Transformer核心原理
简介
在人工智能技术飞速发展的今天,Transformer模型凭借其强大的序列处理能力和自注意力机制,成为自然语言处理、计算机视觉、语音识别等领域的核心技术。本文将从基础理论出发,结合企业级开发实践,深入解析Transformer模型的原理与实现方法。通过完整的代码示例、优化策略及实际应用场景,帮助开发者从零构建高性能AI系统。文章涵盖模型架构设计、训练优化技巧、多模态应用案例等内容,并通过Mermaid流程图直观展示关键概念。无论你是初学者还是进阶开发者,都能通过本文掌握Transformer模型的核心技术,并将其高效应用于实际项目中。
一、Transformer模型的核心原理
1.1 自注意力机制(Self-Attention)
Transformer模型的核心在于自注意力机制,它允许模型动态计算输入序列中每个元素与其他元素的相关性,从而捕捉长距离依赖关系。自注意力机制的计算公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q Q Q、 K K K、 V V V分别表示查询矩阵、键矩阵和值矩阵, d k d_k dk是缩放因子。
流程图:
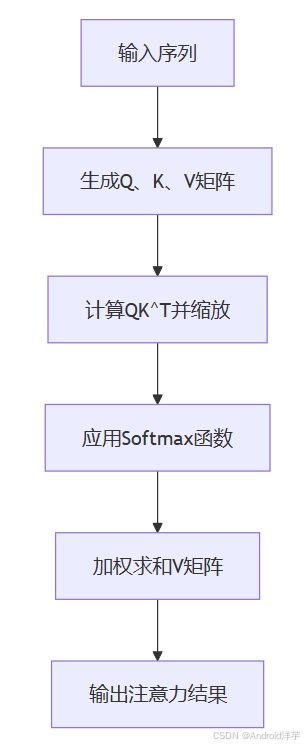
1.2 多头注意力(Multi-Head Attention)
多头注意力通过并行计算多个自注意力子层,增强模型对不同特征的关注能力。每个注意力头独立计算,最终结果通过线性变换合并:
MultiHead ( Q , K , V ) = Concat ( h 1 , h 2 , . . . , h h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(h_1, h_2, ..., h_h)W^O MultiHead(Q,K,V)=Concat(h1,h2,...,hh)WO
其中, h i h_i hi表示第 i i i个注意力头的输出, W O W^O WO是合并权重矩阵。
代码示例(PyTorch实现):
import torch
import torch.nn as nnclass MultiHeadAttention(nn.Module):def __init__(self, embed_dim, num_heads):super(MultiHeadAttention, self).__init__()self.embed_dim = embed_dimself.num_heads = num_headsself.head_dim = embed_dim // num_headsassert self.head_dim * num_heads == embed_dim, "Embedding dimension must be divisible by number of heads"self.qkv = nn.Linear(embed_dim, 3 * embed_dim)self.out = nn.Linear(embed_dim, embed_dim)def forward(self, x):batch_size, seq_len, embed_dim = x.size()qkv = self.qkv(x).reshape(batch_size, seq_len, 3, self.num_heads, self.head_dim)q, k, v = qkv.unbind(2)# 计算注意力分数scores = torch.einsum("bqhd,bkhd->bhqk", q, k) / (self.head_dim ** 0.5)attn_weights = torch.softmax(scores, dim=-1)# 应用注意力权重out = torch.einsum("bhqk,bkhd->bqhd", attn_weights, v)out = out.reshape(batch_size, seq_len, embed_dim)out = self.out(out)return out
1.3 位置编码(Positional Encoding)
Transformer模型通过位置编码引入序列的位置信息。常见的编码方式包括正弦和余弦函数组合:
P E ( p o s , 2 i ) = sin ( p o s 10000 2 i / d ) , P E ( p o s , 2 i + 1 ) = cos ( p o s 10000 2 i / d ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d}}\right), \quad PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d}}\right) PE(pos,2i)=sin(100002i/dpos),PE(pos,2i+1)=cos(100002i/dpos)
流程图:
二、企业级AI开发实战
2.1 模型架构设计
企业级AI应用通常需要处理大规模数据集和复杂任务。以下是Transformer模型的完整架构设计:
2.1.1 编码器-解码器结构
Transformer模型由编码器和解码器组成。编码器将输入序列转换为中间表示,解码器根据编码器输出生成目标序列。
代码示例(PyTorch实现):
class TransformerEncoder(nn.Module):def __init__(self, embed_dim, num_heads, ff_dim, num_layers):super(TransformerEncoder, self).__init__()self.layers = nn.ModuleList([TransformerLayer(embed_dim, num_heads, ff_dim)for _ in range(num_layers)])def forward(self, x):for layer in self.layers:x = layer(x)return xclass TransformerDecoder(nn.Module):def __init__(self, embed_dim, num_heads, ff_dim, num_layers):super(TransformerDecoder, self).__init__()self.layers = nn.ModuleList([TransformerLayer(embed_dim, num_heads, ff_dim)for _ in range(num_layers)])def forward(self, x, encoder_output):for layer in self.layers:x = layer(x, encoder_output)return x
2.1.2 前馈神经网络(FFN)
每个Transformer层包含两个子层:自注意力子层和前馈神经网络子层。FFN用于增加模型的非线性表达能力:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
代码示例(PyTorch实现):
class FeedForward(nn.Module):def __init__(self, embed_dim, ff_dim):super(FeedForward, self).__init__()self.linear1 = nn.Linear(embed_dim, ff_dim)self.linear2 = nn.Linear(ff_dim, embed_dim)self.relu = nn.ReLU()def forward(self, x):x = self.linear1(x)x = self.relu(x)x = self.linear2(x)return x
2.2 模型训练与优化
2.2.1 混合精度训练
混合精度训练通过使用半精度浮点数(FP16)加速计算,同时保持模型精度。以下是一个使用PyTorch实现混合精度训练的示例:
代码示例(PyTorch实现):
from torch.cuda.amp import autocast, GradScalermodel = TransformerModel().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)
scaler = GradScaler()for epoch in range(num_epochs):for inputs, targets in dataloader:optimizer.zero_grad()with autocast():outputs = model(inputs)loss = criterion(outputs, targets)scaler.scale(loss).backward()scaler.step(optimizer)scaler.update()
2.2.2 分布式训练
分布式训练通过多GPU并行计算加速模型训练。以下是一个使用PyTorch分布式数据并行(DDP)的示例:
代码示例(PyTorch实现):
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDPdist.init_process_group(backend="nccl")
model = TransformerModel().to(device)
model = DDP(model)optimizer = torch.optim.Adam(model.parameters(), lr=1e-4)for epoch in range(num_epochs):for inputs, targets in dataloader:optimizer.zero_grad()outputs = model(inputs)loss = criterion(outputs, targets)loss.backward()optimizer.step()
2.3 模型部署与加速
2.3.1 TensorRT加速
TensorRT是NVIDIA推出的深度学习推理加速工具。以下是一个使用TensorRT优化Transformer模型的示例:
代码示例(Python实现):
import tensorrt as trtTRT_LOGGER = trt.Logger(trt.Logger.WARNING)
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
parser = trt.OnnxParser(network, TRT_LOGGER)with open("model.onnx", "rb") as f:parser.parse(f.read())config = builder.create_builder_config()
config.max_workspace_size = 1 << 30 # 1GB
engine = builder.build_engine(network, config)
三、Transformer的多模态应用
3.1 机器翻译
Transformer模型在机器翻译任务中表现出色。以下是一个基于Transformer的英德翻译模型示例:
代码示例(PyTorch实现):
class TransformerTranslationModel(nn.Module):def __init__(self, src_vocab_size, tgt_vocab_size, embed_dim, num_heads, ff_dim, num_layers):super(TransformerTranslationModel, self).__init__()self.encoder = TransformerEncoder(embed_dim, num_heads, ff_dim, num_layers)self.decoder = TransformerDecoder(embed_dim, num_heads, ff_dim, num_layers)self.src_embedding = nn.Embedding(src_vocab_size, embed_dim)self.tgt_embedding = nn.Embedding(tgt_vocab_size, embed_dim)self.fc = nn.Linear(embed_dim, tgt_vocab_size)def forward(self, src, tgt):src_emb = self.src_embedding(src)tgt_emb = self.tgt_embedding(tgt)encoder_output = self.encoder(src_emb)decoder_output = self.decoder(tgt_emb, encoder_output)output = self.fc(decoder_output)return output
3.2 医疗影像分析
Transformer模型在医学影像分析中也展现出强大能力。以下是一个基于Vision Transformer的乳腺癌分类模型示例:
代码示例(PyTorch实现):
class VisionTransformer(nn.Module):def __init__(self, image_size, patch_size, num_classes, embed_dim, num_heads, num_layers):super(VisionTransformer, self).__init__()self.patch_emb = PatchEmbedding(image_size, patch_size, embed_dim)self.cls_token = nn.Parameter(torch.randn(1, 1, embed_dim))self.pos_emb = PositionalEncoding(embed_dim, image_size, patch_size)self.transformer = TransformerEncoder(embed_dim, num_heads, embed_dim * 4, num_layers)self.fc = nn.Linear(embed_dim, num_classes)def forward(self, x):x = self.patch_emb(x)cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)x = torch.cat((cls_tokens, x), dim=1)x = self.pos_emb(x)x = self.transformer(x)x = x[:, 0]x = self.fc(x)return x
四、企业级AI应用案例
4.1 客服机器人
Transformer模型结合业务知识库,可构建高效的客服机器人。以下是一个基于Hugging Face Transformers库的示例:
代码示例(Python实现):
from transformers import AutoTokenizer, AutoModelForCausalLMtokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")def respond_to_query(query):input_ids = tokenizer.encode(query, return_tensors="pt")reply_ids = model.generate(input_ids, max_length=100, num_return_sequences=1)reply = tokenizer.decode(reply_ids[0], skip_special_tokens=True)return replyuser_query = "How can I track my order?"
bot_reply = respond_to_query(user_query)
print("Bot:", bot_reply)
4.2 异常交易检测
Transformer模型可用于银行异常交易检测。以下是一个基于BERT+BiLSTM的示例:
代码示例(PyTorch实现):
class AnomalyDetectionModel(nn.Module):def __init__(self, bert_model, hidden_dim):super(AnomalyDetectionModel, self).__init__()self.bert = BertModel.from_pretrained(bert_model)self.lstm = nn.LSTM(bert.config.hidden_size, hidden_dim, bidirectional=True)self.fc = nn.Linear(hidden_dim * 2, 1)def forward(self, x):outputs = self.bert(x)sequence_output = outputs.last_hidden_statelstm_out, _ = self.lstm(sequence_output)out = self.fc(lstm_out)return out
五、总结
Transformer模型凭借其强大的序列处理能力和自注意力机制,已成为企业级AI应用的核心技术。本文从基础理论出发,结合企业级开发实践,深入解析了Transformer模型的原理与实现方法。通过完整的代码示例、优化策略及实际应用场景,开发者能够高效构建高性能AI系统。未来,随着技术的不断进步,Transformer模型将在更多领域发挥重要作用,推动人工智能技术迈向新的高度。
相关文章:
Transformer核心原理
简介 在人工智能技术飞速发展的今天,Transformer模型凭借其强大的序列处理能力和自注意力机制,成为自然语言处理、计算机视觉、语音识别等领域的核心技术。本文将从基础理论出发,结合企业级开发实践,深入解析Transformer模型的原…...

Grafana-State timeline状态时间线
显示随时间推移的状态变化 状态区域:即状态时间线上的状态显示的条或带,区域长度表示状态持续时间或频率 数据格式要求(可视化效果最佳): 时间戳实体名称(即:正在监控的目标对应名称…...
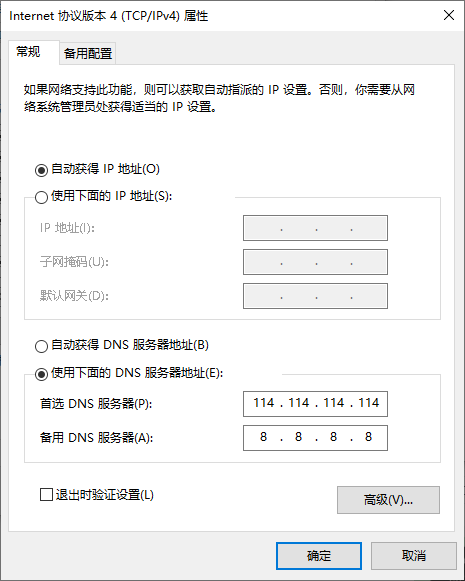
解决CSDN等网站访问不了的问题
原文网址:解决CSDN等网站访问不了的问题-CSDN博客 简介 本文介绍解决CSDN等网站访问不了的方法。 问题描述 CSDN访问不了了,页面是空的。 问题解决 方案1:修改DNS 可能是dns的问题,需要重新配置。 国内常用的dns是&#x…...
)
【华为云Astro Zero】组装设备管理页面开发(图形拖拽 + 脚本绑定)
目录 🧠 一、核心原理概览(类比说明) 🛠 二、完整操作步骤(详细图形拖拽流程) 1. 创建项目页面骨架 2. 定义设备信息的数据模型 equipmentInstance 3. 定义服务模型(接口绑定机器人搬运逻辑) 4. 拖拽组件搭建界面结构 4.1 表格: 4.2 工具栏按钮(新增) 4.…...

PopupImageMenuItem 无响应
Popup Menu | GNOME JavaScript let menuItem new PopupMenu.PopupImageMenuItem(设置, settings, {}); 第三个参数 params (Object) — Additional item properties 写了个 {},我就以为是 function,我还改成了 () > {} ! 正常是通过 connect 响…...

C++ Vector算法精讲与底层探秘:从经典例题到性能优化全解析
前引:在C标准模板库(STL)中,vector作为动态数组的实现,既是算法题解的基石,也是性能优化的关键战场。其连续内存布局、动态扩容机制和丰富的成员函数,使其在面试高频题(如LeetCode、…...

Flowith,有一种Agent叫无限
大家好,我是羊仔,专注AI工具、智能体、编程。 今天羊仔要和大家聊聊一个最近发现的超级实用的Agent平台,名字叫Flowith。 这篇文章会带你从零了解到实战体验,搞清楚Flowith是如何让工作效率飙升好几倍,甚至重新定义未…...

系统思考:短期利益与长期系统影响
一个决策难题:一家公司接到了一个大订单,客户提出了10%的降价要求,而企业的产能还无法满足客户的需求。你会选择增加产能,接受这个订单,还是拒绝?从系统思考的角度来看,这个决策不仅仅是一个简单…...

大数据 ETL 工具 Sqoop 深度解析与实战指南
一、Sqoop 核心理论与应用场景 1.1 设计思想与技术定位 Sqoop 是 Apache 旗下的开源数据传输工具,核心设计基于MapReduce 分布式计算框架,通过并行化的 Map 任务实现高效的数据批量迁移。其特点包括: 批处理特性:基于 MapReduc…...

【学习记录】Django Channels + WebSocket 异步推流开发常用命令汇总
文章目录 📌 摘要🧰 虚拟环境管理✅ 创建虚拟环境✅ 删除虚拟环境✅ 激活/切换虚拟环境 🛠️ Django 项目管理✅ 查看 Django 版本✅ 创建 Django 项目✅ 创建 Django App 💬 Channels 常用操作✅ 查看 Channels 版本 ὐ…...
动手实现多层感知机:深度学习中的非线性建模实战)
(四)动手实现多层感知机:深度学习中的非线性建模实战
1 多层感知机(MLP) 多层感知机(Multilayer Perceptron, MLP)是一种前馈神经网络,包含一个或多个隐藏层。它能够学习数据中的非线性关系,广泛应用于分类和回归任务。MLP的每个神经元对输入信号进行加权求和…...
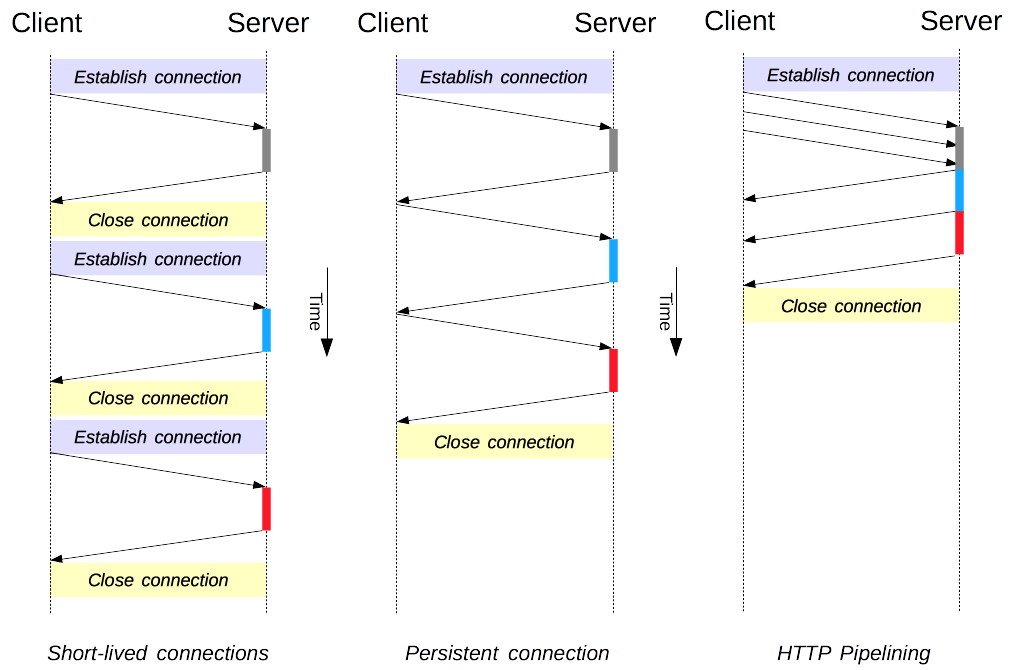
HTTP连接管理——短连接,长连接,HTTP 流水线
连接管理是一个 HTTP 的关键话题:打开和保持连接在很大程度上影响着网站和 Web 应用程序的性能。在 HTTP/1.x 里有多种模型:短连接、_长连接_和 HTTP 流水线。 下面分别来详细解释 短连接 HTTP 协议最初(0.9/1.0)是个非常简单的…...
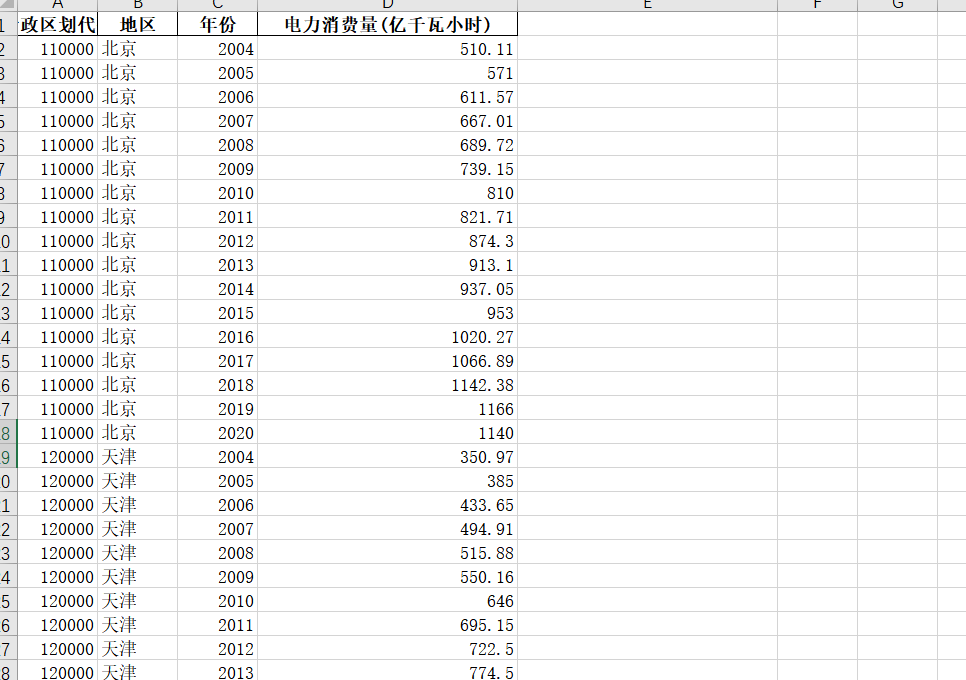
【免费】2004-2020年各省电力消费量数据
2004-2020年各省电力消费量数据 1、时间:2004-2020年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区、年份、电力消费量(亿千瓦小时) 4、范围:31省 5、指标说明:电力消费量是指在一定时期内ÿ…...
 | if语句)
Python编程基础(四) | if语句
引言:很久没有写 Python 了,有一点生疏。这是学习《Python 编程:从入门到实践(第3版)》的课后练习记录,主要目的是快速回顾基础知识。 练习1:条件测试 编写一系列条件测试,将每个条…...

登录的写法,routerHook具体配置,流程
routerHook挂在在index.js/main.js下的,找不到可以去那边看一下 vuex需要做的: //创建token的sate,从本地取 let token window.localStorage.getItem(token) // 存储用户登录信息let currentUserInfo reactive({userinfo: {}}) //存根据不…...

Java-IO流之字节输出流详解
Java-IO流之字节输出流详解 一、Java字节输出流基础概念1.1 Java IO体系与字节输出流的位置1.2 字节输出流的核心类层次结构 二、OutputStream接口核心方法详解2.1 void write(int b)2.2 void write(byte[] b)2.3 void write(byte[] b, int off, int len)2.4 void flush()2.5 v…...
工作服/反光衣检测算法AI智能分析网关V4安全作业风险预警方案:筑牢矿山/工地/工厂等多场景安全防线
一、方案背景 在工地、矿山、工厂等高危作业场景,反光衣是保障人员安全的必备装备。但传统人工巡查存在效率低、易疏漏等问题,难以实现实时监管。AI智能分析网关V4基于人工智能技术,可自动识别人员着装状态,精准定位未穿反光衣…...

采摘机器人项目
采摘对象特点 表皮组织比较柔软,很容易损伤蔬菜或者水果生长的位置具有随机性。挂果的位置是随机的,没有一定的规律果实的成熟期是不具备一致性的。同一颗树上的果实有的熟透了,有的还没成熟果实的大小和形状不一样。成熟度不一样࿰…...

malloc 内存分配机制:brk 与 mmap
一、malloc的两种内存分配策略 malloc 并非直接的系统调用,而是C标准库封装的内存管理函数。它根据应用程序请求的内存大小,智能地选择两种不同的底层机制向操作系统申请内存: 小块内存分配 (< 128KB):brk() / sbrk() 系统调用…...
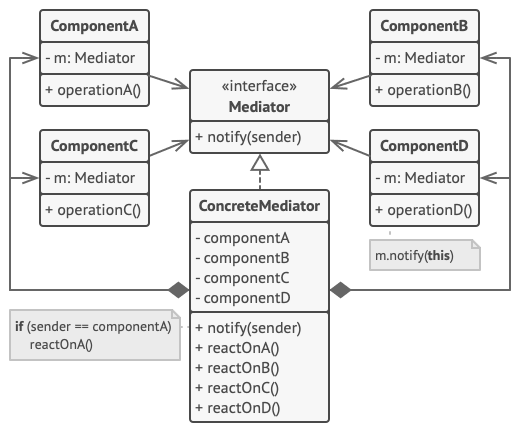
设计模式——中介者设计模式(行为型)
摘要 文章详细介绍了中介者设计模式,这是一种行为型设计模式,通过中介者对象封装多个对象间的交互,降低系统耦合度。文中阐述了其核心角色、优缺点、适用场景,并通过类图、时序图、实现方式、实战示例等多方面进行讲解࿰…...

MinGW-w64的安装详细步骤(c_c++的编译器gcc、g++的windows版,win10、win11真实可用)
文章目录 1、MinGW的定义2、MinGW的主要组件3、MinGW-w64下载与安装 3.1、下载解压安装地址3.2、MinGW-w64环境变量的设置 4、验证MinGW是否安装成功5、编写一段简单的代码验证下6、总结 1、MinGW的定义 MinGW(Minimalist GNU for Windows) 是一个用…...
LabVIEW磁悬浮轴承传感器故障识别
针对工业高端装备中主动磁悬浮轴承(AMB)的位移传感器故障检测需求,基于 LabVIEW 平台构建了一套高精度故障识别系统。通过集成品牌硬件与 LabVIEW 的信号处理能力,实现了传感器探头故障的实时监测与精准定位,解决了传统…...

MongoDB-6.0.24 主从复制搭建和扩容缩容详解
目录 1 操作系统信息 2 MongoDB 集群架构图 3 MongoDB 软件安装及配置 4 初始化存储集群和配置 5 MongoDB主从复制集群测试 6 MongoDB运维管理 7 主从复制集群扩容一个secondary节点 8 主从复制集群缩容一个节点 1 操作系统信息 rootu24-mongo-70:~# cat /etc/issue Ub…...

Resend React Email:用React组件化思维重塑电子邮件开发
在数字化沟通中,电子邮件仍是企业与用户建立联系的核心渠道。然而传统邮件开发依赖繁琐的HTML表格布局和行内样式,效率低下且兼容性难以保障。Resend团队推出的React Email开源框架(https://github.com/resend/react-email)正通过…...

UNION 与 UNION ALL 的区别
UNION 与 UNION ALL 的区别 1. 基本概念 1.1 UNION 操作符 UNION 是SQL中用于合并两个或多个SELECT语句结果集的操作符,它会自动去除重复行并按照默认规则排序。 go专栏:https://duoke360.com/tutorial/path/golang SELECT column1 FROM table1 UNION SELECT column1 FRO…...
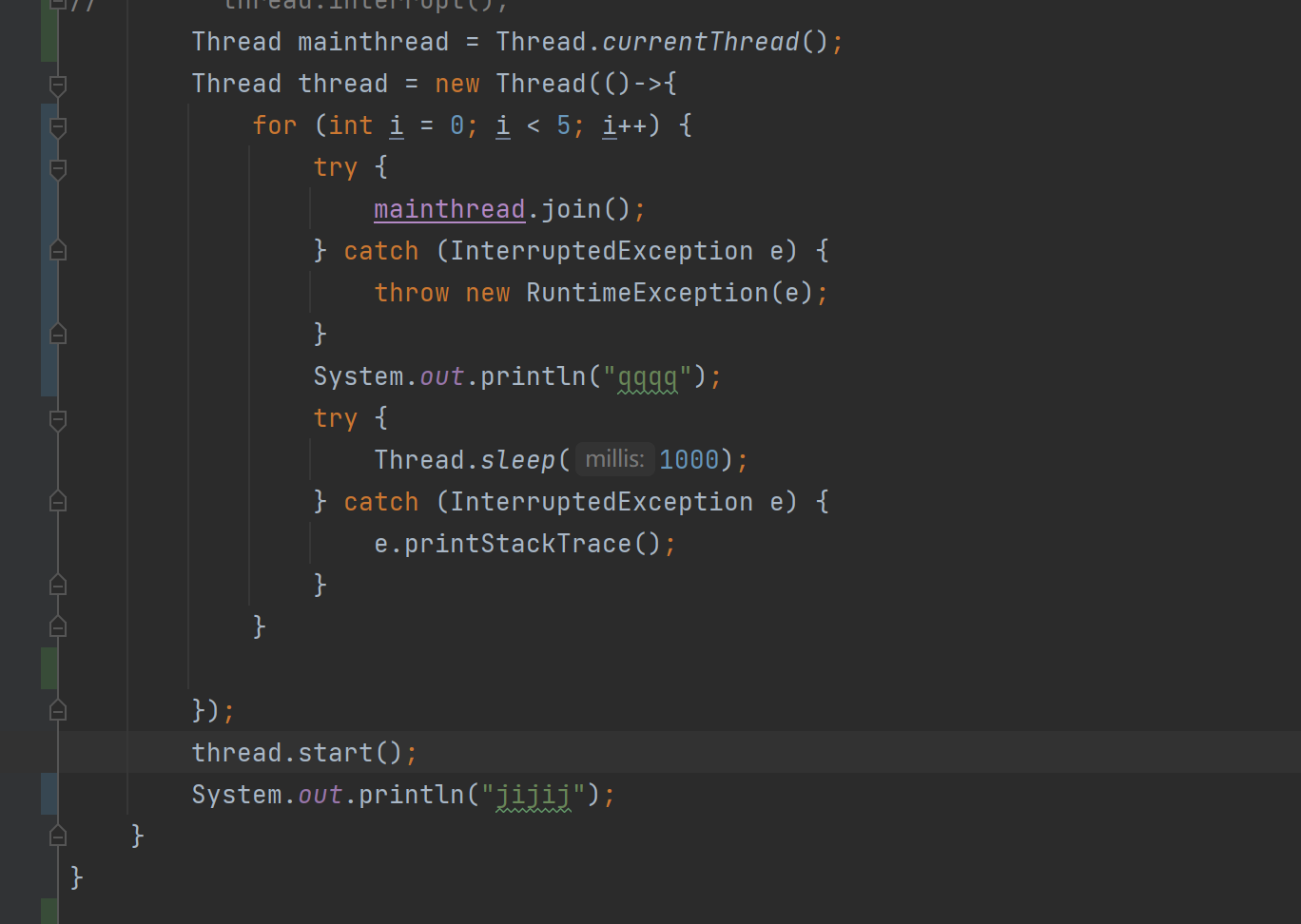
多线程1(Thread)
认识线程(Thread) 在进程中,要创建一个进程和销毁一个进程所消耗的硬件和软件资源是巨大的,因此为了优化上述过程,我们引入了“线程”。 线程是系统调度的基本单位。 1)线程和进程的关系 可以认为进程包…...

NVIDIA DOCA 3.0:引领AI基础设施革命的引擎简析
引言 在当今快速发展的AI时代,大规模AI模型的训练和部署对数据中心基础设施提出了前所未有的挑战。传统的CPU-centric架构已经难以满足超大规模AI工作负载对性能、效率和安全性的需求。NVIDIA于2025年4月正式发布了DOCA 3.0软件框架,这一创新性平台彻底改变了AI基础设施的设计…...
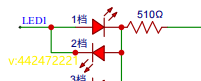
小家电外贸出口新利器:WD8001低成本风扇智能控制方案全解析
低成本单节电池风扇解决方案WD8001 用途 低成本单节电池风扇解决方案WD8001用于小功率风扇供电及控制,具有三个档位调节、自动停机及锁机功能。 基本参数 充电参数:输入5V/500mA,满电4.2V,充电指示灯亮,满电后熄灭…...
)
【软件测试】web自动化:Pycharm+Selenium+Firefox(一)
步骤:配置Pycharm,Firefox安装Selenium IDE插件,下载geckodriver插件,安装至Firefox目录下。https://blog.csdn.net/weixin_61926199/article/details/148383668?fromshareblogdetail&sharetypeblogdetail&sharerId14838…...

C++实现汉诺塔游戏用户交互
目录 一、模型调整(一)模型定义(二)模型实现1.电脑自动完成部分2.SDL图形显示2.1拿起放下盘子的函数2.2左右移动手指的函数 二、处理用户输入,进行人机分流三、总结四、源码下载 上篇文章使用C语言实现汉诺塔游戏电脑自动完成的步骤,还没有实现用户交互&…...