MongoDB(七) - MongoDB副本集安装与配置
文章目录
- 前言
- 一、下载MongoDB
- 1. 下载MongoDB
- 2. 上传安装包
- 3. 创建相关目录
- 二、安装配置MongoDB
- 1. 解压MongoDB安装包
- 2. 重命名MongoDB文件夹名称
- 3. 修改配置文件
- 4. 分发MongoDB文件夹
- 5. 配置环境变量
- 6. 启动副本集
- 7. 进入MongoDB客户端
- 8. 初始化副本集
- 8.1 初始化副本集
- 8.2 添加副本节点
- 三、副本集操作
- 1. 副本集状态介绍
- 2. 查看副本集成员状态
- 3. 数据同步
- 3.1 启用数据同步
- 3.2 测试数据同步
- 4. 故障转移
- 4.1 终止hadoop1的MongoDB的主节点进程
- 4.2 查看从节点是否有一个自动转为主节点
- 5. 配置副本集成员
- 5.1 调整副本集成员的优先级
- 5.2 配置隐藏节点
- 5.3 配置延迟节点
- 5.4 配置副本集成员投票权
- 5.5 将副本节点转为仲裁节点
前言
本文详细介绍了在Linux环境下安装和配置MongoDB副本集的完整流程。主要内容包括:下载MongoDB安装包并上传至服务器;创建必要的数据和日志目录;解压安装包并配置mongod.conf文件;分发MongoDB到集群节点;配置环境变量;启动副本集服务;以及初始化副本集并添加节点。通过图文并茂的方式展示了每个操作步骤的执行过程和验证方法,最终实现了包含hadoop1(主节点)、hadoop2和hadoop3(副本节点)的三节点MongoDB副本集环境。
一、下载MongoDB
1. 下载MongoDB
MongoDB安装包下载地址:https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel70-5.0.30.tgz
2. 上传安装包
通过拖移的方式将下载的MongoDB安装包mongodb-linux-x86_64-rhel70-5.0.30.tgz上传至虚拟机hadoop1的/export/software目录。
3. 创建相关目录
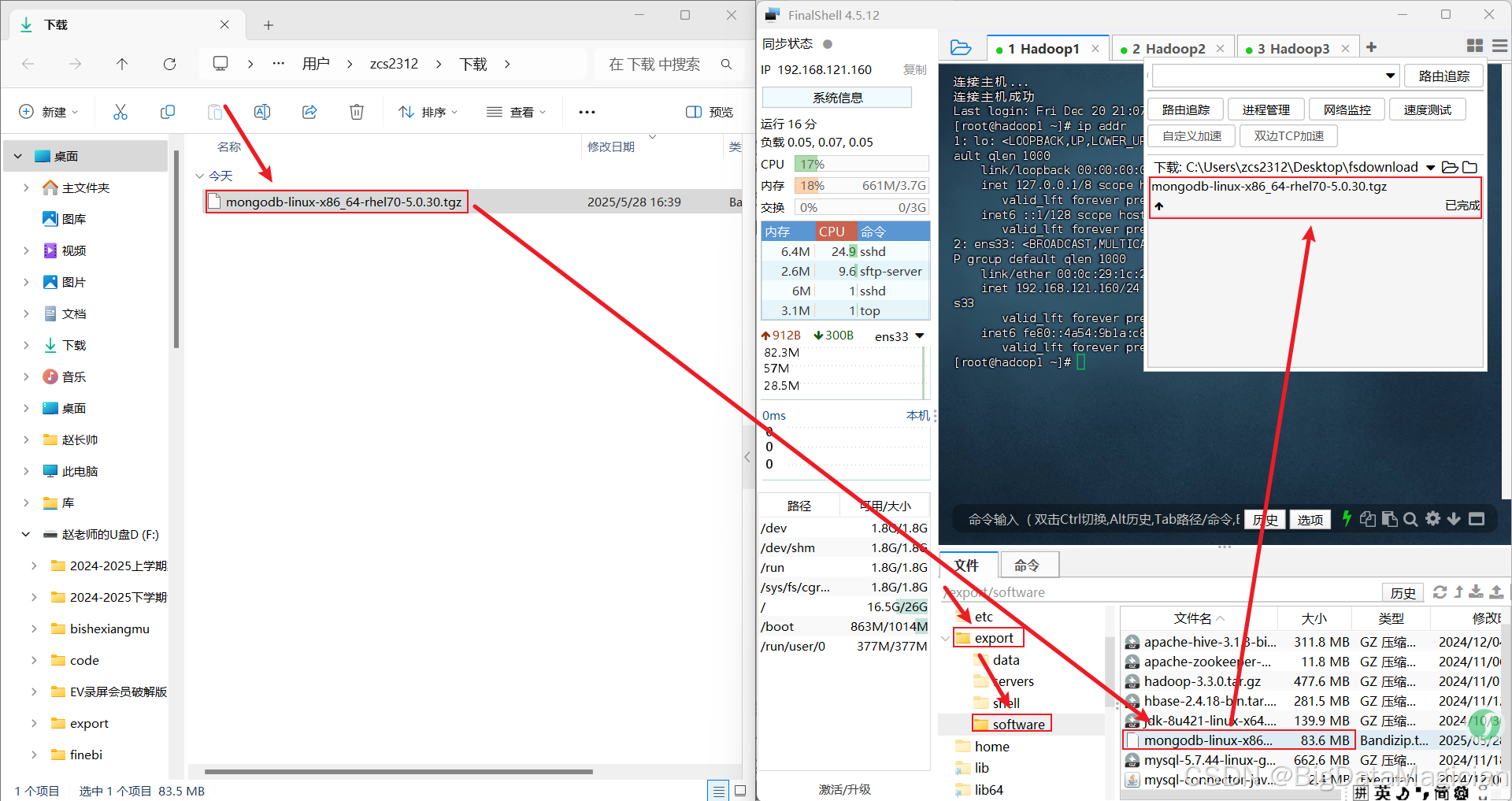
目录/export/data/mongodb/data用于存放副本数据,目录/export/data/mongodb/logs用于存放副本集日志,文件/export/data/mongodb/logs/mongodb.log用于保存日志,MongoDB的数据目录和日志目录不会自动创建,需要手动创建。分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令创建相关目录。
mkdir -p /export/data/mongodb/data
mkdir -p /export/data/mongodb/logs
touch /export/data/mongodb/logs/mongodb.log
二、安装配置MongoDB
1. 解压MongoDB安装包
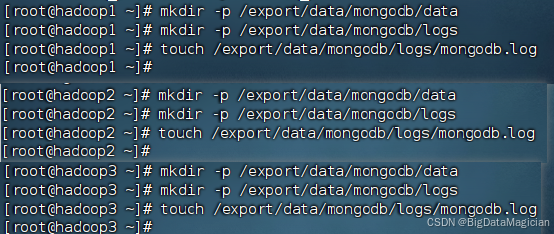
在虚拟机hadoop1上将MongoDB安装包解压至/export/servers目录。
tar -zxvf /export/software/mongodb-linux-x86_64-rhel70-5.0.30.tgz -C /export/servers/
解压完成如下图所示。
2. 重命名MongoDB文件夹名称
把MongoDB文件夹名称按标准命名方式(软件名-版本号)重命名。
mv /export/servers/mongodb-linux-x86_64-rhel70-5.0.30/ /export/servers/mongodb-5.0.30

3. 修改配置文件
参数映射说明
| 命令行参数 | 配置文件路径 | 说明 |
|---|---|---|
--port 27017 | net.port | MongoDB服务监听的端口 |
--bind_ip hadoop1 | net.bindIp | 监听的网络接口(主机名或IP) |
--dbpath=/export/... | storage.dbPath | 数据文件存储路径 |
--logpath=/export/... | systemLog.path | 日志文件路径 |
--logappend | systemLog.logAppend | 以追加模式写入日志(保留历史记录) |
--fork | processManagement.fork | 以守护进程模式运行(后台运行) |
--replSet bigdata_mongodb | replication.replSetName | 副本集名称 |
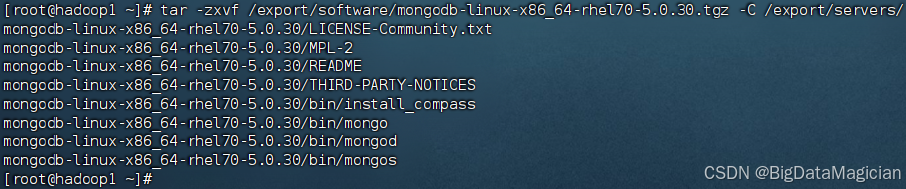
在虚拟机hadoop1执行如下命令创建配置文件目录,并向配置文件mongod.conf中添加配置内容。
mkdir -p /export/servers/mongodb-5.0.30/conf
cat >/export/servers/mongodb-5.0.30/conf/mongod.conf <<EOF
# 网络配置
net:port: 27017bindIp: 0.0.0.0
# 存储配置
storage:dbPath: /export/data/mongodb/data
# 日志配置
systemLog:destination: filepath: /export/data/mongodb/logs/mongodb.loglogAppend: true
# 进程配置
processManagement:fork: true
# 复制集配置
replication:replSetName: "bigdata_mongodb"
EOF
4. 分发MongoDB文件夹
把虚拟机hadoop1中的MongoDB文件夹复制到虚拟机hadoop2和hadoop3中。
scp -r /export/servers/mongodb-5.0.30/ root@hadoop2:/export/servers/
scp -r /export/servers/mongodb-5.0.30/ root@hadoop3:/export/servers/
5. 配置环境变量
分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令,向环境变量配置文件/etc/profile追加环境变量内容。配置环境变量后,需要加载环境变量配置文件/etc/profile,使用hadoop的环境变量生效。
echo >> /etc/profile
echo 'export MONGODB_HOME=/export/servers/mongodb-5.0.30' >> /etc/profile
echo 'export PATH=$PATH:$MONGODB_HOME/bin:$MONGODB_HOME/bin' >> /etc/profile
source /etc/profile
配置好环境变量后,分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令验证环境变量是否配置成功。
mongo --version
成功如下图所示。

6. 启动副本集
以副本集模式启动MongoDB,分别在虚拟机hadoop1、hadoop2和hadoop3执行如下命令启动MongoDB服务。
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf
7. 进入MongoDB客户端
在虚拟机hadoop1执行如下命令进入hadoop1的MongoDB客户端。
mongo --host hadoop1 --port 27017
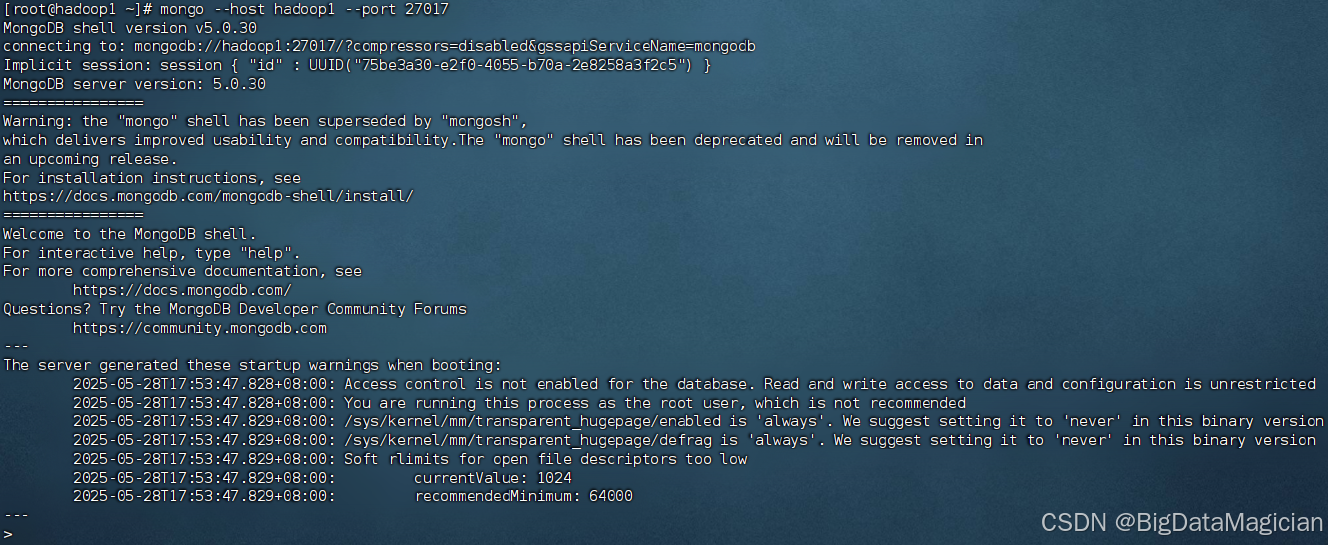
8. 初始化副本集
8.1 初始化副本集
在虚拟机hadoop1执行如下命令初始化副本集。
rs.initiate()
初始化成功如下图所示。

完成初始化后,节点默认处于SECONDARY(副本节点)状态,等待几秒后自动选举自己为PRLMARY(主节点),如下图所示。
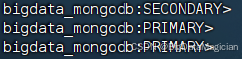
8.2 添加副本节点
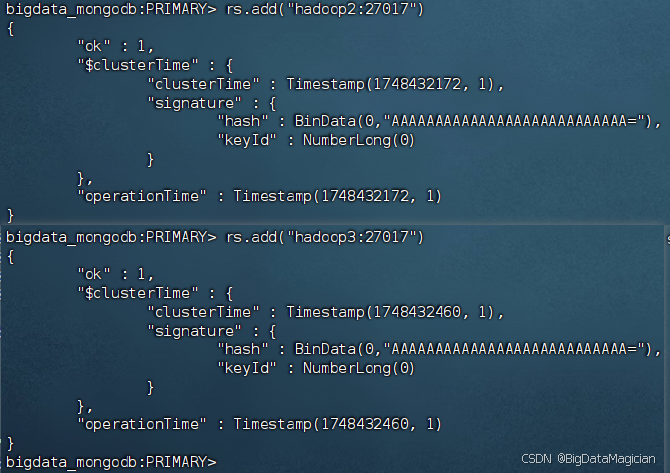
在虚拟机hadoop1执行如下命令将服务器hadoop2和hadoop3以副本节点的角色添加到副本集中。
rs.add("hadoop2:27017")
rs.add("hadoop3:27017")
添加成功如下图所示。
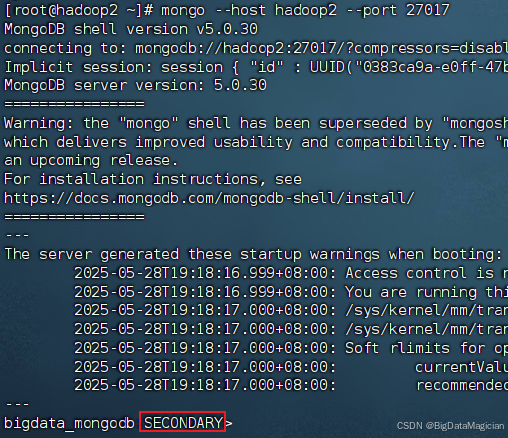
在虚拟机hadoop2执行如下命令进入hadoop2的MongoDB客户端,查看副本集状态。
mongo --host hadoop2 --port 27017
如下图所示,服务器hadoop2是为SECONDARY状态。
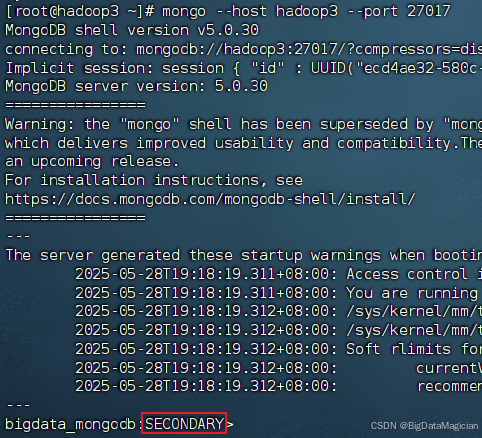
在虚拟机hadoop3执行如下命令进入hadoop3的MongoDB客户端,查看副本集状态。
mongo --host hadoop3 --port 27017
如下图所示,服务器hadoop3是为SECONDARY状态。
三、副本集操作
1. 副本集状态介绍
以下是 MongoDB 副本集(Replica Set)状态的详细介绍。
| 分类 | 状态/概念 | 说明 |
|---|---|---|
| 基本架构 | 副本集(Replica Set) | 由多个 MongoDB 节点组成的集群,实现数据冗余、高可用和故障转移。 |
| 主节点(Primary) | 唯一可写入的节点,处理所有写操作,并将变更同步到从节点(Secondary)。 | |
| 从节点(Secondary) | 复制主节点数据,可用于读操作(默认禁止,需配置 readPreference)。 | |
| 仲裁节点(Arbiter) | 不存储数据,仅参与选举投票,用于解决脑裂问题(奇数节点时非必需)。 | |
| 节点状态 | PRIMARY | 主节点状态,当前集群唯一写入节点。 |
SECONDARY | 从节点状态,同步主节点数据,支持只读(需配置)。 | |
RECOVERING | 节点正在同步数据(如初次加入副本集或数据同步中),不可读/写。 | |
STARTUP | 节点刚启动,正在初始化,尚未完成同步。 | |
STARTUP2 | 节点已完成初始化,正在尝试加入副本集。 | |
DOWN | 节点不可用(如进程停止或网络故障)。 | |
ARBITER | 仲裁节点状态,仅参与选举,不存储数据。 | |
REMOVED | 节点已从副本集中移除(但可能仍存在于配置中)。 | |
| 选举机制 | 主节点选举(Election) | 当主节点故障时,从节点通过心跳检测和投票机制重新选举新主节点。 |
| 心跳(Heartbeat) | 节点间通过定期心跳(默认2秒)检测存活状态。 | |
| 多数派原则(Majority) | 选举需获得副本集多数节点(含主节点)的投票才能生效。 | |
| 数据同步 | oplog(操作日志) | 主节点记录所有写操作的日志,从节点通过回放 oplog 实现数据同步。 |
| 同步延迟(Replication Lag) | 从节点与主节点的数据延迟时间(正常情况下应接近0)。 | |
| 读写策略 | 读偏好(Read Preference) | 控制读请求路由到主节点或从节点,支持 primary、primaryPreferred、secondary、secondaryPreferred、nearest 等模式。 |
| 管理命令 | rs.status() | 查看副本集状态的核心命令,返回各节点状态、同步信息及选举相关参数。 |
rs.initiate() | 初始化副本集配置。 | |
rs.add() | 向副本集添加节点。 | |
rs.remove() | 从副本集移除节点。 | |
| 典型场景 | 故障转移(Failover) | 主节点故障后,从节点自动选举新主节点,业务自动切换(需驱动支持)。 |
| 负载均衡(Read Scaling) | 将读请求分发到从节点,减轻主节点压力(需配置读偏好)。 | |
| 注意事项 | 节点数量建议 | 推荐奇数个节点(如3/5/7个),避免脑裂(偶数节点需搭配仲裁节点)。 |
| 版本兼容性 | 副本集内节点版本必须一致,否则可能导致同步失败或功能异常。 |
2. 查看副本集成员状态
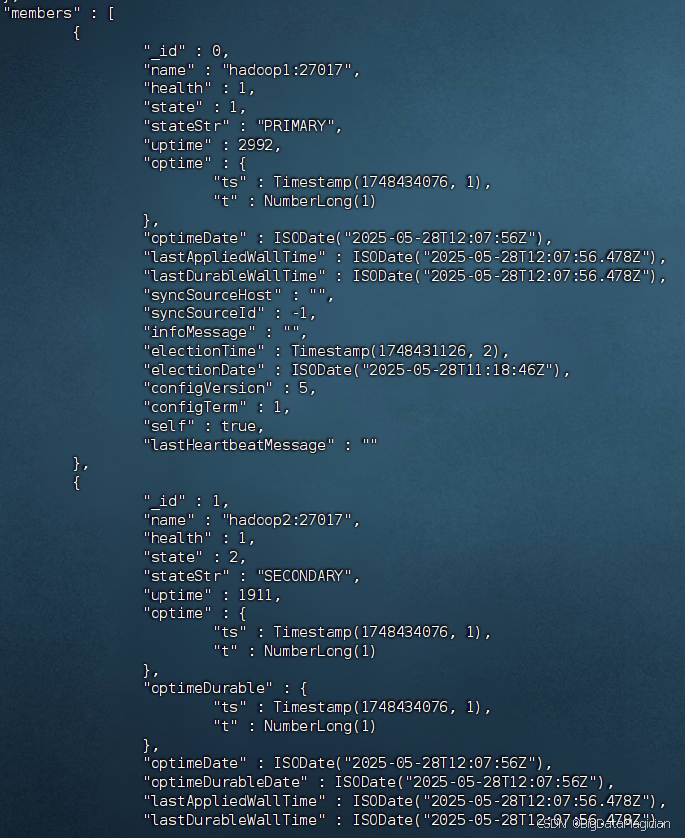
在虚拟机hadoop1执行如下命令查看副本集成员状态。
rs.status()
返回的部分结果如下图所示。
状态码对应关系
| 状态码 | 状态字符串 | 说明 |
|---|---|---|
1 | PRIMARY | 主节点 |
2 | SECONDARY | 从节点 |
3 | RECOVERING | 数据同步中(不可用) |
5 | STARTUP | 节点启动中 |
6 | ARBITER | 仲裁节点 |
8 | DOWN | 节点不可用 |
9 | UNKNOWN | 节点状态未知(如网络隔离) |
3. 数据同步
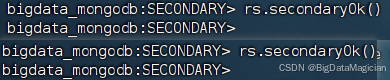
3.1 启用数据同步
分别在虚拟机hadoop2和hadoop3的MongoDB客服端执行如下命令开启数据同步。
rs.secondaryOk()
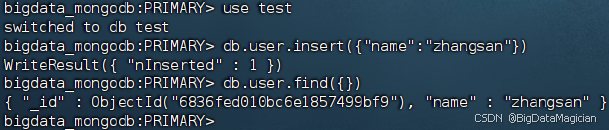
3.2 测试数据同步
在虚拟机hadoop1的MongoDB客服端执行如下命令,切换到test数据库,并向集合user插入一个文档。
use test
db.user.insert({"name":"zhangsan"})
db.user.find({})
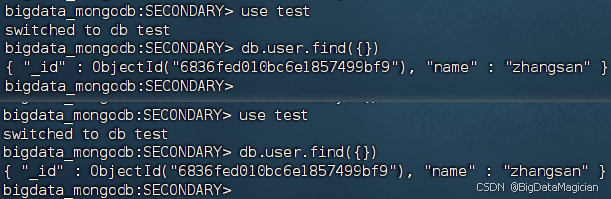
在虚拟机hadoop2和hadoop3的MongoDB客服端执行如下命令,测试数据是否已经同步,可用查询到数据说明数据已经同步到hadoop2和hadoop3。
use test
db.user.find({})
如下图所示。
4. 故障转移
测试方法:终止hadoop1的MongoDB的主节点进程,查看hadoop2和hadoop3这两个从节点是否会有一个自动转为主节点。
4.1 终止hadoop1的MongoDB的主节点进程
查看hadoop1的MongoDB服务进程的PID。
ps -ef | grep mongodb
MongoDB服务进程的PID如下图红框部分所示。

关闭hadoop1的MongoDB服务进程。
kill -9 <PID>
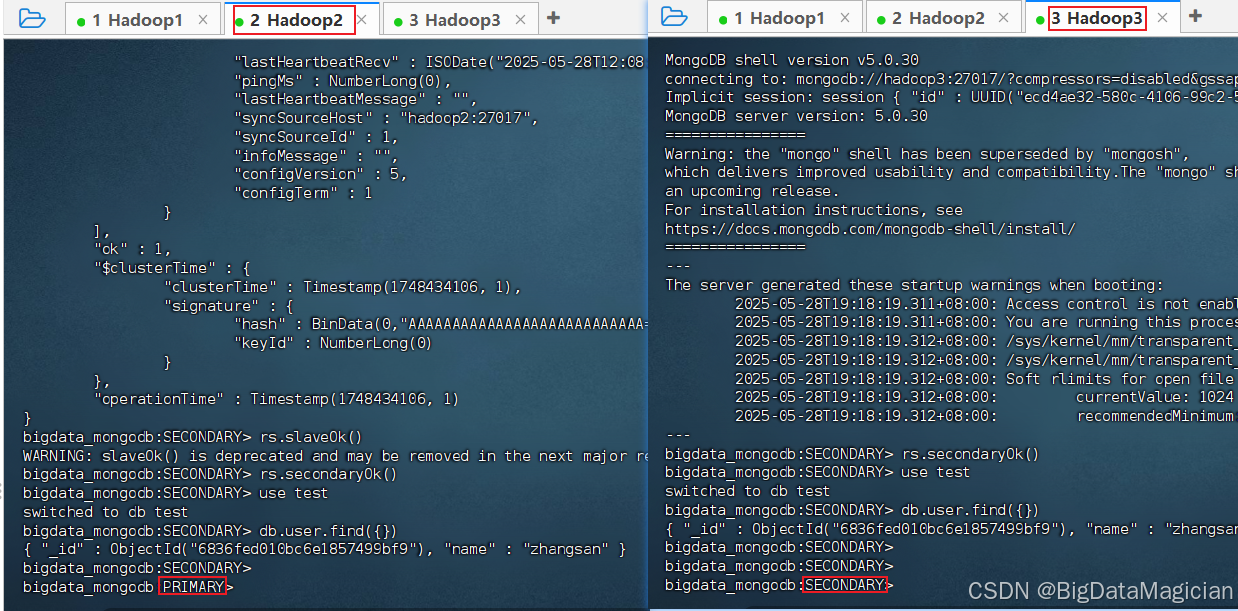
4.2 查看从节点是否有一个自动转为主节点
如下图所示,在hadoop2和hadoop3这两个从节点中,hadoop2转为了主节点。
5. 配置副本集成员
5.1 调整副本集成员的优先级
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
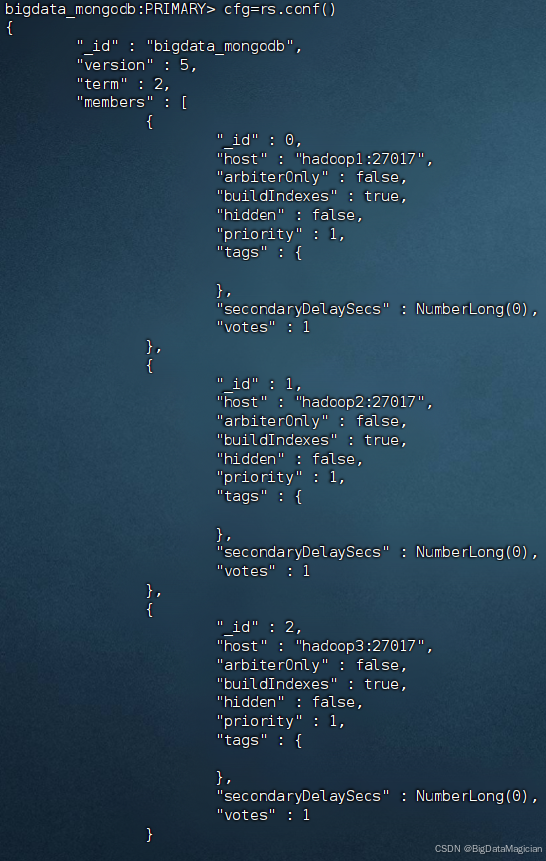
优先级越高越容易被选举为主节点,优先级的范围是0-100(值越大优先级越高),所有节点的优先级默认为1,优先级为0不能成为主节点。
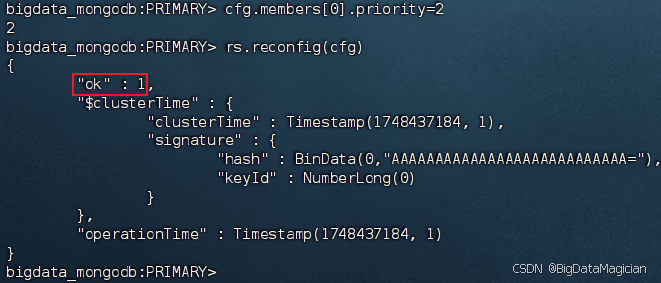
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop1的优先级改为2,并将修改后的配置应用到副本集。
cfg.members[0].priority=2
rs.reconfig(cfg)
配置成功如下图所示。
重新启动hadoop1的MongoDB服务
在虚拟机hadoop1执行如下命令启动MongoDB服务。
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf
启动完成后等待10秒,可以发现hadoop1被重新选举成为主节点(因为hadoop1的优先级比较高),如下图所示。
5.2 配置隐藏节点
隐藏节点是副本集中持有数据副本、对客户端不可见、但可以参与主节点选举和数据同步的特殊节点,可用于数据备份或离线分析等场景。
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2的优先级改为0,使其不能被选举为主节点。
cfg.members[1].priority=0

在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2设置为隐藏节点。
cfg.members[1].hidden=true

在虚拟机主节点的MongoDB客服端执行如下命令将修改后的配置应用到副本集。
rs.reconfig(cfg)
5.3 配置延迟节点
延迟节点(Delayed Node)是副本集中数据落后于主节点指定时间(如1小时)的从节点,用于数据误操作恢复、版本验证等场景。
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2的优先级改为0,使其不能被选举为主节点。
cfg.members[1].priority=0
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2设置为延迟节点,设置延迟时间为3600秒。
cfg.members[1].secondaryDelaySecs=3600

在虚拟机主节点的MongoDB客服端执行如下命令将修改后的配置应用到副本集。
rs.reconfig(cfg)
5.4 配置副本集成员投票权
副本集成员的投票权是指成员在主节点选举中是否具备投票资格,允许有七个拥有投票权的成员,由votes参数控制(默认值为1表示有投票权,0表示无投票权),通常用于控制选举过程或排除特殊节点(如延迟节点、隐藏节点)参与投票。
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
在虚拟机主节点的MongoDB客服端执行如下命令把hadoop2的投票权设置为0,使其不能参与投票。
cfg.members[1].votes=0

在虚拟机主节点的MongoDB客服端执行如下命令将修改后的配置应用到副本集。
rs.reconfig(cfg)
5.5 将副本节点转为仲裁节点
在虚拟机主节点的MongoDB客服端执行如下命令把副本集成员信息赋值到变量cfg中。
cfg=rs.conf()
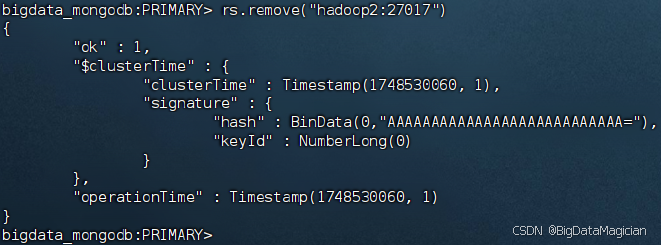
在虚拟机主节点的MongoDB客服端执行如下命令把服务器hadoop2从副本集中移除。
rs.remove("hadoop2:27017")
在虚拟机hadoop2上按Ctrl+C关闭MongoDB客服端,并执行如下操作关闭MongoDB服务进程。
查看hadoop2的MongoDB服务进程的PID。
ps -ef | grep mongodb
MongoDB服务进程的PID如下图红框部分所示。

关闭hadoop2的MongoDB服务进程。
kill -9 <PID>
在虚拟机hadoop2上执行如下命令备份MongoDB数据存放目录。
mv /export/data/mongodb/data /export/data/mongodb/data-old
在虚拟机hadoop2上执行如下命令创建新的数据存放目录,并重新启动MongoDB服务。
mkdir -p /export/data/mongodb/data
mongod -f /export/servers/mongodb-5.0.30/conf/mongod.conf

在虚拟机主节点的MongoDB客服端执行如下命令以仲裁节点角色将hadoop2添加到副本集中。
rs.addArb("hadoop2:27017")
相关文章:
MongoDB(七) - MongoDB副本集安装与配置
文章目录 前言一、下载MongoDB1. 下载MongoDB2. 上传安装包3. 创建相关目录 二、安装配置MongoDB1. 解压MongoDB安装包2. 重命名MongoDB文件夹名称3. 修改配置文件4. 分发MongoDB文件夹5. 配置环境变量6. 启动副本集7. 进入MongoDB客户端8. 初始化副本集8.1 初始化副本集8.2 添…...

131. 分割回文串-两种回溯思路
我们可以将字符串分割成若干回文子串,返回所有可能的方案。如果将问题分解,可以表示为分割长度为n-1的子字符串,这与原问题性质相同,因此可以采用递归方法解决。 为什么回溯与递归存在联系?在解决这个问题时࿰…...
[Java恶补day13] 53. 最大子数组和
休息了一天,开始补上! 给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 子数组是数组中的一个连续部分。 示例 1: 输入:nums …...

摩尔投票算法原理实现一文剖析
摩尔投票算法原理&实现一文剖析 一、算法原理1.1 基本思想1.2 数学原理 二、算法实现2.1 Python实现2.2 Java实现2.3 C实现 三、复杂度分析四、应用场景4.1 多数元素问题4.2 扩展应用:寻找出现次数超过n/3的元素 五、算法优势与注意事项5.1 优势5.2 注意事项 总…...

springboot项目下面的单元测试注入的RedisConnectionFactory类redisConnectionFactory值为什么为空呢?
你遇到的问题是: RedisConnectionFactory redisConnectionFactory 在单元测试中为 null 这是 Spring Boot 单元测试中非常常见的问题,根本原因是你的测试类没有启用 Spring 容器上下文,导致 Resource 注解无法注入 Bean。 ✅ 正确做法&…...

MyBatis操作数据库(2)
1.#{}和${}使用 Interger类型的参数可以看到这里显示的语句是:select username,password,age,gender,phone from userinfo where id? 输入的参数并没有在后面进行拼接,,id的值是使用?进行占位,这种sql称之为"预编译sql".这里,把#{}改成${}观察情况:这里可以看到…...

C++面向对象(二)
面向对象基础内容参考: C面向对象(一)-CSDN博客 友元函数 类的友元函数是定义在类外部,但有权访问类的所有私有(private)成员和保护(protected)成员。尽管友元函数的原型有在类的定…...
【C语言入门级教学】冒泡排序和指针数组
文章目录 1.冒泡排序2.⼆级指针3.指针数组4.指针数组模拟⼆维数组 1.冒泡排序 冒泡排序的核⼼思想:两两相邻的元素进⾏⽐较。 //⽅法1 void bubble_sort(int arr[], int sz)//参数接收数组元素个数 { int i 0;for(i0; i-1; i) { int j 0; for(j0; j-1; j) { …...

shell脚本中常用的命令
一、设置主机名称 通过文件的方式修改通过命令修改 二、nmcli 查看网卡 ip a s ens160 (网卡名称) ifconfig ens160 nmcli device show ens160 nmcli device status nmcli connection show ens160 2.设置网卡 a)当网卡没有被设置时 b)网卡被设定,需要修改 三…...
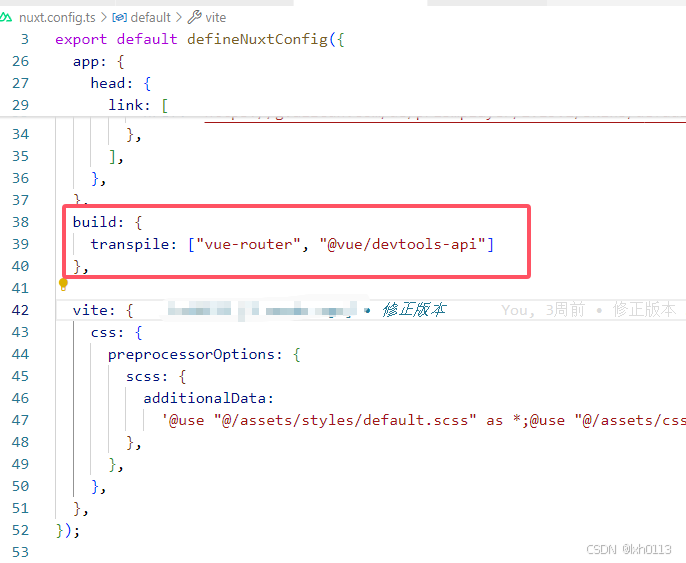
Nuxt3部署
最近接了一个项目,需要用到 nuxt3 技术来满足甲方所要求的需求,在部署的时候遇到了很多问题,这里我一一给大家讲述部署流程,以及所遇到的坑 打包部署 部署分为俩种方式: 静态(spa)部署 和 ssr部署 静态部署 静态部…...

网络攻防技术一:绪论
文章目录 一、网络空间CyberSpace1、定义2、基本四要素 二、网络空间安全1、定义2、保护对象3、安全属性4、作用空间 三、网络攻击1、攻击分类2、攻击过程 四、网络防护1、定义2、安全模型3、安全服务5类4、特定安全机制8种5、普遍性安全机制5种 五、网络安全技术发展简史1、第…...

【人工智能】deepseek七篇论文阅读笔记大纲
七篇文章看了整整五天,加上整理笔记和问ds优化,大致的框架是有了。具体的公式细节比较多,截图也比较麻烦,就不列入大纲去做笔记了。 DeepSeek-LLM:一切的起点,所以探索的东西比较多,包括&#x…...

unix/linux source 命令,在当前的 Shell 会话中读取并执行指定文件中的命令
source 命令 (或者它的POSIX等效命令 .):在当前 Shell 环境中执行脚本 简单来说,source 命令的作用是:在当前的 Shell 会话中读取并执行指定文件中的命令。 这意味着,被 source 执行的脚本中的所有命令,就好像是你直接在当前的命令行提示符下逐行输入并执行的一样。 核…...

[leetcode] 二分算法
本文介绍算法题中常见的二分算法。二分算法的模板框架并不复杂,但是初始左右边界的取值以及左右边界如何向中间移动,往往让我们头疼。本文根据博主自己的刷题经验,总结出四类题型,熟记这四套模板,可以应付大部分二分算…...

imgsz参数设置
在YOLOv8中,imgsz参数控制输入图像的尺寸,它直接影响模型的精度、速度和显存占用。对于1280720像素的原始图片,选择合适的imgsz需要平衡以下因素: 一、推荐设置 1. 兼顾精度与速度(推荐) model<...
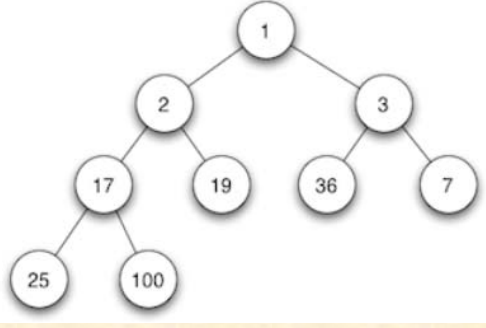
【算法】分支限界
一、基本思想 (分支限界, 分枝限界, 分支界限 文献不同说法但都是一样的) 分支限界法类似于回溯法,也是一种在问题的解空间树上搜索问题解的算法。 但一般情况下,分支限界法与回溯法的求解目标不同。回溯…...

使用 C/C++ 和 OpenCV 调用摄像头
使用 C/C 和 OpenCV 调用摄像头 📸 OpenCV 是一个强大的计算机视觉库,它使得从摄像头捕获和处理视频流变得非常简单。本文将指导你如何使用 C/C 和 OpenCV 来调用摄像头、读取视频帧并进行显示。 准备工作 在开始之前,请确保你已经正确安装…...

历史数据分析——广州港
个股简介 公司简介: 华南地区最大的综合性主枢纽港。 本公司是由广州港集团、国投交通、广州发展作为发起人,共同出资以发起方式设立的股份有限公司。 经营分析: 一般经营项目:企业管理服务(涉及许可经营项目的除外);港务船舶调度服务;船舶通信服务;企业自有资金…...

数据库管理与高可用-MySQL全量,增量备份与恢复
目录 #1.1MySQL数据库备份概述 1.1.1数据备份的重要性 1.1.2数据库备份类型 1.1.3常见的备份方法 #2.1数据库完全备份操作 2.1.1物理冷备份与恢复 2.1.2mysqldump备份与恢复 2.1.3MySQL增量备份与恢复 #3.1制定企业备份策略的思路 #4.1扩展:MySQL的GTID 4.1.1My…...
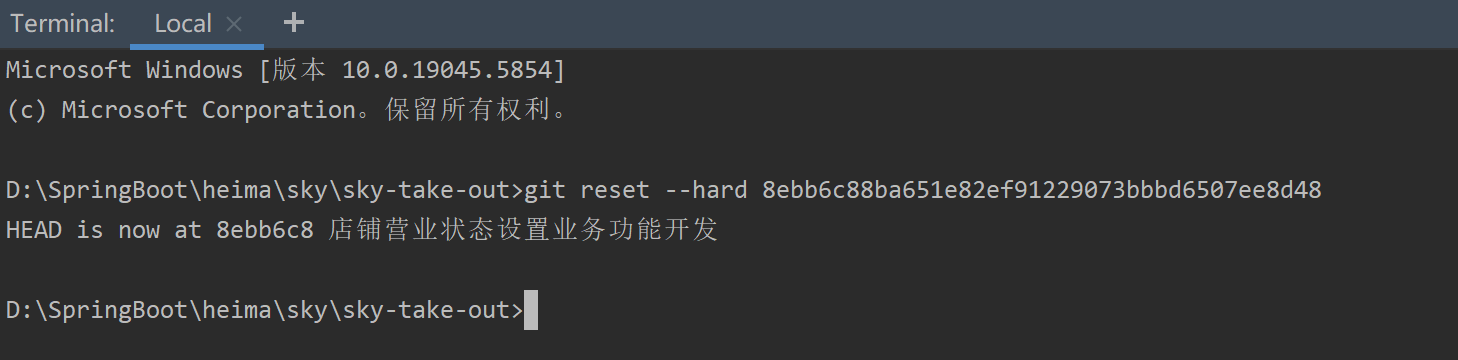
从gitee仓库中恢复IDEA项目某一版本
神奇的功能!!!代码改乱了,但是还有救! 打开终端,输入git log 复制想要恢复版本的提交哈希值,打开终端输入git reset --hard <哈希值> ,就能修复到那时的提交版本了...

用dayjs解析时间戳,我被提了bug
引言 前几天开发中突然接到测试提的一个 Bug,说我的时间组件显示异常。 我很诧异,这里初始化数据是后端返回的,我什么也没改,这bug提给我干啥。我去问后端:“这数据是不是有问题?”。后端答:“…...

[git每日一句]Changes not staged for commit
在 Git 中,"Changes not staged for commit" 的意思是: 你有已修改的文件,但尚未使用 git add 将它们添加到暂存区(Staging Area),因此这些更改不会被包含在下次提交中。 具体含义 已修改但未暂…...

架构师面试题整理
以下是从提供的HTML代码中提取的所有class"title-txt"的文本内容,已排除重复项并按顺序整理: 缓存专题 实战解决大规模缓存击穿导致线上数据库压力暴增面试常问的缓存穿透是怎么回事基于DCL机制解决突发性热点缓存并发重建问题实战Redis分布…...
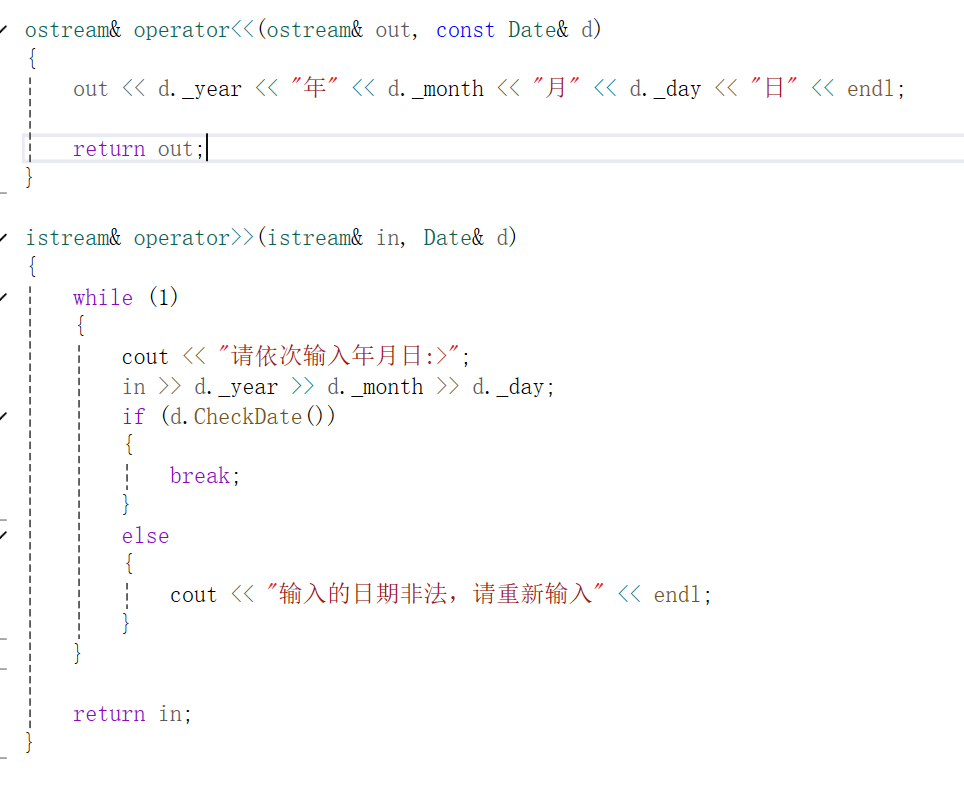
类和对象:实现日期类
目录 概述 一.实现日期类的基本框架 二.实现比较的运算符重载 1.>的运算符重载 2.的运算符重载 3.其余的比较运算符重载 三.加减天数的运算符重载 1.,的运算符重载 2.-,-的运算符重载 3.对1和2的小优化 四.两个日期类相减的重载 1.,--的重…...
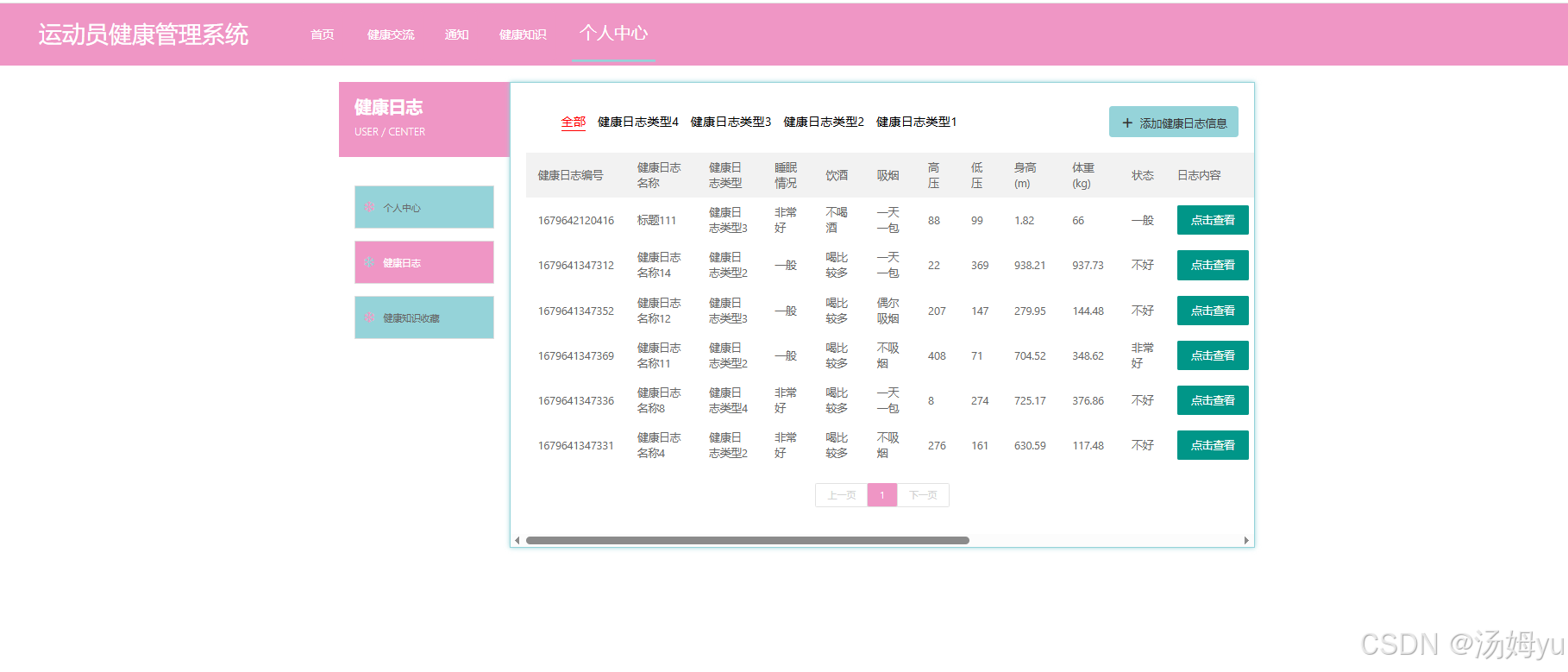
基于springboot的运动员健康管理系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...
华为云Flexus+DeepSeek征文 | 初探华为云ModelArts Studio:部署DeepSeek-V3/R1商用服务的详细步骤
华为云FlexusDeepSeek征文 | 初探华为云ModelArts Studio:部署DeepSeek-V3/R1商用服务的详细步骤 前言一、华为云ModelArts Studio平台介绍1.1 ModelArts Studio介绍1.2 ModelArts Studio主要特点1.3 ModelArts Studio使用场景1.4 ModelArts Studio产品架构 二、访问…...
下载即转化的商业密码:解析华为应用商店CPD广告的智能投放逻辑
在移动互联网流量红利见顶的背景下,华为应用市场凭借其终端生态优势正成为开发者获客的新蓝海。数据显示,2025年Q1华为应用商店全球分发量同比增长27%,其中CPD广告因其"下载才付费"的精准特性,已成为金融、游戏、工具类…...

分布式锁和数据库锁完成接口幂等性
1、分布式锁 唯一主键与乐观锁的本质是使用了数据库的锁,但由于数据库锁的性能不太好,所以我们可使用Redis、Zookeeper等中间件来实现分布式锁的功能,以Redis为例实现幂等:当用户通过浏览器发起请求,服务端接收到请求…...

浅谈JMeter之常见问题Address already in use: connect
浅谈JMeter之常见问题Address already in use: connect 在JMeter高并发测试中出现“address already in use”错误,主要源于Windows系统的TCP端口资源耗尽及连接配置问题,在执行JMeter中查看结果树 原因分析 GET请求默认采用短连接(Conne…...

【机器学习基础】机器学习入门核心算法:随机森林(Random Forest)
机器学习入门核心算法:随机森林(Random Forest) 1. 算法逻辑2. 算法原理与数学推导2.1 核心组件2.2 数学推导2.3 OOB(Out-of-Bag)误差 3. 模型评估评估指标特征重要性可视化 4. 应用案例4.1 医疗诊断4.2 金融风控4.3 遥…...