06-排序
排序
1. 排序的概念及其应用
1.1 排序的概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
1.2 常见的排序算法

2. 常见排序算法的实现
在下面的算法中会频繁使用到比较和交换,这里把这两个功能实现以下,下面直接调用。
// 设置一个比较函数,调整升序降序时只需要修改这个函数即可
bool Com(int a, int b)
{return a < b;// <为升序,>为降序
}// 交换函数
void Swap(int* a, int* b)
{int tmp = *a;*a = *b;*b = tmp;
}
2.1 插入排序
2.1.1 基本思想
思想:把待排序的记录按其关键码值的大小逐个插入到一个已经排好序的有序序列中,直到所有的记录插入完为止,得到一个新的有序序列。
类似于打扑克牌时,码牌的过程。

2.1.2 直接插入排序
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移。
// 插入排序
void InsertSort(int* a, int n)
{for (int i = 1; i < n; i++){int tmp = a[i];int pos = i - 1;while (pos >= 0)if (!Com(a[pos], tmp))a[pos + 1] = a[pos--];elsebreak;a[pos + 1] = tmp;}
}
直接插入排序的特性总结:
-
元素集合越接近有序,直接插入排序算法的时间效率越高
-
时间复杂度: O ( N 2 ) O(N^2) O(N2)
-
空间复杂度: O ( 1 ) O(1) O(1)
-
稳定性:稳定
2.1.3 希尔排序(缩小增量排序)
希尔排序法又称缩小增量法。希尔排序法的基本思想是:先选定一个整数gap,把待排序文件中所有记录分成若干个组,所有距离相同的记录分在同一组内,并对每一组内的记录进行排序。然后减小gap,我们这里使gap=gap/3+1(缩小gap时,必须保证最后的gap为1),重复上述分组和排序的工作。当gap=1时,所有记录在统一组内排好序。
// 希尔排序
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;// 对每个分组进行直接插入排序for (int i = gap; i < n; i++){int tmp = a[i];int pos = i - gap;while (pos >= 0)if (!Com(a[pos], tmp)){a[pos + gap] = a[pos];pos -= gap;}elsebreak;a[pos + gap] = tmp;}}
}
希尔排序的特性总结:
-
希尔排序是对直接插入排序的优化。
-
当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。
-
希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些书中给出的希尔排序的时间复杂度都不固定。
数据结构(C语言版)》— 严蔚敏

《数据结构-用面相对象方法与C++描述》— 殷人昆

我们这里的gap是按照Knuth提出的方式进行取值的,而且Knuth进行了大量的试验统计,我们暂时就按照: O ( N 1.25 ) − O ( 1.6 ∗ N 1.25 ) O(N^{1.25})-O(1.6*N^{1.25}) O(N1.25)−O(1.6∗N1.25)来算。
-
稳定性:不稳定
2.2选择排序
2.2.1 基本思想
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,直到全部待排序的数据元素排完 。
2.2.2 直接选择排序
- 在元素集合array[i]–array[n-1]中选择关键码最大(小)的数据元素
- 若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换
- 在剩余的array[i]–array[n-2](array[i+1]–array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
// 选择排序
void SelectSort(int* a, int n)
{for (int i = n - 1; i > 0; i--){int pos = i;for (int j = 0; j < i; j++)if (Com(a[pos], a[j]))pos = j;Swap(&a[i], &a[pos]);}
}
优化
// 选择排序优化,两端同时进行排序
void SelectSort(int* a, int n)
{int begin = 0;int end = n - 1;while (begin < end){int mini = begin;int maxi = end;for (int i = begin; i <= end; i++){if (Com(a[i], a[mini]))mini = i;if (Com(a[maxi], a[i]))maxi = i;}Swap(&a[begin], &a[mini]);if (maxi == begin)maxi = mini;Swap(&a[end], &a[maxi]);begin++;end--;}
}
直接选择排序的特性总结:
-
直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用
-
时间复杂度: O ( N 2 ) O(N^2) O(N2)
-
空间复杂度: O ( 1 ) O(1) O(1)
-
稳定性:不稳定
2.2.3 堆排序
利用堆这个数据结构进行排序,是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
(关于数据结构—堆,详见05-二叉树-CSDN博客)
// 堆---向下调整
void AdjustDwon(int* a, int n, int root)
{int child = root * 2 + 1;while (child < n){if (child + 1 < n && Com(a[child], a[child + 1]))child++;if (!Com(a[root], a[child])) break;Swap(&a[root], &a[child]);root = child;child = root * 2 + 1;}
}// 堆排序
void HeapSort(int* a, int n)
{for (int i = n / 2; i >= 0; i--)AdjustDwon(a, n, i);for (int i = n - 1; i > 0; i--){Swap(&a[0], &a[i]);AdjustDwon(a, i, 0);}
}
直接选择排序的特性总结:
-
堆排序使用堆来选数,效率就高了很多。
-
时间复杂度: O ( N ∗ l o g N ) O(N*logN) O(N∗logN)
-
空间复杂度: O ( 1 ) O(1) O(1)
-
稳定性:不稳定
2.3 交换排序
2.3.1 基本思想
所谓交换,就是根据序列中两个记录键值的比较结果来对换这两个记录在序列中的位置,交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
2.3.2 冒泡排序
很基础的算法,这里不过多介绍。(详细介绍:012-C语言指针(2)-CSDN博客)
// 冒泡排序
void BubbleSort(int* a, int n)
{for (int i = n - 1; i > 0; i--){bool flag = true;for (int j = 0; j < i; j++)if (Com(a[j + 1], a[j])){flag = false;Swap(&a[j + 1], &a[j]);}if (flag) break;}
}
冒泡排序的特性总结:
-
冒泡排序是一种非常容易理解的排序
-
时间复杂度: O ( N 2 ) O(N^2) O(N2)
-
空间复杂度: O ( 1 ) O(1) O(1)
-
稳定性:稳定
2.3.3 快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
// 假设按照升序对array数组中[left, right)区间中的元素进行排序
void QuickSort(int array[], int left, int right)
{if (right - left <= 1)return;// 按照基准值对array数组的 [left, right)区间中的元素进行划分int div = partion(array, left, right);// 划分成功后以div为边界形成了左右两部分 [left, div) 和 [div+1, right)// 递归排[left, div)QuickSort(array, left, div);// 递归排[div+1, right)QuickSort(array, div + 1, right);
}
上述为快速排序递归实现的主框架,发现与二叉树前序遍历规则非常像,在写递归框架时可想想二叉树前序遍历规则即可快速写出来,后序只需分析如何按照基准值来对区间中数据进行划分的方式即可。
关于选择基准值:
为了提高效率,选择基准值时要尽量避免选择到最值,所以这里实现一个选择函数。
// 筛选key
int GetMidi(int* a, int begin, int end)
{int midi = (end + begin) / 2;if (a[begin] > a[end]){if (a[midi] > a[end]){if (a[begin] > a[midi])return midi;elsereturn begin;}elsereturn end;}else{if (a[begin] > a[midi])return begin;else{if (a[midi] > a[end])return end;elsereturn midi;}}
}
将区间按照基准值划分为左右两半部分的常见方式有三种(这里以升序序列为例):
-
hoare版本
对于一个待排序序列,选择其中任意一个值作为基准值key,把这个基准值拿出来,与序列中的第一个元素交换位置,剩余的序列中,使用两个指针,分别指向序列的头+1(因为现在第一个位置存放了基准值key)和尾(开区间),右指针一直–,直到碰到<key的值,左指针一直++,直到碰到>key的值然后停下,然后将左指针和右指针指向的值交换,再重复上述操作,直到两个指针相遇,此时两个指针都指向<=key的值(这里不做证明,注意上面指针移动的顺序),此时将基准值和这个值进行交换,序列就分成了两段。
int PartSort1(int* a, int begin, int end)// 基础法 {int midi = GetMidi(a, begin, end);// 优化,排除最值做key,提升排序效率Swap(&a[begin], &a[midi]);int keyi = begin;int left = begin;int right = end;while (left < right){while (left < right && !Com(a[right], a[keyi]))right--;while (left < right && !Com(a[keyi], a[left]))left++;Swap(&a[left], &a[right]);}Swap(&a[keyi], &a[left]);return left; } -
挖坑法
对于一个待排序序列,选择一个基准值,将这个基准值和序列第一个值进行交换,然后将这个基准值key记录下来,将左指针和右指针分别指向第一个元素和最后一个元素,此时第一个元素的位置是一个“坑”,因为这里的值已经被我们提取出来了,此时判断右指针指向的元素,只要该元素>=key,右指针–,直到碰见小于key的值,将这个值放到左指针指向的“坑”,此时右指针指向一个“坑”,判断左指针指向的元素,只要该元素<=key左指针++,直到碰见大于key的值,将该值放到右指针指向的“坑”中,反复上面过程,直到左右指针相遇,此时它们共同指向一个坑,将我们记录的基准值放到这个坑中即可。
int PartSort2(int* a, int begin, int end)// 挖坑法 {int midi = GetMidi(a, begin, end);// 优化,排除最值做key,提升排序效率Swap(&a[begin], &a[midi]);int key = a[begin];int left = begin;int right = end;while (left < right){while (right > left && !Com(a[right], key))right--;a[left] = a[right];while (right > left && !Com(key, a[left]))left++;a[right] = a[left];}a[left] = key;return left; } -
前后指针版本
同样,对于一个待排序序列,选一个基准值key,放在第一个位置,此时我们需要两个指针prev和cur,分别指向第一个元素和第二个元素,cur一直++,直到碰到;小于key的元素,将这个元素和prev+1位置的元素交换位置,prev++,然后重复上述操作,直到cur碰到end,交换prev和begin位置(key)的元素,单趟排序结束,在这个过程中,(begin,prev]代表小于等于key的序列,(prev,cur)代表大于等于key的序列,[cur,end)代表待排序序列。
int PartSort3(int* a, int begin, int end)// 双指针法 {int midi = GetMidi(a, begin, end);// 优化,排除最值做key,提升排序效率Swap(&a[begin], &a[midi]);int keyi = begin;int cur = begin + 1;int prev = begin;while (cur <= end){if (Com(a[cur], a[keyi]) && ++prev != cur)Swap(&a[prev], &a[cur]);cur++;}Swap(&a[keyi], &a[prev]);return prev; }
快速排序主体
// 快速排序 - 递归实现
void QuickSort(int* a, int begin, int end)
{if (begin >= end)return;// 当待排序序列较小时,可以直接使用插入排序,可以有效减少递归的深度。当然不加也是可以的。if (end - begin + 1 <= 10)// 小区间优化,减少递归深度,防止栈溢出InsertSort(a + begin, end - begin + 1);else{//三种方法实现单趟排序,此处任选一种单趟排序即可//int keyi = PartSort1(a, begin, end);//常规//int keyi = PartSort2(a, begin, end);//挖坑int keyi = PartSort3(a, begin, end);//双指针QuickSort(a, begin, keyi - 1);QuickSort(a, keyi + 1, end);}
}
上面实现的是递归的快速排序,我们还可以使用迭代的方法来实现,但这需要借助栈的数据结构(关于栈,参考:04-栈和队列-CSDN博客,在下面的实现中,使用这篇文章中实现的栈的接口)。
// 快速排序 - 非递归实现(用栈的数据结构实现)
void QuickSortNonR(int* a, int begin, int end)
{Stack ST;StackInit(&ST);StackPush(&ST, end);StackPush(&ST, begin);while (!StackEmpty(&ST)){int left = StackTop(&ST);StackPop(&ST);int right = StackTop(&ST);StackPop(&ST);//进行单趟排序,任选一种即可//int keyi = PartSort1(a, left, right);//常规//int keyi = PartSort2(a, left, right);//挖坑int keyi = PartSort3(a, left, right);//双指针if (right > keyi + 1){StackPush(&ST, right);StackPush(&ST, keyi + 1);}if (left < keyi - 1){StackPush(&ST, keyi - 1);StackPush(&ST, left);}}StackDestroy(&ST);
}
快速排序的特性总结:
- 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
- 时间复杂度: O ( N ∗ l o g N ) O(N*logN) O(N∗logN)
- 空间复杂度: O ( l o g N ) O(logN) O(logN)
- 稳定性:不稳定
2.4 归并排序
2.4.1 基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤:

2.4.2 具体实现
递归实现
void _MergeSort(int* a, int begin, int end, int* tmp)
{if (begin >= end)return;int midi = (end + begin) / 2;_MergeSort(a, begin, midi, tmp);_MergeSort(a, midi + 1, end, tmp);int begin1 = begin;int begin2 = midi + 1;int i = begin;while (i <= end){if (Com(a[begin1], a[begin2])){tmp[i] = a[begin1];begin1++;}else{tmp[i] = a[begin2];begin2++;}i++;if (begin1 > midi || begin2 > end)break;}if (begin1 > midi)while (i <= end)tmp[i++] = a[begin2++];elsewhile (i <= end)tmp[i++] = a[begin1++];memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}// 归并排序 - 递归实现
void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc error");exit(-1);}_MergeSort(a, 0, n - 1, tmp);free(tmp);
}
迭代实现
// 归并排序 - 非递归实现
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc error");exit(-1);}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;if (end1 >= n || begin2 >= n)break;if (end2 >= n)end2 = n - 1;int j = begin1;while (j <= end2){if (Com(a[begin2], a[begin1]))tmp[j++] = a[begin1++];elsetmp[j++] = a[begin2++];if (begin1 > end1 || begin2 > end2)break;}while (begin1 <= end1)tmp[j++] = a[begin1++];while (begin2 <= end2)tmp[j++] = a[begin2++];memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}
}
归并排序的特性总结:
-
归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。
-
时间复杂度: O ( N ∗ l o g N ) O(N*logN) O(N∗logN)
-
空间复杂度: O ( N ) O(N) O(N)
-
稳定性:稳定
2.5 非比较排序(计数排序)
2.5.1 基本思想
计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
-
统计相同元素出现次数
-
根据统计的结果将序列回收到原来的序列中

2.5.2 具体实现
// 计数排序 - 效率奇高,适用于数据范围较小时
void CountSort(int* a, int n)
{int max = a[0];int min = a[0];for (int i = 0; i < n; i++){if (a[i] > max)max = a[i];if (a[i] < min)min = a[i];}int* count = (int*)calloc(max - min + 1, sizeof(int));if (count == NULL){perror("calloc error");exit(-1);}for (int i = 0; i < n; i++)count[a[i] - min]++;int i = 0;int j = 0;while (i <= max - min){if (count[i]){a[j++] = i + min;count[i]--;}elsei++;}free(count);
}
计数排序的特性总结:
-
计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
-
时间复杂度: O ( M A X ( N , 范围 ) ) O(MAX(N,范围)) O(MAX(N,范围))
-
空间复杂度: O ( 范围 ) O(范围) O(范围)
-
稳定性:稳定
3. 排序算法复杂度及稳定性分析


相关文章:
06-排序
排序 1. 排序的概念及其应用 1.1 排序的概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。 稳定性:假定在待排序的记录序列中,存在多个具有相同的关键…...

python,shell,linux,bash概念的不同和对比联系
一、基本概念理解 1. Linux 是一个 操作系统内核,常与 GNU 工具集成组成完整的 Linux 操作系统。 提供对硬件的管理能力与系统调用接口。 用户通过 Shell 或 GUI 与 Linux 交互。 2. Shell 是用户与 Linux 内核之间的 命令行解释器(CLI)…...
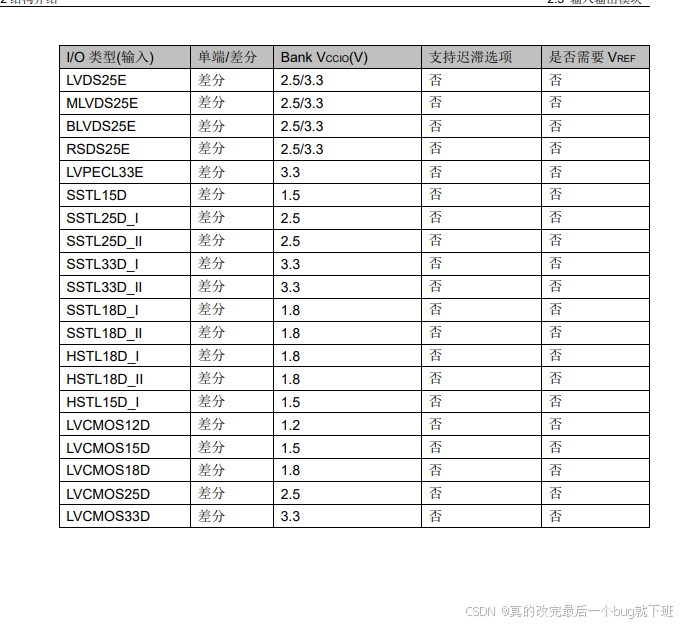
FPGA管脚类型,及选择
fpga的IO Type选择,如下: 具体的定义:...
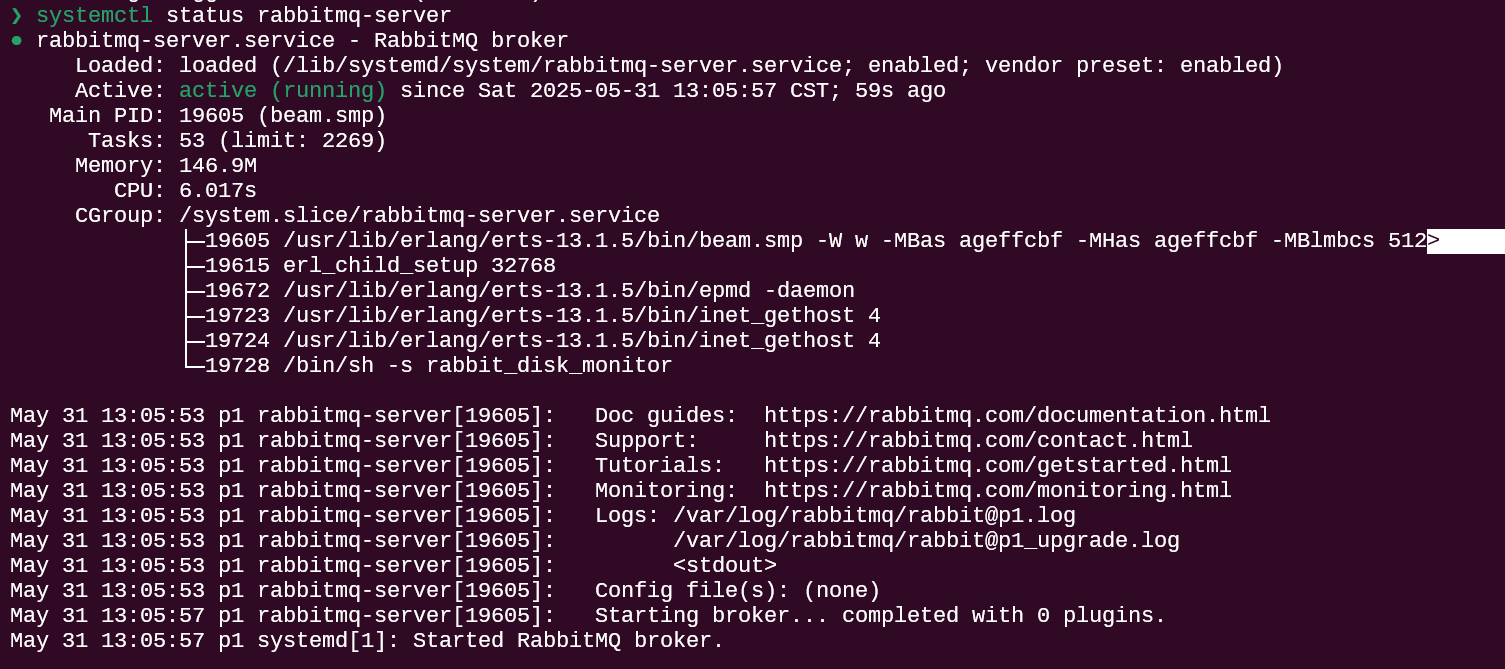
如何在 Ubuntu22.04 上安装并开始使用 RabbitMQ
单体架构学的差不多了,可以朝着微服务进军了,笔者打算实操一下 RabbitMQ(这个和 Redis 一样重要的组件) 笔者这里采用的是本地 wsl2 的 Ubuntu22.04 先按指定的博客进行前置操作 Ubuntu22.04 安装 RabbitMQ 解决 ARM Ubuntu 22.04 缺少 libs…...
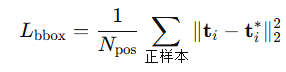
R-CNN 模型算法流程梳理
目录 一、R-CNN整体流程 二、需要注意的地方 论文连接:[1311.2524] Rich feature hierarchies for accurate object detection and semantic segmentation 如果你之前了解过RNN,很容易混淆认为R-CNN也具有RNN的时序循环功能,这种理解是错误…...

细说C语言将格式化输出到FILE *stream流的函数fprintf、_fprintf_I、fwprintf、_fwprintf_I
目录 1、将格式化数据输出到FILE *stream流基本型 (1)语法 (2)参数 (3)示例 2、将格式化数据输出到FILE *stream流并启用并启用在格式字符串中使用参数的顺序的规范 (1)语法 …...
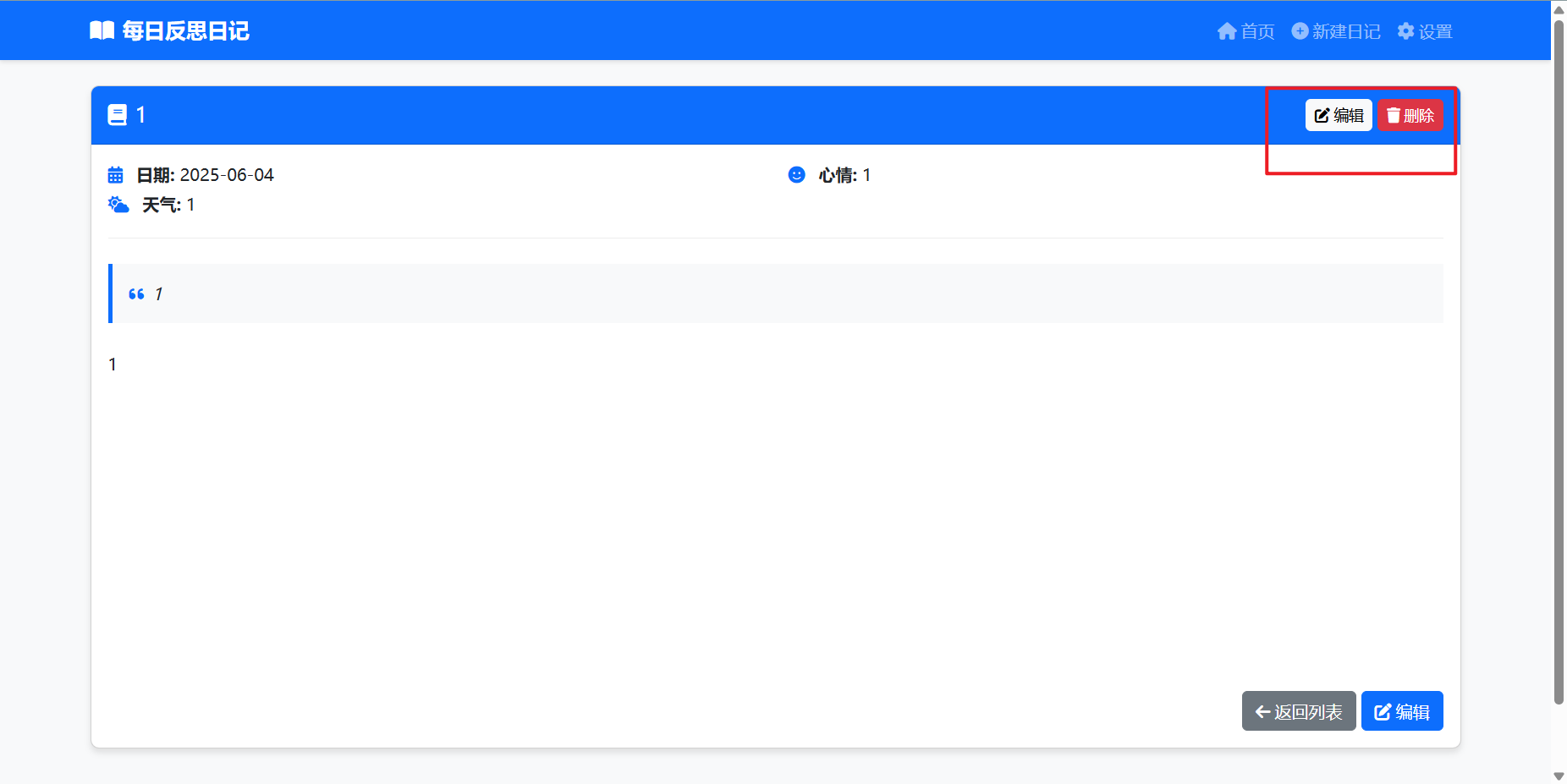
本地日记本,用于记录日常。
文章目录 想法程序说明展望 想法 本人想要复盘以前的事情,所以就想着写一个小程序,记录一下一天发生了什么事情。以后如果忘记了可以随时查看。写日记的想法来自我看的一本书,里面有一段话说的意思是,经验从来都不是随着年龄增长…...
[蓝桥杯]格子刷油漆
格子刷油漆 题目描述 X 国的一段古城墙的顶端可以看成 2N2N 个格子组成的矩形(如下图所示),现需要把这些格子刷上保护漆。 你可以从任意一个格子刷起,刷完一格,可以移动到和它相邻的格子(对角相邻也算数&…...

Monorepo架构: 项目管理工具介绍、需求分析与技术选型
概述 如何实现 monorepo,以及在项目中如何管理多个包,在进行具体项目开发前,有必要强调一个重要思维 — 全局观 即看待技术方案时,要从需求角度出发,综合考量该方案能否长远满足项目或团队需求 为什么要有全局观呢&a…...
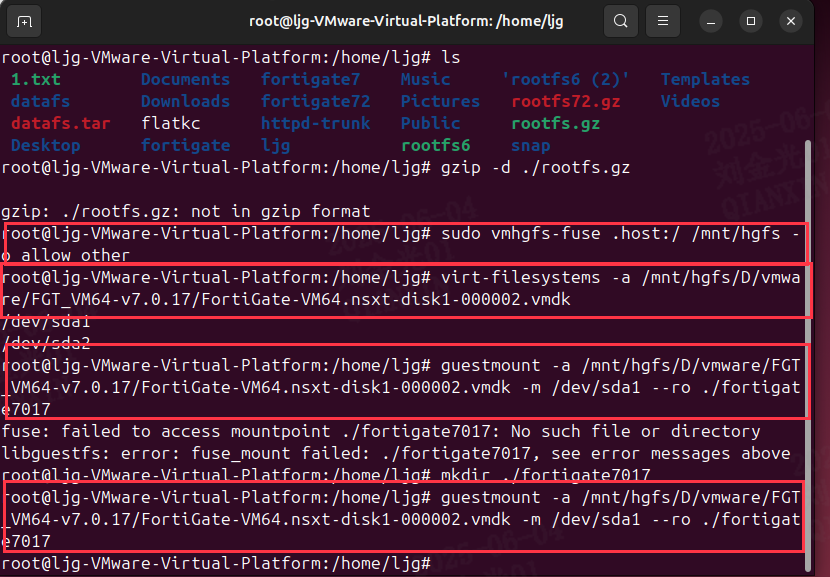
ubuntu下libguestfs-tools
在ubuntu下,使用libguestfs-tools工具挂载其他磁盘和分区。 首先安装libguestfs-tools将vmx虚拟磁盘共享:sudo vmhgfs-fuse .host:/ /mnt/hgfs -o allow_other执行如下命令查看分区名称:virt-filesystems -a /mnt/hgfs/D/vmware/FGT_VM64-v7…...
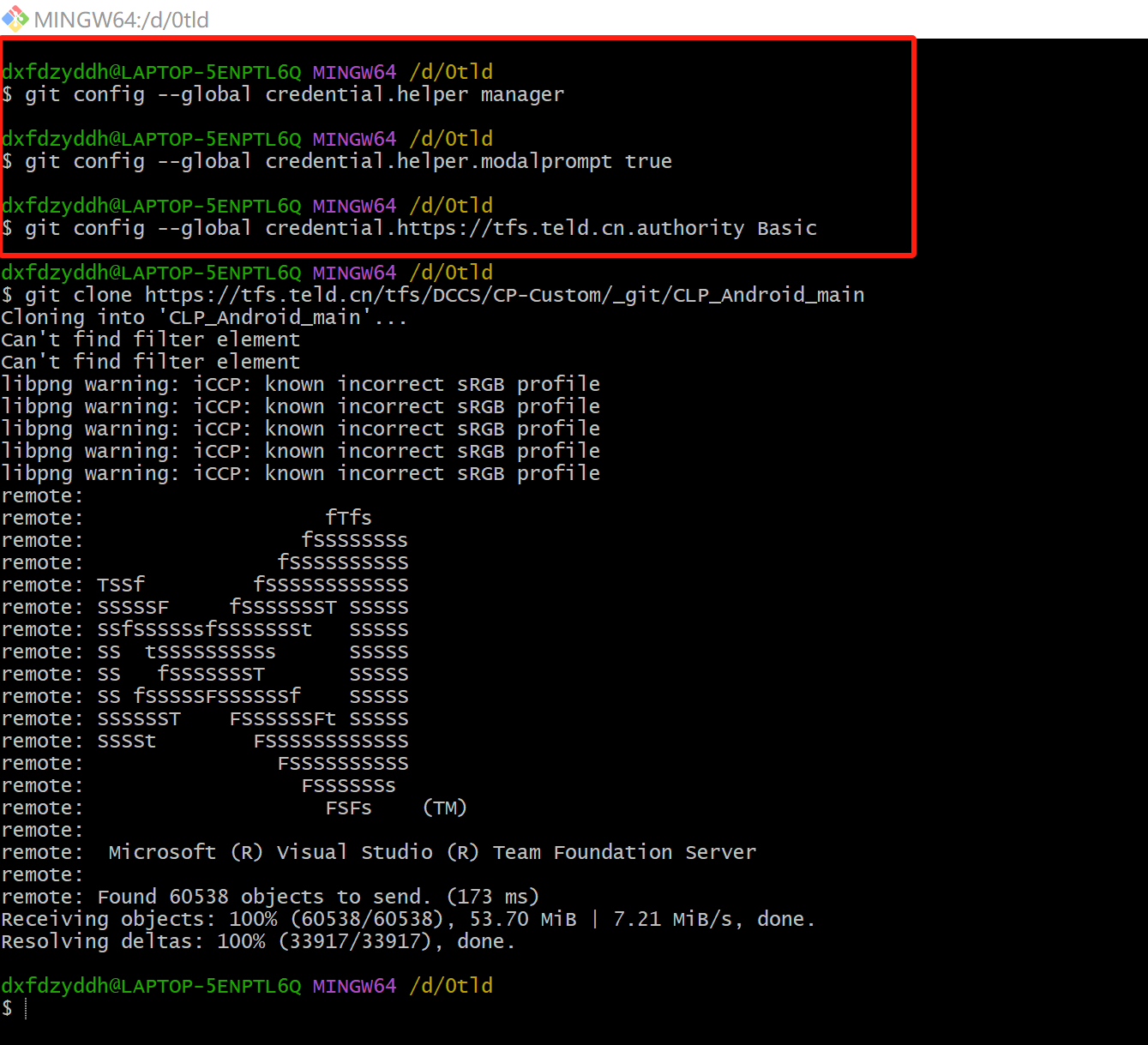
Authentication failed(切换了新的远程仓库tld)
启用 Git Credential Manager git config --global credential.helper manager 强制弹出凭据输入窗口 git config --global credential.helper.modalprompt true 指定 TFS 服务器使用基础认证(Basic Auth) git config --global credential.https://…...
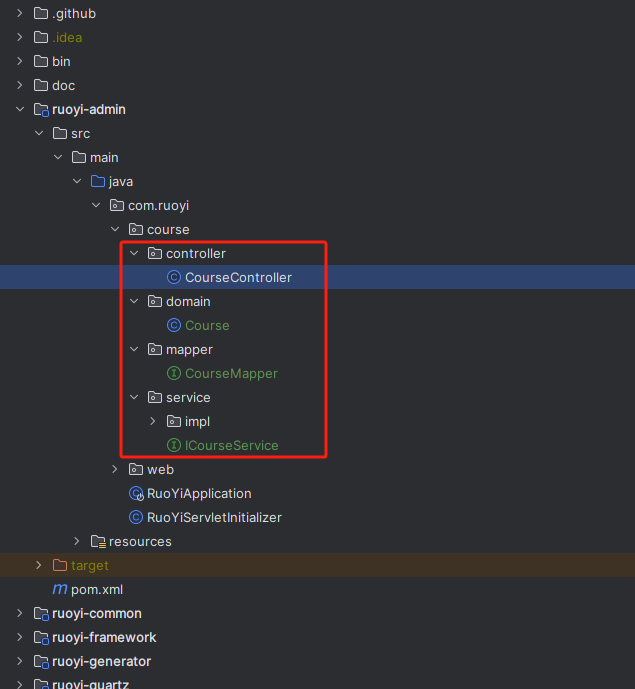
【Web应用】若依框架:基础篇14 源码阅读-后端代码分析-课程管理模块前后端代码分析
文章目录 一、课程管理模块前端代码截图二、前端代码及分析index.vuecourse.js 三、前端执行流程1. 组件初始化2. 查询操作3. 列表操作4. 对话框操作5. API 请求6. 执行流程总结关键点 四、课程管理模块后端代码截图五、后端代码块CourseControllerICourseServiceCourseMapperC…...
)
在 Linux 上安装 `pgvector`(这是一个 PostgreSQL 的向量类型扩展,常用于处理嵌入向量,便于进行向量相似度搜索)
1. 安装 PostgreSQL 确保你已经安装好 PostgreSQL 数据库。 例如在 Ubuntu 上: sudo apt update sudo apt install postgresql postgresql-contrib2. 安装依赖 pgvector 扩展用的是 make、gcc 等开发工具,因此你需要先安装 PostgreSQL 的开发包和编译…...

09.MySQL内外连接
09.MySQL内外连接 文章目录 MySQL内外连接 内连接 外连接 左外连接 右外连接 简单案例 MySQL内外连接 在数据库操作中,表的连接是一个非常重要的概念。简单来说,连接就是将两个或多个表中的数据按照某种规则结合起来,从而获取我们所需要的…...

Python爬虫实战:研究Scrapy-Splash库相关技术
1 引言 1.1 研究背景与意义 网络爬虫作为一种自动获取互联网信息的技术,在数据挖掘、信息检索、舆情分析等领域有着广泛的应用。然而,随着 Web 技术的不断发展,越来越多的网站采用 JavaScript 动态渲染技术,如 React、Vue 等框架构建的单页应用 (SPA)。这些网站的内容通常…...

智能升级:中国新能源汽车充电桩规模化建设与充电桩智慧管理方案
近年来,中国新能源汽车产业快速发展,市场规模持续扩大,但充电基础设施的建设与管理仍面临布局不均、利用率低、智能化水平不足等问题。为推动新能源汽车普及,国家正加速充电桩的规模化建设,并通过智慧化管理提升运营效…...
(1))
AlphaFold3服务器安装与使用(非docker)(1)
1. 服务器显卡驱动准备 这部分我会详细记录一下我踩过的坑及怎样拯救的,原谅啰嗦啦 ^_^ 1.1 服务器旧配置 1.1.1 nvidia-smi [xxxxxxlocalhost ~]# nvidia-smi Thu May 29 20:54:00 2025 -------------------------------------------------------------…...

接口自动化测试之pytest接口关联框架封装
🍅 点击文末小卡片,免费获取软件测试全套资料,资料在手,涨薪更快 一般情况下,我们是通过一个yaml文件进行关联实现 在根目录下新建一个文件yaml,通过上述conftest.py文件实现全局变量的更新: 1.首先需要建…...

M1安装并使用Matlab2024a进行java相机标定
安装 Matlab下载地址:https://www.macxin.com/archives/23771.html注意⚠️:如若需要java调用Matlab函数,则需要java版本为21 使用 安装完成之后运行此节目可以看到: 构建jar 命令行输入deploytool,会有一个弹窗&a…...
02-Redis常见命令
02-Redis常见命令 Redis数据结构介绍 Redis是一个key-value的数据库,key一般是String类型,不过value的类型多种多样: 贴心小建议:命令不要死记,学会查询就好啦 Redis为了方便学习,将操作不同数据类型的命…...

【论文阅读笔记】Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
文章目录 Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation一、论文基本信息1. 文章标题2. 所属刊物/会议3. 发表年份4. 作者列表5. 发表单位 二、摘要三、解决问题四、创新点五、自己的见解和感想六、研究背景七、研究方法(模型、实验数据…...

使用ArcPy进行栅格数据分析
设置工作环境 在开始编写脚本之前,需要设置好工作环境。这包括指定工作空间(workspace)和输出路径。工作空间是包含所有输入数据的文件夹或地理数据库,而输出路径则是处理结果将要保存的位置。 import arcpy from arcpy import …...

华为OD机试真题——告警抑制(2025A卷:100分)Java/python/JavaScript/C/C++/GO最佳实现
2025 A卷 100分 题型 本专栏内全部题目均提供Java、python、JavaScript、C、C++、GO六种语言的最佳实现方式; 并且每种语言均涵盖详细的问题分析、解题思路、代码实现、代码详解、3个测试用例以及综合分析; 本文收录于专栏:《2025华为OD真题目录+全流程解析+备考攻略+经验分…...

Java转Go日记(五十七):gin 中间件
1. 全局中间件 所有请求都经过此中间件 package mainimport ("fmt""time""github.com/gin-gonic/gin" )// 定义中间 func MiddleWare() gin.HandlerFunc {return func(c *gin.Context) {t : time.Now()fmt.Println("中间件开始执行了&quo…...

《树数据结构解析:核心概念、类型特性、应用场景及选择策略》
在数据结构中,树是一种分层的非线性数据结构,由节点和边组成,具有唯一根节点、子树分层结构和无环特性。其核心价值在于高效处理层次化数据或动态集合,广泛应用于算法、数据库、文件系统等领域。 一、树的核心概念 根节点&#…...

在本地查看服务器上的TensorBoard
建立本地服务器与远程服务器的通信,将TensorBoard的映射端口与本地端口连接起来,本地终端运行: ssh -L 本地端口:127.0.0.1:TensorBoard端口 用户名服务器的IP地址 -p 服务器登录端口 e.g. ssh -L 10010:127.0.0.1:39353 sx110.92.137.56 -…...

硬件开发全解:从入门教程到实战案例与丰富项目资源
硬件开发全解:从入门教程到实战案例与丰富项目资源 一、硬件开发基础 1.1 硬件开发概述 硬件开发,简单来说,就是从构思到实现一个电子设备的全过程。这一过程涉及到电子电路设计、嵌入式系统编程、传感器和执行器的集成等多个关键领域。在电子…...
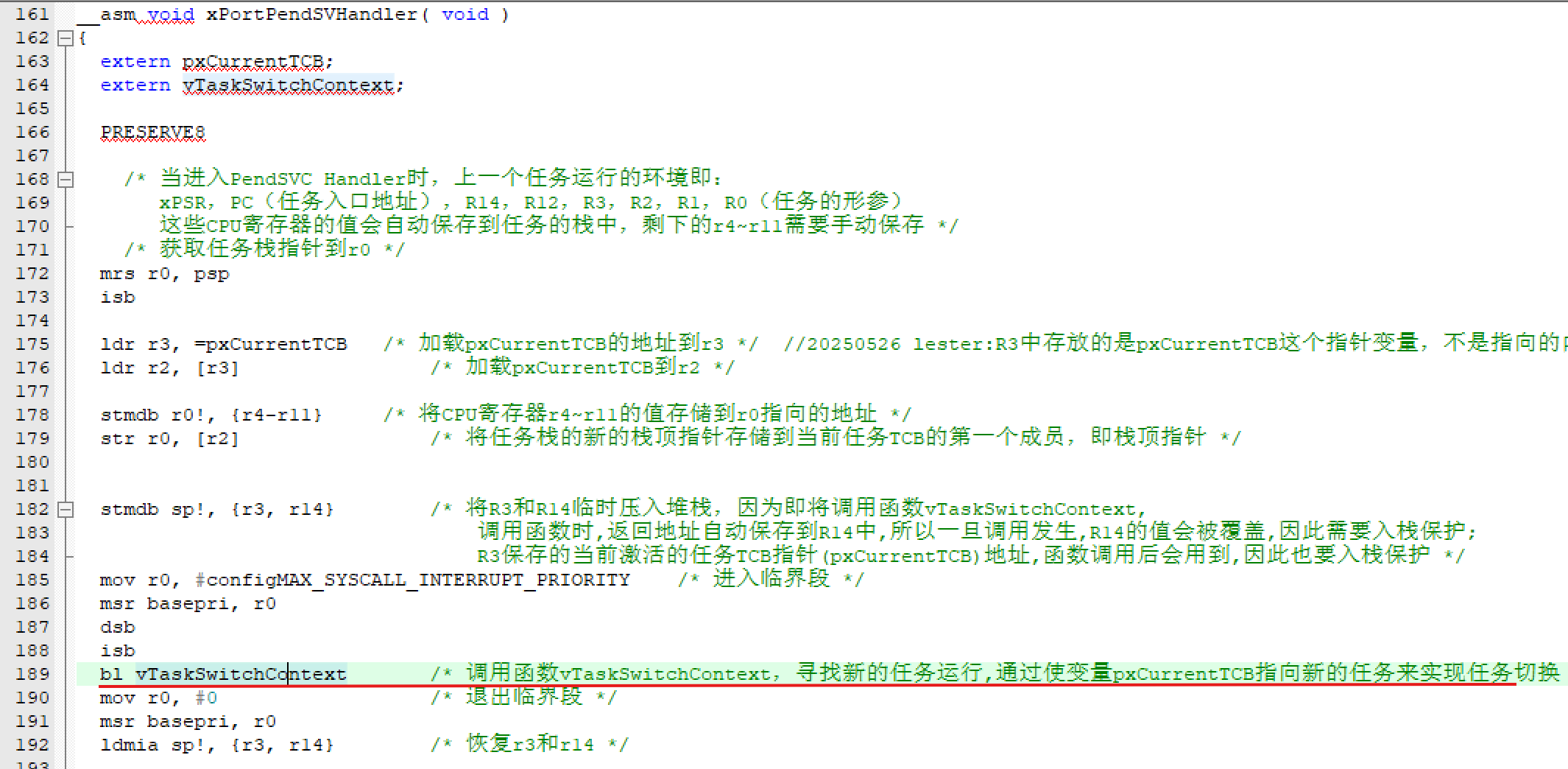
嵌入式学习笔记 - freeRTOS的两种临界禁止
一 禁止中断 通过函数taskENTER_CRITICAL() ,taskEXIT_CRITICAL()实现 更改就绪列表时,通常是通过禁止中断的方式,进入临界段,因为systick中断中有可以更改就绪列表的权利, 就绪列表(如 pxReadyTasksLis…...

202403-02-相似度计算 csp认证
其实这个问题就是求两篇文章的词汇的交集和并集,首先一说到并集,我就想到了set集合数据结构,set中的元素必须唯一。 STL之set的基本使用–博客参考 所以将两个文章的词汇全部加入set中,并求出set的大小,即为并集的大小…...

【Oracle】游标
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 游标基础概述1.1 游标的概念与作用1.2 游标的生命周期1.3 游标的分类 2. 显式游标2.1 显式游标的基本语法2.1.1 声明游标2.1.2 带参数的游标 2.2 游标的基本操作2.2.1 完整的游标操作示例 2.3 游标属性2.3.1…...