力扣题解106:从中序与后序遍历序列构造二叉树
一、题目内容
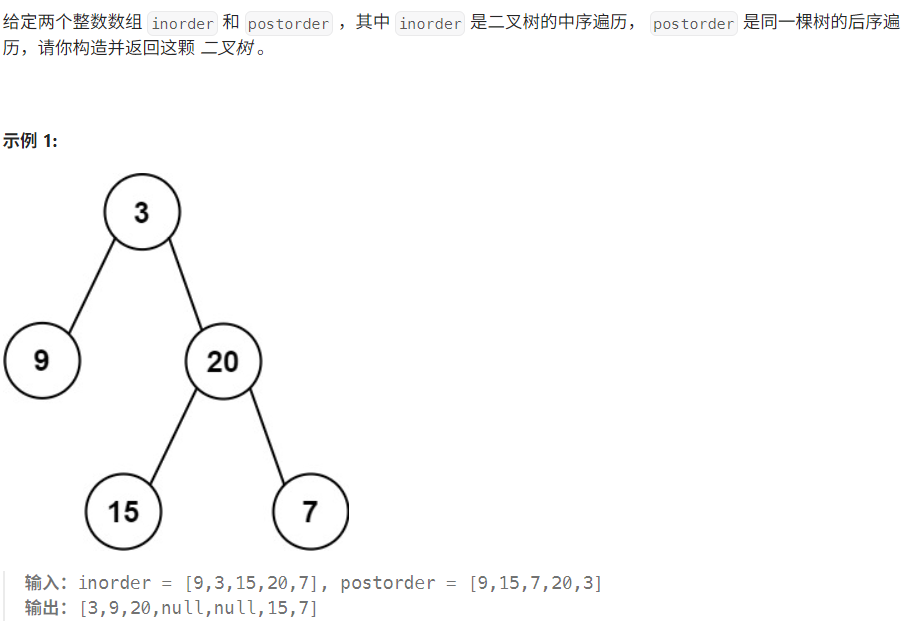
题目要求根据二叉树的中序遍历序列和后序遍历序列来重建二叉树。具体来说,我们需要利用中序遍历序列和后序遍历序列的特点,通过递归的方法逐步构建出完整的二叉树。
中序遍历序列的特点是:左子树 -> 根节点 -> 右子树。后序遍历序列的特点是:左子树 -> 右子树 -> 根节点。因此,后序遍历的最后一个元素一定是根节点。通过这个根节点,我们可以在中序遍历序列中找到左子树和右子树的分界点,从而递归地构建左右子树。
我们需要声明一些变量来记录当前的遍历范围和递归的状态。在递归过程中,我们需要不断更新这些变量的值,以确保正确地构建每个子树。
二、题目分析
输入和输出
输入:
-
两个整数数组
inorder和postorder。-
inorder:二叉树的中序遍历序列。 -
postorder:二叉树的后序遍历序列。
-
输出:
-
构建好的二叉树的根节点(
TreeNode类型)。
递归函数 traversal 的逻辑
参数:
-
inorder:当前子树的中序遍历序列。 -
postorder:当前子树的后序遍历序列。
逻辑:
-
如果
postorder为空,说明当前子树为空,返回NULL。 -
获取当前子树的根节点值
rootvalue,即postorder的最后一个元素。 -
创建根节点
root,值为rootvalue。 -
如果
postorder只有一个元素,说明当前子树只有一个节点,直接返回root。 -
在中序遍历中找到根节点的位置
mid。 -
根据
mid,将中序遍历序列划分为左子树和右子树。 -
根据左子树的大小,将后序遍历序列划分为左子树和右子树。
-
递归构建左子树和右子树。
-
返回根节点
root。
三、代码解答
1. C++代码
class Solution {
public:// 主函数,用于调用递归函数并返回结果TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if (postorder.empty() || inorder.empty()) return NULL;return traversal(inorder, postorder);}private:// 辅助递归函数TreeNode* traversal(vector<int>& inorder, vector<int>& postorder) {// 如果 postorder 为空,说明当前子树为空if (postorder.empty()) return NULL;// 获取当前子树的根节点值int rootvalue = postorder.back();TreeNode* root = new TreeNode(rootvalue);// 如果 postorder 只有一个元素,说明当前子树只有一个节点if (postorder.size() == 1) return root;// 在中序遍历中找到根节点的位置auto it = find(inorder.begin(), inorder.end(), rootvalue);int mid = distance(inorder.begin(), it);// 根据 mid,将中序遍历序列划分为左子树和右子树vector<int> leftInorder(inorder.begin(), inorder.begin() + mid);vector<int> rightInorder(inorder.begin() + mid + 1, inorder.end());// 根据左子树的大小,将后序遍历序列划分为左子树和右子树postorder.pop_back(); // 移除当前根节点vector<int> leftpostorder(postorder.begin(), postorder.begin() + leftInorder.size());vector<int> rightpostorder(postorder.begin() + leftInorder.size(), postorder.end());// 递归构建左子树和右子树root->left = traversal(leftInorder, leftpostorder);root->right = traversal(rightInorder, rightpostorder);return root;}
};详细注释
成员变量
-
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder):主函数,用于调用递归函数并返回结果。 -
TreeNode* traversal(vector<int>& inorder, vector<int>& postorder):辅助递归函数,用于构建当前子树。
辅助递归函数 traversal
TreeNode* traversal(vector<int>& inorder, vector<int>& postorder) {// 如果 postorder 为空,说明当前子树为空if (postorder.empty()) return NULL;// 获取当前子树的根节点值int rootvalue = postorder.back();TreeNode* root = new TreeNode(rootvalue);// 如果 postorder 只有一个元素,说明当前子树只有一个节点if (postorder.size() == 1) return root;// 在中序遍历中找到根节点的位置auto it = find(inorder.begin(), inorder.end(), rootvalue);int mid = distance(inorder.begin(), it);// 根据 mid,将中序遍历序列划分为左子树和右子树vector<int> leftInorder(inorder.begin(), inorder.begin() + mid);vector<int> rightInorder(inorder.begin() + mid + 1, inorder.end());// 根据左子树的大小,将后序遍历序列划分为左子树和右子树postorder.pop_back(); // 移除当前根节点vector<int> leftpostorder(postorder.begin(), postorder.begin() + leftInorder.size());vector<int> rightpostorder(postorder.begin() + leftInorder.size(), postorder.end());// 递归构建左子树和右子树root->left = traversal(leftInorder, leftpostorder);root->right = traversal(rightInorder, rightpostorder);return root;
}-
空子树检查: 如果
postorder为空,说明当前子树为空,返回NULL。 -
获取根节点值: 从后序遍历中获取当前子树的根节点值
rootvalue,即postorder.back()。 -
创建根节点: 创建根节点
root,值为rootvalue。 -
单节点子树检查: 如果
postorder只有一个元素,说明当前子树只有一个节点,直接返回root。 -
找到根节点在中序遍历中的位置: 在中序遍历中找到根节点的位置
mid。 -
划分中序遍历序列: 根据
mid,将中序遍历序列划分为左子树和右子树。 -
划分后序遍历序列: 根据左子树的大小,将后序遍历序列划分为左子树和右子树。
-
递归构建左子树和右子树: 递归调用
traversal函数构建左子树和右子树。 -
返回根节点: 返回构建好的根节点
root。
主函数 buildTree
TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if (postorder.empty() || inorder.empty()) return NULL;return traversal(inorder, postorder);
}-
调用递归函数: 从根节点开始,调用
traversal函数,传入整个中序遍历和后序遍历的序列。 -
返回结果: 返回构建好的二叉树的根节点。
回溯和递归的详细解释
递归
递归是一种函数调用自身的方法,用于解决复杂问题。在本题中,递归用于逐步构建二叉树的每个子树。
每次递归调用时,我们通过后序遍历的最后一个元素确定当前子树的根节点,并在中序遍历中找到该根节点的位置,从而确定左子树和右子树的范围。
递归调用的终止条件是当前子树为空(postorder.empty())。
回溯
回溯是一种在递归调用返回后恢复状态的机制。
在本题中,每次递归调用返回后,我们通过更新 postorder 和边界索引,恢复到当前子树的状态。这样可以确保每次递归返回后,状态正确,不会影响后续的递归调用。
示例
假设中序遍历序列 inorder = [4, 2, 5, 1, 6, 3, 7],后序遍历序列 postorder = [4, 5, 2, 6, 7, 3, 1]。
相关文章:
力扣题解106:从中序与后序遍历序列构造二叉树
一、题目内容 题目要求根据二叉树的中序遍历序列和后序遍历序列来重建二叉树。具体来说,我们需要利用中序遍历序列和后序遍历序列的特点,通过递归的方法逐步构建出完整的二叉树。 中序遍历序列的特点是:左子树 -> 根节点 -> 右子树。后…...

Vue传参Props还是Pinia
Pinia 适用场景 全局状态管理 多个不相关组件需要共享数据需要跨页面/路由共享状态 复杂状态逻辑 包含多个相互关联的状态有复杂的状态修改逻辑 持久化需求 需要将状态保存到localStorage/sessionStorage页面刷新后需要恢复状态(恢复最后一次修改的状态࿰…...

学习STC51单片机25(芯片为STC89C52RCRC)
每日一言 生活就像弹簧,你弱它就强,你强它就弱,别轻易认输。 ESP8266作为路由器模式(AP模式)也就是在局域网内可以有服务器的作用 那么我们需要将pc作为设备进行连接ESP的发射出来的WIFE 叫做这个AI啥的 也有可能叫做…...

宁夏农业科技:创新引领,赋能现代农业新篇章
在广袤的宁夏大地上,农业科技如同一股强劲的春风,吹拂着每一寸土地,为宁夏的农业发展注入了新的活力与希望。近年来,宁夏农业科技以其独特的创新力和实践力,不断推动着现代农业的转型升级,让这片古老的土地…...

Accelerate 2025北亚巡展正式启航!AI智御全球·引领安全新时代
近日,网络安全行业年度盛会Accelerate 2025北亚巡展正式在深圳启航!智库专家、产业领袖及Fortinet高管、产品技术团队和300余位行业客户齐聚一堂,围绕“AI智御全球引领安全新时代”主题,共同探讨AI时代网络安全新范式。大会聚焦三…...
005学生心理咨询评估系统技术解析:搭建科学心理评估平台
学生心理咨询评估系统技术解析:搭建科学心理评估平台 在心理健康教育日益受重视的当下,学生心理咨询评估系统成为了解学生心理状态的重要工具。该系统涵盖试卷管理、试题管理等核心模块,面向管理员和用户两类角色,通过前台展示与…...

azure devops 系列 - 常用的task
任务在管道中执行操作。例如,任务可以构建应用、与 Azure 资源交互、安装工具或运行测试。任务是定义管道中自动化的构建基块。 运行作业时,所有任务都会按顺序依次运行。要在多个代理上并行运行同一组任务,或者在不使用代理的情况下运行某些任务,使用job。 Build Task …...

贪心算法应用:多重背包启发式问题详解
贪心算法应用:多重背包启发式问题详解 多重背包问题是经典的组合优化问题,也是贪心算法的重要应用场景。本文将全面深入地探讨Java中如何利用贪心算法解决多重背包问题。 多重背包问题定义 **多重背包问题(Multiple Knapsack Problem)**是背包问题的变…...

【保姆级教程】PDF批量转图文笔记
如果你有一个PDF文档,然后你想把它发成图文笔记emmm,最好再加个水印,你会怎么做? 其实也不麻烦,打开PDF文档,挨个截图,然后打开PS一张一张图片拖进去,再把水印图片拖进去࿰…...

Pytest Fixture 是什么?
Fixture 是什么? Fixture 是 Pytest 测试框架的核心功能之一,用于为测试函数提供所需的依赖资源或环境。它的核心目标是: ✅ 提供测试数据(如模拟对象、数据库记录) ✅ 初始化系统状态(如配置、临时文件&a…...

Spring Boot 基础知识全面解析:快速构建企业级应用的核心指南
一、Spring Boot 概述:重新定义 Java 开发 1.1 什么是 Spring Boot? Spring Boot 是基于 Spring 框架的快速开发框架,旨在简化 Spring 应用的初始搭建及开发过程。它通过 「约定优于配置」(Convention Over Configuration&#…...

数据库系统概论(十一)SQL 集合查询 超详细讲解(附带例题表格对比带你一步步掌握)
数据库系统概论(十一)SQL 集合查询 超详细讲解(附带例题表格对比带你一步步掌握) 前言一、什么是集合查询?二、集合操作的三种类型1. 并操作2. 交操作3. 差操作 三、使用集合查询的前提条件四、常见问题与注意事项五、…...

[mcu]系统频率
系统主频的选择直接影响性能、功耗和成本,不同厂商的芯片会根据应用场景设计不同的运行频率。 低频段80MHZ~160MHz 典型频率: 80MHz、120MHz、160MHz 特点: 低功耗,适合电池供电设备 处理能力有限,通常仅支持 单天线…...

clickhouse如何查看操作记录,从日志来查看写入是否成功
背景 插入表数据后,因为原本表中就有数据,一时间没想到怎么查看插入是否成功,因为对数据源没有很多的了解,这时候就想怎么查看下插入是否成功呢,于是就有了以下方法 具体方法 根据操作类型查找,比如inse…...

5G-A:开启通信与行业变革的新时代
最近,不少细心的用户发现手机信号标识悄然发生了变化,从熟悉的 “5G” 变成了 “5G-A”。这一小小的改变,却蕴含着通信技术领域的重大升级,预示着一个全新的通信时代正在向我们走来。今天,就让我们深入了解一下 5G-A&a…...

鸿蒙OS在UniApp中集成Three.js:打造跨平台3D可视化应用#三方框架 #Uniapp
在UniApp中集成Three.js:打造跨平台3D可视化应用 引言 在最近的一个项目中,我们需要在UniApp应用中展示3D模型,并实现实时交互功能。经过技术选型和实践,我们选择了Three.js作为3D渲染引擎。本文将分享我们在UniApp中集成Three.…...

Vue 3 组件化设计实践:构建可扩展、高内聚的前端体系
Vue 3 自发布以来,其引入的 Composition API 与改进的组件模型,为前端架构提供了更强的可组合性、复用性与模块化能力。本文将系统性探讨 Vue 3 如何通过组件化设计,实现复杂应用的解耦、扩展与维护,并结合实际工程经验提供最佳实…...

腾讯云 Python3.12.8 通过yum安装 并设置为默认版本
在腾讯云服务器上,直接通过 yum 安装 Python 3.12.8 可能不可行,因为标准仓库通常不包含最新的 Python 版本。不过,我们可以通过添加第三方仓库或手动安装 RPM 包的方式实现。以下是完整解决方案: 方法 1: 通过第三方仓库安装&am…...

鸿蒙OSUniApp页面切换动效实战:打造流畅精致的转场体验#三方框架 #Uniapp
UniApp页面切换动效实战:打造流畅精致的转场体验 引言 在移动应用开发中,页面切换动效不仅能提升用户体验,还能传达应用的品质感。随着HarmonyOS的普及,用户对应用的动效体验要求越来越高。本文将深入探讨如何在UniApp中实现流畅…...

React 泛型组件:用TS来打造灵活的组件。
文章目录 前言一、什么是泛型组件?二、为什么需要泛型组件?三、如何在 React 中定义泛型组件?基础泛型组件示例使用泛型组件 四、泛型组件的高级用法带默认类型的泛型组件多个泛型参数 五、泛型组件的实际应用场景数据展示组件表单组件状态管…...
TDengine 集群运行监控
简介 为了确保集群稳定运行,TDengine 集成了多种监控指标收集机制,并通过 taosKeeper 进行汇总。taosKeeper 负责接收这些数据,并将其写入一个独立的 TDengine 实例中,该实例可以与被监控的 TDengine 集群保持独立。TDengine 中的…...

图像任务中的并发处理:线程池、Ray、Celery 和 asyncio 的比较
在图像缺陷检测任务中,处理大量图像和点云数据时,高效的并发处理是关键。本文将介绍五种流行的并发处理方法:线程池(concurrent.futures.ThreadPoolExecutor)、Ray、Celery、asyncio以及搜狗Workflow,并从原…...

DeepSeek 赋能智能物流:解锁仓储机器人调度的无限可能
目录 一、智能物流仓储机器人调度现状1.1 传统调度面临的挑战1.2 现有智能调度的进展与局限 二、DeepSeek 技术探秘2.1 DeepSeek 核心技术原理2.2 DeepSeek 的独特优势 三、DeepSeek 在智能物流仓储机器人调度中的创新应用3.1 智能任务分配与调度3.2 路径规划与避障优化3.3 实时…...

C#上传图片后压缩
上传的图片尺寸不一,手机拍照的有2000*2000像素的,对实际使用来说 文件尺寸太大,文件也有近4M 下面是直接压缩的方法 1、安装包 Magick.NET-Q16-AnyCPU 2、上代码 /// <summary> /// 缩放图片 /// </summary> /// <param …...
uniapp路由跳转toolbar页面
需要阅读uview-ui的API文档 注意需要使用type参数设置后才起作用 另外route跳转的页面会覆盖toolbar工具栏 toConternt(aid) {console.log(aid:, aid)this.$u.route({// url: "pages/yzpg/detail",url: "pages/yzappl/index",// url: "pages/ind…...

【linux】知识梳理
操作系统的分类 1. 桌⾯操作系统: Windows/macOS/Linux 2. 移动端操作系统: Android(安卓)/iOS(苹果) 3. 服务器操作系统: Linux/Windows Server 4. 嵌⼊式操作系统: Android(底层是 Linux) Liunx介绍 liunx系统:服务器端最常见的操作系统类型 发行版:Centos和Ubuntu 远程连接操…...

PostgreSQL 内置扩展列表
PostgreSQL 内置扩展列表 PostgreSQL 自带了许多内置扩展(built-in extensions),这些扩展提供了额外的功能而不需要额外安装。以下是主要的内置扩展分类和说明: 标准内置扩展(随核心安装) 1. 管理类扩展…...
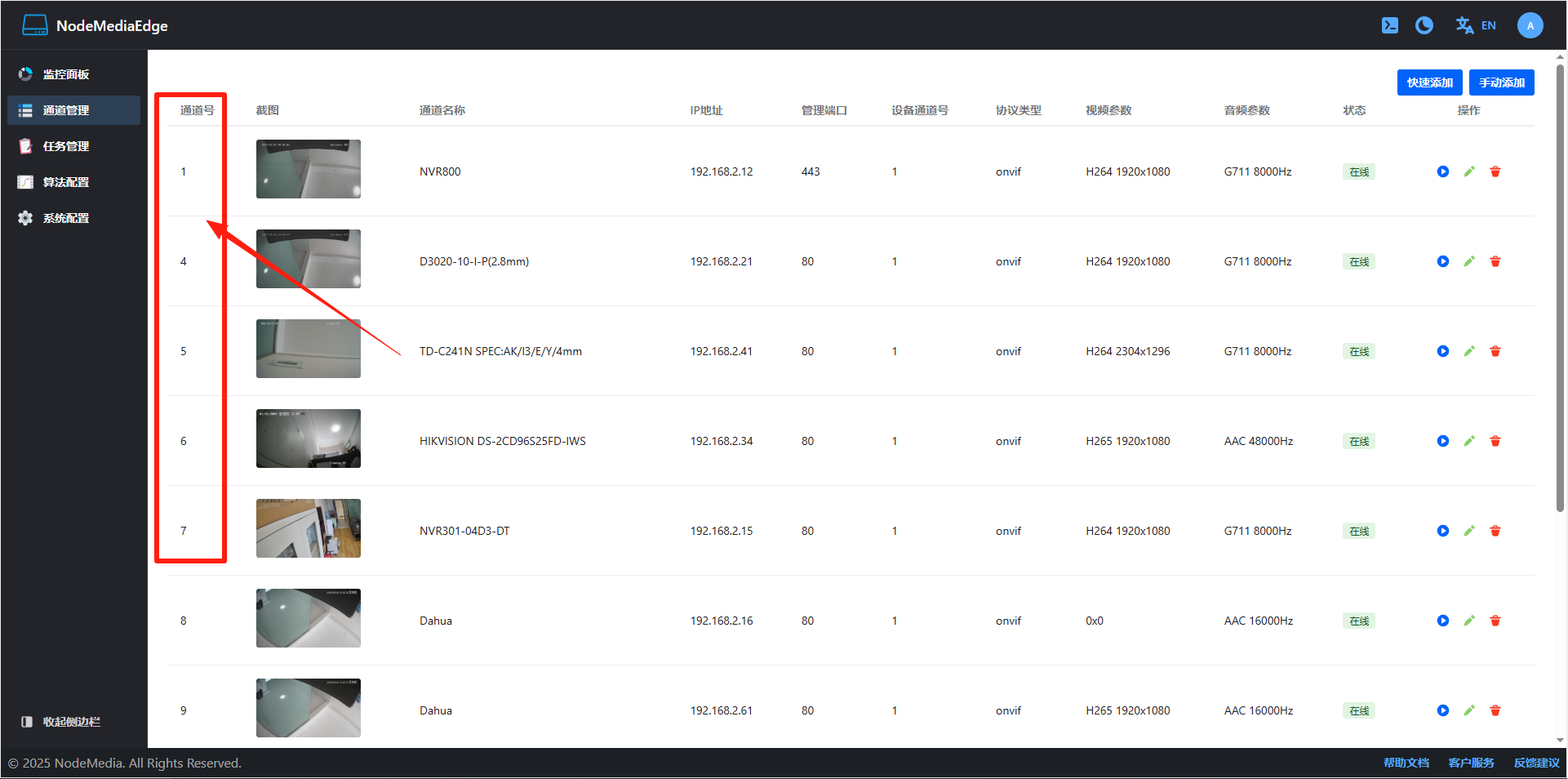
NodeMediaEdge快速上手
NodeMediaEdge快速上手 简介 NodeMediaEdge是一款部署在监控摄像机网络前端中,拉取Onvif或者rtsp/rtmp/http视频流并使用rtmp/kmp推送到公网流媒体服务器的工具。 通过云平台协议注册到NodeMediaServer后,可以同NodeMediaServer结合使用。使用图形化的…...
ChatOn:智能AI聊天助手,开启高效互动新时代
在当今快节奏的生活中,无论是工作、学习还是日常交流,我们常常需要快速获取信息、整理思路并高效完成任务。ChatOn 正是为满足这些需求而生,它基于先进的 ChatGPT 和 GPT-4o 技术,为用户提供市场上最优秀的中文 AI 聊天机器人。这…...
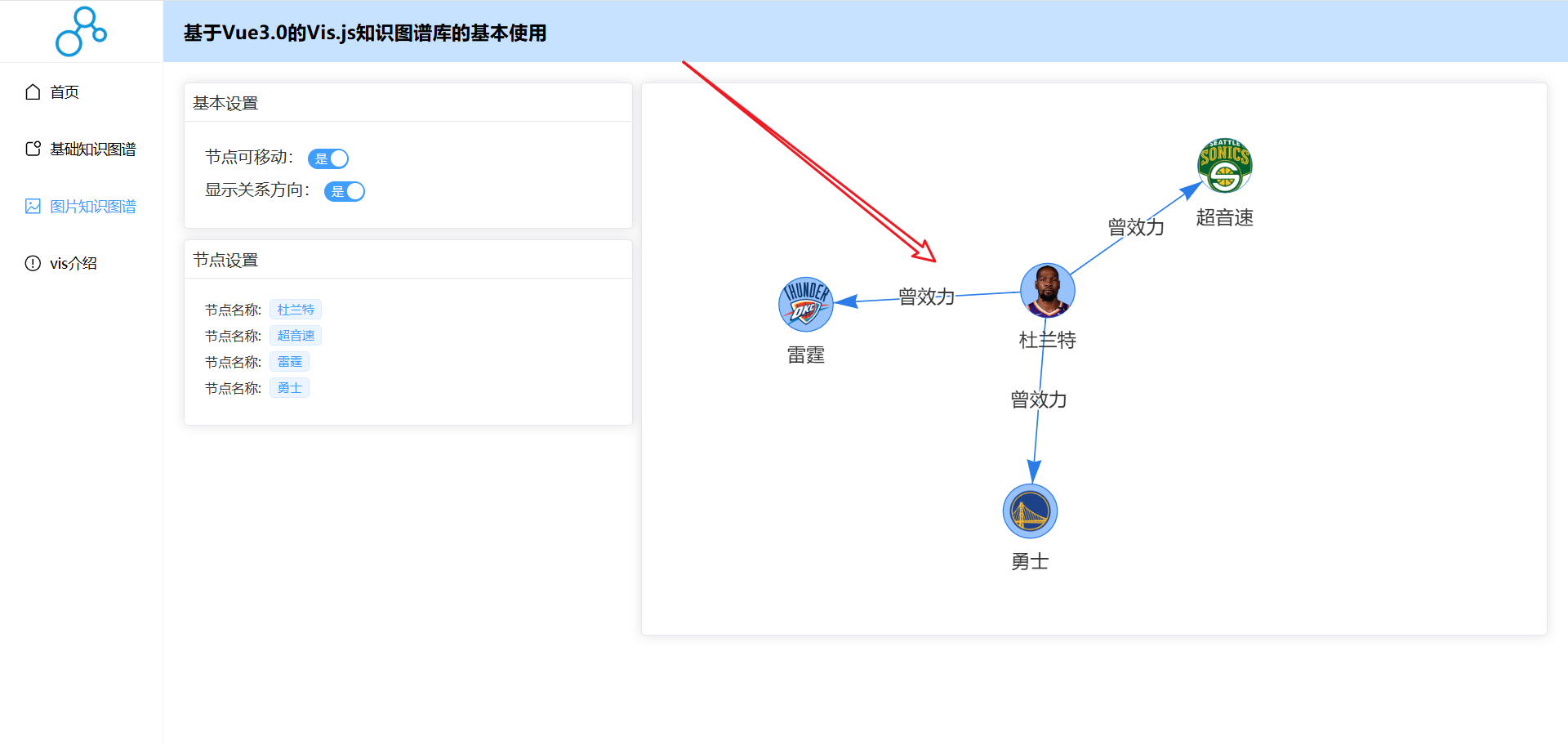
基于Vue3.0的【Vis.js】库基本使用教程(002):图片知识图谱的基本构建和设置
文章目录 3、图片知识图谱3.1 初始化图片知识图谱3.2 修改节点形状3.3 修改节点背景颜色3.4 完整代码下载3、图片知识图谱 3.1 初始化图片知识图谱 1️⃣效果预览: 2️⃣关键代码: 给节点添加image属性: const nodes = ref([{id: 1,...