Python_day43
DAY 43 复习日
作业:
kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化
进阶:并拆分成多个文件
关于 Dataset
从谷歌图片中抓取了 1000 多张猫和狗的图片。问题陈述是构建一个模型,该模型可以尽可能准确地在图像中的猫和狗之间进行分类。
图像大小范围从大约 100x100 像素到 2000x1000 像素。
图像格式为 jpeg。
已删除重复项。
猫狗图像分类 --- Cats and Dogs image classification
步骤
导入所需的模块
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset, Subset
from torchvision import transforms, datasets
import random
import os数据准备和预处理
# 设置随机种子确保可复现
torch.manual_seed(42)
np.random.seed(42)
random.seed(42)# 设置设备(优先使用GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# --- 关键修改1:调整为本地绝对路径并检查目录存在性 ---
data_dir = "d:\\code\\trae\\python_60\\Cat_and_Dog" # 你的本地项目根目录
train_dir = os.path.join(data_dir, "train") # 指向你的实际训练数据目录(需包含类别子文件夹)# 检查训练目录是否存在
if not os.path.isdir(train_dir):raise FileNotFoundError(f"训练目录不存在: {train_dir}\n""请按以下结构准备数据:\n"f"{data_dir}\n""└── train\n"" ├── cat\n" # 类别子文件夹1(如猫)" └── dog\n" # 类别子文件夹2(如狗)"(每个子文件夹存放对应类别的图片)")# --- 关键修改2:优化数据划分逻辑(修正索引生成问题) ---
proportion = 0.2 # 验证集比例
batch_size = 32 # 批量大小# 加载数据集(使用训练目录)
data = datasets.ImageFolder(root=train_dir, transform=transforms.Compose([transforms.Resize(256), # 缩放到256x256transforms.CenterCrop(224), # 中心裁剪224x224transforms.RandomHorizontalFlip(p=0.5), # 50%概率水平翻转transforms.ColorJitter( # 颜色抖动增强brightness=0.2, contrast=0.2, saturation=0.2),transforms.ToTensor(),transforms.Normalize( # ImageNet标准化参数mean=[0.485, 0.456, 0.406],std=[0.229, 0.224, 0.225])
]))n_total = len(data) # 总样本数
all_indices = list(range(n_total)) # 生成0~n_total-1的索引(修正原range(1,n)的0索引遗漏问题)
random.shuffle(all_indices) # 打乱索引确保随机划分# 按比例分割训练集和验证集
n_val = int(proportion * n_total)
val_indices = all_indices[:n_val] # 前n_val个作为验证集
train_indices = all_indices[n_val:] # 剩余作为训练集train_set = Subset(data, train_indices)
val_set = Subset(data, val_indices)# 数据加载器(补充num_workers提升加载效率)
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=4)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=False, num_workers=4)定义卷积神经网络模型
实例化模型并移至计算设备(GPU或CPU)
定义损失函数和优化器(调整学习率和权重衰减)
学习率调度(移除不兼容的verbose参数)
# 定义卷积神经网络模型(优化版)
class SimpleCNN(nn.Module):def __init__(self, dropout_rate=0.5):super().__init__()# 卷积特征提取模块(含残差连接)self.conv_layers = nn.Sequential(# 第一层:输入3通道(RGB)→16通道nn.Conv2d(3, 16, kernel_size=3, padding=1),nn.BatchNorm2d(16),nn.ReLU(),nn.MaxPool2d(2), # 224x224 → 112x112# 第二层:16→32通道 + 残差连接nn.Conv2d(16, 32, kernel_size=3, padding=1),nn.BatchNorm2d(32),nn.ReLU(),nn.Conv2d(32, 32, kernel_size=3, padding=1), # 残差分支nn.BatchNorm2d(32),nn.MaxPool2d(2), # 112x112 → 56x56# 第三层:32→64通道nn.Conv2d(32, 64, kernel_size=3, padding=1),nn.BatchNorm2d(64),nn.ReLU(),nn.Dropout2d(0.1),nn.MaxPool2d(2), # 56x56 → 28x28# 第四层:64→128通道nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.BatchNorm2d(128),nn.ReLU(),nn.Dropout2d(0.1),nn.MaxPool2d(2) # 28x28 → 14x14(与原计算一致))# 动态计算全连接层输入维度(避免硬编码错误)with torch.no_grad(): # 虚拟输入计算特征尺寸dummy_input = torch.randn(1, 3, 224, 224) # 输入尺寸与数据预处理一致dummy_output = self.conv_layers(dummy_input)self.feature_size = dummy_output.view(1, -1).size(1)# 全连接分类模块(增加正则化)self.fc_layers = nn.Sequential(nn.Linear(self.feature_size, 512),nn.BatchNorm1d(512),nn.ReLU(),nn.Dropout(dropout_rate),nn.Linear(512, 256),nn.BatchNorm1d(256),nn.ReLU(),nn.Dropout(dropout_rate),nn.Linear(256, 2) # 修正:二分类输出维度为2)def forward(self, x):x = self.conv_layers(x)x = x.view(x.size(0), -1) # 展平特征x = self.fc_layers(x)return x# 实例化模型并移至计算设备(GPU或CPU)
model = SimpleCNN(dropout_rate=0.3).to(device) # 调整Dropout率(0.3比0.5更温和)# 定义损失函数和优化器(调整学习率和权重衰减)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001, weight_decay=1e-4) # 学习率降至0.001,权重衰减微调# 学习率调度(移除不兼容的verbose参数)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='max', # 监控指标为验证准确率(越大越好)factor=0.5, # 学习率衰减因子patience=2 # 等待2个epoch无提升再衰减
)构建深度学习模型
训练主模型
# 训练模型主函数(优化版)
def train_model(model: nn.Module, train_loader: DataLoader, val_loader: DataLoader, criterion: nn.Module, optimizer: optim.Optimizer, scheduler: optim.lr_scheduler._LRScheduler, epochs: int
) -> tuple[list[float], list[float], list[float], list[float]]:# 初始化训练和验证过程中的监控指标train_losses: list[float] = [] # 存储每个epoch的训练损失val_losses: list[float] = [] # 存储每个epoch的验证损失train_accuracies: list[float] = [] # 存储每个epoch的训练准确率val_accuracies: list[float] = [] # 存储每个epoch的验证准确率# 新增:早停相关变量(可选)best_val_loss: float = float('inf')early_stop_counter: int = 0early_stop_patience: int = 5 # 连续5个epoch无提升则停止# 主训练循环 - 遍历指定轮数for epoch in range(epochs):# 设置模型为训练模式(启用Dropout和BatchNorm等训练特定层)model.train()train_loss: float = 0.0 # 累积训练损失correct: int = 0 # 正确预测的样本数total: int = 0 # 总样本数# 批次训练循环 - 遍历训练数据加载器中的所有批次for inputs, targets in train_loader:# 将数据移至计算设备(GPU或CPU)inputs, targets = inputs.to(device), targets.to(device)# 梯度清零 - 防止梯度累积(每个批次独立计算梯度)optimizer.zero_grad()# 前向传播 - 通过模型获取预测结果outputs = model(inputs)# 计算损失 - 使用预定义的损失函数(如交叉熵)loss = criterion(outputs, targets)# 反向传播 - 计算梯度loss.backward()# 参数更新 - 根据优化器(如Adam)更新模型权重optimizer.step()# 统计训练指标train_loss += loss.item() # 累积批次损失_, predicted = outputs.max(1) # 获取预测类别total += targets.size(0) # 累积总样本数correct += predicted.eq(targets).sum().item() # 累积正确预测数# 计算当前epoch的平均训练损失和准确率train_loss /= len(train_loader) # 平均批次损失train_accuracy = 100.0 * correct / total # 计算准确率百分比train_losses.append(train_loss) # 记录损失train_accuracies.append(train_accuracy) # 记录准确率# 模型验证部分model.eval() # 设置模型为评估模式(禁用Dropout等)val_loss: float = 0.0 # 累积验证损失correct = 0 # 正确预测的样本数total = 0 # 总样本数# 禁用梯度计算 - 验证过程不需要计算梯度,节省内存和计算资源with torch.no_grad():# 遍历验证数据加载器中的所有批次for inputs, targets in val_loader:# 将数据移至计算设备inputs, targets = inputs.to(device), targets.to(device)# 前向传播 - 获取验证预测结果outputs = model(inputs)# 计算验证损失loss = criterion(outputs, targets)# 统计验证指标val_loss += loss.item() # 累积验证损失_, predicted = outputs.max(1) # 获取预测类别total += targets.size(0) # 累积总样本数correct += predicted.eq(targets).sum().item() # 累积正确预测数# 计算当前epoch的平均验证损失和准确率val_loss /= len(val_loader) # 平均验证损失val_accuracy = 100.0 * correct / total # 计算验证准确率val_losses.append(val_loss) # 记录验证损失val_accuracies.append(val_accuracy) # 记录验证准确率# 打印当前epoch的训练和验证指标print(f'Epoch {epoch+1}/{epochs}')print(f'Train Loss: {train_loss:.4f} | Train Acc: {train_accuracy:.2f}%')print(f'Val Loss: {val_loss:.4f} | Val Acc: {val_accuracy:.2f}%')print('-' * 50)# 更新学习率调度器(修正mode为min,匹配验证损失)scheduler.step(val_loss) # 传入验证损失,mode='min'# 新增:早停逻辑(可选)if val_loss < best_val_loss:best_val_loss = val_lossearly_stop_counter = 0# 可选:保存最佳模型权重torch.save(model.state_dict(), 'best_model.pth')else:early_stop_counter += 1if early_stop_counter >= early_stop_patience:print(f"Early stopping at epoch {epoch+1}")break# 返回训练和验证过程中的所有指标,用于后续分析和可视化return train_losses, val_losses, train_accuracies, val_accuracies# 训练模型(保持调用方式不变)
epochs = 20
train_losses, val_losses, train_accuracies, val_accuracies = train_model(model, train_loader, val_loader, criterion, optimizer, scheduler, epochs
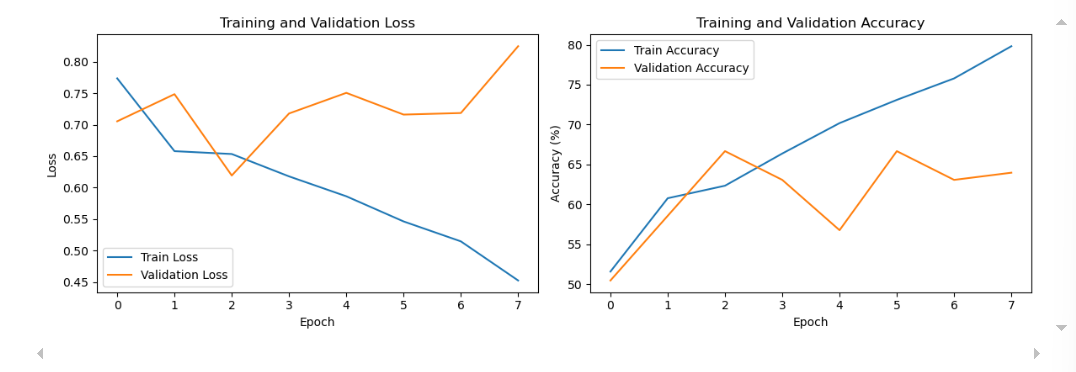
)# 可视化训练过程(保持原函数不变)
def plot_training(train_losses, val_losses, train_accuracies, val_accuracies):plt.figure(figsize=(12, 4))plt.subplot(1, 2, 1)plt.plot(train_losses, label='Train Loss')plt.plot(val_losses, label='Validation Loss')plt.xlabel('Epoch')plt.ylabel('Loss')plt.legend()plt.title('Training and Validation Loss')plt.subplot(1, 2, 2)plt.plot(train_accuracies, label='Train Accuracy')plt.plot(val_accuracies, label='Validation Accuracy')plt.xlabel('Epoch')plt.ylabel('Accuracy (%)')plt.legend()plt.title('Training and Validation Accuracy')plt.tight_layout()plt.show()plot_training(train_losses, val_losses, train_accuracies, val_accuracies)模型评估结构
获取预测
@浙大疏锦行
相关文章:
Python_day43
DAY 43 复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 关于 Dataset 从谷歌图片中抓取了 1000 多张猫和狗的图片。问题陈述是构建一个模型,该模型可以尽可能准确地在图像…...
STM32CubeDAC及DMA配置
STM32CubeDAC及DMA配置 一,问题1二,解决11,宏观思路CubeMX配置2,HAL_TIM_Base_Start(&htim6) 的作用1,作用1:使能TIM6的时钟并让它开始计数2,作用2:当 TIM6 溢出时,会…...

SQL快速入门【转自牛客网】
来源:牛客网 1、SQL 基础查询 在 SQL 中,SELECT 语句是最基本的查询语句,用于从数据库表中检索数据。通过 SELECT 语句,可以选择表中的所有列或特定列,并根据需要进行过滤和排序。 基本语法 SELECT 语句的基本语法如下: SELECT column1, column2, ... FROM table_na…...
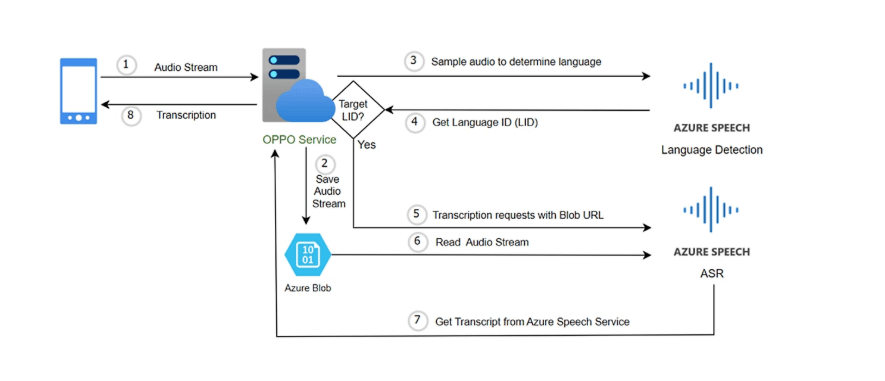
行业案例 | OPPO借助Azure AI Speech国际服务实现音频文件智能转录
OPPO是全球领先的智能终端与移动互联网服务提供商,业务覆盖50余国,通过超40万销售网点和2500个服务中心与全球用户共享科技。作为软硬服一体化科技公司,OPPO以ColorOS为核心优化软件平台,为4.4亿月活用户打造智能操作系统…...

基于 OpenCV 和 DLib 实现面部特征调整(眼间距、鼻子、嘴巴)
摘 要 本文介绍如何利用Dlib面部特征点检测和OpenCV图像处理技术,通过Python实现面部特征的精准调整。我们将以改变眼间距为例,演示包括地标检测、三角剖分变形等关键技术,该方法可扩展至嘴唇、眉毛等面部特征的调整。 技术栈 Python 3.8 …...
spring-boot接入websocket教程以及常见问题解决
我们使用spring-boot接入websocket有三种方式:使用EnableWebSocket、EnableWebSocketMessageBroker以及ServerEndpoint,本文主要介绍使用ServerEndpoint方式的流程以及碰到的问题解决 接入方式 添加依赖 确保spring-boot-starter-websocket依赖 <d…...
迈向分布式智能:解析MCP到A2A的通信范式迁移
智能体与外部世界的桥梁之言: 在深入探讨智能体之间的协作机制之前,我们有必要先厘清一个更基础的问题:**单个智能体如何与外部世界建立连接?** 这就引出了我们此前介绍过的 **MCP(Model Context Protocol&…...
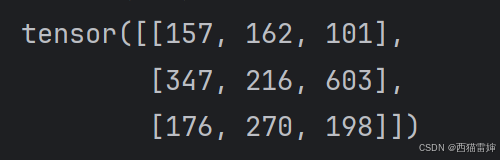
深度学习|pytorch基本运算-hadamard积、点积和矩阵乘法
【1】引言 pytorch对张量的基本运算和线性代数课堂的教学有一些区别,至少存在hadamard积、点积和矩阵乘法三种截然不同的计算方法。 【2】hadamard积 hadamard积是元素对位相乘,用“*”连接张量,代码: # 导入包 import torch …...
FFmpeg移植教程(linux平台)
目录 第三方源码编译三部曲关于 configure 的说明 FFmpeg 移植流程获取源码方法一:git 远程克隆方法二:官网下载压缩包解压 配置安装 第三方源码编译三部曲 Linux平台下有许多开源的第三方库和服务,这些开源代码一般都符合GNU-autotools编码…...
Mybatis:灵活掌控SQL艺术
在前面的文章中,小编分享了spring中相关的知识,但是没有分享到,如何去更高效操作数据库。 操作数据库传统的方法就是通过JDBC来进行操作。 这个传统方法使用上可谓是够麻烦的 1.首先创建一个数据源对象 2.设置该数据源的属性(…...
2025.05.28【Choropleth】群体进化学专用图:区域数据可视化
Load geospatial data Start by loading your geospatial data in R, and build a basic plot. Data from the package The cartography comes with a set of geospatial data included. Learn how to use it to build a choropleth map. 文章目录 Load geospatial dataData …...
)
Java设计模式详解:策略模式(Strategy Pattern)
在软件开发中,设计模式是解决常见问题的经典方法。策略模式(Strategy Pattern)作为一种行为型设计模式,能够将算法或行为的定义与使用分离,使得算法可以独立于客户端代码进行变化和扩展。本文将深入解析策略模式的核心…...
【春秋云镜】CVE-2022-26965 靶场writeup
知识点 网站的主题或者模块位置一般是可以上传文件的,不过一般为压缩包形式主题或者模块可以上github上找到和cms匹配的源码主题被解压后会放到加入到对应的文件夹中,而且还会自动执行对应的info.php文件(需要主题和cms配套才行)我这里取巧了࿰…...
)
爬虫的几种方式(使用什么技术来进行一个爬取数据)
在网页数据爬取中,确实存在多种数据呈现和获取形式,远不止静态HTML解析和简单JS渲染。理解这些形式对于应对不同的反爬机制至关重要: 主要数据获取形式与应对策略 纯静态HTML (基础形式) 特点: 数据直接嵌入在服务器返回的初始HT…...

XML 编码:结构化数据的基石
XML 编码:结构化数据的基石 引言 XML(可扩展标记语言)作为互联网上广泛使用的数据交换格式,已经成为结构化数据存储和传输的重要工具。本文旨在深入探讨XML编码的原理、应用场景以及编码规范,帮助读者更好地理解和运用XML。 XML编码概述 1. XML的起源 XML诞生于1998年…...

nt!CcGetVacbMiss函数分析之设置好nt!_VACB然后调用函数nt!SetVacb
第一部分:MmMapViewInSystemCache函数返回 Status MmMapViewInSystemCache (SharedCacheMap->Section, &Vacb->BaseAddress, &NormalOffset, …...
JSP、HTML和Tomcat
9x9上三角乘法表 乘法表的实现 <% page contentType"text/html;charsetUTF-8" language"java" %> <!DOCTYPE html> <html> <head><title>99 上三角乘法表</title><style>body {font-family: monospace;padding…...
(1)pytest简介和环境准备
1. pytest简介 pytest是python的一种单元测试框架,与python自带的unittest测试框架类似,但是比unittest框架使用起来更简洁,效率更高。根据pytest的官方网站介绍,它具有如下特点: 非常容易上手,入门简单&a…...

Git 入门学习教程
Git 入门学习教程 什么是 Git? Git 是一个分布式版本控制系统,由 Linus Torvalds 为 Linux 内核开发而创建。它可以帮助开发者: 跟踪代码变化协作开发项目回退到之前的版本创建分支进行实验性开发 安装 Git Windows 下载 Git for Windo…...
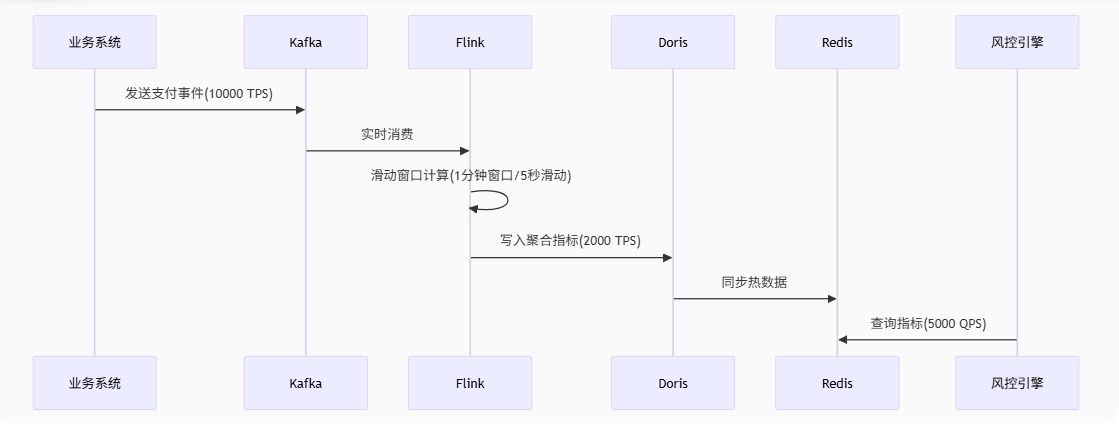
构建高性能风控指标系统
一、引言 在金融风控领域,指标是风险识别的核心依据。风控平台核心系统之一--规则引擎的运行依赖规则、变量和指标,一个高性能的指标系统非常重要,本文将深入探讨风控平台指标系统的全链路技术实现,涵盖从指标配置到查询优化的完…...

openfeignFeign 客户端禁用 SSL
要针对特定的 Feign 客户端禁用 SSL 验证,可以通过自定义配置类实现。以下是完整解决方案: 1. 创建自定义配置类(禁用 SSL 验证) import feign.Client; import feign.httpclient.ApacheHttpClient; import org.apache.http.conn…...

DeepSeek 赋能自动驾驶仿真测试:解锁高效精准新范式
目录 一、自动驾驶仿真测试概述1.1 自动驾驶发展现状1.2 自动驾驶仿真测试流程 二、DeepSeek 技术剖析2.1 DeepSeek 简介2.2 DeepSeek 核心技术原理 三、DeepSeek 在自动驾驶仿真测试中的应用原理3.1 与自动驾驶仿真测试流程的结合点3.2 如何提升仿真测试效果 四、DeepSeek 在自…...
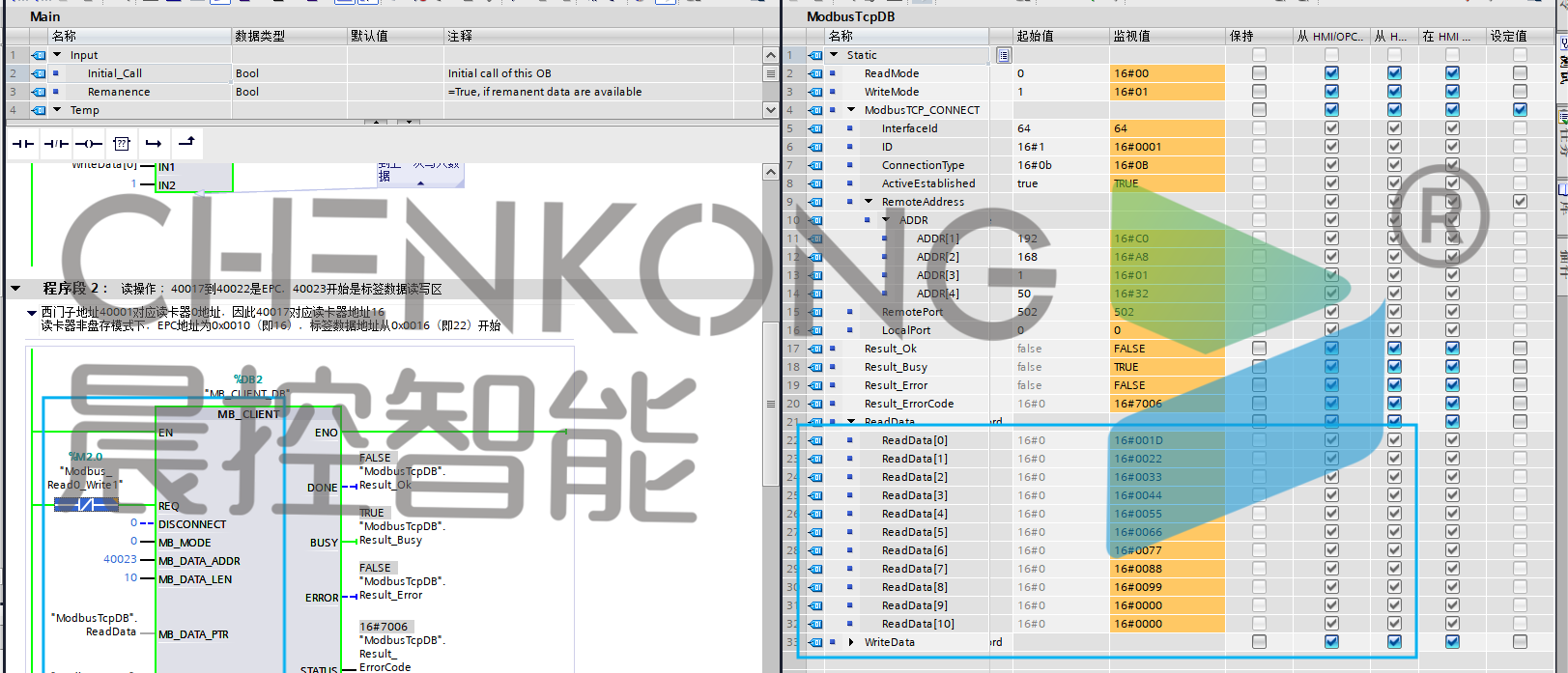
晨控CK-UR12与西门子PLC配置Modbus TCP通讯连接操作手册
晨控CK-UR12与西门子PLC配置Modbus TCP通讯连接操作手册 晨控CK-UR12系列作为晨控智能工业级别RFID读写器,支持大部分工业协议如RS232、RS485、以太网。支持工业协议Modbus RTU、Modbus TCP、Profinet、EtherNet/lP、EtherCat以及自由协议TCP/IP等。 本期主题:围绕…...

实验一:PyTorch基本操作实验
import torch # PyTorch中初始化矩阵常见有以下几种方法 # 1. 直接使用固定值初始化 # M torch.tensor([[1.0, 2.0, 3.0]]) # 1x3矩阵 # 2. 随机初始化 # M torch.rand(1, 3) # 1x3矩阵,元素在0-1之间均匀分布 # M torch.randn(1, 3) # 1x3矩阵,元…...
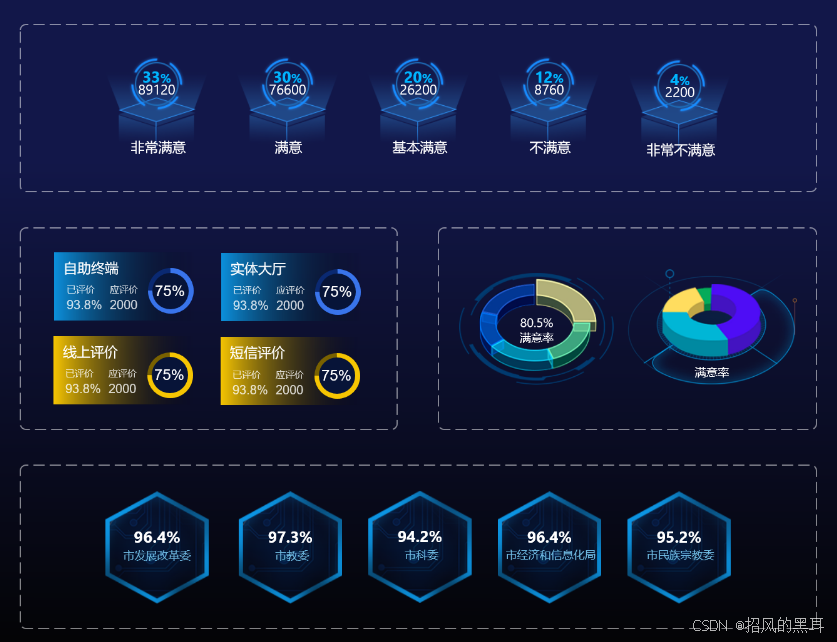
可视化大屏通用模板Axure原型设计案例
本文将介绍一款基于Axure设计的可视化大屏通用模板,适用于城市、网络安全、园区、交通、社区、工业、医疗、能源等多个领域。 模板概述 这款Axure可视化大屏通用模板集成了多种数据展示模块和组件,旨在为用户提供一个灵活、可定制的数据展示平台。无论…...
与正则表达式(Regular Expression)的关系及区别)
通配符(Wildcard)与正则表达式(Regular Expression)的关系及区别
通配符(Wildcard)与正则表达式(Regular Expression)的关系及区别 1. 通配符(Wildcard) 定义:通配符是用于简单模式匹配的特殊符号,主要用于文件名匹配(如命令行操作&…...
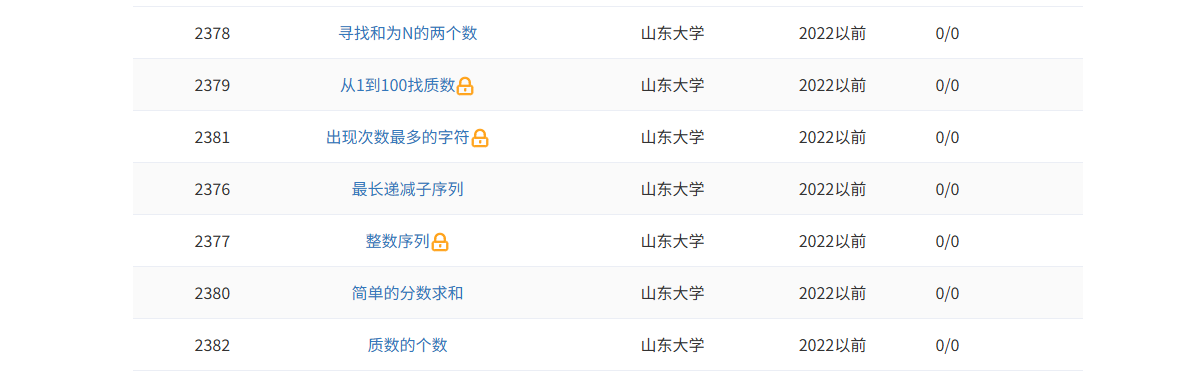
历年山东大学计算机保研上机真题
历年山东大学计算机保研上机真题 2025山东大学计算机保研上机真题 2024山东大学计算机保研上机真题 2023山东大学计算机保研上机真题 在线测评链接:https://pgcode.cn/school 从1到100找质数 题目描述 从 1 1 1 到 100 100 100 中找出所有的质数。 输入格式 …...
Java处理动态的属性:字段不固定、需要动态扩展的 JSON 数据结构
文章目录 引言I `JSONObject` 接收和返回JSONObject 接收和返回数据存储II 签名测试接口dto的定义签名计算III JsonAnySetter 和JsonAnyGetter 注解@JsonAnySetter 的用法@JsonAnyGetter 的用法综合示例引言 应用场景: 签名测试接口、表单配置项、参数列表、插件信息等。技术实…...
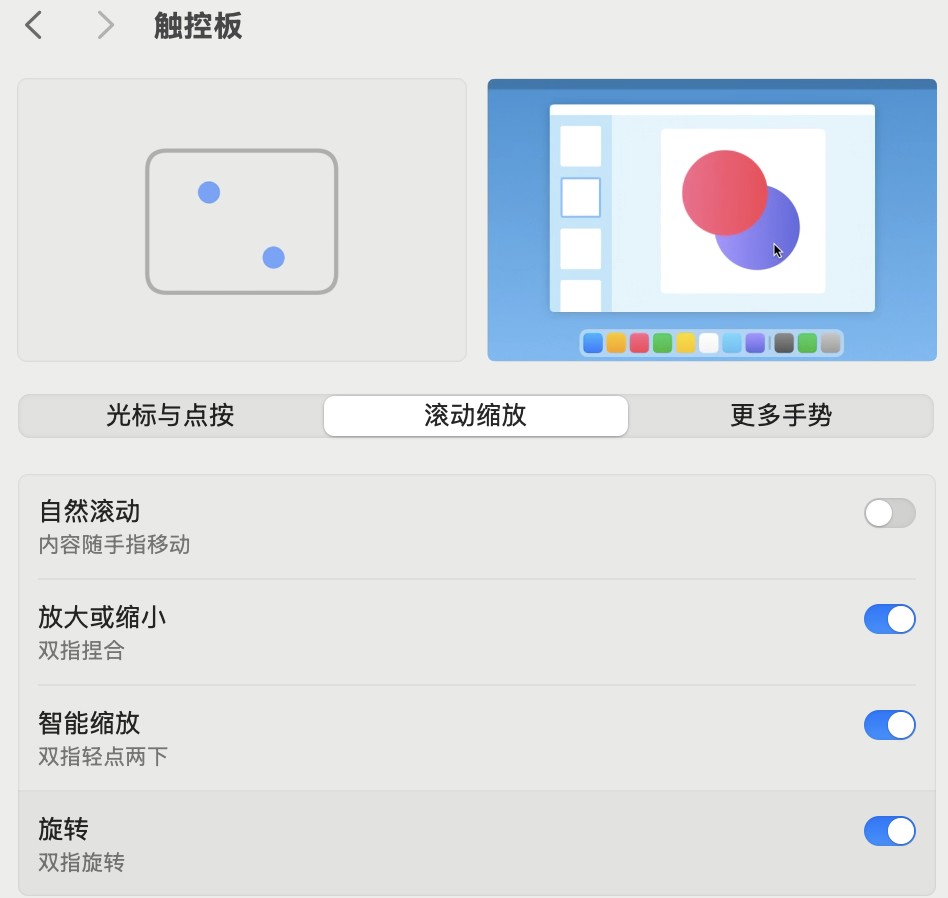
MAC电脑怎么通过触摸屏打开右键
在Mac电脑上,通过触摸屏打开右键菜单的方法如下: 法1:双指轻点:在触控板上同时用两根手指轻点,即可触发右键菜单。这是Mac上常用的右键操作方法。 法2:自定义触控板角落:可以设置触控板的右下角或左下角作为右键区域…...

用 Whisper 打破沉默:AI 语音技术如何重塑无障碍沟通方式?
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...