Python-正则表达式(re 模块)
目录
- 一、re 模块的使用过程
- 二、正则表达式的字符匹配
- 1. 匹配开头结尾
- 2. 匹配单个字符
- 3. 匹配多个字符
- 4. 匹配分组
- 5. Python 代码示例
- 三、re 模块的函数
- 1. 函数一览表
- 2. Python 代码示例
- 1)search 与 finditer
- 2)findall
- 3)sub
- 4)split
- 四、贪婪与非贪婪
- 五、re 模块的可选标志
参考文章:
【re — 正则表达式操作】
【正则表达式指南】
【Python 正则表达式 | 菜鸟教程】
【Python 正则表达式 | 极客教程】
【Python正则表达式详解 (超详细,看完必会!)】
一、re 模块的使用过程
# 导入 re 模块
import re# 使用 match 方法进行匹配操作
# re.match() 能够匹配出以 xxx 开头的字符串
result = re.match(r'正则表达式', '被匹配的字符串')if result:# 如果上一步匹配到数据的话,可以使用 group 方法来提取数据print(result.group())
else:print('匹配失败')
需要注意的是:
Python 中字符串前面加上 r 表示原生字符串。与大多数编程语言相同,正则表达式里使用 “\” 作为转义字符,这就可能造成反斜杠困扰。Python 里的原生字符串很好地解决了这个问题,同时写出来的表达式也更直观。注意 r 只服务于 “\” ,不对其他进行转义。
二、正则表达式的字符匹配
1. 匹配开头结尾
| 字符 | 介绍 |
|---|---|
^ | 匹配字符串的开头 |
$ | 匹配字符串的末尾 |
2. 匹配单个字符
| 字符 | 介绍 |
|---|---|
. | 匹配任意一个字符,除了换行符 \n |
[] | 匹配一个 [ ] 中列举的字符 |
[^] | 匹配除 [ ] 中列举的字符外的字符 |
\d | 匹配任何一个十进制数字,等价于字符类 [0-9] |
\D | 匹配任何一个非数字字符,等价于字符类 [^0-9] |
\s | 匹配任何一个空白字符,等价于字符类 [\t\n\r\f\v] |
\S | 匹配任何一个非空白字符,等价于字符类 [^\t\n\r\f\v] |
\w | 匹配任何一个字母与数字字符,以及下划线,等价于字符类 [a-zA-Z0-9_] |
\W | 匹配任何一个非字母与数字字符,以及非下划线,等价于字符类 [^a-zA-Z0-9_] |
\b | 匹配空字符串,但只在单词开始或结尾的位置 |
\B | 匹配空字符串,但仅限于它不在单词的开头或结尾的情况 |
\A | 匹配字符串开始 |
\Z | 匹配字符串结尾 |
-
\ 是转义特殊字符,\n 代表换行、\r 代表回车、\f 代表换页、\t 代表 Tab 键
-
通过用 ‘-’ 将两个字符连起来可以表示字符范围,比如:
- [a-z] 将匹配任何小写 ASCII 字符, [0-5][0-9] 将匹配从 00 到 59 的两位数字,[0-9A-Fa-f] 将匹配任何十六进制数位。
- 如果 - 进行了转义 (比如 [a\-z])或者它的位置在首位或末尾(如 [-a] 或 [a-]),那么它就只表示普通字符 ‘-’
-
除反斜杠外的特殊字符在 [ ] 中会失去其特殊含义,例如:[(+*)] 将匹配字符为 ( + * 或 ) 中的任何一个
3. 匹配多个字符
| 字符 | 介绍 |
|---|---|
* | 匹配前一个字符出现 0 次或者无限次 |
+ | 匹配前一个字符出现 1 次或者无限次 |
? | 匹配前一个字符出现 1 次或者 0 次 |
{m} | 匹配前一个字符出现 m 次 |
{m,n} | 匹配前一个字符出现从 m 至 n 次 |
{m,} | 匹配前一个字符出现至少 m 次 |
-
ab* 会匹配 ‘a’,‘ab’,或者 ‘a’ 后面跟随任意个 ‘b’
-
ab+ 会匹配 ‘a’ 后面跟随 1 个以上到任意个 ‘b’,它不会匹配 ‘a’
-
ab? 会匹配 ‘a’ 或者 ‘ab’
-
a{6} 将匹配 6 个 ‘a’ , 少于 6 个的话就会导致匹配失败
-
a{3,5} 将匹配 3 到 5 个 ‘a’
4. 匹配分组
| 字符 | 介绍 |
|---|---|
| | | 如果 A 和 B 是正则表达式,A|B 将匹配任何与 A 或 B 匹配的字符串 |
() | 将括号中的字符作为一个分组 |
\num | 引用分组 num 匹配到的字符串 |
(?P<name>) | 分组所匹配到了的字符串可通过符号分组名称 name 来访问 |
(?P=name) | 匹配前面叫 name 的命名组中所匹配到的串 |
5. Python 代码示例
- 匹配出 126、163、qq 的邮箱地址,且 @ 符号之前有 4 到 20 位数字、大写或小写字母和下划线的组合。
import reemail_list = ["Alice27@163.com", "Sam_1122@gmail.com", ".Tom_12@qq.com", "Bob_1988@qq.com.com", "Elowen@126.com", "Ice@qq.com", "nicetomeetyou@qq.com"]for email in email_list:ret = re.match(r"\w{4,20}@(163|126|qq)\.com$", email)if ret:print("%s 是符合规定的邮件地址 , 匹配后的结果是 : %s" % (email, ret.group()))else:print("%s 不符合要求" % email)
结果展示:
Alice27@163.com 是符合规定的邮件地址 , 匹配后的结果是 : Alice27@163.com
Sam_1122@gmail.com 不符合要求
.Tom_12@qq.com 不符合要求
Bob_1988@qq.com.com 不符合要求
Elowen@126.com 是符合规定的邮件地址 , 匹配后的结果是 : Elowen@126.com
Ice@qq.com 不符合要求
nicetomeetyou@qq.com 是符合规定的邮件地址 , 匹配后的结果是 : nicetomeetyou@qq.com
-
匹配 11 位不是以 4、7 结尾的手机号码:
re.match(r"1\d{9}[0-35-68-9]$", tel) -
提取区号和电话号码:
ret = re.match(r"([^-]+)-(\d+)","010-12345678"),此时 ret.group(1) = ‘010’ ,ret.group(2) = ‘12345678’ ,ret.group(0) 等价于 ret.group() 等于 ‘010-12345678’ -
匹配标签,例如:匹配 <html><h1>hello</h1></html> 并提取出 hello
import retexts = ['<html><h1>hello</h1></html>', '<html><h1>world</h1></html1html>','<html><h1>hello</h2></html>']def match():for text in texts:ret = re.match(r'<([a-zA-Z]*)><([a-zA-Z0-9]*)>(\w*)</\2></\1>', text)if ret:print(f'匹配成功,标签为 {ret.group()},信息为 {ret.group(3)}')else:print(f'{text} 标签匹配失败')if __name__ == '__main__':match()
结果展示:
匹配成功,标签为 <html><h1>hello</h1></html>,信息为 hello
<html><h1>world</h1></html1html> 标签匹配失败
<html><h1>hello</h2></html> 标签匹配失败
- 用 (?P<name>) 和 (?P=name) 改进上述示例:
re.match(r'<(?P<name1>[a-zA-Z]*)><(?P<name2>[a-zA-Z0-9]*)>(\w*)</(?P=name2)></(?P=name1)>', text)
注意:字母 P 要大写
三、re 模块的函数
1. 函数一览表
| 函数 | 含义 |
|---|---|
re.compile(pattern, flags=0) | 将正则表达式的样式编译为一个正则表达式对象(正则对象),可以用于匹配 |
re.search(pattern, string, flags=0) | 扫描整个字符串,返回第一个匹配项 |
re.match(pattern, string, flags=0) | 从字符串开始位置匹配正则表达式 |
re.fullmatch(pattern, string, flags=0) | 如果整个 string 与正则表达式 pattern 匹配,则返回相应的 Match |
re.split(pattern, string, maxsplit=0, flags=0) | 按匹配项分割字符串 |
re.findall(pattern, string, flags=0) | 返回字符串中所有匹配的子串 |
re.finditer(pattern, string, flags=0) | 针对正则表达式 pattern 在 string 里的所有非重叠匹配返回一个产生 Match 对象的迭代器 |
re.sub(pattern, repl, string, count=0, flags=0) | 替换字符串中所有匹配正则表达式的部分 |
re.subn(pattern, repl, string, count=0, flags=0) | 行为与 sub() 相同,但是返回一个元组,包含 (替换后的字符串, 替换次数) |
re.escape(pattern) | 转义 pattern 中的特殊字符,结果可直接用作匹配字符串 |
re.purge() | 清除正则表达式的缓存 |
-
result = re.match(pattern, string)等价于prog = re.compile(pattern)和result = prog.match(string)。 -
re.split函数中如果 maxsplit 非零,则最多进行 maxsplit 次分隔,剩下的字符全部返回到列表的最后一个元素。
2. Python 代码示例
1)search 与 finditer
需求:匹配出文章阅读的次数和点赞的次数。
import redef find_second_match(pattern, text):matches = re.finditer(pattern, text)try:next(matches) # 跳过第一个匹配项second_match = next(matches) # 获取第二个匹配项return second_match.group()except StopIteration:return Noneif __name__ == '__main__':p = r"\d+"t = "阅读次数为 9999 , 点赞次数为 19999"ret = re.search(p, t)print(f'阅读次数为 {ret.group()} , 点赞次数为 {find_second_match(p, t)}')
结果展示:
阅读次数为 9999 , 点赞次数为 19999
2)findall
- 需求:统计出相应文章阅读、点赞和收藏的次数。
import reret = re.findall(r"\d+", "read = 9999, thumbs up = 7890, collection = 12345")
print(f'阅读次数 {ret[0]} ,点赞次数 {ret[1]} ,收藏次数 {ret[2]}')
结果展示:
阅读次数 9999 ,点赞次数 7890 ,收藏次数 12345
【拓展】:分组() 内加入 ?: 可以避免只返回分组内的内容。
- 需求:提取出字符串里的日期和时间 。
import reif __name__ == '__main__':s = 'hello world, now is 2020/7/20 18:48, 现在是 2020年7月20日18时48分。'ret_s = re.sub(r'年|月', r'/', s)ret_s = re.sub(r'日|分', r' ', ret_s)ret_s = re.sub(r'时', r':', ret_s)# hello world, now is 2020/7/20 18:48, 现在是 2020/7/20 18:48 。print(ret_s)# findallcom1 = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]')ret1 = com1.findall(ret_s)print(ret1[0]) # 18# 加 ?:com2 = re.compile(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(?:0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]')ret2 = com2.findall(ret_s)print(ret2[0]) # 2020/7/20 18:48# searchret3 = re.search(r'\d{4}/[01]?[0-9]/[1-3]?[0-9]\s(0[0-9]|1[0-9]|2[0-4])\:[0-5][0-9]', ret_s)print(ret3.group()) # 2020/7/20 18:48
3)sub
将匹配到的数据进行替换。
- 需求:将匹配到的阅读次数加 1 。
import redef add(temp):str_num = temp.group()num = int(str_num) + 1return str(num)if __name__ == '__main__':ret = re.sub(r"\d+", '998', "thumbs up = 997")print(ret)ret = re.sub(r"\d+", add, "thumbs up = 997")print(ret)ret = re.sub(r"\d+", lambda x: str(int(x.group()) + 1), "thumbs up = 997")print(ret)print('-' * 30)# count 替换次数text = "apple apple apple apple"pattern = r"apple"replacement = "orange"new_text = re.sub(pattern, replacement, text, count=2)print(new_text)
结果展示:
thumbs up = 998
thumbs up = 998
thumbs up = 998
------------------------------
orange orange apple apple
- 需求:删除字符串中所有的 HTML 标签和
实体,只留下纯文本内容。
import reif __name__ == '__main__':text = ('<div>' + '\n' +'<p>岗位职责:</p>' + '\n' +'<p>完成推荐算法、数据统计、接口、后台等服务器端相关工作</p>' + '\n' +'<p><br></p>' + '\n' +'<p>必备要求:</p>' + '\n' +'<p>良好的自我驱动力和职业素养,工作积极主动、结果导向</p>' + '\n' +'<p> <br></p>' + '\n' +'<p>技术要求:</p>' + '\n' +'<p>1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式</p>' + '\n' +'<p>2、掌握 HTTP 协议,熟悉 MVC、MVVM 等概念以及相关 WEB 开发框架</p>' + '\n' +'<p>3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种<br></p>' + '\n' +'<p>4、掌握 NoSQL、MQ,熟练使用对应技术解决方案</p>' + '\n' +'<p>5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js</p>' + '\n' +'<p> <br></p>' + '\n' +'<p>加分项:</p>' + '\n' +'<p>大数据,数理统计,机器学习,sklearn,高性能,大并发。</p>' + '\n' +'</div>')# print(text)sub_result = re.sub(r"<[^>]*>| ", "", text)print(sub_result)
结果展示:
岗位职责:
完成推荐算法、数据统计、接口、后台等服务器端相关工作必备要求:
良好的自我驱动力和职业素养,工作积极主动、结果导向技术要求:
1、一年以上 Python 开发经验,掌握面向对象分析和设计,了解设计模式
2、掌握 HTTP 协议,熟悉 MVC、MVVM 等概念以及相关 WEB 开发框架
3、掌握关系数据库开发设计,掌握 SQL,熟练使用 MySQL/PostgreSQL 中的一种
4、掌握 NoSQL、MQ,熟练使用对应技术解决方案
5、熟悉 Javascript/CSS/HTML5,JQuery、React、Vue.js加分项:
大数据,数理统计,机器学习,sklearn,高性能,大并发。
解析正则表达式:r"<[^>]*>| "
-
<[^>]*>:匹配一对尖括号 < > 及其内部内容,且内容不包含 > 符号,表示匹配 HTML 标签,比如 <div>, <a href=“…”> 等。 -
|:表示 “或” 操作符。 -
:匹配 HTML 的不间断空格实体 。 -
替换字符串是 “” ,即将匹配的内容替换为空字符串(删除)。
4)split
根据匹配进行切割字符串,并返回一个列表。需求:切割字符串 “info:xiaoZhang 33 shandong” 。
import reret = re.split(r":| ","info:xiaoZhang 33 shandong")
print(ret)
结果展示:
['info', 'xiaoZhang', '33', 'shandong']
四、贪婪与非贪婪
Python 里数量词默认是贪婪的,即总是尝试匹配尽可能多的字符,而非贪婪则相反,总是尝试匹配尽可能少的字符。
可以在 * , ? , + , {m,n} 后面加上非贪婪操作符 ? ,该操作符要求正则匹配的字符越少越好,因而可以将贪婪转变为非贪婪。
Python 代码示例:
import reif __name__ == '__main__':s = "This is a number 234-235-22-423"# 贪婪print(re.match(r".+(\d+-\d+-\d+-\d+)", s).group(1))print(re.match(r"aa(\d+)", "aa2343ddd").group(1))print(re.match(r"aa(\d+)ddd", "aa2343ddd").group(1))print('-' * 30)# 非贪婪print(re.match(r".+?(\d+-\d+-\d+-\d+)", s).group(1))print(re.match(r"aa(\d+?)", "aa2343ddd").group(1))print(re.match(r"aa(\d+?)ddd", "aa2343ddd").group(1))
结果展示:
4-235-22-423
2343
2343
------------------------------
234-235-22-423
2
2343
五、re 模块的可选标志
| 标志 | 介绍 |
|---|---|
re.I | 使匹配对大小写不敏感 |
re.A | 不让 \w 匹配汉字 |
re.L | 做本地化识别(locale-aware)匹配 |
re.M | 多行匹配,影响 ^ 和 $ |
re.S | 使 . 匹配包括换行符 \n 在内的所有字符 |
re.U | 根据 Unicode 字符集解析字符,这个标志影响 \w \W \b \B |
re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解 |
Python 代码示例:
import reif __name__ == '__main__':s1 = 'hello\nworld'ret1 = re.match(r'hello.W', s1, re.S | re.I)if ret1:print(ret1.group()) # hello welse:print('no match')print('-' * 15)s2 = 'hello你好world'ret2 = re.match(r'hello\w*', s2, re.A)if ret2:print(ret2.group()) # helloelse:print('no match')
相关文章:
)
Python-正则表达式(re 模块)
目录 一、re 模块的使用过程二、正则表达式的字符匹配1. 匹配开头结尾2. 匹配单个字符3. 匹配多个字符4. 匹配分组5. Python 代码示例 三、re 模块的函数1. 函数一览表2. Python 代码示例1)search 与 finditer2)findall3)sub4)spl…...
AgenticSeek 本地部署教程(Windows 系统)
#工作记录 Fosowl/agenticSeek:完全本地的 Manus AI。 部署排错参考资料在文末 或查找往期笔记。 AgenticSeek 本地部署教程(Windows 系统) 一、环境准备 1. 安装必备工具 Docker Desktop 下载地址:Docker Desktop 官网 安装后启…...
基于 qiankun + vite + vue3 构建微前端应用实践
核心内容摘要 技术栈组合 采用 Vite Vue3 Qiankun 构建微前端架构主应用和子应用独立开发部署,通过 Qiankun 集成 2. 主应用关键配置通过 registerMicroApps 注册子应用,配置路由匹配规则(activeRule)使用…...

VR教育:开启教育新时代的钥匙
VR 教育,即虚拟现实教育,是将虚拟现实技术(Virtual Reality,简称 VR)应用于教育领域的一种创新教育模式。它借助计算机技术、图形图像技术、传感器技术等,创建出高度逼真的虚拟学习环境,让学生通过头戴式显示设备、手柄…...
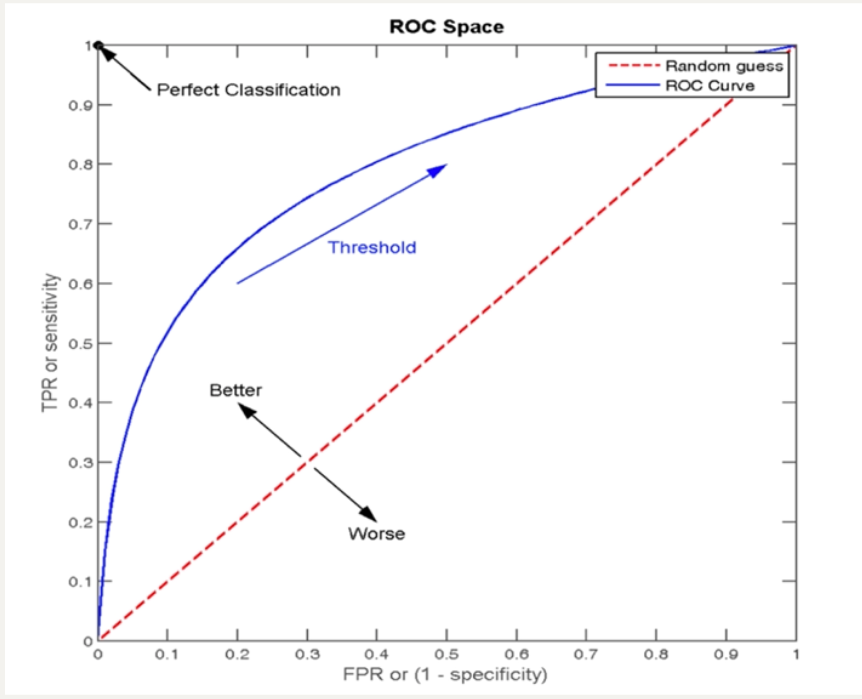
机器学习:逻辑回归与混淆矩阵
本文目录: 一、逻辑回归Logistic Regression二、混淆矩阵(一)精确率precision(二)召回率recall(三)F1-score:了解评估方向的综合预测能力(四)Roc曲线…...

20250602在荣品的PRO-RK3566开发板的Android13下打开HDMI显示
20250602在荣品的PRO-RK3566开发板的Android13下打开HDMI显示 2025/6/2 16:20 缘起:貌似荣品的PRO-RK3566开发板的Android13默认关闭了HDMI显示。 据说:荣品确认RK3566的GPU比较弱,同时开【MIPI接口的】LCD屏显示和HDMI显示容易出现异常。 更…...

【学习记录】快速上手 PyQt6:设置 Qt Designer、PyUIC 和 PyRCC 在 PyCharm中的应用
文章目录 📌 前言✅ 第一步:安装 PyQt6 及其工具包🔧 第二步:找到相关工具路径🧰 第三步:在 PyCharm 中配置外部工具打开设置🛠️ 配置 Qt Designer🛠️ 配置 PyUIC6(UI转…...
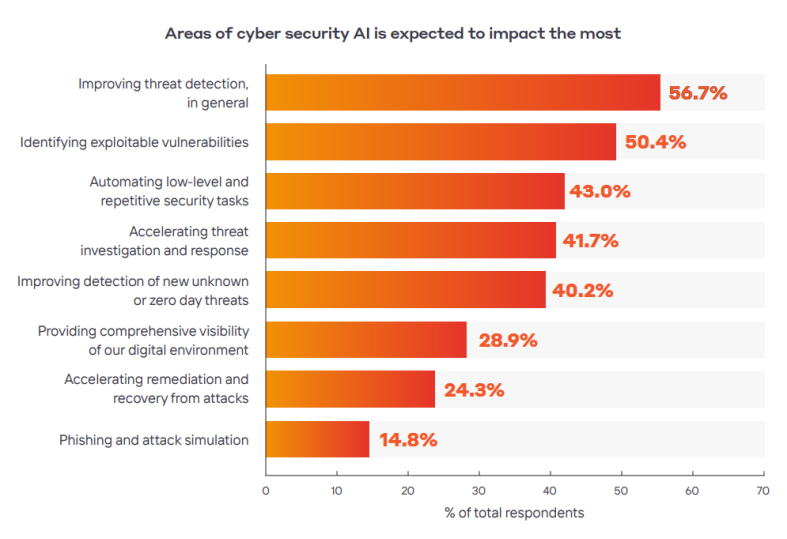
AI在网络安全领域的应用现状和实践
当前,人工智能技术已深度融入网络安全产品,推动传统防御模式向智能化、自适应方向加速演进。各安全厂商通过机器学习、深度学习与知识图谱等技术的融合应用,提高安全产品在威胁检测、攻击溯源、风险评估等场景的能力跃迁,突破传统…...

DrissionPage 异常处理实战指南:构建稳健的网页自动化防线
在网页自动化领域,异常处理能力直接决定了系统的健壮性。作为融合Selenium与Requests特性的创新工具,DrissionPage提供了多层次的异常处理机制。本文将深入剖析其异常体系,结合真实场景案例,为您构建一套完善的自动化容错方案。 …...

鸿蒙任务项设置案例实战
目录 案例效果 资源文件与初始化 string.json color.json CommonConstant 添加任务 首页组件 任务列表初始化 任务列表视图 任务编辑页 添加跳转 任务目标设置模型(formatParams) 编辑页面 详情页 任务编辑列表项 目标设置展示 引入目标…...

TDengine 的 AI 应用实战——运维异常检测
作者: derekchen Demo数据集准备 我们使用公开的 NAB数据集 里亚马逊 AWS 东海岸数据中心一次 API 网关故障中,某个服务器上的 CPU 使用率数据。数据的频率为 5min,单位为占用率。由于 API 网关的故障,会导致服务器上的相关应用…...

DHCP与DNS的配置
在网络管理中,DHCP(动态主机配置协议)和DNS(域名系统)是两个关键组件。DHCP用于自动分配IP地址,而DNS用于将域名解析为IP地址。本文将详细介绍如何在Linux环境下配置DHCP和DNS服务。 一、DHCP配置 1. 安装…...
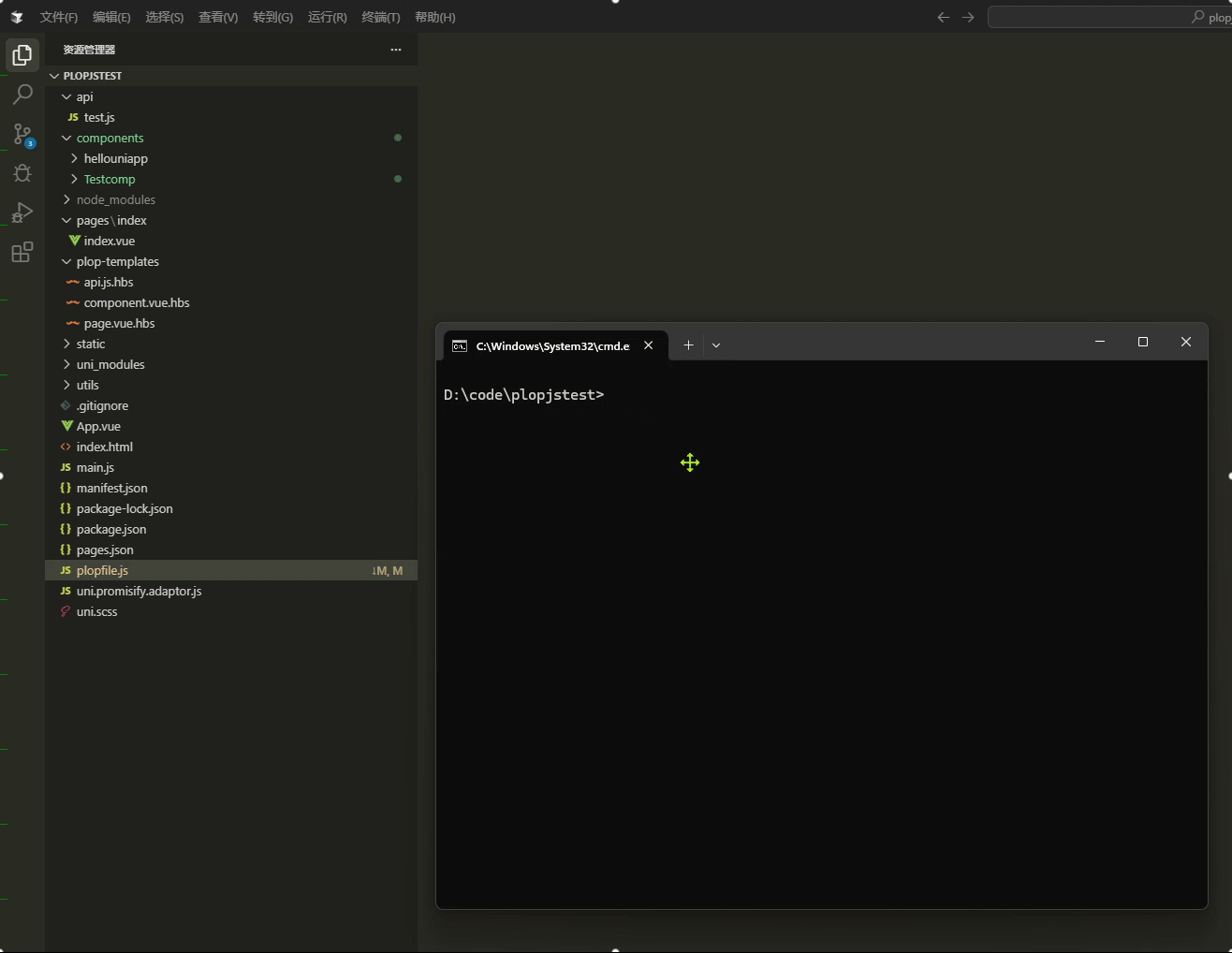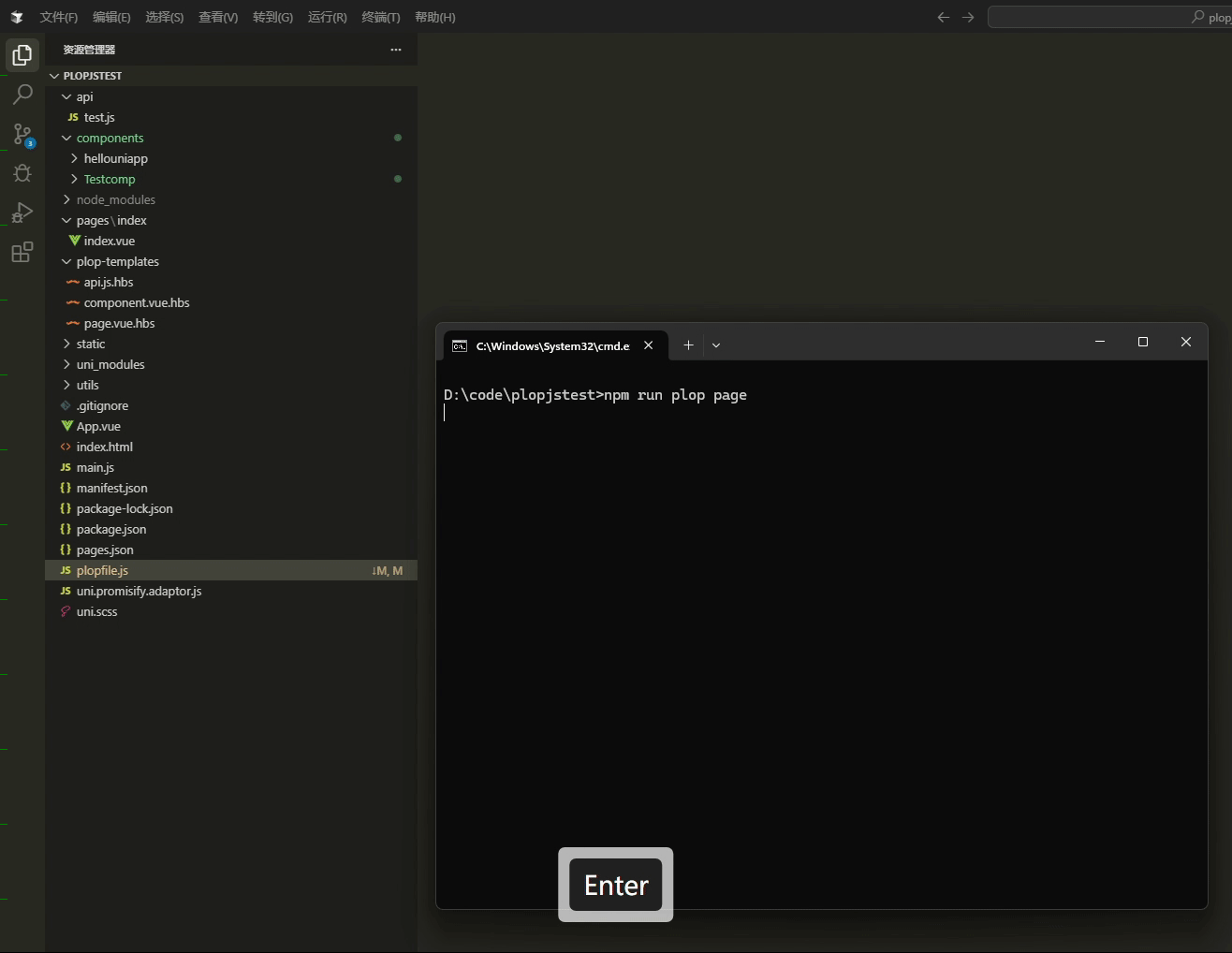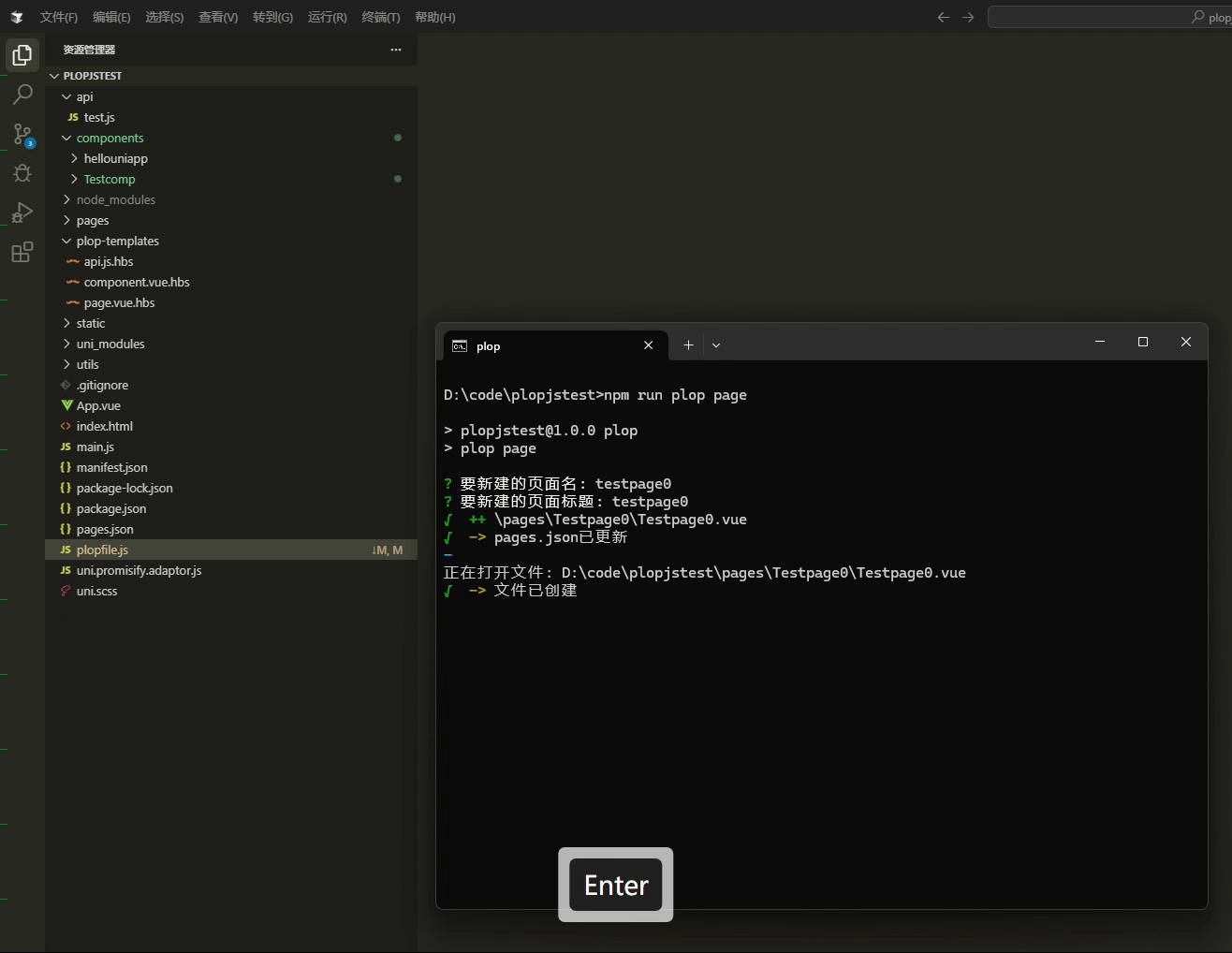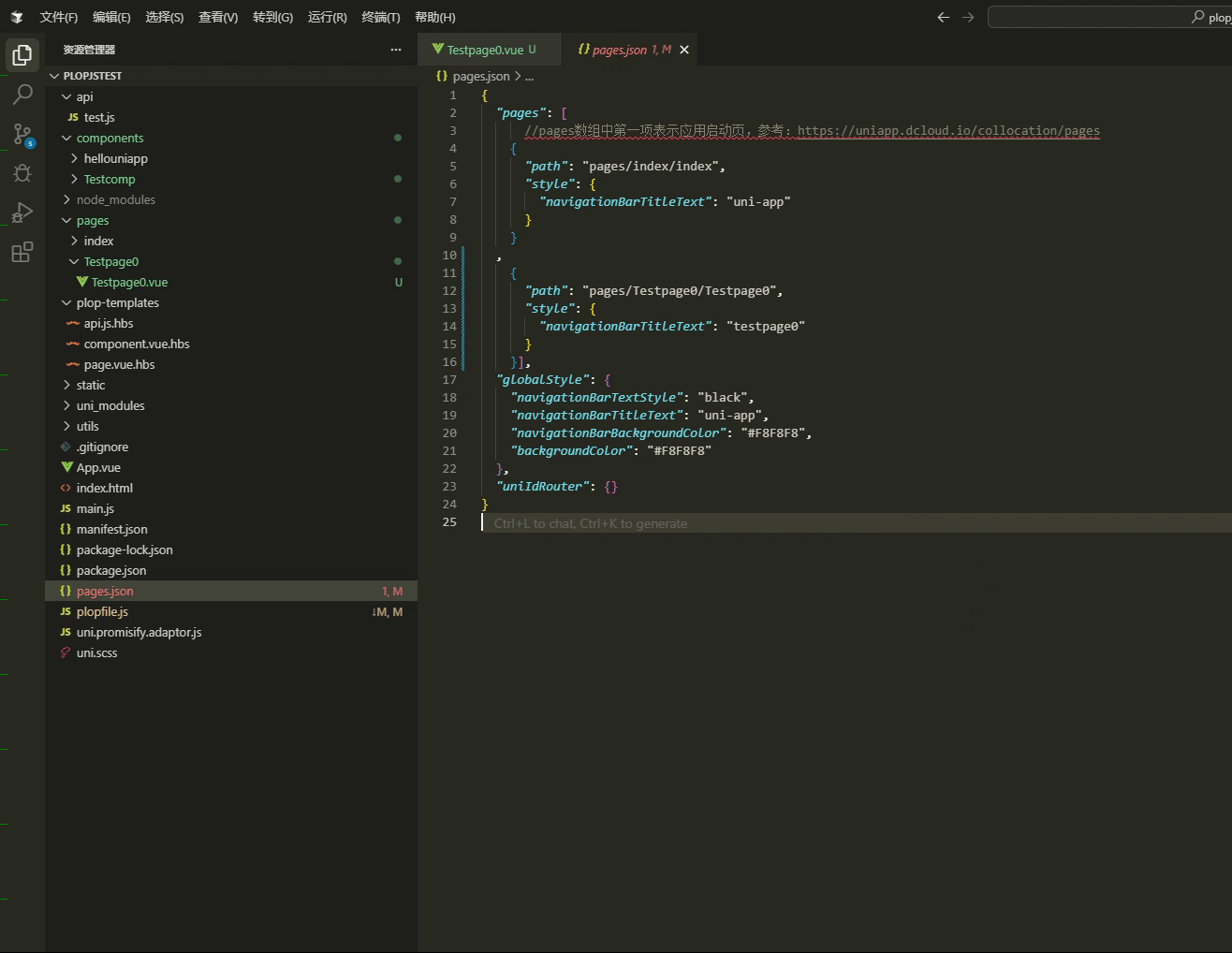
使用Plop.js高效生成模板文件
前情 开发是个创造型的职业,也是枯燥的职业,因为开发绝大多数都是每天在业务的代码中无法自拨,说到开发工作,就永远都逃不开新建文件的步骤,特别现在组件化开发胜行,每天都是在新建新建组件的道路上一去不…...
Vue框架2(vue搭建方式2:利用脚手架,ElementUI)
一.引入vue第二种搭建方式 在以前的前端项目中,一个项目需要多个html文件实现页面之前的切换,如果页面中需要依赖js或者css文件,那么我们就需要在多个html文件中都需要导入vue.js文件,太过繁琐. 现在前端开发都采用单页面结果,一个项目中只有一个html文件 其他不同的内容都写…...
mac 设置cursor (像PyCharm一样展示效果)
一、注册 Cursor - The AI Code Editor 二、配置Python环境 我之前使用pycharm创建的python项目,以及创建了虚拟环境,现在要使用cursor继续开发。 2.1 选择Python 虚拟环境 PyCharm 通常将虚拟环境存储在项目目录下的 venv 或 .venv 文件夹中…...
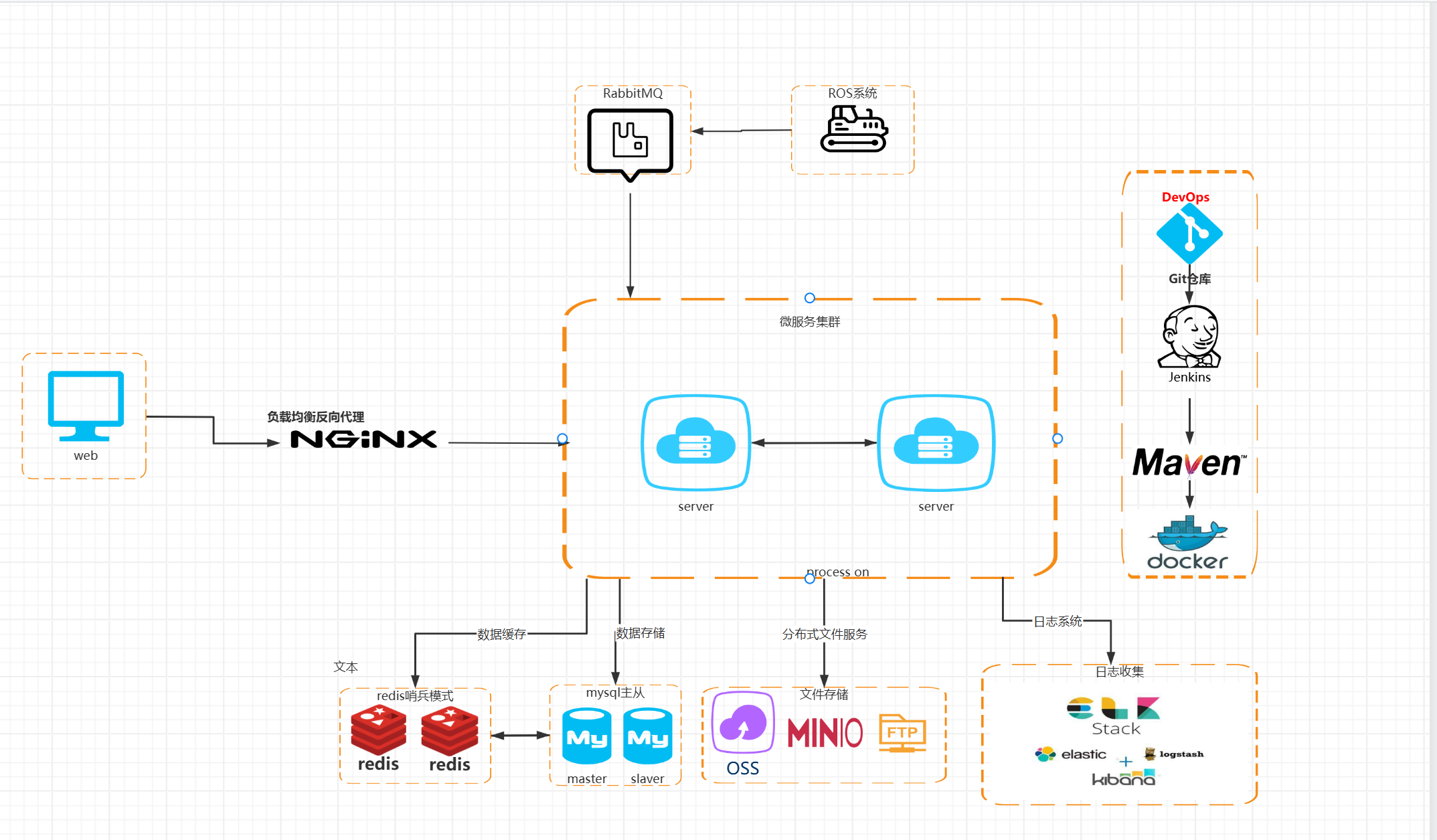
SpringCloudAlibaba微服务架构
技术架构图 SpringCloudAlibaba微服务架构 说明: 1.1、采用SpringCloudAlibaba分布式微服务架构,使用Nginx做代理,服务治理使用Nacos组件,Gateway网关做权限验证、路由、过滤。 1.2、Redis做消息缓存,包括数据大屏、数…...

Java高级 | 【实验三】Springboot 静态资源访问
隶属文章: Java高级 | (二十二)Java常用类库-CSDN博客 系列文章: Java高级 | 【实验一】Spring Boot安装及测试 最新-CSDN博客 Java高级 | 【实验二】Springboot 控制器类相关注解知识-CSDN博客 目录 一、Thymeleaf 1.1 是什么&…...

C语言_预处理详解
1. 预定义符号 C语言设置了一些预定义符号,可以直接使用,预定义符号也是在预处理期间处理的 1 __FILE__ //进行编译的源文件 2 __LINE__//文件当前的行号 3 __DATE__ //文件被编译的日期 4 __TIME__//文件被编译的时间 5 __STDC__//如果编译器遵循ANSI…...

将前后端分离版的前端vue打包成EXE的完整解决方案
将若依前后端分离版的前端打包成EXE的完整解决方案 将若依前后端分离版的Vue前端打包成Windows可执行文件(.exe),同时保持与后端API的通信,需要使用Electron框架来实现。下面是详细的步骤和解决方案。 一、准备工作 1. 环境要求 Node.js (推荐v16+)npm 或 yarn若依前后端分…...
基础概念和设备)
物联网协议之MQTT(一)基础概念和设备
前言: 本文内容均以实战出发,像MQTT概念这种基础内容建议大家自行百度。 推荐资料: mica-mqtt文档 一、MQTT简单介绍 作为当今物联网的主流协议,MQTT的使用范围非常广,如果你想了解甚至是从事物联网行业,…...
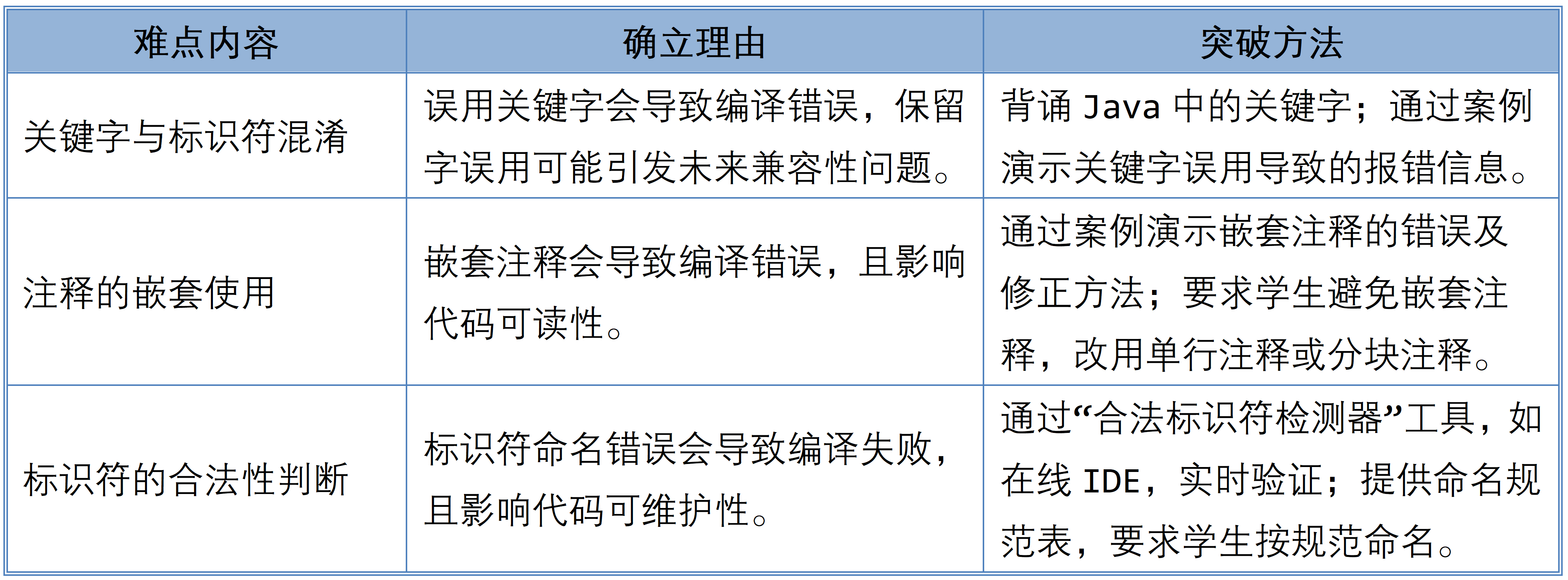
「Java教案」Java程序的构成
课程目标 1.知识目标 能够按照Java标识符的命名规则,规范变量的命名。能够区分Java中的关键字与保留字。能够对注释进行分类,根据注释的用途合理的选择注释方式。 2.能力目标 能编写符合规范的标识符。能识别Java中的关键字和…...

还原Windows防火墙
还原Windows防火墙 1. 背景2. 为何“还原”完胜“关闭”?三大核心优势3. 还原防火墙默认值操作步骤4. 还原防火墙时,系统背后的工作5. 需要还原防火墙场景一招拯救混乱网络!还原Windows防火墙,找回你的“安全速度”1. 背景 你是否曾因一时误操作关闭了Windows防火墙?是…...

区块链可投会议CCF B--EDBT 2026 截止10.8 附录用率
Conference:EDBT: 29th International Conference on Extending Database Technology CCF level:CCF B Categories:数据库/数据挖掘/内容检索 Year:2026 Conference time:24th March - 27th…...
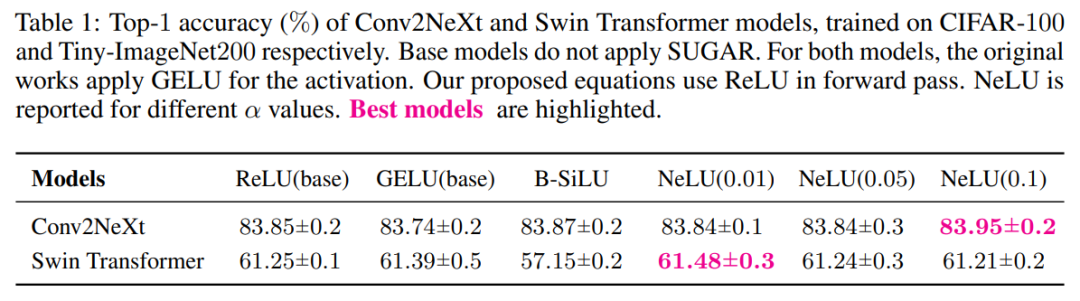
经典ReLU回归!重大缺陷「死亡ReLU问题」已被解决
来源 | 机器之心 在深度学习领域中,对激活函数的探讨已成为一个独立的研究方向。例如 GELU、SELU 和 SiLU 等函数凭借其平滑梯度与卓越的收敛特性,已成为热门选择。 尽管这一趋势盛行,经典 ReLU 函数仍因其简洁性、固有稀疏性及…...

在VSCode中开发一个uni-app项目
创建项目 使用命令行工具(例如 vue-cli)来创建一个新的 uni-app 项目。 创建以JavaScript开发的工程 npx degit dcloudio/uni-preset-vue#vite my-vue3-project //或者 npx degit dcloudio/uni-preset-vue#vite-alpha my-vue3-project创建以TypeScript…...

quic为什么没有被大规模应用?
一、成本 将应用程序从 HTTP/2 迁移到 HTTP/3,或从 TCP 迁移到 UDP 需要付出一定的努力。它需要将整个应用层实现和传输层实现转换到UDP,并在服务器端和客户端构建一个全新的解决方案。对于资源有限的小型流媒体供应商来说,这是一个不小的挑…...

Delft3D软件介绍及建模原理和步骤;Delft3D数值模拟溶质运移模型建立;地表水环境影响评价报告编写思路
📚 教程以地表水数值模拟软件 Delft3D 4.03.00 的操作为核心内容,系统涵盖地表水水动力建模、基础资料获取、边界条件设定、模型率定与验证以及数据分析处理等关键环节。通过全面讲解,学员将掌握地表水数值模拟的全过程实际操作技术。 &…...
0603)
书籍在其他数都出现k次的数组中找到只出现一次的数(7)0603
题目 给定一个整型数组arr和一个大于1的整数k。已知arr中只有1个数出现了1次,其他的数都出现了k次,请返回只出现了1次的数。 解答: 对此题进行思路转换,可以将此题,转换成k进制数。 k进制的两个数c和d,…...
)
开源模型应用落地-OpenAI Agents SDK-集成Qwen3-8B-function_tool(二)
一、前言 在人工智能技术迅猛发展的今天,OpenAI Agents SDK 为开发者提供了一个强大的工具集,用于构建基于 Python 的智能代理应用。这些代理可以执行从简单任务到复杂决策的一系列操作,极大地提升了应用程序的智能化水平。 通过 OpenAI Agents SDK,可以利用 Python 编程语…...
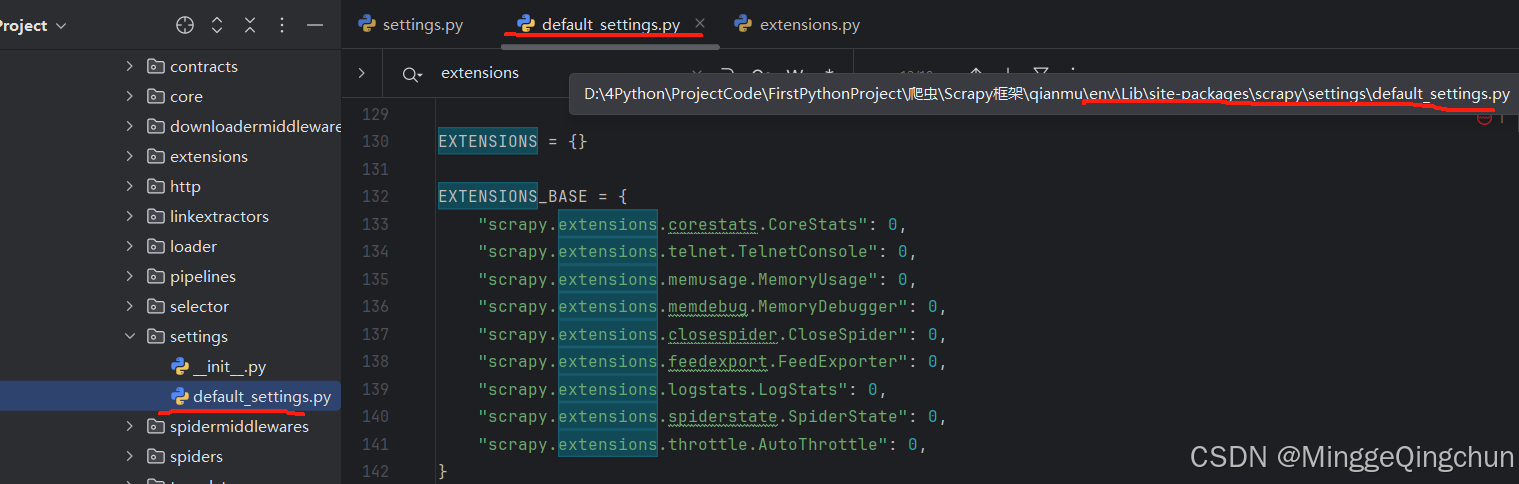
Python - 爬虫;Scrapy框架之插件Extensions(四)
阅读本文前先参考 https://blog.csdn.net/MinggeQingchun/article/details/145904572 在 Scrapy 中,扩展(Extensions)是一种插件,允许你添加额外的功能到你的爬虫项目中。这些扩展可以在项目的不同阶段执行,比如启动…...