RAG:大模型微调的革命性增强——检索增强生成技术深度解析
RAG:大模型微调的革命性增强——检索增强生成技术深度解析
当大模型遇到知识瓶颈,RAG(检索增强生成)为模型装上"外部记忆库",让静态知识库与动态生成能力完美融合。本文将深入拆解RAG的技术原理、微调策略及工程实践。
一、大模型的核心困境:知识固化与幻觉
痛点场景:
- 医疗诊断中模型给出过时治疗方案(知识截止2023年)
- 法律咨询引用已废止的法规条款
- 技术文档生成混淆相似术语(如Kafka与RabbitMQ)
传统微调局限:
- 重新训练成本高:更新1%知识需100%参数调整
- 灾难性遗忘:学习新知识时丢失旧能力
- 静态知识库:无法实时响应信息更新
💡 RAG的破局思路:解耦知识存储与推理能力
“Don’t memorize, retrieve!” —— 让专业的事交给专业模块
二、RAG架构全景:三支柱系统
1. 检索器(Retriever)
- 嵌入模型:
text-embedding-ada-002/BGE-M3 - 检索算法:
- 最大内积搜索(MIPS):
argmax(q·d) - 混合检索:BM25(关键词)+ 向量(语义)
- 最大内积搜索(MIPS):
- 索引优化:
# FAISS高效相似搜索 index = faiss.IndexHNSWFlat(768, 32) index.add(document_embeddings)
2. 向量知识库
- 数据分层:
{"metadata": {"source": "FDA指南2024", "update_time": "2024-03-15"},"content": "药品临床试验三期要求...","embedding": [0.23, -0.87, ..., 0.45] } - 更新机制:
- 实时写入:
kafka -> Spark -> Delta Lake - 增量索引:
faiss.index_add()
- 实时写入:
3. 生成器(Generator)
- 输入重构:
[RET] 文档1:... [/RET] [RET] 文档2:... [/RET] 问题:用户原始提问 - 注意力增强:
# 在Transformer层注入检索信息 class RAGLayer(nn.Module):def forward(self, hidden_states, ret_docs):doc_att = cross_attention(hidden_states, ret_docs)return hidden_states + 0.3 * doc_att # 自适应融合
三、RAG微调策略:四阶段训练法
阶段1:检索器微调(Recall优化)
目标:提升TOP-k召回率
负样本构建:
- 困难负例:语义相似但答案错误的片段
- 批内负例:同一batch中的不相关文档
损失函数:
\mathcal{L}_{ret} = -\log \frac{\exp(q·d^+)}{\sum_{d^-} \exp(q·d^-)}
阶段2:生成器适配(Precision优化)
输入格式:
<|retrieval|> 文档1内容 </retrieval>
<|retrieval|> 文档2内容 </retrieval>
<|question|> 用户问题 </question>
微调技巧:
- 文档截断:滑动窗口保留512token
- 注意力掩码:防止跨文档信息泄露
阶段3:端到端联合优化(RAG-Token)
创新点:每个token可检索不同文档
# 动态检索流程
for t in range(max_length):if need_retrieve(output[:t]): # 基于已生成内容决策new_docs = retrieve(query=output[:t])context = update_context(new_docs)next_token = generator(context)
阶段4:对抗训练(鲁棒性提升)
攻击方式:
- 检索污染:注入错误文档
- 问题改写:同义替换关键术语
防御训练:
\min_G \max_{D_{adv}} \mathbb{E}[\log D_{adv}(G(x|D_{adv}))]
四、性能突破:RAG vs 传统方案
| 指标 | 全参数微调 | Prompt工程 | RAG微调 |
|---|---|---|---|
| 知识更新速度 | 周级 | 分钟级 | 秒级 |
| 事实准确率 | 87.2% | 76.5% | 92.8% |
| 训练成本($) | $18,000 | $50 | $800 |
| 幻觉率↓ | 23% | 35% | 8% |
医疗问答测试集显示:RAG将诊疗建议合规率从64%提升至89%
五、工程实践:LlamaIndex + RAG
最优配置组合
from llama_index import VectorStoreIndex, ServiceContext
from langchain.embeddings import HuggingFaceEmbedding# 1. 构建检索系统
embed_model = HuggingFaceEmbedding("BAAI/bge-large-zh")
index = VectorStoreIndex.from_documents(docs, embed_model=embed_model)# 2. 配置生成器
service_context = ServiceContext.from_defaults(llm=HuggingFaceLLM("meta-llama/Meta-Llama-3-8B-Instruct"),embed_model=embed_model
)# 3. 创建查询引擎
query_engine = index.as_query_engine(similarity_top_k=3,response_mode="tree_summarize" # 多文档融合
)
性能优化技巧
- 分级索引:
- 一级索引:Chroma(高频数据)
- 二级索引:Milvus(全量数据)
- 缓存策略:
- 查询缓存:Redis存储<query_hash, results>
- 嵌入缓存:LMDB存储文档向量
- 混合检索:
retriever = EnsembleRetriever(retrievers=[bm25_retriever, vector_retriever],weights=[0.3, 0.7] )
六、RAG进化方向:智能体协同
1. Self-RAG(自反思架构)
graph TD
A[问题] --> B{是否需要检索?}
B -- Yes --> C[检索相关文档]
B -- No --> D[直接生成]
C --> E{文档可信吗?}
E -- Yes --> F[基于文档生成]
E -- No --> G[标注不确定性]
2. RA-DIT:双指令微调
- 检索指令:
你是一名医学检索专家,请提取诊断关键词 - 生成指令:
你是一名医生,请根据检索结果给出诊疗建议
3. 多模态RAG
# 跨模态检索
def retrieve(image, text):img_vec = clip.encode_image(image)text_vec = clip.encode_text(text)return hybrid_search(img_vec, text_vec)
七、RAG的挑战与应对
| 挑战 | 解决方案 |
|---|---|
| 检索延迟高 | 边缘部署FAISS + GPU加速 |
| 文档质量影响结果 | 可信度评分器 + 元数据过滤 |
| 多跳推理能力弱 | 图检索(Neo4j) + 思维链微调 |
| 上下文长度受限 | 动态摘要 + 递归检索 |
某金融企业案例:通过引入事件图谱检索,将多跳问答准确率从41%提升至79%
结语:知识增强的新范式
RAG不仅解决了大模型的知识更新难题,更重新定义了人机协作的边界:
- 对开发者:训练成本降低10倍,支持实时知识注入
- 对企业:建立可审计的知识溯源系统
- 对用户:获得有据可查的可靠回答
随着工具调用(Tool Calling)与RAG的融合,我们正步入"大模型即操作系统"的时代——模型本身作为智能调度中心,协调检索、计算、生成等专项能力,实现真正的认知智能升级。
“RAG不是过渡方案,而是大模型落地的基础设施”
—— OpenAI技术架构师Lilian Weng
相关文章:

RAG:大模型微调的革命性增强——检索增强生成技术深度解析
RAG:大模型微调的革命性增强——检索增强生成技术深度解析 当大模型遇到知识瓶颈,RAG(检索增强生成)为模型装上"外部记忆库",让静态知识库与动态生成能力完美融合。本文将深入拆解RAG的技术原理、微调策略及…...

DisplayPort 2.0协议介绍(1)
最近开始学习DisplayPort 2.0协议,相比于DP1.4a,最主要的是速率提升到了10Gbps/lane,还有就是128b/132b编码方式的修改。至于速率13.5Gbps和20Gbps还只是可选项,在DP2.1协议才成为必须支持选项。 那在实现技术细节上有哪些变化呢…...
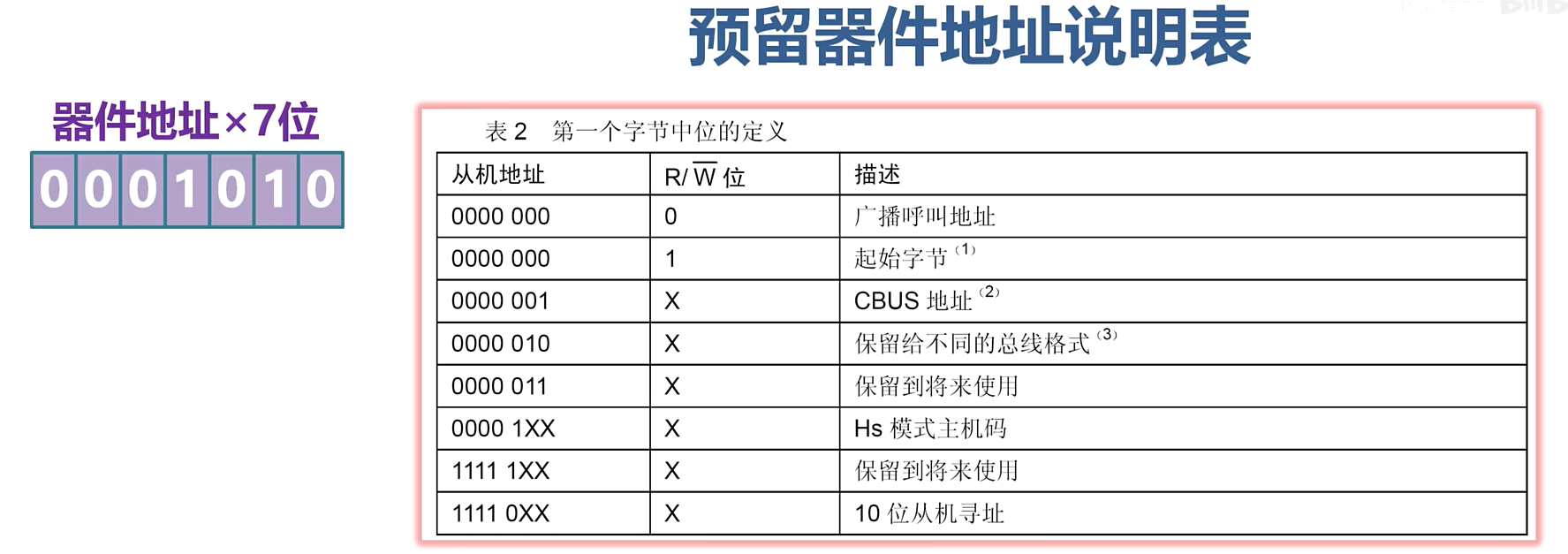
I2C通信讲解
I2C总线发展史 怎么在一条串口线上连接多个设备呢? 由于速度同步线是由主机实时发出的,所以主机可以按需求修改通信速度,这样在一条线上可以挂接不同速度的器件,单片机和性能差的器件通信,就输出较慢的脉冲信号&#x…...
综合知识答案和详解)
【信息系统项目管理师-选择真题】2025上半年(第一批)综合知识答案和详解
更多内容请见: 备考信息系统项目管理师-专栏介绍和目录 文章目录 【第1题】【第2题】【第3题】【第4题】【第5题】【第6题】【第7题】【第8题】【第9题】【第10题】【第11题】【第12题】【第13题】【第14题】【第15题】【第16题】【第17题】【第18题】【第19题】【第20题】【第…...

ABP VNext 在 Kubernetes 中的零停机蓝绿发布
ABP VNext 在 Kubernetes 中的零停机蓝绿发布 🚀 📚 目录 ABP VNext 在 Kubernetes 中的零停机蓝绿发布 🚀📌 一、前提准备 ℹ️🧱 二、项目结构与目标 🎯🐳 三、多阶段 Dockerfile 构建 &#…...

linux 故障处置通用流程-36计-14-27
014:查看系统主要日志 查看以下日志: 主要查以下关键字 error/NIC/fs /"link down"/Oout of memory" /var/log/messages /var/log/dmesg 015:主机通讯是否延迟 执行命令: #ping 网关_IP #ping 关联主机_IP …...

https和http有什么区别-http各个版本有什么区别
http和 https的区别 HTTP(超文本传输协议)和 HTTPS(安全超文本传输协议)是两种用于在网络上传输数据的协议,它们的主要区别在于安全性: HTTP(Hypertext Transfer Protocol)&#x…...
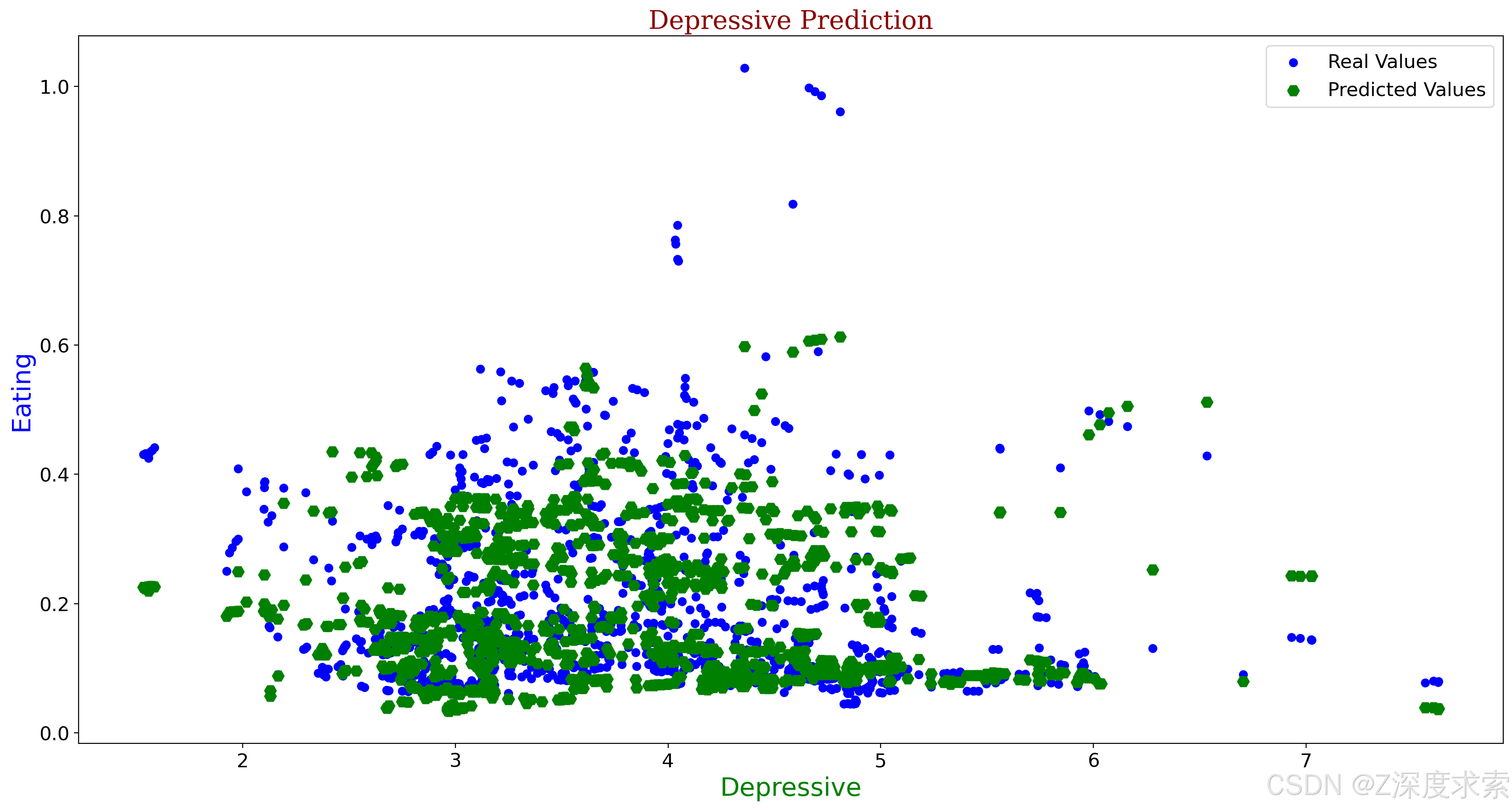
基于回归算法的心理健康预测(EDA + 预测)
心理健康涵盖情感、心理与社会福祉,影响认知、情绪和行为模式,决定压力应对、人际交往及健康决策,且在生命各阶段(从童年至成年)均至关重要。心理健康与身体健康同为整体健康的核心要素:抑郁会增加糖尿病、…...

React Native开发鸿蒙运动健康类应用的项目实践记录
项目名称:HarmonyFitness - 基于React Native的鸿蒙运动健康应用 技术栈:React Native 0.72.5 TypeScript HarmonyOS API ArkTS原生模块 一、环境搭建与项目初始化 双环境配置 React Native环境: npx re…...

【新品解读】一板多能,AXRF49 定义新一代 RFSoC FPGA 开发平台
“硬件系统庞杂、调试周期长” “高频模拟前端不稳定,影响采样精度” “接收和发射链路难以同步,难以扩展更多通道” “数据流量大,处理与存储跟不上” 这些是大部分客户在构建多通道、高频宽的射频采样链路时,面临的主要问题。…...

贪心算法应用:线性规划贪心舍入问题详解
贪心算法应用:线性规划贪心舍入问题详解 贪心算法是一种在每一步选择中都采取当前状态下最优的选择,从而希望导致结果是全局最优的算法策略。在线性规划问题中,贪心算法特别是贪心舍入技术有着广泛的应用。下面我将全面详细地讲解这一主题。…...
YOLO在C#中的完整训练、验证与部署方案
YOLO在C#中的完整训练、验证与部署方案 C# 在 YOLO 部署上优势明显(高性能、易集成),但训练能力较弱,通常需结合 Python 实现。若项目对开发效率要求高且不依赖 C# 生态,建议全程使用 Python;若需深度集成…...
洛谷题目:P2761 软件补丁问题 (本题简单)
个人介绍: 题目传送门: P2761 软件补丁问题 - 洛谷 (luogu.com.cn) 前言: 这道题是一个典型的状态搜索问题,核心目标就是利用给定d额多个补丁程序,将包含若干错误的软件修复成没有错误的状态,并且要使得修复过程当中的总耗时最少。下面是小亦为大家阐述滴思路: 1、状态…...
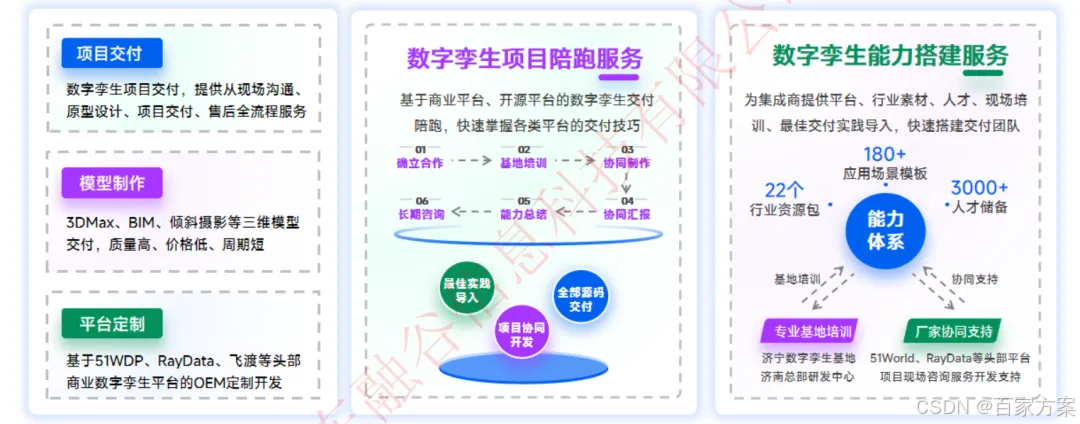
智慧园区数字孪生全链交付方案:降本增效30%,多案例实践驱动全周期交付
在智慧园区建设浪潮中,数字孪生技术正成为破解传统园区管理难题的核心引擎。通过构建与物理园区1:1映射的数字模型,实现数据集成、状态同步与智能决策,智慧园区数字孪生全链交付方案已在多个项目中验证其降本增效价值——某物流园区通过该方案…...
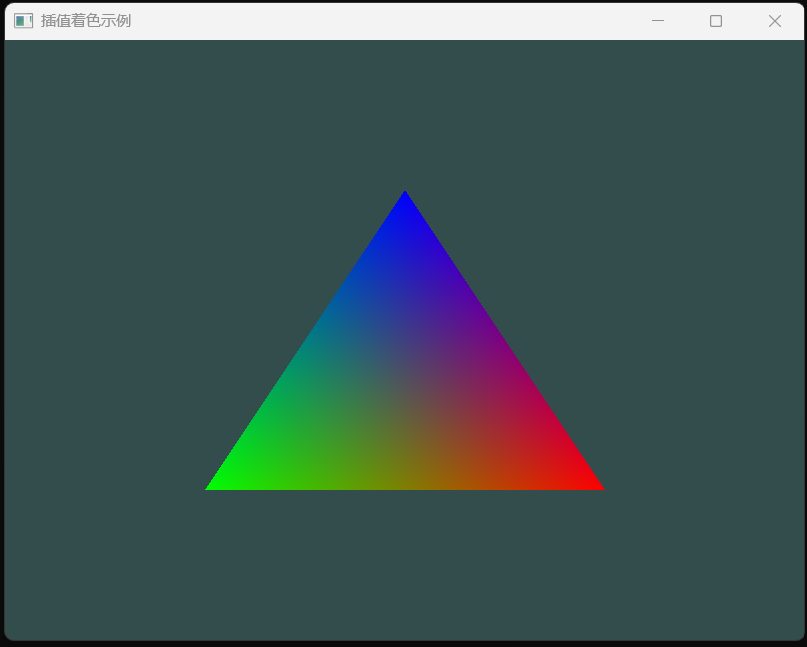
【OpenGL学习】(四)统一着色和插值着色
文章目录 【OpenGL学习】(四)统一着色和插值着色统一着色(Flat/Uniform Shading)插值着色(Interpolated Shading) 【OpenGL学习】(四)统一着色和插值着色 着色器介绍: h…...

42、响应处理-【源码分析】-浏览器与PostMan内容协商完全适配
42、响应处理源码分析浏览器与PostMan内容协商完全适配 要实现浏览器与PostMan在内容协商上的完全适配,需要在Spring Boot应用中自定义内容协商策略,确保服务器能根据浏览器和PostMan的请求头正确返回合适格式的数据。以下是详细的步骤: ### …...
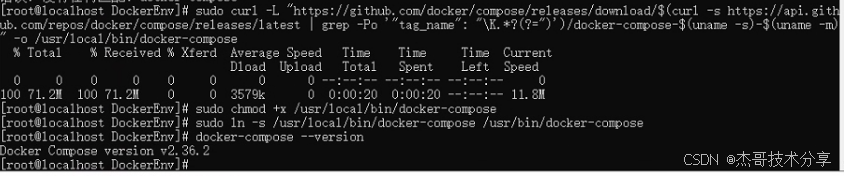
在 CentOS 上安装 Docker 和 Docker Compose 并配置使用国内镜像源
在 CentOS 上安装 Docker 和 Docker Compose 并配置使用国内镜像源,可以加速镜像下载速度。以下是详细的步骤: 一、安装 Docker 移除旧版本的 Docker(如果有): sudo yum remove docker \docker-client \docker-client…...

Java Lambda表达式深度解析:从入门到实战
简介 Lambda表达式是Java 8引入的最重要特性之一,它极大地简化了Java代码的编写方式,使函数式编程风格在Java中成为可能。本文将全面介绍Lambda表达式的概念、语法、应用场景以及与相关特性的配合使用,帮助开发者掌握这一强大的编程工具。 一、Lambda表达式基础 1.1 什么…...
Docker慢慢学
1、Docker DeskTop 2、N8N下载 docker run -p 8888:5678 n8nio/n8n 3、Kafka kafka依赖zookeeper,先启动zookeeper docker pull zookeeper docker run -d --name zookeeper -p 2181:2181 -e ALLOW_ANONYMOUS_LOGINyes zookeeper 启动kafka docker pull confluentinc/cp…...
cursor-free-vip使用
一、项目简介 Cursor-Free-VIP 是一个开源项目,旨在帮助用户免费使用 Cursor AI 的高级功能。它通过自动注册 Cursor 账号、重置机器 ID 和完成 Auth 验证等操作,解决 Cursor AI 中常见的限制提示。 二、系统准备 1…cursor需要更新到最新的版本 三、…...
使用SSH tunnel访问内网的MySQL
文章目录 环境背景方法参考 注:本文是使用SSH tunnel做端口转发的一个示例。有关SSH端口转发,可参考我的几篇文档 https://blog.csdn.net/duke_ding2/article/details/106878081https://blog.csdn.net/duke_ding2/article/details/135627263https://blo…...
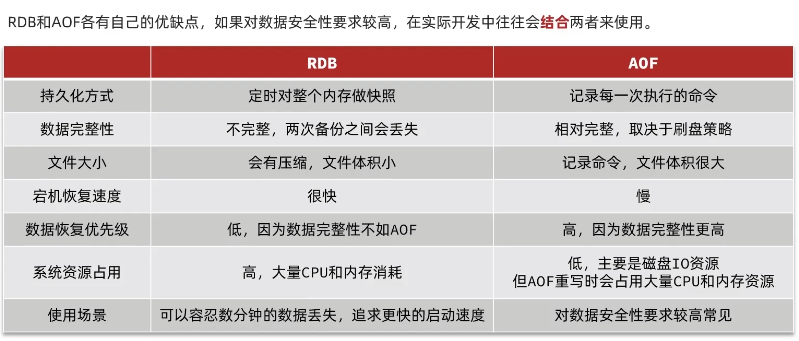
Redis持久化模式RDB与AOF
RDB持久化 RDB也被叫做Redis数据快照。简单来说就是把内存中的所有数据记录到磁盘中。当Redis实例故障重启后重磁盘中读取快照文件进行数据恢复(快照文件默认保存在当前运行目录); 演示Redis正常停机自动执行一次RDB操作 配置Redis触发RDB机制 RDB其它配置也可在red…...

【JS进阶】ES5 实现继承的几种方式
ES5 实现继承的几种方式 1. 原型链继承(Prototype Chaining) function Parent(name) {this.name name || Parent;this.colors [red, blue]; }Parent.prototype.sayName function() {console.log(this.name); };function Child() {}// 关键ÿ…...

【数据结构】树形结构--二叉树(二)
【数据结构】树形结构--二叉树(二) 一.二叉树的实现1.求二叉树结点的个数2.求二叉树叶子结点的个数3.求二叉树第k层结点的个数4.求二叉树的深度(高度)5.在二叉树中查找值为x的结点6.判断二叉树是否为完全二叉树7.二叉树的销毁 一.…...

JavaScript性能优化实战:深入探讨JavaScript性能瓶颈与优化技巧
引言:为什么JavaScript性能至关重要 在现代Web开发中,JavaScript已成为构建交互式应用程序的核心技术。随着单页应用(SPA)和复杂前端架构的普及,JavaScript代码的性能直接影响用户体验、转化率甚至搜索引擎排名。研究表明,页面加载时间每增加1秒,转化率可能下降7%,而性能…...

在 CentOS 上将 Ansible 项目推送到 GitHub 的完整指南
1. 安装 Git 在 CentOS 中使用 yum 安装 Git,Git 是管理代码版本控制的工具: sudo yum install git -y 2. 配置 Git 用户信息 设置你的 Git 用户名和邮箱,这些信息会出现在你每次提交的记录中: git config --global user.nam…...

深度学习题目1
梯度下降法的正确步骤是什么? a.计算预测值和真实值之间的误差 b.重复迭代,直至得到网络权重的最佳值 c.把输入传入网络,得到输出值 d.用随机值初始化权重和偏差 e.对每一个产生误差的神经元,调整相应的(权重ÿ…...

Spring @Scheduled vs XXL-JOB vs DolphinScheduler vs Airflow:任务调度框架全景对比
引言 从单机定时任务到分布式工作流调度,不同场景需要选择匹配的调度框架。 本文对比 Spring Scheduled、XXL-JOB、DolphinScheduler (海豚调度器)和 Apache Airflow 的核心差异,助你避免过度设计或功能不足。 一、核心定位与适用…...

【Oracle】锁
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 锁基础概述1.1 锁的概念与作用1.2 锁的工作原理1.3 Oracle锁的分类 2. 行级锁 (Row-Level Locks)2.1 行级锁的基本概念2.1.1 TX锁(事务锁)2.1.2 行级锁的工作机制 2.2 行级锁的类型2.…...
——什么是Raft?)
共识算法Raft系列(1)——什么是Raft?
Raft 算法是一种分布式一致性算法,由 Diego Ongaro 和 John Ousterhout 在 2014 年提出,旨在解决 Paxos 算法复杂且难以理解的问题。Raft 设计目标是易于理解和实现,同时提供强一致性(CAP 中的 CP 系统),广…...