AI数据集构建:从爬虫到标注的全流程指南
AI数据集构建:从爬虫到标注的全流程指南
系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu
文章目录
- AI数据集构建:从爬虫到标注的全流程指南
- 摘要
- 引言
- 流程图:数据集构建全生命周期
- 一、数据采集:爬虫技术实战
- 1.1 静态网站数据抓取
- 1.2 动态网站数据抓取
- 1.3 API数据采集
- 二、数据清洗与预处理
- 2.1 文本数据清洗
- 2.2 图像数据预处理
- 2.3 噪声数据过滤
- 三、数据标注体系设计
- 3.1 图像标注规范
- 3.2 文本标注示例
- 3.3 多模态标注工具链
- 四、质量评估与迭代
- 4.1 标注一致性评估
- 4.2 主动学习策略
- 五、合规与安全管理
- 5.1 数据脱敏技术
- 5.2 跨境传输合规
- 六、工程化实践案例
- 6.1 工业质检数据集构建
- 6.2 医疗影像数据集
- 七、未来趋势
- 结论
摘要
随着人工智能技术进入大模型时代,高质量数据集成为算法性能的核心驱动力。本文系统梳理了AI数据集构建的完整流程,涵盖数据采集(爬虫技术)、清洗预处理、标注规范、质量评估及合规管理五大模块。通过对比开源数据集构建案例(如ImageNet、LLaMA-2)与工业级数据工程实践,揭示了从学术研究到产业落地的关键差异。结合Python爬虫框架、自动化标注工具链及联邦学习技术,提出了一套可复用的数据工程方法论,为AI工程师、数据科学家及企业数据团队提供全流程指南。
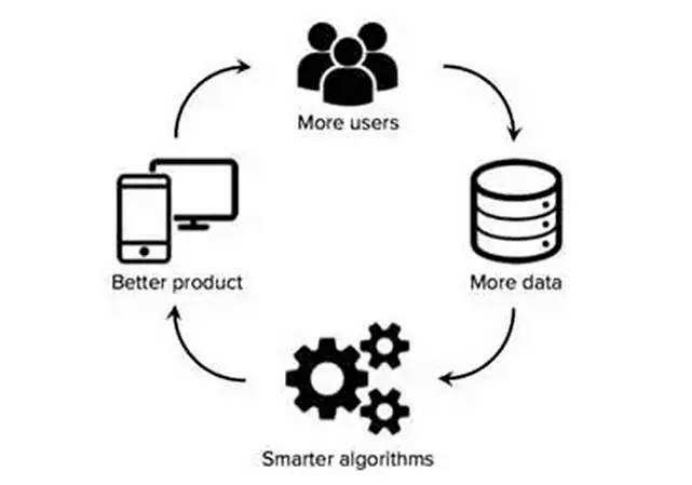
引言
根据斯坦福大学《2023 AI指数报告》,全球AI模型训练数据量年均增长12倍,但工业级数据集构建成本仍占项目总投入的60%-80%。当前行业面临三大挑战:
- 数据合规性:欧盟GDPR要求数据采集需获得用户明确授权
- 标注一致性:多标注员协同作业时,分类标签偏差率达15%-25%
- 工程效率:手动标注10万张图像需200人日,成本超$50万
本文以计算机视觉与自然语言处理(NLP)领域为例,拆解数据集构建的完整技术栈,重点解析以下关键环节:
- 爬虫策略:动态网站数据抓取与反爬机制突破
- 清洗规则:噪声数据过滤与特征工程
- 标注体系:多模态数据标注规范(图像/文本/语音)
- 质量管控:主动学习与人工复核结合机制
- 合规框架:数据脱敏与跨境传输合规方案
流程图:数据集构建全生命周期
一、数据采集:爬虫技术实战
1.1 静态网站数据抓取
# 使用Scrapy框架抓取电商评论数据示例
import scrapy
from scrapy.crawler import CrawlerProcessclass AmazonReviewSpider(scrapy.Spider):name = "amazon_reviews"start_urls = ["https://www.amazon.com/product-reviews/B07YR57H6T"]def parse(self, response):for review in response.css("div.a-section.review"):yield {"user_id": review.css("span.a-profile-name::text").get(),"rating": review.css("i.a-icon-star span::text").get(),"content": review.css("span.a-size-base.review-text::text").get(),"date": review.css("span.review-date::text").get()}next_page = response.css("li.a-last a::attr(href)").get()if next_page:yield response.follow(next_page, self.parse)process = CrawlerProcess(settings={"USER_AGENT": "Mozilla/5.0","ROBOTSTXT_OBEY": False
})
process.crawl(AmazonReviewSpider)
process.start()
- 技术要点:
- 使用User-Agent池规避反爬检测
- 设置请求间隔(1-3秒)防止IP封禁
- 结合Selenium处理动态加载内容
1.2 动态网站数据抓取
// Puppeteer抓取社交媒体动态内容示例
const puppeteer = require('puppeteer');(async () => {const browser = await puppeteer.launch({headless: false});const page = await browser.newPage();await page.setUserAgent('Mozilla/5.0');// 模拟登录await page.goto('https://twitter.com/login');await page.type('#username', 'your_email');await page.type('#password', 'your_password');await page.click('[type="submit"]');// 抓取动态加载的推文await page.waitForSelector('div.tweet-text');const tweets = await page.$$eval('div.tweet-text', tweets => tweets.map(t => t.innerText));console.log(tweets);await browser.close();
})();
- 反爬机制突破:
- 使用IP代理池(如ScraperAPI)
- 实现Cookie持久化存储
- 动态解析JavaScript加密参数
1.3 API数据采集
# 使用Twitter API抓取趋势话题
import tweepyauth = tweepy.OAuthHandler("API_KEY", "API_SECRET")
auth.set_access_token("ACCESS_TOKEN", "ACCESS_SECRET")
api = tweepy.API(auth)trends = api.trends_place(id=1) # 1为全球趋势ID
for trend in trends[0]["trends"]:print(f"{trend['name']}: {trend['tweet_volume']}")
- 合规要点:
- 遵守API速率限制(如Twitter 15分钟15次请求)
- 存储数据时需脱敏处理用户ID
- 定期检查API条款更新
二、数据清洗与预处理
2.1 文本数据清洗
import re
import nltk
from nltk.corpus import stopwordsdef clean_text(text):# 移除特殊字符text = re.sub(r'[^\w\s]', '', text)# 转换为小写text = text.lower()# 分词并移除停用词tokens = nltk.word_tokenize(text)stop_words = set(stopwords.words('english'))tokens = [word for word in tokens if word not in stop_words]return ' '.join(tokens)# 示例应用
dirty_text = "Hello! This is a test sentence, with punctuation."
cleaned = clean_text(dirty_text)
print(cleaned) # 输出: hello test sentence punctuation
2.2 图像数据预处理
from PIL import Image
import numpy as npdef preprocess_image(image_path, target_size=(224, 224)):# 加载图像img = Image.open(image_path)# 调整大小img = img.resize(target_size)# 转换为numpy数组img_array = np.array(img)# 归一化if len(img_array.shape) == 3: # RGB图像img_array = img_array / 255.0return img_array
2.3 噪声数据过滤
- 文本数据:使用TF-IDF过滤低频词
- 图像数据:应用OpenCV检测模糊度(Laplacian算子)
- 表格数据:基于3σ原则检测异常值
三、数据标注体系设计
3.1 图像标注规范
- 分类任务:
- 使用COCO格式标注
- 定义层级分类体系(如"动物>哺乳动物>犬科")
- 检测任务:
- 标注框坐标(xmin, ymin, xmax, ymax)
- 遮挡程度标注(0-3级)
3.2 文本标注示例
# 命名实体识别标注规范示例
entities:- PERSON: ["张三", "李四"]- ORGANIZATION: ["腾讯科技", "阿里巴巴"]- LOCATION: ["北京", "上海"]annotations:- text: "张三在腾讯科技北京分公司工作"labels:- ["张三", 0, 1, PERSON]- ["腾讯科技", 4, 7, ORGANIZATION]- ["北京", 9, 10, LOCATION]
3.3 多模态标注工具链
- LabelImg:图像检测标注
- Doccano:文本分类/序列标注
- CVAT:视频/图像标注
- Label Studio:多模态数据标注
四、质量评估与迭代
4.1 标注一致性评估
- Kappa系数:计算标注员间一致性
from sklearn.metrics import cohen_kappa_scorerater1 = [1, 0, 1, 1, 0] rater2 = [1, 1, 1, 0, 0] kappa = cohen_kappa_score(rater1, rater2) print(f"Kappa系数: {kappa:.2f}") # 输出: 0.40 - Fleiss’ Kappa:适用于多标注员场景
4.2 主动学习策略
# 基于不确定性的主动学习示例
import numpy as np
from sklearn.ensemble import RandomForestClassifierdef active_learning(X, y, budget=100):model = RandomForestClassifier()model.fit(X, y)# 计算样本不确定性probas = model.predict_proba(X)uncertainties = 1 - np.max(probas, axis=1)# 选择不确定性最高的样本selected_indices = np.argsort(uncertainties)[-budget:]return X[selected_indices], y[selected_indices]
五、合规与安全管理
5.1 数据脱敏技术
- 文本数据:正则表达式替换敏感信息
import redef anonymize_text(text):# 替换手机号text = re.sub(r'1[3-9]\d{9}', '[PHONE]', text)# 替换邮箱text = re.sub(r'\w+@\w+\.\w+', '[EMAIL]', text)return text - 图像数据:人脸模糊化处理(OpenCV GaussianBlur)
5.2 跨境传输合规
- 欧盟数据:使用标准合同条款(SCCs)
- 中国数据:通过数据出境安全评估
六、工程化实践案例
6.1 工业质检数据集构建
- 采集:工业相机+边缘计算设备
- 标注:缺陷类型分类(划痕/凹坑/污渍)
- 迭代:每周更新模型,准确率提升0.3%/周
6.2 医疗影像数据集
- 合规:通过HIPAA认证
- 标注:放射科医生+AI辅助标注
- 质量:双盲标注+专家仲裁
七、未来趋势
- 合成数据:GAN生成高保真训练数据
- 联邦学习:隐私保护下的分布式数据训练
- 自动化标注:大模型辅助标注效率提升50%+
结论
AI数据集构建已从"作坊式"生产转向"工业化"流程。通过建立标准化采集规范、自动化清洗管道、智能标注系统及合规管理体系,可将数据工程效率提升3-5倍。随着大模型时代对数据规模与质量的要求持续提升,掌握全流程数据工程能力的团队将在AI竞争中占据核心优势。未来三年,数据集构建将呈现三大趋势:
- 自动化:80%重复性标注工作由AI完成
- 合规化:全球数据治理框架统一化
- 生态化:行业数据联盟促进共享
本文提供的方法论已在实际项目中验证,适用于计算机视觉、自然语言处理、语音识别等多领域AI数据工程实践。
相关文章:
AI数据集构建:从爬虫到标注的全流程指南
AI数据集构建:从爬虫到标注的全流程指南 系统化学习人工智能网站(收藏):https://www.captainbed.cn/flu 文章目录 AI数据集构建:从爬虫到标注的全流程指南摘要引言流程图:数据集构建全生命周期一、数据采…...

Android 颜色百分比对照
本文就是简单写个demo,打印下颜色百分比的数值.方便以后使用. 1: 获取透明色 具体的代码如下: /*** 获取透明色* param percent* param red* param green* param blue* return*/public static int getTransparentColor(int percent, int red, int green, int blue) {int alp…...
AI破局:饿了么如何搅动即时零售江湖
最近,即时零售赛道打的火热,对我们的生活也产生了不少的影响。 美女同事小张就没少吐槽“他们咋样了我不知道,奶茶那么便宜,胖了五六斤不说,钱包也空了,在淘宝买奶茶的时候,换了个手机还买了不少…...
04 APP 自动化- Appium toast 元素定位列表滑动
文章目录 一、toast 元素的定位二、滑屏操作 一、toast 元素的定位 toast 元素就是简易的消息提示框,toast 显示窗口显示的时间有限,一般3秒左右 # -*- codingutf-8 -*- from time import sleep from appium import webdriver from appium.options.an…...

判断它是否引用了外部库
在一个 C# 项目中,要系统性地判断它是否引用了外部库(包括 NuGet 包、引用的 DLL、项目间依赖等),你应从以下几个关键维度入手进行检查和分析: 1. 检查 .csproj 项目文件 C# 项目使用 .csproj 文件(MSBuil…...
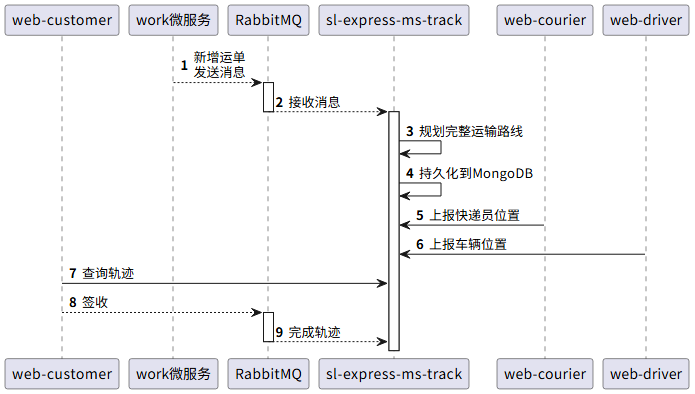
物流项目第十期(轨迹微服务)
本项目专栏: 物流项目_Auc23的博客-CSDN博客 建议先看这期: MongoDB入门之Java的使用-CSDN博客 物流项目第九期(MongoDB的应用之作业范围)-CSDN博客 业务需求 快递员取件成功后,需要将订单转成运单,用…...

Python 入门到进阶全指南:从语言特性到实战项目
一、Python 简介 Python 是一种高级、跨平台、解释型编程语言,以简洁语法和高可读性著称,既适合编程初学者快速入门,也能满足资深开发者的复杂需求。其核心特性与应用场景如下: 核心特性解析 解释型语言:无需编译即可…...

【数据库】关系数据理论--规范化
1.问题的提出 关系模式由五部分组成,是一个五元组: R(U, D, DOM, F) (1)关系名R是符号化的元组语义 (2)U为一组属性 (3)D为属性组U中的属性所来自的域 (4)DOM…...

SQL 中 JOIN 的执行顺序优化指南
SQL 中 JOIN 的执行顺序优化指南 一、JOIN 执行顺序基础原理 在 SQL 查询中,JOIN的执行顺序是查询优化的重要环节。数据库引擎会根据多种因素决定最优的 JOIN 顺序: 逻辑执行顺序:SQL 语句的书写顺序(如 FROM → WHERE → GROUP BY)并不代表实际执行顺序物理执行顺序:由查…...
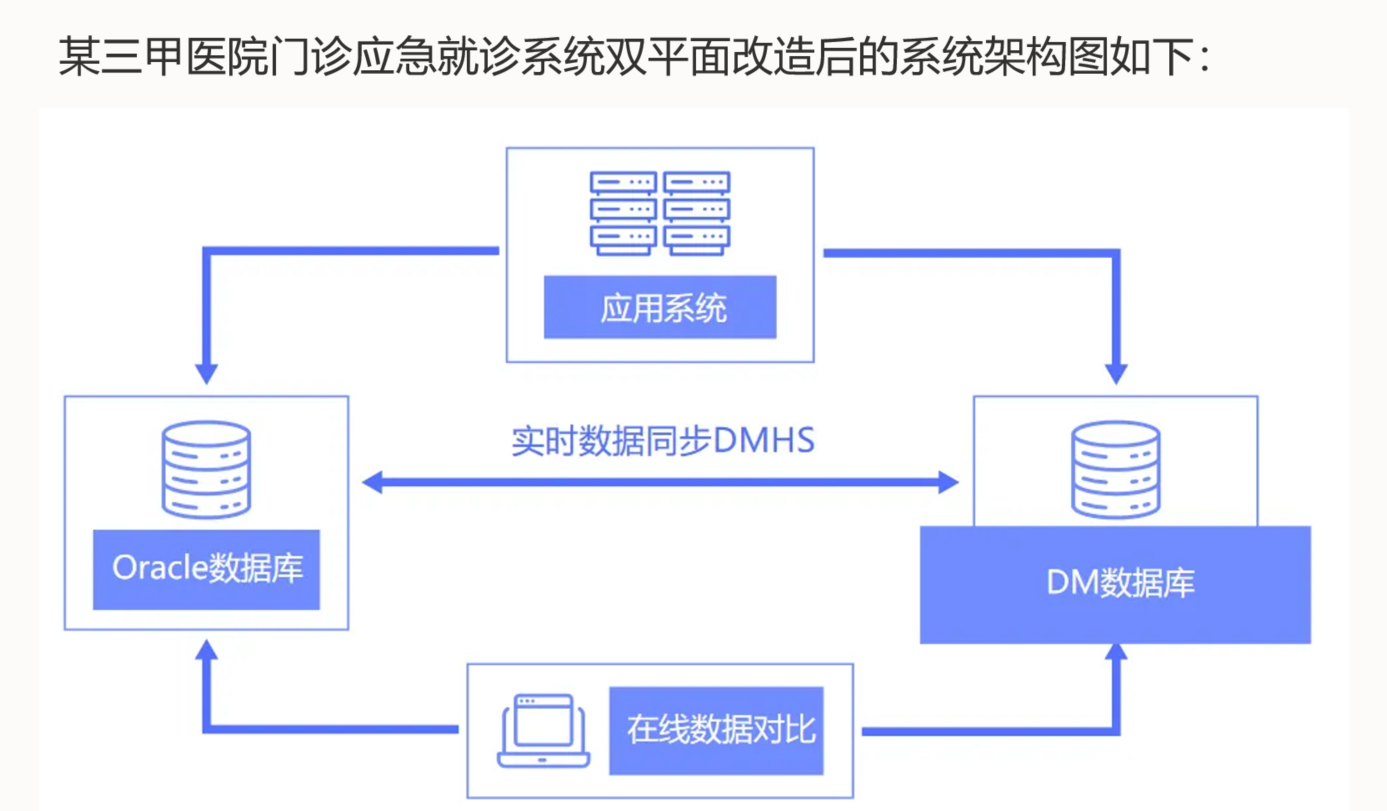
Oracle双平面适用场景讨论会议
4月28日,我在杭州组织召开了Oracle双平面会议讨论沙龙。在国产化数据库浪潮的今天,Oracle数据库作为国产数据库的应急库,在国产数据库发生故障或者性能下降时,如何更好的使用Oracle。会议主题如下: 1、背景与痛点速览&…...

OD 算法题 B卷【矩阵稀疏扫描】
文章目录 矩阵稀疏扫描 矩阵稀疏扫描 如果矩阵中的很多系数都为零,则为稀疏矩阵,给定一个矩阵,如果某行、列存在0的个数超出(包含)了行宽、列宽的一半(整除),则认为该行、列为稀疏的…...
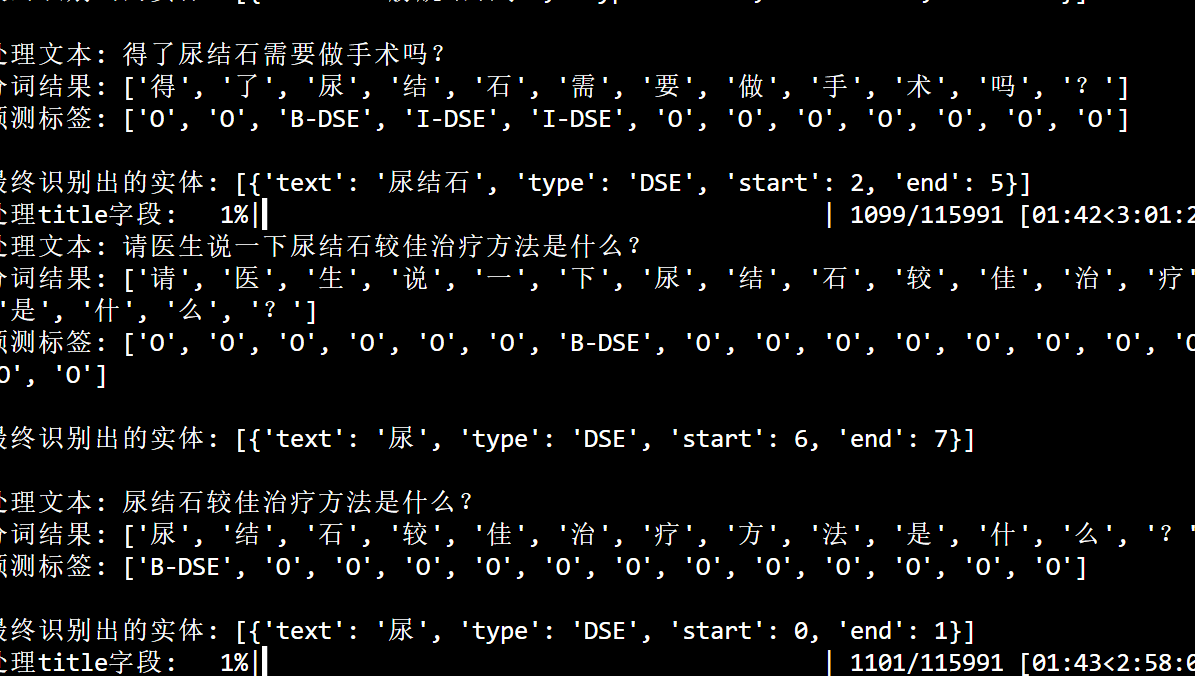
使用BERT/BiLSTM + CRF 模型进行NER进展记录~
使用代码处理数据集,发现了一些问题,以及解决办法~ 下载了一组数据集,数据存放在CSV中,GBK格式。如下: 首先对每一列直接进行NER抽取,结果非常不好: 几乎是乱抽取的,解决办法是自己创…...

HarmonyOS运动开发:精准估算室内运动的距离、速度与步幅
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在室内运动场景中,由于缺乏 GPS 信号,传统的基于卫星定位的运动数据追踪方法无法使用。因此,如何准确估算室内运动的距离、速度和步幅,…...
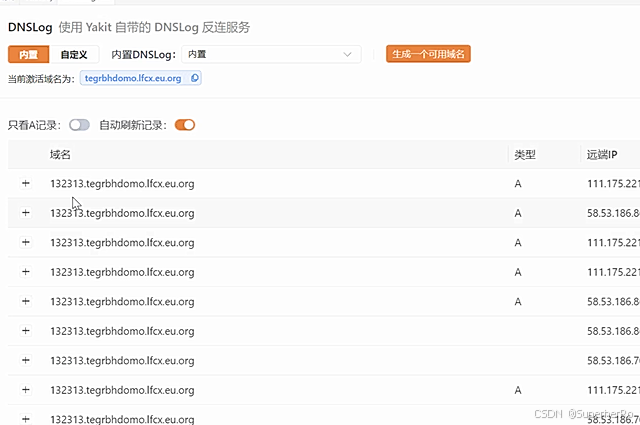
Web攻防-SQL注入高权限判定跨库查询文件读写DNS带外SecurePriv开关绕过
知识点: 1、Web攻防-SQL注入-高权限用户差异 2、Web攻防-SQL注入-跨库注入&文件读写&DNS带外 案例说明: 在应用中,数据库用户不同,可操作的数据库和文件读写权限不一,所有在注入过程中可以有更多的利用思路&a…...
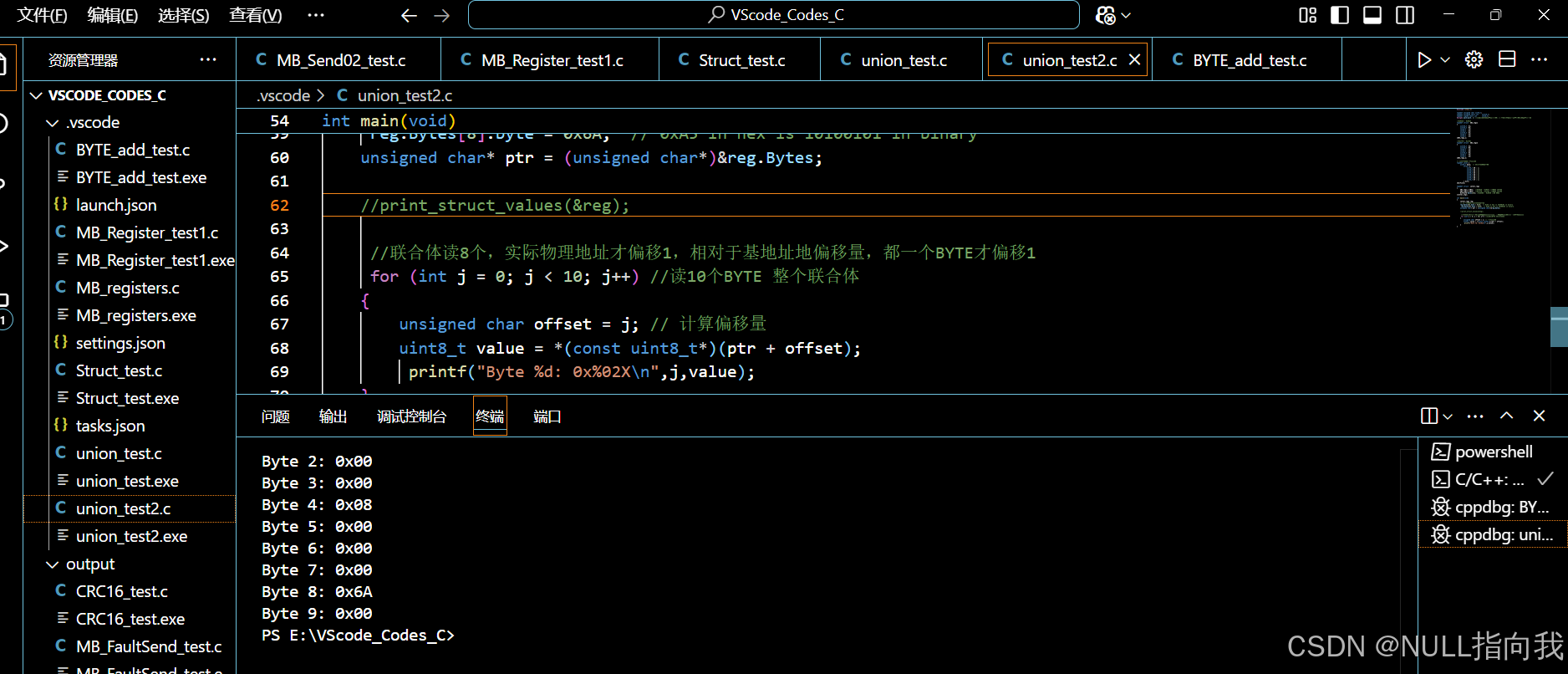
C语言数据结构笔记3:Union联合体+结构体取8位Bool量
本文衔接上文要求,新增8位bool量的获取方式。 目录 问题提出: Union联合体struct结构体(方式1): Union联合体struct结构体(方式2): BYTE方式读取: 问题提出: 在STM32单片机的编程中,无法定义Boo…...

深拷贝与浅拷贝的区别?如何手写实现一个深拷贝?
导语: “深拷贝 VS 浅拷贝”是前端面试中绕不开的经典问题,既能考察 JavaScript 基础功,又能延伸至手写代码、递归、循环引用处理等进阶话题。本文从面试官视角解析其考察重点,并详解如何手写一个实用的深拷贝函数,助你…...
)
grafana 批量视图备份及恢复(含数据源)
一、grafana 批量视图备份 import requests import json import urllib3 import osfrom requests.auth import HTTPBasicAuthfilename_folders_map "folders_map.json" type_folder "dash-folder" type_dashboard "dash-db"# Grafana服务器地…...
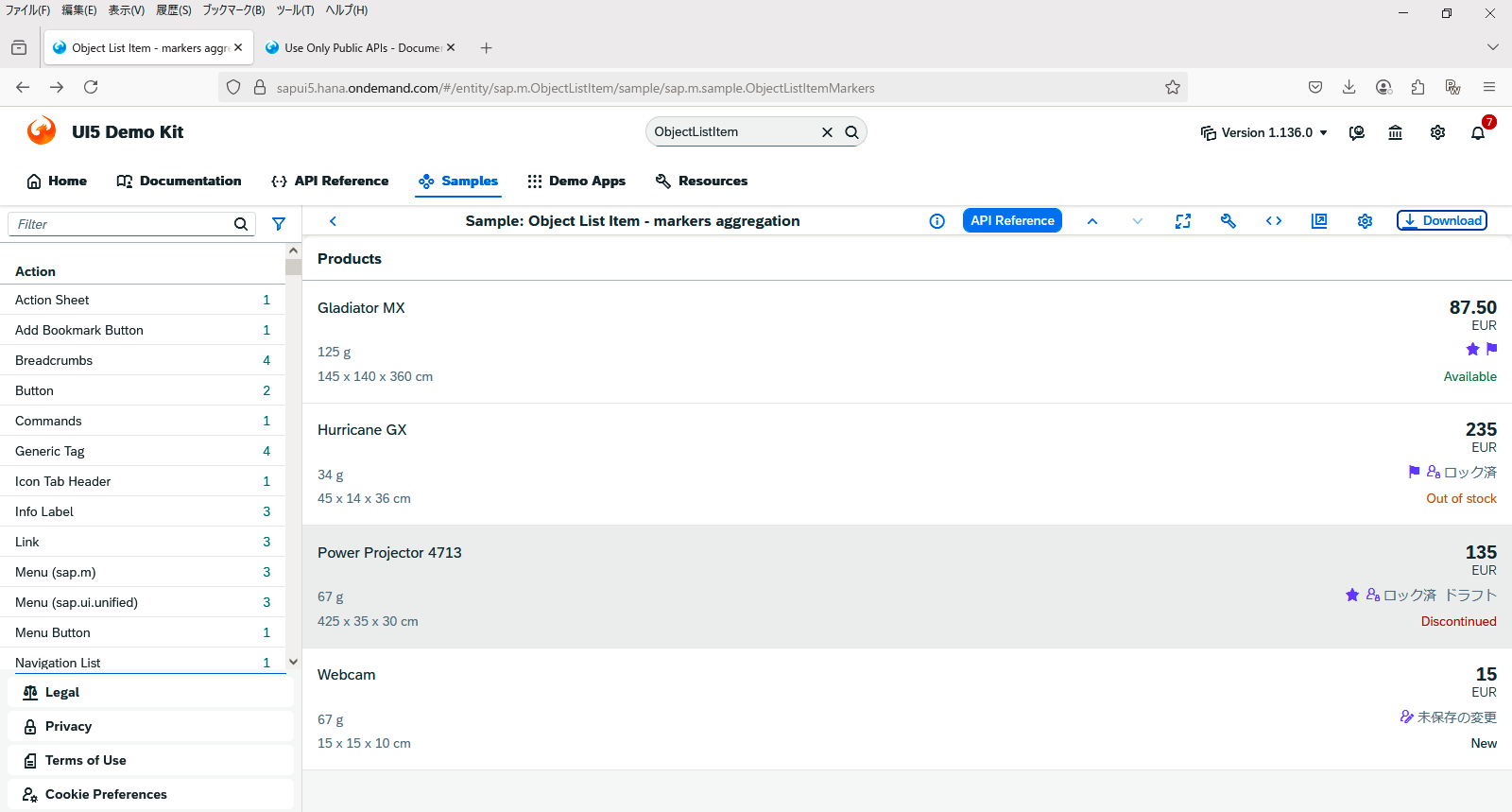
SAP学习笔记 - 开发22 - 前端Fiori开发 数据绑定(Jason),Data Types(数据类型)
上一章讲了Icons(图标),Icon Explorer。 SAP学习笔记 - 开发21 - 前端Fiori开发 Icons(图标),Icon Explorer(图标浏览器)-CSDN博客 本章继续讲SAP Fiori开发的知识。 目录 1&…...
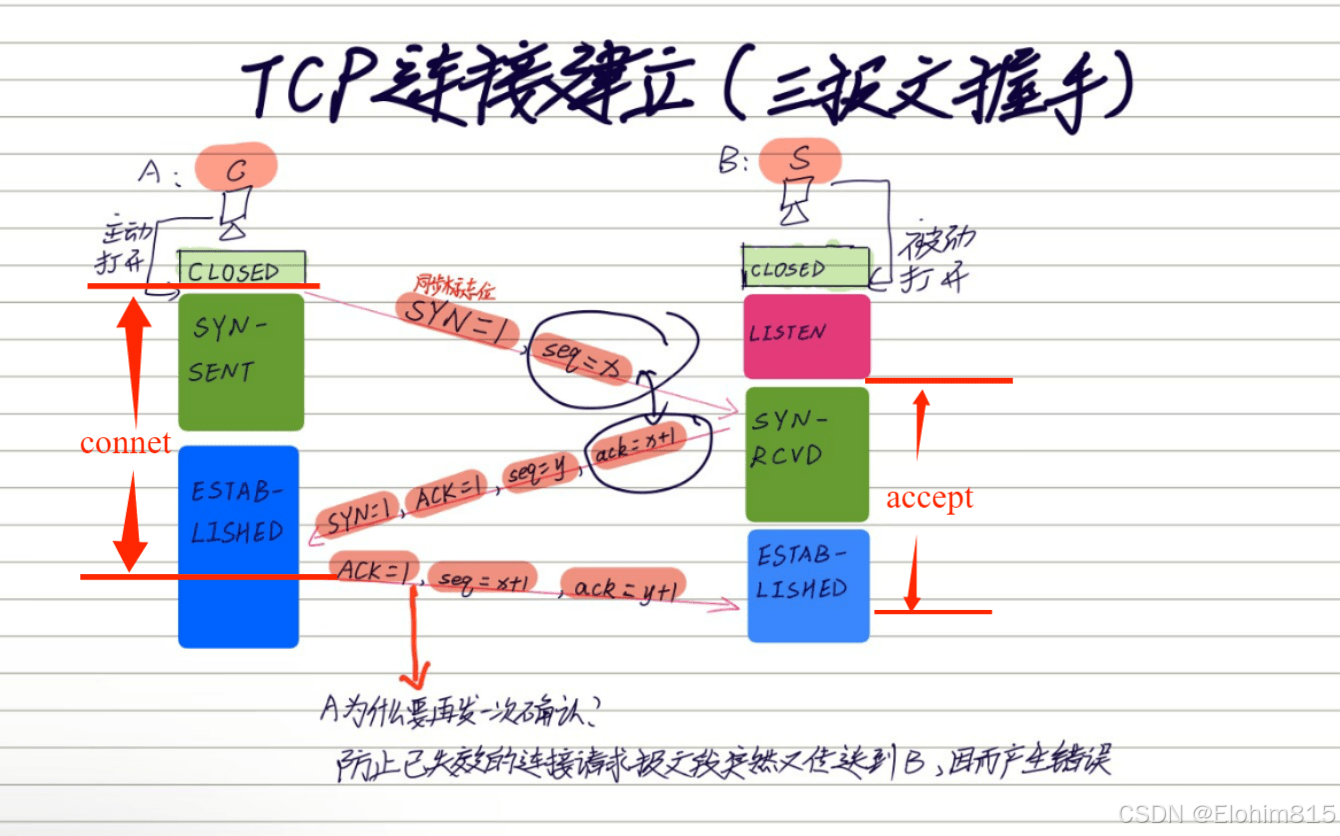
网络编程之TCP编程
基于 C/S :客户端(client)/服务器端(server) 1.流程 2. 函数接口 所有函数所需头文件: #include <sys/types.h> #include <sys/socket.h> 系统定义好了用来存储网络信息的结构体 ipv4通信使…...

C++进阶--C++11(04)
文章目录 C进阶--C11(04)lambdalambda表达式语法捕捉列表lambda的应用lambda的原理 包装器functionbind 总结结语 很高兴和大家见面,给生活加点impetus!!开启今天的编程之路!! 今天我们进一步c…...
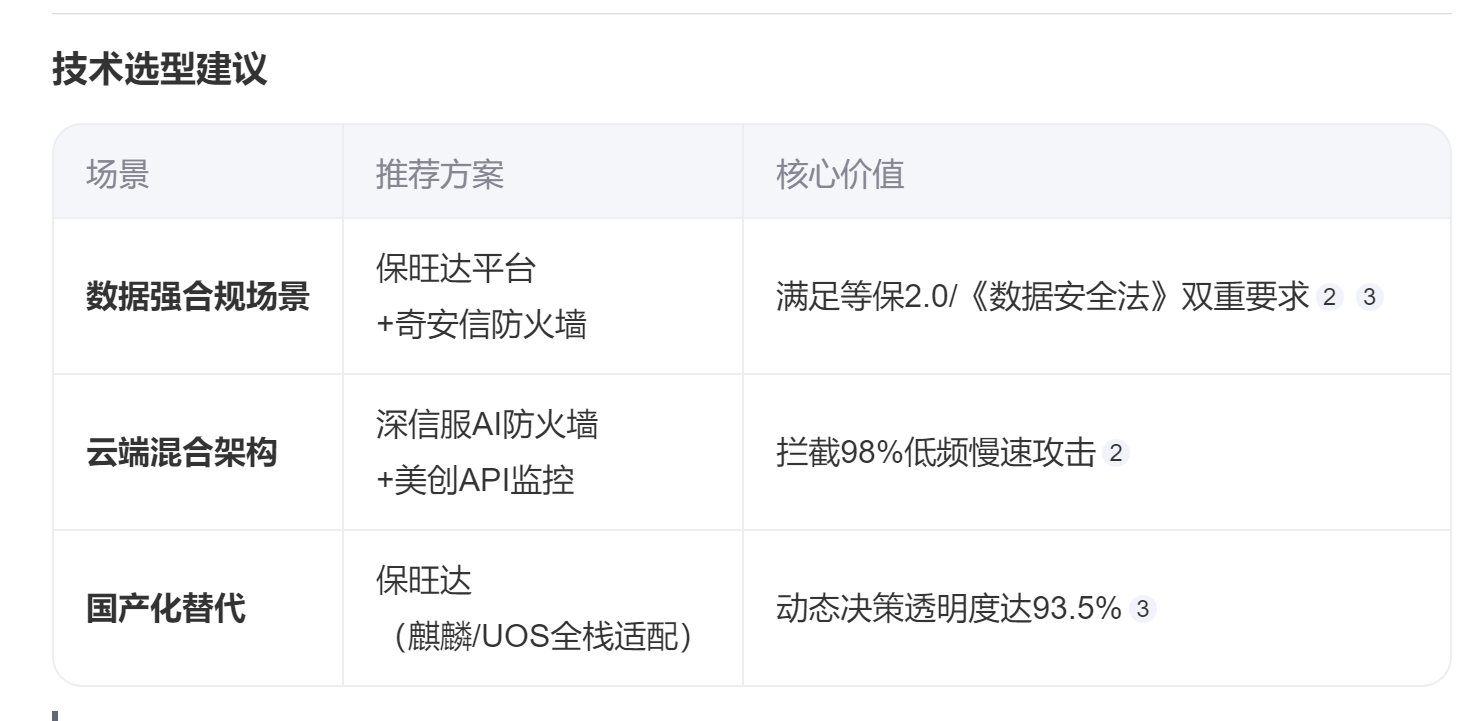
当AI遇上防火墙:新一代智能安全解决方案全景解析
在2025年网络安全攻防升级的背景下,AI与防火墙的融合正重塑安全防御体系。以下三款产品通过机器学习、行为分析等技术创新,为企业提供智能化主动防护: 1. 保旺达数据安全管控平台——AI驱动的动态治理引擎 智能分类分级:基于…...

STL 库基础概念与示例
一、STL 库基础概念与示例 1. 容器分类 顺序容器 核心特性:按元素插入顺序存储,支持下标访问(类似数组),动态扩展内存。典型容器:vector(动态数组)。适用场景:需要频繁…...
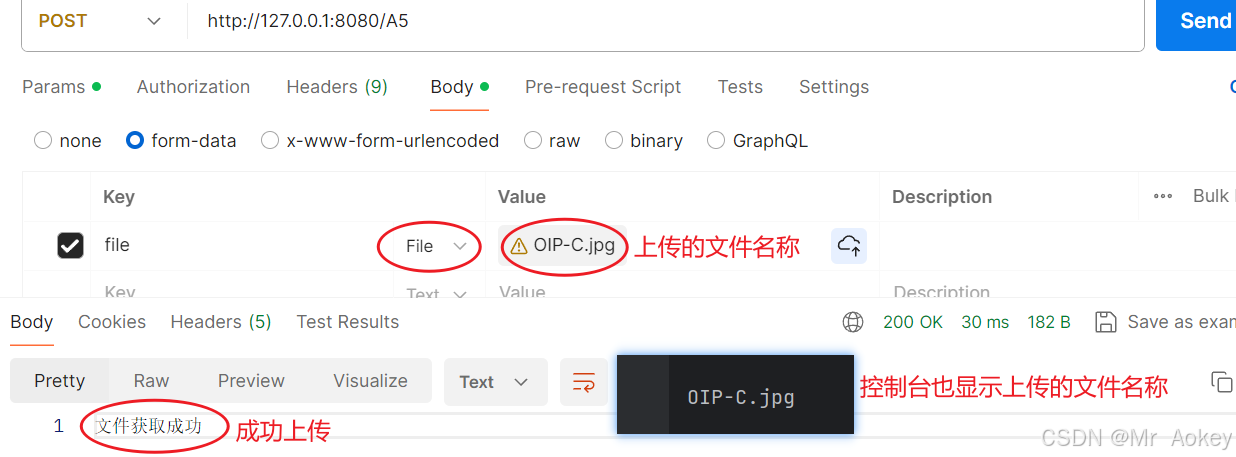
Spring MVC参数绑定终极手册:单多参/对象/集合/JSON/文件上传精讲
我们通过浏览器访问不同的路径,就是在发送不同的请求,在发送请求时,可能会带一些参数,本文将介绍了Spring MVC中处理不同请求参数的多种方式 一、传递单个参数 接收单个参数,在Spring MVC中直接用方法中的参数就可以&…...

Fluence推出“Pointless计划”:五种方式参与RWA算力资产新时代
2025年6月1日,去中心化算力平台 Fluence 正式宣布启动“Pointless 计划”——这是其《Fluence Vision 2026》战略中四项核心举措之一,旨在通过贡献驱动的积分体系,激励更广泛的社区参与,为用户带来现实世界资产(RWA&am…...

innovus: ecoAddRepeater改变hier层级解决办法
我正在「拾陆楼」和朋友们讨论有趣的话题,你⼀起来吧? 拾陆楼知识星球入口 来自星球提问: 星主,我在A/B/C/D/E/U0这个cell后面插入一个BUFF,生成的名字为A/B/C/BUFF1,少了D/E两个层级,不应该是生成A/B/C/…...

华为OD机试真题——硬件产品销售方案(2025A卷:100分)Java/python/JavaScript/C++/C语言/GO六种最佳实现
2025 A卷 100分 题型 本文涵盖详细的问题分析、解题思路、代码实现、代码详解、测试用例以及综合分析; 并提供Java、python、JavaScript、C++、C语言、GO六种语言的最佳实现方式! 2025华为OD真题目录+全流程解析/备考攻略/经验分享 华为OD机试真题《硬件产品销售方案》: 目录…...

突破数据孤岛:StarRocks联邦查询实战指南
随着企业数据生态的复杂化,跨多个数据存储系统进行联合查询的需求日益增长。本文将深入解析如何利用StarRocks构建高效的数据联邦查询体系,实现与Apache Doris和Hive数据仓库的无缝对接。 ### 一、StarRocks联邦查询架构解析 StarRocks采用分布式架构设…...

传统业务对接AI-AI编程框架-Rasa的业务应用实战(1)--项目背景即学习初衷
我的初衷:我想学习AI。具体的方向是这样的:原本传统的平台业务去对接智能体。比如发票业务,发票的开具、审核、计税、回款等。根据用户在业务系统前台界面输入若干提示词 或者 语音输入简短语音信息,可以通过智能体给出需要处理的…...

低功耗架构突破:STM32H750 与 SD NAND (存储芯片)如何延长手环续航至 14 天
低功耗架构突破:STM32H750 与 SD NAND (存储芯片)如何延长手环续航至 14 天 卓越性能强化安全高效能效图形处理优势丰富集成特性 模拟模块实时监控保障数据完整性提升安全性与可靠性测量原理采样率相关结束语 在智能皮电手环及数据存储技术不…...

CSS选择子元素
通过选择器 为所有子元素应用样式。以下是几种常见方法: 1. 选择所有直接子元素(不包括孙级) css 复制 下载 .parent > * {/* 样式规则 */color: red; } > 选择器:只匹配直接子元素 * 通配符:匹配任意类型…...