【机器学习】主成分分析 (PCA)
目录
一、基本概念
二、数学推导
2.1 问题设定:寻炸最大方差的投影方向
2.2 数据中心化
2.3 目标函数:最大化投影后的方差
2.4 约束条件
2.5 拉格朗日乘子法
编辑
2.6 主成分提取
2.7 降维公式
三、SVD
四、实际案例分析
一、基本概念
主成分分析(PCA)是一种经典的降维技术,广泛应用于机器学习和数据分析中。其核心目标是通过线性变换将高维数据投影到低维空间,同时尽可能保留数据的方差(即信息量)。PCA通过找到一组新的正交基(称为主成分),使数据在这些基上的投影具有最大方差,从而实现降维。
- 降维的目的:高维数据通常包含冗余信息或噪声,PCA通过保留主要信息(高方差方向)来减少维度,降低计算复杂度和过拟合风险。
- 正交性:主成分之间是正交的,确保降维后的特征不相关。
- 方差最大化:主成分的方向是数据协方差矩阵的特征向量,对应的特征值表示该方向的方差大小。
二、数学推导
2.1 问题设定:寻炸最大方差的投影方向
假定有n个样本,每个样本是d维的特征向量,记为
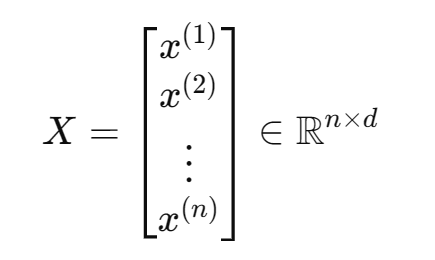
目标:找一个单位向量 w,使得所有样本在 w 上的投影后的方差
2.2 数据中心化
将数据零均值化:

处理后的数据矩阵 X 是 维的,每行是一个样本,且均值为0
2.3 目标函数:最大化投影后的方差
将样本 投影到方向 w上:
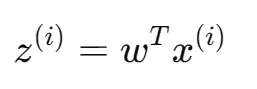
投影后的所有样本为向量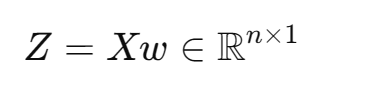
目标是最大化 Z 的方差: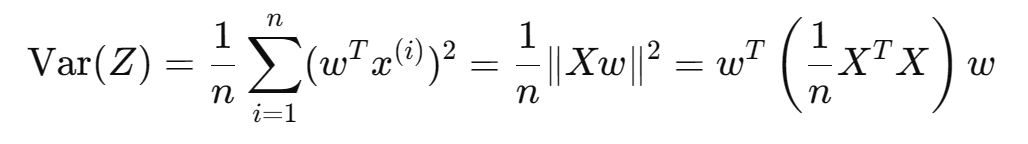
设协方差矩阵: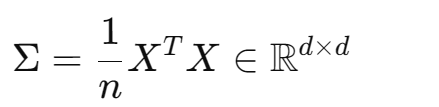
所以目标函数变为:最大化
2.4 约束条件
约束w为单位向量![]()
2.5 拉格朗日乘子法
构造拉格朗日函数
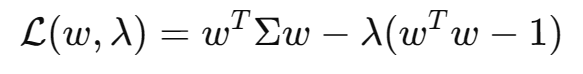
对w求导并令其为0
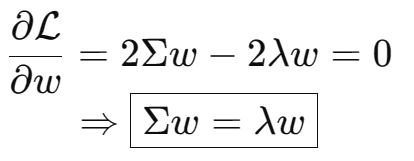
2.6 主成分提取
是对称正定矩阵,因此存在d个正交的特征向量
,以及对应的特征值
- 第一主成分:
(最大方差方向)
- 第二主成分:
,且与
正交
- 以此类推
2.7 降维公式
将前 k个特征向量组成投影矩阵 ,原始样本 X 的降维结果为:
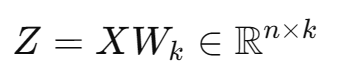
实际案例演示
有如下2D数据集(每一行是一个样本,两个特征
,
):
(1)数据中心化(零均值)
计算均值
:
每个样本减去均值:
(2)计算协方差矩阵
(3)求协方差矩阵的特征值和特征向量
求
的特征值与特征向量:
【具体求解过程】
①求特征值(解特征方程)
,满足:
即有:
行列式展开:
解方程得:
②求特征向量
对于每个特征值
以
为例:
解方程组可得:
(4)投影数据到主成分轴
只保留第一主成分
例如第一个样本:
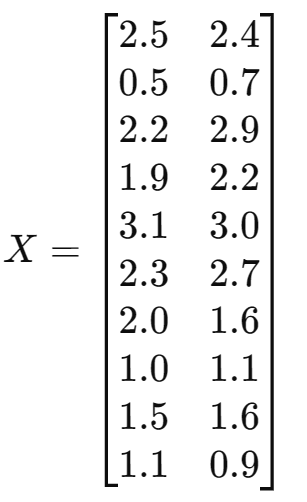
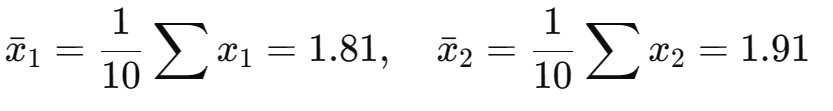

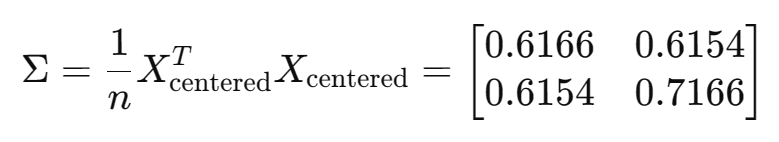

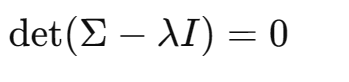

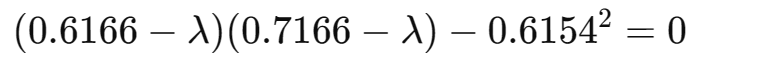
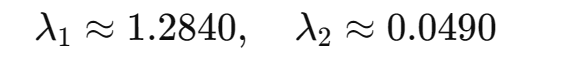
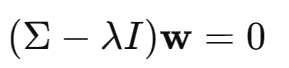
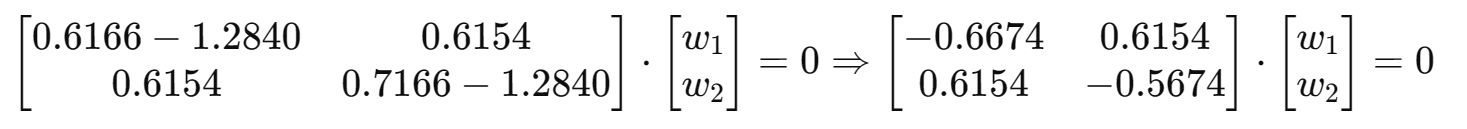
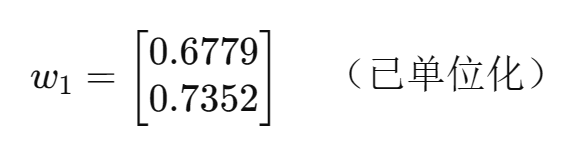
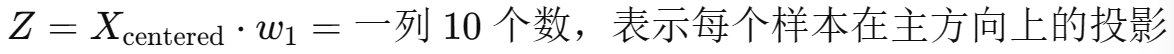
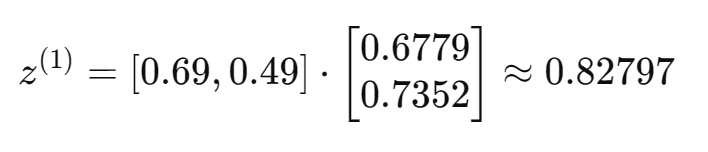
三、SVD
SVD 全称为 Singular Value Decomposition,即奇异值分解,是矩阵分解的一种形式:
对于任意的实矩阵,都可以分解为:
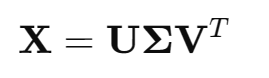
是列正交矩阵,即
是对角矩阵,对角线上的值就是奇异值(从大到小排列)
是行正交矩阵,即
SVD 与 PCA 的关系
- PCA 本质上就是对协方差矩阵做特征分解
- 而协方差矩阵
,其特征分解其实就等价于对 X 做SVD:
因此
- V的列就是PCA的主成分方向(特征向量)
的对角线元素就是协方差矩阵的特征值
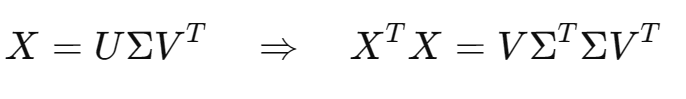
四、实际案例分析
本实验使用 ORL Faces 人脸数据集,通过手动实现的主成分分析(PCA)算法对高维人脸图像数据进行降维处理。代码通过 Python 实现,加载 ORL Faces 数据集(包含 40 个类别的灰度人脸图片,每类约 10 张,格式为 .pgm),执行 PCA 降维,保留前 50 个主成分,并可视化降维后的数据分布以及原始图片与重建图片的对比。实验路径为 D:/Desktop/Code/ML/ML/PCA/ORL_Faces/ORL_Faces,假设图片尺寸为 112×92 112 \times 92 112×92,展平后每张图片为 10,304 维向量。
主要步骤包括:
- 数据加载:读取 ORL Faces 数据集中的 .pgm 图片,展平为一维向量,构建数据矩阵 X X X(形状 N×D N \times D N×D,其中 N≈400 N \approx 400 N≈400,D=112×92=10,304 D = 112 \times 92 = 10,304 D=112×92=10,304)。
- 数据标准化:对数据进行零均值、单位方差标准化。
- 手动 PCA:
- 计算协方差矩阵并进行特征值分解。
- 选择前 50 个主成分(特征向量),投影数据到低维空间。
- 计算解释方差比,评估降维效果。
- 可视化:
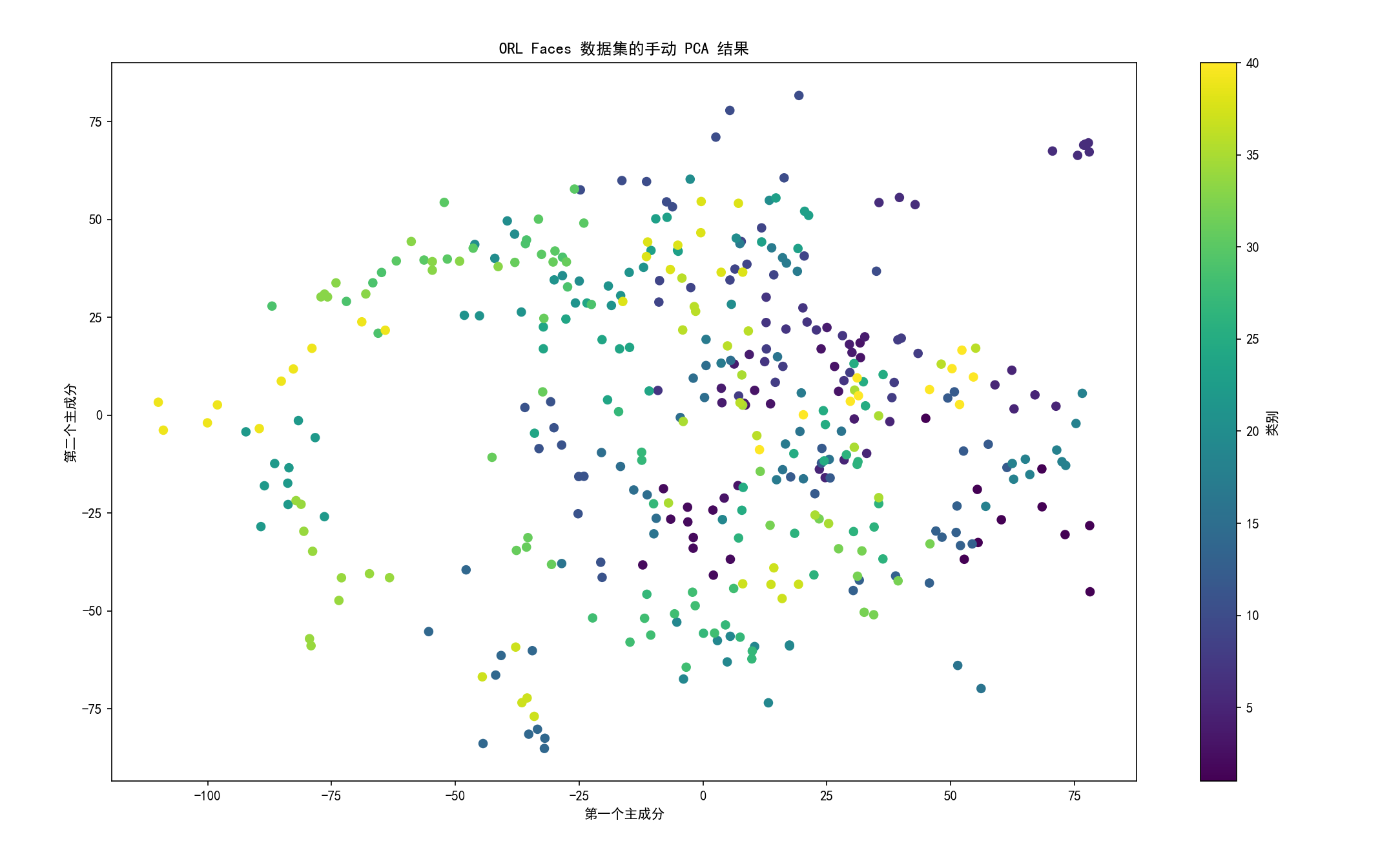
- 绘制前两个主成分的散点图,展示数据在低维空间的分布。
- 随机选择 5 张图片,比较原始图片与 PCA 重建图片的视觉效果。
- 数据保存:将降维后的数据保存为 X_pca_manual.npy。
实验代码:
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt# 1. 加载ORL_Faces数据集
def load_images(base_path):data = []labels = []image_paths = [] # 保存图片路径以便后续显示if not os.path.exists(base_path):raise FileNotFoundError(f"数据集目录不存在: {base_path}")print(f"正在查找数据集: {base_path}")for i in range(1, 41): # s1 to s40folder = os.path.join(base_path, f's{i}')if not os.path.exists(folder):print(f"警告: 子文件夹不存在,跳过: {folder}")continueprint(f"正在处理文件夹: {folder}")for filename in os.listdir(folder):if filename.endswith('.pgm'):img_path = os.path.join(folder, filename)try:img = Image.open(img_path).convert('L') # 转换为灰度图img_array = np.array(img).flatten() # 展平为一维向量data.append(img_array)labels.append(i) # 记录类别image_paths.append(img_path) # 记录图片路径except Exception as e:print(f"加载图片 {img_path} 出错: {e}")if not data:raise ValueError("未找到任何有效的 .pgm 图片。")return np.array(data), np.array(labels), image_paths# 2. 手动实现PCA
def manual_pca(X, n_components):# 标准化数据X_mean = np.mean(X, axis=0)X_std = np.std(X, axis=0)X_std_data = (X - X_mean) / X_std# 计算协方差矩阵cov_matrix = np.cov(X_std_data.T)# 特征值分解eigenvalues, eigenvectors = np.linalg.eigh(cov_matrix)# 按特征值从大到小排序idx = np.argsort(eigenvalues)[::-1]eigenvalues = eigenvalues[idx]eigenvectors = eigenvectors[:, idx]# 计算解释方差比explained_variance_ratio = eigenvalues / np.sum(eigenvalues)print(f"解释方差比: {np.sum(explained_variance_ratio[:n_components]):.4f}")# 选择前n_components个特征向量selected_vectors = eigenvectors[:, :n_components]# 投影到主成分空间X_pca = np.dot(X_std_data, selected_vectors)# 返回重建所需的数据return X_pca, selected_vectors, X_mean, X_std, explained_variance_ratio# 3. 可视化原始和重建图片
def visualize_reconstruction(original_data, reconstructed_data, image_paths, img_shape, num_samples=5):# 随机选择 num_samples 张图片indices = np.random.choice(original_data.shape[0], num_samples, replace=False)# 设置支持中文的字体plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 创建子图fig, axes = plt.subplots(num_samples, 2, figsize=(8, num_samples * 4))if num_samples == 1:axes = [axes] # 确保单张图片时 axes 可迭代for i, idx in enumerate(indices):# 原始图片original_img = original_data[idx].reshape(img_shape)axes[i, 0].imshow(original_img, cmap='gray')axes[i, 0].set_title(f'原始图片 (ID: {idx})')axes[i, 0].axis('off')# 重建图片reconstructed_img = reconstructed_data[idx].reshape(img_shape)axes[i, 1].imshow(reconstructed_img, cmap='gray')axes[i, 1].set_title(f'PCA 重建图片 (ID: {idx})')axes[i, 1].axis('off')plt.suptitle('原始图片与 PCA 重建图片对比')plt.tight_layout(rect=[0, 0, 1, 0.95])plt.show()# 4. 主程序
def main():# 数据集路径base_path = 'D:/Desktop/Code/ML/ML/PCA/ORL_Faces/ORL_Faces' # 请确认实际路径try:X, y, image_paths = load_images(base_path)except Exception as e:print(f"加载图片失败: {e}")return# 保存原始数据和图片尺寸X_original = X.copy()img_shape = (112, 92) # ORL Faces 图片尺寸,通常为 112x92# 应用手动PCAn_components = 50 # 降维后的维度X_pca, selected_vectors, X_mean, X_std, explained_variance = manual_pca(X, n_components)# 重建数据X_reconstructed = np.dot(X_pca, selected_vectors.T) # 逆投影X_reconstructed = X_reconstructed * X_std + X_mean # 恢复标准化前的尺度# 设置支持中文的字体plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# 可视化前两个主成分plt.scatter(X_pca[:, 0], X_pca[:, 1], c=y, cmap='viridis')plt.xlabel('第一个主成分')plt.ylabel('第二个主成分')plt.title('ORL Faces 数据集的手动 PCA 结果')plt.colorbar(label='类别')plt.show()# 可视化原始和重建图片visualize_reconstruction(X_original, X_reconstructed, image_paths, img_shape, num_samples=5)# 保存降维后的数据np.save('X_pca_manual.npy', X_pca)if __name__ == '__main__':main()实验结果:


相关文章:
【机器学习】主成分分析 (PCA)
目录 一、基本概念 二、数学推导 2.1 问题设定:寻炸最大方差的投影方向 2.2 数据中心化 2.3 目标函数:最大化投影后的方差 2.4 约束条件 2.5 拉格朗日乘子法 编辑 2.6 主成分提取 2.7 降维公式 三、SVD 四、实际案例分析 一、基本概念 主…...
二叉树-104.二叉树的最大深度-力扣(LeetCode)
一、题目解析 这里需要注意根节点的深度是1,也就是说计算深度的是从1开始计算的 二、算法原理 解法1:广度搜索,使用队列 解法2:深度搜索,使用递归 当计算出左子树的深度l,与右子树的深度r时,…...

物料转运人形机器人适合应用于那些行业?解锁千行百业的智慧物流革命
当传统物流设备困于固定轨道,当人力搬运遭遇效率与安全的天花板,物料转运人形机器人正以颠覆性姿态重塑产业边界。富唯智能凭借GRID大模型驱动的"感知-决策-执行"闭环系统,让物料流转从机械输送升级为智慧调度——这不仅是工具的革…...

k8s开发webhook使用certmanager生成证书
1.创建 Issuer apiVersion: cert-manager.io/v1 kind: Issuer metadata:name: selfsigned-issuernamespace: default spec:selfSigned: {}2.Certificate(自动生成 TLS 证书) apiVersion: cert-manager.io/v1 kind: Certificate metadata:name: webhook…...
时序预测模型测试总结
0.背景描述 公司最近需要在仿真平台上增加一些AI功能,针对于时序数据,想到的肯定是时序数据处理模型,典型的就两大类:LSTM 和 tranformer 。查阅文献,找到一篇中石化安全工程研究院有限公司的文章,题目为《…...
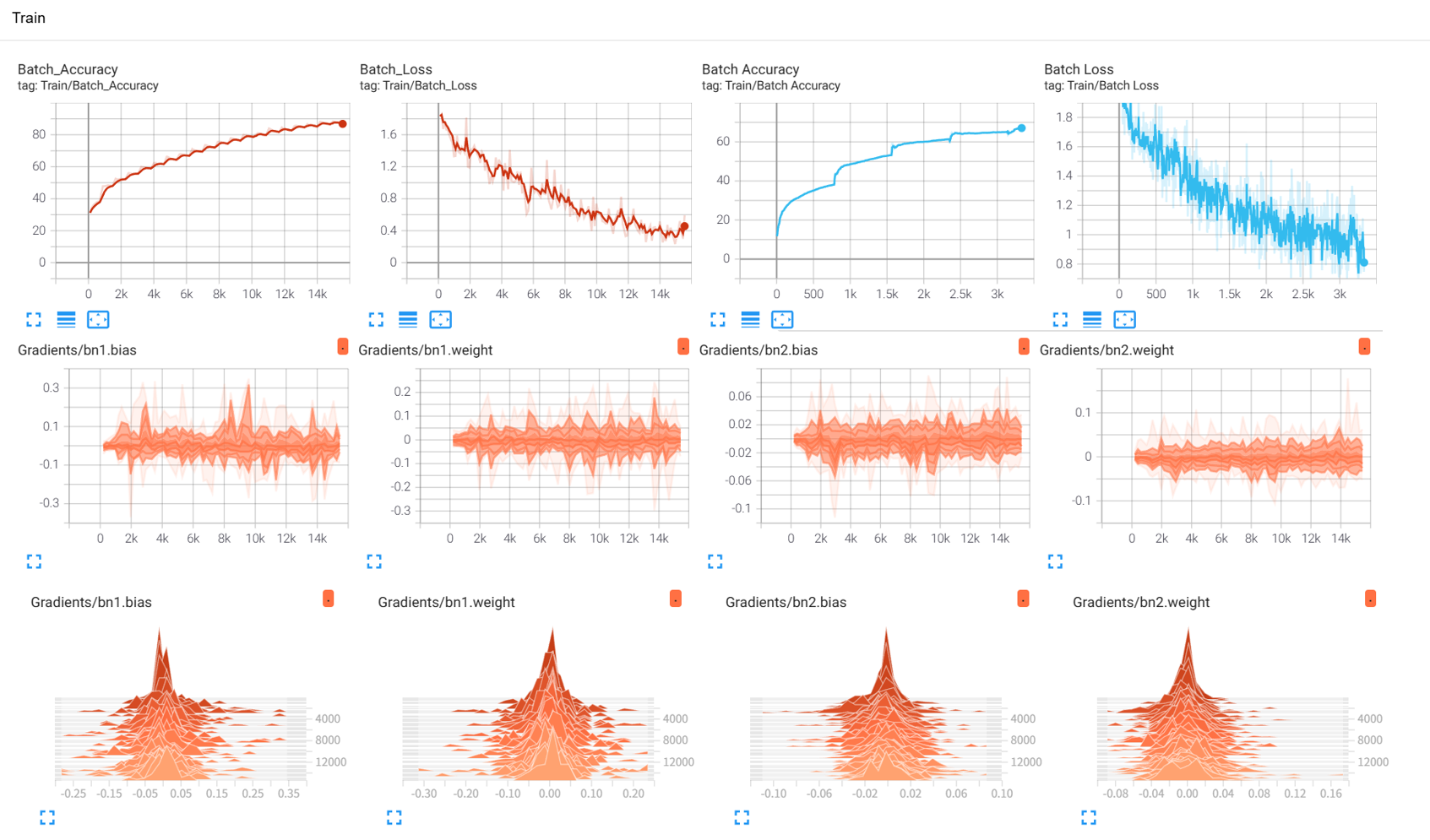
第四十五天打卡
知识点回顾: tensorboard的发展历史和原理 tensorboard的常见操作 tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下,用tensor…...
springboot mysql/mariadb迁移成oceanbase
前言:项目架构为 springbootmybatis-plusmysql 1.部署oceanbase服务 2.springboot项目引入oceanbase依赖(即ob驱动) ps:删除原有的mysql/mariadb依赖 <dependency> <groupId>com.oceanbase</groupId> …...

npm install 报错:npm error: ...node_modules\deasync npm error command failed
npm install 时报错如下: 首先尝试更换node版本,当前node版本20.15.0,更换node版本为16.17.0。再次执行npm install安装成功...
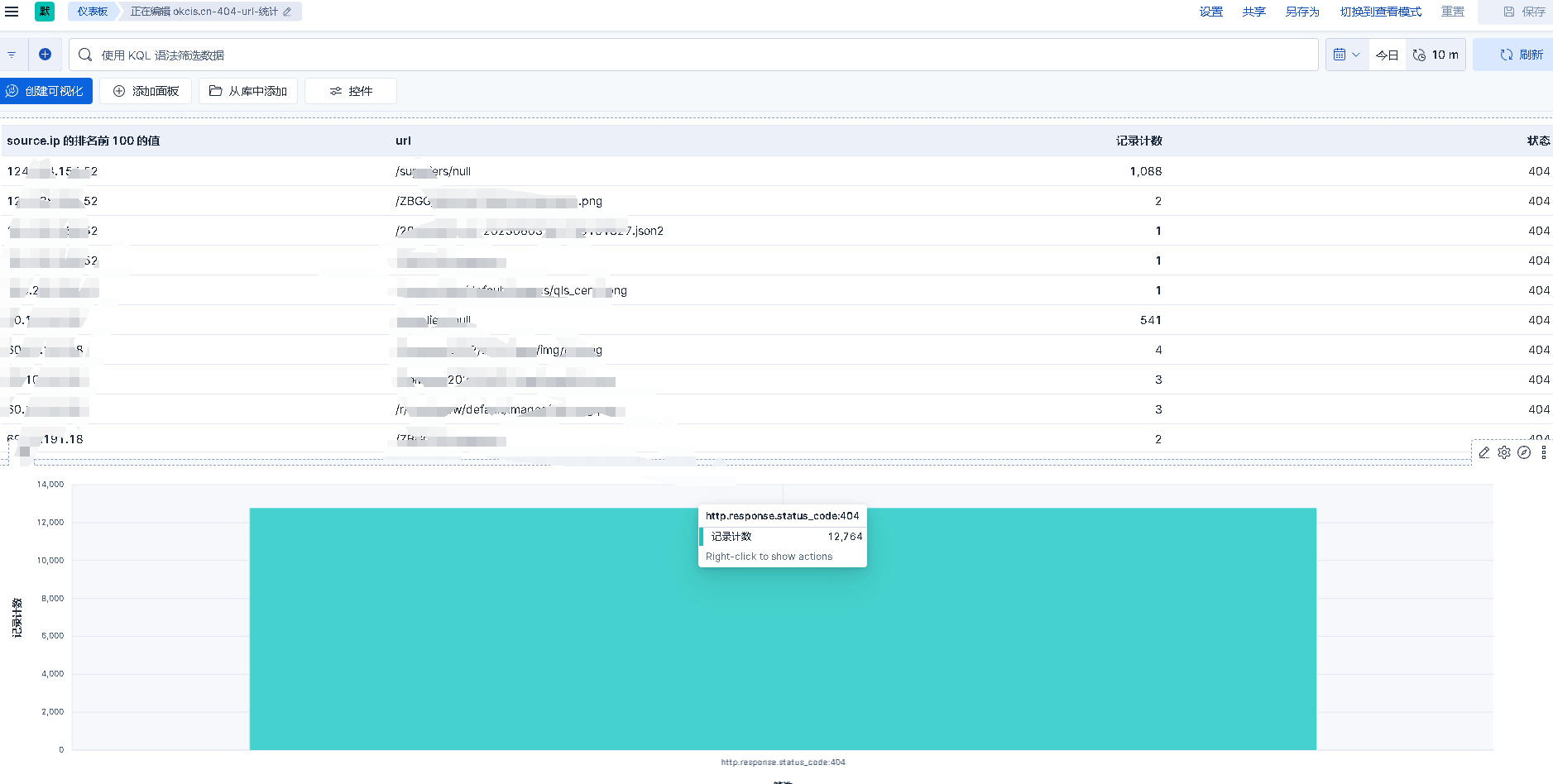
Filebeat收集nginx日志到elasticsearch,最终在kibana做展示(二)
EFK 项目需求是要将 一天或15分钟内 搜索引擎抓取网站次数做个统计,并且 如 200 301 404 状态码 也要区分出来, 访问 404 报错的 url 也要截取出来 前期 收集数据 看这篇文章,点击跳转 收集数据完成之后,使用下面方法做展示 创建一个 仪表…...

halcon c# 自带examples报错 Matching
最近开始学习halcon与C#的联合编程,打开Matching例程时遇到了下面的问题 “System.TypeInitializationException”类型的未经处理的异常在 halcondotnet.dll 中发生 “HalconDotNet.HHandleBase”的类型初始值设定项引发异常。 System.TypeInitializationExceptio…...

服务器重启后配置丢失怎么办?
服务器重启后配置丢失是一个常见问题,特别是在云服务器或容器环境中,若未正确保存或持久化配置,系统重启后就会恢复默认状态。下面是问题分析 解决方案: 🧠 一、常见原因分析 原因描述❌ 配置保存在临时目录如 /tmp、…...

Postgresql常用函数操作
目录 一、字符串函数 二、数学函数 三、日期和时间函数 四、条件表达式函数 五、类型转换函数 六、聚合函数 (常与 GROUP BY 一起使用) 重要提示 PostgreSQL 提供了极其丰富的内置函数,用于操作和处理数据。以下是一些最常用的函数分类和示例: 一…...

用 NGINX 搭建高效 IMAP 代理`ngx_mail_imap_module`
一、模块定位与作用 协议代理 ngx_mail_imap_module 使 NGINX 能在 IMAP 层面充当反向代理,客户端与后端 IMAP 服务器之间的会话流量均由 NGINX 接收并转发。认证控制 通过 imap_auth 指定允许的身份验证方式(如 PLAIN、LOGIN、CRAM-MD5、EXTERNAL&…...
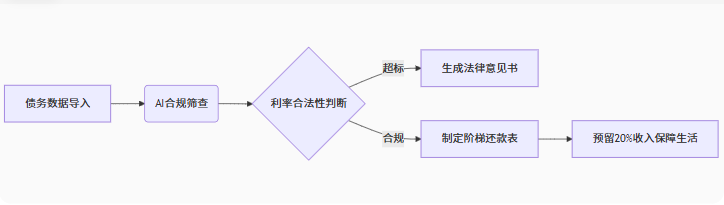
湖北理元理律所债务优化实践:法律技术与人文关怀的双轨服务
一、债务优化的法律逻辑与生活平衡 在债务重组领域,专业机构需同时解决两个核心问题: 法律合规性:依据《民法典》第680条、第671条,对高息债务进行合法性审查; 生活可持续性:根据债务人收入设计分期方案…...
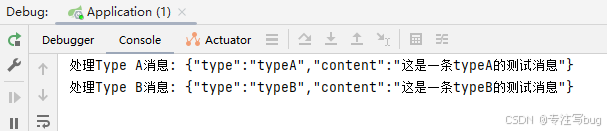
Springboot——整合websocket并根据type区别处理
文章目录 前言架构思想项目结构代码实现依赖引入自定义注解定义具体的处理类定义 TypeAWebSocketHandler定义 TypeBWebSocketHandler 定义路由处理类配置类,绑定point制定前端页面编写测试接口方便跳转进入前端页面 测试验证结语 前言 之前写过一篇类似的博客&…...

Qiskit:量子计算模拟器
参考文献: IBM Qiskit 官网Qiskit DocumentationQiskit Benchpress packageQiskit Algorithms package量子计算:基本概念常见的几类矩阵(正交矩阵、酉矩阵、正规矩阵等)Qiskit 安装指南-博客园使用Python实现量子电路模拟&#x…...
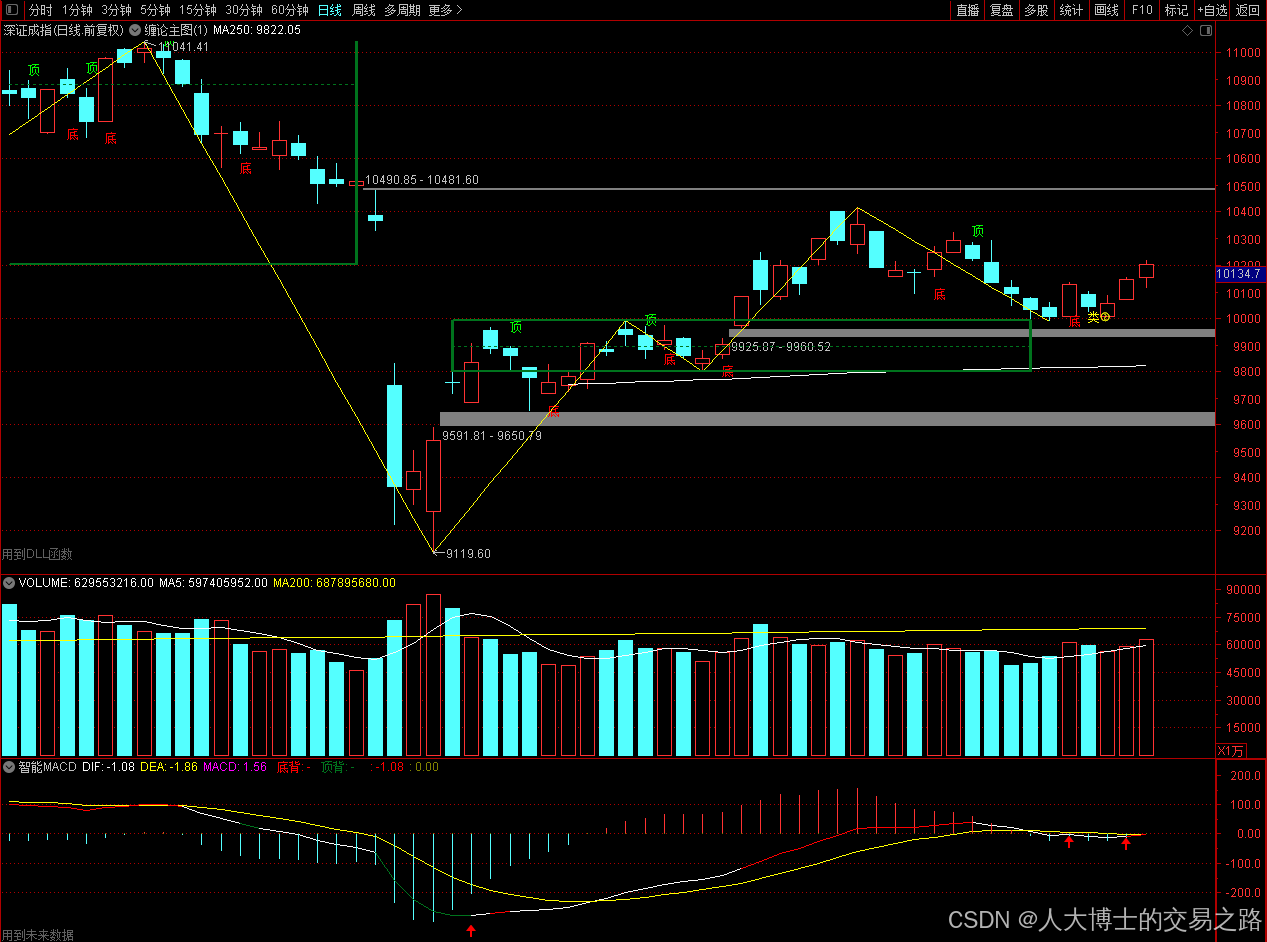
龙虎榜——20250605
上证指数放量收阳线,个股涨跌基本持平,日线持续上涨。 深证指数放量收阳线,日线持续上涨。 2025年6月5日龙虎榜行业方向分析 1. 通信设备 代表标的:生益电子、三维通信、瑞可达 驱动逻辑:5.5G商用牌照发放预期加速&…...
)
PDF 转 HTML5 —— HTML5 填充图形不支持 Even-Odd 奇偶规则?(第二部分)
这是关于该主题的第二部分。如果你还没有阅读第一部分,请先阅读,以便理解“绕组规则”的问题。 快速回顾一下:HTML5 只支持 Non-Zero(非零)绕组规则,而 PDF 同时支持 Non-Zero 和 Even-Odd(奇偶…...

大数据离线同步工具 DataX 深度实践与 DataX Web 可视化指南
一、引言 在大数据领域,异构数据源间的数据同步是核心需求之一。传统工具如 Sqoop 基于磁盘 IO 的 MR 架构在性能上存在瓶颈,而DataX作为阿里巴巴开源的离线数据同步工具,凭借内存级数据传输和分布式并行处理能力,成为国内大数据…...

记一个判决书查询API接口的开发文档
一、引言 在企业风控、背景调查、尽职调查等场景中,判决书查询是一个非常重要的环节。通过判决书查询,可以了解个人或企业的司法涉诉情况,为风险评估提供数据支持。本文将详细介绍如何开发和使用一个司法涉诉查询API接口,包括客户…...

残月个人拟态主页
TwoMicry个人主页 残月个人拟态主页 原项目作者:KAI GE 在此基础上进行二次修改 精简重构一下 项目简介: 一个精美的拟态风格个人主页,采用现代化的玻璃拟态设计和丰富的动画效果 主要特色: 视觉效果: – 玻璃…...

热门消息中间件汇总
文章目录 前言RabbitMQ基本介绍核心特性适用场景 Kafka基本介绍核心特性适用场景 RocketMQ基本介绍核心特性适用场景 NATS基本介绍核心特性适用场景 总结选型建议与未来趋势选型建议未来趋势 结语 前言 大家后,我是沛哥儿。作为技术领域的老湿机,在消息…...
AiPy实战:10分钟用AI造了个音乐游戏!
“在探索AI编程边界时,我尝试了一个实验:能否让自然语言指令直接生成可交互的音乐学习应用?作为新一代智能编程协作框架,AiPy展示了对开发意图的深度理解能力——当输入创建钢琴学习游戏,包含动态难度关卡和即时反馈系…...

Python Rio 【图像处理】库简介
边写代码零食不停口 盼盼麦香鸡味块 、卡乐比(Calbee)薯条三兄弟 独立小包、好时kisses多口味巧克力糖、老金磨方【黑金系列】黑芝麻丸 边写代码边贴面膜 事业美丽两不误 DR. YS 野森博士【AOUFSE/澳芙雪特证】377专研美白淡斑面膜组合 优惠劵 别光顾写…...

贪心算法应用:分数背包问题详解
贪心算法与分数背包问题 贪心算法(Greedy Algorithm)是算法设计中一种重要的思想,它在许多经典问题中展现出独特的优势。本文将用2万字篇幅,深入剖析贪心算法在分数背包问题中的应用,从基础原理到Java实现细节&#x…...
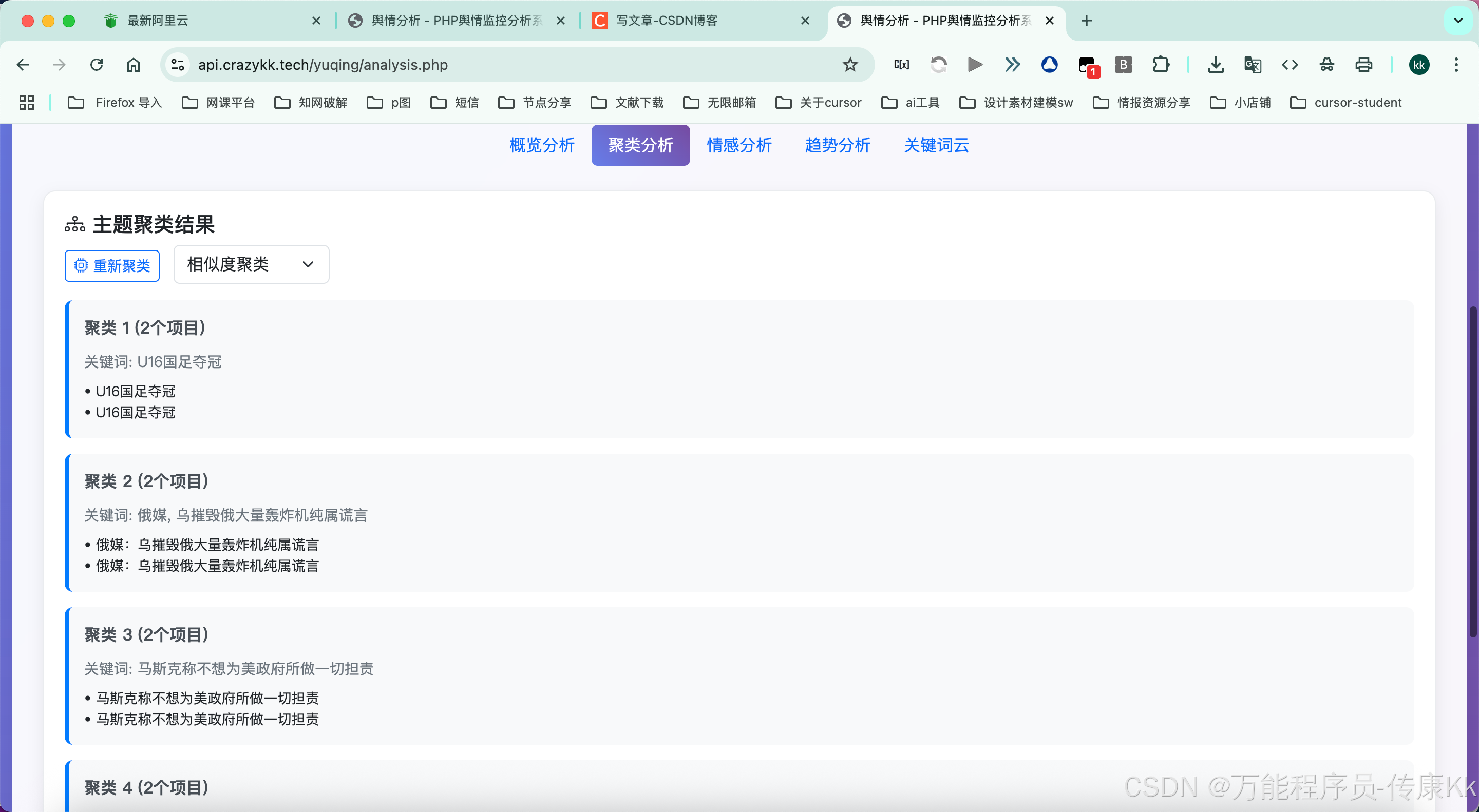
PHP舆情监控分析系统(9个平台)
PHP舆情监控分析系统(9个平台) 项目简介 基于多平台热点API接口的PHP实时舆情监控分析系统,无需数据库,直接调用API实时获取各大平台热点新闻,支持数据采集、搜索和可视化展示。 功能特性 🔄 实时监控 …...
金孚媒重磅推出德国顶级媒体原生广告整合服务,覆盖12家主流媒体
2025年6月1日,为助力中国企业高效开拓德语市场,全球媒体资源直采和新闻分发平台金孚媒Kinfoome Presswire今日正式推出德国大媒体原生广告套餐。该套餐整合德国最具影响力的12家新闻门户资源,以高曝光、强信任度的原生广告形式,为…...

Mnist手写数字
运行实现: import torch from torch.utils.data import DataLoader from torchvision import transforms from torchvision.datasets import MNIST import matplotlib.pyplot as pltclass Net(torch.nn.Module):#net类神经网络主体def __init__(self):#4个全链接层…...
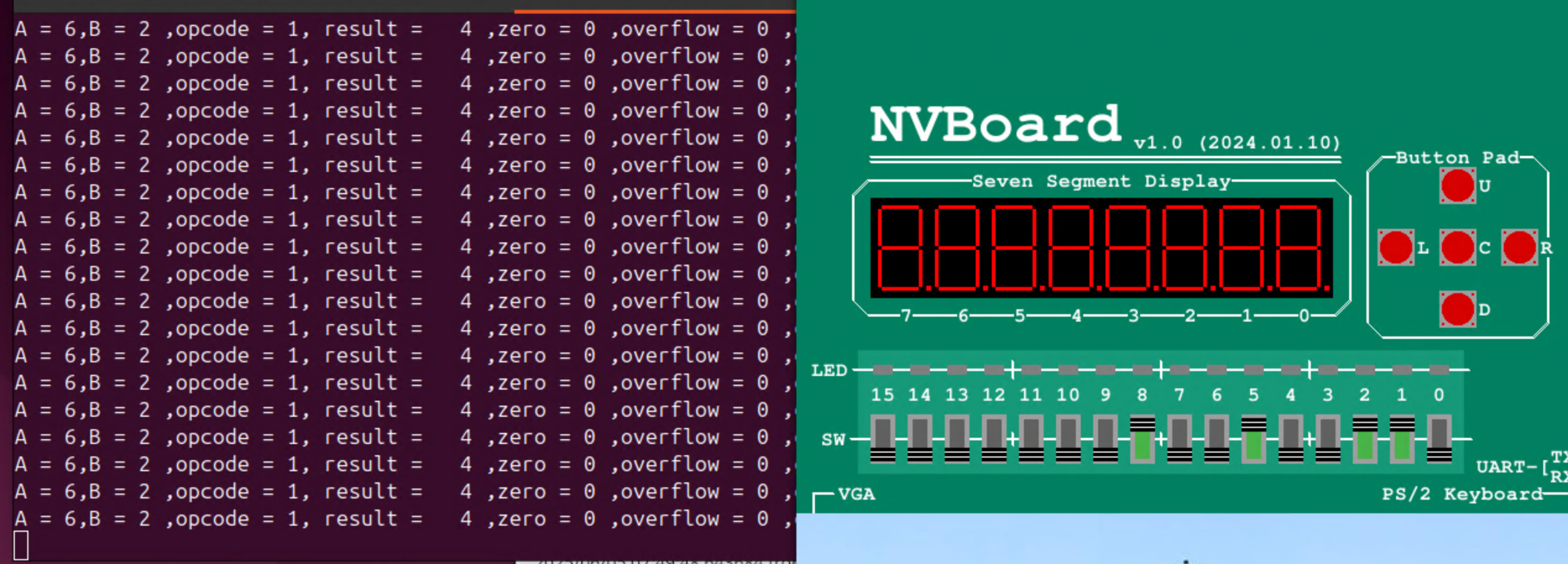
《一生一芯》数字实验三:加法器与ALU
1. 实验目标 设计一个能实现如下功能的4位带符号位的 补码 ALU: Table 4 ALU 功能列表 功能选择 功能 操作 000 加法 AB 001 减法 A-B 010 取反 Not A 011 与 A and B 100 或 A or B 101 异或 A xor B 110 比较大小 If A<B then out1…...

Go 语言并发编程基础:Goroutine 的创建与调度
Go 语言的并发模型是其最显著的语言特性之一。Goroutine 是 Go 实现并发的核心机制,它比线程更轻量,调度效率极高。 本章将带你了解 Goroutine 的基本概念、创建方式以及背后的调度机制。 一、什么是 Goroutine? Goroutine 是由 Go 运行时&a…...