第1天:认识RNN及RNN初步实验(预测下一个数字)
RNN(循环神经网络) 是一种专门设计用来处理序列数据的人工神经网络。它的核心思想是能够“记住”之前处理过的信息,并将其用于当前的计算,这使得它非常适合处理具有时间顺序或上下文依赖关系的数据。
核心概念:循环连接
RNN 与普通的前馈神经网络(如多层感知机)最根本的区别在于它引入了循环连接:
- 输入序列: RNN 接收一个序列作为输入,例如:
- 一个句子(单词序列)
- 一段语音(音频帧序列)
- 股票价格(时间点上的价格序列)
- 视频帧序列
- 隐藏状态: RNN 内部维护一个隐藏状态。这个状态就像是网络的“记忆”,它总结了网络在处理当前输入之前所“看到”的所有历史信息。
- 循环: 在处理序列中的每一个元素时:
- 当前输入 + 前一个隐藏状态: RNN 不仅考虑当前的输入数据,还会结合上一个时间步的隐藏状态。
- 计算新状态和输出: 网络根据当前的输入和前一个隐藏状态,通过激活函数(通常是
tanh或ReLU)计算出新的隐藏状态。 - 产生输出(可选): 这个新的隐藏状态可以用来产生当前时间步的输出(例如,预测序列的下一个元素、对当前元素进行分类等)。
- 传递状态: 这个新的隐藏状态被传递到下一个时间步,作为处理下一个输入元素的“记忆”基础。
- 共享权重: RNN 在处理序列的每个时间步时,使用的是同一套网络参数(权重和偏置)。这意味着它用相同的规则(相同的函数)来处理序列中的每一个元素。
为什么需要 RNN?
传统的前馈神经网络在处理序列数据时存在明显缺陷:
- 固定输入大小: 它们要求输入数据具有固定长度(例如,固定数量的像素或特征)。序列数据(如不同长度的句子)很难直接适配。
- 忽略顺序/上下文: 它们独立处理每个输入,没有机制来记住或利用之前输入的信息。对于序列数据,顺序和上下文往往至关重要(例如,句子中单词的含义依赖于前面的单词)。
RNN 的优势(擅长处理的任务)
RNN 的“记忆”特性使其特别擅长以下任务:
- 自然语言处理:
- 语言建模(预测下一个单词)
- 机器翻译(输入源语言序列,输出目标语言序列)
- 文本生成(写文章、诗歌、代码)
- 情感分析(理解句子情感)
- 命名实体识别(识别文本中的人名、地名等)
- 语音识别(音频信号序列转文本)
- 时间序列预测:
- 股票价格预测
- 天气预测
- 销售预测
- 序列标注:
- 词性标注(为句子中的每个单词标注词性)
- 语音分割
- 其他序列任务:
- 视频分析(理解视频帧序列)
- 音乐生成(生成音符序列)
- 聊天机器人(对话是轮次的序列)
RNN 的挑战(经典问题)
标准的 RNN(通常称为 Vanilla RNN)在处理长序列时会遇到一些著名的困难:
- 梯度消失问题: 这是最主要的问题。在通过时间反向传播训练网络时,梯度(用于更新权重的误差信号)会随着时间步的推移而呈指数级衰减。当序列很长时,早期的输入对最终输出的影响梯度会变得非常小,导致网络很难学习到长距离的依赖关系(即序列开头的信息对序列结尾的影响)。
- 梯度爆炸问题: 相对少见但也会发生,梯度变得非常大,导致训练不稳定。
- 有限的记忆容量: 隐藏状态的大小固定,难以记住非常久远的信息。
- 计算效率: 由于其顺序处理的特性(必须一个时间步接一个时间步地计算),难以并行化,训练速度可能较慢。
改进的 RNN 结构
为了解决标准 RNN 的问题(尤其是梯度消失问题),研究者开发了更强大的变体:
- LSTM: 长短期记忆网络。引入了“门”机制(输入门、遗忘门、输出门)和一个额外的“细胞状态”,可以更精细地控制信息的保留、遗忘和输出,特别擅长学习长期依赖关系。
- GRU: 门控循环单元。LSTM 的一个简化版本,只有两个门(更新门、重置门),计算效率更高,在很多时候能达到与 LSTM 相当甚至更好的效果。
总结:
RNN 是一种具有内部循环连接的网络,允许信息在序列处理过程中持续存在(即拥有“记忆”)。这种结构使其成为处理序列数据(文本、语音、时间序列等)的自然选择。尽管标准 RNN 存在梯度消失等限制其处理长序列能力的问题,但其强大的变体 LSTM 和 GRU 已被证明在广泛的序列建模任务中极其成功,是深度学习和人工智能领域的一项基础性技术。当你看到机器翻译、智能对话或文本生成时,背后很可能就有 RNN 或其变体(LSTM/GRU)在工作。
RNN运行原理图:

尝试(代码实现)
import torch
import torch.nn as nn # 设置随机种子保证可重复性
torch.manual_seed(42) # =====================
# 1. 准备模拟数据
# =====================
# 创建一个简单的序列数据集:输入序列和对应的目标值
# 输入序列: [0,1,2] -> 目标: 3; [1,2,3] -> 目标: 4 等
seq_length = 3 # 输入序列长度
data_size = 100 # 数据集大小 # 生成特征数据 (100个样本,每个样本是长度为3的序列)
X = torch.stack([torch.arange(i, i + seq_length) for i in range(data_size)]).float()
# 生成目标数据 (每个序列的下一个数字)
y = torch.stack([torch.tensor([i + seq_length]) for i in range(data_size)]).float() print("输入数据形状:", X.shape) # torch.Size([100, 3])
print("目标数据形状:", y.shape) # torch.Size([100, 1]) # =====================
# 2. 定义RNN模型
# =====================
class SimpleRNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(SimpleRNN, self).__init__() # 定义RNN层参数 self.hidden_size = hidden_size # RNN层: (input_size, hidden_size) # batch_first=True 表示输入数据的格式为 (batch, seq_len, features) self.rnn = nn.RNN( input_size=input_size, hidden_size=hidden_size, batch_first=True # 输入/输出张量的第一个维度是batch ) # 全连接输出层 self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): # 初始化隐藏状态 (num_layers, batch_size, hidden_size) # 这里只有一层RNN,所以num_layers=1 h0 = torch.zeros(1, x.size(0), self.hidden_size) # RNN前向传播 # out: 所有时间步的隐藏状态 (batch, seq_len, hidden_size) # hn: 最后一个时间步的隐藏状态 (1, batch, hidden_size) out, hn = self.rnn(x.unsqueeze(2), h0) # 注意: x.unsqueeze(2) 将形状从 [batch, seq_len] -> [batch, seq_len, 1] # 因为RNN期望每个时间步有特征维度 # 只取最后一个时间步的输出 (许多序列任务只关心最后输出) last_output = out[:, -1, :] # 通过全连接层 output = self.fc(last_output) return output # =====================
# 3. 初始化模型和训练设置
# =====================
# 模型参数
input_size = 1 # 每个时间步的输入特征维度 (这里我们输入的是单个数字)
hidden_size = 32 # RNN隐藏层大小
output_size = 1 # 输出维度 (预测单个数字) # 创建模型实例
model = SimpleRNN(input_size, hidden_size, output_size) # 损失函数和优化器
criterion = nn.MSELoss() # 均方误差损失 (回归任务)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # =====================
# 4. 训练循环
# =====================
num_epochs = 100 for epoch in range(num_epochs): # 前向传播 outputs = model(X) loss = criterion(outputs, y) # 反向传播和优化 optimizer.zero_grad() # 清除历史梯度 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新参数 # 每10轮打印一次损失 if (epoch + 1) % 10 == 0: print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}') # =====================
# 5. 测试模型
# =====================
# 创建测试序列
test_seq = torch.tensor([7, 8, 9]).float().unsqueeze(0) # 添加batch维度
print("\n测试序列:", test_seq.squeeze().tolist()) # 预测下一个数字
with torch.no_grad(): # 禁用梯度计算 prediction = model(test_seq) print(f"预测下一个数字: {prediction.item():.1f} (期望值: 10.0)")
代码解释:
"""
关键组件说明:
1. nn.RNN 层: - input_size: 每个时间步输入的特征维度 - hidden_size: RNN隐藏状态的大小 - batch_first: 输入/输出张量格式为 (batch, seq_len, features)
2. 隐藏状态 (hidden state): - 存储序列的历史信息 - 初始化为全零张量 (形状: [num_layers, batch_size, hidden_size]) - 在序列处理过程中不断更新
1. 前向传播流程: - 输入形状: [batch_size, seq_len] -> 需要扩展为 [batch_size, seq_len, input_size] - RNN输出两个结果: out: 所有时间步的隐藏状态 [batch, seq_len, hidden_size] hn: 最后一个时间步的隐藏状态 [num_layers, batch, hidden_size] - 我们通常只关心最后一个时间步的输出 (out[:, -1, :]) - 将最后输出传入全连接层得到预测结果 4. 训练过程: - 使用均方误差(MSE)作为回归任务的损失函数 - Adam优化器更新权重 - 循环多个epoch使模型学习序列模式
"""
运行结果:
输入数据形状: torch.Size([100, 3])
目标数据形状: torch.Size([100, 1])
Epoch [10/100], Loss: 3239.7668
Epoch [20/100], Loss: 2960.7173
Epoch [30/100], Loss: 2692.1509
Epoch [40/100], Loss: 2433.7822
Epoch [50/100], Loss: 2194.8665
Epoch [60/100], Loss: 1978.9081
Epoch [70/100], Loss: 1784.7439
Epoch [80/100], Loss: 1610.4106
Epoch [90/100], Loss: 1454.0194
Epoch [100/100], Loss: 1313.7197测试序列: [7.0, 8.0, 9.0]
预测下一个数字: 10.1 (期望值: 10.0)**改变一:修改hidden_size
hidden_size=8
输入数据形状: torch.Size([100, 3])
目标数据形状: torch.Size([100, 1])
Epoch [10/100], Loss: 3465.6765
Epoch [20/100], Loss: 3378.4478
Epoch [30/100], Loss: 3299.8362
Epoch [40/100], Loss: 3214.9880
Epoch [50/100], Loss: 3129.9934
Epoch [60/100], Loss: 3046.5991
Epoch [70/100], Loss: 2965.3425
Epoch [80/100], Loss: 2886.3469
Epoch [90/100], Loss: 2809.4622
Epoch [100/100], Loss: 2734.4731测试序列: [7.0, 8.0, 9.0]
预测下一个数字: 8.5 (期望值: 10.0)
hidden_size=16
输入数据形状: torch.Size([100, 3])
目标数据形状: torch.Size([100, 1])
Epoch [10/100], Loss: 3403.8201
Epoch [20/100], Loss: 3222.7463
Epoch [30/100], Loss: 3082.8389
Epoch [40/100], Loss: 2934.8223
Epoch [50/100], Loss: 2788.8025
Epoch [60/100], Loss: 2648.1326
Epoch [70/100], Loss: 2514.1960
Epoch [80/100], Loss: 2387.1860
Epoch [90/100], Loss: 2266.7705
Epoch [100/100], Loss: 2152.6624测试序列: [7.0, 8.0, 9.0]
预测下一个数字: 9.9 (期望值: 10.0)
hidden_size=64
输入数据形状: torch.Size([100, 3])
目标数据形状: torch.Size([100, 1])
Epoch [10/100], Loss: 2981.0894
Epoch [20/100], Loss: 2482.7971
Epoch [30/100], Loss: 2024.7319
Epoch [40/100], Loss: 1634.8406
Epoch [50/100], Loss: 1318.6863
Epoch [60/100], Loss: 1065.7627
Epoch [70/100], Loss: 864.2839
Epoch [80/100], Loss: 703.8886
Epoch [90/100], Loss: 575.9725
Epoch [100/100], Loss: 473.6202测试序列: [7.0, 8.0, 9.0]
预测下一个数字: 9.9 (期望值: 10.0)
#### hidden_size=128
输入数据形状: torch.Size([100, 3])
目标数据形状: torch.Size([100, 1])
Epoch [10/100], Loss: 2416.3115
Epoch [20/100], Loss: 1606.8107
Epoch [30/100], Loss: 1012.2352
Epoch [40/100], Loss: 632.2427
Epoch [50/100], Loss: 399.0681
Epoch [60/100], Loss: 257.7469
Epoch [70/100], Loss: 171.4580
Epoch [80/100], Loss: 117.6267
Epoch [90/100], Loss: 83.0710
Epoch [100/100], Loss: 60.3334测试序列: [7.0, 8.0, 9.0]
预测下一个数字: 10.0 (期望值: 10.0)hidden_size=256
输入数据形状: torch.Size([100, 3])
目标数据形状: torch.Size([100, 1])
Epoch [10/100], Loss: 1700.6941
Epoch [20/100], Loss: 687.7560
Epoch [30/100], Loss: 225.4265
Epoch [40/100], Loss: 75.9410
Epoch [50/100], Loss: 28.6406
Epoch [60/100], Loss: 12.8711
Epoch [70/100], Loss: 6.8923
Epoch [80/100], Loss: 4.2395
Epoch [90/100], Loss: 2.8668
Epoch [100/100], Loss: 6.7286测试序列: [7.0, 8.0, 9.0]
预测下一个数字: 10.8 (期望值: 10.0)
改个脚本来自动测试一下:
import torch
import torch.nn as nn
from xformers.benchmarks.benchmark_sddmm import results # 设置随机种子保证可重复性
torch.manual_seed(42) # =====================
# 1. 准备模拟数据
# =====================
# 创建一个简单的序列数据集:输入序列和对应的目标值
# 输入序列: [0,1,2] -> 目标: 3; [1,2,3] -> 目标: 4 等
seq_length = 3 # 输入序列长度
data_size = 100 # 数据集大小 # 生成特征数据 (100个样本,每个样本是长度为3的序列)
X = torch.stack([torch.arange(i, i + seq_length) for i in range(data_size)]).float()
# 生成目标数据 (每个序列的下一个数字)
y = torch.stack([torch.tensor([i + seq_length]) for i in range(data_size)]).float() print("输入数据形状:", X.shape) # torch.Size([100, 3])
print("目标数据形状:", y.shape) # torch.Size([100, 1]) # =====================
# 2. 定义RNN模型
# =====================
class SimpleRNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(SimpleRNN, self).__init__() # 定义RNN层参数 self.hidden_size = hidden_size # RNN层: (input_size, hidden_size) # batch_first=True 表示输入数据的格式为 (batch, seq_len, features) self.rnn = nn.RNN( input_size=input_size, hidden_size=hidden_size, batch_first=True # 输入/输出张量的第一个维度是batch ) # 全连接输出层 self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): # 初始化隐藏状态 (num_layers, batch_size, hidden_size) # 这里只有一层RNN,所以num_layers=1 h0 = torch.zeros(1, x.size(0), self.hidden_size) # RNN前向传播 # out: 所有时间步的隐藏状态 (batch, seq_len, hidden_size) # hn: 最后一个时间步的隐藏状态 (1, batch, hidden_size) out, hn = self.rnn(x.unsqueeze(2), h0) # 注意: x.unsqueeze(2) 将形状从 [batch, seq_len] -> [batch, seq_len, 1] # 因为RNN期望每个时间步有特征维度 # 只取最后一个时间步的输出 (许多序列任务只关心最后输出) last_output = out[:, -1, :] # 通过全连接层 output = self.fc(last_output) return output # =====================
# 3. 初始化模型和训练设置
# =====================
# 模型参数
input_size = 1 # 每个时间步的输入特征维度 (这里我们输入的是单个数字)
hidden_size = [8, 16, 32, 64, 128, 256] # RNN隐藏层大小
output_size = 1 # 输出维度 (预测单个数字)
results = {} # 创建模型实例
for hs in hidden_size: model = SimpleRNN(input_size, hs, output_size) # 损失函数和优化器 criterion = nn.MSELoss() # 均方误差损失 (回归任务) optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # ===================== # 4. 训练循环 # ===================== num_epochs = 100 for epoch in range(num_epochs): # 前向传播 outputs = model(X) loss = criterion(outputs, y) # 反向传播和优化 optimizer.zero_grad() # 清除历史梯度 loss.backward() # 反向传播计算梯度 optimizer.step() # 更新参数 # 每10轮打印一次损失 if (epoch + 1) % 10 == 0: print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}') # ===================== # 5. 测试模型 # ===================== # 创建测试序列 test_seq = torch.tensor([7, 8, 9]).float().unsqueeze(0) # 添加batch维度 print("\n测试序列:", test_seq.squeeze().tolist()) # 预测下一个数字 with torch.no_grad(): # 禁用梯度计算 prediction = model(test_seq) # print(f"预测下一个数字: {prediction.item():.1f} (期望值: 10.0)") results[hs] = { "final_loss": loss.item(), "prediction": prediction.item() } # 打印结果
for size, res in results.items(): print(f"hidden_size: {size:<3}, final_loss: {res['final_loss']:.5f}, prediction: {res['prediction']:.2f} (期望值=10)")
结果:
测试序列: [7.0, 8.0, 9.0]
hidden_size: 8 , final_loss: 2734.47314, prediction: 8.52 (期望值=10)
hidden_size: 16 , final_loss: 2143.95459, prediction: 9.99 (期望值=10)
hidden_size: 32 , final_loss: 1293.59521, prediction: 9.95 (期望值=10)
hidden_size: 64 , final_loss: 448.14648, prediction: 9.90 (期望值=10)
hidden_size: 128, final_loss: 60.28671, prediction: 9.60 (期望值=10)
hidden_size: 256, final_loss: 2.17465, prediction: 10.08 (期望值=10)
这个损失率…,有点离谱啊。
尝试解决:归一化
import torch
import torch.nn as nn
from xformers.benchmarks.benchmark_sddmm import results # 设置随机种子保证可重复性
torch.manual_seed(42) # =====================
# 1. 准备模拟数据
# =====================
# 创建一个简单的序列数据集:输入序列和对应的目标值
# 输入序列: [0,1,2] -> 目标: 3; [1,2,3] -> 目标: 4 等
seq_length = 3 # 输入序列长度
data_size = 100 # 数据集大小 # 生成特征数据 (100个样本,每个样本是长度为3的序列)
X_raw = torch.stack([torch.arange(i, i + seq_length) for i in range(data_size)]).float()
# 生成目标数据 (每个序列的下一个数字)
y_raw = torch.stack([torch.tensor([i + seq_length]) for i in range(data_size)]).float() # print("输入数据形状:", X.shape) # torch.Size([100, 3])
# print("目标数据形状:", y.shape) # torch.Size([100, 1]) # 数据归一化
def normalize(tensor, mean=None, std=None): if mean is None or std is None: mean = tensor.mean() std = tensor.std() return (tensor - mean) / std, mean, std # 归一化数据,并保存归一化参数
X, X_mean, X_std = normalize(X_raw)
y, y_mean, y_std = normalize(y_raw) print(f"归一化后输入范围: {X.min().item():.4f} to {X.max().item():.4f}")
print(f"归一化后目标范围: {y.min().item():.4f} to {y.max().item():.4f}") # =====================
# 2. 定义RNN模型
# =====================
class SimpleRNN(nn.Module): def __init__(self, input_size, hidden_size, output_size): super(SimpleRNN, self).__init__() # 定义RNN层参数 self.hidden_size = hidden_size # RNN层: (input_size, hidden_size) # batch_first=True 表示输入数据的格式为 (batch, seq_len, features) self.rnn = nn.RNN( input_size=input_size, hidden_size=hidden_size, batch_first=True # 输入/输出张量的第一个维度是batch ) # 全连接输出层 self.fc = nn.Linear(hidden_size, output_size) def forward(self, x): # 初始化隐藏状态 (num_layers, batch_size, hidden_size) # 这里只有一层RNN,所以num_layers=1 h0 = torch.zeros(1, x.size(0), self.hidden_size) # RNN前向传播 # out: 所有时间步的隐藏状态 (batch, seq_len, hidden_size) # hn: 最后一个时间步的隐藏状态 (1, batch, hidden_size) out, hn = self.rnn(x.unsqueeze(2), h0) # 注意: x.unsqueeze(2) 将形状从 [batch, seq_len] -> [batch, seq_len, 1] # 因为RNN期望每个时间步有特征维度 # 只取最后一个时间步的输出 (许多序列任务只关心最后输出) last_output = out[:, -1, :] # 通过全连接层 output = self.fc(last_output) return output # =====================
# 3. 初始化模型和训练设置
# =====================
# 模型参数
input_size = 1 # 每个时间步的输入特征维度 (这里我们输入的是单个数字)
hidden_size = [8, 16, 32, 64, 128, 256] # RNN隐藏层大小
output_size = 1 # 输出维度 (预测单个数字)
results = {} # 创建模型实例
for hs in hidden_size: model = SimpleRNN(input_size, hs, output_size) # 损失函数和优化器 criterion = nn.MSELoss() # 均方误差损失 (回归任务) optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # ===================== # 4. 训练循环 # ===================== num_epochs = 100 for epoch in range(num_epochs): # 前向传播 outputs = model(X) loss = criterion(outputs, y) # 反向传播和优化 optimizer.zero_grad() # 清除历史梯度 loss.backward() # 反向传播计算梯度 # 梯度裁剪(防止梯度爆炸) torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0) optimizer.step() # 更新参数 # 每10轮打印一次损失 if (epoch + 1) % 10 == 0: print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item():.4f}') # ===================== # 5. 测试模型 # ===================== # 创建测试序列 test_seq = torch.tensor([7, 8, 9]).float() test_seq_norm = (test_seq - X_mean) / X_std test_seq_norm = test_seq_norm.unsqueeze(0) # 添加batch维度 # print("\n测试序列:", test_seq.squeeze().tolist()) # 预测下一个数字 with torch.no_grad(): # 禁用梯度计算 prediction_norm = model(test_seq_norm) # print(f"预测下一个数字: {prediction.item():.1f} (期望值: 10.0)") # 将预测结果反归一化到原始空间 prediction = prediction_norm * y_std + y_mean results[hs] = { "final_loss": loss.item(), "prediction": prediction.item() } # 打印结果
for size, res in results.items(): print(f"hidden_size: {size:<3}, final_loss: {res['final_loss']:.5f}, prediction: {res['prediction']:.2f} (期望值=10)")
运行结果:
hidden_size: 8 , final_loss: 0.00042, prediction: 10.35 (期望值=10)
hidden_size: 16 , final_loss: 0.00073, prediction: 10.73 (期望值=10)
hidden_size: 32 , final_loss: 0.00129, prediction: 10.18 (期望值=10)
hidden_size: 64 , final_loss: 0.00069, prediction: 10.54 (期望值=10)
hidden_size: 128, final_loss: 0.00040, prediction: 10.63 (期望值=10)
hidden_size: 256, final_loss: 0.01118, prediction: 8.55 (期望值=10)
结论
hidden_size(隐藏层大小)是RNN中最关键的超参数之一,它直接影响模型的表达能力、学习能力和最终结果。让我们深入分析它与结果的关系:
1. 模型容量与表达能力
- 较小的hidden_size (如4-16):
- ✅ 训练更快,内存占用小
- ❌ 模型容量低,只能学习简单模式
- ➡️ 适合简单序列(如等差数列)
- 较大的hidden_size (如64-256):
- ✅ 能学习复杂模式和非线性关系
- ❌ 需要更多数据和训练时间
- ❌ 可能过拟合(记忆训练数据但泛化差)
- ➡️ 适合真实世界数据(如自然语言)
2. 实际建议(针对初学者)
- 起始点:从
hidden_size=32开始(良好平衡点) - 调整策略:
- 如果欠拟合(训练损失高)→ 增大hidden_size
- 如果过拟合(训练损失低但测试差)→ 减小hidden_size或添加正则化
相关文章:
第1天:认识RNN及RNN初步实验(预测下一个数字)
RNN(循环神经网络) 是一种专门设计用来处理序列数据的人工神经网络。它的核心思想是能够“记住”之前处理过的信息,并将其用于当前的计算,这使得它非常适合处理具有时间顺序或上下文依赖关系的数据。 核心概念:循环连…...

全文索引详解及适用场景分析
全文索引详解及适用场景分析 1. 全文索引基本概念 1.1 定义与核心原理 全文索引(Full-Text Index)是一种特殊的数据库索引类型,专门设计用于高效处理文本数据的搜索需求。与传统的B树索引不同,全文索引不是基于精确匹配,而是通过建立倒排索引(Inverted Index)结构来实现对…...

利用DeepSeek编写能在DuckDB中读PostgreSQL表的表函数
前文实现了UDF和UDAF,还有一类函数是表函数,它放在From 子句中,返回一个集合。DuckDB中已有PostgreSQL插件,但我们可以用pqxx库实现一个简易的只读read_pg()表函数。 提示词如下: 请将libpqxx库集成到我们的程序&#…...
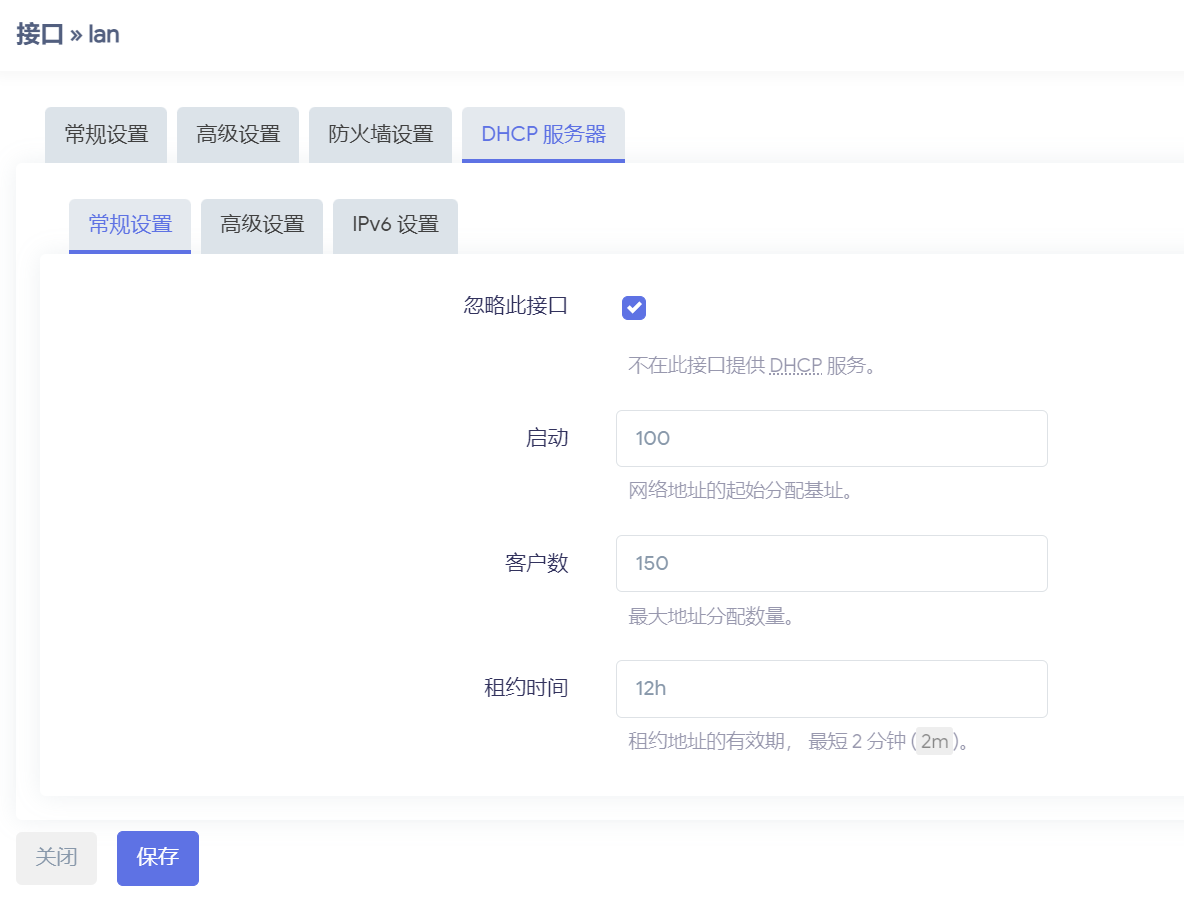
树莓派安装openwrt搭建软路由(ImmortalWrt固件方案)
🤣👉我这里准备了两个版本的openwrt安装方案给大家参考使用,分别是原版的OpenWrt固件以及在原版基础上进行改进的ImmortalWrt固件。推荐使用ImmortalWrt固件,当然如果想直接在原版上进行开发也可以,看个人选择。 &…...

排序算法——详解
排序算法 (冒泡、选择、插入、快排、归并、堆排、计数、桶、基数) 稳定性 (Stability): 如果排序算法能保证,当待排序序列中存在值相等的元素时,排序后这些元素的相对次序保持不变,那么该算法就是稳定的。 例如&#…...

Go整合Redis2.0发布订阅
Go整合Redis2.0发布订阅 Redis goredis-cli --version redis-cli 5.0.14.1 (git:ec77f72d)Go go get github.com/go-redis/redis/v8package redisimport ("MyKindom-Server-v2.0/com/xzm/core/config/yaml""MyKindom-Server-v2.0/com/xzm/core/config/yaml/po…...
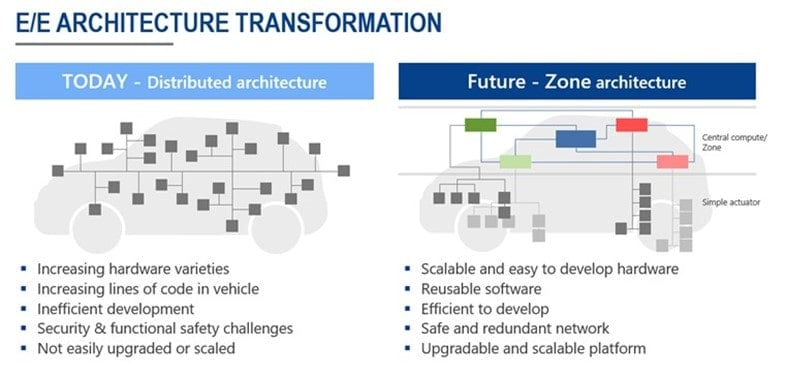
电子电气架构 --- 如何应对未来区域式电子电气(E/E)架构的挑战?
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 做到欲望极简,了解自己的真实欲望,不受外在潮流的影响,不盲从,不跟风。把自己的精力全部用在自己。一是去掉多余,凡事找规律,基础是诚信;二是…...

鸿蒙OS基于UniApp的区块链钱包开发实践:打造支持鸿蒙生态的Web3应用#三方框架 #Uniapp
基于UniApp的区块链钱包开发实践:打造支持鸿蒙生态的Web3应用 前言 最近在带领团队开发一个支持多链的区块链钱包项目时,我们选择了UniApp作为开发框架。这个选择让我们不仅实现了传统移动平台的覆盖,还成功将应用引入了快速发展的鸿蒙生态…...
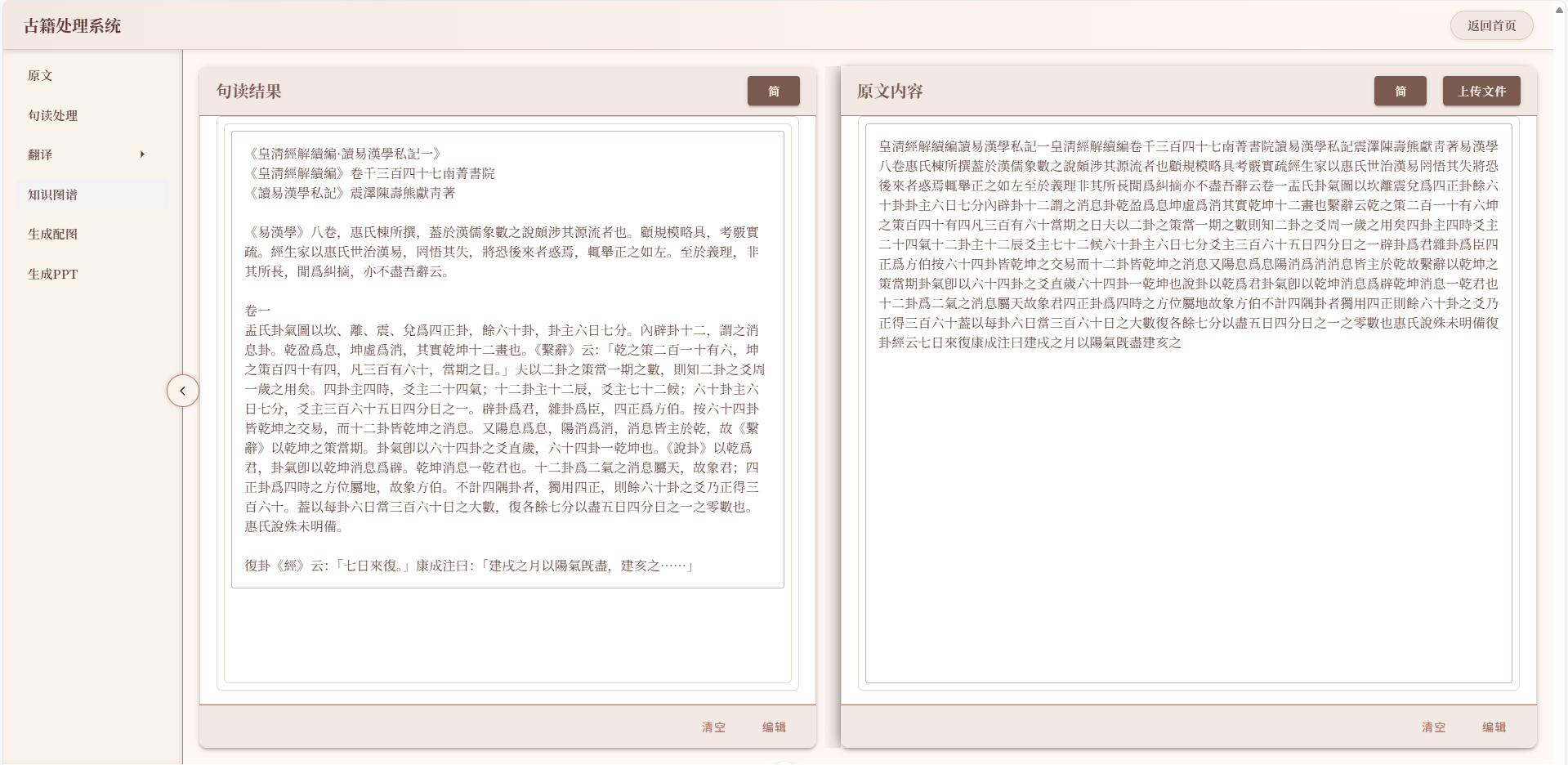
易学探索助手-个人记录(十二)
近期我完成了古籍处理板块页面升级,补充完成原文、句读、翻译的清空、保存和编辑(其中句读仅可修改标点)功能,新增原文和句读的繁简体切换功能 一、古籍处理板块整体页面升级 将原来一整个页面呈现的布局改为分栏呈现࿰…...

Windows 账号管理与安全指南
Windows 账号管理与安全指南 概述 Windows 账号管理是系统安全的基础,了解如何正确创建、管理和保护用户账户对于系统管理员和安全专业人员至关重要。本文详细介绍 Windows 系统中的账户管理命令、隐藏账户创建方法以及安全防护措施。 基础账户管理命令 net use…...
Python窗体编程技术详解
文章目录 1. Tkinter简介示例代码优势劣势 2. PyQt/PySide简介示例代码(PyQt5)优势劣势 3. wxPython简介示例代码优势劣势 4. Kivy简介示例代码优势劣势 5. PySimpleGUI简介示例代码优势劣势 技术对比总结选择建议 Python提供了多种实现图形用户界面(GUI)编程的技术,…...

思维链提示:激发大语言模型推理能力的突破性方法
论文出处: Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 作者: Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, Denny Zhou 机构: Google Research, B…...

NVMe协议简介之AXI总线更新
更新AXI4总线知识 AXI4总线协议 AXI4总线协议是由ARM公司提出的一种片内总线协议 ,旨在实现SOC中各模块之间的高效可靠的数据传输和管理。AXI4协议具有高性能、高吞吐量和低延迟等优点,在SOC设计中被广泛应用 。随着时间的推移,AXI4的影响不…...
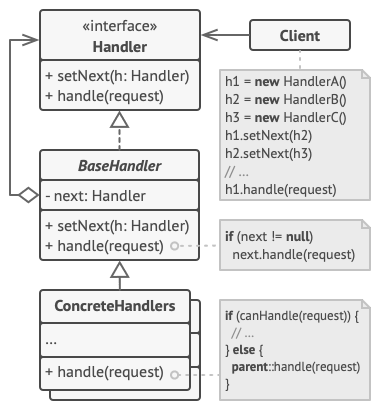
设计模式——责任链设计模式(行为型)
摘要 责任链设计模式是一种行为型设计模式,旨在将请求的发送者与接收者解耦,通过多个处理器对象按链式结构依次处理请求,直到某个处理器处理为止。它包含抽象处理者、具体处理者和客户端等核心角色。该模式适用于多个对象可能处理请求的场景…...
基于Android的医院陪诊预约系统
博主介绍:java高级开发,从事互联网行业六年,熟悉各种主流语言,精通java、python、php、爬虫、web开发,已经做了六年的毕业设计程序开发,开发过上千套毕业设计程序,没有什么华丽的语言࿰…...
基于Spring Boot 电商书城平台系统设计与实现(源码+文档+部署讲解)
技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习等设计与开发。 主要内容:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文…...
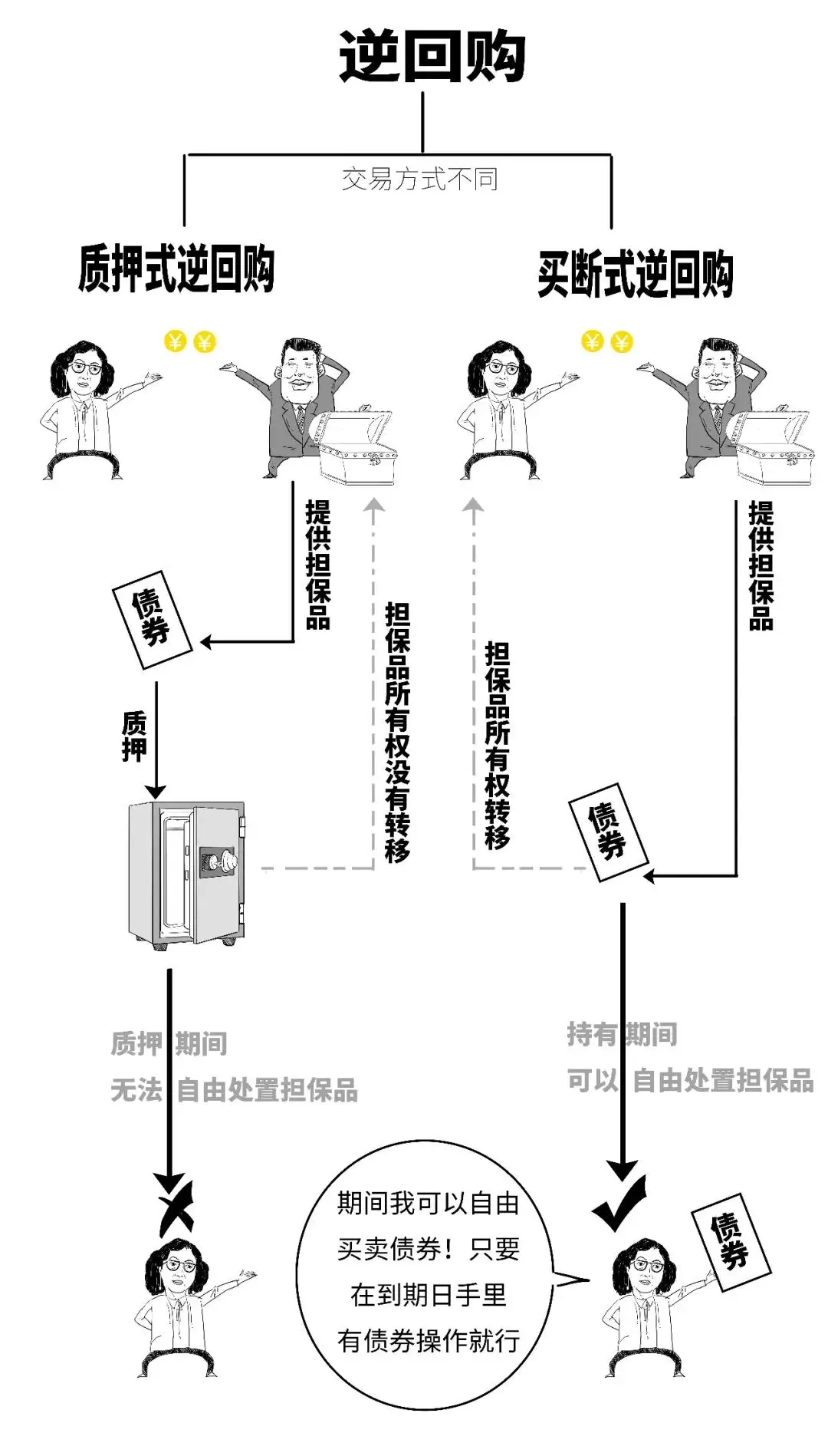
【金融基础学习】债券回购方式
债券回购作为货币市场的重要工具,本质上是一种以债券为抵押的短期资金借贷行为。在银行间市场,质押式回购与**买断式回购*是两种主要形式。 1. 质押式回购(Pledged Repo, RP) – 所有权不转移的短期融资工具 1.1 质押式回购概述 质押式回购是交易双方…...
第五十九节:性能优化-GPU加速 (CUDA 模块)
在计算机视觉领域,实时性往往是关键瓶颈。当传统CPU处理高分辨率视频流或复杂算法时,力不从心。本文将深入探索OpenCV的CUDA模块,揭示如何通过GPU并行计算实现数量级的性能飞跃。 一、GPU加速:计算机视觉的必由之路 CPU的强项在于复杂逻辑和低延迟任务,但面对图像处理中高…...

单元测试-概述入门
目录 main方法测试缺点: 在pom.xm中,引入junit的依赖。,在test/java目录下,创建测试类,并编写对应的测试方法,并在方法上声明test注解。 练习:验证身份证合法性 测试成功 测试失败 main方法测试缺点&am…...

⚡ Hyperlane —— 比 Rocket 更快的 Rust Web 框架!
⚡ Hyperlane —— 比 Rocket 更快的 Rust Web 框架! 在现代 Web 服务开发中,开发者需要一个既轻量级又高性能的 HTTP 服务器库来简化开发流程,同时确保服务的高效运行。Hyperlane 正是为此而生——一个专为 Rust 开发者设计的 HTTP 服务器库…...

《AI Agent项目开发实战》DeepSeek R1模型蒸馏入门实战
一、模型蒸馏环境部署 注:本次实验仍然采用Ubuntu操作系统,基本配置如下: 需要注意的是,本次公开课以Qwen 1.5-instruct模型为例进行蒸馏,从而能省略冷启动SFT过程,并且 由于Qwen系列模型本身性能较强&…...
失效?一行命令解决)
Ubuntu 24.04 LTS Chrome 中文输入法(搜狗等)失效?一行命令解决
Ubuntu 24.04 LTS Chrome 中文输入法(搜狗等)失效?一行命令解决 在 Ubuntu 24.04 LTS 中,如果你发现 Chrome 浏览器用不了搜狗输入法或其他 Fcitx5 中文输入法,可以试试下面的方法。 直接上解决方案: 打…...

字节golang后端二面
前端接口使用restful格式,post与get的区别是什么? HTTP网络返回的状态码有哪些? go语言切片与数组的区别是什么? MySQL实现并发安全避免两个事务同时对一个记录写操作的手段有哪些? 如何实现业务的幂等性(在…...

计算机网络物理层基础练习
第二章 物理层 填空题 从通信双方信息交互的方式来看,通信的三种基本方式为单工、半双工和全双工。其中,单工数据传输只支持数据在一个方向上传输,全双工数据传输则允许数据同时在两个方向上传输。最基本的带通调制方法包括三种:…...
vscode + cmake + ninja+ gcc 搭建MCU开发环境
vscode cmake ninja gcc 搭建MCU开发环境 文章目录 vscode cmake ninja gcc 搭建MCU开发环境1. 前言2. 工具安装及介绍2.1 gcc2.1.1 gcc 介绍2.1.2 gcc 下载及安装 2.2 ninja2.2.1 ninja 介绍2.2 ninja 安装 2.3 cmake2.3.1 cmake 介绍2.3.2 cmake 安装 2.4 VScode 3. 上手…...
三种经典算法优化无线传感器网络(WSN)覆盖(SSA-WSN、PSO-WSN、GWO-WSN),MATLAB代码实现
三种经典算法优化无线传感器网络(WSN)覆盖(SSA-WSN、PSO-WSN、GWO-WSN),MATLAB代码实现 目录 三种经典算法优化无线传感器网络(WSN)覆盖(SSA-WSN、PSO-WSN、GWO-WSN),MATLAB代码实现效果一览基本介绍程序设…...
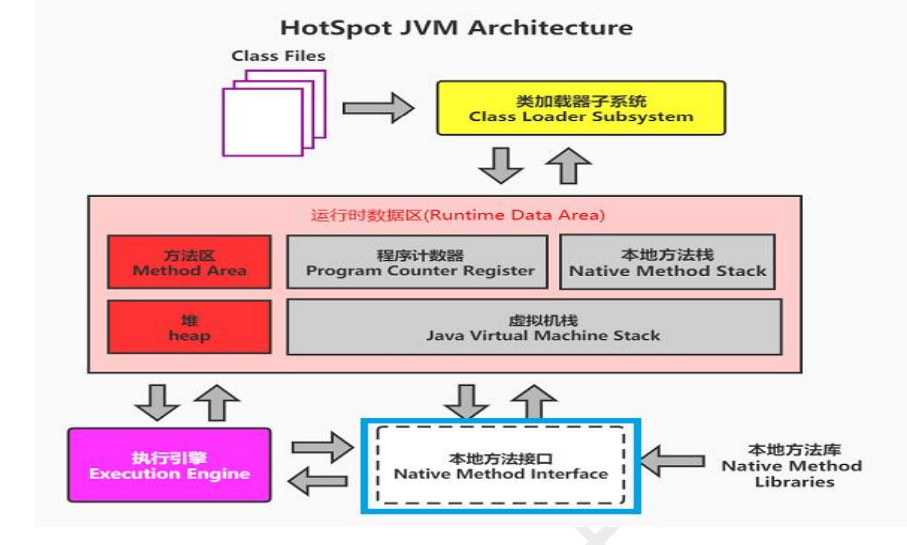
JVM 核心组件深度解析:堆、方法区、执行引擎与本地方法接口
一、JVM 堆内存:对象的生存与消亡之地 作为 Java 虚拟机中最大的内存区域,堆内存是所有对象实例的 “出生地” 与 “安息所”。从程序运行的角度看,所有通过new关键字创建的对象都在堆中分配内存,其生命周期完全由垃圾回收机制&am…...
OpenCV4.4.0下载及初步配置(Win11)
目录 OpenCV4.4.0工具下载安装环境变量系统配置 OpenCV4.4.0 工具 系统:Windows 11 下载 OpenCV全版本百度网盘链接:: https://pan.baidu.com/s/15qTzucC6ela3bErdZ285oA?pwdjxuy 提取码: jxuy找到 opencv-4.0.0-vc14_vc15 下载得到 安装 运行op…...
笔记-13】App版本不升级时本地数据库sqlite更新逻辑一)
【iOS(swift)笔记-13】App版本不升级时本地数据库sqlite更新逻辑一
App版本不升级时,又想即时更新本地数据库怎么办? 办法一:直接从服务器下载最新的sqlite数据库替换掉本地的 具体逻辑 1、首先本地数据库里一定要有一个字段(名字自己取) 比如dbVersion,可用数字&#x…...

Flink CDC将MySQL数据同步到数据湖
此项目可以理解为MySQL数据迁移,由Flink Stream监听MySQL的Binlog日志写入Kafka,在Kafka消费端将消息写入Doris或其他外部对象存储。 涉及的环境与版本 组件版本flink1.20.1flink-cdc3.4.0kafka2.13-4.0.0Dragonwell17 引入相关依赖 <?xml versio…...