【AI学习】KV-cache和page attention
目录
带着问题学AI
KV-cache
KV-cache是什么?
之前每个token生成的K V矩阵给缓存起来有什么用?
为啥缓存K、V,没有缓存Q?
KV-cache为啥在训练阶段不需要,只在推理阶段需要?
KV cache的过程图解
阶段一:KV cache的prefill阶段
阶段二:KV cache的decode阶段
prefill阶段,K V是一把计算得到吗?
decode阶段,K V是一把计算得到吗?
KV cache的内存问题?
瓶颈分析
page attention
传统KV cache浪费显存的原因有哪些?
vLLM是什么?是解决什么问题的?
page attention是怎么解决内存利用率低的问题的?
什么是虚拟内存?
page attention的改进1:利用虚拟内存和页管理,将利用率从20-40%提升到90%
page attention的改进2:利用sharing KV blocks(共享block), 减少内存占用。
还能优化beam search里的显存占用?
附录
带着问题学AI
今天来学习下transform模型中一个推理加速的算法--page attention。
一、KV-cache
KV-cache是什么?
是在推理阶段,decode为了节省计算量,将每个token在transform时乘以Wk,Wv这俩参数矩阵的结果(K、V)缓存下来。
如果每生成一个token,都要将之前所有的token去乘以Wk,Wv这俩参数矩阵,计算代价非常大。所有缓存起来就叫KV-Cache.
之前每个token生成的K V矩阵给缓存起来有什么用?
试想如果每次都不存,后边每生成一个token,根据attention公式,需要计算attention值要将Q乘以K的转置,每增加一个token,X多一行,则Q多一行,K多一行,V多一行。但其实第0到n-1行的K、V是不变的。没有必要每次都重新计算整个K、V矩阵(乘以Wk,Wv)。如果有缓存,直接将第0到n-1行拿来用即可,省去了重新全部计算的过程。--减少计算,以空间换时间
为啥缓存K、V,没有缓存Q?
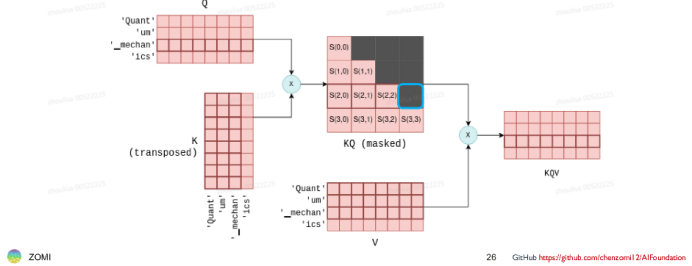
根据attention计算公式,生成第n个token,都依赖Q的第n个向量和K\V前n个向量(即之前的所有KV)。即第n个token的生成,和Q之前的n个向量无关。所以不需要缓存Q。
下图是生成第3个token(_machan)的过程:
KV-cache为啥在训练阶段不需要,只在推理阶段需要?
因为训练阶段,Wk,Wv这些参数的值是要根据迭代不断变化的。缓存起来没有用,下次就变了。但是推理阶段,Wk,Wv这些参数的值已经是确定了的,不会变化。
KV cache的过程图解
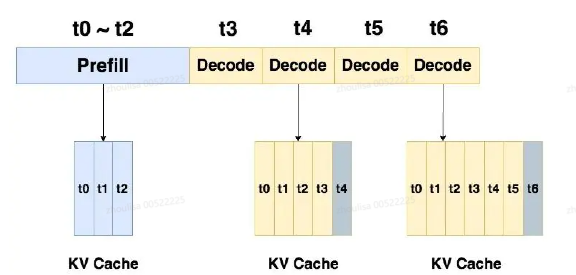
阶段一:KV cache的prefill阶段
把整段 prompt 输入模型执行,采用 KV cache 技术,Prefill阶段中会把prompt的token计算得到的K\V保存在cache K和cache V中。这样后面的token计算attention时,就不需要对前面 token 重复计算,可以节省推理时间。
假设 prompt 中含有 3 个 token,prefill 阶段结束后,这三个 token 相关的 KV 值都被装进了cache。即计算输入的所有token的KV,缓存起来
阶段二:KV cache的decode阶段
Decode 阶段根据 prompt 的 prefill 结果,一个 token 一个 token 地生成 response;
采用 KV cache 每一个 decode 把对应 response的 token KV 值存入 cache 中,能加速计算,节省后续token的K\V计算量;
t4 与 cache 中 t0~t3 的 KV 值计算完 attention 后,就把自己的 KV 值也装进 cache 中。
prefill阶段,K V是一把计算得到吗?
prefill阶段是计算prompt的token的attention,可以一把计算,K=X*Wk, 这里X是所有prompt的token,Wk是已经确定的参数矩阵。所以可以一把计算出K,这就对算力要求比较高。矩阵V同理。
decode阶段,K V是一把计算得到吗?
不行。decode阶段,因为下一个token的生成依赖下一个Q的向量和之前所有的KV向量,每次都得一个token一个token的计算。所以是只能串行计算,所以有计算瓶颈。所以才有KV cache算法,用空间换时间,节约计算。
KV cache的内存问题?
从上述过程中,可以发现 KV cache 推理时特点:
1. 随着推理序列变长,KV cache 也变大,对 GPU 显存造成压力
2. 由于输出的序列长度无法预先知道,所以很难提前为 KV cache 量身定制存储空间。
显存会有大量的碎片页,导致内存资源浪费。为了解决KV cache的内存bound问题,提出了一些算法。
瓶颈分析
LLM 推理 Prefill & Decoding 阶段 Roofline Model 近似如下,其中:
1. 三角Prefill(计算密集型):设Batch size=1,Sequence Length越大计算强度越大,通常属于Compute Bound
2. 原型Decoding:Batch size越大,计算强度越大,理论性能峰值越大,通常属于Memory Bound
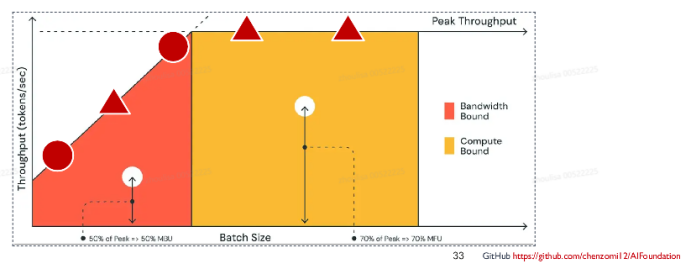
备注:Roofline模型是一种用于理解和分析高性能计算(HPC)应用程序性能的可视化工具。它提供了一种直观的方法来展示应用程序的计算能力和内存带宽之间的关系,并帮助识别性能瓶颈。
二、page attention
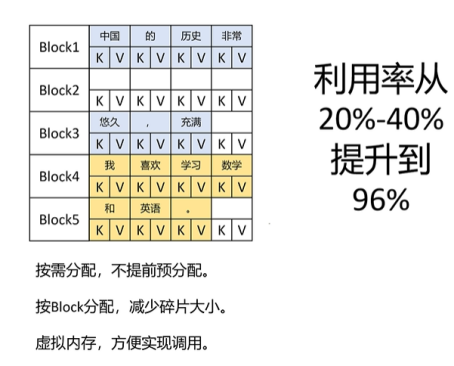
以13B的模型为例,在推理时,参数占显存65%, KV cache占显存的30%。但是KV cache里实际的显存利用率只有30%-40%, 大部分KV cache里的显存都被浪费了。

传统KV cache浪费显存的原因有哪些?
1、在大模型生成时,并不知道要生成多少token,即不知道输出序列会是多长。所以总是按照生成参数里设置的最大的token数来预分配KV cache. 比如模型最大token数是1000,但是实际只生成100个token时就输出终止符结束了,这样有大量被预分配的KV cache显存被浪费了
2、假设一个样本真的可以输出1000个token,但在它输出第一个token的时候,剩下的token的预分配空间还未用到,但是显存已经被预分配占用了。这时其他的请求也无法被响应。而未被响应的请求,有可能只需要输出10个token就结束了。本来可以和正在进行输出的样本并行处理。因此,这也是显存的浪费。
3、显存之间的碎片。即使最大生成长度一致,但是因为prompt的长度不同,每次预分配的KV cache大小也不同。当一个请求生成完毕,释放缓存,但是下一个请求的prompt的长度大于释放的这个请求的prompt长度,所以无法放入被释放的缓存中。这种无法被使用的缓存就是碎片。

vLLM是什么?是解决什么问题的?
vLLM是什么?
vLLM 是一个旨在提高大语言模型(Large Language Models, LLMs)推理效率的开源库。它特别针对现代硬件(如GPU和TPU)进行了优化,以便能够更高效地运行大型语言模型。vLLM的主要目标是通过优化内存使用、加速计算过程以及支持先进的技术特性来提升语言模型的服务性能。
解决什么问题?
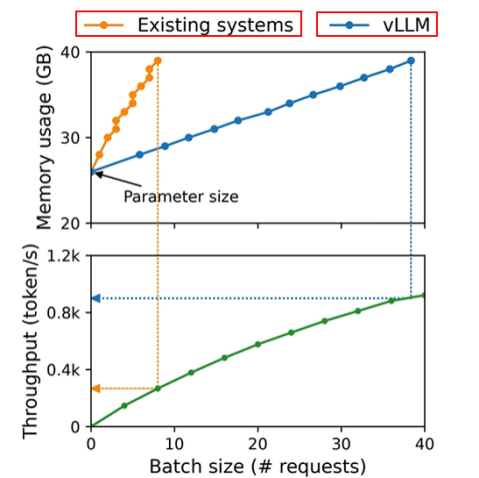
vLLM就是解决了传统KV cache里的显存资源浪费的问题。vLLM和既有系统相比,内存占用更少,吞吐率更高。对比见下图
page attention是怎么解决内存利用率低的问题的?
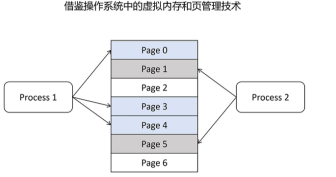
其实类似的问题,操作系统也遇到过。page attention是借鉴操作系统的虚拟内存和页管理技术。
操作系统给每个程序怎么预分配内存?程序关闭后怎么回收内存?内存碎片怎么处理?怎么最大化的利用内存?操作系统是利用虚拟内存和页管理技术来解决的。操作系统分配内存是按照最小单元页来分配,每个页是4K,物理内存被分为很多页。每个进程要用的内存被映射到不同页上。
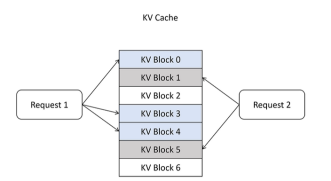
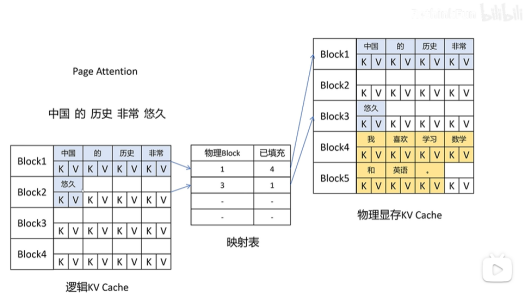
page attention把显存也划分为KV block, 显存按照KV block来管理KV cache,每个请求需要的KV cache被划分到显存不同的KV block里。比如每个KV block里可以缓存4个token的KV向量。
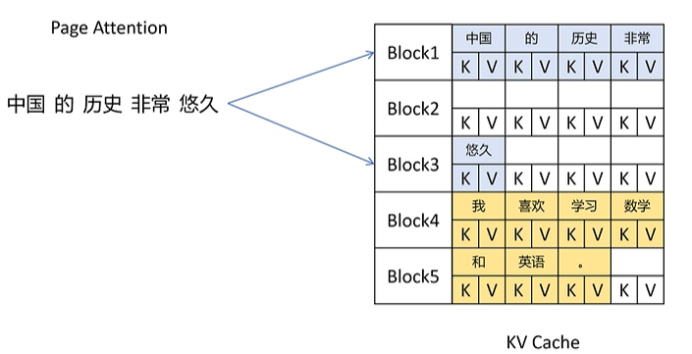
比如“中国的历史非常悠久”,被划分到2个block里,这俩block在物理显存里可以是不连续的。随着大模型的推理,产生了新的token,比如“中国的历史非常悠久,”的逗号,它会继续存在未被填满的block里。直到当前block被填满。
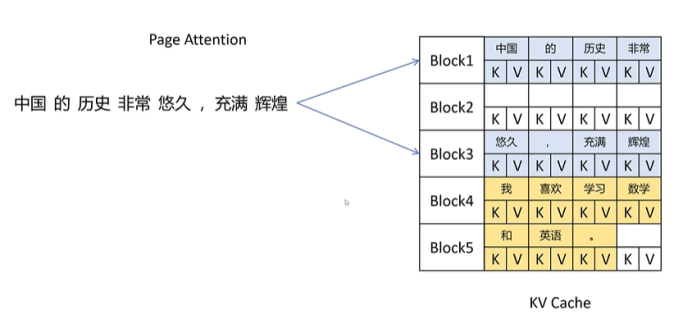
可以发现,vLLM克服了传统KV cache预分配的问题,它是按需分配,不提前占用。并且是按块分配,这样就减少了内存碎片。因为都是按照4个token占用1个block进行分配,碎片最大只有3个token的kv cache。
什么是虚拟内存?
虚拟内存是每个请求都有一个逻辑的KV cache。在逻辑的KV cache里,显存是连续的,vLLM的框架会在后台维护一个逻辑KV cache到实际显存上KV block的映射表。类似操作系统的虚拟内存和物理内存的映射,用户态只感知虚拟内存,不感知物理内存。用户态预先分配的内存都是虚拟内存,感知到的内存是连续的,实际物理内存是可以不连续的,只不过用户不感知。
根据映射表,在进行page attention计算时,会自动找到物理显存上block的KV 向量进行计算,每个请求都有自己的逻辑内存的KV cache,其中的prompt和生成的新token的KV向量看起来好像都是放在连续的缓存上,方便程序操作。
vLLM框架内部维护了映射表,在进行page attention计算时,会根据映射表找到物理显存上block的KV 向量。
page attention的改进1:利用虚拟内存和页管理,将利用率从20-40%提升到90%
page attention的改进2:利用sharing KV blocks(共享block), 减少内存占用。
当我们在利用大模型进行生成时,有时候会想用一个prompt生成多个不同的输出,比如我们想让大模型对一句中文生成多个不同的英文翻译(一个问题,多个答案)。
在vLLM的sampling参数里,可以设置N为大于一的一个整数来实现这个功能。这样同一个prompt会产生2个不同的序列。比如,请把这句话翻译为英文:色即是空。生成2个序列,但是这2个序列,在显卡的显存里只存放了一份prompt token的kv block,每个block都标记着自己现在被2个序列引用着,只有当引用数为0时,这个block占用的显存才会被释放。
接着,第一个序列开始生成,他生成的第一个token是color,这时会触发copy on write机制,也就是它发现自己要继续写入的block的引用数是2,表示该block被2个序列引用着,所以它不能直接写入,必须自己拷贝一份来写,拷贝一份后,在自己的拷贝上写入color这个token的kv cache。然后,原来那个block的引用数就减为1了。新拷贝的这个block的引用数变为1,表明被1个序列引用。接着序列2生成自己的下一个token是matter,写入block。然后两个序列就各自往下生成,完全一样的block(4个token都一样),则保持共享;不同的则各自占用block。就是共享的这部分block,就节省了一份显存。
还能优化beam search里的显存占用?
kv block的共享,还可以优化beam search里的显存占用,原理也是相同的block(4个token都一样),多beam共享。
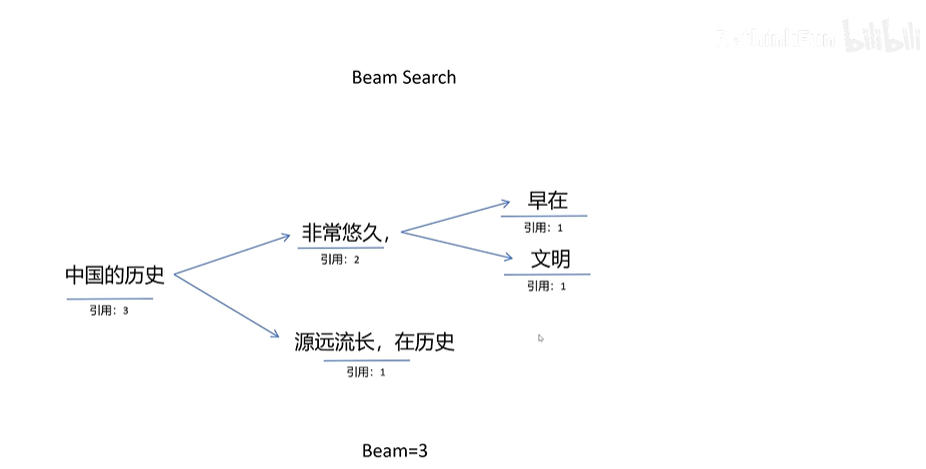
beam search是什么?
Beam Search(集束搜索/束搜索) 是一种用于序列生成任务的启发式搜索算法,它广泛应用于自然语言处理(NLP)中的机器翻译、语音识别、文本摘要等任务。相比于贪心搜索(Greedy Search),Beam Search能够在一定程度上探索更多的可能性,从而找到更好的解。
附录
讲解视频:
【大模型推理】大模型推理 Prefill 和 Decoder 阶段详解_哔哩哔哩_bilibili
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention_哔哩哔哩_bilibili
文档:图解大模型计算加速系列之:vLLM核心技术PagedAttention原理
zomi github: https://github.com/chenzomi12/aiinfra/blob/main/05Infer/01Foundation/01Introduction.pptx
相关文章:
【AI学习】KV-cache和page attention
目录 带着问题学AI KV-cache KV-cache是什么? 之前每个token生成的K V矩阵给缓存起来有什么用? 为啥缓存K、V,没有缓存Q? KV-cache为啥在训练阶段不需要,只在推理阶段需要? KV cache的过程图解 阶段一:KV cac…...
七彩喜智慧养老平台:科技赋能下的市场蓝海,满足多样化养老服务需求
在人口老龄化加速与科技快速发展的双重驱动下,七彩喜智慧养老平台正成为破解养老服务供需矛盾、激活银发经济的核心引擎。 这一领域依托物联网、人工智能、大数据等技术,构建起覆盖居家、社区、机构的多层次服务体系。 既满足老年人多样化需求…...
《Pytorch深度学习实践》ch8-多分类
------B站《刘二大人》 1.Softmax Layer 在多分类问题中,输出的是每类的概率: 计算公式:保证了每类概率大于 0 ,又由保证了概率之和为 1; 举例如下: 2.Cross Entropy 计算损失: y np.array…...

国产录播一体机:科技赋能智慧教育信息化
在数字化时代,教育正经历着前所未有的变革。国产工控机作为信息化教育的核心载体,正在重新定义学习方式,赋能教师与学生,打造高效、互动、智能的教学环境,让我们一起感受科技与教育的深度融合!高能计算机推…...

关于逻辑回归的见解
逻辑回归通过将线性回归的输出映射到 [ 0 , 1 ] \left[0,1\right] [0,1]区间,来表示某个类别的概率。也就是其本质是先通过线性回归的预测值 y \boldsymbol{y} y输入到映射函数,既将线性回归的输出通过映射函数映射到 [ 0 , 1 ] \left[0,1\right] [0,1].常用的映射函数是sigm…...
Amazon Augmented AI:人类智慧与AI协作,破解机器学习审核难题
在人工智能日益渗透业务核心的今天,你是否遭遇过这样的困境:自动化AI处理海量数据时,面对模糊、复杂或高风险的场景频频“卡壳”?人工审核团队则被低效、重复的任务压得喘不过气?Amazon Augmented AI (A2I) 的诞生&…...

CMake入门:3、变量操作 set 和 list
在 CMake 中,set 和 list 是两个核心命令,用于变量管理和列表操作。理解它们的用法对于编写高效的 CMakeLists.txt 文件至关重要。下面详细介绍这两个命令的功能和常见用法: 一、set 命令:变量定义与赋值 set 命令用于创建、修改…...

聊聊FlaUI:让Windows UI自动化测试优雅起飞!
你还在为手动点点点测试Windows应用而感到膝盖疼?更愁于自动化测试工具价格贵得让钱包瑟瑟发抖?今天,我要给你安利一款“野路子有余,正经事儿也能干”的.NET UI自动化神器——FlaUI!别眨眼,看完你能少加三个…...
VIN码车辆识别码解析接口如何用C#进行调用?
一、什么是VIN码车辆识别码解析接口 输入17位vin码,获取到车辆的品牌、型号、出厂日期、发动机类型、驱动类型、车型、年份等信息。无论是汽车电商平台、二手车商、维修厂,还是保险公司、金融机构,都能通过接入该API实现信息自动化、决策智能…...

[论文阅读] 人工智能 | 用大语言模型解决软件元数据“身份谜题”:科研软件的“认脸”新方案
用大语言模型解决软件元数据“身份谜题”:科研软件的“认脸”新方案 论文信息 作者: Eva Martn del Pico, Josep Llus Gelp, Salvador Capella-Gutirrez 标题: Identity resolution of software metadata using Large Language Models 年份: 2025 来源: arX…...

gorm多租户插件的使用
一、关于gorm多租户插件的使用 1、安装依赖 go get -u github.com/kuangshp/gorm-tenant2、创建一个mysql数据表 DROP TABLE IF EXISTS user; CREATE TABLE user (id int(11) NOT NULL AUTO_INCREMENT primary key COMMENT 主键id,name varchar(50) not null comment 名称,ten…...

Playwright 测试框架 - Java
🚀【Playwright + Java 实战教程】从零到一掌握自动化测试利器! 🔧 本文专为 Java 开发者量身打造,通过详尽示例带你快速掌握 Playwright 自动化测试。涵盖基础操作、表单交互、测试框架集成、高阶功能及常见实战技巧,适用于企业 UI 测试与 CI/CD 场景。 🛠️ 一、环境…...

力扣100题之128. 最长连续序列
方法1 使用了hash 方法思路 使用哈希集合:首先将数组中的所有数字存入一个哈希集合中,这样可以在 O(1) 时间内检查某个数字是否存在。 寻找连续序列:遍历数组中的每一个数字,对于每一个数字, 检查它是否是某个连续序列…...
算法打卡12天
19.链表相交 (力扣面试题 02.07. 链表相交) 给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表没有交点,返回 null 。 图示两个链表在节点 c1 开始相交**:** 题目数据…...
:图像/视频的输入输出(highgui模块 高层GUI和媒体I/O))
OpenCV C++ 学习笔记(四):图像/视频的输入输出(highgui模块 高层GUI和媒体I/O)
文章目录 图片读取创建窗口图片显示图片保存视频输入输出 图片读取 cv::Mat imread( const String& filename, int flags IMREAD_COLOR );enum ImreadModes {IMREAD_UNCHANGED -1, //!< If set, return the loaded image as is (with alpha channel, othe…...

我的创作纪念日——聊聊我想成为一个创作者的动机
2025年6月4日,是我在CSDN写下第一篇技术博客的第1024天。 1024,这个数字对于程序员来说意义非凡,它不仅是内存单位的基础,更是我们这群“码农”的节日符号。而对我来说,它更像是一段旅程的里程碑:从一个曾想…...
蓝桥杯国赛训练 day1 Java大学B组
目录 k倍区间 舞狮 交换瓶子 k倍区间 取模后算组合数就行 import java.util.HashMap; import java.util.Map; import java.util.Scanner;public class Main {static Scanner sc new Scanner(System.in);public static void main(String[] args) {solve();}public static vo…...
PyTorch——非线性激活(5)
非线性激活函数的作用是让神经网络能够理解更复杂的模式和规律。如果没有非线性激活函数,神经网络就只能进行简单的加法和乘法运算,没法处理复杂的问题。 非线性变化的目的就是给我们的网络当中引入一些非线性特征 Relu 激活函数 Relu处理图像 # 导入必…...

OPenCV CUDA模块目标检测----- HOG 特征提取和目标检测类cv::cuda::HOG
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 cv::cuda::HOG 是 OpenCV 的 CUDA 模块中对 HOG 特征提取和目标检测 提供的 GPU 实现。它与 CPU 版本的 cv::HOGDescriptor 类似,但利…...

MATLAB读取文件内容:Excel、CSV和TXT文件解析
MATLAB读取文件内容:Excel、CSV和TXT文件解析 MATLAB 是一款强大的数学与工程计算工具,广泛应用于数据分析、模型构建和图像处理等领域。在处理实际问题时,我们常常需要从文件中读取数据进行分析。本文将介绍如何使用 MATLAB 读取常见的文件…...
Spring MVC 之 异常处理
使用Spring MVC可以很灵活地完成数据的绑定和响应,极大的简化了Java Web的开发。但Spring MVC提供的便利不仅仅如此,使用Spring MVC还可以很便捷地完成项目中的异常处理、自定义拦截器以及文件上传和下载等高级功能。本章将对Spring MVC提供的这些高级功…...

缓存控制HTTP标头设置为“无缓存、无存储、必须重新验证”
文章目录 说明示例核心响应头设置实现原理代码实现1. 原生 Node.js (使用 http 模块)2. Express 框架3. 针对特定路由设置 (Express) 验证方法(使用 cURL)关键注意事项 说明 日期:2025年6月4日。 对于安全内容,请确保缓存控制HT…...
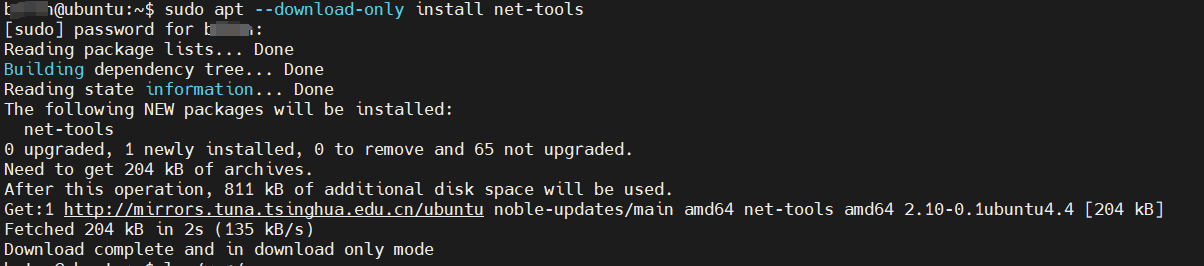
ubuntu24.04 使用apt指令只下载不安装软件
比如我想下载net-tools工具包及其依赖包可以如下指令 apt --download-only install net-tools 自动下载的软件包在/var/cache/apt/archives/目录下...

macOS 上使用 Homebrew 安装redis-cli
在 macOS 上使用 Homebrew 安装 redis-cli(Redis 命令行工具)非常简单,以下是详细步骤: 1. 安装 Redis(包含 redis-cli) 运行以下命令安装 Redis: brew install redis这会安装完整的 Redis 服…...

计算机网络安全问答数据集(1788条) ,AI智能体知识库收集! AI大模型训练数据!
继续收集数据集,话不多说,见下文! 今天分享一个计算机网络安全问答数据集(1788条),适用于AI大模型训练、智能体知识库构建、安全教育系统开发等多种场景! 一、数据特点 结构清晰:共计1788条&…...
WinCC学习系列-高阶应用(WinCC REST通信)
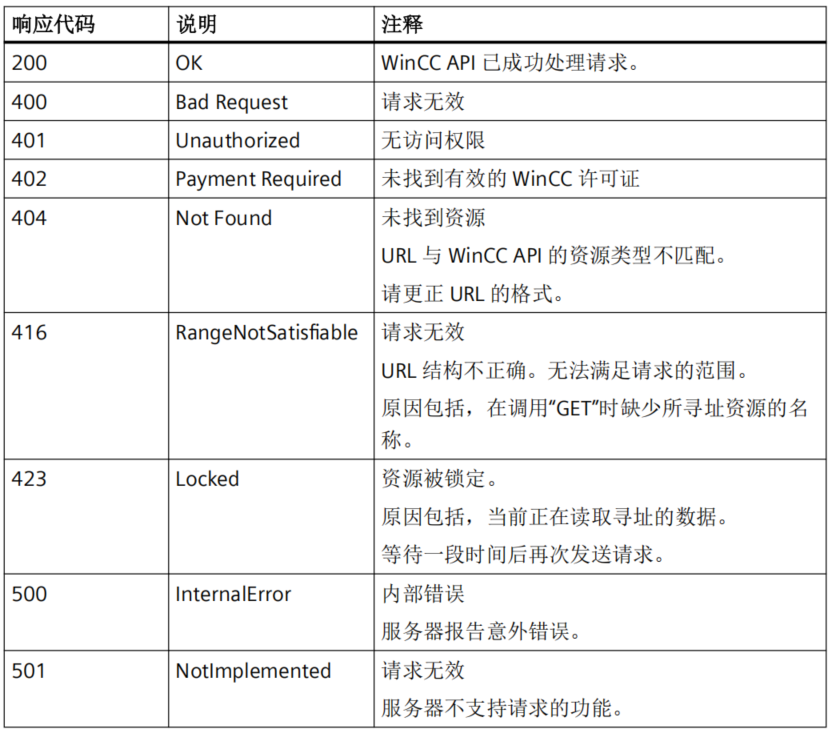
WinCC作为一个经典SCADA系统,它是OT与IT数据无缝集成桥梁,自WinCC7.5版本开始,可以直接提供Rest服务用于其它系统数据访问和操作。 WinCC REST 服务允许外部应用程序访问 WinCC 数据。 外部应用程序可以通过 REST 接口读取和写入 WinCC 组态…...

八、Python模块、包
目录 1. 模块 1.1 什么是模块? 1.2 创建模块 1.3 导入模块 1.4 模块的命名空间 1.5 模块的搜索路径 1.6 模块的重新加载 2. 包 2.1 什么是包? 2.2 创建包 2.3 导入包中的模块 2.4 包的层次结构 3. 模块和包的管理 3.1 安装模块 3.2 卸载模…...
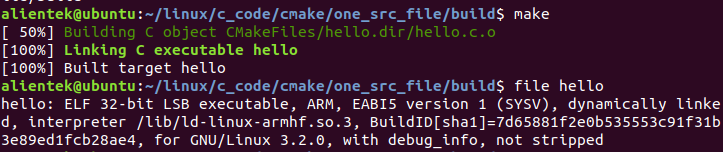
使用交叉编译工具提示stubs-32.h:7:11: fatal error: gnu/stubs-soft.h: 没有那个文件或目录的解决办法
0 前言 使用ST官方SDK提供的交叉编译工具、cmake生成Makefile,使用make命令生成可执行文件提示fatal error: gnu/stubs-soft.h: 没有那个文件或目录的解决办法,如下所示: 根据这一错误提示,按照网上的解决方案逐一尝试均以失败告…...
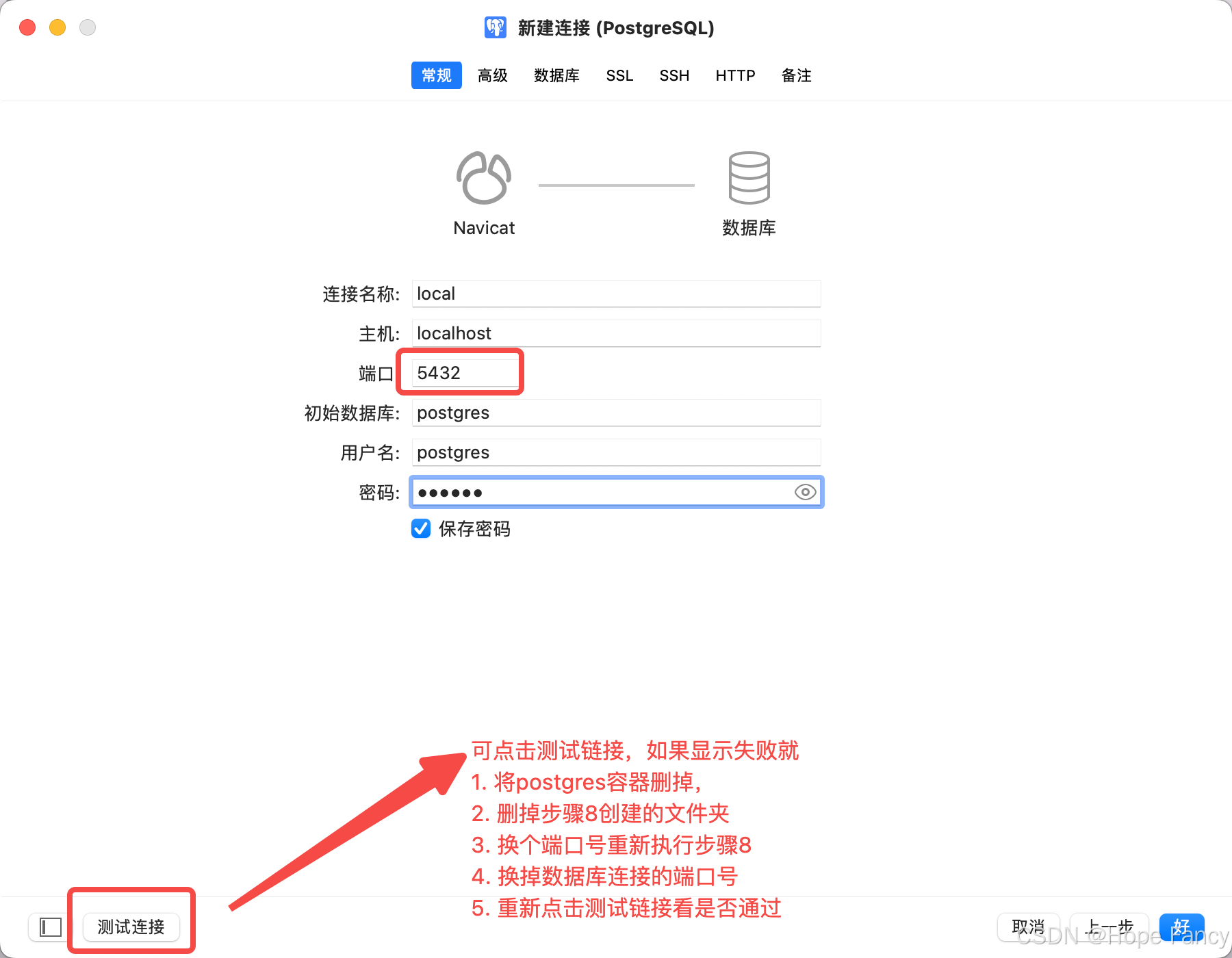
macOS 连接 Docker 运行 postgres,使用navicat添加并关联数据库
下载 docker注册一个账号,登录 Docker创建 docke r文件 mkdir -p ~/.docker && touch ~/.docker/daemon.json写入配置(全量替换) {"builder": {"gc": {"defaultKeepStorage": "20GB",&quo…...
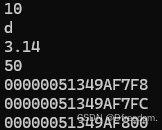
指针的使用——基本数据类型、数组、结构体
1 引言 对于学习指针要弄清楚如下问题基本可以应付大部分的场景: ① 指针是什么? ② 指针的类型是什么? ③ 指针指向的类型是什么? ④ 指针指向了哪里? 2 如何使用指针 任何东西的学习最好可以总结成一种通用化的…...