c++ stl容器之map用法
目录
(1)map介绍
(2)map、multimap、unordered_map区别
(3)map用法
1.map接口表
2.使用举例
插入数据与遍历数据
查找关键字和值
删除元素
按照值排序
(4)multimap用法
(5)unordered_map用法
(1)map介绍
map是STL的一个关联容器,以键值对存储的数据,其类型可以自己定义,每个关键字在map中只能出现一次,关键字不能修改,值可以修改。
map同set、multiset、multimap内部数据结构都是红黑树,而java中的hashmap是以hash table实现的。所以map内部有序(自动排序,单词时按照字母序排序),查找时间复杂度为O(logn)。
multimap与map的差别仅在于multimap允许键重复,有多个相同的键,而map要求键的唯一性。
(2)map、multimap、unordered_map区别
在C++中,std::map和std::unordered_map都是关联容器,它们存储的元素都是键值对(key-value pairs),并且每个键在容器中都是唯一的。然而,它们在内部实现、性能特性以及适用场景上有所不同。
对于std::map(基于红黑树实现),insert()函数会保持元素的排序顺序。而对于std::unordered_map(基于哈希表实现),元素的顺序是随机的。
主要区别如下表:
| 特性 | std::map | std::multimap | std::unordered_map |
| 键的唯一性 | 键唯一(不允许重复) | 键可重复(允许重复) | 键唯一(不允许重复) |
| 元素有序性 | 按键升序排序(红黑树实现) | 按键升序排序(红黑树实现) | 无序(哈希表实现) |
| 查找复杂度 | O(log N) | O(log N) | 平均 O(1),最坏 O(N)(哈希冲突) |
| 插入/删除复杂度 | O(log N) | O(log N) | 平均 O(1),最坏 O(N)(哈希冲突) |
| 适用场景 | 需要有序遍历或范围查询 | 需要有序遍历且键可重复 | 需要快速查找且不关心顺序 |
在选择使用std::map还是std::unordered_map时,你需要考虑你的具体需求。如果你需要元素保持排序或者对迭代器稳定性有要求,那么应该使用std::map。如果你对性能有严格要求,并且可以接受非确定性的迭代顺序,那么应该使用std::unordered_map。
(3)map用法
1.map接口表
| 操作 | 示例 |
| 构造对象 | #include <map> // 第一种 map<string,int> mymap1; // 也可以这样 typedef map<string,int> My_Map; My_Map mymap2; |
| insert() 插入数据 | 插入单个元素 std::map<int, std::string> myMap; myMap.insert(std::pair<int, std::string>(1, "one")); // 或者使用make_pair myMap.insert(std::make_pair(2, "two")); // 或者使用初始化列表(C++11及更高版本) myMap.insert({3, "three"}); |
| 检查是否插入成功 auto result = myMap.insert(std::pair<int, std::string>(1, "one")); if (result.second == false) { // 插入失败,键1已存在 } | |
| 插入多个元素 std::vector<std::pair<int, std::string>> elements = {{4, "four"}, {5, "five"}}; myMap.insert(elements.begin(), elements.end()); // 或者使用初始化列表(C++11及更高版本) myMap.insert({{6, "six"}, {7, "seven"}}); | |
| 从C++11开始,std::map和std::unordered_map都提供了emplace()函数,该函数允许你直接在容器中构造元素,这通常比先构造一个临时对象然后再插入更高效。 myMap.emplace(1, "one"); // 直接在map中构造元素 | |
| find() 查找元素 | // 查找键为2的元素 auto it = myMap.find(2); if (it != myMap.end()) { // 找到 } else { std::cout << "Key 2 not found." << std::endl; } |
| clear() 清空元素 | // 清除映射中的所有元素 myMap.clear(); |
| erase() 删除一个元素 | myMap.erase(2); // 移除键为2的元素 |
| auto it = myMap.find(3); // 查找键为3的元素的迭代器 if (it != myMap.end()) { myMap.erase(it); // 移除找到的元素 } | |
| // 假设我们想移除所有键在2到4(包括2但不包括4)之间的元素 auto range_start = myMap.lower_bound(2); // 找到第一个不小于2的元素的迭代器 auto range_end = myMap.upper_bound(4); // 找到第一个大于4的元素的迭代器 myMap.erase(range_start, range_end); // 移除范围内的元素 | |
| erase()会返回指向下一个有效元素的迭代器。 | |
| my_map.size() | map的长度大小 |
| my_map.begin() | 返回指向map头部的迭代器 |
| my_map.end() | 返回指向map末尾的迭代器 |
| my_map.rbegin() | 返回一个指向map尾部的逆向迭代器 |
| my_map.rend() | 返回一个指向map头部的逆向迭代器 |
| my_map.empty() | map为空时返回true |
| swap() | 交换两个map,两个map中所有元素都交换 |
2.使用举例
插入数据与遍历数据
通过map对象的方法获取的iterator数据类型是一个std::pair对象,包括两个数据iterator->first和iterator->second,分别代表关键字和value值。
在C++中,std::map默认就是按照键(key)的升序进行排序和存储的。因此,你只需要使用标准的迭代器来遍历std::map,就可以按照键的升序来获取元素。
#include <iostream>
using namespace std;#include <map>// 自定义打印map的函数
void printMap(map<string, int> mymymap)
{cout << "----------" << endl;map<string, int>::iterator it;for (it = mymymap.begin(); it != mymymap.end(); it++)cout << it->first << "=" << it->second << endl; // key=valuecout << "----------" << endl;
}int main()
{map<string, int> mymap;//第一种:用insert函数插入pair数据mymap.insert(pair<string, int>("first", 1));mymap.insert(pair<string, int>("second", 2));//第二种:用insert函数插入value_type数据mymap.insert(map<string, int>::value_type("third", 3));mymap.insert(map<string, int>::value_type("fourth", 4));//迭代器遍历map<string, int>::iterator it;cout << "----------" << endl;for (it = mymap.begin(); it != mymap.end(); it++)cout << it->first << "=" << it->second << endl; // key=valuecout << "----------" << endl;//第三种:更简便mymap["first"] = 100;mymap["fifth"] = 5; //新加入的元素会被放到容器的第一个位置printMap(mymap);return 0;
}
查找关键字和值
第一种:用count函数来判断关键字是否出现,其缺点是无法定位元素出现的位置。由于map一对一的映射关系,count函数的返回值要么是0,要么是1。
#include <iostream>
using namespace std;#include <map>int main()
{map<string, int> my_map;my_map["first"] = 1;cout << my_map.count("first") << endl; //输出1cout << my_map.count("second") << endl; //输出0return 0;
}第二种:用find函数来定位元素出现的位置,它返回一个迭代器,当数据出现时,返回的是数据所在位置的迭代器;若map中没有要查找的数据,返回的迭代器等于end函数返回的迭代器。
#include <map>
#include <string>
#include <iostream>using namespace std;int main()
{map<int, string> my_map;my_map.insert(pair<int, string>(1, "student_one"));my_map.insert(pair<int, string>(2, "student_two"));my_map.insert(pair<int, string>(3, "student_three"));map<int, string>::iterator it;it = my_map.find(1);if (it != my_map.end())cout << "Find, the value is " << it->second << endl;elsecout << "Do not Find" << endl;it = my_map.find(4);if (it != my_map.end())cout << "Find, the value is " << it->second << endl;elsecout << "Do not Find" << endl;return 0;
}删除元素
map对象的erase函数传入参数即可以是迭代器又可以是key
#include <map>
#include <string>
#include <iostream>using namespace std;void printMap(map<int, string> mymymap)
{cout << "----------" << endl;map<int, string>::iterator it;for (it = mymymap.begin(); it != mymymap.end(); it++)cout << it->first << "=" << it->second << endl; // key=valuecout << "----------" << endl;
}int main()
{map<int, string> my_map;my_map.insert(pair<int, string>(1, "one"));my_map.insert(pair<int, string>(2, "two"));my_map.insert(pair<int, string>(3, "three"));my_map.insert(pair<int, string>(4, "fourth"));printMap(my_map);// 第1种,用迭代器删除 关键字为 1 的数据map<int, string>::iterator it;it = my_map.find(1);my_map.erase(it); //如果要删除1,用关键字删除printMap(my_map);// 第2种,直接用关键字删除int n = my_map.erase(2); //如果成功删除了会返回1,否则返回0printMap(my_map);// 第2种,用迭代器,成片的删除,可以达到直接清空所有数据my_map.erase(my_map.begin(), my_map.end());// 成片删除要注意的是,也是STL的特性,删除区间是一个左闭右开的集合printMap(my_map);return 0;
}按照值排序
map中元素是自动按key升序排序(从小到大)的;按照value排序时,想直接使用sort函数是做不到的,sort函数只支持数组、vector、list、queue等的排序,无法对map排序,那么就需要把map放在vector中,再对vector进行排序。
例子1
#include <iostream>
#include <string>
#include <map>
#include <algorithm>
#include <vector>
using namespace std;void printMap(map<string, int> mymymap)
{cout << "----------" << endl;map<string, int>::iterator it;for (it = mymymap.begin(); it != mymymap.end(); it++)cout << it->first << "=" << it->second << endl; // key=valuecout << "----------" << endl;
}bool cmp(pair<string, int> a, pair<string, int> b)
{return a.second < b.second; // 严格升序
}int main()
{map<string, int> ma;ma["Alice"] = 86;ma["Bob"] = 78;ma["Zip"] = 92;ma["Stdevn"] = 88;printMap(ma);// 第一种方式传递到vector中vector<pair<string, int>> vec(ma.begin(), ma.end());// 第二种方式传递到vector中vector<pair<string, int>> vec2;for (map<string, int>::iterator it = ma.begin(); it != ma.end(); it++)vec2.push_back(pair<string, int>(it->first, it->second));// std::pair<std::string, int> tempPair(name, grade); // 对vec排序sort(vec.begin(), vec.end(), cmp);for (vector<pair<string, int>>::iterator it = vec.begin(); it != vec.end(); ++it){cout << it->first << "=" << it->second << endl;}return 0;
}例子2
#include <iostream>
#include <map>
#include <vector>
#include <algorithm>
#include <functional> bool judge_func(const std::pair<int, std::string>& a, const std::pair<int, std::string>& b){return a.second < b.second; // 严格弱序比较// 等值的元素在排序后的序列中保持其原始相对顺序// return a.second <= b.second; // 非严格弱序比较// 在大多数情况下,你应该使用严格弱序比较(即a.second < b.second)来确保排序的稳定性和可预测性
}int main() { std::map<int, std::string> m = {{1, "Z"}, {2, "B"}, {3, "A"}, {4, "C"}}; std::vector<std::pair<int, std::string>> v(m.begin(), m.end()); // c++中sort方法使用匿名函数排序// [](参数a, 参数b){函数体返回bool, a.x < b.x /*返回true表示升序*/}// std::sort(v.begin(), v.end(), [](const std::pair<int, std::string>& a, const std::pair<int, std::string>& b) { // return a.second < b.second; // }); // 有名函数排序std::sort(v.begin(), v.end(), judge_func);// 输出排序后的结果 for (const auto& pair : v) { std::cout << pair.first << ": " << pair.second << std::endl; } return 0;
}(4)multimap用法
multimap是关联式容器,按照特定顺序存储键值对<key、value>,其中多个键值对之间的key可以重复。
multimap与map唯一不同就是,map中key是唯一的,multimap中key是可以重复的。
Multimap 案例:
- 1个key值可以对应多个valude =分组
- 公司有销售部 sale (员工2名)、技术研发部 development (2人)、财务部 Financial (2人)
- 人员信息有:姓名,年龄,电话、工资等组成
- 通过 multimap进行 信息的插入、保存、显示
- 分部门显示员工信息
- 按条件搜索修改
#include <iostream>
#include <string>
#include <map>
using namespace std;class Person
{
public:string name;int age;string telephone;double salary;
};void test()
{Person p1, p2, p3, p4, p5, p6;p1.name = "王1";p1.age = 31;p2.name = "王2";p2.age = 32;p3.name = "张3";p3.age = 33;p4.name = "赵4";p4.age = 35;p5.name = "张5";p5.age = 34;p6.name = "赵6";p6.age = 35;// 1.构造multimap<string, Person> map2;// 2.插入数据//sale部门map2.insert(make_pair("sale", p1) );map2.insert(make_pair("sale", p2) );//development 部门map2.insert(make_pair("development", p3) );map2.insert(make_pair("development", p5) );//Financial 部门map2.insert(make_pair("Financial", p4) );map2.insert(make_pair("Financial", p6) );// 3.遍历multimap类型multimap<string, Person>::iterator it = map2.begin();for (it; it != map2.end(); it++){cout << it->first << "\t" << it->second.name << endl;}/*Financial 赵4Financial 赵6development 张3development 张5sale 王1sale 王2*/// 4.统计development部门的人数int num2 = map2.count("development");cout << "development num = " << num2 << endl; // 2// 5.查找development部门员工信息// find若查找到则出现在第一次位置,若未查找到则map2.end()multimap<string, Person>::iterator it2 = map2.find("development");int tag = 0;while (it2 != map2.end() && tag < num2){cout << it2->first << "\t" << it2->second.name << endl;it2++;tag++;}/*development 张3development 张5*/// 可以注意到multimap会将同一个key的多个value挨着// 所以这里用find方法得到的迭代器再++时,全是development部门的值// 6.按照条件 检索数据 进行修改cout << "-----------------" << endl;for(multimap<string, Person>::iterator it=map2.begin(); it!=map2.end(); it++){if (it->second.age == 32 ){it->second.name = "name32";}}for( multimap<string, Person>::iterator it=map2.begin(); it!=map2.end(); it++){cout << it->first << "\t" << it->second.age << "\t" << it->second.name << endl;}/*Financial 35 赵4Financial 35 赵6development 33 张3development 34 张5sale 31 王1sale 32 name32*/
}int main()
{test();return 0;
}(5)unordered_map用法
- 键唯一性:每个键只能出现一次,重复插入会覆盖原有值。
- 无序性:元素存储顺序不确定(由哈希函数决定)。
- 底层实现:基于哈希表(哈希桶 + 链表或树)。
适用场景:
需要快速查找、插入或删除,且不关心顺序。示例:缓存系统、字典查询。
例子
#include <unordered_map>
#include <iostream>int main() {std::unordered_map<int, std::string> umap = {{1, "Alice"},{2, "Bob"},{3, "Charlie"}};// 输出顺序不确定(可能是 2, 3, 1 或其他)for (const auto& [key, value] : umap) {std::cout << key << ": " << value << std::endl;}// 可能的输出:// 2: Bob// 3: Charlie// 1: Alice
}end
相关文章:

c++ stl容器之map用法
目录 (1)map介绍 (2)map、multimap、unordered_map区别 (3)map用法 1.map接口表 2.使用举例 插入数据与遍历数据 查找关键字和值 删除元素 按照值排序 (4)multimap用法 &…...
Linux-文件管理及归档压缩
1.根下的目录作用说明: /:Linux系统中所有的文件都在根下/bin:(二进制命令目录)存放常用的用户命令/boot:系统启动时的引导文件(内核的引导配置文件,grub配置文件,内核配置文件) 例…...

结合Jenkins、Docker和Kubernetes等主流工具,部署Spring Boot自动化实战指南
基于最佳实践的Spring Boot自动化部署实战指南,结合Jenkins、Docker和Kubernetes等主流工具,提供从环境搭建到生产部署的完整流程: 一、环境准备与工具选型 1.基础设施 Jenkins服务器:安装Jenkins LTS版本,配置JDK(推荐JDK 11+)及Maven/Gradle插…...

微软认证考试科目众多?该如何选择?
在云计算、人工智能、数据分析等技术快速发展的今天,微软认证(Microsoft Certification)已成为IT从业者、开发者、数据分析师提升竞争力的重要凭证。但面对众多考试科目,很多人不知道如何选择。本文将详细介绍微软认证的考试方向、…...

MCP协议在LLM系统中的架构与实现原理研究
MCP协议的角色和功能定位 模型上下文协议(Model Context Protocol, MCP) 是由Anthropic公司(Claude模型的发布方)提出的一种开放协议,旨在标准化大型语言模型(LLM)与外部数据源、工具和服务之间的交互方式。可以将MCP类比为AI应用的“USB-C接口”:通过统一的接口协议,…...
Dify工作流实践—根据word需求文档编写测试用例到Excel中
前言 这篇文章依赖到的操作可查阅我之前的文章: dify里的大模型是怎么添加进来的:在Windows本地部署Dify详细操作 flask 框架app.route()函数的开发和调用:PythonWeb开发框架—Flask工程创建和app.route使用详解 结构化提示词的编写&…...
【LC实战派】小智固件编译
这篇写给立创吴总,是节前答应他配合git代码的说明;也给所有对小智感兴趣的小伙伴。 请多提意见,让这份文档更有价值 - 第一当然是拉取源码 - git clone https://github.com/78/xiaozhi-esp32.git 完成后,先查看固件中实际的…...
详解)
HTTP(超文本传输协议)详解
目录 一、基本概念 二、HTTP报文(结构) (一) 请求报文 (二) 响应报文 三、HTTP请求方法 1. GET方法 2. POST方法 3. PUT方法 4. HEAD方法 5. DELETE 6. OPTIONS 一、知识扩展 7. TRACE 8. CONNECT 四、HTTP持久通信 (一) HTTP keep-alive…...

Unity安卓平台开发,启动app并传参
using UnityEngine; using System;public class IntentReceiver : MonoBehaviour {public bool isVR1;void Start(){Debug.LogError("app1111111111111111111111111");if (isVR1){LaunchAnotherApp("com.HappyMaster.DaKongJianVR2");}else{// 检查是否有传…...
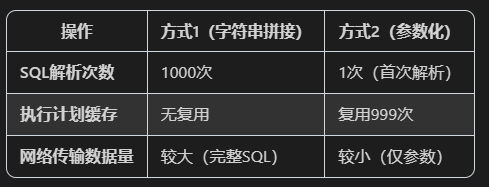
jdbcTemplate.query备忘录
jdbcTemplate.query中使用全部字符串和参数注入, 查询速度为什么差距这么大 如何正确使用JdbcTemplate参数化查询 1、使用?占位符 String sql "SELECT * FROM users WHERE name LIKE ?"; List<User> users jdbcTemplate.query(sql,new Object[…...
如何搭建Z-Blog PHP版本:详细指南
Z-Blog是一款功能强大且易于使用的博客平台,支持PHP和ASP两种环境。本文将重点介绍如何在PHP环境下搭建Z-Blog博客系统,帮助您快速上线自己的个人博客站点。 准备工作 1. 获取Z-Blog PHP版本 首先,访问Z-Blog官方网站下载最新版本的Z-Blog…...

Docker 常用命令详解
🐳 Linux 安装 Docker 及常用命令详解(适用于 Ubuntu) 📦 一、安装 Docker(Ubuntu 系统) 1. 更新系统 sudo apt update sudo apt upgrade -y2. 安装必要依赖 sudo apt install -y apt-transport-https …...

uniapp uni-id-co errCode“:“uni-id-captcha-required“,“errMsg“:“Captcha required
连续登录失败后就会出现图形验证码校验,如果前端不需要图形验证码校验,uni-id-co文件夹下找到module下的login文件夹下的login.js,注释掉Captcha相关校验,关掉即可 const {preLoginWithPassword,postLogin } require(../../lib/utils/login)…...

Github Copilot新特性:Copilot Spaces-成为某个主题的专家
概述 当今的工程团队都会面临知识碎片化的问题。关键的上下文分散在代码、文档和团队成员的头脑中,这使得他们很难在一个新的领域快速上手并完成工作。Copilot Spaces 通过集中您的项目上下文解决了这个问题,因此 Copilot 可以根据您的工作提供更智能、…...

React 第五十三节 Router中 useRouteError 的使用详解和案例分析
前言 useRouteError 是 React Router v6.4 引入的关键错误处理钩子,用于在 路由错误边界(Error Boundary) 中获取路由操作过程中发生的错误信息。 它提供了优雅的错误处理机制,让开发者能够创建用户友好的错误界面。 一、useRou…...

12分钟讲解主流React库
本内容是对 Every React Library Explained in 12 Minutes 内容的翻译与整理。 React Router React Router 是一个用于控制网站导航的库,同时也允许你自定义网站的 URL。它使用自定义组件,如 BrowserRouter、Routes 和 Route 组件,以创建 UR…...

《doubao-lite-32k 模型缓存机制使用指南》
doubao-lite-32k 模型缓存机制使用指南 一、缓存概述 1. 缓存作用 doubao-lite-32k 模型的缓存(Session 缓存)主要用于多轮对话场景,实现以下功能: 存储历史对话信息(Token),避免重复传输上下文,减少计算资源消耗。 优化长上下文(最长 32K Token)处理效率,提升多…...

攻防世界-XCTF-Web安全最佳刷题路线
每次写序都是最烦恼的,都不知道写什么,CTF是团队竞赛,有很多分支(Web安全,密码学,杂项,Pwn,逆向,安卓),可以每个领域都涉猎,或许感觉那…...
t021-高校物品捐赠管理系统【包含源码材料!!!!】
视频演示地址 摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装高校物品捐赠管理系统软件来发挥其高效地信息…...
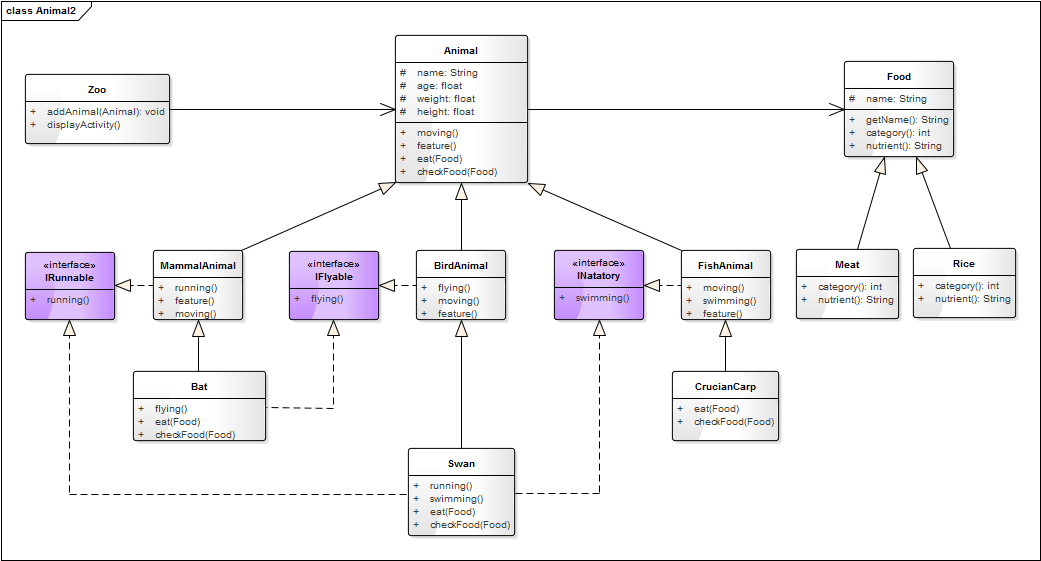
设计模式——面向对象设计六大原则
摘要 本文详细介绍了设计模式中的六大基本原则,包括单一职责原则、开放封闭原则、里氏替换原则、接口隔离原则、依赖倒置原则和合成复用原则。每个原则都通过定义、理解、示例三个部分进行阐述,旨在帮助开发者提高代码的可维护性和灵活性。通过具体代码…...
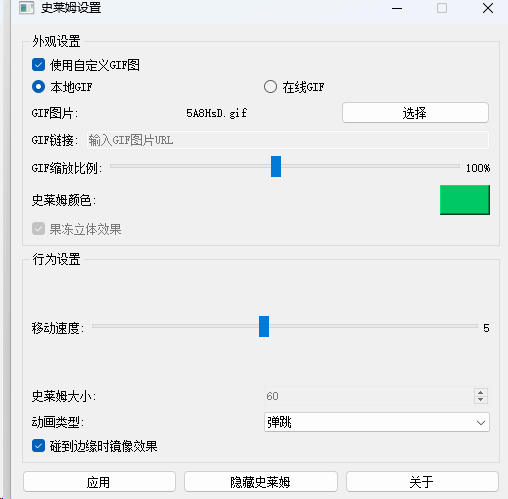
Python制作史莱姆桌面宠物!可爱的
史莱姆桌面宠物 一个可爱的桌面史莱姆宠物,它会在您的任务栏上移动并提供可视化设置界面。 这里写目录标题 史莱姆桌面宠物功能特点安装与运行直接运行方式创建可执行文件 使用说明自定义GIF说明打包说明开源地址 功能特点 可爱的史莱姆在任务栏上自动移动支持…...

React hook之userReducer
在 React 中,useReducer 是一个用于管理复杂状态逻辑的 Hook,它类似于 Redux 中的 reducer 模式,但更轻量且适用于组件内部或结合 Context API 实现全局状态管理。以下是 useReducer 的详细用法指南: 1. 基本语法 const [state, …...
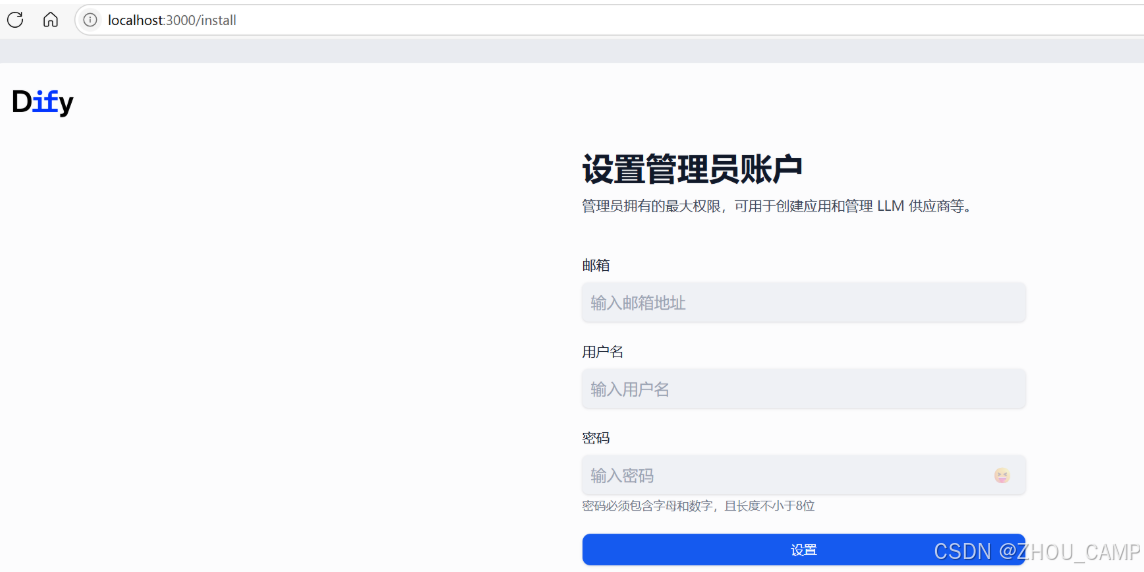
Dify源码教程:账户和密码传递分析
概述 Dify系统中账户创建过程中的密码处理是Web应用安全的重要环节。本教程详细分析了从前端表单到后端存储的完整流程,展示了Dify如何安全地处理用户凭据。 前端部分 在 dify/web/app/install/installForm.tsx 文件中,当用户填写完表单并点击安装按钮…...
中那种‘冗余’和‘多样性’,还是可以只保留最优解?)
如果科技足够发达,是否还需要维持自然系统(例如生物多样性)中那种‘冗余’和‘多样性’,还是可以只保留最优解?
这是一个非常深刻的问题,触及到了进化生物学、复杂系统理论和未来科技哲学的交汇点。 你可以这样理解这个问题的结构: “如果科技足够发达,是否还需要维持自然系统(例如生物多样性)中那种‘冗余’和‘多样性’&#x…...
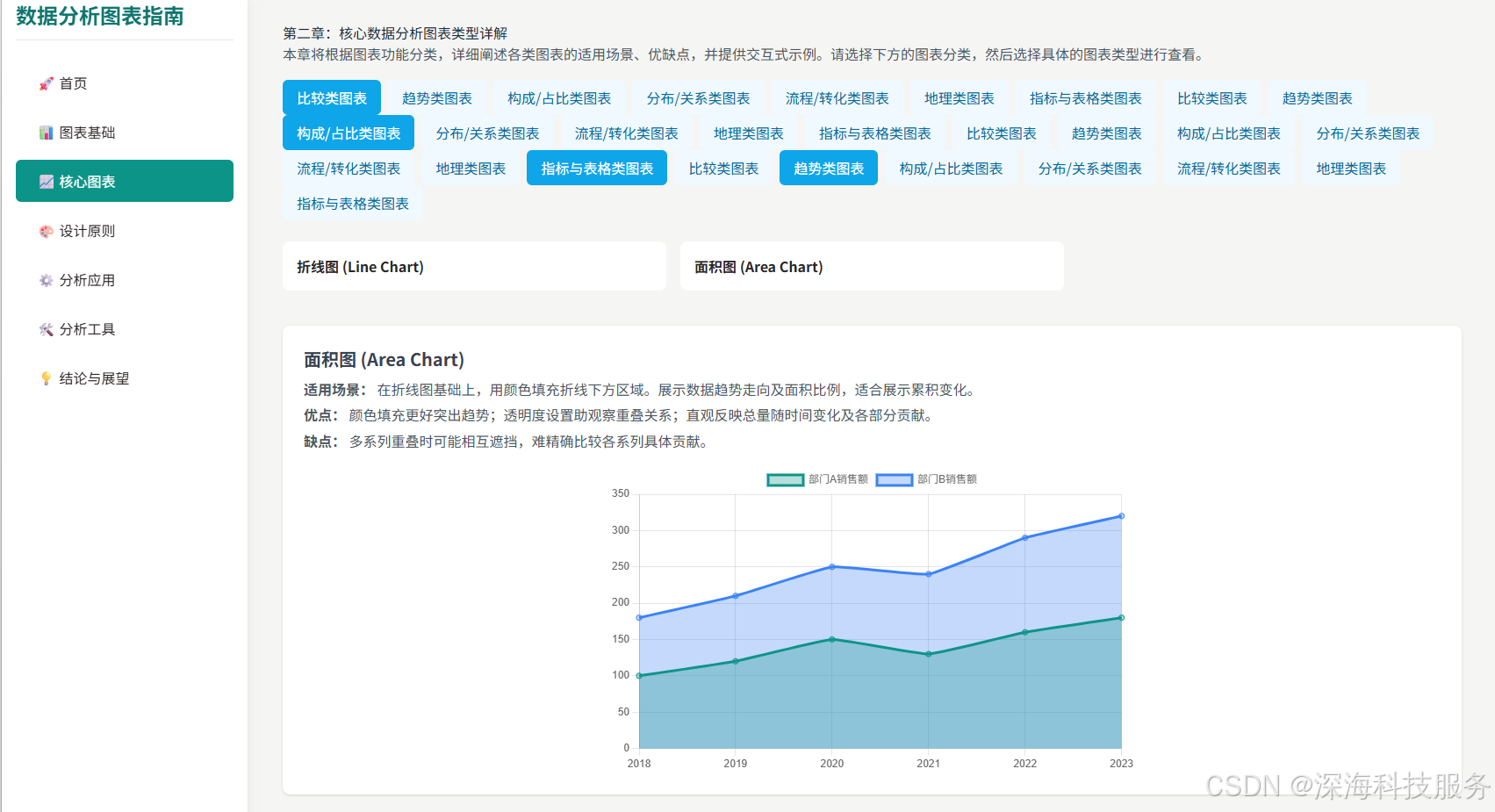
数据分析图表类型及其应用场景
说明:顶部HTML文件下载后可以直接查看,带有示图。 摘要 数据可视化作为现代数据分析的核心环节,旨在将复杂、抽象的数据转化为直观、易懂的图形形式。这种转化显著提升了业务决策能力,优化了销售与营销活动,开辟了新…...

第四十二天打卡
知识点回顾 回调函数lambda函数hook函数的模块钩子和张量钩子Grad-CAM的示例 作业:理解下今天的代码即可 # 定义一个回调函数 def handle_result(result):"""处理计算结果的回调函数"""print(f"计算结果是: {result}")# 定…...
Github 2025-06-03Python开源项目日报 Top10
根据Github Trendings的统计,今日(2025-06-03统计)共有10个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目10Rust项目1HTML项目1C项目1 系统设计指南 创建周期:2507 天开发语言:Pyt…...

Vim查看文件十六进制方法
在 Vim 中查看文件的十六进制格式,可以通过以下步骤实现: 方法 1:使用内置命令(无需插件) 用 Vim 以二进制模式打开文件: vim -b 文件名或打开文件后执行: :set binary转换为十六进制视图&…...

电脑提示dll文件缺失怎么办 dll修复方法
当你在使用某些应用程序或启动电脑时,看到提示“DLL文件缺失”的错误信息,这通常意味着某个必要的动态链接库(DLL)文件无法被找到或加载,导致软件无法正常运行。本文将详细介绍如何排查和修复DLL文件缺失的问题&#x…...

【自动思考记忆系统】demo (Java版)
背景:看了《人工智能》中的一段文章,于是有了想法。想从另一种观点(⭕️)出发,尝试编码,告别传统程序员一段代码解决一个问题的方式。下图是文章原文和我的思考涂鸦✍️,于是想写一个自动思考记…...