Java高效批量读取Redis数据:原理、方案与实战案例
Java高效批量读取Redis数据:原理、方案与实战案例
在电商大促场景中,某平台需要实时展示用户购物车数据,面对每秒10万+的请求,传统单次读取Redis的方式导致响应延迟高达500ms。通过批量读取优化,最终将延迟降至20ms以内——本文将深入剖析Java批量操作Redis的核心技术与实战方案。
一、为什么需要批量读取Redis?
1.1 性能瓶颈分析
- 网络开销:每次请求产生RTT(Round-Trip Time),单次操作平均耗时1-2ms
- 连接消耗:频繁创建/销毁连接增加系统负载
- 吞吐量限制:单线程Redis处理能力受限(10万QPS左右)
// 传统单次读取模式(性能低下)
for (String key : keys) {String value = jedis.get(key); // 产生N次网络请求
}
1.2 批量读取核心价值
| 指标 | 单次读取 | 批量读取 | 提升幅度 |
|---|---|---|---|
| 网络请求次数 | O(n) | O(1) | 90%+ |
| 吞吐量 | 1-2万QPS | 8-10万QPS | 5-8倍 |
| 平均延迟 | 50-100ms | 5-20ms | 80%+ |
二、核心批量读取技术方案
2.1 MGET命令:静态键值批量获取
适用场景:已知完整Key集合的批量查询
// Jedis实现
try (Jedis jedis = pool.getResource()) {List<String> values = jedis.mget("key1", "key2", "key3");
}// Lettuce实现(异步)
RedisClient client = RedisClient.create("redis://localhost");
StatefulRedisConnection<String, String> connection = client.connect();
List<String> values = connection.sync().mget("key1", "key2").stream().map(KeyValue::getValue).collect(Collectors.toList());
执行原理:
Client: MGET key1 key2 key3
Server: 返回 ["value1", "value2", "value3"]
2.2 Pipeline:动态批量操作管道
适用场景:混合操作(读/写)或未知Key集合的批量处理
// Jedis Pipeline
try (Jedis jedis = pool.getResource()) {Pipeline p = jedis.pipelined();for (String key : keys) {p.get(key); // 将命令放入缓冲区}List<Object> results = p.syncAndReturnAll(); // 一次性发送
}// Lettuce Pipeline(异步)
List<RedisFuture<String>> futures = new ArrayList<>();
for (String key : keys) {futures.add(commands.get(key)); // 非阻塞提交
}
// 统一获取结果
List<String> values = futures.stream().map(RedisFuture::get).collect(Collectors.toList());
性能对比实验(读取1000个Key):
| 方式 | 耗时 | 网络请求数 | CPU占用 |
|---|---|---|---|
| 单次GET | 1250ms | 1000 | 45% |
| MGET | 35ms | 1 | 12% |
| Pipeline | 55ms | 1 | 15% |
三、实战优化案例:用户画像实时查询
3.1 业务场景
- 需求:根据用户ID列表实时获取用户标签(性别、兴趣、消费等级)
- 数据规模:每次请求最多100个用户ID
- 当前痛点:响应时间波动大(50ms-300ms)
3.2 优化方案
// 基于Spring Data Redis的批量实现
@Autowired
private RedisTemplate<String, UserProfile> redisTemplate;public Map<String, UserProfile> batchGetUserProfiles(List<String> userIds) {// 1. 构建Key列表List<String> keys = userIds.stream().map(id -> "user:profile:" + id).collect(Collectors.toList());// 2. 执行批量查询List<UserProfile> profiles = redisTemplate.opsForValue().multiGet(keys);// 3. 组装返回结果Map<String, UserProfile> result = new HashMap<>();for (int i = 0; i < userIds.size(); i++) {result.put(userIds.get(i), profiles.get(i));}return result;
}
3.3 性能优化
- Key压缩设计
// 原始Key:user_profile_{userId} // 优化后:u:p:{userId} (减少内存占用30%+) - 连接池配置
# application.yml spring:redis:jedis:pool:max-active: 100 # 最大连接数max-idle: 50min-idle: 10 - 结果缓存优化
// 使用本地缓存减少Redis访问 Cache<String, UserProfile> localCache = Caffeine.newBuilder().maximumSize(10_000).expireAfterWrite(5, TimeUnit.MINUTES).build();
优化效果:
- 平均响应时间:38ms → 8ms
- 99分位延迟:210ms → 25ms
- Redis CPU使用率:75% → 35%
四、高级技巧与避坑指南
4.1 超大Key集合处理方案
// 分批次处理(每批100个Key)
int batchSize = 100;
List<List<String>> partitions = Lists.partition(keys, batchSize);Map<String, String> result = new HashMap<>();
for (List<String> batch : partitions) {List<String> values = jedis.mget(batch.toArray(new String[0]));// 合并结果...
}
4.2 Pipeline与事务的差异
| 特性 | Pipeline | 事务(MULTI) |
|---|---|---|
| 原子性 | ❌ | ✅ |
| 错误处理 | 继续执行 | 回滚 |
| 性能 | 极高 | 中等 |
| 适用场景 | 批量读/写 | 需要原子操作 |
4.3 常见问题解决方案
-
部分Key不存在问题
// 返回结果与输入Key顺序一致,不存在时为null List<String> values = jedis.mget(keys); for (int i = 0; i < keys.size(); i++) {if (values.get(i) != null) {// 处理有效数据} } -
内存溢出预防
// 限制单次批量操作Key数量 if (keys.size() > MAX_BATCH_SIZE) {throw new IllegalArgumentException("Too many keys"); } -
热点Key分散策略
// 通过分片分散压力 int shard = key.hashCode() % SHARD_COUNT; Jedis jedis = shardPool[shard].getResource();
五、性能监控与调优
5.1 关键监控指标
# Redis服务器监控
redis-cli info stats # 查看ops_per_sec
redis-cli info memory # 分析内存碎片率# Java应用监控
JVM GC日志:观察GC频率与暂停时间
连接池指标:等待连接数、活跃连接数
5.2 压测工具使用
// 使用JMH进行基准测试
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.SECONDS)
public class RedisBatchBenchmark {@Benchmarkpublic void testMget(Blackhole bh) {List<String> values = jedis.mget(keys);bh.consume(values);}
}
5.3 配置优化参数
# redis.conf 关键参数
tcp-keepalive 60 # 保持连接活跃
maxmemory-policy allkeys-lru # 内存淘汰策略
client-output-buffer-limit normal 2gb 1gb 60 # 客户端输出缓冲
六、架构演进:从批量读取到分布式方案
当单Redis实例无法满足需求时,考虑升级方案:
-
读写分离架构
-
Redis Cluster分片
// 使用JedisCluster Set<HostAndPort> nodes = new HashSet<>(); nodes.add(new HostAndPort("127.0.0.1", 7000)); try (JedisCluster cluster = new JedisCluster(nodes)) {cluster.mget("key1", "key2"); // 自动路由 } -
二级缓存架构
结语:批量操作的最佳实践
通过合理使用MGET和Pipeline,Java应用可以实现Redis读取性能的飞跃式提升。根据实际测试数据,在千级数据量场景下:
- MGET方案 适用于确定Key集合的简单查询
- Pipeline方案 更适合混合操作或动态Key场景
- 当Key量超过500时,分批处理可避免阻塞风险
黄金法则:
“永远不要在循环中执行网络I/O操作——批量处理是高性能系统的基石。”
建议在项目中:
- 使用连接池管理Redis连接
- 对超过100个Key的操作强制分批
- 建立监控告警机制(如单次批量操作耗时>50ms)
- 定期进行性能压测(推荐使用JMH)
相关文章:

Java高效批量读取Redis数据:原理、方案与实战案例
Java高效批量读取Redis数据:原理、方案与实战案例 在电商大促场景中,某平台需要实时展示用户购物车数据,面对每秒10万的请求,传统单次读取Redis的方式导致响应延迟高达500ms。通过批量读取优化,最终将延迟降至20ms以内…...

基于RK3568的多网多串电力能源1U机箱解决方案,支持B码,4G等
基于RK3568的多网多串电力能源1U机箱解决方案,结合B码对时和4G通信能力,可满足电力自动化、能源监控等场景的高可靠性需求。核心特性如下: 一、硬件配置 处理器平台 搭载RK3568四核Cortex-A55处理器,主频1.8GHz-2.0GHz&#…...
面试题:Java多线程并发
继承 Thread 类 Thread 类本质上是实现了 Runnable 接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过 Thread 类的 start()实例方法。start()方法是一个 native 方法,它将启动一个新线程,并执行 run()方法。 public class M…...
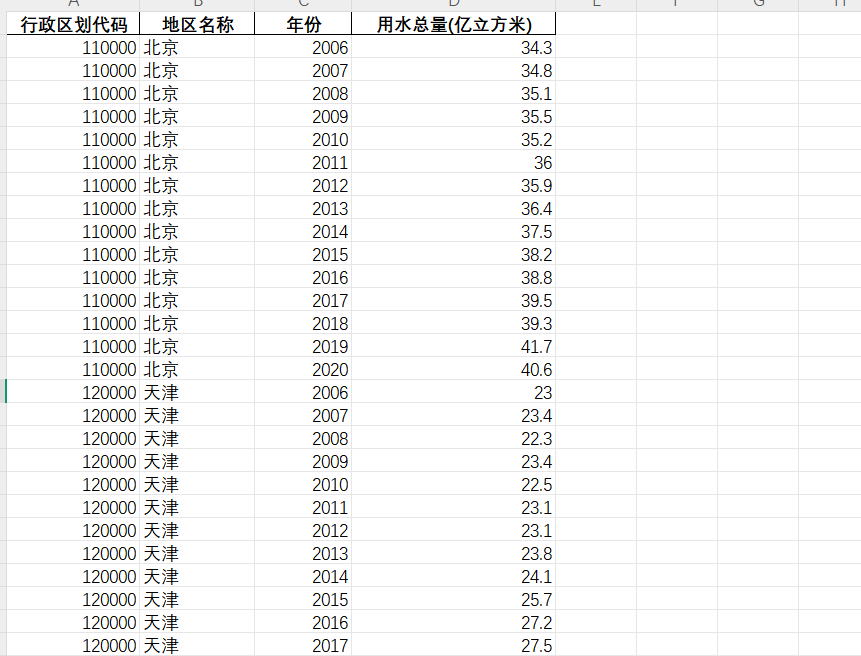
2006-2020年各省用水总量数据
2006-2020年各省用水总量数据 1、时间:2006-2020年 2、来源:国家统计局、统计年鉴 3、指标:行政区划代码、地区名称、年份、用水总量 4、范围:31省 5、指标说明:用水总量是指一个国家或地区在一定时期内ÿ…...

舵机在弹簧刀无人机中的作用是什么?
随着俄乌冲突的越发激烈,美国国防部宣布向乌克兰提供“弹簧刀”600型无人机。对于美国接连不断向乌克兰输送武器的做法,俄罗斯方面已经多次指责美国是在“火上浇油”,从而使俄乌冲突持续下去。 那么,弹簧刀究竟是一款怎样的无人机…...
进行加密和解密的基本操作)
c++ openssl 使用 DES(数据加密标准)进行加密和解密的基本操作
使用 DES(数据加密标准)进行加密和解密的基本操作,重点展示了 ECB 和 CBC 模式,并且通过篡改密文的方式来进行攻击。下面是对每个部分的详细解析。 1. 结构体 Slip struct Slip {char from[16] { 0 }; // 交易的发起者&#x…...
Git忽略规则.gitignore不生效解决
我在gitlab中新建了一个项目仓库,先把项目文件目录绑定到仓库,并全部文件都上传到了仓库中。 然后又从别的项目复制了忽略文件配置过来,怎么搞他都不能生效忽略我不要提交仓库的文件。 从网上查到说在本地仓库目录中,打开命…...

Excel高级函数使用FILTER、UNIQUE、INDEX
IFERROR(INDEX(UNIQUE(FILTER(明细表副本!B:B,(明细表副本!I:I>$B$1)*(明细表副本!I:I<$B$2)*(明细表副本!C:C<>$B$3)*(明细表副本!V:V$B$4))),ROW(明细表副本!B2)),"")解读 一、FILTER 过滤 FILTER(过滤列,过滤条件过滤条件) 过滤…...
6月5日day45
Tensorboard使用介绍 知识点回顾: tensorboard的发展历史和原理tensorboard的常见操作tensorboard在cifar上的实战:MLP和CNN模型 效果展示如下,很适合拿去组会汇报撑页数: 作业:对resnet18在cifar10上采用微调策略下&a…...

Linux 系统 rsyslog 配置
Linux 系统 rsyslog 配置指南 rsyslog 是 Linux 系统的下一代日志处理系统,功能强大且高效。以下是从基础到高级的全面配置指南: 1. 安装与基础配置 安装 rsyslog # Ubuntu/Debian sudo apt update sudo apt install rsyslog# CentOS/RHEL sudo yum …...
基于rpc框架Dubbo实现的微服务转发实战
目录 rpc微服务模块 导入依赖 配置dubbo 注解 开启Dubbo Dubbo的使用 特殊点 并没有使用 Reference 注入 微服务之间调用 可以选用Http 也可以Dubbo 我们 Dubbo 的实现需要一个注册中心 我作为一个服务的提供者 我需要把我的服务注册到注册中心去 调用方需要注册中心…...

matlab基于GUI实现水果识别
基于GUI实现水果识别系统,限一个图片内存在一种水果 图像处理是一种利用计算机分析图像以达到预期结果的技术。图像处理一般指数字图像处理,而数字图像指由工业相机、摄像机、扫描仪等设备捕捉到的二维数组,数组中的元素称为像素,…...

视频爬虫的Python库
1. 请求与网络库 最基础的 HTTP 请求库,用于发送 GET/POST 请求获取网页内容。 示例:获取视频页面 HTML 或 API 响应。 import requests response requests.get(https://example.com/video/123) aiohttp 异步 HTTP 请求库,适合大规模并发下…...
深度学习N2周:构建词典
🍨 本文为🔗365天深度学习训练营中的学习记录博客🍖 原作者:K同学啊 本周任务:使用N1周的.txt文件构建词典,停用词请自定义 1.导入数据 from torchtext.vocab import build_vocab_from_iterator from co…...
)
Qt多线程访问同一个数据库源码分享(基于Sqlite实现)
Qt多线程访问同一个数据库源码分享(基于Sqlite实现) 一、实现难点线程安全问题死锁风险连接管理问题数据一致性性能瓶颈跨线程信号槽最佳实践建议 二、源码分享三、测试1、新建一个多线程类2、开启多线程插入数据 一、实现难点 多线程环境下多个线程同时…...

多类别分类中的宏平均和加权平均
前言 在处理多类别分类问题时,宏平均(Macro-average)和加权平均(Weighted-average)是评估模型性能时常用的两种聚合指标。它们都能将每个类别的独立指标(如精确率、召回率、F1分数等)整合成一个…...

电子电路:什么是扩散电容?
PN结的电容效应主要有两种:势垒电容和扩散电容。势垒电容是由于耗尽层宽度变化引起的,而扩散电容可能和载流子的扩散过程有关。扩散电容通常出现在正向偏置的情况下,因为这时候多子注入到对方区域,形成电荷的积累。 当PN结正向偏置时,电子从N区注入到P区,空穴从P区注入到…...

贪心算法应用:装箱问题(FFD问题)详解
贪心算法应用:装箱问题(FFD问题)详解 1. 装箱问题概述 装箱问题(Bin Packing Problem)是计算机科学和运筹学中的一个经典组合优化问题。问题的描述如下: 给定一组物品,每个物品有一定的体积,以及若干容量相同的箱子,…...

机器学习的数学基础:假设检验
假设检验 默认以错误率为性能度量,错误率由下式给出: E ( f , D ) ∫ x ∼ D I I ( f ( x ) ≠ y ) p ( x ) d x E(f,\mathcal{D})\int_{\boldsymbol{x}\sim \mathcal{D}}\mathbb{II}(f(\boldsymbol{x})\ne y )p(\boldsymbol{x})\text{d}\boldsymbol{x…...

余氯传感器在智慧水务系统中如何实现IoT集成
现代余氯传感器(关键词:智能余氯监测、物联网水质传感器、LoRaWAN水监测)通过(关键词:Modbus RTU、4-20mA输出、NB-IoT传输)协议与SCADA系统对接,实现(关键词:远程氯浓度…...
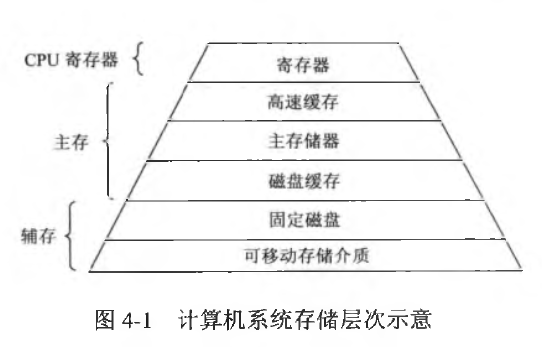
操作系统学习(九)——存储系统
一、存储系统 在操作系统中,存储系统(Storage System) 是计算机系统的核心组成部分之一,它负责数据的存储、组织、管理和访问。 它不仅包括物理设备(如内存、硬盘),还包括操作系统提供的逻辑抽…...

服务器安装软件失败或缺依赖怎么办?
服务器在安装软件时失败或提示缺少依赖,是运维中非常常见的问题。这个问题大多发生在 Linux 云服务器环境,原因和解决方法也有共性。以下是详细说明和解决建议: 🧠 一、常见原因分析 问题类型描述🔌 软件源不可用服务器…...

linux nm/objdump/readelf/addr2line命令详解
我们在开发过程中通过需要反汇编查看问题,那么我们这里使用rk3568开发板来举例nm/objdump/readelf/addr2line 分析动态库和可执行文件以及.o文件。 1,我们举例nm/objdump/readelf/addr2line解析linux 内核文件vmlinux (1),addr2…...
006网上订餐系统技术解析:打造高效便捷的餐饮服务平台
网上订餐系统技术解析:打造高效便捷的餐饮服务平台 在数字化生活方式普及的当下,网上订餐系统成为连接餐饮商家与消费者的重要桥梁。该系统以菜品分类、订单管理等模块为核心,通过前台展示与后台录入的分工协作,为管理员和会员提…...

[10-2]MPU6050简介 江协科技学习笔记(22个知识点)
1 2 3 欧拉角是描述三维空间中刚体或坐标系之间相对旋转的一种方法。它们由三个角度组成,通常表示为: • 偏航角(Yaw):绕垂直轴(通常是z轴)的旋转,表示偏航方向的变化。 • 俯仰角&a…...

基于行为分析的下一代安全防御指南
一、技术原理演进 从特征匹配到行为建模传统防火墙依赖特征库匹配(如病毒指纹),而行为分析技术通过建立用户/设备/应用的正常行为基线(基线构建误差<0.8%),利用隐马尔可夫模型检测异常。微软Az…...

Redis持久化机制详解:RDB与AOF的深度剖析
一、为什么需要持久化? Redis作为内存数据库,数据存储在易失性内存中。持久化机制解决两大核心问题: 数据安全:防止服务器宕机导致数据丢失灾难恢复:支持数据备份与快速重建 二、RDB:内存快照持久化 ▶ …...

记录一次 apt-key curl导入失败的处理方式
在配置 Kubernetes APT 仓库的过程中,我们通常会执行如下命令来添加阿里云的 GPG 公钥: curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -但这次在某台新机器上执行时,出现了访问失败的问题。具体表现为 cu…...
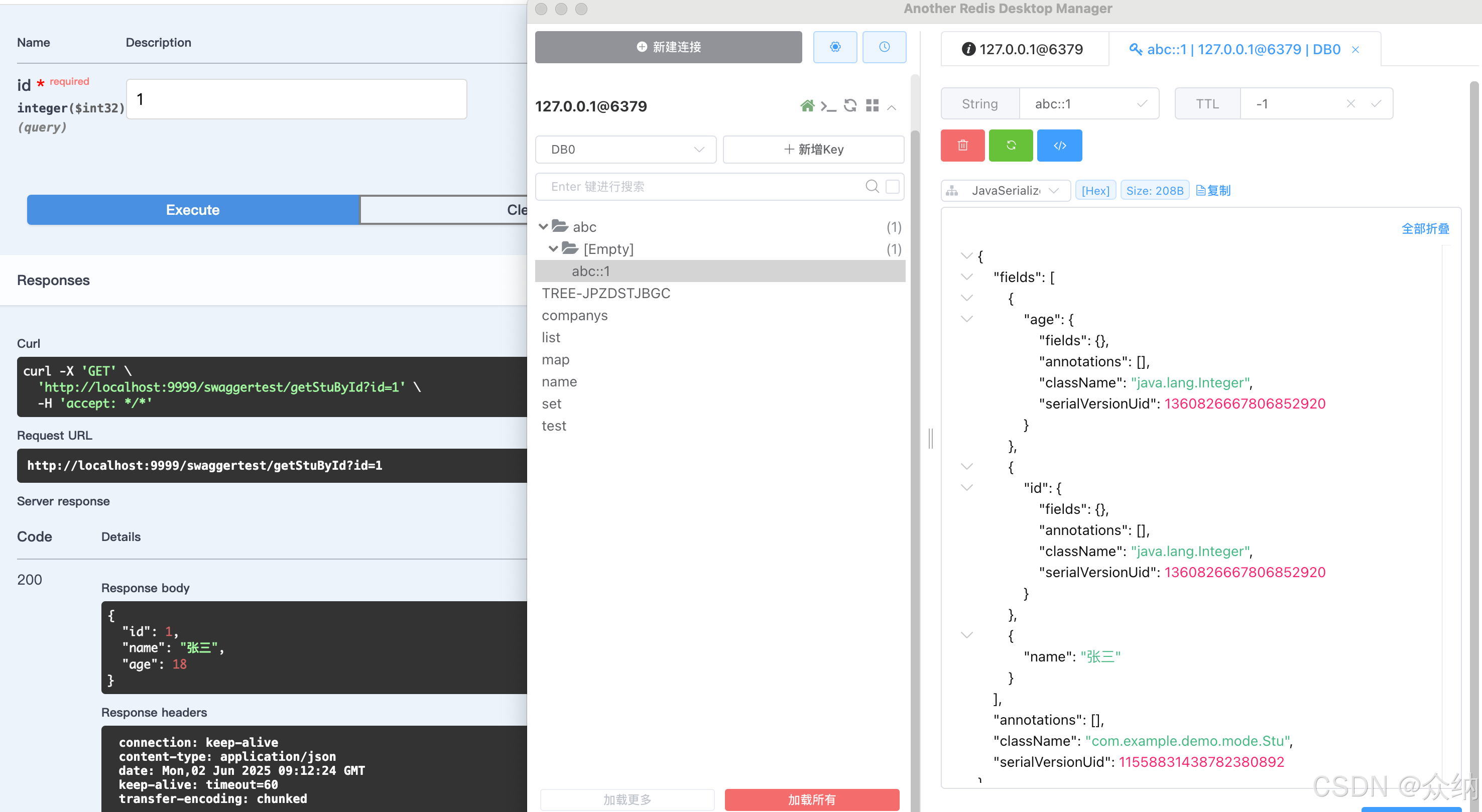
Spring Boot 3.X 下Redis缓存的尝试(二):自动注解实现自动化缓存操作
前言 上文我们做了在Spring Boot下对Redis的基本操作,如果频繁对Redis进行操作而写对应的方法显示使用注释更会更高效; 比如: 依之前操作对一个业务进行定入缓存需要把数据拉取到后再定入; 而今天我们可以通过注释的方式不需要额外…...
【03】完整开发腾讯云播放器SDK的UniApp官方UTS插件——优雅草上架插件市场-卓伊凡
【03】完整开发腾讯云播放器SDK的UniApp官方UTS插件——优雅草上架插件市场-卓伊凡 一、项目背景与转型原因 1.1 原定计划的变更 本系列教程最初规划是开发即构美颜SDK的UTS插件,但由于甲方公司内部战略调整,原项目被迫中止。考虑到: 技术…...