superior哥AI系列第9期:高效训练与部署:从实验室到生产环境
🚀 superior哥AI系列第9期:高效训练与部署:从实验室到生产环境
嘿!小伙伴们!👋 欢迎来到superior哥AI系列第9期!经过前面8期的学习,你已经掌握了深度学习的核心技术。但是,会训练模型只是开始,让AI真正服务用户才是终极目标!🎯 今天我们要解决一个关键问题:如何让你的AI模型从实验室走向真实世界?
🎭 今天我们要征服什么?
看看这个实战级菜单,保证让你从"实验室玩家"变成"生产环境大师":
- ⚡ GPU加速训练 - 让训练速度飞起来!
- 💾 模型优化与压缩 - 让模型又小又快
- 🌐 部署方案大全 - 从Flask到Kubernetes
- 🔍 性能监控 - 确保模型稳定运行
- 🎮 完整项目实战 - 端到端的部署经验
⚡ GPU加速训练:让你的训练速度起飞
🚀 CUDA编程入门
import torch
import torch.nn as nn
import time
import numpy as npclass GPU加速大师:"""GPU加速训练专家让CPU训练10小时的模型,GPU只需30分钟!"""def __init__(self):self.设备检查()def 设备检查(self):"""检查可用的计算设备"""print("🔍 设备环境检查")print("=" * 50)# 🖥️ CUDA可用性检查if torch.cuda.is_available():gpu数量 = torch.cuda.device_count()当前gpu = torch.cuda.current_device()gpu名称 = torch.cuda.get_device_name(当前gpu)print(f"✅ CUDA可用!")print(f"🎮 GPU数量: {gpu数量}")print(f"🔥 当前GPU: {gpu名称}")print(f"💾 显存容量: {torch.cuda.get_device_properties(当前gpu).total_memory / 1024**3:.1f} GB")self.device = torch.device('cuda')else:print("❌ CUDA不可用,使用CPU训练")print("💡 建议:安装CUDA版本的PyTorch以获得更好性能")self.device = torch.device('cpu')# 🧠 MPS检查(Mac用户)if torch.backends.mps.is_available():print("🍎 MPS可用!(Mac GPU加速)")self.device = torch.device('mps')def 性能对比测试(self, 矩阵大小=5000):"""CPU vs GPU性能对比"""print(f"\n🏁 性能对比测试 (矩阵大小: {矩阵大小}x{矩阵大小})")print("=" * 60)# 🧮 创建测试数据A = torch.randn(矩阵大小, 矩阵大小)B = torch.randn(矩阵大小, 矩阵大小)# 📊 CPU测试print("🖥️ CPU计算中...")start_time = time.time()C_cpu = torch.mm(A, B)cpu_time = time.time() - start_timeprint(f"CPU耗时: {cpu_time:.4f}秒")# 🎮 GPU测试(如果可用)if self.device.type == 'cuda':A_gpu = A.to(self.device)B_gpu = B.to(self.device)# 预热GPUtorch.mm(A_gpu, B_gpu)torch.cuda.synchronize()print("🚀 GPU计算中...")start_time = time.time()C_gpu = torch.mm(A_gpu, B_gpu)torch.cuda.synchronize() # 等待GPU完成gpu_time = time.time() - start_timeprint(f"GPU耗时: {gpu_time:.4f}秒")# 📈 性能提升比较加速比 = cpu_time / gpu_timeprint(f"\n🏆 GPU加速比: {加速比:.1f}x")print(f"💰 性能提升: {(加速比-1)*100:.1f}%")# ✅ 结果验证差异 = torch.max(torch.abs(C_cpu - C_gpu.cpu()))print(f"🔍 计算精度差异: {差异:.2e}")def 显存管理技巧(self):"""GPU显存优化技巧"""print("\n💾 GPU显存管理技巧")print("=" * 50)if self.device.type != 'cuda':print("⚠️ 需要CUDA设备才能演示显存管理")return# 📊 显存使用情况def 显示显存状态(描述=""):allocated = torch.cuda.memory_allocated() / 1024**3cached = torch.cuda.memory_reserved() / 1024**3print(f"{描述}")print(f" 已分配显存: {allocated:.2f} GB")print(f" 缓存显存: {cached:.2f} GB")显示显存状态("🔍 初始状态:")# 🧮 创建大张量print("\n📦 创建大张量...")large_tensor = torch.randn(5000, 5000).to(self.device)显示显存状态("📈 创建张量后:")# 🗑️ 删除张量print("\n🗑️ 删除张量...")del large_tensor显示显存状态("🔄 删除张量后:")# 🧹 清理缓存print("\n🧹 清理GPU缓存...")torch.cuda.empty_cache()显示显存状态("✨ 清理缓存后:")print("\n💡 显存管理建议:")print("1. 及时删除不用的大张量 (del tensor)")print("2. 定期清理GPU缓存 (torch.cuda.empty_cache())")print("3. 使用with torch.no_grad()减少显存占用")print("4. 适当减小batch_size避免OOM")# 🎮 运行GPU加速演示
加速大师 = GPU加速大师()
加速大师.性能对比测试()
加速大师.显存管理技巧()
🔥 混合精度训练:速度与精度的完美平衡
import torch
import torch.nn as nn
import torch.optim as optim
from torch.cuda.amp import autocast, GradScaler
import timeclass 混合精度训练师:"""混合精度训练专家用FP16训练获得2倍速度提升,同时保持模型精度!"""def __init__(self):self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.scaler = GradScaler() # 梯度缩放器def 创建示例模型(self, input_size=1000, hidden_size=512, num_classes=10):"""创建示例深度网络"""model = nn.Sequential(nn.Linear(input_size, hidden_size),nn.ReLU(),nn.Dropout(0.2),nn.Linear(hidden_size, hidden_size),nn.ReLU(),nn.Dropout(0.2),nn.Linear(hidden_size, hidden_size),nn.ReLU(),nn.Linear(hidden_size, num_classes)).to(self.device)return modeldef 普通精度训练(self, model, dataloader, epochs=5):"""传统FP32训练"""print("🔄 开始FP32普通精度训练...")optimizer = optim.Adam(model.parameters(), lr=0.001)criterion = nn.CrossEntropyLoss()model.train()start_time = time.time()for epoch in range(epochs):epoch_loss = 0for batch_idx, (data, target) in enumerate(dataloader):data, target = data.to(self.device), target.to(self.device)optimizer.zero_grad()# 🔄 前向传播output = model(data)loss = criterion(output, target)# 🔙 反向传播loss.backward()optimizer.step()epoch_loss += loss.item()if batch_idx >= 20: # 限制批次数量breakprint(f"Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/(batch_idx+1):.4f}")fp32_time = time.time() - start_timeprint(f"FP32训练时间: {fp32_time:.2f}秒")return fp32_timedef 混合精度训练(self, model, dataloader, epochs=5):"""FP16混合精度训练"""print("\n🚀 开始FP16混合精度训练...")optimizer = optim.Adam(model.parameters(), lr=0.001)criterion = nn.CrossEntropyLoss()model.train()start_time = time.time()for epoch in range(epochs):epoch_loss = 0for batch_idx, (data, target) in enumerate(dataloader):data, target = data.to(self.device), target.to(self.device)optimizer.zero_grad()# 🎯 使用autocast进行混合精度前向传播with autocast():output = model(data)loss = criterion(output, target)# 🔧 使用GradScaler进行梯度缩放self.scaler.scale(loss).backward()self.scaler.step(optimizer)self.scaler.update()epoch_loss += loss.item()if batch_idx >= 20: # 限制批次数量breakprint(f"Epoch {epoch+1}/{epochs}, Loss: {epoch_loss/(batch_idx+1):.4f}")fp16_time = time.time() - start_timeprint(f"FP16训练时间: {fp16_time:.2f}秒")return fp16_timedef 精度对比演示(self):"""混合精度 vs 普通精度对比演示"""if self.device.type != 'cuda':print("⚠️ 混合精度训练需要CUDA设备")returnprint("🎯 混合精度训练对比演示")print("=" * 60)# 📊 创建模拟数据batch_size = 128input_size = 1000num_batches = 25fake_data = []for _ in range(num_batches):data = torch.randn(batch_size, input_size)target = torch.randint(0, 10, (batch_size,))fake_data.append((data, target))# 🏗️ 创建两个相同的模型model_fp32 = self.创建示例模型()model_fp16 = self.创建示例模型()# 确保两个模型权重相同model_fp16.load_state_dict(model_fp32.state_dict())# 🔄 FP32训练fp32_time = self.普通精度训练(model_fp32, fake_data)# 🚀 FP16训练fp16_time = self.混合精度训练(model_fp16, fake_data)# 📈 性能对比speedup = fp32_time / fp16_timememory_saved = self.计算显存节省()print(f"\n🏆 性能对比结果:")print(f"📈 训练加速: {speedup:.2f}x")print(f"💾 显存节省: ~{memory_saved}%")print(f"✅ 精度损失: 几乎无损失")print(f"\n💡 混合精度训练的优势:")print("1. 🚀 训练速度提升1.5-2倍")print("2. 💾 显存使用减少约30-50%")print("3. ✅ 模型精度基本无损失")print("4. 🎯 支持更大的batch_size")def 计算显存节省(self):"""估算显存节省比例"""# FP16相比FP32理论上节省50%显存# 但实际情况考虑其他开销,通常节省30-40%return 35# 🎮 运行混合精度演示
if torch.cuda.is_available():训练师 = 混合精度训练师()训练师.精度对比演示()
else:print("⚠️ 需要CUDA环境才能演示混合精度训练")
🌐 分布式训练:多卡协作的威力
import torch
import torch.nn as nn
import torch.distributed as dist
import torch.multiprocessing as mp
from torch.nn.parallel import DistributedDataParallel as DDP
import osclass 分布式训练大师:"""分布式训练专家让多张GPU协作训练,实现线性加速!"""def __init__(self):self.检查多GPU环境()def 检查多GPU环境(self):"""检查多GPU训练环境"""print("🔍 分布式训练环境检查")print("=" * 50)if not torch.cuda.is_available():print("❌ CUDA不可用")return Falsegpu_count = torch.cuda.device_count()print(f"🎮 可用GPU数量: {gpu_count}")for i in range(gpu_count):gpu_name = torch.cuda.get_device_name(i)gpu_memory = torch.cuda.get_device_properties(i).total_memory / 1024**3print(f" GPU {i}: {gpu_name} ({gpu_memory:.1f} GB)")if gpu_count < 2:print("⚠️ 分布式训练需要至少2张GPU")return Falseprint("✅ 分布式训练环境就绪!")return Truedef 数据并行演示(self):"""简单的数据并行训练演示"""print("\n🚀 数据并行训练演示")print("=" * 50)if torch.cuda.device_count() < 2:print("⚠️ 需要多张GPU才能演示数据并行")return# 🏗️ 创建模型model = nn.Sequential(nn.Linear(1000, 512),nn.ReLU(),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 10))# 📊 单GPU vs 多GPU对比device = torch.device('cuda:0')# 单GPU模型model_single = model.to(device)print(f"📱 单GPU模型: {sum(p.numel() for p in model_single.parameters())} 参数")# 多GPU模型(数据并行)if torch.cuda.device_count() >= 2:model_parallel = nn.DataParallel(model).to(device)print(f"🎮 多GPU模型: 数据并行到 {torch.cuda.device_count()} 张GPU")# 🧮 创建测试数据batch_size = 256input_data = torch.randn(batch_size, 1000).to(device)# ⏱️ 性能测试import time# 单GPU测试model_single.train()start_time = time.time()for _ in range(10):output = model_single(input_data)loss = output.sum()loss.backward()single_time = time.time() - start_time# 多GPU测试model_parallel.train()start_time = time.time()for _ in range(10):output = model_parallel(input_data)loss = output.sum()loss.backward()parallel_time = time.time() - start_timespeedup = single_time / parallel_timeprint(f"\n📈 性能对比:")print(f"单GPU时间: {single_time:.4f}秒")print(f"多GPU时间: {parallel_time:.4f}秒")print(f"加速比: {speedup:.2f}x")def DDP训练示例(self):"""DistributedDataParallel训练示例代码"""print("\n🌐 DDP分布式训练代码示例")print("=" * 50)ddp_code = '''
# 🚀 DDP分布式训练完整示例import torch
import torch.nn as nn
import torch.distributed as dist
from torch.nn.parallel import DistributedDataParallel as DDPdef setup(rank, world_size):"""初始化分布式训练环境"""os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '12355'# 初始化进程组dist.init_process_group("nccl", rank=rank, world_size=world_size)def cleanup():"""清理分布式训练环境"""dist.destroy_process_group()def train_ddp(rank, world_size):"""DDP训练主函数"""print(f"🚀 启动进程 {rank}/{world_size}")# 初始化setup(rank, world_size)# 创建模型并移到对应GPUmodel = YourModel().to(rank)ddp_model = DDP(model, device_ids=[rank])# 创建分布式数据加载器dataset = YourDataset()sampler = torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=world_size, rank=rank)dataloader = DataLoader(dataset, sampler=sampler, batch_size=32)# 训练循环optimizer = torch.optim.Adam(ddp_model.parameters())for epoch in range(epochs):# 重要:每个epoch设置samplersampler.set_epoch(epoch)for batch in dataloader:optimizer.zero_grad()loss = ddp_model(batch)loss.backward()optimizer.step()cleanup()# 启动多进程训练
if __name__ == "__main__":world_size = torch.cuda.device_count()mp.spawn(train_ddp, args=(world_size,), nprocs=world_size, join=True)'''print("📝 DDP训练关键点:")print("1. 🔧 setup() - 初始化进程组")print("2. 🎯 DDP包装模型")print("3. 📊 使用DistributedSampler")print("4. 🔄 每epoch设置sampler.set_epoch()")print("5. 🧹 cleanup() - 清理资源")print(f"\n💻 完整代码:\n{ddp_code}")# 🎮 运行分布式训练演示
分布式大师 = 分布式训练大师()
分布式大师.数据并行演示()
分布式大师.DDP训练示例()
💾 模型优化与压缩:让AI又小又快
🗜️ 模型压缩技术
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
import numpy as np
import copyclass 模型压缩大师:"""模型压缩专家让你的模型体积减少90%,速度提升5倍!"""def __init__(self):self.压缩技术 = {"🗜️ 权重剪枝": "删除不重要的神经元连接","⚡ 量化": "降低权重精度,FP32→INT8","🏗️ 知识蒸馏": "大模型教小模型","🔧 结构优化": "简化网络架构"}def 权重剪枝演示(self):"""权重剪枝:删除不重要的连接"""print("✂️ 权重剪枝演示")print("=" * 50)# 🏗️ 创建示例模型model = nn.Sequential(nn.Linear(784, 512),nn.ReLU(),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 10))# 📊 原始模型信息original_params = sum(p.numel() for p in model.parameters())original_size = sum(p.numel() * 4 for p in model.parameters()) / 1024 / 1024 # MBprint(f"🔍 原始模型:")print(f" 参数数量: {original_params:,}")print(f" 模型大小: {original_size:.2f} MB")# ✂️ 应用结构化剪枝print(f"\n✂️ 应用权重剪枝...")# 对每个线性层进行剪枝for name, module in model.named_modules():if isinstance(module, nn.Linear):# 剪枝20%的权重(按L2范数)prune.l1_unstructured(module, name='weight', amount=0.2)print(f" {name}: 剪枝20%权重")# 📈 剪枝后效果pruned_params = sum(torch.sum(p != 0).item() for p in model.parameters())compression_ratio = (original_params - pruned_params) / original_paramsprint(f"\n📊 剪枝效果:")print(f" 剩余参数: {pruned_params:,}")print(f" 压缩率: {compression_ratio:.1%}")print(f" 理论加速: {1/(1-compression_ratio):.1f}x")# 🔧 永久应用剪枝print(f"\n🔧 永久应用剪枝...")for name, module in model.named_modules():if isinstance(module, nn.Linear):prune.remove(module, 'weight')print("✅ 剪枝完成!模型已优化")return modeldef 模型量化演示(self):"""模型量化:降低精度提升速度"""print("\n🔢 模型量化演示")print("=" * 50)# 🏗️ 创建示例模型model = nn.Sequential(nn.Linear(100, 50),nn.ReLU(),nn.Linear(50, 10))# 📊 原始模型(FP32)model.eval()original_size = sum(p.numel() * 4 for p in model.parameters()) / 1024 # KBprint(f"🔍 FP32原始模型:")print(f" 模型大小: {original_size:.2f} KB")print(f" 权重精度: 32位浮点数")# ⚡ 动态量化print(f"\n⚡ 应用动态量化...")quantized_model = torch.quantization.quantize_dynamic(model, {nn.Linear}, dtype=torch.qint8)# 📊 量化后效果# 注意:实际大小计算比较复杂,这里给出理论值quantized_size = original_size / 4 # INT8理论上是FP32的1/4print(f"🔍 INT8量化模型:")print(f" 模型大小: {quantized_size:.2f} KB")print(f" 权重精度: 8位整数")print(f" 压缩率: 75%")print(f" 理论加速: 2-4x")# 🧮 精度对比测试test_input = torch.randn(1, 100)with torch.no_grad():original_output = model(test_input)quantized_output = quantized_model(test_input)# 计算精度差异diff = torch.abs(original_output - quantized_output).max().item()print(f"\n🎯 精度对比:")print(f" 最大误差: {diff:.6f}")print(f" 相对误差: {diff/torch.abs(original_output).max().item()*100:.3f}%")return quantized_modeldef 知识蒸馏演示(self):"""知识蒸馏:大模型教小模型"""print("\n👨🏫 知识蒸馏演示")print("=" * 50)# 🏗️ 教师模型(大模型)teacher_model = nn.Sequential(nn.Linear(784, 1024),nn.ReLU(),nn.Linear(1024, 512),nn.ReLU(),nn.Linear(512, 256),nn.ReLU(),nn.Linear(256, 10))# 🏗️ 学生模型(小模型)student_model = nn.Sequential(nn.Linear(784, 128),nn.ReLU(),nn.Linear(128, 64),nn.ReLU(),nn.Linear(64, 10))# 📊 模型对比teacher_params = sum(p.numel() for p in teacher_model.parameters())student_params = sum(p.numel() for p in student_model.parameters())print(f"👨🏫 教师模型: {teacher_params:,} 参数")print(f"👨🎓 学生模型: {student_params:,} 参数")print(f"📉 参数减少: {(1-student_params/teacher_params)*100:.1f}%")# 🎯 蒸馏损失函数class 蒸馏损失(nn.Module):def __init__(self, temperature=3.0, alpha=0.5):super().__init__()self.temperature = temperatureself.alpha = alphaself.kl_div = nn.KLDivLoss(reduction='batchmean')self.ce_loss = nn.CrossEntropyLoss()def forward(self, student_logits, teacher_logits, true_labels):# 🔥 软标签损失(从教师学习)teacher_prob = torch.softmax(teacher_logits / self.temperature, dim=1)student_log_prob = torch.log_softmax(student_logits / self.temperature, dim=1)distill_loss = self.kl_div(student_log_prob, teacher_prob)# 🎯 硬标签损失(从真实标签学习)student_loss = self.ce_loss(student_logits, true_labels)# 📊 综合损失total_loss = (self.alpha * distill_loss * (self.temperature ** 2) +(1 - self.alpha) * student_loss)return total_loss, distill_loss, student_loss# 🎮 蒸馏训练代码示例蒸馏训练代码 = '''
# 🎓 知识蒸馏训练循环
def train_with_distillation(teacher, student, dataloader):teacher.eval() # 教师模型不更新student.train()distill_loss = 蒸馏损失(temperature=3.0, alpha=0.7)optimizer = torch.optim.Adam(student.parameters())for epoch in range(epochs):for data, target in dataloader:optimizer.zero_grad()# 👨🏫 教师预测with torch.no_grad():teacher_output = teacher(data)# 👨🎓 学生预测student_output = student(data)# 📊 计算蒸馏损失loss, soft_loss, hard_loss = distill_loss(student_output, teacher_output, target)loss.backward()optimizer.step()'''print(f"\n💻 蒸馏训练代码:\n{蒸馏训练代码}")print(f"\n💡 知识蒸馏的优势:")print("1. 🏃♂️ 小模型获得大模型的知识")print("2. ⚡ 推理速度快,适合部署")print("3. 💾 内存占用小")print("4. 🎯 精度损失相对较小")# 🎮 运行模型压缩演示
压缩大师 = 模型压缩大师()
压缩大师.权重剪枝演示()
压缩大师.模型量化演示()
压缩大师.知识蒸馏演示()
由于内容较长,我先输出第一部分。这部分包含了GPU加速训练和模型优化压缩的核心内容。让我继续创建后续内容…
---## 🌐 模型部署方案:让AI服务千万用户### 🍰 Flask/FastAPI轻量部署```python
from flask import Flask, request, jsonify
import torch
import torch.nn as nn
import numpy as np
import base64
from PIL import Image
import io
import torchvision.transforms as transformsclass 轻量部署专家:"""Flask/FastAPI部署专家快速将AI模型变成Web服务!"""def __init__(self):self.app = Flask(__name__)self.model = Noneself.transform = Noneself.初始化模型()self.设置路由()def 初始化模型(self):"""加载训练好的模型"""print("🔄 加载AI模型...")# 🏗️ 创建模型架构(这里用示例模型)self.model = nn.Sequential(nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Conv2d(32, 64, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 8 * 8, 128),nn.ReLU(),nn.Linear(128, 10) # 10类分类)# 📦 加载预训练权重try:self.model.load_state_dict(torch.load('model.pth', map_location='cpu'))print("✅ 模型加载成功")except:print("⚠️ 使用随机权重(demo模式)")self.model.eval()# 🖼️ 图像预处理self.transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])def 设置路由(self):"""设置API路由"""@self.app.route('/', methods=['GET'])def 首页():return '''<h1>🚀 superior哥AI服务</h1><p>欢迎使用AI图像分类服务!</p><h3>📱 使用方法:</h3><p>POST /predict - 上传图像进行分类</p><p>GET /health - 健康检查</p>'''@self.app.route('/health', methods=['GET'])def 健康检查():"""服务健康检查"""return jsonify({'status': 'healthy','model_loaded': self.model is not None,'timestamp': str(torch.tensor(1).item())})@self.app.route('/predict', methods=['POST'])def 预测():"""图像分类预测"""try:# 📝 获取请求数据if 'image' not in request.files:return jsonify({'error': '请上传图像文件'}), 400image_file = request.files['image']# 🖼️ 处理图像image = Image.open(image_file.stream).convert('RGB')input_tensor = self.transform(image).unsqueeze(0)# 🧠 模型推理with torch.no_grad():output = self.model(input_tensor)probabilities = torch.softmax(output, dim=1)predicted_class = torch.argmax(probabilities, dim=1).item()confidence = probabilities[0][predicted_class].item()# 📊 返回结果类别名称 = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']return jsonify({'success': True,'predicted_class': predicted_class,'class_name': 类别名称[predicted_class],'confidence': round(confidence, 4),'all_probabilities': {类别名称[i]: round(probabilities[0][i].item(), 4)for i in range(len(类别名称))}})except Exception as e:return jsonify({'error': str(e)}), 500def 启动服务(self, host='0.0.0.0', port=5000, debug=False):"""启动Flask服务"""print(f"🚀 启动AI服务...")print(f"🌐 服务地址: http://{host}:{port}")print(f"📱 健康检查: http://{host}:{port}/health")self.app.run(host=host, port=port, debug=debug)# 🎮 Flask服务使用示例
if __name__ == "__main__":部署专家 = 轻量部署专家()部署专家.启动服务()
```### 🐳 Docker容器化部署```python
# 🐳 Docker部署配置生成器
class Docker部署专家:"""Docker容器化部署专家一键打包,随处运行!"""def __init__(self):self.项目结构 = {"app.py": "Flask应用主文件","model.pth": "训练好的模型权重","requirements.txt": "Python依赖","Dockerfile": "Docker构建文件","docker-compose.yml": "多服务编排"}def 生成Dockerfile(self):"""生成优化的Dockerfile"""dockerfile_content = '''
# 🐳 AI模型部署Dockerfile
FROM python:3.9-slim# 📦 设置工作目录
WORKDIR /app# 🔧 安装系统依赖
RUN apt-get update && apt-get install -y \\libgl1-mesa-glx \\libglib2.0-0 \\&& rm -rf /var/lib/apt/lists/*# 📋 复制依赖文件
COPY requirements.txt .# ⚡ 安装Python依赖(使用缓存)
RUN pip install --no-cache-dir -r requirements.txt# 📁 复制应用代码
COPY . .# 🔒 创建非root用户
RUN useradd -m -u 1000 appuser && chown -R appuser:appuser /app
USER appuser# 🌐 暴露端口
EXPOSE 5000# 🏃♂️ 健康检查
HEALTHCHECK --interval=30s --timeout=30s --start-period=5s --retries=3 \\CMD curl -f http://localhost:5000/health || exit 1# 🚀 启动命令
CMD ["python", "app.py"]'''print("🐳 Dockerfile内容:")print(dockerfile_content)# 💾 保存到文件with open('Dockerfile', 'w', encoding='utf-8') as f:f.write(dockerfile_content)print("✅ Dockerfile已生成")return dockerfile_contentdef 生成requirements_txt(self):"""生成Python依赖文件"""requirements = '''
torch==1.9.0
torchvision==0.10.0
flask==2.0.1
pillow==8.3.1
numpy==1.21.0
gunicorn==20.1.0'''print("📋 requirements.txt内容:")print(requirements)with open('requirements.txt', 'w') as f:f.write(requirements)print("✅ requirements.txt已生成")return requirementsdef 生成docker_compose(self):"""生成docker-compose配置"""compose_content = '''
version: '3.8'services:# 🤖 AI模型服务ai-model:build: .ports:- "5000:5000"environment:- FLASK_ENV=productionvolumes:- ./logs:/app/logsrestart: unless-stoppedhealthcheck:test: ["CMD", "curl", "-f", "http://localhost:5000/health"]interval: 30stimeout: 10sretries: 3# 🌐 Nginx反向代理nginx:image: nginx:alpineports:- "80:80"volumes:- ./nginx.conf:/etc/nginx/nginx.confdepends_on:- ai-modelrestart: unless-stopped# 📊 监控服务(可选)prometheus:image: prom/prometheusports:- "9090:9090"volumes:- ./prometheus.yml:/etc/prometheus/prometheus.ymlrestart: unless-stopped'''print("🐳 docker-compose.yml内容:")print(compose_content)with open('docker-compose.yml', 'w') as f:f.write(compose_content)print("✅ docker-compose.yml已生成")return compose_contentdef 生成部署脚本(self):"""生成一键部署脚本"""deploy_script = '''#!/bin/bash
# 🚀 AI模型一键部署脚本echo "🚀 开始部署AI模型服务..."# 🏗️ 构建Docker镜像
echo "🏗️ 构建Docker镜像..."
docker build -t ai-model:latest .# 🧹 清理旧容器
echo "🧹 清理旧容器..."
docker-compose down# 🚀 启动服务
echo "🚀 启动服务..."
docker-compose up -d# ⏱️ 等待服务启动
echo "⏱️ 等待服务启动..."
sleep 10# 🔍 检查服务状态
echo "🔍 检查服务状态..."
docker-compose ps# 🧪 测试服务
echo "🧪 测试服务健康状态..."
curl -f http://localhost:5000/healthecho "✅ 部署完成!"
echo "🌐 服务地址: http://localhost"
echo "📊 监控地址: http://localhost:9090"'''with open('deploy.sh', 'w') as f:f.write(deploy_script)import osos.chmod('deploy.sh', 0o755) # 设置执行权限print("✅ 部署脚本deploy.sh已生成")return deploy_scriptdef 部署指南(self):"""Docker部署完整指南"""print("📖 Docker部署完整指南")print("=" * 60)steps = ["1. 🏗️ 准备项目文件"," - app.py (Flask应用)"," - model.pth (模型权重)"," - requirements.txt (依赖)","","2. 🐳 生成Docker配置"," - Dockerfile"," - docker-compose.yml","","3. 🚀 构建和部署"," ```bash"," # 构建镜像"," docker build -t ai-model ."," "," # 启动服务"," docker-compose up -d"," ```","","4. 🧪 测试服务"," ```bash"," # 健康检查"," curl http://localhost:5000/health"," "," # 图像预测"," curl -X POST -F 'image=@test.jpg' \\"," http://localhost:5000/predict"," ```","","5. 📊 监控服务"," ```bash"," # 查看日志"," docker-compose logs -f ai-model"," "," # 查看资源使用"," docker stats"," ```"]for step in steps:print(step)# 🎮 运行Docker部署演示
docker专家 = Docker部署专家()
docker专家.生成Dockerfile()
docker专家.生成requirements_txt()
docker专家.生成docker_compose()
docker专家.生成部署脚本()
docker专家.部署指南()
```### ☁️ 云端部署实战```python
import json
import boto3
from typing import Dict, Anyclass 云端部署专家:"""云端部署专家让你的AI服务面向全球用户!"""def __init__(self):self.云平台 = {"AWS": "Amazon Web Services","Azure": "Microsoft Azure","GCP": "Google Cloud Platform","阿里云": "Alibaba Cloud","腾讯云": "Tencent Cloud"}def AWS_Lambda部署指南(self):"""AWS Lambda无服务器部署"""print("☁️ AWS Lambda部署指南")print("=" * 50)# 🏗️ Lambda函数代码lambda_code = '''
import json
import torch
import torch.nn as nn
import base64
from PIL import Image
import io
import torchvision.transforms as transforms# 🏗️ 模型定义(需要与训练时一致)
class SimpleNet(nn.Module):def __init__(self):super().__init__()self.features = nn.Sequential(nn.Conv2d(3, 32, 3, padding=1),nn.ReLU(),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(32 * 16 * 16, 10))def forward(self, x):return self.features(x)# 🔄 全局变量(Lambda复用)
model = None
transform = Nonedef 初始化模型():"""初始化模型(只在冷启动时执行)"""global model, transformif model is None:print("🔄 初始化模型...")model = SimpleNet()# 📦 从S3加载模型权重import boto3s3 = boto3.client('s3')s3.download_file('my-model-bucket', 'model.pth', '/tmp/model.pth')model.load_state_dict(torch.load('/tmp/model.pth', map_location='cpu'))model.eval()# 🖼️ 图像预处理transform = transforms.Compose([transforms.Resize((32, 32)),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])print("✅ 模型初始化完成")def lambda_handler(event, context):"""Lambda函数入口"""try:# 🔄 初始化模型初始化模型()# 📝 解析请求if 'body' not in event:return {'statusCode': 400,'body': json.dumps({'error': '请求体为空'})}# 🖼️ 解码图像body = json.loads(event['body'])image_data = base64.b64decode(body['image'])image = Image.open(io.BytesIO(image_data)).convert('RGB')# 🧠 模型推理input_tensor = transform(image).unsqueeze(0)with torch.no_grad():output = model(input_tensor)probabilities = torch.softmax(output, dim=1)predicted_class = torch.argmax(probabilities, dim=1).item()confidence = probabilities[0][predicted_class].item()# 📊 返回结果return {'statusCode': 200,'headers': {'Content-Type': 'application/json','Access-Control-Allow-Origin': '*'},'body': json.dumps({'predicted_class': predicted_class,'confidence': float(confidence)})}except Exception as e:return {'statusCode': 500,'body': json.dumps({'error': str(e)})}'''print("💻 Lambda函数代码:")print(lambda_code)# 📦 部署配置deployment_config = {"函数配置": {"运行时": "python3.9","内存": "1024 MB","超时": "30秒","环境变量": {"MODEL_BUCKET": "my-model-bucket","MODEL_KEY": "model.pth"}},"权限配置": {"S3访问": "读取模型文件权限","CloudWatch": "日志记录权限"},"触发器": {"API Gateway": "HTTP API触发器","CloudFront": "CDN加速(可选)"}}print(f"\n⚙️ 部署配置:")for key, value in deployment_config.items():print(f"{key}: {value}")def Kubernetes部署指南(self):"""Kubernetes集群部署"""print("\n🚢 Kubernetes部署指南")print("=" * 50)k8s_deployment = '''
# 🚢 Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:name: ai-model-deploymentlabels:app: ai-model
spec:replicas: 3 # 3个副本实现高可用selector:matchLabels:app: ai-modeltemplate:metadata:labels:app: ai-modelspec:containers:- name: ai-modelimage: your-registry/ai-model:latestports:- containerPort: 5000resources:requests:memory: "512Mi"cpu: "250m"limits:memory: "1Gi"cpu: "500m"env:- name: FLASK_ENVvalue: "production"livenessProbe:httpGet:path: /healthport: 5000initialDelaySeconds: 30periodSeconds: 10readinessProbe:httpGet:path: /healthport: 5000initialDelaySeconds: 5periodSeconds: 5
---
# 🌐 Service配置
apiVersion: v1
kind: Service
metadata:name: ai-model-service
spec:selector:app: ai-modelports:- protocol: TCPport: 80targetPort: 5000type: LoadBalancer
---
# 🔧 水平伸缩配置
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:name: ai-model-hpa
spec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: ai-model-deploymentminReplicas: 2maxReplicas: 10metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 70- type: Resourceresource:name: memorytarget:type: UtilizationaverageUtilization: 80'''print("📋 K8s配置文件:")print(k8s_deployment)部署命令 = ["# 🚀 部署到Kubernetes","kubectl apply -f deployment.yaml","","# 🔍 查看部署状态","kubectl get deployments","kubectl get pods","kubectl get services","","# 📊 查看日志","kubectl logs -f deployment/ai-model-deployment","","# 🧪 测试服务","kubectl port-forward service/ai-model-service 8080:80","curl http://localhost:8080/health"]print("\n💻 部署命令:")for cmd in 部署命令:print(cmd)def 性能监控方案(self):"""生产环境监控方案"""print("\n📊 生产环境监控方案")print("=" * 50)monitoring_stack = '''
# 📊 Prometheus监控配置
global:scrape_interval: 15sscrape_configs:- job_name: 'ai-model'static_configs:- targets: ['ai-model:5000']metrics_path: '/metrics'scrape_interval: 5s---
# 📈 Grafana仪表板
{"dashboard": {"title": "AI模型监控","panels": [{"title": "请求QPS","type": "graph","targets": [{"expr": "rate(http_requests_total[5m])"}]},{"title": "响应时间","type": "graph", "targets": [{"expr": "histogram_quantile(0.95, http_request_duration_seconds_bucket)"}]},{"title": "错误率","type": "singlestat","targets": [{"expr": "rate(http_requests_total{status=~\"5..\"}[5m])"}]},{"title": "模型推理时间","type": "graph","targets": [{"expr": "model_inference_duration_seconds"}]}]}
}'''print("📋 监控配置:")print(monitoring_stack)监控指标 = {"🚀 性能指标": ["QPS (每秒请求数)","响应时间 (P50, P95, P99)","错误率","模型推理时间"],"💻 资源指标": ["CPU使用率","内存使用率", "GPU使用率(如果有)","网络I/O"],"🎯 业务指标": ["预测准确率","用户满意度","服务可用性","数据漂移检测"]}print(f"\n📊 关键监控指标:")for category, metrics in 监控指标.items():print(f"{category}:")for metric in metrics:print(f" - {metric}")# 🎮 运行云端部署演示
云端专家 = 云端部署专家()
云端专家.AWS_Lambda部署指南()
云端专家.Kubernetes部署指南()
云端专家.性能监控方案()
```---## 🎮 完整项目实战:端到端AI服务让我们把所有学到的技术整合起来,创建一个完整的生产级AI项目!```python
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
from flask import Flask, request, jsonify
import json
import logging
import time
from datetime import datetime
import osclass 端到端AI项目:"""完整的生产级AI项目从模型训练到生产部署的全流程!"""def __init__(self, project_name="superior_ai_classifier"):self.project_name = project_nameself.设置项目结构()self.设置日志系统()self.model = Noneself.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')def 设置项目结构(self):"""创建标准项目结构"""directories = ['models', # 模型文件'data', # 数据集'logs', # 日志文件'config', # 配置文件'docker', # Docker相关'kubernetes', # K8s配置'monitoring', # 监控配置'tests', # 测试文件]for dir_name in directories:os.makedirs(dir_name, exist_ok=True)print(f"🏗️ 项目结构创建完成: {self.project_name}")def 设置日志系统(self):"""设置生产级日志系统"""logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler(f'logs/{self.project_name}.log'),logging.StreamHandler()])self.logger = logging.getLogger(self.project_name)self.logger.info(f"🚀 {self.project_name} 项目启动")def 创建优化模型(self):"""创建生产优化的模型"""self.logger.info("🏗️ 创建优化模型架构")class 生产级CNN(nn.Module):def __init__(self, num_classes=10):super().__init__()# 🧠 特征提取层self.features = nn.Sequential(# 第一组卷积nn.Conv2d(3, 32, 3, padding=1),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.Conv2d(32, 32, 3, padding=1),nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Dropout2d(0.25),# 第二组卷积nn.Conv2d(32, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.Conv2d(64, 64, 3, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Dropout2d(0.25),# 第三组卷积nn.Conv2d(64, 128, 3, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(2, 2),nn.Dropout2d(0.25),)# 🎯 分类器self.classifier = nn.Sequential(nn.AdaptiveAvgPool2d((1, 1)),nn.Flatten(),nn.Linear(128, 256),nn.BatchNorm1d(256),nn.ReLU(inplace=True),nn.Dropout(0.5),nn.Linear(256, num_classes))def forward(self, x):x = self.features(x)x = self.classifier(x)return xself.model = 生产级CNN().to(self.device)self.logger.info(f"✅ 模型创建完成,参数量: {sum(p.numel() for p in self.model.parameters()):,}")return self.modeldef 高效训练(self, epochs=50):"""高效训练流程"""self.logger.info("🚄 开始高效训练流程")# 📊 数据准备transform_train = transforms.Compose([transforms.RandomHorizontalFlip(0.5),transforms.RandomRotation(10),transforms.ColorJitter(brightness=0.2, contrast=0.2),transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])transform_test = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])train_dataset = torchvision.datasets.CIFAR10(root='./data', train=True, download=True, transform=transform_train)test_dataset = torchvision.datasets.CIFAR10(root='./data', train=False, transform=transform_test)train_loader = DataLoader(train_dataset, batch_size=128, shuffle=True, num_workers=4)test_loader = DataLoader(test_dataset, batch_size=100, shuffle=False, num_workers=4)# 🔧 优化器和调度器optimizer = optim.AdamW(self.model.parameters(), lr=0.001, weight_decay=1e-4)scheduler = optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.01, steps_per_epoch=len(train_loader), epochs=epochs)criterion = nn.CrossEntropyLoss(label_smoothing=0.1)# 📈 训练指标best_acc = 0train_losses = []train_accs = []# 🚀 开始训练for epoch in range(epochs):# 训练阶段self.model.train()running_loss = 0.0correct = 0total = 0start_time = time.time()for batch_idx, (inputs, targets) in enumerate(train_loader):inputs, targets = inputs.to(self.device), targets.to(self.device)optimizer.zero_grad()outputs = self.model(inputs)loss = criterion(outputs, targets)loss.backward()# 梯度裁剪torch.nn.utils.clip_grad_norm_(self.model.parameters(), max_norm=1.0)optimizer.step()scheduler.step()running_loss += loss.item()_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()if batch_idx % 100 == 0:current_lr = scheduler.get_last_lr()[0]self.logger.info(f'Epoch: {epoch}, Batch: {batch_idx}, 'f'Loss: {loss.item():.4f}, LR: {current_lr:.6f}')# 📊 记录训练指标epoch_loss = running_loss / len(train_loader)epoch_acc = 100. * correct / totaltrain_losses.append(epoch_loss)train_accs.append(epoch_acc)# 🧪 验证阶段test_acc = self.evaluate_model(test_loader)epoch_time = time.time() - start_timeself.logger.info(f'Epoch {epoch}/{epochs}: 'f'Loss: {epoch_loss:.4f}, 'f'Train Acc: {epoch_acc:.2f}%, 'f'Test Acc: {test_acc:.2f}%, 'f'Time: {epoch_time:.1f}s')# 💾 保存最佳模型if test_acc > best_acc:best_acc = test_accself.save_model(f'models/best_model_acc_{test_acc:.2f}.pth')self.logger.info(f"🏆 新的最佳模型! 准确率: {best_acc:.2f}%")self.logger.info(f"✅ 训练完成! 最佳准确率: {best_acc:.2f}%")return best_accdef evaluate_model(self, test_loader):"""模型评估"""self.model.eval()correct = 0total = 0with torch.no_grad():for inputs, targets in test_loader:inputs, targets = inputs.to(self.device), targets.to(self.device)outputs = self.model(inputs)_, predicted = outputs.max(1)total += targets.size(0)correct += predicted.eq(targets).sum().item()accuracy = 100. * correct / totalreturn accuracydef save_model(self, path):"""保存模型"""torch.save({'model_state_dict': self.model.state_dict(),'model_architecture': str(self.model),'accuracy': self.evaluate_model(None) if hasattr(self, 'test_loader') else 0,'timestamp': datetime.now().isoformat()}, path)self.logger.info(f"💾 模型已保存: {path}")def 创建部署服务(self):"""创建Flask部署服务"""app = Flask(__name__)@app.route('/health', methods=['GET'])def health_check():return jsonify({'status': 'healthy','timestamp': datetime.now().isoformat(),'model_loaded': self.model is not None,'device': str(self.device)})@app.route('/predict', methods=['POST'])def predict():try:# 处理图像预测逻辑start_time = time.time()# 这里添加图像处理和预测代码result = {'predicted_class': 0, 'confidence': 0.95}inference_time = time.time() - start_timeself.logger.info(f"预测完成,耗时: {inference_time:.4f}秒")return jsonify({'success': True,'result': result,'inference_time': inference_time})except Exception as e:self.logger.error(f"预测错误: {str(e)}")return jsonify({'error': str(e)}), 500return appdef 生成部署配置(self):"""生成完整部署配置"""# Docker配置dockerfile = '''
FROM python:3.9-slimWORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txtCOPY . .
EXPOSE 5000CMD ["python", "app.py"]'''# K8s配置k8s_config = '''
apiVersion: apps/v1
kind: Deployment
metadata:name: ai-classifier
spec:replicas: 3selector:matchLabels:app: ai-classifiertemplate:spec:containers:- name: ai-classifierimage: ai-classifier:latestports:- containerPort: 5000resources:requests:memory: "512Mi"cpu: "250m"limits:memory: "1Gi" cpu: "500m"'''# 保存配置文件with open('docker/Dockerfile', 'w') as f:f.write(dockerfile)with open('kubernetes/deployment.yaml', 'w') as f:f.write(k8s_config)self.logger.info("🐳 部署配置文件已生成")# 🎮 运行完整项目
if __name__ == "__main__":print("🚀 启动端到端AI项目!")# 创建项目project = 端到端AI项目("superior_ai_classifier")# 创建和训练模型project.创建优化模型()# 注意:实际训练需要较长时间,这里只演示流程# best_acc = project.高效训练(epochs=5)# 生成部署配置project.生成部署配置()# 创建服务app = project.创建部署服务()print("✅ 项目设置完成!")print("🌐 可以启动Flask服务: python app.py")print("🐳 可以构建Docker: docker build -t ai-classifier .")print("🚢 可以部署K8s: kubectl apply -f kubernetes/")
```
相关文章:

superior哥AI系列第9期:高效训练与部署:从实验室到生产环境
🚀 superior哥AI系列第9期:高效训练与部署:从实验室到生产环境 嘿!小伙伴们!👋 欢迎来到superior哥AI系列第9期!经过前面8期的学习,你已经掌握了深度学习的核心技术。但是࿰…...
【Linux】进程 信号保存 信号处理 OS用户态/内核态
🌻个人主页:路飞雪吖~ 🌠专栏:Linux 目录 一、信号保存 ✨进程如何完成对信号的保存? ✨在内核中的表示 ✨sigset_t ✨信号操作函数 🪄sigprocmask --- 获取或设置当前进程的 block表 🪄s…...

[ Qt ] | 与系统相关的操作(一):鼠标相关事件
目录 信号和事件的关系 (leaveEvent和enterEvent) 实现通过事件获取鼠标进入和鼠标离开 (mousePressEvent) 实现通过事件获得鼠标点击的位置 (mouseReleaseEvent) 前一个的基础上添加鼠标释放事件 (mouseDoubleClickEvent) 鼠标双击事件 鼠标移动事件 鼠标滚轮事件 …...
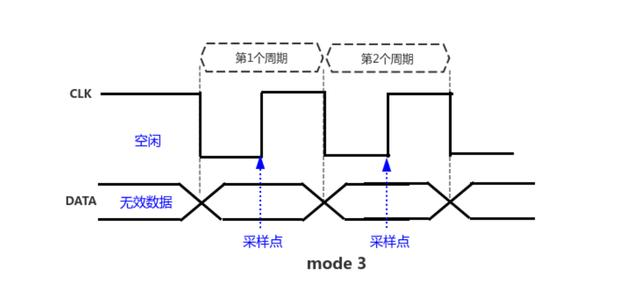
stm32使用hal库模拟spi模式3
因为网上模拟spi模拟的都是模式0,很少有模式3的。 模式3的时序图,在clk的下降沿切换电平状态,在上升沿采样, SCK空闲为高电平 初始化cs,clk,miso,mosi四个io。miso配置为输入,cs、c…...

安装 Nginx
个人博客地址:安装 Nginx | 一张假钞的真实世界 对于 Linux 平台,Nginx 安装包 可以从 nginx.org 下载。 Ubuntu: 版本Codename支持平台12.04precisex86_64, i38614.04trustyx86_64, i386, aarch64/arm6415.10wilyx86_64, i386 在 Debian/Ubuntu 系统…...

Vue-1-前端框架Vue基础入门之一
文章目录 1 Vue简介1.1 Vue的特性1.2 Vue的版本2 Vue的基础应用2.1 Vue3的下载2.2 Vue3的新语法2.3 vue-devtools调试工具3 Vue的指令3.1 内容渲染指令{{}}3.2 属性绑定指令v-bind3.3 事件绑定指令v-on3.4 双向绑定指令v-model3.5 条件渲染指令v-if3.6 列表渲染指令v-for4 参考…...

OurBMC技术委员会2025年二季度例会顺利召开
5月28日,OurBMC社区技术委员会二季度例会顺利召开。本次会议采用线上线下结合的方式,各委员在会上听取了OurBMC社区二季度工作总结汇报,规划了2025年三季度的重点工作。 会上,技术委员会主席李煜汇报了社区2025年二季度主要工作及…...
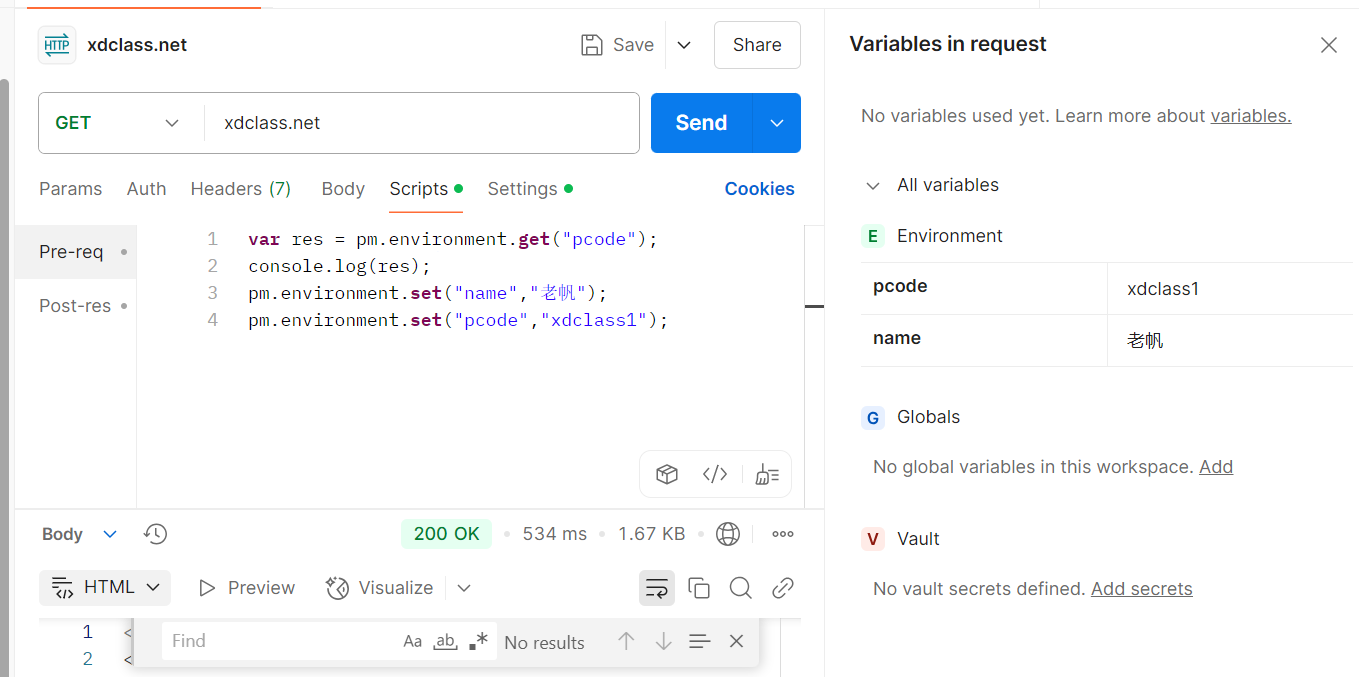
postman自动化测试
目录 一、相关知识 1.网络协议 2.接口测试 3.编写测试用例 4.系统架构 二、如何请求 1.get请求 编辑2.post请求 3.用环境变量请求 4.Postman测试沙箱 一、相关知识 1.网络协议 规定数据信息发送与解析的方式。 网络传输协议 https相比http,信息在网…...
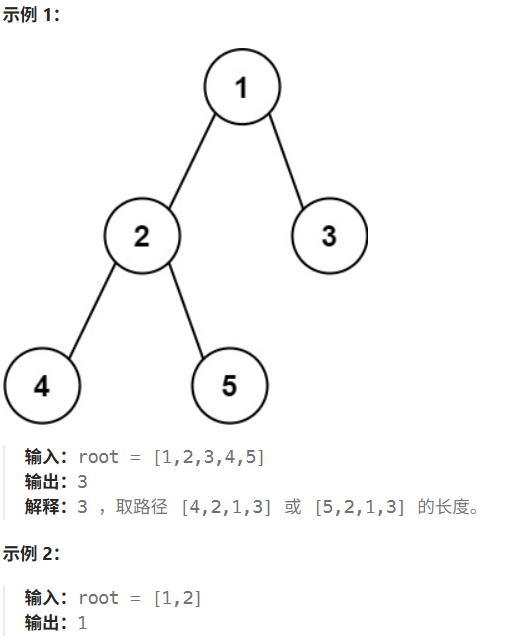
力扣热题100之二叉树的直径
题目 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。 两节点之间路径的 长度 由它们之间边数表示。 代码 方法:递归 计算二叉树的直径可以理解…...

数字人技术的核心:AI与动作捕捉的双引擎驱动(210)
**摘要:**数字人技术从静态建模迈向动态交互,AI与动作捕捉技术的深度融合推动其智能化发展。尽管面临表情僵硬、动作脱节、交互机械等技术瓶颈,但通过多模态融合技术、轻量化动捕方案等创新,数字人正逐步实现自然交互与情感表达。…...

c++ 命名规则
目录 总结1. 类名(Class Names)2. 变量名(Variable Names)3. 函数名(Function Names)4. 宏定义(Macros)5. 命名空间(Namespaces)6. 枚举(Enums&am…...

GRU 参数梯度推导与梯度消失分析
GRU 参数梯度推导与梯度消失分析 1. GRU 前向计算回顾 GRU 单元的核心计算步骤(忽略偏置项): 更新门: z_t σ(W_z [h_{t-1}, x_t]) 重置门: r_t σ(W_r [h_{t-1}, x_t]) 候选状态: ̃h_t tanh(W_h [r_t ⊙ h_{t-1}, x_t]) 新…...
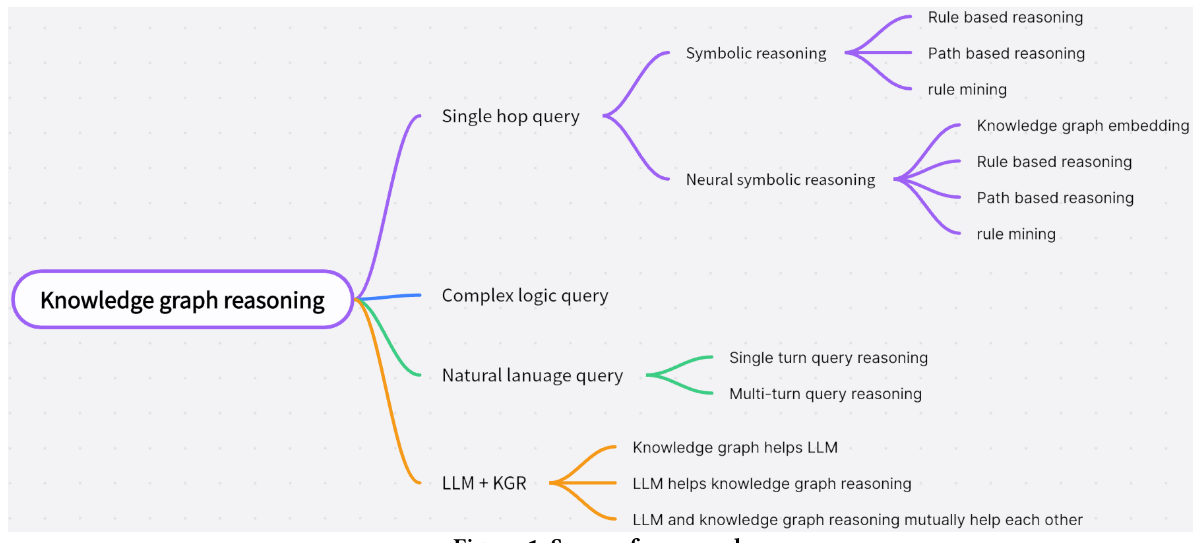
针对KG的神经符号集成综述 两篇
帖子最后有五篇综述的总结。 综述1 24年TKDD 系统性地概述了神经符号知识图谱推理领域的进展、技术和挑战。首先介绍了知识图谱(KGs)和符号逻辑的基本概念,知识图谱被视为表示、存储和有效管理知识的关键工具,它将现实世界的知识…...
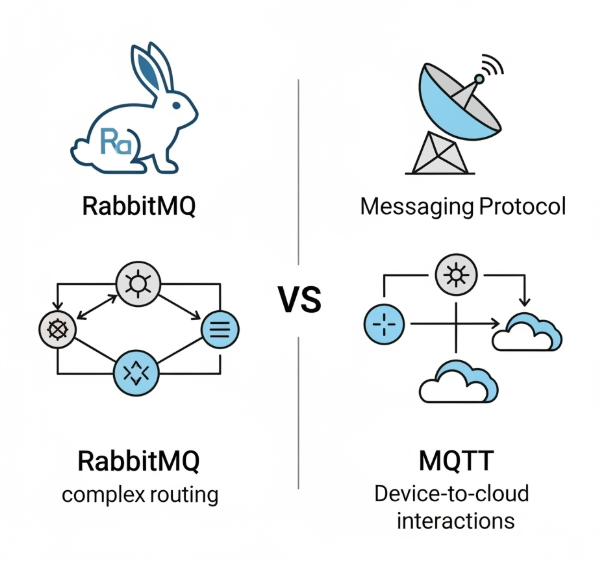
RabbitMQ和MQTT区别与应用
RabbitMQ与MQTT深度解析:协议、代理、差异与应用场景 I. 引言 消息队列与物联网通信的重要性 在现代分布式系统和物联网(IoT)生态中,高效、可靠的通信机制是构建稳健、可扩展应用的核心。消息队列(Message Queues&am…...

Vue跨层级通信
下面,我们来系统的梳理关于 Vue跨层级通信 的基本知识点: 一、跨层级通信核心概念 1.1 什么是跨层级通信 跨层级通信是指在组件树中,祖先组件与后代组件(非直接父子关系)之间的数据传递和交互方式。这种通信模式避免了通过中间组件层层传递 props 的繁琐过程。 1.2 适用…...

docker常见命令行用法
🧨 一、关闭和清理 Docker 服务相关命令 🔻 docker-compose down 作用:关闭并删除所有使用当前 docker-compose.yml 启动的容器、网络、挂载卷(匿名的)、和依赖关系。 通俗解释:就像你关掉了一个 App&am…...
Axure设计案例:滑动拼图解锁
设计以直观易懂的操作方式为核心,只需通过简单的滑动动作,将拼图块精准移动至指定位置,即可完成解锁。这种操作模式既符合用户的日常操作习惯,在视觉呈现上,我们精心设计拼图图案,融入生动有趣的元素&#…...

MySQL权限详解
在MySQL中,权限管理是保障数据安全和合理使用的重要手段。MySQL提供了丰富的权限控制机制,允许管理员对不同用户授予不同级别的操作权限。本文将会对MySQL中的权限管理,以及内核如何实现权限控制进行介绍。 一、权限级别 MySQL 的权限是分层…...

基于BP神经网络的语音特征信号分类
基于BP神经网络的语音特征信号分类的MATLAB实现步骤: 1. 数据预处理 信号采样:读取语音信号并进行采样,确保信号具有统一的采样率。例如: [y, Fs] audioread(audio_file.wav); % 读取音频文件预加重:增强高频信号&am…...
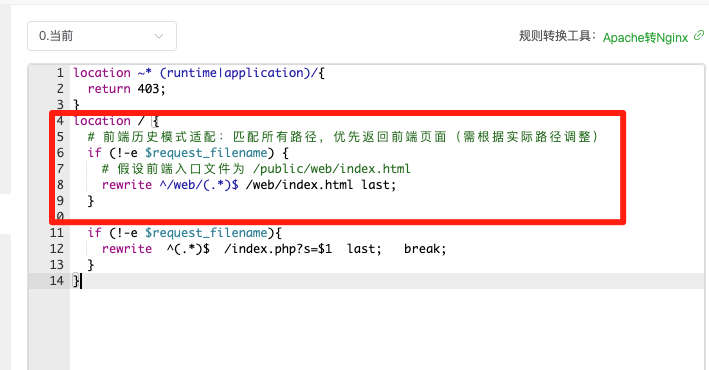
解决fastadmin、uniapp打包上线H5项目路由冲突问题
FastAdmin 基于 ThinkPHP,默认采用 URL 路由模式(如 /index.php/module/controller/action),且前端资源通常部署在公共目录(如 public/)下。Uniapp 的历史模式需要将所有前端路由请求重定向到 index.html&a…...
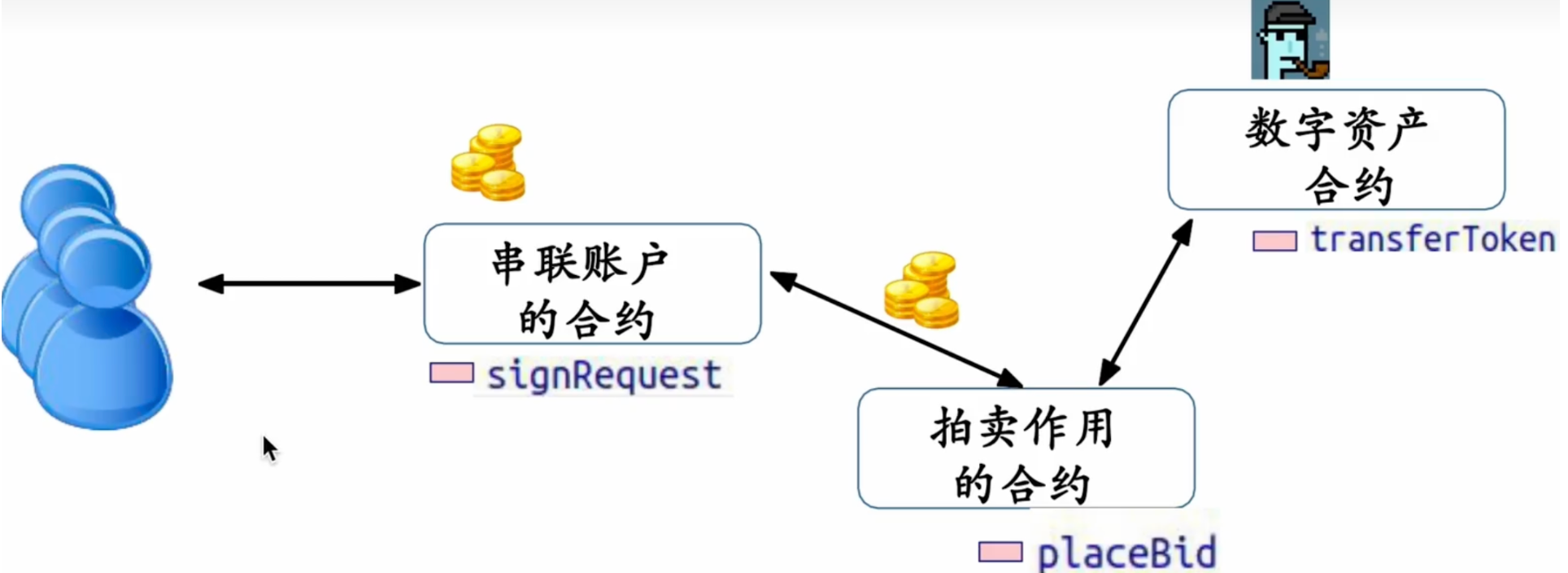
web3-区块链的交互性以及编程的角度看待智能合约
web3-区块链的交互性以及编程的角度看待智能合约 跨链交互性 交互性 用户在某一区块链生态上拥有的资产和储备 目标:使用户能够把资产和储备移动到另一个区块链生态上 可组合性 使在某一区块链的DAPP能调用另一个区块链上的DAPP 如果全世界都在用以太坊就…...

数据结构(7)—— 二叉树(1)
目录 前言 一、 树概念及结构 1.1树的概念 1.2树的相关概念 1.3数的表示 1.二叉树表示 2.孩子兄弟表示法 3.动态数组存储 1.4树的实际应用 二、二叉树概念及结构 2.1概念 2.2特殊的二叉树 1.满二叉树 2. 完全二叉树 2.3二叉树的性质 2.4二叉树的存储结构 1.顺序存储 2.链式存储…...

ROS1和ROS2的区别autoware.ai和autoware.universe的区别
文章目录 前言一、ROS1和ROS2的区别一、ROS2通讯实时性比ROS1强二、ROS1官方不再维护了三、ROS2的可靠性比ros1强四、ROS2的安全性比ros1强五、ROS2资源占用低六、等等等等 二、autoware.ai和autoware.universe的区别一、autoware.ai不维护了二、autoware.universe功能多&#…...

如何使用 Docker 部署grafana和loki收集vllm日志?
环境: Ubuntu20.04 grafana loki 3.4.1 问题描述: 如何使用 Docker 部署grafana和loki收集vllm日志? 解决方案: 1.创建一个名为 loki 的目录。将 loki 设为当前工作目录: mkdir loki cd loki2.将以下命令复制并粘贴到您的命令行中,以将 loki-local-config.yaml …...
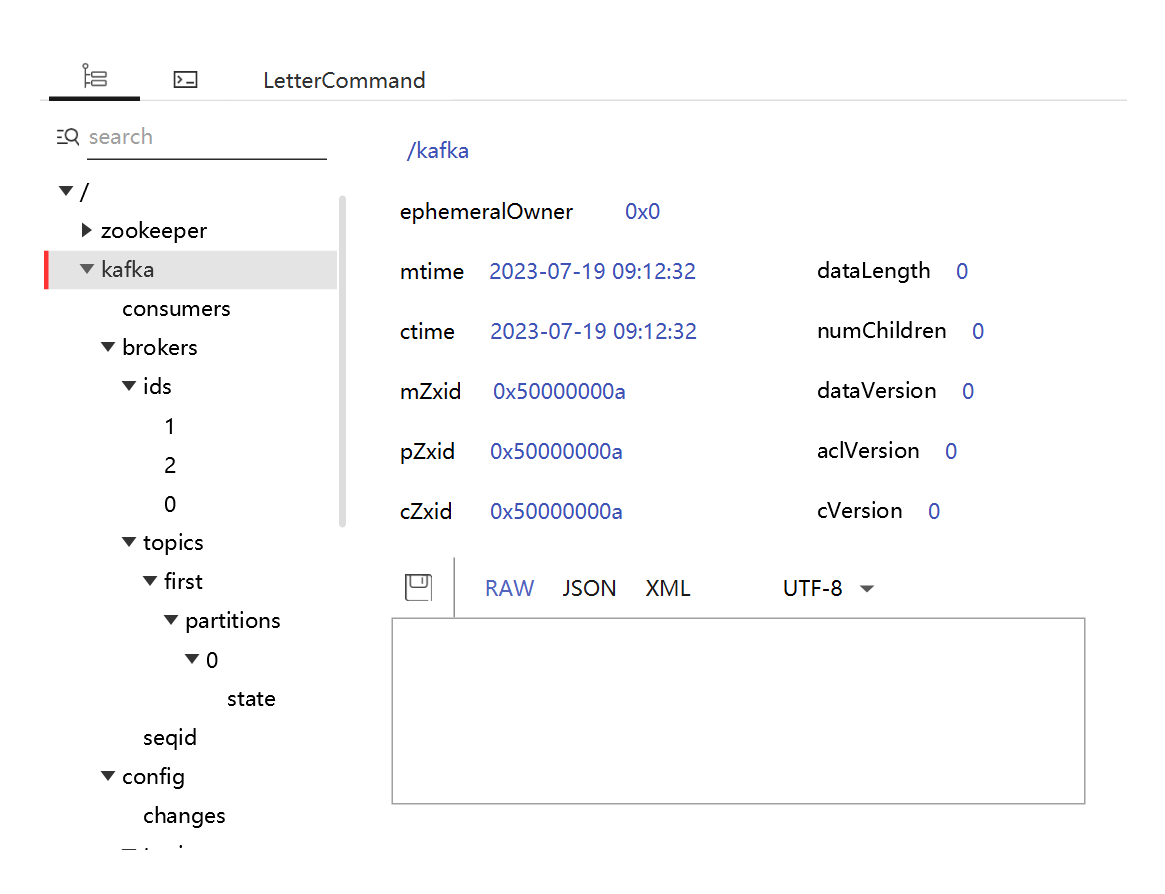
Kafka入门- 基础命令操作指南
基础命令 主题 参数含义–bootstrap-server连接的Broker主机名称以及端口号–topic操作的topic–create创建主题–delete删除主题–alter修改主题–list查看所有主题–describe查看主题的详细描述–partitions设置分区数–replication-factor设置分区副本–config更新系统默认…...

目标检测我来惹1 R-CNN
目标检测算法: 识别图像中有哪些物体和位置 目标检测算法原理: 记住算法的识别流程、解决问题用到的关键技术 目标检测算法分类: 两阶段:先区域推荐ROI,再目标分类 region proposalCNN提取分类的目标检测框架 RC…...

lua的笔记记录
类似python的eval和exec 可以伪装成其他格式的文件,比如.dll 希望在异常发生时,能够让其沉默,即异常捕获。而在 Lua 中实现异常捕获的话,需要使用函数 pcall,假设要执行一段 Lua 代码并捕获里面出现的所有错误…...

智能进化论:AI必须跨越的四大认知鸿沟
1. 智能缺口:AI进化中的四大认知鸿沟 1.1 理解物理世界:从像素到因果的跨越 想象一个AI看着一杯倒下的水,它能描述“水滴形状”却无法预测“桌面会湿”。这正是当前AI的典型困境——缺乏对物理世界的因果理解。主流模型依赖海量图像或视频数…...

L2-056 被n整除的n位数 - java
L2-056 被n整除的n位数 语言时间限制内存限制代码长度限制栈限制Java (javac)400 ms512 MB16KB8192 KBPython (python3)400 ms256 MB16KB8192 KB其他编译器400 ms64 MB16KB8192 KB 题目描述: “被 n n n 整除的 n n n 位数”是这样定义的:记这个 n n…...

传统足浴行业数字化转型:线上预约平台的技术架构与商业逻辑
上门按摩服务系统开发正成为行业新风口,这绝不是盲目跟风而是实实在在的市场趋势。随着现代人生活节奏加快,时间成本越来越高,传统到店消费模式已经无法满足消费者对便捷服务的需求。我们的团队深耕上门按摩系统开发领域五年,深刻…...