打卡day42
DAY 42 Grad-CAM与Hook函数
知识点回顾
- 回调函数
- lambda函数
- hook函数的模块钩子和张量钩子
- Grad-CAM的示例
作业:理解下今天的代码即可
1、回调函数
回调函数(Callback Function)是一种特殊的函数,它作为参数传递给另一个函数,然后在那个函数内部被调用执行。简单来说,回调函数就是 "被别人调用的函数"。
回调函数的核心价值在于:
解耦逻辑:将通用逻辑与特定处理逻辑分离,使代码更模块化。
事件驱动编程:在异步操作、事件监听(如点击按钮、网络请求完成)等场景中广泛应用。
延迟执行:允许在未来某个时间点执行特定代码,而不必立即执行。
# 定义一个回调函数
def handle_result(result):"""处理计算结果的回调函数"""print(f"计算结果是: {result}")# 定义一个接受回调函数的函数
def calculate(a, b, callback): # callback是一个约定俗成的参数名"""这个函数接受两个数值和一个回调函数,用于处理计算结果。执行计算并调用回调函数"""result = a + bcallback(result) # 在计算完成后调用回调函数# 使用回调函数
calculate(3, 5, handle_result) # 输出: 计算结果是: 82、lambda函数
lambda函数,它是一种匿名函数(没有正式名称的函数),最大特点是用完即弃,无需提前命名和定义。它的语法形式非常简约,仅需一行即可完成定义,格式如下:
lambda 参数列表: 表达式
参数列表:可以是单个参数、多个参数或无参数
表达式:函数的返回值(无需 return 语句,表达式结果直接返回)
square=lambda a:a**2
print(square(4)) #输出:163、Hook函数
Hook 函数是一种回调函数,它可以在不干扰模型正常计算流程的情况下,插入到模型的特定位置,以便获取或修改中间层的输出或梯度。(这里的 "正常计算流程" 指的是前向传播和反向传播的整体执行顺序。)
3.1 模块钩子(Module Hooks)
模块钩子允许我们在模块的输入或输出经过时进行监听。PyTorch 提供了两种模块钩子:
register_forward_hook:在前向传播时监听模块的输入和输出
register_backward_hook:在反向传播时监听模块的输入梯度和输出梯度
3.1.1 前向钩子(Forward Hook)
前向钩子是一个函数,它会在模块的前向传播完成后立即被调用。这个函数可以访问模块的输入和输出,但不能修改它们。
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plttorch.manual_seed(42)
np.random.seed(42)# 定义一个简单的卷积神经网络
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()# 定义卷积层:输入通道1,输出通道2,卷积核3x3,填充1保持尺寸不变self.conv = nn.Conv2d(1, 2, kernel_size=3, padding=1)# 定义ReLU激活函数self.relu = nn.ReLU()# 定义全连接层:输入特征2*4*4,输出10分类self.fc = nn.Linear(2 * 4 * 4, 10)def forward(self, x):# 卷积层x = self.conv(x)# ReLU激活x = self.relu(x)# 展平x = x.view(-1,2*4*4)# 全连接层x = self.fc(x)return x# 创建模型实例
model = SimpleModel()# 创建一个列表用于存储中间层的输出
conv_outputs = []# 定义前向钩子函数 - 用于在模型前向传播过程中获取中间层信息
def forward_hook(module, input, output):"""前向钩子函数,会在模块每次执行前向传播后被自动调用参数:module: 当前应用钩子的模块实例input: 传递给该模块的输入张量元组output: 该模块产生的输出张量"""print(f"钩子被调用!模块类型: {type(module)}")print(f"输入形状: {input[0].shape}") # input是一个元组,对应 (image, label)print(f"输出形状: {output.shape}")# 保存卷积层的输出用于后续分析# 使用detach()避免追踪梯度,防止内存泄漏conv_outputs.append(output.detach())# 在卷积层注册前向钩子
# register_forward_hook返回一个句柄,用于后续移除钩子
hook_handle = model.conv.register_forward_hook(forward_hook) # 创建一个随机输入张量 (批次大小=1, 通道=1, 高度=4, 宽度=4)
x = torch.randn(1, 1, 4, 4)# 执行前向传播 - 此时会自动触发钩子函数
output = model(x)# 释放钩子 - 重要!防止在后续模型使用中持续调用钩子造成意外行为或内存泄漏
hook_handle.remove()# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 让我们可视化卷积层的输出
if conv_outputs:plt.figure(figsize=(10, 5))# 原始输入图像plt.subplot(1, 3, 1)plt.title('输入图像')plt.imshow(x[0, 0].detach().numpy(), cmap='gray') # 显示灰度图像# 第一个卷积核的输出plt.subplot(1, 3, 2)plt.title('卷积核1输出')plt.imshow(conv_outputs[0][0, 0].detach().numpy(), cmap='gray')# 第二个卷积核的输出plt.subplot(1, 3, 3)plt.title('卷积核2输出')plt.imshow(conv_outputs[0][0, 1].detach().numpy(), cmap='gray')plt.tight_layout()plt.show()3.1.2 反向钩子(Backward Hook)
反向钩子与前向钩子类似,但它是在反向传播过程中被调用的。反向钩子可以用来获取或修改梯度信息。
# 定义一个存储梯度的列表
conv_gradients = []# 定义反向钩子函数
def backward_hook(module, grad_input, grad_output):# 模块:当前应用钩子的模块# grad_input:模块输入的梯度# grad_output:模块输出的梯度print(f"反向钩子被调用!模块类型: {type(module)}")print(f"输入梯度数量: {len(grad_input)}")print(f"输出梯度数量: {len(grad_output)}")# 保存梯度供后续分析conv_gradients.append((grad_input, grad_output))# 在卷积层注册反向钩子
hook_handle = model.conv.register_backward_hook(backward_hook)# 创建一个随机输入并进行前向传播
x = torch.randn(1, 1, 4, 4, requires_grad=True)
output = model(x)# 定义一个简单的损失函数并进行反向传播
loss = output.sum()
loss.backward()# 释放钩子
hook_handle.remove()3.2 张量钩子(Tensor Hook)
PyTorch 还提供了张量钩子,允许我们直接监听和修改张量的梯度。张量钩子有两种:
register_hook:用于监听张量的梯度
register_full_backward_hook:用于在完整的反向传播过程中监听张量的梯度(PyTorch 1.4+)
# 创建一个需要计算梯度的张量
x = torch.tensor([2.0], requires_grad=True)
y = x ** 2
z = y ** 3# 定义一个钩子函数,用于修改梯度
def tensor_hook(grad):print(f"原始梯度: {grad}")# 修改梯度,例如将梯度减半return grad / 2# 在y上注册钩子
hook_handle = y.register_hook(tensor_hook)# 计算梯度
z.backward()print(f"x的梯度: {x.grad}")# 释放钩子
hook_handle.remove()4、Grad-CAM的示例
Grad-CAM (Gradient-weighted Class Activation Mapping) 算法是一种强大的可视化技术,用于解释卷积神经网络 (CNN) 的决策过程。它通过计算特征图的梯度来生成类激活映射(Class Activation Mapping,简称 CAM ),直观地显示图像中哪些区域对模型的特定预测贡献最大。
Grad-CAM 的核心思想是:通过反向传播得到的梯度信息,来衡量每个特征图对目标类别的重要性。
1. 梯度信息:通过计算目标类别对特征图的梯度,得到每个特征图的重要性权重。
2. 特征加权:用这些权重对特征图进行加权求和,得到类激活映射。
3. 可视化:将激活映射叠加到原始图像上,高亮显示对预测最关键的区域。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image# 设置随机种子确保结果可复现
# 在深度学习中,随机种子可以让每次运行代码时,模型初始化参数、数据打乱等随机操作保持一致,方便调试和对比实验结果
torch.manual_seed(42)
np.random.seed(42)# 加载CIFAR-10数据集
# 定义数据预处理步骤,先将图像转换为张量,再进行归一化操作
# 归一化的均值和标准差是(0.5, 0.5, 0.5),这里的均值和标准差是对CIFAR-10数据集的经验值,使得数据分布更有利于模型训练
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])# 加载测试集,指定数据集根目录为'./data',设置为测试集(train=False),如果数据不存在则下载(download=True),并应用上述定义的预处理
testset = torchvision.datasets.CIFAR10(root='./cifar_data', train=False,download=True, transform=transform
)# 定义类别名称,CIFAR-10数据集包含这10个类别
classes = ('飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车')# 定义一个简单的CNN模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 第一个卷积层,输入通道为3(彩色图像),输出通道为32,卷积核大小为3x3,填充为1以保持图像尺寸不变self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)# 第二个卷积层,输入通道为32,输出通道为64,卷积核大小为3x3,填充为1self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)# 第三个卷积层,输入通道为64,输出通道为128,卷积核大小为3x3,填充为1self.conv3 = nn.Conv2d(64, 128, kernel_size=3, padding=1)# 最大池化层,池化核大小为2x2,步长为2,用于下采样,减少数据量并提取主要特征self.pool = nn.MaxPool2d(2, 2)# 第一个全连接层,输入特征数为128 * 4 * 4(经过前面卷积和池化后的特征维度),输出为512self.fc1 = nn.Linear(128 * 4 * 4, 512)# 第二个全连接层,输入为512,输出为10(对应CIFAR-10的10个类别)self.fc2 = nn.Linear(512, 10)def forward(self, x):# 第一个卷积层后接ReLU激活函数和最大池化操作,经过池化后图像尺寸变为原来的一半,这里输出尺寸变为16x16x = self.pool(F.relu(self.conv1(x))) # 第二个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为8x8x = self.pool(F.relu(self.conv2(x))) # 第三个卷积层后接ReLU激活函数和最大池化操作,输出尺寸变为4x4x = self.pool(F.relu(self.conv3(x))) # 将特征图展平为一维向量,以便输入到全连接层x = x.view(-1, 128 * 4 * 4)# 第一个全连接层后接ReLU激活函数x = F.relu(self.fc1(x))# 第二个全连接层输出分类结果x = self.fc2(x)return x# 初始化模型
model = SimpleCNN()
print("模型已创建")# 如果有GPU则使用GPU,将模型转移到对应的设备上
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device)# 训练模型(简化版,实际应用中应该进行完整训练)
def train_model(model, epochs=1):# 加载训练集,指定数据集根目录为'./data',设置为训练集(train=True),如果数据不存在则下载(download=True),并应用前面定义的预处理trainset = torchvision.datasets.CIFAR10(root='./cifar_data', train=True,download=True, transform=transform)# 创建数据加载器,设置批量大小为64,打乱数据顺序(shuffle=True),使用2个线程加载数据trainloader = torch.utils.data.DataLoader(trainset, batch_size=64,shuffle=True, num_workers=2)# 定义损失函数为交叉熵损失,用于分类任务criterion = nn.CrossEntropyLoss()# 定义优化器为Adam,用于更新模型参数,学习率设置为0.001optimizer = torch.optim.Adam(model.parameters(), lr=0.001)for epoch in range(epochs):running_loss = 0.0for i, data in enumerate(trainloader, 0):# 从数据加载器中获取图像和标签inputs, labels = data# 将图像和标签转移到对应的设备(GPU或CPU)上inputs, labels = inputs.to(device), labels.to(device)# 清空梯度,避免梯度累加optimizer.zero_grad()# 模型前向传播得到输出outputs = model(inputs)# 计算损失loss = criterion(outputs, labels)# 反向传播计算梯度loss.backward()# 更新模型参数optimizer.step()running_loss += loss.item()if i % 100 == 99:# 每100个批次打印一次平均损失print(f'[{epoch + 1}, {i + 1}] 损失: {running_loss / 100:.3f}')running_loss = 0.0print("训练完成")# 训练模型(可选,如果有预训练模型可以加载)
# 取消下面这行的注释来训练模型
# train_model(model, epochs=1)# 或者尝试加载预训练模型(如果存在)
try:# 尝试加载名为'cifar10_cnn.pth'的模型参数model.load_state_dict(torch.load('cifar10_cnn.pth'))print("已加载预训练模型")
except:print("无法加载预训练模型,使用未训练模型或训练新模型")# 如果没有预训练模型,可以在这里调用train_model函数train_model(model, epochs=1)# 保存训练后的模型参数torch.save(model.state_dict(), 'cifar10_cnn.pth')# 设置模型为评估模式,此时模型中的一些操作(如dropout、batchnorm等)会切换到评估状态
model.eval()# Grad-CAM实现
class GradCAM:def __init__(self, model, target_layer):self.model = modelself.target_layer = target_layerself.gradients = Noneself.activations = None# 注册钩子,用于获取目标层的前向传播输出和反向传播梯度self.register_hooks()def register_hooks(self):# 前向钩子函数,在目标层前向传播后被调用,保存目标层的输出(激活值)def forward_hook(module, input, output):self.activations = output.detach()# 反向钩子函数,在目标层反向传播后被调用,保存目标层的梯度def backward_hook(module, grad_input, grad_output):self.gradients = grad_output[0].detach()# 在目标层注册前向钩子和反向钩子self.target_layer.register_forward_hook(forward_hook)self.target_layer.register_backward_hook(backward_hook)def generate_cam(self, input_image, target_class=None):# 前向传播,得到模型输出model_output = self.model(input_image)if target_class is None:# 如果未指定目标类别,则取模型预测概率最大的类别作为目标类别target_class = torch.argmax(model_output, dim=1).item()# 清除模型梯度,避免之前的梯度影响self.model.zero_grad()# 反向传播,构造one-hot向量,使得目标类别对应的梯度为1,其余为0,然后进行反向传播计算梯度one_hot = torch.zeros_like(model_output)one_hot[0, target_class] = 1model_output.backward(gradient=one_hot)# 获取之前保存的目标层的梯度和激活值gradients = self.gradientsactivations = self.activations# 对梯度进行全局平均池化,得到每个通道的权重,用于衡量每个通道的重要性weights = torch.mean(gradients, dim=(2, 3), keepdim=True)# 加权激活映射,将权重与激活值相乘并求和,得到类激活映射的初步结果cam = torch.sum(weights * activations, dim=1, keepdim=True)# ReLU激活,只保留对目标类别有正贡献的区域,去除负贡献的影响cam = F.relu(cam)# 调整大小并归一化,将类激活映射调整为与输入图像相同的尺寸(32x32),并归一化到[0, 1]范围cam = F.interpolate(cam, size=(32, 32), mode='bilinear', align_corners=False)cam = cam - cam.min()cam = cam / cam.max() if cam.max() > 0 else camreturn cam.cpu().squeeze().numpy(), target_classimport warnings
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 选择一个随机图像
# idx = np.random.randint(len(testset))
idx = 102 # 选择测试集中的第101张图片 (索引从0开始)
image, label = testset[idx]
print(f"选择的图像类别: {classes[label]}")# 转换图像以便可视化
def tensor_to_np(tensor):img = tensor.cpu().numpy().transpose(1, 2, 0)mean = np.array([0.5, 0.5, 0.5])std = np.array([0.5, 0.5, 0.5])img = std * img + meanimg = np.clip(img, 0, 1)return img# 添加批次维度并移动到设备
input_tensor = image.unsqueeze(0).to(device)# 初始化Grad-CAM(选择最后一个卷积层)
grad_cam = GradCAM(model, model.conv3)# 生成热力图
heatmap, pred_class = grad_cam.generate_cam(input_tensor)# 可视化
plt.figure(figsize=(12, 4))# 原始图像
plt.subplot(1, 3, 1)
plt.imshow(tensor_to_np(image))
plt.title(f"原始图像: {classes[label]}")
plt.axis('off')# 热力图
plt.subplot(1, 3, 2)
plt.imshow(heatmap, cmap='jet')
plt.title(f"Grad-CAM热力图: {classes[pred_class]}")
plt.axis('off')# 叠加的图像
plt.subplot(1, 3, 3)
img = tensor_to_np(image)
heatmap_resized = np.uint8(255 * heatmap)
heatmap_colored = plt.cm.jet(heatmap_resized)[:, :, :3]
superimposed_img = heatmap_colored * 0.4 + img * 0.6
plt.imshow(superimposed_img)
plt.title("叠加热力图")
plt.axis('off')plt.tight_layout()
plt.savefig('grad_cam_result.png')
plt.show()# print("Grad-CAM可视化完成。已保存为grad_cam_result.png")@浙大疏锦行
相关文章:

打卡day42
DAY 42 Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 1、回调函数 回调函数(Callback Function)是一种特殊的函数,它作为参数传递给另一个函数&am…...

小白的进阶之路系列之八----人工智能从初步到精通pytorch综合运用的讲解第一部分
PyTorch Tensors 通过大量实例学习编程应用是最有效的方法。 本篇是PyTorch综合运用,旨在让读者通过一行行代码亲自掌握Pytorch工具包的各种功能,有利于大家部署自己的神经网络人工智能计算工程。 首先,载入torch库。 import torch我们来看看一些基本的张量操作。首先,…...

724.寻找数组的中心下标前缀和
题目链接: https://leetcode.cn/problems/find-pivot-index/ 这道题目我们可以使用暴力解法,就一个下标前数组之和,再求一个下标后数组之和,时间复杂度达到n方,我们来写一下: int pivotIndex(vector<in…...
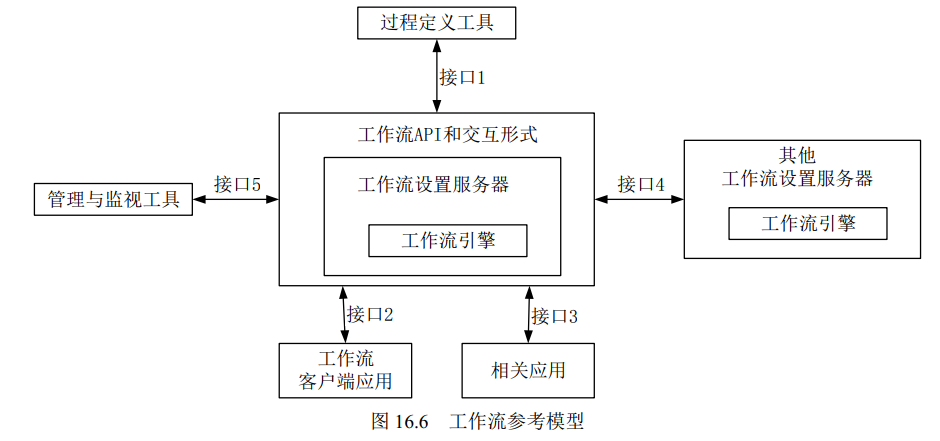
软考-系统架构设计师-第十六章 层次式架构设计理论与实践
层次式架构设计理论与实践 16.2 表现层框架设计16.3 中间层框架设计16.4 数据访问层设计16.5 数据架构规划与设计16.6 物联网层次架构设计 软件体系结构为软件系统提供了结构、行为和属性的高级抽象,由构成系统的元素描述这些元素的相互作用、指导元素集成的模式以及…...

甘特图 dhtmlxGantt.js UA实例
摘要:本文介绍了一个基于AngularJS的排产资源占用甘特图系统,包含前端界面展示和后端控制逻辑。系统通过HTML模板实现甘特图展示区域、查询条件表单和数据绑定,使用JavaScript控制器处理数据查询、甘特图初始化和交互逻辑。主要功能包括&…...

Docker学习笔记:基础知识
本文是自己的学习笔记 1、什么是Docker2、Docker的架构设计2.1、镜像(Image)2.2、容器(Container)2.3、仓库(Repository)2.4、Docker使用场景案例 1、什么是Docker Docker是基于Go语言实现的云开源项目。它的角色是作…...

5.2 初识Spark Streaming
在本节实战中,我们初步探索了Spark Streaming,它是Spark的流式数据处理子框架,具备高吞吐量、可伸缩性和强容错能力。我们了解了Spark Streaming的基本概念和运行原理,并通过两个案例演示了如何利用Spark Streaming实现词频统计。…...

uv:一个现代化的 Python 依赖管理工具
在 Python 的生态系统中,依赖管理和 Python 版本管理一直是开发者关注的核心问题。传统的工具如 pip、poetry 和 pyenv 虽然功能强大,但在性能和使用体验上仍有改进空间。uv 是由 Python 核心开发者开发的 现代化依赖管理工具,旨在提供更快、…...
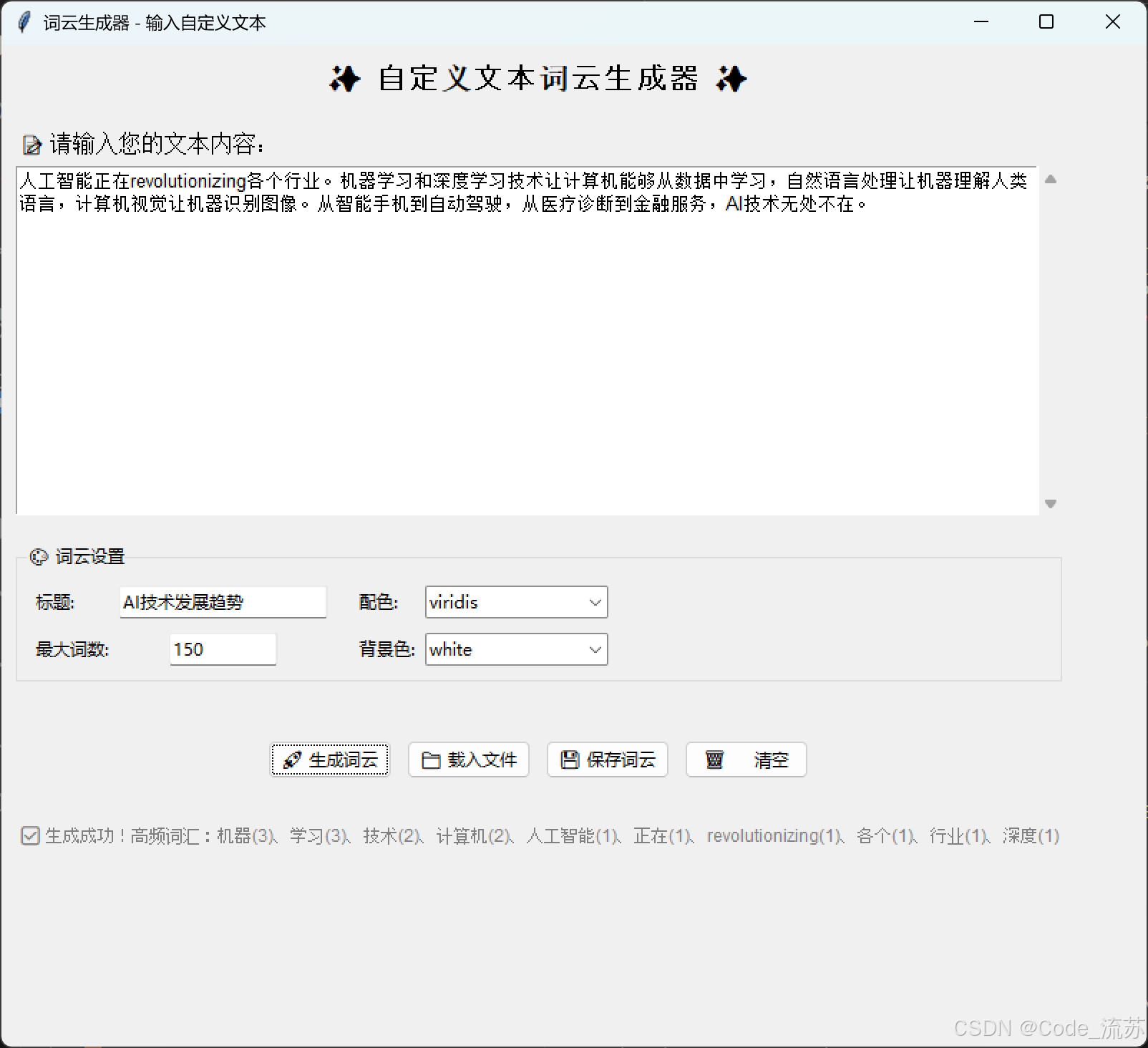
Python趣学篇:交互式词云生成器(jieba + Tkinter + WordCloud等)
名人说:路漫漫其修远兮,吾将上下而求索。—— 屈原《离骚》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、为什么要做词云?让文字"活"起来!二、核心…...
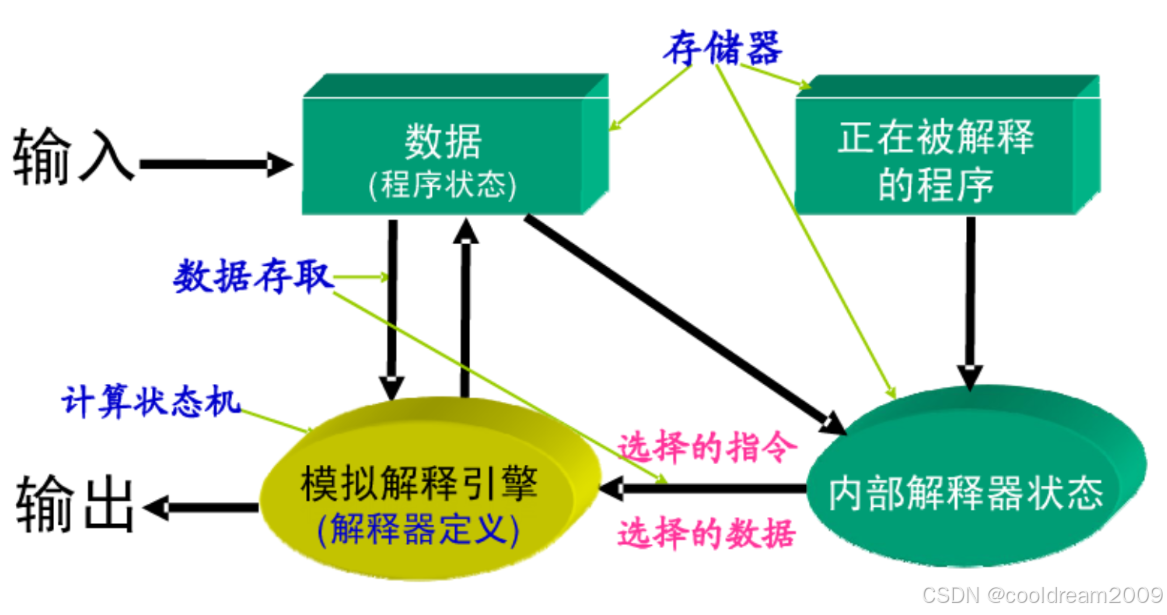
理解解释器架构:原理、组成与运行机制全解析
目录 前言1. 什么是解释器架构2. 解释器的基本组成2.1 被解释执行的程序2.2 解释器引擎2.3 解释器内部状态2.4 程序执行的当前状态2.5 存储器模型 3. 解释器的工作原理3.1 解析源代码3.2 初始化运行环境3.3 逐条执行语法结构3.4 维护程序状态3.5 内存管理与变量作用域 4. 举例&…...
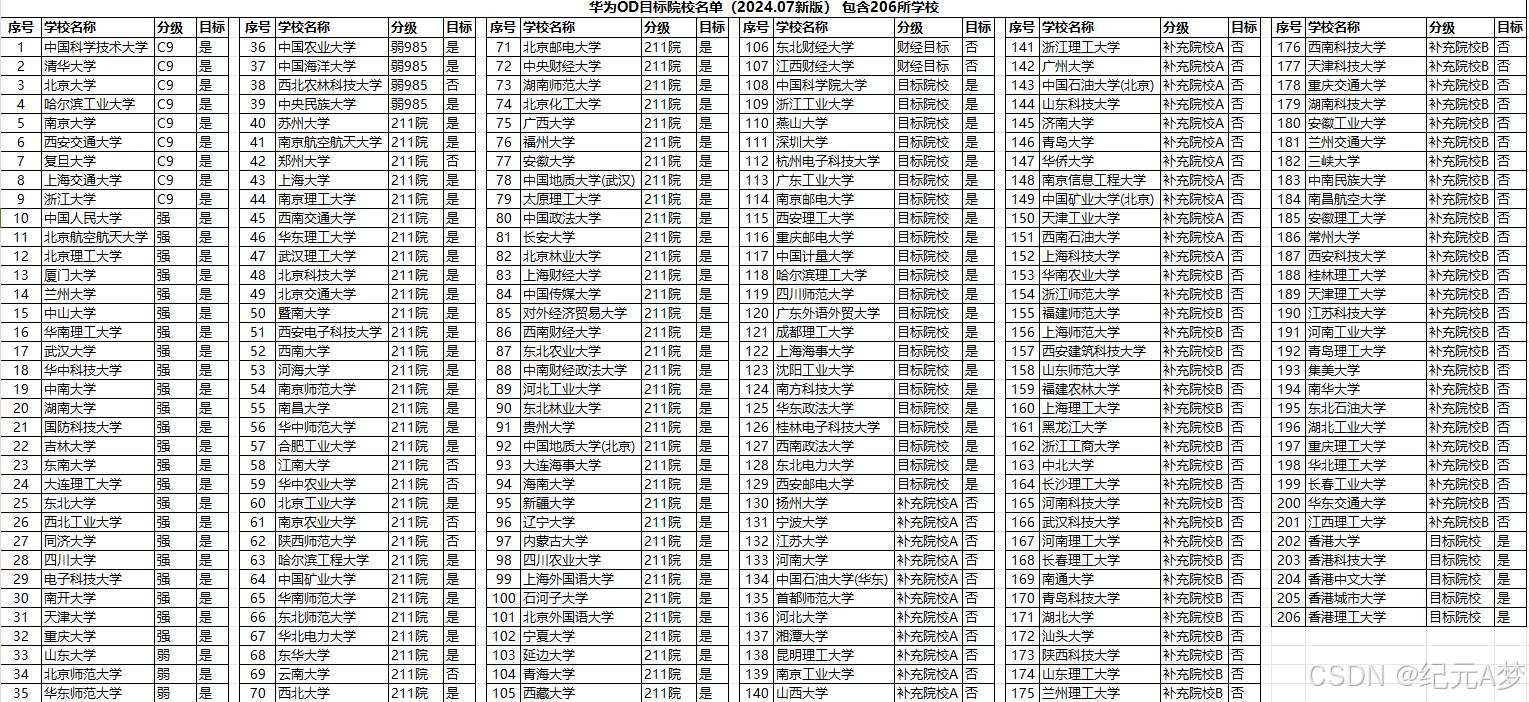
2025华为OD机试真题+全流程解析+备考攻略+经验分享+Java/python/JavaScript/C++/C/GO六种语言最佳实现
华为OD全流程解析,备考攻略 快捷目录 华为OD全流程解析,备考攻略一、什么是华为OD?二、什么是华为OD机试?三、华为OD面试流程四、华为OD薪资待遇及职级体系五、ABCDE卷类型及特点六、题型与考点七、机试备考策略八、薪资与转正九、…...

Python应用for循环临时变量作用域
大家好!如果你刚开始学习Python,可能会对for循环中临时变量的作用域感到好奇。下面通过一个简单的练习,帮助你理解这个概念。 代码呈现: i 0 for i in range(5):print(i)print(i)代码介绍: 首先我们初始化变量i 0然后进入for循环,这里i成为…...
设计模式——桥接设计模式(结构型)
摘要 桥接设计模式是一种结构型设计模式,用于将抽象与实现解耦,使二者可以独立变化。它通过将一个类拆分为“抽象”和“实现”两部分,并通过桥接关系组合,避免了类继承层次结构过于庞大。桥接模式包含抽象类、扩充抽象类、实现类…...

LLaDa——基于 Diffusion 的大语言模型 打平 LLama 3
这里分享一篇文章《Large Language Diffusion Models》,来自人民大学高领人工智能学院,一篇尝试改变传统自回归范(预测下一个token) LLM 架构,探索扩散模型在 LLM 上的作用,通过随机掩码-预测逆向思维&…...

Apache SeaTunnel部署技术详解:模式选择、技巧与最佳实践
Apache SeaTunnel(原Waterdrop)作为高性能、分布式数据集成平台,支持海量数据的离线与实时同步。其灵活多样的部署模式可适配不同规模的生产环境需求。本文将系统解析SeaTunnel的部署架构、技术要点及最佳实践,帮助用户高效构建稳…...

2. 数据结构基本概念 (2)
本文部分ppt、视频截图来自:[青岛大学-王卓老师的个人空间-王卓老师个人主页-哔哩哔哩视频] 1. 数据结构基本概念 1.1 数据类型和抽象数据类型 (1) 数据类型(Data Type) 概念 数据类型是一组性质相同的值的集合以及定义于这个值集合上的一组操作的总称。 在使用…...

鸿蒙5.0+ 多协议设备发现与分布式软总线技术实践
一、技术演进与架构升级 1.1 多协议发现机制演进 鸿蒙5.0重构设备发现层,支持三模异构发现: 经典蓝牙(BLE 5.2):低功耗设备发现Wi-Fi Aware:高带宽设备预连接PLC࿰…...
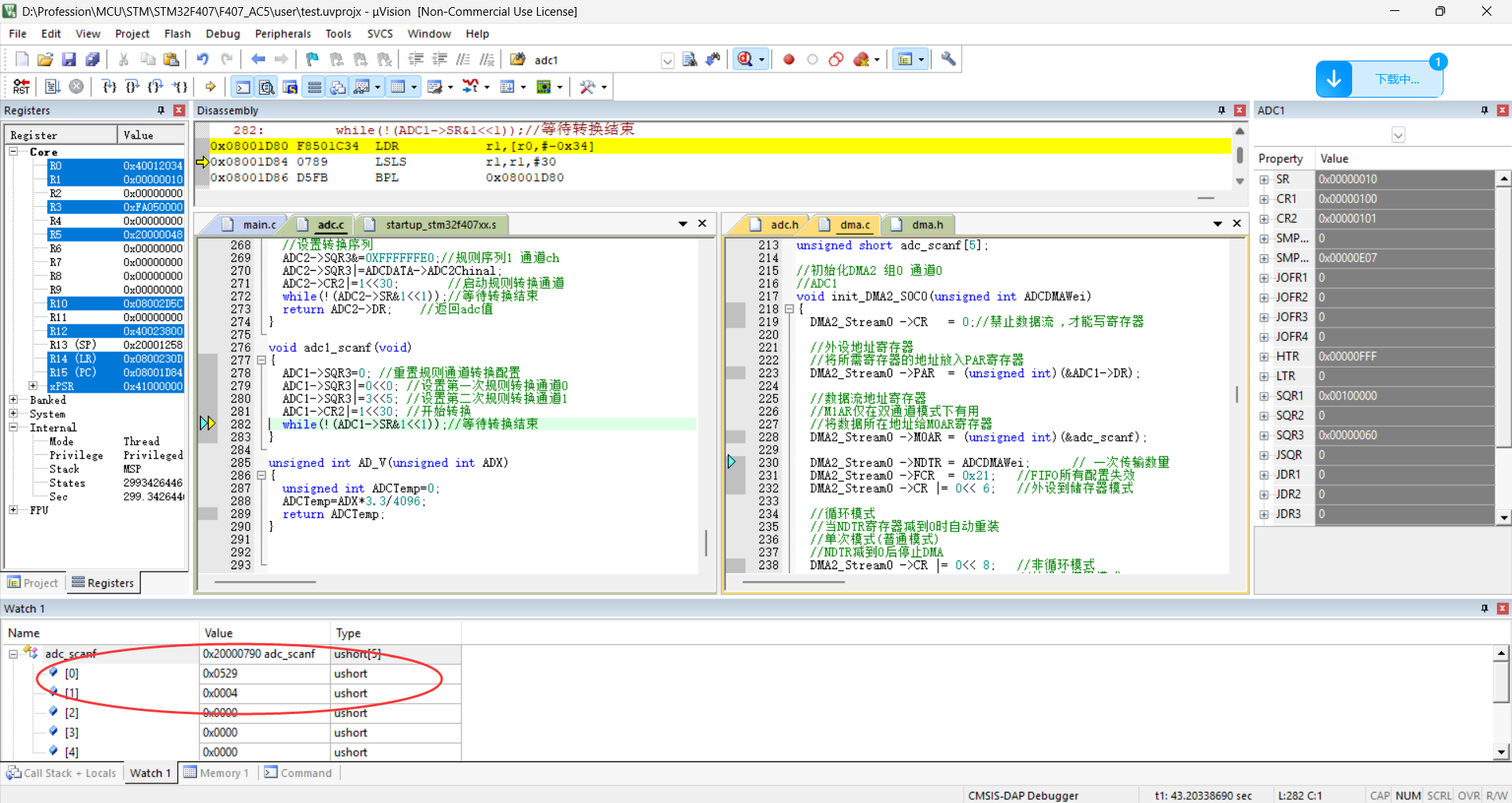
STM32F407寄存器操作(多通道单ADC+DMA)
1.前言 又是半年没更新了,趁着端午放假有点时间,并且最近项目要用这块知识,我就顺带研究一下ADC吧。 一般来说ADC主要用法包含了1.单通道软件触发(这是最简单和最常用的用法)2.单通道多次采集(需要快速采…...
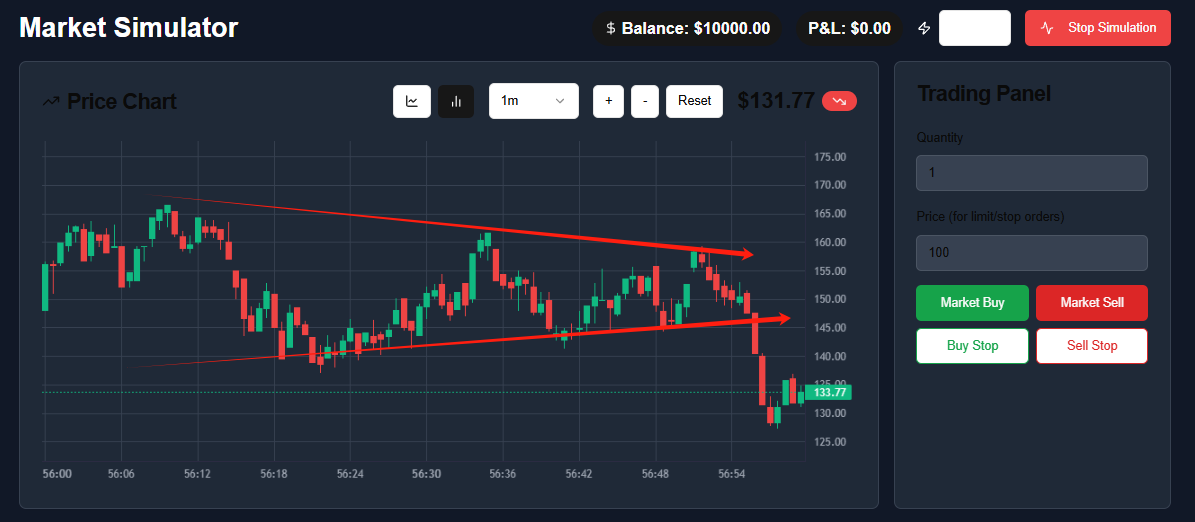
基于React和TypeScript的金融市场模拟器开发与模式分析
基于React和TypeScript的金融市场模拟器开发与模式分析 项目概述 本项目开发了一个基于React和TypeScript的金融市场模拟器,通过模拟订单流和价格发现机制,重现了真实市场的动态特性。该模拟器不仅提供了实时价格图表、订单簿和交易功能,还…...

剑指offer13_剪绳子
剪绳子 给你一根长度为 n 绳子,请把绳子剪成 m 段(m、n都是整数,2≤n≤58 并且 m≥2)。 每段的绳子的长度记为 k[1]、k[2]、……、k[m]。 k[1]k[2]…k[m] 可能的最大乘积是多少? 例如当绳子的长度是 8 时࿰…...

reverse_ssh 建立反向 SSH 连接指南 混淆AV [好东西哟]
目录 🌐 工具简介 ⚙️ 前提条件 攻击主机 (Linux) 目标主机 (Windows) 📋 详细步骤 步骤 1:安装 Go 环境 步骤 2:安装必要依赖 步骤 3:下载并编译 reverse_ssh 步骤 4:配置密钥 步骤 5ÿ…...
)
vue+elementUi+axios实现分页(MyBatis、Servlet)
vueelementUiaxios实现分页 文章目录 vueelementUiaxios实现分页1.代码实现【HTML】**【Servlet层】****【Service层】****【Dao层】** 2.总结步骤3.实现要点4.注意事项4.注意事项 注:此项目 前端为 html、 后端采用 mybatis、servlet实现 1.代码实现 【HTML】…...

WebBuilder数据库:企业数据管理的能力引擎
在数据成为核心生产要素的时代,企业对数据库的需求早已超越“存储与查询”的基础功能,转而追求高性能、高安全、高兼容与高效开发的综合能力。WebBuilder作为企业级快速开发平台的佼佼者,其数据库能力正式破解数据管理难题的关键钥匙。本文将…...

QtWidgets,QtCore,QtGui
目录 三者的关系示例代码主要功能模块QtCore**一、核心功能与常用类****1. 信号与槽机制(Signals and Slots)****2. 事件处理(Event Handling)****3. 定时器(Timers)****4. 线程(Threading)****5. 文件与目录操作****6. 属性系统(Property System)****二、高级特性**…...
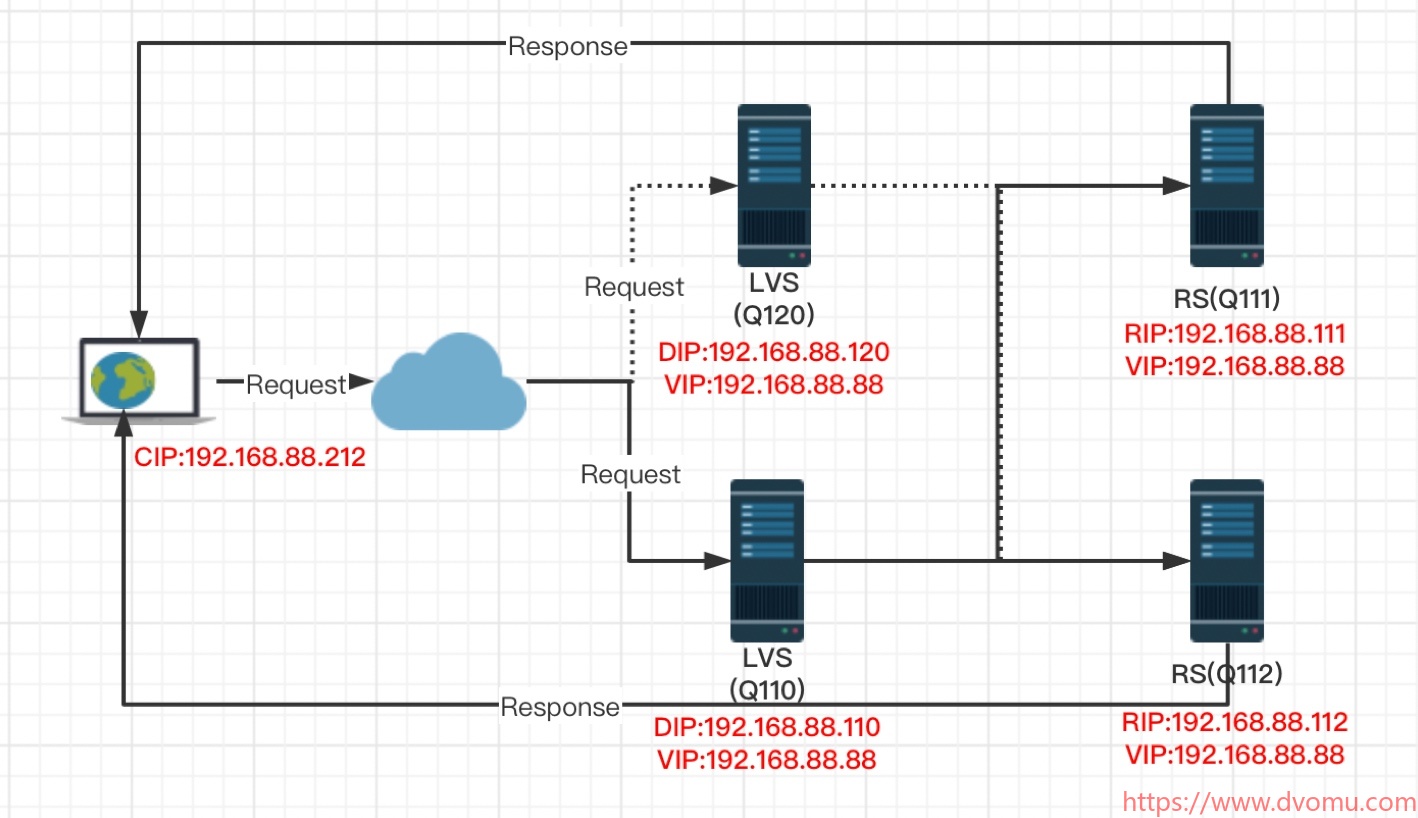
lvs-keepalived高可用群集
目录 1.Keepalived 概述及安装 1.1 Keepalived 的热备方式 1.2 keepalived的安装与服务控制 (1)安装keep alived (2)控制 Keepalived 服务DNF 安装 keepalived 后,执行以下命令将keepalived 服务设置为开机启动。 2.使用 Keepalived 实现双机热备 …...

【Elasticsearch】suggest
在Elasticsearch中,suggest 是一个非常强大的功能,用于实现自动补全、拼写纠错和模糊搜索等功能。它可以帮助用户更快地找到他们想要的内容,同时提升搜索体验。以下是关于 suggest 的详细使用方法和常见场景。 1\. Suggest 的基本概念 sugges…...
高速收发器
一、高速收发器 1.FPGA高速收发器:GTP,GTX,GTH,GTZ 2.每个Quad有4对高速收发器GT(4个TX和4个RX)和一个COmmon 3.走差分,提高抗干扰性 4.CPLL是每个lane私有的,QPLL是整个Quad的所有通道共享的 5.每个MGT的bank有两对差分参考时钟 6.CPLL的时钟…...

webpack的安装及其后序部分
npm install原理 这个其实就是npm从registry下载项目到本地,没有什么好说的 值得一提的是npm的缓存机制,如果多个项目都需要同一个版本的axios,每一次重新从registry中拉取的成本过大,所以会有缓存,如果缓存里有这个…...

如何利用自动生成文档工具打造出色的技术文档
文章目录 每日一句正能量前言一、自动生成文档工具的优势(一)提高效率(二)保持一致性(三)实时更新 二、常见的自动生成文档工具(一)Sphinx(二)Javadoc&#x…...
:深入理解Go语言的程序结构)
读《Go语言圣经记录》(二):深入理解Go语言的程序结构
读《Go语言圣经记录》(二):深入理解Go语言的程序结构 在编程的世界里,Go语言以其简洁、高效和强大的并发能力而备受开发者青睐。今天,我将带大家深入探索Go语言的程序结构,通过详细解读《Go语言圣经》中的…...