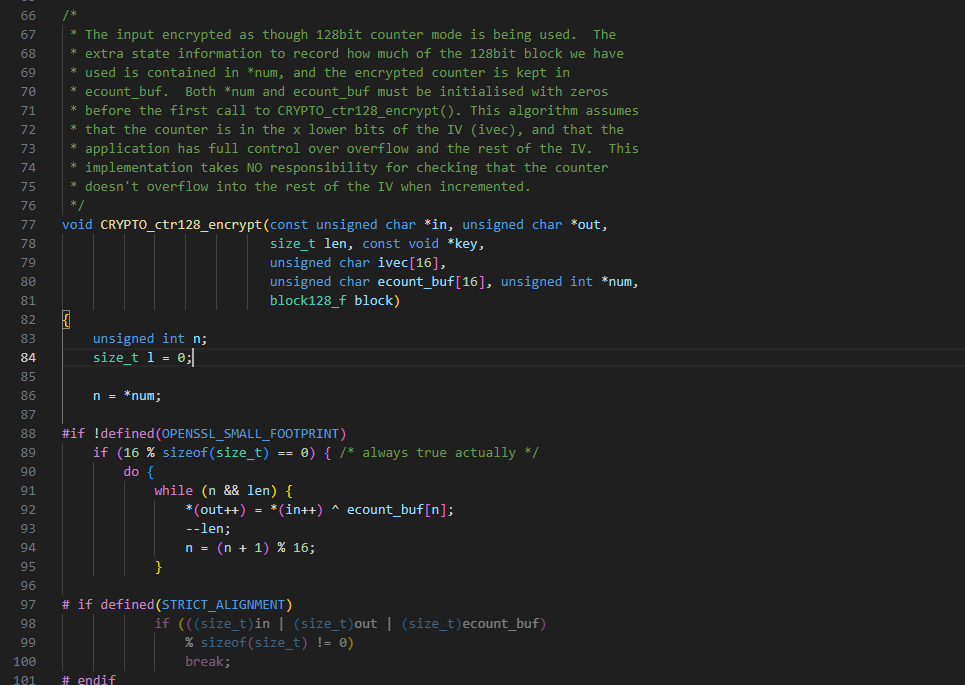
openssl-aes-ctr使用openmp加速
openssl-aes-ctr使用openmp加速 openssl-aes-ctropenmp omp for openssl-aes-ctr 本文采用openssl-1.1.1w进行开发验证开发;因为aes-ctr加解密模式中,不依赖与上一个模块的加/解密的内容,所以对于aes-ctr加解密模式是比较适合进行并行加速的…...

PHP+MySQL开发语言 在线下单订水送水小程序源码及搭建指南
随着互联网技术的不断发展,在线下单订水送水服务为人们所需要。分享一款 PHP 和 MySQL 搭建一个功能完善的在线订水送水小程序源码及搭建教程。这个系统将包含用户端和管理端两部分,用户可以在线下单、查询订单状态,管理员可以处理订单、管理…...

计算机网络第1章(上):网络组成与三种交换方式全解析
目录 一、计算机网络的概念二、计算机网络的组成和功能2.1 计算机网络的组成2.2 计算机网络的功能 三、电路交换、报文交换、分组交换3.1 电路交换(Circuit Switching)3.2 报文交换(Message Switching)3.3 分组交换(Pa…...
Android studio进阶开发(七)---做一个完整的登录系统(前后端连接)
我们已经讲过了okhttp和登录系统的使用,我们今天做一个完整的登录系统,后端用springmybatis去做 数据库内容 -- 创建学生信息表 CREATE TABLE student_info (id SERIAL PRIMARY KEY, -- 添加自增主键name VARCHAR(255) NOT NULL,number INT NOT NULL,…...
计算机网络第1章(下):网络性能指标与分层模型全面解析
目录 一、计算机网络的性能指标1.1 性能指标1:速率1.2 性能指标2:带宽1.3 性能指标3:吞吐量1.4 性能指标4:时延1.5 性能指标5:时延带宽积1.6 性能指标6:往返时延1.7 性能指标7:信道利用率 二、计…...