Redis底层数据结构之跳表(SkipList)
SkipList是Redis有序结合ZSet底层的数据结构,也是ZSet的灵魂所在。与之相应的,Redis还有一个无序集合Set,这两个在底层的实现是不一样的。
标准的SkipList:
跳表的本质是一个链表。链表这种结构虽然简单清晰,但是在查询时的效率比较低(O(n)),而在有序集合的场景中,我们希望运用有序这个前提条件,来提高我们增删查的效率。在算法中,有一种针对有序集合的搜索算法叫二分查找,Redis中的ZSet底层在设计时也参考了二分查找的思想,引入了跳表。跳表在链表的基础上,引入了多级索引,通过索引可以一次实现多个节点的跳跃,提高查询性能,下面是跳表的结构图:
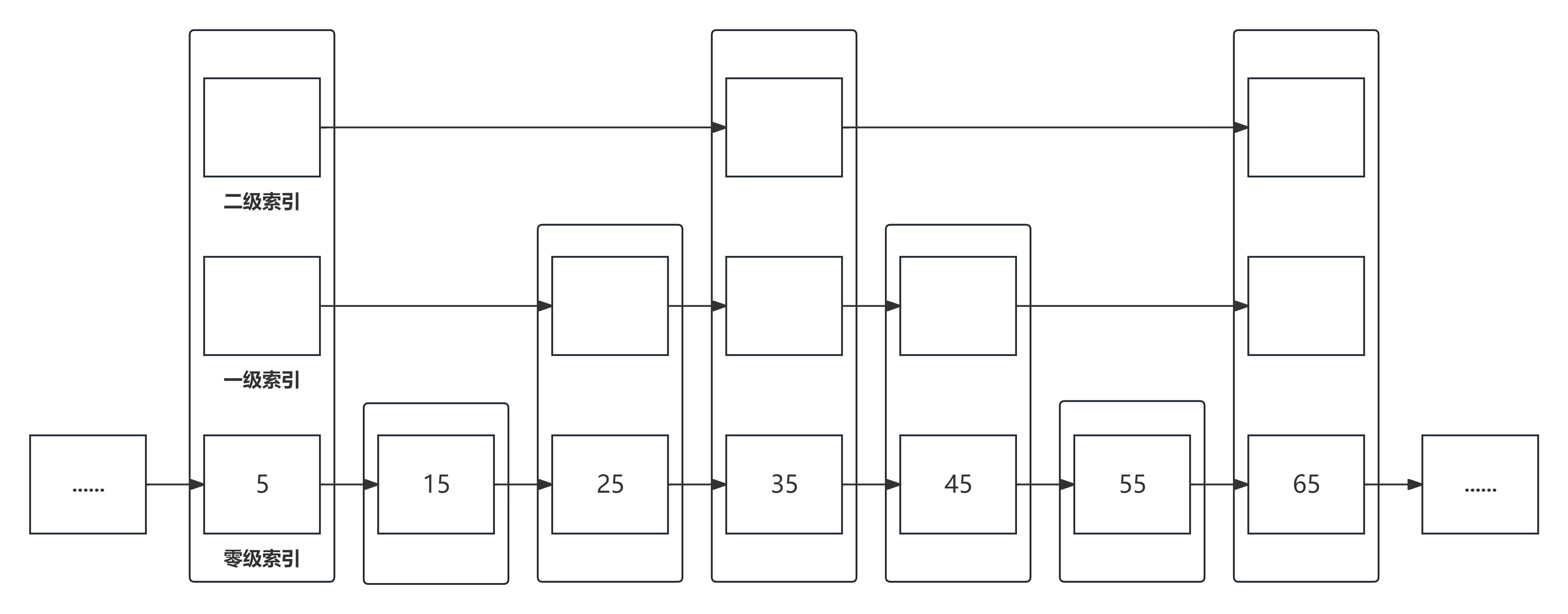
可以看到,图中的某些节点不光只有一层。如果使用普通的节点,那么每一步只能查询后方的一个节点,如果用这种有高层的节点,那么可以实现一步查询后方相隔多个的节点。理论上,层次越高,对应的步长就越大,但是实际上并不像上图一样是绝对均衡的,节点的层高其实是概率随机的,下面会具体分析到,这里我们先这样简单理解。
为了理解这种结构有什么好处,我们根据上方的图分几个来进行分析。
(1)查找分数为35的数据。
如果只有原始链表的话,那需要走4步,如果有图中的二级索引,那么只用走一步。如果要找的值是45呢?其实就是从第一个节点出发,通过二级索引走到节点值为35,再查看二级索引对应的下一个节点值为65,已经超过要查询的节点值,所以在值为35的节点上,二级索引下降到一级索引向后遍历,再走一次就到了值为45的节点。整个查询的过程其实和二分查找十分相似。
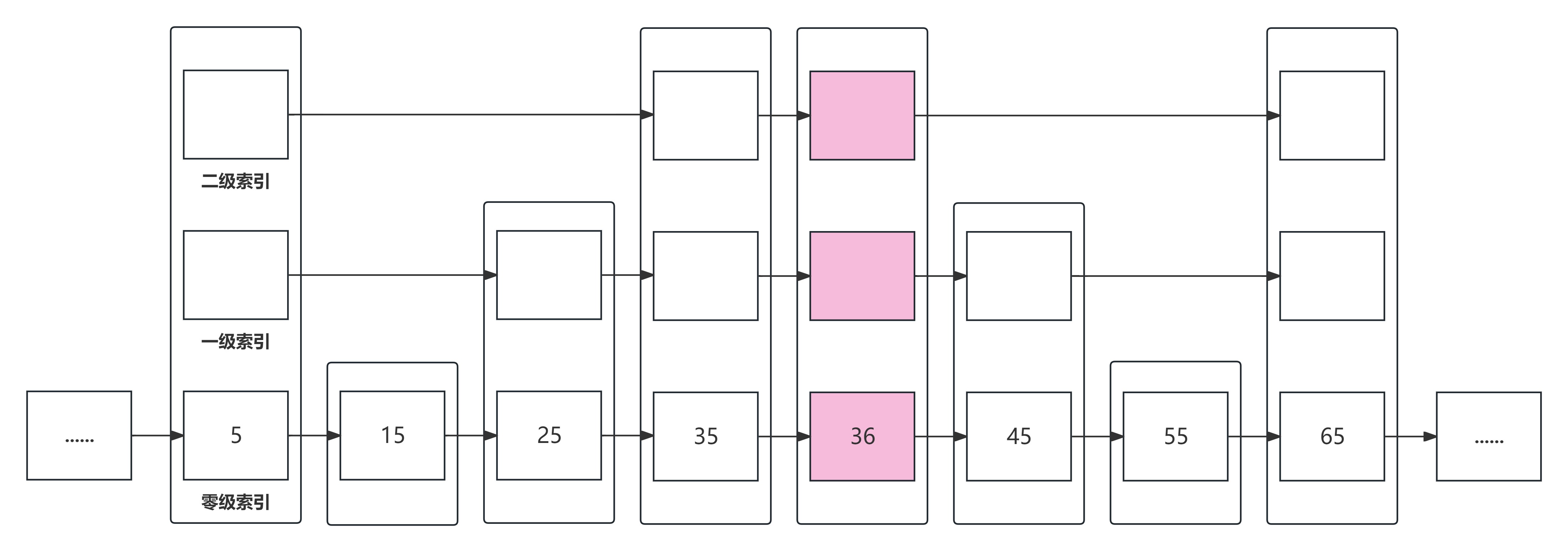
(2)插入一条score为36的数据。
要插入一个值为36的节点,那么我们首先应该定位到一个值比36大的节点,也就是图中值为45的节点,定位的方式与查询类似。然后构造一个新的值为36的节点,这里我们假设节点的层高随机到3,(具体的随机算法我们后面会讲),最后将各层链表补齐,其实就是在每一层进行链接,完成后效果如下图所示:
标准的跳表会存在如下两种限制:
①score值不能重复,也就是在底层链表中不允许存在两个值相同的节点。
②底层链表只有前向指针(next),而没有退回指针(prev)。
Redis中的SkipList:
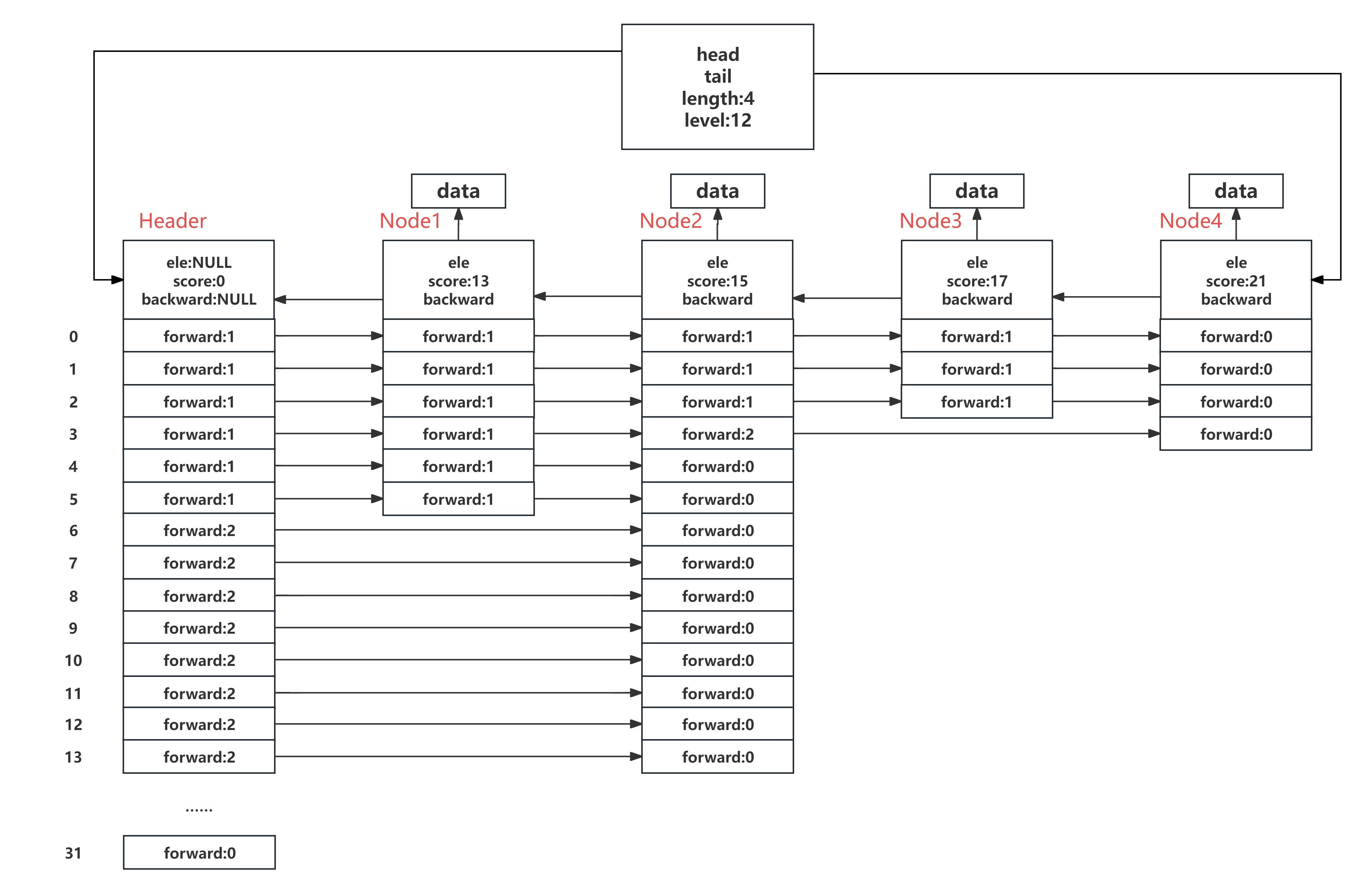
在Redis中,跳表是用来支持有序集合的,所以Redis对标准跳表做了一些优化,使得链表中的score值可以重复,并且增加了回退指针,具体的结构如下图所示:
zskiplistNode:
typedef struct zskiplistNode {sds ele;double score;struct zskiplistNode *backward;struct zskiplistLevel {struct zskiplistNode *forward;unsigned int span;} level[];
} zskiplistNode;
ele:用来存储数据,使用的是SDS数据结构。
score:用来存储节点的分数,采用double数据类型。
backword:指向上一个节点的回退指针,支持链表从尾到头的遍历,也就是ZREVRANGE这个命令。
level[]:level结构体数组是用来保存各个索引层级的forward指针和span信息的。具体来说,level[0]存储的就是第一层索引(最底层索引),level[1]存储的就是第二层索引,以此类推。higher level的forward指针可以指向更远的节点,可以用来快速遍历。span记录索引跨度。通过维护多级索引,跳表可以通过较高层级的索引快速定位到目标节点附近,然后再在底层索引进行线性查找。所以,level数组在跳表中的作用就是记录多级索引的数据,让跳表可以实现更快的查找、遍历、排序等操作。
zskiplist:
typedef struct zskiplist {struct zskiplistNode *header, *tail;unsigned long length;int level;
} zskiplist;
*header:指向跳表的头结点(头结点不存储任何数据,并且其level数组的大小为32)。
*tail:指向跳表的尾节点。
length:存储跳表中除去头结点后其余节点个数。
level:存储跳表中除去头结点后其余节点中level数组最大长度。
内存分布:
Redis中的SkipList内存分布如下图所示:
Redis中跳表的Node中的level数组长度怎么决定?
长度的决定需要比较随机,才能在各个场景中表现出较为平均的性能。Redis使用概率均衡的思路来确定新插入节点的层数:Redis跳表决定每一个节点,是否增加一层的概率为25%,而最大层数限制在Redis5.0时是64层,在Redis7.0时是32层。
Redis使用跳表对性能究竟优化了多少?
与二分查找的平均时间复杂度是一样的,Redis使用跳表将增删查的时间复杂度从O(n)降低到了O(logn)。
Redis为什么不使用哈希表或者平衡树?
先来看一看作者是怎么回答这个问题的:
There are a few reasons:They are not very memory intensive. It's up to you basically. Changing parameters about the probability of a node to have a given number of levels will make then less memory intensive than btrees.
A sorted set is often target of many ZRANGE or ZREVRANGE operations, that is, traversing the skip list as a linked list. With this operation the cache locality of skip lists is at least as good as with other kind of balanced trees.They are simpler to implement, debug, and so forth. For instance thanks to the skip list simplicity I received a patch (already in Redis master) with augmented skip lists implementing ZRANK in O(log(N)). It required little changes to the code.About the Append Only durability & speed, I don't think it is a good idea to optimize Redis at cost of more code and more complexity for a use case that IMHO should be rare for the Redis target (fsync() at every command). Almost no one is using this feature even with ACID SQL databases, as the performance hint is big anyway.
About threads: our experience shows that Redis is mostly I/O bound. I'm using threads to serve things from Virtual Memory. The long term solution to exploit all the cores, assuming your link is so fast that you can saturate a single core, is running multiple instances of Redis (no locks, almost fully scalable linearly with number of cores), and using the "Redis Cluster" solution that I plan to develop in the future.
说人话就是跳表的实现更加简单,并且达到了类似的效果。
首先回答一下为什么不使用哈希表。最大的原因就是哈希表的存储是无序的,因此哈希表更适合解决对单个键的查询工作,而不适合解决范围查找问题(查找哪些值在两个数之间的节点的这类问题)。
接着回答为什么不使用平衡树。平衡树可以解决范围查找的问题,但是与SkipList相比,平衡树在进行范围查找时的操作更加复杂,当我们在平衡树上找到指定范围的小值时,还需要以中序遍历的顺序继续寻找其他不超过指定范围的大值的节点,而SkipList的操作就很简单了,只需要在找到小值之后,进行若干步的遍历即可。平衡树在进行插入和删除操作时可能引发树的自平衡调整,逻辑复杂,而SkipList在进行指定节点的插入和删除时,只需要修改相邻节点的指针就可以了,逻辑和操作都很简单。
所以,Redis在实现复杂度和性能上,最终选择的是SkipList数据结构。
Redis底层数据结构篇文章到这里就迎来一个小结了,有什么问题或者勘误欢迎评论区留言,笔者看到都会回复的。
相关文章:
Redis底层数据结构之跳表(SkipList)
SkipList是Redis有序结合ZSet底层的数据结构,也是ZSet的灵魂所在。与之相应的,Redis还有一个无序集合Set,这两个在底层的实现是不一样的。 标准的SkipList: 跳表的本质是一个链表。链表这种结构虽然简单清晰,但是在查…...

跨架构镜像打包问题及解决方案
问题背景: 需求: 有一个镜像是 docker.io 的,是 docker.io/aquasec/kube-bench:v0.10.6,我想把该镜像在本地电脑(可翻墙)下载下来,然后 docker save 打包成一个 tar 包,传输到服务器…...

云原生时代 Kafka 深度实践:05性能调优与场景实战
5.1 性能调优全攻略 Producer调优 批量发送与延迟发送 通过调整batch.size和linger.ms参数提升吞吐量: props.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384); // 默认16KB props.put(ProducerConfig.LINGER_MS_CONFIG, 10); // 等待10ms以积累更多消息ba…...

Ubuntu安装Docker命令清单(以20.04为例)
在你虚拟机上完成Ubuntu的下载后打开终端!!! Ubuntu安装Docker终极命令清单(以20.04为例) # 1. 卸载旧版本(全新系统可跳过) sudo apt-get remove docker docker-engine docker.io containerd …...

使用 Python 制作 GIF 动图,并打包为 EXE 可执行程序
文章目录 成品百度网盘下载🎬 使用 Python 制作 GIF 动图,并打包为 EXE 可执行程序(含图形界面)🧰 环境准备💻 功能预览🧑💻 完整代码(图形界面 功能)如何…...
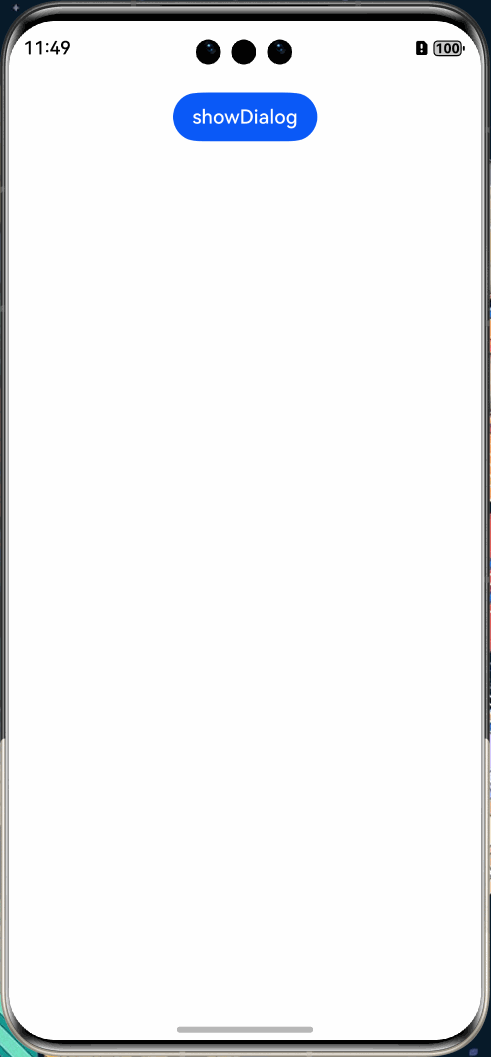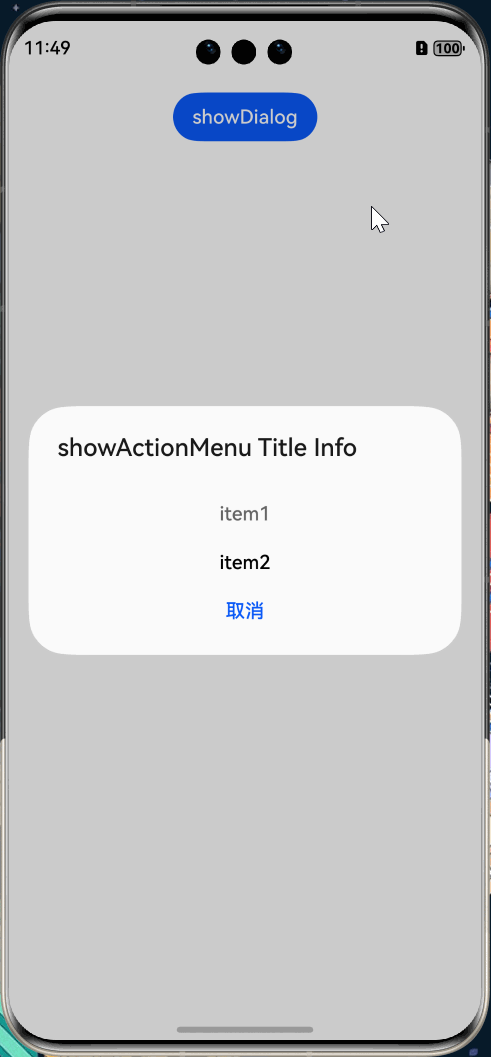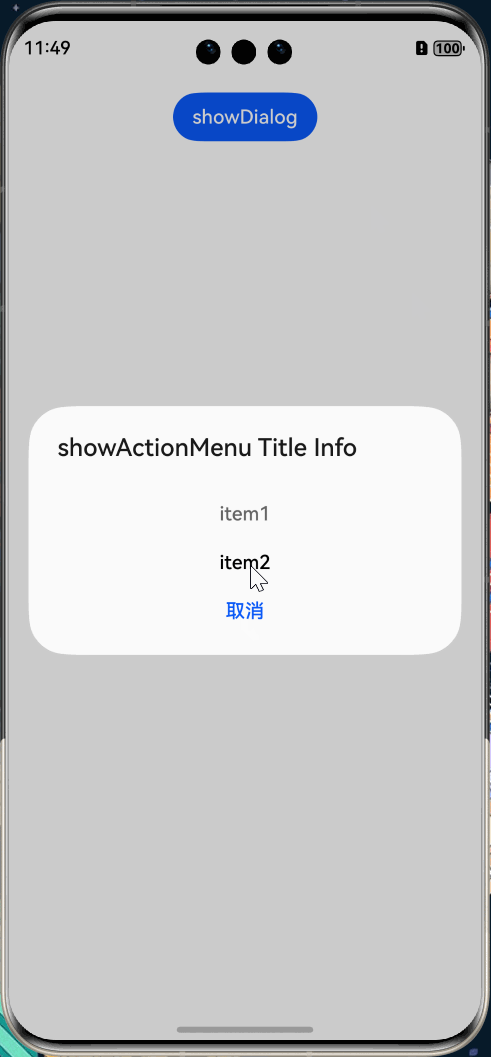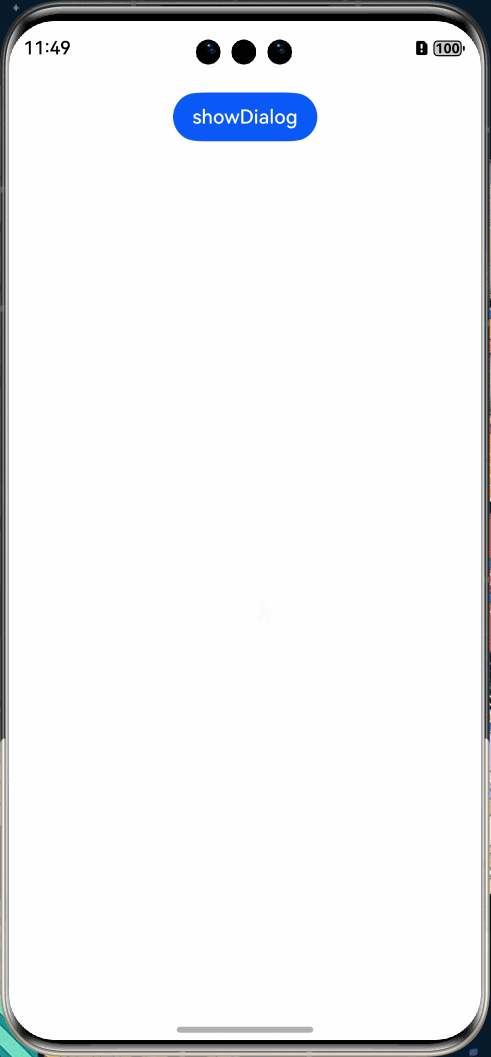
HarmonyOS Next 弹窗系列教程(2)
HarmonyOS Next 弹窗系列教程(2) 上一章节我们讲了自定义弹出框 (openCustomDialog),那对于一些简单的业务场景,不一定需要都是自定义,也可以使用 HarmonyOS Next 内置的一些弹窗效果。比如: 名称描述不依…...

Ubuntu 18.04 上源码安装 protobuf 3.7.0
🔧 1️⃣ 安装依赖 sudo apt update sudo apt install -y autoconf automake libtool curl make g unzip📥 2️⃣ 下载源码 cd ~ git clone https://github.com/protocolbuffers/protobuf.git cd protobuf git checkout v3.7.0⚙️ 3️⃣ 编译 & 安…...

中小企业搭建网站选择虚拟主机还是云服务器?华为云有话说
这是一个很常见的问题,许多小企业在搭建网站时都会面临这个选择。虚拟主机和云服务器都有各自的优缺点,需要根据自己的需求和预算来决定。 虚拟主机是指将一台物理服务器分割成多个虚拟空间,每个空间都可以运行一个网站。虚拟主机的优点是价格…...
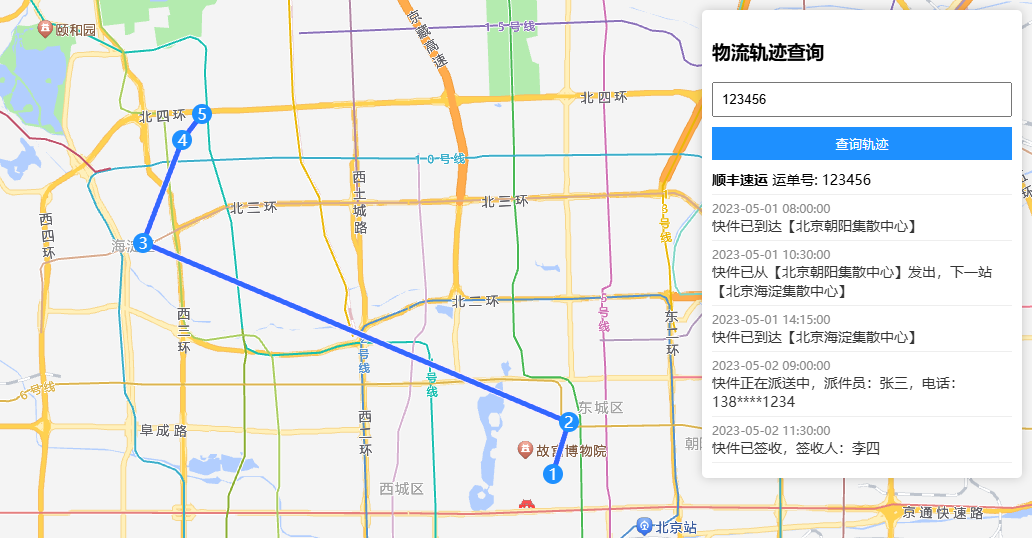
使用 HTML + JavaScript 在高德地图上实现物流轨迹跟踪系统
在电商行业蓬勃发展的今天,物流信息查询已成为人们日常生活中的重要需求。本文将详细介绍如何基于高德地图 API 利用 HTML JavaScript 实现物流轨迹跟踪系统的开发。 效果演示 项目概述 本项目主要包含以下核心功能: 地图初始化与展示运单号查询功能…...
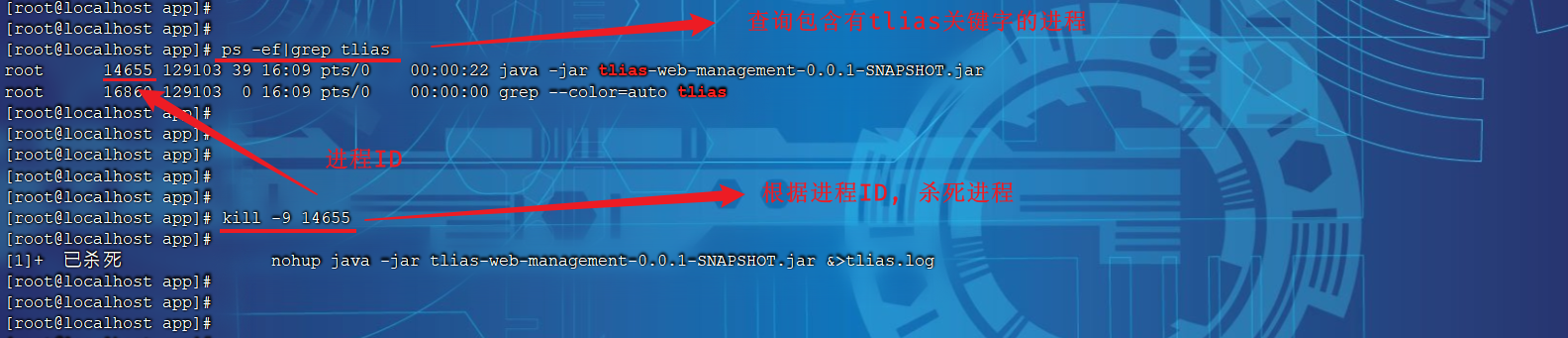
19-项目部署(Linux)
Linux是一套免费使用和自由传播的操作系统。说到操作系统,大家比较熟知的应该就是Windows和MacOS操作系统,我们今天所学习的Linux也是一款操作系统。 我们作为javaEE开发工程师,将来在企业中开发时会涉及到很多的数据库、中间件等技术&#…...
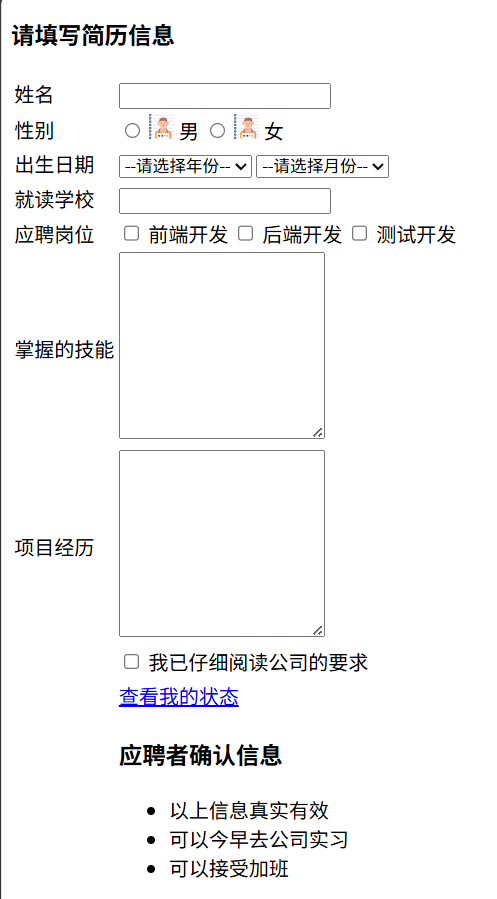
html基础01:前端基础知识学习
html基础01:前端基础知识学习 1.个人建立打造 -- 之前知识的小总结1.1个人简历展示1.2简历信息填写页面 1.个人建立打造 – 之前知识的小总结 1.1个人简历展示 <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8&qu…...

Golang学习之旅
Golang学习之旅:初探Go语言的奥秘 在当今这个快速发展的技术时代,编程语言层出不穷,每一种都有其独特的魅力和适用场景。作为一名对技术充满热情的开发者,我一直在探索新的知识,以提升自己的编程技能。最近࿰…...

【RoadRunner】自动驾驶模拟3D场景构建 | 软件简介与视角控制
💯 欢迎光临清流君的博客小天地,这里是我分享技术与心得的温馨角落 💯 🔥 个人主页:【清流君】🔥 📚 系列专栏: 运动控制 | 决策规划 | 机器人数值优化 📚 🌟始终保持好奇心&…...

基于RK3576+FPGA芯片构建的CODESYS软PLC Linux实时系统方案,支持6T AI算力
基于RK3576芯片构建的CODESYS软PLC Linux实时系统方案,结合了异构计算架构与工业实时控制技术,主要特点如下: 一、硬件架构设计 异构多核协同 Cortex-A72四核(2.3GHz):处理运动轨迹规划、AI视觉等…...

鸿蒙OSUniApp复杂表单与动态验证实践:打造高效的移动端表单解决方案#三方框架 #Uniapp
UniApp复杂表单与动态验证实践:打造高效的移动端表单解决方案 引言 在移动应用开发中,表单处理一直是一个既常见又具有挑战性的任务。随着HarmonyOS生态的蓬勃发展,越来越多的开发者开始关注跨平台解决方案。本文将深入探讨如何使用UniApp框…...
)
在linux系统上搭建git服务器(ssh协议)
1.在windows上生成RSA密钥对 ssh-keygen -t rsa -b 2048 -C"git用户名/邮箱地址" 命令执行后会在 C:\Users\${windows登录账户}\.ssh 目录下生成密钥对 其中 id_rsa 为私钥,id_rsa.pub 为公钥 2.在 linux 系统上登记公钥 vim ~/.ssh/authorized_keys…...

适配器模式:让不兼容接口协同工作
文章目录 1. 适配器模式概述2. 适配器模式的分类2.1 类适配器2.2 对象适配器 3. 适配器模式的结构4. C#实现适配器模式4.1 对象适配器实现4.2 类适配器实现 5. 适配器模式的实际应用场景5.1 第三方库集成5.2 遗留系统集成5.3 系统重构与升级5.4 跨平台开发 6. 类适配器与对象适…...

NodeJS全栈开发面试题讲解——P12高性能场景题
12.1 设计一个高并发点赞接口,如何优化性能? 设计要点: 问题: 点赞操作是高频写操作,数据库直接写可能成为瓶颈。 优化方案: 缓存计数 异步落库 点赞先写缓存(Redis Hash / Sorted Set&…...
DDP与FSDP:分布式训练技术全解析
DDP与FSDP:分布式训练技术全解析 DDP(Distributed Data Parallel)和 FSDP(Fully Sharded Data Parallel)均为用于深度学习模型训练的分布式训练技术,二者借助多 GPU 或多节点来提升训练速度。 1. DDP(Distributed Data Parallel) 实现原理 数据并行:把相同的模型复…...

【Spring AI 1.0.0】Spring AI 1.0.0框架快速入门(1)——Chat Client API
Spring AI框架快速入门 一、前言二、前期准备2.1 运行环境2.2 maven配置2.3 api-key申请 三、Chat Client API3.1 导入pom依赖3.2 配置application.properties文件3.3 创建 ChatClient3.3.1 使用自动配置的 ChatClient.Builder3.3.2 使用多个聊天模型 3.4 ChatClient请求3.5 Ch…...
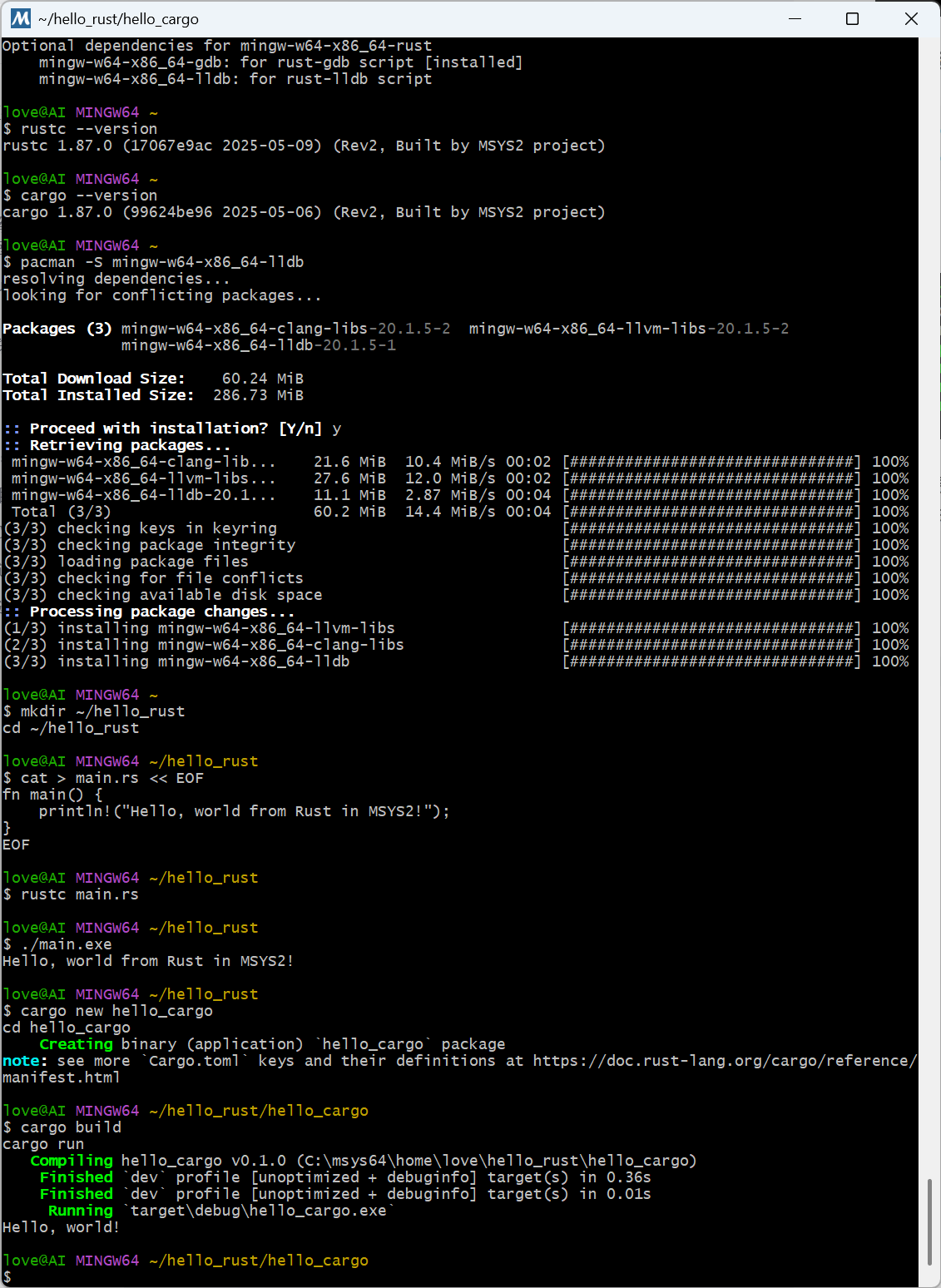
【笔记】在 MSYS2(MINGW64)中正确安装 Rust
#工作记录 1. 环境信息 Windows系统: MSYS2 MINGW64当前时间: 2025年6月1日Rust 版本: rustc 1.87.0 (17067e9ac 2025-05-09) (Rev2, Built by MSYS2 project) 2. 安装步骤 步骤 1: 更新系统包数据库并升级已安装的包 首先,确保我们的 MSYS2 系统是最新状态。打…...
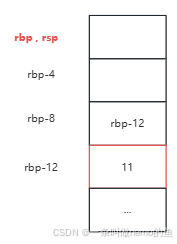
从汇编的角度揭秘C++引用,豁然开朗
C中的引用是指已有对象的别名,可以通过该别名访问并修改被引用的对象。那么其背后的原理是什么呢?引用是否会带来额外的开销呢?我们从一段代码入手,来分析一下引用的本质。 #include <stdio.h> int main() {int a 10;int …...
:建造者模式(Builder))
设计模式系列(07):建造者模式(Builder)
本文为设计模式系列第7篇,聚焦创建型模式中的建造者模式,涵盖定义、原理、实际业务场景、优缺点、最佳实践及详细代码示例,适合系统学习与实战应用。 目录 1. 模式概述2. 使用场景3. 优缺点分析4. 实际应用案例5. 结构与UML类图6. 代码示例7…...

Maven 项目中集成数据库文档生成工具
在 Maven 项目中,可以通过集成 数据库文档生成工具(如 screw-maven-plugin、mybatis-generator 或 liquibase)来自动生成数据库文档。以下是使用 screw-maven-plugin(推荐)的完整配置步骤: 1. 添加插件配置…...

聊聊Tomato Architecture
序 本文主要研究一下Tomato Architecture Clean/Onion/Hexagonal/Ports&Adapters Architectures Clean Architecture clean architecture定义了四层结构,最内层是entities(enterprise business rules),再往外是use cases(application business ru…...

小白的进阶之路系列之十二----人工智能从初步到精通pytorch综合运用的讲解第五部分
在本笔记本中,我们将针对Fashion-MNIST数据集训练LeNet-5的变体。Fashion-MNIST是一组描绘各种服装的图像瓦片,有十个类别标签表明所描绘的服装类型。 # PyTorch model and training necessities import torch import torch.nn as nn import torch.nn.functional as F impor…...

Java并发编程实战 Day 6:Future与异步编程模型
【Java并发编程实战 Day 6】Future与异步编程模型 在今天的课程中,我们将深入学习Java中的Future与异步编程模型。这是为期30天的"Java并发编程实战"系列的第6天。 理论基础 Future接口 Future接口是Java提供的用于表示异步计算的结果。它提供了以下方…...
 攻击)
.NET Core 中预防跨网站请求伪造 (XSRFCSRF) 攻击
.NET Core 中预防跨网站请求伪造 (XSRF/CSRF) 攻击 在如今的网络环境中,安全问题一直是开发者们不可忽视的重要方面。跨网站请求伪造(Cross-Site Request Forgery,简称 CSRF)就是一种常见且具有威胁性的网络攻击方式。攻击者通过…...

MFC Resource.h 文件详解与修改指南
MFC Resource.h 文件详解与修改指南 Resource.h 是 Visual C 和 MFC 项目中用于集中管理资源标识符(Resource ID)的头文件。它由 Visual Studio 的资源编辑器自动生成并维护,也可以手动编辑。理解并合理使用该文件对于管理对话框、控件、菜单…...

2025年06月03日Github流行趋势
项目名称:onlook 项目地址url:https://github.com/onlook-dev/onlook项目语言:TypeScript历史star数:12871今日star数:624项目维护者:Kitenite, drfarrell, spartan-vutrannguyen, apps/devin-ai-integrati…...