机器学习基础(三) 逻辑回归
目录
- 逻辑回归的概念
- 核心思想
- Sigmoid 函数
- 逻辑回归的原理和底层优化手段
- 伯努利分布
- 最大似然估计 Maximum Likelihood Estimation (MLE)
- 伯努利分布的似然函数
- 交叉熵损失函数(Cross-Entropy Loss),也称为 对数损失(Log Loss)
- 实操代码
- 逻辑回归解决多分类问题
- OVR
- 核心思想:
- 优点
- 缺点
- 一对一(One-vs-One)OvO
- 核心思想
- 优点
- 缺点
- 适用场景
逻辑回归的概念
逻辑回归(Logistic Regression)是一种广泛应用于分类问题的统计方法,尤其适用于二分类问题。
注意: 尽管名称中有"回归"二字,但它实际上是一种分类算法。
核心思想
逻辑回归通过将线性回归的输出映射到(0,1)区间,使用Sigmoid函数将连续值转换为概率值,然后根据概率值进行分类预测。
Sigmoid 函数
Sigmoid函数可以将任何实数映射到(0,1)区间内,可以解释为概率。
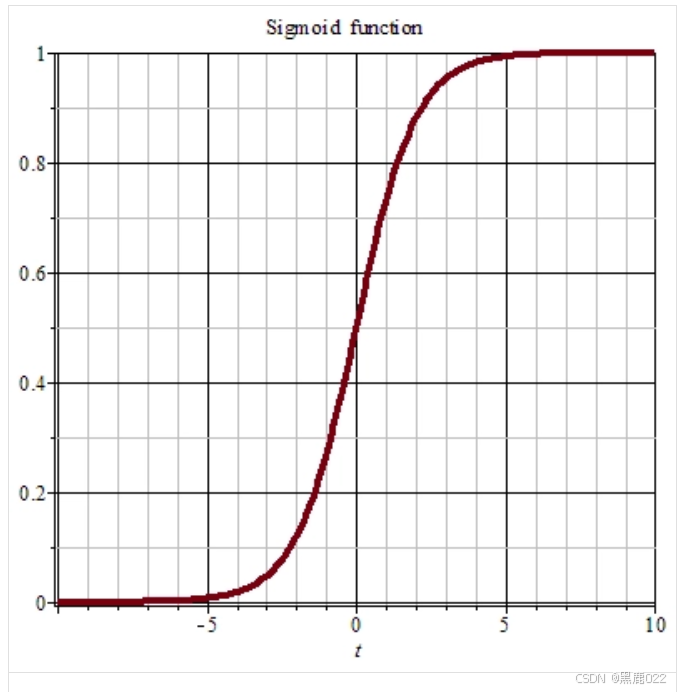 sigmoid 公式: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
sigmoid 公式: σ ( z ) = 1 1 + e − z \sigma(z)=\frac{1}{1+e^{-z}} σ(z)=1+e−z1
其中 z = ω T x + b z=\omega^Tx+b z=ωTx+b , ω \omega ω是权重向量(类似线性回归中的回归系数),x是特征向量,b是偏置。
逻辑回归的原理和底层优化手段
伯努利分布
伯努利分布也就是0,1分布:
P ( X = k ) = { p i f k = 1 1 − p i f k = 0 P(X=k)=\begin{cases} p & \quad if \; k=1 \\ 1-p & \quad if \; k=0 \end{cases} P(X=k)={p1−pifk=1ifk=0
或者简写为: P ( X = k ) = p k ( 1 − p ) 1 − k , k ∈ { 0 , 1 } P(X=k)=p^k(1-p)^{1-k},\qquad k\in \{0,1\} P(X=k)=pk(1−p)1−k,k∈{0,1}
逻辑回归的假设是:标签服从伯努利分布,因此我们可以套用伯努利分布的公式。
最大似然估计 Maximum Likelihood Estimation (MLE)
最大似然估计的核心思想是:“在已知观测数据的情况下,选择使得这些数据出现概率最大的参数值。” 我们可以通过最大化似然估计函数,来找到一个最优的参数。
伯努利分布的似然函数
由于样本标签是服从伯努利分布的,我们可以套用伯努利的最大似然函数公式:

交叉熵损失函数(Cross-Entropy Loss),也称为 对数损失(Log Loss)
直接最大化似然函数 L ( p ) L(p) L(p)在数学和计算上都不方便,所以我们对 L ( p ) L(p) L(p)取对数,将乘法变成加法,又因为优化算法(如梯度下降)通常被设计为最小化一个损失函数(成本函数),而不是最大化,因此,我们取对数似然函数 l o g ( L ( p ) ) log(L(p)) log(L(p)) 的负值,将其转化为一个最小化问题,这时的 − l o g ( L ( p ) ) -log(L(p)) −log(L(p))或者说 L o s s ( L ) Loss(L) Loss(L)就是二分类的交叉熵损失函数!

最后我们通过 L o s s ( L ) Loss(L) Loss(L)使用梯度下降方法求得最优的参数值。
实操代码
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import confusion_matrix, accuracy_score, precision_score, recall_score, f1_score, classification_report# 1. 加载并了解数据
data = pd.read_csv("癌症.csv")
print("数据头5行内容:")
print(data.head())
print("------------------------------------------"*3)
# 注意info()方法在内部就调用了print 不用手动print
print("数据详细描述信息:")
data.info()
print("------------------------------------------"*3)
print("数据列名称:")
print(data.columns)
print("------------------------------------------"*3)# 2. 处理数据
# 处理缺失值
data = data.replace('?', np.NaN)
data = data.dropna()
# 提取特征和标签
features = data.iloc[:, 1:-1]
label = data.iloc[:, -1]
# 划分训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(features, label, test_size=0.2, random_state=666)# 3. 特征工程
# 数据标准化
ss = StandardScaler()
x_train = ss.fit_transform(x_train)
x_test = ss.transform(x_test)# 使用逻辑回归模型
logit_model = LogisticRegression()
logit_model.fit(x_train, y_train)
y_predict = logit_model.predict(x_test)# 输出模型评估指标
print("模型混淆矩阵:\n", confusion_matrix(y_test, y_predict))
print("模型准确率:", accuracy_score(y_test, y_predict))
print("模型精准率(precision_score):", precision_score(y_test, y_predict, pos_label=2))
print("模型召回率(recall_score):", recall_score(y_test, y_predict, pos_label=2))
print("模型f1score:", f1_score(y_test, y_predict, pos_label=2))
print("模型分类报告:", classification_report(y_test, y_predict))"""
数据头5行内容:Sample code number Clump Thickness ... Mitoses Class
0 1000025 5 ... 1 2
1 1002945 5 ... 1 2
2 1015425 3 ... 1 2
3 1016277 6 ... 1 2
4 1017023 4 ... 1 2[5 rows x 11 columns]
------------------------------------------------------------------------------------------------------------------------------
数据详细描述信息:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 699 entries, 0 to 698
Data columns (total 11 columns):# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 Sample code number 699 non-null int64 1 Clump Thickness 699 non-null int64 2 Uniformity of Cell Size 699 non-null int64 3 Uniformity of Cell Shape 699 non-null int64 4 Marginal Adhesion 699 non-null int64 5 Single Epithelial Cell Size 699 non-null int64 6 Bare Nuclei 699 non-null object7 Bland Chromatin 699 non-null int64 8 Normal Nucleoli 699 non-null int64 9 Mitoses 699 non-null int64 10 Class 699 non-null int64
dtypes: int64(10), object(1)
memory usage: 60.2+ KB
------------------------------------------------------------------------------------------------------------------------------
数据列名称:
Index(['Sample code number', 'Clump Thickness', 'Uniformity of Cell Size','Uniformity of Cell Shape', 'Marginal Adhesion','Single Epithelial Cell Size', 'Bare Nuclei', 'Bland Chromatin','Normal Nucleoli', 'Mitoses', 'Class'],dtype='object')
------------------------------------------------------------------------------------------------------------------------------
模型混淆矩阵:[[83 1][ 1 52]]
模型准确率: 0.9854014598540146
模型精准率(precision_score): 0.9880952380952381
模型召回率(recall_score): 0.9880952380952381
模型f1score: 0.9880952380952381
模型分类报告: precision recall f1-score support2 0.99 0.99 0.99 844 0.98 0.98 0.98 53accuracy 0.99 137macro avg 0.98 0.98 0.98 137
weighted avg 0.99 0.99 0.99 137"""逻辑回归解决多分类问题
OVR
一对其余(One-vs-Rest) OVR
核心思想:
对于 K 个类别的问题,训练 K 个独立的二分类器
第 i 个分类器负责将第 i 个类别(作为“正类”)与所有其他 K-1 个类别(合并作为“负类”)区分开来。
在预测时,将新样本输入到这 K 个分类器中。
每个分类器 i 会输出一个分数(通常是属于其“正类”的概率 p_i)。
选择输出概率 p_i 最高的那个分类器所对应的类别 i 作为样本的最终预测类别。
优点
概念简单直观,易于理解和实现。
训练复杂度相对较低(只需要训练 K 个模型)。
是 scikit-learn 中 LogisticRegression 类默认的多分类处理策略(当 multi_class=‘ovr’ 时)。
缺点
类别不平衡: 对于每个分类器,负类样本的数量通常远大于正类样本(尤其是当 K 较大时)。虽然逻辑回归本身对类别不平衡有一定鲁棒性(通过概率输出),但这仍可能影响模型的训练效果和决策边界。通常需要仔细调整样本权重(class_weight)
决策模糊: 如果多个分类器都给出较高的概率,或者所有概率都很低(样本可能不属于任何已知类别),决策可能会变得模糊或不可靠。
不一致性: 每个分类器都是在“该类 vs 所有其他类”的定义下训练的,而“所有其他类”本身是一个异构的集合。这可能导致学习到的决策边界不够精确。
一对一(One-vs-One)OvO
核心思想
对于 K 个类别的问题,训练 C(K, 2) = K(K-1)/2 个独立的二分类器。
每个分类器只负责区分一对特定的类别 (i, j) (i < j)。
在预测时,将新样本输入到所有 K(K-1)/2 个分类器中。
每个分类器对样本属于其两个类别中的哪一个进行投票。
统计所有分类器的投票结果,获得票数最多的类别作为样本的最终预测类别。
优点
训练数据更均衡: 每个分类器只使用涉及的两个类别的样本进行训练,避免了 OvR 中严重的类别不平衡问题。对于大规模数据集,这尤其有利。
可能更准确: 每个分类器只需学习区分两个类别之间的边界,任务通常比 OvR 中区分一个类别和所有其他类别的边界更简单、更清晰。
缺点
训练复杂度高: 需要训练 O(K²) 个分类器。当类别数量 K 很大时(例如成百上千),训练所需的时间和存储空间会显著增加。
预测复杂度高: 预测时需要运行 O(K²) 个分类器并进行投票统计,预测速度比 OvR 慢。
需要更多存储: 需要保存所有 O(K²) 个模型。
投票平局: 可能出现多个类别得票相同的情况,需要额外的策略处理平局。
适用场景
类别数量 K 适中时(不能太大);当训练集非常大,且类别不平衡在 OvR 中成为主要问题时;对预测速度要求不是极其苛刻时。scikit-learn 的 LogisticRegression 可以通过 multi_class=‘multinomial’ 使用(内部优化实现),但传统的 OvO 策略也常用于 SVM 等算法。
相关文章:
机器学习基础(三) 逻辑回归
目录 逻辑回归的概念核心思想 Sigmoid 函数 逻辑回归的原理和底层优化手段伯努利分布最大似然估计 Maximum Likelihood Estimation (MLE)伯努利分布的似然函数交叉熵损失函数(Cross-Entropy Loss),也称为 对数损失&…...

系统调试——ADB 工具
ADB 工具 1.1 概述 ADB(Android Debug Bridge) 是 Android SDK 里的一个工具, 用这个工具可以操作管理Android 模拟器或真实的 Android 设备。 主要功能有: 运行设备的 shell(命令行)管理模拟器或设备的端…...
Qwen-3 微调实战:用 Python 和 Unsloth 打造专属 AI 模型
虽然大家都忙着在 DeepSeek 上构建应用,但那些聪明的开发者们却悄悄发现了 Qwen-3 的微调功能,这可是一个隐藏的宝藏,能把通用型 AI 变成你的专属数字专家。 通过这篇文章,你将学到如何针对特定用途微调最新的 Qwen-3 模型。无论…...
微软Build 2025:Copilot Studio升级,解锁多智能体协作未来
微软Build 2025大会圆满落幕,作为年度科技盛会,它一直是开发与AI技术突破性创新的重要展示平台。对于工程师、创作者和领域专家来说,这是了解微软生态未来动向的关键时刻。今年,Microsoft Copilot Studio推出了一系列新功能&#…...
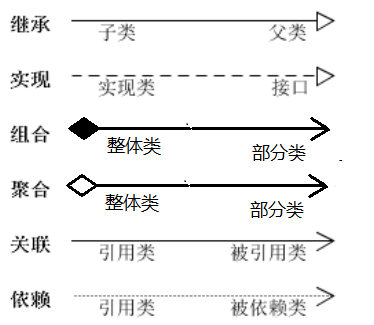
设计模式——系统数据建模设计
摘要 本文主要介绍了UML在软件系统分析和设计中的应用,详细阐述了六大类关系(泛化、实现、依赖、关联、聚合、组合)及其在UML类图中的表示方法,并通过具体例子说明了这些关系在实际编程中的应用。同时,文章还概述了UM…...
解决docker运行zentao 报错:ln: failed to create symbolic link ‘/opt/zbox/tmp/mysq
1 背景描述 禅道使用docker部署运行过一段,服务正常。 后因服务器断电重启,禅道服务也随docker一起启动,但是服务却无法访问。如下如: 2 查看日志,定位原因 查看禅道日志: # docker logs zentao容器di…...

Spring Boot MVC自动配置与Web应用开发详解
Spring Boot MVC自动配置机制 Spring Boot通过自动配置功能为MVC应用提供了开箱即用的默认配置,开发者无需手动配置即可获得完整的Web支持。以下是核心功能的实现原理: 静态资源支持 默认情况下,Spring Boot会自动从以下classpath目录提供…...
OA工程自动化办公系统 – 免费Java源码
概述 功能完备的OA工程自动化办公系统Java源码,采用主流技术栈开发,无论是学习SpringBoot框架还是开发企业级应用,都是不可多得的优质资源。 主要内容 技术架构 后端技术栈: 核心框架:SpringBoot 2.xORM框…...

Apache IoTDB V2.0.3 发布|新增元数据导入导出脚本适配表模型功能
Release Announcement Version 2.0.3 Apache IoTDB V2.0.3 已经发布! V2.0.3 作为树表双模型正式版本,主要新增元数据导入导出脚本适配表模型、Spark 生态集成(表模型)、AINode 返回结果新增时间戳,表模型新增部分聚…...
某校体育场馆结构自动化监测
1. 项目简介 某小学学校成立于2020年,是一所公办小学,以高起点定位为该区优质教育新增长极,依托当地学院及教师进修学院附属小学资源,注重学生综合素质培养,近年来,该小学聚焦“五育” 领域,不…...

MySQL 9.0 相较于 MySQL 8.0 引入了多项重要改进和新特性
MySQL 9.0 相较于 MySQL 8.0 引入了多项重要改进和新特性,以下是两者的主要区别及其详细说明: 1. 认证机制 MySQL 8.0 支持 mysql_native_password 和 caching_sha2_password 认证插件。默认使用 caching_sha2_password,但未完全移除 mysql_native_password。MySQL 9.0 完全…...

Android 3D球形水平圆形旋转,旋转动态更换图片
看效果图 1、事件监听类 OnItemClickListener:3D旋转视图项点击监听器接口 public interface OnItemClickListener {/*** 当旋转视图中的项被点击时调用** param view 被点击的视图对象* param position 被点击项在旋转视图中的位置索引(从0开始&a…...

数据结构与算法学习笔记(Acwing 提高课)----动态规划·树形DP
数据结构与算法学习笔记----动态规划树形DP author: 明月清了个风 first publish time: 2025.6.4 ps⭐️树形动态规划(树形DP)是处理树结构问题的一种动态规划方法,特征也很明显,会有一个树形结构,其实是DFS的优化。…...

FTP 和 SFTP 介绍及 C/C++ 实现分析
1. FTP 协议概述 FTP(File Transfer Protocol)是一种用于在网络上进行文件传输的标准协议,诞生于 1971 年,是互联网上最早的应用层协议之一。它基于客户端 - 服务器模型,使用 TCP 作为传输层协议,默认通过 …...

leetcode hot100刷题日记——36.最长连续序列
解答: 实际上在哈希表中存储不重复的数字。 然后遍历哈希表,找间隔,更新最大间隔。 class Solution { public:int longestConsecutive(vector<int>& nums) {unordered_set<int>hash;for(int num:nums){hash.insert(num);}in…...
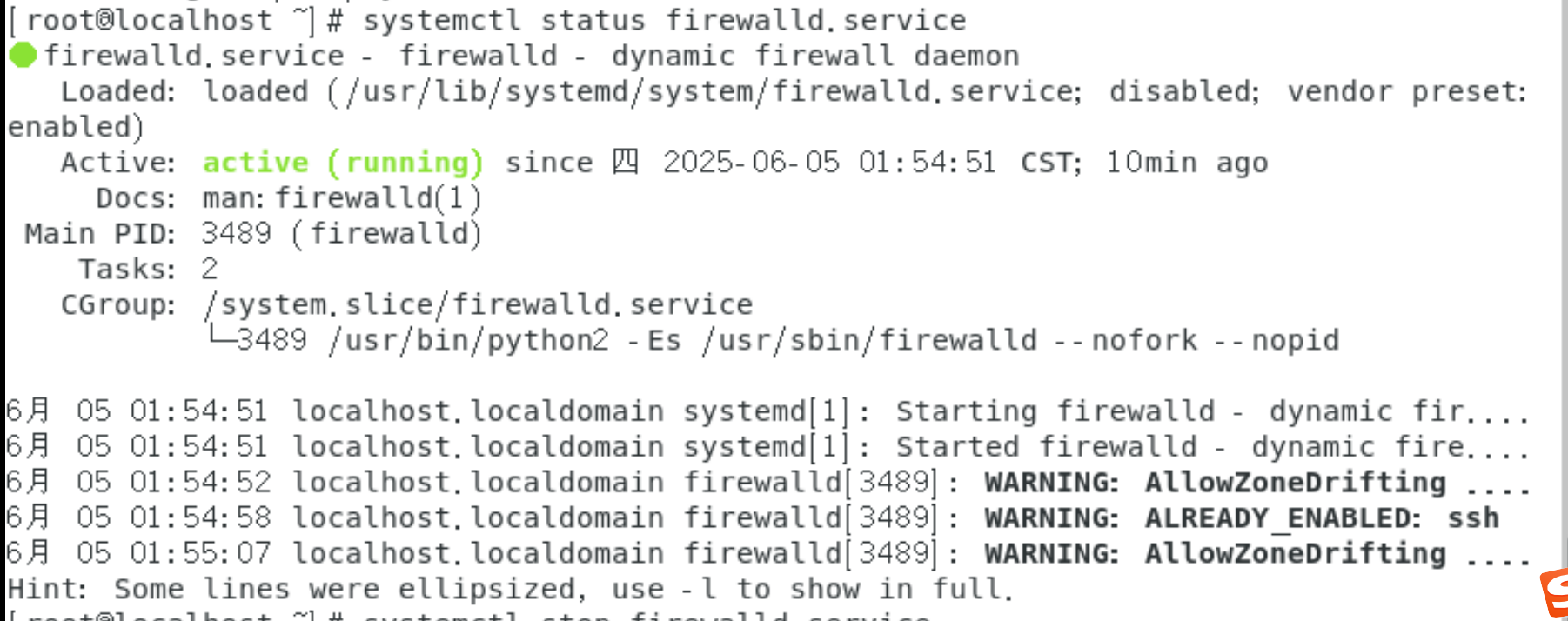
CentOS7关闭防火墙、Linux开启关闭防火墙
文章目录 一、firewalld开启、关闭防火墙1、查看防火墙状态 一、firewalld开启、关闭防火墙 以下命令在linux系统CentOS7中操作开启关闭防火墙 # 查询防火墙状态 systemctl status firewalld.service # 开启防火墙 systemctl start firewalld.service # 开机自启动防火墙 syste…...

PyTorch——搭建小实战和Sequential的使用(7)
import torch from torch import nn from torch.nn import Conv2d, MaxPool2d, Flatten, Linearclass TY(nn.Module):def __init__(self):"""初始化TY卷积神经网络模型模型结构:3层卷积池化,2层全连接设计目标:处理32x32像素的…...

基于大模型的腔隙性脑梗塞风险预测及治疗方案研究
目录 一、引言 1.1 研究背景与意义 1.2 研究目的与方法 1.3 国内外研究现状 二、腔隙性脑梗塞概述 2.1 定义与分类 2.2 发病机制与病理生理过程 2.3 临床表现与诊断方法 三、大模型技术原理与应用现状 3.1 基本概念与技术架构 3.2 在医疗领域的应用案例与优势 3.3 …...
Python 开发效率秘籍:PyCharm、VS Code 与 Anaconda 配置与实战全解
目录 一、IDE(集成开发环境)是什么?二、Python IDE有哪些,哪款适合初学者?三、Visual Studio Code下载和安装教程3.1 VS Code下载和安装3.2 VS Code运行Python程序 四、PyCharm下载和安装教程4.1 PyCharm下载4.2 PyCharm安装4.3 运行PyCharm4.4 创建工程…...

[C]C语言日志系统宏技巧解析
代码解释:日志标签字符串化宏 这段代码定义了一个名为 _LOG_TAG 的宏,用于将 LOG_TAG_CONST 转换为字符串形式。这在日志系统中很常见,用于为不同模块添加标识前缀。 宏结构分析 #define _LOG_TAG STR(LOG_TAG_CON…...

自动驾驶系统研发系列—激光雷达感知延迟:自动驾驶安全的隐形隐患?
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。 🚀 探索专栏:学…...

内网应用如何实现外网访问?无公网IP本地端口网址服务提供互联网连接
一、应用程序外网访问遇到的问题 在现实的工作场景中,在公司内网的服务器上有很多的应用系统,这些系统只能局限于在公司内部使用,而在外网却无法使用。 二、外网访问内网应用常见的解决方案 如何在外网使用这些系统呢?下面简单…...
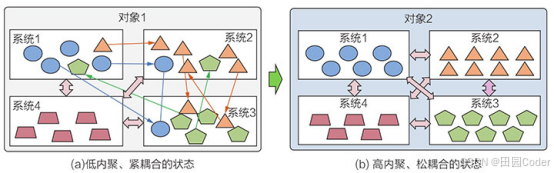
大话软工笔记—组合要素1之要素
1. 要素来源 对象是要素的来源,要素是从对象分解而来的。可将对象分为优化类和非优化类,如下图所示。 对象分类图 2. 要素的概念 2.1 要素的定义 要素,是构成事物必不可少的因素,要素的集合体构成了对象。 2.2 要素的内容 要…...

oracle从表B更新拼接字段到表A
oracle中表A怎么从表B中追加相对应的编码到表A字段里, 在Oracle数据库中,如果你想从表B中获取数据并更新到表A的某个字段里,可以使用UPDATE语句结合子查询来实现。假设表A有一个字段叫做code,你希望根据某个键(比如id&…...

平台化 LIMS 系统架构 跨行业协同与资源共享的实现路径
在科技快速发展的今天,质检行业正面临着效率、合规和数据安全的多重挑战。新一代质检 LIMS 系统以智能化与平台化为核心,为实验室管理提供了全新的解决方案。 一、智能化:从数据采集到分析的全流程升级 传统质检流程中,人工数据录…...

RedisTemplate查询不到redis中的数据问题(序列化)
RedisTemplate查询不到redis中的数据问题(序列化) 一.问题描述 存入Redis中的值取出来却为null,问题根本原因就是RedisTemplate和StringRedisTemplate的序列化问题、代码示例: SpringBootTest class Redis02SpringbootApplicationTests {Autowiredprivate RedisTe…...

如何利用乐维网管进行IP管理
IP管理是网络管理中的关键环节,对于保障网络的正常运行、提升资源利用效率以及保障网络安全等方面都具有不可忽视的重要性。乐维网管在IP管理方面具有多种实用功能,以下从IP规划与分配、IP状态监测、IP冲突处理、IP审计与报表生成四个方面,介…...

unix/linux,sudo,其历史争议、兼容性、生态、未来展望
sudo作为一个广泛应用的系统工具,在其发展历程中,自然也伴随着一些讨论、挑战和对未来的展望。 一、 历史争议与讨论 (Historical Controversies and Discussions) 虽然sudo被广泛认为是成功的,但也存在一些历史上的讨论点或潜在的争议: 复杂性 vs. 简洁性 (sudoers语法)…...

git stash命令用法
git stash 是 Git 中一个非常有用的命令,它可以临时保存当前工作区的修改,让你可以切换到其他分支或者处理其他任务,而不需要提交这些还未完成的修改。 一、基本用法 1. 保存当前修改(包括暂存区和工作区的内容) git…...
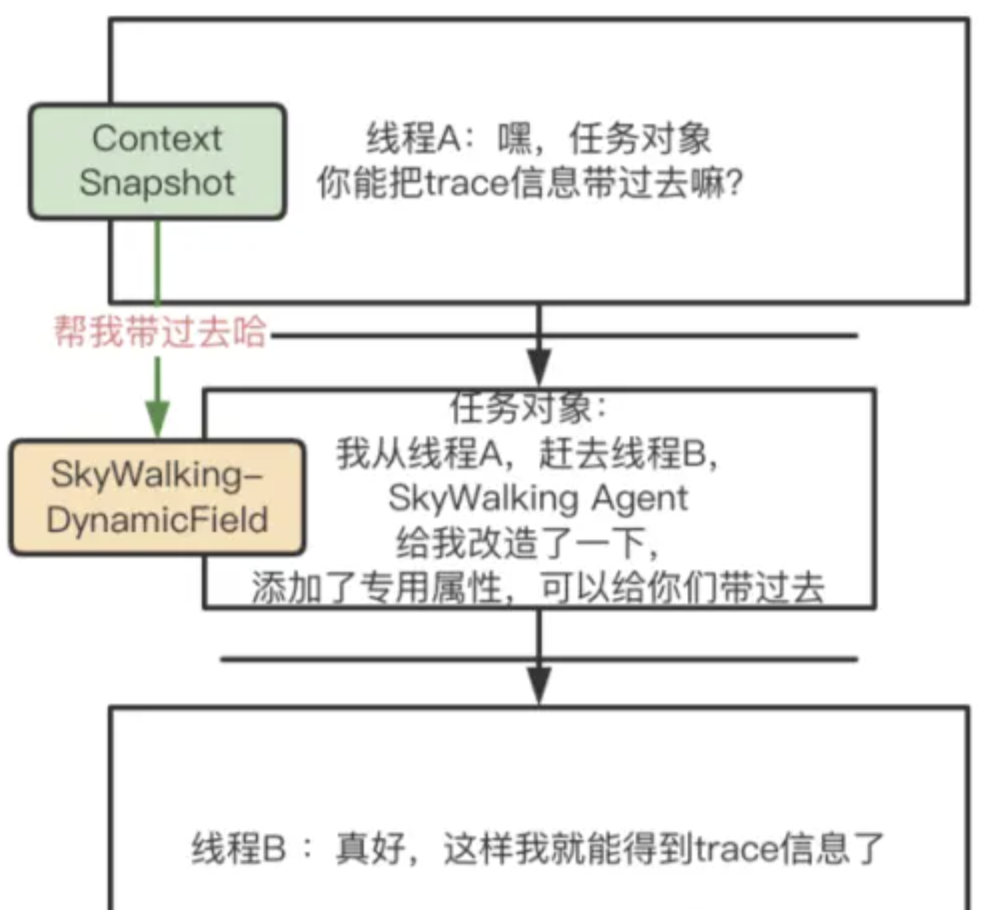
SkyWalking如何实现跨线程Trace传递
一、概述 SkyWalking 的中构建 Trace 信息时会借助 ThreadLocal来存储一些上下文信息,当遇到跨线程的时候,如果 Trace 的上下文信息没有传递到新线程的ThreadLocal 中,那么链路就断开了。那么SkyWalking是如何解决这个问题的呢? …...