PostgreSQL-基于PgSQL17和11版本导出所有的超表建表语句
最新版本更新
https://code.jiangjiesheng.cn/article/368?from=csdn
推荐 《高并发 & 微服务 & 性能调优实战案例100讲 源码下载》
1. 基于pgsql 17.4 研究
查询psql版本:SELECT version();
查看已知1条建表语句和db中数据关系
SELECT create_hypertable('t_water_real_data_main', 'data_time', 'monitor_id', chunk_time_interval => INTERVAL '30 day',number_partitions => 4, associated_table_prefix=>'t_water_real_data_main', migrate_data => true);SELECT * from timescaledb_information.dimensions WHERE hypertable_name = 't_water_real_data_main';//生成表格,navicat导出html,然后截图,给AI生成md表格| hypertable_schema | hypertable_name | dimension_number | column_name | column_type | dimension_type | time_interval | integer_interval | integer_now_func | num_partitions |
|-------------------|---------------------------|------------------|--------------|----------------------------|----------------|---------------|------------------|------------------|----------------|
| public | t_water_real_data_main | 1 | data_time | timestamp without time zone| Time | 30 days | | | |
| public | t_water_real_data_main | 2 | monitor_id | integer | Space | | | | 4 |
解读create_hypertable建表
这条 SQL 语句使用了 TimescaleDB 的 create_hypertable 函数,将一个普通的 PostgreSQL 表转换为 hypertable(超表),以便高效地处理时间序列数据。
我们来逐部分解读:
✅ 原始语句:
SELECT create_hypertable('t_water_real_data_main', 'data_time', 'monitor_id', chunk_time_interval => INTERVAL '30 day',number_partitions => 4, associated_table_prefix=>'t_water_real_data_main.',migrate_data => true
);
🔍 各参数解释:
1. 't_water_real_data_main'
这是你要转换为 hypertable 的原始普通表的名称。该表必须已经存在,并且至少包含一个时间类型的列(如 data_time)。
2. 'data_time'
这是你指定的时间维度列名,用于对数据进行分区。这个列通常是 TIMESTAMP, TIMESTAMPTZ, 或 DATE 类型。
3. 'monitor_id'
这是你的空间维度(或称“第二维度”),通常是一个标识符,比如设备 ID、传感器 ID 等。它用于对数据进行水平分区(即分片)。
TimescaleDB 支持多维分区:首先是按时间(time partitioning),其次是按空间(space partitioning,即这里的
monitor_id)。
4. chunk_time_interval => INTERVAL '30 day'
这表示每个基于时间的 chunk(数据块)覆盖 30天 的数据。
- Chunk 是 hypertable 的底层存储单元。
- 指定较短的时间间隔可以提高查询性能(因为扫描的数据更少),但会增加元数据开销。
- 如果不显式指定,TimescaleDB 会根据表中的数据自动选择一个默认值。
5. number_partitions => 4
这表示对 monitor_id 进行哈希分区时,创建 4个分区。
- 即使有成千上万个不同的
monitor_id,TimescaleDB 也会通过哈希将其映射到这 4 个分区中。 - 更多分区可以带来更好的并行性,但也可能增加管理开销。
6. associated_table_prefix=>'t_water_real_data_main.'
这是一个可选参数,用于指定关联表(如连续聚合视图、策略等)的命名前缀。
- 它主要用于后续管理对象(如压缩策略、保留策略、连续聚合)的命名组织。
- 注意这里有个写法错误:
=>后面应该是字符串,建议改为:
(去掉最后那个多余的点)associated_table_prefix => 't_water_real_data_main'
7. migrate_data => true
这表示在转换为 hypertable 的过程中,把原表中的现有数据迁移到新的 hypertable 结构中。
- 如果设为
false,则只转换结构,不迁移历史数据。 - 通常首次转换时设置为
true。
🧠 总结功能:
这条语句的作用是:
将名为
t_water_real_data_main的普通表转换为 TimescaleDB 的 hypertable,使用data_time作为时间维度,monitor_id作为空间维度,每个时间 chunk 包含 30 天的数据,并对 monitor_id 哈希分成 4 个分区。同时将原表中的所有数据迁移到新结构中,并为后续相关对象指定命名前缀。
⚠️ 注意事项:
- 转换完成后,原表会被重命名为
_timescaledb_internal._hyper_X_chunk中的 chunk 表,而t_water_real_data_main会成为一个指向这些 chunk 的视图。 - 一旦转换为 hypertable,不能直接回退为普通表。
- 建议在低峰期执行此操作,因为数据迁移可能会锁定表一段时间。
根据已有表数据批量生成所有建超表语句AI提示词
-- 已知 "timescaledb_information"."dimensions" 有以下字段,示例,有的表有2个维度,有的表有1个维度:
INSERT INTO "timescaledb_information"."dimensions" ("hypertable_schema", "hypertable_name", "dimension_number", "column_name", "column_type", "dimension_type", "time_interval", "integer_interval", "integer_now_func", "num_partitions") VALUES ('public', 'bcs_log_receive_20x1', 1, 'receive_time', 'timestamp without time zone', 'Time', '1 day', NULL, NULL, NULL);
INSERT INTO "timescaledb_information"."dimensions" ("hypertable_schema", "hypertable_name", "dimension_number", "column_name", "column_type", "dimension_type", "time_interval", "integer_interval", "integer_now_func", "num_partitions") VALUES ('public', 'bcs_log_receive_20x1', 2, 'mn', 'character varying', 'Space', NULL, NULL, NULL, 16);
INSERT INTO "timescaledb_information"."dimensions" ("hypertable_schema", "hypertable_name", "dimension_number", "column_name", "column_type", "dimension_type", "time_interval", "integer_interval", "integer_now_func", "num_partitions") VALUES ('public', 'bcs_log_receive_3020', 1, 'receive_time', 'timestamp without time zone', 'Time', '1 day', NULL, NULL, NULL);-- 怎么根据这个表的数据,批量生成原始的建超表的语句:
SELECT create_hypertable('t_water_real_data_main', 'data_time', 'monitor_id', chunk_time_interval => INTERVAL '30 day',number_partitions => 4, associated_table_prefix=>'t_water_real_data_main', migrate_data => true);select create_hypertable('bcs_log_receive_3020', 'receive_time', chunk_time_interval=> interval '1 day', associated_table_prefix=>'_bcs_log_receive_3020',migrate_data => true);
分片时间未转换:
SELECT h.hypertable_name,CASE WHEN d.hypertable_name IS NOT NULL THENformat('SELECT create_hypertable(''%s'', ''%s''%s%s%s%s%s);',h.hypertable_name,max(CASE WHEN d.dimension_type = 'Time' THEN d.column_name END),COALESCE(', ''' || max(CASE WHEN d.dimension_type = 'Space' THEN d.column_name END) || '''', ''),COALESCE(', chunk_time_interval => INTERVAL ''' || max(d.time_interval) || '''', ''),COALESCE(', number_partitions => ' || max(d.num_partitions), ''),', associated_table_prefix=>''_' || replace(h.hypertable_name, '''', '''''') || '''',', migrate_data => true')ELSE NULLEND AS create_statement
FROM timescaledb_information.hypertables h -- 用于校验是否遗漏 ,v17以下版本timescaledb_information.hypertable.table_name
LEFT JOIN timescaledb_information.dimensions d ON h.hypertable_schema = d.hypertable_schema AND h.hypertable_name = d.hypertable_name
WHERE h.hypertable_schema = 'public'AND h.hypertable_name IN ('t_water_real_data_main', 'bcs_log_receive_3020')
GROUP BY h.hypertable_name, d.hypertable_name
ORDER BY h.hypertable_name;
经过多次调试和修正后 最终结果 :
CREATE OR REPLACE FUNCTION infer_best_time_unit(days INT)
RETURNS TEXT AS $$
BEGINIF days IS NULL OR days <= 0 THENRETURN NULL;END IF;IF days % 360 = 0 THENRETURN (days / 360)::TEXT || ' year' || CASE WHEN (days / 360) = 1 THEN '' ELSE 's' END;ELSIF days % 30 = 0 THENRETURN (days / 30)::TEXT || ' month' || CASE WHEN (days / 30) = 1 THEN '' ELSE 's' END;ELSIF days % 7 = 0 THENRETURN (days / 7)::TEXT || ' week' || CASE WHEN (days / 7) = 1 THEN '' ELSE 's' END;ELSERETURN days::TEXT || ' day' || CASE WHEN days = 1 THEN '' ELSE 's' END;END IF;
END;
$$ LANGUAGE plpgsql IMMUTABLE;SELECT h.hypertable_name,CASE WHEN d.hypertable_name IS NOT NULL THENformat('SELECT create_hypertable(''%s'', ''%s''%s%s%s%s%s);',h.hypertable_name,max(CASE WHEN d.dimension_type = 'Time' THEN d.column_name END),COALESCE(', ''' || max(CASE WHEN d.dimension_type = 'Space' THEN d.column_name END) || '''', ''),COALESCE(', chunk_time_interval => INTERVAL ''' ||infer_best_time_unit(floor((regexp_match(max(d.time_interval)::text, '^(\d+\.?\d*)\s*day'))[1]::NUMERIC)::INT) || '''',''),COALESCE(', number_partitions => ' || max(d.num_partitions), ''),', associated_table_prefix=>''_' || replace(h.hypertable_name, '''', '''''') || '''',', migrate_data => true')ELSE NULLEND AS create_statement
FROM timescaledb_information.hypertables h -- 用于校验是否遗漏 ,v17以下版本timescaledb_information.hypertable.table_name
LEFT JOIN timescaledb_information.dimensions d ON h.hypertable_schema = d.hypertable_schema AND h.hypertable_name = d.hypertable_name
WHERE h.hypertable_schema = 'public'AND h.hypertable_name IN ('t_water_real_data_main', 'bcs_log_receive_3020','t_water_md_run_log_sub')
GROUP BY h.hypertable_name, d.hypertable_name
ORDER BY 验证:
| hypertable_name | create_statement |
|-----------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| bcs_log_receive_3020 | SELECT create_hypertable('bcs_log_receive_3020', 'receive_time', chunk_time_interval => INTERVAL '1 day', associated_table_prefix=>'_bcs_log_receive_3020', migrate_data => true); || t_water_md_run_log_sub | SELECT create_hypertable('t_water_md_run_log_sub', 'data_time', chunk_time_interval => INTERVAL '1 year', associated_table_prefix=>'_t_water_md_run_log_sub', migrate_data => true); || t_water_real_data_main | SELECT create_hypertable('t_water_real_data_main', 'data_time', 'monitor_id', chunk_time_interval => INTERVAL '1 month', number_partitions => 4, associated_table_prefix=>'_t_water_real_data_main', migrate_data => true); |
如果需要校验下待执行的目标库是否已有部分表,
先查已有的超表,然后加入到where not in:
SELECT hypertable_name FROM timescaledb_information.hypertables WHERE hypertable_schema = 'public';然后将上面的sql改成
AND h.hypertable_name NOT IN (...)v11.9版本
SELECT table_name FROM timescaledb_information.hypertable WHERE TABLE_SCHEMA = 'public' ORDER BY "table_name";
2. 基于pgsql 11.9 研究
查询已有的超表:
SELECT table_name FROM timescaledb_information.hypertable ORDER BY "table_name";
查询所有的所有的超表建表语句
特别注意:低版本没有原始的时间分片长度的入参保存,所以要推断。另外1 year默认是360天,不一定365天,月可能也是类似。如果可以尝试从业务表得到一部分的时间分片drop_chunks_policy_config (INSERT INTO “drop_chunks_policy_config” (“table_name”, “drop_chunks_date”) VALUES ( ‘t_air_no_org_real_his_sub’, ‘5 year’))
CREATE OR REPLACE FUNCTION normalize_interval(microseconds BIGINT)
RETURNS TEXT AS $$
DECLAREyear_us CONSTANT BIGINT := 31104000000000; -- 360 天month_us CONSTANT BIGINT := 2592000000000; -- 30 天week_us CONSTANT BIGINT := 604800000000;day_us CONSTANT BIGINT := 86400000000;hour_us CONSTANT BIGINT := 3600000000;quantity NUMERIC;
BEGINIF microseconds >= year_us AND (microseconds % year_us) = 0 THENRETURN (microseconds / year_us)::INT || ' years';ELSIF microseconds >= month_us AND (microseconds % month_us) = 0 THENRETURN (microseconds / month_us)::INT || ' months';ELSIF microseconds >= week_us AND (microseconds % week_us) = 0 THENRETURN (microseconds / week_us)::INT || ' weeks';ELSIF microseconds >= day_us AND (microseconds % day_us) = 0 THENRETURN (microseconds / day_us)::INT || ' days';ELSIF microseconds >= hour_us AND (microseconds % hour_us) = 0 THENRETURN (microseconds / hour_us)::INT || ' hours';ELSE-- 如果不整除任何单位,则保留到小时RETURN CEIL(microseconds::NUMERIC / hour_us) || ' hours';END IF;
END;
$$ LANGUAGE plpgsql IMMUTABLE;SELECT h.table_name,format('SELECT create_hypertable(''%s'', ''%s''%s, chunk_time_interval => INTERVAL ''%s''%s%s%s);',h.table_name,-- 第一个维度(时间)max(time_dim.column_name),-- 第二个维度(空间)名称(可能为空)COALESCE(', ''' || max(space_dim.column_name) || '''', ''),-- 时间间隔(优先自定义策略)COALESCE(NULLIF(p.drop_chunks_date, ''), normalize_interval(time_dim.interval_length)),-- 空间分区参数(number_partitions => N)CASE WHEN space_dim.num_slices IS NOT NULL THEN ', number_partitions => ' || space_dim.num_slices::TEXT ELSE '' END,-- associated_table_prefix', associated_table_prefix => ''_' || replace(h.table_name, '''', '') || '''',-- 固定参数', migrate_data => true') AS create_statement
FROM _timescaledb_catalog.hypertable h
-- 时间维度
JOIN LATERAL (SELECT d.column_name, d.interval_lengthFROM _timescaledb_catalog.dimension dWHERE d.hypertable_id = h.idAND d.column_type IN ('timestamp without time zone', 'timestamp with time zone')AND d.interval_length IS NOT NULLORDER BY d.idLIMIT 1
) AS time_dim ON TRUE
-- 空间维度
LEFT JOIN LATERAL (SELECT d.column_name, d.num_slicesFROM _timescaledb_catalog.dimension dWHERE d.hypertable_id = h.idAND d.num_slices IS NOT NULLORDER BY d.idLIMIT 1
) AS space_dim ON TRUE
-- 自定义策略配置(定时任务清除过期数据的业务表也会记录原始时间分片长度入参,优先读取)
LEFT JOIN drop_chunks_policy_config p ON h.table_name = p.table_name
WHERE h.schema_name = 'public'
AND h.table_name in ('t_air_miss_data_detail','t_water_md_run_log_sub')
GROUP BY h.table_name, time_dim.column_name,time_dim.interval_length, space_dim.column_name,space_dim.num_slices, p.drop_chunks_date
ORDER BY h.table_name;
结果
| table_name | create_statement |
|-----------------------------|------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| t_air_miss_data_detail | SELECT create_hypertable('t_air_miss_data_detail', 'warning_time', 'monitor_id', chunk_time_interval => INTERVAL '1 years', number_partitions => 4, associated_table_prefix => '_t_air_miss_data_detail', migrate_data => true); |
| t_water_md_run_log_sub | SELECT create_hypertable('t_water_md_run_log_sub', 'data_time', chunk_time_interval => INTERVAL '5 year', associated_table_prefix => '_t_water_md_run_log_sub', migrate_data => true); |
注意:最终导出的sql执行前后加上
-- ROLLBACK;
BEGIN;
...
COMMIT;
出现问题1
ERROR: trigger “ts_insert_blocker” for relation “bcs_log_receive_3020” already exists, 找到同步表结构时带出的ts_insert_blocker触发器,这个触发器在创建超表时可以自动创建。通过执行下面的sql,找到消息中的批量sql: [双击 navicat中报错的消息列,就能定位到具体哪一行的sql]
DO $$
DECLAREr RECORD;
BEGINFOR r INSELECT tgrelid::regclass AS table_nameFROM pg_triggerWHERE tgname = 'ts_insert_blocker'AND NOT tgisinternal -- 排除内部系统触发器LOOP<!--只打印删除的sql-->RAISE NOTICE 'DROP TRIGGER IF EXISTS ts_insert_blocker ON %;', r.table_name;<!--直接执行删除--><!--EXECUTE format('DROP TRIGGER IF EXISTS ts_insert_blocker ON %s', r.table_name);--><!--RAISE NOTICE 'Trigger "ts_insert_blocker" dropped on table %', r.table_name;-->END LOOP;
END;
$$;
出现问题2
ERROR: cannot create a unique index without the column “start_time” (used in partitioning) [双击 navicat中报错的消息列,就能定位到具体哪一行的sql]
ALTER TABLE "public"."t_water_event_md" DROP CONSTRAINT "t_water_event_md_pkey",ADD CONSTRAINT "t_water_event_md_pkey" PRIMARY KEY ("id", "start_time");
最新版本更新
https://code.jiangjiesheng.cn/article/368?from=csdn
推荐 《高并发 & 微服务 & 性能调优实战案例100讲 源码下载》
相关文章:

PostgreSQL-基于PgSQL17和11版本导出所有的超表建表语句
最新版本更新 https://code.jiangjiesheng.cn/article/368?fromcsdn 推荐 《高并发 & 微服务 & 性能调优实战案例100讲 源码下载》 1. 基于pgsql 17.4 研究 查询psql版本:SELECT version(); 查看已知1条建表语句和db中数据关系 SELECT create_hypert…...
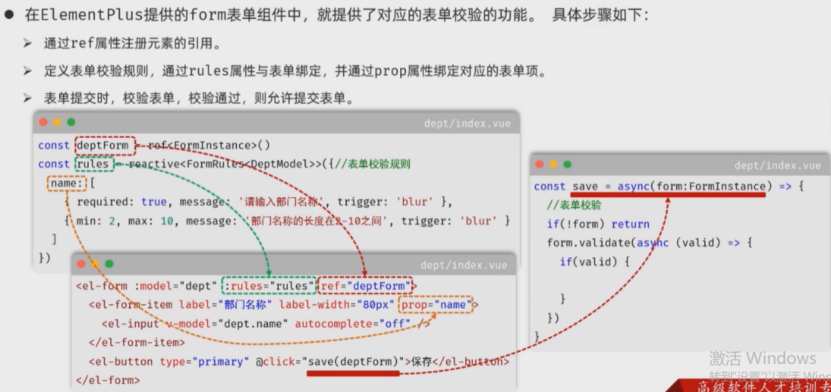
JavaWeb:前后端分离开发-部门管理
今日内容 前后端分离开发 准备工作 页面布局 整体布局-头部布局 Container 布局容器 左侧布局 资料\04. 基础文件\layout/index.vue <script setup lang"ts"></script><template><div class"common-layout"><el-containe…...

ArcGIS计算多个栅格数据的平均栅格
3种方法计算多个栅格数据的平均栅格 1->使用“ 栅格计算器”工具 原理就是把多幅影像数据相加,然后除以个数,就能得到平均栅格。 2-> 使用“像元统计数据”工具,如果是ArcGIS pro,则是“像元统计”工具。使用这个工具可以…...
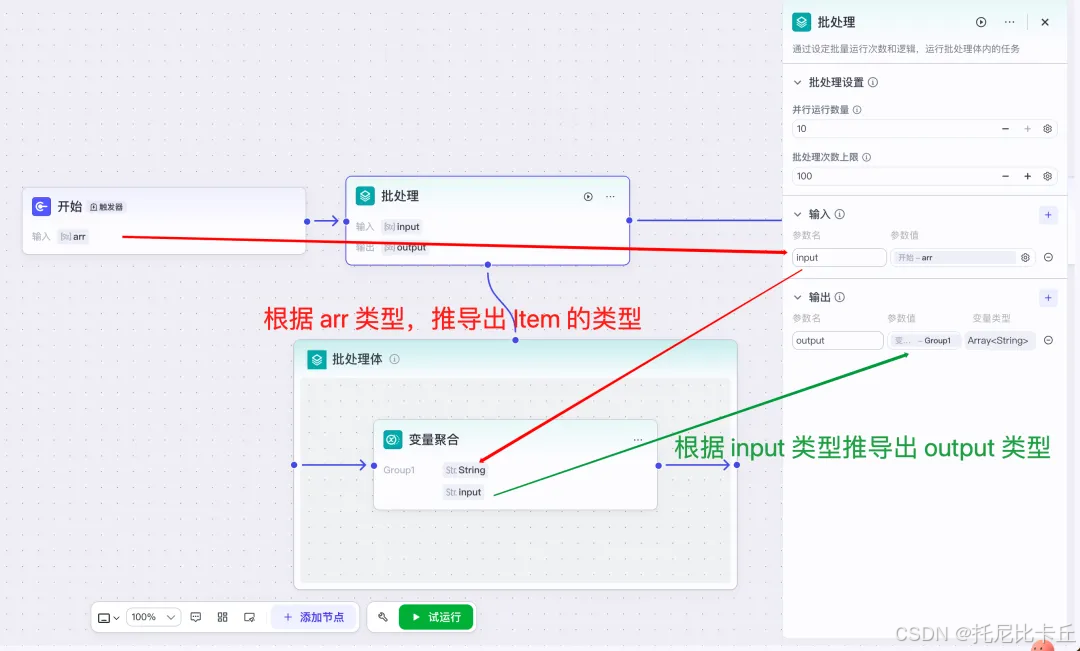
字节开源FlowGram:AI时代可视化工作流新利器
字节终于开源“扣子”同款引擎了!FlowGram:AI 时代的可视化工作流利器 字节FlowGram创新性地融合图神经网络与多模态交互技术,构建了支持动态拓扑重构的可视化流程引擎。该系统通过引入 f ( G ) ( V ′ , E ′ ) f(\mathcal{G})…...

如何选择合适的分库分表策略
选择合适的分库分表策略需要综合考虑业务特点、数据规模、访问模式、技术成本等多方面因素。以下是系统性的选择思路和关键决策点: 一、核心决策因素 业务需求分析 数据规模:当前数据量(如亿级)、增长速度(如每日新增百…...

(LeetCode 每日一题)3403. 从盒子中找出字典序最大的字符串 I (贪心+枚举)
题目:3403. 从盒子中找出字典序最大的字符串 I 题目:贪心枚举字符串,时间复杂度0(n)。 最优解的长度一定是在[1,n-numFriends]之间。 字符串在前缀都相同的情况下,长度越长越大。 C版本: class Solution { public:st…...
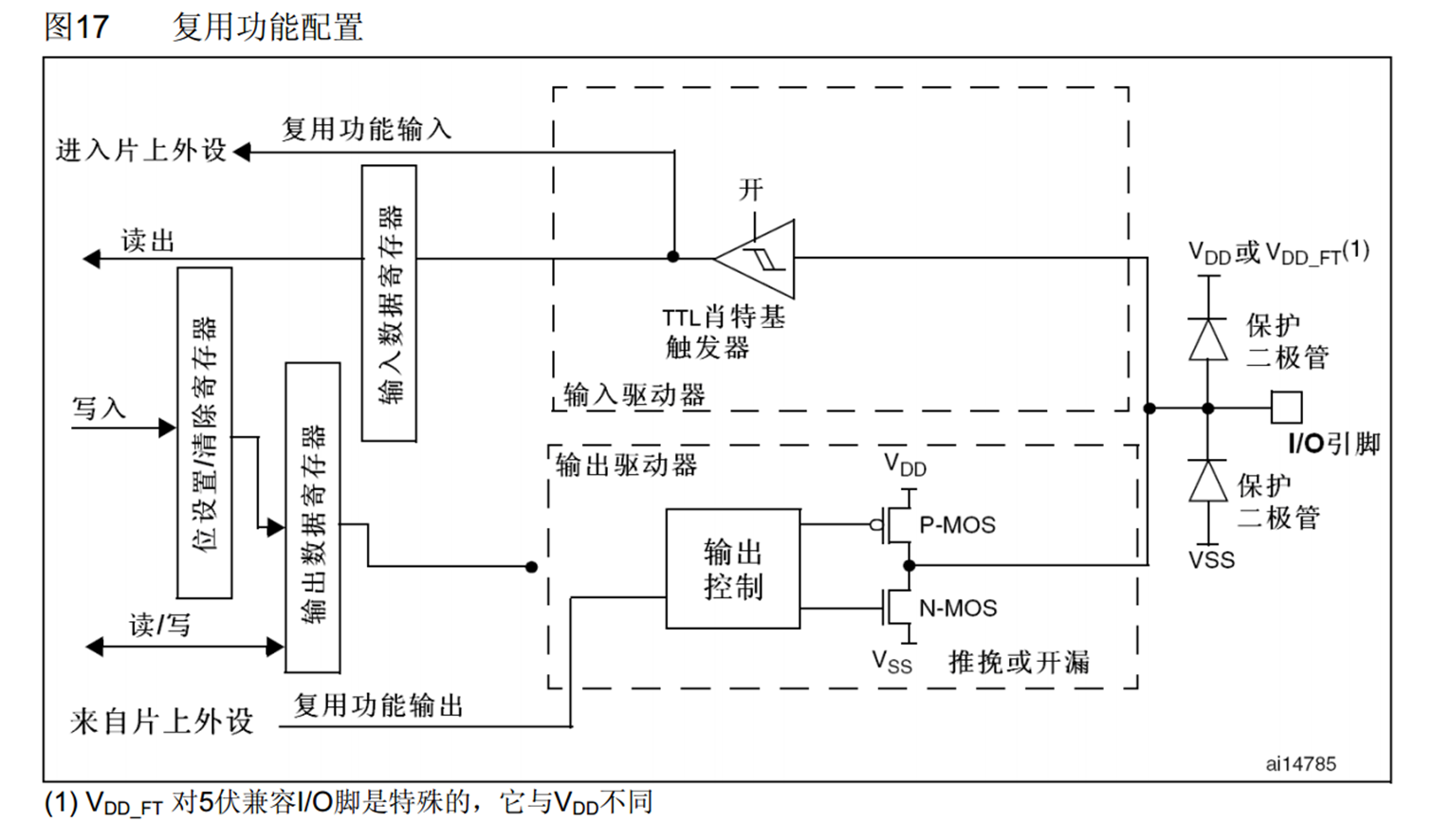
GPIO的内部结构与功能解析
一、GPIO总体结构 总体构成 1.APB2(外设总线) APB2总线是微控制器内部连接CPU与外设(如GPIO)的总线,负责CPU对GPIO寄存器的读写访问,支持低速外设通信 2.寄存器 控制GPIO的配置(输入/输出模式、上拉/下拉等&#x…...

Python训练打卡Day42
Grad-CAM与Hook函数 知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 在深度学习中,我们经常需要查看或修改模型中间层的输出或梯度。然而,标准的前向传播和反向传播过程通常是一个黑盒,我们很难直接访问中间层的信…...

深度学习中的负采样
深度学习中的负采样 负采样(Negative Sampling) 是一种在训练大型分类或概率模型(尤其是在输出类别很多时)中,用来加速训练、降低计算量的方法。 它常用于: 词向量训练(如 Word2Vecÿ…...

php7+mysql5.6单用户中医处方管理系统V1.0
php7mysql5.6中医处方管理系统说明文档 一、系统简介 ----------- 本系统是一款专为中医诊所设计的处方管理系统,基于PHPMySQL开发,不依赖第三方框架,采用原生HTML5CSS3AJAX技术,适配手机和电脑访问。 系统支持药品管理、处方开…...

Java 大视界 — Java 大数据在智能安防视频监控中的异常事件快速响应与处理机制
/*Java 大数据在智能安防视频监控中的异常事件快速响应与处理机制(简化示例)*/// 1. Event.java - 异常事件模型 package com.security.model;public class Event {private String id;private String type; // 如: "入侵", "火警"pr…...
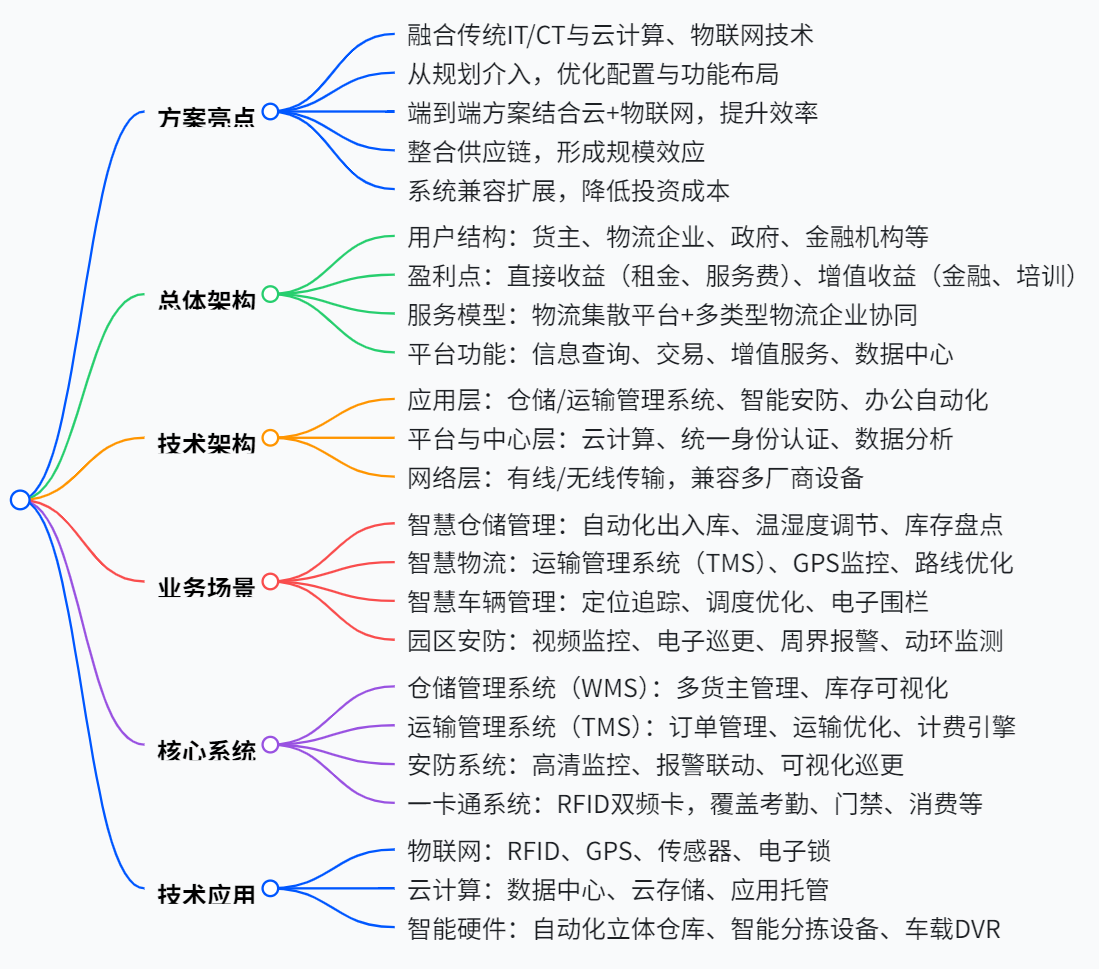
智慧物流园区整体解决方案
该智慧物流园区整体解决方案借助云计算、物联网、ICT 等技术,从咨询规划阶段介入,整合供应链上下游资源,实现物流自动化、信息化与智能化。方案涵盖智慧仓储管理(如自动化立体仓储系统、温湿度监控)、智慧物流(运输管理系统 TMS、GPS 监控)、智慧车辆管理(定位、调度、…...

审批流程管理系统开发记录:layui前端交互的实践
一、需求拆解与技术选型 本次开发围绕企业审批流程管理场景,需实现以下核心功能: 前端申请表单与流程进度可视化底部滑动审批弹窗交互多版本MySQL数据库支持流程数据的增删改查与状态管理技术栈选择: 前端采用LayUI框架,利用其时间线组件(lay-timeline)实现流程进度展示…...
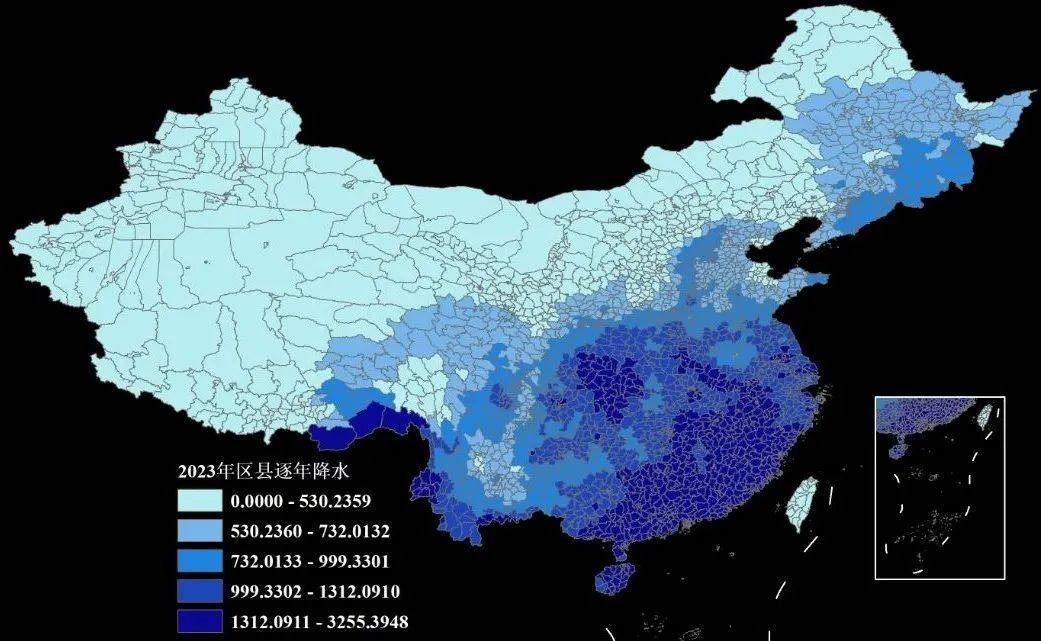
【会员专享数据】1960—2023年我国省市县三级逐年降水量数据(Shp/Excel格式)
之前我们分享过1960-2023年我国0.1分辨率的逐日、逐月、逐年降水栅格数据(可查看之前的文章获悉详情),是研究者Jinlong Hu与Chiyuan Miao分享在Zenodo平台上的数据,很多小伙伴拿到数据后反馈栅格数据不太方便使用,问我…...

2025年精通MVCC
今年找工作,无一例外又问到了MVCC这个知识点。几乎每次换工作都会被问到这个面试有用,工作毫无 * 用的知识。但是环境就是这样,既然如此,我们用一篇文章彻底搞懂MVCC 1.MVCC是什么 MVCC(Multi-Version Concurrency C…...

硬路由与软路由
目录 核心区别 ⚙️ 性能与功能定位 如何选择? 核心区别 硬路由: 本质: 专用的硬件设备。构成: 厂家将特定的路由器操作系统(通常是高度定制化、封闭或精简的)固化在专用的硬件平台上。硬件:…...

OpenCV C++ 心形雨动画
❤️ OpenCV C 心形雨动画 ❤️ 本文将引导你使用 C 和 OpenCV 库创建一个可爱的心形雨动画。在这个动画中,心形会从屏幕顶部的随机位置落下,模拟下雨的效果。使用opencv定制自己的专属背景 目录 简介先决条件核心概念实现步骤 创建项目定义心形结构…...

Fullstack 面试复习笔记:Java 基础语法 / 核心特性体系化总结
Fullstack 面试复习笔记:Java 基础语法 / 核心特性体系化总结 上一篇笔记:Fullstack 面试复习笔记:操作系统 / 网络 / HTTP / 设计模式梳理 目前上来说,这个系列的笔记本质上来说,是对不理解的知识点进行的一个梳理&…...

安卓Compose实现鱼骨加载中效果
安卓Compose实现鱼骨加载中效果 文章目录 安卓Compose实现鱼骨加载中效果背景与简介适用场景Compose骨架屏与传统View实现对比Shimmer动画原理简介常见问题与优化建议参考资料 本文首发地址 https://h89.cn/archives/404.html 背景与简介 在移动应用开发中,加载中占…...

使用qt 定义全局钩子 捕获系统的键盘事件
使用qt 定义全局钩子 捕获系统的键盘事件 即使焦点不在自定义软件上,也能够触发 以下待接口代码: class Hook :public QObject { Q_OBJECT public: Hook(); enum Type { CTRL_E, CTRL_W, SPACE, Enter, C };//自定义枚举,定义“修改”、“撤回…...

FreeType 字体信息检查工具 - 现代C++实现
文章目录 获取字体的版权信息工具简介主要特点1. 现代C实现2. 完整的功能3. 健壮的错误处理4. 国际化支持 使用说明技术亮点 获取字体的版权信息 #include <iostream> // 标准输入输出流库 #include <string> // 字符串处理库 #include <vector>…...

el-table 树形数据,子行数据可以异步加载
1、 <el-tableborder:header-cell-style"tableStyle?.headerCellStyle"ref"tableRef":data"tableData"row-key"id":default-expand-all"false" // 默认不展开所有树形节点:tree-props"{ children: children, hasC…...
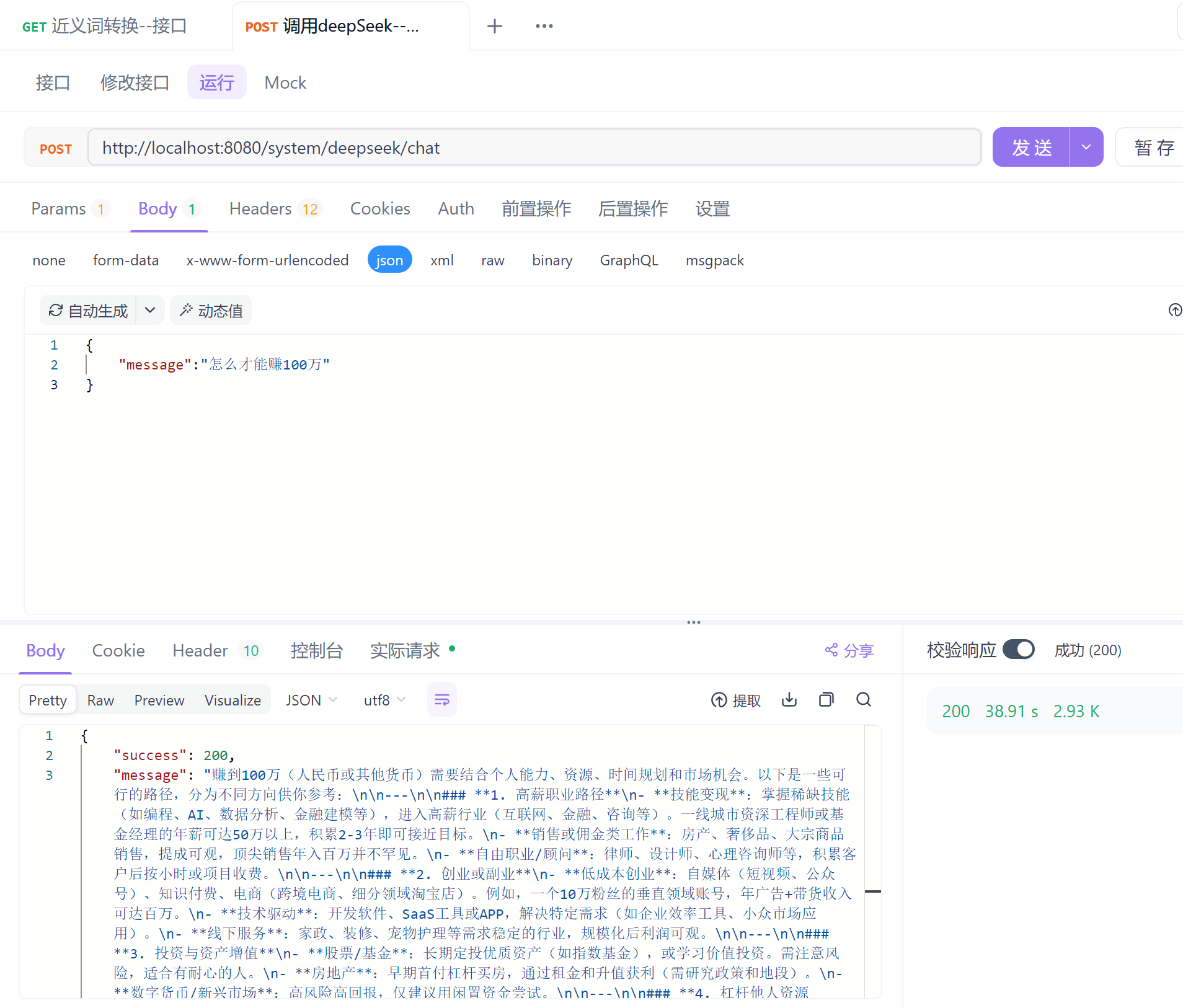
【使用JAVA调用deepseek】实现自能回复
在Spring Boot系统中接入DeepSeek服务,并将其提供给用户使用,通常需要以下步骤: 一、准备工作 (1)注册DeepSeek开发者账号 访问DeepSeek官网,注册并创建应用,获取API Key。 API文档࿱…...

【Linux系列】rsync命令详解与实践
博客目录 高效文件同步的艺术:rsync 命令详解与实践rsync 命令解析rsync 的核心优势1. 增量传输:效率的革命2. 归档模式(-a):保留文件所有属性3. 人性化输出(-h)与进度显示(--progress) 实际应用场景1. 文件备份与版本管理2. 跨设备同步3. 大…...
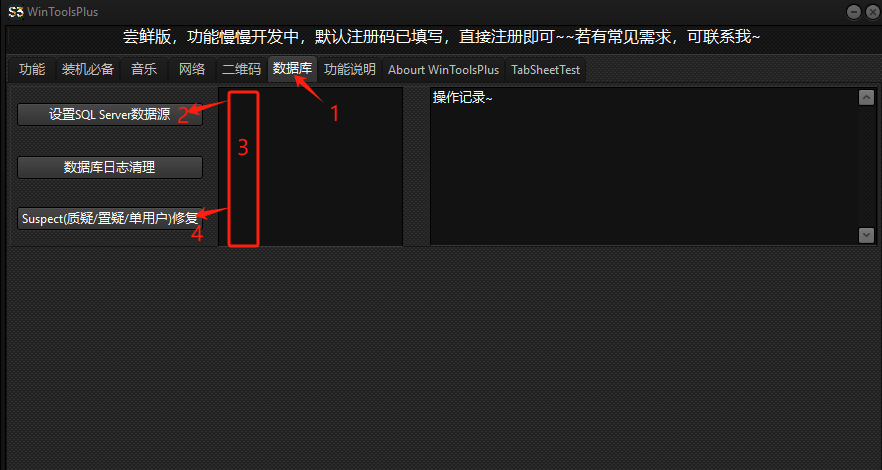
Windows系统工具:WinToolsPlus 之 SQL Server Suspect/质疑/置疑/可疑/单用户等 修复
数据库在数据库列表状态是 Suspect/质疑/置疑/可疑/单用户等 非正常状态时, 使用WinToolsPlus 数据库页签 先设置 数据源 , 选择 需要清理日志的数据库, 点击 Suspect/质疑/置疑/可疑/单用户 按钮即可进修复。 修复过程会有数据库服务停止和启…...
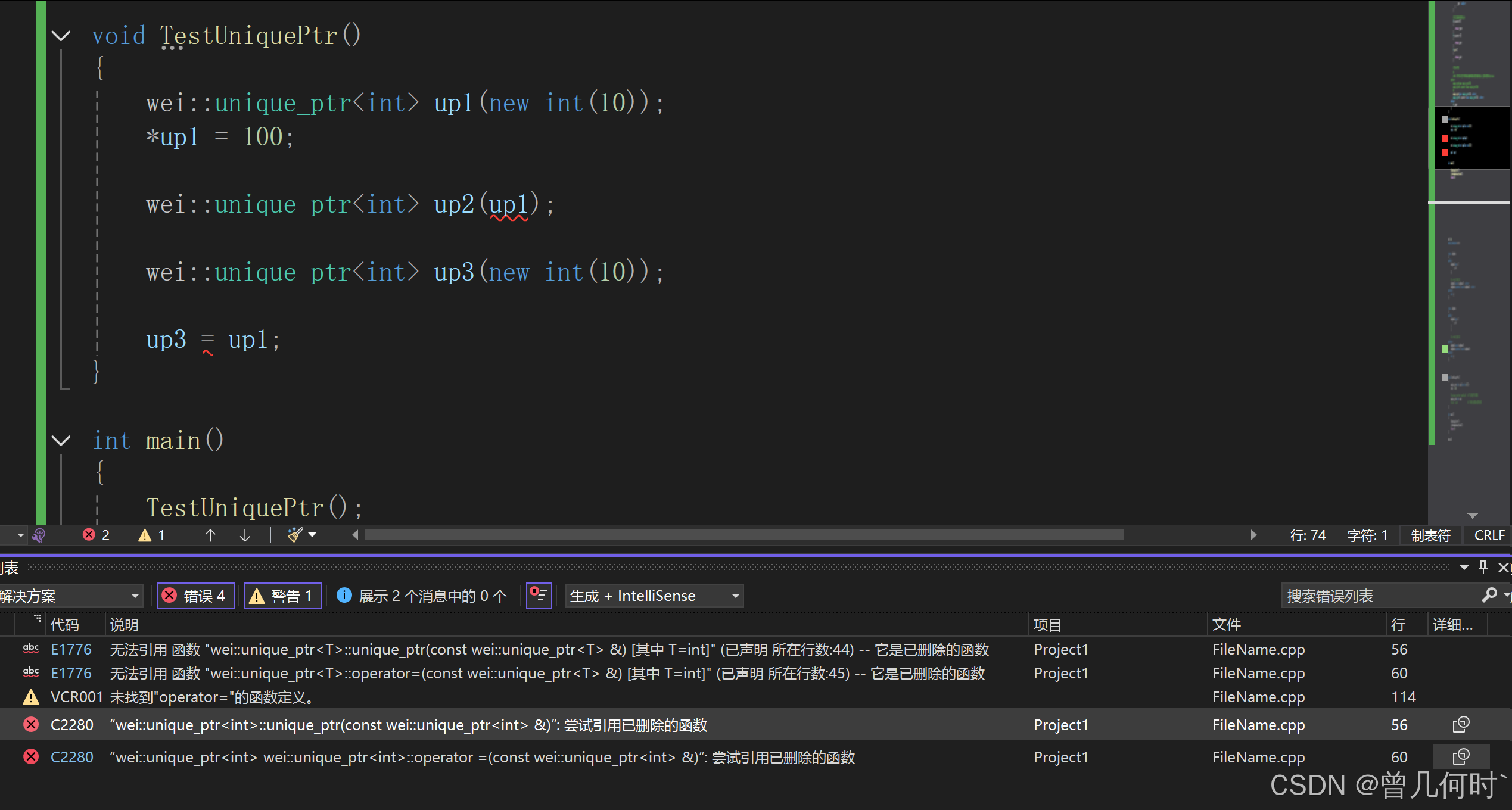
C++——智能指针 unique_ptr
unique_ptr的实现原理:简单粗暴的防拷贝 目录 一、使用C11中的新用法unique_ptr 二、使用c11模拟实现 三、使用c98特性实现 四、模拟实现unique_ptr 五、发现问题 一、使用C11中的新用法unique_ptr 由于限制了拷贝以及赋值 导致缺陷:unique_ptr管理…...

【Python训练营打卡】day43 @浙大疏锦行
DAY 43 复习日 作业: kaggle找到一个图像数据集,用cnn网络进行训练并且用grad-cam做可视化 进阶:并拆分成多个文件 我选择的是music_instruments 链接:Musical Instruments (kaggle.com) #导包 import torch import torch.nn as…...

1-【源码剖析】kafka核心概念
从今天开始开始在csdn上记录学习的笔记,主要包括以下几个方面: kafkaflinkdoris 本系列笔记主要记录Kafka学习相关的内容。在进行kafka源码学习之前,先介绍一下Kafka的核心概念。 消息 消息是kafka中最基本的数据单元,由key和…...
)
JavaScript中判断两个对象是否相同(所有属性的值是否都相同)
在JavaScript中,判断两个对象的所有属性是否相同(包括嵌套对象)需要深度比较(deep comparison)。以下是几种实现方法: 方法1:简易深度比较(不考虑循环引用、Symbol和特殊对象&#x…...

Flask 应用的生产环境部署指南
Flask 是一个轻量级的 Python Web 应用框架,常用于快速开发 Web 应用或 API。然而,Flask 内置的开发服务器仅适用于开发和调试阶段,并不适合直接用于生产环境。本文将详细介绍在生产环境中部署 Flask 应用的最佳实践,包括使用专业…...