Python训练营---Day44
DAY 44 预训练模型
知识点回顾:
- 预训练的概念
- 常见的分类预训练模型
- 图像预训练模型的发展史
- 预训练的策略
- 预训练代码实战:resnet18
作业:
- 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同
- 尝试通过ctrl进入resnet的内部,观察残差究竟是什么
选用 DenseNet121预训练模型,注意DenseNet121 模型的最后分类层名为classifier,而不是 ResNet 中的fc
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import os
from torchvision.models import resnet18, densenet121, vgg16# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")# 1. 数据预处理(训练集增强,测试集标准化)
train_transform = transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),transforms.RandomRotation(15),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])test_transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])# 2. 加载CIFAR-10数据集
train_dataset = datasets.CIFAR10(root='./cifar_data',train=True,download=True,transform=train_transform
)test_dataset = datasets.CIFAR10(root='./cifar_data',train=False,transform=test_transform
)# 3. 创建数据加载器
batch_size = 64
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)# 4. 定义DenseNet121模型
def create_densenet121(pretrained=True, num_classes=10):model = models.densenet121(pretrained=pretrained)# 修改最后一层全连接层in_features = model.classifier.in_featuresmodel.classifier = nn.Linear(in_features, num_classes) # DenseNet121 的最后一层分类器名称是classifierreturn model.to(device)# 5. 冻结/解冻模型层的函数
# 这种设计允许我们在迁移学习中保留预训练模型的特征提取部分(卷积层),只训练新添加的分类层(全连接层)。
def freeze_model(model, freeze=True):"""冻结或解冻模型的卷积层参数"""# 冻结/解冻除fc层外的所有参数for name, param in model.named_parameters():if 'classifier' not in name: #排除名称中包含 "fc" 的参数,这些通常是全连接层的参数param.requires_grad = not freeze #param.requires_grad是 PyTorch 中控制参数是否参与反向传播和梯度更新的标志# 打印冻结状态frozen_params = sum(p.numel() for p in model.parameters() if not p.requires_grad) #统计所有requires_grad=False的参数数量total_params = sum(p.numel() for p in model.parameters())if freeze:print(f"已冻结模型卷积层参数 ({frozen_params}/{total_params} 参数)")else:print(f"已解冻模型所有参数 ({total_params}/{total_params} 参数可训练)")return model# 6. 训练函数(支持阶段式训练)
def train_with_freeze_schedule(model, train_loader, test_loader, criterion, optimizer, scheduler, device, epochs, freeze_epochs=5):"""前freeze_epochs轮冻结卷积层,之后解冻所有层进行训练"""train_loss_history = []test_loss_history = []train_acc_history = []test_acc_history = []all_iter_losses = []iter_indices = []# 初始冻结卷积层if freeze_epochs > 0:model = freeze_model(model, freeze=True)for epoch in range(epochs):# 解冻控制:在指定轮次后解冻所有层if epoch == freeze_epochs:model = freeze_model(model, freeze=False)# 解冻后调整优化器(可选)optimizer.param_groups[0]['lr'] = 1e-4 # 降低学习率防止过拟合model.train() # 设置为训练模式running_loss = 0.0correct_train = 0total_train = 0for batch_idx, (data, target) in enumerate(train_loader):data, target = data.to(device), target.to(device)optimizer.zero_grad()output = model(data)loss = criterion(output, target)loss.backward()optimizer.step()# 记录Iteration损失iter_loss = loss.item()all_iter_losses.append(iter_loss)iter_indices.append(epoch * len(train_loader) + batch_idx + 1)# 统计训练指标running_loss += iter_loss_, predicted = output.max(1)total_train += target.size(0)correct_train += predicted.eq(target).sum().item()# 每100批次打印进度if (batch_idx + 1) % 100 == 0:print(f"Epoch {epoch+1}/{epochs} | Batch {batch_idx+1}/{len(train_loader)} "f"| 单Batch损失: {iter_loss:.4f}")# 计算 epoch 级指标epoch_train_loss = running_loss / len(train_loader)epoch_train_acc = 100. * correct_train / total_train# 测试阶段model.eval()correct_test = 0total_test = 0test_loss = 0.0with torch.no_grad():for data, target in test_loader:data, target = data.to(device), target.to(device)output = model(data)test_loss += criterion(output, target).item()_, predicted = output.max(1)total_test += target.size(0)correct_test += predicted.eq(target).sum().item()epoch_test_loss = test_loss / len(test_loader)epoch_test_acc = 100. * correct_test / total_test# 记录历史数据train_loss_history.append(epoch_train_loss)test_loss_history.append(epoch_test_loss)train_acc_history.append(epoch_train_acc)test_acc_history.append(epoch_test_acc)# 更新学习率调度器if scheduler is not None:scheduler.step(epoch_test_loss)# 打印 epoch 结果print(f"Epoch {epoch+1} 完成 | 训练损失: {epoch_train_loss:.4f} "f"| 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%")# 绘制损失和准确率曲线plot_iter_losses(all_iter_losses, iter_indices)plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)return epoch_test_acc # 返回最终测试准确率# 7. 绘制Iteration损失曲线
def plot_iter_losses(losses, indices):plt.figure(figsize=(10, 4))plt.plot(indices, losses, 'b-', alpha=0.7)plt.xlabel('Iteration(Batch序号)')plt.ylabel('损失值')plt.title('训练过程中的Iteration损失变化')plt.grid(True)plt.show()# 8. 绘制Epoch级指标曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):epochs = range(1, len(train_acc) + 1)plt.figure(figsize=(12, 5))# 准确率曲线plt.subplot(1, 2, 1)plt.plot(epochs, train_acc, 'b-', label='训练准确率')plt.plot(epochs, test_acc, 'r-', label='测试准确率')plt.xlabel('Epoch')plt.ylabel('准确率 (%)')plt.title('准确率随Epoch变化')plt.legend()plt.grid(True)# 损失曲线plt.subplot(1, 2, 2)plt.plot(epochs, train_loss, 'b-', label='训练损失')plt.plot(epochs, test_loss, 'r-', label='测试损失')plt.xlabel('Epoch')plt.ylabel('损失值')plt.title('损失值随Epoch变化')plt.legend()plt.grid(True)plt.tight_layout()plt.show()# 主函数:训练模型
def main():# 参数设置epochs = 40 # 总训练轮次freeze_epochs = 5 # 冻结卷积层的轮次learning_rate = 1e-3 # 初始学习率weight_decay = 1e-4 # 权重衰减# 创建DenseNet121模型(加载预训练权重)model = create_densenet121(pretrained=True, num_classes=10)# 定义优化器和损失函数optimizer = optim.Adam(model.parameters(), lr=learning_rate, weight_decay=weight_decay)criterion = nn.CrossEntropyLoss()# 定义学习率调度器scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=2, verbose=True)# 开始训练(前5轮冻结卷积层,之后解冻)final_accuracy = train_with_freeze_schedule(model=model,train_loader=train_loader,test_loader=test_loader,criterion=criterion,optimizer=optimizer,scheduler=scheduler,device=device,epochs=epochs,freeze_epochs=freeze_epochs)print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")# # 保存模型# torch.save(model.state_dict(), 'resnet18_cifar10_finetuned.pth')# print("模型已保存至: resnet18_cifar10_finetuned.pth")if __name__ == "__main__":main()相关文章:

Python训练营---Day44
DAY 44 预训练模型 知识点回顾: 预训练的概念常见的分类预训练模型图像预训练模型的发展史预训练的策略预训练代码实战:resnet18 作业: 尝试在cifar10对比如下其他的预训练模型,观察差异,尽可能和他人选择的不同尝试通…...

前端项目初始化
目录 1. 安装 nvm 2. 配置 nvm 并切换到 Node.js 16.15.0 3. 安装 LightProxy 代理 4. GIT安装 1. 配置用户名和邮箱(这些信息将用于您在提交代码时的标识): 2. 生成SSH密钥(用于将本地代码仓库与远程存储库连…...

USB扩展器与USB服务器的2个主要区别
在现代办公和IT环境中,连接和管理USB设备是常见需求。USB扩展器(常称USB集线器)与USB服务器(如朝天椒USB服务器)是两类功能定位截然不同的解决方案。前者主要解决物理接口数量不足的“近身”连接扩展问题,而…...
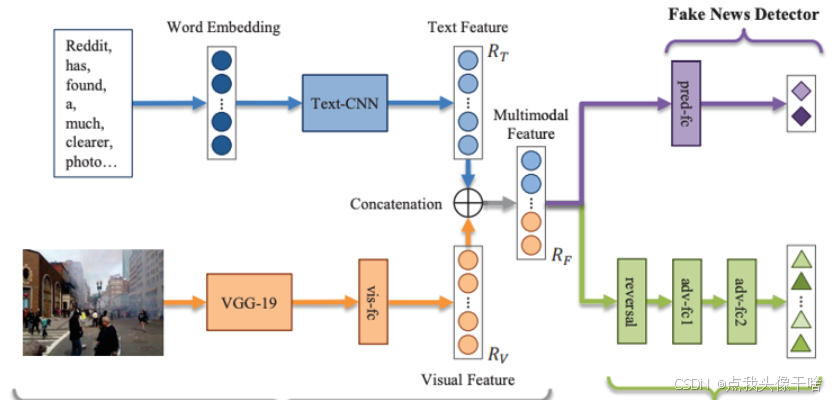
第46节:多模态分类(图像+文本)
一、多模态分类概述 多模态分类是指利用来自不同模态(如图像、文本、音频等)的数据进行联合分析和分类的任务。 在当今大数据时代,信息往往以多种形式存在,例如社交媒体上的图片配文字、视频附带字幕、医疗检查中的影像与报告等。单一模态的数据往往只能提供有限的信息,…...

spring获取注册的bean并注册到自定义工厂中管理
背景 在开发的时候,对于同一个对象的按照某个字段的不同有很多的处理方式。想着开发一个类似于工厂模式,由上层工厂统一分配。 由于是基于springboot开发,所以有很多自动注入的对象,如果由工厂统一创建new对象的方式,那…...

IDEA 中 Maven Dependencies 出现红色波浪线的原因及解决方法
在使用 IntelliJ IDEA 开发 Java 项目时,尤其是基于 Maven 的项目,开发者可能会遇到 Maven Dependencies 中出现红色波浪线的问题。这种现象通常表示项目依赖未能正确解析或下载,导致代码提示错误、编译失败等问题。本文将详细分析该问题的常…...
springMVC-10验证及国际化
验证 概述 ● 概述 1. 对输入的数据(比如表单数据),进行必要的验证,并给出相应的提示信息。 2. 对于验证表单数据,springMVC提供了很多实用的注解, 这些注解由JSR303 验证框架提供. ●JSR 303 验证框架 1. JSR 303 的含义 JSR࿰…...

使用Python和TensorFlow实现图像分类
最近研学过程中发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击链接跳转到网站人工智能及编程语言学习教程。读者们可以通过里面的文章详细了解一下人工智能及其编程等教程和学习方法。下面开始对正文内容的…...
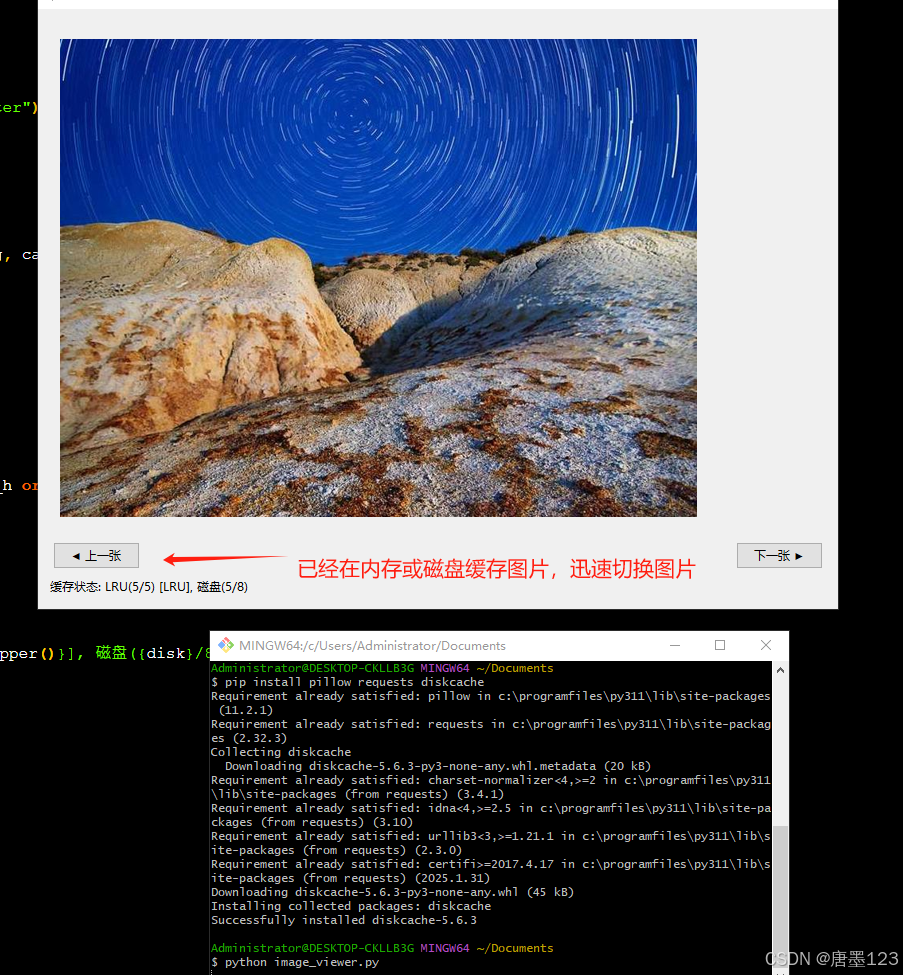
LRU 和 DiskLRU实现相册缓存器
我是写Linux后端的(golang、c、py),后端缓存算法通常是指的是内存里面的lru、或diskqueue,都是独立使用。 很少有用内存lru与disklru结合的场景需求。近段时间研究android开发,里面有一些设计思想值得后端学习。 写这…...
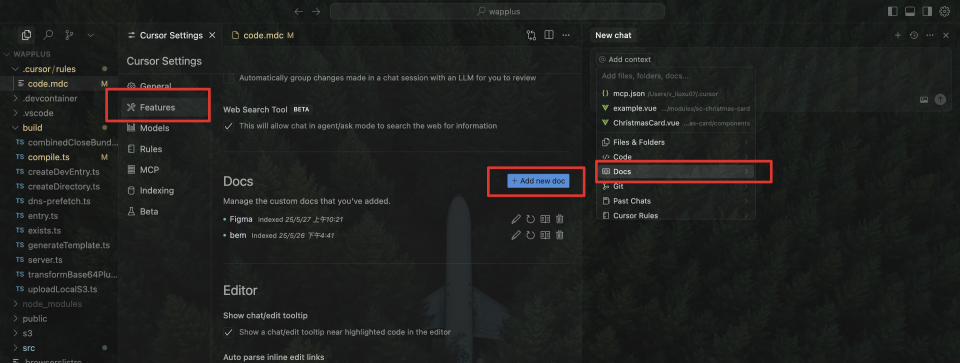
figma MCP + cursor如何将设计稿生成前端页面
一、准备工作 figma MCP需要通过figma key来获取设计稿权限,key的生成步骤如下 1. 打开figma网页版/APP,进入账户设定 2. 点击生成token 3. 填写内容生成token(一定要确认复制了,不然关闭弹窗后就不会显示了) 二、配置MCP 4. 进入到cursor…...
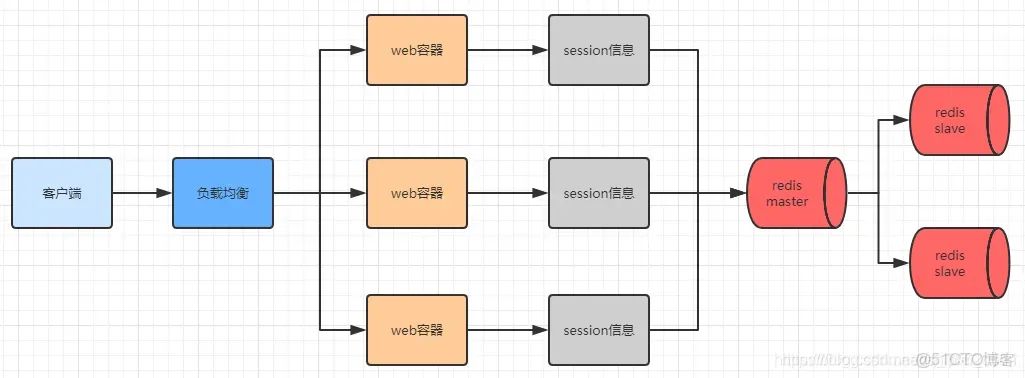
如何理解OSI七层模型和TCP/IP四层模型?HTTP作为如何保存用户状态?多服务器节点下 Session方案怎么做
本篇概览: OSI 七层模型是什么?每一层的作用是什么?TCP/IP四层模型和OSI七层模型的区别是什么? HTTP 本身是无状态协议,HTTP如何保存用户状态? 能不能具体说一下Cookie的工作原理、生命周期、作用域?使用…...

Flask 核心概念速览:路由、请求、响应与蓝图
一、路由参数与请求方法 Flask 路由允许定义多种参数类型,并通过 methods 属性限制请求方法。 1. 路由参数类型: 除了默认的 string,Flask 还支持: int: 匹配整数,自动转换为 Python int 类型。非数字输入会返回 404。 float: 匹配浮点数,自动转换为 Python float 类型…...

Spring Boot消息系统开发指南
消息系统基础概念 消息系统作为分布式架构的核心组件,实现了不同系统模块间的高效通信机制。其应用场景从即时通讯软件延伸至企业级应用集成,形成了现代软件架构中不可或缺的基础设施。 通信模式本质特征 同步通信要求收发双方必须同时在线交互&#…...
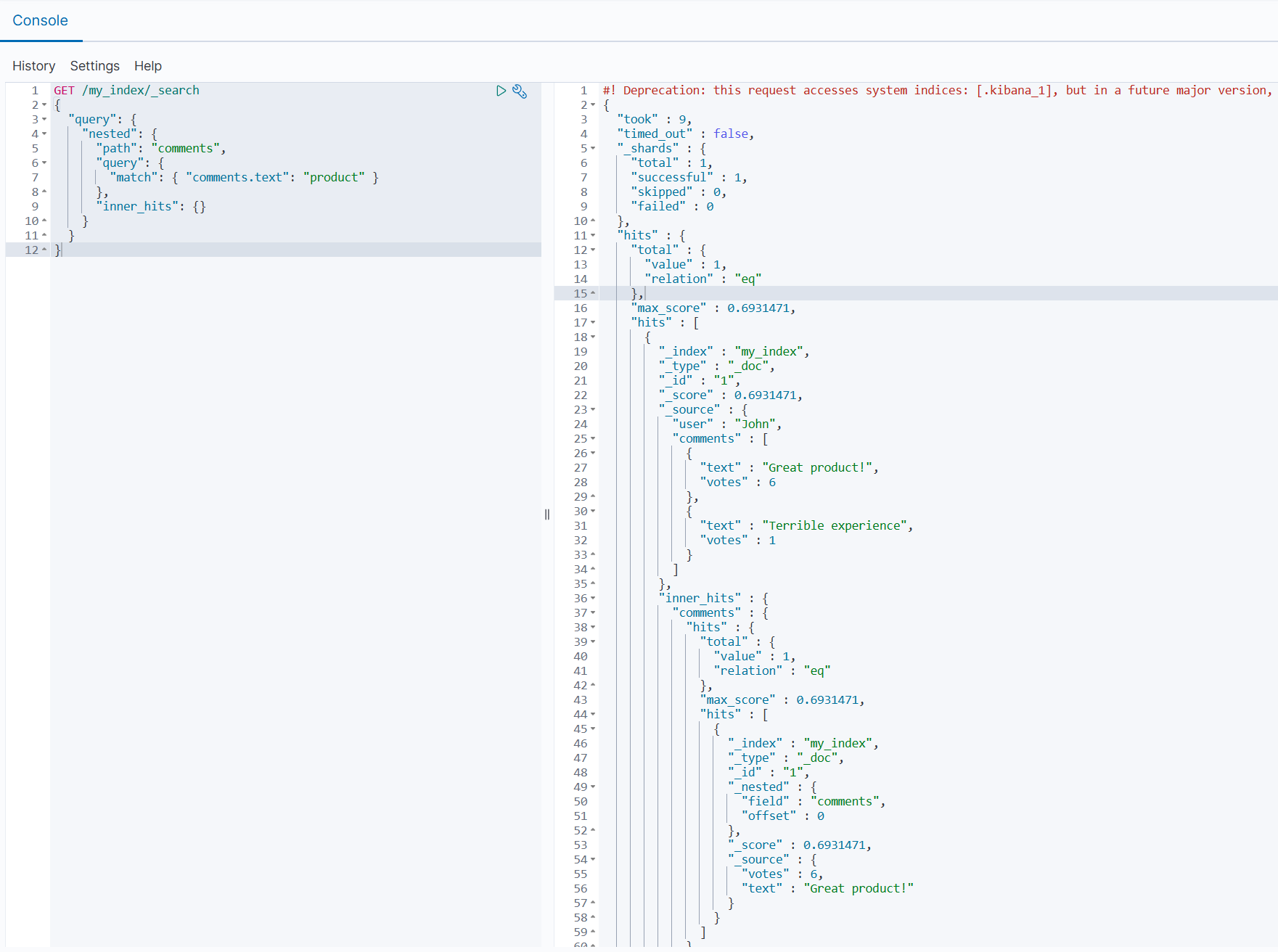
【Elasticsearch】映射:Nested 类型
映射:Nested 类型 1.为什么需要 Nested 类型2.如何定义 Nested 类型3.相关操作3.1 索引包含 Nested 数据的文档3.2 查询 Nested 数据3.3 聚合 Nested 数据3.4 排序 Nested 数据3.5 更新 Nested 文档中的特定元素 4.Nested 类型的高级操作4.1 内嵌 inner hits4.2 多级…...
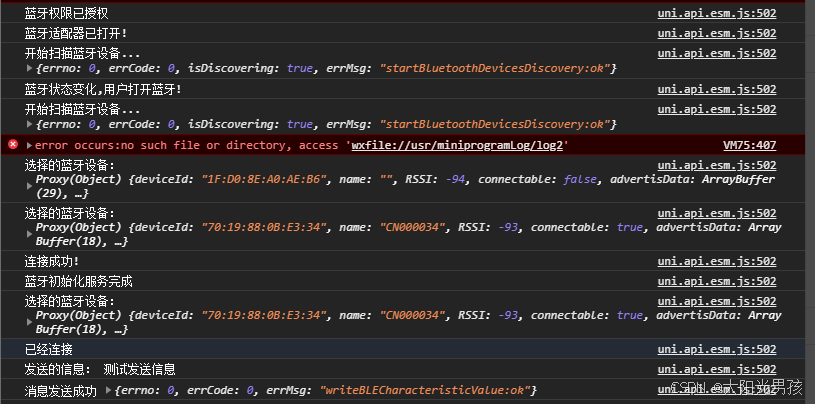
Vue3 + UniApp 蓝牙连接与数据发送(稳定版)
本教程适用于使用 uni-app Vue3 (script setup) 开发的跨平台 App(支持微信小程序、H5、Android/iOS 等) 🎯 功能目标 ✅ 获取蓝牙权限✅ 扫描周围蓝牙设备✅ 连接指定蓝牙设备✅ 获取服务和特征值✅ 向设备发送数据包(ArrayBu…...
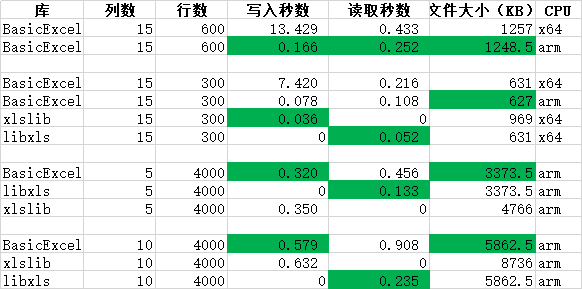
三种读写传统xls格式文件开源库libxls、xlslib、BasicExcel的比较
最近准备读写传统xls格式文件,而不是较新的xlsx,询问DeepSeek有哪些开源库,他给出了如下的简介和建议,还给出了相应链接,不过有的链接已失效。最后还不忘提醒,现在该用xlsx格式了。 以下是几个可以处理传统…...
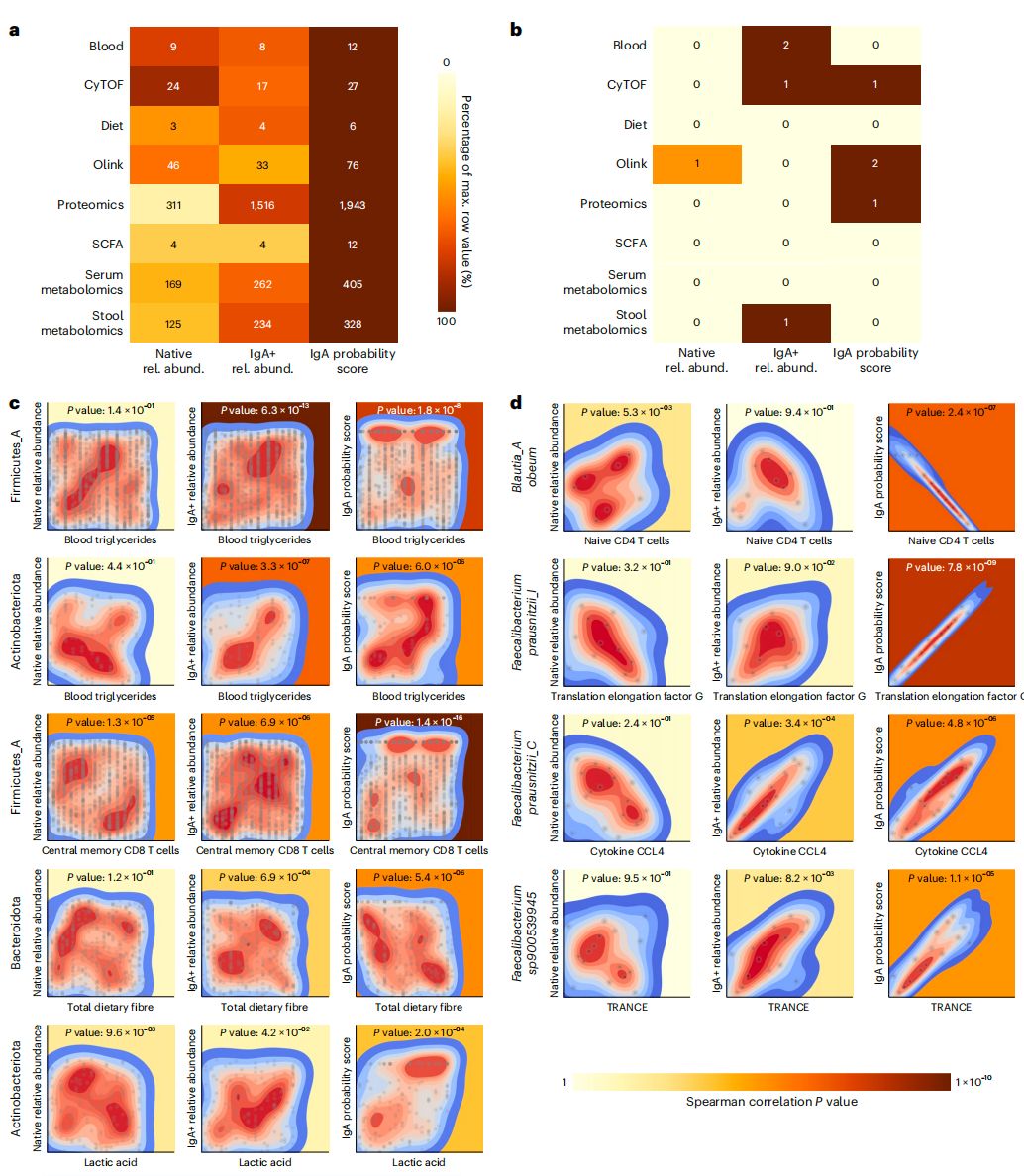
Nature子刊同款的宏基因组免疫球蛋白测序怎么做?
免疫球蛋白A(IgA)是人体肠道黏膜分泌的主要抗体,它在塑造肠道微生物群落和维持肠道稳态中起着关键作用,有研究发现缺乏IgA的患者更容易患自身免疫性疾病和感染性疾病。 目前用于研究IgA结合的主要技术是IgA-SEQ,结合了…...

2025年牛客网秋招/社招高质量 Java 面试八股文整理
Java 面试 不论是校招还是社招都避免不了各种面试。笔试,如何去准备这些东西就显得格外重要。不论是笔试还是面试都是有章可循的。关键在于理解企业的需求,明确自己的定位,以及掌握一定的应试技巧。 笔试部分,通常是对基础知识、…...
ADI的BF609双核DSP怎么做开发,我来说一说(五)LAN口测试
作者的话 ADI的双核DSP,第二颗是Blackfin系列的BF609,这颗DSP我用了很久,比较熟悉,且写过一些给新手的教程。 硬件准备 ADSP-BF609-CORE:ADI BF609开发板 产品链接:https://item.taobao.com/item.htm?…...

行业赋能篇-2-能源行业安全运维升级
在能源行业,尤其是风电领域,运维作业往往面临“三高”挑战——高风险环境、高异构数据量)、高合规要求。以海上风电场为例,传统运维依赖卫星电话沟通,数据记录碎片化,故障因信息传递延迟导致损失扩大。如何…...
飞云智能波段主图+多空短线决策副图指标,组合操盘技术图文解说
如上图,组合指标:主图-飞云智能波段,红线上红色K线标记,波段做多.副图指标-多空短线决策,跟踪做短线,红柱做多,绿柱短线卖出或做空。 实战操作中,我们在主图红色线支撑上红色K线出现…...

【51单片机】1. 基础点灯大师
1. 新建一个项目集一些基本操作 打开Keli软件,然后: 【Project】→【new μVision Project】→选择项目保存位置 建议文件名选一些通用的名字,如【Project】 左下角选择【Atmel】的【AT89C52】 弹出的【是否添加启动文件到文件夹下】&…...

RNN和CNN使用场景区别
RNN(循环神经网络)和 CNN(卷积神经网络)是深度学习中两种核心架构,它们的使用场景主要取决于数据结构和任务需求。以下是两者的关键区别及典型应用场景: 核心差异对比 维度RNN(循环神经网络&a…...
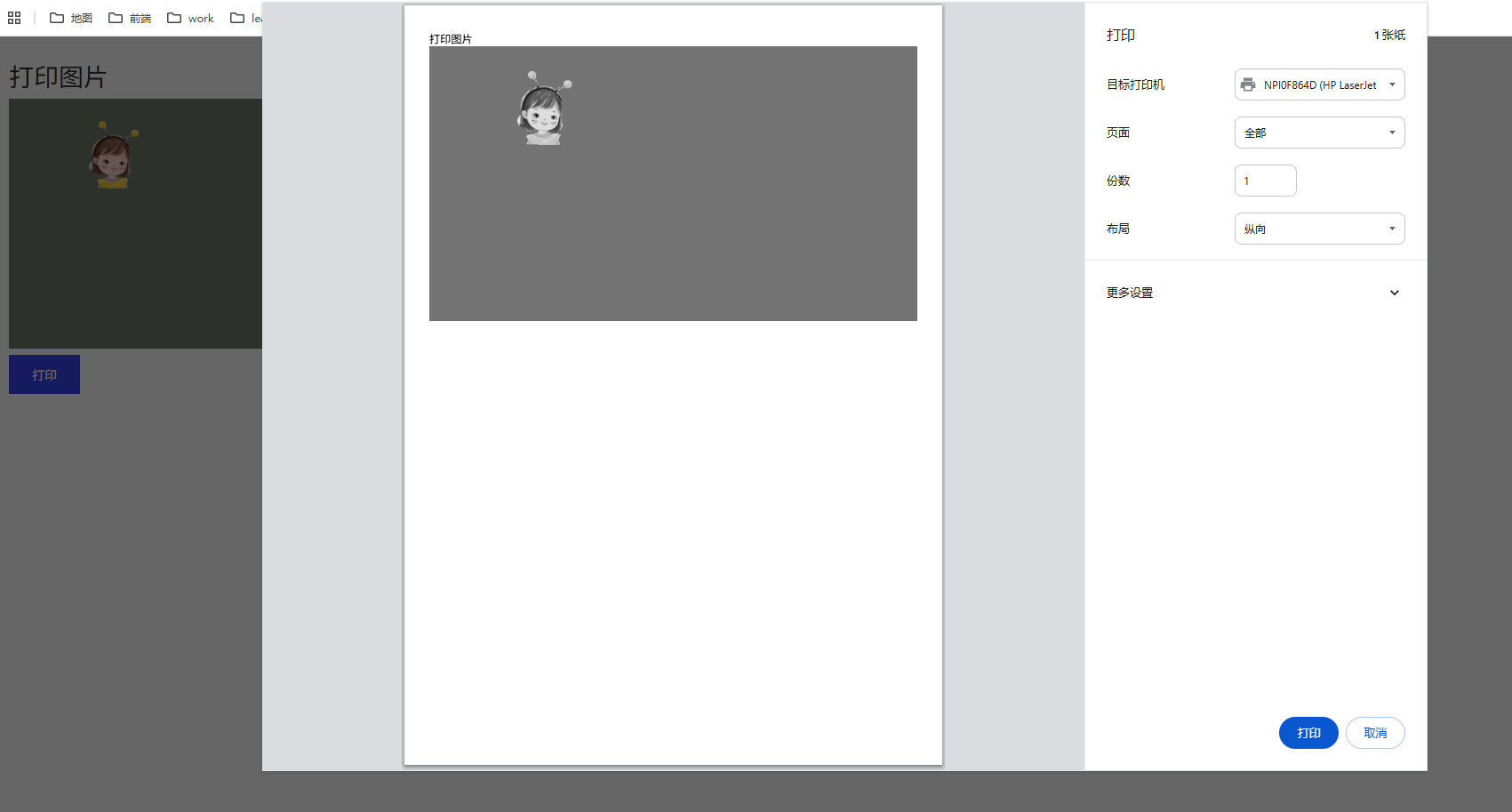
PC端直接打印功能(包括两张图片合并功能)
一、 效果图 二、demo代码 <template><div class"box"><divref"printContent"class"print-content"><div class"print-title">打印图片</div><imgclass"preview-image":src"merged…...
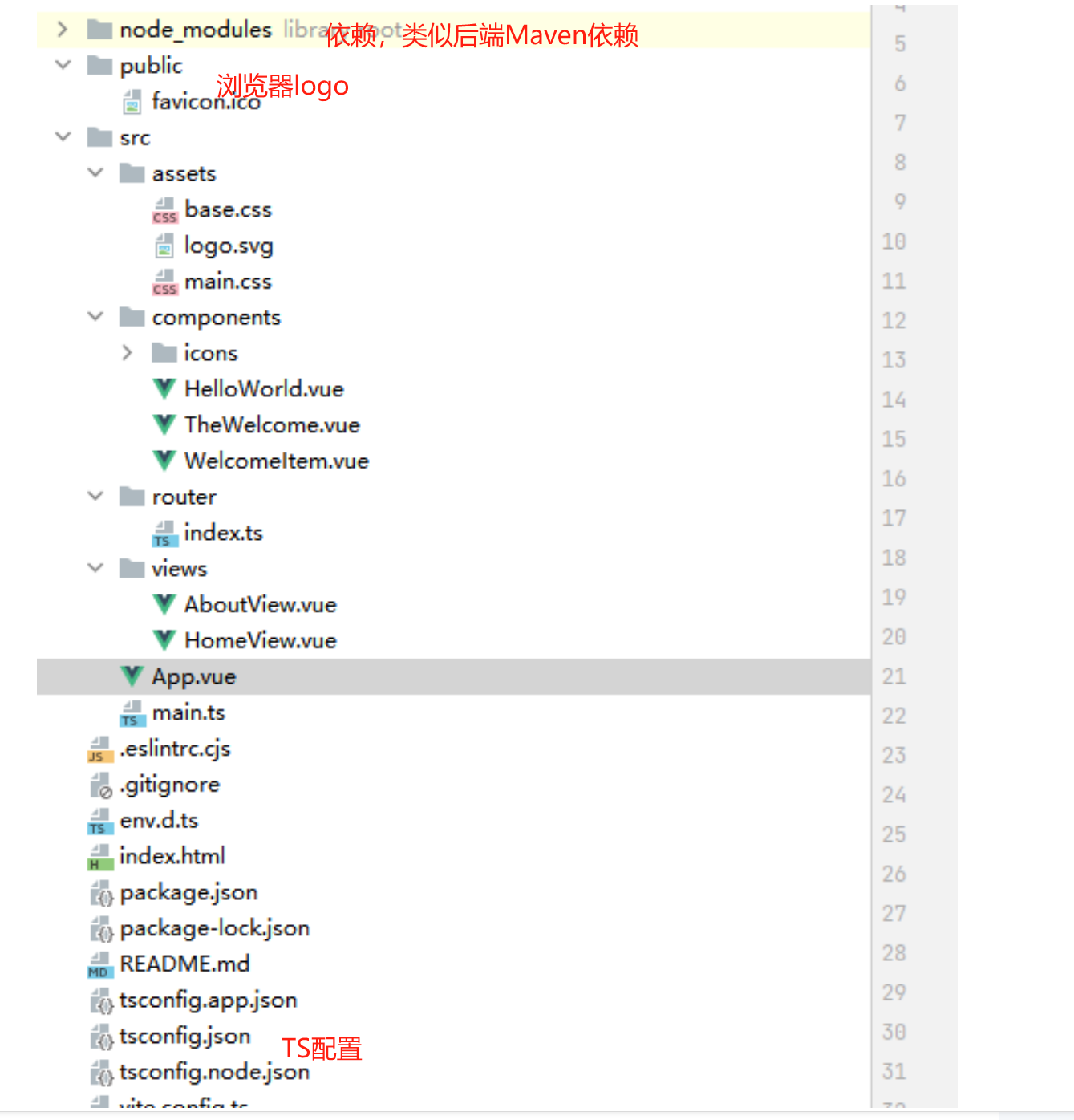
Vue前端篇——项目目录结构介绍
📘 前言 在正式开始学习 Vue 3 开发之前,了解并熟悉其项目目录结构是非常关键的第一步。一个清晰、规范的目录结构不仅有助于开发者高效地组织代码,还能显著提升项目的可读性和可维护性。 Vue 3 作为现代前端开发中广泛使用的主流框架之一&…...

基于端到端深度学习模型的语音控制人机交互系统
基于端到端深度学习模型的语音控制人机交互系统 摘要 本文设计并实现了一个基于端到端深度学习模型的人机交互系统,通过语音指令控制其他设备的程序运行,并将程序运行结果通过语音合成方式反馈给用户。系统采用Python语言开发,使用PyTorch框架实现端到端的语音识别(ASR)…...
)
原生js操作元素类名(classList,classList.add...)
1、classList classList属性是一个只读属性,返回元素的类名,作为一个DOMTokenList集合(用于在元素中添加,移除及切换css类) length:返回类列表中类的数量,该属性是只读的 <style> .lis { width: 200px; …...
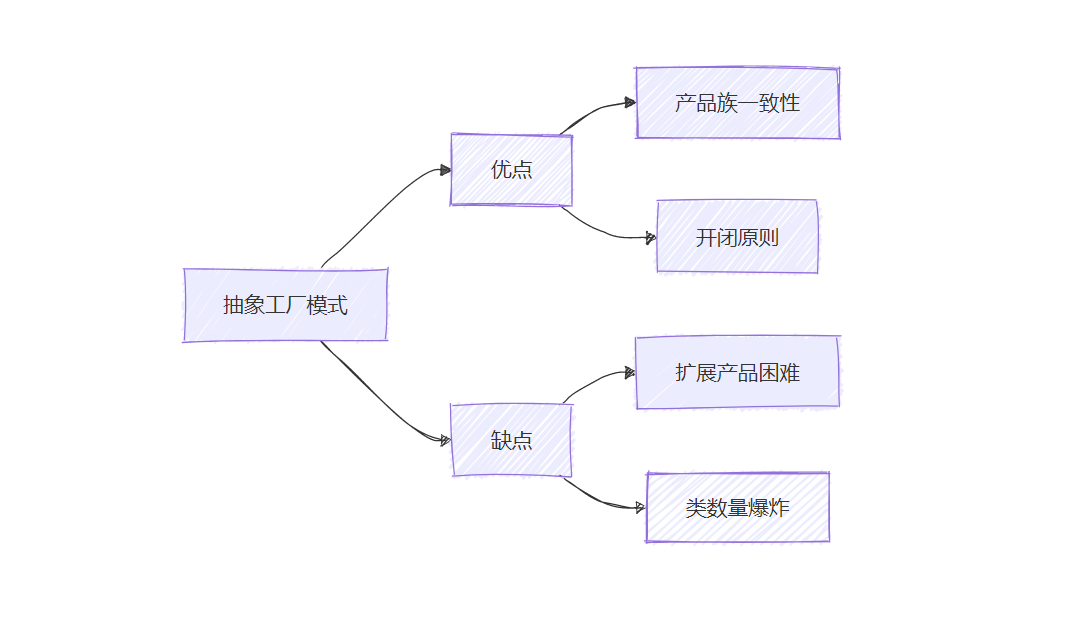
抽象工厂模式深度解析:从原理到与应用实战
作者简介 我是摘星,一名全栈开发者,专注 Java后端开发、AI工程化 与 云计算架构 领域,擅长Python技术栈。热衷于探索前沿技术,包括大模型应用、云原生解决方案及自动化工具开发。日常深耕技术实践,乐于分享实战经验与…...

35.成功解决编写关于“江协科技”编写技巧第二期标志位积累的问题
江科大学长又发布了第二期的编写技巧! 大家可以看看:https://space.bilibili.com/383400717 最后面给了一个未完成的任务: 这里我已经把这个问题给解决了! 总代码放在资源里面,key.c放在文章最后面!同时感…...
Linux常用命令学习手册
Linux常用命令学习手册https://download.csdn.net/download/2401_87690752/90953550 《Linux常用命令学习手册》提供了一份实用的Linux操作指南,主要收录了系统管理和文件操作等基础命令。内容涵盖了目录切换、文件查看、权限设置等核心功能,适合Linux初…...