手写multi-head Self-Attention,各个算子详细注释版
文章目录
- MultiHeadAttentionFormal的实现
- 操作详解
- 1. 🔍 attention_mask
- 2. 🔍 matmul
- ✅ 其他实现方式
- 1. 使用 `@` 运算符(推荐简洁写法)
- 2. 使用 `torch.einsum()`(爱因斯坦求和约定)
- 3. 使用 `torch.bmm()`(批量矩阵乘法)
- 4. 使用 `unsqueeze` + `squeeze` 控制维度(兼容高维)
- 5. 使用 `F.linear()` 实现投影(不常用)
- 📌 对比总结表
- 💡 示例对比(均等效)
- 3. 🔍 transpose
- 📌 定义
- 🧠 在多头注意力中的典型应用场景
- ✅ 其他实现方式
- 1. 使用 `permute(*dims)` —— 更灵活的维度重排
- 2. 使用 `swapaxes(dim0, dim1)` —— 与 transpose 等效
- 📌 总结对比表
- 💡 示例说明
- 🛠 实际应用建议
- 4. 🔍 view()
- 🔄 其他等效实现方式
- 1. `torch.reshape(tensor, shape)`
- 2. 使用 `flatten(start_dim, end_dim)` 合并维度
- 3. 使用 `einops.rearrange`(推荐用于可读性)
- ✅ 总结对比
- 💡 实际应用建议
- 5. 🔍 masked_fill()
- 🧠 函数定义
- 示例解析
- ✅ 实际案例演示
- ⚠️ 注意事项
- 💡 应用场景
- ✅ 总结
- 📌 最佳实践建议
- 参考材料
MultiHeadAttentionFormal的实现
import torch
import torch.nn as nn
import mathclass MultiHeadAttentionFormal(nn.Module):def __init__(self, hidden_dim, head_num, attention_dropout=0.1):super().__init__()self.hidden_dim = hidden_dimself.head_num = head_numself.head_dim = hidden_dim // head_num # head_num * head_dim = hidden_dimself.q_proj = nn.Linear(hidden_dim, hidden_dim) # (hidden_dim, head_dim * head_num)self.k_proj = nn.Linear(hidden_dim, hidden_dim)self.v_proj = nn.Linear(hidden_dim, hidden_dim)self.output = nn.Linear(hidden_dim, hidden_dim)self.attention_dropout = nn.Dropout(attention_dropout)def forward(self, x, attention_mask=None):# X (batch_size, seq_len, hidden_dim)batch_size, seq_len, _ = x.shape# Q/K/V的shape: (batch_size, seq_len, hidden_dim)Q = self.q_proj(x)K = self.k_proj(x)V = self.v_proj(x)# (batch_size, seq_len, hidden_dim),其中 hidden_dim = head_num * head_dim# -> (batch_size, seq_len, head_num, head_dim)# -> (batch_size, head_num, seq_len, head_dim)q_state = Q.view(batch_size, seq_len, self.head_num, self.head_dim).transpose(1, 2)k_state = K.view(batch_size, seq_len, self.head_num, self.head_dim).transpose(1, 2)v_state = V.view(batch_size, seq_len, self.head_num, self.head_dim).transpose(1, 2)# k_state的转置# (batch_size, head_num, seq_len, head_dim)# -> (batch_size, head_num, head_dim, seq_len)# 相乘的结果,shape为(batch_size, head_num, seq_len, seq_len)atten_weight = torch.matmul(q_state, k_state.transpose(-2, -1)) / math.sqrt(self.head_dim)print("stage1, atten_weight.shape: ", atten_weight.shape)if attention_mask is not None:atten_weight = atten_weight.masked_fill(attention_mask==0, float("-inf"))print("stage2, atten_weight.shape: ", atten_weight.shape)atten_weight = torch.softmax(atten_weight, dim=-1)print("stage3, atten_weight.shape: ", atten_weight.shape)atten_weight = self.attention_dropout(atten_weight)print("stage4, atten_weight.shape: ", atten_weight.shape)# atten_weight: (batch_size, head_num, seq_len, seq_len)# v_state: (batch_size, head_num, seq_len, head_dim)# => (batch_size, head_num, seq_len, head_dim)output_mid = torch.matmul(atten_weight, v_state)print("stage1, output_mid.shape: ", output_mid.shape, "v_state.shape: ", v_state.shape)# transpose后,张量的内存可能变得不连续,所以需要用contiguous把内存连续化;view()、reshape()、flatten()、torch.nn.Linear、torch.matmul 等操作对输入张量有连续性的要求。output_mid = output_mid.transpose(1, 2).contiguous()print("stage2, output_mid.shape: ", output_mid.shape)output_mid = output_mid.view(batch_size, seq_len, self.hidden_dim)print("stage3, output_mid.shape: ", output_mid.shape)output = self.output(output_mid)return outputattention_mask = torch.tensor([[1,1],[1,0],[1,0]]
).unsqueeze(1).unsqueeze(2).expand(3, 8, 2, 2)# batch_size, seq_len, hidden_dim
X = torch.rand(3, 2, 128)net = MultiHeadAttentionFormal(128, 8) # hidden_dim = 128, head_num = 8 -> head_dim = 16
net(X, attention_mask)操作详解
1. 🔍 attention_mask
首先是创建一个随机张量,shape为(batch_size, seq_len)
attention_mask = torch.tensor([[1, 1],[1, 0],[1, 0]
])这是一个形状为 (3, 2) 的张量。
每一行表示一个样本(batch)的 attention mask:
1 表示该位置是有效的;
0 表示该位置是 padding,需要被屏蔽
然后增加维度
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2)---------------------
tensor([[[[1, 1]]],[[[1, 0]]],[[[1, 0]]]])第一次 unsqueeze(1):增加第 1 维度(head_num),形状变为 (3, 1, 2)
第二次 unsqueeze(2):增加第 2 维度(seq_len),形状变为 (3, 1, 1, 2)
此时维度含义为:(batch_size, 1, 1, seq_len)
注意:此时还没有考虑 head_num,只是准备好了 mask 的基本结构
现在扩展到head_num
attention_mask = attention_mask.expand(3, 8, 2, 2)
-------------
tensor([[[[1, 1], [1, 1]], # 头1[[1, 1], [1, 1]], # 头2[[1, 1], [1, 1]], # 头3[[1, 1], [1, 1]], # 头4[[1, 1], [1, 1]], # 头5[[1, 1], [1, 1]], # 头6[[1, 1], [1, 1]], # 头7[[1, 1], [1, 1]], # 头8][[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]]],[[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]],[[1, 0], [1, 0]]]])expand() 是 PyTorch 中用于广播张量的方法,不会复制数据,而是共享内存。
将 (3, 1, 1, 2) 扩展为 (3, 8, 2, 2):
3:batch size
8:head_num,每个 head 都使用相同的 mask
2:query 的序列长度(seq_len)
2:key/value 的序列长度(seq_len)attention_mask.shape为(batch_size, head_num, seq_len, seq_len)
2. 🔍 matmul
以这行代码为例:
output_mid = torch.matmul(atten_weight, v_state)
其中:
atten_weight.shape = (batch_size, head_num, seq_len, seq_len),即注意力权重矩阵(通常是 softmax 后的结果)v_state.shape = (batch_size, head_num, seq_len, head_dim),即 value 的状态
这个操作本质上是将 attention weight 与 value 进行矩阵乘法,得到加权后的输出。
✅ 其他实现方式
1. 使用 @ 运算符(推荐简洁写法)
output_mid = atten_weight @ v_state
- 等价于
torch.matmul - 更加 Pythonic,代码更简洁
- 支持广播机制
2. 使用 torch.einsum()(爱因斯坦求和约定)
output_mid = torch.einsum('bhij,bhjd->bhid', atten_weight, v_state)
- 非常灵活,适用于多头注意力、交叉注意力等复杂结构
- 显式控制每个维度的运算规则,可读性略差但表达能力更强
- 在调试或构建复杂模型时非常有用
3. 使用 torch.bmm()(批量矩阵乘法)
# 将 batch 和 head 合并成一个大 batch 维度
batch_size, head_num, seq_len, _ = atten_weight.shape
atten_weight_flat = atten_weight.view(-1, seq_len, seq_len) # shape: (B*H, T, T)
v_state_flat = v_state.view(-1, seq_len, head_dim) # shape: (B*H, T, D)output_flat = torch.bmm(atten_weight_flat, v_state_flat) # shape: (B*H, T, D)
output_mid = output_flat.view(batch_size, head_num, seq_len, head_dim)
- 只支持 3D 张量,不支持自动广播
- 性能接近
matmul,但需要手动处理维度变形
4. 使用 unsqueeze + squeeze 控制维度(兼容高维)
output_mid = torch.matmul(atten_weight.unsqueeze(-2), v_state.unsqueeze(-1)
).squeeze(-1)
- 通过添加/删除维度来精确控制 matmul 操作维度
- 适合在图像、视频等 attention 中使用
5. 使用 F.linear() 实现投影(不常用)
虽然不是标准做法,但如果 atten_weight 是某种投影权重矩阵,也可以用线性层模拟。但在 attention 中通常不适用。
📌 对比总结表
| 方法 | 输入要求 | 是否支持 batch | 是否支持 broadcasting | 推荐用于 Attention |
|---|---|---|---|---|
torch.matmul | 任意维度 | ✅ | ✅ | ✅✅✅ |
@ | 任意维度 | ✅ | ✅ | ✅✅✅(简洁) |
torch.einsum | 需要指定索引 | ✅ | ✅ | ✅✅✅(多头) |
torch.bmm | 必须为 3D | ✅ | ❌ | ✅(简单 attention) |
unsqueeze + matmul | 手动控制维度 | ✅ | ✅ | ✅(特殊场景) |
💡 示例对比(均等效)
# 原始写法
output_mid = torch.matmul(atten_weight, v_state)# 使用 @ 符号
output_mid = atten_weight @ v_state# 使用 einsum
output_mid = torch.einsum('bhij,bhjd->bhid', atten_weight, v_state)# 使用 bmm(需 flatten + reshape)
batch_size, head_num, seq_len, _ = atten_weight.shape
atten_weight_flat = atten_weight.view(-1, seq_len, seq_len)
v_state_flat = v_state.view(-1, seq_len, head_dim)
output_flat = torch.bmm(atten_weight_flat, v_state_flat)
output_mid = output_flat.view(batch_size, head_num, seq_len, -1)
3. 🔍 transpose
output_mid = output_mid.transpose(1, 2)
这行代码的作用是交换张量的第 1 维和第 2 维。用于处理多头注意力(Multi-Head Attention)中张量形状的调整。
📌 定义
torch.Tensor.transpose(dim0, dim1) -> Tensor
- 功能:返回一个新的张量,其中指定的两个维度被交换。
- 参数:
dim0: 第一个维度dim1: 第二个维度
⚠️ 注意:这个操作不会复制数据,而是返回原始张量的一个视图(view)。如果后续需要使用 view() 或 reshape(),可能需要调用 .contiguous() 来确保内存连续。
🧠 在多头注意力中的典型应用场景
# 假设 input shape: (batch_size, head_num, seq_len, head_dim)
output_mid = output_mid.transpose(1, 2)
原始形状:
output_mid.shape = (batch_size, head_num, seq_len, head_dim)
转置后形状:
output_mid.shape = (batch_size, seq_len, head_num, head_dim)
然后一般会进行 view() 操作来合并 head_num 和 head_dim,得到最终输出:
output_mid = output_mid.contiguous().view(batch_size, seq_len, -1)
# 最终 shape: (batch_size, seq_len, hidden_dim)
这是将多头注意力结果重新拼接回原始隐藏层大小的关键步骤。
✅ 其他实现方式
除了使用 transpose(),还有以下几种方法可以实现类似效果:
1. 使用 permute(*dims) —— 更灵活的维度重排
output_mid = output_mid.permute(0, 2, 1, 3)
permute()可以一次重排多个维度- 示例前后的 shape 对应关系:
# 原 shape: (batch_size, head_num, seq_len, head_dim) # 新 shape: (batch_size, seq_len, head_num, head_dim)
✅ 推荐用于更复杂的维度变换场景
2. 使用 swapaxes(dim0, dim1) —— 与 transpose 等效
output_mid = output_mid.swapaxes(1, 2)
- 与
transpose()功能相同 - 更语义化,适合阅读时强调“交换”而非“转置”
📌 总结对比表
| 方法 | 支持任意维 | 是否返回 view | 是否支持链式操作 | 推荐用途 |
|---|---|---|---|---|
transpose() | ❌ 仅限两个维度 | ✅ | ✅ | 简单交换两个维度 |
permute() | ✅ 多维支持 | ✅ | ✅ | 高阶张量维度重排(推荐) |
swapaxes() | ✅ | ✅ | ✅ | 强调“交换”,语义更强 |
💡 示例说明
假设输入为:
output_mid.shape = (3, 8, 2, 16) # batch_size=3, head_num=8, seq_len=2, head_dim=16
使用 transpose(1, 2):
output_mid = output_mid.transpose(1, 2)
# output_mid.shape
(batch_size, head_num, seq_len, head_dim)
=> (batch_size, seq_len, head_num, head_dim)
(3, 8, 2, 16)
=> (3, 2, 8, 16)
使用 permute(0, 2, 1, 3):
output_mid = output_mid.permute(0, 2, 1, 3)
# output_mid.shape => (3, 2, 8, 16)
两者等价,但 permute() 更具通用性。
🛠 实际应用建议
- 如果只是交换两个维度 →
transpose() - 如果涉及多维重排 →
permute() - 如果要合并/拆分某些维度 →
permute()+contiguous()+view()
4. 🔍 view()
在 PyTorch 中,view() 是一个用于 改变张量形状(reshape) 的函数。它不会修改张量的数据,只是重新解释其形状。
语法:
tensor.view(shape)
示例代码:
output_mid = output_mid.view(batch_size, seq_len, self.hidden_dim)
前提条件:
output_mid当前的 shape 是(batch_size, seq_len, head_num, head_dim)head_num * head_dim == hidden_dim- 所以 view 后变为
(batch_size, seq_len, hidden_dim)
作用:
将多头注意力中每个 head 的输出拼接起来,恢复成原始的 hidden_dim 维度。
比如:
# 假设 batch_size=3, seq_len=2, head_num=8, head_dim=16
output_mid.shape = (3, 8, 2, 16) # transpose + contiguous 后
output_mid = output_mid.view(3, 2, 128) # 8*16 = 128
⚠️ 注意:使用
view()前必须保证张量是连续的(contiguous),否则会报错。所以前面通常有.contiguous()调用。
🔄 其他等效实现方式
除了 view(),还有以下几种方式可以实现类似功能:
1. torch.reshape(tensor, shape)
与 view() 类似,但更灵活,可以在非连续内存上运行。
output_mid = output_mid.reshape(batch_size, seq_len, self.hidden_dim)
✅ 推荐使用这个替代 view(),因为不需要关心是否是连续内存。
2. 使用 flatten(start_dim, end_dim) 合并维度
output_mid = output_mid.transpose(1, 2).flatten(start_dim=2, end_dim=3)
这相当于把第 2 和第 3 维合并,效果等同于 reshape 或 view。
3. 使用 einops.rearrange(推荐用于可读性)
来自 einops 库(einop库安装及介绍),提供更直观的维度操作方式:
from einops import rearrangeoutput_mid = rearrange(output_mid, 'b h s d -> b s (h d)')
优点:
- 更易读
- 不需要关心是否连续
- 可扩展性强(支持更多复杂变换)
✅ 总结对比
| 方法 | 是否要求连续 | 易读性 | 灵活性 | 推荐场景 |
|---|---|---|---|---|
view() | ❌ 必须连续 | ⬇️ 差 | ⬇️ 一般 | 小规模调试 |
reshape() | ✅ 不要求 | ⬆️ 好 | ⬆️ 强 | 通用替换 view |
flatten() | ✅ 不要求 | ⬆️ 好 | ⬆️ 强 | 多维合并 |
einops.rearrange() | ✅ 不要求 | ⬆️ 很好 | ⬆️ 非常强 | 工程项目 |
💡 实际应用建议
如果你在写正式项目或模型工程化,推荐使用:
from einops import rearrangeoutput_mid = rearrange(output_mid, 'b h s d -> b s (h d)')
或者安全版本(不依赖连续内存):
output_mid = output_mid.transpose(1, 2)
output_mid = output_mid.flatten(2) # (b, s, h*d)
这样不仅代码清晰,也避免了对 .contiguous() 的依赖问题。
5. 🔍 masked_fill()
在 PyTorch 中,masked_fill() 是一个非常常用的函数,用于 根据布尔掩码(mask)对张量的某些位置进行填充。它常用于 NLP 任务中,比如 Transformer 模型中的 attention mask 处理。
🧠 函数定义
torch.Tensor.masked_fill(mask, value)
参数说明:
mask: 一个布尔类型的张量(True/False),形状必须与原张量相同。value: 要填充的值,可以是标量或广播兼容的张量。
行为:
- 对于
mask中为True的位置,将原张量对应位置的值替换为value。 False的位置保持不变。
示例解析
atten_weight = atten_weight.masked_fill(attention_mask == 0, float("-inf"))
解释:
attention_mask == 0:- 这是一个布尔操作,生成一个和
attention_mask形状相同的布尔张量。 - 所有等于 0 的位置变成
True,表示这些位置是 pad 或无效 token,不应该参与 attention 计算。
- 这是一个布尔操作,生成一个和
float("-inf"):- 将这些被 mask 的位置填入负无穷大。
- 在后续 softmax 中,
exp(-inf)会变成 0,从而实现“忽略这些位置”的效果。
✅ 实际案例演示
输入示例:
import torch# 原始 attention 权重 (模拟)
atten_weight = torch.tensor([[0.1, 0.2, 0.3, 0.4],[0.5, 0.6, 0.7, 0.8]
])# attention mask (pad 位置为 0)
attention_mask = torch.tensor([[1, 1, 0, 0],[1, 0, 0, 0]
])# 应用 masked_fill
atten_weight = atten_weight.masked_fill(attention_mask == 0, float("-inf"))
print(atten_weight)
输出结果:
tensor([[ 0.1000, 0.2000, -inf, -inf],[ 0.5000, -inf, -inf, -inf]])
后续 softmax 结果:
import torch.nn.functional as F
F.softmax(atten_weight, dim=-1)
输出:
tensor([[0.4621, 0.5379, 0.0000, 0.0000],[1.0000, 0.0000, 0.0000, 0.0000]])
可以看到,mask 为 0 的位置在 softmax 后变成了 0,不会影响最终注意力分布。
⚠️ 注意事项
-
mask 张量的 shape 必须与目标张量一致:
- 如果你有一个
(batch_size, seq_len)的 mask,而atten_weight是(batch_size, head_num, seq_len, seq_len),你需要通过unsqueeze和expand调整 mask 的维度。 - 示例:
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) # -> (batch_size, 1, 1, seq_len) attention_mask = attention_mask.expand(batch_size, num_heads, seq_len, seq_len)
- 如果你有一个
-
不能直接使用 int 类型的 mask:
masked_fill只接受布尔类型作为 mask,所以要确保使用了比较操作如==,!=等。
💡 应用场景
| 场景 | 描述 |
|---|---|
| padding mask | 防止模型关注到 padding 的 token |
| look-ahead mask | 防止 decoder 在预测时看到未来 token |
| 自定义屏蔽机制 | 如屏蔽某些特定词、句子结构等 |
✅ 总结
| 方法 | 作用 | 推荐指数 |
|---|---|---|
masked_fill(mask == 0, -inf) | 屏蔽不需要关注的位置 | ⭐⭐⭐⭐⭐ |
F.softmax(..., dim=-1) | 使屏蔽位置变为 0 | ⭐⭐⭐⭐ |
| mask 维度适配 | 使用 unsqueeze + expand 调整 mask 到与 attn weight 相同 | ⭐⭐⭐⭐⭐ |
📌 最佳实践建议
# 假设 attention_mask: (batch_size, seq_len)
# attn_weights: (batch_size, num_heads, seq_len_q, seq_len_k)# Step 1: 添加两个维度,使其匹配 attn_weights 的 shape
attention_mask = attention_mask.unsqueeze(1).unsqueeze(2) # -> (B, 1, 1, S)# Step 2: 扩展 mask 使得其与 attn_weights 形状完全一致
attention_mask = attention_mask.expand_as(attn_weights) # -> same shape as attn_weights# Step 3: 应用 mask,填入 -inf
attn_weights = attn_weights.masked_fill(attention_mask == 0, float('-inf'))
这样就能保证每个 head 和 query 的位置都能正确屏蔽掉 pad 或无效 token。
参考材料
https://bruceyuan.com/hands-on-code/from-self-attention-to-multi-head-self-attention.html#%E7%AC%AC%E5%9B%9B%E9%87%8D-multi-head-self-attention
einop库安装及介绍
相关文章:

手写multi-head Self-Attention,各个算子详细注释版
文章目录 MultiHeadAttentionFormal的实现操作详解1. 🔍 attention_mask2. 🔍 matmul✅ 其他实现方式1. 使用 运算符(推荐简洁写法)2. 使用 torch.einsum()(爱因斯坦求和约定)3. 使用 torch.bmm()…...

基于 Three.js 的文本粒子解体效果技术原理剖析
文章目录 一、整体架构与核心库引入二、Three.js 场景初始化三、文本粒子数据创建五、动画与交互实现在前端开发领域,通过代码实现炫酷的视觉效果总能给用户带来独特的体验。本文将深入剖析一段基于 Three.js 的代码,解读其实现文本粒子解体效果的技术原理。 实现效果: 一、…...

Vue组件定义
下面,我们来系统的梳理关于 Vue 组件定义 的基本知识点 一、组件化核心思想 组件(Component) 是 Vue 的核心功能,允许将 UI 拆分为独立可复用的代码单元。每个组件包含: 模板:声明式渲染结构逻辑:处理数据与行为样式:作用域 CSS(通过 <style scoped>)二、组件…...
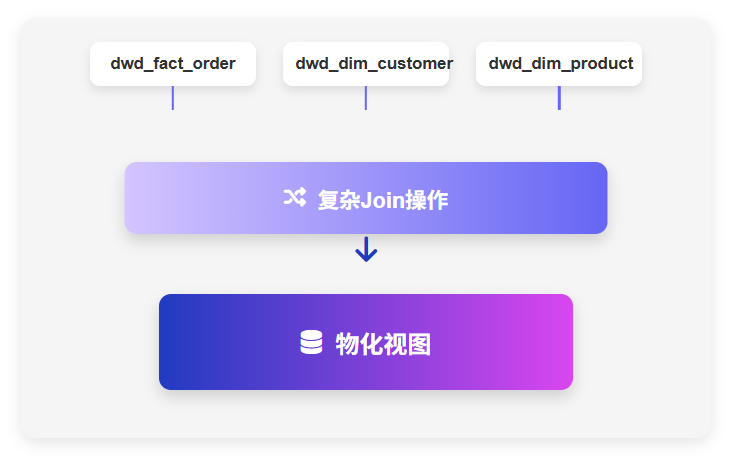
数据仓库分层 4 层模型是什么?
企业每天都在产生和收集海量数据。然而,面对这些数据,许多企业却陷入了困境:如何高效管理、处理和分析这些数据?如何从数据中提取有价值的信息来支持业务决策?这些问题困扰着众多数据分析师和 IT 管理者。 在众多架构…...
基于亚博K210开发板——物体分类测试
开发板 亚博K210开发板 实验目的 本次测试主要学习 K210 如何物体分类,然后通过 LCD 显示屏实时显示当前物体的分类名称。本节采用百度出的 PaddlePaddle 平台开发。 实验元件 OV2640 摄像头/OV9655 摄像头/GC2145 摄像头、LCD 显示屏 硬件连接 K210 开发板…...
核心架构解析与实用命令大全)
Kubernetes(K8s)核心架构解析与实用命令大全
在容器化技术席卷全球的今天,Kubernetes(简称K8s,以“8”代替“ubernete”八个字母)已成为云原生应用部署和管理的核心基础设施。作为Google基于内部Borg系统开源打造的容器编排引擎,K8s不仅解决了大规模容器管理的难题…...
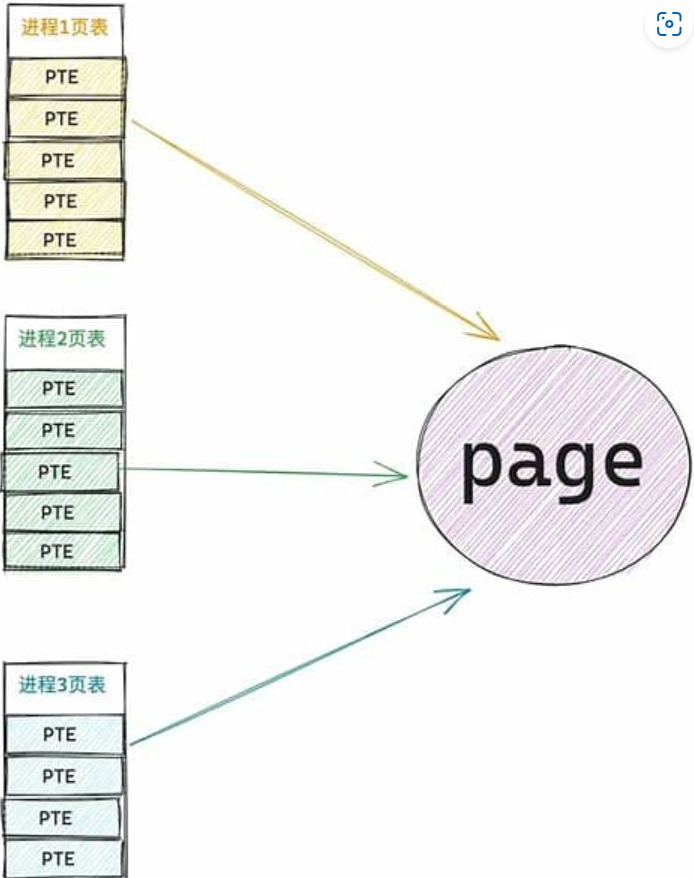
什么是缺页中断(缺页中断详解)
文章目录 【操作系统】什么是缺页中断(缺页中断详解)一、缺页中断的本质与背景1. **虚拟内存与分页机制**2. **缺页中断的定义** 二、缺页中断的触发场景1. **首次访问新分配的虚拟页**2. **内存置换导致的页缺失**3. **访问权限冲突**4. **页表项无效**…...

解决:MySQL client, error code: 1251, SQLState: 08004
问题: Client does not support authentication protocol requested by server; consider upgrading MySQL client, error code: 1251, SQLState: 08004 原因: 客户端不支持服务器(8.0默认)caching_sha2_password 方式的链接认证…...

【echarts】仪表盘
<div style"width:50%;height:33%"><Yibiaopan echart_id"ybpChart2" :series_data"gaugeData2" title"火电" unit"MWh" :colorList"[#DFA58F,#F89061,#FF8E59]" /></div> 链接:ht…...

java27
1.IO流 FileOutPutStream字节输出流基本用法: 一次性写入一个字符串的内容: 注意:\r或者\n表示把普通的r或者n的字符转义成回车的意思,所以不需要\\ FileInputStream字节输入流基本用法 -1在ASCII码里面对应的符号: 不…...
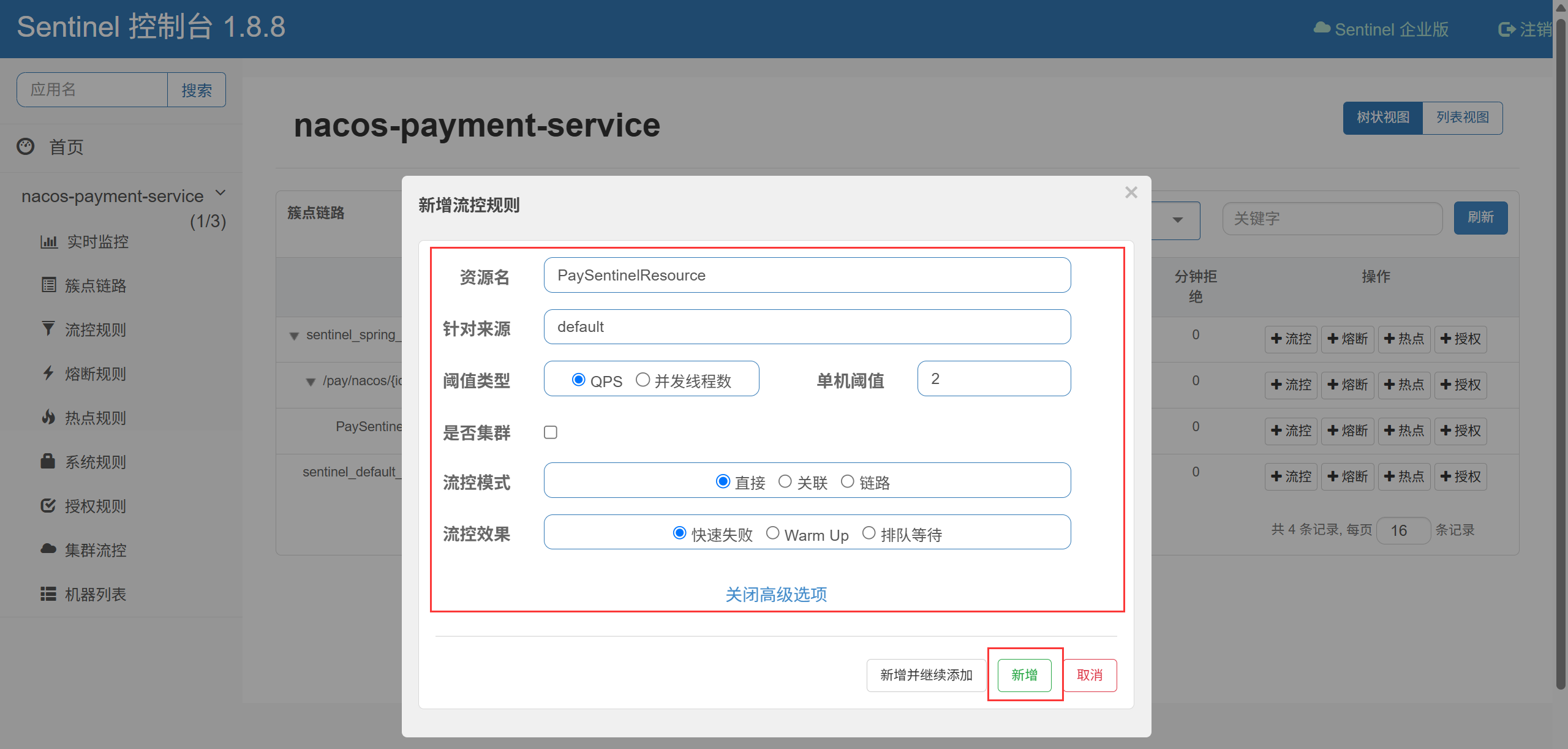
OpenFeign和Gateway集成Sentinel实现服务降级
目录 OpenFeign集成Sentinel实现fallback服务降级cloud-alibaba-payment8003(支付服务)cloud-common-api(通用模块)cloud-alibaba-order9003(订单服务)Sentinel配置流控规则测试结果 Gateway集成Sentinel实现服务降级cloud-gateway9527(网关)测试结果 总结 OpenFeign集成Sentin…...

Gin项目脚手架与标配组件
文章目录 前言设计思想和原则✨ 技术栈视频实况教程sponge 内置了丰富的组件(按需使用)几个标配常用组件主要技术点另一个参考链接 前言 软件和汽车一样,由多个重要零部件组装而成。 本文堆积了一些常用部件,还没来得及好好整理。先放着。 神兵利器虽多…...

ros2总结-常用消息包类型以及查询消息包命令
ROS2官方提供了多个常用的消息包(message packages),这些消息包定义了标准的数据结构,用于机器人系统中的通信和数据交换。以下是ROS2官方常见的消息包及其用途: ### 1. **std_msgs** - **用途**:提供基…...

C#·常用快捷键
一、大小写转换 CTRL U转小写 CTRL SHIFT U转大写 二、调试快捷键 F6: 生成解决方案 CtrlF6: 生成当前项目 F7: 查看代码 ShiftF7: 查看窗体设计器 F5: 启动调试 CtrlF5: 开始执行(不调试) ShiftF5: 停止调试 CtrlShiftF5: 重启调试 F9: 切换断点 CtrlF9: 启用/停止断点 C…...

CSS3实现的账号密码输入框提示效果
以下是通过CSS3实现输入框提示效果的常用方法,包含浮动标签和动态提示两种经典实现方案: 一、浮动标签效果 <div class"input-group"><input type"text" required><label>用户名</label> </div><…...

沉浸式 VR 汽车之旅:汽车虚拟展厅与震撼试驾体验
在传统的汽车销售模式里,消费者的看车选车过程极为艰辛。他们常常需要花费大量的时间和精力,亲自前往一家又一家的 4S 店。有时候,为了对比不同品牌、不同型号的汽车,可能要穿梭于城市的各个角落,耗费一整天甚至数天的…...

低秩矩阵、奇异值矩阵和正交矩阵
低秩矩阵 低秩矩阵(Low-rank Matrix)是指秩(rank)远小于其行数和列数的矩阵,即 r a n k ( M ) r ≪ min ( m , n ) rank(M) r \ll \min(m,n) rank(M)r≪min(m,n)。其核心特点是信息冗余性,可通过少量…...

CS144 - LAB0
CS144 - Lab 0 telnet 发送请求 如图,很简单,但是注意输入时间太久会超时 发邮箱 首先我们需要用命令行去发邮箱,这里我用企业微信邮箱给自己的 qq 邮箱发送~ 整个命令如下! 对于其中的参数,其实从英文就可以看出来…...

论文浅尝 | 将复杂知识图谱问答对齐为约束代码生成(COLING2025)
笔记整理:康家溱,东南大学在读硕士,研究方向为代码大语言模型 论文链接:https://aclanthology.org/2025.coling-main.267.pdf 发表会议:COLING 2025 1. 动机 近年来,随着大语言模型(LLM…...

【Linux命令】scp远程拷贝
文章目录 1. 基本语法与常用选项2. 使用场景和使用示例本地文件->远程主机远程主机文件->本地远程主机->另一台远程主机 3. 使用注意事项 scp(Secure Copy Protocol)是linux中基于ssh的安全文件传输工具,用于在本地和远程主机之前安…...

Golang|分布式搜索引擎中所使用到的设计模式
迭代器模式 定义:在遍历接口时,提供统一的方法函数供调用,保持一致性。核心思想:与大众习惯保持一致,方便第三方实现容器类时保持一致。常见方法:如next()方法,适用于所有集合类,简化…...
Ubuntu22.04通过命令行安装qt5
环境: VMware17Pro ubuntu-22.04.5-desktop-amd64.iso 步骤: 安装好虚拟机进入shell,或通过ssh登录,确保虚拟机能上外网,执行命令: sudo apt update sudo apt install build-essential sudo snap in…...

【仿生机器人】仿生机器人系统架构设计2.0——具备可执行性
结合我的需求后,来自Claude4.0 的结构设计 仿生机器人系统架构设计 一、系统总体架构 1.1 核心设计理念 涌现式情感:情感不是预设的规则,而是从环境感知、记忆关联和内在状态的复杂交互中涌现出来动态人格塑造:性格特质随着经…...
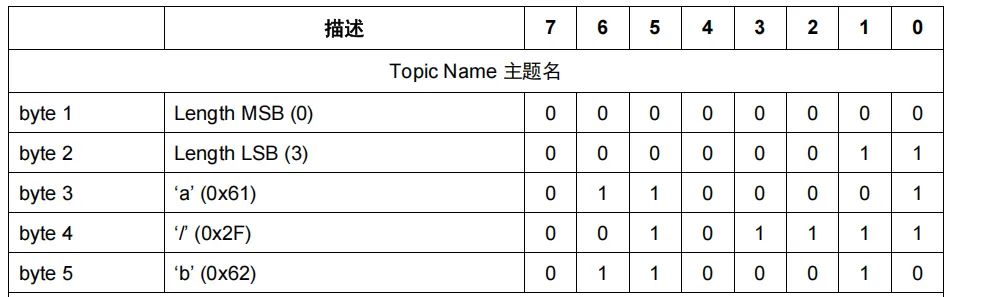
STM32:ESP8266 + MQTT 云端与报文全解析
知识点1【MQTT的概述】 1、概述 MQTT是一种基于发布/订阅模式的轻量级应用层协议,运行在TCP/IP协议之上,专用物联网(IoT)和机器对机器(M2M)设计,其核心目标是低带宽,高延迟或不稳定…...
HTML5 Canvas 星空战机游戏开发全解析
HTML5 Canvas 星空战机游戏开发全解析 一、游戏介绍 这是一款基于HTML5 Canvas开发的2D射击游戏,具有以下特色功能: 🚀 纯代码绘制的星空动态背景✈️ 三种不同特性的敌人类型🎮 键盘控制的玩家战机📊 完整的分数统…...
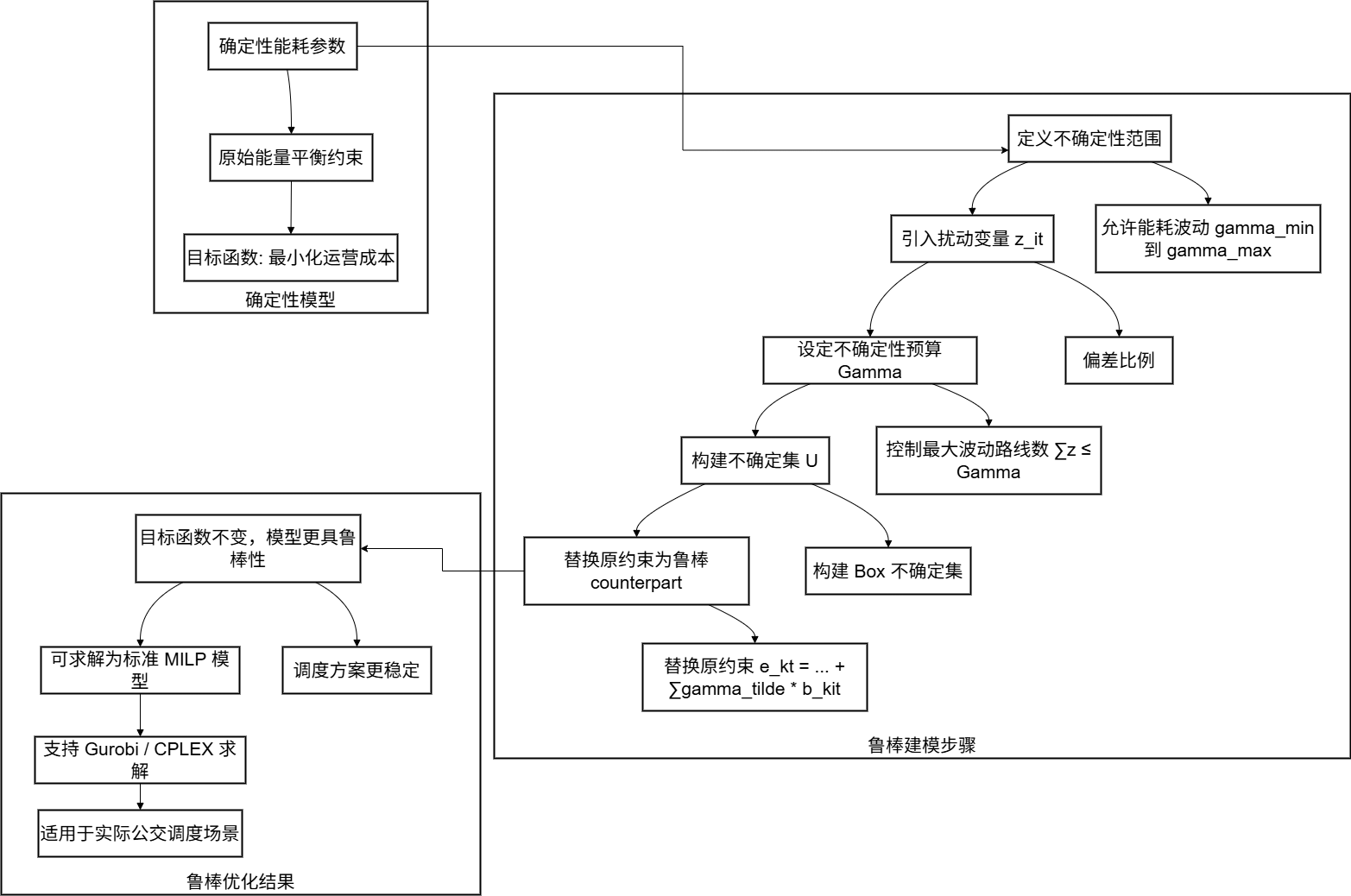
箱式不确定集
“箱式不确定集(Box Uncertainty Set)”可以被认为是一种 相对简单但实用的不确定集建模方式。 ✅ 一、什么是“简单的不确定集”? 在鲁棒优化领域,“简单不确定集”通常指的是: 特点描述形式直观数学表达简洁&#…...
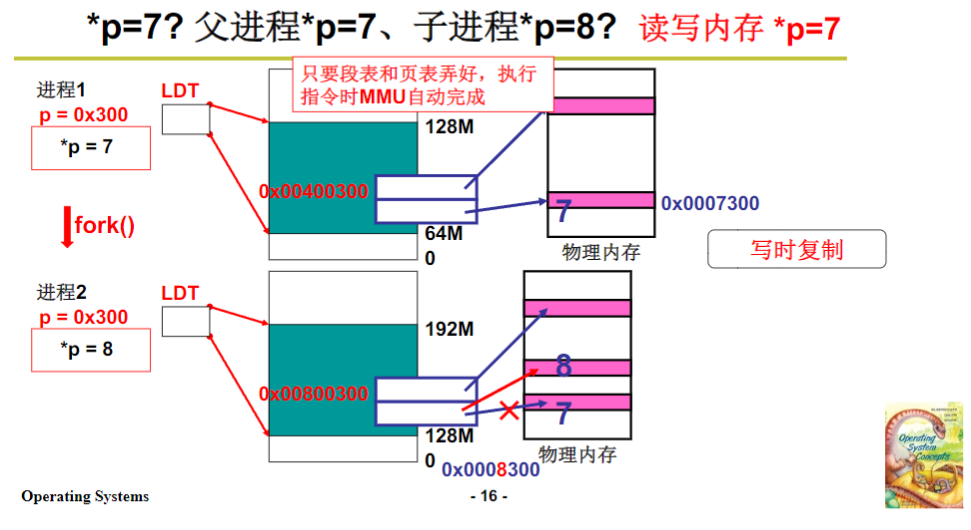
内存管理 : 04段页结合的实际内存管理
一、课程核心主题引入 这一讲,我要给大家讲的是真正的内存管理,也就是段和页结合在一起的内存管理方式。之前提到过,我们先学习了分段管理内存的工作原理,知道操作系统采用分段的方式,让用户程序能以分段的结构进行编…...

不使用绑定的方法
public partial class MainWindow : Window { public MainWindow() { InitializeComponent(); // 初始设置 A 控件的宽度 ControlA.Width ControlB.Width / 2; // 监听 B 控件的 SizeChanged 事件 ControlB.SizeChanged (sender, e) > { ControlA.Width ControlB.Actual…...

Spring Boot 中的 Web 应用与 Reactive Web 应用
该判断题表述为:“Spring Boot启动过程中会判断当前应用类型是Web应用还是Reactive Web应用。” 这个说法是 正确的。Spring Boot 的自动配置机制会检查类路径,以确定是将应用程序配置为传统的 Servlet Web 应用还是 Reactive Web 应用。 Spring Boot 中…...

基于 stm32 的农用车控制系统设计
一、系统功能需求分析 农用车控制系统需实现多方面功能,以满足农业生产多样化需求。在动力控制方面,要实现发动机转速调节、挡位自动切换;作业控制涵盖农机具升降、播种施肥量调节、喷洒农药的流量与压力控制等;同时,还需具备车辆状态监测功能,实时监控发动机温度、油压…...