Python爬虫爬取天猫商品数据,详细教程【Python经典实战项目】
Python爬取天猫商品数据详细教程
一、前期准备
1. 环境配置
- Python环境:确保已安装Python 3.x版本,建议使用Anaconda或直接从Python官网下载安装。
- 第三方库:
requests:用于发送HTTP请求。BeautifulSoup:用于解析HTML内容。lxml:作为BeautifulSoup的解析器,提高解析效率。selenium(可选):用于处理动态加载的内容。pandas(可选):用于数据处理和存储。
安装命令:
pip install requests beautifulsoup4 lxml selenium pandas2. 了解天猫的反爬机制
天猫等电商平台通常有完善的反爬虫机制,包括但不限于:
- User-Agent检测:检查请求头中的User-Agent字段。
- IP限制:频繁请求可能导致IP被封禁。
- 验证码:部分操作可能需要输入验证码。
- 动态加载:部分内容通过JavaScript动态加载。
二、爬取天猫商品数据的基本步骤
1. 分析目标页面
- 打开天猫商品页面:在浏览器中打开天猫商品详情页,右键选择“检查”或按
F12打开开发者工具。 - 查看网络请求:在开发者工具的“Network”选项卡中,刷新页面,查看请求的URL和响应内容。
- 定位数据:找到包含商品信息的HTML元素,记录其标签名、类名或ID。
2. 发送HTTP请求
使用requests库发送HTTP请求,获取页面内容。
import requestsurl = 'https://detail.tmall.com/item.htm?id=商品ID' # 替换为实际的商品ID
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}response = requests.get(url, headers=headers)
if response.status_code == 200:html_content = response.text
else:print(f"请求失败,状态码:{response.status_code}")3. 解析HTML内容
使用BeautifulSoup解析HTML内容,提取商品信息。
import requestsurl = 'https://detail.tmall.com/item.htm?id=商品ID' # 替换为实际的商品ID
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}response = requests.get(url, headers=headers)
if response.status_code == 200:html_content = response.text
else:print(f"请求失败,状态码:{response.status_code}")
4. 处理动态加载的内容(可选)
如果商品信息是通过JavaScript动态加载的,可以使用selenium模拟浏览器行为。
from selenium import webdriver
from selenium.webdriver.common.by import By
import time# 配置ChromeDriver路径
driver_path = 'path/to/chromedriver' # 替换为实际的ChromeDriver路径
driver = webdriver.Chrome(executable_path=driver_path)driver.get(url)
time.sleep(5) # 等待页面加载完成# 提取动态加载的内容(示例:提取商品标题)
title_element = driver.find_element(By.CSS_SELECTOR, 'span.J_TSearch_Title')
title = title_element.text.strip()print(f"商品标题:{title}")# 关闭浏览器
driver.quit()
5. 存储数据
将爬取的数据保存到本地文件或数据库中。
保存到CSV文件
import pandas as pddata = {'商品标题': [title],'商品价格': [price],'商品销量': [sales]
}df = pd.DataFrame(data)
df.to_csv('tmall_products.csv', index=False, encoding='utf-8-sig')保存到数据库(以MySQL为例)
import pymysql# 连接数据库
conn = pymysql.connect(host='localhost',user='username',password='password',database='database_name',charset='utf8mb4'
)cursor = conn.cursor()# 创建表(如果不存在)
cursor.execute('''
CREATE TABLE IF NOT EXISTS tmall_products (id INT AUTO_INCREMENT PRIMARY KEY,title VARCHAR(255),price VARCHAR(50),sales VARCHAR(50)
)
''')# 插入数据
sql = '''
INSERT INTO tmall_products (title, price, sales)
VALUES (%s, %s, %s)
'''
cursor.execute(sql, (title, price, sales))# 提交事务
conn.commit()# 关闭连接
cursor.close()
conn.close()三、高级技巧与注意事项
1. 处理分页
如果需要爬取多页商品数据,可以分析分页URL的规律,通过循环实现。
base_url = 'https://list.tmall.com/search_product.htm?q=关键词&s=' # 替换为实际的搜索关键词for page in range(0, 100, 44): # 每页44个商品,假设爬取前3页url = f"{base_url}{page}"response = requests.get(url, headers=headers)if response.status_code == 200:html_content = response.textsoup = BeautifulSoup(html_content, 'lxml')# 提取当前页的商品信息(示例:提取商品标题)product_tags = soup.find_all('div', class_='product')for product in product_tags:title_tag = product.find('a', class_='product-title')if title_tag:title = title_tag.get_text().strip()print(f"商品标题:{title}")2. 使用代理IP
为了避免IP被封禁,可以使用代理IP。
proxies = {'http': 'http://your_proxy_ip:port','https': 'https://your_proxy_ip:port'
}response = requests.get(url, headers=headers, proxies=proxies)3. 遵守法律法规和网站规则
- 遵守robots.txt协议:在爬取前,检查目标网站的
robots.txt文件,确保爬取行为符合网站规定。 - 合理设置请求间隔:避免频繁请求,给服务器造成过大压力。
- 不侵犯隐私:确保爬取的数据不涉及用户隐私。
4. 异常处理
在实际应用中,应添加异常处理机制,以应对网络请求失败、HTML结构变化等情况。
try:response = requests.get(url, headers=headers, timeout=10)response.raise_for_status() # 如果响应状态码不是200,抛出HTTPError异常html_content = response.textsoup = BeautifulSoup(html_content, 'lxml')# 提取商品信息...except requests.exceptions.RequestException as e:print(f"请求发生错误:{e}")
except Exception as e:print(f"发生未知错误:{e}")四、完整代码示例
import requests
from bs4 import BeautifulSoup
import pandas as pd
import time
import randomdef crawl_tmall_product(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}try:response = requests.get(url, headers=headers, timeout=10)response.raise_for_status()html_content = response.textsoup = BeautifulSoup(html_content, 'lxml')# 提取商品标题title_tag = soup.find('span', class_='J_TSearch_Title')title = title_tag.get_text().strip() if title_tag else '未找到商品标题'# 提取商品价格price_tag = soup.find('span', class_='tm-price')price = price_tag.get_text().strip() if price_tag else '未找到商品价格'# 提取商品销量(以月销为例)sales_tag = soup.find('div', class_='tm-detail-hd-sale')sales = sales_tag.find('span').get_text().strip().replace('月销', '') if sales_tag else '未找到商品销量'return {'商品标题': title,'商品价格': price,'商品销量': sales}except requests.exceptions.RequestException as e:print(f"请求发生错误:{e}")return Noneexcept Exception as e:print(f"发生未知错误:{e}")return Nonedef main():# 示例:爬取单个商品product_url = 'https://detail.tmall.com/item.htm?id=商品ID' # 替换为实际的商品IDproduct_data = crawl_tmall_product(product_url)if product_data:print(f"商品标题:{product_data['商品标题']}")print(f"商品价格:{product_data['商品价格']}")print(f"商品销量:{product_data['商品销量']}")# 保存到CSV文件data = [product_data]df = pd.DataFrame(data)df.to_csv('tmall_products.csv', index=False, encoding='utf-8-sig')print("数据已保存到tmall_products.csv")if __name__ == '__main__':main()五、总结
通过以上步骤,你可以使用Python爬取天猫商品数据。在实际应用中,需要根据目标网站的具体情况调整代码,并注意遵守相关法律法规和网站规则。希望本教程对你有所帮助!
相关文章:

Python爬虫爬取天猫商品数据,详细教程【Python经典实战项目】
Python爬取天猫商品数据详细教程 一、前期准备 1. 环境配置 Python环境:确保已安装Python 3.x版本,建议使用Anaconda或直接从Python官网下载安装。第三方库: requests:用于发送HTTP请求。BeautifulSoup:用于解析HTM…...

Oracle 的 SEC_CASE_SENSITIVE_LOGON 参数
Oracle 的SEC_CASE_SENSITIVE_LOGON 参数 关键版本信息 SEC_CASE_SENSITIVE_LOGON 参数在以下版本中被弃用: Oracle 12c Release 1 (12.1): 该参数首次被标记为"过时"(obsolete)但依然保持功能有效 Oracle 18c/19c 及更高版本: …...

Docker构建自定义的镜像
构建自定义的 Docker 镜像是 Docker 使用中的核心操作之一。通过自定义镜像,你可以将应用程序及其依赖环境打包成一个可移植的容器化镜像。以下是详细的步骤和注意事项: 1. 准备工作 在构建自定义镜像之前,你需要准备以下内容: D…...
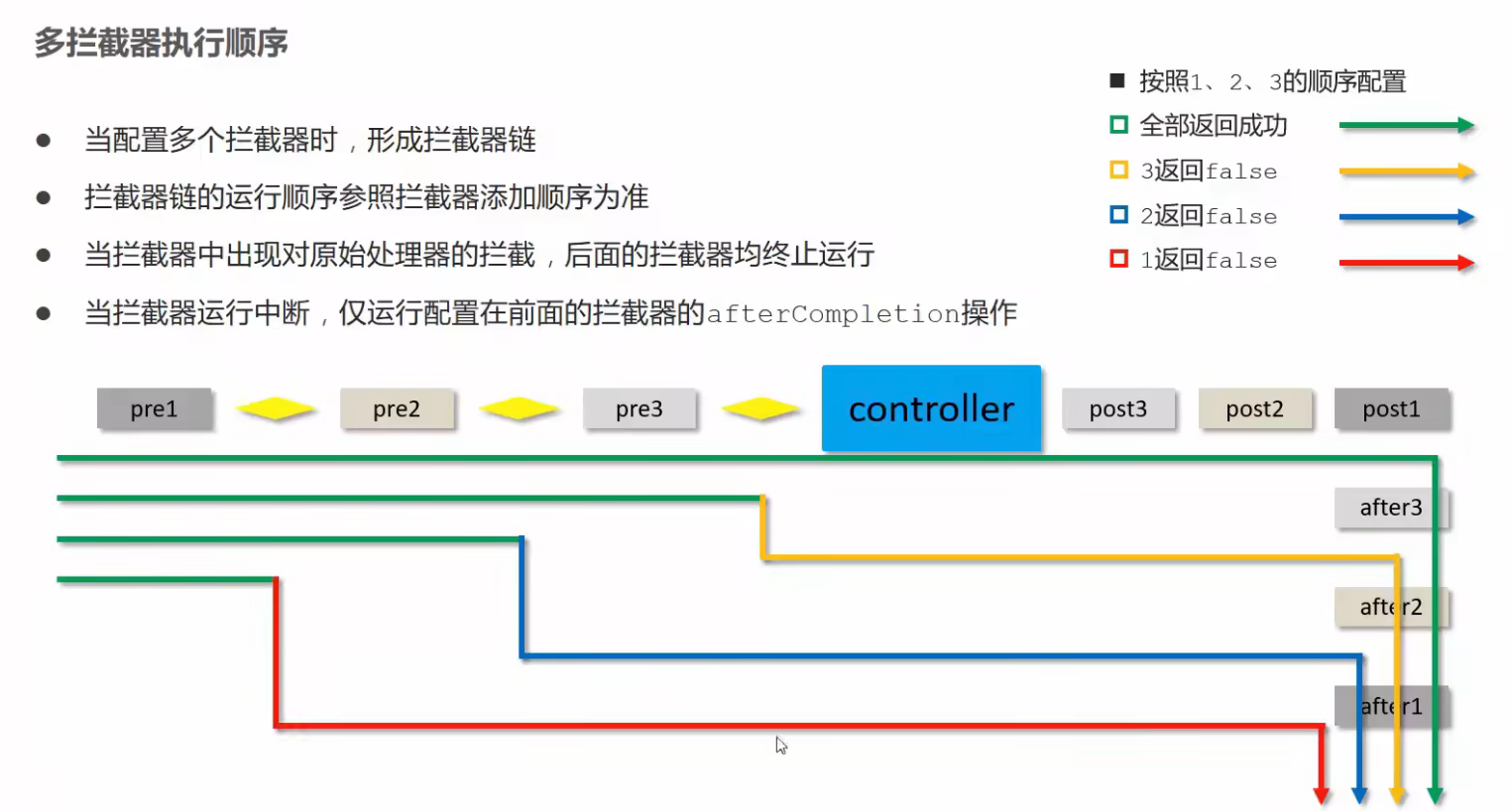
【SSM】SpringMVC学习笔记8:拦截器
这篇学习笔记是Spring系列笔记的第8篇,该笔记是笔者在学习黑马程序员SSM框架教程课程期间的笔记,供自己和他人参考。 Spring学习笔记目录 笔记1:【SSM】Spring基础: IoC配置学习笔记-CSDN博客 对应黑马课程P1~P20的内容。 笔记2…...
井川里予瓜pdf完整版
井川里予瓜pdf完整版 下载链接: 链接:https://pan.quark.cn/s/c75455d6be60 在网红文化盛行的当下,井川里予无疑是一位备受瞩目的人物。这位2001年出生于广东湛江的姑娘,凭借独特风格在网络世界掀起波澜,其发展轨迹…...

UI自动化常见的一些问题解决方式
1、遇到元素无法定位的情况 解决方法:(1)手写css 先找到父级的唯一元素 (2)手写xpath、 (3)js在浏览器控制台去定位 控制台定位样例:(1)…...
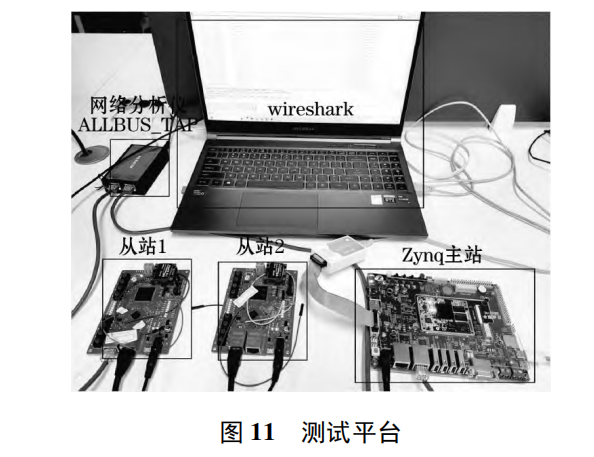
基于 Zynq 平台的 EtherCAT 主站的软硬件协同设计
摘要: 针对工业自动化对控制能力和强实时性的需求,提出了一种基于 FPGA 的改进型 EtherCAT 硬件主站方案 。 该方案利用 Zynq-7000 平台,在 PL 端实现 FPGA 协议栈,以保证核心功能的高效执 行 。 基于 AXI4 总线设计…...
聊一聊 .NET在Linux下的IO多路复用select和epoll
一:背景 1. 讲故事 在windows平台上,相信很多人都知道.NET异步机制是借助了Windows自带的 IO完成端口 实现的异步交互,那在 Linux 下.NET 又是怎么玩的呢?主要还是传统的 select,poll,epoll 的IO多路复用…...
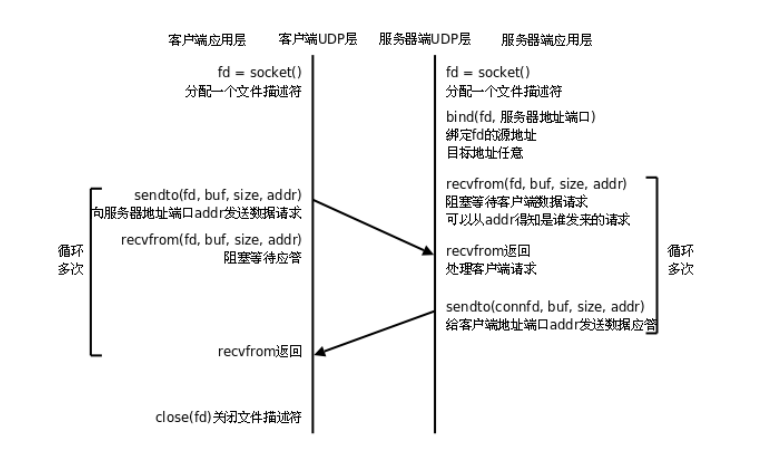
从零开始的嵌入式学习day33
网络编程及相关概念 UDP网络通信程序 UDP网络通信操作 一、网络编程及相关概念 1. 网络编程概念: 指通过计算机网络实现程序间通信的技术,涉及协议、套接字、数据传输等核心概念。常见的应用场景包括客户端-服务器模型、分布式系统、实时通信等。…...

ArcGIS Pro 3.4 二次开发 - 宗地
环境:ArcGIS Pro SDK 3.4 + .NET 8 文章目录 宗地1 宗地1.1 向地图添加宗地图层1.2 获取活动记录1.3 设置活动记录1.4 创建新记录1.5 将标准线要素复制到宗地类型1.6 将宗地线复制到宗地类型1.7 将要素分配给活动记录1.8 创建宗地种子1.9 构建地块1.10 重复地块1.11 设置地块为…...

前端面试准备-7
1.定义class的实现 //定义class class Person{//公有属性nameage 18//构造函数constructor(name){//构造函数内部的this实例化对象this.name name//动态添加属性(不推荐)this.food [🐂,🐎,🐏]}//公有方法sayHi(){c…...

黑马Java面试笔记之框架篇(Spring、SpringMvc、Springboot)
一. 单例bean Spring框架中的单例bean是线程安全的吗? Spring框架中的bean是单例的,可以在注解Scope()进行设置 singleton:bean在每一个Spring IOC容器中只有一个实例。prototype:一个bean的定义可以有多个实例 总结 二. AOP AOP称…...
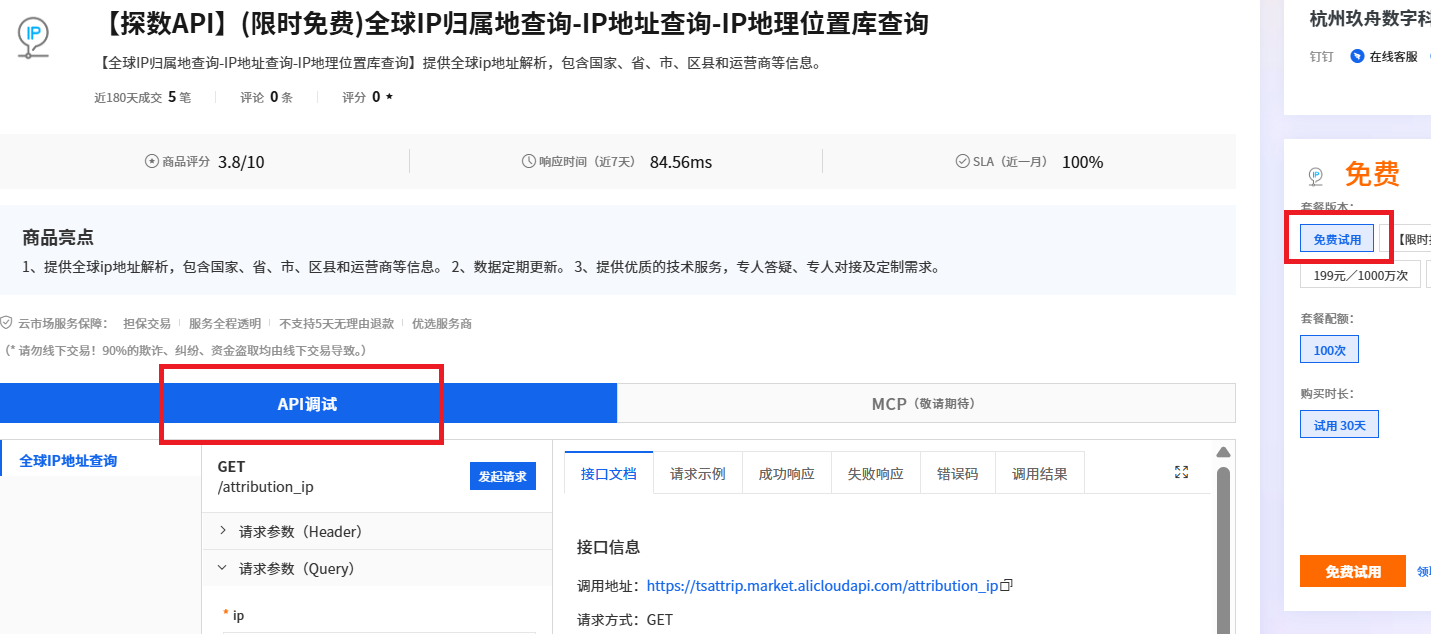
全球IP归属地查询接口如何用C#进行调用?
一、什么是全球IP归属地查询接口 在全球化互联网时代,IP地址作为网络世界的地理位置标识,扮演着至关重要的角色。全球IP归属地查询接口通过解析IP地址,提供包括国家、省、市、区县和运营商在内的详细信息。 二、应用场景 1. 访问识别 全球…...
NumPy 比较、掩码与布尔逻辑
文章目录 比较、掩码与布尔逻辑示例:统计下雨天数作为通用函数(Ufuncs)的比较运算符使用布尔数组计数条目布尔运算符 布尔数组作为掩码使用关键字 and/or 与运算符 &/| 的区别 比较、掩码与布尔逻辑 本文介绍如何使用布尔掩码来检查和操…...
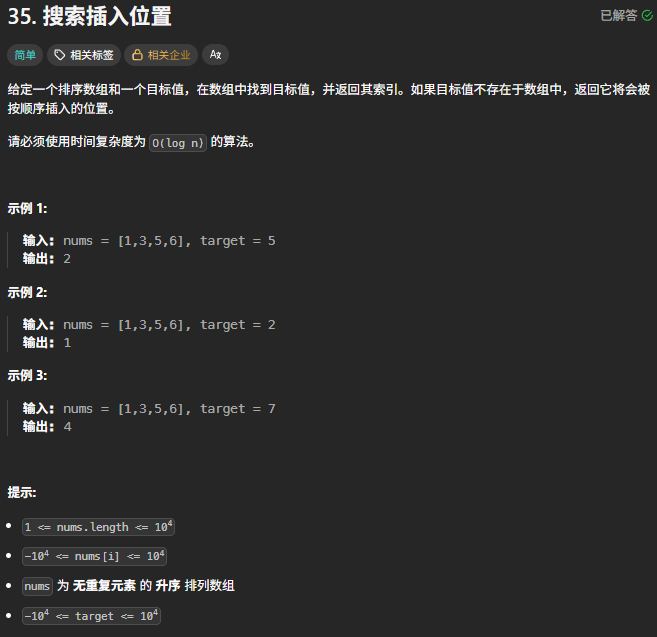
力扣HOT100之二分查找:35. 搜索插入位置
这道题属于是二分查找的入门题了,我依稀记得一些二分查找的编码要点,但是最后还是写出了一个死循环,无语(ˉ▽ˉ;)…又回去看了下自己当时的博客和卡哥的视频,这才发现自己分情况只分了两种,最后导致死循环…...
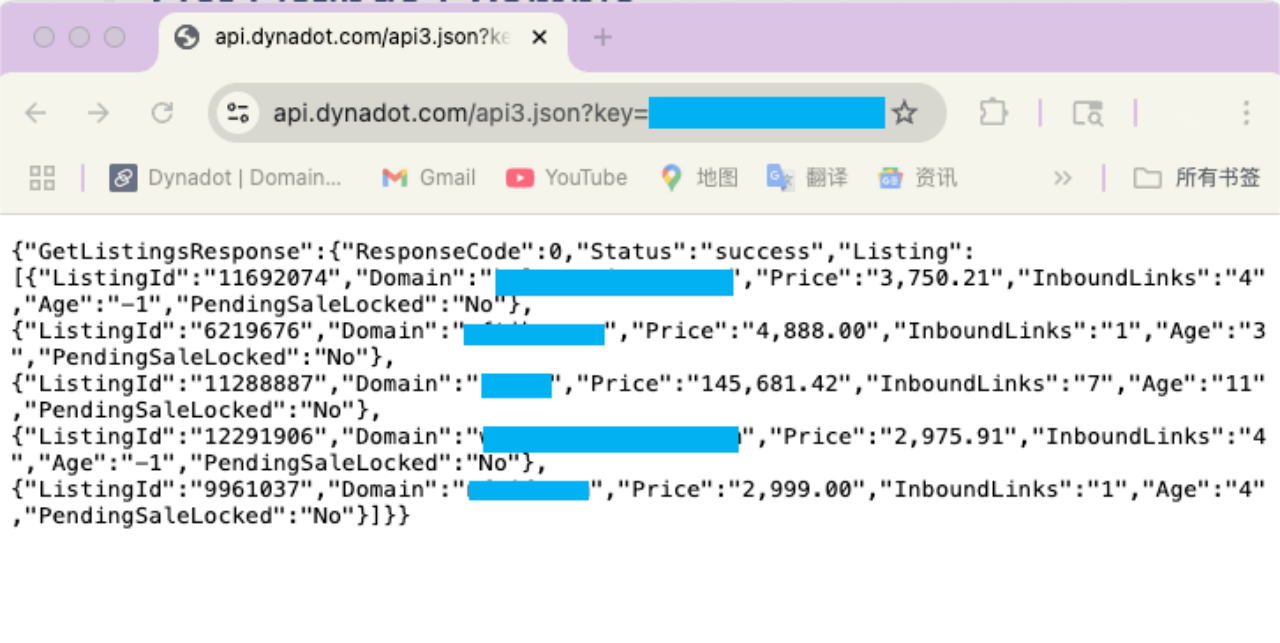
使用API有效率地管理Dynadot域名,查看域名市场中所售域名的详细信息
关于Dynadot Dynadot是通过ICANN认证的域名注册商,自2002年成立以来,服务于全球108个国家和地区的客户,为数以万计的客户提供简洁,优惠,安全的域名注册以及管理服务。 Dynadot平台操作教程索引(包括域名邮…...

IM即时通讯软件,构建企业局域网内安全协作
安全与权限:协同办公的企业级保障 在协同办公场景中,BeeWorks 将安全机制贯穿全流程。文件在局域网内传输与存储时均采用加密处理,企业网盘支持水印预览、离线文档权限回收等功能,防止敏感资料外泄;多人在线编辑文档时…...
VueScan:全能扫描,高清输出
在数字化办公和图像处理的领域,扫描仪扮演着不可或缺的角色。无论是文档的数字化存档、照片的高清复制,还是创意项目的素材采集,一款性能卓越、操作便捷的扫描软件能大幅提升工作效率和成果质量。VueScan正是这样一款集多功能于一身的扫描仪软…...

PyCharm项目和文件运行时使用conda环境的教程
打开【文件】—【新建项目】 按照下图配置环境 可以看到我这个项目里,报错“No module named modelscope” 点击终端,输入命令 #显示所有的conda环境 conda env list #选择需要激活的conda环境 conda activate XXX在终端中,执行pip install …...
:组件的幕后工作)
第八部分:第五节 - 生命周期与副作用 (`useEffect` Hook):组件的幕后工作
知识点: 组件生命周期(挂载 Mounting, 更新 Updating, 卸载 Unmounting - 高级概念),副作用 (Side Effects),useEffect Hook (用于处理副作用,如数据获取、订阅、DOM 操作),useEffect 的依赖数组…...
)
docker 搭建php 开发环境 添加扩展redis、swoole、xdebug(2)
3、创建compose 的yml文件 version: "3.9" services:#配置nginxnginx:#镜像名称 nginx:latestimage: nginx#自定义容器的名称#container_name: c_nginxports:- "80:80"#lnmp目录和容器的/usr/share/nginx/html目录进行绑定,设置rw权限#将宿主机的~/lnmp/…...

DeepSwiftSeek 开源软件 |用于 DeepSeek LLM 模型的 Swift 客户端 |轻量级和高效的 DeepSeek 核心功能通信
一、软件介绍 文末提供程序和源码下载 DeepSeek Swift SDK 是一个轻量级且高效的基于 Swift 的客户端,用于与 DeepSeek API 进行交互。它支持聊天消息完成、流式处理、错误处理以及使用高级参数配置 DeepSeekLLM。 二、Features 特征 Supports chat completion …...
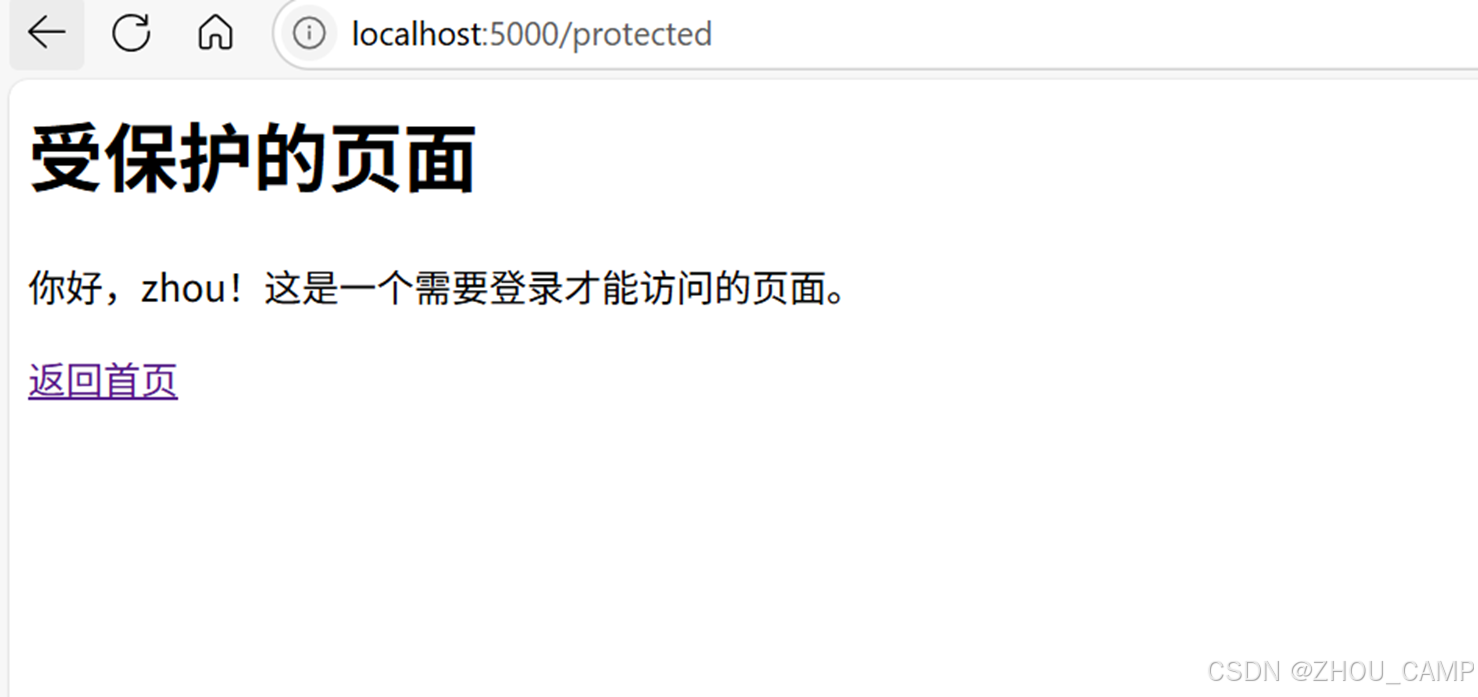
Flask-Login使用示例
项目结构 首先创建以下文件结构: flask_login_use/ ├── app.py ├── models.py ├── requirements.txt └── templates/├── base.html├── index.html├── login.html├── register.html└── profile.html1. requirements.txt Flask2.3.3 Fl…...

React Hooks 基础指南
React Hooks 是 React 16.8 引入的重要特性,它允许开发者在函数组件中使用状态和其他 React 特性。本文将详细介绍 6 个最常用的 React Hooks。 1. useState useState 是最常用的 Hook,用于在函数组件中添加 state。 import React, { useState } from…...
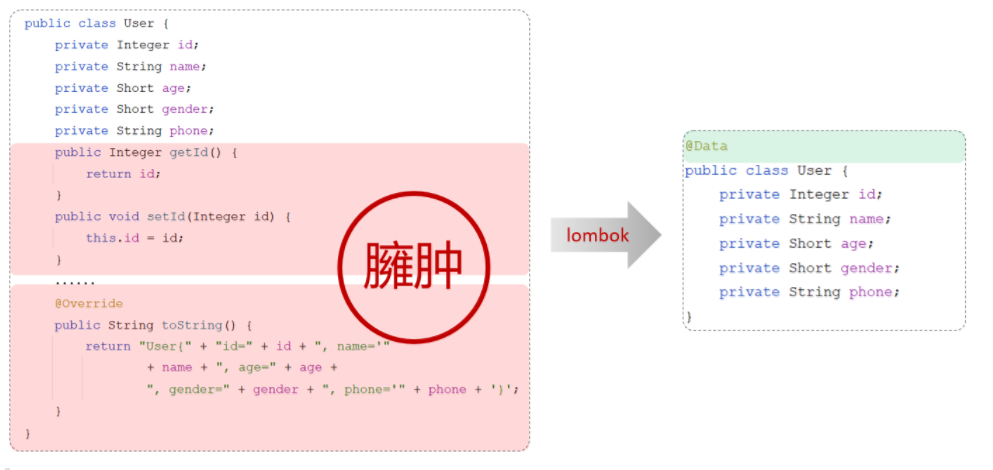
web第九次课后作业--SpringBoot基于mybatis实现对数据库的操作
前言 在前面我们学习MySQL数据库时,都是利用图形化客户端工具(如:idea、datagrip),来操作数据库的。 在客户端工具中,编写增删改查的SQL语句,发给MySQL数据库管理系统,由数据库管理系统执行SQL语句并返回执…...

沪铜6月想法
市场回顾 2025年5月,沪铜期货主力合约价格整体呈现震荡走势。从月初到月末,价格在7.67-7.82万元/吨之间波动。截至5月31日,沪铜主力合约收盘价为7.76万元/吨。本月铜价围绕供需基本面和宏观政策预期展开波动,尤其在5月14日至5月1…...

网络通信核心概念全解析:从IP地址到TCP/UDP实战
一、网络基础架构三要素 1. IP地址:互联网的“门牌号” 本质:32位整数标识主机位置(IPv4)表示法:点分十进制(如 192.168.1.1)功能:全球唯一标识网络设备特殊地址: 127.…...

Spring 中的disposableBean介绍
在 Spring 框架中,DisposableBean 是一个接口,用于定义 Bean 在被销毁前需要执行的清理逻辑。它是 Spring 容器生命周期回调机制的一部分。 🌱 什么是 DisposableBean DisposableBean 接口是 Spring 提供的一个标准接口,用于通知…...

【Linux命令学习】获取cpu信息 - lscpu命令学习
lscpu命令显示的是服务器cpu架构相关信息,lscpu从伪文件系统(sysfs)、/proc/cpuinfo和任何可用的特定体系架构库中收集cpu架构信息。输出内容包括:CPU、线程、内核的数量以及非同一存储器存取节点。此外还包括关于CPU高速缓存和高速缓存共享的信息&#…...

wordpress免费主题网站
这是一款WordPress主题,由jianzhanpress开发,可以免费下载。专为中小微企业设计,提供专业的网站建设、网站运营维护、网站托管和网站优化等服务。主题设计简约、现代,适合多种行业需求。 主要特点: 多样化展示&#…...