期末复习(学习)之机器学习入门基础
上课没听过报道。欢迎补充交流!
前言:老师画的重点其实可以完全不用看,我这里只是看了一眼书顺着书本敲一遍。
比较干货的部分,直接看学习通的内容就好。最重要的是把学习通的内容记好。
目录

老师划的重点:P50
结构化记忆:from sklearn库 import 包名称
P51
P53
作业2 填空题
作业十五
我记得老师说有20个选择题,10道判断题,一共50分。 背学习通。
学习通上的有的选择判断书上也有,大家可以在学习通上做一遍之后,再在书上做一遍检查。
程序填空题20分,应用题包含计算题30分。
所以咱们得把学习通所有的填空题搞懂...毕竟20分,不能空着。
KD树划分、P106评价指标、最后一节课讲了P175的题反向传播算法也不知道考不考。
OK有了方向就可以开始学习:
1.学习通 占比50分
2.填空题 20分
3.几个计算题 30分
老师划的重点:P50
Scikit-learn概述:Scikit-Learn是基于python语言的机器学习工具。它是建立在Numpy、Scipy、Panda和Matplotlib之上。
Scikit-learn库的算法主要是四类:分类、回归、聚类、降维。
常用的回归:线性回归、决策树回归
常用的降维:K均值、层次聚类
常用的聚类:K均值
常用的降维:线性判别分析
导入工具包:从库中导入包 这里都是scikit-learn库 简写:sklearn。
基本建模的符号标记随便看一看理解。
结构化记忆:from sklearn库 import
from sklearn import 包名称
from sklearn .库名称 import 包名称
#导入数据集 数据预处理库
from sklearn import datasets,preprocessing
#从模型选择库导入数据切分包
from sklearn .model_selection import train_test_split
#从线性模型库导入线性回归包
from sklearn .linnner_model import LinearRegression
#从评价指标库导入R2评价指标
from sklearn .metrics import r2 score
P51
可以直接使用的自带数据集
顾名思义意思就是,给你补充的多的数据集可以直接用的

load_boston 波士顿房屋价格
load_digits 手写字
load_iris 鸢尾花
P53
咱们可以品一品书上的代码,因为python属于弱类型语言,不必声明变量的类型

关键点总结
- 数据结构:
iris.data是特征矩阵(二维数组),iris.target是标签向量(一维数组)。 - 用途:这种分离是机器学习的标准操作,便于后续进行模型训练和预测。
- 命名约定:
X和Y是通用符号,也常用features和labels等更具描述性的名称。
机器学习的数据集可以划分为测试集、验证集、训练集。
也可以划分为训练集、测试集。
P54
这里我把代码敲一敲,有个印象即可。。。
# 数据预处理
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test=train_test_split(X,Y,random_state=12,stratify=y,test_size=0.3)
#将完整数据集70%作为训练集,30%作为数据集,并使得测试集和训练集中各类别数据的比例与原始数据集比例一致
from Flower_Classic import X_train
#自己总是会蹦上去这行
from sklearn.preprocessing import StandardScaler
# 数据变换操作
scaler =StandardScaler();
#拟合及转换
scaler.fit_transform(X_train)最大最小标准化:MinMaxScaler
缺失值填补:Imputer
监督学习算法——回归
线性回归是一种通过属性的线性组合来进行预测的线性模型,目的是找到一条直线或一个平面或更高维的超平面,使预测值与真实值之间的误差最小化。
库 大概要写成:from sklearn.linear_model import Ridge
线性回归:
岭回归:
LASSON回归:
ElasticNet回归:这里大家可以把这些英文单词背下来去对照我这里
决策树回归:tree.DecisionTreeRegressor
代码实现流程是,引入库包,构建模型,训练模型,做出预测
from sklearn.linear_model import LinearRegression
lr=LinearRegression(normalize=true)
lr.fit(x_train,y_train)
y_pred=lr.predict(X_test)监督学习-分类
要知道有逻辑回归、支持向量机、KNN、GBDT
聚类算法:K-means
评价指标:P58
反正我也搞不懂我想问真的会考吗?
P133 C4.5 :简称C4.5比ID3好,好在哪里!
ID3算法的核心思想就说以信息增益来度量特征选择,选择信息增益最大的特征进行分裂。ID3算法有以下缺点:
1.ID3没有减枝策略,容易过拟合
2.信息增益准则对可取值数目较多的特征有所偏好。
3.只能用于处理离散分布的特征
4.没有考虑缺失值
C4.5算法概述:C4.5是对ID3算法的改进。
主要改进如下:
1.ID3选择属性用的是子树的信息增益,C4.5算法最大的特点是克服了ID3对特征数目的偏重这一缺点,引入了信息增益率来作为分类标准
2.在决策树构造过程中进行剪枝,引入悲观剪枝策略进行后剪枝。
3.对非离散数据也能处理。
4.能够对不完整数据进行处理。
学习通作业2 填空题
# (1) 字符串操作
str = 'the National Day'
print(str[4:10]) # 提取'nation'
# (2) 列表操作
lst = ['the', 'National', 'Day']
print(lst[1]) # 提取'national'
# (3) 元组操作(元组不可变,需修改内部可变对象)
tpl = (['10.1','is','the'],'National','Day')
tpl[0][0] = 'Today' # 修改列表元素
print(tpl)
# (4) 字典操作
Hotel = {'name':'J Hotel','count':35,'price':162}
Hotel['count'] = 36 # 修改值
print(Hotel)
# (5) 集合操作
Htls = {'A Hotel', 'B Hotel', 'C Hotel'}
result = 'E Hotel' in Htls # 检查存在性
print(result)
混淆矩阵
打开书本106 静下心多看一会儿书 很快就能学会 你会发现准确率就是对角线上的数除以所有的数,这是很容易学会的。也就是视频里面的薄荷绿颜色。
【小萌五分钟】机器学习 | 混淆矩阵 Confusion Matrix_哔哩哔哩_bilibili

假如有一个A类机器,能够识别是不是汉堡,我们要估算这个机器的准确率,用这样的图片表示显然不能直观看到评价指标,那么我们使用这样的混淆矩阵图就可以表示了
| 预测值 | |||
| 真实值 | 是汉堡 | 不是汉堡 | |
| 是汉堡 | 1 | 2 | |
| 不是汉堡 | 2 | 5 |
感觉就是挺奇妙的,一个小表居然把所有的情况都列出来了。而且所有数加起来就是样本数!
太久没有这样的逻辑思维,我认为这样的知识是十分奇妙的!我乐于学习这样神奇的知识!
而且,我们想知道机器预测的准不准,就只需要看他做得对不对!真实是汉堡,预测出来也是汉堡!真实不是汉堡,预测出来也不是汉堡!就是准的!所以一整个对角线上,1+5就是准确的情况。所以准确率就是60%。
我们再结合,结合书本106的公式。
作业十五
请以对手写数字体分类问题为背景出一个基于混淆矩阵计算分类精度的练习题目。 在手写数字识别任务中,我们训练了一个分类模型对测试集(共 100 个样本)进行预测。数据集包含数字 0~9 共 10 个类别。模型的预测结果由以下混淆矩阵表示(部分数据已省略,仅显示部分行和列): 真实 \ 预测 0 1 2 3 4 5 6 7 8 9 0 9 0 0 0 0 0 0 0 1 0 1 0 11 0 0 0 0 0 0 0 0 2 0 1 8 0 0 0 0 1 0 0 3 0 0 0 10 0 1 0 0 0 0 4 0 0 0 0 9 0 0 0 0 1 5 0 0 0 1 0 8 0 0 1 0 6 0 0 0 0 0 0 10 0 0 0 7 0 0 1 0 0 0 0 9 0 0 8 0 0 0 0 1 0 0 0 8 1 9 0 0 0 0 0 0 0 1 0 9 问题: 1). 计算模型的整体分类精度(Accuracy)。 2). 计算数字 3 和数字 8 的分类错误率(Misclassification Rate)。 3). 哪个数字的分类效果最好?哪个数字的分类效果最差?请说明原因。
我们基于以上的认识,就能很快做出第一问和第三问。
老师真是的,也不给咱们列个表格,不知道考试的时候是不是还得自己画,粗心画错咋办。


作业16
好我看了一眼完全都是程序填空题。芭比Q!烤肉。
永不起祈求平坦的路,而是拥有应对困难的力量.
写在本子上多记记吧。
KD树划分
这个知识,我二分查找树还是学得不错的。但是相比二分查找又有些出入。二分查找树是找左子树右子树中间值,偶数列的时候是取左边的值作为根节点。
但是KD树是二维的,而且偶数列的时候取的是中位数的值,也就是右边的值,首先给X轴排序,再以X轴,Y轴,X轴,Y轴来划分。咱们可以让豆包给出一组坐标然后我们画在本子上让豆包检查。

相关文章:
期末复习(学习)之机器学习入门基础
上课没听过报道。欢迎补充交流! 前言:老师画的重点其实可以完全不用看,我这里只是看了一眼书顺着书本敲一遍。 比较干货的部分,直接看学习通的内容就好。最重要的是把学习通的内容记好。 目录 老师划的重点:P50 结构…...
网络各类型(BMA,NBMA,P2P)
网络类型—基于二层(数据链路层)使用的协议不同从而导致数据包封装方式不同,工作方式也有所区别,从而对网络本身进行分类 一、网络类型分类 2. 关键差异对比 1. HDLC(高级数据链路控制协议) 协议特点&…...

Linux 库文件的查看和管理
Linux 库文件说明1、库文件的类型2、库文件存储路径3、库文件查找顺序 Linux 库文件管理1、查看动态库相关信息2、添加动态库查找路径 Linux 库文件说明 1、库文件的类型 Linux 中的库文件本质上就是封装好的功能模块,某个应用程序如果要实现某个功能,…...

Java设计模式深度解析:策略模式的核心原理与实战应用
目录 策略模式基础解析策略模式实现指南策略模式典型应用场景Java生态中的策略模式实践策略模式进阶技巧策略模式最佳实践总结与展望1. 策略模式基础解析 1.1 核心概念与定义 策略模式(Strategy Pattern)是一种行为型设计模式,它定义了一系列算法族,将每个算法封装成独立…...

【计算机网络】第3章:传输层—概述、多路复用与解复用、UDP
目录 一、概述和传输层服务 二、多路复用与解复用 三、无连接传输:UDP 四、总结 (一)多路复用与解复用 (二)UDP 一、概述和传输层服务 二、多路复用与解复用 三、无连接传输:UDP 四、总结 (…...
服务的步骤)
6、在树莓派上安装 NTP(Network Time Protocol )服务的步骤
在树莓派上安装 NTP(Network Time Protocol )服务的步骤: 1. 安装 NTP 服务 打开树莓派终端,输入以下命令更新软件包列表: sudo apt-get update然后安装 NTP 服务: sudo apt-get install ntp2. 配置 NT…...
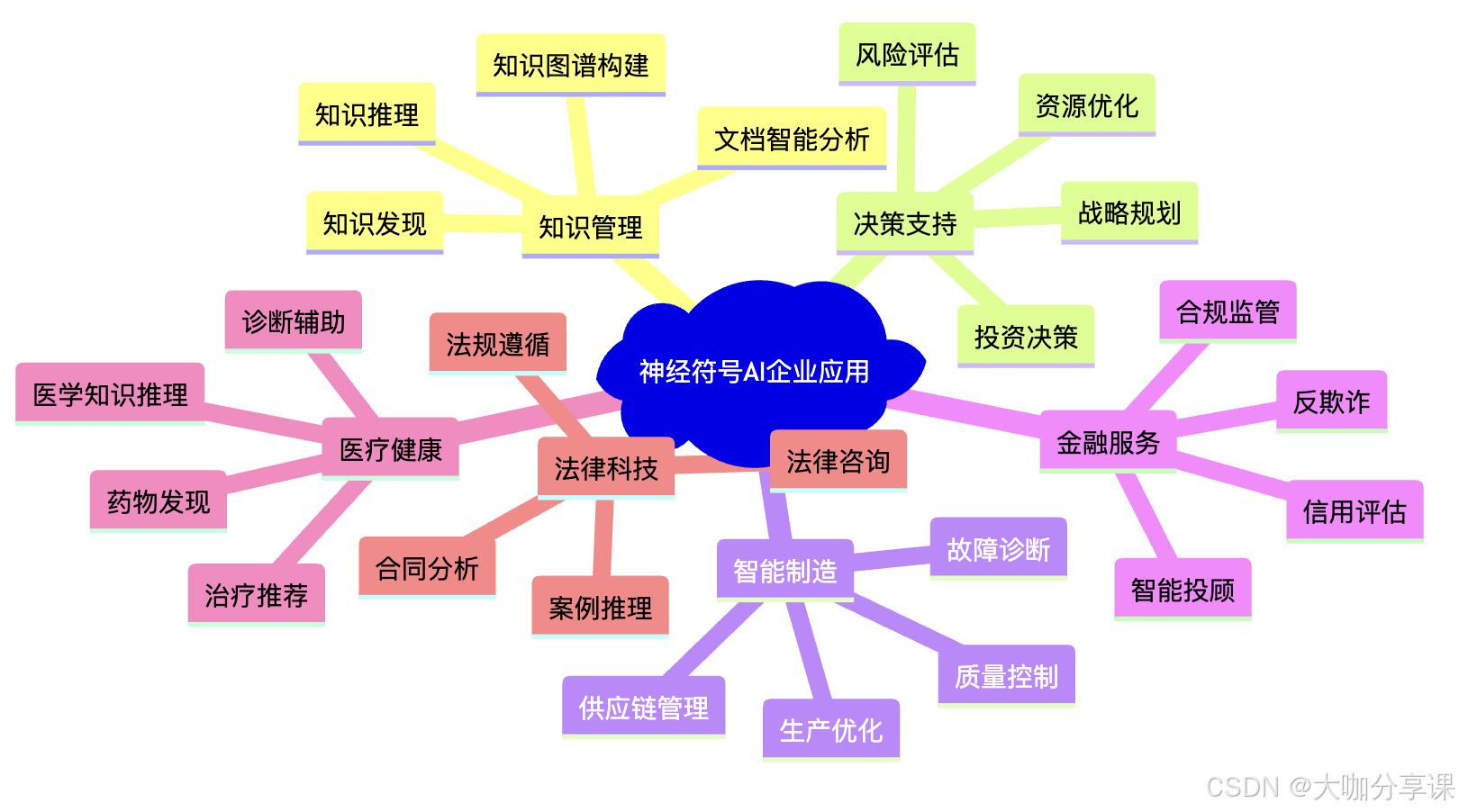
神经符号AI的企业应用:结合符号推理与深度学习的混合智能
💡 技术前沿: 神经符号AI代表了人工智能发展的新阶段,它将深度学习的模式识别能力与符号推理的逻辑分析能力有机结合,创造出更加智能、可解释且可靠的AI系统。这种混合智能技术正在重塑企业的智能化应用,从自动化决策到…...
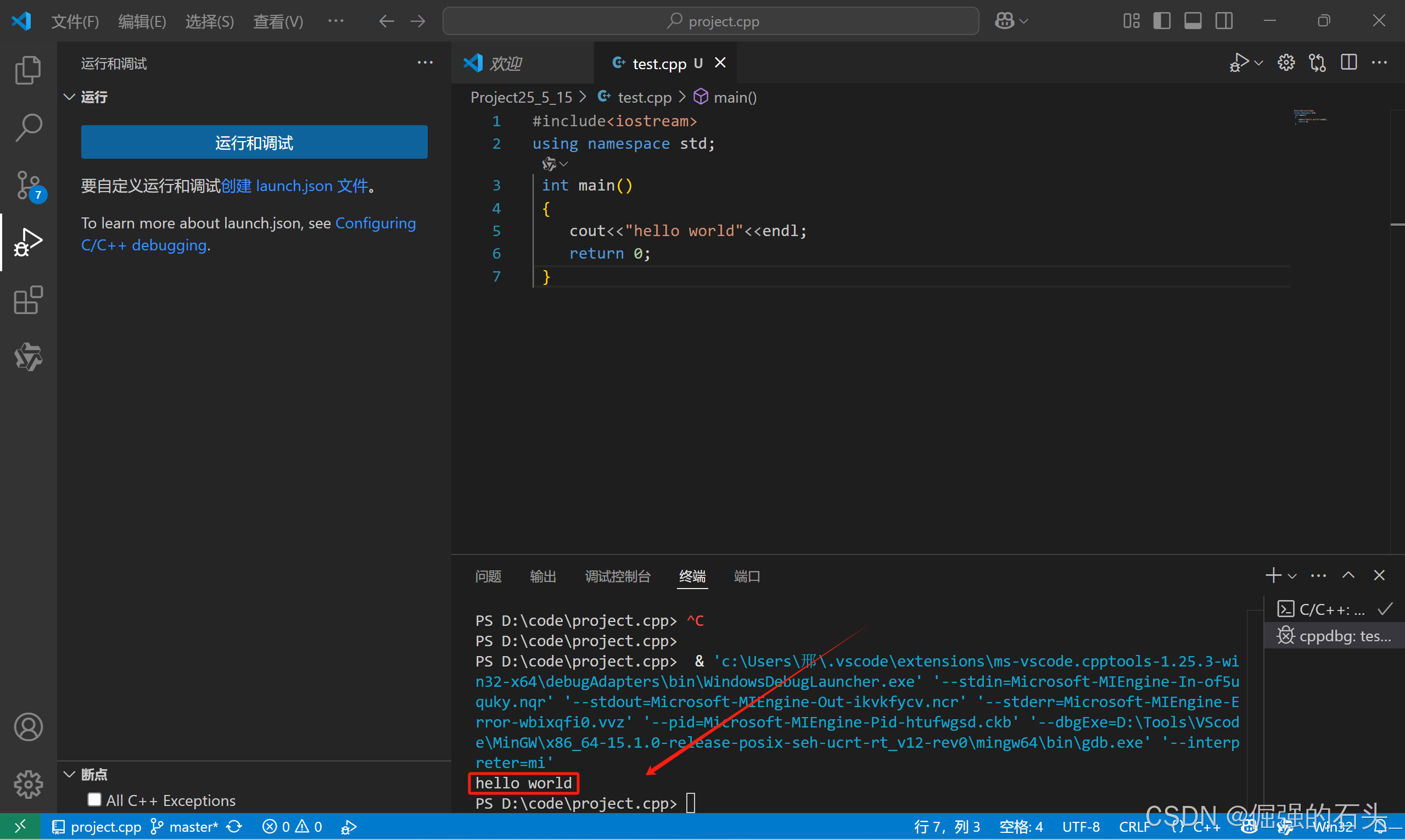
VSCode 中 C/C++ 安装、配置、使用全攻略:小白入门指南
引言 本文为Windows系统下安装配置与使用VSCode编写C/C代码的完整攻略,示例机器为Windows11。 通过本文的指导,你可以成功在Windows 机器上上使用VSCode进行C/C开发。 在文章开始之前,你可以先阅读下面这段话,以便于对步骤有个大…...

重温经典算法——希尔排序
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 基本原理 希尔排序是插入排序的改进版,通过按增量分组并逐步缩小增量实现排序。时间复杂度取决于增量序列,平均约为 O(n log n) 到 O(n^(3/2))&…...
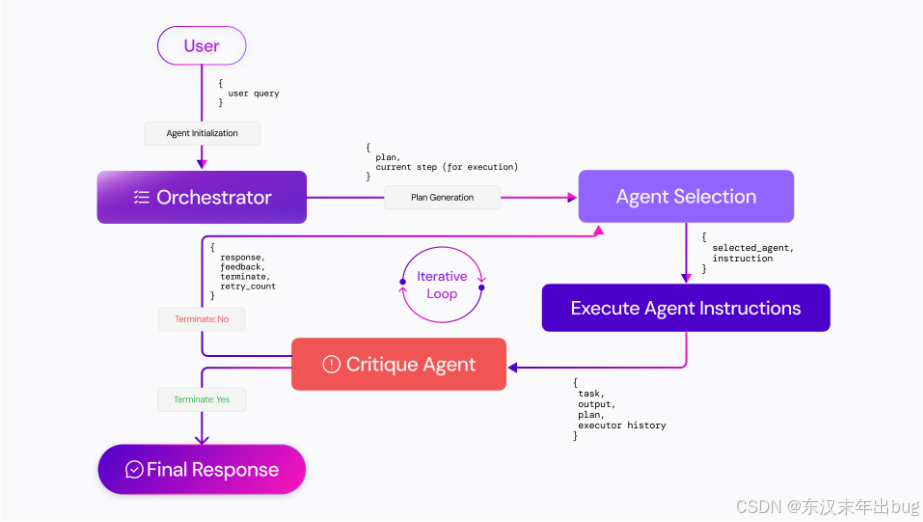
CortexON:开源的多代理AI系统无缝自动化和简化日常任务
简介 CortexON是一个开源的多代理AI系统,灵感来自Manus和OpenAI DeepResearch等高级代理平台。CortexON旨在无缝自动化和简化日常任务,擅长执行复杂的工作流程,包括全面的研究任务、技术操作和复杂的业务流程自动化。 技术架构 CortexON的技…...
海信IP810N-海思MV320芯片-安卓9-2+16G-免拆优盘卡刷固件包
海信IP810N-海思MV320芯片-安卓9-216G-免拆优盘卡刷固件包 线刷方法:(新手参考借鉴一下) 1.准备一个优盘,最佳是4G,卡刷强刷刷机,用一个usb2.0的8G以下U盘,fat32,2048块单分区格式化…...

【Golang】使用gin框架导出excel和csv文件
目录 1、背景2、go库【1】excel库下载【2】csv标准库 3、代码示例4、使用方法 1、背景 项目中可能会遇到导入导出一批数据的功能,对于批量大数据可能用表格的方式直观性更好,所以本篇文件来讲一下go中导出excel和csv文件的方式。 2、go库 【1】excel库…...
和AssetBundleBrowser的使用介绍)
【unity游戏开发入门到精通——通用篇】AssetBundle(AB包)和AssetBundleBrowser的使用介绍
文章目录 前言1、什么是AssetBundle?2、AB包与Resources系统对比3、AB包核心价值一、AB包打包工具Asset Bundle Browser1、下载安装AssetBundles-Browser2、打开Asset Bundle Browser窗口3、如何让资源关联AB包二、AssetBundleBrowser参数相关1、Configure 配置页签2、Build 构…...
2025年6月4日收获
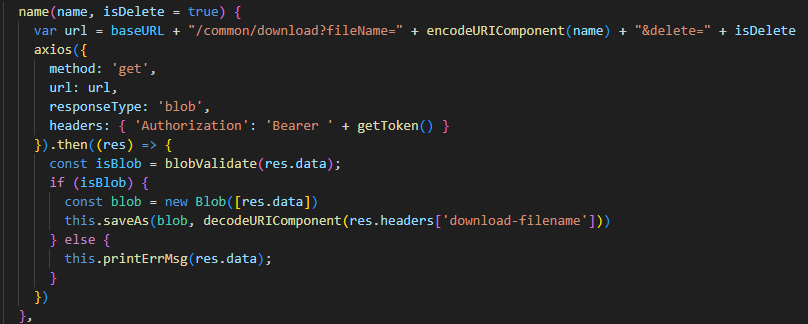
Authorization Authorization是一种通用的、标准化的权限控制和认证的通用框架,它能够使跨系统和跨域的身份验证和授权管理更容易,使不同应用程序之间能够更轻松地实现单点登录(SSO)、用户身份验证和授权控制等。 在前端使用 axi…...
leetcode hot100 链表(二)
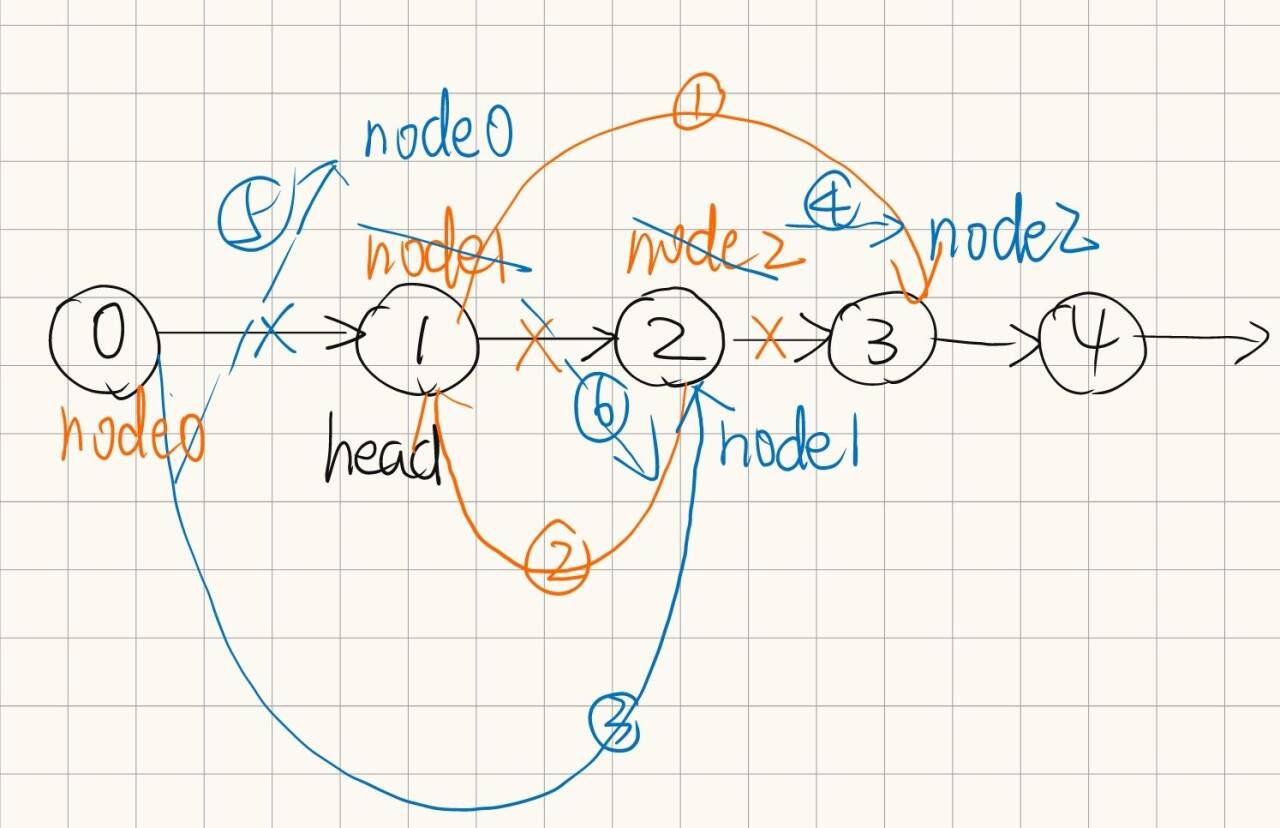
书接上回: leetcode hot100 链表(一)-CSDN博客 8.删除链表的倒数第N个结点 class Solution { public:ListNode* removeNthFromEnd(ListNode* head, int n) {ListNode* currhead;int len0;while(curr){currcurr->next;len;}int poslen-n…...
6. MySQL基本查询
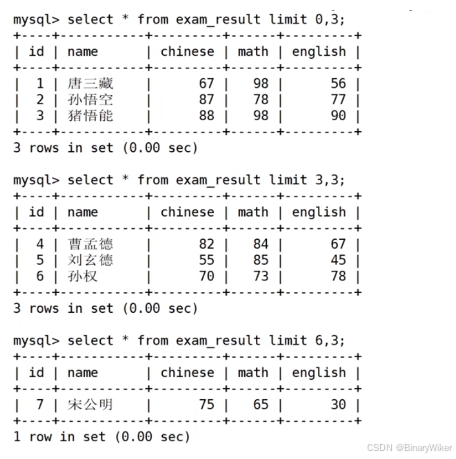
1. 表的增删改查 Create(创建), Retrieve(读取), Update(更新), Delete(删除) 2. Create & Insert 语法: insert [info] table_name () values () 2.1. 案例: 创建一个学生表 指定列单行插入, 如果values前省略, 则默认是全属性插入多行指定列插入, 中间分隔符为, 3. 插入替…...

JavaWeb简介
目录 1.1 JavaWeb 简介 1.2 JavaWeb 技术栈 1.3 JavaWeb 交互模式 1.4 JavaWeb 的 C/S 和 B/S 模式 C/S 模式 (Client-Server / 客户端-服务器模式) B/S 模式 (Browser-Server / 浏览器-服务器模式) 1.5 JavaWeb 实现前…...
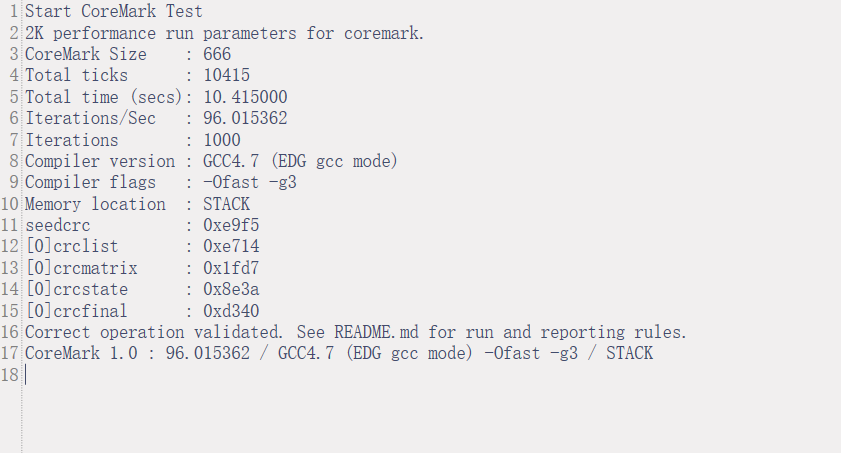
CMS32M65xx/67xx系列CoreMark跑分测试
CMS32M65xx/67xx系列CoreMark跑分测试 1、参考资料准备 1.1、STM32官方跑分链接 1.2、官网链接 官方移植文档,如下所示,点击红框处-移植文档: A new whitepaper and video explain how to port CoreMark-Pro to bare-metal 1.3、测试软件git下载链接 …...
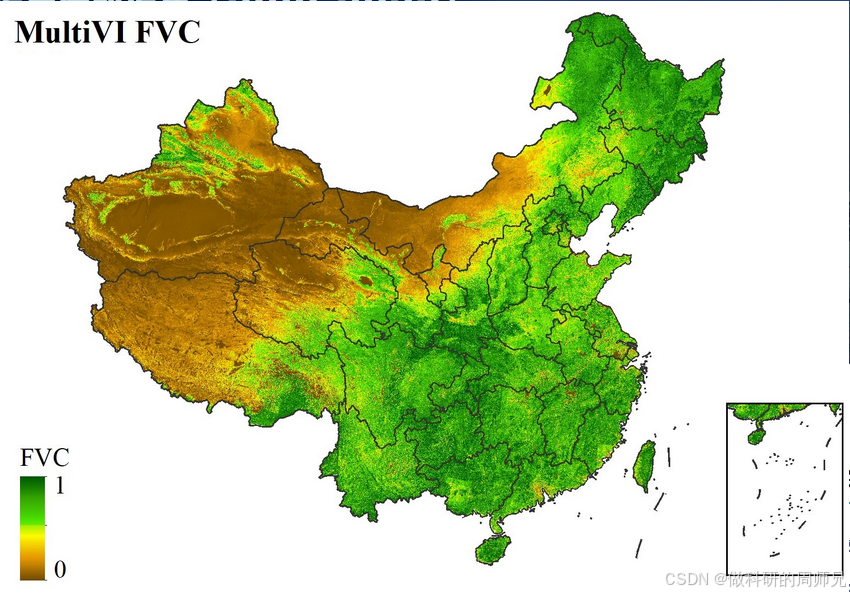
中国区域30m/15天植被覆盖度数据集(2010-2022)
时间分辨率:日空间分辨率;:10m - 100m共享方:式开放获取数据大小:2.98 TB数据时间范围:2010-01-01 — 2022-12-31元数据更新时间:2024-12-23 数据集摘要 高时空分辨率的植被覆盖度产品存在着广…...

LabVIEW准分子激光器智能控制系统
LabVIEW 开发准分子激光器智能控制系统,针对放电激励型准分子激光器强电磁干扰环境下的控制难题,采用 “PC 端 LabVIEW 人机交互 MCU 端实时控制 光纤隔离通信” 架构,实现激光能量闭环控制、腔体环境监测、气路自动管理等功能。硬件选用 N…...

微服务面试资料1
在当今快速发展的技术领域,微服务架构已经成为构建复杂系统的重要方式之一。本文将围绕微服务的核心概念、技术栈、分布式事务处理、微服务拆分与设计,以及敏捷开发实践等关键问题展开深入探讨,旨在为准备面试的 Java 开发者提供一份全面的复…...

Pytest Fixture 详解
Pytest Fixture 详解 Fixture 是 pytest 最强大的功能之一,用于提供测试所需的依赖资源(如数据库连接、临时文件、模拟对象等),并支持复用、作用域控制和自动清理。以下是全面详解: 1. 基本用法 定义 Fixture 使用 …...
力扣HOT100之二分查找:74. 搜索二维矩阵
这道题直接a了,我们可以参考上一道题:35.搜索插入位置的思路,详情见我的上一篇博客。将每一行的第一个元素当作一个数组中的元素,然后对这个数组进行二分查找,如果直接找到了target,则直接返回true…...

【前端】前后端通信
前端开发主要完成的两件事: 1)界面搭建 2)数据交互 本知识页参考: https://juejin.cn/post/6925296067378429960 0. XMLHttpRequest 客户端的一个API,为浏览器和服务器通信提供了一个便携通道。现代浏览器支持XMLHttp…...

编程技能:格式化打印04,sprintf
专栏导航 本节文章分别属于《Win32 学习笔记》和《MFC 学习笔记》两个专栏,故划分为两个专栏导航。读者可以自行选择前往哪个专栏。 (一)WIn32 专栏导航 上一篇:编程技能:格式化打印03,printf 回到目录…...
【函数1】)
C语言基础(11)【函数1】
内容提要 函数 文章目录 内容提要函数函数的描述函数的分类相关概念函数的定义:定义:案例: 形参和实参形参(形式参数)实参(实际参数)案例: 函数的返回值案例: 函数 函数…...
R语言基础| 下载、安装
在此前的单细胞教程中,许多小伙伴都曾因为R语言基础不足而十分苦恼。R语言是一种开源的编程语言和软件环境,专门用于统计分析、图形表示和数据挖掘。它最初由Ross Ihaka和Robert Gentleman在1993年创建,旨在为统计学家和数据分析师提供一个广…...

【hive sql】窗口函数
参考 包括窗口函数在内的执行顺序 from & join --确定数据源 where --行级过滤 group by --分组 having --组级过滤 窗口函数 --计算窗口函数结果 select --选择列 distinct --去重 order by --最终排序(可对窗口函数结果进行排序) limit/offset -…...

Ubuntu24.04 交叉编译 aarch64 ffmpeg
ffmpeg 官网: https://ffmpeg.org文档: https://ffmpeg.org/documentation.html 编译参数说明: https://trac.ffmpeg.org/wiki/CompilationGuide/Generic在Linux下编译: https://trac.ffmpeg.org/wiki/CompilationGuide 下载页: https://ffmpeg.org/download.html 安装依赖 …...

《AI角色扮演反诈技术解析:原理、架构与核心挑战》
AI角色扮演反诈技术解析:原理、架构与核心挑战 研究目标 技术栈梳理: 系统总结AI角色扮演在执法场景中的实现路径,涵盖大型语言模型(LLM)、提示词工程(Prompt Engineering)、多模态交互链路等…...