「数据分析 - Pandas 函数」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 105 篇 -
Date: 2025 - 06 - 05
Author: 郑龙浩/仟墨
Pandas 核心功能详解与示例
文章目录
- Pandas 核心功能详解与示例
- 1. 数据结构基础
- 1.1 Series 创建与操作
- 1.2 DataFrame 创建与操作
- 2. 数据选择与过滤
- 2.1 基本选择方法
- 2.2 布尔索引
- 3. 数据处理与清洗
- 3.1 缺失值处理
- 3.2 数据转换
- 4. 数据分组与聚合
- 4.1 基本分组操作
- 4.2 聚合函数
- 5. 数据合并与连接
- 5.1 concat 连接
- 5.2 merge 合并
- 6. 时间序列处理
- 7. 文件读写
- 7.1 CSV文件
- 7.2 Excel文件
- 7.3 JSON文件
1. 数据结构基础
1.1 Series 创建与操作
Series 是 Pandas 库中的一维带标签数组,可以简单理解为 Excel 中的单列数据(但功能更强大)。它是构建 DataFrame 的基础组件,也是数据操作的核心对象之一。
创建Series:
pd.Series(data=None, # 数据(列表、字典、标量等)index=None, # 索引(标签)dtype=None, # 数据类型name=None, # Series 名称copy=False, # 是否复制数据fastpath=False # 内部优化参数(通常不直接使用)
)
data是必须的,其他参数可选。index用于自定义标签,dtype控制数据类型,name用于命名 Series。copy一般不用改,除非需要避免数据被意外修改。
import pandas as pd
import numpy as np# 从列表创建
arr1 = pd.Series([1, 2, 3]) # 自动生成整数索引
print(arr1)
'''
0 1
1 2
2 3
dtype: int64
'''arr2 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) # 自定义索引
print(arr2)
'''
a 1
b 2
c 3
dtype: int64
'''arr3 = pd.Series([1, 2, 3], dtype=float) # 指定float类型
print(arr3)
'''
0 1.0
1 2.0
2 3.0
dtype: float64
'''# 从字典创建(自动使用字典键作为索引)
arr4 = pd.Series({'a': 1, 'b': 2, 'c': 3})
print(arr4)
'''
a 1
b 2
c 3
dtype: int64
'''data = [10, 20, 30]
idx = ['A', 'B', 'C']
arr5 = pd.Series(data=data, index=idx, name='名字')
print(arr5)
'''
A 10
B 20
C 30
Name: 名字, dtype: int64
'''
Series操作:
import pandas as pd
import numpy as np
#
# # 从列表创建
# arr1 = pd.Series([1, 2, 3]) # 自动生成整数索引
# print(arr1)
# '''
# 0 1
# 1 2
# 2 3
# dtype: int64
# '''
#
# arr2 = pd.Series([1, 2, 3], index=['a', 'b', 'c']) # 自定义索引
# print(arr2)
# '''
# a 1
# b 2
# c 3
# dtype: int64
# '''
#
# arr3 = pd.Series([1, 2, 3], dtype=float) # 指定float类型
# print(arr3)
# '''
# 0 1.0
# 1 2.0
# 2 3.0
# dtype: float64
# '''
#
# # 从字典创建(自动使用字典键作为索引)
# arr4 = pd.Series({'a': 1, 'b': 2, 'c': 3})
# print(arr4)
# '''
# a 1
# b 2
# c 3
# dtype: int64
# '''data = [10, 20, 30]
idx = ['A', 'B', 'C']
arr5 = pd.Series(data=data, index=idx, name='名字')
print(arr5)
'''
A 10
B 20
C 30
Name: 名字, dtype: int64
'''# 索引访问某个元素
print(arr5['B']) # 20# 向量化运算
print(arr5 * 2) # 所有元素 * 2
'''
A 20
B 40
C 60
Name: 名字, dtype: int64
'''# 布尔索引
print(arr5[arr5 > 15]) # 取出 arr5 中,大于15的元素
'''
B 20
C 30
Name: 名字, dtype: int64
'''
1.2 DataFrame 创建与操作
DataFrame 是 Pandas 库中最核心的二维表格型数据结构,相当于 Python 中的"电子表格"或"SQL表"。它的主要作用是为数据分析和处理提供高效灵活的工具,以下是其核心作用和特点
创建DataFrame:
import pandas as pd
import numpy as np# 从字典创建
df1 = pd.DataFrame({'A': 1.0,'B': pd.Timestamp('2025-06-05'),'C': pd.Series(1, index=list(range(4))),'D': np.array([3] * 4),'E': pd.Categorical(["test", "train", "test", "train"]),'F': 'aaa'
})
print(df1)
"""A B C D E F
0 1.0 2025-06-05 1 3 test aaa
1 1.0 2025-06-05 1 3 train aaa
2 1.0 2025-06-05 1 3 test aaa
3 1.0 2025-06-05 1 3 train aaa
"""# 从二维数组创建
df2 = pd.DataFrame(np.random.randn(6, 4), columns=list('ABCD'))
print(df2.head(2))
"""A B C D
0 -1.043791 -0.519411 -0.204117 -1.169345
1 -0.386409 0.978335 -0.092777 -1.832369
"""
DataFrame操作:
# 查看前几行
print(df2.head(2))# 查看统计信息
print(df2.describe())
"""A B C D
count 6.000000 6.000000 6.000000 6.000000
mean 0.073711 -0.431125 -0.687758 -0.233103
std 0.843157 0.922818 0.779887 0.973118
min -0.861849 -2.104569 -1.509059 -1.135632
25% -0.611510 -0.600794 -1.368714 -1.006602
50% 0.022072 -0.228039 -0.767252 -0.386671
75% 0.658444 0.041933 -0.034326 0.461706
max 1.212112 0.567020 0.276232 1.491390
"""# 转置
print(df2.T)
2. 数据选择与过滤
2.1 基本选择方法
# 选择列
print(df2['A']) # 选择单列
print(df2[['A', 'C']]) # 选择多列# 使用loc按标签选择
print(df2.loc[0:3, ['A', 'B']])
"""A B
0 0.469112 -0.282863
1 1.212112 -0.173215
2 -0.861849 -2.104569
3 0.721555 -0.706771
"""# 使用iloc按位置选择
print(df2.iloc[1:3, 0:2])
"""A B
1 1.212112 -0.173215
2 -0.861849 -2.104569
"""
2.2 布尔索引
# 简单条件过滤
print(df2[df2['A'] > 0])
"""A B C D
0 0.469112 -0.282863 -1.509059 -1.135632
1 1.212112 -0.173215 0.119209 -1.044236
3 0.721555 -0.706771 -1.039575 0.271860
5 0.404705 0.577046 -1.715002 -1.039268
"""# 多条件组合
print(df2[(df2['A'] > 0) & (df2['B'] < 0)])
"""A B C D
0 0.469112 -0.282863 -1.509059 -1.135632
1 1.212112 -0.173215 0.119209 -1.044236
3 0.721555 -0.706771 -1.039575 0.271860
"""
3. 数据处理与清洗
3.1 缺失值处理
# 创建含缺失值的DataFrame
df3 = pd.DataFrame({'A': [1, 2, np.nan, 4],'B': [5, np.nan, np.nan, 8],'C': [10, 20, 30, 40]
})
print(df3)
"""A B C
0 1.0 5.0 10
1 2.0 NaN 20
2 NaN NaN 30
3 4.0 8.0 40
"""# 检测缺失值
print(df3.isnull())
"""A B C
0 False False False
1 False True False
2 True True False
3 False False False
"""# 删除缺失值
print(df3.dropna())
"""A B C
0 1.0 5.0 10
3 4.0 8.0 40
"""# 填充缺失值
print(df3.fillna(value=0))
"""A B C
0 1.0 5.0 10
1 2.0 0.0 20
2 0.0 0.0 30
3 4.0 8.0 40
"""
3.2 数据转换
# 应用函数
print(df3['A'].apply(lambda x: x**2 if not pd.isnull(x) else 0))
"""
0 1.0
1 4.0
2 0.0
3 16.0
Name: A, dtype: float64
"""# 元素级转换
print(df3.applymap(lambda x: '%.1f' % x if not pd.isnull(x) else 'NaN'))
"""A B C
0 1.0 5.0 10.0
1 2.0 NaN 20.0
2 NaN NaN 30.0
3 4.0 8.0 40.0
"""
4. 数据分组与聚合
4.1 基本分组操作
df4 = pd.DataFrame({'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],'C': np.random.randn(8),'D': np.random.randn(8)
})
print(df4)
"""A B C D
0 foo one 0.469112 -0.861849
1 bar one -0.282863 -2.104569
2 foo two -1.509059 -0.494929
3 bar three -1.135632 1.071804
4 foo two 1.212112 0.721555
5 bar two -0.173215 -0.706771
6 foo one 0.119209 -1.039575
7 foo three -1.044236 0.271860
"""# 单列分组
grouped = df4.groupby('A')
print(grouped.mean())
"""C D
A
bar -0.530570 -0.579845
foo -0.150572 -0.280588
"""# 多列分组
print(df4.groupby(['A', 'B']).mean())
"""C D
A B
bar one -0.282863 -2.104569three -1.135632 1.071804two -0.173215 -0.706771
foo one 0.294161 -0.950712three -1.044236 0.271860two -0.148473 0.113313
"""
4.2 聚合函数
# 多种聚合函数
print(grouped.agg(['sum', 'mean', 'std']))
"""C D sum mean std sum mean std
A
bar -1.591710 -0.530570 0.526860 -1.739536 -0.579845 1.591985
foo -0.752862 -0.150572 1.113308 -1.402938 -0.280588 0.739965
"""# 不同列应用不同聚合
print(grouped.agg({'C': 'sum', 'D': ['min', 'max']}))
"""C D sum min max
A
bar -1.591710 -2.104569 1.071804
foo -0.752862 -1.039575 0.721555
"""
5. 数据合并与连接
5.1 concat 连接
df5 = pd.DataFrame(np.random.randn(3, 4), columns=['A', 'B', 'C', 'D'])
df6 = pd.DataFrame(np.random.randn(2, 3), columns=['A', 'B', 'C'])# 纵向连接
print(pd.concat([df5, df6]))
"""A B C D
0 1.075770 -0.109050 1.643563 -1.469388
1 0.357021 -0.674600 -1.776904 -0.968914
2 -1.294524 0.413738 0.276662 -0.472035
0 -0.013960 -0.362543 -0.006154 NaN
1 -0.923061 0.895717 0.805244 NaN
"""# 横向连接
print(pd.concat([df5, df6], axis=1))
"""A B C D A B C
0 1.075770 -0.109050 1.643563 -1.469388 -0.013960 -0.362543 -0.006154
1 0.357021 -0.674600 -1.776904 -0.968914 -0.923061 0.895717 0.805244
2 -1.294524 0.413738 0.276662 -0.472035 NaN NaN NaN
"""
5.2 merge 合并
left = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'A': ['A0', 'A1', 'A2', 'A3'],'B': ['B0', 'B1', 'B2', 'B3']
})right = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K3'],'C': ['C0', 'C1', 'C2', 'C3'],'D': ['D0', 'D1', 'D2', 'D3']
})# 内连接
print(pd.merge(left, right, on='key'))
"""key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
"""# 左连接
print(pd.merge(left, right, how='left', on='key'))
"""key A B C D
0 K0 A0 B0 C0 D0
1 K1 A1 B1 C1 D1
2 K2 A2 B2 C2 D2
3 K3 A3 B3 C3 D3
"""
6. 时间序列处理
# 创建时间序列
date_rng = pd.date_range(start='1/1/2025', end='1/08/2025', freq='D')
df7 = pd.DataFrame(date_rng, columns=['date'])
df7['data'] = np.random.randint(0,100,size=(len(date_rng)))
print(df7)
"""date data
0 2025-01-01 95
1 2025-01-02 27
2 2025-01-03 63
3 2025-01-04 60
4 2025-01-05 49
5 2025-01-06 42
6 2025-01-07 96
7 2025-01-08 99
"""# 重采样
df7.set_index('date', inplace=True)
print(df7.resample('3D').mean())
"""data
date
2025-01-01 61.666667
2025-01-04 50.333333
2025-01-07 97.500000
"""
7. 文件读写
7.1 CSV文件
# 写入CSV
df7.to_csv('sample.csv')# 读取CSV
df_read = pd.read_csv('sample.csv')
print(df_read.head())
"""date data
0 2025-01-01 95
1 2025-01-02 27
2 2025-01-03 63
3 2025-01-04 60
4 2025-01-05 49
"""
7.2 Excel文件
# 写入Excel
df7.to_excel('sample.xlsx', sheet_name='Sheet1')# 读取Excel
df_excel = pd.read_excel('sample.xlsx')
print(df_excel.head())
7.3 JSON文件
# 写入JSON
df7.to_json('sample.json')# 读取JSON
df_json = pd.read_json('sample.json')
print(df_json.head())
相关文章:

「数据分析 - Pandas 函数」【数据分析全栈攻略:爬虫+处理+可视化+报告】
- 第 105 篇 - Date: 2025 - 06 - 05 Author: 郑龙浩/仟墨 Pandas 核心功能详解与示例 文章目录 Pandas 核心功能详解与示例1. 数据结构基础1.1 Series 创建与操作1.2 DataFrame 创建与操作 2. 数据选择与过滤2.1 基本选择方法2.2 布尔索引 3. 数据处理与清洗3.1 缺失值处理3.…...
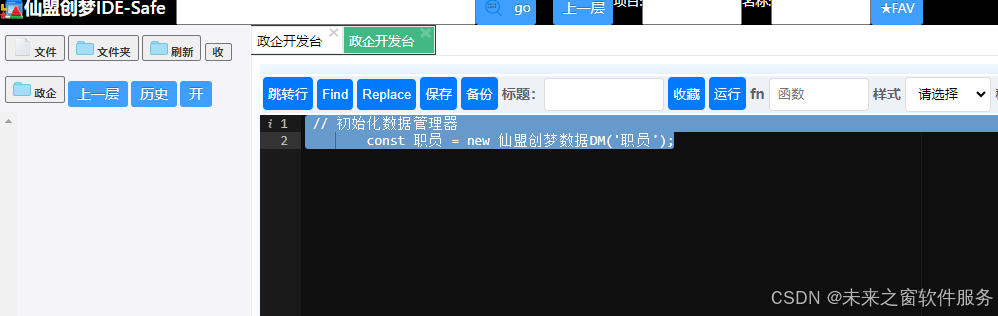
JAVASCRIPT 简化版数据库--智能编程——仙盟创梦IDE
// 数据模型class 仙盟创梦数据DM {constructor(key) {this.key ${STORAGE_PREFIX}${key};this.data this.加载数据();}加载数据() {return JSON.parse(localStorage.getItem(this.key)) || [];}保存() {localStorage.setItem(this.key, JSON.stringify(this.data));}新增(it…...

YAML在自动化测试中的三大核心作用
YAML在自动化测试中的三大核心作用 配置中心:管理测试环境/参数 # config.yaml environments:dev: url: "http://dev.api.com"timeout: 5prod:url: "https://api.com"timeout: 10数据驱动:分离测试数据与脚本 # test_data.yaml lo…...
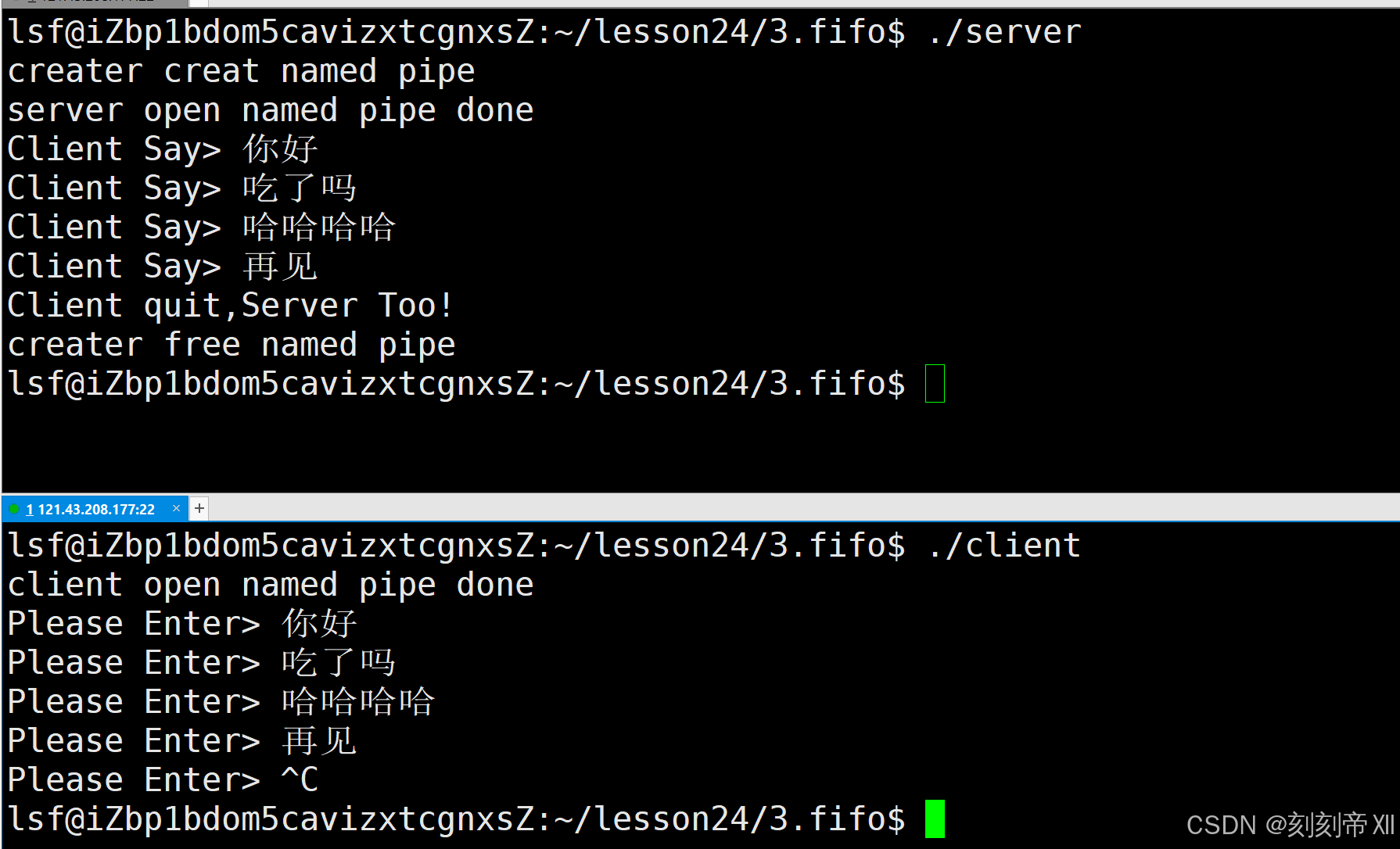
命名管道实现本地通信
目录 命名管道实现通信 命名管道通信头文件 创建命名管道mkfifo 删除命名管道unlink 构造函数 以读方式打开命名管道 以写方式打开命名管道 读操作 写操作 析构函数 服务端 客户端 运行结果 命名管道实现通信 命名管道通信头文件 #pragma#include <iostream> #include &l…...
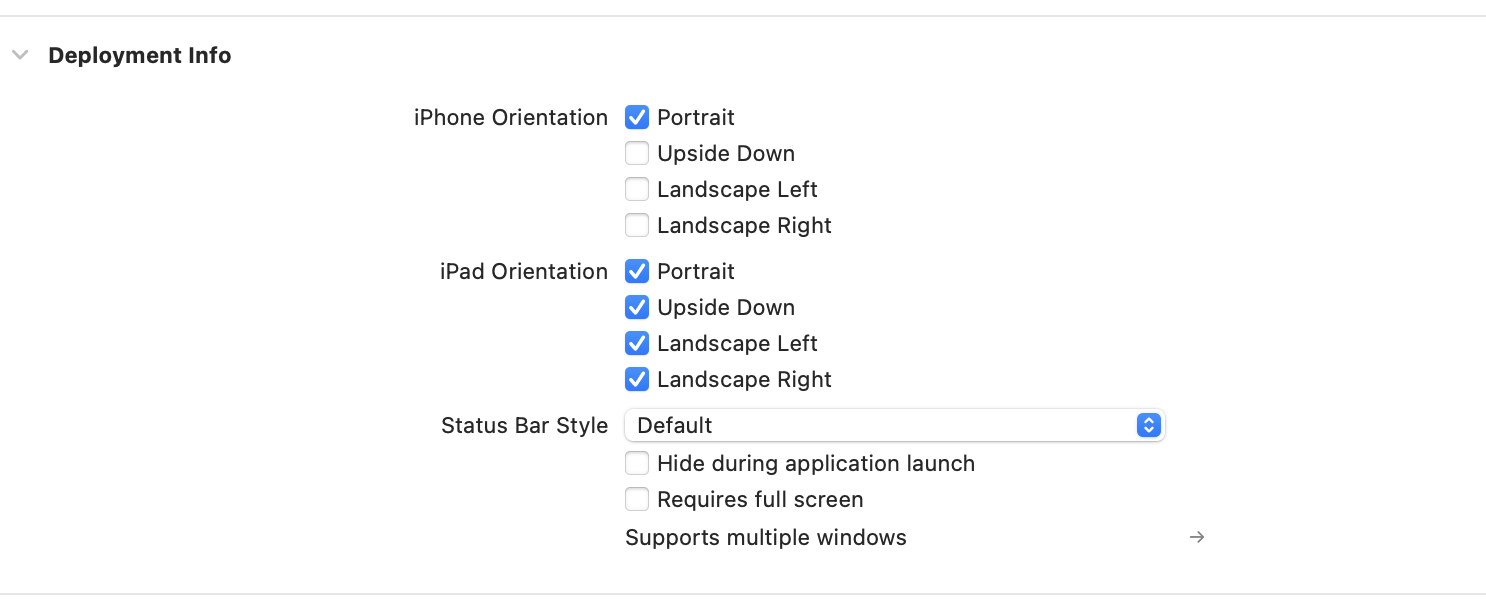
iOS上传应用包错误问题 “Invalid bundle. The “UIInterfaceOrientationPortrait”“
引言 在开发 iOS 应用的整个生命周期中,打包上传到 App Store 是一个至关重要的步骤。每一次提交,Xcode 都会在后台执行一系列严格的校验流程,包括对 Info.plist 配置的检查、架构兼容性的验证、资源完整性的审查等。如果某些关键项配置不当…...
)
【LeetCode】1061. 按字典序排列最小的等效字符串(并查集)
LeetCode 1061. 按字典序排列最小的等效字符串 (中等) 题目链接:LeetCode 1061. 按字典序排列最小的等效字符串 (中等) 题目描述 给出长度相同的两个字符串s1 和 s2 ,还有一个字符串 baseStr 。 其中 s1[i] 和 s2[i] 是一组等价字符。 举个例子&#…...

猎板厚铜PCB工艺能力如何?
在电子产业向高功率、高集成化狂奔的今天,电路板早已不是沉默的配角。当5G基站、新能源汽车、工业电源等领域对电流承载、散热效率提出严苛要求时,一块能够“扛得住大电流、耐得住高温”的厚铜PCB,正成为决定产品性能的关键拼图。而在这条赛道…...
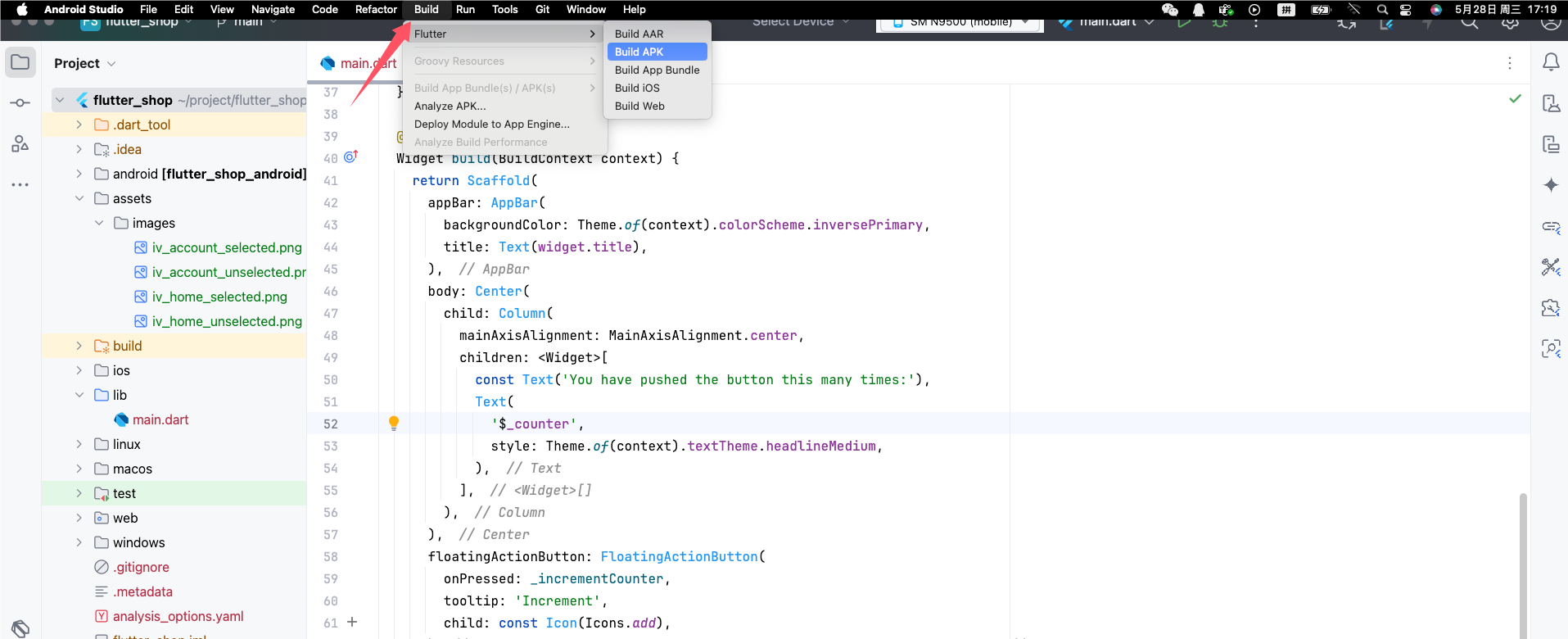
Flutter快速上手,入门教程
目录 一、参考文档 二、准备工作 下载Flutter SDK: 配置环境 解决环境报错 zsh:command not found:flutter 执行【flutter doctor】测试效果 安装Xcode IOS环境 需要安装brew,通过brew安装CocoaPods. 复制命令行,打开终端 分别执行…...

算法:前缀和
1.【模版】前缀和 【模板】前缀和_牛客题霸_牛客网 这道题如果使用暴力解法时间复杂度为O(n*m),会超时,所以要使用前缀和算法。 前缀和->快速求出数组中某一个连续区间的和。 第一步:预处理出一个前缀和数组 dp。 dp[i]表示[1, i] 区间…...
DEVICENET转MODBUS TCP网关与AB数据输出模块的高效融合方案研究
在工业自动化领域,多样化的设备通常采用不同的通信协议,这为系统集成带来了显著的挑战。特别是在需要将遵循DeviceNet协议的设备与基于MODBUS TCP协议的系统进行互连时,这一挑战尤为突出。AB数据输出作为一种功能卓越的DeviceNet分布式输入/输…...
牛客小白月赛113
前言:这场的E题补的我头皮都发麻了。 A. 2025 题目大意:一个仅有‘-’‘*’组成的字符串,初始有一个sum 1, 从左到右依次遍历字符串,遇到-就让sum--;遇到*就让sum* 2,问sum有没有可能大于等于…...
Mac版本Android Studio配置LeetCode插件
第一步:Android Studio里面找到Settings,找到Plugins,在Marketplace里面搜索LeetCode Editor。 第二步:安装对应插件,并在Tools->LeetCode Plugin页面输入帐号和密码。 理论上,应该就可以使用了。但是&a…...

电子电路基础1(杂乱)
电路基础知识 注意:电压源与电流源的表现形式 注意:在同一根导线上电势相等 电阻电路的等效变换 电子元器件基础 电阻...

rocketmq延迟消息的底层原理浅析
rocketmq延迟消息的底层原理 消息实体 延时消息是指允许消息在指定延迟时间后才被消费者消费 Apache RocketMQ 中,消息的核心实体类是 org.apache.rocketmq.common.message.Message public class Message implements Serializable {private String topic; …...

【openssl】升级为3.3.1,避免安全漏洞
本文档旨在形成 对Linux系统openssl版本进行升级 的搭建标准操作过程,搭建完成后,实现 openssl 达到3.3以上版本,避免安全漏洞 效果。 一、查看当前版本 版本不高于3.1的,均需要升级。 # 服务器上运行以下命令,查看…...
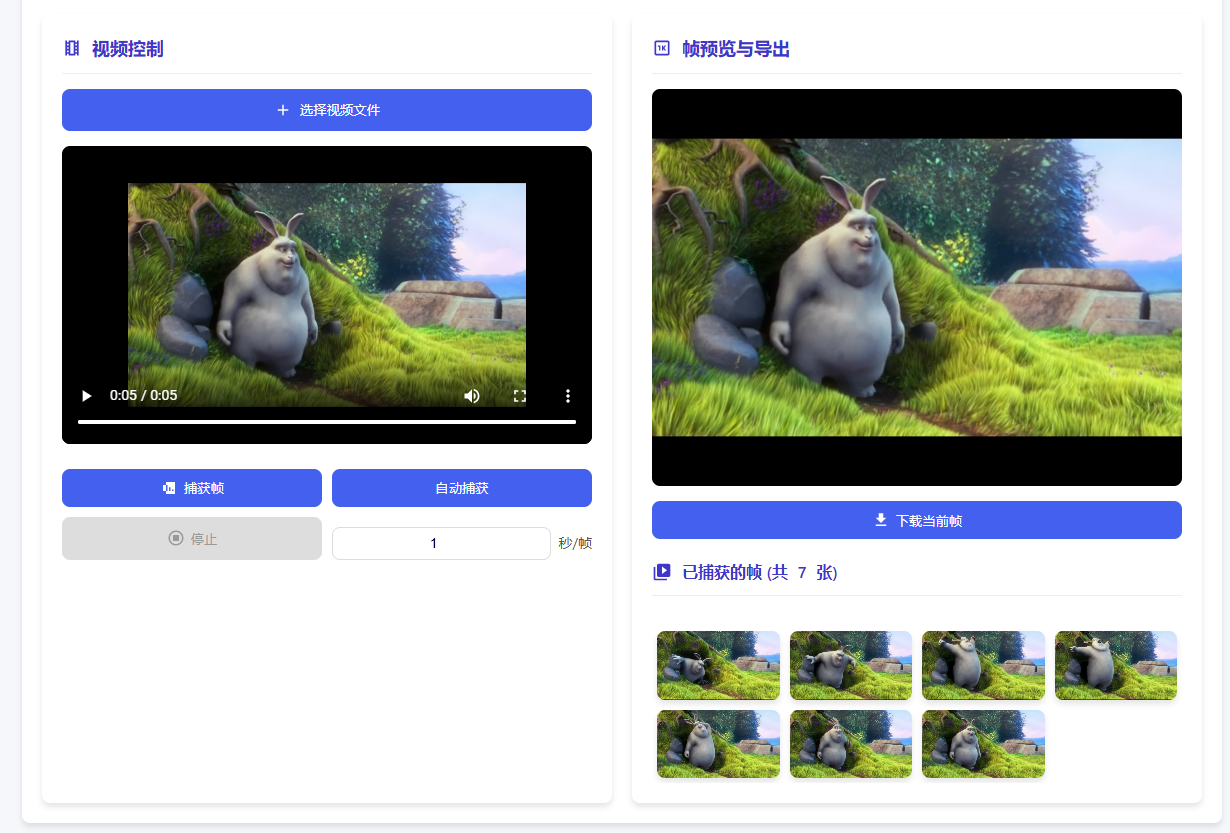
使用 HTML +JavaScript 从零构建视频帧提取器
在视频编辑、内容分析和多媒体处理领域,常常需要从视频中提取关键帧。手动截取不仅效率低下,还容易遗漏重要画面。本文介绍的视频帧提取工具通过 HTML5 技术栈实现了一个完整的浏览器端解决方案,用户可以轻松选择视频文件并进行手动或自动帧捕…...

基于若依前后分离版-用户密码错误锁定
sys_config配置参数 user.password.maxRetryCount:最大错误次数 user.password.lockTime:锁定时长 //SysLoginController//登录 PostMapping("/login") public AjaxResult login(RequestBody LoginBody loginBody) {AjaxResult ajax AjaxR…...
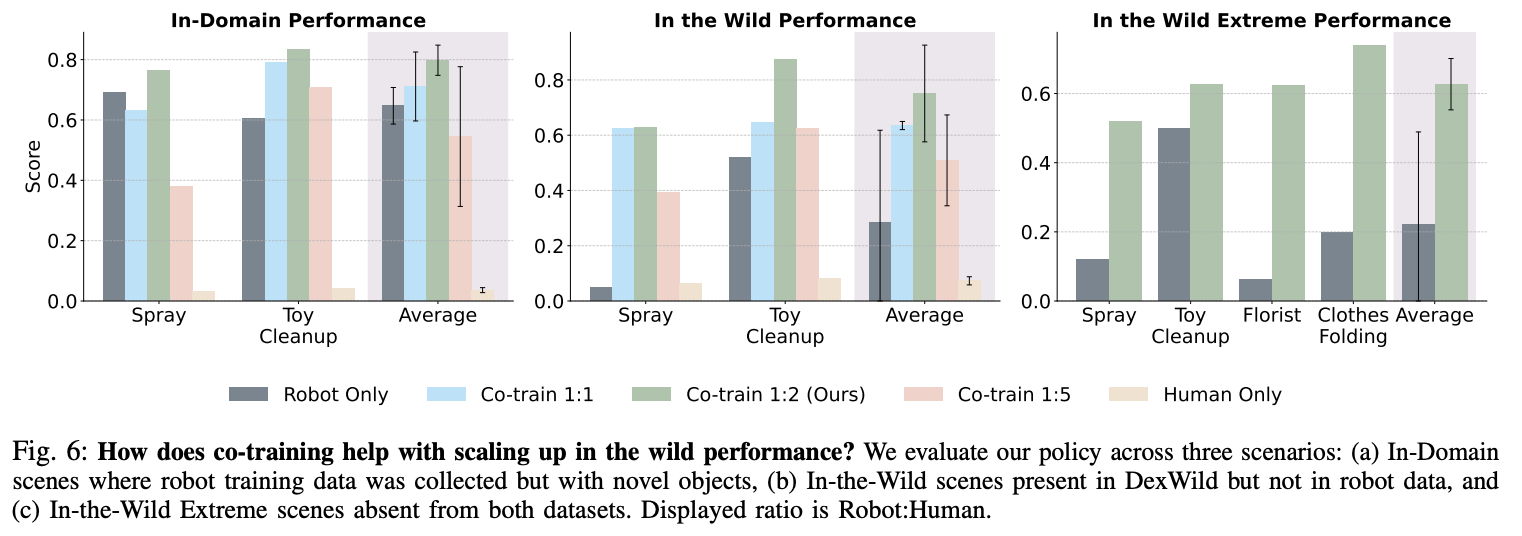
论文速读《DexWild:野外机器人策略的灵巧人机交互》
项目链接:https://dexwild.github.io/ 论文链接:https://arxiv.org/pdf/2505.07813 0. 简介 2025年5月,卡内基梅隆大学(CMU)发布了一篇突破性论文《DexWild: Dexterous Human Interactions for In-the-Wild Robot Pol…...
Bug问题
一、list 页面 import React, { useEffect, useState } from react; import { shallowEqual, useHistory, useSelector } from dva; import { Button, message } from choerodon-ui/pro; import formatterCollections from hzero-front/lib/utils/intl/formatterCollections; …...
【数据结构】5. 双向链表
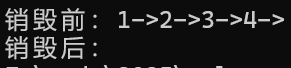
文章目录 一、链表的分类1、双向链表的结构 二、双向链表的实现0、准备工作1、初始化2、打印3、尾插4、头插5、尾删6、头删7、查找8、在指定位置之后插入数据9、删除指定位置10、销毁 一、链表的分类 链表总共分为8种,具体的分组方式如图所示: 带头指的…...
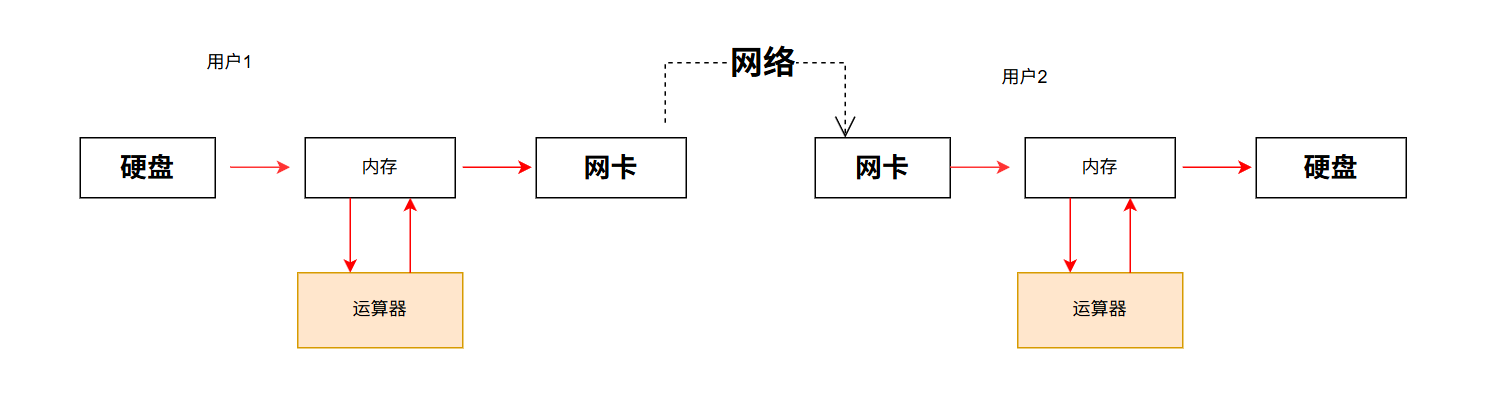
【Linux手册】冯诺依曼体系结构
目录 前言 五大组件 数据信号 存储器(内存)有必要吗 常见面试题 前言 冯诺依曼体系结构是当代计算机基本架构,冯诺依曼体系有五大组件,通过这五大组件直观的描述了计算机的工作原理;学习冯诺依曼体系可以让给我们更…...
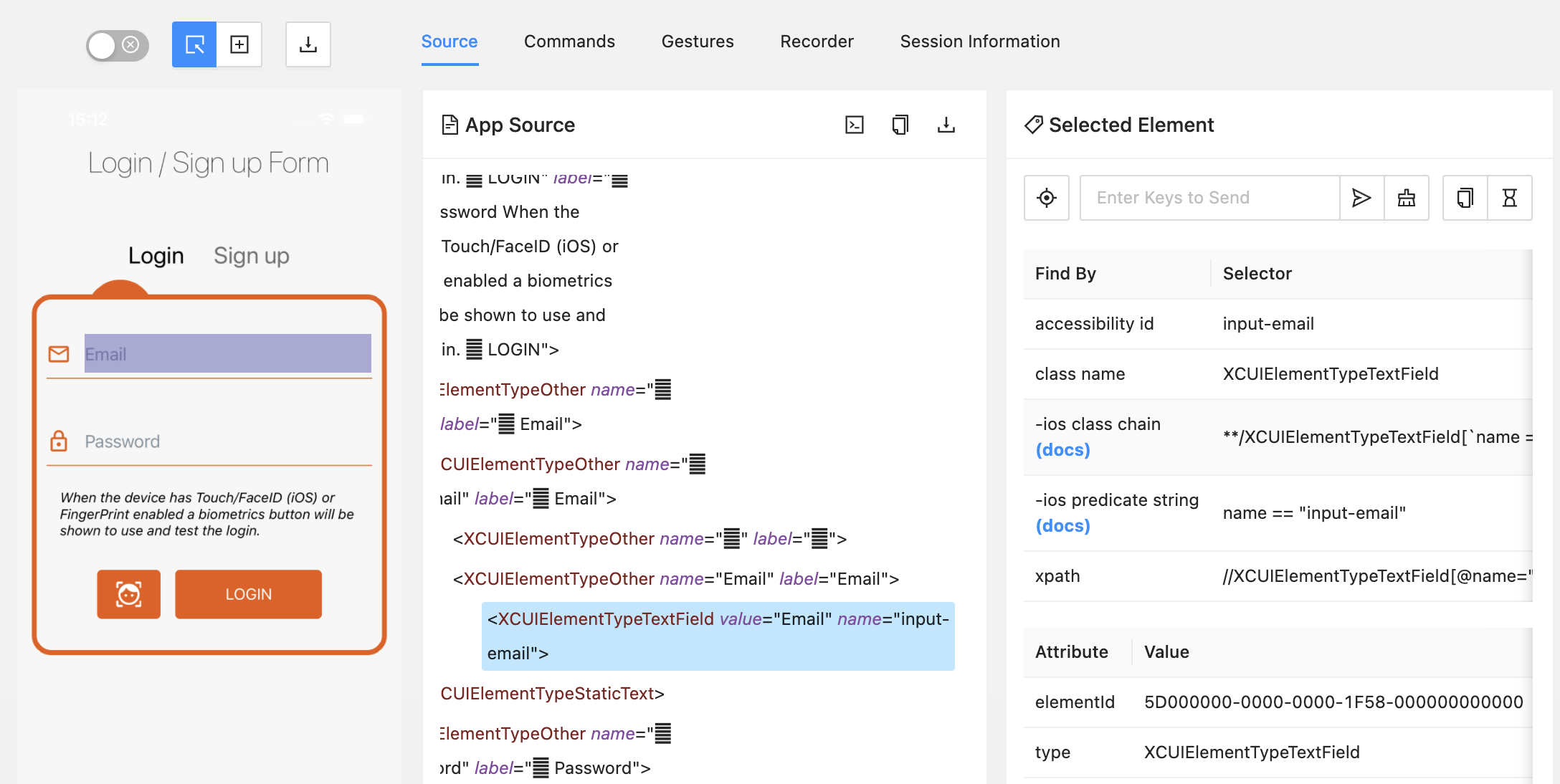
Mobile App UI自动化locator
在开展mobile app UI层自动化测试时,编写目标元素的locator是比较耗时的一个环节,弄清楚locator背后的逻辑,可以有效降低UI层测试维护成本。此篇博客以webdriverioappium作为UI自动化工具为例子,看看有哪些selector方法࿰…...
)
PaloAlto-Expedition OS命令注入漏洞复现(CVE-2025-0107)
免责申明: 本文所描述的漏洞及其复现步骤仅供网络安全研究与教育目的使用。任何人不得将本文提供的信息用于非法目的或未经授权的系统测试。作者不对任何由于使用本文信息而导致的直接或间接损害承担责任。如涉及侵权,请及时与我们联系,我们将尽快处理并删除相关内容。 前…...

(LeetCode 每日一题) 1061. 按字典序排列最小的等效字符串 (并查集)
题目:1061. 按字典序排列最小的等效字符串 思路:使用并查集,来将等价的字符连起来,形成一棵树。这棵树最小的字母,就代表整颗树,时间复杂度0(n),细节看注释。 C版本: class Solutio…...

linux 安装mysql8.0;支持国产麒麟,统信uos系统
一:使用我已经改好的mysql linux mysql8.0解压可用,点我下载 也在国产麒麟系统,统信uos系统也测试过,可用; 下载后,上传mysql.tar.gz 然后使用root角色去执行几个命令即可;数据库密码…...
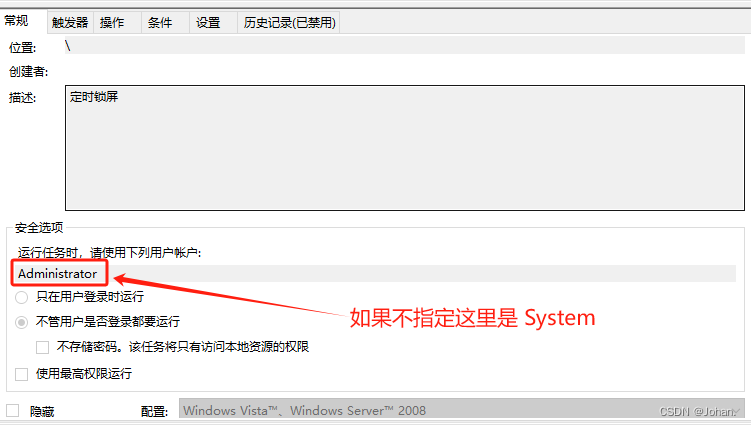
C#实现远程锁屏
前言 这是一次提前下班没有锁屏进而引发的一次思考后的产物,思考的主要场景是当人离开电脑后,怎么能控制电脑锁屏,避免屏幕上的聊天记录被曝光。 首先想到通过系统的电源计划设置闲置超时时间熄屏,这可能是最接近场景的解决方案&a…...

历史记录隐藏的安全风险
引言 在数字化生活与工作场景中,历史记录功能广泛存在于浏览器、办公软件、移动应用等各类平台。它通过记录用户的搜索内容、操作痕迹、访问路径等信息,为用户提供便捷的操作体验和个性化服务。然而,这种看似便利的功能背后,却隐藏…...

SpringBoot3整合MySQL8的注意事项
版权声明 本文原创作者:谷哥的小弟作者博客地址:http://blog.csdn.net/lfdfhl 注意事项 1、请添加添加如下依赖: <dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><…...

网络安全大模型理解
一、网络安全大模型的概述 网络安全大模型是一种用于识别和应对各种网络安全威胁的模型。它通过分析网络数据包、网络行为等信息,识别潜在的网络安全事件,并采取相应的措施进行防御。网络安全大模型主要包括以下几个部分: 1. 数据预处理&am…...

智语心桥:当AI遇上“星星的孩子”,科技如何点亮沟通之路?
目录: 引言:当科技的温度,遇见“星星的孩子”“智语心桥”:一座为孤独症儿童搭建的AI沟通之桥核心技术探秘:AI如何赋能“读心”与“对话”?个性化魔法:AI如何实现“千人千面”的精准干预?应用场景畅想:从家庭到机构,AI的全方位支持为什么是“智语心桥”?——价值、可…...