llama.cpp:纯 C/C++ 实现的大语言模型推理引擎详解一
🚀 llama.cpp:纯 C/C++ 实现的大语言模型推理引擎详解
一、什么是 llama.cpp?
llama.cpp 是一个由 Georgi Gerganov 开源的项目,旨在使用纯 C/C++ 在 CPU 上运行 Meta 的 LLaMA 系列大语言模型。
它通过量化、优化注意力机制和内存管理,在消费级硬件上实现了高效推理,甚至可以在没有 GPU 的设备上运行 LLaMA-7B 或更大模型。
二、llama.cpp 的核心原理
1. 模型加载与量化
llama.cpp 支持对原始模型进行量化处理,将浮点数(如 float32、float16)压缩为更低精度的整数表示(如 int4、int5、int8),从而大幅减少内存占用并提升推理速度。
常见量化方式:
| 类型 | 描述 |
|---|---|
| GGUF(原 GGML) | 自定义格式,支持多种量化方式 |
| Q4_0 / Q4_1 | 使用 4bit 量化,适合中等性能设备 |
| Q5_0 / Q5_1 | 使用 5bit 量化,平衡精度与速度 |
| Q8_0 | 使用 8bit 量化,保留更多细节 |
示例命令:
python convert.py --model-dir models/llama-7b --outfile ggml-model-f16.gguf
然后使用 quantize 工具进行量化:
./quantize ggml-model-f16.gguf ggml-model-q4_0.gguf q4_0
2. KV Cache 管理优化
llama.cpp 使用自定义的缓存结构来存储 Key/Value 向量,避免重复计算 attention 中的历史信息,显著提升推理效率。
3. 多线程加速
llama.cpp 支持多线程推理,充分利用现代 CPU 的多核能力。你可以指定线程数量:
./main -m models/llama-7b.gguf -n 256 -t 8
其中 -t 8 表示使用 8 个线程。
4. 低内存占用设计
llama.cpp 的设计目标之一是最小化内存消耗,因此所有操作都尽量避免使用临时变量或高精度张量运算。
例如,它不使用 PyTorch,而是直接操作内存中的权重矩阵,通过 SIMD 指令加速向量运算。
三、真实训练数据样例(LLaMA 数据集)
llama.cpp 并不用于训练模型,而是用于部署和推理。我们可以看看原始 LLaMA 模型使用的训练数据结构:
示例训练数据(LLaMA)
{"text": "Instruct: What is the capital of France?\n\nOutput: The capital of France is Paris."
}
这类数据通常来自大规模语料库(如 Common Crawl、Books、Wikipedia 等),经过 tokenization 和上下文窗口切分后输入模型。
注意:llama.cpp 仅用于推理,不涉及训练过程。
四、数学原理与公式解析
1. 注意力机制简化版
在 llama.cpp 中,注意力机制被高度优化,但其核心逻辑如下:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中:
- $ Q = W_Q \cdot h $
- $ K = W_K \cdot h $
- $ V = W_V \cdot h $
为了提升性能,llama.cpp 对 attention 进行了多项优化,包括:
- 手动展开循环
- 利用 BLAS 加速矩阵乘法
- 使用 PagedAttention 思想管理长文本
2. 旋转位置编码(RoPE)
LLaMA 系列模型采用 RoPE 编码方式注入位置信息,其核心公式如下:
对于第 $ i $ 个 token 的 Query 和 Key:
q i ′ = R i ⋅ q i , k j ′ = R j ⋅ k j q_i' = R_i \cdot q_i,\quad k_j' = R_j \cdot k_j qi′=Ri⋅qi,kj′=Rj⋅kj
最终 attention score 为:
( q i ′ ) T k j ′ (q_i')^T k_j' (qi′)Tkj′
这种编码方式支持任意长度的上下文,非常适合 llama.cpp 的轻量级架构。
五、简单代码实现与调用示例
1. 构建 llama.cpp 项目
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
make
2. 下载并转换模型
你需要先下载 LLaMA 权重文件(需申请 Meta 授权),然后将其转换为 GGUF 格式:
python convert.py --model-dir models/llama-7b --outfile ggml-model-f16.gguf
再进行量化:
./quantize ggml-model-f16.gguf ggml-model-q4_0.gguf q4_0
3. 使用 main 推理接口
./main -m models/llama-7b.gguf -p "Explain quantum computing in simple terms." -n 128
输出结果:
Quantum computing uses quantum bits (qubits) that can exist in superposition and entanglement states to perform computations faster than classical computers.
六、llama.cpp 的实现逻辑核心详解
1. 模型加载机制
llama.cpp 使用自定义的 GGUF 文件格式加载模型权重。GGUF 是一种轻量级模型存储格式,支持不同量化策略。
// model loading code in llama.cpp
bool llama_model_load(const char * fname_model, struct llama_model * model, gpt_vocab * vocab) {...// read from .gguf file...
}
该机制允许开发者灵活控制每个层的参数加载方式,并支持跨平台读取。
2. 量化推理实现
llama.cpp 的核心在于如何在不依赖 PyTorch 的前提下,完成高效的量化推理。以 ggml 库为基础,它实现了多种量化 kernel,如 vec_dot_q4_0, vec_dot_q4_1 等。
这些函数利用底层指令(如 AVX、NEON、CUDA)手动编写,极大提升了推理效率。
3. KV Cache 实现
KV Cache 是 Transformer 模型生成过程中最耗时的部分。llama.cpp 使用以下方式实现高效管理:
struct llama_kv_cache {struct ggml_tensor * k;struct ggml_tensor * v;int n; // current number of tokensint n_max; // max tokens allowed
};
每次生成新 token 时,只需更新当前 token 的 Query,并复用之前缓存的 K/V 向量进行 attention 计算。
4. Attention 层优化
llama.cpp 将 attention 层进行了大量手动优化,包括:
- 使用
ggml库实现高效的矩阵运算 - 避免中间 tensor 的频繁分配
- 利用静态数组和内存池优化内存访问
static void llama_decode_attention(const struct llama_model * model,const struct llama_cparams * cparams,struct llama_context * ctx,int n_tokens,int n_past,...) {...// Compute attention scores...
}
5. RoPE 编码实现
llama.cpp 实现了完整的 RoPE 编码逻辑,用于处理位置信息:
void rope_custom_f32(float * dst,int n_dims,int n_ctx,int off,bool is_neox_style) {...// Apply rotation based on position index...
}
这个函数会在每次生成新 token 时被调用,确保位置信息正确注入到 Query 和 Key 向量中。
七、总结
| 特性 | 描述 |
|---|---|
| 跨平台支持 | 可在 Windows、Linux、macOS 上运行 |
| 不依赖 GPU | 纯 C/C++ 实现,无需 CUDA |
| 高度可移植 | 可嵌入到各种终端应用中 |
| 社区活跃 | 支持 LLaMA、Mistral、Phi-2、Gemma 等多个模型 |
| 易于扩展 | 支持插件系统,开发者可定制功能模块 |
八、llama.cpp 的优势与适用场景
| 场景 | 说明 |
|---|---|
| 本地推理 | 无需依赖云端,适合隐私敏感型业务 |
| 教学科研实验 | 在消费级 GPU 上运行 LLM |
| 嵌入式部署 | 如树莓派、Android 设备 |
| API 服务 | 结合 llama-api-server 快速构建后端服务 |
| 浏览器端推理 | WASM 编译后可在浏览器运行小型模型 |
九、(Q&A)
1. llama.cpp 是用来做什么的?
答:llama.cpp 是一个基于 C/C++ 的项目,用于在本地 CPU 上运行 LLaMA 系列大语言模型,支持推理、对话、指令跟随等功能。
2. 为什么 llama.cpp 不需要 GPU?
答:因为它是纯 C/C++ 实现,利用了 CPU 的多线程、SIMD 指令集和量化技术,使得即使在没有 GPU 的设备上也能运行大型语言模型。
3. llama.cpp 支持哪些模型?
答:LLaMA、LLaMA2、LLaMA3、Mistral、Phi-2、Gemma、TinyLlama、Zephyr、CodeLlama 等主流开源模型。
4. 如何对模型进行量化?
答:使用内置的
quantize工具,将 FP16 模型转为 INT4、INT8 等低精度版本。
5. 量化会对模型效果造成影响吗?
答:会有些许影响,但在 Q4_0 模式下,大多数任务仍能保持较高准确率。
6. llama.cpp 如何实现注意力机制?
答:通过手动展开 attention 计算,并结合 BLAS 库优化矩阵运算,同时使用 RoPE 注入位置信息。
7. 是否支持流式输出?
答:是的,可以通过设置参数
--stream启用流式生成。
8. llama.cpp 是否支持中文?
答:支持,只要模型本身包含中文训练数据即可,如 Chinese-LLaMA、ChatGLM-embedding 等。
9. llama.cpp 的性能如何?
答:在 Mac M2 上运行 LLaMA-7B-Q4_0 模型,吞吐量可达 12~15 tokens/s。
10. 如何控制生成长度?
答:使用
-n参数控制最大生成 token 数量。
11. llama.cpp 支持哪些操作系统?
答:支持 Linux、macOS、Windows(WSL 或 MSVC 编译器均可)。
12. 如何启用交互模式?
答:使用
-i参数进入交互模式,用户可连续提问。
13. 能否在嵌入式设备上运行?
答:是的,部分开发者已在树莓派、Android 设备上成功部署。
14. llama.cpp 的许可证是什么?
答:MIT License,允许商业用途。
16. llama.cpp 如何处理上下文长度?
答:支持上下文长度扩展,可通过编译时修改
LLAMA_MAX_POSITIONS来调整最大长度。
17. 是否有 API 接口?
答:社区提供了 RESTful API 封装方案(如 llama-api-server),便于集成到 Web 应用中。
18. llama.cpp 是否支持语音合成?
答:不支持,但它可以与 TTS 引擎配合使用。
19. llama.cpp 如何实现推理过程可视化?
答:虽然不提供图形界面,但可通过 Python 绑定(如 llama-cpp-python)与 Streamlit、Gradio 等工具实现可视化。
十、结语
llama.cpp 是一个极具潜力的开源项目,它让大语言模型真正走向“平民化”,不再受限于昂贵的 GPU 环境。无论是个人开发者、研究人员还是企业产品团队,都可以从中受益。
如果你正在寻找一种在本地运行 LLaMA 系列模型的方法,llama.cpp 绝对值得一试!
📌 欢迎点赞、收藏,并关注我,我会持续更新更多关于 AI、LLM、视觉-语言模型等内容!
相关文章:

llama.cpp:纯 C/C++ 实现的大语言模型推理引擎详解一
🚀 llama.cpp:纯 C/C 实现的大语言模型推理引擎详解 一、什么是 llama.cpp? llama.cpp 是一个由 Georgi Gerganov 开源的项目,旨在使用纯 C/C 在 CPU 上运行 Meta 的 LLaMA 系列大语言模型。 它通过量化、优化注意力机制和内存…...
【亲测有效 | Cursor Pro每月500次快速请求扩5倍】(Windows版)Cursor中集成interactive-feedback-mcp
前言:使用这个interactive-feedback-mcp组件可以根据用户反馈来决定是否结束这一次的请求。如果本次请求并没有解决我们的问题,那我们便可以选择继续这次请求流程,直到问题解决。这样的话,就可以避免为了修复bug而白白多出的请求。…...

BaseTypeHandler用法-笔记
1.BaseTypeHandler简介 org.apache.ibatis.type.BaseTypeHandler 是 MyBatis 提供的一个抽象类,通过继承该类并实现关键方法,可用于实现 Java 类型 与 JDBC 类型 之间的双向转换。当数据库字段类型与 Java 对象属性类型不一致时(如ÿ…...

鸿蒙OSUniApp集成WebGL:打造跨平台3D视觉盛宴#三方框架 #Uniapp
UniApp集成WebGL:打造跨平台3D视觉盛宴 在移动应用开发日新月异的今天,3D视觉效果已经成为提升用户体验的重要手段。本文将深入探讨如何在UniApp中集成WebGL技术,实现炫酷的3D特效,并特别关注鸿蒙系统(HarmonyOS)的适配与优化。 …...

华为盘古 Ultra MoE 模型:国产 AI 的技术突破与行业影响
2025 年 5 月 30日,华为正式发布参数规模达 7180 亿的盘古 Ultra MoE 模型,全程基于昇腾 AI 计算平台完成训练。这一进展标志着中国在超大规模人工智能模型领域的自主研发能力达到新高度,同时也为全球 AI 技术发展提供了新的技术路径。 盘古 …...

Payload CMS:开发者优先的Next.js原生开源解决方案,重新定义无头内容管理
在无头内容管理系统(CMS)竞争激烈的今天,Payload CMS凭借其独特的开发理念和技术架构迅速崛起,成为Microsoft、ASICS、Blue Origin等创新企业的选择。这款基于Node.js与TypeScript构建的开源解决方案,正在彻底改变开发…...

CRM管理软件的数据可视化功能使用技巧:让数据驱动决策
在当今数据驱动的商业环境中,CRM管理系统的数据可视化功能已成为企业优化客户管理、提升销售效率的核心工具。据企销客研究显示,具备优秀可视化能力的CRM系统,用户决策效率可提升47%。本文将深入解析如何通过数据可视化功能最大化CRM管理软件…...

linux批量创建文件
文章目录 批量创建空文件touch命令批量创建空文件循环结构创建 创建含内容文件echo重定向多行内容写入 按日期创建日志文件根据文件中的列内容,创建文件一行只有一列内容一行有多列内容 批量创建空文件 touch命令批量创建空文件 # 创建文件file1.txt到file10.txt …...
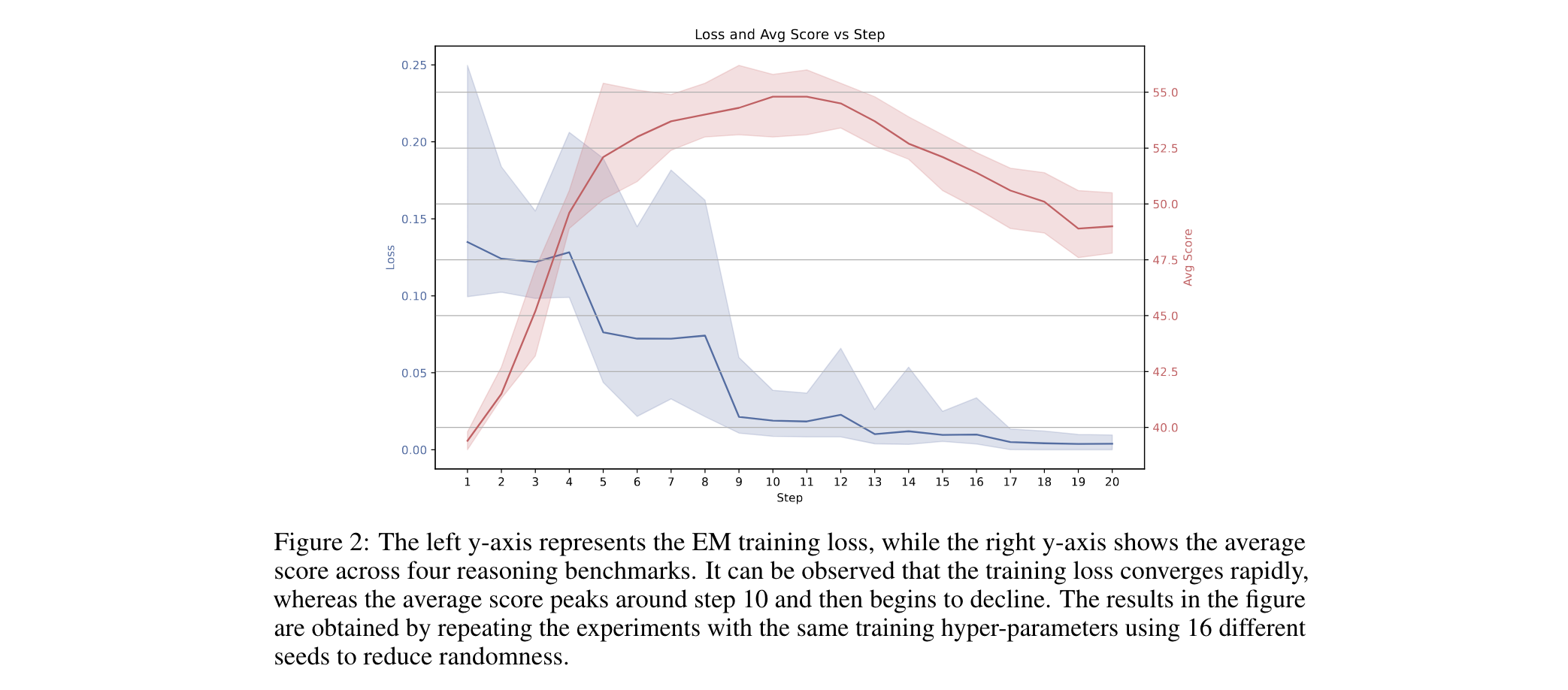
颠覆传统!单样本熵最小化如何重塑大语言模型训练范式?
颠覆传统!单样本熵最小化如何重塑大语言模型训练范式? 大语言模型(LLM)的训练往往依赖大量标注数据与复杂奖励设计,但最新研究发现,仅用1条无标注数据和10步优化的熵最小化(EM)方法…...

华为数据之道 精读——【173页】读书笔记【附全文阅读】
在数字化浪潮中,企业数据管理的优劣直接关乎竞争力。华为凭借丰富实践经验总结的《华为数据之道》,为企业提供了全面且深入的数据治理方案。 笔记聚焦数字化转型与数据治理的紧密联系。华为作为非数字原生企业,在转型过程中克服了产业链条长、数据复杂等诸多难题,其…...

数据库OCP专业认证培训
认证简介 OCP 即 Oracle 数据库认证专家(Oracle Certified Professional),是 Oracle 公司的 Oracle 数据库 DBA(Database Administrator 数据库管理员)认证课程。通过该认证,表明持证人能够管理大型数据库…...
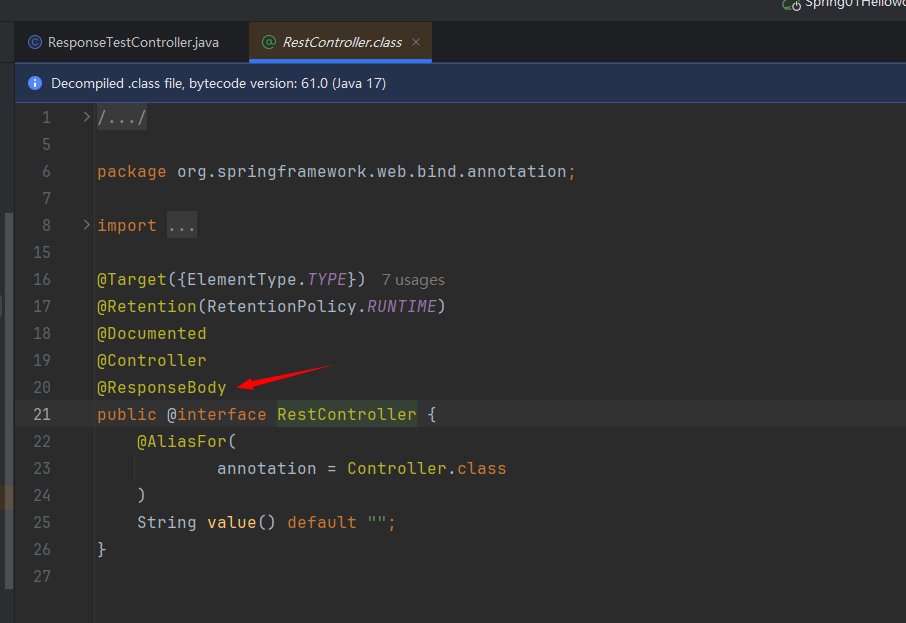
ssm学习笔记day04
RequestMapping 首先添加依赖 Maven的配置 测试 在controller创建HelloController,如果只加RequestMapping,默认跳转到新页面 如果要是加上ResponseBody就把数据封装在包(JSON),标签RestController是前后分离的注解(因为默认用…...
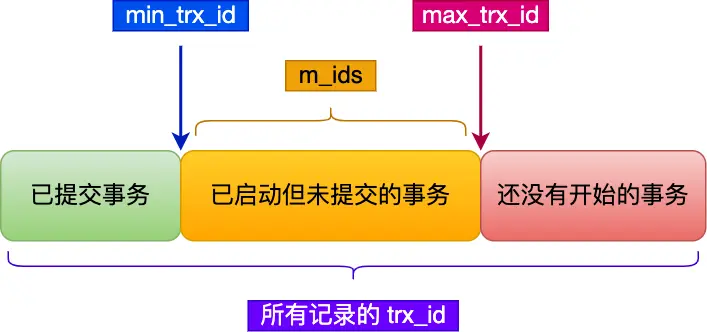
Read View在MVCC里如何工作
Read View的结构 Read View中有四个重要的字段: m_ids:创建 Read View 时,数据库中启动但未提交的「活跃事务」的事务 id 列表 。min_trx_id:创建 Read View 时,「活跃事务」中事务 id 最小的值,即 m_ids …...

HDFS 写入和读取流程
HDFS 写入流程细化 1. 主线流程速记口诀 “先找主脑定文件,分配块副找节点;流水传块多副本,写完通知主脑存。” 2. 详细流程拆解 1. 客户端请求上传(Create 文件) 关键方法: org.apache.hadoop.fs.File…...
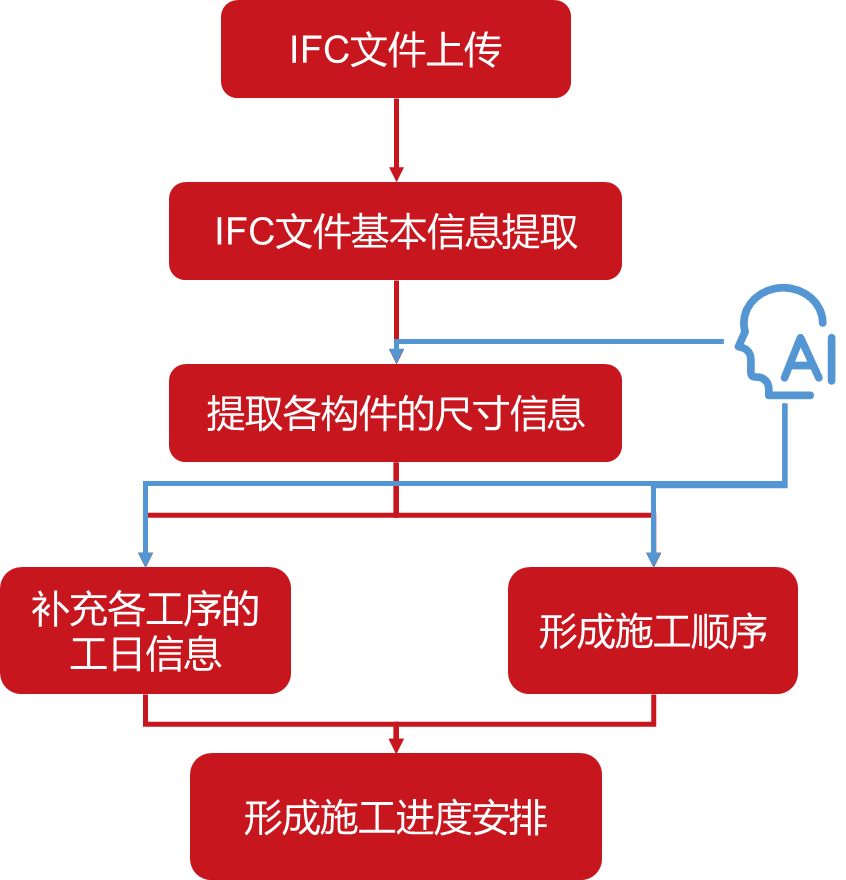
建筑工程施工进度智能编排系统 (SCS-BIM)
建筑工程施工进度智能编排 (SCS-BIM) 源码可见于:https://github.com/Asionm/SCS-BIM 项目简介 本项目是一个面向建筑工程的施工进度智能编制平台,用户只需上传一份标准 IFC 建筑信息模型文件,系统将自动完成以下任务: 解析模…...

Laravel模型状态:深入理解Eloquent的隐秘力量
Laravel的Eloquent ORM(对象关系映射)提供了强大且灵活的功能来处理数据库操作。深入理解Eloquent模型状态对于优化应用程序性能和维护代码的简洁性至关重要。本文将详细探讨Laravel Eloquent的模型状态及其隐秘力量。 一、Eloquent模型的基本概念 Elo…...

Spring Cloud Eureka:微服务架构中的服务注册与发现核心组件
前言 在微服务架构日益流行的今天,服务注册与发现机制成为了构建弹性、可扩展分布式系统的关键。作为Spring Cloud生态中的核心组件,Eureka为微服务架构提供了高效的服务注册与发现解决方案。本文将深入探讨Eureka的设计原理、核心机制以及在实际项目中…...

matlab实现求解兰伯特问题
求解兰伯特问题的matlab代码,非常好用 solve_lambertLYP.m , 1899 StumpffC.m , 136 StumpffdF.m , 294 StumpffF.m , 151 StumpffS.m , 167 Stumpffy.m , 96 text2.m , 104...

iOS 集成网易云信的音视频呼叫组件
云信官方文档在这 前提是集成了云信IM,并且已经IM登录成功,如果没有集成IM的看这里:iOS 集成网易云信IM-CSDN博客 1、CocoPods集成 #云信 pod NIMSDK_LITE, 10.8.0pod NERtcSDK, 5.6.50#rtc基础SDK pod NEChatUIKit#呼叫组件API组件 pod NE…...

【Elasticsearch】search_after不支持随机到哪一页,只能用于上一页或下一页的场景
search_after 确实不支持随机访问(即直接跳到任意一页),因此在前端需要随机跳转到某一页的场景中,使用 search_after 是不合适的。这种情况下,更适合使用 from 和 size 来实现分页。 为什么 search_after 不支持随机访…...

深度解析 Qt 最顶层类 QObject:继承关系与内存生命周期管理
文章目录 深度解析 Qt 最顶层类 QObject:继承关系与内存生命周期管理QObject 的继承关系QObject 的内存与生命周期管理父子对象树结构构造函数中的父对象参数父对象删除时自动删除子对象的原理举例说明 父子对象关系的好处继承关系与构造函数调用顺序信号槽机制与对…...
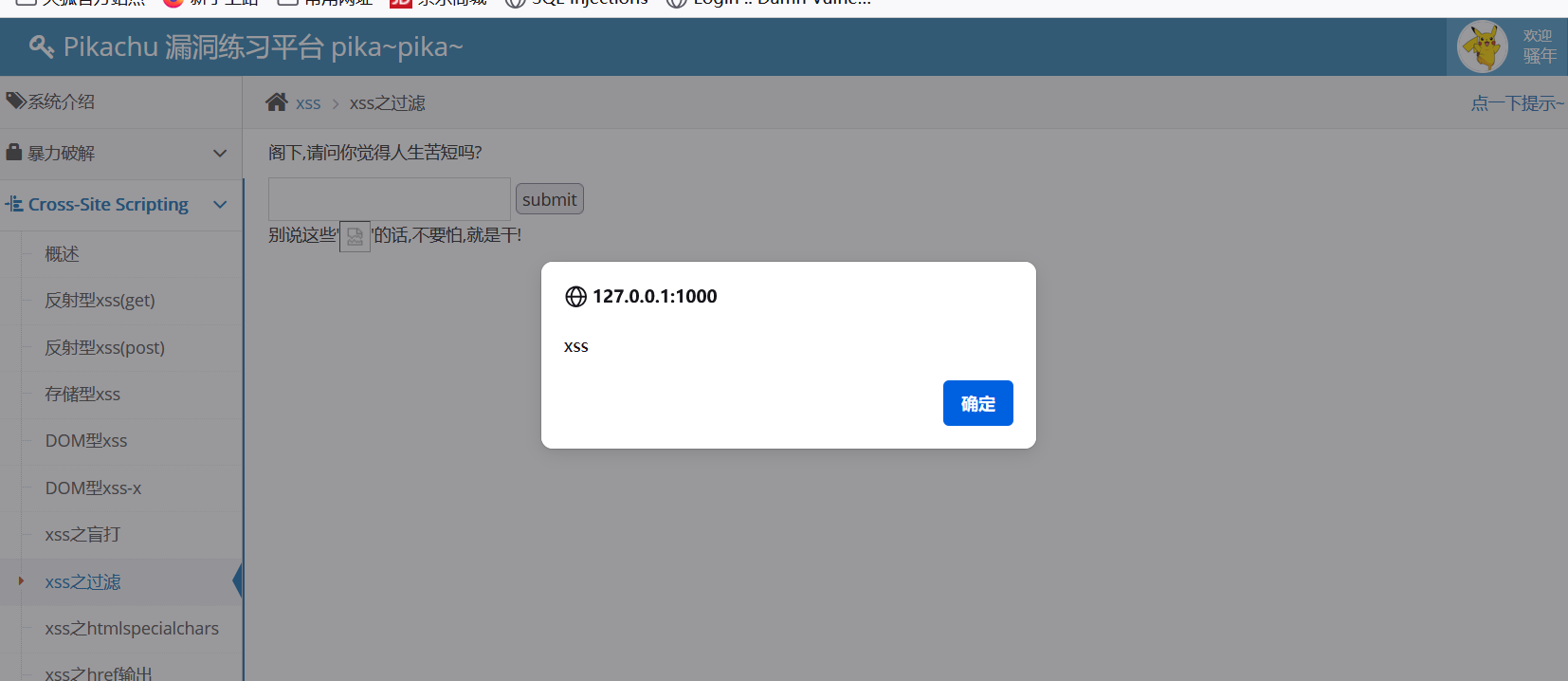
pikachu通关教程-XSS
XSS XSS漏洞原理 XSS被称为跨站脚本攻击(Cross Site Scripting),由于和层叠样式表(Cascading Style Sheets,CSS)重名,改为XSS。主要基于JavaScript语言进行恶意攻击,因为js非常灵活…...

k8s fsGroup
fsGroup 是 Kubernetes 中 securityContext 的一个字段,用于为 Pod 中的所有容器设置共享的文件系统组 ID(GID)。当你在 Pod 的 securityContext 中设置了 fsGroup,Kubernetes 会对挂载到 Pod 的 所有 volume(卷&#…...

Spring Boot,注解,@ConfigurationProperties
好的,这是上面关于 ConfigurationProperties 注解和 setter 方法的判断题及其解析的中文版本: 该判断题表述为:“使用ConfigurationProperties 注解注入属性值时,必须为对应的属性提供setter方法。” 这个说法是 正确的。 Config…...

AIGC学习笔记(9)——AI大模型开发工程师
文章目录 AI大模型开发工程师008 LangChain之Chains模块1 Chain模块核心知识2 Chain模块代码实战LLMSequentialTransformationRouter AI大模型开发工程师 008 LangChain之Chains模块 1 Chain模块核心知识 组合常用的模块 LLM:最常见的链式操作类型SequentialChain…...

git管理github上的repository
1. 首先注册github并创建一个仓库,这个很简单,网上教程也很多,就不展开说了 2. 安装git,这个也很简单,不过这里有个问题就是你当前windows的用户名即:C/Users/xxx 这个路径不要有中文,因为git …...
)
STM32学习之WWDG(原理+实操)
📢:如果你也对机器人、人工智能感兴趣,看来我们志同道合✨ 📢:不妨浏览一下我的博客主页【https://blog.csdn.net/weixin_51244852】 📢:文章若有幸对你有帮助,可点赞 👍…...
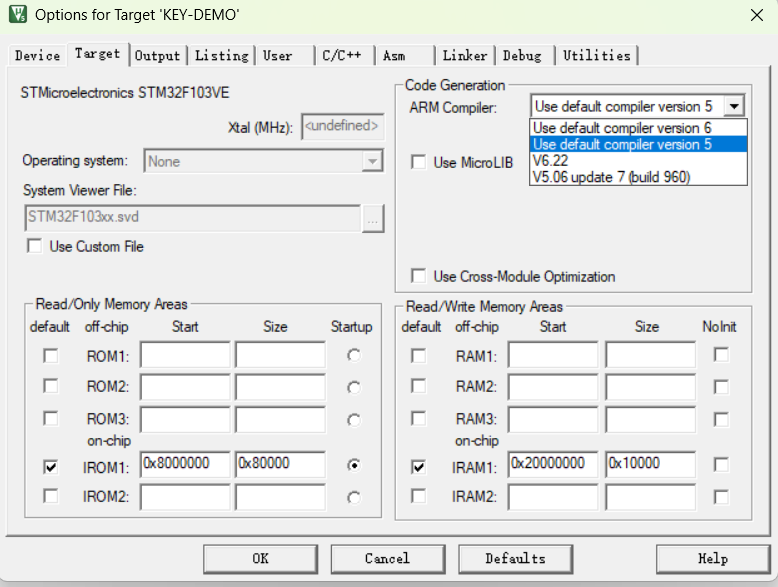
Keil MDK5.37或更高版本不再预装ARM Compiler Version5导致编译错误的解决方法
Keil MDK5.37预装的是最新的ARM Compiler Version6 我们可以先右击查看工程属性 在Target标签下,我们可以看到Compiler Version5就是丢失的 在Target标签下,我们可以看到Compiler Version5就是丢失的 图1 以固件库方式编程,编译之后全是错…...
笔记-14】App版本不升级时本地数据库sqlite更新逻辑二)
【iOS(swift)笔记-14】App版本不升级时本地数据库sqlite更新逻辑二
App版本不升级时,又想即时更新本地数据库怎么办? 办法二:从服务器下载最新的sqlite数据替换掉本地的数据(注意是数据不是文件) 稍加调整, // !!!注意!&…...

前端性能优化:提升用户体验的关键策略
引言 在当今快速发展的互联网时代,用户对网页加载速度和交互流畅度的要求越来越高。前端性能优化已成为提升用户体验、降低跳出率、提高转化率的关键因素。本文将深入探讨前端优化的核心策略和实践方法,帮助开发者构建更快、更高效的Web应用。 一、网络…...