数据库系统概论(十)SQL 嵌套查询 超详细讲解(附带例题表格对比带你一步步掌握)
数据库系统概论(十)SQL 嵌套查询 超详细讲解(附带例题表格对比带你一步步掌握)
- 前言
- 一、什么是嵌套查询?
- 1. 基础组成:查询块
- 2. 嵌套的两种常见位置
- (1)藏在 FROM 子句里(当子查询是一张“临时表”)
- (2)藏在 WHERE 子句里(用子查询结果作条件)
- 3. 多层嵌套
- 4. 子查询的限制:不能用 ORDER BY
- 二、带有 IN 谓词的子查询
- 1. IN谓词的核心作用
- 2. 子查询 vs 连接查询
- (1)连接查询(表关联法)
- (2)子查询(分步筛选法)
- 3. 不相关子查询
- 4. IN子查询的常见用法场景
- 三、带有比较运算符的子查询
- 1. 带比较运算符的子查询是什么?
- 2. 子查询的分类
- (1)不相关子查询
- (2)相关子查询
- 3. 经典案例:查每门课的最高分学生
- 四、带有ANY(SOME)或ALL谓词的子查询
- 1. 什么是ANY和ALL?
- 2. ANY/ALL怎么用?
- 3. 经典案例
- 案例1:查非计算机专业中,比计算机专业任意一个学生年龄小的学生(出生日期更晚)
- 案例2:查非计算机专业中,比计算机专业所有学生年龄都小的学生(出生日期更晚)
- 4. ANY/ALL和聚集函数的等价表
- 五、带有 EXISTS 谓词的子查询
- 1. EXISTS谓词的基本概念
- 2. 经典案例
- 案例1:查询选修了81001号课程的学生姓名。
- 案例2:查询没有选修81001号课程的学生姓名。
- 3. EXISTS与IN的对比
- 4. 用EXISTS实现全称量词查询
- 案例:查询选修了全部课程的学生姓名。
前言
- 在前几期博客中,我们探讨了 SQL 连接查询和单表查询技术。
- 从本节开始,我们将深入讲解 SQL 中嵌套查询的知识点。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
一、什么是嵌套查询?
核心概念:
嵌套查询就像“大问题拆分成小问题”,把一个查询(小问题)藏在另一个查询(大问题)里,层层解决。
1. 基础组成:查询块
- 查询块:一个完整的
SELECT-FROM-WHERE语句,比如:SELECT Sno FROM SC WHERE Cno='81001' -- 小问题:查选了81001课程的学号 - 嵌套:把小问题的结果,当作大问题的条件。大问题叫 外层查询(父查询),小问题叫 内层查询(子查询)。
2. 嵌套的两种常见位置
(1)藏在 FROM 子句里(当子查询是一张“临时表”)
示例:
SELECT Sname -- 大问题:查学生姓名
FROM Student, (SELECT Sno FROM SC WHERE Cno='81001') AS SC1 -- 小问题:先查选了81001课的学号,当作临时表SC1
WHERE Student.Sno=SC1.Sno; -- 用临时表SC1的学号,匹配学生表找姓名
逻辑:先得到选了81001课的学号列表(SC1),再从学生表中找到这些学号对应的姓名。
(2)藏在 WHERE 子句里(用子查询结果作条件)
示例:
SELECT Sname -- 大问题:查学生姓名
FROM Student
WHERE Sno IN (SELECT Sno FROM SC WHERE Cno='81002'); -- 小问题:查选了81002课的学号,用IN判断是否在其中
逻辑:先查选了81002课的学号,再在学生表中筛选出学号在这个列表里的学生姓名。
3. 多层嵌套
特点:子查询里还可以再套子查询(最多嵌套多少层?SQL标准没限制,但实际别写太复杂),像剥洋葱一样层层查询
示例:
SELECT Sname -- 大问题:查“所有课程都选了”的学生姓名
FROM Student
WHERE NOT EXISTS ( -- 外层:不存在“该学生没选的课程”SELECT * FROM Course WHERE NOT EXISTS ( -- 内层:不存在“该课程没被该学生选”SELECT * FROM SC WHERE Sno= Student.Sno -- 学生学号AND Cno= Course.Cno -- 课程编号)
);
逻辑:
- 外层
NOT EXISTS:找“不存在没选的课程”的学生。 - 内层
NOT EXISTS:对每门课程,检查“学生是否没选这门课”。 - 两层结合:如果所有课程都被学生选了(内层都不存在没选的情况),外层就会选中该学生。
4. 子查询的限制:不能用 ORDER BY
- 原因:子查询只是给外层提供数据(比如学号列表),不需要排序,排序留给外层做。
- 正确做法:
SELECT Sname FROM Student WHERE Sno IN (SELECT Sno FROM SC WHERE Cno='81002' -- 内层不排序 ) ORDER BY Sname; -- 排序放在外层
二、带有 IN 谓词的子查询
1. IN谓词的核心作用
一句话理解:
IN 就像“在名单里”,判断某个值是否在子查询返回的集合中。
场景举例:
想查“选了‘信息系统概论’这门课的学生”,可以分两步:
- 先查这门课的课程号(比如81004)→ 得到一个“课程号名单”。
- 再查选了这个课程号的学生学号 → 得到“学号名单”。
- 最后从学生表中找出学号在“学号名单”里的学生 → 用
IN判断是否在名单中。
2. 子查询 vs 连接查询
相同目标:查选修“信息系统概论”的学生学号和姓名。
(1)连接查询(表关联法)
SELECT Sno, Sname
FROM Student
JOIN SC ON Student.Sno = SC.Sno -- 学生表和选课表用学号关联
JOIN Course ON SC.Cno = Course.Cno -- 选课表和课程表用课程号关联
WHERE Course.Cname = '信息系统概论'; -- 直接通过表关联找到对应课程的学生
逻辑:把三张表“拼”在一起,像拼图一样直接找到符合条件的行。
(2)子查询(分步筛选法)
SELECT Sno, Sname
FROM Student
WHERE Sno IN ( -- 学号是否在“选了这门课的学号名单”里?SELECT Sno FROM SC WHERE Cno IN ( -- 课程号是否在“信息系统概论的课程号名单”里?SELECT Cno FROM Course WHERE Cname='信息系统概论' -- 先查课程号)
);
逻辑:
- 最内层:先查“信息系统概论”的课程号(比如81004)→ 得到课程号名单。
- 中间层:再查选了这个课程号的学号 → 得到学号名单。
- 最外层:从学生表中筛选学号在名单里的学生 → 用
IN做判断。
对比总结:
- 连接查询:适合“直接拼表关联”的简单场景,性能可能更高。
- 子查询:适合“分步解决问题”的逻辑,思路更清晰,尤其适合多层筛选。
3. 不相关子查询
定义:子查询的条件不依赖父查询,可以独立运行,结果直接给父查询用。
特点:
- 子查询先执行,结果是一个固定的集合(比如学号列表、课程号列表)。
- 父查询再用这个集合做条件筛选。
示例:查平均分高于85分的学生
SELECT Sno, Sname, Smajor -- 父查询:从学生表找学生
FROM Student
WHERE Sno IN ( SELECT Sno FROM SC -- 子查询:先查平均分>85的学号GROUP BY Sno -- 按学号分组,算每个学生的平均分HAVING AVG(grade) > 85
);
执行步骤:
- 子查询独立运行:按学号分组,算出平均分>85的学号列表(如{001, 003})。
- 父查询用
IN判断学生学号是否在列表里,返回结果。
4. IN子查询的常见用法场景
| 场景描述 | 示例SQL(简化版) |
|---|---|
| 查选了某课程的学生 | SELECT 姓名 FROM 学生 WHERE 学号 IN (SELECT 学号 FROM 选课 WHERE 课程号='81002') |
| 查某类课程的学生信息 | 多层IN嵌套,先查课程号,再查学号 |
| 查分组统计后的结果(如平均分) | SELECT ... WHERE 学号 IN (SELECT 学号 FROM 选课 GROUP BY 学号 HAVING AVG(成绩)>85) |
三、带有比较运算符的子查询
1. 带比较运算符的子查询是什么?
核心思路:子查询的结果是一个单一值(比如一个数字、一个名字),这时可以用 > < = 等比较运算符,把这个单一值和父查询的数据做对比。
举个例子:
想查和“刘晨”同一个专业的学生。
- 子查询先找出刘晨的专业:
SELECT Smajor FROM Student WHERE Sname = '刘晨',结果是一个值(比如“计算机”)。 - 父查询用
=比较,找出专业等于这个值的学生:SELECT Sno, Sname, Smajor FROM Student WHERE Smajor = (子查询结果)
注意!
子查询必须跟在比较符后面,不能写反!
❌ 错误写法:WHERE (子查询) = Smajor
✅ 正确写法:WHERE Smajor = (子查询)
2. 子查询的分类
(1)不相关子查询
- 特点:子查询的条件不依赖父查询,可以先独立运行子查询,再把结果传给父查询。
- 执行顺序:先算子查询 → 得到结果 → 再用结果执行父查询。
- 例子:查刘晨同系的学生(子查询只需要查一次“刘晨的系”)。
SELECT Sno, Sname, Sdept FROM Student WHERE Sdept = (SELECT Sdept FROM Student WHERE Sname = '刘晨')
(2)相关子查询
- 特点:子查询的条件依赖父查询当前行的数据,需要父查询和子查询“联动”执行。
- 执行顺序:
- 父查询先取第一行数据,把相关值(比如学号)传给子查询;
- 子查询用这个值计算结果(比如该学号的平均分);
- 父查询用结果判断当前行是否符合条件,符合就保留;
- 重复步骤1-3,直到处理完所有行。
- 例子:查每个学生超过自己平均分的课程成绩。
通俗理解:SELECT Sno, Cno FROM SC x -- x是外层表的别名 WHERE Grade >= (SELECT AVG(Grade) FROM SC y -- y是内层表的别名WHERE y.Sno = x.Sno -- 内层用x的学号找对应数据 )- 先看第一个学生(比如学号20180001),子查询算出他的平均分是89;
- 父查询检查他的每门课成绩是否≥89,符合条件的就选出来;
- 再处理下一个学生,重复这个过程。
3. 经典案例:查每门课的最高分学生
需求:找出每门课成绩最高的学生的学号、课程号和成绩。
SQL写法:
SELECT sno, cno, grade
FROM sc x
WHERE grade = (SELECT MAX(grade) FROM sc yWHERE y.cno = x.cno -- 内层根据外层的课程号(x.cno)找最高分
)
执行逻辑:
- 外层先取第一行数据(比如课程81001,学号20180001,成绩85);
- 子查询根据课程号81001,算出该课程的最高分是85;
- 比较当前成绩85是否等于最高分85,等于就保留;
- 处理下一行(比如课程81002,学号20180002,成绩98),子查询算出该课程最高分98,符合条件,保留;
- 以此类推,直到所有行处理完。
四、带有ANY(SOME)或ALL谓词的子查询
1. 什么是ANY和ALL?
-
ANY = 任意一个(只要满足集合中的某一个值)
-
类似“至少有一个行符合条件”。
-
ALL = 所有(必须满足集合中的每一个值)
-
类似“所有行都要符合条件”。
举个生活例子:
- 如果你说“我要选一门 比ANY数学课分数高 的课” → 只要有一门数学课分数比它低就行;
- 如果你说“我要选一门 比ALL数学课分数高 的课” → 必须所有数学课分数都比它低!
2. ANY/ALL怎么用?
格式:
比较运算符 + ANY/ALL + (子查询)
比如:
> ANY:大于子查询结果中的某个值< ALL:小于子查询结果中的所有值
常见搭配表:
| 需求 | 用ANY/ALL | 等价于聚集函数 | 例子 |
|---|---|---|---|
| 等于集合中某个值 | = ANY | IN | Sno IN (子查询) 等价于 Sno = ANY (子查询) |
| 不等于集合中所有值 | <> ALL | NOT IN | Sno NOT IN (子查询) 等价于 Sno <> ALL (子查询) |
| 大于集合中最小的 | > ANY | > MIN | 比任意一个值大 → 只要大于最小值就行 |
| 大于集合中最大的 | > ALL | > MAX | 比所有值大 → 必须大于最大值 |
| 小于集合中最大的 | < ANY | < MAX | 比某个值小 → 只要小于最大值就行 |
| 小于集合中最小的 | < ALL | < MIN | 比所有值小 → 必须小于最小值 |
3. 经典案例
场景:学生表中有计算机专业和其他专业,想找非计算机专业中年龄相关的学生。
表结构:
| Sname | Smajor | Sbirthdate |
|---|---|---|
| 张三 | 计算机 | 2000-01-01 |
| 李四 | 信息安全 | 2001-03-08 |
| 王五 | 计算机 | 2000-12-31 |
| 赵六 | 数据科学 | 2002-06-12 |
案例1:查非计算机专业中,比计算机专业任意一个学生年龄小的学生(出生日期更晚)
需求翻译:只要比计算机专业里至少一个人年龄小(即出生日期晚于计算机专业的某个人)。
SELECT Sname, Smajor, Sbirthdate
FROM Student
WHERE Smajor <> '计算机' -- 排除计算机专业AND Sbirthdate > ANY (SELECT Sbirthdate FROM Student WHERE Smajor = '计算机');
执行逻辑:
- 子查询先找出计算机专业的所有出生日期:
2000-01-01和2000-12-31; > ANY表示只要大于其中任意一个值就行 → 比如赵六的2002-06-12大于2000-01-01,符合条件。
等价写法:用MIN聚集函数
SELECT ...
WHERE Sbirthdate > (SELECT MIN(Sbirthdate) FROM Student WHERE Smajor='计算机');
(因为只要大于最小值,必然大于某个值)
案例2:查非计算机专业中,比计算机专业所有学生年龄都小的学生(出生日期更晚)
需求翻译:必须比计算机专业里所有人年龄都小(出生日期晚于计算机专业的所有人)。
SELECT Sname, Smajor, Sbirthdate
FROM Student
WHERE Smajor <> '计算机' AND Sbirthdate > ALL (SELECT Sbirthdate FROM Student WHERE Smajor = '计算机');
执行逻辑:
> ALL表示必须大于所有值 → 计算机专业最大的出生日期是2000-12-31,只有赵六的2002-06-12大于它,所以只有赵六符合。
等价写法:用MAX聚集函数
SELECT ...
WHERE Sbirthdate > (SELECT MAX(Sbirthdate) FROM Student WHERE Smajor='计算机');
(必须大于最大值,才能大于所有值)
4. ANY/ALL和聚集函数的等价表
| 需求 | 用ANY/ALL | 等价的聚集函数写法 |
|---|---|---|
| 大于某个值 | > ANY | > MIN |
| 大于所有值 | > ALL | > MAX |
| 小于某个值 | < ANY | < MAX |
| 小于所有值 | < ALL | < MIN |
| 等于某个值(IN) | = ANY | IN |
| 不等于所有值(NOT IN) | <> ALL | NOT IN |
五、带有 EXISTS 谓词的子查询
1. EXISTS谓词的基本概念
核心作用:判断子查询是否有结果,返回的是true或者false,并不关注子查询的具体内容。
- 当
EXISTS后的子查询能查出数据(结果不为空)时,就返回true,此时外层查询的条件得以成立; - 若子查询没有结果(结果为空),则返回
false,外层查询的条件不成立。
语法格式:
WHERE EXISTS (子查询);
WHERE NOT EXISTS (子查询); -- 子查询为空时返回true
特别说明:
- 子查询通常用
SELECT *,这是因为我们只关心子查询有没有结果,而不关心具体查出来的内容是什么。
2. 经典案例
案例1:查询选修了81001号课程的学生姓名。
使用EXISTS的写法:
SELECT Sname
FROM Student
WHERE EXISTS (SELECT * FROM SC WHERE Sno = Student.Sno AND Cno = '81001'
);
执行步骤:
- 外层查询从
Student表中取出一行数据,获取当前学生的学号,比如20180001; - 子查询开始执行,查看
SC表中是否存在学号为20180001且课程号为81001的记录; - 若存在这样的记录,子查询返回
true,那么这个学生的姓名就会被添加到结果中; - 若不存在,子查询返回
false,该学生的姓名不会出现在结果里; - 重复上述步骤,直到处理完
Student表中的所有行。
案例2:查询没有选修81001号课程的学生姓名。
使用NOT EXISTS的写法:
SELECT Sname
FROM Student
WHERE NOT EXISTS (SELECT * FROM SC WHERE Sno = Student.Sno AND Cno = '81001'
);
关键逻辑:
- 当子查询没有结果时,
NOT EXISTS返回true,意味着这个学生没有选修该课程。
3. EXISTS与IN的对比
这两种方式在很多情况下可以实现相同的查询效果,但也存在一些差异。
| 场景 | EXISTS | IN |
|---|---|---|
| 查询选修了课程的学生 | WHERE EXISTS (SELECT * FROM SC WHERE SC.Sno = Student.Sno) | WHERE Sno IN (SELECT Sno FROM SC) |
| 适用情况 | 适合子查询结果集较大的情况,它是通过判断是否存在来筛选的 | 适合子查询结果集较小的情况,它需要先计算出子查询的所有结果 |
4. 用EXISTS实现全称量词查询
在SQL里没有直接表示全称量词(∀)的操作符,不过可以借助NOT EXISTS来间接实现。
案例:查询选修了全部课程的学生姓名。
需求理解:要找出这样的学生,对于所有课程而言,他们都有选修记录。
SQL写法:
SELECT Sname
FROM Student
WHERE NOT EXISTS (-- 查找一门课程SELECT * FROM Course WHERE NOT EXISTS (-- 检查该学生是否选修了这门课SELECT * FROM SC WHERE Sno = Student.Sno AND Cno = Course.Cno)
);
逻辑拆解:
- 从外层看,对于每个学生,先假设存在一门他没选修的课程;
- 中间的子查询负责遍历所有课程;
- 最内层的子查询去验证该学生是否选修了这门课程;
- 如果对于某门课程,学生没有选修记录,那么
NOT EXISTS就会返回false,这个学生就不符合要求; - 只有当所有课程都被学生选修了,也就是对于所有课程,内层子查询都能查到记录,
NOT EXISTS才会返回true,这个学生才会被查询出来。
以上就是这篇博客的全部内容,下一篇我们将继续探索更多精彩内容。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343
我的数据库系统概论专栏
https://blog.csdn.net/2402_83322742/category_12911520.html?spm=1001.2014.3001.5482
| 非常感谢您的阅读,喜欢的话记得三连哦 |

相关文章:
数据库系统概论(十)SQL 嵌套查询 超详细讲解(附带例题表格对比带你一步步掌握)
数据库系统概论(十)SQL 嵌套查询 超详细讲解(附带例题表格对比带你一步步掌握) 前言一、什么是嵌套查询?1. 基础组成:查询块2. 嵌套的两种常见位置(1)藏在 FROM 子句里(当…...
Git仓库大文件清理指南
前言 当大文件被提交到 Git 仓库后又删除,但仓库体积仍然很大时,这是因为 Git 保留了这些文件的历史记录。要彻底清理这些文件并减小仓库体积,你需要重写 Git 历史。 注意事项 这会重写历史 - 所有协作者都需要重新克隆仓库 备份你的仓库 …...

华为OD机试真题——最小矩阵宽度(宽度最小的子矩阵)(2025A卷:200分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 200分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...
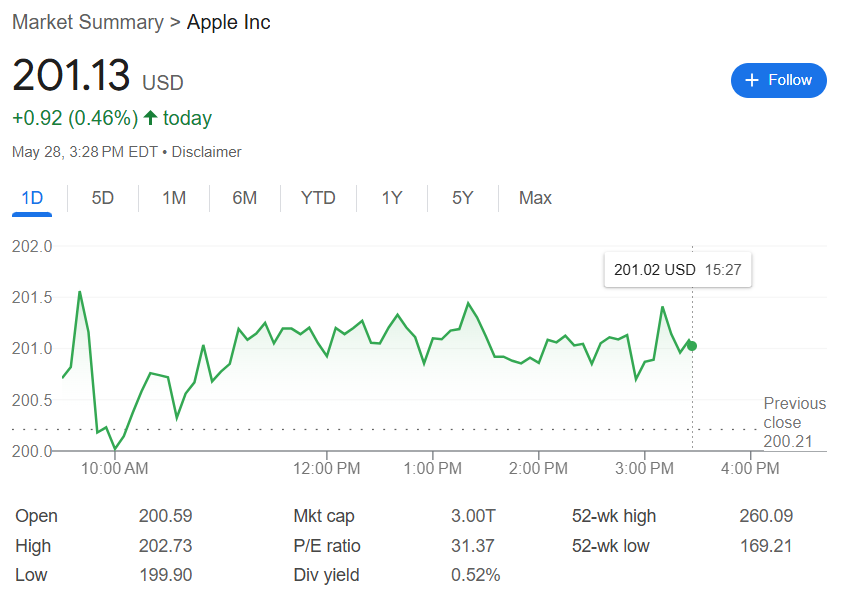
苹果公司计划按年份来重命名重大的软件,将升级iOS 18软件至iOS 26
苹果公司计划从今年开始,所有苹果操作系统将统一采用年份标识,而非此前混乱的版本号体系。苹果将在6月9日的全球开发者大会上正式宣布这一变革。周三截至发稿,苹果股价震荡微涨0.46%,重回3万亿美元市值。 苹果公司正在筹划其操作…...
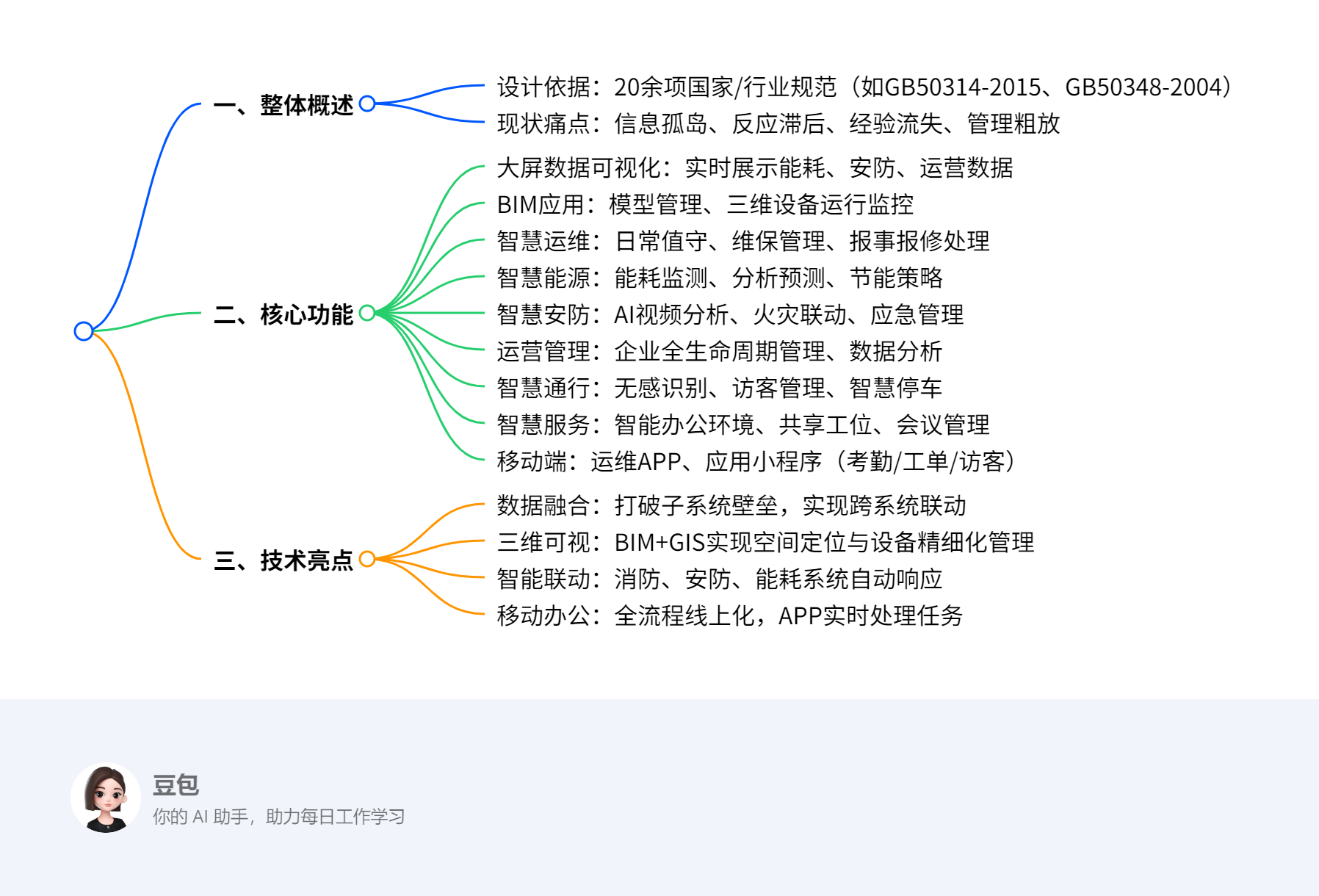
园区智能化集成平台汇报方案
该方案为园区智能化集成平台设计,依据《智能建筑设计标准》等 20 余项国家与行业规范,针对传统园区信息孤岛、反应滞后、经验流失、管理粗放等痛点,构建可视化智慧园区管理平台,实现大屏数据可视化、三维设备监控、智慧运维(含工单管理、巡检打卡)、能源能耗分析、AI 安防…...

奥威BI+AI——高效智能数据分析工具,引领数据分析新时代
随着数据量的激增,企业对高效、智能的数据分析工具——奥威BIAI的需求日益迫切。奥威BIAI,作为一款颠覆性的数据分析工具,凭借其独特功能,正在引领数据分析领域的新纪元。 一、零报表环境下的极致体验 奥威BIAI突破传统报表限…...

Spark on Hive表结构变更
Spark on Hive表结构变更 1、表结构变更概述1、表结构变更概述 在Spark on Hive架构中,表结构(Schema)变更是一个常见且重要的操作。理解其背景、使用场景以及具体方式对于大数据平台管理至关重要 1.1、Spark on Hive元数据管理 Hive Metastore(HMS): 核心组件。它是一个…...
)
python做题日记(11)
第二十五题 第二十五题是k个一组翻转链表,意思是给定一个链表,将每k个结点化成一组,对它们进行翻转操作,在对每一组都进行翻转操作之后,将它们重新连接起来,返回这个新的链表。所以代码思路也很好想&#x…...

2025——》NumPy中的np.logspace使用/在什么场景下适合使用np.logspace?NumPy中的np.logspace用法详解
1.NumPy中的np.logspace使用: 在 NumPy 中,np.logspace函数用于生成对数尺度上等间距分布的数值序列,适用于科学计算、数据可视化等需要对数间隔数据的场景。以下是其核心用法和关键细节: 一、基础语法与参数解析: numpy.logspace(start, stop, num=50, endpoint=True, ba…...
STM32F407VET6学习笔记8:UART5串口接收中断的Cubemx配置
之前的工程对串口的配置没有完善串口接受中断,这里补充配置UART5串口接收中断,实现串口回送功能 之前的文章: STM32F407VET6学习笔记5:STM32CubeMX配置串口工程_HAL库-CSDN博客 目录 中断配置: 中断服务函数࿱…...
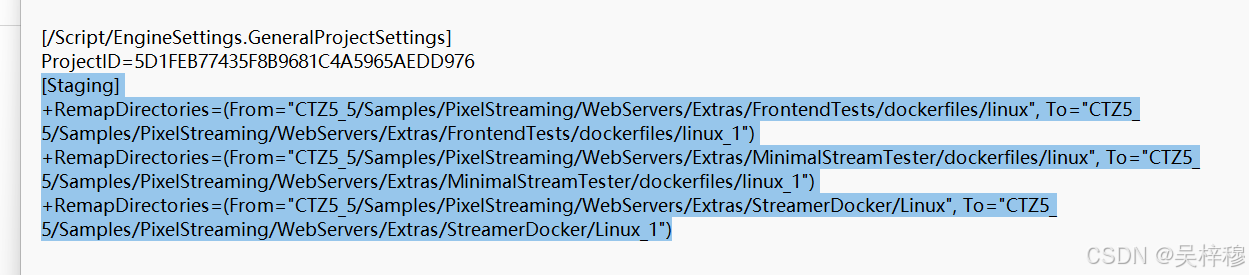
UE5.5 pixelstreaming插件打包报错
文章目录 错误内容如下解决方案推流服务器不能使用 错误内容如下 The following files are set to be staged, but contain restricted folder names ("Linux"): CTZ5_5/Samples/PixelStreaming/WebServers/Extras/FrontendTests/dockerfiles/linux/Dockerfile CTZ5…...

Python Django完整教程与代码示例
边写代码零食不停口 盼盼麦香鸡味块 、卡乐比(Calbee)薯条三兄弟 独立小包、好时kisses多口味巧克力糖、老金磨方【黑金系列】黑芝麻丸 边写代码边贴面膜 事业美丽两不误 DR. YS 野森博士【AOUFSE/澳芙雪特证】377专研美白淡斑面膜组合 优惠劵 别光顾写…...

Spring Boot,两种配置文件
Spring Boot 主要支持两种配置文件格式,它们允许你外部化应用程序的配置:.properties 文件和 .yml (或 .yaml) 文件。以下是关于这两种配置文件的关键知识点: 1. application.properties 文件 格式: 基于键值对的纯文本文件。 语法: keyvalu…...

OpenLayers 地图标注之图文标注
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 地图标注是将空间位置信息点与地图关联、通过图标、窗口等形式把相关信息展现到地图上。在WebGIS中地图标注是重要的功能之一,可以为用户提供…...
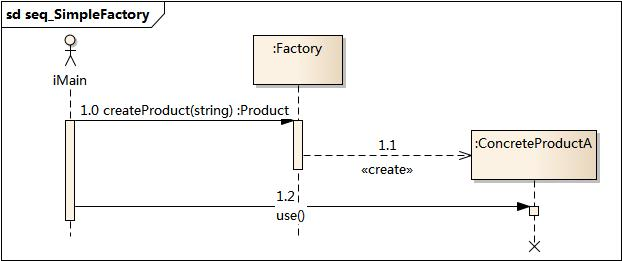
设计模式——简单工厂模式(创建型)
摘要 本文主要介绍了简单工厂模式,包括其定义、结构、实现方式、适用场景、实战示例以及思考。简单工厂模式是一种创建型设计模式,通过工厂类根据参数决定创建哪一种产品类的实例,封装了对象创建的细节,使客户端无需关心具体类的…...
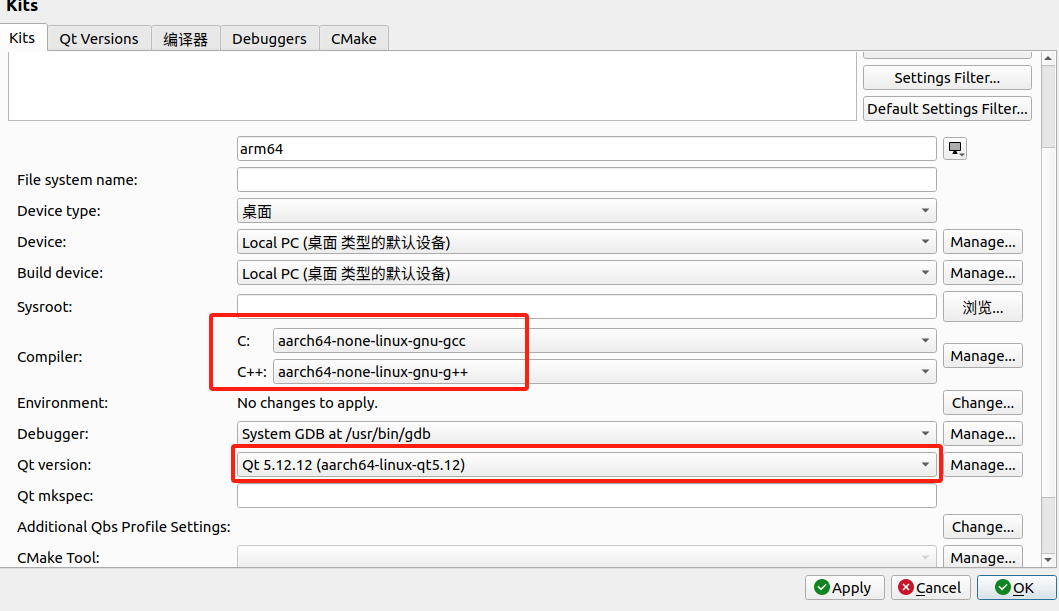
qt ubuntu 20.04 交叉编译
一、交叉编译环境搭建 1.下载交叉编译工具链:https://developer.arm.com/downloads/-/gnu-a 可以根据自己需要下载对应版本,当前最新版本是10.3, 笔者使用10.3编译后的glibc.so版本太高(glibc_2.3.3, glibc_2.3.4, glibc_2.3.5)…...

java中cocurrent包常用的集合类操作
文章目录 前置ConcurrentHashMapCopyOnWriteArrayList/CopyOnWriteArraySet 前置 常规的集合类,比如 ArrayList,HashMap 当作为多线程下共享的变量时候,操作它们时会涉及线程安全的问题 ConcurrentHashMap 适合:需要频繁读写的…...

晶振频率稳定性:5G 基站与航天设备的核心竞争力
在当今科技飞速发展的时代,电子设备的性能和可靠性至关重要。晶振作为电子设备中的核心部件,为系统提供精确的时间和频率基准。晶振的频率稳定性直接影响着设备的整体性能,从日常生活中广泛使用的智能手机、智能穿戴设备,到对精度…...
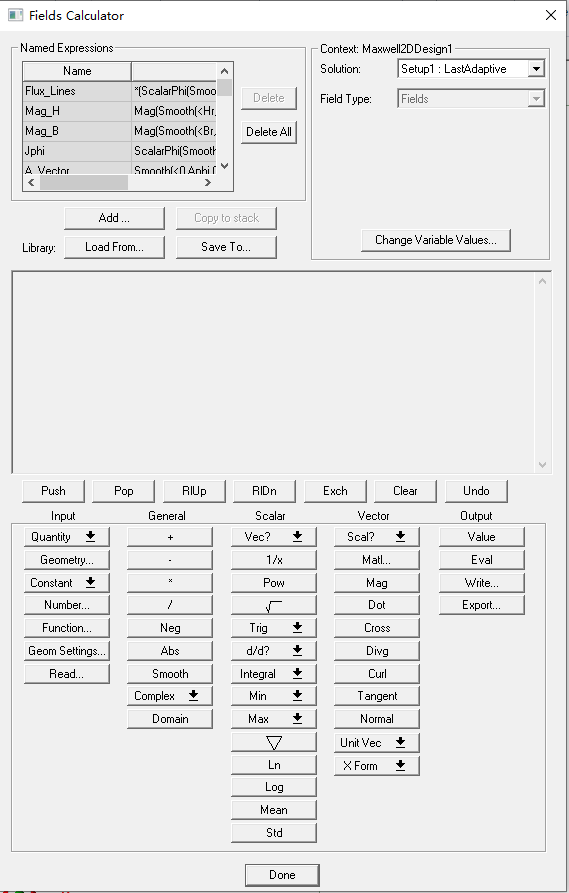
基于python脚本进行Maxwell自动化仿真
本文为博主进行Maxwell自动化研究过程的学习记录,同时对Maxwell自动化脚本(pythonIron)实现方法进行分享。 文章目录 脚本使用方法脚本录制与查看常用脚本代码通用开头定义项目调整设计变量软件内对应位置脚本 设置求解器软件内对应位置脚本…...
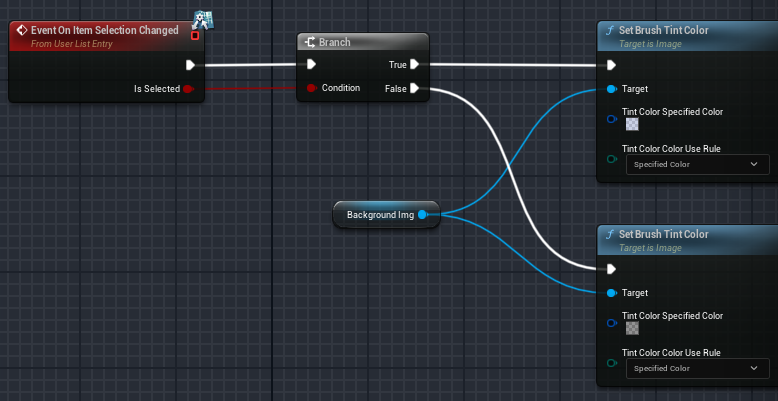
Blueprints - List View Widget
一些学习笔记归档; 需要读取动态数据把多个条目显示在UI上的时候,可能用到List View组件;假如有Widget要使用在List View中,此Widget需要继承相关接口: 这样就能在List View控件中选择已经继承接口的Widget组件了&…...
docker-compose搭建prometheus以及grafana
1. 什么是 Prometheus? Prometheus 是一个开源的系统监控和告警工具,由 SoundCloud 于 2012 年开始开发,现为 CNCF(Cloud Native Computing Foundation)项目之一。它特别适合云原生环境和容器编排系统(如 …...
(帮你生成 模块划分+页面+表设计、状态机、工作流、ER模型))
进阶智能体实战八、需求分析助手(基于qwen多模态大模型对图文需求文档分析)(帮你生成 模块划分+页面+表设计、状态机、工作流、ER模型)
🚀 基于通义千问大模型的智能需求分析助手:一键生成需求分析、模块划分、ER 图和工作流! 在软件开发的早期阶段,需求分析是至关重要的一环。然而传统方式往往需要产品经理和架构师投入大量精力分析需求文档、划分模块、设计数据结构,效率低、容易出错。 为了解决这一痛…...

Git -> Git Stash临时保存当前工程分支修改
Git Stash 基本概念 git stash 用于临时保存当前工作目录的修改,让你可以快速切换到一个干净的工作状态,之后再恢复这些修改。 1. 保存当前修改 git stash # 或者添加描述信息 git stash save "修改描述"2. 查看stash列表 git stash list3…...
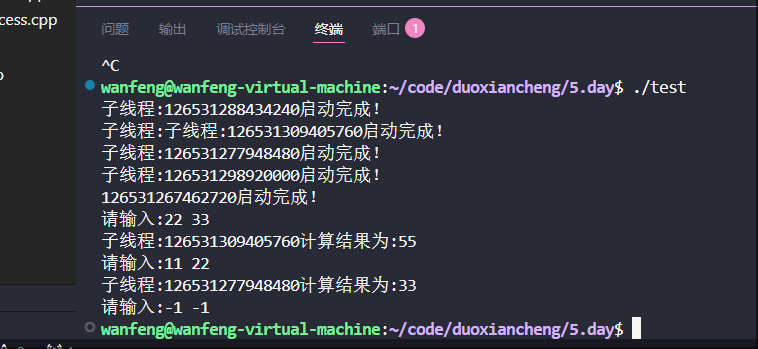
多线程和并发之线程
线程 前面讲到进程:为了并发执行任务(程序),现代操作系统才引进进程的概念 分析: 创建开销问题:创建一个进程开销:大 子进程需要拷贝父进程的整个地址空间 通信开销问题:进程间的通…...
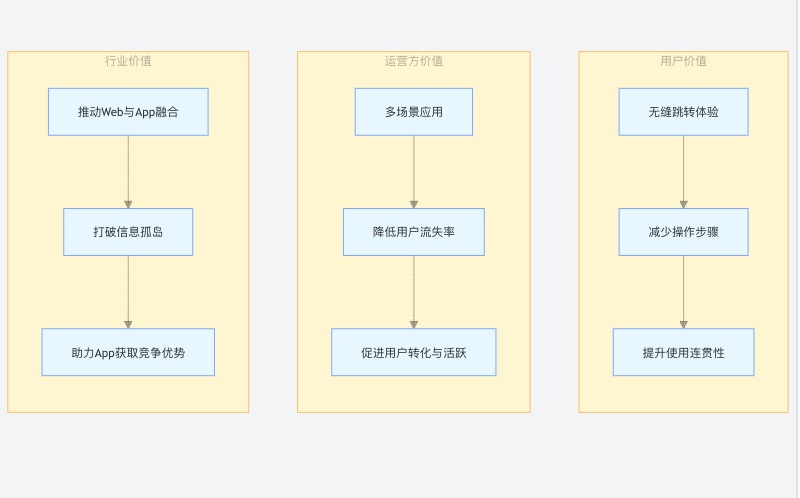
apptrace 的优势以及对 App 的价值
官网地址:AppTrace - 专业的移动应用推广追踪平台 apptrace 的优势以及对 App 的价值 App 拉起作为移动端深度链接技术的关键应用,能实现从 H5 网页到 App 的无缝跳转,并精准定位到 App 内指定页面。apptrace 凭借专业的技术与丰富的经验…...
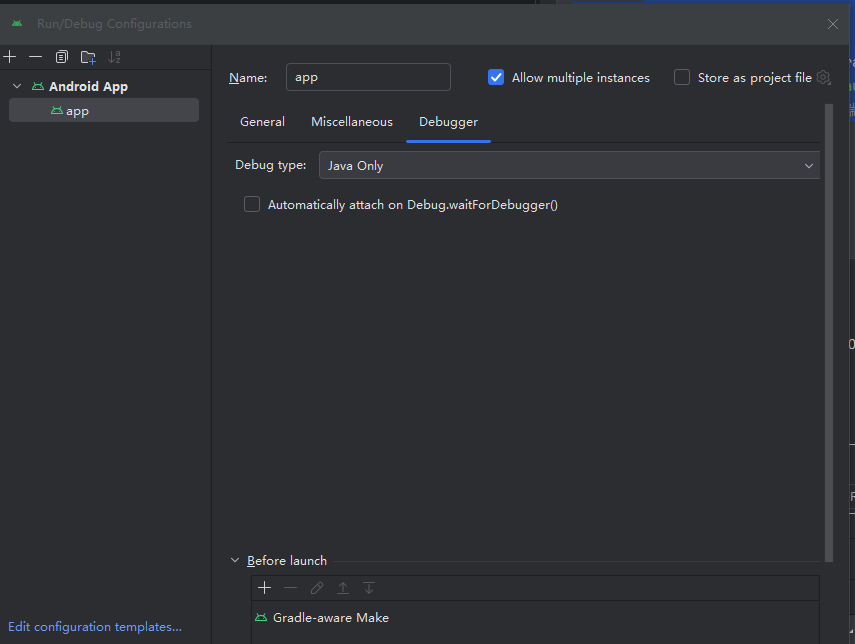
android studio debug调试出现 IOException异常
解决Android调试端口无法打开的问题,出现"Unable to open debugger port"错误时,可以进入app设置,选择Debugger选项,将Debug type更改为Java Only模式。这个方法适用于Android Studio调试时遇到的端口连接问题ÿ…...

PySpark 中使用 SQL 语句和表进行计算
PySpark 中使用 SQL 语句和表进行计算 PySpark 完全支持使用 SQL 语句和表进行 Spark 计算。以下是几种常见的使用方式: 1. 使用 Spark SQL from pyspark.sql import SparkSession# 创建 SparkSession spark SparkSession.builder.appName("SQLExample&quo…...

[Python] Python中的多重继承
文章目录 Lora中的例子 Lora中的例子 https://github.com/michaelnny/QLoRA-LLM/blob/main/qlora_llm/models/lora.py#L211C1-L243C10如果继承两个父类,并且父类的__init__参数不一样,则可以显式的调用父类init;如果用super().__init__()则需…...
中安装 pythonnet 和 .NET Core 的完整指南)
在 RedHat 系统(RHEL 7/8/9)中安装 pythonnet 和 .NET Core 的完整指南
1. 安装 .NET Core SDK RHEL 8/9(推荐) bash # 添加微软仓库 sudo rpm -Uvh https://packages.microsoft.com/config/rhel/8/packages-microsoft-prod.rpm# 安装 .NET 8 SDK(包含运行时) sudo dnf install -y dot…...
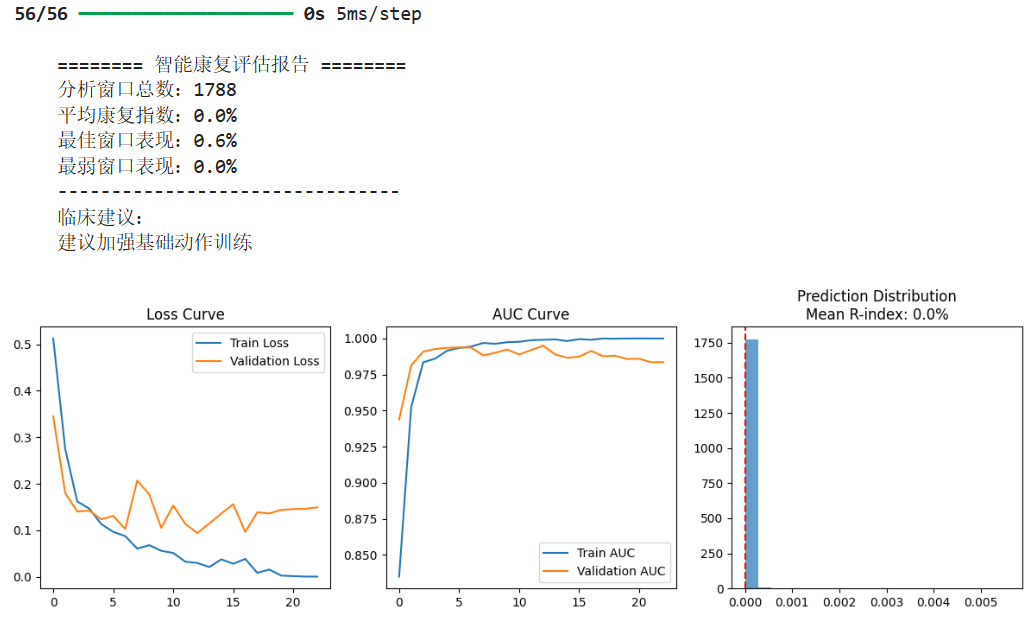
vr中风--数据处理模型搭建与训练
# -*- coding: utf-8 -*- """ MUSED-I康复评估系统(增强版) 包含:多通道sEMG数据增强、混合模型架构、标准化处理 """ import numpy as np import pandas as pd from sklearn.model_selection import train_te…...